M2 GL UE DOC «In memory analytics»
|
|
|
- Madeleine Lheureux
- il y a 8 ans
- Total affichages :
Transcription
1 M2 GL UE DOC «In memory analytics» Alexandre Termier 2014/2015

2 Sources Travaux Amplab, U.C. Berkeley Slides Ion Stoica Présentations Databricks Slides Pat McDonough Articles de M. Zaharia et al. sur les RDD et Spark

3 Introduction «Data is the new oil» Monétiser les données : Google, Facebook, Twitter Grande distribution Opérateurs de télécommunications Nouveaux services Bitly (2008) Moniteurs Fitbit (2011). Améliorer la QoS Analyse de logs (ex: attaques réseaux) Analyses de traces d exécution
.")
4 Méthodes pour analyser de grosses données BD relationnelles -> taille (très) limitée Entrepôts de données -> prix élevé, taille limitée Cluster Hadoop -> prix abordable, taille importante Données = fichiers HDFS / tables Hbase Requêtes = Code Map/Reduce PIG -> compilé en Map/Reduce Hive -> compilé en Map/Reduce

 Transfert de données entre ces phases : stockage sur")
5 Limitations de Map/Reduce Difficulté d écriture du code Modèle contraint Une phase de Map puis une phase de Reduce Parfois, besoin de faire plusieurs phases Map/Reduce Algorithmes complexes Algorithmes itératifs (PageRank, K-Means) Transfert de données entre ces phases : stockage sur disque (HDFS)
 Transfert de données entre ces phases : stockage sur")

6 Problème Analyse de données : Successions de traitements (filtrages, transformations) Algos de machine learning / data mining : itératifs Ex: k-means Buts Réponses interactives sur données historiques Analyse de flux en temps réel Analyses complexes de données massives

7 Premières solutions Cascading Workflows complexes en MapReduce Limites : Facilite le codage, mais n accélère pas les traitements! Le runtime est toujours basé sur Map/Reduce Haloop Modif de MapReduce pour gérer les calculs itératifs Utilise des mécanismes de cache pour accélérer les calculs Limites Il faut changer Hadoop!


8 Nouveau moteur d exécution distribué Logistic regression Exécution des calculs en mémoire ou sur disque Suites de transformations complexes Itérations Applications interactives Peut exploiter les infrastructures Hadoop avec YARN Données dans HDFS, Hbase,

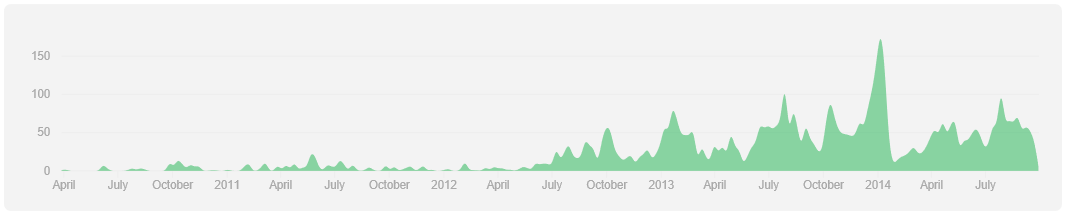
9 Spark : une popularité grandissante
10 Au cœur de Spark : les RDDs RDD = Resilient Distributed Dataset Collections distribuées d objets en lecture seule Stockés en mémoire ou sur le disque Collections construites par des transformations parallèles Reconstruction en cas de panne

11 Premier exemple Rouge : opération sur les RDD Noir : code Scala classique Vert : résultat scala> val lesmiserables = sc.textfile("data/*.txt") lesmiserables: org.apache.spark.rdd.rdd[string] = data/*.txt MappedRDD[5] at textfile at <console>:12 scala> lesmiserables.take(5).foreach(println) The Project Gutenberg EBook of Les misérables Tome I, by Victor Hugo This ebook is for the use of anyone anywhere at no cost and with almost no restrictions whatsoever. You may copy it, give it away or re-use it under the terms of the Project Gutenberg License included scala> lesmiserables.count() res1: Long = 52711

12 scala> val linesvaljean = lesmiserables.filter(x => x.contains("valjean")) linesvaljean: org.apache.spark.rdd.rdd[string] = FilteredRDD[6] at filter at <console>:14 scala> linesvaljean.cache() res2: linesvaljean.type = FilteredRDD[2] at filter at <console>:14 scala> linesvaljean.count() res3: Long = 911 scala> linesvaljean.take(10).foreach(println) Chapitre VI Jean Valjean nom? Vous vous appelez Jean Valjean. Maintenant voulez-vous que je vous --Voici. Je m'appelle Jean Valjean. Je suis un galérien. J'ai passé qu'on a mis sur le passeport: «Jean Valjean, forçat libéré, natif «--Monsieur Jean Valjean, c'est à Pontarlier que vous allez? Pontarlier, où vous allez, monsieur Valjean, une industrie toute homme, qui s'appelle Jean Valjean, n'avait que trop sa misère présente à que tous les soirs, et il a soupé avec ce Jean Valjean du même air et de Jean Valjean Vers le milieu de la nuit, Jean Valjean se réveilla. Rouge : opération sur les RDD Noir : code Scala classique Vert : résultat

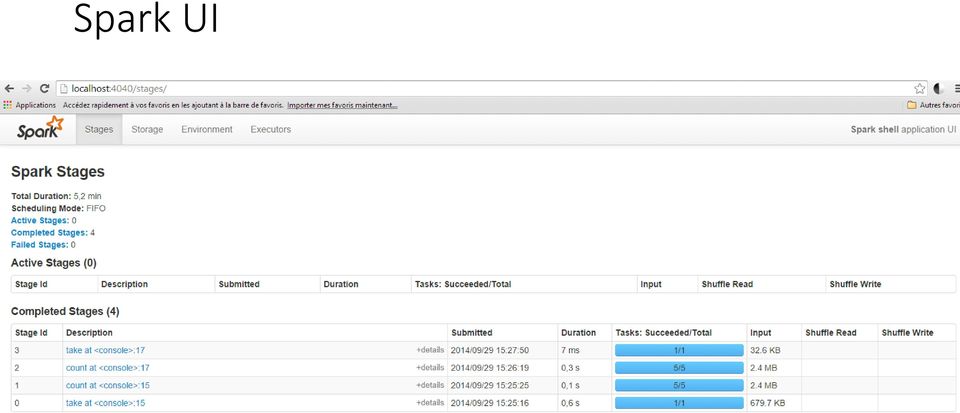
13 Spark UI
14 Opérations sur les RDD Transformations RDD -> RDD transformé Suite des transformations loggée «lignée» (lineage en anglais) Exécution paresseuse et parallèle Quelques transformations map reduce filter groupby join sort Actions Exécution d un calcul Stockage extene Quelques actions count take first save fold sample

15 RDD lineage (lignée en français) Un RDD enregistre toutes les transformations nécessaires pour le construire Reconstruction efficace en cas de panne val lesmiserables = sc.textfile("data/*.txt") val linesvaljean = lesmiserables.filter(x => x.contains("valjean")).textfile( ).filter( ) Fichier MappedRDD FilteredRDD
).textfile( ).")

16 Partitions et dépendances partitions RDD RDD divisé en partitions Contrôle sur le partitionnement Dépendances différentes en fonction des transformations Narrow Wide Impact sur les performances en cas de panne Figure : Matei Zaharia, PhD dissertation

17 Persistance Contrôle sur la persistance : Mémoire seulement, objets désérialisés (défaut) Stocke RDD en mémoire, partitions qui ne tiennent pas sont recalculées à la volée Mémoire seulement, objets sérialisés Stocke RDD en mémoire en sérialisant : prend moins de place, coûte plus de CPU Mémoire et disque, objets désérialisés Stocke RDD en mémoire, partitions qui ne tiennent pas sauvées sur disque Mémoire et disque, objets sérialisés Disque seulement

18 scala> val wc = lesmiserables.flatmap(_.split(" ")).map((_,1)).reducebykey(_+_) wc: org.apache.spark.rdd.rdd[(string, Int)] = ShuffledRDD[5] at reducebykey at <console>:14 scala> wc.take(5).foreach(println) (créanciers;,1) (abondent.,1) (plaisir,,5) (déplaçaient,1) (sociale,,7) scala> val cw = wc.map(p => (p._2, p._1)) Wordcount en Spark cw: org.apache.spark.rdd.rdd[(int, String)] = MappedRDD[5] at map at <console>:16 scala> val sortedcw = cw.sortbykey(false) sortedcw: org.apache.spark.rdd.rdd[(int, String)] = ShuffledRDD[11] at sortbykey at <console>:18 scala> sortedcw.take(5).foreach(println) (16757,de) (14683,) (11025,la) (9794,et) (8471,le) scala> sortedcw.filter(x => "Cosette".equals(x._2)).collect.foreach(println) (353,Cosette)
![rdd[(int, String)] = MappedRDD[5] at map at <console>:16 scala> val sortedcw = cw.sortbykey(false) sortedcw: org.apache.spark.rdd.rdd[(int, String)] = ShuffledRDD[11] at sortbykey at <console>:18 scala> sortedcw.](/docs-images/44/1865253/images/page_18.jpg "take(5).foreach(println) (16757,de) (14683,) (11025,la) (9794,et) (8471,le) scala> sortedcw.filter(x => \"Cosette\".equals(x._2)).collect.foreach(println) (353,Cosette)")

19 Performances, code itératif Figure : Matei Zaharia, PhD dissertation


20 Performance en cas de panne (k-means) Figure : Matei Zaharia, PhD dissertation


21 Performance w.r.t. utilisation mémoire Régression logistique, 100 GB données, 25 machines Figure : Matei Zaharia, PhD dissertation

22 Performances, requêtes interactives Utilisation de 100 machines Figure : Matei Zaharia, PhD dissertation

23 Berkley Data Analytics Stack (BDAS)

24 Ecosystème BDAS Au dessus de Spark Shark -> Spark SQL Spark Streaming GraphX MLib
25 Autre approche : SAP Hana Spark : nécessite un cluster Pas accessible à tout le monde TCO (Total Cost of Ownership) assez important SAP Hana : base de donnée + analytics en mémoire sur une (grosse) machine Idée : dans 10 ans, n importe quelle machine aura > 1 TO de RAM
26
27 Promesses des «in-memory analytics» Accès beaucoup plus rapides aux données Intégration et traitement très rapide des données produites en temps réel Résultats à des requêtes complexes en quelques secondes => Améliorer la rapidité de réaction, décisions rapides
28 Exemples (source : Intel + SAP) Yodobashi Calcul de points de fidélités pour 5 millions de clients Avant : 1 fois par mois, 3 jours de calcul Maintenant : 2 secondes de calcul -> offres dynamiques basées sur points + inventaires T-Mobile Rapports sur 2 milliards d enregistrements de clients (21 millions de clients) 5 secondes de calcul Ont pu passer de 3 à 4 mois d historique pour les analyses Maintenance prédictive Normalement : maintenance de tous équipements tous les 3 mois Analyse des données de capteur pour prédire les pannes -> Maintenance préemptive pour équipements suspects, tous les 7 mois pour les autres

29
30 Conclusion Evolution rapide paysage BD / analytics Direction : la RAM! Besoin de traitements rapides Analyses de plus en plus poussées des données Conséquences pour vous? (M2 GL) Suivre ces technos de près Bien comprendre l utilisation des collections Accès facilité au parallélisme Se documenter sur les requêtes / algorithmes complexes permis par ces nouveaux systèmes Machine learning Data mining
Hadoop, Spark & Big Data 2.0. Exploiter une grappe de calcul pour des problème des données massives
 Hadoop, Spark & Big Data 2.0 Exploiter une grappe de calcul pour des problème des données massives Qui suis-je? Félix-Antoine Fortin Génie info. (B. Ing, M. Sc, ~PhD) Passionné de Python, Data Analytics,
Hadoop, Spark & Big Data 2.0 Exploiter une grappe de calcul pour des problème des données massives Qui suis-je? Félix-Antoine Fortin Génie info. (B. Ing, M. Sc, ~PhD) Passionné de Python, Data Analytics,
HADOOP ET SON ÉCOSYSTÈME
 HADOOP ET SON ÉCOSYSTÈME Mars 2013 2012 Affini-Tech - Diffusion restreinte 1 AFFINI-TECH Méthodes projets Outils de reporting & Data-visualisation Business & Analyses BigData Modélisation Hadoop Technos
HADOOP ET SON ÉCOSYSTÈME Mars 2013 2012 Affini-Tech - Diffusion restreinte 1 AFFINI-TECH Méthodes projets Outils de reporting & Data-visualisation Business & Analyses BigData Modélisation Hadoop Technos
4 Exemples de problèmes MapReduce incrémentaux
 4 Exemples de problèmes MapReduce incrémentaux 1 / 32 Calcul des plus courtes distances à un noeud d un graphe Calcul des plus courts chemins entre toutes les paires de noeuds d un graphe Algorithme PageRank
4 Exemples de problèmes MapReduce incrémentaux 1 / 32 Calcul des plus courtes distances à un noeud d un graphe Calcul des plus courts chemins entre toutes les paires de noeuds d un graphe Algorithme PageRank
L écosystème Hadoop Nicolas Thiébaud ni.thiebaud@gmail.com. Tuesday, July 2, 13
 L écosystème Hadoop Nicolas Thiébaud ni.thiebaud@gmail.com HUG France 250 membres sur la mailing liste 30 présentations 9 meetups organisés, de 20 à 100 invités Présence de Cloudera, MapR, Hortonworks,
L écosystème Hadoop Nicolas Thiébaud ni.thiebaud@gmail.com HUG France 250 membres sur la mailing liste 30 présentations 9 meetups organisés, de 20 à 100 invités Présence de Cloudera, MapR, Hortonworks,
Big Data. Cyril Amsellem Consultant avant-vente. 16 juin 2011. Talend 2010 1
 Big Data Cyril Amsellem Consultant avant-vente 16 juin 2011 Talend 2010 1 Big Data Architecture globale Hadoop Les projets Hadoop (partie 1) Hadoop-Core : projet principal. HDFS : système de fichiers distribués
Big Data Cyril Amsellem Consultant avant-vente 16 juin 2011 Talend 2010 1 Big Data Architecture globale Hadoop Les projets Hadoop (partie 1) Hadoop-Core : projet principal. HDFS : système de fichiers distribués
Programmation parallèle et distribuée
 Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2015) Marc Parizeau, Département de génie électrique et de génie informatique Plan Données massives («big data») Architecture Hadoop distribution
Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2015) Marc Parizeau, Département de génie électrique et de génie informatique Plan Données massives («big data») Architecture Hadoop distribution
Les technologies du Big Data
 Les technologies du Big Data PRÉSENTÉ AU 40 E CONGRÈS DE L ASSOCIATION DES ÉCONOMISTES QUÉBÉCOIS PAR TOM LANDRY, CONSEILLER SENIOR LE 20 MAI 2015 WWW.CRIM.CA TECHNOLOGIES: DES DONNÉES JUSQU'À L UTILISATEUR
Les technologies du Big Data PRÉSENTÉ AU 40 E CONGRÈS DE L ASSOCIATION DES ÉCONOMISTES QUÉBÉCOIS PAR TOM LANDRY, CONSEILLER SENIOR LE 20 MAI 2015 WWW.CRIM.CA TECHNOLOGIES: DES DONNÉES JUSQU'À L UTILISATEUR
Panorama des solutions analytiques existantes
 Arnaud LAROCHE Julien DAMON Panorama des solutions analytiques existantes SFdS Méthodes et Logiciels - 16 janvier 2014 - Données Massives Ne sont ici considérés que les solutions autour de l environnement
Arnaud LAROCHE Julien DAMON Panorama des solutions analytiques existantes SFdS Méthodes et Logiciels - 16 janvier 2014 - Données Massives Ne sont ici considérés que les solutions autour de l environnement
Formation Cloudera Data Analyst Utiliser Pig, Hive et Impala avec Hadoop
 Passez au niveau supérieur en termes de connaissance grâce à la formation Data Analyst de Cloudera. Public Durée Objectifs Analystes de données, business analysts, développeurs et administrateurs qui ont
Passez au niveau supérieur en termes de connaissance grâce à la formation Data Analyst de Cloudera. Public Durée Objectifs Analystes de données, business analysts, développeurs et administrateurs qui ont
Big Data Concepts et mise en oeuvre de Hadoop
 Introduction 1. Objectif du chapitre 9 2. Le Big Data 10 2.1 Introduction 10 2.2 Informatique connectée, objets "intelligents" et données collectées 11 2.3 Les unités de mesure dans le monde Big Data 12
Introduction 1. Objectif du chapitre 9 2. Le Big Data 10 2.1 Introduction 10 2.2 Informatique connectée, objets "intelligents" et données collectées 11 2.3 Les unités de mesure dans le monde Big Data 12
Anticiper et prédire les sinistres avec une approche Big Data
 Anticiper et prédire les sinistres avec une approche Big Data Julien Cabot Directeur Big Data Analytics OCTO jcabot@octo.com @julien_cabot OCTO 2013 50, avenue des Champs-Elysées 75008 Paris - FRANCE Tél
Anticiper et prédire les sinistres avec une approche Big Data Julien Cabot Directeur Big Data Analytics OCTO jcabot@octo.com @julien_cabot OCTO 2013 50, avenue des Champs-Elysées 75008 Paris - FRANCE Tél
Les enjeux du Big Data Innovation et opportunités de l'internet industriel. Datasio 2013
 Les enjeux du Big Data Innovation et opportunités de l'internet industriel François Royer froyer@datasio.com Accompagnement des entreprises dans leurs stratégies quantitatives Valorisation de patrimoine
Les enjeux du Big Data Innovation et opportunités de l'internet industriel François Royer froyer@datasio.com Accompagnement des entreprises dans leurs stratégies quantitatives Valorisation de patrimoine
Programmation parallèle et distribuée
 Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2014) Marc Parizeau, Département de génie électrique et de génie informatique Plan Mégadonnées («big data») Architecture Hadoop distribution
Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2014) Marc Parizeau, Département de génie électrique et de génie informatique Plan Mégadonnées («big data») Architecture Hadoop distribution
Introduction aux algorithmes MapReduce. Mathieu Dumoulin (GRAAL), 14 Février 2014
, 14 Février 2014") Introduction aux algorithmes MapReduce Mathieu Dumoulin (GRAAL), 14 Février 2014 Plan Introduction de la problématique Tutoriel MapReduce Design d algorithmes MapReduce Tri, somme et calcul de moyenne
Introduction aux algorithmes MapReduce Mathieu Dumoulin (GRAAL), 14 Février 2014 Plan Introduction de la problématique Tutoriel MapReduce Design d algorithmes MapReduce Tri, somme et calcul de moyenne
Labs Hadoop Février 2013
 SOA - BRMS - ESB - BPM CEP BAM - High Performance Compute & Data Grid - Cloud Computing - Big Data NoSQL - Analytics Labs Hadoop Février 2013 Mathias Kluba Managing Consultant Responsable offres NoSQL
SOA - BRMS - ESB - BPM CEP BAM - High Performance Compute & Data Grid - Cloud Computing - Big Data NoSQL - Analytics Labs Hadoop Février 2013 Mathias Kluba Managing Consultant Responsable offres NoSQL
Fouillez facilement dans votre système Big Data. Olivier TAVARD
 Fouillez facilement dans votre système Big Data Olivier TAVARD A propos de moi : Cofondateur de la société France Labs Développeur (principalement Java) Formateur en technologies de moteurs de recherche
Fouillez facilement dans votre système Big Data Olivier TAVARD A propos de moi : Cofondateur de la société France Labs Développeur (principalement Java) Formateur en technologies de moteurs de recherche
Ricco Rakotomalala http://eric.univ-lyon2.fr/~ricco/cours/cours_programmation_r.html. R.R. Université Lyon 2
 Ricco Rakotomalala http://eric.univ-lyon2.fr/~ricco/cours/cours_programmation_r.html 1 Plan de présentation 1. L écosystème Hadoop 2. Principe de programmation MapReduce 3. Programmation des fonctions
Ricco Rakotomalala http://eric.univ-lyon2.fr/~ricco/cours/cours_programmation_r.html 1 Plan de présentation 1. L écosystème Hadoop 2. Principe de programmation MapReduce 3. Programmation des fonctions
Introduction à MapReduce/Hadoop et Spark
 1 / 36 Introduction à MapReduce/Hadoop et Spark Certificat Big Data Ludovic Denoyer et Sylvain Lamprier UPMC Plan 2 / 36 Contexte 3 / 36 Contexte 4 / 36 Data driven science: le 4e paradigme (Jim Gray -
1 / 36 Introduction à MapReduce/Hadoop et Spark Certificat Big Data Ludovic Denoyer et Sylvain Lamprier UPMC Plan 2 / 36 Contexte 3 / 36 Contexte 4 / 36 Data driven science: le 4e paradigme (Jim Gray -
BIG Data et R: opportunités et perspectives
 BIG Data et R: opportunités et perspectives Guati Rizlane 1 & Hicham Hajji 2 1 Ecole Nationale de Commerce et de Gestion de Casablanca, Maroc, rguati@gmail.com 2 Ecole des Sciences Géomatiques, IAV Rabat,
BIG Data et R: opportunités et perspectives Guati Rizlane 1 & Hicham Hajji 2 1 Ecole Nationale de Commerce et de Gestion de Casablanca, Maroc, rguati@gmail.com 2 Ecole des Sciences Géomatiques, IAV Rabat,
Organiser vos données - Big Data. Patrick Millart Senior Sales Consultant
 Organiser vos données - Big Data Patrick Millart Senior Sales Consultant The following is intended to outline our general product direction. It is intended for information purposes only, and may not be
Organiser vos données - Big Data Patrick Millart Senior Sales Consultant The following is intended to outline our general product direction. It is intended for information purposes only, and may not be
Déploiement d une architecture Hadoop pour analyse de flux. françois-xavier.andreu@renater.fr
 Déploiement d une architecture Hadoop pour analyse de flux françois-xavier.andreu@renater.fr 1 plan Introduction Hadoop Présentation Architecture d un cluster HDFS & MapReduce L architecture déployée Les
Déploiement d une architecture Hadoop pour analyse de flux françois-xavier.andreu@renater.fr 1 plan Introduction Hadoop Présentation Architecture d un cluster HDFS & MapReduce L architecture déployée Les
20 ans du Master SIAD de Toulouse - BigData par l exemple - Julien DULOUT - 22 mars 2013. 20 ans du SIAD -"Big Data par l'exemple" -Julien DULOUT
 20 ans du Master SIAD de Toulouse - BigData par l exemple - Julien DULOUT - 22 mars 2013 20 ans du SIAD -"BigData par l'exemple" -Julien DULOUT Qui a déjà entendu parler du phénomène BigData? Qui a déjà
20 ans du Master SIAD de Toulouse - BigData par l exemple - Julien DULOUT - 22 mars 2013 20 ans du SIAD -"BigData par l'exemple" -Julien DULOUT Qui a déjà entendu parler du phénomène BigData? Qui a déjà
Les participants repartiront de cette formation en ayant une vision claire de la stratégie et de l éventuelle mise en œuvre d un Big Data.
 Big Data De la stratégie à la mise en oeuvre Description : La formation a pour objet de brosser sans concession le tableau du Big Data. Les participants repartiront de cette formation en ayant une vision
Big Data De la stratégie à la mise en oeuvre Description : La formation a pour objet de brosser sans concession le tableau du Big Data. Les participants repartiront de cette formation en ayant une vision
Offre formation Big Data Analytics
 Offre formation Big Data Analytics OCTO 2014 50, avenue des Champs-Elysées 75008 Paris - FRANCE Tél : +33 (0)1 58 56 10 00 Fax : +33 (0)1 58 56 10 01 www.octo.com 1 Présentation d OCTO Technology 2 Une
Offre formation Big Data Analytics OCTO 2014 50, avenue des Champs-Elysées 75008 Paris - FRANCE Tél : +33 (0)1 58 56 10 00 Fax : +33 (0)1 58 56 10 01 www.octo.com 1 Présentation d OCTO Technology 2 Une
Hadoop, les clés du succès
 Hadoop, les clés du succès Didier Kirszenberg, Responsable des architectures Massive Data, HP France Copyright 2015 Hewlett-Packard Development Company, L.P. The information contained herein is subject
Hadoop, les clés du succès Didier Kirszenberg, Responsable des architectures Massive Data, HP France Copyright 2015 Hewlett-Packard Development Company, L.P. The information contained herein is subject
DEMARRER UN PROJET BIGDATA EN QUELQUES MINUTES GRACE AU CLOUD
 DEMARRER UN PROJET BIGDATA EN QUELQUES MINUTES GRACE AU CLOUD BIGDATA PARIS LE 1/4/2014 VINCENT HEUSCHLING @VHE74! 1 NOUS 100% Bigdata Infrastructure IT + Data Trouver vos opportunités Implémenter les
DEMARRER UN PROJET BIGDATA EN QUELQUES MINUTES GRACE AU CLOUD BIGDATA PARIS LE 1/4/2014 VINCENT HEUSCHLING @VHE74! 1 NOUS 100% Bigdata Infrastructure IT + Data Trouver vos opportunités Implémenter les
Big Graph Data Forum Teratec 2013
 Big Graph Data Forum Teratec 2013 MFG Labs 35 rue de Châteaudun 75009 Paris, France www.mfglabs.com twitter: @mfg_labs Julien Laugel MFG Labs julien.laugel@mfglabs.com @roolio SOMMAIRE MFG Labs Contexte
Big Graph Data Forum Teratec 2013 MFG Labs 35 rue de Châteaudun 75009 Paris, France www.mfglabs.com twitter: @mfg_labs Julien Laugel MFG Labs julien.laugel@mfglabs.com @roolio SOMMAIRE MFG Labs Contexte
Cartographie des solutions BigData
 Cartographie des solutions BigData Panorama du marché et prospective 1 1 Solutions BigData Défi(s) pour les fournisseurs Quel marché Architectures Acteurs commerciaux Solutions alternatives 2 2 Quels Défis?
Cartographie des solutions BigData Panorama du marché et prospective 1 1 Solutions BigData Défi(s) pour les fournisseurs Quel marché Architectures Acteurs commerciaux Solutions alternatives 2 2 Quels Défis?
NoSQL. Introduction 1/23. I NoSQL : Not Only SQL, ce n est pas du relationnel, et le contexte. I table d associations - Map - de couples (clef,valeur)
") 1/23 2/23 Anne-Cécile Caron Master MIAGE - BDA 1er trimestre 2013-2014 I : Not Only SQL, ce n est pas du relationnel, et le contexte d utilisation n est donc pas celui des SGBDR. I Origine : recherche
1/23 2/23 Anne-Cécile Caron Master MIAGE - BDA 1er trimestre 2013-2014 I : Not Only SQL, ce n est pas du relationnel, et le contexte d utilisation n est donc pas celui des SGBDR. I Origine : recherche
API04 Contribution. Apache Hadoop: Présentation et application dans le domaine des Data Warehouses. Introduction. Architecture
 API04 Contribution Apache Hadoop: Présentation et application dans le domaine des Data Warehouses Introduction Cette publication a pour but de présenter le framework Java libre Apache Hadoop, permettant
API04 Contribution Apache Hadoop: Présentation et application dans le domaine des Data Warehouses Introduction Cette publication a pour but de présenter le framework Java libre Apache Hadoop, permettant
Big data et données géospatiales : Enjeux et défis pour la géomatique. Thierry Badard, PhD, ing. jr Centre de Recherche en Géomatique
 Big data et données géospatiales : Enjeux et défis pour la géomatique Thierry Badard, PhD, ing. jr Centre de Recherche en Géomatique Événement 25e anniversaire du CRG Université Laval, Qc, Canada 08 mai
Big data et données géospatiales : Enjeux et défis pour la géomatique Thierry Badard, PhD, ing. jr Centre de Recherche en Géomatique Événement 25e anniversaire du CRG Université Laval, Qc, Canada 08 mai
NoSQL. Introduction 1/30. I NoSQL : Not Only SQL, ce n est pas du relationnel, et le contexte. I table d associations - Map - de couples (clef,valeur)
") 1/30 2/30 Anne-Cécile Caron Master MIAGE - SGBD 1er trimestre 2014-2015 I : Not Only SQL, ce n est pas du relationnel, et le contexte d utilisation n est donc pas celui des SGBDR. I Origine : recherche
1/30 2/30 Anne-Cécile Caron Master MIAGE - SGBD 1er trimestre 2014-2015 I : Not Only SQL, ce n est pas du relationnel, et le contexte d utilisation n est donc pas celui des SGBDR. I Origine : recherche
Acquisition des données - Big Data. Dario VEGA Senior Sales Consultant
 Acquisition des données - Big Data Dario VEGA Senior Sales Consultant The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated
Acquisition des données - Big Data Dario VEGA Senior Sales Consultant The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated
BIG DATA en Sciences et Industries de l Environnement
 BIG DATA en Sciences et Industries de l Environnement François Royer www.datasio.com 21 mars 2012 FR Big Data Congress, Paris 2012 1/23 Transport terrestre Traçabilité Océanographie Transport aérien Télémétrie
BIG DATA en Sciences et Industries de l Environnement François Royer www.datasio.com 21 mars 2012 FR Big Data Congress, Paris 2012 1/23 Transport terrestre Traçabilité Océanographie Transport aérien Télémétrie
Hadoop dans l entreprise: du concept à la réalité. Pourquoi et comment?
 Hadoop dans l entreprise: du concept à la réalité. Pourquoi et comment? Jean-Marc Spaggiari Cloudera jms@cloudera.com @jmspaggi Mai 2014 1 2 Avant qu on commence Agenda -Qu est-ce que Hadoop et pourquoi
Hadoop dans l entreprise: du concept à la réalité. Pourquoi et comment? Jean-Marc Spaggiari Cloudera jms@cloudera.com @jmspaggi Mai 2014 1 2 Avant qu on commence Agenda -Qu est-ce que Hadoop et pourquoi
MapReduce. Malo Jaffré, Pablo Rauzy. 16 avril 2010 ENS. Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15
 MapReduce 16 avril 2010 1 / 15") MapReduce Malo Jaffré, Pablo Rauzy ENS 16 avril 2010 Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15 Qu est ce que c est? Conceptuellement Données MapReduce est un framework de calcul distribué
MapReduce Malo Jaffré, Pablo Rauzy ENS 16 avril 2010 Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15 Qu est ce que c est? Conceptuellement Données MapReduce est un framework de calcul distribué
MapReduce. Nicolas Dugué nicolas.dugue@univ-orleans.fr. M2 MIAGE Systèmes d information répartis
 MapReduce Nicolas Dugué nicolas.dugue@univ-orleans.fr M2 MIAGE Systèmes d information répartis Plan 1 Introduction Big Data 2 MapReduce et ses implémentations 3 MapReduce pour fouiller des tweets 4 MapReduce
MapReduce Nicolas Dugué nicolas.dugue@univ-orleans.fr M2 MIAGE Systèmes d information répartis Plan 1 Introduction Big Data 2 MapReduce et ses implémentations 3 MapReduce pour fouiller des tweets 4 MapReduce
Le nouveau visage de la Dataviz dans MicroStrategy 10
 Le nouveau visage de la Dataviz dans MicroStrategy 10 Pour la première fois, MicroStrategy 10 offre une plateforme analytique qui combine une expérience utilisateur facile et agréable, et des capacités
Le nouveau visage de la Dataviz dans MicroStrategy 10 Pour la première fois, MicroStrategy 10 offre une plateforme analytique qui combine une expérience utilisateur facile et agréable, et des capacités
Cassandra et Spark pour gérer la musique On-line
 Cassandra et Spark pour gérer la musique On-line 16 Juin 2015 @ Paris Hammed RAMDANI Architecte SI 3.0 et BigData mramdani@palo-it.com +33 6 80 22 20 70 Appelez-moi Hammed ;-) (Sidi Mo)Hammed Ramdani @smramdani
Cassandra et Spark pour gérer la musique On-line 16 Juin 2015 @ Paris Hammed RAMDANI Architecte SI 3.0 et BigData mramdani@palo-it.com +33 6 80 22 20 70 Appelez-moi Hammed ;-) (Sidi Mo)Hammed Ramdani @smramdani
Groupe de Discussion Big Data Aperçu des technologies et applications. Stéphane MOUTON stephane.mouton@cetic.be
 Groupe de Discussion Big Data Aperçu des technologies et applications Stéphane MOUTON stephane.mouton@cetic.be Recherche appliquée et transfert technologique q Agréé «Centre Collectif de Recherche» par
Groupe de Discussion Big Data Aperçu des technologies et applications Stéphane MOUTON stephane.mouton@cetic.be Recherche appliquée et transfert technologique q Agréé «Centre Collectif de Recherche» par
Analytics & Big Data. Focus techniques & nouvelles perspectives pour les actuaires. Université d Eté de l Institut des Actuaires Mardi 8 juillet 2014
 Analytics & Big Data Focus techniques & nouvelles perspectives pour les actuaires Local Optimization European Minded Université d Eté de l Institut des Actuaires Mardi 8 juillet 2014 Intervenants : Alexandre
Analytics & Big Data Focus techniques & nouvelles perspectives pour les actuaires Local Optimization European Minded Université d Eté de l Institut des Actuaires Mardi 8 juillet 2014 Intervenants : Alexandre
Surmonter les 5 défis opérationnels du Big Data
 Surmonter les 5 défis opérationnels du Big Data Jean-Michel Franco Talend Connect 9 octobre 2014 Talend 2014 1 Agenda Agenda Le Big Data depuis la découverte jusqu au temps réel en passant par les applications
Surmonter les 5 défis opérationnels du Big Data Jean-Michel Franco Talend Connect 9 octobre 2014 Talend 2014 1 Agenda Agenda Le Big Data depuis la découverte jusqu au temps réel en passant par les applications
Big Data et Graphes : Quelques pistes de recherche
 Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de Lyon/Université Claude Bernard Lyon 1/Université
Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de Lyon/Université Claude Bernard Lyon 1/Université
Big Data : utilisation d un cluster Hadoop HDFS Map/Reduce HBase
 Big Data : utilisation d un cluster cluster Cécile Cavet cecile.cavet at apc.univ-paris7.fr Centre François Arago (FACe), Laboratoire APC, Université Paris Diderot LabEx UnivEarthS 14 Janvier 2014 C. Cavet
Big Data : utilisation d un cluster cluster Cécile Cavet cecile.cavet at apc.univ-paris7.fr Centre François Arago (FACe), Laboratoire APC, Université Paris Diderot LabEx UnivEarthS 14 Janvier 2014 C. Cavet
Fouille de données massives avec Hadoop
 Fouille de données massives avec Hadoop Sebastiao Correia scorreia@talend.com Talend 2013 AAFD'14 29-30 avril 2014 1 Agenda Présentation de Talend Définition du Big Data Le framework Hadoop 3 thématiques
Fouille de données massives avec Hadoop Sebastiao Correia scorreia@talend.com Talend 2013 AAFD'14 29-30 avril 2014 1 Agenda Présentation de Talend Définition du Big Data Le framework Hadoop 3 thématiques
Le projet Gaïa, le Big Data au service du traitement de données satellitaires CRIP - 16/10/2013 Pierre-Marie Brunet
 Le projet Gaïa, le Big Data au service du traitement de données satellitaires CRIP - 16/10/2013 Pierre-Marie Brunet 1 SOMMAIRE Le calcul scientifique au CNES Le BigData au CNES, le cas Gaïa HPC et BigData
Le projet Gaïa, le Big Data au service du traitement de données satellitaires CRIP - 16/10/2013 Pierre-Marie Brunet 1 SOMMAIRE Le calcul scientifique au CNES Le BigData au CNES, le cas Gaïa HPC et BigData
Quels choix de base de données pour vos projets Big Data?
 Quels choix de base de données pour vos projets Big Data? Big Data? Le terme "big data" est très à la mode et naturellement un terme si générique est galvaudé. Beaucoup de promesses sont faites, et l'enthousiasme
Quels choix de base de données pour vos projets Big Data? Big Data? Le terme "big data" est très à la mode et naturellement un terme si générique est galvaudé. Beaucoup de promesses sont faites, et l'enthousiasme
MapReduce et Hadoop. Alexandre Denis Alexandre.Denis@inria.fr. Inria Bordeaux Sud-Ouest France ENSEIRB PG306
 MapReduce et Hadoop Alexandre Denis Alexandre.Denis@inria.fr Inria Bordeaux Sud-Ouest France ENSEIRB PG306 Fouille de données Recherche & indexation de gros volumes Appliquer une opération simple à beaucoup
MapReduce et Hadoop Alexandre Denis Alexandre.Denis@inria.fr Inria Bordeaux Sud-Ouest France ENSEIRB PG306 Fouille de données Recherche & indexation de gros volumes Appliquer une opération simple à beaucoup
Les quatre piliers d une solution de gestion des Big Data
 White Paper Les quatre piliers d une solution de gestion des Big Data Table des Matières Introduction... 4 Big Data : un terme très vaste... 4 Le Big Data... 5 La technologie Big Data... 5 Le grand changement
White Paper Les quatre piliers d une solution de gestion des Big Data Table des Matières Introduction... 4 Big Data : un terme très vaste... 4 Le Big Data... 5 La technologie Big Data... 5 Le grand changement
11/01/2014. Le Big Data Mining enjeux et approches techniques. Plan. Introduction. Introduction. Quelques exemples d applications
 Plan Le Big Data Mining enjeux et approches techniques Bernard Dousset Professeur des universités Institut de Recherche en Informatique de Toulouse UMR 5505 Université de Toulouse 118, Route de Narbonne,
Plan Le Big Data Mining enjeux et approches techniques Bernard Dousset Professeur des universités Institut de Recherche en Informatique de Toulouse UMR 5505 Université de Toulouse 118, Route de Narbonne,
 Préface Dunod Toute reproduction non autorisée est un délit. Les raisons de l émergence du Big Data sont bien connues. Elles sont d abord économiques et technologiques. La chute exponentielle des coûts
Préface Dunod Toute reproduction non autorisée est un délit. Les raisons de l émergence du Big Data sont bien connues. Elles sont d abord économiques et technologiques. La chute exponentielle des coûts
Jean-François Boulicaut & Mohand-Saïd Hacid
 e siècle! Jean-François Boulicaut & Mohand-Saïd Hacid http://liris.cnrs.fr/~jboulica http://liris.cnrs.fr/mohand-said.hacid Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205
e siècle! Jean-François Boulicaut & Mohand-Saïd Hacid http://liris.cnrs.fr/~jboulica http://liris.cnrs.fr/mohand-said.hacid Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205
Our experience in using Apache Giraph for computing the diameter of large graphs. Paul Bertot - Flavian Jacquot
 Our experience in using Apache Giraph for computing the diameter of large graphs Paul Bertot - Flavian Jacquot Plan 1. 2. 3. 4. 5. 6. Contexte Hadoop Giraph L étude Partitionnement ifub 2 1. Contexte -
Our experience in using Apache Giraph for computing the diameter of large graphs Paul Bertot - Flavian Jacquot Plan 1. 2. 3. 4. 5. 6. Contexte Hadoop Giraph L étude Partitionnement ifub 2 1. Contexte -
Certificat Big Data - Master MAthématiques
 1 / 1 Certificat Big Data - Master MAthématiques Master 2 Auteur : Sylvain Lamprier UPMC Fouille de données et Medias Sociaux 2 / 1 Rich and big data: Millions d utilisateurs Millions de contenus Multimedia
1 / 1 Certificat Big Data - Master MAthématiques Master 2 Auteur : Sylvain Lamprier UPMC Fouille de données et Medias Sociaux 2 / 1 Rich and big data: Millions d utilisateurs Millions de contenus Multimedia
CENTAI : Big Data & Big Analytics Réunion DGPN / Thales Octobre 2013
 www.thalesgroup.com CENTAI : Big Data & Big Analytics Réunion DGPN / Thales Octobre 2013 2 / Sommaire CENTAI : Présentation du laboratoire Plate-forme OSINT LAB Détection de la fraude à la carte bancaire
www.thalesgroup.com CENTAI : Big Data & Big Analytics Réunion DGPN / Thales Octobre 2013 2 / Sommaire CENTAI : Présentation du laboratoire Plate-forme OSINT LAB Détection de la fraude à la carte bancaire
Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop
 Julien Gerlier Siman Chen Rapport de projet de fin d étude ASR 2010/2011 Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop Encadrants
Julien Gerlier Siman Chen Rapport de projet de fin d étude ASR 2010/2011 Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop Encadrants
Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop
 Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop Soutenance de projet ASR 27/01/2011 Julien Gerlier Siman Chen Encadrés par Bruno
Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop Soutenance de projet ASR 27/01/2011 Julien Gerlier Siman Chen Encadrés par Bruno
AVRIL 2014. Au delà de Hadoop. Panorama des solutions NoSQL
 AVRIL 2014 Panorama des solutions NoSQL QUI SOMMES NOUS? Avril 2014 2 SMILE, EN QUELQUES CHIFFRES 1er INTÉGRATEUR EUROPÉEN DE SOLUTIONS OPEN SOURCE 3 4 NOS EXPERTISES ET NOS CONVICTIONS DANS NOS LIVRES
AVRIL 2014 Panorama des solutions NoSQL QUI SOMMES NOUS? Avril 2014 2 SMILE, EN QUELQUES CHIFFRES 1er INTÉGRATEUR EUROPÉEN DE SOLUTIONS OPEN SOURCE 3 4 NOS EXPERTISES ET NOS CONVICTIONS DANS NOS LIVRES
Bases de données documentaires et distribuées Cours NFE04
 Bases de données documentaires et distribuées Cours NFE04 Cloud et scalabilité Auteurs : Raphaël Fournier-S niehotta, Philippe Rigaux, Nicolas Travers prénom.nom@cnam.fr Département d informatique Conservatoire
Bases de données documentaires et distribuées Cours NFE04 Cloud et scalabilité Auteurs : Raphaël Fournier-S niehotta, Philippe Rigaux, Nicolas Travers prénom.nom@cnam.fr Département d informatique Conservatoire
Projet Xdata. Cinequant, Data Publica, EDF, ESRI, Hurence, INRIA, Institut Mines Telecom, La Poste, Orange, Veolia
 Projet Xdata Cinequant, Data Publica, EDF, ESRI, Hurence, INRIA, Institut Mines Telecom, La Poste, Orange, Veolia Mutualisation des données XData = Cross Data En croisant des données d origine diverses,
Projet Xdata Cinequant, Data Publica, EDF, ESRI, Hurence, INRIA, Institut Mines Telecom, La Poste, Orange, Veolia Mutualisation des données XData = Cross Data En croisant des données d origine diverses,
Big Data et Graphes : Quelques pistes de recherche
 Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci http://liris.cnrs.fr/hamamache.kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de
Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci http://liris.cnrs.fr/hamamache.kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de
Les journées SQL Server 2013
 Les journées SQL Server 2013 Un événement organisé par GUSS Les journées SQL Server 2013 Romain Casteres MVP SQL Server Consultant BI @PulsWeb Yazid Moussaoui Consultant Senior BI MCSA 2008/2012 Etienne
Les journées SQL Server 2013 Un événement organisé par GUSS Les journées SQL Server 2013 Romain Casteres MVP SQL Server Consultant BI @PulsWeb Yazid Moussaoui Consultant Senior BI MCSA 2008/2012 Etienne
Introduction Big Data
 Introduction Big Data SOMMAIRE Rédacteurs : Réf.: SH. Lazare / F. Barthélemy AXIO_BD_V1 QU'EST-CE QUE LE BIG DATA? ENJEUX TECHNOLOGIQUES ENJEUX STRATÉGIQUES BIG DATA ET RH ANNEXE Ce document constitue
Introduction Big Data SOMMAIRE Rédacteurs : Réf.: SH. Lazare / F. Barthélemy AXIO_BD_V1 QU'EST-CE QUE LE BIG DATA? ENJEUX TECHNOLOGIQUES ENJEUX STRATÉGIQUES BIG DATA ET RH ANNEXE Ce document constitue
VirtualScale L expert infrastructure de l environnement Open source HADOOP Sofiane Ammar sofiane.ammar@virtualscale.fr
 VirtualScale L expert infrastructure de l environnement Open source HADOOP Sofiane Ammar sofiane.ammar@virtualscale.fr Avril 2014 Virtualscale 1 Sommaire Les enjeux du Big Data et d Hadoop Quels enjeux
VirtualScale L expert infrastructure de l environnement Open source HADOOP Sofiane Ammar sofiane.ammar@virtualscale.fr Avril 2014 Virtualscale 1 Sommaire Les enjeux du Big Data et d Hadoop Quels enjeux
R+Hadoop = Rhadoop* Des logiciels libres complémentaires, une implémentation, une réponse au nouveau paradigme du bigdata!
 R+Hadoop = Rhadoop* * Des logiciels libres complémentaires, une implémentation, une réponse au nouveau paradigme du bigdata! 27 Janvier 2014 / Université Paul Sabatier / DTSI / David Tsang-Hin-Sun Big
R+Hadoop = Rhadoop* * Des logiciels libres complémentaires, une implémentation, une réponse au nouveau paradigme du bigdata! 27 Janvier 2014 / Université Paul Sabatier / DTSI / David Tsang-Hin-Sun Big
Comment Créer une Base de Données Ab Initio
 Comment Créer une Base de Données Ab Initio Diffusé par Le Projet Documentation OpenOffice.org Table des Matières 1. Création de la Source de Données...3 2. Ajout de Tables dans une Source de Données...3
Comment Créer une Base de Données Ab Initio Diffusé par Le Projet Documentation OpenOffice.org Table des Matières 1. Création de la Source de Données...3 2. Ajout de Tables dans une Source de Données...3
L Art d être Numérique. Thierry Pierre Directeur Business Development SAP France
 L Art d être Numérique Thierry Pierre Directeur Business Development SAP France La Transformation Numérique «Plus largement, l impact potentiel des technologies numériques disruptives (cloud, impression
L Art d être Numérique Thierry Pierre Directeur Business Development SAP France La Transformation Numérique «Plus largement, l impact potentiel des technologies numériques disruptives (cloud, impression
Stephan Hadinger, Sr. Mgr Solutions Architecture, AWS. Salon du Big Data 11 mars 2015
 Stephan Hadinger, Sr. Mgr Solutions Architecture, AWS Salon du Big Data 11 mars 2015 Accélération de l innovation +500 +280 Amazon EC2 Container Service +159 AWS Storage Gateway Amazon Elastic Transcoder
Stephan Hadinger, Sr. Mgr Solutions Architecture, AWS Salon du Big Data 11 mars 2015 Accélération de l innovation +500 +280 Amazon EC2 Container Service +159 AWS Storage Gateway Amazon Elastic Transcoder
Le BigData, aussi par et pour les PMEs
 Parole d expert Le BigData, aussi par et pour les PMEs Stéphane MOUTON, CETIC Département Software and Services Technologies Avec le soutien de : LIEGE CREATIVE Le Big Data, aussi par et pour les PMEs
Parole d expert Le BigData, aussi par et pour les PMEs Stéphane MOUTON, CETIC Département Software and Services Technologies Avec le soutien de : LIEGE CREATIVE Le Big Data, aussi par et pour les PMEs
Vos experts Big Data. contact@hurence.com. Le Big Data dans la pratique
 Vos experts Big Data contact@hurence.com Le Big Data dans la pratique Expert Expert Infrastructure Data Science Spark MLLib Big Data depuis 2011 Expert Expert Hadoop / Spark NoSQL HBase Couchbase MongoDB
Vos experts Big Data contact@hurence.com Le Big Data dans la pratique Expert Expert Infrastructure Data Science Spark MLLib Big Data depuis 2011 Expert Expert Hadoop / Spark NoSQL HBase Couchbase MongoDB
Comment booster vos applications SAP Hana avec SQLSCRIPT
 DE LA TECHNOLOGIE A LA PLUS VALUE METIER Comment booster vos applications SAP Hana avec SQLSCRIPT 1 Un usage optimum de SAP Hana Votre contexte SAP Hana Si vous envisagez de migrer vers les plateformes
DE LA TECHNOLOGIE A LA PLUS VALUE METIER Comment booster vos applications SAP Hana avec SQLSCRIPT 1 Un usage optimum de SAP Hana Votre contexte SAP Hana Si vous envisagez de migrer vers les plateformes
La rencontre du Big Data et du Cloud
 La rencontre du Big Data et du Cloud Libérez le potentiel de toutes vos données Visualisez et exploitez plus rapidement les données de tous types, quelle que soit leur taille et indépendamment de leur
La rencontre du Big Data et du Cloud Libérez le potentiel de toutes vos données Visualisez et exploitez plus rapidement les données de tous types, quelle que soit leur taille et indépendamment de leur
Map-Reduce : un cadre de programmation parallèlle pour l analyse de grandes données. Stéphane Genaud ENSIIE
 Map-Reduce : un cadre de programmation parallèlle pour l analyse de grandes données Stéphane Genaud ENSIIE Traitement de données distribuées Google a introduit Map-Reduce [Dean and Ghemawat 2004] Ils s
Map-Reduce : un cadre de programmation parallèlle pour l analyse de grandes données Stéphane Genaud ENSIIE Traitement de données distribuées Google a introduit Map-Reduce [Dean and Ghemawat 2004] Ils s
BIG DATA et DONNéES SEO
 BIG DATA et DONNéES SEO Vincent Heuschling vhe@affini-tech.com @vhe74 2012 Affini-Tech - Diffusion restreinte 1 Agenda Affini-Tech SEO? Application Généralisation 2013 Affini-Tech - Diffusion restreinte
BIG DATA et DONNéES SEO Vincent Heuschling vhe@affini-tech.com @vhe74 2012 Affini-Tech - Diffusion restreinte 1 Agenda Affini-Tech SEO? Application Généralisation 2013 Affini-Tech - Diffusion restreinte
Encryptions, compression et partitionnement des données
 Encryptions, compression et partitionnement des données Version 1.0 Grégory CASANOVA 2 Compression, encryption et partitionnement des données Sommaire 1 Introduction... 3 2 Encryption transparente des
Encryptions, compression et partitionnement des données Version 1.0 Grégory CASANOVA 2 Compression, encryption et partitionnement des données Sommaire 1 Introduction... 3 2 Encryption transparente des
TRANSFORM IT + BUSINESS + YOURSELF
 TRANSFORM IT + BUSINESS + YOURSELF Copyright 2012 EMC Corporation. All rights reserved. 2 Vos environnements SAP sont complexes et couteux : pensez «replatforming» TRANSFORM IT+ BUSINESS + YOURSELF Alexandre
TRANSFORM IT + BUSINESS + YOURSELF Copyright 2012 EMC Corporation. All rights reserved. 2 Vos environnements SAP sont complexes et couteux : pensez «replatforming» TRANSFORM IT+ BUSINESS + YOURSELF Alexandre
Big Data, un nouveau paradigme et de nouveaux challenges
 Big Data, un nouveau paradigme et de nouveaux challenges Sebastiao Correia 21 Novembre 2014 Séminaire Thématique : Traitement et analyse statistique des données massives, Poitiers. 1 Présentation Sebastiao
Big Data, un nouveau paradigme et de nouveaux challenges Sebastiao Correia 21 Novembre 2014 Séminaire Thématique : Traitement et analyse statistique des données massives, Poitiers. 1 Présentation Sebastiao
http://blog.khaledtannir.net
 Algorithme de parallélisations des traitements Khaled TANNIR Doctorant CIFRE LARIS/ESTI http://blog.khaledtannir.net these@khaledtannir.net 2e SéRI 2010-2011 Jeudi 17 mars 2011 Présentation Doctorant CIFRE
Algorithme de parallélisations des traitements Khaled TANNIR Doctorant CIFRE LARIS/ESTI http://blog.khaledtannir.net these@khaledtannir.net 2e SéRI 2010-2011 Jeudi 17 mars 2011 Présentation Doctorant CIFRE
Comment sauvegarder ses documents
 Comment sauvegarder ses documents Diffusé par Le Projet Documentation OpenOffice.org OpenOffice.org Documentation Project How-To Table des Matières 1. Préliminaires...3 2. Enregistrer un nouveau document...4
Comment sauvegarder ses documents Diffusé par Le Projet Documentation OpenOffice.org OpenOffice.org Documentation Project How-To Table des Matières 1. Préliminaires...3 2. Enregistrer un nouveau document...4
Technologies du Web. Ludovic DENOYER - ludovic.denoyer@lip6.fr. Février 2014 UPMC
 Technologies du Web Ludovic DENOYER - ludovic.denoyer@lip6.fr UPMC Février 2014 Ludovic DENOYER - ludovic.denoyer@lip6.fr Technologies du Web Plan Retour sur les BDs Le service Search Un peu plus sur les
Technologies du Web Ludovic DENOYER - ludovic.denoyer@lip6.fr UPMC Février 2014 Ludovic DENOYER - ludovic.denoyer@lip6.fr Technologies du Web Plan Retour sur les BDs Le service Search Un peu plus sur les
Tables Rondes Le «Big Data»
 Tables Rondes Le «Big Data» 2012-2013 1 Plan Introduc9on 1 - Présenta9on Ingensi 2 - Le Big Data c est quoi? 3 - L histoire 4 - Le monde du libre : Hadoop 5 - Le système HDFS 6 - Les algorithmes distribués
Tables Rondes Le «Big Data» 2012-2013 1 Plan Introduc9on 1 - Présenta9on Ingensi 2 - Le Big Data c est quoi? 3 - L histoire 4 - Le monde du libre : Hadoop 5 - Le système HDFS 6 - Les algorithmes distribués
Document réalisé par Khadidjatou BAMBA
 Comprendre le BIG DATA Document réalisé par Khadidjatou BAMBA 1 Sommaire Avant propos. 3 Historique du Big Data.4 Introduction.....5 Chapitre I : Présentation du Big Data... 6 I. Généralités sur le Big
Comprendre le BIG DATA Document réalisé par Khadidjatou BAMBA 1 Sommaire Avant propos. 3 Historique du Big Data.4 Introduction.....5 Chapitre I : Présentation du Big Data... 6 I. Généralités sur le Big
Pentaho Business Analytics Intégrer > Explorer > Prévoir
 Pentaho Business Analytics Intégrer > Explorer > Prévoir Pentaho lie étroitement intégration de données et analytique. En effet, les services informatiques et les utilisateurs métiers peuvent accéder aux
Pentaho Business Analytics Intégrer > Explorer > Prévoir Pentaho lie étroitement intégration de données et analytique. En effet, les services informatiques et les utilisateurs métiers peuvent accéder aux
Présentation du module Base de données spatio-temporelles
 Présentation du module Base de données spatio-temporelles S. Lèbre slebre@unistra.fr Université de Strasbourg, département d informatique. Partie 1 : Notion de bases de données (12,5h ) Enjeux et principes
Présentation du module Base de données spatio-temporelles S. Lèbre slebre@unistra.fr Université de Strasbourg, département d informatique. Partie 1 : Notion de bases de données (12,5h ) Enjeux et principes
Cassandra chez Chronopost pour traiter en temps réel 1,5 milliard d événements par an
 Cassandra chez Chronopost pour traiter en temps réel 1,5 milliard d événements par an Qui suis-je? Alexander DEJANOVSKI Ingénieur EAI Depuis 15 ans chez Chronopost @alexanderdeja Chronopost International
Cassandra chez Chronopost pour traiter en temps réel 1,5 milliard d événements par an Qui suis-je? Alexander DEJANOVSKI Ingénieur EAI Depuis 15 ans chez Chronopost @alexanderdeja Chronopost International
Business Intelligence, Etat de l art et perspectives. ICAM JP Gouigoux 10/2012
 Business Intelligence, Etat de l art et perspectives ICAM JP Gouigoux 10/2012 CONTEXTE DE LA BI Un peu d histoire Premières bases de données utilisées comme simple système de persistance du contenu des
Business Intelligence, Etat de l art et perspectives ICAM JP Gouigoux 10/2012 CONTEXTE DE LA BI Un peu d histoire Premières bases de données utilisées comme simple système de persistance du contenu des
Programmation parallèle et distribuée (Master 1 Info 2015-2016)
") Programmation parallèle et distribuée (Master 1 Info 2015-2016) Hadoop MapReduce et HDFS Note bibliographique : ce cours est largement inspiré par le cours de Benjamin Renaut (Tokidev SAS) Introduction
Programmation parallèle et distribuée (Master 1 Info 2015-2016) Hadoop MapReduce et HDFS Note bibliographique : ce cours est largement inspiré par le cours de Benjamin Renaut (Tokidev SAS) Introduction
Innovative BI with SAP Jean-Michel JURBERT D. de Marché BI, HANA, BIG DATA _ SAP France
 Innovative BI with SAP Jean-Michel JURBERT D. de Marché BI, HANA, BIG DATA _ SAP France 2013 SAP AG. All rights reserved. Customer 1 Rôles et Attentes Instantanéité BIG DATA Users IT Real Time SAP HANA
Innovative BI with SAP Jean-Michel JURBERT D. de Marché BI, HANA, BIG DATA _ SAP France 2013 SAP AG. All rights reserved. Customer 1 Rôles et Attentes Instantanéité BIG DATA Users IT Real Time SAP HANA
Big Data On Line Analytics
 Fdil Fadila Bentayeb Lb Laboratoire ERIC Lyon 2 Big Data On Line Analytics ASD 2014 Hammamet Tunisie 1 Sommaire Sommaire Informatique décisionnelle (BI Business Intelligence) Big Data Big Data analytics
Fdil Fadila Bentayeb Lb Laboratoire ERIC Lyon 2 Big Data On Line Analytics ASD 2014 Hammamet Tunisie 1 Sommaire Sommaire Informatique décisionnelle (BI Business Intelligence) Big Data Big Data analytics
Notes de cours Practical BigData
 Notes de cours Practical BigData Nguyen-Nhut DOAN 15 janvier 2015 Introduction Ces notes personnelles traduisent la deuxième partie du cours INF553 de l Ecole Polytechnique sur les bases de données et
Notes de cours Practical BigData Nguyen-Nhut DOAN 15 janvier 2015 Introduction Ces notes personnelles traduisent la deuxième partie du cours INF553 de l Ecole Polytechnique sur les bases de données et
Exploration des Big Data pour optimiser la Business Intelligence
 Intel IT Meilleures pratiques IT Business Intelligence Juillet 2012 Exploration des Big Data pour optimiser la Business Intelligence Vue d ensemble La capacité à extraire et analyser les Big Data permet
Intel IT Meilleures pratiques IT Business Intelligence Juillet 2012 Exploration des Big Data pour optimiser la Business Intelligence Vue d ensemble La capacité à extraire et analyser les Big Data permet
Une nouvelle génération de serveur
 Séminaire Aristote 27 Mars 2013 Une nouvelle génération de serveur Sommaire L'équipe État de l'art et vision Présentation de l'innovation Les points forts de la solution Cas d'usage Questions? 2 L'équipe
Séminaire Aristote 27 Mars 2013 Une nouvelle génération de serveur Sommaire L'équipe État de l'art et vision Présentation de l'innovation Les points forts de la solution Cas d'usage Questions? 2 L'équipe
Change the game with smart innovation
 Change the game with smart innovation Master Thesis 2013 2014 Faculty of Science engineering 12/08/2012 Master Thesis proposal for the academic year 2013. TABLE OF CONTENTS Section Un Introduction... 3
Change the game with smart innovation Master Thesis 2013 2014 Faculty of Science engineering 12/08/2012 Master Thesis proposal for the academic year 2013. TABLE OF CONTENTS Section Un Introduction... 3
Importation et exportation de données dans HDFS
 1 Importation et exportation de données dans HDFS Introduction Dans une installation type, Hadoop se trouve au cœur d un flux de données complexe. Ces données proviennent souvent de systèmes disparates
1 Importation et exportation de données dans HDFS Introduction Dans une installation type, Hadoop se trouve au cœur d un flux de données complexe. Ces données proviennent souvent de systèmes disparates
Me#re le Big Data sur la carte : défis et avenues rela6fs à l exploita6on de la localisa6on
 Me#re le Big Data sur la carte : défis et avenues rela6fs à l exploita6on de la localisa6on Thierry Badard, PhD, ing. jr Centre de Recherche en Géoma6que Conférence ITIS - Big Data et Open Data au coeur
Me#re le Big Data sur la carte : défis et avenues rela6fs à l exploita6on de la localisa6on Thierry Badard, PhD, ing. jr Centre de Recherche en Géoma6que Conférence ITIS - Big Data et Open Data au coeur
T o u s d r o i t s r é s e r v é s 2 0 1 4-2 0 1 5 O S I s o f t, L L C. SÉMINAIRES RÉGIONAUX
 Le parcours vers l intelligence opérationnelle Présenté par Martin Jetté, directeur, Marketing et opérations Amérique du Nord mjette@osisoft.com Horaire de la présentation Le parcours vers l intelligence
Le parcours vers l intelligence opérationnelle Présenté par Martin Jetté, directeur, Marketing et opérations Amérique du Nord mjette@osisoft.com Horaire de la présentation Le parcours vers l intelligence
Benjamin Cornu Florian Joyeux. Les choses à connaître pour (essayer) de concurrencer Facebook.
 de concurrencer Facebook.") Benjamin Cornu Florian Joyeux Les choses à connaître pour (essayer) de concurrencer Facebook. 1 Sommaire Présentation générale Historique Facebook La face cachée de l iceberg (back end) Architecture globale
Benjamin Cornu Florian Joyeux Les choses à connaître pour (essayer) de concurrencer Facebook. 1 Sommaire Présentation générale Historique Facebook La face cachée de l iceberg (back end) Architecture globale