Systèmes Répartis. Mr. Mehrez Boulares, Mr. Nour Ben Yahia
|
|
|
- Denise Marie-Françoise Bernard
- il y a 8 ans
- Total affichages :
Transcription

1 Systèmes Répartis Mr. Mehrez Boulares, Mr. Nour Ben Yahia

2 Introduction aux systèmes répartis 2 Les ordinateurs ont subi des changements incroyables depuis leur mise en opération vers 1945: plus en plus de puissance, coût de fabrication a constamment diminué permettant aux usagers de disposer d'un objet peu dispendieux compte tenu de ce qu'il nous offre en retour. Les appareils subissent des changements constants et de plus en plus rapides tant du point de vue logiciel que matériel. Depuis très peu de temps, nous retrouvons sur le marché des systèmes multiprocesseurs, des systèmes d'exploitation pour le traitement parallèle et des réseaux puissants d'interconnexion. C'est là l'importance de prendre brièvement connaissance avec le système d'exploitation de demain. Nous sommes déjà entrés quelque peu dans l'informatique répartie qui elle nous amènera vers l'informatique distribuée /2014

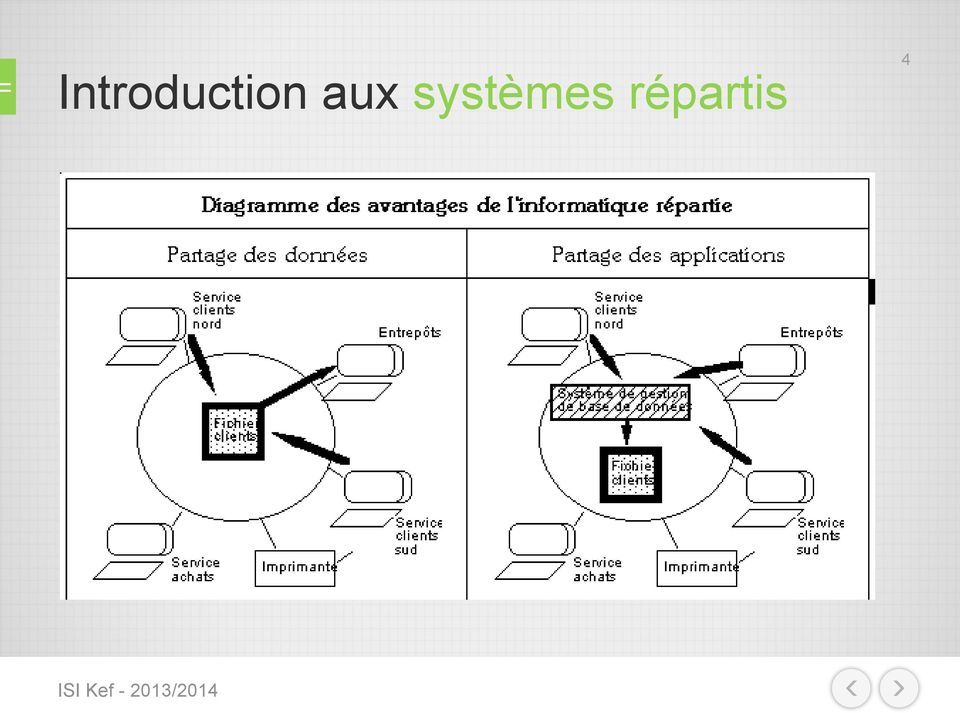
3 Introduction aux systèmes répartis 3 L'informatique répartie s'oppose à la fois à l'informatique centralisée, celle des gros ordinateurs, et à l'informatique individuelle, celle des micro-ordinateurs. Elle pallie certains désavantages de cette dernière par : Le partage des données grâce à un accès individuel, en lecture, par le réseau à des fichiers communs situés sur un disque quelconque ainsi que par le transfert de fichiers d'un disque à un autre. Le partage des applications. Pour l'exploitation individuelle, par le réseau, d'un seul logiciel de base de données sur le disque d'une des machines connectées. Le partage des ressources : chaque utilisateur connecté peut utiliser une même imprimante. les communications : envoi par le réseau de courrier dans une boîte aux lettres électronique à un ou plusieurs utilisateurs connectés. Accès par le réseau téléphonique à des services d'informations : annuaires, banques de données, etc /2014

4 Introduction aux systèmes répartis /2014
5 Introduction aux systèmes répartis /2014
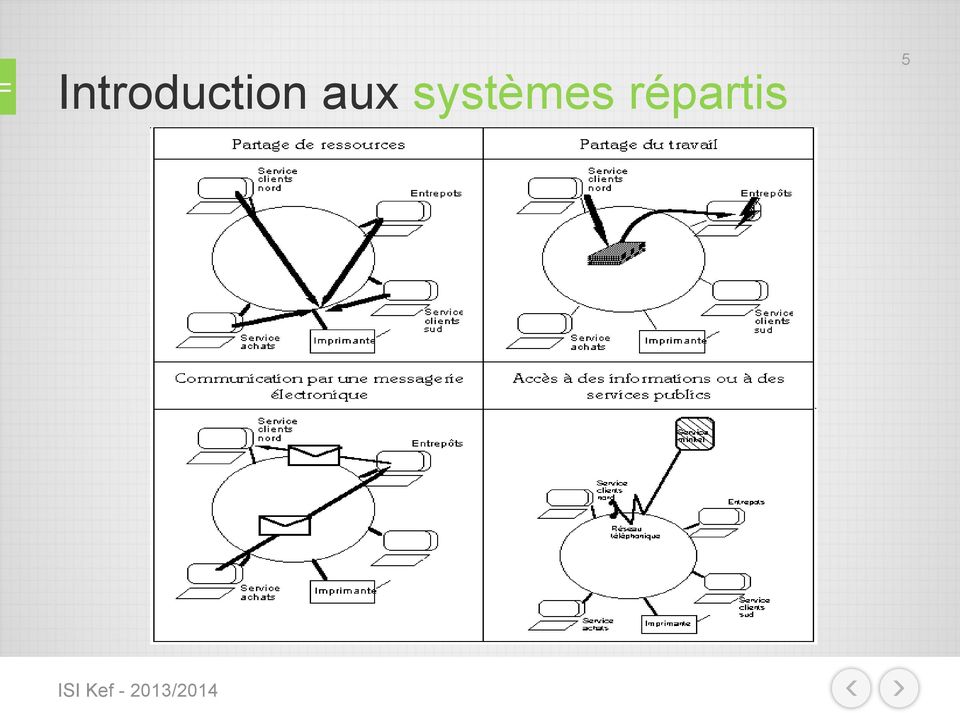
6 Exemple de Système Réparti : Un intranet 6 Source : Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edition 3, Addison-Wesley /2014

7 Pourquoi une informatique répartie 7 Raisons budgétaires : économie de logiciels, de matériels Raisons intrinsèques : adapter le système à l application BDD réparties, Web, systèmes bancaires Besoin de partager des informations : fichiers, BDD, messages des ressources : unités de stockage, imprimantes, serveurs Des services Accélérer le calcul Parallélisation de tâches Alléger la charge : réduire les goulots d'étranglement Augmenter la fiabilité : duplication de machines, de données réalisation de systèmes à haute disponibilité Qualité de service : diminuer les coûts, les délais, augmenter la disponibilité Réaliser des systèmes ouverts, évolutifs : adjonction facile de matériels et logiciels /2014

8 Inconvénients 8 Très peu de logiciels existent sur le marché. Le réseau peut très vite saturer. La sécurisation des données sensibles est compliquée. La mise en œuvre est difficile /2014

9 Définitions (1) 9 Un système à plusieurs processeurs n est pas forcément un système réparti Qu est-ce qu un système réparti, distribué, parallèle? Classification de flynn [1972]: On différencie les systèmes sur la base du flux d instructions et de données. SISD : PC monoprocesseur SIMD : machines vectorielles MISD : pipeline MIMD : machines multiprocesseurs faiblement et fortement couplées (systèmes parallèles, systèmes distribués, systèmes d exploitation réseaux) /2014
![Classification de flynn [1972]: On différencie les systèmes sur la base du flux d instructions et de données.](/docs-images/40/1912974/images/page_9.jpg "SISD : PC monoprocesseur SIMD : machines vectorielles MISD : pipeline MIMD : machines multiprocesseurs faiblement et")

10 - 2013/


11 Classification de Flynn 11 L'acronyme PU, de l'anglais, signifie processeur. Le terme «Instruction Pool» représente l'ensemble des instructions disponibles pour le ou les PU. Le terme «Data Pool» représente l'ensemble des données nécessaires aux calculs /2014

12 Définitions (1) 12 MIMD à mémoire partagée Les processeurs ont accès à la mémoire comme un espace d'adressage global. Tout changement dans une case mémoire est vu par les autres CPU. La communication inter-cpu est effectuée via la mémoire globale. MIMD à mémoire distribuée Chaque CPU a sa propre mémoire et son propre système d'exploitation. Ce second cas de figure nécessite un middleware pour la synchronisation et la communication. Un système MIMD hybride est l'architecture la plus utilisée par les superordinateurs. Ces systèmes hybrides possèdent l'avantage d'être très extensibles, performants et à faible coût /2014

13 Définitions (2) 13 Un système réparti est un ensemble de sites reliés par un réseau, comportant chacun une ou plusieurs machines. "Un système réparti est un système qui vous empêche de travailler quand une machine dont vous n avez jamais entendu parler tombe en panne" Lamport "Du point de vue utilisateur, un système réparti se comporte comme un système traditionnel, mais s exécute sur de multiples unités indépendantes" Tanenbaum Un système d exploitation réparti fournit et contrôle l accès aux ressources du système réparti. Un système d exploitation parallèle contrôle l exécution de programmes sur une machine parallèle (multiprocesseurs). Un système d exploitation de réseaux fournit une plateforme de machines reliées par un réseau chacune exécutant son propre système d exploitation /2014
.")
14 Exemples de SRs 14 WWW, FTP, Mail. Guichet de banque, agence de voyage. Téléphones portables (et bornes). Télévision interactive. Agents intelligents. Robots footballeurs /2014


15 Les différentes structures 15 Les structures centralisées Tous les courriers sont stockés sur C (station centrale). 1 usager = 1 boîte aux lettres sur C. Volume de stockage important sur C. Disponibilité du service = disponibilité de C. 1 opération = 1 transfert d'informations. L'architecture centralisée consiste en un noyau central fort autour duquel tous les périphériques sont regroupés (ou centralisées). Ce noyau central prend la plupart des actions. L'avantage est une facilité d'administration /2014

16 Les différentes structures 16 Structure décentralisée-ou répartie les architectures de réseau informatique se sont de plus en plus orientées vers une distribution des ressources et de la puissance informatique. Internet est sans doute l'exemple le plus marquant d'un réseau à architecture distribuée puisqu'il ne possède aucun site central. Dans la mise en œuvre de réseaux de moins grande ampleur, le degré de distribution (ou de centralisation) de la puissance de calcul, des périphériques, des bases de données dépend de différentes considérations stratégiques, humaines et professionnelles /2014
 de la puissance de calcul, des périphériques,")

17 Les différentes structures 17 Structure parallèles (Systèmes de haute performance) Les ordinateurs parallèles sont des machines qui comportent une architecture parallèle, constituée de plusieurs processeurs identiques, ou non, qui concourent au traitement d'une application. La performance d'une architecture parallèle est la combinaison des performances de ses ressources et de leur agencement. (Latence, débit) /2014

18 Les différentes structures 18 Structure parallèles (Systèmes de haute performance) Architectures parallèles : Pas de limite de mémoire. Pas de limite de processeurs. Accélération des calculs complexes ou coûteux en temps d'occupation CPU (calcul matriciel, simulation numérique, transformée de fourrier...). Calcul répétitif sur un large ensemble de données structuré. Traitement indépendant /2014
.")
19 Les différentes structures 19 Structure parallèles (Systèmes de haute performance) Le parallélisme est la conséquence : Besoin des applications. Calcul scientifique. Traitement d'images. Bases de données qui demandent des ressources en CPU et en temps de calcul de plus en plus importantes. Limites des architectures séquentielles. Performance. Capacité d'accès à la mémoire. Tolérance aux pannes /2014

20 Comparaison entre différentes architectures Comparaison des deux architectures de Systèmes de haute performance et de Systèmes distribués 20 Un système parallèle de HP est une réponse à un besoin de HP : Une solution au problème. Un système distribué est une solution à un problème de distribution géographique (historiquement). Mais de nos jours, la distribution peut résoudre un problème de HP. Donc, dans certains cas, un SD peut être considéré comme un système de HP /2014

21 Comparaison entre différentes architectures Comparaison des deux architectures centralisée et distribuée L'architecture centralisée supporte un noyau central alors que l'architecture distribuée peut supporter plusieurs. 21 Le coût de l'une ou l'autre architecture varie suivant le domaine. En règle générale, si les périphériques ne sont pas utilisés à plein temps (par exemple, une imprimante), l'architecture centralisée est plus économique (car on économise en se basant sur le fait que tous les périphériques ne seront jamais tous utilisés en même temps). Dans le cas contraire (carte vidéo, réseau de PC), c'est l'architecture distribuée la plus économique (un gros ordinateur coûte plus cher que 10 petits ordinateurs 10 fois moins puissants) /2014
22 Comparaison entre différentes architectures Comparaison des deux architectures centralisée et distribuée 22 Du point de vu de l architecture : Pas parallèle/pas distribué : Machine séquentielle (un seul processeur). Parallèle/Pas Distribué : Machines vectorielles, Machines à mémoires partagées, Machines SIMD. Pas Parallèle/Distribué : Réseau d ordinateurs avec communication lente exemple : Internet. Parallèle/Distribué : Réseau haut débit /2014

23 - 2013/

24 - 2013/
25 25 Systèmes parallèles Systèmes répartis Systèmes d exploitation de réseaux Processeurs Sites Ressources Homogènes Hétérogènes Hétérogènes Partage ou non de mémoire Mémoires individuelles Mémoires individuelles Couplage fort Couplage failbe Couplage failbe Topologie du réseau d interconnexion Les users sont au courant de la multiplicité des Processeurs Réseau LAN + WAN Les users ont l impression d être dans un système centralisé Réseau LAN Les users sont au courant de la multiplicité des Machines /2014
26 Identification des problèmes 26 Que doit résoudre un système réparti? Tolérance aux pannes. Passage à l échelle. Nommage et accès aux applications. Intégration de l existant. Déploiement des applications. Sécurité et authentification. Disponibilité de l application /2014
27 Tolérance aux pannes 27 En anglais : reliability, fault tolerance. Un serveur participant à l application tombe en panne. Un serveur envoie des informations erronées. Un serveur n est plus atteignable (mais pas en panne) puis le redevient. Atomicité dans les applications réparties /2014
28 Passage à l échelle 28 En anglais : scalability. Ce qui marche pour un utilisateur, marchera-t-il pour ? Ce qui marche pour un objet, marchera-t-il pour ? Ce qui marche pour un site, marchera-t-il pour 1000? Exemple : les applications de gestion de commerce électronique /2014
29 Nommage et accès aux applications 29 Nommage et accès aux applications En anglais : naming. Comment retrouver les objets distants? Un objet = un identifiant + un état + un comportement. Applications non réparties : nommage géré par le langage (référence) ou par l OS (adressage). Applications réparties : nommage explicite, dynamique? Exemple de nommage : DNS, URL, /2014
30 Intégration de l existant 30 En anglais : legacy. Connexion sur toutes les ressources d une entreprise. Interopérabilité des applications. Transactions réparties /2014
31 Déploiement des applications 31 Comment installer tous les composants logiciels sur différents clients et serveurs? Lorsque je change un nom de serveur ou j en ajoute un, je recompile? je redéploie? ou je peux configurer automatiquement le redéploiement? /2014
32 Sécurité et authentification 32 Confidentialité. Intégrité : Droits d accès, Pare-Feu. Authentification : Identification des applications partenaires. Non-répudiation. Messages authentifiés. Combien de personnes utilisent l application, qui sont-ils? Nécessité de se protéger contre les intrusions. Nécessité de stocker les accès des clients dans des fichiers journaux /2014
33 Disponibilité d une application 33 répartie Exemple : un serveur qui fait de la tolérance aux pannes ne peut plus assurer d autres tâches. Permettre des accès simultanés sur un même objet : Sérialiser les objets. Paralléliser les accès. Appliquer différentes politiques. Multi-threading /2014
34 Notions de Middleware 34 Middleware = Intergiciel = classe de logiciels systèmes agissant en qualité d infrastructure pour le développement ou le déploiement d applications reparties: exemple CORBA Supporte des applications tournant sur des plateformes matérielles et logicielles différentes. Le middleware fournit : un support de haut niveau pour la distribution exemple invocation de méthodes à distance. Des services de désignation, sécurité, transactionnels /2014
35 35 Le Middleware conceptualise et réalise les fonctions suivantes : communications entre les applications réparties, échanges de données, facilités de mise en œuvre. Il résout les problèmes d intégration et d interopérabilité : indépendance entre les applications et le système d exploitation, portabilité des applications, partage des services distribués. Services d un Middleware : communication, localisation, transactions, sécurité, administration /2014
36 Types de Middleware 36 Middleware de bases de données (ODBC) Middleware à messages MOM Message OrientedMiddleware : IBM MQSeries, Microsoft Message Queues. Middleware à objets répartis (CORBA, JAVA RMI) Middleware à composants (EJB, COM/DCOM, Web services) Middleware à environnement : XML /2014
37 Historique et état de l art Syst. temps partagé(unix), envir. Graphiques, réseaux 1970 Ordinateurs personnels, Stations de travail Client/serveur, Réseaux locaux : Ethernet XeroxDFS 1980 Systèmes ouverts,tolérance aux fautes Premiers serveurs de fichiers Évolution du C/S : Appel de procédures àdistance DNS en 85, Amoebaen 84, Mach en 86, Chorus en Internet, E-commerce AFS, NFS, LDAP DCE, corba, com/dcom /2014
38 Le modèle Client-Serveur (1/2) 38 Coté serveur : Externalisation de services. Attente de requêtes en provenances de clients puis exécution des requêtes en séquentiel ou en parallèle. Interface : Skeleton reçoit l appel sous forme de «stream» décapsule les paramètres demande l exécution renvoi les paramètres (par références) et les résultats Coté client : Émission de requêtes puis attente de la réponse. Initiateur du dialogue. Interface : Stub Reçoit l appel en local encapsule les paramètres attends les résultats du serveur décapsule les résultats redonne la main à la fonction appelante /2014
39 Le modèle Client-Serveur (2/2) 39 Client/Serveur «traditionnel» : RPC Client/Serveur «à objets» : RMI, CORBA, DCOM Client/Serveur «de données» : Requêtes SQL Client/Serveur «WEB» : CGI, Servlet, asp, jsp, php, /2014

40 Du centralisé vers le réparti /2014
41 Gestion du temps dans les SRs Mehrez Boulares, Nour Ben Yahia ISI KEF 2013/2014
42 INTRODUCTION 2 Les systèmes répartis sont présents dans toutes les applications et sont, par nature, très complexes. Le problème principal est qu il n y a plus d état global connu de toutes les parties mais seulement des états locaux permettant de faire émerger un état global. La propriété d émergence est souvent mentionnée dans les systèmes à agents ou systèmes multi agents : l activité de chacun concourt à la réalisation d un objectif global. Très naturellement, le contrôle de ces systèmes répartis n est pas simple mais il est important de pouvoir s assurer de la réalisation d un objectif donné par un ensemble d activités élémentaires.
43 INTRODUCTION 3 Un système réparti est constitué de N composants (processus ou sites) communiquant par messages (et uniquement de cette manière). Chacun de ces composants agit comme un automate : il réalise des opérations qui modifient son état. Les opérations réalisées par un des composants sont naturellement ordonnées par l'ordre dans lequel elles sont réalisées : s il s'agit d'un processus abritant plusieurs activités (threads), sur un système monoprocesseur, c'est l'ordre de l'exécution des instructions des instructions sur ce processeur qui ordonne les événements. La définition de l'ordre des événements sur un système multiprocesseurs (fortement et a fortiori faiblement couplés) est plus problématique du fait de la difficulté de maintenir une notion de temps absolu cohérente.
44 INTRODUCTION 4 Dans un contexte de répartition: L observation des programmes en exécution présente des difficultés qui rendent le problème non trivial. Un programme réparti est constitué d un ensemble de processus s exécutant en parallèle et communiquant seulement par envoi de messages sur des canaux les interconnectant. Il n y a pas d horloge commune aux différents processus, et de plus, les temps de transfert des messages ne sont pas bornés (dans un contexte de communication fiable, ils sont toutefois finis). Dans ces conditions, il est impossible d effectuer une observation simultanée de l état des différents processus et canaux. La réalisation d une observation cohérente qui reflète un état global constitué des états locaux des différentes parties du système, pris à des instants physiques différents mais de manière à rendre une information utile sur l état du système dans son intégralité, constitue donc un problème désormais classique, connu sous le nom de détection d un état global réparti cohérent.
45 PROBLEMATIQUE 5 Obtenir une vision instantanée d'un système réparti, consistant en la collection des états des différents sites le composant (typiquement une image mémoire de chacun des sites) est difficile à obtenir sans figer chacun des systèmes. L'absence de mémoire commune et le caractère aléatoire des délais d'acheminement des messages échangés entre les sites rendent impossible le calcul d'un état global du système dans un système réparti. Typiquement, l'image qu'un site possédera de l'état des autres sites ne pourra lui être communiquée qu'au travers de messages et ne pourra de ce fait correspondre qu'à un état du passé de ces sites : la chronologie des différentes images ainsi collectées n'est pas connue a priori.
46 PROBLEMATIQUE 6 L'absence d'un état global accessible directement constitue incontestablement une caractéristique de la répartition et est source de difficultés dans le développement d'applications relatives à : l'interblocage ou verrou mortel (deadlock): situation dans laquelle un ensemble de processus est en situation de blocage du fait de l'existence d'un cycle dans le graphe d'allocations et de demandes des ressources à ces processus ; le ramasse-miettes (garbage collecting), opération consistant en le épération des ressources allouées à un objet inutilisé ; la mise au point (debugging): opération incluant par exemple la consultation et/ou la modification des valeurs de variables dans différents composants à un instant donné.
47 PROBLEMATIQUE 7 Les Systèmes répartis ont une évolution asynchrone pas de mémoire commune (communication par messages) pas d horloge commune Les horloges locales ne sont pas synchrones et dérivent L état d un site distant ne peut être connu que par des informations véhiculées par les messages. De plus, les communications introduisent des délais L'ordre des messages n'est pas forcément préservé Conséquences : Perception différente des mêmes événements depuis des sites distincts Chaque site a sa propre horloge, la notion d'état global n'existe pas On ne peut pas mettre en œuvre des algorithmes répartis basés sur le temps.
48 CONSTRUCTION D UN ÉTAT GLOBAL 8 L'exécution d'un algorithme réparti est une succession d'événements, chacun d'eux se produisant sur un site donné (Un événement : émission/ réception de message, calcul local au site) Une horloge unique permet de donner une date à chacun des événements et de les ordonner entre eux. Sur chaque site, il est possible de définir un état local et de définir un ordre entre les événements Deux processus de deux sites différents peuvent avoir des informations différentes sur l état du système et sur l ordre des événements qui s y produisent. La solution de synchronisation des sites entre eux est donnée par la construction d'un état global Utilisation d'horloges : logiques, vectorielles, matricielles Utilisation d états locaux des sites et de messages en transit entre eux
49 LE MODÈLE DE CALCUL 9 Un système réparti est constitué d un ensemble fini de processus qui ne communiquent que par envoi de messages. La structure d un tel système peut être modélisée par un graphe orienté: les sommets de ce graphe sont les processus et les arcs représentent les canaux de communication unidirectionnels (canaux virtuels) reliant des processus entre eux. A priori, aucune hypothèse particulière n est faite quant à la topologie du graphe. Les processus seront désignés par P1, P2,..., Pn et le canal allant de Pi vers Pj, s il existe, sera désigné par C i j.
50 LE MODÈLE DE CALCUL 10 Les processus ne partagent ni mémoire commune ni horloge globale, et aucune hypothèse n est faite quant à leur vitesse relative. L envoi et la réception de messages sont effectués de manière asynchrone, mais aucun délai maximum de transfert des messages n est supposé connu. La seule hypothèse générale sur les communications concerne leur fiabilité: les messages ne sont ni perdus (le délai de transfert est fini: tout message émis est reçu) ni altérés ni dupliqués (tout message reçu a été émis). De telles hypothèses caractérisent ce qu il est convenu d appeler un système réparti asynchrone fiable
51 ETAT GLOBAL 11 Chaque processus et chaque canal possède à tout moment un état local. L état local «el i» d un processus «P i» résulte de son état initial et de la séquence d événements dont ce processus a été le siège. L état EC ij d un canal C ij est l ensemble des messages en transit sur ce canal, c est à dire qui ont été émis par le processus P i et n ont pas encore été reçus par le processus P j. L évolution du système est régie par un ensemble d événements. Chaque événement met en jeu un processus et éventuellement un canal. Il y a trois sortes d événements: les événements internes à un processus, qui ne modifient que l état local du processus, les émissions de messages, qui modifient l état local du processus émetteur et l état du canal sortant sur lequel est émis le message et les réceptions de messages, qui modifient l état local du processus récepteur et l état du canal entrant par lequel le message a été reçu.
52 ETAT GLOBAL 12 Schématiquement on a, à ce niveau de description (m désigne un message): événement interne sur P i : provoque la transition de el i à el' i, états avant et après l événement émission de m par P i sur C i j (cet événement est noté émission i (m)): provoque la transition de el i à el' i et l affectation EC i j := EC i j U {m} réception de m par P i sur C j i (cet événement est noté réceptioni(m)): provoque la transition de el i à el' i et l affectation EC j i := EC j i \ {m}.
53 ETAT GLOBAL 13 Chacun de ces événements est supposé atomique. On dit qu un événement e est capté dans l état local el i d un processus P i si e appartient à la séquence d événements ayant conduit P i dans l état el i. Il est important de remarquer que l état local d un processus n est immédiatement observable que par un observateur local à ce processus (c est à dire ayant accès en lecture à la mémoire locale de ce processus), tandis que l état local d un canal C i j n est immédiatement observable ni par son origine P i ni par son extrémité P j (P i - resp. P j - n a pas connaissance immédiate des événements de réception -resp. d émission-); c est notamment ce fait qui rend difficile le problème de l observation cohérente dans un système réparti. L état global S d un système réparti est constitué de l ensemble des états locaux des processus et des canaux qui le constituent
54 ETAT GLOBAL 14 Un état global cohérent correspond à un état global dans lequel le système peut se trouver. Formellement, cela signifie: i) i : eli est un état local du processus Pi. ii) Les conditions C1 et C2 qui suivant sont vérifiées: C1: si l événement émissioni(m) est capté dans eli, alors l événement réceptionj(m) est soit capté dans elj, soit le message m appartient à ecij. C2: si l événement émissioni(m) n est pas capté dans eli, l événement réceptionj(m) n est pas non plus capté dans elj.
55 ETAT GLOBAL 15 Considérons l exécution représentée par la figure 2, où trois processus Pi, Pj et Pk captent respectivement leurs états locaux eli, elj et elk (le graphe de communication est celui de la figure 1).
56 ETAT GLOBAL 16 L ensemble { eli, elj, elk} ne forme pas un état global. Si l on considère la paire (Pk, Pj), l émission du message m3 est enregistrée dans l état local elk du processus Pk alors que sa réception ne l est pas dans l état local elj du processus Pj. La condition C1 est mise en défaut, puisque l état du canal EC kj n est pas considéré (un éventuel redémarrage de Pj et de Pk, suite à une reprise après défaillance, à partir de cet état global entraînerait la perte du message m3). D autre part, même en considérant l état des canaux dans l état global, la cohérence n est pas assurée car la réception du message m4 est enregistrée dans elj sans que son émission le soit dans ELk, ce qui met en défaut la condition C2 (les deux états locaux elj et elk et l état du canal ECjk ne sont pas mutuellement cohérents).
57 NOTION DE PRÉCÉDENCE CAUSALE 17 Pour définir un état global il faut tout d abord pouvoir ordonner les événements entre eux, afin que : Si un des événements contient l émission d un message et que l autre contient la réception du même message, alors le premier a eu lieu avant le second. Si un site émet une demande d allocation d une ressource, il est considéré avant un autre site qui aurait émis sa requête après le premier. Cette relation d ordre partiel sur les événements est appelée relation de causalité. On définit la précédence comme suit : Un événement e précède un événement f si et seulement si : Ou bien e et f se déroulent sur le même site dans cet ordre Ou bien e contient l émission d un message m et f contient la réception du même message m.
58 NOTION DE PRÉCÉDENCE CAUSALE 18 Un événement E1 sur un site 1 précède un autre événement E2 sur un site 2 si E1 a été généré avant E2 : Il y a une précédence causale entre E1 et E2. Il existe une chaine d événement qui démarre à E1 et finit par E2 et qui consiste par un enchainement émission, exécution et réception. La précédence causale est concrétisée par le mécanisme d horloge logique, une notion logique permettant de comparer logiquement les événements de point de vu leur ordre d exécution quelque soit le site. Afin de dater les événements des horloges logiques de différents types peuvent être utilisées : Scalaire, Vectorielle, Matricielle.
59 NOTION DE PRÉCÉDENCE CAUSALE 19
60 NOTION DE PRÉCÉDENCE 20 CAUSALE Cette relation définit un ordre partiel des événements. Des événements e et e' non comparables sont dits concurrents, ce qu'on note e e'. A un événement e on peut alors associer trois ensembles d'événements : Passé(e) : ensemble des événements antérieurs à e dans l'ordre causal (e appartient à cet ensemble) ; Futur(e): ensemble des événements postérieurs à e dans l'ordre causal (e appartient à cet ensemble) ; Concurrent(e) : ensemble des événements concurrents avec e.
61 NOTION DE PRÉCÉDENCE CAUSALE 21 La précédence causale est concrétisée par le mécanisme des horloges logiques, une notion de temps logique permettant de comparer logiquement des événements du point de vue de leur ordre d'exécution quel que soit le site. Afin de dater les événements, des horloges logiques de différents types peuvent être définies afin de rendre compte de la relation de causalité entre les événements. Les valeurs des horloges associées à des événements (leurs estampilles logiques) comparables doivent être elles-mêmes comparables et refléter l'ordre des événements
62 HORLOGE LOGIQUE 22 Lamport a proposé de définir pour ce type de systèmes une notion de temps logique permettant de comparer logiquement des événements du point de vue de leur ordre d'exécution : d'une part, sur un site, les événements locaux peuvent être ordonnés en se basant sur l'ordre de leur exécution (ou le temps absolu s'il est défini) et d'autre part l'émission d'un message sur le site émetteur précède toujours sa réception sur le site récepteur. Cela correspond à la notion de précédence causale.
63 HORLOGE LOGIQUE 23 Selon Leslie Lamport l'horloge logique permet de comparer logiquement des événements (requêtes, messages ) du point de vue de leur ordre d'exécution (Horloges scalaires) Chaque site gère une horloge de type compteur dont la valeur est un entier (initialisé à 0 au lancement du système). La valeur de l'horloge logique d'un site est incrémentée chaque fois qu'un événement local s'y produit : opération locale, ou envoi/réception d'un message. Dans le cas d'un envoi, la valeur courante (après incrémentation) de l'horloge de l'émetteur est embarquée avec le message et sert à l'estampiller (La réception d'un message permet de synchroniser l'horloge du récepteur avec celle de l'émetteur du message qui est transportée par le message. Le principe est simple : il consiste à attribuer à l'horloge du récepteur une valeur supérieure à la fois à la valeur courante de l'horloge du site et à celle de l'estampille du message reçu.) La réception d'un message permet de synchroniser l'horloge du récepteur avec celle de l'émetteur du message qui est transportée par le message.

64 HORLOGE LOGIQUE SCALAIRE 24 Principe : attribuer à l'horloge du récepteur une valeur supérieure à la fois à a valeur courante de l'horloge du site et à celle de l'estampille du message reçu. Conséquence : Garantit que la réception sera postérieure à l'émission.
65 HORLOGE LOGIQUE SCALAIRE 25
66 HORLOGE LOGIQUE SCALAIRE 26
67 HORLOGE LOGIQUE SCALAIRE 27 Cette technique permet donc d'associer à chaque événement une date (estampille logique) correspondant à la valeur de l'horloge de son site modifiée selon les règles que nous venons de définir. On peut observer que : l'ordre des événements qui est ainsi défini n'est pas un ordre strict : plusieurs événements peuvent porter la même valeur. C'est le cas (parmi d'autres) sur notre exemple des événements e, o et x appartenant respectivement à P, Q et R qui ont chacun 6 comme date. Il est facile de rendre cet ordre strict en modifiant légèrement le système de datation : la date d'un événement sur un site est obtenue en adjoignant à la valeur de l'horloge scalaire de ce site l'identification du site (par exemple un entier attribué artificiellement ou une adresse IP ou physique).
68 HORLOGE LOGIQUE SCALAIRE 28 La règle de comparaison des dates est alors :
69 HORLOGE LOGIQUE SCALAIRE 29 De nombreux algorithmes répartis : Algorithmes utilisant une file d attente virtuelle répartie (Exclusion mutuelle répartie, mise à jour de copies multiples, diffusion cohérente (ordre de réception uniforme)) Détermination de l accès le plus récent (gestion cohérente de caches multiples, mémoire virtuelle répartie) Synchronisation des horloges physiques (borne supérieure sur la dérive entre sites) Algorithmes de détection de terminaison, d'élection, de diffusion de messages,
70 HORLOGE LOGIQUE VECTORIELLE 30 Nous venons de voir que le système de datation par estampilles scalaires d'une part introduisait un ordre artificiel sur des événements concurrents et d'autre part ne permettait pas de corriger les défaillances vis-à-vis de la relation FIFO des canaux de communication. Le mécanisme de datation par estampilles vectorielles (et les horloges vectorielles maintenues par les différents composants d'un système) permet de pallier ces deux inconvénients. Chaque site gère une horloge vectorielle constituée de n entiers (n est le nombre de composants du système). Une telle horloge permet de dater les événements d'un site et est mise à jour lors de l'occurrence des événements. Comme pour les horloges scalaires, les messages envoyés par un site sont estampillés en utilisant la valeur courante de l'horloge vectorielle du site émetteur et la réception d'un message pemet au site récepteur de synchroniser son horloge vectorielle avec celle du site émetteur du message. De manière plus précise, les règles suivantes sont appliquées pour la gestion des horloges vectorielles:
71 HORLOGE LOGIQUE VECTORIELLE 31
72 HORLOGE LOGIQUE VECTORIELLE 32
73 HORLOGE LOGIQUE VECTORIELLE 33 La propriété fondamentale que possèdent les estampilles vectorielles déduites des horloges vectorielles et de leur actualisation par les règles énoncées est que Par exemple l'estampille vectorielle de l'événement p est [4, 7, 5]. Cela correspond au fait que Passé(p) contient 4 événements sur P (a, b, c, d); 7 événements sur Q (j, k, l, m, n, o, p); 5 événements sur R (u, v, w, x, z).
74 HORLOGE LOGIQUE VECTORIELLE 34 La relation d'ordre suivante peut par ailleurs être définie sur les estampilles vectorielles : Par exemple [4,7,5] est plus petite que [6,7,8], plus grande que [4,6,4] et incomparable avec [6,5,7]
75 HORLOGE LOGIQUE VECTORIELLE 35 Muni de cette relation d'ordre, le système de datation par estampilles vectorielles a la remarquable propriété de refléter exactement la relation de précédence causale entre événements :
76 HORLOGE LOGIQUE VECTORIELLE 36 On peut vérifier sur notre exemple que : les estampilles vectorielles des événements précédant causalement p sont inférieures (au sens qui a été défini) à l'estampille vectorielle de p ([4,7,5]). Par exemple l'estampille vectorielle de l'événement d antérieur à p est ([4,1,0]) qui est inférieure à ([4,7,5]); les estampilles vectorielles des événements suivant causalement p sont supérieures à l'estampille vectorielle de p. Par exemple l'estampille vectorielle de l'événement C postérieur à p est ([8,9,9]) qui est supérieure à ([4,7,5]); les estampilles vectorielles des événements concurrents de p sont incomparables avec l'estampille vectorielle de p; Par exemple l'estampille vectorielle de l'événement e concurrent avec l'événement p est ([5,3,3]) qui est incomparable avec ([4,7,5]).
77 Correction TD 37
78 Correction TD 38 Considérons l'événement p. Il appartient à son propre passé et est précédé directement par o et y. - On a Passé(p) = {p} + Passé(o) + Passé(y) Le calcul de Passé(p) suppose donc le calcul de celui de o et y. - On a Passé(o) = {o} + Passé(n) + Passé(d) En pousuivant le calcul: - Passé(n) = {n} + Passé(m) - Passé(m) = {m} + Passé(l) + Passé(a) - Passé(l) = {l} + Passé(k) - Passé(k) = {k} + Passé(j) + Passé(u) - Passé(j) = {j} - Passé(u) = {u} - Passé(a) = {a} - Passé(d) = {d} + Passé(c) - Passé(c) = {c} + Passé(b) - Passé(b) = {b} + Passé(a) + Passé(j) - Passé(y) = {y} + Passé(x) - Passé(x) = {x} + Passé(w) + Passé(n) - Passé(w) = {w} + Passé(v) - Passé(v) = {v} + Passé(u) + Passé(l) Par conséquent Passé(p) = {a, b, c, d, j, k, l, m, n, o, p, u, v, w, x, y}
79 Correction TD 39 Par un calcul analogue, on obtient: Futur(p) = {g, h, i, p, q, r, s, t, C, D} Finalement les événements n'appartenant ni à Passé(p), ni à Futur(p) sont concurrents avec p. On a donc Concurrent(p) = {e, f, z, A, B}
80 Correction TD 40
81 Correction TD 41
82 Correction TD 42
83 Accès concurrent dans les SR Mehrez Boulares, Nour Ben Yahia
84 Les accès concurrents : rappels 2 Un problème d'accès concurrent a lieu quand deux processus partagent une ressource logicielle ou matérielle: on parle de section critique au niveau du programme. Exemples: section de ligne ferroviaire à voie unique. Trains dans un sens ou dans l'autre, mais pas dans les deux sens en même temps. Lecteurs/rédacteurs, producteurs/consommateurs On rentre en section critique, par une section d'entrée qui met en œuvre une condition et on la quitte par une section de sortie. Section d'entrée Section critique : inst1, inst2, inst3 Section de sortie
85 Les accès concurrents : rappels 3 Rappelons tout d'abord en quoi consiste ce problème. Des applications s'exécutant de manière concurrente et partageant des ressources peuvent, dans certaines circonstances, avoir besoin d'accéder de manière exclusive à une ou plusieurs de ces ressources appelées ressources critiques. Le code exécuté nécessitant cet accès exclusif est lui-même appelé une section critique. On fait couramment le parallèle avec une voie de chemin de fer ou un pont étroit supportant une charge limitée susceptibles d'être empruntés par des véhicules dans les deux sens. Le bon fonctionnement (et la survie des usagers) suppose que seul un véhicule ne puisse utiliser, à un instant donné, la section de rail ou de route correspondante. D'un point de vue informatique, ce problème est fréquent. Citons-en quelques exemples : suite d'opérations dans un fichier ou une base de données ; accès à une ressource telle qu'une imprimante ; accès à une zone de mémoire centrale ; (segment de mémoire partagée) par plusieurs processus
86 Les états d'un processus 4 Un processus est dans 3 états possibles, par rapport à l'accès à la ressource Demandeur : demande à utiliser la ressource, à entrer dans la section Dedans : dans la section critique, utilise la ressource partagée Dehors : en dehors de la section et non demandeur d'y entrer Changement d'état par un processus De dehors à demandeur pour demander à accéder à la ressource De dedans à dehors pour préciser qu'il libère la ressource Le passage de l'état demandeur à l'état dedans est géré par le système et/ou l'algorithme de gestion d'accès à la ressource
87 Propriétés d'un algorithme d'exclusion mutuelle 5 Une solution n'est considérée correcte que si elle respecte les propriétés suivantes Sûreté (safety) : au plus un processus est à la fois dans la section critique (dans l'état dedans) Vivacité (liveness) : tout processus demandant à entrer dans la section critique (à passer dans l'état dedans) y entre en un temps fini Un algorithme qui assure ces deux propriétés assure également l'absence de deux problèmes, l'interblocage et la famine: Interblocage (Deadlock) : est une situation du système où il y a plusieurs sites à l'état Demandeur et aucun ne peut accéder à la SC. Famine (Starvation) : aura lieu si un site qui se trouve à l'état Demandeur ne passe jamais à l'état Dedans.
88 Solutions 6 On parle d'exclusion mutuelle quand un seul processus à la fois a le droit de rentrer en section critique. Solutions logicielles : Sémaphores, Moniteurs. Solutions matérielles : Désactiver les interruptions.
89 Solutions matérielles 7 La solution la plus simple, mais qui ne peut s'appliquer que dans le cas de machines monoprocesseurs, consiste à masquer les interruptions susceptibles de provoquer une concurrence relativement à une ressource critique. Dans le mode superviseur des processeurs, il est possible de manipuler le masque d'interruption du processeur, ce qui est largement utilisé lors du développement des systèmes d'exploitation.
90 Solutions logicielles 8 Nous nous intéressons ici à la possibilité de résoudre le problème de l'exclusion mutuelle sans faire appel à des instructions spécifiques et donc en se basant sur les seules opérations d'affectation et de test. Ainsi qu'on va le voir au travers de solutions erronées, cela n'est pas immédiat et nécessite certaines précautions. La première idée qui vient à l'esprit consiste à utiliser une variable booléenne ayant la valeur VRAI lorsqu'un processus est en section critique.
91 Les accès concurrents : les sémaphores 9 Sémaphores binaires qui peuvent prendre la valeur 0 ou 1 et les sémaphores n-aires. Le système gère l'entrée à la section en endormant les processus qui arrivent alors que le sémaphore est attribué, Les primitives P et V sont indivisibles P(S) permet de prendre le sémaphore : Si S > 0 Finsi. Alors s = s -1 Sinon s'endormir V(S) permet de libérer le sémaphore et un processus bloqué s'il y en a Si un processus est bloqué sur S Finsi. Alors le libérer Sinon s =s+1
92 Les accès concurrents dans un environnement réparti Un processus bloqué appartient à la file des processus en attente, une fois libéré il passe dans celle des prêts Le système gère des contextes de processus. Peut-on gérer des contextes à distance? NON 10 Plusieurs grandes familles de méthodes Contrôle par un serveur qui centralise les demandes d'accès à la ressource partagée Contrôle par jeton Un jeton circule entre les processus et donne l'accès à la ressource La gestion et l'affectation du jeton et donc l'accès à la ressource est faite par les processus entre eux Deux approches : jeton circulant en permanence ou affecté à la demande des processus Contrôle par permission Les processus s'autorisent mutuellement à accéder à la ressource
93 Définitions 11 Une commutation de contexte (context switch) en informatique consiste à sauvegarder l'état d'un processus ou d'un processus léger et à restaurer l'état d'un autre processus (léger) de façon à ce que des processus multiples puissent partager les ressources d'un seul processeur dans le cadre d'un système d'exploitation multitâche. Le contexte d'un processus est l'ensemble des informations dynamiques qui représente l'état d'exécution d'un processus (e.g. où est-ce que le processus en est de son exécution).
94 Exemple 12 La commutation de contexte invoque au moins trois étapes. Par exemple, en présumant que l'on veut commuter l'utilisation du processeur par le processus P 1 vers le processus P 2 : Sauvegarder le contexte du processus P 1 quelque part en mémoire (usuellement sur la pile de P 1 ). Retrouver le contexte de P 2 en mémoire (usuellement sur la pile de P 2 ). Restaurer le contexte de P 2 dans le processeur, la dernière étape de la restauration consistant à reprendre l'exécution de P 2 à son point de dernière exécution.
95 Solution du coordinateur 13 Principe général Un serveur centralise et gère l'accès à la ressource Algorithme Un processus voulant accéder à la ressource (quand il passe dans l'état demandeur) envoie une requête au serveur Quand le serveur lui envoie l'autorisation, il accède à la ressource (passe dans l'état dedans) Il informe le serveur quand il relâche la ressource (passe dans l'état dehors) Le serveur reçoit les demandes d'accès et envoie les autorisations d'accès aux processus demandeurs Avec par exemple une gestion FIFO : premier processus demandeur, premier autorisé à accéder à la ressource
96 Solution du coordinateur 14 Un coordinateur gère l'accès à la ressource Tout processus remplace P(S) par une requête bloquante au coordinateur Puis-je? V(S) est remplacé par une primitive qui envoie un message de terminaison au coordinateur Avantages Très simple à mettre en œuvre Simple pour gérer la concurrence d'accès à la ressource Inconvénients : Sollicitation excessive du coordinateur Panne du coordinateur, il faut élire un nouveau coordinateur Tous doivent se mettre d'accord pour n'en élire qu'un seul, mais il faut en élire un au bout d'un temps fini
97 Solution du coordinateur 15 Suppression du serveur centralisateur Via par exemple une méthode à jeton : le processus qui a le jeton peut accéder à la ressource La gestion et l'affectation du jeton est faite par les processus entre eux Pas de besoin de serveur centralisateur
98 Algorithme à base de jeton 16 Anneau logique (indépendant de la structure du réseau physique) : chaque site a un successeur Jeton circulant : un site non demandeur transmet le jeton à son successeur un site demandeur attend le jeton pour obtenir l'exclusion mutuelle un site qui sort d'exclusion mutuelle transmet le jeton à successeur Un jeton unique circule entre tous les processus Le processus qui a le jeton est le seul qui peut accéder à la section critique Respect des propriétés Sûreté : unicité du jeton Vivacité : l'algorithme doit assurer que le jeton circule bien entre tous les processus voulant accéder à la ressource
99 Algorithmes 17 Algorithme de [Le Lann, 77] Algorithme de [ Ricart & Agrawala, 83 ]
100 Les accès concurrents : solutions réparties (en théorie) 18 Chaque processus connaît les N autres processus conflictuels. Chaque processus désirant rentrer en section critique : Envoie un message aux N processus : puis_je? Attend N réponses Réception N réponses: début de la section critique Réception N-1 réponses : un processus est probablement en section critique La réponse du processus s'est perdue Aucun respect de l'ordre des demandes Risque de famine SOLUTION : estampiller les messages Algorithmes à base de permission (Un processus candidat doit demander a d'autres processus la permission d'entrer en exclusion )
101 Méthodes par permission 19 Un processus doit avoir l'autorisation des autres processus pour accéder à la ressource Principe général Un processus demande l'autorisation à un sous-ensemble donné de tous les processus Deux modes Permission individuelle : un processus peut donner sa permission à plusieurs autres à la fois Permission par arbitre : un processus ne donne sa permission qu'à un seul processus à la fois
102 Les accès concurrents: l'algorithme de Lamport 20 Proposé en 1978, vise à satisfaire les demandes des différents sites dans où elles sont formulées Cet algorithme suppose que les canaux de communication entre les différents sites respectent la propriété FIFO. Chacun des composants du système utilise une horloge scalaire qu'il synchronise lors de la réception de messages en provenance des autres composants du système. Trois types de messages (estampillés lors de leur envoi) sont utilisés et chacun des messages sera systématiquement envoyé à tous les autres participants : REQUETE : un tel message est envoyé lorsqu'un site veut entrer en section critique; REPONSE : un tel message est envoyé par un site qui reçoit un message du type précédent ; LIBERATION : un tel message est envoyé par un site lorsqu'il sort de section critique.
103 Les accès concurrents: l'algorithme de Lamport Chaque site gère une file d'attente dans laquelle il place, dans l'ordre induit par la valeur de leurs estampilles, toutes les requêtes pour entrer en section critique (y compris les siennes) et leurs estampilles. En fait, la file des requêtes sera répliquée sur chaque site, si bien que chaque site peut décider de la possibilité d'entrer en section critique sur la base des informations qu'il possède. 21

104 l'algorithme de Lamport 22
105 l'algorithme de Lamport 23 Elle repose sur les observations suivantes : la propriété FIFO de chacun des canaux de communication et la synchronisation des horloges, implique que si un site a reçu un message d'accord (de type REPONSE) en provenance du site j toute requête antérieure de ce même site lui est nécessairement arrivée; toute demande lui arrivant en provenance de ce site sera postérieure à la sienne, s'il en a formulé une. Si un site a reçu l'accord de tous les sites et que sa demande est la plus ancienne, aucune demande antérieure ne lui parviendra d'un autre site; l'existence d'un ordre total sur les demandes implique que seul un site pourra rentrer en section critique, les autres devant nécessairement attendre que la demande en tête de file soit retirée de la file (donc que le site élu sorte de section critique et envoie un message de type LIBERATION).
106 l'algorithme de Lamport 24 Nombre de messages échangés Le traitement complet (entrée et sortie) d'une phase de section critique requiert, pour un système de N composants, 3*(N-1) messages (N-1 messages de chacun des types).
107 Exemple 25 Dans cet exemple impliquant trois sites, les sites S 1 et S 2 veulent entrer en section critique alors que leurs horloges scalaires ont respectivement 3 et 2 comme valeur. Les messages envoyés par S 1 à S 2 et S 3 sont donc estampillés 3.1. Les messages envoyés par S 2 à S 1 et S 3 sont quant à eux estampillés 2.2. Dans la figure ci-dessous : les envois de messages de type REQUETE correspondent aux flèches bleues; les envois de messages de type REPONSE correspondent aux flèches vertes; les envois de messages de type LIBERATION correspondent aux flèches rouges.
108 l'algorithme de Lamport 26
109 l'algorithme de Lamport 27
110 l'algorithme de Lamport 28
111 l'algorithme de Lamport 29
112 l'algorithme de Lamport 30
113 l'algorithme de Lamport 31
114 l'algorithme de Lamport 32
115 l'algorithme de Lamport 33
116 l'algorithme de Lamport 34
117 l'algorithme de Lamport 35
118 l'algorithme de Lamport 36
119 Algorithmes 37 Algorithme de [Ricart & Agrawala, 81] [Carvalho & Roucairol, 83] [Chandy & Misra, 84]
120 Inter blocage dans les SRs Mehrez Boulares, Nour Ben Yahia
121 Inter blocage: introduction 2 Solution accès concurrents ne veut pas dire absence d inter blocage. Inter blocage : situation pour un ensemble de processus(ou transactions) où chacun d entre eux est dans l attente de la réalisation d un événement de la part d un autre. Mauvaise programmation risque d inter blocage : Sections critiques emboitées on doit interdire des appels récursifs d une section critique (appels récursifs à l intérieure d une SC). Besoin de plusieurs ressources : inter-blocages
122 Inter blocage: introduction 3 Un ensemble de processus sont en interblocage si chaque processus dans cet ensemble est bloqué en attente d un événement qui seulement un autre processus de cet même ensemble peut déclencher. L événement attendu peut être la libération d une ressource ou l envoie d un message. En cas d interblocage aucun processus ne peut Ni continuer son exécution Ni libérer une ressource Ni être réveillé
123 Inter blocage : introduction 4 L inter-blocage demande la présence simultanée de 4 conditions (conditions nécessaires) 1. Exclusion mutuelle: A un instant précis, une ressource est allouée à un seul processus. 2. Saisie et attente (hold and wait): un processus détient une ressource non partageable et en attend des autres pour compléter sa tâche. 3. Pas de préemption : un processus qui détient une ressource non partageable la garde jusqu à ce qu il aura complété sa tâche. 4. Attente circulaire: il y a un cycle de processus tel que chaque processus pour compléter doit utiliser une ressource non partageable qui est utilisée par le suivant, et que le suivant gardera jusqu`à sa terminaison.

124 Inter blocage : introduction 5 Exemple : Exclusion mutuelle: Seulement une voiture occupe un endroit particulier de la route à un instant donné. Saisie et attente : Aucune voiture ne peut faire marche arrière. Pas de préemption: On ne permet pas à une voiture de pousser une autre voiture en dehors de la route. Attente circulaire: Chaque coin de la rue contient des voitures dont le mouvement dépend des voitures qui bloquent la prochaine intersection.

125 Modélisation des inters blocages 6 Processus Ressource possédant 4 exemplaires (instances) Pi demande un exemplaire de Ri, bloqué en attente de la ressource Pj détient un exemplaire de Rj ou Rj est affecté à Pj

126 Modélisation des inters blocages 7
127 Modélisation des inters blocages 8
128 Explication des graphes 9 - Dans G2 de fait que P1 n utilise plus qu une seule ressource la condition 3 n est pas vérifiée, ainsi que dès que P1 libère la ressource, P3 peut y accéder en mettant fin ainsi à un éventuel inter blocage. * Existence de 2 cycles :
129 Explication des graphes 10 Tous les cycles ne sont pas bloquants : Tout graphe d allocation de ressource avec une seule occurrence des ressources peut être converti en graphe d attente WFG (Wait For Graph).

130 Explication des graphes 11 Simplification possible lorsqu un processus demande une ressource spécifique identifiée : Sommet processus ; Arc étiqueté par la ressource demandée.
131 Inter blocage : Solutions 12 Ignorer le problème (L algorithme de l autruche) D évitement : le système alloue une ressource si elle n entraînera pas d interblocage (disposer à l avance d informations sur l utilisation des ressources par un processus, et décider dynamiquement de l allocation) Préventives : le système empêche les inters blocages d avoir lieu (s assurer que l une des conditions nécessaires n est jamais remplie) Détection et guérison : le système ne fait aucun effort à priori. Une fois qu un inter blocage est détecté, il le corrige (requiert un algorithme de détection et un algorithme de correction. Surcharge de travail pour le système.) Les algorithmes différents selon le nombre d instances des ressources.
132 Inter blocage : Solutions 13 - Problématique différente : Détection difficile. Respect de l ordre d accès aux ressources, difficile.
133 Solution basée sur la prévention 14 A- Allocation par classe de ressource : Consiste à classer les ressources et à les demander dans un certain ordre. Soit un processus qui détient Ri, et qui demande Rj il ne sera autorisé à demander Rj que si classe(ri) < classe(rj) autrement il libère Ri. Inconvénient : ne s applique pas aux ressources logiciels et nécessite la K de l ordre d accès au ressources. B- Allocation par estampilles : Chaque processus acquiert au démarrage une estampille. Il s agit de respecter une allocation basée sur un ordre croissant des estampilles. 2 versions: Wait/Die, Wound/Wait RosenKrantz(1978).
134 Solution basée sur la prévention 15 - Les algorithmes Attente/Mort (Wait/Die) et Blessé/Attente (Wound/Wait) sont deux autres méthodes d'évitement qui utilisent une technique de rupture de la symétrie. Dans ces deux algorithmes on prend en compte l'âge des processus et l'on distingue un processus âgé (A) et un processus jeune (J). - L'âge d'un processus peut être déterminé par horodatage (timestamp) lors de sa création. Les dates les plus petites appartiennent à des processus plus âgés, les plus grandes à des processus plus jeunes.
135 Solution basée sur la prévention 16 Il est important de se rendre compte qu'un processus peut être dans un état non-sûr sans pour autant forcément conduire à un inter blocage. La notion de sûr/non-sûr fait uniquement référence à la possibilité que le système entre dans un inter blocage ou non. Par exemple, si un processus fait une requête sur une ressource A qui résulte en un état non-sûr, mais relâche une ressource B pour éviter une attente circulaire, alors l'état est non-sûr mais le système n'est pas en inter blocage.
 > E(Pj) {demande Pj est plus ancienne}. Pj est autorisé à attendre. Sinon {demande Pi est plus ancienne}. Pj est tué. - Les vieux attendent, les jeunes meurent.")
136 Wait / Die 17 Un processus n est autorisé à attendre que s il est plus vieux (estampille plus petite). Pi détient la ressource, Pj demande la ressource. Si E(Pi) > E(Pj) {demande Pj est plus ancienne}. Pj est autorisé à attendre. Sinon {demande Pi est plus ancienne}. Pj est tué. - Les vieux attendent, les jeunes meurent. Risque de famine pour les jeunes.
Conception des systèmes répartis
 Conception des systèmes répartis Principes et concepts Gérard Padiou Département Informatique et Mathématiques appliquées ENSEEIHT Octobre 2012 Gérard Padiou Conception des systèmes répartis 1 / 37 plan
Conception des systèmes répartis Principes et concepts Gérard Padiou Département Informatique et Mathématiques appliquées ENSEEIHT Octobre 2012 Gérard Padiou Conception des systèmes répartis 1 / 37 plan
Chapitre 4 : Exclusion mutuelle
 Chapitre 4 : Exclusion mutuelle Pierre Gançarski Juillet 2004 Ce support de cours comporte un certain nombre d erreurs : je décline toute responsabilité quant à leurs conséquences sur le déroulement des
Chapitre 4 : Exclusion mutuelle Pierre Gançarski Juillet 2004 Ce support de cours comporte un certain nombre d erreurs : je décline toute responsabilité quant à leurs conséquences sur le déroulement des
PROGRAMME DU CONCOURS DE RÉDACTEUR INFORMATICIEN
 PROGRAMME DU CONCOURS DE RÉDACTEUR INFORMATICIEN 1. DÉVELOPPEMENT D'APPLICATION (CONCEPTEUR ANALYSTE) 1.1 ARCHITECTURE MATÉRIELLE DU SYSTÈME INFORMATIQUE 1.1.1 Architecture d'un ordinateur Processeur,
PROGRAMME DU CONCOURS DE RÉDACTEUR INFORMATICIEN 1. DÉVELOPPEMENT D'APPLICATION (CONCEPTEUR ANALYSTE) 1.1 ARCHITECTURE MATÉRIELLE DU SYSTÈME INFORMATIQUE 1.1.1 Architecture d'un ordinateur Processeur,
PROBLEMES D'ORDONNANCEMENT AVEC RESSOURCES
 Leçon 11 PROBLEMES D'ORDONNANCEMENT AVEC RESSOURCES Dans cette leçon, nous retrouvons le problème d ordonnancement déjà vu mais en ajoutant la prise en compte de contraintes portant sur les ressources.
Leçon 11 PROBLEMES D'ORDONNANCEMENT AVEC RESSOURCES Dans cette leçon, nous retrouvons le problème d ordonnancement déjà vu mais en ajoutant la prise en compte de contraintes portant sur les ressources.
REALISATION d'un. ORDONNANCEUR à ECHEANCES
 REALISATION d'un ORDONNANCEUR à ECHEANCES I- PRÉSENTATION... 3 II. DESCRIPTION DU NOYAU ORIGINEL... 4 II.1- ARCHITECTURE... 4 II.2 - SERVICES... 4 III. IMPLÉMENTATION DE L'ORDONNANCEUR À ÉCHÉANCES... 6
REALISATION d'un ORDONNANCEUR à ECHEANCES I- PRÉSENTATION... 3 II. DESCRIPTION DU NOYAU ORIGINEL... 4 II.1- ARCHITECTURE... 4 II.2 - SERVICES... 4 III. IMPLÉMENTATION DE L'ORDONNANCEUR À ÉCHÉANCES... 6
Cours de Systèmes d Exploitation
 Licence d informatique Synchronisation et Communication inter-processus Hafid Bourzoufi Université de Valenciennes - ISTV Introduction Les processus concurrents s exécutant dans le système d exploitation
Licence d informatique Synchronisation et Communication inter-processus Hafid Bourzoufi Université de Valenciennes - ISTV Introduction Les processus concurrents s exécutant dans le système d exploitation
NOTIONS DE RESEAUX INFORMATIQUES
 NOTIONS DE RESEAUX INFORMATIQUES GENERALITES Définition d'un réseau Un réseau informatique est un ensemble d'équipements reliés entre eux afin de partager des données, des ressources et d'échanger des
NOTIONS DE RESEAUX INFORMATIQUES GENERALITES Définition d'un réseau Un réseau informatique est un ensemble d'équipements reliés entre eux afin de partager des données, des ressources et d'échanger des
Plan du cours. Autres modèles pour les applications réparties Introduction. Mode de travail. Introduction
 Plan du cours Autres modèles pour les applications réparties Introduction Riveill@unice.fr http://rangiroa.polytech.unice.fr Notre terrain de jeu : les systèmes répartis Un rappel : le modèle dominant
Plan du cours Autres modèles pour les applications réparties Introduction Riveill@unice.fr http://rangiroa.polytech.unice.fr Notre terrain de jeu : les systèmes répartis Un rappel : le modèle dominant
Partie 7 : Gestion de la mémoire
 INF3600+INF2610 Automne 2006 Partie 7 : Gestion de la mémoire Exercice 1 : Considérez un système disposant de 16 MO de mémoire physique réservée aux processus utilisateur. La mémoire est composée de cases
INF3600+INF2610 Automne 2006 Partie 7 : Gestion de la mémoire Exercice 1 : Considérez un système disposant de 16 MO de mémoire physique réservée aux processus utilisateur. La mémoire est composée de cases
Windows Internet Name Service (WINS)
") Windows Internet Name Service (WINS) WINDOWS INTERNET NAME SERVICE (WINS)...2 1.) Introduction au Service de nom Internet Windows (WINS)...2 1.1) Les Noms NetBIOS...2 1.2) Le processus de résolution WINS...2
Windows Internet Name Service (WINS) WINDOWS INTERNET NAME SERVICE (WINS)...2 1.) Introduction au Service de nom Internet Windows (WINS)...2 1.1) Les Noms NetBIOS...2 1.2) Le processus de résolution WINS...2
ORDONNANCEMENT CONJOINT DE TÂCHES ET DE MESSAGES DANS LES RÉSEAUX TEMPS RÉELS 4. QUELQUES EXEMPLES DU DYNAMISME ACTUEL DU TEMPS RÉEL
 i LE TEMPS RÉEL 1. PRÉSENTATION DU TEMPS RÉEL 1.1. APPLICATIONS TEMPS RÉEL 1.2. CONTRAINTES DE TEMPS RÉEL 2. STRUCTURES D'ACCUEIL POUR LE TEMPS RÉEL 2.1. EXÉCUTIFS TEMPS RÉEL 2.2. RÉSEAUX LOCAUX TEMPS
i LE TEMPS RÉEL 1. PRÉSENTATION DU TEMPS RÉEL 1.1. APPLICATIONS TEMPS RÉEL 1.2. CONTRAINTES DE TEMPS RÉEL 2. STRUCTURES D'ACCUEIL POUR LE TEMPS RÉEL 2.1. EXÉCUTIFS TEMPS RÉEL 2.2. RÉSEAUX LOCAUX TEMPS
Chapitre 1 : Introduction aux bases de données
 Chapitre 1 : Introduction aux bases de données Les Bases de Données occupent aujourd'hui une place de plus en plus importante dans les systèmes informatiques. Les Systèmes de Gestion de Bases de Données
Chapitre 1 : Introduction aux bases de données Les Bases de Données occupent aujourd'hui une place de plus en plus importante dans les systèmes informatiques. Les Systèmes de Gestion de Bases de Données
Julien MATHEVET Alexandre BOISSY GSID 4. Rapport RE09. Load Balancing et migration
 Julien MATHEVET Alexandre BOISSY GSID 4 Rapport Load Balancing et migration Printemps 2001 SOMMAIRE INTRODUCTION... 3 SYNTHESE CONCERNANT LE LOAD BALANCING ET LA MIGRATION... 4 POURQUOI FAIRE DU LOAD BALANCING?...
Julien MATHEVET Alexandre BOISSY GSID 4 Rapport Load Balancing et migration Printemps 2001 SOMMAIRE INTRODUCTION... 3 SYNTHESE CONCERNANT LE LOAD BALANCING ET LA MIGRATION... 4 POURQUOI FAIRE DU LOAD BALANCING?...
WEA Un Gérant d'objets Persistants pour des environnements distribués
 Thèse de Doctorat de l'université P & M Curie WEA Un Gérant d'objets Persistants pour des environnements distribués Didier Donsez Université Pierre et Marie Curie Paris VI Laboratoire de Méthodologie et
Thèse de Doctorat de l'université P & M Curie WEA Un Gérant d'objets Persistants pour des environnements distribués Didier Donsez Université Pierre et Marie Curie Paris VI Laboratoire de Méthodologie et
1 LE L S S ERV R EURS Si 5
 1 LES SERVEURS Si 5 Introduction 2 Un serveur réseau est un ordinateur spécifique partageant ses ressources avec d'autres ordinateurs appelés clients. Il fournit un service en réponse à une demande d un
1 LES SERVEURS Si 5 Introduction 2 Un serveur réseau est un ordinateur spécifique partageant ses ressources avec d'autres ordinateurs appelés clients. Il fournit un service en réponse à une demande d un
Plan du Travail. 2014/2015 Cours TIC - 1ère année MI 30
 Plan du Travail Chapitre 1: Internet et le Web : Définitions et historique Chapitre 2: Principes d Internet Chapitre 3 : Principaux services d Internet Chapitre 4 : Introduction au langage HTML 2014/2015
Plan du Travail Chapitre 1: Internet et le Web : Définitions et historique Chapitre 2: Principes d Internet Chapitre 3 : Principaux services d Internet Chapitre 4 : Introduction au langage HTML 2014/2015
Le modèle client-serveur
 Le modèle client-serveur Olivier Aubert 1/24 Sources http://www.info.uqam.ca/~obaid/inf4481/a01/plan.htm 2/24 Historique architecture centralisée terminaux passifs (un seul OS, systèmes propriétaires)
Le modèle client-serveur Olivier Aubert 1/24 Sources http://www.info.uqam.ca/~obaid/inf4481/a01/plan.htm 2/24 Historique architecture centralisée terminaux passifs (un seul OS, systèmes propriétaires)
Systèmes et algorithmes répartis
 Systèmes et algorithmes répartis Tolérance aux fautes Philippe Quéinnec Département Informatique et Mathématiques Appliquées ENSEEIHT 4 novembre 2014 Systèmes et algorithmes répartis V 1 / 45 plan 1 Sûreté
Systèmes et algorithmes répartis Tolérance aux fautes Philippe Quéinnec Département Informatique et Mathématiques Appliquées ENSEEIHT 4 novembre 2014 Systèmes et algorithmes répartis V 1 / 45 plan 1 Sûreté
Introduction aux algorithmes répartis
 Objectifs et plan Introduction aux algorithmes répartis Sacha Krakowiak Université Joseph Fourier Projet Sardes (INRIA et IMAG-LSR http://sardes.inrialpes.fr/people/krakowia! Introduction aux algorithmes
Objectifs et plan Introduction aux algorithmes répartis Sacha Krakowiak Université Joseph Fourier Projet Sardes (INRIA et IMAG-LSR http://sardes.inrialpes.fr/people/krakowia! Introduction aux algorithmes
Guide d'utilisation du Serveur USB
 Guide d'utilisation du Serveur USB Copyright 20-1 - Informations de copyright Copyright 2010. Tous droits réservés. Avis de non responsabilité Incorporated ne peut être tenu responsable des erreurs techniques
Guide d'utilisation du Serveur USB Copyright 20-1 - Informations de copyright Copyright 2010. Tous droits réservés. Avis de non responsabilité Incorporated ne peut être tenu responsable des erreurs techniques
Installation d'un serveur DHCP sous Windows 2000 Serveur
 Installation d'un serveur DHCP sous Windows 2000 Serveur Un serveur DHCP permet d'assigner des adresses IP à des ordinateurs clients du réseau. Grâce à un protocole DHCP (Dynamic Host Configuration Protocol),
Installation d'un serveur DHCP sous Windows 2000 Serveur Un serveur DHCP permet d'assigner des adresses IP à des ordinateurs clients du réseau. Grâce à un protocole DHCP (Dynamic Host Configuration Protocol),
Processus! programme. DIMA, Systèmes Centralisés (Ph. Mauran) " Processus = suite d'actions = suite d'états obtenus = trace
 Processus = suite d'actions = suite d'états obtenus = trace") Processus 1) Contexte 2) Modèles de Notion de Points de vue Modèle fourni par le SX Opérations sur les 3) Gestion des Représentation des Opérations 4) Ordonnancement des Niveaux d ordonnancement Ordonnancement
Processus 1) Contexte 2) Modèles de Notion de Points de vue Modèle fourni par le SX Opérations sur les 3) Gestion des Représentation des Opérations 4) Ordonnancement des Niveaux d ordonnancement Ordonnancement
Architecture N-Tier. Ces données peuvent être saisies interactivement via l interface ou lues depuis un disque. Application
 Architecture Multi-Tier Traditionnellement une application informatique est un programme exécutable sur une machine qui représente la logique de traitement des données manipulées par l application. Ces
Architecture Multi-Tier Traditionnellement une application informatique est un programme exécutable sur une machine qui représente la logique de traitement des données manipulées par l application. Ces
Initiation au HPC - Généralités
 Initiation au HPC - Généralités Éric Ramat et Julien Dehos Université du Littoral Côte d Opale M2 Informatique 2 septembre 2015 Éric Ramat et Julien Dehos Initiation au HPC - Généralités 1/49 Plan du cours
Initiation au HPC - Généralités Éric Ramat et Julien Dehos Université du Littoral Côte d Opale M2 Informatique 2 septembre 2015 Éric Ramat et Julien Dehos Initiation au HPC - Généralités 1/49 Plan du cours
CH.3 SYSTÈMES D'EXPLOITATION
 CH.3 SYSTÈMES D'EXPLOITATION 3.1 Un historique 3.2 Une vue générale 3.3 Les principaux aspects Info S4 ch3 1 3.1 Un historique Quatre générations. Préhistoire 1944 1950 ENIAC (1944) militaire : 20000 tubes,
CH.3 SYSTÈMES D'EXPLOITATION 3.1 Un historique 3.2 Une vue générale 3.3 Les principaux aspects Info S4 ch3 1 3.1 Un historique Quatre générations. Préhistoire 1944 1950 ENIAC (1944) militaire : 20000 tubes,
Gestion répartie de données - 1
 Gestion répartie de données - 1 Sacha Krakowiak Université Joseph Fourier Projet Sardes (INRIA et IMAG-LSR) http://sardes.inrialpes.fr/~krakowia Gestion répartie de données Plan de la présentation Introduction
Gestion répartie de données - 1 Sacha Krakowiak Université Joseph Fourier Projet Sardes (INRIA et IMAG-LSR) http://sardes.inrialpes.fr/~krakowia Gestion répartie de données Plan de la présentation Introduction
Chapitre VII : Principes des réseaux. Structure des réseaux Types de réseaux La communication Les protocoles de communication
 Chapitre VII : Principes des réseaux Structure des réseaux Types de réseaux La communication Les protocoles de communication Introduction Un système réparti est une collection de processeurs (ou machines)
Chapitre VII : Principes des réseaux Structure des réseaux Types de réseaux La communication Les protocoles de communication Introduction Un système réparti est une collection de processeurs (ou machines)
L exclusion mutuelle distribuée
 L exclusion mutuelle distribuée L algorithme de L Amport L algorithme est basé sur 2 concepts : L estampillage des messages La distribution d une file d attente sur l ensemble des sites du système distribué
L exclusion mutuelle distribuée L algorithme de L Amport L algorithme est basé sur 2 concepts : L estampillage des messages La distribution d une file d attente sur l ensemble des sites du système distribué
Fiche Technique Windows Azure
 Le 25/03/2013 OBJECTIF VIRTUALISATION mathieuc@exakis.com EXAKIS NANTES Identification du document Titre Projet Date de création Date de modification Fiche Technique Objectif 25/03/2013 27/03/2013 Windows
Le 25/03/2013 OBJECTIF VIRTUALISATION mathieuc@exakis.com EXAKIS NANTES Identification du document Titre Projet Date de création Date de modification Fiche Technique Objectif 25/03/2013 27/03/2013 Windows
Cours Bases de données
 Informations sur le cours Cours Bases de données 9 (10) séances de 3h Polycopié (Cours + TD/TP) 3 année (MISI) Antoine Cornuéjols www.lri.fr/~antoine antoine.cornuejols@agroparistech.fr Transparents Disponibles
Informations sur le cours Cours Bases de données 9 (10) séances de 3h Polycopié (Cours + TD/TP) 3 année (MISI) Antoine Cornuéjols www.lri.fr/~antoine antoine.cornuejols@agroparistech.fr Transparents Disponibles
Chapitre V : La gestion de la mémoire. Hiérarchie de mémoires Objectifs Méthodes d'allocation Simulation de mémoire virtuelle Le mapping
 Chapitre V : La gestion de la mémoire Hiérarchie de mémoires Objectifs Méthodes d'allocation Simulation de mémoire virtuelle Le mapping Introduction Plusieurs dizaines de processus doivent se partager
Chapitre V : La gestion de la mémoire Hiérarchie de mémoires Objectifs Méthodes d'allocation Simulation de mémoire virtuelle Le mapping Introduction Plusieurs dizaines de processus doivent se partager
SafeKit. Sommaire. Un livre blanc de Bull Evidian
 Un livre blanc de Bull Evidian SafeKit Une solution de haute disponibilité logicielle packageable avec n'importe quelle application Windows ou Unix Par Bruno Rochat Sommaire Novembre 2005 Haute disponibilité
Un livre blanc de Bull Evidian SafeKit Une solution de haute disponibilité logicielle packageable avec n'importe quelle application Windows ou Unix Par Bruno Rochat Sommaire Novembre 2005 Haute disponibilité
La continuité de service
 La continuité de service I INTRODUCTION Si la performance est un élément important de satisfaction de l'utilisateur de réseau, la permanence de la disponibilité des ressources l'est encore davantage. Ici
La continuité de service I INTRODUCTION Si la performance est un élément important de satisfaction de l'utilisateur de réseau, la permanence de la disponibilité des ressources l'est encore davantage. Ici
Implémentation des SGBD
 Implémentation des SGBD Structure générale des applications Application utilisateur accédant à des données d'une base Les programmes sous-jacents contiennent du code SQL Exécution : pendant l'exécution
Implémentation des SGBD Structure générale des applications Application utilisateur accédant à des données d'une base Les programmes sous-jacents contiennent du code SQL Exécution : pendant l'exécution
Concept de machine virtuelle
 Concept de machine virtuelle Chap. 5: Machine virtuelle Alain Sandoz Semestre été 2007 1 Introduction: Java Virtual Machine Machine Virtuelle Java: qu est-ce que c est? c est la spécification d une machine
Concept de machine virtuelle Chap. 5: Machine virtuelle Alain Sandoz Semestre été 2007 1 Introduction: Java Virtual Machine Machine Virtuelle Java: qu est-ce que c est? c est la spécification d une machine
La haute disponibilité de la CHAINE DE
 Pare-feu, proxy, antivirus, authentification LDAP & Radius, contrôle d'accès des portails applicatifs La haute disponibilité de la CHAINE DE SECURITE APPLICATIVE 1.1 La chaîne de sécurité applicative est
Pare-feu, proxy, antivirus, authentification LDAP & Radius, contrôle d'accès des portails applicatifs La haute disponibilité de la CHAINE DE SECURITE APPLICATIVE 1.1 La chaîne de sécurité applicative est
Les transactions 1/46. I même en cas de panne logicielle ou matérielle. I Concept de transaction. I Gestion de la concurrence : les solutions
 1/46 2/46 Pourquoi? Anne-Cécile Caron Master MAGE - SGBD 1er trimestre 2014-2015 Le concept de transaction va permettre de définir des processus garantissant que l état de la base est toujours cohérent
1/46 2/46 Pourquoi? Anne-Cécile Caron Master MAGE - SGBD 1er trimestre 2014-2015 Le concept de transaction va permettre de définir des processus garantissant que l état de la base est toujours cohérent
Informatique industrielle A7-19571 Systèmes temps-réel J.F.Peyre. Partie I : Introduction
 Informatique industrielle A7-19571 Systèmes temps-réel J.F.Peyre Partie I : Introduction Plan de la première partie Quelques définitions Caractéristiques communes des applications temps-réel Exemples d
Informatique industrielle A7-19571 Systèmes temps-réel J.F.Peyre Partie I : Introduction Plan de la première partie Quelques définitions Caractéristiques communes des applications temps-réel Exemples d
Présentation du modèle OSI(Open Systems Interconnection)
") Présentation du modèle OSI(Open Systems Interconnection) Les couches hautes: Responsables du traitement de l'information relative à la gestion des échanges entre systèmes informatiques. Couches basses:
Présentation du modèle OSI(Open Systems Interconnection) Les couches hautes: Responsables du traitement de l'information relative à la gestion des échanges entre systèmes informatiques. Couches basses:
Cours de Génie Logiciel
 Cours de Génie Logiciel Sciences-U Lyon Diagrammes UML (2) http://www.rzo.free.fr Pierre PARREND 1 Avril 2005 Sommaire Les Diagrammes UML Diagrammes de Collaboration Diagrammes d'etats-transitions Diagrammes
Cours de Génie Logiciel Sciences-U Lyon Diagrammes UML (2) http://www.rzo.free.fr Pierre PARREND 1 Avril 2005 Sommaire Les Diagrammes UML Diagrammes de Collaboration Diagrammes d'etats-transitions Diagrammes
LE PROBLEME DU PLUS COURT CHEMIN
 LE PROBLEME DU PLUS COURT CHEMIN Dans cette leçon nous définissons le modèle de plus court chemin, présentons des exemples d'application et proposons un algorithme de résolution dans le cas où les longueurs
LE PROBLEME DU PLUS COURT CHEMIN Dans cette leçon nous définissons le modèle de plus court chemin, présentons des exemples d'application et proposons un algorithme de résolution dans le cas où les longueurs
Module BDR Master d Informatique (SAR)
") Module BDR Master d Informatique (SAR) Cours 9- Transactions réparties Anne Doucet Anne.Doucet@lip6.fr Transactions réparties Gestion de transactions Transactions dans un système réparti Protocoles de
Module BDR Master d Informatique (SAR) Cours 9- Transactions réparties Anne Doucet Anne.Doucet@lip6.fr Transactions réparties Gestion de transactions Transactions dans un système réparti Protocoles de
Métriques de performance pour les algorithmes et programmes parallèles
 Métriques de performance pour les algorithmes et programmes parallèles 11 18 nov. 2002 Cette section est basée tout d abord sur la référence suivante (manuel suggéré mais non obligatoire) : R. Miller and
Métriques de performance pour les algorithmes et programmes parallèles 11 18 nov. 2002 Cette section est basée tout d abord sur la référence suivante (manuel suggéré mais non obligatoire) : R. Miller and
Allocation de l adressage IP à l aide du protocole DHCP.doc
 Allocation de l adressage IP à l aide du protocole DHCP.doc Sommaire 1. Ajout et autorisation d un service Serveur DHCP...2 1.1. Comment le protocole DHCP alloue des adresses IP...2 1.2. Processus de
Allocation de l adressage IP à l aide du protocole DHCP.doc Sommaire 1. Ajout et autorisation d un service Serveur DHCP...2 1.1. Comment le protocole DHCP alloue des adresses IP...2 1.2. Processus de
Présentation d'un Réseau Eole +
 Présentation d'un Réseau Eole + Le Pourquoi du comment... Comprendre les différents types de documentation fournit avec la solution Eole Plus. Novice Confirmé Expert Version 1.0 Mai 2006 Permission est
Présentation d'un Réseau Eole + Le Pourquoi du comment... Comprendre les différents types de documentation fournit avec la solution Eole Plus. Novice Confirmé Expert Version 1.0 Mai 2006 Permission est
NFP111 Systèmes et Applications Réparties
 NFP111 Systèmes et Applications Réparties 1 de 34 NFP111 Systèmes et Applications Réparties Cours 7 - CORBA/Partie 1 Claude Duvallet Université du Havre UFR Sciences et Techniques 25 rue Philippe Lebon
NFP111 Systèmes et Applications Réparties 1 de 34 NFP111 Systèmes et Applications Réparties Cours 7 - CORBA/Partie 1 Claude Duvallet Université du Havre UFR Sciences et Techniques 25 rue Philippe Lebon
2. MAQUETTAGE DES SOLUTIONS CONSTRUCTIVES. 2.2 Architecture fonctionnelle d un système communicant. http://robert.cireddu.free.
 2. MAQUETTAGE DES SOLUTIONS CONSTRUCTIVES 2.2 Architecture fonctionnelle d un système communicant Page:1/11 http://robert.cireddu.free.fr/sin LES DÉFENSES Objectifs du COURS : Ce cours traitera essentiellement
2. MAQUETTAGE DES SOLUTIONS CONSTRUCTIVES 2.2 Architecture fonctionnelle d un système communicant Page:1/11 http://robert.cireddu.free.fr/sin LES DÉFENSES Objectifs du COURS : Ce cours traitera essentiellement
NIVEAU D'INTERVENTION DE LA PROGRAMMATION CONCURRENTE
 NIVEAU D'INTERVENTION DE LA PROGRAMMATION CONCURRENTE Une application se construit par étapes 1) CAHIER DES CHARGES + ANALYSE FONCTIONNELLE = organisation fonctionnelle (QUE FAIRE) 2) ANALYSE OPERATIONNELLE
NIVEAU D'INTERVENTION DE LA PROGRAMMATION CONCURRENTE Une application se construit par étapes 1) CAHIER DES CHARGES + ANALYSE FONCTIONNELLE = organisation fonctionnelle (QUE FAIRE) 2) ANALYSE OPERATIONNELLE
VMWare Infrastructure 3
 Ingénieurs 2000 Filière Informatique et réseaux Université de Marne-la-Vallée VMWare Infrastructure 3 Exposé système et nouvelles technologies réseau. Christophe KELLER Sommaire Sommaire... 2 Introduction...
Ingénieurs 2000 Filière Informatique et réseaux Université de Marne-la-Vallée VMWare Infrastructure 3 Exposé système et nouvelles technologies réseau. Christophe KELLER Sommaire Sommaire... 2 Introduction...
Préparation à l installation d Active Directory
 Laboratoire 03 Étape 1 : Installation d Active Directory et du service DNS Noter que vous ne pourrez pas réaliser ce laboratoire sans avoir fait le précédent laboratoire. Avant de commencer, le professeur
Laboratoire 03 Étape 1 : Installation d Active Directory et du service DNS Noter que vous ne pourrez pas réaliser ce laboratoire sans avoir fait le précédent laboratoire. Avant de commencer, le professeur
Les diagrammes de modélisation
 L approche Orientée Objet et UML 1 Plan du cours Introduction au Génie Logiciel L approche Orientée Objet et Notation UML Les diagrammes de modélisation Relations entre les différents diagrammes De l analyse
L approche Orientée Objet et UML 1 Plan du cours Introduction au Génie Logiciel L approche Orientée Objet et Notation UML Les diagrammes de modélisation Relations entre les différents diagrammes De l analyse
Présentation de Active Directory
 Brevet de Technicien Supérieur Informatique de gestion. Benoît HAMET Session 2001 2002 Présentation de Active Directory......... Présentation d Active Directory Préambule...4 Introduction...5 Définitions...5
Brevet de Technicien Supérieur Informatique de gestion. Benoît HAMET Session 2001 2002 Présentation de Active Directory......... Présentation d Active Directory Préambule...4 Introduction...5 Définitions...5
Ce document décrit une solution de single sign-on (SSO) sécurisée permettant d accéder à Microsoft Exchange avec des tablettes ou smartphones.
 sécurisée permettant d accéder à Microsoft Exchange avec des tablettes ou smartphones.") PERSPECTIVES Le Single Sign-On mobile vers Microsoft Exchange avec OWA et ActiveSync Ce document décrit une solution de single sign-on (SSO) sécurisée permettant d accéder à Microsoft Exchange avec des
PERSPECTIVES Le Single Sign-On mobile vers Microsoft Exchange avec OWA et ActiveSync Ce document décrit une solution de single sign-on (SSO) sécurisée permettant d accéder à Microsoft Exchange avec des
Projet : PcAnywhere et Le contrôle à distance.
 Projet : PcAnywhere et Le contrôle à distance. PAGE : 1 SOMMAIRE I)Introduction 3 II) Qu'est ce que le contrôle distant? 4 A.Définition... 4 B. Caractéristiques.4 III) A quoi sert le contrôle distant?.5
Projet : PcAnywhere et Le contrôle à distance. PAGE : 1 SOMMAIRE I)Introduction 3 II) Qu'est ce que le contrôle distant? 4 A.Définition... 4 B. Caractéristiques.4 III) A quoi sert le contrôle distant?.5
Cisco Certified Network Associate
 Cisco Certified Network Associate Version 4 Notions de base sur les réseaux Chapitre 3 01 Quel protocole de la couche application sert couramment à prendre en charge les transferts de fichiers entre un
Cisco Certified Network Associate Version 4 Notions de base sur les réseaux Chapitre 3 01 Quel protocole de la couche application sert couramment à prendre en charge les transferts de fichiers entre un
1 Mesure de la performance d un système temps réel : la gigue
 TP TR ENSPS et MSTER 1 Travaux Pratiques Systèmes temps réel et embarqués ENSPS ISV et Master TP1 - Ordonnancement et communication inter-processus (IPC) Environnement de travail Un ordinateur dual-core
TP TR ENSPS et MSTER 1 Travaux Pratiques Systèmes temps réel et embarqués ENSPS ISV et Master TP1 - Ordonnancement et communication inter-processus (IPC) Environnement de travail Un ordinateur dual-core
Introduction aux applications réparties
 Introduction aux applications réparties Noël De Palma Projet SARDES INRIA Rhône-Alpes http://sardes.inrialpes.fr/~depalma Noel.depalma@inrialpes.fr Applications réparties Def : Application s exécutant
Introduction aux applications réparties Noël De Palma Projet SARDES INRIA Rhône-Alpes http://sardes.inrialpes.fr/~depalma Noel.depalma@inrialpes.fr Applications réparties Def : Application s exécutant
MANUEL PROGRAMME DE GESTION DU CPL WI-FI
 MANUEL PROGRAMME DE GESTION DU CPL WI-FI Le programme de gestion du CPL Wi-Fi sert à régler tous les paramètres de l'adaptateur. En effet, le CPL Wi-Fi possède une interface de configuration. Cette interface
MANUEL PROGRAMME DE GESTION DU CPL WI-FI Le programme de gestion du CPL Wi-Fi sert à régler tous les paramètres de l'adaptateur. En effet, le CPL Wi-Fi possède une interface de configuration. Cette interface
Qu'est-ce que c'est Windows NT?
 Qu'est-ce que c'est Windows NT? Que faire en cas de blocage d'une station NT? Profils «errants» avec win NT : des éclaircissements Echange de fichiers entre les deux environnements PC/Mac Blocage réseau
Qu'est-ce que c'est Windows NT? Que faire en cas de blocage d'une station NT? Profils «errants» avec win NT : des éclaircissements Echange de fichiers entre les deux environnements PC/Mac Blocage réseau
Programmation Objet - Cours II
 Programmation Objet - Cours II - Exercices - Page 1 Programmation Objet - Cours II Exercices Auteur : E.Thirion - Dernière mise à jour : 05/07/2015 Les exercices suivants sont en majorité des projets à
Programmation Objet - Cours II - Exercices - Page 1 Programmation Objet - Cours II Exercices Auteur : E.Thirion - Dernière mise à jour : 05/07/2015 Les exercices suivants sont en majorité des projets à
Module 0 : Présentation de Windows 2000
 Module 0 : Présentation de Table des matières Vue d'ensemble Systèmes d'exploitation Implémentation de la gestion de réseau dans 1 Vue d'ensemble Donner une vue d'ensemble des sujets et des objectifs de
Module 0 : Présentation de Table des matières Vue d'ensemble Systèmes d'exploitation Implémentation de la gestion de réseau dans 1 Vue d'ensemble Donner une vue d'ensemble des sujets et des objectifs de
Ebauche Rapport finale
 Ebauche Rapport finale Sommaire : 1 - Introduction au C.D.N. 2 - Définition de la problématique 3 - Etat de l'art : Présentatio de 3 Topologies streaming p2p 1) INTRODUCTION au C.D.N. La croissance rapide
Ebauche Rapport finale Sommaire : 1 - Introduction au C.D.N. 2 - Définition de la problématique 3 - Etat de l'art : Présentatio de 3 Topologies streaming p2p 1) INTRODUCTION au C.D.N. La croissance rapide
Itium XP. Guide Utilisateur
 Itium XP 06/2007 - Rev. 3 1 Sommaire 1 Sommaire... 2 2 Généralités... 3 3 ItiumSysLock... 4 3.1 Enregistrer l état actuel du système... 4 3.2 Désactiver ItiumSysLock... 5 3.3 Activer ItiumSysLock... 5
Itium XP 06/2007 - Rev. 3 1 Sommaire 1 Sommaire... 2 2 Généralités... 3 3 ItiumSysLock... 4 3.1 Enregistrer l état actuel du système... 4 3.2 Désactiver ItiumSysLock... 5 3.3 Activer ItiumSysLock... 5
Didacticiel de mise à jour Web
 Didacticiel de mise à jour Web Copyright 1995-2012 Esri All rights reserved. Table of Contents Didacticiel : Création d'une application de mise à jour Web.................. 0 Copyright 1995-2012 Esri.
Didacticiel de mise à jour Web Copyright 1995-2012 Esri All rights reserved. Table of Contents Didacticiel : Création d'une application de mise à jour Web.................. 0 Copyright 1995-2012 Esri.
Messagerie asynchrone et Services Web
 Article Messagerie asynchrone et Services Web 1 / 10 Messagerie asynchrone et Services Web SOAP, WSDL SONT DES STANDARDS EMERGEANT DES SERVICES WEB, LES IMPLEMENTATIONS DE CEUX-CI SONT ENCORE EN COURS
Article Messagerie asynchrone et Services Web 1 / 10 Messagerie asynchrone et Services Web SOAP, WSDL SONT DES STANDARDS EMERGEANT DES SERVICES WEB, LES IMPLEMENTATIONS DE CEUX-CI SONT ENCORE EN COURS
VRM Monitor. Aide en ligne
 VRM Monitor fr Aide en ligne VRM Monitor Table des matières fr 3 Table des matières 1 Introduction 3 2 Vue d'ensemble du système 3 3 Getting started 4 3.1 Démarrage de VRM Monitor 4 3.2 Démarrage de Configuration
VRM Monitor fr Aide en ligne VRM Monitor Table des matières fr 3 Table des matières 1 Introduction 3 2 Vue d'ensemble du système 3 3 Getting started 4 3.1 Démarrage de VRM Monitor 4 3.2 Démarrage de Configuration
INTRODUCTION AUX SYSTEMES D EXPLOITATION. TD2 Exclusion mutuelle / Sémaphores
 INTRODUCTION AUX SYSTEMES D EXPLOITATION TD2 Exclusion mutuelle / Sémaphores Exclusion mutuelle / Sémaphores - 0.1 - S O M M A I R E 1. GENERALITES SUR LES SEMAPHORES... 1 1.1. PRESENTATION... 1 1.2. UN
INTRODUCTION AUX SYSTEMES D EXPLOITATION TD2 Exclusion mutuelle / Sémaphores Exclusion mutuelle / Sémaphores - 0.1 - S O M M A I R E 1. GENERALITES SUR LES SEMAPHORES... 1 1.1. PRESENTATION... 1 1.2. UN
Software Engineering and Middleware A Roadmap
 Software Engineering and Middleware A Roadmap Ecrit par: Dr. Wolfgang Emmerich Présenté par : Mustapha Boushaba Cours : IFT6251 Wolfgang Emmerich Enseignant à University College London: Distributed Systems
Software Engineering and Middleware A Roadmap Ecrit par: Dr. Wolfgang Emmerich Présenté par : Mustapha Boushaba Cours : IFT6251 Wolfgang Emmerich Enseignant à University College London: Distributed Systems
Définition. Caractéristiques. - Du partage des ressources : espace de stockage, imprimantes, lignes de communication.
 CONNECTER LES SYSTEMES ENTRE EUX L informatique, au cœur des tâches courantes, a permis de nombreuses avancées technologiques. Aujourd hui, la problématique est de parvenir à connecter les systèmes d information
CONNECTER LES SYSTEMES ENTRE EUX L informatique, au cœur des tâches courantes, a permis de nombreuses avancées technologiques. Aujourd hui, la problématique est de parvenir à connecter les systèmes d information
Services OSI. if G.Beuchot. Services Application Services Présentation - Session Services Transport - Réseaux - Liaison de Données - Physique
 Services OSI Services Application Services Présentation - Session Services Transport - Réseaux - Liaison de Données - Physique 59 SERVICES "APPLICATION" Architecture spécifique : ALS (Application Layer
Services OSI Services Application Services Présentation - Session Services Transport - Réseaux - Liaison de Données - Physique 59 SERVICES "APPLICATION" Architecture spécifique : ALS (Application Layer
Oléane VPN : Les nouvelles fonctions de gestion de réseaux. Orange Business Services
 Oléane VPN : Les nouvelles fonctions de gestion de réseaux Orange Business Services sommaire 1. Qu'est-ce que la fonction serveur/relais DHCP? Comment cela fonctionne-t-il?...3 1.1. Serveur DHCP...3 1.2.
Oléane VPN : Les nouvelles fonctions de gestion de réseaux Orange Business Services sommaire 1. Qu'est-ce que la fonction serveur/relais DHCP? Comment cela fonctionne-t-il?...3 1.1. Serveur DHCP...3 1.2.
Cours CCNA 1. Exercices
 Cours CCNA 1 TD3 Exercices Exercice 1 Enumérez les sept étapes du processus consistant à convertir les communications de l utilisateur en données. 1. L utilisateur entre les données via une interface matérielle.
Cours CCNA 1 TD3 Exercices Exercice 1 Enumérez les sept étapes du processus consistant à convertir les communications de l utilisateur en données. 1. L utilisateur entre les données via une interface matérielle.
CEG4566/CSI4541 Conception de systèmes temps réel
 CEG4566/CSI4541 Conception de systèmes temps réel Chapitre 6 Vivacité, sécurité (Safety), fiabilité et tolérance aux fautes dans les systèmes en temps réel 6.1 Introduction générale aux notions de sécurité
CEG4566/CSI4541 Conception de systèmes temps réel Chapitre 6 Vivacité, sécurité (Safety), fiabilité et tolérance aux fautes dans les systèmes en temps réel 6.1 Introduction générale aux notions de sécurité
Le travail collaboratif et l'intelligence collective
 THÈME INFORMATION ET INTELLIGENCE COLLECTIVE Pour l organisation, l information est le vecteur de la communication, de la coordination et de la connaissance, tant dans ses relations internes que dans ses
THÈME INFORMATION ET INTELLIGENCE COLLECTIVE Pour l organisation, l information est le vecteur de la communication, de la coordination et de la connaissance, tant dans ses relations internes que dans ses
ITIL V3. Exploitation des services : Les fonctions
 ITIL V3 Exploitation des services : Les fonctions Création : juin 2013 Mise à jour : juin 2013 A propos A propos du document Ce document de référence sur le référentiel ITIL V3 a été réalisé en se basant
ITIL V3 Exploitation des services : Les fonctions Création : juin 2013 Mise à jour : juin 2013 A propos A propos du document Ce document de référence sur le référentiel ITIL V3 a été réalisé en se basant
Systemes d'exploitation des ordinateurs
 ! " #$ % $ &' ( $ plan_ch6_m1 Systemes d'exploitation des ordinateurs Conception de Systèmes de Gestion de la Mémoire Centrale Objectifs 1. Conception de systèmes paginés 2. Conception des systèmes segmentés
! " #$ % $ &' ( $ plan_ch6_m1 Systemes d'exploitation des ordinateurs Conception de Systèmes de Gestion de la Mémoire Centrale Objectifs 1. Conception de systèmes paginés 2. Conception des systèmes segmentés
//////////////////////////////////////////////////////////////////// Administration systèmes et réseaux
 ////////////////////// Administration systèmes et réseaux / INTRODUCTION Réseaux Un réseau informatique est un ensemble d'équipements reliés entre eux pour échanger des informations. Par analogie avec
////////////////////// Administration systèmes et réseaux / INTRODUCTION Réseaux Un réseau informatique est un ensemble d'équipements reliés entre eux pour échanger des informations. Par analogie avec
Fiche de l'awt Le modèle peer to peer
 Fiche de l'awt Le modèle peer to peer L'arrivée du peer to peer (point à point) bouleverse le modèle traditionnel client-serveur. Dorénavant, toute application peut être à la fois client et serveur. Quels
Fiche de l'awt Le modèle peer to peer L'arrivée du peer to peer (point à point) bouleverse le modèle traditionnel client-serveur. Dorénavant, toute application peut être à la fois client et serveur. Quels
FORMATION PcVue. Mise en œuvre de WEBVUE. Journées de formation au logiciel de supervision PcVue 8.1. Lieu : Lycée Pablo Neruda Saint Martin d hères
 FORMATION PcVue Mise en œuvre de WEBVUE Journées de formation au logiciel de supervision PcVue 8.1 Lieu : Lycée Pablo Neruda Saint Martin d hères Centre ressource Génie Electrique Intervenant : Enseignant
FORMATION PcVue Mise en œuvre de WEBVUE Journées de formation au logiciel de supervision PcVue 8.1 Lieu : Lycée Pablo Neruda Saint Martin d hères Centre ressource Génie Electrique Intervenant : Enseignant
Installation d un serveur DHCP sous Gnu/Linux
 ROYAUME DU MAROC Office de la Formation Professionnelle et de la Promotion du Travail Installation d un serveur DHCP sous Gnu/Linux DIRECTION RECHERCHE ET INGENIERIE DE FORMATION SECTEUR NTIC Installation
ROYAUME DU MAROC Office de la Formation Professionnelle et de la Promotion du Travail Installation d un serveur DHCP sous Gnu/Linux DIRECTION RECHERCHE ET INGENIERIE DE FORMATION SECTEUR NTIC Installation
L apprentissage automatique
 L apprentissage automatique L apprentissage automatique L'apprentissage automatique fait référence au développement, à l analyse et à l implémentation de méthodes qui permettent à une machine d évoluer
L apprentissage automatique L apprentissage automatique L'apprentissage automatique fait référence au développement, à l analyse et à l implémentation de méthodes qui permettent à une machine d évoluer
PARAGON SYSTEM BACKUP 2010
 PARAGON SYSTEM BACKUP 2010 Paragon System Backup 2010 2 Manuel d'utilisation SOMMAIRE 1 Introduction...3 1.1 Comment System Backup protège mon ordinateur?...3 1.1.1 Emplacement du stockage des clichés...
PARAGON SYSTEM BACKUP 2010 Paragon System Backup 2010 2 Manuel d'utilisation SOMMAIRE 1 Introduction...3 1.1 Comment System Backup protège mon ordinateur?...3 1.1.1 Emplacement du stockage des clichés...
Exclusion Mutuelle. Arnaud Labourel Courriel : arnaud.labourel@lif.univ-mrs.fr. Université de Provence. 9 février 2011
 Arnaud Labourel Courriel : arnaud.labourel@lif.univ-mrs.fr Université de Provence 9 février 2011 Arnaud Labourel (Université de Provence) Exclusion Mutuelle 9 février 2011 1 / 53 Contexte Epistémologique
Arnaud Labourel Courriel : arnaud.labourel@lif.univ-mrs.fr Université de Provence 9 février 2011 Arnaud Labourel (Université de Provence) Exclusion Mutuelle 9 février 2011 1 / 53 Contexte Epistémologique
Version en date du 01 avril 2010
 O V H S E N E G A L CONDITIONS PARTICULIERES D'HÉBERGEMENT MUTUALISÉ Version en date du 01 avril 2010 ARTICLE 1 : OBJET Les présentes conditions particulières ont pour objet de définir les conditions techniques
O V H S E N E G A L CONDITIONS PARTICULIERES D'HÉBERGEMENT MUTUALISÉ Version en date du 01 avril 2010 ARTICLE 1 : OBJET Les présentes conditions particulières ont pour objet de définir les conditions techniques
But de cette présentation
 Réseaux poste à poste ou égal à égal (peer to peer) sous Windows But de cette présentation Vous permettre de configurer un petit réseau domestique (ou de tpe), sans serveur dédié, sous Windows (c est prévu
Réseaux poste à poste ou égal à égal (peer to peer) sous Windows But de cette présentation Vous permettre de configurer un petit réseau domestique (ou de tpe), sans serveur dédié, sous Windows (c est prévu
Virtualiser ou ne pas virtualiser?
 1 Virtualiser ou ne pas virtualiser? C est la première question à laquelle vous devrez répondre par vous-même avant d investir une quantité significative de temps ou d argent dans un projet de virtualisation.
1 Virtualiser ou ne pas virtualiser? C est la première question à laquelle vous devrez répondre par vous-même avant d investir une quantité significative de temps ou d argent dans un projet de virtualisation.
Ordonnancement temps réel
 Ordonnancement temps réel Laurent.Pautet@enst.fr Version 1.5 Problématique de l ordonnancement temps réel En fonctionnement normal, respecter les contraintes temporelles spécifiées par toutes les tâches
Ordonnancement temps réel Laurent.Pautet@enst.fr Version 1.5 Problématique de l ordonnancement temps réel En fonctionnement normal, respecter les contraintes temporelles spécifiées par toutes les tâches
1. Introduction à la distribution des traitements et des données
 2A SI 1 - Introduction aux SI, et à la distribution des traitements et des données Stéphane Vialle Stephane.Vialle@supelec.fr http://www.metz.supelec.fr/~vialle Support de cours élaboré avec l aide de
2A SI 1 - Introduction aux SI, et à la distribution des traitements et des données Stéphane Vialle Stephane.Vialle@supelec.fr http://www.metz.supelec.fr/~vialle Support de cours élaboré avec l aide de
Administration de systèmes
 Administration de systèmes Windows NT.2000.XP.2003 Copyright IDEC 2002-2004. Reproduction interdite. Sommaire... 2 Eléments logiques et physiques du réseau... 5 Annuaire et domaine... 6 Les utilisateurs
Administration de systèmes Windows NT.2000.XP.2003 Copyright IDEC 2002-2004. Reproduction interdite. Sommaire... 2 Eléments logiques et physiques du réseau... 5 Annuaire et domaine... 6 Les utilisateurs
Backup Exec 2014 Management Pack for Microsoft SCOM. - Guide de l'utilisateur
 Backup Exec 2014 Management Pack for Microsoft SCOM Management Pack for Microsoft SCOM - Guide de l'utilisateur Management Pack for Microsoft Operations Ce document traite des sujets suivants: Backup Exec
Backup Exec 2014 Management Pack for Microsoft SCOM Management Pack for Microsoft SCOM - Guide de l'utilisateur Management Pack for Microsoft Operations Ce document traite des sujets suivants: Backup Exec
Formateurs : Jackie DAÖN Franck DUBOIS Médiapôle de Guyancourt
 Client sur un domaine stage personnes ressources réseau en établissement janvier 2004 Formateurs : Jackie DAÖN Franck DUBOIS Médiapôle de Guyancourt Lycée de Villaroy 2 rue Eugène Viollet Le Duc BP31 78041
Client sur un domaine stage personnes ressources réseau en établissement janvier 2004 Formateurs : Jackie DAÖN Franck DUBOIS Médiapôle de Guyancourt Lycée de Villaroy 2 rue Eugène Viollet Le Duc BP31 78041
Nouvelles Plateformes Technologiques
 Cycle de présentation du développement Nouvelles Plateformes Technologiques Observatoire Technologique, CTI Observatoire Technologique 4 mai 2004 p 1 Plan de la présentation 1. Historique du projet 2.
Cycle de présentation du développement Nouvelles Plateformes Technologiques Observatoire Technologique, CTI Observatoire Technologique 4 mai 2004 p 1 Plan de la présentation 1. Historique du projet 2.
INTERSYSTEMS CACHÉ COMME ALTERNATIVE AUX BASES DE DONNÉES RÉSIDENTES EN MÉMOIRE
 I N T E RS Y S T E M S INTERSYSTEMS CACHÉ COMME ALTERNATIVE AUX BASES DE DONNÉES RÉSIDENTES EN MÉMOIRE David Kaaret InterSystems Corporation INTERSySTEMS CAChé CoMME ALTERNATIvE AUx BASES de données RéSIdENTES
I N T E RS Y S T E M S INTERSYSTEMS CACHÉ COMME ALTERNATIVE AUX BASES DE DONNÉES RÉSIDENTES EN MÉMOIRE David Kaaret InterSystems Corporation INTERSySTEMS CAChé CoMME ALTERNATIvE AUx BASES de données RéSIdENTES
Les Réseaux sans fils : IEEE 802.11. F. Nolot
 Les Réseaux sans fils : IEEE 802.11 F. Nolot 1 Les Réseaux sans fils : IEEE 802.11 Historique F. Nolot 2 Historique 1er norme publiée en 1997 Débit jusque 2 Mb/s En 1998, norme 802.11b, commercialement
Les Réseaux sans fils : IEEE 802.11 F. Nolot 1 Les Réseaux sans fils : IEEE 802.11 Historique F. Nolot 2 Historique 1er norme publiée en 1997 Débit jusque 2 Mb/s En 1998, norme 802.11b, commercialement
portnox pour un contrôle amélioré des accès réseau Copyright 2008 Access Layers. Tous droits réservés.
 portnox Livre blanc réseau Janvier 2008 Access Layers portnox pour un contrôle amélioré des accès access layers Copyright 2008 Access Layers. Tous droits réservés. Table des matières Introduction 2 Contrôle
portnox Livre blanc réseau Janvier 2008 Access Layers portnox pour un contrôle amélioré des accès access layers Copyright 2008 Access Layers. Tous droits réservés. Table des matières Introduction 2 Contrôle
Cours Programmation Système
 Cours Programmation Système Filière SMI Semestre S6 El Mostafa DAOUDI Département de Mathématiques et d Informatique, Faculté des Sciences Université Mohammed Premier Oujda m.daoudi@fso.ump.ma Février
Cours Programmation Système Filière SMI Semestre S6 El Mostafa DAOUDI Département de Mathématiques et d Informatique, Faculté des Sciences Université Mohammed Premier Oujda m.daoudi@fso.ump.ma Février
Network musical jammin
 Network musical jammin Projet PC2R - 2015 Pour ce projet, nous allons réaliser une application permettant d effectuer des jams sessions en temps-réel entre des musiciens répartis à travers le monde. Le
Network musical jammin Projet PC2R - 2015 Pour ce projet, nous allons réaliser une application permettant d effectuer des jams sessions en temps-réel entre des musiciens répartis à travers le monde. Le
Principes de DHCP. Le mécanisme de délivrance d'une adresse IP à un client DHCP s'effectue en 4 étapes : COMMUTATEUR 1. DHCP DISCOVER 2.
 DHCP ET TOPOLOGIES Principes de DHCP Présentation du protocole Sur un réseau TCP/IP, DHCP (Dynamic Host Configuration Protocol) permet d'attribuer automatiquement une adresse IP aux éléments qui en font
DHCP ET TOPOLOGIES Principes de DHCP Présentation du protocole Sur un réseau TCP/IP, DHCP (Dynamic Host Configuration Protocol) permet d'attribuer automatiquement une adresse IP aux éléments qui en font