Programmation parallèle et distribuée
|
|
|
- Sébastien Leclerc
- il y a 8 ans
- Total affichages :
Transcription
1 Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2014) Marc Parizeau, Département de génie électrique et de génie informatique

2 Plan Mégadonnées («big data») Architecture Hadoop distribution des données processus map / shuffle / reduce extensibilité Exemples 2

3 Mégadonnées Voici quelques données à propos du WWW en x pages web sur Internet 48 x 10 9 pages indexées par Google 14 x 10 9 pages indexées par Bing 672 x octets de données accessibles 44 x octets de traffic Internet Temps de lecture d un disque de 4 To 11 heures (en supposant 100 Mo/sec) 3

4 Problèmes trop de données pour un seul ordinateur; les données ne rentrent même pas dans la mémoire d un ordinateur; elles ne rentrent pas non plus sur un seul disque! Solution utiliser Hadoop 4

5 Hadoop Projet Apache ( logiciel libre implanté en Java en fait, une boite à outils contenant divers composants Créé en 2004 par Doug Cutting, à partir d articles publiés par Google le nom Hadoop était celui de l éléphant en pluches de son fils Pour la programmation distribuée sur de grosses grappes de calcul pas nécessairement très performantes mais qui résistent aux défaillances (elles surviennent fréquemment) et qui sont extensibles (linéairement) 5

6 Qui l utilise? 6

7 Traitement vs data Traditionnellement, on sépare les traitements des données Cependant, beaucoup d applications peu exigeante en CPU viennent taxer les entrées / sorties 7

8 Avec Hadoop, on tente de regrouper le traitement et le stockage sur un même nœud le code est généralement petit relativement aux données 8

9 Résilience Pour un grand nombre de nœuds de traitement, les défaillances sont communes à chaque semaine parfois à chaque jour Hadoop est conçu pour résister aux pannes les données sont répliquées les tâches sont redémarrées au besoin 9

10 Abstraction de la complexité Beaucoup de la complexité inhérente aux applications concurrentes et distribuées est assumée par Hadoop l utilisateur n a qu à définir un petit nombre de composants et à spécifier des interfaces simples entre ces composants Tous les défis tels que la gestions des courses critiques, la construction de pipeline, le partitionnement des données, etc., sont gérés automatiquement L utilisateur peut se concentrer sur les spécificités de son application 10

11 Environnement Hadoop Deux composants principaux HDFS : «Hadoop Distributed File System» MapReduce : cadriciel pour le traitement distribué Mais également d autres composants HBase : «Hadoop column database» Pipes : permet de travailler en C++ Streaming : permet de travailler avec un langage quelconque, en utilisant les «standard input/output» etc. 11

12 HDFS Système de fichiers distribué Inspiré du système équivalent chez Google apparaît comme un seul disque mais est en fait distribué sur les nœuds de la grappe Résiste aux pannes de disque les fichiers sont découpés en gros blocs les blocs sont copiés sur plusieurs disques Conçu pour un nombre modéré de gros fichiers mal adapté à un grand nombre de petits fichiers 12

13 HDFS : architecture Deux types de nœuds Namenode : pour gérer les métadonnées Datanode : pour stocker les blocs de données 13

14 HDFS : fichiers et blocs 14

15 HDFS : taille des blocs Typiquement 64 Mo ou 128 Mo par défaut 64 Mo afin d amortir les mouvements de têtes de lecture des disques Les petits fichiers gaspillent cependant beaucoup d espace! 15

16 HDFS : réplication Les Namenodes déterminent les l emplacement des bloc répliqués En tenant compte de l emplacement des cabinets on recherche un équilibre entre la fiabilité et la performance afin notamment de réduire la bande passante Par défaut on sauvegarde 3 copies dans un nœud d un cabinet dans un nœud différent du même cabinet dans un cabinet différent 16

17 HDFS : écriture 17
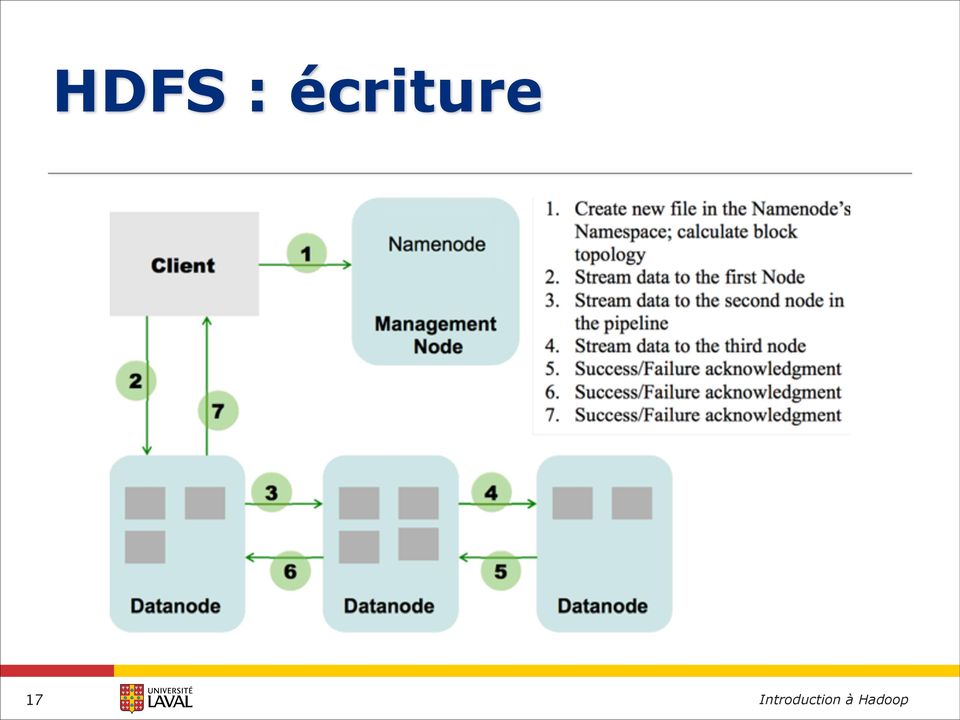
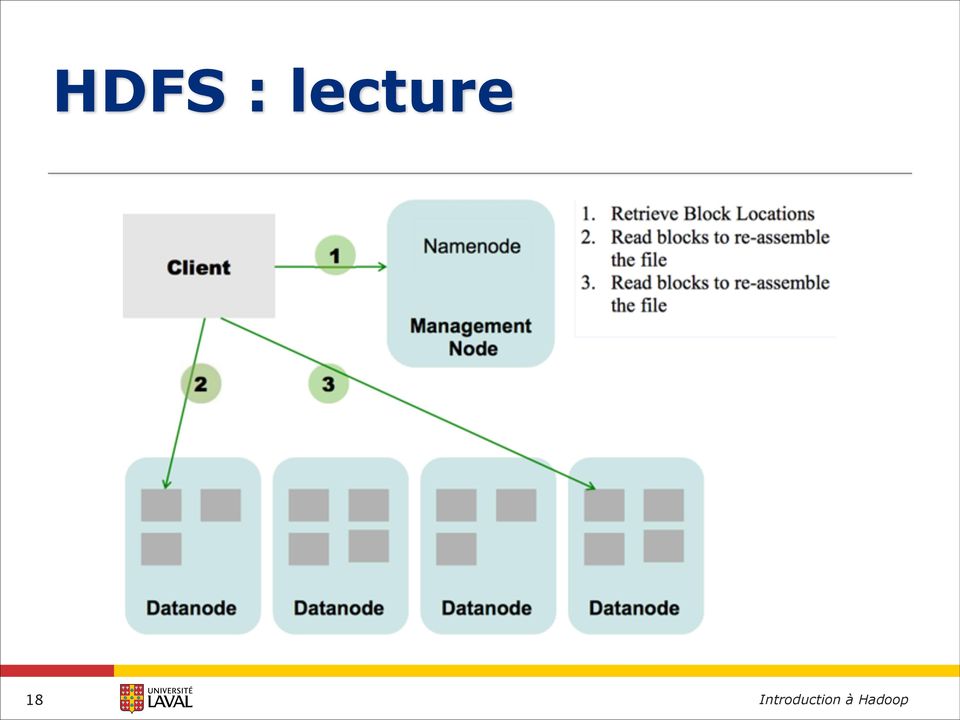
18 HDFS : lecture 18
19 MapReduce : architecture On commence par déplacer les données HDFS qui s occupe de les distribuer pour vous Puis on effectue un Map / Shuffle / Reduce 19

20 20
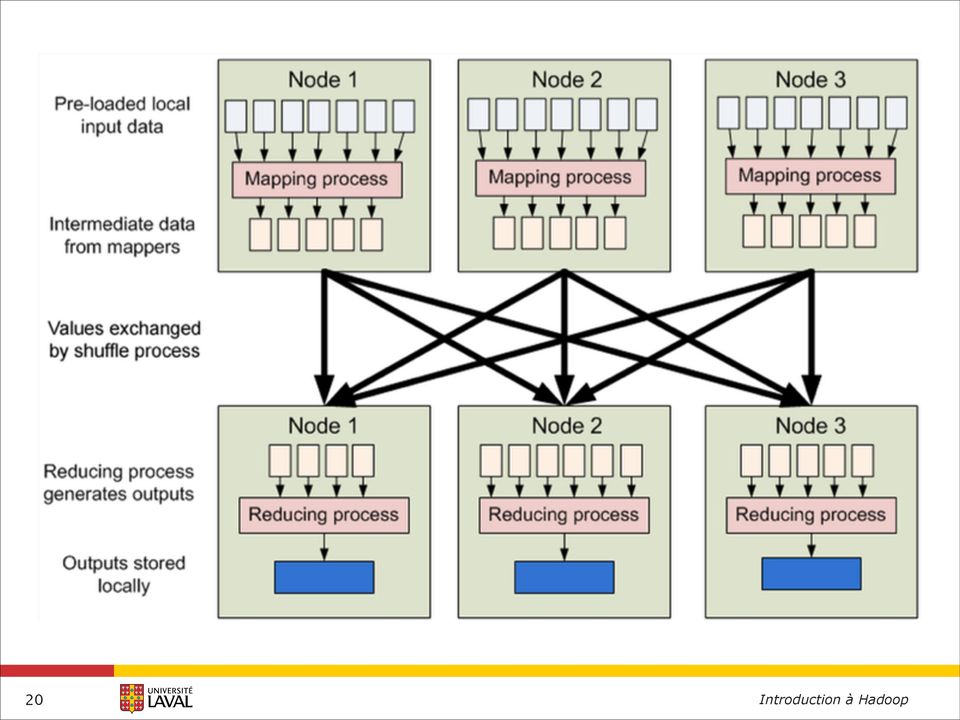
21 Couples (clé:valeur) Avec Hadoop, on manipule toujours des couples (clé: valeur) autant en entrée qu en sortie Et on définit des fonctions «map» et «reduce» map : (c1: v1) > liste de (c2: v2) reduce : (c2: liste de v2) > list de (c3: v3) Algorithme 1. on applique map à tous les couples (c1: v1) 2. map génère une liste couples (c2: v2) intermédiaires 3. les couples intermédiaires de même clés sont groupées et triées afin de produire le couple (c2: liste de v2) 4. reduce est appliquée sur les couples (c2: liste de v2) afin de produire de nouveaux couples (c3: v3) 21
22 Exemple simple Compter les mots dans un corpus d une multitude de fichiers chacun de grande dimension On veut connaître la liste des mots et leur fréquence respective Le «map» reçoit des lignes de texte et pour chaque mot de la ligne produit le couple (mot: 1) Le «reduce» reçoit alors en entrée des couples (mot: [liste_de_nombres]) et produit en sortie des couples (mot: fréquence), après avoir fait la somme des nombres de la liste 22
23 nœud 1 nœud 2 23
24 24
25 Autre exemple Dans un corpus, compter le nombre de mot ayant une longueur de 1, 2, 3, 4, etc. map(mot) > (long: mot) reduce(long: liste de mots) > (long: nombre) 25
26 Étape du «shuffle» On applique simplement une fonction de hachage («hash function») afin d associé un id unique à chaque nœud en supposant n nœuds de réduction hash(clé) % n Le nombre de nœuds de réduction est fixé à l avance ainsi chaque processus de map peut déterminer luimême à qui transmettre ses couples de sortie 26
27 Remarques diverses Les processus de map ne traitent typiquement que les blocs des fichiers qui sont physiquement stockés sur le nœud local Ce sont les lignes du fichier qui sont typiquement transmises aux processus de map en fait, le processus reçoit un couple (offset: ligne) HDFS va répartir automatiquement les différents blocs des différents fichiers sur l ensemble des nœuds On peut appliquer un MapReduce sur la sortie d un autre MapReduce on crée ainsi une cascade de traitement 27
28 Conclusion Hadoop est un cadriciel qui permet de distribuer des tâches de type MapReduce sur une grappe de serveurs en fait un map suivi d un shuffle suivi d un sort suivi d un reduce les maps sont affectés à un grand nombre de nœuds les reduces aussi, potentiellement aux mêmes nœuds les nombres de maps et de reduces sont programmables Hadoop possède une grande extensibilité car les tâches MapReduce sont indépendantes («they share nothing») D autres composants de plus haut niveau sont également disponibles 28
29 Pour en savoir plus Tutoriels mapred_tutorial.html Design patterns mapreduce-patterns/ 29
Programmation parallèle et distribuée
 Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2015) Marc Parizeau, Département de génie électrique et de génie informatique Plan Données massives («big data») Architecture Hadoop distribution
Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2015) Marc Parizeau, Département de génie électrique et de génie informatique Plan Données massives («big data») Architecture Hadoop distribution
Programmation parallèle et distribuée (Master 1 Info 2015-2016)
") Programmation parallèle et distribuée (Master 1 Info 2015-2016) Hadoop MapReduce et HDFS Note bibliographique : ce cours est largement inspiré par le cours de Benjamin Renaut (Tokidev SAS) Introduction
Programmation parallèle et distribuée (Master 1 Info 2015-2016) Hadoop MapReduce et HDFS Note bibliographique : ce cours est largement inspiré par le cours de Benjamin Renaut (Tokidev SAS) Introduction
API04 Contribution. Apache Hadoop: Présentation et application dans le domaine des Data Warehouses. Introduction. Architecture
 API04 Contribution Apache Hadoop: Présentation et application dans le domaine des Data Warehouses Introduction Cette publication a pour but de présenter le framework Java libre Apache Hadoop, permettant
API04 Contribution Apache Hadoop: Présentation et application dans le domaine des Data Warehouses Introduction Cette publication a pour but de présenter le framework Java libre Apache Hadoop, permettant
Fouillez facilement dans votre système Big Data. Olivier TAVARD
 Fouillez facilement dans votre système Big Data Olivier TAVARD A propos de moi : Cofondateur de la société France Labs Développeur (principalement Java) Formateur en technologies de moteurs de recherche
Fouillez facilement dans votre système Big Data Olivier TAVARD A propos de moi : Cofondateur de la société France Labs Développeur (principalement Java) Formateur en technologies de moteurs de recherche
Introduction à MapReduce/Hadoop et Spark
 1 / 36 Introduction à MapReduce/Hadoop et Spark Certificat Big Data Ludovic Denoyer et Sylvain Lamprier UPMC Plan 2 / 36 Contexte 3 / 36 Contexte 4 / 36 Data driven science: le 4e paradigme (Jim Gray -
1 / 36 Introduction à MapReduce/Hadoop et Spark Certificat Big Data Ludovic Denoyer et Sylvain Lamprier UPMC Plan 2 / 36 Contexte 3 / 36 Contexte 4 / 36 Data driven science: le 4e paradigme (Jim Gray -
Big Data Concepts et mise en oeuvre de Hadoop
 Introduction 1. Objectif du chapitre 9 2. Le Big Data 10 2.1 Introduction 10 2.2 Informatique connectée, objets "intelligents" et données collectées 11 2.3 Les unités de mesure dans le monde Big Data 12
Introduction 1. Objectif du chapitre 9 2. Le Big Data 10 2.1 Introduction 10 2.2 Informatique connectée, objets "intelligents" et données collectées 11 2.3 Les unités de mesure dans le monde Big Data 12
Ricco Rakotomalala http://eric.univ-lyon2.fr/~ricco/cours/cours_programmation_r.html. R.R. Université Lyon 2
 Ricco Rakotomalala http://eric.univ-lyon2.fr/~ricco/cours/cours_programmation_r.html 1 Plan de présentation 1. L écosystème Hadoop 2. Principe de programmation MapReduce 3. Programmation des fonctions
Ricco Rakotomalala http://eric.univ-lyon2.fr/~ricco/cours/cours_programmation_r.html 1 Plan de présentation 1. L écosystème Hadoop 2. Principe de programmation MapReduce 3. Programmation des fonctions
Déploiement d une architecture Hadoop pour analyse de flux. françois-xavier.andreu@renater.fr
 Déploiement d une architecture Hadoop pour analyse de flux françois-xavier.andreu@renater.fr 1 plan Introduction Hadoop Présentation Architecture d un cluster HDFS & MapReduce L architecture déployée Les
Déploiement d une architecture Hadoop pour analyse de flux françois-xavier.andreu@renater.fr 1 plan Introduction Hadoop Présentation Architecture d un cluster HDFS & MapReduce L architecture déployée Les
Cartographie des solutions BigData
 Cartographie des solutions BigData Panorama du marché et prospective 1 1 Solutions BigData Défi(s) pour les fournisseurs Quel marché Architectures Acteurs commerciaux Solutions alternatives 2 2 Quels Défis?
Cartographie des solutions BigData Panorama du marché et prospective 1 1 Solutions BigData Défi(s) pour les fournisseurs Quel marché Architectures Acteurs commerciaux Solutions alternatives 2 2 Quels Défis?
Big Data. Cyril Amsellem Consultant avant-vente. 16 juin 2011. Talend 2010 1
 Big Data Cyril Amsellem Consultant avant-vente 16 juin 2011 Talend 2010 1 Big Data Architecture globale Hadoop Les projets Hadoop (partie 1) Hadoop-Core : projet principal. HDFS : système de fichiers distribués
Big Data Cyril Amsellem Consultant avant-vente 16 juin 2011 Talend 2010 1 Big Data Architecture globale Hadoop Les projets Hadoop (partie 1) Hadoop-Core : projet principal. HDFS : système de fichiers distribués
NoSQL. Introduction 1/23. I NoSQL : Not Only SQL, ce n est pas du relationnel, et le contexte. I table d associations - Map - de couples (clef,valeur)
") 1/23 2/23 Anne-Cécile Caron Master MIAGE - BDA 1er trimestre 2013-2014 I : Not Only SQL, ce n est pas du relationnel, et le contexte d utilisation n est donc pas celui des SGBDR. I Origine : recherche
1/23 2/23 Anne-Cécile Caron Master MIAGE - BDA 1er trimestre 2013-2014 I : Not Only SQL, ce n est pas du relationnel, et le contexte d utilisation n est donc pas celui des SGBDR. I Origine : recherche
Big Data. Les problématiques liées au stockage des données et aux capacités de calcul
 Big Data Les problématiques liées au stockage des données et aux capacités de calcul Les problématiques liées au Big Data La capacité de stockage - Traitement : Ponctuel ou permanent? - Cycle de vie des
Big Data Les problématiques liées au stockage des données et aux capacités de calcul Les problématiques liées au Big Data La capacité de stockage - Traitement : Ponctuel ou permanent? - Cycle de vie des
Document réalisé par Khadidjatou BAMBA
 Comprendre le BIG DATA Document réalisé par Khadidjatou BAMBA 1 Sommaire Avant propos. 3 Historique du Big Data.4 Introduction.....5 Chapitre I : Présentation du Big Data... 6 I. Généralités sur le Big
Comprendre le BIG DATA Document réalisé par Khadidjatou BAMBA 1 Sommaire Avant propos. 3 Historique du Big Data.4 Introduction.....5 Chapitre I : Présentation du Big Data... 6 I. Généralités sur le Big
Formation Cloudera Data Analyst Utiliser Pig, Hive et Impala avec Hadoop
 Passez au niveau supérieur en termes de connaissance grâce à la formation Data Analyst de Cloudera. Public Durée Objectifs Analystes de données, business analysts, développeurs et administrateurs qui ont
Passez au niveau supérieur en termes de connaissance grâce à la formation Data Analyst de Cloudera. Public Durée Objectifs Analystes de données, business analysts, développeurs et administrateurs qui ont
Labs Hadoop Février 2013
 SOA - BRMS - ESB - BPM CEP BAM - High Performance Compute & Data Grid - Cloud Computing - Big Data NoSQL - Analytics Labs Hadoop Février 2013 Mathias Kluba Managing Consultant Responsable offres NoSQL
SOA - BRMS - ESB - BPM CEP BAM - High Performance Compute & Data Grid - Cloud Computing - Big Data NoSQL - Analytics Labs Hadoop Février 2013 Mathias Kluba Managing Consultant Responsable offres NoSQL
Organiser vos données - Big Data. Patrick Millart Senior Sales Consultant
 Organiser vos données - Big Data Patrick Millart Senior Sales Consultant The following is intended to outline our general product direction. It is intended for information purposes only, and may not be
Organiser vos données - Big Data Patrick Millart Senior Sales Consultant The following is intended to outline our general product direction. It is intended for information purposes only, and may not be
L écosystème Hadoop Nicolas Thiébaud ni.thiebaud@gmail.com. Tuesday, July 2, 13
 L écosystème Hadoop Nicolas Thiébaud ni.thiebaud@gmail.com HUG France 250 membres sur la mailing liste 30 présentations 9 meetups organisés, de 20 à 100 invités Présence de Cloudera, MapR, Hortonworks,
L écosystème Hadoop Nicolas Thiébaud ni.thiebaud@gmail.com HUG France 250 membres sur la mailing liste 30 présentations 9 meetups organisés, de 20 à 100 invités Présence de Cloudera, MapR, Hortonworks,
Tables Rondes Le «Big Data»
 Tables Rondes Le «Big Data» 2012-2013 1 Plan Introduc9on 1 - Présenta9on Ingensi 2 - Le Big Data c est quoi? 3 - L histoire 4 - Le monde du libre : Hadoop 5 - Le système HDFS 6 - Les algorithmes distribués
Tables Rondes Le «Big Data» 2012-2013 1 Plan Introduc9on 1 - Présenta9on Ingensi 2 - Le Big Data c est quoi? 3 - L histoire 4 - Le monde du libre : Hadoop 5 - Le système HDFS 6 - Les algorithmes distribués
NoSQL. Introduction 1/30. I NoSQL : Not Only SQL, ce n est pas du relationnel, et le contexte. I table d associations - Map - de couples (clef,valeur)
") 1/30 2/30 Anne-Cécile Caron Master MIAGE - SGBD 1er trimestre 2014-2015 I : Not Only SQL, ce n est pas du relationnel, et le contexte d utilisation n est donc pas celui des SGBDR. I Origine : recherche
1/30 2/30 Anne-Cécile Caron Master MIAGE - SGBD 1er trimestre 2014-2015 I : Not Only SQL, ce n est pas du relationnel, et le contexte d utilisation n est donc pas celui des SGBDR. I Origine : recherche
Les technologies du Big Data
 Les technologies du Big Data PRÉSENTÉ AU 40 E CONGRÈS DE L ASSOCIATION DES ÉCONOMISTES QUÉBÉCOIS PAR TOM LANDRY, CONSEILLER SENIOR LE 20 MAI 2015 WWW.CRIM.CA TECHNOLOGIES: DES DONNÉES JUSQU'À L UTILISATEUR
Les technologies du Big Data PRÉSENTÉ AU 40 E CONGRÈS DE L ASSOCIATION DES ÉCONOMISTES QUÉBÉCOIS PAR TOM LANDRY, CONSEILLER SENIOR LE 20 MAI 2015 WWW.CRIM.CA TECHNOLOGIES: DES DONNÉES JUSQU'À L UTILISATEUR
MapReduce. Nicolas Dugué nicolas.dugue@univ-orleans.fr. M2 MIAGE Systèmes d information répartis
 MapReduce Nicolas Dugué nicolas.dugue@univ-orleans.fr M2 MIAGE Systèmes d information répartis Plan 1 Introduction Big Data 2 MapReduce et ses implémentations 3 MapReduce pour fouiller des tweets 4 MapReduce
MapReduce Nicolas Dugué nicolas.dugue@univ-orleans.fr M2 MIAGE Systèmes d information répartis Plan 1 Introduction Big Data 2 MapReduce et ses implémentations 3 MapReduce pour fouiller des tweets 4 MapReduce
Les participants repartiront de cette formation en ayant une vision claire de la stratégie et de l éventuelle mise en œuvre d un Big Data.
 Big Data De la stratégie à la mise en oeuvre Description : La formation a pour objet de brosser sans concession le tableau du Big Data. Les participants repartiront de cette formation en ayant une vision
Big Data De la stratégie à la mise en oeuvre Description : La formation a pour objet de brosser sans concession le tableau du Big Data. Les participants repartiront de cette formation en ayant une vision
MapReduce et Hadoop. Alexandre Denis Alexandre.Denis@inria.fr. Inria Bordeaux Sud-Ouest France ENSEIRB PG306
 MapReduce et Hadoop Alexandre Denis Alexandre.Denis@inria.fr Inria Bordeaux Sud-Ouest France ENSEIRB PG306 Fouille de données Recherche & indexation de gros volumes Appliquer une opération simple à beaucoup
MapReduce et Hadoop Alexandre Denis Alexandre.Denis@inria.fr Inria Bordeaux Sud-Ouest France ENSEIRB PG306 Fouille de données Recherche & indexation de gros volumes Appliquer une opération simple à beaucoup
Livre. blanc. Solution Hadoop d entreprise d EMC. Stockage NAS scale-out Isilon et Greenplum HD. Février 2012
 Livre blanc Solution Hadoop d entreprise d EMC Stockage NAS scale-out Isilon et Greenplum HD Par Julie Lockner et Terri McClure, Analystes seniors Février 2012 Ce livre blanc d ESG, qui a été commandé
Livre blanc Solution Hadoop d entreprise d EMC Stockage NAS scale-out Isilon et Greenplum HD Par Julie Lockner et Terri McClure, Analystes seniors Février 2012 Ce livre blanc d ESG, qui a été commandé
20 ans du Master SIAD de Toulouse - BigData par l exemple - Julien DULOUT - 22 mars 2013. 20 ans du SIAD -"Big Data par l'exemple" -Julien DULOUT
 20 ans du Master SIAD de Toulouse - BigData par l exemple - Julien DULOUT - 22 mars 2013 20 ans du SIAD -"BigData par l'exemple" -Julien DULOUT Qui a déjà entendu parler du phénomène BigData? Qui a déjà
20 ans du Master SIAD de Toulouse - BigData par l exemple - Julien DULOUT - 22 mars 2013 20 ans du SIAD -"BigData par l'exemple" -Julien DULOUT Qui a déjà entendu parler du phénomène BigData? Qui a déjà
MapReduce. Malo Jaffré, Pablo Rauzy. 16 avril 2010 ENS. Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15
 MapReduce 16 avril 2010 1 / 15") MapReduce Malo Jaffré, Pablo Rauzy ENS 16 avril 2010 Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15 Qu est ce que c est? Conceptuellement Données MapReduce est un framework de calcul distribué
MapReduce Malo Jaffré, Pablo Rauzy ENS 16 avril 2010 Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15 Qu est ce que c est? Conceptuellement Données MapReduce est un framework de calcul distribué
Certificat Big Data - Master MAthématiques
 1 / 1 Certificat Big Data - Master MAthématiques Master 2 Auteur : Sylvain Lamprier UPMC Fouille de données et Medias Sociaux 2 / 1 Rich and big data: Millions d utilisateurs Millions de contenus Multimedia
1 / 1 Certificat Big Data - Master MAthématiques Master 2 Auteur : Sylvain Lamprier UPMC Fouille de données et Medias Sociaux 2 / 1 Rich and big data: Millions d utilisateurs Millions de contenus Multimedia
HADOOP ET SON ÉCOSYSTÈME
 HADOOP ET SON ÉCOSYSTÈME Mars 2013 2012 Affini-Tech - Diffusion restreinte 1 AFFINI-TECH Méthodes projets Outils de reporting & Data-visualisation Business & Analyses BigData Modélisation Hadoop Technos
HADOOP ET SON ÉCOSYSTÈME Mars 2013 2012 Affini-Tech - Diffusion restreinte 1 AFFINI-TECH Méthodes projets Outils de reporting & Data-visualisation Business & Analyses BigData Modélisation Hadoop Technos
Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop
 Julien Gerlier Siman Chen Rapport de projet de fin d étude ASR 2010/2011 Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop Encadrants
Julien Gerlier Siman Chen Rapport de projet de fin d étude ASR 2010/2011 Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop Encadrants
Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop
 Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop Soutenance de projet ASR 27/01/2011 Julien Gerlier Siman Chen Encadrés par Bruno
Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop Soutenance de projet ASR 27/01/2011 Julien Gerlier Siman Chen Encadrés par Bruno
Sommaire. 3. Les grands principes de GFS L architecture L accès de fichier en lecture L accès de fichier en écriture Bilan
 1 Sommaire 1. Google en chiffres 2. Les raisons d être de GFS 3. Les grands principes de GFS L architecture L accès de fichier en lecture L accès de fichier en écriture Bilan 4. Les Evolutions et Alternatives
1 Sommaire 1. Google en chiffres 2. Les raisons d être de GFS 3. Les grands principes de GFS L architecture L accès de fichier en lecture L accès de fichier en écriture Bilan 4. Les Evolutions et Alternatives
Bases de données documentaires et distribuées Cours NFE04
 Bases de données documentaires et distribuées Cours NFE04 Cloud et scalabilité Auteurs : Raphaël Fournier-S niehotta, Philippe Rigaux, Nicolas Travers prénom.nom@cnam.fr Département d informatique Conservatoire
Bases de données documentaires et distribuées Cours NFE04 Cloud et scalabilité Auteurs : Raphaël Fournier-S niehotta, Philippe Rigaux, Nicolas Travers prénom.nom@cnam.fr Département d informatique Conservatoire
Sauvegarde collaborative entre pairs Ludovic Courtès LAAS-CNRS
 Sauvegarde collaborative entre pairs 1 Sauvegarde collaborative entre pairs Ludovic Courtès LAAS-CNRS Sauvegarde collaborative entre pairs 2 Introduction Pourquoi pair à pair? Utilisation de ressources
Sauvegarde collaborative entre pairs 1 Sauvegarde collaborative entre pairs Ludovic Courtès LAAS-CNRS Sauvegarde collaborative entre pairs 2 Introduction Pourquoi pair à pair? Utilisation de ressources
Hadoop : une plate-forme d exécution de programmes Map-Reduce
 Hadoop : une plate-forme d exécution de programmes Map-Reduce Jonathan Lejeune UPMC 8 octobre 2013 PSIA 2013 Inspiré du cours des années précédentes de Luciana Arantes J. Lejeune (UPMC) Hadoop Map-Reduce
Hadoop : une plate-forme d exécution de programmes Map-Reduce Jonathan Lejeune UPMC 8 octobre 2013 PSIA 2013 Inspiré du cours des années précédentes de Luciana Arantes J. Lejeune (UPMC) Hadoop Map-Reduce
Sauvegarde collaborative en pair-à-pair
 Sauvegarde collaborative en pair-à-pair Fabrice Le Fessant Fabrice.Le_Fessant@inria.fr ASAP Team INRIA Saclay Île de France Octobre 2008 Fabrice Le Fessant () Backup en pair-à-pair Rennes 2008 1 / 21 Plan
Sauvegarde collaborative en pair-à-pair Fabrice Le Fessant Fabrice.Le_Fessant@inria.fr ASAP Team INRIA Saclay Île de France Octobre 2008 Fabrice Le Fessant () Backup en pair-à-pair Rennes 2008 1 / 21 Plan
Acquisition des données - Big Data. Dario VEGA Senior Sales Consultant
 Acquisition des données - Big Data Dario VEGA Senior Sales Consultant The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated
Acquisition des données - Big Data Dario VEGA Senior Sales Consultant The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated
AVRIL 2014. Au delà de Hadoop. Panorama des solutions NoSQL
 AVRIL 2014 Panorama des solutions NoSQL QUI SOMMES NOUS? Avril 2014 2 SMILE, EN QUELQUES CHIFFRES 1er INTÉGRATEUR EUROPÉEN DE SOLUTIONS OPEN SOURCE 3 4 NOS EXPERTISES ET NOS CONVICTIONS DANS NOS LIVRES
AVRIL 2014 Panorama des solutions NoSQL QUI SOMMES NOUS? Avril 2014 2 SMILE, EN QUELQUES CHIFFRES 1er INTÉGRATEUR EUROPÉEN DE SOLUTIONS OPEN SOURCE 3 4 NOS EXPERTISES ET NOS CONVICTIONS DANS NOS LIVRES
Les bases de données relationnelles
 Bases de données NO SQL et SIG : d un existant restreint à un avenir prometteur CHRISTIAN CAROLIN, AXES CONSEIL CAROLIN@AXES.FR - HTTP://WWW.AXES.FR Les bases de données relationnelles constituent désormais
Bases de données NO SQL et SIG : d un existant restreint à un avenir prometteur CHRISTIAN CAROLIN, AXES CONSEIL CAROLIN@AXES.FR - HTTP://WWW.AXES.FR Les bases de données relationnelles constituent désormais
Les journées SQL Server 2013
 Les journées SQL Server 2013 Un événement organisé par GUSS Les journées SQL Server 2013 Romain Casteres MVP SQL Server Consultant BI @PulsWeb Yazid Moussaoui Consultant Senior BI MCSA 2008/2012 Etienne
Les journées SQL Server 2013 Un événement organisé par GUSS Les journées SQL Server 2013 Romain Casteres MVP SQL Server Consultant BI @PulsWeb Yazid Moussaoui Consultant Senior BI MCSA 2008/2012 Etienne
R+Hadoop = Rhadoop* Des logiciels libres complémentaires, une implémentation, une réponse au nouveau paradigme du bigdata!
 R+Hadoop = Rhadoop* * Des logiciels libres complémentaires, une implémentation, une réponse au nouveau paradigme du bigdata! 27 Janvier 2014 / Université Paul Sabatier / DTSI / David Tsang-Hin-Sun Big
R+Hadoop = Rhadoop* * Des logiciels libres complémentaires, une implémentation, une réponse au nouveau paradigme du bigdata! 27 Janvier 2014 / Université Paul Sabatier / DTSI / David Tsang-Hin-Sun Big
ÉCOLE DE TECHNOLOGIE SUPÉRIEURE UNIVERSITÉ DU QUÉBEC RAPPORT DE PROJET PRÉSENTÉ À L ÉCOLE DE TECHNOLOGIE SUPÉRIEURE
 ÉCOLE DE TECHNOLOGIE SUPÉRIEURE UNIVERSITÉ DU QUÉBEC RAPPORT DE PROJET PRÉSENTÉ À L ÉCOLE DE TECHNOLOGIE SUPÉRIEURE COMME EXIGENCE PARTIELLE À L OBTENTION DE LA MAÎTRISE EN GÉNIE PAR Sébastien SERVOLES
ÉCOLE DE TECHNOLOGIE SUPÉRIEURE UNIVERSITÉ DU QUÉBEC RAPPORT DE PROJET PRÉSENTÉ À L ÉCOLE DE TECHNOLOGIE SUPÉRIEURE COMME EXIGENCE PARTIELLE À L OBTENTION DE LA MAÎTRISE EN GÉNIE PAR Sébastien SERVOLES
Hadoop, Spark & Big Data 2.0. Exploiter une grappe de calcul pour des problème des données massives
 Hadoop, Spark & Big Data 2.0 Exploiter une grappe de calcul pour des problème des données massives Qui suis-je? Félix-Antoine Fortin Génie info. (B. Ing, M. Sc, ~PhD) Passionné de Python, Data Analytics,
Hadoop, Spark & Big Data 2.0 Exploiter une grappe de calcul pour des problème des données massives Qui suis-je? Félix-Antoine Fortin Génie info. (B. Ing, M. Sc, ~PhD) Passionné de Python, Data Analytics,
4 Exemples de problèmes MapReduce incrémentaux
 4 Exemples de problèmes MapReduce incrémentaux 1 / 32 Calcul des plus courtes distances à un noeud d un graphe Calcul des plus courts chemins entre toutes les paires de noeuds d un graphe Algorithme PageRank
4 Exemples de problèmes MapReduce incrémentaux 1 / 32 Calcul des plus courtes distances à un noeud d un graphe Calcul des plus courts chemins entre toutes les paires de noeuds d un graphe Algorithme PageRank
Introduc)on à Map- Reduce. Vincent Leroy
on à Map- Reduce. Vincent Leroy") Introduc)on à Map- Reduce Vincent Leroy Sources Apache Hadoop Yahoo! Developer Network Hortonworks Cloudera Prac)cal Problem Solving with Hadoop and Pig Les cours seront mis en ligne sur hhp://membres.liglab.fr/leroy/
Introduc)on à Map- Reduce Vincent Leroy Sources Apache Hadoop Yahoo! Developer Network Hortonworks Cloudera Prac)cal Problem Solving with Hadoop and Pig Les cours seront mis en ligne sur hhp://membres.liglab.fr/leroy/
BIG DATA en Sciences et Industries de l Environnement
 BIG DATA en Sciences et Industries de l Environnement François Royer www.datasio.com 21 mars 2012 FR Big Data Congress, Paris 2012 1/23 Transport terrestre Traçabilité Océanographie Transport aérien Télémétrie
BIG DATA en Sciences et Industries de l Environnement François Royer www.datasio.com 21 mars 2012 FR Big Data Congress, Paris 2012 1/23 Transport terrestre Traçabilité Océanographie Transport aérien Télémétrie
Hadoop : une plate-forme d exécution de programmes Map-Reduce
 Hadoop : une plate-forme d exécution de programmes Map-Reduce Jonathan Lejeune École des Mines de Nantes Janvier 2015 CODEL 2014/2015 J. Lejeune (École des Mines de Nantes) Hadoop Map-Reduce Janvier 2015
Hadoop : une plate-forme d exécution de programmes Map-Reduce Jonathan Lejeune École des Mines de Nantes Janvier 2015 CODEL 2014/2015 J. Lejeune (École des Mines de Nantes) Hadoop Map-Reduce Janvier 2015
Département Informatique 5 e année 2013-2014. Hadoop: Optimisation et Ordonnancement
 École Polytechnique de l Université de Tours 64, Avenue Jean Portalis 37200 TOURS, FRANCE Tél. +33 (0)2 47 36 14 14 www.polytech.univ-tours.fr Département Informatique 5 e année 2013-2014 Hadoop: Optimisation
École Polytechnique de l Université de Tours 64, Avenue Jean Portalis 37200 TOURS, FRANCE Tél. +33 (0)2 47 36 14 14 www.polytech.univ-tours.fr Département Informatique 5 e année 2013-2014 Hadoop: Optimisation
VirtualScale L expert infrastructure de l environnement Open source HADOOP Sofiane Ammar sofiane.ammar@virtualscale.fr
 VirtualScale L expert infrastructure de l environnement Open source HADOOP Sofiane Ammar sofiane.ammar@virtualscale.fr Avril 2014 Virtualscale 1 Sommaire Les enjeux du Big Data et d Hadoop Quels enjeux
VirtualScale L expert infrastructure de l environnement Open source HADOOP Sofiane Ammar sofiane.ammar@virtualscale.fr Avril 2014 Virtualscale 1 Sommaire Les enjeux du Big Data et d Hadoop Quels enjeux
Big Data : utilisation d un cluster Hadoop HDFS Map/Reduce HBase
 Big Data : utilisation d un cluster cluster Cécile Cavet cecile.cavet at apc.univ-paris7.fr Centre François Arago (FACe), Laboratoire APC, Université Paris Diderot LabEx UnivEarthS 14 Janvier 2014 C. Cavet
Big Data : utilisation d un cluster cluster Cécile Cavet cecile.cavet at apc.univ-paris7.fr Centre François Arago (FACe), Laboratoire APC, Université Paris Diderot LabEx UnivEarthS 14 Janvier 2014 C. Cavet
M2 GL UE DOC «In memory analytics»
 M2 GL UE DOC «In memory analytics» Alexandre Termier 2014/2015 Sources Travaux Amplab, U.C. Berkeley Slides Ion Stoica Présentations Databricks Slides Pat McDonough Articles de M. Zaharia et al. sur les
M2 GL UE DOC «In memory analytics» Alexandre Termier 2014/2015 Sources Travaux Amplab, U.C. Berkeley Slides Ion Stoica Présentations Databricks Slides Pat McDonough Articles de M. Zaharia et al. sur les
Panorama des solutions analytiques existantes
 Arnaud LAROCHE Julien DAMON Panorama des solutions analytiques existantes SFdS Méthodes et Logiciels - 16 janvier 2014 - Données Massives Ne sont ici considérés que les solutions autour de l environnement
Arnaud LAROCHE Julien DAMON Panorama des solutions analytiques existantes SFdS Méthodes et Logiciels - 16 janvier 2014 - Données Massives Ne sont ici considérés que les solutions autour de l environnement
ACCOMPAGNER L EXPLOSION DES VOLUMES DE DONNEES : LES NOUVEAUX ENJEUX DU STOCKAGE
 Livre Blanc ACCOMPAGNER L EXPLOSION DES VOLUMES DE DONNEES : LES NOUVEAUX ENJEUX DU STOCKAGE Abstract En 2012, l explosion des volumes de données n est plus une hypothèse lointaine mais bien une réalité.
Livre Blanc ACCOMPAGNER L EXPLOSION DES VOLUMES DE DONNEES : LES NOUVEAUX ENJEUX DU STOCKAGE Abstract En 2012, l explosion des volumes de données n est plus une hypothèse lointaine mais bien une réalité.
http://blog.khaledtannir.net
 Algorithme de parallélisations des traitements Khaled TANNIR Doctorant CIFRE LARIS/ESTI http://blog.khaledtannir.net these@khaledtannir.net 2e SéRI 2010-2011 Jeudi 17 mars 2011 Présentation Doctorant CIFRE
Algorithme de parallélisations des traitements Khaled TANNIR Doctorant CIFRE LARIS/ESTI http://blog.khaledtannir.net these@khaledtannir.net 2e SéRI 2010-2011 Jeudi 17 mars 2011 Présentation Doctorant CIFRE
Encryptions, compression et partitionnement des données
 Encryptions, compression et partitionnement des données Version 1.0 Grégory CASANOVA 2 Compression, encryption et partitionnement des données Sommaire 1 Introduction... 3 2 Encryption transparente des
Encryptions, compression et partitionnement des données Version 1.0 Grégory CASANOVA 2 Compression, encryption et partitionnement des données Sommaire 1 Introduction... 3 2 Encryption transparente des
Groupe de Discussion Big Data Aperçu des technologies et applications. Stéphane MOUTON stephane.mouton@cetic.be
 Groupe de Discussion Big Data Aperçu des technologies et applications Stéphane MOUTON stephane.mouton@cetic.be Recherche appliquée et transfert technologique q Agréé «Centre Collectif de Recherche» par
Groupe de Discussion Big Data Aperçu des technologies et applications Stéphane MOUTON stephane.mouton@cetic.be Recherche appliquée et transfert technologique q Agréé «Centre Collectif de Recherche» par
Ebauche Rapport finale
 Ebauche Rapport finale Sommaire : 1 - Introduction au C.D.N. 2 - Définition de la problématique 3 - Etat de l'art : Présentatio de 3 Topologies streaming p2p 1) INTRODUCTION au C.D.N. La croissance rapide
Ebauche Rapport finale Sommaire : 1 - Introduction au C.D.N. 2 - Définition de la problématique 3 - Etat de l'art : Présentatio de 3 Topologies streaming p2p 1) INTRODUCTION au C.D.N. La croissance rapide
Professeur-superviseur Alain April
 RAPPORT TECHNIQUE PRÉSENTÉ À L ÉCOLE DE TECHNOLOGIE SUPÉRIEURE DANS LE CADRE DU COURS GTI792 BASE DE DONNÉES DISTRIBUÉE APPLIQUÉE EN GÉNÉTIQUE DANS LE CADRE DE L'ANALYSE DE SÉQUENÇAGE GÉNOMIQUE JEAN-PHILIPPE
RAPPORT TECHNIQUE PRÉSENTÉ À L ÉCOLE DE TECHNOLOGIE SUPÉRIEURE DANS LE CADRE DU COURS GTI792 BASE DE DONNÉES DISTRIBUÉE APPLIQUÉE EN GÉNÉTIQUE DANS LE CADRE DE L'ANALYSE DE SÉQUENÇAGE GÉNOMIQUE JEAN-PHILIPPE
Les quatre piliers d une solution de gestion des Big Data
 White Paper Les quatre piliers d une solution de gestion des Big Data Table des Matières Introduction... 4 Big Data : un terme très vaste... 4 Le Big Data... 5 La technologie Big Data... 5 Le grand changement
White Paper Les quatre piliers d une solution de gestion des Big Data Table des Matières Introduction... 4 Big Data : un terme très vaste... 4 Le Big Data... 5 La technologie Big Data... 5 Le grand changement
Problématiques de stockage d un Data Center
 Problématiques de stockage d un Data Center ALBERT SHIH 1 1 Observatoire de Paris - Meudon 12 mars 2008 Buts Proposer des solutions de stockage/archivage/sauvegarde pour des volumes de données importantes.
Problématiques de stockage d un Data Center ALBERT SHIH 1 1 Observatoire de Paris - Meudon 12 mars 2008 Buts Proposer des solutions de stockage/archivage/sauvegarde pour des volumes de données importantes.
Hadoop / Big Data. Benjamin Renaut <renaut.benjamin@tokidev.fr> MBDS 2014-2015
 Hadoop / Big Data Benjamin Renaut MBDS 2014-2015 6 map/reduce et Hadoop: exemples plus avancés Exemple: parcours de graphe 6-1 On cherche à déterminer la profondeur maximale
Hadoop / Big Data Benjamin Renaut MBDS 2014-2015 6 map/reduce et Hadoop: exemples plus avancés Exemple: parcours de graphe 6-1 On cherche à déterminer la profondeur maximale
Hadoop / Big Data. Benjamin Renaut <renaut.benjamin@tokidev.fr> MBDS 2014-2015
 Hadoop / Big Data Benjamin Renaut MBDS 2014-2015 TP 1 Méthodologie Map/Reduce - programmation Hadoop. 1 Installer VirtualBox (https://www.virtualbox.org/). Importer la machine
Hadoop / Big Data Benjamin Renaut MBDS 2014-2015 TP 1 Méthodologie Map/Reduce - programmation Hadoop. 1 Installer VirtualBox (https://www.virtualbox.org/). Importer la machine
4. Utilisation d un SGBD : le langage SQL. 5. Normalisation
 Base de données S. Lèbre slebre@unistra.fr Université de Strasbourg, département d informatique. Présentation du module Contenu général Notion de bases de données Fondements / Conception Utilisation :
Base de données S. Lèbre slebre@unistra.fr Université de Strasbourg, département d informatique. Présentation du module Contenu général Notion de bases de données Fondements / Conception Utilisation :
Offre formation Big Data Analytics
 Offre formation Big Data Analytics OCTO 2014 50, avenue des Champs-Elysées 75008 Paris - FRANCE Tél : +33 (0)1 58 56 10 00 Fax : +33 (0)1 58 56 10 01 www.octo.com 1 Présentation d OCTO Technology 2 Une
Offre formation Big Data Analytics OCTO 2014 50, avenue des Champs-Elysées 75008 Paris - FRANCE Tél : +33 (0)1 58 56 10 00 Fax : +33 (0)1 58 56 10 01 www.octo.com 1 Présentation d OCTO Technology 2 Une
Map-Reduce : un cadre de programmation parallèlle pour l analyse de grandes données. Stéphane Genaud ENSIIE
 Map-Reduce : un cadre de programmation parallèlle pour l analyse de grandes données Stéphane Genaud ENSIIE Traitement de données distribuées Google a introduit Map-Reduce [Dean and Ghemawat 2004] Ils s
Map-Reduce : un cadre de programmation parallèlle pour l analyse de grandes données Stéphane Genaud ENSIIE Traitement de données distribuées Google a introduit Map-Reduce [Dean and Ghemawat 2004] Ils s
EMC Data Domain Boost for Oracle Recovery Manager (RMAN)
") Livre blanc EMC Data Domain Boost for Oracle Recovery Manager (RMAN) Résumé EMC fournit aux administrateurs de base de données un contrôle total sur la sauvegarde, la restauration et la reprise après sinistre
Livre blanc EMC Data Domain Boost for Oracle Recovery Manager (RMAN) Résumé EMC fournit aux administrateurs de base de données un contrôle total sur la sauvegarde, la restauration et la reprise après sinistre
Cours Bases de données
 Informations sur le cours Cours Bases de données 9 (10) séances de 3h Polycopié (Cours + TD/TP) 3 année (MISI) Antoine Cornuéjols www.lri.fr/~antoine antoine.cornuejols@agroparistech.fr Transparents Disponibles
Informations sur le cours Cours Bases de données 9 (10) séances de 3h Polycopié (Cours + TD/TP) 3 année (MISI) Antoine Cornuéjols www.lri.fr/~antoine antoine.cornuejols@agroparistech.fr Transparents Disponibles
Introduction aux algorithmes MapReduce. Mathieu Dumoulin (GRAAL), 14 Février 2014
, 14 Février 2014") Introduction aux algorithmes MapReduce Mathieu Dumoulin (GRAAL), 14 Février 2014 Plan Introduction de la problématique Tutoriel MapReduce Design d algorithmes MapReduce Tri, somme et calcul de moyenne
Introduction aux algorithmes MapReduce Mathieu Dumoulin (GRAAL), 14 Février 2014 Plan Introduction de la problématique Tutoriel MapReduce Design d algorithmes MapReduce Tri, somme et calcul de moyenne
BlobSeerFS : un système de fichiers pour le calcul hautes performances sous Hadoop MapReduce
 BlobSeerFS : un système de fichiers pour le calcul hautes performances sous Hadoop MapReduce Rapport de Stage Matthieu DORIER matthieu.dorier@eleves.bretagne.ens-cachan.fr Sous la direction de : Luc Bougé,
BlobSeerFS : un système de fichiers pour le calcul hautes performances sous Hadoop MapReduce Rapport de Stage Matthieu DORIER matthieu.dorier@eleves.bretagne.ens-cachan.fr Sous la direction de : Luc Bougé,
Projet Xdata. Cinequant, Data Publica, EDF, ESRI, Hurence, INRIA, Institut Mines Telecom, La Poste, Orange, Veolia
 Projet Xdata Cinequant, Data Publica, EDF, ESRI, Hurence, INRIA, Institut Mines Telecom, La Poste, Orange, Veolia Mutualisation des données XData = Cross Data En croisant des données d origine diverses,
Projet Xdata Cinequant, Data Publica, EDF, ESRI, Hurence, INRIA, Institut Mines Telecom, La Poste, Orange, Veolia Mutualisation des données XData = Cross Data En croisant des données d origine diverses,
Introduction Big Data
 Introduction Big Data SOMMAIRE Rédacteurs : Réf.: SH. Lazare / F. Barthélemy AXIO_BD_V1 QU'EST-CE QUE LE BIG DATA? ENJEUX TECHNOLOGIQUES ENJEUX STRATÉGIQUES BIG DATA ET RH ANNEXE Ce document constitue
Introduction Big Data SOMMAIRE Rédacteurs : Réf.: SH. Lazare / F. Barthélemy AXIO_BD_V1 QU'EST-CE QUE LE BIG DATA? ENJEUX TECHNOLOGIQUES ENJEUX STRATÉGIQUES BIG DATA ET RH ANNEXE Ce document constitue
Professeur-superviseur Alain April
 RAPPORT TECHNIQUE PRÉSENTÉ À L ÉCOLE DE TECHNOLOGIE SUPÉRIEURE DANS LE CADRE DU COURS GTI792 PROJET DE FIN D'ÉTUDES EN GÉNIE DES TI BASE DE DONNÉES DISTRIBUÉE APPLIQUÉE À LA GÉNÉTIQUE DANS LE CADRE DE
RAPPORT TECHNIQUE PRÉSENTÉ À L ÉCOLE DE TECHNOLOGIE SUPÉRIEURE DANS LE CADRE DU COURS GTI792 PROJET DE FIN D'ÉTUDES EN GÉNIE DES TI BASE DE DONNÉES DISTRIBUÉE APPLIQUÉE À LA GÉNÉTIQUE DANS LE CADRE DE
Présentation du module Base de données spatio-temporelles
 Présentation du module Base de données spatio-temporelles S. Lèbre slebre@unistra.fr Université de Strasbourg, département d informatique. Partie 1 : Notion de bases de données (12,5h ) Enjeux et principes
Présentation du module Base de données spatio-temporelles S. Lèbre slebre@unistra.fr Université de Strasbourg, département d informatique. Partie 1 : Notion de bases de données (12,5h ) Enjeux et principes
6 - Le système de gestion de fichiers F. Boyer, UJF-Laboratoire Lig, Fabienne.Boyer@imag.fr
 6 - Le système de gestion de fichiers F. Boyer, UJF-Laboratoire Lig, Fabienne.Boyer@imag.fr Interface d un SGF Implémentation d un SGF Gestion de la correspondance entre la structure logique et la structure
6 - Le système de gestion de fichiers F. Boyer, UJF-Laboratoire Lig, Fabienne.Boyer@imag.fr Interface d un SGF Implémentation d un SGF Gestion de la correspondance entre la structure logique et la structure
Hadoop, les clés du succès
 Hadoop, les clés du succès Didier Kirszenberg, Responsable des architectures Massive Data, HP France Copyright 2015 Hewlett-Packard Development Company, L.P. The information contained herein is subject
Hadoop, les clés du succès Didier Kirszenberg, Responsable des architectures Massive Data, HP France Copyright 2015 Hewlett-Packard Development Company, L.P. The information contained herein is subject
Stephan Hadinger, Sr. Mgr Solutions Architecture, AWS. Salon du Big Data 11 mars 2015
 Stephan Hadinger, Sr. Mgr Solutions Architecture, AWS Salon du Big Data 11 mars 2015 Accélération de l innovation +500 +280 Amazon EC2 Container Service +159 AWS Storage Gateway Amazon Elastic Transcoder
Stephan Hadinger, Sr. Mgr Solutions Architecture, AWS Salon du Big Data 11 mars 2015 Accélération de l innovation +500 +280 Amazon EC2 Container Service +159 AWS Storage Gateway Amazon Elastic Transcoder
11/01/2014. Le Big Data Mining enjeux et approches techniques. Plan. Introduction. Introduction. Quelques exemples d applications
 Plan Le Big Data Mining enjeux et approches techniques Bernard Dousset Professeur des universités Institut de Recherche en Informatique de Toulouse UMR 5505 Université de Toulouse 118, Route de Narbonne,
Plan Le Big Data Mining enjeux et approches techniques Bernard Dousset Professeur des universités Institut de Recherche en Informatique de Toulouse UMR 5505 Université de Toulouse 118, Route de Narbonne,
Bases de données Cours 1 : Généralités sur les bases de données
 Cours 1 : Généralités sur les bases de données POLYTECH Université d Aix-Marseille odile.papini@univ-amu.fr http://odile.papini.perso.esil.univmed.fr/sources/bd.html Plan du cours 1 1 Qu est ce qu une
Cours 1 : Généralités sur les bases de données POLYTECH Université d Aix-Marseille odile.papini@univ-amu.fr http://odile.papini.perso.esil.univmed.fr/sources/bd.html Plan du cours 1 1 Qu est ce qu une
Big Data, un nouveau paradigme et de nouveaux challenges
 Big Data, un nouveau paradigme et de nouveaux challenges Sebastiao Correia 21 Novembre 2014 Séminaire Thématique : Traitement et analyse statistique des données massives, Poitiers. 1 Présentation Sebastiao
Big Data, un nouveau paradigme et de nouveaux challenges Sebastiao Correia 21 Novembre 2014 Séminaire Thématique : Traitement et analyse statistique des données massives, Poitiers. 1 Présentation Sebastiao
Sauvegarde d une base de données
 Sauvegarde d une base de données Version 1.0 Grégory CASANOVA 2 Sauvegarde d une base de données Sommaire 1 Introduction... 3 2 Différents types de sauvegarde... 4 2.1 Sauvegarde complète de base de données...
Sauvegarde d une base de données Version 1.0 Grégory CASANOVA 2 Sauvegarde d une base de données Sommaire 1 Introduction... 3 2 Différents types de sauvegarde... 4 2.1 Sauvegarde complète de base de données...
NoSQL. Etat de l art et benchmark
 NoSQL Etat de l art et benchmark Travail de Bachelor réalisé en vue de l obtention du Bachelor HES par : Adriano Girolamo PIAZZA Conseiller au travail de Bachelor : David BILLARD, Professeur HES Genève,
NoSQL Etat de l art et benchmark Travail de Bachelor réalisé en vue de l obtention du Bachelor HES par : Adriano Girolamo PIAZZA Conseiller au travail de Bachelor : David BILLARD, Professeur HES Genève,
Hibernate vs. le Cloud Computing
 Hibernate vs. le Cloud Computing Qui suis-je? Julien Dubois Co-auteur de «Spring par la pratique» Ancien de SpringSource Directeur du consulting chez Ippon Technologies Suivez-moi sur Twitter : @juliendubois
Hibernate vs. le Cloud Computing Qui suis-je? Julien Dubois Co-auteur de «Spring par la pratique» Ancien de SpringSource Directeur du consulting chez Ippon Technologies Suivez-moi sur Twitter : @juliendubois
Structure fonctionnelle d un SGBD
 Fichiers et Disques Structure fonctionnelle d un SGBD Requetes Optimiseur de requetes Operateurs relationnels Methodes d acces Gestion de tampon Gestion de disque BD 1 Fichiers et Disques Lecture : Transfert
Fichiers et Disques Structure fonctionnelle d un SGBD Requetes Optimiseur de requetes Operateurs relationnels Methodes d acces Gestion de tampon Gestion de disque BD 1 Fichiers et Disques Lecture : Transfert
Anticiper et prédire les sinistres avec une approche Big Data
 Anticiper et prédire les sinistres avec une approche Big Data Julien Cabot Directeur Big Data Analytics OCTO jcabot@octo.com @julien_cabot OCTO 2013 50, avenue des Champs-Elysées 75008 Paris - FRANCE Tél
Anticiper et prédire les sinistres avec une approche Big Data Julien Cabot Directeur Big Data Analytics OCTO jcabot@octo.com @julien_cabot OCTO 2013 50, avenue des Champs-Elysées 75008 Paris - FRANCE Tél
DÉPLOIEMENT DE QLIKVIEW POUR DES ANALYSES BIG DATA CHEZ KING.COM
 DÉPLOIEMENT DE QLIKVIEW POUR DES ANALYSES BIG DATA CHEZ KING.COM Étude de cas technique QlikView : Big Data Juin 2012 qlikview.com Introduction La présente étude de cas technique QlikView se consacre au
DÉPLOIEMENT DE QLIKVIEW POUR DES ANALYSES BIG DATA CHEZ KING.COM Étude de cas technique QlikView : Big Data Juin 2012 qlikview.com Introduction La présente étude de cas technique QlikView se consacre au
Techniques de stockage. Techniques de stockage, P. Rigaux p.1/43
 Techniques de stockage Techniques de stockage, P. Rigaux p.1/43 Techniques de stockage Contenu de ce cours : 1. Stockage de données. Supports, fonctionnement d un disque, technologie RAID 2. Organisation
Techniques de stockage Techniques de stockage, P. Rigaux p.1/43 Techniques de stockage Contenu de ce cours : 1. Stockage de données. Supports, fonctionnement d un disque, technologie RAID 2. Organisation
Notes de cours Practical BigData
 Notes de cours Practical BigData Nguyen-Nhut DOAN 15 janvier 2015 Introduction Ces notes personnelles traduisent la deuxième partie du cours INF553 de l Ecole Polytechnique sur les bases de données et
Notes de cours Practical BigData Nguyen-Nhut DOAN 15 janvier 2015 Introduction Ces notes personnelles traduisent la deuxième partie du cours INF553 de l Ecole Polytechnique sur les bases de données et
Introduction aux SGBDR
 1 Introduction aux SGBDR Pour optimiser une base Oracle, il est important d avoir une idée de la manière dont elle fonctionne. La connaissance des éléments sous-jacents à son fonctionnement permet de mieux
1 Introduction aux SGBDR Pour optimiser une base Oracle, il est important d avoir une idée de la manière dont elle fonctionne. La connaissance des éléments sous-jacents à son fonctionnement permet de mieux
Introduction à Hadoop & MapReduce
 Introduction à Hadoop & MapReduce Cours 2 Benjamin Renaut MOOC / FUN 2014-2015 5 Hadoop: présentation Apache Hadoop 5-1 Projet Open Source fondation Apache. http://hadoop.apache.org/
Introduction à Hadoop & MapReduce Cours 2 Benjamin Renaut MOOC / FUN 2014-2015 5 Hadoop: présentation Apache Hadoop 5-1 Projet Open Source fondation Apache. http://hadoop.apache.org/
Fast and furious decision tree induction
 Institut National des Sciences Appliquées de Rennes Rapport de pré-étude Encadrants : Nikolaos Parlavantzas - Christian Raymond Fast and furious decision tree induction Andra Blaj Nicolas Desfeux Emeline
Institut National des Sciences Appliquées de Rennes Rapport de pré-étude Encadrants : Nikolaos Parlavantzas - Christian Raymond Fast and furious decision tree induction Andra Blaj Nicolas Desfeux Emeline
EMC AVAMAR. Logiciel et système de sauvegarde avec déduplication
 EMC AVAMAR Logiciel et système de sauvegarde avec déduplication Avantages clés Les données sont dédupliquées à la source (client), avant leur transfert sur le réseau Idéal pour la protection des environnements
EMC AVAMAR Logiciel et système de sauvegarde avec déduplication Avantages clés Les données sont dédupliquées à la source (client), avant leur transfert sur le réseau Idéal pour la protection des environnements
Hadoop / Big Data 2014-2015 MBDS. Benjamin Renaut <renaut.benjamin@tokidev.fr>
 Hadoop / Big Data Benjamin Renaut MBDS 2014-2015 1 Introduction Programme Planning Objectifs TP/Évaluations Introduction 1-1 Benjamin Renaut Tokidev SAS - Bureau d'étude -
Hadoop / Big Data Benjamin Renaut MBDS 2014-2015 1 Introduction Programme Planning Objectifs TP/Évaluations Introduction 1-1 Benjamin Renaut Tokidev SAS - Bureau d'étude -
Benjamin Cornu Florian Joyeux. Les choses à connaître pour (essayer) de concurrencer Facebook.
 de concurrencer Facebook.") Benjamin Cornu Florian Joyeux Les choses à connaître pour (essayer) de concurrencer Facebook. 1 Sommaire Présentation générale Historique Facebook La face cachée de l iceberg (back end) Architecture globale
Benjamin Cornu Florian Joyeux Les choses à connaître pour (essayer) de concurrencer Facebook. 1 Sommaire Présentation générale Historique Facebook La face cachée de l iceberg (back end) Architecture globale
Big Graph Data Forum Teratec 2013
 Big Graph Data Forum Teratec 2013 MFG Labs 35 rue de Châteaudun 75009 Paris, France www.mfglabs.com twitter: @mfg_labs Julien Laugel MFG Labs julien.laugel@mfglabs.com @roolio SOMMAIRE MFG Labs Contexte
Big Graph Data Forum Teratec 2013 MFG Labs 35 rue de Châteaudun 75009 Paris, France www.mfglabs.com twitter: @mfg_labs Julien Laugel MFG Labs julien.laugel@mfglabs.com @roolio SOMMAIRE MFG Labs Contexte
Hadoop / Big Data. Benjamin Renaut <renaut.benjamin@tokidev.fr> MBDS 2013-2014
 Hadoop / Big Data Benjamin Renaut MBDS 2013-2014 1 Introduction Programme Planning Objectifs TP/Évaluations Introduction 1-1 Benjamin Renaut Tokidev SAS - Bureau d'étude -
Hadoop / Big Data Benjamin Renaut MBDS 2013-2014 1 Introduction Programme Planning Objectifs TP/Évaluations Introduction 1-1 Benjamin Renaut Tokidev SAS - Bureau d'étude -
Analytics & Big Data. Focus techniques & nouvelles perspectives pour les actuaires. Université d Eté de l Institut des Actuaires Mardi 8 juillet 2014
 Analytics & Big Data Focus techniques & nouvelles perspectives pour les actuaires Local Optimization European Minded Université d Eté de l Institut des Actuaires Mardi 8 juillet 2014 Intervenants : Alexandre
Analytics & Big Data Focus techniques & nouvelles perspectives pour les actuaires Local Optimization European Minded Université d Eté de l Institut des Actuaires Mardi 8 juillet 2014 Intervenants : Alexandre
Big Data et Graphes : Quelques pistes de recherche
 Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de Lyon/Université Claude Bernard Lyon 1/Université
Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de Lyon/Université Claude Bernard Lyon 1/Université
Plateforme de capture et d analyse de sites Web AspirWeb
 Projet Java ESIAL 2A 2009-2010 Plateforme de capture et d analyse de sites Web AspirWeb 1. Contexte Ce projet de deuxième année permet d approfondir par la pratique les méthodes et techniques acquises
Projet Java ESIAL 2A 2009-2010 Plateforme de capture et d analyse de sites Web AspirWeb 1. Contexte Ce projet de deuxième année permet d approfondir par la pratique les méthodes et techniques acquises
PROTEGER SA CLE USB AVEC ROHOS MINI-DRIVE
 PROTEGER SA CLE USB AVEC ROHOS MINI-DRIVE Protéger sa clé USB avec un système de cryptage par mot de passe peut s avérer très utile si l on veut cacher certaines données sensibles, ou bien rendre ces données
PROTEGER SA CLE USB AVEC ROHOS MINI-DRIVE Protéger sa clé USB avec un système de cryptage par mot de passe peut s avérer très utile si l on veut cacher certaines données sensibles, ou bien rendre ces données