GMIN206 Info. Biologique et Outils bioinformatiques. Elodie Cassan
|
|
|
- Romain Laurin
- il y a 8 ans
- Total affichages :
Transcription
1 M Bioinformatique, Connaissances et Données Année GMIN206 Info. Biologique et Outils bioinformatiques Banques de données biologiques (3h de Cours +,5h de TD + 4h de TP) Elodie Cassan Anne-Muriel Arigon Chifolleau http ://www2.lirmm.fr/ arigon/enseignement/gmin206/ LIRMM - UM2/UM

2 Plan Introduction Banques de données de séquences nucléiques Banques de données de séquences protéiques Encore des banques de données Interrogation des banques de données Formats de fichiers en bioinformatique Références

3 Sources de données biologiques (/2) 2 Comprendre ce qui constitue le livre du vivant : Comment le génome d un organisme (millions ou milliards de bases) contient l information nécessaire à la cellule pour la production des processus métaboliques essentiels à la survie de l organisme ; information qui est propagée de génération en génération? Pour comprendre comment cette collection de simple nucléotides est à la base de la vie, on doit collecter d immense quantité de données de séquences, les stocker et les organiser de manière à pouvoir les analyser et les retrouver facilement. Volume de données généré trop important pour être géré par les techniques de publication traditionnelle. Création et maintenance des sources de données biologiques pour l archivage, le stockage, la diffusion et l exploitation des données biologiques

4 Sources de données biologiques (2/2) 3 Source de données en biologie = collection organisée d informations mémorisées sur un support permanent et pouvant être restituées au biologiste de manière opportune Banque de données : collection de fichiers structurés Base de données : collection de données structurées Différence = élément de base considéré fichier de données ou donnée Séquence = élément central autour duquel les banques et bases de données se sont constituées

5 Bref historique (/3) 4 960s Margaret Dayhoff et ses collaborateurs du PIR (Protein Information Ressource) collectent toutes les séquences de protéines connues et les regroupent dans l Atlas of protein 50 entrées Version papier jusqu en 78, puis version électronique

6 Bref historique (2/3) EMBL (European Molecular Biology Laboratory) et le NCBI (National Center for Biotechnology Information) transcrivent et interprètent les séquences publiées dans les journaux au format électronique Véritable explosion de la quantité de séquences disponibles Rapidement, la DDBJ (DNA DataBank of Japan) se joint à la collaboration pour la collecte de données 988 Meeting de ces 3 groupes (appelés maintenant International Nucleotide Sequence Database Collaboration) Accord pour un format commun Échange des données journalier Chaque groupe gère les mises à jour des séquences qu il a créées
 Accord pour un format commun Échange des données journalier Chaque groupe gère les mises à jour des séquences")
7 International Nucleotide Sequence Database Collaboration

8 International Nucleotide Sequence Database Collaboration

9 Bref historique (3/3) Création de SWISSPROT par Amos Bairoch (3900 prot.) : conversion de l Atlas du PIR en un format similaire à celui d EMBL + ajout d information pour chaque protéine Notoriété de SWISSPROT comme banque de haute qualité Collaboration entre SWISSPROT et EMBL But : mettre à disposition rapidement les séquences de protéines non encore annotées par SWISSPROT Création de TrEMBL (Translation of TrEMBL nucleotide sequences) Fin 2003 Création de UNIPROT (UNIversal PROTein Ressource) en joignant les informations de SWISSPROT, TrEMBL et PIR. UNIPROT à 3 composants : UniProtKB (UniProt KnowledgeBase) = SWISSPROT + TrEMBL UniRef (UniProt Reference Clusters) regroupe en entrée les séquences similaires pour accélérer les recherches UniParc (UniProt Archive) utilisé pour garder une trace des séquences et de leur idendifiants
 en joignant les informations de SWISSPROT, TrEMBL et PIR.")
10 Forme actuelle des banques de séquences 7 Recherche publique donc données publiques Partage international des données Évite qu une expérience soit refaite par différents laboratoires Permet la comparaison des résultats Beaucoup de données générées par l expérimentation Outils adaptés à de grands volumes de données Gestion des grandes banques par des organismes spécialisés Accès fréquent à ces données Interrogation via internet Une source d informations pour l interprétation Ma séquence est-elle déjà présente dans les banques? Quelles sont les séquences similaires à la mienne? Quelles sont les protéines similaires à la mienne (structure, fonction)?...

11 Les données 8 Quelle est la qualité des données? Erreurs de frappe Erreurs dans les séquences Erreurs d annotation Redondance des données Où sont les données? Dans les laboratoires Dans des banques ou bases de données spécialisées : souvent maintenues par un laboratoire Dans des banques de données généralistes : maintenues par des consortiums Différentiations possibles des banques de données Banque primaire ou secondaire Banque généraliste ou spécialisée

12 Banques de données primaires et secondaires 9 Banques primaires archives Banques secondaires données vérifiées (corrigées et annotées) La plus grande contribution des banques de données à la communauté des biologistes est de rendre les séquences accessibles Les banques primaires contiennent majoritairement des résultats expérimentaux (avec qqs interprétations), mais qui ne sont pas vérifiés, ni analysés les séquences nucléiques d EMBL/GenBank/DDBJ sont issues du séquençage d une molécule biologique qui existe dans un tube à essai, qqpart dans un labo ; elles ne représentent pas les séquences qui sont un consensus d une population Ceci a des conséquences sur l interprétation de l analyse des séquences : informations parfois très utiles ou trompeuses

13 Les banques de données généralistes 0 Ces banques contiennent des données hétérogènes (collecte la plus exhaustive possible) Banques de séquences nucléiques (GenBank, EMBL, DDBJ) Banques de séquences protéiques (PIR, SWISSPROT, UNIPROT) Banques de localisation (mapping databases GeneLoc) Banques de structures 3D de macromolécules (PDB) Banques génomiques (UCSC, Ensembl) Banques d articles scientifiques (PubMed) Avantage : tout est consultable en une fois Inconvénient : difficiles à maintenir, difficiles à interroger
 Avantage : tout est consultable en une fois Inconvénient : difficiles à maintenir,")
14 Les banques de données spécialisées Ces banques contiennent des données homogènes Collecte établie autour d une thématique particulière Ex : banque spécialisée pour un génome spécifique, banques de séquences immunologiques, de voies métaboliques, de cartes génétiques, de motifs protéiques, d expression de gènes, de structures,... Avantage : facilité pour mettre à jour les données, vérifier leur intégrité, offrir une interface adaptée,... Inconvénient : ne cible pas toujours exactement ce que l on veut, toutes les banques possibles n existent pas

15 Plan 2 Introduction Banques de données de séquences nucléiques Banques de données de séquences protéiques Encore des banques de données Interrogation des banques de données Formats de fichiers en bioinformatique Références

16 Les banques nucléiques 3 Les trois principales banques : EMBL (Europe, 82) GenBank (É-U, 82) DDBJ (Japon, 86) Échange quotidien des données entre ces banques depuis 88 Répartition de la collecte des données : chaque banque collecte les données de son continent Mise à jour : nouvelles version disponibles plsr fois par an (date et num de version), mise à disposition des Updates Format de stockage similaire : les fichiers (flatfiles) représentent l unité d information élémentaire
 représentent l unité d information")
17 Format des fichiers 4 Chaque entrée (séquence + informations) est stockée dans un fichier (flatfile) Ces fichiers se composent de trois parties : Entête (header) : description générale de l entrée Les caractéristiques (features) : objets biologiques présents sur la séquence La séquence elle-même Les formats de DDBJ et de GenBank sont très similaires Chaque ligne commence par un mot clé Deux lettres pour EMBL Maximum 2 lettres pour GenBank et DDBJ Fin d une entrée par //

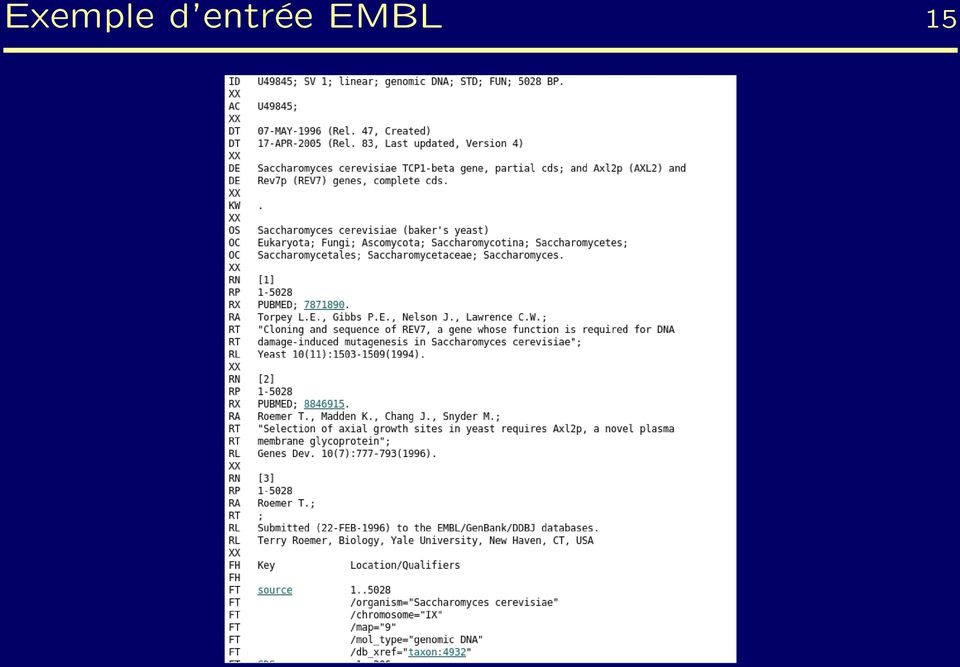
18 Exemple d entrée EMBL 5
19 Exemple d entrée GenBank/DDBJ 6

20 Les flatfiles en détails (/8) 7. Les différentes informations de l entête (header) : Première ligne : Locus/ID Embl ID U49845 ; SV ; linear ; genomic DNA ; STD ; FUN ; 5028 BP. DDBJ/GenBank LOCUS SCU bp DNA linear PLN 2-JUN-999 Le champ date (chez EMBL uniquement) DT 07-MAY-996 (Rel. 47, Created) DT 7-APR-2005 (Rel. 83, Last updated, Version 4) Lignes de définition : synthèse du contenu biologique DE and DE Saccharomyces cerevisiae TCP-beta gene, partial cds ; and Axl2p (AXL2) Rev7p (REV7) genes, complete cds. DEFINITION Saccharomyces cerevisiae TCP-beta gene, partial cds ; and Axl2p (AXL2) and Rev7p (REV7) genes, complete cds.
 Lignes de définition : synthèse du contenu biologique DE and DE Saccharomyces cerevisiae TCP-beta gene, partial cds ; and Axl2p")
21 Division en organisme 8 Utilisée dans les 3 principales banques de séquences nucléiques Division DDBJ EMBL GenBank BCT Bacterial FUN Fungal HUM Homo sapiens INV Invertebrate MAM Other mammalian ORG Organelle PHG Phage PLN Plant (also see FUN) PRI Primate (also see HUM) PRO Prokaryotic ROD Rodent SYN Synthetic and chimeric VRL Viral VRT Other vertebrate
22 Les flatfiles en détails (2/8) 9 Le numéro d accession : un identificateur unique AC U49845 ; ACCESSION U49845 La version (équivalent à SV dans la re ligne d EMBL) VERSION U GI :29363 Lignes avec des mots-clés (KEYWORDS ou KW) Lignes de taxonomie OS Saccharomyces cerevisiae (baker s yeast) OC Eukaryota ; Fungi ; Dikarya ; Ascomycota ; Saccharomycotina ; Saccharomycetes ; OC Saccharomycetales ; Saccharomycetaceae ; Saccharomyces. SOURCE ORGANISM Saccharomyces cerevisiae (baker s yeast) Saccharomyces cerevisiae Eukaryota ; Fungi ; Dikarya ; Ascomycota ; Saccharomycotina ; Saccharomycetes ; Saccharomycetales ; Saccharomycetaceae ; Saccharomyces.
23 Les flatfiles en détails (3/8) 20 Les références : publication ou origine de la soumission RN [] RP RX PUBMED ; RA Torpey L.E., Gibbs P.E., Nelson J., Lawrence C.W. ; RT Cloning and sequence of REV7, a gene whose function is required for DNA RT damage-induced mutagenesis in Saccharomyces cerevisiae ; RL Yeast 0() : (994). XX RN [2] RP RX PUBMED ; RA Roemer T., Madden K., Chang J., Snyder M. ; RT Selection of axial growth sites in yeast requires Axl2p, a novel plasma RT membrane glycoprotein ; RL Genes Dev. 0(7) : (996). XX RN [3] RP RA Roemer T. ; RT ; RL Submitted (22-FEB-996) to the EMBL/GenBank/DDBJ databases. RL Terry Roemer, Biology, Yale University, New Haven, CT, USA
24 Les flatfiles en détails (4/8) 2 REFERENCE (bases to 5028) AUTHORS Torpey,L.E., Gibbs,P.E., Nelson,J. and Lawrence,C.W. TITLE Cloning and sequence of REV7, a gene whose function is required for DNA damage-induced mutagenesis in Saccharomyces cerevisiae JOURNAL Yeast 0 (), (994) PUBMED REFERENCE 2 (bases to 5028) AUTHORS Roemer,T., Madden,K., Chang,J. and Snyder,M. TITLE Selection of axial growth sites in yeast requires Axl2p, a novel plasma membrane glycoprotein JOURNAL Genes Dev. 0 (7), (996) PUBMED REFERENCE 3 (bases to 5028) AUTHORS Roemer,T. TITLE Direct Submission JOURNAL Submitted (22-FEB-996) Terry Roemer, Biology, Yale University, New Haven, CT, USA
25 Les flatfiles en détails (5/8) Les caractéristiques (features) Features table : annotation des séquences, gestion du transfert d information, localisation des éléments biologiques Mise à disposition d un vocabulaire étendu controlé (Gene Ontology) pour décrire les caractéristiques biologiques des séquences (annotations) Annotation = information additionnelle venant enrichir un document d intérêt Annotation structurale : caractériser les gènes au travers, notamment, de leur structure intron-exon, signaux de régultaion, sites d épissage,... Annotation fonctionnelle : anticiper sur les motifs fonctionnels qui seront retrouvés au niveau protéiques, caractérisation des fonctions biologiques des produits d expression des gènes
26 Les flatfiles en détails (6/8) 23 FT source FT /organism= Saccharomyces cerevisiae FT /chromosome= IX FT /map= 9 FT /mol type= genomic DNA FT /db xref= taxon :4932 FT CDS <..206 FT /codon start=3 FT /product= TCP-beta FT /db xref= GOA :P39076 FT /db xref= UniProtKB/Swiss-Prot :P39076 FT /protein id= AAA FT /translation= SSIYNGISTSGLDLNNGTIADMRQLGIVESYKLKRAVVSSASEAA FT EVLLRVDNIIRARPRTANRQHM [...] FT CDS complement( ) FT /codon start= FT /gene= REV7 FT /product= Rev7p FT /db xref= GOA :P38927 FT /db xref= InterPro :IPR0035 FT /db xref= SGD :S4 FT /db xref= UniProtKB/Swiss-Prot :P38927 FT /protein id= AAA FT /translation= MNRWVEKWLRVYLKCYINLILFYRNVYPPQSFDYTTYQSFNLPQF FT VPINRHPALIDYIEELILDVLSKLTHVYRFSICIINKKNDLCIEKYVLDFSELQHVDKD FT DQIITETEVFDEFRSSLNSLIMHLEKLPKVNDDTITFEAVINAIELELGHKLDRNRRVD FT SLEEKAEIERDSNWVKCQEDENLPDNNGFQPPKIKLTSLVGSDVGPLIIHQFSEKLISG FT DDKILNGVYSQYEEGESIFGSLF
27 Les flatfiles en détails (7/8) 24 FEATURES Location/Qualifiers source /organism= Saccharomyces cerevisiae /mol type= genomic DNA /db xref= taxon :4932 /chromosome= IX /map= 9 CDS <..206 /codon start=3 /product= TCP-beta /protein id= AAA /db xref= GI :29364 /translation= SSIYNGISTSGLDLNNGTIADMRQLGIVESYKLKRAVVSSASEA AEVLLRVDNIIRARPRTANRQHM [...] gene complement( ) /gene= REV7 CDS complement( ) /gene= REV7 /codon start= /product= Rev7p /protein id= AAA /db xref= GI :29366 /translation= MNRWVEKWLRVYLKCYINLILFYRNVYPPQSFDYTTYQSFNLPQ FVPINRHPALIDYIEELILDVLSKLTHVYRFSICIINKKNDLCIEKYVLDFSELQHVD KDDQIITETEVFDEFRSSLNSLIMHLEKLPKVNDDTITFEAVINAIELELGHKLDRNR RVDSLEEKAEIERDSNWVKCQEDENLPDNNGFQPPKIKLTSLVGSDVGPLIIHQFSEK LISGDDKILNGVYSQYEEGESIFGSLF
28 Les flatfiles en détails (8/8) La séquence de nucléotides EMBL GenBank
29 À vous de jouer 26 Répondez aux questions suivantes en vous référant aux 2 fiches distribuées Une des fiches vient d EMBL, l autre de GenBank, identifiez-les Trouvez le nom des organismes d où proviennent les séquences Que sont ces séquences? À quelle division d organisme appartiennent-elles? Quelle séquence a été entrée le + récemment? Ont-elles été modifiées? Qui a soumis ces séquences? De quel type de molécule s agit-il? Peut-on localiser ces séquences sur un chromosome?
30 Plan 27 Introduction Banques de données de séquences nucléiques Banques de données de séquences protéiques Encore des banques de données Interrogation des banques de données Formats de fichiers en bioinformatique Références
31 Origine des informations sur les protéines 28 Origine des séquences Traduction automatique de séquences d ADN (majoritairement) Séquençage de protéines (rare car long et coûteux) Protéines dont la structure 3D est connue Origine des annotations Spectrométrie de masse : régulation, rythme et localisation de l expression des protéines ; mais aussi identification et modification post-transcriptionnelle Études d interactions : comment les protéines s assemblent entre elles ou avec d autres molécules pour former des complexes moléculaires Cristallographie et résonance magnétique nucléaire : pour déterminer la forme 3D finale de la protéine
32 Les banques de séquences protéiques 29 Les données stockées : séquences + annotations (protéines entières ou fragment de protéines) Banques généralistes : protéines de toutes les espèces Banques spécialisées : familles de protéines particulières, groupes de protéines ou d un organisme particulier GenPept : entrées = traductions des séquences de DDBJ/EMBL/GenBank (champ CDS) ; les annotations sont les mêmes ; la banque n est pas vérifiée archive basique RefSeq : projet NCBI ; but : fournir une vue d ensemble, intégrée et non-redondante de séquences d ADN, d ARN et de protéines ; lien explicite entre les séq. nucléiques et protéiques ; numéro d accession particulier format 2 + 6, ex : NT UniProt : assemblage de SWISSPROT, TrEMBL et PIR
33 RefSeq 30 Avantages Non redondante Liens explicites entre les séquences nucléiques et protéiques Mise à jour régulière par le personnel du NCBI avec indication du statut de l entrée Validation des données et consistance des formats Synthèse des informations issues de plusieurs entrées nucléiques ou protéiques Différents niveaux de correction des données (champ COMMENT) : Reviewed, Validated, Provisional, Predicted Quelques numéros d accession de RefSeq NR : autres ARN NM : ARNm NC : chromosomes NP : protéines
34 UNIPROT 3
35 UniProtKB, ses deux banques 32 SWISSPROT Données corrigées et validées par des experts Haut niveau d annotation Redondance minimale Nombreux liens vers d autres banques ( 60) TrEMBL Entrées supplémentaires à SWISSPROT (pas encore annotées) Traduction automatique des CDS d EMBL et soumissions spontanées Annotation automatique des protéines
36 Exemple d entrée SWISSPROT 33
37 Plan 34 Introduction Banques de données de séquences nucléiques Banques de données de séquences protéiques Encore des banques de données Interrogation des banques de données Formats de fichiers en bioinformatique Références
38 Banques de données de localisation 35 Localisation génomique :. Cartographie : carte physique, carte cytogénétique, liaison génétique (genetic linkage), Identification : trouver où sont les objets d intérêt biologiques comme les gènes, les variations génétiques ou les locus de prédisposition à des maladies association d une signature moléculaire à un résultat biologique Ex : localiser des nouveaux gènes ou affiner des régions d intérêt Genome Database (GDB), egenome, LBD2000, GeneCards et GeneLoc, GeneLynx, EuGenes, AceView,... Cartes comparatives entre plusieurs génomes (Mouse Genome Informatics Database (MGI),... )
39 Banques de données génomiques re séquence complète d un génome eucaroyte Saccharomyces cerevisiae, chromosomes entre 270 et 500 Kb ; limite d une entrée dans GenBank à cette époque : 350 Kb Mise en place d une section spécifique pour les génomes, re vue graphique des séquences génomiques 20 première ébauche du génome humain ; chromosomes entre 46 et 246 Mb Navigateur de génomes : NCBI Map Viewer, UCSC Genome Browser, Ensembl (EBI et Sanger Institute) Attention au version d assemblage qui peuvent changer sans avertissement

40 Séquençage des génomes 37
41 Banques de familles de protéines 38 Regroupement des protéines ayant des fonctions identiques ou proches Construites souvent par comparaison de toutes les protéines entre elles puis constitution de groupes Nombreuses banques : HomoloGene, COG (NCBI) KEGG SSDB (Sequence Similarity DataBase) Clustr (EBI) Autres banques basées sur la structure 3D des protéines SSF, SCOP, CATH,...
42 Banques de motifs et domaines protéiques 39 Une famille de protéines peut-être caractérisée par un motif ou un domaine protéique Séquence plus ou moins conservée importante pour la fonction des protéines de la famille Déterminée à partir d un alignement multiple Plusieurs représentations possibles : consensus, expression régulière, alignement, matrices, HMM,... Nombreuses banques Prosite, PFAM, BLOCKS, Prodom, CDD,...
43 Plan 40 Introduction Banques de données de séquences nucléiques Banques de données de séquences protéiques Encore des banques de données Interrogation des banques de données Formats de fichiers en bioinformatique Références
44 Accessibilité des ressources 4 Le réseau internet : google,... Des centres de ressources NCBI : EBI : Des catalogues d outils EMBOSS : Institut Pasteur : Des systèmes d interrogation GQuery, anciennement nommée Entrez : développé et utilisé par le NCBI SRS : développé par LION bioscience AG et utilisé par différentes institutions sous différentes versions (miroirs) dont la plus utilisée était celle de l EBI (non maintenue)...
45 Interrogation d une banque 42 But Obtenir des information nouvelles et pertinentes Aide à la mise au point d expérience Validation des résultats d une expérience Contraintes pour un système d interrogation Obtention de données pertinentes (pas trop de résultats mais tous ceux relatifs à notre problématique) Simplicité d utilisation (syntaxe d interrogation intuitive) Réponse rapide Possibilité d analyse des résultats (couplage à des outils)
46 Un peu de logique ARNm Homme Souris Droso. Arabido. Toutes séquences contenant Homme : Séquences contenant Homme ou Souris : Tous les ARNm de la drosophile : Tous les ARNm sauf ceux d arabidopsis :
47 Un peu de logique ARNm Homme Souris Droso. Arabido. Toutes séquences contenant Homme : Homme Séquences contenant Homme ou Souris : Tous les ARNm de la drosophile : Tous les ARNm sauf ceux d arabidopsis :
48 Un peu de logique ARNm Homme Souris Droso. Arabido. Toutes séquences contenant Homme : Homme Séquences contenant Homme ou Souris : Homme OU Souris Tous les ARNm de la drosophile : Tous les ARNm sauf ceux d arabidopsis :
49 Un peu de logique ARNm Homme Souris Droso. Arabido. Toutes séquences contenant Homme : Homme Séquences contenant Homme ou Souris : Homme OU Souris Tous les ARNm de la drosophile : Droso. ET ARNm Tous les ARNm sauf ceux d arabidopsis :
50 Un peu de logique ARNm Homme Souris Droso. Arabido. Toutes séquences contenant Homme : Homme Séquences contenant Homme ou Souris : Homme OU Souris Tous les ARNm de la drosophile : Droso. ET ARNm Tous les ARNm sauf ceux d arabidopsis : ARNm NON Arabido.
51 Un peu de logique... plus difficile ARNm 000 Apoptose Homme Souris Droso. Arabido. ARNm impliqués dans l apoptose chez l homme : Séquences de la souris ou de la droso. impliquées dans l apoptose mais qui ne sont pas des ARNm :
52 Un peu de logique... plus difficile ARNm 000 Apoptose Homme Souris Droso. Arabido. ARNm impliqués dans l apoptose chez l homme : ARNm ET Apoptose ET Homme Séquences de la souris ou de la droso. impliquées dans l apoptose mais qui ne sont pas des ARNm :
53 Un peu de logique... plus difficile ARNm 000 Apoptose Homme Souris Droso. Arabido. ARNm impliqués dans l apoptose chez l homme : ARNm ET Apoptose ET Homme Séquences de la souris ou de la droso. impliquées dans l apoptose mais qui ne sont pas des ARNm : ((Souris OU Droso.) ET Apoptose) NON ARNm

54 GQuery, le système d interrogation du NCBI 45 Intégration légère de diverses banques de données au travers de la notion de référence croisée choix de rubriques
55 GQuery, le système d interrogation du NCBI 46 Interface propriétaire (ne peut être installée par autrui) Requête simple/manuelle (possibilité de mettre le nom du champs entre crochets) Exemple : homo sapiens [organism] Requête avancée (choix des champs dans une liste déroulante) Aide dans Preview/Index Historique (lien History ) Ajout de limites (lien Limits ) Sauvegarde, format Boutons Display, send to Menus déroulants associés
56 GQuery, syntaxe de requête 47 Terme Locution (groupe de terme) : mot mot2... Connecteurs logiques : ET (AND ou rien), OU (OR), NON (NOT) Caractère joker : * Expression complexe : parenthèse () (ET prioritaire) Couple propriété/valeur en fonction des rubriques (ex : organism, gene, slen, author, title,... ) Exemples de requêtes Human hemoglobin Human [organism] hemoglobin* [protein name] Human [organism] OR Mouse [organism] 000 :2000 [SLEN] (Human [organism] OR Mouse [organism]) 000 :2000 [SLEN] NOT Human [organism]
 PubMed : publications dans les journaux, revues, conférences (Medline) Taxonomy : classification du vivant... Exemple de champs de la rubrique Gene")
57 GQuery, les rubriques 48 Nucleotide : séquences nucléiques Gene : synthèse sur les gènes Protein : séquences protéiques (Genpept, Swissprot) CDD : domaines protéiques fonctionnels (Conserv Domain protein database) PubMed : publications dans les journaux, revues, conférences (Medline) Taxonomy : classification du vivant... Exemple de champs de la rubrique Gene
58 GQuery, formulaire de requête et résultats d une recherche sur toutes les rubriques 49
59 GQuery, formulaire de requête avancé sur une rubrique (ex : Nucleotide) 50
")
60 GQuery, résultats d une recherche sur une rubrique (ex : Nucleotide) 5
61 SRS 52 Système libre, de nombreuses versions (miroirs) existent mais ne donnent pas accés aux mêmes banques de données ou aux mêmes fonctionnalités Onglet Select Databanks Choix de la ou des banques interrogées Lancement du formulaire de requêtes Onglet Query Form formulaire de requêtes simple : choix des champs dans une liste déroulante formulaire de requêtes étendu : plus de champs et de critères dans la liste déroulante Onglet Results Historique des requêtes Onglet Custom Views Création du format d affichage
62 Interrogation via SRS 53 Sauvegarde, format Bouton Save / Rerun query Options associés Analyse bioinformatique des entrées Bouton Launch Syntaxe des requêtes (trés proche de Entrez) Terme Locution (groupe de terme) : mot mot2... Connecteurs logiques : ET (&), OU ( ), NON (!) Caractère joker : * Expression complexe : parenthèse () (ET prioritaire)
, onglet")
63 SRS, version du consortium CEINGE (Italie), onglet Databank 54
, formulaire de requêtes")
64 SRS, version du consortium CEINGE (Italie), formulaire de requêtes 55
, résultats d une recherche")
65 SRS, version du consortium CEINGE (Italie), résultats d une recherche 56
66 Plan 57 Introduction Banques de données de séquences nucléiques Banques de données de séquences protéiques Encore des banques de données Interrogation des banques de données Formats de fichiers en bioinformatique Références
67 Quelques formats classiques en bioinformatique 58. Les fichiers des banques de séquences (flatfiles) Ceux qu on a vu mais aussi ceux d autres banques 2. Le format FASTA : une re ligne de définition introduite par un >, contenant un identifiant sans espace et une description suivie de la séquence elle-même, sur plusieurs lignes (de taille 60 ou 80 classiquement) >embl U49845 U49845 Saccharomyces cerevisiae TCP-beta gene, partial cds; and Axl2p (AXL2) and Rev7p (REV7) genes, complet gatcctccatatacaacggtatctccacctcaggtttagatctcaacaacggaaccattg ccgacatgagacagttaggtatcgtcgagagttacaagctaaaacgagcagtagtcagct ctgcatctgaagccgctgaagttctactaagggtggataacatcatccgtgcaagaccaa gaaccgccaatagacaacatatgtaacatatttaggatatacctcgaaaataataaaccg ccacactgtcattattataattagaaacagaacgcaaaaattatccactatataattcaa agacgcgaaaaaaaaagaacaacgcgtcatagaacttttggcaattcgcgtcacaaataa attttggcaacttatgtttcctcttcgagcagtactcgagccctgtctcaagaatgtaat aatacccatcgtaggtatggttaaagatagcatctccacaacctcaaagctccttgccga
68 Quelques formats classiques en bioinformatique Les formats des outils phylogénétiques Le format NEXUS [Maddison et al., 97] (utilisé par PAUP) #nexus BEGIN Taxa; DIMENSIONS ntax=6; TAXLABELS [] Europe [2] Albania [3] Andorra [4] Belarus [5] Belgium [6] BosniaHerzeg ; END; [Taxa] BEGIN Distances; DIMENSIONS ntax=6; FORMAT labels=left diagonal triangle=both; MATRIX [] Europe [2] Albania [3] Andorra [4] Belarus [5] Belgium [6] BosniaHerzeg ; END; [Distances]
69 Quelques formats classiques en bioinformatique 60 Le format Phylip (suite EMBOSS) : la re ligne contient le nb de séquences suivi de leur taille (les séq. ayant été alignées, elles ont nécessairement toutes la même taille). Viennent ensuite les informations concernant chaque espèce ou gène C C2 C3 C4 C5 C6 C GCCAACCCCA CGGTCACTCT GTTCCCGCCC TCCTGGAGCT CCAAGACAAG GCTGCCCCCT CGGTCACTCT GTTCCCGCCC TCCTGGAGCT TCAAGACAAG GCTGCCCCCT CGGTCACTCT GTTCCCACCC TCCTGGAGCT TCAAGACAAG GAGACACCTT CATCTCCTCT GACCCCAGAG GCAGGGAGCT CCAAGACAAG GCCACCCCCT TGGTCACTCT GTTC---CCC TCCTGGAGCT CCAAGACAAG GCTGCCCCAT CGGTCACTCT GTTCCCGCCC TCCTGGAGCT TCAAGACAAG GCTGCCCCCT CGGTCACTCT GTTCCCACCC TCCTGGAGCT TCAAGACAAG
70 Quelques formats classiques en bioinformatique 6 4. Les formats d échange GFF (Generic Feature Format) : exploiter la richesse informationnelle des annotations au travers d une structure tabulaire à 9 colonnes Rendre compte de la présence de sous-régions fonctionnelles imbriquées Outils de validation ##gff-version 3 ##gff-version 3 ctg23 GenBank exon ID=exon;note=chromobox homolog 8 ctg23 GenBank gene ID=gene;Dbxref=GeneID: ctg23 GenBank exon ID=exon2 ctg23 GenBank intron ID=intron ctg23 GenBank snp ID=snp
71 Quelques formats classiques en bioinformatique 62 ASN. (Abstract Syntax Notation number one) : norme qui définit un formalisme de description de types de données abstraits Standard international ; format semi-structuré ; format de base pour les données du NCBI Seq-entry ::= set { level, class nuc-prot, descr { title "Mus musculus Brca mrna, and translated products", source { org { taxname "Mus musculus", db { { db "taxon", tag id 0090 } }, orgname { name binomial { genus "Mus", species "musculus" },...
72 Quelques formats classiques en bioinformatique 63 XML (extensible Markup Language) : fournit une moyen pour implémenter des ontologies (vocabulaire structuré) Langage à balise comme HTML ; standard international ; format semi-structuré <?xml version=".0"?> <!DOCTYPE GBSeq PUBLIC "-//NCBI//NCBI GBSeq/EN" <GBSet> <GBSeq> <GBSeq_locus>MMU3564</GBSeq_locus> <GBSeq_length>5538</GBSeq_length> <GBSeq_strandedness value="not-set">0</gbseq_strandedness> <GBSeq_moltype value="mrna">5</gbseq_moltype> <GBSeq_topology value="linear"></gbseq_topology> <GBSeq_division>ROD</GBSeq_division> <GBSeq_update-date>8-OCT-996</GBSeq_update-date> <GBSeq_create-date>25-OCT-995</GBSeq_create-date> <GBSeq_definition>Mus musculus Brca mrna, complete cds</gbseq_definition> <GBSeq_primary-accession>U3564</GBSeq_primary-accession> <GBSeq_accession-version>U3564.</GBSeq_accession-version>...
73 Quelques formats classiques en bioinformatique Formats correspondants aux alignements multiples MSF Multiple Sequence Format MAFMultiple Alignment Format ALN (CLUSTALW) Cette liste de formats classiques en bioinformatique n est bien sûr pas exhaustive Pour certains formats, représentation entrelacée (interleaved) ou séquentielle (sequential) possible Certains formats tendent à devenir des standards ou sont plus génériques que d autres, il faut encourager leur utilisation
74 Conversion des formats et visualisation 65 Les logiciels peuvent n accepter qu un type de format particulier Des outils existent pour transformer un format en un autre : ReadSeq Formats supportés : IG/Stanford, GenBank/GB, NBRF, EMBL, GCG, DNAStrider, Fitch, Pearson/Fasta, Phylip3.2, Phylip, PIR/CODATA, MSF, ASN. et PAUP/NEXUS SEQIO (plus ancien et non maintenu) http: :// gusfield/seqio.html Des outils de visualisation de données existent et acceptent, en général, plusieurs formats (AnnotationSketch, Seaview, MEGA,... )
Introduction aux bases de données: application en biologie
 Introduction aux bases de données: application en biologie D. Puthier 1 1 ERM206/Technologies Avancées pour le Génome et la Clinique, http://tagc.univ-mrs.fr/staff/puthier, puthier@tagc.univ-mrs.fr ESIL,
Introduction aux bases de données: application en biologie D. Puthier 1 1 ERM206/Technologies Avancées pour le Génome et la Clinique, http://tagc.univ-mrs.fr/staff/puthier, puthier@tagc.univ-mrs.fr ESIL,
Bibliographie Introduction à la bioinformatique
 Bibliographie Introduction à la bioinformatique 5. Les bases de données biologiques, SQL et la programmation Python/C++ Zvelebil et Baum, Understanding bioinformatics Beighley, Head First SQL Chari, A
Bibliographie Introduction à la bioinformatique 5. Les bases de données biologiques, SQL et la programmation Python/C++ Zvelebil et Baum, Understanding bioinformatics Beighley, Head First SQL Chari, A
! Séquence et structure des macromolécules. " Séquences protéiques (UniProt) " Séquences nucléotidiques (EMBL / ENA, Genbank, DDBJ)
 Séquences nucléotidiques (EMBL / ENA, Genbank, DDBJ)") Introduction à la Bioinformatique Introduction! Les bases de données jouent un rôle crucial dans l organisation des connaissances biologiques.! Nous proposons ici un tour rapide des principales bases de
Introduction à la Bioinformatique Introduction! Les bases de données jouent un rôle crucial dans l organisation des connaissances biologiques.! Nous proposons ici un tour rapide des principales bases de
Module Analyse de Génomes 2011-2012 Master 2 module FMBS 326 Immunoinformatique
 Module Analyse de Génomes 2011-2012 Master 2 module FMBS 326 Immunoinformatique Planning du Module : Date Heure Salle 12/12 9h-12h TD info TA1Z bat 25 13h-17h TD info TA1Z bat 25 13/12 9h-12h TD info TA1Z
Module Analyse de Génomes 2011-2012 Master 2 module FMBS 326 Immunoinformatique Planning du Module : Date Heure Salle 12/12 9h-12h TD info TA1Z bat 25 13h-17h TD info TA1Z bat 25 13/12 9h-12h TD info TA1Z
La gestion de données dans le cadre d une application de recherche d alignement de séquence : BLAST.
 La gestion de données dans le cadre d une application de recherche d alignement de séquence : BLAST. Gaël Le Mahec - p. 1/12 L algorithme BLAST. Basic Local Alignment Search Tool est un algorithme de recherche
La gestion de données dans le cadre d une application de recherche d alignement de séquence : BLAST. Gaël Le Mahec - p. 1/12 L algorithme BLAST. Basic Local Alignment Search Tool est un algorithme de recherche
Base de données bibliographiques Pubmed-Medline
 Chapitre 1 ; Domaine 1 ; Documentation ; Champs référentiels 1.1.1, 1.1.2 et 1.1.3 Base de données bibliographiques Pubmed-Medline D r Patrick Deschamps,, 30 mai 2007 PLAN C2i métiers de la santé Introduction
Chapitre 1 ; Domaine 1 ; Documentation ; Champs référentiels 1.1.1, 1.1.2 et 1.1.3 Base de données bibliographiques Pubmed-Medline D r Patrick Deschamps,, 30 mai 2007 PLAN C2i métiers de la santé Introduction
MENER UNE RECHERCHE D INFORMATION
 MENER UNE RECHERCHE D INFORMATION Pourquoi ne pas chercher seulement ses informations dans Google? Crédits photo : Flickr On N importe qui publie n importe quoi sur le Web! Parce que... Les résultats sont
MENER UNE RECHERCHE D INFORMATION Pourquoi ne pas chercher seulement ses informations dans Google? Crédits photo : Flickr On N importe qui publie n importe quoi sur le Web! Parce que... Les résultats sont
présentée DEVANT L UNIVERSITÉ DE RENNES 1 pour obtenir le grade de : DOCTEUR DE L UNIVERSITÉ DE RENNES 1 PAR Emilie GUÉRIN TITRE DE LA THÈSE :
 N Ordre de la Thèse 3282 THÈSE présentée DEVANT L UNIVERSITÉ DE RENNES 1 pour obtenir le grade de : DOCTEUR DE L UNIVERSITÉ DE RENNES 1 Mention : BIOLOGIE PAR Emilie GUÉRIN Équipe d accueil : École Doctorale
N Ordre de la Thèse 3282 THÈSE présentée DEVANT L UNIVERSITÉ DE RENNES 1 pour obtenir le grade de : DOCTEUR DE L UNIVERSITÉ DE RENNES 1 Mention : BIOLOGIE PAR Emilie GUÉRIN Équipe d accueil : École Doctorale
CHAPITRE 3 LA SYNTHESE DES PROTEINES
 CHAITRE 3 LA SYNTHESE DES ROTEINES On sait qu un gène détient dans sa séquence nucléotidique, l information permettant la synthèse d un polypeptide. Ce dernier caractérisé par sa séquence d acides aminés
CHAITRE 3 LA SYNTHESE DES ROTEINES On sait qu un gène détient dans sa séquence nucléotidique, l information permettant la synthèse d un polypeptide. Ce dernier caractérisé par sa séquence d acides aminés
Big data et sciences du Vivant L'exemple du séquençage haut débit
 Big data et sciences du Vivant L'exemple du séquençage haut débit C. Gaspin, C. Hoede, C. Klopp, D. Laborie, J. Mariette, C. Noirot, MS. Trotard bioinfo@genopole.toulouse.inra.fr INRA - MIAT - Plate-forme
Big data et sciences du Vivant L'exemple du séquençage haut débit C. Gaspin, C. Hoede, C. Klopp, D. Laborie, J. Mariette, C. Noirot, MS. Trotard bioinfo@genopole.toulouse.inra.fr INRA - MIAT - Plate-forme
BASE. Vous avez alors accès à un ensemble de fonctionnalités explicitées ci-dessous :
 BASE BioArray Software Environment (BASE) est une base de données permettant de gérer l importante quantité de données générées par des analyses de bio-puces. BASE gère les informations biologiques, les
BASE BioArray Software Environment (BASE) est une base de données permettant de gérer l importante quantité de données générées par des analyses de bio-puces. BASE gère les informations biologiques, les
Perl Orienté Objet BioPerl There is more than one way to do it
 Perl Orienté Objet BioPerl There is more than one way to do it Bérénice Batut, berenice.batut@udamail.fr DUT Génie Biologique Option Bioinformatique Année 2014-2015 Perl Orienté Objet - BioPerl Rappels
Perl Orienté Objet BioPerl There is more than one way to do it Bérénice Batut, berenice.batut@udamail.fr DUT Génie Biologique Option Bioinformatique Année 2014-2015 Perl Orienté Objet - BioPerl Rappels
Formavie 2010. 2 Différentes versions du format PDB...3. 3 Les champs dans les fichiers PDB...4. 4 Le champ «ATOM»...5. 6 Limites du format PDB...
 Formavie 2010 Les fichiers PDB Les fichiers PDB contiennent les informations qui vont permettre à des logiciels de visualisation moléculaire (ex : RasTop ou Jmol) d afficher les molécules. Un fichier au
Formavie 2010 Les fichiers PDB Les fichiers PDB contiennent les informations qui vont permettre à des logiciels de visualisation moléculaire (ex : RasTop ou Jmol) d afficher les molécules. Un fichier au
Bases de données et outils bioinformatiques utiles en génétique
 Bases de données et outils bioinformatiques utiles en génétique Collège National des Enseignants et Praticiens de Génétique Médicale C. Beroud Date de création du document 2010-2011 Table des matières
Bases de données et outils bioinformatiques utiles en génétique Collège National des Enseignants et Praticiens de Génétique Médicale C. Beroud Date de création du document 2010-2011 Table des matières
SysFera. Benjamin Depardon
 SysFera Passage d applications en SaaS Benjamin Depardon CTO@SysFera SysFera Technologie 2001 Création 2010 Spin Off INRIA Direction par un consortium d investisseurs 12 personnes 75% en R&D Implantation
SysFera Passage d applications en SaaS Benjamin Depardon CTO@SysFera SysFera Technologie 2001 Création 2010 Spin Off INRIA Direction par un consortium d investisseurs 12 personnes 75% en R&D Implantation
Extraction d information des bases de séquences biologiques avec R
 Extraction d information des bases de séquences biologiques avec R 21 novembre 2006 Résumé Le module seqinr fournit des fonctions pour extraire et manipuler des séquences d intérêt (nucléotidiques et protéiques)
Extraction d information des bases de séquences biologiques avec R 21 novembre 2006 Résumé Le module seqinr fournit des fonctions pour extraire et manipuler des séquences d intérêt (nucléotidiques et protéiques)
MABioVis. Bio-informatique et la
 MABioVis Modèles et Algorithmes pour la Bio-informatique et la Visualisation Visite ENS Cachan 5 janvier 2011 MABioVis G GUY MELANÇON (PR UFR Maths Info / EPI GRAVITE) (là, maintenant) - MABioVis DAVID
MABioVis Modèles et Algorithmes pour la Bio-informatique et la Visualisation Visite ENS Cachan 5 janvier 2011 MABioVis G GUY MELANÇON (PR UFR Maths Info / EPI GRAVITE) (là, maintenant) - MABioVis DAVID
Semestre 2 Spécialité «Analyse in silico des complexes macromolécules biologiques-médicaments»
 Master In silico Drug Design Semestre 2 Spécialité «Analyse in silico des complexes macromolécules biologiques-médicaments» 30NU01IS INITIATION A LA PROGRAMMATION (6 ECTS) Responsables : D. MESTIVIER,
Master In silico Drug Design Semestre 2 Spécialité «Analyse in silico des complexes macromolécules biologiques-médicaments» 30NU01IS INITIATION A LA PROGRAMMATION (6 ECTS) Responsables : D. MESTIVIER,
Cours Bases de données
 Informations sur le cours Cours Bases de données 9 (10) séances de 3h Polycopié (Cours + TD/TP) 3 année (MISI) Antoine Cornuéjols www.lri.fr/~antoine antoine.cornuejols@agroparistech.fr Transparents Disponibles
Informations sur le cours Cours Bases de données 9 (10) séances de 3h Polycopié (Cours + TD/TP) 3 année (MISI) Antoine Cornuéjols www.lri.fr/~antoine antoine.cornuejols@agroparistech.fr Transparents Disponibles
Guide de recherche documentaire à l usage des doctorants. Partie 1 : Exploiter les bases de données académiques
 Guide de recherche documentaire à l usage des doctorants Partie : Exploiter les bases de données académiques Sylvia Cheminel Dernière mise à jour : décembre 04 PANORAMA DES SOURCES DOCUMENTAIRES ACADEMIQUES...
Guide de recherche documentaire à l usage des doctorants Partie : Exploiter les bases de données académiques Sylvia Cheminel Dernière mise à jour : décembre 04 PANORAMA DES SOURCES DOCUMENTAIRES ACADEMIQUES...
Biomarqueurs en Cancérologie
 Biomarqueurs en Cancérologie Définition, détermination, usage Biomarqueurs et Cancer: définition Anomalie(s) quantitative(s) ou qualitative(s) Indicative(s) ou caractéristique(s) d un cancer ou de certaines
Biomarqueurs en Cancérologie Définition, détermination, usage Biomarqueurs et Cancer: définition Anomalie(s) quantitative(s) ou qualitative(s) Indicative(s) ou caractéristique(s) d un cancer ou de certaines
Dr E. CHEVRET UE2.1 2013-2014. Aperçu général sur l architecture et les fonctions cellulaires
 Aperçu général sur l architecture et les fonctions cellulaires I. Introduction II. Les microscopes 1. Le microscope optique 2. Le microscope à fluorescence 3. Le microscope confocal 4. Le microscope électronique
Aperçu général sur l architecture et les fonctions cellulaires I. Introduction II. Les microscopes 1. Le microscope optique 2. Le microscope à fluorescence 3. Le microscope confocal 4. Le microscope électronique
Programmation Web. Madalina Croitoru IUT Montpellier
 Programmation Web Madalina Croitoru IUT Montpellier Organisation du cours 4 semaines 4 ½ h / semaine: 2heures cours 3 ½ heures TP Notation: continue interrogation cours + rendu à la fin de chaque séance
Programmation Web Madalina Croitoru IUT Montpellier Organisation du cours 4 semaines 4 ½ h / semaine: 2heures cours 3 ½ heures TP Notation: continue interrogation cours + rendu à la fin de chaque séance
UTILISATION DE LA PLATEFORME WEB D ANALYSE DE DONNÉES GALAXY
 UTILISATION DE LA PLATEFORME WEB D ANALYSE DE DONNÉES GALAXY Yvan Le Bras yvan.le_bras@irisa.fr Cyril Monjeaud, Mathieu Bahin, Claudia Hériveau, Olivier Quenez, Olivier Sallou, Aurélien Roult, Olivier
UTILISATION DE LA PLATEFORME WEB D ANALYSE DE DONNÉES GALAXY Yvan Le Bras yvan.le_bras@irisa.fr Cyril Monjeaud, Mathieu Bahin, Claudia Hériveau, Olivier Quenez, Olivier Sallou, Aurélien Roult, Olivier
Magento. Magento. Réussir son site e-commerce. Réussir son site e-commerce BLANCHARD. Préface de Sébastien L e p e r s
 Mickaël Mickaël BLANCHARD BLANCHARD Préface de Sébastien L e p e r s Magento Préface de Sébastien L e p e r s Magento Réussir son site e-commerce Réussir son site e-commerce Groupe Eyrolles, 2010, ISBN
Mickaël Mickaël BLANCHARD BLANCHARD Préface de Sébastien L e p e r s Magento Préface de Sébastien L e p e r s Magento Réussir son site e-commerce Réussir son site e-commerce Groupe Eyrolles, 2010, ISBN
IMMUNOLOGIE. La spécificité des immunoglobulines et des récepteurs T. Informations scientifiques
 IMMUNOLOGIE La spécificité des immunoglobulines et des récepteurs T Informations scientifiques L infection par le VIH entraîne des réactions immunitaires de l organisme qui se traduisent par la production
IMMUNOLOGIE La spécificité des immunoglobulines et des récepteurs T Informations scientifiques L infection par le VIH entraîne des réactions immunitaires de l organisme qui se traduisent par la production
Introduction. La bioinformatique : Traitement des informations biologiques par des méthodes informatiques et/ou mathématiques.
 Introduction La bioinformatique : Traitement des informations biologiques par des méthodes informatiques et/ou mathématiques. Interdisciplinaire par nature, la bioinformatique est fondée sur les acquis
Introduction La bioinformatique : Traitement des informations biologiques par des méthodes informatiques et/ou mathématiques. Interdisciplinaire par nature, la bioinformatique est fondée sur les acquis
Recherche bibliographique avec PubMed/MedLine
 Recherche bibliographique avec PubMed/MedLine Nicolas Doux Mise à jour : Anne Tramut - 2011 Bu Médecine-Pharmacie Introduction L objectif principal de cette formation est de vous donner les outils pour
Recherche bibliographique avec PubMed/MedLine Nicolas Doux Mise à jour : Anne Tramut - 2011 Bu Médecine-Pharmacie Introduction L objectif principal de cette formation est de vous donner les outils pour
Master de Bioinformatique et Biologie des Systèmes Toulouse http://m2pbioinfo.biotoul.fr Responsable : Pr. Gwennaele Fichant
 Master de Bioinformatique et Biologie des Systèmes Toulouse http://m2pbioinfo.biotoul.fr Responsable : Pr. Gwennaele Fichant Parcours: Master 1 : Bioinformatique et biologie des Systèmes dans le Master
Master de Bioinformatique et Biologie des Systèmes Toulouse http://m2pbioinfo.biotoul.fr Responsable : Pr. Gwennaele Fichant Parcours: Master 1 : Bioinformatique et biologie des Systèmes dans le Master
CATALOGUE DES PRESTATIONS DE LA
 1/23 La plate-forme Biopuces et Séquençage de Strasbourg est équipée des technologies Affymetrix et Agilent pour l étude du transcriptome et du génome sur puces à ADN. SOMMAIRE ANALYSE TRANSCRIPTIONNELLE...
1/23 La plate-forme Biopuces et Séquençage de Strasbourg est équipée des technologies Affymetrix et Agilent pour l étude du transcriptome et du génome sur puces à ADN. SOMMAIRE ANALYSE TRANSCRIPTIONNELLE...
Sélection d un moteur de recherche pour intranet : Les sept points à prendre en compte
 Sélection d un moteur de recherche pour intranet : Les sept points à prendre en compte 1Les bases : vos objectifs 2 Sélection d un moteur de recherche pour intranet : Les sept points à prendre en compte
Sélection d un moteur de recherche pour intranet : Les sept points à prendre en compte 1Les bases : vos objectifs 2 Sélection d un moteur de recherche pour intranet : Les sept points à prendre en compte
4. Utilisation d un SGBD : le langage SQL. 5. Normalisation
 Base de données S. Lèbre slebre@unistra.fr Université de Strasbourg, département d informatique. Présentation du module Contenu général Notion de bases de données Fondements / Conception Utilisation :
Base de données S. Lèbre slebre@unistra.fr Université de Strasbourg, département d informatique. Présentation du module Contenu général Notion de bases de données Fondements / Conception Utilisation :
La base de données dans ArtemiS SUITE
 08/14 Vous préférez passer votre temps à analyser vos données plutôt qu à chercher un fichier? La base de données d ArtemiS SUITE vous permet d administrer et d organiser confortablement vos données et
08/14 Vous préférez passer votre temps à analyser vos données plutôt qu à chercher un fichier? La base de données d ArtemiS SUITE vous permet d administrer et d organiser confortablement vos données et
ENDNOTE X2 SOMMAIRE. 1. La bibliothèque EndNote 1.1. Créer une nouvelle bibliothèque 1.2. Ouvrir une bibliothèque EndNote 1.3. Fermer une bibliothèque
 1 ENDNOTE X2 SOMMAIRE 1. La bibliothèque EndNote 1.1. Créer une nouvelle bibliothèque 1.2. Ouvrir une bibliothèque EndNote 1.3. Fermer une bibliothèque 2. Manipuler une bibliothèque EndNote 2.1. La saisie
1 ENDNOTE X2 SOMMAIRE 1. La bibliothèque EndNote 1.1. Créer une nouvelle bibliothèque 1.2. Ouvrir une bibliothèque EndNote 1.3. Fermer une bibliothèque 2. Manipuler une bibliothèque EndNote 2.1. La saisie
Bases de données des mutations
 Bases de données des mutations CFMDB CFTR2 CFTR-France / Registre Corinne THEZE, Corinne BAREIL Laboratoire de génétique moléculaire Montpellier Atelier Muco, Lille, 25-27 septembre 2014 Accès libre http://www.genet.sickkids.on.ca/app
Bases de données des mutations CFMDB CFTR2 CFTR-France / Registre Corinne THEZE, Corinne BAREIL Laboratoire de génétique moléculaire Montpellier Atelier Muco, Lille, 25-27 septembre 2014 Accès libre http://www.genet.sickkids.on.ca/app
Problématiques de recherche. Figure Research Agenda for service-oriented computing
 Problématiques de recherche 90 Figure Research Agenda for service-oriented computing Conférences dans le domaine ICWS (International Conference on Web Services) Web services specifications and enhancements
Problématiques de recherche 90 Figure Research Agenda for service-oriented computing Conférences dans le domaine ICWS (International Conference on Web Services) Web services specifications and enhancements
Introduction aux concepts d ez Publish
 Introduction aux concepts d ez Publish Tutoriel rédigé par Bergfrid Skaara. Traduit de l Anglais par Benjamin Lemoine Mercredi 30 Janvier 2008 Sommaire Concepts d ez Publish... 3 Système de Gestion de
Introduction aux concepts d ez Publish Tutoriel rédigé par Bergfrid Skaara. Traduit de l Anglais par Benjamin Lemoine Mercredi 30 Janvier 2008 Sommaire Concepts d ez Publish... 3 Système de Gestion de
Comment interroger PubMed pour accéder aux revues en ligne AP-HP sur Intranet
 Comment interroger PubMed pour accéder aux revues en ligne AP-HP sur Intranet SOMMAIRE Recherche à partir d'un terme 3 Recherche à partir de plusieurs termes ou expressions 5 Recherche par mots-clés via
Comment interroger PubMed pour accéder aux revues en ligne AP-HP sur Intranet SOMMAIRE Recherche à partir d'un terme 3 Recherche à partir de plusieurs termes ou expressions 5 Recherche par mots-clés via
Bases de données et interfaces Génie logiciel
 Bases de données et interfaces Génie logiciel Merlet benjamin Merlet-Billon Maryvonne Hueber Yann Jamin Guillaume Giraud Sandra Département Génie Biologique Professeurs responsables : Option BIMB Promotion
Bases de données et interfaces Génie logiciel Merlet benjamin Merlet-Billon Maryvonne Hueber Yann Jamin Guillaume Giraud Sandra Département Génie Biologique Professeurs responsables : Option BIMB Promotion
Exemple accessible via une interface Web. Bases de données et systèmes de gestion de bases de données. Généralités. Définitions
 Exemple accessible via une interface Web Une base de données consultable en ligne : Bases de données et systèmes de gestion de bases de données The Trans-atlantic slave trade database: http://www.slavevoyages.org/tast/index.faces
Exemple accessible via une interface Web Une base de données consultable en ligne : Bases de données et systèmes de gestion de bases de données The Trans-atlantic slave trade database: http://www.slavevoyages.org/tast/index.faces
Introduc)on à Ensembl/ Biomart : Par)e pra)que
on à Ensembl/ Biomart : Par)e pra)que") Introduc)on à Ensembl/ Biomart : Par)e pra)que Stéphanie Le Gras Jean Muller NAVIGUER DANS ENSEMBL : PARTIE PRATIQUE 2 Naviga)on dans Ensembl : Pra)que Exercice 1 1.a. Quelle est la version de l assemblage
Introduc)on à Ensembl/ Biomart : Par)e pra)que Stéphanie Le Gras Jean Muller NAVIGUER DANS ENSEMBL : PARTIE PRATIQUE 2 Naviga)on dans Ensembl : Pra)que Exercice 1 1.a. Quelle est la version de l assemblage
GénoToul 2010, Hôtel de Région Midi Pyrénées, Toulouse, 10 décembre 2010
 GénoToul 2010, Hôtel de Région Midi Pyrénées, Toulouse, 10 décembre 2010 Analyse de la diversité moléculaire des régions génomiques de 30 gènes du développement méristématique dans une core collection
GénoToul 2010, Hôtel de Région Midi Pyrénées, Toulouse, 10 décembre 2010 Analyse de la diversité moléculaire des régions génomiques de 30 gènes du développement méristématique dans une core collection
Galaxy Training days. Liste des sessions disponibles : http://bioinfo.genotoul.fr. Les formateurs :
 -- 1 -- Galaxy Training days Durée / Programme : 3 journées. Galaxy : First step. Galaxy : Reads alignment and SNP calling. Galaxy : RNAseq alignment and transcripts assemblies. Public : Personnes souhaitant
-- 1 -- Galaxy Training days Durée / Programme : 3 journées. Galaxy : First step. Galaxy : Reads alignment and SNP calling. Galaxy : RNAseq alignment and transcripts assemblies. Public : Personnes souhaitant
Bases de données élémentaires Maude Manouvrier
 Licence MI2E- 1ère année Outils en Informatique Bases de données élémentaires Maude Manouvrier Définitions générales et positionnement du cours dans la formation Vocabulaire relatif aux bases de données
Licence MI2E- 1ère année Outils en Informatique Bases de données élémentaires Maude Manouvrier Définitions générales et positionnement du cours dans la formation Vocabulaire relatif aux bases de données
Mise en place de serveurs Galaxy dans le cadre du réseau CATI BBRIC
 Mise en place de serveurs Galaxy dans le cadre du réseau CATI BBRIC {Sebastien.Carrere, Ludovic.Legrand,Jerome.Gouzy}@toulouse.inra.fr {Fabrice.Legeai,Anthony.Bretaudeau}@rennes.inra.fr CATI BBRIC 35 bioinformaticiens
Mise en place de serveurs Galaxy dans le cadre du réseau CATI BBRIC {Sebastien.Carrere, Ludovic.Legrand,Jerome.Gouzy}@toulouse.inra.fr {Fabrice.Legeai,Anthony.Bretaudeau}@rennes.inra.fr CATI BBRIC 35 bioinformaticiens
XML, PMML, SOAP. Rapport. EPITA SCIA Promo 2004 16 janvier 2003. Julien Lemoine Alexandre Thibault Nicolas Wiest-Million
 XML, PMML, SOAP Rapport EPITA SCIA Promo 2004 16 janvier 2003 Julien Lemoine Alexandre Thibault Nicolas Wiest-Million i TABLE DES MATIÈRES Table des matières 1 XML 1 1.1 Présentation de XML.................................
XML, PMML, SOAP Rapport EPITA SCIA Promo 2004 16 janvier 2003 Julien Lemoine Alexandre Thibault Nicolas Wiest-Million i TABLE DES MATIÈRES Table des matières 1 XML 1 1.1 Présentation de XML.................................
Les bases de données transcriptionnelles en ligne
 Les bases de données transcriptionnelles en ligne Différents concepts en régulation transcriptionnelle sites de fixation - in vitro/vivo? - quelle technique? - degré de confiance? facteur de transcription
Les bases de données transcriptionnelles en ligne Différents concepts en régulation transcriptionnelle sites de fixation - in vitro/vivo? - quelle technique? - degré de confiance? facteur de transcription
UE 8 Systèmes d information de gestion Le programme
 UE 8 Systèmes d information de gestion Le programme Légende : Modifications de l arrêté du 8 mars 2010 Suppressions de l arrêté du 8 mars 2010 Partie inchangée par rapport au programme antérieur Indications
UE 8 Systèmes d information de gestion Le programme Légende : Modifications de l arrêté du 8 mars 2010 Suppressions de l arrêté du 8 mars 2010 Partie inchangée par rapport au programme antérieur Indications
Programmation Internet Cours 4
 Programmation Internet Cours 4 Kim Nguy ên http://www.lri.fr/~kn 17 octobre 2011 1 / 23 Plan 1. Système d exploitation 2. Réseau et Internet 3. Web 3.1 Internet et ses services 3.1 Fonctionnement du Web
Programmation Internet Cours 4 Kim Nguy ên http://www.lri.fr/~kn 17 octobre 2011 1 / 23 Plan 1. Système d exploitation 2. Réseau et Internet 3. Web 3.1 Internet et ses services 3.1 Fonctionnement du Web
Génétique et génomique Pierre Martin
 Génétique et génomique Pierre Martin Principe de la sélections Repérage des animaux intéressants X Accouplements Programmés Sélection des meilleurs mâles pour la diffusion Index diffusés Indexation simultanée
Génétique et génomique Pierre Martin Principe de la sélections Repérage des animaux intéressants X Accouplements Programmés Sélection des meilleurs mâles pour la diffusion Index diffusés Indexation simultanée
Guide de démarrage rapide du TruVision NVR 10
 Guide de démarrage rapide du TruVision NVR 10 P/N 1072767B-FR REV 1.0 ISS 09OCT14 Copyright 2014 United Technologies Corporation. Interlogix fait partie d UTC Building & Industrial Systems, une unité de
Guide de démarrage rapide du TruVision NVR 10 P/N 1072767B-FR REV 1.0 ISS 09OCT14 Copyright 2014 United Technologies Corporation. Interlogix fait partie d UTC Building & Industrial Systems, une unité de
Chapitre IX. L intégration de données. Les entrepôts de données (Data Warehouses) Motivation. Le problème
 Motivation. Le problème") Chapitre IX L intégration de données Le problème De façon très générale, le problème de l intégration de données (data integration) est de permettre un accès cohérent à des données d origine, de structuration
Chapitre IX L intégration de données Le problème De façon très générale, le problème de l intégration de données (data integration) est de permettre un accès cohérent à des données d origine, de structuration
Module pour la solution e-commerce Magento
 Module pour la solution e-commerce Magento sommaire 1. Introduction... 3 1.1. Objet du document... 3 1.2. Liste des documents de référence... 3 1.3. Avertissement... 3 1.4. Contacts... 3 1.5. Historique
Module pour la solution e-commerce Magento sommaire 1. Introduction... 3 1.1. Objet du document... 3 1.2. Liste des documents de référence... 3 1.3. Avertissement... 3 1.4. Contacts... 3 1.5. Historique
Recherche et veille documentaire scientifique
 Recherche et veille documentaire scientifique Élodie Chattot BU Médecine Pharmacie juin 2006 Introduction Le but de cet atelier est de vous initier à la méthodologie de recherche documentaire scientifique,
Recherche et veille documentaire scientifique Élodie Chattot BU Médecine Pharmacie juin 2006 Introduction Le but de cet atelier est de vous initier à la méthodologie de recherche documentaire scientifique,
Module BD et sites WEB
 Module BD et sites WEB Cours 8 Bases de données et Web Anne Doucet Anne.Doucet@lip6.fr 1 Le Web Architecture Architectures Web Client/serveur 3-tiers Serveurs d applications Web et BD Couplage HTML-BD
Module BD et sites WEB Cours 8 Bases de données et Web Anne Doucet Anne.Doucet@lip6.fr 1 Le Web Architecture Architectures Web Client/serveur 3-tiers Serveurs d applications Web et BD Couplage HTML-BD
Cours Base de données relationnelles. M. Boughanem, IUP STRI
 Cours Base de données relationnelles 1 Plan 1. Notions de base 2. Modèle relationnel 3. SQL 2 Notions de base (1) Définition intuitive : une base de données est un ensemble d informations, (fichiers),
Cours Base de données relationnelles 1 Plan 1. Notions de base 2. Modèle relationnel 3. SQL 2 Notions de base (1) Définition intuitive : une base de données est un ensemble d informations, (fichiers),
Architecture N-Tier. Ces données peuvent être saisies interactivement via l interface ou lues depuis un disque. Application
 Architecture Multi-Tier Traditionnellement une application informatique est un programme exécutable sur une machine qui représente la logique de traitement des données manipulées par l application. Ces
Architecture Multi-Tier Traditionnellement une application informatique est un programme exécutable sur une machine qui représente la logique de traitement des données manipulées par l application. Ces
Chapitre 5 LE MODELE ENTITE - ASSOCIATION
 Chapitre 5 LE MODELE ENTITE - ASSOCIATION 1 Introduction Conception d une base de données Domaine d application complexe : description abstraite des concepts indépendamment de leur implémentation sous
Chapitre 5 LE MODELE ENTITE - ASSOCIATION 1 Introduction Conception d une base de données Domaine d application complexe : description abstraite des concepts indépendamment de leur implémentation sous
1 Introduction et installation
 TP d introduction aux bases de données 1 TP d introduction aux bases de données Le but de ce TP est d apprendre à manipuler des bases de données. Dans le cadre du programme d informatique pour tous, on
TP d introduction aux bases de données 1 TP d introduction aux bases de données Le but de ce TP est d apprendre à manipuler des bases de données. Dans le cadre du programme d informatique pour tous, on
4D v11 SQL BREAKING THE LIMITS * Les nouveautés
 BREAKING THE LIMITS * *Dépasser les limites 4D v11 SQL Les nouveautés SQL natif intégré Nouveau moteur de base de données ultra-performant Productivité de développement inégalée Architecture Universal
BREAKING THE LIMITS * *Dépasser les limites 4D v11 SQL Les nouveautés SQL natif intégré Nouveau moteur de base de données ultra-performant Productivité de développement inégalée Architecture Universal
Europresse.com. Pour les bibliothèques publiques et de l enseignement. Votre meilleur outil de recherche en ligne. Guide version 1.
 Europresse.com Pour les bibliothèques publiques et de l enseignement Votre meilleur outil de recherche en ligne Guide version 1.5 CEDROM-SNi Comprendre la page d accueil 1. Bandeau de navigation 2. Espace
Europresse.com Pour les bibliothèques publiques et de l enseignement Votre meilleur outil de recherche en ligne Guide version 1.5 CEDROM-SNi Comprendre la page d accueil 1. Bandeau de navigation 2. Espace
DÉFIS DU SÉQUENÇAGE NOUVELLE GÉNÉRATION
 DÉFIS DU SÉQUENÇAGE NOUVELLE GÉNÉRATION PRINCIPES DE BASE SUR LES DONNEES ET LE CALCUL HAUTE PERFORMANCE Lois de Gray sur l ingénierie des données 1 : Les calculs scientifiques traitent des volumes considérables
DÉFIS DU SÉQUENÇAGE NOUVELLE GÉNÉRATION PRINCIPES DE BASE SUR LES DONNEES ET LE CALCUL HAUTE PERFORMANCE Lois de Gray sur l ingénierie des données 1 : Les calculs scientifiques traitent des volumes considérables
Introduction à la Génomique Fonctionnelle
 Introduction à la Génomique Fonctionnelle Cours aux étudiants de BSc Biologie 3ème année Philippe Reymond, MER PLAN DU COURS - Séquençage des génomes - Fabrication de DNA microarrays - Autres méthodes
Introduction à la Génomique Fonctionnelle Cours aux étudiants de BSc Biologie 3ème année Philippe Reymond, MER PLAN DU COURS - Séquençage des génomes - Fabrication de DNA microarrays - Autres méthodes
Les bases de données
 Les bases de données Introduction aux fonctions de tableur et logiciels ou langages spécialisés (MS-Access, Base, SQL ) Yves Roggeman Boulevard du Triomphe CP 212 B-1050 Bruxelles (Belgium) Idée intuitive
Les bases de données Introduction aux fonctions de tableur et logiciels ou langages spécialisés (MS-Access, Base, SQL ) Yves Roggeman Boulevard du Triomphe CP 212 B-1050 Bruxelles (Belgium) Idée intuitive
Ingénieur R&D en bio-informatique
 Ingénieur R&D en bio-informatique Spécialisé Bases De Données 33 ans, Célibataire. Biologie & Informatique gabriel.chandesris[at]laposte.net {06 56 41 97 37} Use the bipper! http://gabriel.chandesris.free.fr/
Ingénieur R&D en bio-informatique Spécialisé Bases De Données 33 ans, Célibataire. Biologie & Informatique gabriel.chandesris[at]laposte.net {06 56 41 97 37} Use the bipper! http://gabriel.chandesris.free.fr/
Introduction à MATLAB R
 Introduction à MATLAB R Romain Tavenard 10 septembre 2009 MATLAB R est un environnement de calcul numérique propriétaire orienté vers le calcul matriciel. Il se compose d un langage de programmation, d
Introduction à MATLAB R Romain Tavenard 10 septembre 2009 MATLAB R est un environnement de calcul numérique propriétaire orienté vers le calcul matriciel. Il se compose d un langage de programmation, d
Information utiles. cinzia.digiusto@gmail.com. webpage : Google+ : http://www.ibisc.univ-evry.fr/ digiusto/
 Systèmes de gestion de bases de données Introduction Université d Evry Val d Essonne, IBISC utiles email : cinzia.digiusto@gmail.com webpage : http://www.ibisc.univ-evry.fr/ digiusto/ Google+ : https://plus.google.com/u/0/b/103572780965897723237/
Systèmes de gestion de bases de données Introduction Université d Evry Val d Essonne, IBISC utiles email : cinzia.digiusto@gmail.com webpage : http://www.ibisc.univ-evry.fr/ digiusto/ Google+ : https://plus.google.com/u/0/b/103572780965897723237/
e-biogenouest CNRS UMR 6074 IRISA-INRIA / Plateforme de Bioinformatique GenOuest yvan.le_bras@irisa.fr Programme fédérateur Biogenouest co-financé
 e-biogenouest Coordinateur : Olivier Collin Animateur : Yvan Le Bras CNRS UMR 6074 IRISA-INRIA / Plateforme de Bioinformatique GenOuest yvan.le_bras@irisa.fr Programme fédérateur Biogenouest co-financé
e-biogenouest Coordinateur : Olivier Collin Animateur : Yvan Le Bras CNRS UMR 6074 IRISA-INRIA / Plateforme de Bioinformatique GenOuest yvan.le_bras@irisa.fr Programme fédérateur Biogenouest co-financé
Structuration des décisions de jurisprudence basée sur une ontologie juridique en langue arabe
 Structuration des décisions de jurisprudence basée sur une ontologie juridique en langue arabe Karima Dhouib, Sylvie Després Faiez Gargouri ISET - Sfax Tunisie, BP : 88A Elbustan ; Sfax karima.dhouib@isets.rnu.tn,
Structuration des décisions de jurisprudence basée sur une ontologie juridique en langue arabe Karima Dhouib, Sylvie Després Faiez Gargouri ISET - Sfax Tunisie, BP : 88A Elbustan ; Sfax karima.dhouib@isets.rnu.tn,
Learning Object Metadata
 Page 1 of 7 Learning Object Metadata Le LOM (Learning Object Metadata), est un schéma de description de ressources d enseignement et d apprentissage. Le LOM peut être utilisé pour décrire des ressources
Page 1 of 7 Learning Object Metadata Le LOM (Learning Object Metadata), est un schéma de description de ressources d enseignement et d apprentissage. Le LOM peut être utilisé pour décrire des ressources
Le modèle de données
 Le modèle de données Introduction : Une fois que l étude des besoins est complétée, deux points importants sont à retenir : Les données du système étudié Les traitements effectués par le système documentaire.
Le modèle de données Introduction : Une fois que l étude des besoins est complétée, deux points importants sont à retenir : Les données du système étudié Les traitements effectués par le système documentaire.
Hépatite chronique B Moyens thérapeutiques
 Hépatite chronique B Moyens thérapeutiques Dr Olfa BAHRI Laboratoire de Virologie Clinique Institut Pasteur de Tunis INTRODUCTION Plus de 300. 10 6 porteurs chroniques de VHB dans le monde Hépatite chronique
Hépatite chronique B Moyens thérapeutiques Dr Olfa BAHRI Laboratoire de Virologie Clinique Institut Pasteur de Tunis INTRODUCTION Plus de 300. 10 6 porteurs chroniques de VHB dans le monde Hépatite chronique
PUBMED. Vous pouvez rentrer l adresse de ce support dans vos favoris : http://www.pasteur.fr/infosci/biblio/services/formations/#pubmed
 PUBMED Vous pouvez rentrer l adresse de ce support dans vos favoris : http://www.pasteur.fr/infosci/biblio/services/formations/#pubmed 1. INTRODUCTION p.2 1.1. Qu est-ce que PubMed? p.2 1.2. Présentation
PUBMED Vous pouvez rentrer l adresse de ce support dans vos favoris : http://www.pasteur.fr/infosci/biblio/services/formations/#pubmed 1. INTRODUCTION p.2 1.1. Qu est-ce que PubMed? p.2 1.2. Présentation
L. Granjon, E. Le Goff, A. Millereux, L. Saligny MSH Dijon
 Le projet d un GeoCatalogue CArGOS CAtalogue de données GéOgraphiques pour les Sciences humaines et sociales http://cargos.tge-adonis.fr GeoSource.7 Présentation de l application Qu est-ce que CArGOS?
Le projet d un GeoCatalogue CArGOS CAtalogue de données GéOgraphiques pour les Sciences humaines et sociales http://cargos.tge-adonis.fr GeoSource.7 Présentation de l application Qu est-ce que CArGOS?
erma (Instructions d utilisateur )
") erma (Instructions d utilisateur ) Table des Matières S enregistrer en tant qu utilisateur externe Page 3 8 Comment soumettre une demande d erma Page 9 16 Demandes Soumises Et après? Page 17 22 Demandes
erma (Instructions d utilisateur ) Table des Matières S enregistrer en tant qu utilisateur externe Page 3 8 Comment soumettre une demande d erma Page 9 16 Demandes Soumises Et après? Page 17 22 Demandes
MAB Solut. vos projets. MABLife Génopole Campus 1 5 rue Henri Desbruères 91030 Evry Cedex. www.mabsolut.com. intervient à chaque étape de
 Mabsolut-DEF-HI:Mise en page 1 17/11/11 17:45 Page1 le département prestataire de services de MABLife de la conception à la validation MAB Solut intervient à chaque étape de vos projets Création d anticorps
Mabsolut-DEF-HI:Mise en page 1 17/11/11 17:45 Page1 le département prestataire de services de MABLife de la conception à la validation MAB Solut intervient à chaque étape de vos projets Création d anticorps
Access et Org.Base : mêmes objectifs? Description du thème : Création de grilles d écran pour une école de conduite.
 Access et Org.Base : mêmes objectifs? Description du thème : Création de grilles d écran pour une école de conduite. Mots-clés : Niveau : Bases de données relationnelles, Open Office, champs, relations,
Access et Org.Base : mêmes objectifs? Description du thème : Création de grilles d écran pour une école de conduite. Mots-clés : Niveau : Bases de données relationnelles, Open Office, champs, relations,
Leçon 1 : Les principaux composants d un ordinateur
 Chapitre 2 Architecture d un ordinateur Leçon 1 : Les principaux composants d un ordinateur Les objectifs : o Identifier les principaux composants d un micro-ordinateur. o Connaître les caractéristiques
Chapitre 2 Architecture d un ordinateur Leçon 1 : Les principaux composants d un ordinateur Les objectifs : o Identifier les principaux composants d un micro-ordinateur. o Connaître les caractéristiques
BUSINESS INTELLIGENCE
 GUIDE COMPARATIF BUSINESS INTELLIGENCE www.viseo.com Table des matières Business Intelligence :... 2 Contexte et objectifs... 2 Une architecture spécifique... 2 Les outils de Business intelligence... 3
GUIDE COMPARATIF BUSINESS INTELLIGENCE www.viseo.com Table des matières Business Intelligence :... 2 Contexte et objectifs... 2 Une architecture spécifique... 2 Les outils de Business intelligence... 3
GESTION LOGISTIQUE GESTION COMMERCIALE GESTION DE PRODUCTION
 GESTION LOGISTIQUE GESTION COMMERCIALE GESTION DE PRODUCTION Votre contact : Pierre Larchères 06 30 35 96 46 18, rue de la Semm - 68000 COLMAR p.larcheres@agelis.fr PRESENTATION GENERALE LES PROGICIELS
GESTION LOGISTIQUE GESTION COMMERCIALE GESTION DE PRODUCTION Votre contact : Pierre Larchères 06 30 35 96 46 18, rue de la Semm - 68000 COLMAR p.larcheres@agelis.fr PRESENTATION GENERALE LES PROGICIELS
Tutoriel de formation SurveyMonkey
 Tutoriel de formation SurveyMonkey SurveyMonkey est un service de sondage en ligne. SurveyMonkey vous permet de créer vos sondages rapidement et facilement. SurveyMonkey est disponible à l adresse suivante
Tutoriel de formation SurveyMonkey SurveyMonkey est un service de sondage en ligne. SurveyMonkey vous permet de créer vos sondages rapidement et facilement. SurveyMonkey est disponible à l adresse suivante
Gènes Diffusion - EPIC 2010
 Gènes Diffusion - EPIC 2010 1. Contexte. 2. Notion de génétique animale. 3. Profil de l équipe plateforme. 4. Type et gestion des données biologiques. 5. Environnement Matériel et Logiciel. 6. Analyses
Gènes Diffusion - EPIC 2010 1. Contexte. 2. Notion de génétique animale. 3. Profil de l équipe plateforme. 4. Type et gestion des données biologiques. 5. Environnement Matériel et Logiciel. 6. Analyses
Base de données relationnelle et requêtes SQL
 Base de données relationnelle et requêtes SQL 1e partie Anne-Marie Cubat Une question pour commencer : que voyez-vous? Cela reste flou Les plans de «Prison Break»? Non, cherchons ailleurs! Et de plus près,
Base de données relationnelle et requêtes SQL 1e partie Anne-Marie Cubat Une question pour commencer : que voyez-vous? Cela reste flou Les plans de «Prison Break»? Non, cherchons ailleurs! Et de plus près,
ÉCOLE DE TECHNOLOGIE SUPÉRIEURE UNIVERSITÉ DU QUÉBEC RAPPORT DE PROJET PRÉSENTÉ À L ÉCOLE DE TECHNOLOGIE SUPÉRIEURE
 ÉCOLE DE TECHNOLOGIE SUPÉRIEURE UNIVERSITÉ DU QUÉBEC RAPPORT DE PROJET PRÉSENTÉ À L ÉCOLE DE TECHNOLOGIE SUPÉRIEURE COMME EXIGENCE PARTIELLE À L OBTENTION DE LA MAÎTRISE EN GÉNIE PAR Sébastien SERVOLES
ÉCOLE DE TECHNOLOGIE SUPÉRIEURE UNIVERSITÉ DU QUÉBEC RAPPORT DE PROJET PRÉSENTÉ À L ÉCOLE DE TECHNOLOGIE SUPÉRIEURE COMME EXIGENCE PARTIELLE À L OBTENTION DE LA MAÎTRISE EN GÉNIE PAR Sébastien SERVOLES
Etude et développement d un moteur de recherche
 Ministère de l Education Nationale Université de Montpellier II Projet informatique FLIN607 Etude et développement d un moteur de recherche Spécifications fonctionnelles Interface utilisateur Responsable
Ministère de l Education Nationale Université de Montpellier II Projet informatique FLIN607 Etude et développement d un moteur de recherche Spécifications fonctionnelles Interface utilisateur Responsable
INTRODUCTION AUX BASES de DONNEES
 INTRODUCTION AUX BASES de DONNEES Équipe Bases de Données LRI-Université Paris XI, Orsay Université Paris Sud Année 2003 2004 1 SGBD : Fonctionnalités et Principes Qu est qu une base de données? Un Système
INTRODUCTION AUX BASES de DONNEES Équipe Bases de Données LRI-Université Paris XI, Orsay Université Paris Sud Année 2003 2004 1 SGBD : Fonctionnalités et Principes Qu est qu une base de données? Un Système
Soon_AdvancedCache. Module Magento SOON. Rédacteur. Relecture & validation technique. Historique des révisions
 Module Magento SOON Soon_AdvancedCache Rédacteur Hervé G. Lead développeur Magento herve@agence-soon.fr AGENCE SOON 81 avenue du Bac 94210 LA VARENNE ST HILAIRE Tel : +33 (0)1 48 83 95 96 Fax : +33 (0)1
Module Magento SOON Soon_AdvancedCache Rédacteur Hervé G. Lead développeur Magento herve@agence-soon.fr AGENCE SOON 81 avenue du Bac 94210 LA VARENNE ST HILAIRE Tel : +33 (0)1 48 83 95 96 Fax : +33 (0)1
AssetCenter Notes de version
 Peregrine AssetCenter Notes de version PART NUMBER AC-4.1.0-FRE-01015-00189 AssetCenter Copyright 2002 Peregrine Systems, Inc. Tous droits réservés. Les informations contenues dans ce document sont la
Peregrine AssetCenter Notes de version PART NUMBER AC-4.1.0-FRE-01015-00189 AssetCenter Copyright 2002 Peregrine Systems, Inc. Tous droits réservés. Les informations contenues dans ce document sont la
Les Différents types de Requêtes dans Access
 Les Différents types de Requêtes dans Access Il existe six types de requêtes. Les Requêtes «Sélection», qui sont le mode par défaut et correspondent à des «vues» des tables originelles. Cela signifie que
Les Différents types de Requêtes dans Access Il existe six types de requêtes. Les Requêtes «Sélection», qui sont le mode par défaut et correspondent à des «vues» des tables originelles. Cela signifie que
Memento de la recherche documentaire en santé
 Memento de la recherche documentaire en santé Optimiser ses recherches - Se procurer les documents Rédiger sa bibliographie 1. QUELQUES CONSEILS DE METHODE Avant toute chose, bien choisir ses mots-clés
Memento de la recherche documentaire en santé Optimiser ses recherches - Se procurer les documents Rédiger sa bibliographie 1. QUELQUES CONSEILS DE METHODE Avant toute chose, bien choisir ses mots-clés
IBM Workplace : Live!
 IBM Workplace : Live! Portail et Gestion de Contenu Logiciels présentés: - WebSphere Portal v5.1 - IBM Workplace Web Content Management v5.1 Benjamin Bollaert Agenda Le portail par l exemple : l Intranet
IBM Workplace : Live! Portail et Gestion de Contenu Logiciels présentés: - WebSphere Portal v5.1 - IBM Workplace Web Content Management v5.1 Benjamin Bollaert Agenda Le portail par l exemple : l Intranet
ASTER et ses modules
 ASTER et ses modules Sommaire Caractéristiques du site internet Rubriques et pages... page 3 Actualités... page 3 Agenda... page 4 Sons... page 4 Documents à télécharger... page 4 Liens... page 4 Albums
ASTER et ses modules Sommaire Caractéristiques du site internet Rubriques et pages... page 3 Actualités... page 3 Agenda... page 4 Sons... page 4 Documents à télécharger... page 4 Liens... page 4 Albums
Mise en place d'une démarche qualité et maintien de la certification ISO 9001:2008 dans un système d'information
 Mise en place d'une démarche qualité et maintien de la certification ISO 9001:2008 dans un système d'information IMGT The international ImMunoGeneTics information system Joumana Jabado-Michaloud IE Bioinformatique,
Mise en place d'une démarche qualité et maintien de la certification ISO 9001:2008 dans un système d'information IMGT The international ImMunoGeneTics information system Joumana Jabado-Michaloud IE Bioinformatique,
Procédure de Migration de G.U.N.T.3 KoXo Administrator
 Procédure de Migration de G.U.N.T.3 KoXo Administrator 1 - Introduction L application G.U.N.T.3 (CRDP de Bretagne) utilise une structuration dans Active Directory qui est similaire à celle de KoXo Administrator.
Procédure de Migration de G.U.N.T.3 KoXo Administrator 1 - Introduction L application G.U.N.T.3 (CRDP de Bretagne) utilise une structuration dans Active Directory qui est similaire à celle de KoXo Administrator.
Mise en place d une plateforme de gestion de matériels biologiques : quels avantages pour les chercheurs?
 Mise en place d une plateforme de gestion de matériels biologiques : quels avantages pour les chercheurs? Dr Xavier Manival, Laboratoire IMoPA, CR, CNRS Françoise Tisserand-Bedri, Documentaliste, Inist-CNRS
Mise en place d une plateforme de gestion de matériels biologiques : quels avantages pour les chercheurs? Dr Xavier Manival, Laboratoire IMoPA, CR, CNRS Françoise Tisserand-Bedri, Documentaliste, Inist-CNRS
Chapitre 7 : Structure de la cellule Le noyau cellulaire
 UE2 : Structure générale de la cellule Chapitre 7 : Structure de la cellule Le noyau cellulaire Professeur Michel SEVE Année universitaire 2010/2011 Université Joseph Fourier de Grenoble - Tous droits
UE2 : Structure générale de la cellule Chapitre 7 : Structure de la cellule Le noyau cellulaire Professeur Michel SEVE Année universitaire 2010/2011 Université Joseph Fourier de Grenoble - Tous droits
Gestion collaborative de documents
 Gestion collaborative de documents ANT box, le logiciel qui simplifie votre GED Les organisations (entreprises, collectivités, associations...) génèrent chaque jour des millions de documents, e-mails,
Gestion collaborative de documents ANT box, le logiciel qui simplifie votre GED Les organisations (entreprises, collectivités, associations...) génèrent chaque jour des millions de documents, e-mails,
ESPACE COLLABORATIF SHAREPOINT
 Conseil de l Europe Service des Technologies de l Information ESPACE COLLABORATIF SHAREPOINT DOSSIER D UTILISATEUR 1/33 Sommaire 1. Présentation de SharePoint... 3 1.1. Connexion... 4 2. Les listes...
Conseil de l Europe Service des Technologies de l Information ESPACE COLLABORATIF SHAREPOINT DOSSIER D UTILISATEUR 1/33 Sommaire 1. Présentation de SharePoint... 3 1.1. Connexion... 4 2. Les listes...