Super Calculateur HPC, pour High Performance Computing
|
|
|
- Agathe Gaulin
- il y a 8 ans
- Total affichages :
Transcription
1 Super Calculateur HPC, pour High Performance Computing Certaines applications ont besoin de faire un grand nombre de calcul, souvent pour des problèmes de simulation. météorologie, physique (nucléaire sismiques, automobiles. avions,... 1
 sismiques, automobiles.")
2 Historique / Super Calculateur Quelques Dates : 1642 : Pascal Pascaline (addition, soustractions) 1884 : Herman Hollerith crée une tabulatrice à cartes perforées (recensement) 1896 : Herman Hollerith, crée Tabulating Machine Corporation (TMC) 1924 : TMC devient International Business Machine (IBM) ( 2
 (http://histoire.info.online.")
3 Historique / Super Calculateur Quelques Dates : 1935 : IBM commercialise l'ibm 601 à 1500 ex. (comptabilité, scientifiques relais + cartes) : La bombe, le colossus (décryptage) 1946 : Création de l'eniac (Electronic Numerical Integrator and Computer) 30 tonnes, 72 m2 140 kilowatts. Horloge : 100 KHz. 330 multiplications par seconde 3
 1946 : Création de l'eniac (Electronic Numerical Integrator and")
4 Historique / Super Calculateur Quelques Dates : 1951 : La Compagnie des Machines Bull réalise son premier ordinateur : le Gamma : Mise au point du tambour de masse magnétique ERA Il s'agit de la première mémoire de masse. Capacité : 1 Mbits : Invention du premier compilateur A0 4

5 Historique / Super Calculateur Quelques Dates : 1955 : IBM lance l'ibm 704 premier coprocesseur mathématique 5 kflops 1955 : Premier réseau informatique à but commercial : SABRE (Semi Automated Business Related Environment) 1200 téléscripteurs 1958 : Lancement du premier ordinateur commercial entièrement transistorisé, le CDC 1604, développé par Seymour Cray. 5

6 Historique / Super Calculateur Quelques Dates : 1964 : Lancement du super ordinateur CDC 6600 développé par Seymour Cray 1976 : Cray Research Inc. architecture vectorielle : le CRAY I : Annonce du Cray X-MP, le premier super-ordinateur Cray multiprocesseur. 6

7 FLOPS FLoating point Operations Per Second megaflop gigaflop teraflop petaflop exaflop zettaflop yottaflop 10^6 10^9 10^12 10^15 10^18 10^21 10^24 7

8 Le Cray XMP un super calculateur de type vectoriel MFLOPS(wikipedia) 8

9 Le Cray 2 un des ordinateurs le plus puissant de 1985 à ,9 GFLOP (wikipedia) 9

10 Processeur Vectoriel / Vector processor Processeur conçu pour effectuer des opérations mathématiques simultanéments sur des données différentes. Souvent pour effectuer du calcul matriciel 10

11 Calcul Parallèle utilisation de machines ou de processus séparés, ces éléments communiquent par échange d'information. 11

12 Types de parallèlisme Toutes ces méthodes utilisent différentes données pour chaque processus : SIMD Data-parallel : Mêmes opérations sur des données différentes. (SIMD, Single Instruction Multiple Data), SPMD : Même programme avec des données différentes, MIMD : Différents programmes avec des données différentes. 12
, SPMD : Même programme avec des")
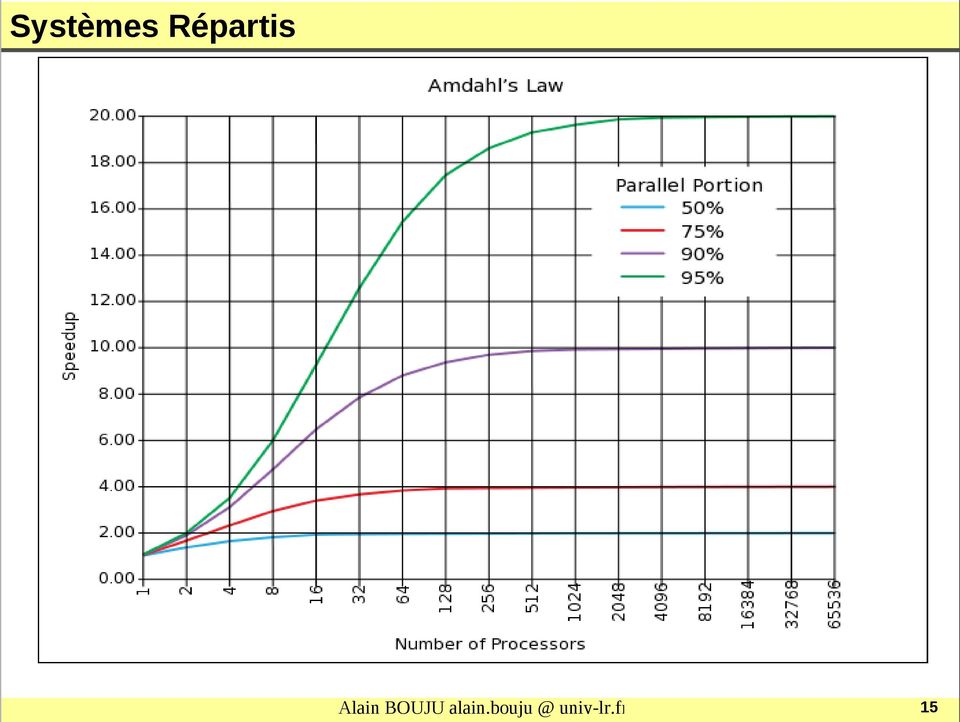
13 Loi d'amdhal Gene Myron Amdahl (16/11/1922, ) (architecte IBM - Amdahl Corporation) 1 P 1 P N P : proportion du code parallèle N : nb processeurs 13

14 Loi d'amdhal Quelques exemples : P=0,5 N=2 -> 1,33 N=4 -> 1,6 N=8 -> 1,78 N=16 -> 1,88 N=32 -> 1,94 N=64 -> 1,97 N=128 -> 1,98 14

15 15
16 Historique / Super Calculateur 1986 : La société Thinking Machines la Connection Machine CM-1 pouvant comporter jusqu'à : Connection Machine CM-5 (65,5 GFLOPS) mi-90 : chute du marché des super-calculateur 2002 : NEC Earth Simulator (35.86 TFLOPS) (Le plus rapide processeurs) 16

17 Historique / Super Calculateur 2004 : IBM Blue Gene/L (70.72 TFLOPS) (dual power-pc) 2007 : IBM Blue Gene/L (478.2 TFLOPS) 2008 : IBM Roadrunner (1.026 PFLOPS ) (12,960 IBM PowerXCell et 6,480 AMD Opteron dual-core) 17
 (12,960 IBM PowerXCell et 6,480 AMD")
18 TOP Roadrunner 1,105 PFLOPS Etats-Unis DOE 2 - Jaguar - Cray XT5 1,059 PFLOPS Etats-Unis Oak Ridge 3 - Pleiades - SGI Altix 0,487 PFLOPS Etats-Unis NASA 4 - BlueGene/L 0,478 PFLOPS Etats-Unis DOE 5 - Blue Gene/P 0,450 PFLOPS Etats-Unis Argonne 6 - Ranger SunBlade 0,433 PFLOPS Etats-Unis Univ. Texas 7 - Franklin - Cray XT4 0,266 PFLOPS Etats-Unis DOE-Berkeley 8 - Jaguar - Cray XT4 0,205 PFLOPS Etats-Unis Oak Ridge 9 - Cray Red Storm 0,204 PFLOPS Etats-Unis Sandia 10 - Dawning 5000A 0,180 PFLOPS Chine Shangai 11 - Blue Gene/P 0,180 PFLOPS Allemagne 14 - Jade - SGI Altix Xeon 0,128 PFLOPS France 18

19 TOP 500 Rmax - Valeur maximale LINPACK Rpeak Performance maximale théorique Puissance en KW 19

20 LINPACK C'est une bibliothèque fortran de calcul linéaire remplacé par LAPACK 20


21 Système d'exploitation Au début des systèmes par machine puis souvent UNIX, puis LINUX 21
22 CISC Complex instruction set computer Processeurs PDP11, 680x0, x86 Ce sont des processeurs avec de larges jeux d'instruction et des modes d'adressages de la mémoire complexes Souvent des mécanismes de microprogrammation 22
23 RISC Reduced instruction set computer Un nombre réduit d'instruction avec le même nombre de cycle, Un mécanisme de pipeline pour commencer une instruction par cycle Moins d'instruction donc optimisation du compilateur plus simple Inconvénient code assembleur peu lisible et code exécutable plus important 23

24 Processeurs Drawn by おむこさん志望. 24
25 Processeurs i Intel RISC (25-50 MHz) MIPS - Microprocessor without Interlocked Pipeline Stages (8 MHz 1 GHz) PA-RISC Precision Architecture HP (66MHz 1,1 GHz) IA-64 Itanium, Itanium 2 Intel/HP (733 MHz -1,66 GHz) SPARC Scalable Processor Architecture TI, Atmel, Fujitsu (14,2MHz 2,5 GHz) 25
26 Processeurs X , 8088, 80186, (MMU) -16 bits ,486, Pentium, Pentium MMX 32 bits Pentium Pro, AMD K5, K6 32 bits (PAE) Athlon64, Opteron, Pentium 4 64 bits Intel Core 2, Phenom (multi-core)
27 Alpha Processeur DEC Alpha RISC 64 bits MHz 1,3 GHz 27
28 CELL (Sony, Toshiba, IBM) vers 2006 Un processeur conçu pour la Playstation 3 Un power processing element et 8 Synergistic Processing Elements (25.6 GFLOPS en simple précision) 28
29 CELL PowerXCell 8i Une version adaptée pour les super calculateurs qui fournit au total 102 GFLOPS en double précision 29
30 GPU Graphics processing unit Processeur dédié pour le graphisme, Calcul en virgule flotante (3D) GPGPU General Purpose GPUs Utilisation d'une carte graphique pour faire du calcul (GeForce 8800 GTX à GFLOPS performance théorique) 30
31 Repère Cortex humain 100 (10¹¹) milliards de neurones et 10¹⁴ synapses La puissance pour simulation est d'environ 36,8 petaflops et une mémoire de 3,2 petabytes 31
32 Calcul Parallèle/Répartis Quelques éléments : OpenMP MPI BOINC Folding@home... 32
33 Approche MIMD Utilisation de MPI «The Message Passing Interface» Permet d'utiliser le parallélisme sur un grand nombre d'architecture et en particulier les réseaux de stations ou de PC. 33
34 Communication Les données doivent être echangées entre processus : Coopérative : les processus doivent être d'accord pour réaliser un transfert d'information, Supervisé : un processus réalise les échanges de données. 34
35 Historique Depuis longtemps il existe des bibliothèques de calcul parallèle pour super-calculateur : Intel's NX, PVM (Parallel Virtual Machine), MPI (Message Passing Interface Standard), Fortran 90,... 35
36 Communication Coopérative L'envoie de message est une approche qui permet un échange d'information de façon coopérative. Les données doivent être émise et reçue de manière explicite. Un avantage est que la mémoire du récepteur est modifié qu'avec la participation du processus récepteur. 36
37 Communication Coopérative 37
38 Communication unilatéral Un processus écrit directement des données dans la mémoire d'un autre processus, L'avantage est qu'il n'y a pas d'attente entre les processus, L'inconvénient on peut avoir une perte de la cohérence des données. 38
39 Communication unilatéral 39
40 Aspect matériels (Hardware) Les architectures : Mémoire distribuée (ex. Paragon, IBM SPs, Workstation network), Mémoire partagée, (ex. SGI Power Challenge, Cray T3D) 40
41 Qu'est ce MPI? La spécification d'une librairie par envoie de message, un modèle d'envoie de message, ce n'est pas les spécifications d'un compilateur, ce n'est pas un produit, Conçu pour les ordinateurs parallèles, les clusters d'ordinateurs, et les réseaux hétérogènes, 41
42 Qu'est ce MPI? C'est un système complet, Il est conçu pour permettre le développement de librairies, Il permet l'utilisation de systèmes parallèles pour : des utilisateurs, des développeurs de librairies, des développeurs d'outils. 42
43 Avantages Système modulaire, Bonne performance, Portable, Peut fonctionner avec des machines hétérogènes, Permet différentes topologies de communications, Il existe des outils de mesures des performances. 43
44 Qui a développé MPI? Vendeurs, IBM, Intel, TMC, Meico, Cray, Convex, Ncube. Développeurs (de librairies), PVM, p4, Zipcode, TCGMSG, Chameleon, Express, Linda, 44
45 Modèle séquentiel Le programme est exécuté par un seul processeur Toutes les variables et constantes du programme sont allouées dans la mémoire centrale du processeur 45
46 Modèle par échange de messages Plusieurs processus travaillant sur des données locales. Chaque processus a ses propres variables et il n a pas accès directement aux variables des autres processus Le partage des données entre processus se fait par envoi et réception explicites de messages Les processus peuvent s exécuter sur des processeurs différents ou identiques. 46
47 Modèle par échange de messages SPMD Single Program Multiple Data Le même programme s exécute pour tous les processus Les données sont échangées par messages Les données sont en générales différentes pour chaque processus 47
48 Modèle par échange de messages Avantages : Peut être implémenter sur une grande variété de plates-formes : Calculateur à mémoire distribuée, à mémoire partagée, réseau de stations mono ou multiprocesseurs, station mono-processeur Permet en général un plus grand contrôle de la localisation des données et par conséquent une meilleure performance des accès aux données. 48
49 Programmation parallèle Permet en général d'obtenir de meilleures performances que la version séquentielle Traiter de façon performante un volume de données plus important (répartition des données) Pour obtenir de bonnes performances : Équilibrer les charges sur chaque processus Minimiser les communications Minimiser les parties non parallèle 49
50 Performance des communications Le mode de transfert : Avec recopie ou sans recopie des données transferrées Bloquant et non bloquant Synchrone et non synchrone 50
51 Performance des communications Les performances du réseau : Latence : temps mis pour envoyer un message de taille nulle Débit ou bande passante le choix d un mode de transfert adapté et effectuer des calculs pendant les communications 51
52 Caractéristiques de MPI Générale, Les communications se font dans un contexte et un groupe pour la sécurité, Le système supporte le mécanisme des Thread. Communication point-à-point, Communication de structure et de type de données, pour des architectures hétérogènes. La gestion de nombreux modes de communication (bloquant, non bloquant,...). 52
53 Quand utiliser MPI? Pour : on souhaite un programme parallèle portable, on veut écrire une librairie de code parallèle, on souhaite un système parallèle spécifique (dynamique,...). 53
54 Quand utiliser MPI? Contre : vous pouvez utiliser Fortran 90 (code Fortran), on n'a pas besoin de parallèlisme, on peut utiliser une librairie, dans certain cas on peut utiliser OpenMP 54
55 Routines de base de MPI Gestion des communications Initialisation et fin des communications Création de groupe et de topologie virtuelle Routines de communications entre deux processus Routines de communications collectives Création de types dérivés 55
56 Programme MPI include «fichier entête MPI» #include <mpi.h> Déclarations des variables Initialisation de MPI (par chaque processus) Même programme exécuté par tous les processus Fermeture de MPI (par chaque processus) 56
57 Programme MPI minimal #include <mpi.h> #include <stdio.h> int main(int argc, char *argv[]) { /* Initialisation */ MPI_Init(&argc, &argv); /* code */ MPI_Finalize(); /* terminaison */ return(0); } 57
58 Programme MPI minimal MPI_Init(&argc, &argv); Initialisation de MPI et passage des paramètres MPI_Finalize(); Terminaison de MPI Toutes les fonctions non-mpi sont locales, par exemple un printf sera exécuté sur chaque processus. 58
59 Compilation Il est conseillé de créer un Makefile, Il existe aussi la commande mpicc -o exec exec.c pour compiler un fichier. Options : -mpilog Génère un fichier de log des appels MPI -mpitrace -mpianim 59
60 Execution d'un programme MPI mpirun -np 2 executable -v Option verbose, le système indique les opérations effectuées. -help Indique toutes les options possibles, 60
61 Communicateur MPI Un communicateur définit un ensemble de processus succeptibles de communiquer entre eux MPI_COMM_WORLD est le communicateur par défaut constitué de tous les processus de l application: 61
62 Problème de la programmation parallèle Combien sommes-nous a travailler? MPI_Comm_size Indique combien il y a de processus, Qui suis-je (pour répartir le travail)? MPI_Comm_rank Indique le numéro du processus, entre 0 et le nombre de processus
63 Example MPI_Comm_rank( MPI_COMM_WORLD, &rank); MPI_Comm_size( MPI_COMM_WORLD, &size); printf("bonjour Hello World je suis le %d parmi %d\n",rank, size); Chaque processus va indiquer son numéro et le nombre total de processus. 63
64 Envoie et réception de messages Problèmes : a qui envoie-t-on les données? qu'est-ce qu'on envoie? comment les identifier à la réception? 64
65 Envoie et réception de messages 65
66 Utilisation d'un Buffer Pour MPI on utilise une adresse de départ, un type, un nombre d'éléments, les types sont : les types élélmentaires (C et Fortran), les tableaux a une dimension des types élémentaires,..., 66
67 Communication Simple (Envoie) int MPI_Send(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm) void * buf adresse de début de buffer, count nombre d'éléments, MPI_Datatype datatype type de chaque élément, int dest processus destinataire, int tag identifieur du message, MPI_Comm comm groupe de communication. 67
68 Communication Simple (Réception) int MPI_Recv(void* buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status) void * buf adresse de début de buffer, count nombre d'éléments, MPI_Datatype datatype type de chaque élément, int source processus de provenance, int tag identifieur du message, MPI_Comm comm groupe de communication, MPI_Status *status information d'état 68
69 Communication Simple (Brodcast) int MPI_Bcast(void* buffer, int count, MPI_Datatype datatype, int root, MPI_Comm comm ) Permet de répartir des données. void * buf adresse de début de buffer, count nombre d'éléments, MPI_Datatype datatype type de chaque élément, int root identificateur de l'expéditeur, MPI_Comm comm groupe de communication, 69
70 Communication Simple (Reduce) int MPI_Reduce(void* sendbuf, void* recvbuf, int count, MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm comm) void* sendbuf adresse de début de buffer, void* recvbuf adresse de début de buffer, int count nombre d'éléments, MPI_Datatype datatype type des données, MPI_Op op opération à effectuer, int root processus root, MPI_Comm comm gr. de communication. 70
71 Communication Simple (Reduce) Opérateurs : MPI_MAX maximum, MPI_MIN minimum, MPI_SUM sum, MPI_PROD product, MPI_LAND logical and, MPI_LOR logical or,... 71
72 Types de données Types : MPI_CHAR (char) MPI_INT (int) MPI_FLOAT (float) MPI_DOUBLE (double)... 72
73 Informations sur les messages MPI_Status status; MPI_Recv(..., &status); Si MPI_ANY_TAG ou MPI_ANY_SOURCE alors status.mpi_tag et MPI_Get_count obtenir des informations sur l'état de la communication 73
74 Informations sur les messages MPI_Get_count(MPI_Status *status, MPI_Datatype datatype, int *count); MPI_Get_count permet d'obtenir le nombre d'éléments reçus. MPI_Status *status le status de la communication, MPI_Datatype datatype le type des éléments, int *count le nombre d'éléments reçus. 74
75 Informations sur les messages MPI_Status status; MPI_Recv(..., &status); Si MPI_ANY_TAG ou MPI_ANY_SOURCE alors status.mpi_tag et MPI_Get_count obtenir des informations sur l'état de la communication 75
76 Informations sur les messages MPI_Get_count(MPI_Status *status, MPI_Datatype datatype, int *count); MPI_Get_count permet d'obtenir le nombre d'éléments reçus. MPI_Status *status le status de la communication, MPI_Datatype datatype le type des éléments, int *count le nombre d'éléments reçus. 76
77 MPI_2 Gestion dynamique des processus Entrées/Sorties parallèles Interfacage c++, fortran 90 Communication mémoire à mémoire Possibilité de définir des interfaces externes (processus léger) 77
78 MPI_2 I/0 Les applications qui font des calculs volumineux font en général également de nombreuses entrées-sorties (données à traiter et résultats) Le traitement de ces entrées-sorties représente une part importante dans le temps globale l application L optimisation des E/S d une application parallèle se fait : Par leur parallèlisation Et /ou leur recouvrement par des calculs 78
79 MPI_2 I/0 Propriétés d'accés aux fichiers Positionnement explicite Nb octets depuis le début du fichier Positionnement implicite pointeur Individuel pour un processus Commun pour tous les processus Synchronisation Bloquant Non bloquant 79
80 MPI_2 I/0 E/S parallèle C'est à dire : Entrée/Sortie réalisée par plusieurs tâches ou processus A partir d'un même espace mémoire A partir d'espaces mémoire séparés Avantages Éviter de créer des goulets d étranglement Techniques au niveau de la programmation permettant de gérer les lectures/écritures asynchrones Performances: opérations spécifiques prises en charge par le système 80
81 MPI_2 I/0 E/S parallèle C'est à dire : Fermeture et ouverture de fichier sont des opérations collectives associées à un communicateur Chaque opération de transfert est associée à un type de donnée Type de base MPI Type dérivé MPI: transfert d un zone discontinue de la mémoire vers un stockage continu sur fichier ou inversement 81
82 MPI_2 I/0 E/S parallèle Descripteur(file handle): objet caché créé à l ouverture et détruit à la fermeture du fichier Pointeurs tenu à jour automatiquement par MPI (associé à chaque file handle) Individuel : propre à chaque processus ayant ouvert le fichier Partagé : commun à chaque processus ayant ouvert le fichier 82
83 MPI_2 I/0 Fonctions MPI_File_open(): associe un descripteur à un fichier MPI_File_seek(): déplace le pointeur de fichier vers une position donnée MPI_File_read(): lit à partir de la position courante une quantité de données(pointeur individuel) 83
84 MPI_2 I/0 Fonctions MPI_File_write(): écrit une quantité de données à partir de la position courante (pointeur individuel) MPI_File_close(): élimine le descripteur MPI_File_sync(): force l écriture sur disque des buffers associés à un descripteur 84
85 MPI_2 I/0 Fonctions Valeur courante du pointeur : Individuel: MPI_File_get_position() Partagé: MPI_File_get_position_shared() Positionner le pointeur Individuel: MPI_File_seek() Partagé: MPI_File_seek_shared() 85
86 MPI_2 I/0 Fonctions Trois manières de positionner le pointeur : Une valeur absolue: MPI_SEEK_SET Une valeur relative : MPI_SEEK_CUR À la fin d un fichier: MPI_SEEK_END int MPI_File_seek(MPI_File mpi_fh, MPI_Offset offset, int whence); 86
87 MPI_2 Communication non bloquante Deux appels séparés par communication: Initialisation de la communication Complétion de la communication Un identificateur de requête de communication 87
88 MPI_2 Communication non bloquante Permet : d éviter les deadlocks De superposer les communications et les calculs (L algorithme doit gérer la synchronisation des processus) Les étapes de communication sous-jacentes sont les mêmes, ce qui diffère ce sont les interfaces avec la bibliothèque 88
89 MPI_2 Envoi non bloquant Appel de MPI_Isend Initialise un envoi Retour immédiat au programme Même argument que MPI_Send + un argument identifiant la requête 89
90 MPI_2 Envoi non bloquant Appel de MPI_Irecv Initialise une réception Retour immédiat au programme Pas d argument status (pas de complétion ) Un argument identifiant la requête 90
91 MPI_2 Complétion Test de complétion sans bloquer le processus sur la complétion: int MPI_Test(MPI_Request *request, int *flag, MPI_Status *status) request [in] MPI request (handle) flag [out] true if operation completed (logical) status [out] status object (Status). peut-être MPI_STATUS_IGNORE. 91
92 MPI_2 Complétion Attendre la complétion: MPI_WAIT int MPI_Wait(MPI_Request *request,mpi_status *status); request [in] request (handle) status [out] status object (Status). peut-être MPI_STATUS_IGNORE. 92
93 MPI_2 Avantages/Inconvénients Avantages: Évite les deadlocks Couvrir les communications par des calculs Inconvénients Augmente la complexité des algorithmes Difficile à déboguer 93
94 MPI_2 8 Fonctions Send Standard Synchrone Ready Bufferisé bloquant MPI_SEND MPI_SSEND MPI_RSEND MPI_BSEND non bloquant MPI_ISEND MPI_ISSEND MPI_IRSEND MPI_IBSEND 94
95 MPI_2 Optimisation Algorithmique: il faut minimiser la part de communication Communications: lorsque la part des communications est importante par rapport au calcul Recouvrir les communications par les calculs Éviter la recopie des messages dans un espace mémoire temporaire 95
96 MPI_2 Communications persistantes Pour une boucle on peut mettre en place un schéma persistant de communication Par exemple : Envoi standard: MPI_SEND_INIT() 96
97 MPI_2 Communications collectives Synchronisation globale: MPI_BARRIER() Transfert des données: Diffusion globale des données: MPI_Bcast() Diffusion sélective des données: MPI_Scatter() Collecte des données réparties: MPI_Gather() 97
98 MPI_2 Communications collectives Collecte par tous les processus des données réparties: MPI_ALLGather() Diffusion sélective, par tous les processus, des données réparties: MPI_Alltoall() Communication et opérations sur les données Réduction de type prédéfinie ou personnel: MPI_Reduce() Réduction avec diffusion du résultat: MPI_Allreduce() 98
99 MPI_2 Barrière de synchronisation Impose un point synchronisation à tous les processus du communicateur Routine MPI_Barrier int MPI_Barrier(MPI_Comm comm); Bloque tous les processus jusqu'a l'appel de tous les processus 99
100 MPI_2 Echange Routine MPI_Alltoall() int MPI_Alltoall( void *sendbuf, int sendcount, MPI_Datatype sendtype, void *recvbuf, int recvcount, MPI_Datatype recvtype, MPI_Comm comm); 100
101 MPI_2 Echange Routine MPI_ALLTOALL() P0 P1 P2 P3... A0 B0 C0 D0 A1 B1 C1 D1 A2 B2 C2 D2 A3 B3 C3 D3 A0 A1 A2 A3 B0 B1 B2 B3 C0 C1 C2 C3 D0 D1 D2 D3 101
102 MPI_2 Implémentation MPICH: MPI I/O partiel, Type dérivé partiel LAM : Gestion dynamique, MPI I/O partiel, Type dérivé partiel Fujitsu : Gestion dynamique, MPI I/O, Type dérivé NEC : Gestion dynamique, MPI I/O, Type dérivé IBM : MPI I/O, Type dérivé
103 OpenMP Architecture Review Board Permanent Members of the ARB: AMD (David Leibs) Cray (James Beyer) Fujitsu (Matthijs van Waveren) HP (Uriel Schafer) IBM (Kelvin Li) Intel (Sanjiv Shah) NEC (Kazuhiro Kusano) The Portland Group, Inc. (Michael Wolfe) SGI (Lori Gilbert) Sun Microsystems (Nawal Copty) Microsoft (-) 103
104 OpenMP Est une API adaptée aux architectures multicoeur. Elle est conçu pour une utilisation en multithread et avec de la mémoire partagée. 104
105 OpenMP Tous les threads peuvent utiliser la même mémoire partagée, Les données peuvent être privées ou partagées Les données partagées sont utilisables par tout les threads Les données privées sont accessibles que par le thread qui les possède 105
106 OpenMP Les transferts de données sont transparents pour le programmeur La synchronisation est généralement implicite Les données possèdent des étiquettes 106
107 OpenMP Les données sont de deux types : Partagées : Il y a qu'une instance des données, Tous les threads peuvent lire ou écrire simultanément (par défaut) Toutes les modifications sont visibles pour tout les threads, (mais pas nécessairement immédiatement) 107
108 OpenMP Master thread Region parallèle- worker thread Synchronisation Master thread Region parallèle- worker thread Synchronisation
109 OpenMP Utilisation d'une boucle parallèle int main(int argc, char *argv[]) { const int N = ; int i, a[n]; #pragma omp parallel for for (i=0;i<n;i++) a[i]= 2*i; return 0; } 109
110 OpenMP Thread 0 Thread 1 Thread 2 Thread 3 Thread 4 Thread 5 Thread 6 Thread 7... i= a[i]= 2*i i= a[i]= 2*i i= a[i]= 2*i i= a[i]= 2*i i= a[i]= 2*i i= a[i]= 2*i i= a[i]= 2*i i= a[i]= 2*i 110
111 Strucuture OpenMP Directives et clauses de compilation (pragma) : elles servent à définir le partage du travail, la synchronisation et le statut privé ou partagé des données ; elles sont considérées par le compilateur comme des lignes de commentaires à moins de spécifier une option adéquate de compilation pour qu'elles soient interprétées. 111
112 Strucuture OpenMP Fonctions et sous-programmes : ils font partie d'une bibliothèque chargée à l'édition de liens du programme. Variables d'environnement : une fois positionnées, leurs valeurs sont prises en compte à l'exécution. 112
113 OpenMP/MPI MPI est un modèle multiprocessus dont le mode de communication est explicite OpenMP est un modèle multitâche ont le mode de communication est implicite (compilateur) 113
114 Forme OpenMP Définition des fonctions #include <omp.h> Directive au compilateur #pragma omp parallel
115 Forme OpenMP Dans une region parallèle, par défaut, le statut des variables est partagé Au sein d'une même région parallèle toutes les tâches concurrentes exécutent le même code Il y a une barrière implicite à la fin de région parallèle 115
116 Forme OpenMP #pragma omp parallel if (n > thre)\ shared(n,x,y) private(i,j) If (expression) indique si une exécution séquentielle ou parallèle private (i,j) référence à des variables locales privées shared (n,x,y) variable utilisable par tous les threads 116
117 Forme OpenMP Pour certaine directive on peut supprimer la synchronisation en fin de zone parallèle. #pragma omp for nowait Dans ce cas il n'y a pas d'attente de synchronisation 117
118 Forme OpenMP #pragma omp sections (clause) { #pragma omp section block 1 #pragma omp section block 2 } block 1 // block 2 118
119 Forme OpenMP #pragma omp single (clause) { block 1 } Un thread execute le block 1 119
120 Forme OpenMP #pragma omp master (clause) { block 1 } Le thread master execute le block 1 dans ce cas il n'y a pas de barrier implicite 120
121 Forme OpenMP #pragma omp critical (nom) { block 1 } Permet de définir des zones critiques tous les threads executent le code mais un seul à la fois 121
122 Forme OpenMP #pragma omp atomic a[indx[i]] += b[i]; Permet de faire des opérations sur des variables de manière atomique (version particulière de section critique) 122
123 GOMP gcc fopenmp test.c o test OMP_NUM_THREADS =4 Exemple pour 4 thread avec gcc >
124 LUSTRE Lustre est un système de fichier de type objet, C'est un système distribué, Il a été conçu par SUN ( ) Lustre Lustre Lustre Lustre
125 LUSTRE Lustre utilise des systèmes de fichier de type : ext3 ou zfs Pour le noyau système, on charge un module, le système est comme un système de fichier global 125
126 ZFS ZFS est un système de fichier conçu par SUN ( ) («Zettabyte File System») Il supporte le RAID 0, RAID 1,... Système de fichier 128 bits 126
127 ZFS Quelques chiffres 2^⁴⁸ entrée dans un répertoire, 2^⁶⁴ octets pour la taille d'un fichier 2^⁶⁴ octets pour la taille d'un fichier 2^⁷⁸ taille d'un zpool... possibilité de faire des snapshots, mécanisme de transaction 127
128 Calculateur ULR ymir est une SGI Altix ICE 8200 XE Cluster de 16 noeuds reliés par un réseau infiniband. Chaque noeud de calcul comporte deux processeurs Intel Xeon 5472 (Quad core, 3Ghz) et de 16 Giga de mémoire ; soit au total 128 cores et 256 Giga de mémoire. L ensemble du système fonctionne avec le système d exploitation SUSE (SLES 10). 128
129 Calculateur ULR Intel MPI 3.1 Librairie MPI Intel MPI
130 Strucuture OpenMP Directives et clauses de compilation (pragma) : elles servent à définir le partage du travail, la synchronisation et le statut privé ou partagé des données ; elles sont considérées par le compilateur comme des lignes de commentaires à moins de spécifier une option adéquate de compilation pour qu'elles soient interprétées. 130
131 Fin 131
Introduction à la Programmation Parallèle: MPI
 Introduction à la Programmation Parallèle: MPI Frédéric Gava et Gaétan Hains L.A.C.L Laboratoire d Algorithmique, Complexité et Logique Cours du M2 SSI option PSSR Plan 1 Modèle de programmation 2 3 4
Introduction à la Programmation Parallèle: MPI Frédéric Gava et Gaétan Hains L.A.C.L Laboratoire d Algorithmique, Complexité et Logique Cours du M2 SSI option PSSR Plan 1 Modèle de programmation 2 3 4
Initiation au HPC - Généralités
 Initiation au HPC - Généralités Éric Ramat et Julien Dehos Université du Littoral Côte d Opale M2 Informatique 2 septembre 2015 Éric Ramat et Julien Dehos Initiation au HPC - Généralités 1/49 Plan du cours
Initiation au HPC - Généralités Éric Ramat et Julien Dehos Université du Littoral Côte d Opale M2 Informatique 2 septembre 2015 Éric Ramat et Julien Dehos Initiation au HPC - Généralités 1/49 Plan du cours
Introduction to Parallel Programming with MPI
 Introduction to Parallel Programming with MPI Master Modélisation et Simulation - ENSTA cours A1-2 Pierre Kestener pierre.kestener@cea.fr CEA-Saclay, DSM, France Maison de la Simulation MDLS, September,
Introduction to Parallel Programming with MPI Master Modélisation et Simulation - ENSTA cours A1-2 Pierre Kestener pierre.kestener@cea.fr CEA-Saclay, DSM, France Maison de la Simulation MDLS, September,
Systèmes parallèles et distribués
 Systèmes parallèles et distribués Grégory Mounié 2013-12 Grégory Mounié Systèmes parallèles et distribués 2013-12 1 / 58 Outline 1 Introduction 2 Performances 3 Problèmes du calcul parallèle 4 Intergiciels
Systèmes parallèles et distribués Grégory Mounié 2013-12 Grégory Mounié Systèmes parallèles et distribués 2013-12 1 / 58 Outline 1 Introduction 2 Performances 3 Problèmes du calcul parallèle 4 Intergiciels
Parallélisme et bioinformatique
 Master EGOIST - Rouen Plan 1 Introduction Parallélisme? Open MPI 2 Historique 3 Pour qui? Pour quoi? Parallélisme? C est quoi le parallélisme? Principe regrouper (physiquement ou logiquement) un ensemble
Master EGOIST - Rouen Plan 1 Introduction Parallélisme? Open MPI 2 Historique 3 Pour qui? Pour quoi? Parallélisme? C est quoi le parallélisme? Principe regrouper (physiquement ou logiquement) un ensemble
Eléments d architecture des machines parallèles et distribuées
 M2-RISE - Systèmes distribués et grille Eléments d architecture des machines parallèles et distribuées Stéphane Vialle Stephane.Vialle@supelec.fr http://www.metz.supelec.fr/~vialle Notions d architecture
M2-RISE - Systèmes distribués et grille Eléments d architecture des machines parallèles et distribuées Stéphane Vialle Stephane.Vialle@supelec.fr http://www.metz.supelec.fr/~vialle Notions d architecture
Systèmes et traitement parallèles
 Systèmes et traitement parallèles Mohsine Eleuldj Département Génie Informatique, EMI eleuldj@emi.ac.ma 1 Système et traitement parallèle Objectif Etude des architectures parallèles Programmation des applications
Systèmes et traitement parallèles Mohsine Eleuldj Département Génie Informatique, EMI eleuldj@emi.ac.ma 1 Système et traitement parallèle Objectif Etude des architectures parallèles Programmation des applications
MPI-1 2ème partie : Programmation «non bloquante» et communications de groupe
 3A-SI Programmation parallèle MPI-1 2ème partie : Programmation «non bloquante» et communications de groupe Stéphane Vialle Stephane.Vialle@supelec.fr http://www.metz.supelec.fr/~vialle MPI-1 2ème partie
3A-SI Programmation parallèle MPI-1 2ème partie : Programmation «non bloquante» et communications de groupe Stéphane Vialle Stephane.Vialle@supelec.fr http://www.metz.supelec.fr/~vialle MPI-1 2ème partie
Architecture des ordinateurs
 Décoder la relation entre l architecture et les applications Violaine Louvet, Institut Camille Jordan CNRS & Université Lyon 1 Ecole «Découverte du Calcul» 2013 1 / 61 Simulation numérique... Physique
Décoder la relation entre l architecture et les applications Violaine Louvet, Institut Camille Jordan CNRS & Université Lyon 1 Ecole «Découverte du Calcul» 2013 1 / 61 Simulation numérique... Physique
Plan de la formation. Calcul parallèle avec MPI. Pourquoi paralléliser? Parallélisation. Présentation, environnement MPI. Communications point à point
 Plan de la formation Calcul parallèle avec MPI Guy Moebs Parallélisation Présentation, environnement MPI Communications point à point Laboratoire de Mathématiques Jean Leray, CNRS, Université de Nantes,
Plan de la formation Calcul parallèle avec MPI Guy Moebs Parallélisation Présentation, environnement MPI Communications point à point Laboratoire de Mathématiques Jean Leray, CNRS, Université de Nantes,
Programmation C. Apprendre à développer des programmes simples dans le langage C
 Programmation C Apprendre à développer des programmes simples dans le langage C Notes de cours sont disponibles sur http://astro.u-strasbg.fr/scyon/stusm (attention les majuscules sont importantes) Modalités
Programmation C Apprendre à développer des programmes simples dans le langage C Notes de cours sont disponibles sur http://astro.u-strasbg.fr/scyon/stusm (attention les majuscules sont importantes) Modalités
CH.3 SYSTÈMES D'EXPLOITATION
 CH.3 SYSTÈMES D'EXPLOITATION 3.1 Un historique 3.2 Une vue générale 3.3 Les principaux aspects Info S4 ch3 1 3.1 Un historique Quatre générations. Préhistoire 1944 1950 ENIAC (1944) militaire : 20000 tubes,
CH.3 SYSTÈMES D'EXPLOITATION 3.1 Un historique 3.2 Une vue générale 3.3 Les principaux aspects Info S4 ch3 1 3.1 Un historique Quatre générations. Préhistoire 1944 1950 ENIAC (1944) militaire : 20000 tubes,
Grid Computing. Mihaela JUGANARU-MATHIEU mathieu@emse.fr 2014-2015. École Nationale Supérieure des Mines de St Etienne
 Mihaela JUGANARU-MATHIEU mathieu@emse.fr École Nationale Supérieure des Mines de St Etienne 2014-2015 Bibliographie (livres et revues) : Frédéric Magoulès, Jie Pan, Kiat-An, Tan Abhinit Kumar Introduction
Mihaela JUGANARU-MATHIEU mathieu@emse.fr École Nationale Supérieure des Mines de St Etienne 2014-2015 Bibliographie (livres et revues) : Frédéric Magoulès, Jie Pan, Kiat-An, Tan Abhinit Kumar Introduction
Tout savoir sur le matériel informatique
 Tout savoir sur le matériel informatique Thème de l exposé : Les Processeurs Date : 05 Novembre 2010 Orateurs : Hugo VIAL-JAIME Jérémy RAMBAUD Sommaire : 1. Introduction... 3 2. Historique... 4 3. Relation
Tout savoir sur le matériel informatique Thème de l exposé : Les Processeurs Date : 05 Novembre 2010 Orateurs : Hugo VIAL-JAIME Jérémy RAMBAUD Sommaire : 1. Introduction... 3 2. Historique... 4 3. Relation
Quantification d incertitude et Tendances en HPC
 Quantification d incertitude et Tendances en HPC Laurence Viry E cole de Physique des Houches 7 Mai 2014 Laurence Viry Tendances en HPC 7 Mai 2014 1 / 47 Contents 1 Mode lisation, simulation et quantification
Quantification d incertitude et Tendances en HPC Laurence Viry E cole de Physique des Houches 7 Mai 2014 Laurence Viry Tendances en HPC 7 Mai 2014 1 / 47 Contents 1 Mode lisation, simulation et quantification
Les environnements de calcul distribué
 2 e Atelier CRAG, 3 au 8 Décembre 2012 Par Blaise Omer YENKE IUT, Université de Ngaoundéré, Cameroun. 4 décembre 2012 1 / 32 Calcul haute performance (HPC) High-performance computing (HPC) : utilisation
2 e Atelier CRAG, 3 au 8 Décembre 2012 Par Blaise Omer YENKE IUT, Université de Ngaoundéré, Cameroun. 4 décembre 2012 1 / 32 Calcul haute performance (HPC) High-performance computing (HPC) : utilisation
AMBASSADE DE FRANCE EN ALLEMAGNE SERVICE POUR LA SCIENCE ET LA TECHNOLOGIE
 AMBASSADE DE FRANCE EN ALLEMAGNE SERVICE POUR LA SCIENCE ET LA TECHNOLOGIE Le Conseiller pour la Science et la Technologie SST/PR Berlin, le 23 novembre 2010 Etat des lieux comparatif dans le domaine des
AMBASSADE DE FRANCE EN ALLEMAGNE SERVICE POUR LA SCIENCE ET LA TECHNOLOGIE Le Conseiller pour la Science et la Technologie SST/PR Berlin, le 23 novembre 2010 Etat des lieux comparatif dans le domaine des
Exécution des instructions machine
 Exécution des instructions machine Eduardo Sanchez EPFL Exemple: le processeur MIPS add a, b, c a = b + c type d'opération (mnémonique) destination du résultat lw a, addr opérandes sources a = mem[addr]
Exécution des instructions machine Eduardo Sanchez EPFL Exemple: le processeur MIPS add a, b, c a = b + c type d'opération (mnémonique) destination du résultat lw a, addr opérandes sources a = mem[addr]
Les clusters Linux. 4 août 2004 Benoît des Ligneris, Ph. D. benoit.des.ligneris@revolutionlinux.com. white-paper-cluster_fr.sxw, Version 74 Page 1
 Les clusters Linux 4 août 2004 Benoît des Ligneris, Ph. D. benoit.des.ligneris@revolutionlinux.com white-paper-cluster_fr.sxw, Version 74 Page 1 Table des matières Introduction....2 Haute performance (High
Les clusters Linux 4 août 2004 Benoît des Ligneris, Ph. D. benoit.des.ligneris@revolutionlinux.com white-paper-cluster_fr.sxw, Version 74 Page 1 Table des matières Introduction....2 Haute performance (High
Programmation parallèle et distribuée
 ppd/mpassing p. 1/43 Programmation parallèle et distribuée Communications par messages Philippe MARQUET Philippe.Marquet@lifl.fr Laboratoire d informatique fondamentale de Lille Université des sciences
ppd/mpassing p. 1/43 Programmation parallèle et distribuée Communications par messages Philippe MARQUET Philippe.Marquet@lifl.fr Laboratoire d informatique fondamentale de Lille Université des sciences
Infrastructures Parallèles de Calcul
 Infrastructures Parallèles de Calcul Clusters Grids Clouds Stéphane Genaud 11/02/2011 Stéphane Genaud () 11/02/2011 1 / 8 Clusters - Grids - Clouds Clusters : assemblage de PCs + interconnexion rapide
Infrastructures Parallèles de Calcul Clusters Grids Clouds Stéphane Genaud 11/02/2011 Stéphane Genaud () 11/02/2011 1 / 8 Clusters - Grids - Clouds Clusters : assemblage de PCs + interconnexion rapide
MODULE I1. Plan. Introduction. Introduction. Historique. Historique avant 1969. R&T 1ère année. Sylvain MERCHEZ
 MODULE I1 Plan Chapitre 1 Qu'est ce qu'un S.E? Introduction Historique Présentation d'un S.E Les principaux S.E R&T 1ère année Votre environnement Sylvain MERCHEZ Introduction Introduction Rôles et fonctions
MODULE I1 Plan Chapitre 1 Qu'est ce qu'un S.E? Introduction Historique Présentation d'un S.E Les principaux S.E R&T 1ère année Votre environnement Sylvain MERCHEZ Introduction Introduction Rôles et fonctions
Architecture des calculateurs
 Formation en Calcul Scientifique - LEM2I Architecture des calculateurs Violaine Louvet 1 1 Institut Camille jordan - CNRS 12-13/09/2011 Introduction Décoder la relation entre l architecture et les applications
Formation en Calcul Scientifique - LEM2I Architecture des calculateurs Violaine Louvet 1 1 Institut Camille jordan - CNRS 12-13/09/2011 Introduction Décoder la relation entre l architecture et les applications
Rapport 2014 et demande pour 2015. Portage de Méso-NH sur Machines Massivement Parallèles du GENCI Projet 2015 : GENCI GEN1605 & CALMIP-P0121
 Rapport 2014 et demande pour 2015 Portage de Méso-NH sur Machines Massivement Parallèles du GENCI Projet 2015 : GENCI GEN1605 & CALMIP-P0121 Rappel sur Méso-NH : Modélisation à moyenne échelle de l atmosphère
Rapport 2014 et demande pour 2015 Portage de Méso-NH sur Machines Massivement Parallèles du GENCI Projet 2015 : GENCI GEN1605 & CALMIP-P0121 Rappel sur Méso-NH : Modélisation à moyenne échelle de l atmosphère
Détection d'intrusions en environnement haute performance
 Symposium sur la Sécurité des Technologies de l'information et des Communications '05 Détection d'intrusions en environnement haute performance Clusters HPC Fabrice Gadaud (fabrice.gadaud@cea.fr) 1 Sommaire
Symposium sur la Sécurité des Technologies de l'information et des Communications '05 Détection d'intrusions en environnement haute performance Clusters HPC Fabrice Gadaud (fabrice.gadaud@cea.fr) 1 Sommaire
Introduction au langage C
 Introduction au langage C Cours 1: Opérations de base et premier programme Alexis Lechervy Alexis Lechervy (UNICAEN) Introduction au langage C 1 / 23 Les premiers pas Sommaire 1 Les premiers pas 2 Les
Introduction au langage C Cours 1: Opérations de base et premier programme Alexis Lechervy Alexis Lechervy (UNICAEN) Introduction au langage C 1 / 23 Les premiers pas Sommaire 1 Les premiers pas 2 Les
Cours Programmation Système
 Cours Programmation Système Filière SMI Semestre S6 El Mostafa DAOUDI Département de Mathématiques et d Informatique, Faculté des Sciences Université Mohammed Premier Oujda m.daoudi@fso.ump.ma Février
Cours Programmation Système Filière SMI Semestre S6 El Mostafa DAOUDI Département de Mathématiques et d Informatique, Faculté des Sciences Université Mohammed Premier Oujda m.daoudi@fso.ump.ma Février
INFO-F-404 : Techniques avancées de systèmes d exploitation
 Nikita Veshchikov e-mail : nikita.veshchikov@ulb.ac.be téléphone : 02/650.58.56 bureau : 2N8.213 URL : http://student.ulb.ac.be/~nveshchi/ INFO-F-404 : Techniques avancées de systèmes d exploitation Table
Nikita Veshchikov e-mail : nikita.veshchikov@ulb.ac.be téléphone : 02/650.58.56 bureau : 2N8.213 URL : http://student.ulb.ac.be/~nveshchi/ INFO-F-404 : Techniques avancées de systèmes d exploitation Table
Rappels d architecture
 Assembleur Rappels d architecture Un ordinateur se compose principalement d un processeur, de mémoire. On y attache ensuite des périphériques, mais ils sont optionnels. données : disque dur, etc entrée
Assembleur Rappels d architecture Un ordinateur se compose principalement d un processeur, de mémoire. On y attache ensuite des périphériques, mais ils sont optionnels. données : disque dur, etc entrée
Programmation parallèle pour le calcul scientifique
 Méthodologie M2 Programmation parallèle pour le calcul scientifique Benoît Semelin 2014 Préliminaire 1000 x ε ~ ε - Loguez vous sur rubicon.obspm.fr puis sur momentum.obspm.fr - Ecrire un programme qui:
Méthodologie M2 Programmation parallèle pour le calcul scientifique Benoît Semelin 2014 Préliminaire 1000 x ε ~ ε - Loguez vous sur rubicon.obspm.fr puis sur momentum.obspm.fr - Ecrire un programme qui:
Limitations of the Playstation 3 for High Performance Cluster Computing
 Introduction Plan Limitations of the Playstation 3 for High Performance Cluster Computing July 2007 Introduction Plan Introduction Intérêts de la PS3 : rapide et puissante bon marché L utiliser pour faire
Introduction Plan Limitations of the Playstation 3 for High Performance Cluster Computing July 2007 Introduction Plan Introduction Intérêts de la PS3 : rapide et puissante bon marché L utiliser pour faire
Compilation (INF 564)
") Présentation du cours Le processeur MIPS Programmation du MIPS 1 Compilation (INF 564) Introduction & architecture MIPS François Pottier 10 décembre 2014 Présentation du cours Le processeur MIPS Programmation
Présentation du cours Le processeur MIPS Programmation du MIPS 1 Compilation (INF 564) Introduction & architecture MIPS François Pottier 10 décembre 2014 Présentation du cours Le processeur MIPS Programmation
Parallélisme et Répartition
 Parallélisme et Répartition Master Info Françoise Baude Université de Nice Sophia-Antipolis UFR Sciences Département Informatique baude@unice.fr web du cours : deptinfo.unice.fr/~baude Septembre 2009 Chapitre
Parallélisme et Répartition Master Info Françoise Baude Université de Nice Sophia-Antipolis UFR Sciences Département Informatique baude@unice.fr web du cours : deptinfo.unice.fr/~baude Septembre 2009 Chapitre
Communications performantes par passage de message entre machines virtuelles co-hébergées
 Communications performantes par passage de message entre machines virtuelles co-hébergées François Diakhaté1,2 1 CEA/DAM Île de France 2 INRIA Bordeaux Sud Ouest, équipe RUNTIME Renpar 2009 1 Plan Introduction
Communications performantes par passage de message entre machines virtuelles co-hébergées François Diakhaté1,2 1 CEA/DAM Île de France 2 INRIA Bordeaux Sud Ouest, équipe RUNTIME Renpar 2009 1 Plan Introduction
INITIATION AU LANGAGE C SUR PIC DE MICROSHIP
 COURS PROGRAMMATION INITIATION AU LANGAGE C SUR MICROCONTROLEUR PIC page 1 / 7 INITIATION AU LANGAGE C SUR PIC DE MICROSHIP I. Historique du langage C 1972 : naissance du C dans les laboratoires BELL par
COURS PROGRAMMATION INITIATION AU LANGAGE C SUR MICROCONTROLEUR PIC page 1 / 7 INITIATION AU LANGAGE C SUR PIC DE MICROSHIP I. Historique du langage C 1972 : naissance du C dans les laboratoires BELL par
Présentation de l ORAP
 Présentation de l ORAP Marie-Alice Foujols foujols@ipsl.jussieu.fr Jacques David 23/06/2008 Conseil Scientifique CIRA 1 Qu est-ce que l ORAP? ORganisation Associative du Parallélisme Association, créée
Présentation de l ORAP Marie-Alice Foujols foujols@ipsl.jussieu.fr Jacques David 23/06/2008 Conseil Scientifique CIRA 1 Qu est-ce que l ORAP? ORganisation Associative du Parallélisme Association, créée
Qu est ce qu un un serveur?
 Virtualisation de serveur et Systèmes d exploitations. d Par Thierry BELVIGNE Président MicroNet 91 Qu est ce qu un un serveur? Un serveur est un programme informatique qui «rend service» à plusieurs ordinateurs
Virtualisation de serveur et Systèmes d exploitations. d Par Thierry BELVIGNE Président MicroNet 91 Qu est ce qu un un serveur? Un serveur est un programme informatique qui «rend service» à plusieurs ordinateurs
Concept de machine virtuelle
 Concept de machine virtuelle Chap. 5: Machine virtuelle Alain Sandoz Semestre été 2007 1 Introduction: Java Virtual Machine Machine Virtuelle Java: qu est-ce que c est? c est la spécification d une machine
Concept de machine virtuelle Chap. 5: Machine virtuelle Alain Sandoz Semestre été 2007 1 Introduction: Java Virtual Machine Machine Virtuelle Java: qu est-ce que c est? c est la spécification d une machine
Intel Corporation Nicolas Biguet Business Development Manager Intel France
 Les serveurs pour l Entreprise Intel Corporation Nicolas Biguet Business Development Manager Intel France 1 Les orientations stratégiques Clients Réseaux Serveurs Fournir les les éléments de de base des
Les serveurs pour l Entreprise Intel Corporation Nicolas Biguet Business Development Manager Intel France 1 Les orientations stratégiques Clients Réseaux Serveurs Fournir les les éléments de de base des
Contribution à la conception à base de composants logiciels d applications scientifiques parallèles.
 - École Normale Supérieure de LYON - Laboratoire de l Informatique du Parallélisme THÈSE en vue d obtenir le grade de Docteur de l École Normale Supérieure de Lyon - Université de Lyon Discipline : Informatique
- École Normale Supérieure de LYON - Laboratoire de l Informatique du Parallélisme THÈSE en vue d obtenir le grade de Docteur de l École Normale Supérieure de Lyon - Université de Lyon Discipline : Informatique
Initiation. àl algorithmique et à la programmation. en C
 Initiation àl algorithmique et à la programmation en C Initiation àl algorithmique et à la programmation en C Cours avec 129 exercices corrigés Illustration de couverture : alwyncooper - istock.com Dunod,
Initiation àl algorithmique et à la programmation en C Initiation àl algorithmique et à la programmation en C Cours avec 129 exercices corrigés Illustration de couverture : alwyncooper - istock.com Dunod,
Programmation système I Les entrées/sorties
 Programmation système I Les entrées/sorties DUT 1 re année Université de Marne La vallée Les entrées-sorties : E/O Entrées/Sorties : Opérations d échanges d informations dans un système informatique. Les
Programmation système I Les entrées/sorties DUT 1 re année Université de Marne La vallée Les entrées-sorties : E/O Entrées/Sorties : Opérations d échanges d informations dans un système informatique. Les
03/04/2007. Tâche 1 Tâche 2 Tâche 3. Système Unix. Time sharing
 3/4/27 Programmation Avancée Multimédia Multithreading Benoît Piranda Équipe SISAR Université de Marne La Vallée Besoin Programmes à traitements simultanés Réseau Réseau Afficher une animation en temps
3/4/27 Programmation Avancée Multimédia Multithreading Benoît Piranda Équipe SISAR Université de Marne La Vallée Besoin Programmes à traitements simultanés Réseau Réseau Afficher une animation en temps
Architecture des Ordinateurs. Partie II:
 Architecture des Ordinateurs Partie II: Le port Floppy permet le raccordement du lecteur de disquette àla carte mère. Remarque: Le lecteur de disquette a disparu il y a plus de 6 ans, son port suivra.
Architecture des Ordinateurs Partie II: Le port Floppy permet le raccordement du lecteur de disquette àla carte mère. Remarque: Le lecteur de disquette a disparu il y a plus de 6 ans, son port suivra.
Introduction à Java. Matthieu Herrb CNRS-LAAS. Mars 2014. http://homepages.laas.fr/matthieu/cours/java/java.pdf
 Introduction à Java Matthieu Herrb CNRS-LAAS http://homepages.laas.fr/matthieu/cours/java/java.pdf Mars 2014 Plan 1 Concepts 2 Éléments du langage 3 Classes et objets 4 Packages 2/28 Histoire et motivations
Introduction à Java Matthieu Herrb CNRS-LAAS http://homepages.laas.fr/matthieu/cours/java/java.pdf Mars 2014 Plan 1 Concepts 2 Éléments du langage 3 Classes et objets 4 Packages 2/28 Histoire et motivations
<Insert Picture Here> Solaris pour la base de donnés Oracle
 Solaris pour la base de donnés Oracle Alain Chéreau Oracle Solution Center Agenda Compilateurs Mémoire pour la SGA Parallélisme RAC Flash Cache Compilateurs
Solaris pour la base de donnés Oracle Alain Chéreau Oracle Solution Center Agenda Compilateurs Mémoire pour la SGA Parallélisme RAC Flash Cache Compilateurs
Conception de circuits numériques et architecture des ordinateurs
 Conception de circuits numériques et architecture des ordinateurs Frédéric Pétrot Année universitaire 2014-2015 Structure du cours C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 C11 Codage des nombres en base 2, logique
Conception de circuits numériques et architecture des ordinateurs Frédéric Pétrot Année universitaire 2014-2015 Structure du cours C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 C11 Codage des nombres en base 2, logique
Processus! programme. DIMA, Systèmes Centralisés (Ph. Mauran) " Processus = suite d'actions = suite d'états obtenus = trace
 Processus = suite d'actions = suite d'états obtenus = trace") Processus 1) Contexte 2) Modèles de Notion de Points de vue Modèle fourni par le SX Opérations sur les 3) Gestion des Représentation des Opérations 4) Ordonnancement des Niveaux d ordonnancement Ordonnancement
Processus 1) Contexte 2) Modèles de Notion de Points de vue Modèle fourni par le SX Opérations sur les 3) Gestion des Représentation des Opérations 4) Ordonnancement des Niveaux d ordonnancement Ordonnancement
INF6500 : Structures des ordinateurs. Sylvain Martel - INF6500 1
 INF6500 : Structures des ordinateurs Sylvain Martel - INF6500 1 Cours 4 : Multiprocesseurs Sylvain Martel - INF6500 2 Multiprocesseurs Type SISD SIMD MIMD Communication Shared memory Message-passing Groupe
INF6500 : Structures des ordinateurs Sylvain Martel - INF6500 1 Cours 4 : Multiprocesseurs Sylvain Martel - INF6500 2 Multiprocesseurs Type SISD SIMD MIMD Communication Shared memory Message-passing Groupe
I00 Éléments d architecture
 I00 I Exemples d ordinateur Pour les informaticiens, différentes machines de la vie courante sont des ordinateurs : par exemple les ordinateurs portables, les ordinateurs fixes, mais aussi les supercalculateurs,
I00 I Exemples d ordinateur Pour les informaticiens, différentes machines de la vie courante sont des ordinateurs : par exemple les ordinateurs portables, les ordinateurs fixes, mais aussi les supercalculateurs,
EPREUVE OPTIONNELLE d INFORMATIQUE CORRIGE
 EPREUVE OPTIONNELLE d INFORMATIQUE CORRIGE QCM Remarque : - A une question correspond au moins 1 réponse juste - Cocher la ou les bonnes réponses Barème : - Une bonne réponse = +1 - Pas de réponse = 0
EPREUVE OPTIONNELLE d INFORMATIQUE CORRIGE QCM Remarque : - A une question correspond au moins 1 réponse juste - Cocher la ou les bonnes réponses Barème : - Une bonne réponse = +1 - Pas de réponse = 0
Systèmes distribués et virtualisation de ressources
 p. 1/18 Systèmes distribués et virtualisation de ressources Tanguy RISSET (Transparents : Antoine Fraboulet) tanguy.risset@insa-lyon.fr p. 2/18 Plan 1 Distribution de ressources 1. Distribution de ressources
p. 1/18 Systèmes distribués et virtualisation de ressources Tanguy RISSET (Transparents : Antoine Fraboulet) tanguy.risset@insa-lyon.fr p. 2/18 Plan 1 Distribution de ressources 1. Distribution de ressources
Architecture matérielle des systèmes informatiques
 Architecture matérielle des systèmes informatiques IDEC, Renens. Version novembre 2003. Avertissement : ce support de cours n est pas destiné à l autoformation et doit impérativement être complété par
Architecture matérielle des systèmes informatiques IDEC, Renens. Version novembre 2003. Avertissement : ce support de cours n est pas destiné à l autoformation et doit impérativement être complété par
REALISATION d'un. ORDONNANCEUR à ECHEANCES
 REALISATION d'un ORDONNANCEUR à ECHEANCES I- PRÉSENTATION... 3 II. DESCRIPTION DU NOYAU ORIGINEL... 4 II.1- ARCHITECTURE... 4 II.2 - SERVICES... 4 III. IMPLÉMENTATION DE L'ORDONNANCEUR À ÉCHÉANCES... 6
REALISATION d'un ORDONNANCEUR à ECHEANCES I- PRÉSENTATION... 3 II. DESCRIPTION DU NOYAU ORIGINEL... 4 II.1- ARCHITECTURE... 4 II.2 - SERVICES... 4 III. IMPLÉMENTATION DE L'ORDONNANCEUR À ÉCHÉANCES... 6
Équilibrage Dynamique de Charge pour des Calculs Parallèles sur Cluster Linux - Une Évaluation de l Environnement AMPI.
 Facultés Universitaires Notre-Dame de la Paix, Namur Institut d Informatique Année académique 2003-2004 Équilibrage Dynamique de Charge pour des Calculs Parallèles sur Cluster Linux - Une Évaluation de
Facultés Universitaires Notre-Dame de la Paix, Namur Institut d Informatique Année académique 2003-2004 Équilibrage Dynamique de Charge pour des Calculs Parallèles sur Cluster Linux - Une Évaluation de
Programmation système de commandes en C
 Programmation système de commandes en C Cours de Programmation système Tuyêt Trâm DANG NGOC Université de Cergy-Pontoise 2012 2013 Tuyêt Trâm DANG NGOC Programmation système de commandes
Programmation système de commandes en C Cours de Programmation système Tuyêt Trâm DANG NGOC Université de Cergy-Pontoise 2012 2013 Tuyêt Trâm DANG NGOC Programmation système de commandes
M2-Images. Rendu Temps Réel - OpenGL 4 et compute shaders. J.C. Iehl. December 18, 2013
 Rendu Temps Réel - OpenGL 4 et compute shaders December 18, 2013 résumé des épisodes précédents... création des objets opengl, organisation des données, configuration du pipeline, draw,... opengl 4.3 :
Rendu Temps Réel - OpenGL 4 et compute shaders December 18, 2013 résumé des épisodes précédents... création des objets opengl, organisation des données, configuration du pipeline, draw,... opengl 4.3 :
Symantec Endpoint Protection
 Fiche technique : Sécurité des terminaux Symantec Endpoint Protection La nouvelle technologie antivirus de Symantec Présentation Protection avancée contre les menaces Symantec Endpoint Protection associe
Fiche technique : Sécurité des terminaux Symantec Endpoint Protection La nouvelle technologie antivirus de Symantec Présentation Protection avancée contre les menaces Symantec Endpoint Protection associe
en version SAN ou NAS
 tout-en-un en version SAN ou NAS Quand avez-vous besoin de virtualisation? Les opportunités de mettre en place des solutions de virtualisation sont nombreuses, quelque soit la taille de l'entreprise. Parmi
tout-en-un en version SAN ou NAS Quand avez-vous besoin de virtualisation? Les opportunités de mettre en place des solutions de virtualisation sont nombreuses, quelque soit la taille de l'entreprise. Parmi
Rapport de stage de 2ème année. Filière Télécommunication
 Institut Supérieur d'informatique, de Modélisation et de leurs Applications Complexe de Cézeaux BP 125 63173 Aubière Cedex www.isima.fr 1 rue de Provence BP 208-38432 Echirolles Cedex www.bull.com Rapport
Institut Supérieur d'informatique, de Modélisation et de leurs Applications Complexe de Cézeaux BP 125 63173 Aubière Cedex www.isima.fr 1 rue de Provence BP 208-38432 Echirolles Cedex www.bull.com Rapport
Chapitre 1. Infrastructures distribuées : cluster, grilles et cloud. Grid and Cloud Computing
 Chapitre 1. Infrastructures distribuées : cluster, grilles et cloud Grid and Cloud Computing Problématique Besoins de calcul croissants Simulations d'expériences coûteuses ou dangereuses Résolution de
Chapitre 1. Infrastructures distribuées : cluster, grilles et cloud Grid and Cloud Computing Problématique Besoins de calcul croissants Simulations d'expériences coûteuses ou dangereuses Résolution de
Plan du cours 2014-2015. Cours théoriques. 29 septembre 2014
 numériques et Institut d Astrophysique et de Géophysique (Bât. B5c) Bureau 0/13 email:.@ulg.ac.be Tél.: 04-3669771 29 septembre 2014 Plan du cours 2014-2015 Cours théoriques 16-09-2014 numériques pour
numériques et Institut d Astrophysique et de Géophysique (Bât. B5c) Bureau 0/13 email:.@ulg.ac.be Tél.: 04-3669771 29 septembre 2014 Plan du cours 2014-2015 Cours théoriques 16-09-2014 numériques pour
UE Programmation Impérative Licence 2ème Année 2014 2015
 UE Programmation Impérative Licence 2 ème Année 2014 2015 Informations pratiques Équipe Pédagogique Florence Cloppet Neilze Dorta Nicolas Loménie prenom.nom@mi.parisdescartes.fr 2 Programmation Impérative
UE Programmation Impérative Licence 2 ème Année 2014 2015 Informations pratiques Équipe Pédagogique Florence Cloppet Neilze Dorta Nicolas Loménie prenom.nom@mi.parisdescartes.fr 2 Programmation Impérative
Parallélisme et bioinformatique
 Master EGOIST - Rouen Plan Généralités Plan Généralités 1 Généralités 2 Généralités La science informatique n est pas plus la science des ordinateurs que l astronomie n est celle des télescopes (ou la
Master EGOIST - Rouen Plan Généralités Plan Généralités 1 Généralités 2 Généralités La science informatique n est pas plus la science des ordinateurs que l astronomie n est celle des télescopes (ou la
WEA Un Gérant d'objets Persistants pour des environnements distribués
 Thèse de Doctorat de l'université P & M Curie WEA Un Gérant d'objets Persistants pour des environnements distribués Didier Donsez Université Pierre et Marie Curie Paris VI Laboratoire de Méthodologie et
Thèse de Doctorat de l'université P & M Curie WEA Un Gérant d'objets Persistants pour des environnements distribués Didier Donsez Université Pierre et Marie Curie Paris VI Laboratoire de Méthodologie et
vbladecenter S! tout-en-un en version SAN ou NAS
 vbladecenter S! tout-en-un en version SAN ou NAS Quand avez-vous besoin de virtualisation? Les opportunités de mettre en place des solutions de virtualisation sont nombreuses, quelque soit la taille de
vbladecenter S! tout-en-un en version SAN ou NAS Quand avez-vous besoin de virtualisation? Les opportunités de mettre en place des solutions de virtualisation sont nombreuses, quelque soit la taille de
Éléments de programmation et introduction à Java
 Éléments de programmation et introduction à Java Jean-Baptiste Vioix (jean-baptiste.vioix@iut-dijon.u-bourgogne.fr) IUT de Dijon-Auxerre - LE2I http://jb.vioix.free.fr 1-20 Les différents langages informatiques
Éléments de programmation et introduction à Java Jean-Baptiste Vioix (jean-baptiste.vioix@iut-dijon.u-bourgogne.fr) IUT de Dijon-Auxerre - LE2I http://jb.vioix.free.fr 1-20 Les différents langages informatiques
Rapport d activité. Mathieu Souchaud Juin 2007
 Rapport d activité Mathieu Souchaud Juin 2007 Ce document fait la synthèse des réalisations accomplies durant les sept premiers mois de ma mission (de novembre 2006 à juin 2007) au sein de l équipe ScAlApplix
Rapport d activité Mathieu Souchaud Juin 2007 Ce document fait la synthèse des réalisations accomplies durant les sept premiers mois de ma mission (de novembre 2006 à juin 2007) au sein de l équipe ScAlApplix
Matériel & Logiciels (Hardware & Software)
") CHAPITRE 2 HARDWARE & SOFTWARE P. 1 Chapitre 2 Matériel & Logiciels (Hardware & Software) 2.1 Matériel (Hardware) 2.1.1 Présentation de l'ordinateur Un ordinateur est un ensemble de circuits électronique
CHAPITRE 2 HARDWARE & SOFTWARE P. 1 Chapitre 2 Matériel & Logiciels (Hardware & Software) 2.1 Matériel (Hardware) 2.1.1 Présentation de l'ordinateur Un ordinateur est un ensemble de circuits électronique
Protection des données avec les solutions de stockage NETGEAR
 Protection des données avec les solutions de stockage NETGEAR Solutions intelligentes pour les sauvegardes de NAS à NAS, la reprise après sinistre pour les PME-PMI et les environnements multi-sites La
Protection des données avec les solutions de stockage NETGEAR Solutions intelligentes pour les sauvegardes de NAS à NAS, la reprise après sinistre pour les PME-PMI et les environnements multi-sites La
Histoire de l Informatique
 Histoire de l Informatique Abdelaaziz EL HIBAOUI Université Abdelelmalek Essaadi Faculté des Sciences de-tétouan hibaoui.ens@gmail.com 14 Feb 2015 A. EL HIBAOUI (FS-Tétouan) Architecture des ordinateurs
Histoire de l Informatique Abdelaaziz EL HIBAOUI Université Abdelelmalek Essaadi Faculté des Sciences de-tétouan hibaoui.ens@gmail.com 14 Feb 2015 A. EL HIBAOUI (FS-Tétouan) Architecture des ordinateurs
Symantec Backup Exec 11d pour serveurs Windows Options/Agents
 Symantec Backup Exec 11d pour serveurs Windows Options/Agents Introduction Symantec Backup Exec 11d pour serveurs Windows est une solution complète de protection et de récupération des données Windows,
Symantec Backup Exec 11d pour serveurs Windows Options/Agents Introduction Symantec Backup Exec 11d pour serveurs Windows est une solution complète de protection et de récupération des données Windows,
Retour d expérience en Astrophysique : utilisation du Cloud IaaS pour le traitement de données des missions spatiales
 Retour d expérience en Astrophysique : utilisation du Cloud IaaS pour le traitement de données des missions spatiales Cécile Cavet cecile.cavet at apc.univ-paris7.fr Centre François Arago (FACe), Laboratoire
Retour d expérience en Astrophysique : utilisation du Cloud IaaS pour le traitement de données des missions spatiales Cécile Cavet cecile.cavet at apc.univ-paris7.fr Centre François Arago (FACe), Laboratoire
Hands on Openstack : Introduction
 Hands on Openstack : Introduction Tags : openstack cloud Alban Crommer 2013 Octopuce Connaître Openstack Niveau 0 : Connaissance des composants Connaître Openstack Niveau 1 : Utilisation des services et
Hands on Openstack : Introduction Tags : openstack cloud Alban Crommer 2013 Octopuce Connaître Openstack Niveau 0 : Connaissance des composants Connaître Openstack Niveau 1 : Utilisation des services et
3IS - Système d'exploitation linux - Programmation système
 3IS - Système d'exploitation linux - Programmation système 2010 David Picard Contributions de : Arnaud Revel, Mickaël Maillard picard@ensea.fr Environnement Les programmes peuvent être exécutés dans des
3IS - Système d'exploitation linux - Programmation système 2010 David Picard Contributions de : Arnaud Revel, Mickaël Maillard picard@ensea.fr Environnement Les programmes peuvent être exécutés dans des
Programmation impérative
 Programmation impérative Cours 4 : Manipulation des fichiers en C Catalin Dima Organisation des fichiers Qqs caractéristiques des fichiers : Nom (+ extension). Chemin d accès absolu = suite des noms des
Programmation impérative Cours 4 : Manipulation des fichiers en C Catalin Dima Organisation des fichiers Qqs caractéristiques des fichiers : Nom (+ extension). Chemin d accès absolu = suite des noms des
Chapitre 2 : Abstraction et Virtualisation
 Virtualisation et Cloud Computing Chapitre 2 : Abstraction et Virtualisation Objectifs Présenter la notion de niveaux d abstraction séparés par des interfaces bien définies Description des avantages et
Virtualisation et Cloud Computing Chapitre 2 : Abstraction et Virtualisation Objectifs Présenter la notion de niveaux d abstraction séparés par des interfaces bien définies Description des avantages et
Exigences système Commercial & Digital Printing
 Exigences système OneVision Software AG Sommaire Speedflow Check 10.0, Speedflow Check Plus 10.0, Speedflow Edit 10.0 (Windows),... 2 Speedflow Recompose 10.0...2 Speedflow Edit 10.0 (Macintosh OSX)...2
Exigences système OneVision Software AG Sommaire Speedflow Check 10.0, Speedflow Check Plus 10.0, Speedflow Edit 10.0 (Windows),... 2 Speedflow Recompose 10.0...2 Speedflow Edit 10.0 (Macintosh OSX)...2
THEME 1 : L ORDINATEUR ET SON ENVIRONNEMENT. Objectifs
 Architecture Matérielle des Systèmes Informatiques. S1 BTS Informatique de Gestion 1 ère année THEME 1 : L ORDINATEUR ET SON ENVIRONNEMENT Dossier 1 L environnement informatique. Objectifs Enumérer et
Architecture Matérielle des Systèmes Informatiques. S1 BTS Informatique de Gestion 1 ère année THEME 1 : L ORDINATEUR ET SON ENVIRONNEMENT Dossier 1 L environnement informatique. Objectifs Enumérer et
Exigences système Edition & Imprimeries de labeur
 Exigences système Edition & Imprimeries de labeur OneVision Software France Sommaire Asura 10.2, Asura Pro 10.2, Garda 10.2...2 PlugBALANCEin10.2, PlugCROPin 10.2, PlugFITin 10.2, PlugRECOMPOSEin 10.2,
Exigences système Edition & Imprimeries de labeur OneVision Software France Sommaire Asura 10.2, Asura Pro 10.2, Garda 10.2...2 PlugBALANCEin10.2, PlugCROPin 10.2, PlugFITin 10.2, PlugRECOMPOSEin 10.2,
Gestion de mémoire secondaire F. Boyer, Laboratoire Sardes Fabienne.Boyer@imag.fr
 Gestion de mémoire secondaire F. Boyer, Laboratoire Sardes Fabienne.Boyer@imag.fr 1- Structure d un disque 2- Ordonnancement des requêtes 3- Gestion du disque - formatage - bloc d amorçage - récupération
Gestion de mémoire secondaire F. Boyer, Laboratoire Sardes Fabienne.Boyer@imag.fr 1- Structure d un disque 2- Ordonnancement des requêtes 3- Gestion du disque - formatage - bloc d amorçage - récupération
Chapitre I Notions de base et outils de travail
 Chapitre I Notions de base et outils de travail Objectifs Connaître les principes fondateurs et l historique du langage Java S informer des principales caractéristiques du langage Java Connaître l environnement
Chapitre I Notions de base et outils de travail Objectifs Connaître les principes fondateurs et l historique du langage Java S informer des principales caractéristiques du langage Java Connaître l environnement
Gestion de clusters de calcul avec Rocks
 Gestion de clusters de calcul avec Laboratoire de Chimie et Physique Quantiques / IRSAMC, Toulouse scemama@irsamc.ups-tlse.fr 26 Avril 2012 Gestion de clusters de calcul avec Outline Contexte 1 Contexte
Gestion de clusters de calcul avec Laboratoire de Chimie et Physique Quantiques / IRSAMC, Toulouse scemama@irsamc.ups-tlse.fr 26 Avril 2012 Gestion de clusters de calcul avec Outline Contexte 1 Contexte
Exécutif temps réel Pierre-Yves Duval (cppm)
") Exécutif temps réel Pierre-Yves Duval (cppm) Ecole d informatique temps réel - La Londes les Maures 7-11 Octobre 2002 Plan Exécutif Tâches Evénements et synchronisation Partage de ressources Communications
Exécutif temps réel Pierre-Yves Duval (cppm) Ecole d informatique temps réel - La Londes les Maures 7-11 Octobre 2002 Plan Exécutif Tâches Evénements et synchronisation Partage de ressources Communications
Présentation d HyperV
 Virtualisation sous Windows 2008 Présentation d HyperV Agenda du module Présentation d Hyper-V Installation d Hyper-V Configuration d Hyper-V Administration des machines virtuelles Offre de virtualisation
Virtualisation sous Windows 2008 Présentation d HyperV Agenda du module Présentation d Hyper-V Installation d Hyper-V Configuration d Hyper-V Administration des machines virtuelles Offre de virtualisation
4. Utilisation d un SGBD : le langage SQL. 5. Normalisation
 Base de données S. Lèbre slebre@unistra.fr Université de Strasbourg, département d informatique. Présentation du module Contenu général Notion de bases de données Fondements / Conception Utilisation :
Base de données S. Lèbre slebre@unistra.fr Université de Strasbourg, département d informatique. Présentation du module Contenu général Notion de bases de données Fondements / Conception Utilisation :
Le langage C++ est un langage de programmation puissant, polyvalent, on serait presque tenté de dire universel, massivement utilisé dans l'industrie
 Chapitre I : Les bases du C++ Le langage C++ est un langage de programmation puissant, polyvalent, on serait presque tenté de dire universel, massivement utilisé dans l'industrie du logiciel, et ce depuis
Chapitre I : Les bases du C++ Le langage C++ est un langage de programmation puissant, polyvalent, on serait presque tenté de dire universel, massivement utilisé dans l'industrie du logiciel, et ce depuis
Évaluation et implémentation des langages
 Évaluation et implémentation des langages Les langages de programmation et le processus de programmation Critères de conception et d évaluation des langages de programmation Les fondations de l implémentation
Évaluation et implémentation des langages Les langages de programmation et le processus de programmation Critères de conception et d évaluation des langages de programmation Les fondations de l implémentation
1. Structure d un programme C. 2. Commentaire: /*..texte */ On utilise aussi le commentaire du C++ qui est valable pour C: 3.
 1. Structure d un programme C Un programme est un ensemble de fonctions. La fonction "main" constitue le point d entrée pour l exécution. Un exemple simple : #include int main() { printf ( this
1. Structure d un programme C Un programme est un ensemble de fonctions. La fonction "main" constitue le point d entrée pour l exécution. Un exemple simple : #include int main() { printf ( this
GESTION DE LA MEMOIRE
 GESTION DE LA MEMOIRE MEMOIRE CENTRALE (MC) MEMOIRE SECONDAIRE (MS) 1. HIÉRARCHIE ET DIFFÉRENTS TYPES DE MÉMOIRE... 2 2. MÉMOIRE CACHE... 3 3. MODÈLE D'ALLOCATION CONTIGUË (MC OU MS)... 5 3.1. STRATÉGIE
GESTION DE LA MEMOIRE MEMOIRE CENTRALE (MC) MEMOIRE SECONDAIRE (MS) 1. HIÉRARCHIE ET DIFFÉRENTS TYPES DE MÉMOIRE... 2 2. MÉMOIRE CACHE... 3 3. MODÈLE D'ALLOCATION CONTIGUË (MC OU MS)... 5 3.1. STRATÉGIE
I. Introduction aux fonctions : les fonctions standards
 Chapitre 3 : Les fonctions en C++ I. Introduction aux fonctions : les fonctions standards A. Notion de Fonction Imaginons que dans un programme, vous ayez besoin de calculer une racine carrée. Rappelons
Chapitre 3 : Les fonctions en C++ I. Introduction aux fonctions : les fonctions standards A. Notion de Fonction Imaginons que dans un programme, vous ayez besoin de calculer une racine carrée. Rappelons
Performances de la programmation multi-thread
 UFR Sciences et techniques de Franche-Comté Projet semestriel 2ème année de Master Informatique Performances de la programmation multi-thread Auteur(s) : Beuque Eric Moutenet Cyril Tuteur(s) : Philippe
UFR Sciences et techniques de Franche-Comté Projet semestriel 2ème année de Master Informatique Performances de la programmation multi-thread Auteur(s) : Beuque Eric Moutenet Cyril Tuteur(s) : Philippe
IRL : Simulation distribuée pour les systèmes embarqués
 IRL : Simulation distribuée pour les systèmes embarqués Yassine El Khadiri, 2 ème année Ensimag, Grenoble INP Matthieu Moy, Verimag Denis Becker, Verimag 19 mai 2015 1 Table des matières 1 MPI et la sérialisation
IRL : Simulation distribuée pour les systèmes embarqués Yassine El Khadiri, 2 ème année Ensimag, Grenoble INP Matthieu Moy, Verimag Denis Becker, Verimag 19 mai 2015 1 Table des matières 1 MPI et la sérialisation
Cahier des charges. driver WIFI pour chipset Ralink RT2571W. sur hardware ARM7
 Cahier des charges driver WIFI pour chipset Ralink RT2571W sur hardware ARM7 RevA 13/03/2006 Création du document Sylvain Huet RevB 16/03/2006 Fusion des fonctions ARP et IP. SH Modification des milestones
Cahier des charges driver WIFI pour chipset Ralink RT2571W sur hardware ARM7 RevA 13/03/2006 Création du document Sylvain Huet RevB 16/03/2006 Fusion des fonctions ARP et IP. SH Modification des milestones
Tests de performance du matériel
 3 Tests de performance du matériel Après toute la théorie du dernier chapitre, vous vous demandez certainement quelles sont les performances réelles de votre propre système. En fait, il y a plusieurs raisons
3 Tests de performance du matériel Après toute la théorie du dernier chapitre, vous vous demandez certainement quelles sont les performances réelles de votre propre système. En fait, il y a plusieurs raisons
ERP Service Negoce. Pré-requis CEGID Business version 2008. sur Plate-forme Windows. Mise à jour Novembre 2009
 ERP Service Negoce Pré-requis CEGID Business version 2008 sur Plate-forme Windows Mise à jour Novembre 2009 Service d'assistance Téléphonique 0 825 070 025 Pré-requis Sommaire 1. PREAMBULE... 3 Précision
ERP Service Negoce Pré-requis CEGID Business version 2008 sur Plate-forme Windows Mise à jour Novembre 2009 Service d'assistance Téléphonique 0 825 070 025 Pré-requis Sommaire 1. PREAMBULE... 3 Précision
Architecture des ordinateurs
 Architecture des ordinateurs Cours 4 5 novembre 2012 Archi 1/22 Micro-architecture Archi 2/22 Intro Comment assembler les différents circuits vus dans les cours précédents pour fabriquer un processeur?
Architecture des ordinateurs Cours 4 5 novembre 2012 Archi 1/22 Micro-architecture Archi 2/22 Intro Comment assembler les différents circuits vus dans les cours précédents pour fabriquer un processeur?
Cours 1 : La compilation
 /38 Interprétation des programmes Cours 1 : La compilation Yann Régis-Gianas yrg@pps.univ-paris-diderot.fr PPS - Université Denis Diderot Paris 7 2/38 Qu est-ce que la compilation? Vous avez tous déjà
/38 Interprétation des programmes Cours 1 : La compilation Yann Régis-Gianas yrg@pps.univ-paris-diderot.fr PPS - Université Denis Diderot Paris 7 2/38 Qu est-ce que la compilation? Vous avez tous déjà
Réseau longue distance et application distribuée dans les grilles de calcul : étude et propositions pour une interaction efficace
 1 Réseau longue distance et application distribuée dans les grilles de calcul : étude et propositions pour une interaction efficace Réseau longue distance et application distribuée dans les grilles de
1 Réseau longue distance et application distribuée dans les grilles de calcul : étude et propositions pour une interaction efficace Réseau longue distance et application distribuée dans les grilles de
Plan du cours. Historique du langage http://www.oracle.com/technetwork/java/index.html. Nouveautés de Java 7
 Université Lumière Lyon 2 Faculté de Sciences Economiques et Gestion KHARKIV National University of Economic Introduction au Langage Java Master Informatique 1 ère année Julien Velcin http://mediamining.univ-lyon2.fr/velcin
Université Lumière Lyon 2 Faculté de Sciences Economiques et Gestion KHARKIV National University of Economic Introduction au Langage Java Master Informatique 1 ère année Julien Velcin http://mediamining.univ-lyon2.fr/velcin