Année Biostatistiques. Rappels de cours et travaux dirigés. Analyse des données M2.
|
|
|
- Edith Émilie Milot
- il y a 8 ans
- Total affichages :
Transcription
1 Année Biostatistiques Rappels de cours et travaux dirigés Analyse des données M2 auteur : Jean-Marc Labatte jean-marc.labatte@univ-angers.fr - 1 -

2 Table des matières SOMMAIRE VIII ANALYSE EN COMPOSANTES PRINCIPALES...4 Fiche 36 Principe de la méthode ACP...6 Fiche 37 Aides à l'interprétation...8 Fiche 38 Représentation graphique des variables...10 Fiche 39 Représentation graphique des individus...11 IX ANALYSE FACTORIELLE DES CORRESPONDANCES...14 Fiche 40 Principe de l'afc...15 Fiche 41 Aides à l'interprétation...17 Fiche 42 Représentation graphique des profils...19 X CLASSIFICATION...22 Fiche 43 Exemple manuel de CAH...24 Fiche 44 Exemple de CAH avec ade ANNEXES...28 Annexe A : Lois de probabilités usuelles...29 Annexe B : Construction d'un test statistique...32 Annexe C : Installation de R

3 VIII ANALYSE EN COMPOSANTES PRINCIPALES Objectifs et données pour l'acp Cette technique s'applique à des tableaux décrivant chaque individu par p variables quantitatives X k. Les techniques classiques ne permettent que l'étude de la liaison entre deux variables : corrélation, régression et nuage de points par exemple. L'objectif est ici de faire une synthèse de l'ensemble du tableau afin de : synthétiser les liaisons entre variables (cercle des corrélations), définir les variables qui vont dans le même sens, dans un sens opposé, indépendantes... représenter dans un plan les individus afin de déterminer les individus proches ou éloignés, les regrouper en classe homogène,... On parle de topologie des individus. construire de nouvelles variables, appelées composantes principales, non corrélées et qui permettent de synthétiser l'information Ainsi, au lieu d'analyser le tableau à travers p variables, on se limitera à l'étude de quelques variables synthétiques, les composantes principales. La difficulté sera de donner un sens à ces variables et de proposer une analyse des résultats. Le tableau se présente sous la forme : X 1... X j... X p individu 1 x 11 x 1 j x 1 p... individu i x i1 x ij x ip... individu n x n1 x nj x np Exemple : Nous étudions dans cette partie les masses de différentes parties d'un groupe de 23 bovins constitué de 12 charolais (1 à 12) et 11 zebus (13 à 23). Les variables représentent: poids vif. poids de la carcasse. poids de la viande de première qualité. poids de la viande totale. poids du gras. poids des os. Retrouver à l'aide du logiciel R et son interface R-commander les différents résultats ci-dessous et expliquer leur apport respectif dans l'analyse des données. 1. Paramètres statistiques: Moyenne et écart-type par race Variable: carc mean sd n Variable: os mean sd n Variable: tota mean sd n Variable: gras mean sd n Variable: qsup mean sd n Variable: vif mean sd n Matrice des corrélations vif carc qsup tota gras os vif carc qsup tota gras os

 >attach(zebu) >col <- ifelse(race==1,\"blue\",\"red\") >plot3d(gras,tota,qsup,type=\"s\",col=col) les échelles sont différentes suivant les axes")
4 2. Représentation graphique 3. Nuage de points Dans R, on peut utiliser les commandes suivantes pour construire des nuages 3d. On pourra changer les 3 variables. A défaut, utiliser R commander. >library(rgl) >attach(zebu) >col <- ifelse(race==1,"blue","red") >plot3d(gras,tota,qsup,type="s",col=col) les échelles sont différentes suivant les axes >plot3d(gras,tota,qsup,type="s",col=col,xlim=c(0,450),ylim=c(0,450),zlim=c(0,450)) les échelles sont les mêmes Quelques liens :
,ylim=c(0,450),zlim=c(0,450)) les échelles sont les mêmes Quelques liens : http://pbil.univ-lyon1.fr/r/enseignement.")
5 Fiche 1 Principe de la méthode ACP Chaque individu est décrit ici par p=6 variables quantitatives. Un individu est représenté par un point dont les coordonnées sont les valeurs prises par les 6 variables (espace à p=6 dimensions). On peut ainsi mesurer la distance entre deux individus à l'aide d'une distance classique entre deux points. Le principe de l'acp répond simultanément aux deux objectifs suivant : Pour les individus L'objectif de la méthode ACP est de projeter les individus sur des axes appelés axes factoriels en conservant le mieux possible les distances entre individus. Cela revient à déformer le moins possible le nuage de points initial lorsqu'on le projette sur un axe ou un plan. Dans la pratique, la projection sur l'axe F 1 permet d'obtenir le maximum de dispersion (=inertie = variance en une dimension) des points projetés sur l'axe. Pour les variables Cela revient à construire des variables, appelées composantes principales, par combinaison linéaire des variables initiales et telles que ces nouvelles variables aient la plus grande variance possible. Les composantes principales sont de plus non corrélées. On ne s'intéresse alors qu'aux composantes principales qui ont la plus forte variance (=valeur propre de l'axe). On construit ensuite des nuages de points des individus en fonction de ces composantes principales dans les plans factoriels F 1 F 2, ou F 1 F 3... Interprétation graphique de l'acp Régression linéaire de y en x ACP avec x, y XY[,2] XY[,2] XY[,1] XY[,1] Remarque importante : En général, du fait de l'hétérogénéité des variables initiales et de leurs unités, on réduit ces variables. On parle alors d'acp normée. Une variable est dite réduite quand sa variance vaut 1. De la sorte, chaque variable initiale aura une même importance dans l'analyse car sa contribution est proportionnelle à sa variance. Dans la pratique, on normalise presque toujours et surtout lorsque les variables sont exprimées dans des unités différentes. L'objectif est ainsi de construire des variables qui synthétisent la dispersion du nuage. Si plusieurs variables initiales sont ainsi fortement corrélées entre elles, celles-ci sont alors représentées par une - 5 -

6 composante principale qui les résume. Au final, au lieu de travailler avec p=6 variables, on peut espérer travailler sur 2 ou 3 variables synthétiques qui résument l'essentiel de l'information. On retrouve une partie des résultats de l'acp dans Rcmdr, statistiques, ajustement multivarié. Projection des individus dans les plans définis par les axes Projection de l'inertie sur les F 1 F 2 F 3 différents axes factoriels Mais il est fortement conseillé sous R d'utiliser la librairie ade4. >library(ade4) >zebu.acp <- dudi.pca(zebu[,1:6]) >zebu.acp$eig (valeurs propres) >zebu.acp$li (composantes principales) >zebu.acp$co (coordonnées des variables). voir l'aide en ligne Guide pratique de l'analyse ACP Etape 1 : Sélection des axes et des plans retenus principalement par rapport aux valeurs propres. Etape 2 : Projection des variables et individus dans un plan donné ( F 1 F 2 en premier) Examen des qlt dans le plan pour éliminer les individus mal représentés Bilan des ctr pour un axe afin de donner un sens à cet axe (opposition, tendance...) Topographie des variables et individus afin d'identifier des groupes, des oppositions, des tendances notamment à l'aide de la fonction s.class Utiliser ses connaissances sur le sujet pour proposer des explications sur les résultats de l'analyse Utiliser des individus ou variables supplémentaires ou des profils type (moyenne des H et des F par exemple) - 6 -
 >zebu.acp <- dudi.pca(zebu[,1:6]) >zebu.acp$eig (valeurs propres) >zebu.acp$li (composantes principales) >zebu.acp$co (coordonnées des variables).")
7 1. Valeurs propres et choix des axes Fiche 2 Aides à l'interprétation Pour définir le nombre d'axes étudiés, on étudie les valeurs propres obtenues. Chaque valeur propre correspond à la part d'inertie projetée sur un axe donné. Remarque importante: La somme des valeurs propres est égale à l'inertie totale du nuage (= nombre de variables en ACP normé). On caractérise ainsi chaque axe par le pourcentage d'inertie qu'il permet d'expliquer. On ne retient donc que les axes avec les plus fortes valeurs propres. Le choix des axes retenus est un peu délicat. On peut donner quelques règles : Règle de Kaiser en ACP normée: on ne s'intéresse qu 'aux axes avec une valeur propre supérieure à 1 (= inertie d'une variable initiale). Règle de l'inertie minimale : On sélectionne les premiers axes afin d'atteindre un % donné d'inertie expliquée (70% par exemple). Règle du coude : On observe souvent de fortes valeurs propres au départ puis ensuite de faibles valeurs avec un décrochage dans le diagramme. On retient les axes avant le décrochage. Règle de bon sens : On analyse les plans et axes et on ne retient que ceux interprétables. Exemple zebu > round(acp$eig,2) [1] > round(acp$eig/sum(acp$eig)*100) [1] Avec ade4: réaliser l'acp >acp=dudi.pca(tableau) Extraire les valeurs propres >acp$eig Calcul des % >acp$eig/sum(acp$eig)* Qualité de représentation qlt Les individus représentés dans un plan factoriel ne sont pas forcément correctement représentés

8 Qualité de représentation qlt: Si l'angle est grand, le point initial est éloigné de sa projection. On utilise le paramètre cos 2 pour caractériser la qualité de représentation (qlt) sur un axe. Plus qlt i est proche de 1 plus il est bien représenté. Plus qlt i est proche de 0 plus il est mal représenté. Dans un plan, on calcule la somme des deux qlt, par exemple qlt F1 + qlt F2 pour le plan F 1 F 2. qlt correspond en fait au rapport de l'inertie du projeté sur l'inertie du point initial. Qualité globale : Dans un plan donné, on définit également la qualité globale comme le pourcentage d'inertie qu'explique le plan. C'est par rapport à cette qualité globale que l'on évalue la qlt d'un individu ou d'une variable. Remarque : La qlt des variables peut s'analyser de la même façon mais l'utilisation du cercle des corrélation est plus intuitive. Bilan : On commencera donc toujours l'analyse d'un plan factoriel en précisant l'existence (ou non) d'individus ou variables mal représentés et en justifiant par les qlt. 3. Contribution ctr Lors de la construction d'un axe factoriel, certaines variables et certains individus ont des rôles plus importants. On calcule un paramètre appelé contribution, ctr, qui permet de calculer cette influence. Définition: La contribution ctr est définie comme la proportion de l'inertie de l'axe expliquée par la variable ou l'individu. Règles d'interprétation : L'analyse se fait axe par axe, en parallèle sur les variables et les individus. Plus ctr est grande, plus l'influence de l'individu est grande. On ne retient donc que les plus fortes valeurs (il y a souvent un décrochage après quelques valeurs). ctr est considéré comme positif si l'individu est dans la partie positive de l'axe. ctr est considéré comme négatif si l'individu est dans la partie négative de l'axe. Le bilan des ctr peut être présenter pour un axe donné sous forme d'un tableau avec les principales ctr + et des individus et des variables, en précisant la valeur de ctr : ctr axe F 1 : - + Variables : Individus : On réalise ensuite une interprétation. Sous R, ces paramètres sont obtenus avec les commandes suivantes : Pour les lignes (individus) >inertiel<-inertia.dudi(acp, row.inertia=true) ctr des lignes en % >inertiel$row.abs/100 qlt des lignes en % >inertiel$row.rel/100 Pour les colonnes (variables) ctr des colonnes en % qlt des colonnes en % >inertiec<-inertia.dudi(acp, col.inertia=true) >inertiec$col.abs/100 >inertiec$col.rel/

9 Fiche 3 Représentation graphique des variables Les composantes principales sont construites comme des combinaisons linéaires des variables initiales. Pour visualiser les liaisons entre la composante principale et les variables initiales, on représente en ACP normée les variables dans les plans factoriels. Les coordonnées des variables sont les coefficients de corrélation de ces variables avec les composantes principales. Les règles de lecture du cercle des corrélations sont : On ne prend en compte que les variables proches du cercle des corrélations. Dans le cas contraire, la variable est non corrélée à la composante principale et est donc mal représentée. La liaison entre variables bien représentées s'analyse à travers la direction et le sens de leur vecteur : si les vecteurs ont même direction et même sens, les variables sont corrélées positivement, si les vecteurs ont même direction mais de sens contraire, les variables sont corrélées négativement, si les vecteurs sont perpendiculaires, les variables sont non corréles. On synthétise chaque axe en précisant les variables qui contribuent le plus en positif ou en négatif (étude des ctr) Exemple : inertiev=inertia.dudi(acp,col.inertia=true) Composante principale > round(acp$co,2) Comp1 Comp2 ctr / inertiev$col.abs Comp1 Comp2 FL FL RW RW CL CL CW CW BD BD qlt / inertiev$col.rel Comp1 Comp2 con.tra FL RW CL CW BD > s.corcircle(zebu.zebu.acp$co,xax=1,yax=2) - 9 -

10 Fiche 4 Représentation graphique des individus Les individus sont associés à des points de l'espace dont les coordonnées sont les variables. On peut mesurer la distance entre ces individus en utilisant simplement la distance euclidienne classique entre ces deux points (comme au collège...). La construction des composantes principales conduit à rendre minimale la déformation des distances entre individus lorsque l'on projette les individus dans le plan factoriel F 1 F 2. Ainsi les distances que l'on observe entre les individus dans le plan factoriel sont globalement les plus proches possible des distances réelles entre ces individus. L'analyse des plans factoriels permet ainsi d'observer les individus proches entre eux ou au contraire éloignés. Il est ainsi possible de construire des groupes, d'observer des tendances... Les règles de lecture des plans factoriels sont : Seuls les individus bien représentés sont pris en compte dans l'interprétation. On calcule la somme des qlt dans le plan et on vérifie que cette somme n'est pas trop faible par rapport à la qualité moyenne du plan. On réalise le bilan en positif et en négatif des individus qui ont la plus forte contribution pour un axe donné. On donne ainsi en parallèle avec l'analyse des variables une signification concrête à ces axes en terme d'opposition entre individus et variables ou tendance particulière. On réalise des groupes, à l'aide éventuelle de la fonction s.class, dans le cas de groupes préexistants (homme-femme par exemple) ou on construit arbitrairement ces groupes en raison des proximités entre individus. En présence de trop nombreux individus, on peut utiliser des individus type et réaliser une analyse sur ce individus. L'utilisation d'individus supplémentaires non utilisés dans l'ajustement mais a posteriori permet également d'éclairer l'analyse. inertie <-inertia.dudi(acp, row.inertia=true) Composantes principales > round(acp$li,3) Axis1 Axis2 Axis3 [CTR en 10000ième] > inertie$row.abs Axis1 Axis2 Axis [Qlt en 10000ième] > inertie$row.re Axis1 Axis2 Axis3 con.tra

11 Plan F 1 F 2 Plan F 1 F 3 > s.label(zebu.acp$li,xax=1,yax=2) > s.label(zebu.acp$li,xax=1,yax=3) d = 1 d = >s.class(dfxy=zebu.acp$li,fac=race,col=col,xax=1,yax=2) d =

12 - 12 -
13 IX ANALYSE FACTORIELLE DES CORRESPONDANCES Objectifs et données pour l'afc Cette technique s'applique à des tableaux de contingence croisant deux variables qualitatives avec de nombreuses modalités chacune. Les données sont donc les effectifs des individus croisant deux modalités données. Pour de tels tableaux nous disposons du test d'indépendance du 2. L'objectif est ici de faire une synthèse de l'ensemble du tableau afin de répondre aux questions : Pour une variable donnée, certaines modalités sont-elles proches ou éloignées. La proximité de deux modalités se mesure en comparant leur distribution par rapport à l'autre variable. Par exemple, yeux bleus et verts sont proches si les deux groupes ont les mêmes distribution de couleurs de cheveux. Entre les deux variables, certaines modalités «s'atirent-elles» davantage ou au contraire «se repoussent». On compare la fréquence observée par rapport à la fréquence attendue sous l'hypothèse d'indépendance, si la fréquence observée est plus forte il y a une plus forte association entre les deux et inversement. Par exemple, les yeux bleus et les cheveux blond «s'attirent», au contraire des yeux noirs et des cheveux blond. Remarque : L'AFC n'a d'intérêt que si il y a dépendance entre les deux variables, en cas contraire elle n'apporte pas d'information. Le tableau se présente sous la forme : variable qualitative 2 modalité 1... modalité j... modalité J modalité 1 n 11 n 1 j n 1 J variable... qualitative modalité i n i1 n ij n ij 1... modalité I n I1 n Ij n IJ On constate la symétrie du tableau contrairement au tableau utilisé en ACP. Exemple 1 (trivial) On examine la répartition des couleurs de cheveux et d'yeux. Tableau de contingence Tableau théorique sous H 0 (Indépendance) \cheveux blond roux brun total \cheveux blond roux brun total yeux yeux bleu bleu vert vert marron marron total total Test du 2 d'indépendance

14 Fiche 5 Principe de l'afc Pour mesurer les distances entre modalités, il est nécessaire de calculer au préalable la distribution de chaque modalité d'une variable en fonction de l'autre variable. On définit ainsi les profils colonnes et les profils ligne qui sont les distributions respectives des modalités des deux variables. Un profil ligne (colonne) est déterminé en divisant la ligne (colonne) par le total de la ligne (colonne). Profils lignes \cheveux yeux bleu vert marron total Profils colonnes blond roux brun total \cheveux blond roux brun total yeux bleu vert marron total Chaque profil est alors assimilé à un point de coordonnées les proportions par rapport aux modalités de l'autre variable. Le nuage des profils ligne est alors projeté sur des axes factoriels en conservant le maximum d'inertie et il en est de même pour le nuage des profils colonne. Les principales différences avec l'acp sont : Lignes et colonnes sont transformées au préalable en profil et jouent un rôle symétrique. La distance entre deux profils est calculée à l'aide de la distance du 2 (distance entre deux distributions) : d ² χ ² ( i, i' ) = J 1 f j = 1. j Les profils sont tous dans un hyperplan car la somme de leurs coordonnées est 1. On a donc un axe de moins qu'en ACP et une valeur propre en moins. Les valeurs propres (inertie projetée sur l'axe) sont inférieures à 1. Les deux nuages représentent des profils et il est d'usage de représenter les deux nuages dans un même plan (le profil d'une modalité est «quasi» le barycentre des profils des modalités de l'autre variable). La proximité entre modalités des deux variables indique une attirance entre ces modalités (l'effectif observé est supérieur à celui attendu sous H 0 ). La proximité entre modalités d'une même variable indique que les distributions sont voisines pour ces deux modalités au regard de l'autre variable. Exemple 1 : Les résultats de l'ajustement donnent : > afc$eig [1] > (afc$eig/sum(afc$eig)) [1] f f ij i. f i' j f i'

15 ma d = 0.5 BR d = 0.5 BR ma d = 0.5 bl BD bl BD ve Profils ligne dans le plan F 1 F 2 Profils colonne Projection simultanée Exemple 2 : CSP Le tableau décrit la consommation annuelle en francs d'un ménage pour différentes denrées alimentaires en MA, EM, CA indiquent la catégorie socio-professionnelle et 2,3,4,5 la taille du foyer. > csp=read.table("csp.txt") pain legu frui vian vola lait vin MA EM Statistiques élémentaires chisq.test(csp) Pearson's Chi-squared test X-squared = , df = 66, p-value < 2.2e-16 RO ve RO Calcul des profils : Profils ligne > round(csp/apply(csp,1,sum),2) pain legu frui vian vola lait vin MA2 EM CA MA EM CA MA EM CA MA EM CA Profils colonne > round(t(t(csp)/apply(t(csp),1,sum)),2) pain legu frui vian vola lait vin MA EM CA MA EM CA MA EM CA MA EM CA Poids des lignes et colonnes > round(apply(csp,1,sum)/sum(csp),2) MA2 EM2 CA2 MA3 EM3 CA3 MA4 EM4 CA4 MA5 EM5 CA > round(apply(csp,2,sum)/sum(csp),2) pain legu frui vian vola lait vin Comment décrire ce tableau? Quelles sont les relations entre variables et modalités de chaque variables? Comment présenter ce tableau à un public non averti?
 pain legu frui vian vola lait vin MA2 332 428 354 1437 526 247 427 EM2 293 559 388 1527 567 239 258... Statistiques élémentaires chisq.test(csp) Pearson's Chi-squared test X-squared = 1290.")
16 1. Valeurs propres et choix des axes Fiche 6 Aides à l'interprétation Pour définir le nombre d'axes étudiés, on étudie les valeurs propres obtenues. Chaque valeur propre correspond à la part d'inertie projeté sur un axe donné. Remarques importantes: La somme des valeurs propres est toujours égale à l'inertie totale du nuage. On caractérise ainsi chaque axe par le % d'inertie qu'il permet d'expliquer. En AFC, les valeurs propres sont toutes inférieures à 1. On ne retient donc que les axes avec les plus fortes valeurs propres. Le choix des axes retenus est un peu délicat. On peut donner quelques règles : Règle du coude : On observe souvent de fortes valeurs propres au départ puis ensuite de faibles valeurs avec un décrochage dans le diagramme. On retient les axes avant le décrochage. Règle de l'inertie minimale : On sélectionne les premiers axes afin d'atteindre un % donné d'inertie expliquée (70% par exemple). Règle du bon sens : On analyse les plans et axes et on ne retient que ceux interprétables. Exemple 2 CSP Avec ade4: réaliser l'afc >afc=dudi.coa(tableau) Extraire les valeurs propres >afc$eig Calcul des % >afc$eig/sum(afc$eig) > round(afc$eig,3) [1] > round(afc$eig/sum(afc$eig)*100) [1] Qualité de représentation qlt Les profils projetés dans un plan factoriel ne sont pas forcément correctement représentés. Dans ce cas, les interprétations sont erronées. Il est indispensable de vérifier la bonne représentation au préalable

17 Qualité de représentation qlt: Si l'angle est grand, le point initial est éloigné de sa projection. On utilise le paramètre cos 2 pour caractériser la qualité de représentation (qlt) sur un axe. Plus qlt i est proche de 1 plus il est bien représenté. Plus qlt i est proche de 0 plus il est mal représenté. Dans un plan, on calcule la somme des deux qlt, par exemple qlt F1 + qlt F2 pour le plan F 1 F 2. qlt correspond en fait au rapport de l'inertie du projeté sur l'inertie du point initial. Qualité globale : Dans un plan donné, on définit également la qualité globale comme le pourcentage d'inertie qu'explique le plan. C'est par rapport à cette qualité globale que l'on évalue la qlt d'un profil. Bilan : On commencera donc toujours l'analyse d'un plan factoriel en précisant l'existence (ou non) de profils mal représentés et en justifiant par les qlt. 3. Contribution ctr Lors de la construction d'un axe factoriel, certains profils ont des rôles plus importants. On calcule un paramètre appelé contribution, ctr, qui permet de calculer cette influence. Définition: La contribution ctr est définie comme la proportion de l'inertie de l'axe expliquée par le profil pour un axe donné. Règles d'interprétation : L'analyse se fait axe par axe, en parallèle sur les profils ligne et colonne. Plus ctr est grande, plus l'influence du profil est grande. On ne retient donc que les plus fortes valeurs (il y a souvent un décrochage après quelques valeurs). ctr est considéré comme positif si le profil est dans la partie positive de l'axe. ctr est considéré comme négatif si le profil est dans la partie négative de l'axe. Le bilan des ctr peut être présenter pour un axe donné sous forme d'un tableau avec les principles ctr + et des profils, en précisant la valeur de ctr : ctr axe F 1 : - + Profils colonnes : Profils lignes : On réalise ensuite une interprétation. Sous R, ces paramètres sont obtenus avec les commandes suivantes : Pour les lignes >inertiel<-inertia.dudi(acp, row.inertia=true) ctr des lignes en % >inertiel$row.abs/100 qlt des lignes en % >inertiel$row.rel/100 Pour les colonnes >inertiec<-inertia.dudi(acp, col.inertia=true) ctr des colonnes en % >inertiec$col.abs/100 qlt des colonnes en % >inertiec$col.rel/

18 Fiche 7 Représentation graphique des profils Les profils ligne (respectivement colonne) sont associés à des points de l'espace dont les coordonnées sont les distributions conditionnelles. On peut mesurer la distance entre ces profils en utilisant la distance du 2 entre ces deux points. La construction des composantes principales conduit à rendre minimale la déformation des distances entre profils lorsque l'on projette les profils dans le plan factoriel F 1 F 2. Ainsi les distances que l'on observe entre les profils dans le plan factoriel sont globalement les plus proches possible des distances réelles entre ces profils. L'analyse des plans factoriels permet ainsi d'observer les profils proches entre eux (distribution similaire) ou au contraire éloignés. Il est ainsi possible de construire des groupes, d'observer des tendances... Les règles de lecture des plans factoriels sont : Les profils ligne et colonne sont projetés simultanément afin notamment d'observer les modalités des deux variables présentant de fortes (attraction) ou faibles (répulsion) associations. Seuls les profils bien représentés sont pris en compte dans l'interprétation. On calcule la somme des qtl dans le plan et on vérifie que cette somme n'est pas trop faible par rapport à la qualité moyenne du plan. On réalise le bilan en positif et en négatif des profils qui ont la plus forte contribution pour un axe donné. On donne ainsi en parallèle sur les lignes et colonnes une signification concrête à ces axes en terme d'attraction, de similarité, entre modalités ou en tendance particulière. On réalise des groupes, à l'aide éventuelle de la fonction s.class, dans le cas de groupes préexistants (homme-femme par exemple) ou on construit arbitrairement ces groupes en raison des proximités entre profils. L'utilisation de profils supplémentaires non utilisés dans l'ajustement mais a posteriori permet également d'éclairer l'analyse. Guide pratique de l'analyse AFC Etape 1 : Sélection des axes et des plans retenus principalement par rapport aux valeurs propres. Etape 2 : Projection des profils ligne et colonne dans un plan donné ( F 1 F 2 en premier) Examen des qlt dans le plan pour éliminer les profils mal représentés Bilan des ctr pour un axe afin de donner un sens à cet axe (opposition, tendance...) Topographie des profils afin d'dentifier des groupes, des oppositions, des tendances notamment à l'aide de la fonction s.class Utiliser ses connaissances sur le sujet pour proposer des explications sur les résultats de l'analyse Utiliser des profils supplémentaires ou des profils type (moyenne des H et des F par exemple)

19 Exemple 2 csp Profils lignes et colonnes > inertie <-inertia.dudi(afc, row.inertia=true) Coordonnées profils ligne > round(afc$li,2) Axis1 Axis2 MA EM CA MA EM CA MA EM CA MA EM CA [CTR en %] > round(inertie$row.abs/100) Axis1 Axis2 MA EM2 1 0 CA MA3 8 3 EM3 3 0 CA MA EM4 2 0 CA MA EM CA [QLT en %] > round(inertie$row.re/100) Axis1 Axis2 con.tra MA EM CA MA EM CA MA EM CA MA EM CA colonne > round(afc$co,2) Comp1 Comp2 pain legu frui vian vola lait vin [CTR en %] > round(inertie$col.abs/100) Comp1 Comp2 pain 22 3 legu 0 13 frui 11 0 vian 4 5 vola 17 1 lait vin [QLT en %] > round(inertie$col.re/100) Comp1 Comp2 con.tra pain legu frui vian vola lait vin > s.label(afc$li,xax=1,yax=2) > s.label(afc$co,xax=1,yax=2,add.plot=t,boxes=f)
![abs/100) Axis1 Axis2 MA2 4 24 EM2 1 0 CA2 4 14 MA3 8 3 EM3 3 0 CA3 18 4 MA4 13 1 EM4 2 0 CA4 20 1 MA5 18 2 EM5 1 27 CA5 10 24 [QLT en %] > round(inertie$row.re/100) Axis1 Axis2 con.](/docs-images/42/6770336/images/page_19.jpg "tra MA2-29 -64 10 EM2 31-5 2 CA2 34-49 7 MA3-86 -11 6 EM3-80 -2 3 CA3 87-7 14 MA4-94 2 9 EM4-81 -2 1 CA4 90-1 14 MA5-91 3 13 EM5-5 89 8 CA5 46 43 14 colonne > round(afc$co,2) Comp1 Comp2 pain -0.19 0.")
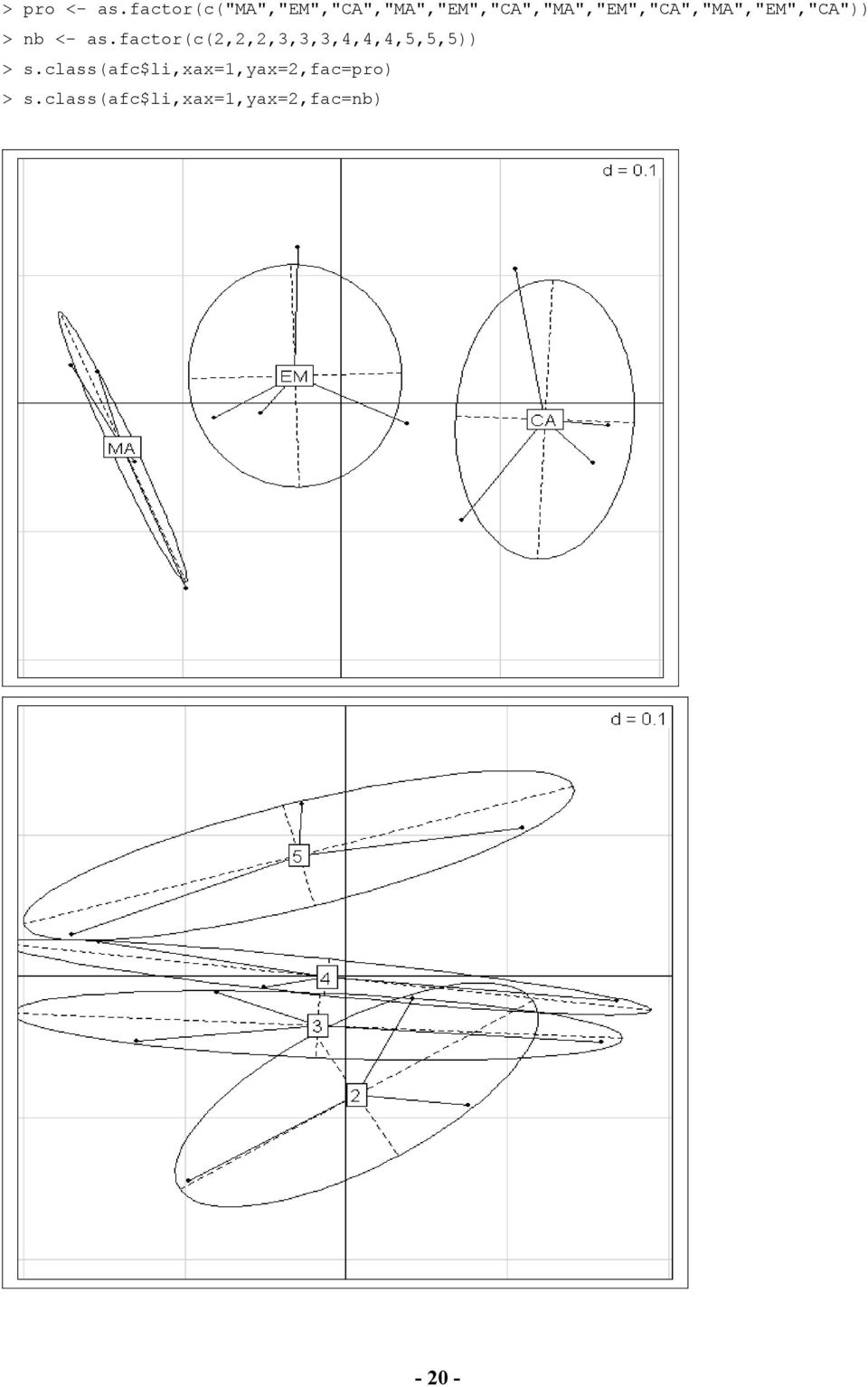
20 > pro <- as.factor(c("ma","em","ca","ma","em","ca","ma","em","ca","ma","em","ca")) > nb <- as.factor(c(2,2,2,3,3,3,4,4,4,5,5,5)) > s.class(afc$li,xax=1,yax=2,fac=pro) > s.class(afc$li,xax=1,yax=2,fac=nb)
21 X CLASSIFICATION Objectifs et données : On dispose de n objets caractérisés par des variables ou par les distances entre ces objets (tableau de distance). L'objectif de la classification est de construire des groupes d'objets homogènes avec comme principe : au sein d'un groupe, les objets sont les plus similaires possibles, entre les groupes, les différences sont le plus grandes possibles. Lien avec l'afc et l'acp : L'analyse factorielle et la classification sont souvent conduites en parallèle. On peut ainsi effectuer une classification sur les profils, les variables, les individus. Les résultats de ces classifications peuvent ainsi être mis en parallèle avec l'analyse factorielle et améliorer l'interprétation. Les méthodes de classification repose sur la notion de similarité ou de dissimilarité (distance) entre les objets que l'on souhaite regrouper en classes homogènes. On est donc souvent conduit à manipuler des tableaux de distance. Soit E un ensemble de n objets. Une application d de E E dans R + est appelée dissimilarité si elle vérifie pour tout couple (i,j) de E² : d i, j =d j, i d i, j ³0 et d i, i =0 si de plus d i, j d i, k d k, i, d est appelée distance Une application s de E E dans R + est appelée similarité si elle vérifie pour tout couple (i,j) de E² : s i, j = s j, i s(i,j) 0 s(i,i) s i, j Exemples de distance et similarité Données numériques (individus et variables quantitatives) Pour des objets décrits par des variables quantitatives, on peut utiliser la distance euclidienne classique (ACP) Tableaux de contingence (profils) Pour des profils de modalités dans un tableau de contingence, on utilisera la distance du ² (AFC). Pour des données binaires (présence/absence d'une caractéristique) Plusieurs indices de similarité existent, comme l'indice de Jaccard : J= avec a le nombre de caractéristiques communes, b celui possédé par i et pas par j c celui possédé par j et pas par i. a a b c Exemple : Construire le tableau des indices de Jaccard pour les individus A à E C1 C2 C3 C4 A B C D
22 Distance génétique (Chessel et al., Principe de la Classification Ascendante Hiérarchique (CAH) La CAH est une méthode itérative. 1. Au départ chaque objet représente un groupe. 2. A chaque étape est construite une nouvelle partition de moins en moins fine, contenant une classe de moins à chaque étape. A la première étape, on regroupe les deux objets les plus proches et on ne dispose plus alors que de n 1 classes. Cette méthode aboutit à un emboîtement de partitions visualisé graphiquement par un arbre hiérarchique indicé (dendrogramme). On regroupe à chaque étape les 2 objets ou les 2 groupes d'objets dont la ressemblance est la plus forte. Cette méthode nécessite ensuite de recalculer la distance des objets restant au groupe ainsi formé. Ces méthodes de calculs s'appellent le critère d'agrégation et définissent la méthode : Critère du saut minimal : la distance entre h et h' est celle définie par les deux éléments les plus proches. Critère du diamètre ou distance maximale: la distance entre h et h' est celle définie par les deux éléments les plus éloignées Critère de la moyenne (UPGMA): la distance entre h et h' est celle définie par la distance moyenne entre les éléments de h et de h'. Critère de Ward : Le critère est calculé pour h et h' par hh ' = p p 2 h h' d gh, g p h p h '. Le h' critère de Ward correspond à l'augmentation de l'inertie intra résultant du regroupement de h et h'. Dans la pratique, le critère de Ward est le plus largement utilisé en CAH. Liens sur internet :
23 Fiche 8 Exemple manuel de CAH Un laboratoire veut étudier la ressemblance génétique de cinq lignées de sorgho (A, B, C, D, E). Pour cela, il réalise une analyse par RFLP avec l'enzyme de restriction Eco RI et une sonde d'origine inconnue. Les fragments d ADN ainsi amplifiés sont ensuite séparés par electrophorèse. Les résultats de l electrophorèse donnent les profils suivants: NB : Deux lignées de sorgho présentent autant de fragments d ADN identiques que de bandes révélées à la même hauteur sur les profils de l electrophorèse. lignées A B C D E Question 1 : Construisez la matrice de similarité entre les cinq lignées de sorgho à partir du coefficient de similarité de Dice (Sxy) défini ci-dessous. S XY = N XY N X N Y Similarité A B C D E A B C D E Nx = nombre de bandes de la lignée X Ny = nombre de bandes de la lignée Y Nxy = nombre de bandes identiques entre les lignées X et Y Question 2 : Déterminez la matrice de dissimilarité en utilisant la fonction de similitude linéaire : Dxy = 1 Sxy Dissimilarité A B C D E A B C D E Question 3 : Effectuez sur la matrice de dissimilarité la CAH en utilisant le critère du saut maximal. Dij Dij Dij Dendrogramme
24 Exemple zebu > library(ade4) > acp = dudi.pca(zebu[,1:6]) Fiche 9 Exemple de CAH avec ade4 CAH sur les individus > dzebu = dist.dudi(acp, amongrow=true) > round(dzebu,1) (extrait pour les 10 premiers individus) > cah=hclust(dzebu^2,method="ward") > barplot(cah$height[order(cah$height,decreasing=true)]) > plot(cah,hang=-1) > rect.hclust(cah,h=20) Cluster Dendrogram Height dzebu^2 hclust (*, "ward") > cutree(cah,h=20) > s.label(acp$li) > s.class(dfxy=acp$li,fac=as.factor(cutree(cah,h=20))) d = 1 d =
25 CAH sur les variables > dzebu = dist.dudi(acp, amongrow=false) > round(dzebu,1) (extrait pour les 10 premiers individus) > cah=hclust(dzebu^2,method="ward") > barplot(cah$height[order(cah$height,decreasing=true)]) > plot(cah,hang=-1) > rect.hclust(cah,h=1) Cluster Dendrogram Height qsup tota vif carc gras os dzebu^2 hclust (*, "ward") > cutree(cah,h=1) vif carc qsup tota gras os > s.label(acp$co) > s.class(dfxy=acp$co,fac=as.factor(cutree(cah,h=1))) d = 0.5 d = 0.5 carc vif 1 gras 3 tota qsup 2 os
26 Complé m e n t s pour l'analy s e de donné e s sou s R FactoMineR Sou s R, taper : > sourc e(" er.fre e.fr/install- facto.r ") (sou s rés erv e d'acc é s à internet) Utilis ation de FactoMineR sou s Rcmdr Sélectionner le tableau sous Rcmdr puis dans le menu FactoMineR choisir la méthode. Vous pouvez choisir les variables et les individus en supplémentaires. Les résultats sont disponibles sous R dans le fichier de sortie noté par défaut res. Vous pouvez également sauver un fichier excel avec outputs. Pour afficher des plans factoriels, sélectionner dans FactoMineR les axes à représenter Aides à l'interprét ation s à récup ér er dan s le fichier R res ou le fichier exc el: ACP AFC valeurs propres : res$eig qlt et ctr : Sous R, les qlt sont sous la forme res$var$cos2 ou res$ind$cos2, les ctr res$var$contrib ou res$ind$contrib. Tous sur les variables et individus : res$var ou res$ind variables supplémentaire : res$quanti.sup et res$ind.sup valeurs propres : res$eig qlt et ctr : Sous R, les qlt sont sous la forme res$col$cos2 ou res$row$cos2, les ctr res$col$contrib ou res$row$contrib. Tous sur les profils ligne et colonne : res$col ou res$var profil supplémentaire : res$col.sup res$row.sup
La classification automatique de données quantitatives
 La classification automatique de données quantitatives 1 Introduction Parmi les méthodes de statistique exploratoire multidimensionnelle, dont l objectif est d extraire d une masse de données des informations
La classification automatique de données quantitatives 1 Introduction Parmi les méthodes de statistique exploratoire multidimensionnelle, dont l objectif est d extraire d une masse de données des informations
Déroulement d un projet en DATA MINING, préparation et analyse des données. Walid AYADI
 1 Déroulement d un projet en DATA MINING, préparation et analyse des données Walid AYADI 2 Les étapes d un projet Choix du sujet - Définition des objectifs Inventaire des données existantes Collecte, nettoyage
1 Déroulement d un projet en DATA MINING, préparation et analyse des données Walid AYADI 2 Les étapes d un projet Choix du sujet - Définition des objectifs Inventaire des données existantes Collecte, nettoyage
INTRODUCTION À L ANALYSE FACTORIELLE DES CORRESPONDANCES
 INTRODUCTION À L ANALYSE FACTORIELLE DES CORRESPONDANCES Dominique LAFFLY Maître de Conférences, Université de Pau Laboratoire Société Environnement Territoire UMR 5603 du CNRS et Université de Pau Domaine
INTRODUCTION À L ANALYSE FACTORIELLE DES CORRESPONDANCES Dominique LAFFLY Maître de Conférences, Université de Pau Laboratoire Société Environnement Territoire UMR 5603 du CNRS et Université de Pau Domaine
L'analyse des données à l usage des non mathématiciens
 Montpellier L'analyse des données à l usage des non mathématiciens 2 ème Partie: L'analyse en composantes principales AGRO.M - INRA - Formation Permanente Janvier 2006 André Bouchier Analyses multivariés.
Montpellier L'analyse des données à l usage des non mathématiciens 2 ème Partie: L'analyse en composantes principales AGRO.M - INRA - Formation Permanente Janvier 2006 André Bouchier Analyses multivariés.
L ANALYSE EN COMPOSANTES PRINCIPALES (A.C.P.) Pierre-Louis GONZALEZ
 Pierre-Louis GONZALEZ") L ANALYSE EN COMPOSANTES PRINCIPALES (A.C.P.) Pierre-Louis GONZALEZ INTRODUCTION Données : n individus observés sur p variables quantitatives. L A.C.P. permet d eplorer les liaisons entre variables et
L ANALYSE EN COMPOSANTES PRINCIPALES (A.C.P.) Pierre-Louis GONZALEZ INTRODUCTION Données : n individus observés sur p variables quantitatives. L A.C.P. permet d eplorer les liaisons entre variables et
Introduction. Préambule. Le contexte
 Préambule... INTRODUCTION... BREF HISTORIQUE DE L ACP... 4 DOMAINE D'APPLICATION... 5 INTERPRETATIONS GEOMETRIQUES... 6 a - Pour les n individus... 6 b - Pour les p variables... 7 c - Notion d éléments
Préambule... INTRODUCTION... BREF HISTORIQUE DE L ACP... 4 DOMAINE D'APPLICATION... 5 INTERPRETATIONS GEOMETRIQUES... 6 a - Pour les n individus... 6 b - Pour les p variables... 7 c - Notion d éléments
SERIE 1 Statistique descriptive - Graphiques
 Exercices de math ECG J.P. 2 ème A & B SERIE Statistique descriptive - Graphiques Collecte de l'information, dépouillement de l'information et vocabulaire La collecte de l information peut être : directe:
Exercices de math ECG J.P. 2 ème A & B SERIE Statistique descriptive - Graphiques Collecte de l'information, dépouillement de l'information et vocabulaire La collecte de l information peut être : directe:
1 Complément sur la projection du nuage des individus
 TP 0 : Analyse en composantes principales (II) Le but de ce TP est d approfondir nos connaissances concernant l analyse en composantes principales (ACP). Pour cela, on reprend les notations du précédent
TP 0 : Analyse en composantes principales (II) Le but de ce TP est d approfondir nos connaissances concernant l analyse en composantes principales (ACP). Pour cela, on reprend les notations du précédent
Logiciel XLSTAT version 7.0. 40 rue Damrémont 75018 PARIS
 Logiciel XLSTAT version 7.0 Contact : Addinsoft 40 rue Damrémont 75018 PARIS 2005-2006 Plan Présentation générale du logiciel Statistiques descriptives Histogramme Discrétisation Tableau de contingence
Logiciel XLSTAT version 7.0 Contact : Addinsoft 40 rue Damrémont 75018 PARIS 2005-2006 Plan Présentation générale du logiciel Statistiques descriptives Histogramme Discrétisation Tableau de contingence
ACP Voitures 1- Méthode
 acp=princomp(voit,cor=t) ACP Voitures 1- Méthode Call: princomp(x = voit, cor = T) Standard deviations: Comp.1 Comp.2 Comp.3 Comp.4 Comp.5 Comp.6 2.1577815 0.9566721 0.4903373 0.3204833 0.2542759 0.1447788
acp=princomp(voit,cor=t) ACP Voitures 1- Méthode Call: princomp(x = voit, cor = T) Standard deviations: Comp.1 Comp.2 Comp.3 Comp.4 Comp.5 Comp.6 2.1577815 0.9566721 0.4903373 0.3204833 0.2542759 0.1447788
La segmentation à l aide de EG-SAS. A.Bouhia Analyste principal à la Banque Nationale du Canada. Chargé de cours à l UQAM
 La segmentation à l aide de EG-SAS A.Bouhia Analyste principal à la Banque Nationale du Canada. Chargé de cours à l UQAM Définition de la segmentation - Au lieu de considérer une population dans son ensemble,
La segmentation à l aide de EG-SAS A.Bouhia Analyste principal à la Banque Nationale du Canada. Chargé de cours à l UQAM Définition de la segmentation - Au lieu de considérer une population dans son ensemble,
Structure du cours : Il existe de nombreuses méthodes intéressantes qui couvrent l Analyse des Données
 Structure du cours : Il existe de nombreuses méthodes intéressantes qui couvrent l Analyse des Données et le Data Mining Nous suivons le plan suivant : Fonctionnement de Spad Catalogue des méthodes (statistiques
Structure du cours : Il existe de nombreuses méthodes intéressantes qui couvrent l Analyse des Données et le Data Mining Nous suivons le plan suivant : Fonctionnement de Spad Catalogue des méthodes (statistiques
Chapitre 3. Les distributions à deux variables
 Chapitre 3. Les distributions à deux variables Jean-François Coeurjolly http://www-ljk.imag.fr/membres/jean-francois.coeurjolly/ Laboratoire Jean Kuntzmann (LJK), Grenoble University 1 Distributions conditionnelles
Chapitre 3. Les distributions à deux variables Jean-François Coeurjolly http://www-ljk.imag.fr/membres/jean-francois.coeurjolly/ Laboratoire Jean Kuntzmann (LJK), Grenoble University 1 Distributions conditionnelles
Initiation à l analyse en composantes principales
 Fiche TD avec le logiciel : tdr601 Initiation à l analyse en composantes principales A.B. Dufour & J.R. Lobry Une première approche très intuitive et interactive de l ACP. Centrage et réduction des données.
Fiche TD avec le logiciel : tdr601 Initiation à l analyse en composantes principales A.B. Dufour & J.R. Lobry Une première approche très intuitive et interactive de l ACP. Centrage et réduction des données.
Introduction au datamining
 Introduction au datamining Patrick Naïm janvier 2005 Définition Définition Historique Mot utilisé au départ par les statisticiens Le mot indiquait une utilisation intensive des données conduisant à des
Introduction au datamining Patrick Naïm janvier 2005 Définition Définition Historique Mot utilisé au départ par les statisticiens Le mot indiquait une utilisation intensive des données conduisant à des
Classification non supervisée
 AgroParisTech Classification non supervisée E. Lebarbier, T. Mary-Huard Table des matières 1 Introduction 4 2 Méthodes de partitionnement 5 2.1 Mesures de similarité et de dissimilarité, distances.................
AgroParisTech Classification non supervisée E. Lebarbier, T. Mary-Huard Table des matières 1 Introduction 4 2 Méthodes de partitionnement 5 2.1 Mesures de similarité et de dissimilarité, distances.................
SIG ET ANALYSE EXPLORATOIRE
 SIG ET ANALYSE EXPLORATOIRE VERS DE NOUVELLES PRATIQUES EN GÉOGRAPHIE Jean-Marc ORHAN Equipe P.A.R.I.S., URA 1243 du CNRS Paris Résumé L'offre actuelle dans le domaine des logiciels de type Système d'information
SIG ET ANALYSE EXPLORATOIRE VERS DE NOUVELLES PRATIQUES EN GÉOGRAPHIE Jean-Marc ORHAN Equipe P.A.R.I.S., URA 1243 du CNRS Paris Résumé L'offre actuelle dans le domaine des logiciels de type Système d'information
Extraction d informations stratégiques par Analyse en Composantes Principales
 Extraction d informations stratégiques par Analyse en Composantes Principales Bernard DOUSSET IRIT/ SIG, Université Paul Sabatier, 118 route de Narbonne, 31062 Toulouse cedex 04 dousset@irit.fr 1 Introduction
Extraction d informations stratégiques par Analyse en Composantes Principales Bernard DOUSSET IRIT/ SIG, Université Paul Sabatier, 118 route de Narbonne, 31062 Toulouse cedex 04 dousset@irit.fr 1 Introduction
Traitement des données avec Microsoft EXCEL 2010
 Traitement des données avec Microsoft EXCEL 2010 Vincent Jalby Septembre 2012 1 Saisie des données Les données collectées sont saisies dans une feuille Excel. Chaque ligne correspond à une observation
Traitement des données avec Microsoft EXCEL 2010 Vincent Jalby Septembre 2012 1 Saisie des données Les données collectées sont saisies dans une feuille Excel. Chaque ligne correspond à une observation
1 - PRESENTATION GENERALE...
 Contenu PREAMBULE... 2 INTRODUCTION... 2 1 - PRESENTATION GENERALE... 4 Qualité et optimalité... 8 2 - AGREGATION AUTOUR DE CENTRES MOBILES... 9 2.1 LES BASES DE L'ALGORITHME... 10 2.2 TECHNIQUES CONNEXES...
Contenu PREAMBULE... 2 INTRODUCTION... 2 1 - PRESENTATION GENERALE... 4 Qualité et optimalité... 8 2 - AGREGATION AUTOUR DE CENTRES MOBILES... 9 2.1 LES BASES DE L'ALGORITHME... 10 2.2 TECHNIQUES CONNEXES...
t 100. = 8 ; le pourcentage de réduction est : 8 % 1 t Le pourcentage d'évolution (appelé aussi taux d'évolution) est le nombre :
 est le nombre :") Terminale STSS 2 012 2 013 Pourcentages Synthèse 1) Définition : Calculer t % d'un nombre, c'est multiplier ce nombre par t 100. 2) Exemples de calcul : a) Calcul d un pourcentage : Un article coûtant
Terminale STSS 2 012 2 013 Pourcentages Synthèse 1) Définition : Calculer t % d'un nombre, c'est multiplier ce nombre par t 100. 2) Exemples de calcul : a) Calcul d un pourcentage : Un article coûtant
Arbres binaires de décision
 1 Arbres binaires de décision Résumé Arbres binaires de décision Méthodes de construction d arbres binaires de décision, modélisant une discrimination (classification trees) ou une régression (regression
1 Arbres binaires de décision Résumé Arbres binaires de décision Méthodes de construction d arbres binaires de décision, modélisant une discrimination (classification trees) ou une régression (regression
1. Vocabulaire : Introduction au tableau élémentaire
 L1-S1 Lire et caractériser l'information géographique - Le traitement statistique univarié Statistique : le terme statistique désigne à la fois : 1) l'ensemble des données numériques concernant une catégorie
L1-S1 Lire et caractériser l'information géographique - Le traitement statistique univarié Statistique : le terme statistique désigne à la fois : 1) l'ensemble des données numériques concernant une catégorie
Analyse de la variance Comparaison de plusieurs moyennes
 Analyse de la variance Comparaison de plusieurs moyennes Biostatistique Pr. Nicolas MEYER Laboratoire de Biostatistique et Informatique Médicale Fac. de Médecine de Strasbourg Mars 2011 Plan 1 Introduction
Analyse de la variance Comparaison de plusieurs moyennes Biostatistique Pr. Nicolas MEYER Laboratoire de Biostatistique et Informatique Médicale Fac. de Médecine de Strasbourg Mars 2011 Plan 1 Introduction
Statistique Descriptive Multidimensionnelle. (pour les nuls)
") Publications de l Institut de Mathématiques de Toulouse Statistique Descriptive Multidimensionnelle (pour les nuls) (version de mai 2010) Alain Baccini Institut de Mathématiques de Toulouse UMR CNRS 5219
Publications de l Institut de Mathématiques de Toulouse Statistique Descriptive Multidimensionnelle (pour les nuls) (version de mai 2010) Alain Baccini Institut de Mathématiques de Toulouse UMR CNRS 5219
L'analyse de données. Polycopié de cours ENSIETA - Réf. : 1463. Arnaud MARTIN
 L'analyse de données Polycopié de cours ENSIETA - Réf : 1463 Arnaud MARTIN Septembre 2004 Table des matières 1 Introduction 1 11 Domaines d'application 2 12 Les données 2 13 Les objectifs 3 14 Les méthodes
L'analyse de données Polycopié de cours ENSIETA - Réf : 1463 Arnaud MARTIN Septembre 2004 Table des matières 1 Introduction 1 11 Domaines d'application 2 12 Les données 2 13 Les objectifs 3 14 Les méthodes
Analyse des correspondances avec colonne de référence
 ADE-4 Analyse des correspondances avec colonne de référence Résumé Quand une table de contingence contient une colonne de poids très élevé, cette colonne peut servir de point de référence. La distribution
ADE-4 Analyse des correspondances avec colonne de référence Résumé Quand une table de contingence contient une colonne de poids très élevé, cette colonne peut servir de point de référence. La distribution
Analyse en Composantes Principales
 Analyse en Composantes Principales Anne B Dufour Octobre 2013 Anne B Dufour () Analyse en Composantes Principales Octobre 2013 1 / 36 Introduction Introduction Soit X un tableau contenant p variables mesurées
Analyse en Composantes Principales Anne B Dufour Octobre 2013 Anne B Dufour () Analyse en Composantes Principales Octobre 2013 1 / 36 Introduction Introduction Soit X un tableau contenant p variables mesurées
Objectifs. Clustering. Principe. Applications. Applications. Cartes de crédits. Remarques. Biologie, Génomique
 Objectifs Clustering On ne sait pas ce qu on veut trouver : on laisse l algorithme nous proposer un modèle. On pense qu il existe des similarités entre les exemples. Qui se ressemble s assemble p. /55
Objectifs Clustering On ne sait pas ce qu on veut trouver : on laisse l algorithme nous proposer un modèle. On pense qu il existe des similarités entre les exemples. Qui se ressemble s assemble p. /55
Statistique Descriptive Élémentaire
 Publications de l Institut de Mathématiques de Toulouse Statistique Descriptive Élémentaire (version de mai 2010) Alain Baccini Institut de Mathématiques de Toulouse UMR CNRS 5219 Université Paul Sabatier
Publications de l Institut de Mathématiques de Toulouse Statistique Descriptive Élémentaire (version de mai 2010) Alain Baccini Institut de Mathématiques de Toulouse UMR CNRS 5219 Université Paul Sabatier
Couples de variables aléatoires discrètes
 Couples de variables aléatoires discrètes ECE Lycée Carnot mai Dans ce dernier chapitre de probabilités de l'année, nous allons introduire l'étude de couples de variables aléatoires, c'est-à-dire l'étude
Couples de variables aléatoires discrètes ECE Lycée Carnot mai Dans ce dernier chapitre de probabilités de l'année, nous allons introduire l'étude de couples de variables aléatoires, c'est-à-dire l'étude
Exemples de Projets SAFI
 Exemples de Projets SAFI Analyse sismique simplifiée (CNB-95) Société Informatique SAFI Inc. 3393, chemin Sainte-Foy Ste-Foy, Québec, G1X 1S7 Canada Contact: Rachik Elmaraghy, P.Eng., M.A.Sc. Tél.: 1-418-654-9454
Exemples de Projets SAFI Analyse sismique simplifiée (CNB-95) Société Informatique SAFI Inc. 3393, chemin Sainte-Foy Ste-Foy, Québec, G1X 1S7 Canada Contact: Rachik Elmaraghy, P.Eng., M.A.Sc. Tél.: 1-418-654-9454
Statistiques. Rappels de cours et travaux dirigés. Master 1 Biologie et technologie du végétal. Année 2010-2011
 Master 1 Biologie et technologie du végétal Année 010-011 Statistiques Rappels de cours et travaux dirigés (Seul ce document sera autorisé en examen) auteur : Jean-Marc Labatte jean-marc.labatte@univ-angers.fr
Master 1 Biologie et technologie du végétal Année 010-011 Statistiques Rappels de cours et travaux dirigés (Seul ce document sera autorisé en examen) auteur : Jean-Marc Labatte jean-marc.labatte@univ-angers.fr
UFR de Sciences Economiques Année 2008-2009 TESTS PARAMÉTRIQUES
 Université Paris 13 Cours de Statistiques et Econométrie I UFR de Sciences Economiques Année 2008-2009 Licence de Sciences Economiques L3 Premier semestre TESTS PARAMÉTRIQUES Remarque: les exercices 2,
Université Paris 13 Cours de Statistiques et Econométrie I UFR de Sciences Economiques Année 2008-2009 Licence de Sciences Economiques L3 Premier semestre TESTS PARAMÉTRIQUES Remarque: les exercices 2,
Evaluation de la variabilité d'un système de mesure
 Evaluation de la variabilité d'un système de mesure Exemple 1: Diamètres des injecteurs de carburant Problème Un fabricant d'injecteurs de carburant installe un nouveau système de mesure numérique. Les
Evaluation de la variabilité d'un système de mesure Exemple 1: Diamètres des injecteurs de carburant Problème Un fabricant d'injecteurs de carburant installe un nouveau système de mesure numérique. Les
INTRODUCTION GENERALE...1 LA CONNEXION ODBC :...1. CONNEXION AU TRAVERS D EXCEL(tm)...6. LOGICIEL QUANTUM GIS (Qgis)... 10
...6. LOGICIEL QUANTUM GIS (Qgis)... 10") PROGRAMME RÉGIONAL DE RENFORCEMENT DE LA COLLECTE DES DONNÉES STATISTIQUES DES PECHES DANS LES ÉTATS MEMBRES ET DE CREATION D UNE BASE DE DONNÉES REGIONALE Manuel de formation TABLE DES MATIERES INTRODUCTION
PROGRAMME RÉGIONAL DE RENFORCEMENT DE LA COLLECTE DES DONNÉES STATISTIQUES DES PECHES DANS LES ÉTATS MEMBRES ET DE CREATION D UNE BASE DE DONNÉES REGIONALE Manuel de formation TABLE DES MATIERES INTRODUCTION
Feuille 6 : Tests. Peut-on dire que l usine a respecté ses engagements? Faire un test d hypothèses pour y répondre.
 Université de Nantes Année 2013-2014 L3 Maths-Eco Feuille 6 : Tests Exercice 1 On cherche à connaître la température d ébullition µ, en degrés Celsius, d un certain liquide. On effectue 16 expériences
Université de Nantes Année 2013-2014 L3 Maths-Eco Feuille 6 : Tests Exercice 1 On cherche à connaître la température d ébullition µ, en degrés Celsius, d un certain liquide. On effectue 16 expériences
ISFA 2 année 2002-2003. Les questions sont en grande partie indépendantes. Merci d utiliser l espace imparti pour vos réponses.
 On considère la matrice de données : ISFA 2 année 22-23 Les questions sont en grande partie indépendantes Merci d utiliser l espace imparti pour vos réponses > ele JCVGE FM1 GM JCRB FM2 JMLP Paris 61 29
On considère la matrice de données : ISFA 2 année 22-23 Les questions sont en grande partie indépendantes Merci d utiliser l espace imparti pour vos réponses > ele JCVGE FM1 GM JCRB FM2 JMLP Paris 61 29
Projet de traitement d'image - SI 381 reconstitution 3D d'intérieur à partir de photographies
 Projet de traitement d'image - SI 381 reconstitution 3D d'intérieur à partir de photographies Régis Boulet Charlie Demené Alexis Guyot Balthazar Neveu Guillaume Tartavel Sommaire Sommaire... 1 Structure
Projet de traitement d'image - SI 381 reconstitution 3D d'intérieur à partir de photographies Régis Boulet Charlie Demené Alexis Guyot Balthazar Neveu Guillaume Tartavel Sommaire Sommaire... 1 Structure
Introduction à l'analyse multivariée (factorielle) sous R. Stéphane CHAMPELY
 sous R. Stéphane CHAMPELY") Introduction à l'analyse multivariée (factorielle) sous R Stéphane CHAMPELY 7 septembre 2005 2 Table des matières 1 Introduction 5 1.1 Les données multivariées....................... 5 1.2 L'approche factorielle
Introduction à l'analyse multivariée (factorielle) sous R Stéphane CHAMPELY 7 septembre 2005 2 Table des matières 1 Introduction 5 1.1 Les données multivariées....................... 5 1.2 L'approche factorielle
Relation entre deux variables : estimation de la corrélation linéaire
 CHAPITRE 3 Relation entre deux variables : estimation de la corrélation linéaire Parmi les analyses statistiques descriptives, l une d entre elles est particulièrement utilisée pour mettre en évidence
CHAPITRE 3 Relation entre deux variables : estimation de la corrélation linéaire Parmi les analyses statistiques descriptives, l une d entre elles est particulièrement utilisée pour mettre en évidence
INF6304 Interfaces Intelligentes
 INF6304 Interfaces Intelligentes filtres collaboratifs 1/42 INF6304 Interfaces Intelligentes Systèmes de recommandations, Approches filtres collaboratifs Michel C. Desmarais Génie informatique et génie
INF6304 Interfaces Intelligentes filtres collaboratifs 1/42 INF6304 Interfaces Intelligentes Systèmes de recommandations, Approches filtres collaboratifs Michel C. Desmarais Génie informatique et génie
VI. Tests non paramétriques sur un échantillon
 VI. Tests non paramétriques sur un échantillon Le modèle n est pas un modèle paramétrique «TESTS du CHI-DEUX» : VI.1. Test d ajustement à une loi donnée VI.. Test d indépendance de deux facteurs 96 Différentes
VI. Tests non paramétriques sur un échantillon Le modèle n est pas un modèle paramétrique «TESTS du CHI-DEUX» : VI.1. Test d ajustement à une loi donnée VI.. Test d indépendance de deux facteurs 96 Différentes
Tableau 1 : Structure du tableau des données individuelles. INDIV B i1 1 i2 2 i3 2 i4 1 i5 2 i6 2 i7 1 i8 1
 UN GROUPE D INDIVIDUS Un groupe d individus décrit par une variable qualitative binaire DÉCRIT PAR UNE VARIABLE QUALITATIVE BINAIRE ANALYSER UN SOUS-GROUPE COMPARER UN SOUS-GROUPE À UNE RÉFÉRENCE Mots-clés
UN GROUPE D INDIVIDUS Un groupe d individus décrit par une variable qualitative binaire DÉCRIT PAR UNE VARIABLE QUALITATIVE BINAIRE ANALYSER UN SOUS-GROUPE COMPARER UN SOUS-GROUPE À UNE RÉFÉRENCE Mots-clés
PLAN. Ricco Rakotomalala Tutoriels Tanagra - http://tutoriels-data-mining.blogspot.fr/ 2
 Apprentissage non-supervisé ou apprentissage multi-supervisé? Ricco RAKOTOMALALA Tutoriels Tanagra - http://tutoriels-data-mining.blogspot.fr/ PLAN. Classification automatique, typologie, etc.. Interprétation
Apprentissage non-supervisé ou apprentissage multi-supervisé? Ricco RAKOTOMALALA Tutoriels Tanagra - http://tutoriels-data-mining.blogspot.fr/ PLAN. Classification automatique, typologie, etc.. Interprétation
FORMULAIRE DE STATISTIQUES
 FORMULAIRE DE STATISTIQUES I. STATISTIQUES DESCRIPTIVES Moyenne arithmétique Remarque: population: m xμ; échantillon: Mx 1 Somme des carrés des écarts "# FR MOYENNE(série) MOYENNE(série) NL GEMIDDELDE(série)
FORMULAIRE DE STATISTIQUES I. STATISTIQUES DESCRIPTIVES Moyenne arithmétique Remarque: population: m xμ; échantillon: Mx 1 Somme des carrés des écarts "# FR MOYENNE(série) MOYENNE(série) NL GEMIDDELDE(série)
Christophe CANDILLIER Cours de DataMining mars 2004 Page 1
 Christophe CANDILLIER Cours de DataMining mars 2004 age 1 1. Introduction 2. rocessus du DataMining 3. Analyse des données en DataMining 4. Analyse en Ligne OLA 5. Logiciels 6. Bibliographie Christophe
Christophe CANDILLIER Cours de DataMining mars 2004 age 1 1. Introduction 2. rocessus du DataMining 3. Analyse des données en DataMining 4. Analyse en Ligne OLA 5. Logiciels 6. Bibliographie Christophe
TABLE DES MATIÈRES. Bruxelles, De Boeck, 2011, 736 p.
 STATISTIQUE THÉORIQUE ET APPLIQUÉE Tome 2 Inférence statistique à une et à deux dimensions Pierre Dagnelie TABLE DES MATIÈRES Bruxelles, De Boeck, 2011, 736 p. ISBN 978-2-8041-6336-5 De Boeck Services,
STATISTIQUE THÉORIQUE ET APPLIQUÉE Tome 2 Inférence statistique à une et à deux dimensions Pierre Dagnelie TABLE DES MATIÈRES Bruxelles, De Boeck, 2011, 736 p. ISBN 978-2-8041-6336-5 De Boeck Services,
Scénario: Données bancaires et segmentation de clientèle
 Résumé Scénario: Données bancaires et segmentation de clientèle Exploration de données bancaires par des méthodes uni, bi et multidimensionnelles : ACP, AFCM k-means, CAH. 1 Présentation Le travail proposé
Résumé Scénario: Données bancaires et segmentation de clientèle Exploration de données bancaires par des méthodes uni, bi et multidimensionnelles : ACP, AFCM k-means, CAH. 1 Présentation Le travail proposé
Rapport du projet CFD 2010
 ISAE-ENSICA Rapport du projet CFD 2010 Notice explicative des différents calculs effectués sous Fluent, Xfoil et Javafoil Tanguy Kervern 19/02/2010 Comparaison des performances de différents logiciels
ISAE-ENSICA Rapport du projet CFD 2010 Notice explicative des différents calculs effectués sous Fluent, Xfoil et Javafoil Tanguy Kervern 19/02/2010 Comparaison des performances de différents logiciels
Lois de probabilité. Anita Burgun
 Lois de probabilité Anita Burgun Problème posé Le problème posé en statistique: On s intéresse à une population On extrait un échantillon On se demande quelle sera la composition de l échantillon (pourcentage
Lois de probabilité Anita Burgun Problème posé Le problème posé en statistique: On s intéresse à une population On extrait un échantillon On se demande quelle sera la composition de l échantillon (pourcentage
Élément 424b Introduction à la statistique descriptive
 CTU Master AGPS De la donnée à la connaissance : traitement, analyse et transmission Élément 44b Introduction à la statistique descriptive Prof. Marie-Hélène de Sède-Marceau Année / Statistique Introduction
CTU Master AGPS De la donnée à la connaissance : traitement, analyse et transmission Élément 44b Introduction à la statistique descriptive Prof. Marie-Hélène de Sède-Marceau Année / Statistique Introduction
TUTORIAL 1 ETUDE D UN MODELE SIMPLIFIE DE PORTIQUE PLAN ARTICULE
 TUTORIAL 1 ETUDE D UN MODELE SIMPLIFIE DE PORTIQUE PLAN ARTICULE L'objectif de ce tutorial est de décrire les différentes étapes dans CASTOR Concept / FEM permettant d'effectuer l'analyse statique d'une
TUTORIAL 1 ETUDE D UN MODELE SIMPLIFIE DE PORTIQUE PLAN ARTICULE L'objectif de ce tutorial est de décrire les différentes étapes dans CASTOR Concept / FEM permettant d'effectuer l'analyse statique d'une
PREPROCESSING PAR LISSAGE LOESS POUR ACP LISSEE
 PREPROCESSING PAR LISSAGE LOESS POUR ACP LISSEE Jean-Paul Valois, Claude Mouret & Nicolas Pariset Total, 64018 Pau Cédex MOTS CLEFS : Analyse spatiale, ACP, Lissage, Loess PROBLEMATIQUE En analyse multivariée,
PREPROCESSING PAR LISSAGE LOESS POUR ACP LISSEE Jean-Paul Valois, Claude Mouret & Nicolas Pariset Total, 64018 Pau Cédex MOTS CLEFS : Analyse spatiale, ACP, Lissage, Loess PROBLEMATIQUE En analyse multivariée,
Analyses multivariées avec R Commander (via le package FactoMineR) Qu est ce que R? Introduction à R Qu est ce que R?
 Qu est ce que R? Introduction à R Qu est ce que R?") Analyses multivariées avec R Commander Analyses multivariées avec R Commander (via le package FactoMineR) Plate-forme de Support en Méthodologie et Calcul Statistique (SMCS) - UCL 1 Introduction à R 2
Analyses multivariées avec R Commander Analyses multivariées avec R Commander (via le package FactoMineR) Plate-forme de Support en Méthodologie et Calcul Statistique (SMCS) - UCL 1 Introduction à R 2
Lecture critique d article. Bio statistiques. Dr MARC CUGGIA MCU-PH Laboratoire d informatique médicale EA-3888
 Lecture critique d article Rappels Bio statistiques Dr MARC CUGGIA MCU-PH Laboratoire d informatique médicale EA-3888 Plan du cours Rappels fondamentaux Statistiques descriptives Notions de tests statistiques
Lecture critique d article Rappels Bio statistiques Dr MARC CUGGIA MCU-PH Laboratoire d informatique médicale EA-3888 Plan du cours Rappels fondamentaux Statistiques descriptives Notions de tests statistiques
Stéphane Tufféry DATA MINING & STATISTIQUE DÉCISIONNELLE. 04/04/2008 Stéphane Tufféry - Data Mining - http://data.mining.free.fr
 Stéphane Tufféry DATA MINING & STATISTIQUE DÉCISIONNELLE 1 Plan du cours Qu est-ce que le data mining? A quoi sert le data mining? Les 2 grandes familles de techniques Le déroulement d un projet de data
Stéphane Tufféry DATA MINING & STATISTIQUE DÉCISIONNELLE 1 Plan du cours Qu est-ce que le data mining? A quoi sert le data mining? Les 2 grandes familles de techniques Le déroulement d un projet de data
données en connaissance et en actions?
 1 Partie 2 : Présentation de la plateforme SPSS Modeler : Comment transformer vos données en connaissance et en actions? SPSS Modeler : l atelier de data mining Large gamme de techniques d analyse (algorithmes)
1 Partie 2 : Présentation de la plateforme SPSS Modeler : Comment transformer vos données en connaissance et en actions? SPSS Modeler : l atelier de data mining Large gamme de techniques d analyse (algorithmes)
Statistiques - Cours. 1. Gén éralités. 2. Statistique descriptive univari ée. 3. Statistique descriptive bivariée. 4. Régression orthogonale dans R².
 Statistiques - Cours Page 1 L I C E N C E S c i e n t i f i q u e Cours Henri IMMEDIATO S t a t i s t i q u e s 1 Gén éralités Statistique descriptive univari ée 1 Repr é s e n t a t i o n g r a p h i
Statistiques - Cours Page 1 L I C E N C E S c i e n t i f i q u e Cours Henri IMMEDIATO S t a t i s t i q u e s 1 Gén éralités Statistique descriptive univari ée 1 Repr é s e n t a t i o n g r a p h i
Introduction au Data-Mining
 Introduction au Data-Mining Alain Rakotomamonjy - Gilles Gasso. INSA Rouen -Département ASI Laboratoire PSI Introduction au Data-Mining p. 1/25 Data-Mining : Kèkecé? Traduction : Fouille de données. Terme
Introduction au Data-Mining Alain Rakotomamonjy - Gilles Gasso. INSA Rouen -Département ASI Laboratoire PSI Introduction au Data-Mining p. 1/25 Data-Mining : Kèkecé? Traduction : Fouille de données. Terme
Evaluation de la typicité des vins liés au terroir : proposition de méthodes pour les professionnels de la filière
 Evaluation de la typicité des vins liés au terroir : proposition de méthodes pour les professionnels de la filière Ronan SYMONEAUX, Isabelle MAITRE, Frédérique JOURJON UMT VINITERA- Laboratoire GRAPPE
Evaluation de la typicité des vins liés au terroir : proposition de méthodes pour les professionnels de la filière Ronan SYMONEAUX, Isabelle MAITRE, Frédérique JOURJON UMT VINITERA- Laboratoire GRAPPE
Souad EL Bernoussi. Groupe d Analyse Numérique et Optimisation Rabat http ://www.fsr.ac.ma/ano/
 Recherche opérationnelle Les démonstrations et les exemples seront traités en cours Souad EL Bernoussi Groupe d Analyse Numérique et Optimisation Rabat http ://www.fsr.ac.ma/ano/ Table des matières 1 Programmation
Recherche opérationnelle Les démonstrations et les exemples seront traités en cours Souad EL Bernoussi Groupe d Analyse Numérique et Optimisation Rabat http ://www.fsr.ac.ma/ano/ Table des matières 1 Programmation
Exercices supplémentaires sur l introduction générale à la notion de probabilité 2009-2010
 Exercices supplémentaires sur l introduction générale à la notion de probabilité 2009-2010 Exercices fortement conseillés : 6, 10 et 14 1) Un groupe d étudiants est formé de 20 étudiants de première année
Exercices supplémentaires sur l introduction générale à la notion de probabilité 2009-2010 Exercices fortement conseillés : 6, 10 et 14 1) Un groupe d étudiants est formé de 20 étudiants de première année
EXCEL PERFECTIONNEMENT CALCULS AVANCES
 TABLE DES MATIÈRES FORMATS... 2 Formats personnalisés... 2 ADRESSAGE DE CELLULES... 3 relatif & absolu Rappel... 3 Adressage par nom... 4 Valider avec la touche Entrée... 4 FONCTIONS SI-ET-OU... 6 LA FONCTION
TABLE DES MATIÈRES FORMATS... 2 Formats personnalisés... 2 ADRESSAGE DE CELLULES... 3 relatif & absolu Rappel... 3 Adressage par nom... 4 Valider avec la touche Entrée... 4 FONCTIONS SI-ET-OU... 6 LA FONCTION
Régression linéaire. Nicolas Turenne INRA nicolas.turenne@jouy.inra.fr
 Régression linéaire Nicolas Turenne INRA nicolas.turenne@jouy.inra.fr 2005 Plan Régression linéaire simple Régression multiple Compréhension de la sortie de la régression Coefficient de détermination R
Régression linéaire Nicolas Turenne INRA nicolas.turenne@jouy.inra.fr 2005 Plan Régression linéaire simple Régression multiple Compréhension de la sortie de la régression Coefficient de détermination R
La survie nette actuelle à long terme Qualités de sept méthodes d estimation
 La survie nette actuelle à long terme Qualités de sept méthodes d estimation PAR Alireza MOGHADDAM TUTEUR : Guy HÉDELIN Laboratoire d Épidémiologie et de Santé publique, EA 80 Faculté de Médecine de Strasbourg
La survie nette actuelle à long terme Qualités de sept méthodes d estimation PAR Alireza MOGHADDAM TUTEUR : Guy HÉDELIN Laboratoire d Épidémiologie et de Santé publique, EA 80 Faculté de Médecine de Strasbourg
LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING»
 LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING» Gilbert Saporta Professeur de Statistique Appliquée Conservatoire National des Arts et Métiers Dans leur quasi totalité, les banques et organismes financiers
LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING» Gilbert Saporta Professeur de Statistique Appliquée Conservatoire National des Arts et Métiers Dans leur quasi totalité, les banques et organismes financiers
Programmation linéaire
 1 Programmation linéaire 1. Le problème, un exemple. 2. Le cas b = 0 3. Théorème de dualité 4. L algorithme du simplexe 5. Problèmes équivalents 6. Complexité de l Algorithme 2 Position du problème Soit
1 Programmation linéaire 1. Le problème, un exemple. 2. Le cas b = 0 3. Théorème de dualité 4. L algorithme du simplexe 5. Problèmes équivalents 6. Complexité de l Algorithme 2 Position du problème Soit
SAP BusinessObjects Web Intelligence (WebI) BI 4
 BI 4") Présentation de la Business Intelligence 1. Outils de Business Intelligence 15 2. Historique des logiciels décisionnels 16 3. La suite de logiciels SAP BusinessObjects Business Intelligence Platform 18
Présentation de la Business Intelligence 1. Outils de Business Intelligence 15 2. Historique des logiciels décisionnels 16 3. La suite de logiciels SAP BusinessObjects Business Intelligence Platform 18
Individus et informations supplémentaires
 ADE-4 Individus et informations supplémentaires Résumé La fiche décrit l usage des individus supplémentaires dans des circonstances variées. En particulier, cette pratique est étendue aux analyses inter
ADE-4 Individus et informations supplémentaires Résumé La fiche décrit l usage des individus supplémentaires dans des circonstances variées. En particulier, cette pratique est étendue aux analyses inter
Projet SINF2275 «Data mining and decision making» Projet classification et credit scoring
 Projet SINF2275 «Data mining and decision making» Projet classification et credit scoring Année académique 2006-2007 Professeurs : Marco Saerens Adresse : Université catholique de Louvain Information Systems
Projet SINF2275 «Data mining and decision making» Projet classification et credit scoring Année académique 2006-2007 Professeurs : Marco Saerens Adresse : Université catholique de Louvain Information Systems
CAPTEURS - CHAINES DE MESURES
 CAPTEURS - CHAINES DE MESURES Pierre BONNET Pierre Bonnet Master GSI - Capteurs Chaînes de Mesures 1 Plan du Cours Propriétés générales des capteurs Notion de mesure Notion de capteur: principes, classes,
CAPTEURS - CHAINES DE MESURES Pierre BONNET Pierre Bonnet Master GSI - Capteurs Chaînes de Mesures 1 Plan du Cours Propriétés générales des capteurs Notion de mesure Notion de capteur: principes, classes,
RÉSOLUTION DE SYSTÈMES À DEUX INCONNUES
 RÉSOLUTION DE SYSTÈMES À DEUX INCONNUES Sommaire 1 Méthodes de résolution... 3 1.1. Méthode de Substitution... 3 1.2. Méthode des combinaisons linéaires... 6 La rubrique d'aide qui suit s'attardera aux
RÉSOLUTION DE SYSTÈMES À DEUX INCONNUES Sommaire 1 Méthodes de résolution... 3 1.1. Méthode de Substitution... 3 1.2. Méthode des combinaisons linéaires... 6 La rubrique d'aide qui suit s'attardera aux
Quelques éléments de statistique multidimensionnelle
 ANNEXE 1 Quelques éléments de statistique multidimensionnelle Les méthodes d analyse statistique exploratoire utilisées au cours des chapitres précédents visent à mettre en forme de vastes ensembles de
ANNEXE 1 Quelques éléments de statistique multidimensionnelle Les méthodes d analyse statistique exploratoire utilisées au cours des chapitres précédents visent à mettre en forme de vastes ensembles de
La contrefaçon par équivalence en France
 BREVETS La contrefaçon par équivalence en France I. Introduction Si l'on considère une revendication de brevet qui remplit les conditions de validité au regard de l'art antérieur, le cas de contrefaçon
BREVETS La contrefaçon par équivalence en France I. Introduction Si l'on considère une revendication de brevet qui remplit les conditions de validité au regard de l'art antérieur, le cas de contrefaçon
Les conducteurs automobiles évaluent-ils correctement leur risque de commettre un accident?
 Les conducteurs automobiles évaluent-ils correctement leur risque de commettre un accident? Nathalie LEPINE GREMAQ, Université de Toulouse1, 31042 Toulouse, France GRAPE, Université Montesquieu-Bordeaux
Les conducteurs automobiles évaluent-ils correctement leur risque de commettre un accident? Nathalie LEPINE GREMAQ, Université de Toulouse1, 31042 Toulouse, France GRAPE, Université Montesquieu-Bordeaux
Fonctions de plusieurs variables
 Module : Analyse 03 Chapitre 00 : Fonctions de plusieurs variables Généralités et Rappels des notions topologiques dans : Qu est- ce que?: Mathématiquement, n étant un entier non nul, on définit comme
Module : Analyse 03 Chapitre 00 : Fonctions de plusieurs variables Généralités et Rappels des notions topologiques dans : Qu est- ce que?: Mathématiquement, n étant un entier non nul, on définit comme
La structure de la base de données et l utilisation de PAST. Musée Royal de l Afrique Centrale (MRAC Tervuren)
") La structure de la base de données et l utilisation de PAST La structure de la base de données données originales SPÉCIMENS Code des spécimens: Identification des spécimens individuels. Dépend du but de
La structure de la base de données et l utilisation de PAST La structure de la base de données données originales SPÉCIMENS Code des spécimens: Identification des spécimens individuels. Dépend du but de
Le Data Mining au service du Scoring ou notation statistique des emprunteurs!
 France Le Data Mining au service du Scoring ou notation statistique des emprunteurs! Comme le rappelle la CNIL dans sa délibération n 88-083 du 5 Juillet 1988 portant adoption d une recommandation relative
France Le Data Mining au service du Scoring ou notation statistique des emprunteurs! Comme le rappelle la CNIL dans sa délibération n 88-083 du 5 Juillet 1988 portant adoption d une recommandation relative
Méthodes quantitatives en sciences humaines. 2 Pratique : 2 Étude personnelle : 2. BUREAU poste courriel ou site web
 360-300-RE HIVER 2008 MATHÉMATIQUES Plan de cours COURS : Méthodes quantitatives en sciences humaines PROGRAMME : 300.A0 Sciences humaines DISCIPLINE : Mathématiques Pondération : Théorie : 2 Pratique
360-300-RE HIVER 2008 MATHÉMATIQUES Plan de cours COURS : Méthodes quantitatives en sciences humaines PROGRAMME : 300.A0 Sciences humaines DISCIPLINE : Mathématiques Pondération : Théorie : 2 Pratique
Molécules et Liaison chimique
 Molécules et liaison chimique Molécules et Liaison chimique La liaison dans La liaison dans Le point de vue classique: l approche l de deux atomes d hydrogd hydrogènes R -0,9-1 0 0,5 1 1,5,5 3 3,5 4 R
Molécules et liaison chimique Molécules et Liaison chimique La liaison dans La liaison dans Le point de vue classique: l approche l de deux atomes d hydrogd hydrogènes R -0,9-1 0 0,5 1 1,5,5 3 3,5 4 R
Aide-mémoire de statistique appliquée à la biologie
 Maxime HERVÉ Aide-mémoire de statistique appliquée à la biologie Construire son étude et analyser les résultats à l aide du logiciel R Version 5(2) (2014) AVANT-PROPOS Les phénomènes biologiques ont cela
Maxime HERVÉ Aide-mémoire de statistique appliquée à la biologie Construire son étude et analyser les résultats à l aide du logiciel R Version 5(2) (2014) AVANT-PROPOS Les phénomènes biologiques ont cela
Utiliser Access ou Excel pour gérer vos données
 Page 1 of 5 Microsoft Office Access Utiliser Access ou Excel pour gérer vos données S'applique à : Microsoft Office Access 2007 Masquer tout Les programmes de feuilles de calcul automatisées, tels que
Page 1 of 5 Microsoft Office Access Utiliser Access ou Excel pour gérer vos données S'applique à : Microsoft Office Access 2007 Masquer tout Les programmes de feuilles de calcul automatisées, tels que
Chapitre 7. Statistique des échantillons gaussiens. 7.1 Projection de vecteurs gaussiens
 Chapitre 7 Statistique des échantillons gaussiens Le théorème central limite met en évidence le rôle majeur tenu par la loi gaussienne en modélisation stochastique. De ce fait, les modèles statistiques
Chapitre 7 Statistique des échantillons gaussiens Le théorème central limite met en évidence le rôle majeur tenu par la loi gaussienne en modélisation stochastique. De ce fait, les modèles statistiques
Projet Matlab/Octave : segmentation d'un ballon de couleur dans une image couleur et insertion d'un logo
 Projet Matlab/Octave : segmentation d'un ballon de couleur dans une image couleur et insertion d'un logo Dans ce projet, nous allons réaliser le code qui permet d'insérer sur une image, un logo sur un
Projet Matlab/Octave : segmentation d'un ballon de couleur dans une image couleur et insertion d'un logo Dans ce projet, nous allons réaliser le code qui permet d'insérer sur une image, un logo sur un
TEXT MINING. 10.6.2003 1 von 7
 TEXT MINING 10.6.2003 1 von 7 A LA RECHERCHE D'UNE AIGUILLE DANS UNE BOTTE DE FOIN Alors que le Data Mining recherche des modèles cachés dans de grandes quantités de données, le Text Mining se concentre
TEXT MINING 10.6.2003 1 von 7 A LA RECHERCHE D'UNE AIGUILLE DANS UNE BOTTE DE FOIN Alors que le Data Mining recherche des modèles cachés dans de grandes quantités de données, le Text Mining se concentre
Copropriété: 31, rue des Abondances 92100 Boulogne-Billancourt
 Eléments utilisés: Copropriété: 31, rue des Abondances 92100 Boulogne-Billancourt Notice explicative sur la ventilation de la facture EDF annuelle entre les différents postes de consommation à répartir
Eléments utilisés: Copropriété: 31, rue des Abondances 92100 Boulogne-Billancourt Notice explicative sur la ventilation de la facture EDF annuelle entre les différents postes de consommation à répartir
COMMUNICATEUR BLISS COMMANDE PAR UN SENSEUR DE POSITION DE L'OEIL
 COMMUNICATEUR BLISS COMMANDE PAR UN SENSEUR DE POSITION DE L'OEIL J. TICHON(1) (2), J.-M. TOULOTTE(1), G. TREHOU (1), H. DE ROP (2) 1. INTRODUCTION Notre objectif est de réaliser des systèmes de communication
COMMUNICATEUR BLISS COMMANDE PAR UN SENSEUR DE POSITION DE L'OEIL J. TICHON(1) (2), J.-M. TOULOTTE(1), G. TREHOU (1), H. DE ROP (2) 1. INTRODUCTION Notre objectif est de réaliser des systèmes de communication
Catalogue des connaissances de base en mathématiques dispensées dans les gymnases, lycées et collèges romands.
 Catalogue des connaissances de base en mathématiques dispensées dans les gymnases, lycées et collèges romands. Pourquoi un autre catalogue en Suisse romande Historique En 1990, la CRUS (Conférences des
Catalogue des connaissances de base en mathématiques dispensées dans les gymnases, lycées et collèges romands. Pourquoi un autre catalogue en Suisse romande Historique En 1990, la CRUS (Conférences des
Évaluation de la régression bornée
 Thierry Foucart UMR 6086, Université de Poitiers, S P 2 M I, bd 3 téléport 2 BP 179, 86960 Futuroscope, Cedex FRANCE Résumé. le modèle linéaire est très fréquemment utilisé en statistique et particulièrement
Thierry Foucart UMR 6086, Université de Poitiers, S P 2 M I, bd 3 téléport 2 BP 179, 86960 Futuroscope, Cedex FRANCE Résumé. le modèle linéaire est très fréquemment utilisé en statistique et particulièrement
UNE REPRESENTATION GRAPHIQUE DE LA LIAISON STATISTIQUE ENTRE DEUX VARIABLES ORDONNEES. Éric TÉROUANNE 1
 33 Math. Inf. Sci. hum., (33 e année, n 130, 1995, pp.33-42) UNE REPRESENTATION GRAPHIQUE DE LA LIAISON STATISTIQUE ENTRE DEUX VARIABLES ORDONNEES Éric TÉROUANNE 1 RÉSUMÉ Le stéréogramme de liaison est
33 Math. Inf. Sci. hum., (33 e année, n 130, 1995, pp.33-42) UNE REPRESENTATION GRAPHIQUE DE LA LIAISON STATISTIQUE ENTRE DEUX VARIABLES ORDONNEES Éric TÉROUANNE 1 RÉSUMÉ Le stéréogramme de liaison est
Agrégation des portefeuilles de contrats d assurance vie
 Agrégation des portefeuilles de contrats d assurance vie Est-il optimal de regrouper les contrats en fonction de l âge, du genre, et de l ancienneté des assurés? Pierre-O. Goffard Université d été de l
Agrégation des portefeuilles de contrats d assurance vie Est-il optimal de regrouper les contrats en fonction de l âge, du genre, et de l ancienneté des assurés? Pierre-O. Goffard Université d été de l
Analyse de la vidéo. Chapitre 4.1 - La modélisation pour le suivi d objet. 10 mars 2015. Chapitre 4.1 - La modélisation d objet 1 / 57
 Analyse de la vidéo Chapitre 4.1 - La modélisation pour le suivi d objet 10 mars 2015 Chapitre 4.1 - La modélisation d objet 1 / 57 La représentation d objets Plan de la présentation 1 La représentation
Analyse de la vidéo Chapitre 4.1 - La modélisation pour le suivi d objet 10 mars 2015 Chapitre 4.1 - La modélisation d objet 1 / 57 La représentation d objets Plan de la présentation 1 La représentation
Introduction : présentation de la Business Intelligence
 Les exemples cités tout au long de cet ouvrage sont téléchargeables à l'adresse suivante : http://www.editions-eni.fr Saisissez la référence ENI de l'ouvrage RI3WXIBUSO dans la zone de recherche et validez.
Les exemples cités tout au long de cet ouvrage sont téléchargeables à l'adresse suivante : http://www.editions-eni.fr Saisissez la référence ENI de l'ouvrage RI3WXIBUSO dans la zone de recherche et validez.
«Manuel Pratique» Gestion budgétaire
 11/06/01 B50/v2.31/F/MP005.01 «Manuel Pratique» Gestion budgétaire Finance A l usage des utilisateurs de Sage BOB 50 Solution Sage BOB 50 2 L éditeur veille à la fiabilité des informations publiées, lesquelles
11/06/01 B50/v2.31/F/MP005.01 «Manuel Pratique» Gestion budgétaire Finance A l usage des utilisateurs de Sage BOB 50 Solution Sage BOB 50 2 L éditeur veille à la fiabilité des informations publiées, lesquelles
Leçon N 4 : Statistiques à deux variables
 Leçon N 4 : Statistiques à deux variables En premier lieu, il te faut relire les cours de première sur les statistiques à une variable, il y a tout un langage à se remémorer : étude d un échantillon d
Leçon N 4 : Statistiques à deux variables En premier lieu, il te faut relire les cours de première sur les statistiques à une variable, il y a tout un langage à se remémorer : étude d un échantillon d
Historique. Architecture. Contribution. Conclusion. Définitions et buts La veille stratégique Le multidimensionnel Les classifications
 L intelligence économique outil stratégique pour l entreprise Professeur Bernard DOUSSET dousset@irit.fr http://atlas.irit.fr Institut de Recherche en Informatique de Toulouse (IRIT) Equipe Systèmes d
L intelligence économique outil stratégique pour l entreprise Professeur Bernard DOUSSET dousset@irit.fr http://atlas.irit.fr Institut de Recherche en Informatique de Toulouse (IRIT) Equipe Systèmes d
Mémo d'utilisation de BD Dico1.6
 Mémo d'utilisation de BD Dico1.6 L'application BDDico a été développée par la Section Cadastre et Géomatique de la RCJU. Son utilisation demeure réservée aux personnes autorisées. Les demandes d'utilisation
Mémo d'utilisation de BD Dico1.6 L'application BDDico a été développée par la Section Cadastre et Géomatique de la RCJU. Son utilisation demeure réservée aux personnes autorisées. Les demandes d'utilisation
Séance 0 : Linux + Octave : le compromis idéal
 Séance 0 : Linux + Octave : le compromis idéal Introduction Linux est un système d'exploitation multi-tâches et multi-utilisateurs, basé sur la gratuité et développé par une communauté de passionnés. C'est
Séance 0 : Linux + Octave : le compromis idéal Introduction Linux est un système d'exploitation multi-tâches et multi-utilisateurs, basé sur la gratuité et développé par une communauté de passionnés. C'est
Vision industrielle et télédétection - Détection d ellipses. Guillaume Martinez 17 décembre 2007
 Vision industrielle et télédétection - Détection d ellipses Guillaume Martinez 17 décembre 2007 1 Table des matières 1 Le projet 3 1.1 Objectif................................ 3 1.2 Les choix techniques.........................
Vision industrielle et télédétection - Détection d ellipses Guillaume Martinez 17 décembre 2007 1 Table des matières 1 Le projet 3 1.1 Objectif................................ 3 1.2 Les choix techniques.........................