Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop
|
|
|
- Marianne Boisvert
- il y a 8 ans
- Total affichages :
Transcription

1 Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop Soutenance de projet ASR 27/01/2011 Julien Gerlier Siman Chen Encadrés par Bruno Defude Elisabeth Brunet Amin Sakka

2 Sommaire I. Présentation du projet II. Cassandra III. Hadoop IV. Mise en place du prototype V. Difficultés rencontrées 2



3 Présentation du projet Dématérialisation des gestions de documents des entreprises Nécessité de mémoriser les opérations effectuées sur les documents Système de traçabilité Objectif: distribuer le service de traçabilité Technologies envisagées : Cassandra & Hadoop 3

4 Cassandra Base NoSQL Base de données classique: orientée lignes Cassandra: orientée colonnes Adaptée aux évolutions horizontales Elements clés:»keyspace»column»supercolumn»columnfamily 4

5 Cassandra -Column Triplet: Nom, Valeur, Timestamp Exemple avec la notation de JSON: { // this is a column name: " address", value: "arin@example.com", timestamp:

6 Cassandra - SuperColumn Paire Nom/Valeur Valeur=un ensemble de columns en nombre non limité { // this is a SuperColumn name: "homeaddress", // with an infinite list of Columns value: { // note the keys is the name of the Column street: {name: "street", value: "1234 x street", timestamp: , city: {name: "city", value: "san francisco", timestamp: , zip: {name: "zip", value: "94107", timestamp: , Après simplification: homeaddress: { street: "1234 x street", city: "san francisco", zip: "94107", 6

7 Cassandra - ColumnFamily Contenu des columnfamilies de type standard: infinité de lignes de colomns UserProfile = { // this is a ColumnFamily phatduckk: { // this is the key to this Row inside the CF // now we have an infinite # of columns in this row username: "phatduckk", "phatduckk@example.com", phone: "(900) ", // end row ieure: { // this is the key to another row in the CF // now we have another infinite # of columns in this row username: "ieure", "ieure@example.com", phone: "(888) " age: "66", gender: "undecided", 7
 976-6666\", // end row ieure: { // this is the key to another row in the CF // now we have another infinite # of columns")

8 Cassandra En résumé 8
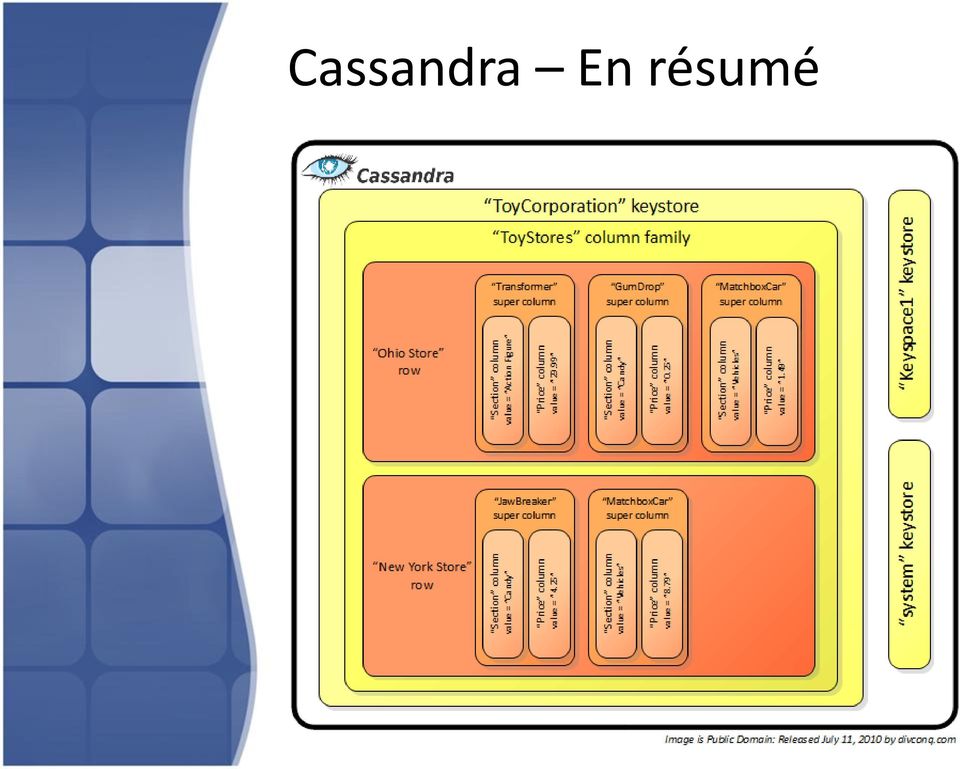
9 { Cassandra Structure de LX Track "Document" (SCF) { RowKey: ApplicationReference { SCKey: OwnerReference { {name:"tuuid" value: TUUID {name: form, value: FingerPrint "Track" (SCF) { RowKey: "Declaration" { SCKey: TUUID { {name: timestamp, value: declarationcontent RowKey: "Document" { SCKey: TUUID { {name: ApplicationReference, value: OwnerReference RowKey: "Fingerprint" { SCKey: TUUID { {name: form, value: FingerPrint "Fingerprint" (SCF) { RowKey: "Document" { SCKey: FingerPrint { {name: ApplicationReference, value: OwnerReference RowKey: "Track" { SCKey: FingePrint { {name: algorithm, value: TUUID 9

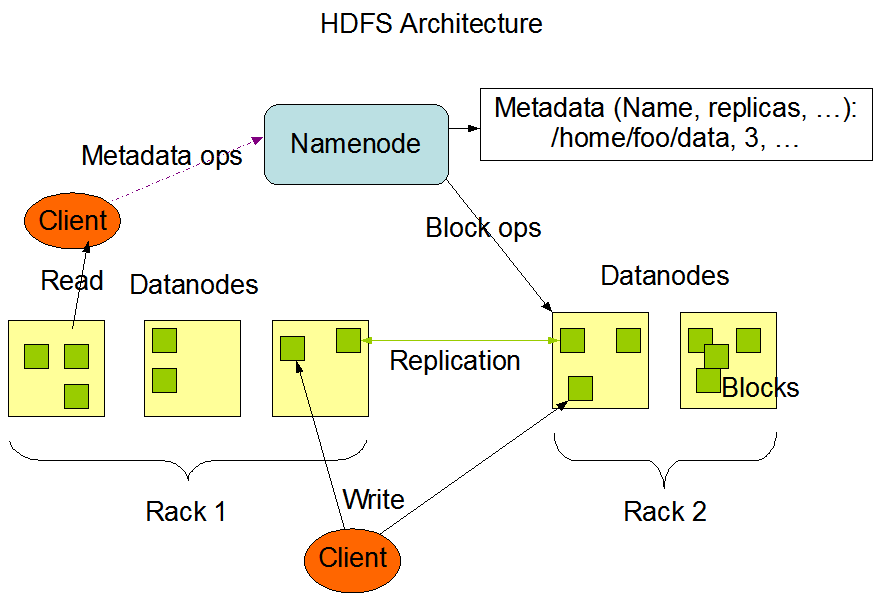
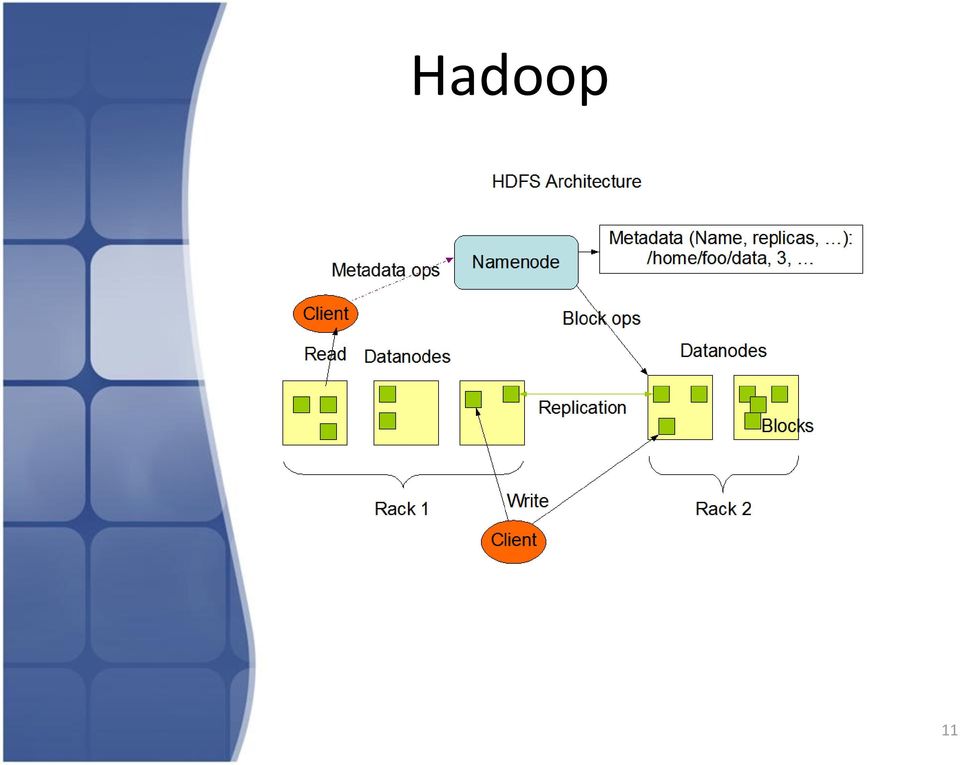
10 Hadoop Système de fichiers distribué associé: HDFS Grande tolérance aux fautes Faibles coûts Haut débit d accès aux données Adapté pour les applications qui nécessitent de grands groupes de données Chaque fichier est divisé en bloc de 64 MB par défaut => convient mieux aux fichiers de grande taille Adapté à de grande scalabilité, aux gros clusters 10

11 Hadoop 11

12 Hadoop Gestion des données et des Jobs 12


13 Hadoop Gestion des données et des Jobs 13

14 Hadoop Map Reduce Opération Map: produit une paire clé/valeur intermédiaire pour chaque paire de clé/valeur reçue en entrée la librairie MapReduce groupe toutes les clés intermédiaires associées à la même valeur d entrée et les passe à la fonction Reduce. L'opération Reduce: fusionne les valeurs d'une même clé intermédiaire afin de renvoyer un unique couple clé intermédiaire/valeur en sortie. Exemple classique: WordCount 14


15 Test : insertion dans Cassandra Insertion massive de données dans Cassandra 5 machines : insertions Problème de flush sur le disque 15

16 Mise en place de l architecture Hadoop/Cassandra Cassandra et Hadoop mis en place individuellement Objectif : interroger Cassandra via Hadoop Recherche de traces Récupération massives de méta-données Echec : problème de compatibilité? 16

17 Difficultés rencontrées Technologies nouvelles encore en développement Peu de documentation Encore des problèmes de compatibilité Nécessite un matériel performant Possibilité de s orienter vers Hbase : plus adapté à Hadoop 17

18 Conclusion Des technologies au fort potentiel Des connaissances précieuses Maitriser la configuration est primordiale Un peu de frustration : échec de la mise en place du prototype Majorité du temps passée à configurer Limités par le matériel 18

Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop
 Julien Gerlier Siman Chen Rapport de projet de fin d étude ASR 2010/2011 Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop Encadrants
Julien Gerlier Siman Chen Rapport de projet de fin d étude ASR 2010/2011 Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop Encadrants
MapReduce. Malo Jaffré, Pablo Rauzy. 16 avril 2010 ENS. Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15
 MapReduce 16 avril 2010 1 / 15") MapReduce Malo Jaffré, Pablo Rauzy ENS 16 avril 2010 Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15 Qu est ce que c est? Conceptuellement Données MapReduce est un framework de calcul distribué
MapReduce Malo Jaffré, Pablo Rauzy ENS 16 avril 2010 Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15 Qu est ce que c est? Conceptuellement Données MapReduce est un framework de calcul distribué
Big Data. Cyril Amsellem Consultant avant-vente. 16 juin 2011. Talend 2010 1
 Big Data Cyril Amsellem Consultant avant-vente 16 juin 2011 Talend 2010 1 Big Data Architecture globale Hadoop Les projets Hadoop (partie 1) Hadoop-Core : projet principal. HDFS : système de fichiers distribués
Big Data Cyril Amsellem Consultant avant-vente 16 juin 2011 Talend 2010 1 Big Data Architecture globale Hadoop Les projets Hadoop (partie 1) Hadoop-Core : projet principal. HDFS : système de fichiers distribués
MapReduce. Nicolas Dugué nicolas.dugue@univ-orleans.fr. M2 MIAGE Systèmes d information répartis
 MapReduce Nicolas Dugué nicolas.dugue@univ-orleans.fr M2 MIAGE Systèmes d information répartis Plan 1 Introduction Big Data 2 MapReduce et ses implémentations 3 MapReduce pour fouiller des tweets 4 MapReduce
MapReduce Nicolas Dugué nicolas.dugue@univ-orleans.fr M2 MIAGE Systèmes d information répartis Plan 1 Introduction Big Data 2 MapReduce et ses implémentations 3 MapReduce pour fouiller des tweets 4 MapReduce
Introduction à MapReduce/Hadoop et Spark
 1 / 36 Introduction à MapReduce/Hadoop et Spark Certificat Big Data Ludovic Denoyer et Sylvain Lamprier UPMC Plan 2 / 36 Contexte 3 / 36 Contexte 4 / 36 Data driven science: le 4e paradigme (Jim Gray -
1 / 36 Introduction à MapReduce/Hadoop et Spark Certificat Big Data Ludovic Denoyer et Sylvain Lamprier UPMC Plan 2 / 36 Contexte 3 / 36 Contexte 4 / 36 Data driven science: le 4e paradigme (Jim Gray -
Programmation parallèle et distribuée
 Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2014) Marc Parizeau, Département de génie électrique et de génie informatique Plan Mégadonnées («big data») Architecture Hadoop distribution
Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2014) Marc Parizeau, Département de génie électrique et de génie informatique Plan Mégadonnées («big data») Architecture Hadoop distribution
Programmation parallèle et distribuée
 Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2015) Marc Parizeau, Département de génie électrique et de génie informatique Plan Données massives («big data») Architecture Hadoop distribution
Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2015) Marc Parizeau, Département de génie électrique et de génie informatique Plan Données massives («big data») Architecture Hadoop distribution
Cartographie des solutions BigData
 Cartographie des solutions BigData Panorama du marché et prospective 1 1 Solutions BigData Défi(s) pour les fournisseurs Quel marché Architectures Acteurs commerciaux Solutions alternatives 2 2 Quels Défis?
Cartographie des solutions BigData Panorama du marché et prospective 1 1 Solutions BigData Défi(s) pour les fournisseurs Quel marché Architectures Acteurs commerciaux Solutions alternatives 2 2 Quels Défis?
Ricco Rakotomalala http://eric.univ-lyon2.fr/~ricco/cours/cours_programmation_r.html. R.R. Université Lyon 2
 Ricco Rakotomalala http://eric.univ-lyon2.fr/~ricco/cours/cours_programmation_r.html 1 Plan de présentation 1. L écosystème Hadoop 2. Principe de programmation MapReduce 3. Programmation des fonctions
Ricco Rakotomalala http://eric.univ-lyon2.fr/~ricco/cours/cours_programmation_r.html 1 Plan de présentation 1. L écosystème Hadoop 2. Principe de programmation MapReduce 3. Programmation des fonctions
Fouillez facilement dans votre système Big Data. Olivier TAVARD
 Fouillez facilement dans votre système Big Data Olivier TAVARD A propos de moi : Cofondateur de la société France Labs Développeur (principalement Java) Formateur en technologies de moteurs de recherche
Fouillez facilement dans votre système Big Data Olivier TAVARD A propos de moi : Cofondateur de la société France Labs Développeur (principalement Java) Formateur en technologies de moteurs de recherche
Big Data Concepts et mise en oeuvre de Hadoop
 Introduction 1. Objectif du chapitre 9 2. Le Big Data 10 2.1 Introduction 10 2.2 Informatique connectée, objets "intelligents" et données collectées 11 2.3 Les unités de mesure dans le monde Big Data 12
Introduction 1. Objectif du chapitre 9 2. Le Big Data 10 2.1 Introduction 10 2.2 Informatique connectée, objets "intelligents" et données collectées 11 2.3 Les unités de mesure dans le monde Big Data 12
Bases de données documentaires et distribuées Cours NFE04
 Bases de données documentaires et distribuées Cours NFE04 Cloud et scalabilité Auteurs : Raphaël Fournier-S niehotta, Philippe Rigaux, Nicolas Travers prénom.nom@cnam.fr Département d informatique Conservatoire
Bases de données documentaires et distribuées Cours NFE04 Cloud et scalabilité Auteurs : Raphaël Fournier-S niehotta, Philippe Rigaux, Nicolas Travers prénom.nom@cnam.fr Département d informatique Conservatoire
HADOOP ET SON ÉCOSYSTÈME
 HADOOP ET SON ÉCOSYSTÈME Mars 2013 2012 Affini-Tech - Diffusion restreinte 1 AFFINI-TECH Méthodes projets Outils de reporting & Data-visualisation Business & Analyses BigData Modélisation Hadoop Technos
HADOOP ET SON ÉCOSYSTÈME Mars 2013 2012 Affini-Tech - Diffusion restreinte 1 AFFINI-TECH Méthodes projets Outils de reporting & Data-visualisation Business & Analyses BigData Modélisation Hadoop Technos
NoSQL. Introduction 1/30. I NoSQL : Not Only SQL, ce n est pas du relationnel, et le contexte. I table d associations - Map - de couples (clef,valeur)
") 1/30 2/30 Anne-Cécile Caron Master MIAGE - SGBD 1er trimestre 2014-2015 I : Not Only SQL, ce n est pas du relationnel, et le contexte d utilisation n est donc pas celui des SGBDR. I Origine : recherche
1/30 2/30 Anne-Cécile Caron Master MIAGE - SGBD 1er trimestre 2014-2015 I : Not Only SQL, ce n est pas du relationnel, et le contexte d utilisation n est donc pas celui des SGBDR. I Origine : recherche
API04 Contribution. Apache Hadoop: Présentation et application dans le domaine des Data Warehouses. Introduction. Architecture
 API04 Contribution Apache Hadoop: Présentation et application dans le domaine des Data Warehouses Introduction Cette publication a pour but de présenter le framework Java libre Apache Hadoop, permettant
API04 Contribution Apache Hadoop: Présentation et application dans le domaine des Data Warehouses Introduction Cette publication a pour but de présenter le framework Java libre Apache Hadoop, permettant
Certificat Big Data - Master MAthématiques
 1 / 1 Certificat Big Data - Master MAthématiques Master 2 Auteur : Sylvain Lamprier UPMC Fouille de données et Medias Sociaux 2 / 1 Rich and big data: Millions d utilisateurs Millions de contenus Multimedia
1 / 1 Certificat Big Data - Master MAthématiques Master 2 Auteur : Sylvain Lamprier UPMC Fouille de données et Medias Sociaux 2 / 1 Rich and big data: Millions d utilisateurs Millions de contenus Multimedia
Les participants repartiront de cette formation en ayant une vision claire de la stratégie et de l éventuelle mise en œuvre d un Big Data.
 Big Data De la stratégie à la mise en oeuvre Description : La formation a pour objet de brosser sans concession le tableau du Big Data. Les participants repartiront de cette formation en ayant une vision
Big Data De la stratégie à la mise en oeuvre Description : La formation a pour objet de brosser sans concession le tableau du Big Data. Les participants repartiront de cette formation en ayant une vision
http://blog.khaledtannir.net
 Algorithme de parallélisations des traitements Khaled TANNIR Doctorant CIFRE LARIS/ESTI http://blog.khaledtannir.net these@khaledtannir.net 2e SéRI 2010-2011 Jeudi 17 mars 2011 Présentation Doctorant CIFRE
Algorithme de parallélisations des traitements Khaled TANNIR Doctorant CIFRE LARIS/ESTI http://blog.khaledtannir.net these@khaledtannir.net 2e SéRI 2010-2011 Jeudi 17 mars 2011 Présentation Doctorant CIFRE
Groupe de Discussion Big Data Aperçu des technologies et applications. Stéphane MOUTON stephane.mouton@cetic.be
 Groupe de Discussion Big Data Aperçu des technologies et applications Stéphane MOUTON stephane.mouton@cetic.be Recherche appliquée et transfert technologique q Agréé «Centre Collectif de Recherche» par
Groupe de Discussion Big Data Aperçu des technologies et applications Stéphane MOUTON stephane.mouton@cetic.be Recherche appliquée et transfert technologique q Agréé «Centre Collectif de Recherche» par
Labs Hadoop Février 2013
 SOA - BRMS - ESB - BPM CEP BAM - High Performance Compute & Data Grid - Cloud Computing - Big Data NoSQL - Analytics Labs Hadoop Février 2013 Mathias Kluba Managing Consultant Responsable offres NoSQL
SOA - BRMS - ESB - BPM CEP BAM - High Performance Compute & Data Grid - Cloud Computing - Big Data NoSQL - Analytics Labs Hadoop Février 2013 Mathias Kluba Managing Consultant Responsable offres NoSQL
Map-Reduce : un cadre de programmation parallèlle pour l analyse de grandes données. Stéphane Genaud ENSIIE
 Map-Reduce : un cadre de programmation parallèlle pour l analyse de grandes données Stéphane Genaud ENSIIE Traitement de données distribuées Google a introduit Map-Reduce [Dean and Ghemawat 2004] Ils s
Map-Reduce : un cadre de programmation parallèlle pour l analyse de grandes données Stéphane Genaud ENSIIE Traitement de données distribuées Google a introduit Map-Reduce [Dean and Ghemawat 2004] Ils s
BIG DATA en Sciences et Industries de l Environnement
 BIG DATA en Sciences et Industries de l Environnement François Royer www.datasio.com 21 mars 2012 FR Big Data Congress, Paris 2012 1/23 Transport terrestre Traçabilité Océanographie Transport aérien Télémétrie
BIG DATA en Sciences et Industries de l Environnement François Royer www.datasio.com 21 mars 2012 FR Big Data Congress, Paris 2012 1/23 Transport terrestre Traçabilité Océanographie Transport aérien Télémétrie
NoSQL. Introduction 1/23. I NoSQL : Not Only SQL, ce n est pas du relationnel, et le contexte. I table d associations - Map - de couples (clef,valeur)
") 1/23 2/23 Anne-Cécile Caron Master MIAGE - BDA 1er trimestre 2013-2014 I : Not Only SQL, ce n est pas du relationnel, et le contexte d utilisation n est donc pas celui des SGBDR. I Origine : recherche
1/23 2/23 Anne-Cécile Caron Master MIAGE - BDA 1er trimestre 2013-2014 I : Not Only SQL, ce n est pas du relationnel, et le contexte d utilisation n est donc pas celui des SGBDR. I Origine : recherche
Acquisition des données - Big Data. Dario VEGA Senior Sales Consultant
 Acquisition des données - Big Data Dario VEGA Senior Sales Consultant The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated
Acquisition des données - Big Data Dario VEGA Senior Sales Consultant The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated
De 20 000 à 4 millions. Khanh Tuong Maudoux @jetoile
 De 20 000 à 4 millions Khanh Tuong Maudoux @jetoile 2 Qui suis- Khanh Tuong Maudoux Développeur Java indépendant blog : http://blog.jetoile.fr @jetoile khanh.maudoux@jetoile.fr 3 Contexte Collecteur Stockage
De 20 000 à 4 millions Khanh Tuong Maudoux @jetoile 2 Qui suis- Khanh Tuong Maudoux Développeur Java indépendant blog : http://blog.jetoile.fr @jetoile khanh.maudoux@jetoile.fr 3 Contexte Collecteur Stockage
Les technologies du Big Data
 Les technologies du Big Data PRÉSENTÉ AU 40 E CONGRÈS DE L ASSOCIATION DES ÉCONOMISTES QUÉBÉCOIS PAR TOM LANDRY, CONSEILLER SENIOR LE 20 MAI 2015 WWW.CRIM.CA TECHNOLOGIES: DES DONNÉES JUSQU'À L UTILISATEUR
Les technologies du Big Data PRÉSENTÉ AU 40 E CONGRÈS DE L ASSOCIATION DES ÉCONOMISTES QUÉBÉCOIS PAR TOM LANDRY, CONSEILLER SENIOR LE 20 MAI 2015 WWW.CRIM.CA TECHNOLOGIES: DES DONNÉES JUSQU'À L UTILISATEUR
Panorama des solutions analytiques existantes
 Arnaud LAROCHE Julien DAMON Panorama des solutions analytiques existantes SFdS Méthodes et Logiciels - 16 janvier 2014 - Données Massives Ne sont ici considérés que les solutions autour de l environnement
Arnaud LAROCHE Julien DAMON Panorama des solutions analytiques existantes SFdS Méthodes et Logiciels - 16 janvier 2014 - Données Massives Ne sont ici considérés que les solutions autour de l environnement
Programmation parallèle et distribuée (Master 1 Info 2015-2016)
") Programmation parallèle et distribuée (Master 1 Info 2015-2016) Hadoop MapReduce et HDFS Note bibliographique : ce cours est largement inspiré par le cours de Benjamin Renaut (Tokidev SAS) Introduction
Programmation parallèle et distribuée (Master 1 Info 2015-2016) Hadoop MapReduce et HDFS Note bibliographique : ce cours est largement inspiré par le cours de Benjamin Renaut (Tokidev SAS) Introduction
Technologies du Web. Ludovic DENOYER - ludovic.denoyer@lip6.fr. Février 2014 UPMC
 Technologies du Web Ludovic DENOYER - ludovic.denoyer@lip6.fr UPMC Février 2014 Ludovic DENOYER - ludovic.denoyer@lip6.fr Technologies du Web Plan Retour sur les BDs Le service Search Un peu plus sur les
Technologies du Web Ludovic DENOYER - ludovic.denoyer@lip6.fr UPMC Février 2014 Ludovic DENOYER - ludovic.denoyer@lip6.fr Technologies du Web Plan Retour sur les BDs Le service Search Un peu plus sur les
Le NoSQL - Cassandra
 Le NoSQL - Cassandra Thèse Professionnelle Xavier MALETRAS 27/05/2012 Ce document présente la technologie NoSQL au travers de l utilisation du projet Cassandra. Il présente des situations ainsi que des
Le NoSQL - Cassandra Thèse Professionnelle Xavier MALETRAS 27/05/2012 Ce document présente la technologie NoSQL au travers de l utilisation du projet Cassandra. Il présente des situations ainsi que des
Les quatre piliers d une solution de gestion des Big Data
 White Paper Les quatre piliers d une solution de gestion des Big Data Table des Matières Introduction... 4 Big Data : un terme très vaste... 4 Le Big Data... 5 La technologie Big Data... 5 Le grand changement
White Paper Les quatre piliers d une solution de gestion des Big Data Table des Matières Introduction... 4 Big Data : un terme très vaste... 4 Le Big Data... 5 La technologie Big Data... 5 Le grand changement
L écosystème Hadoop Nicolas Thiébaud ni.thiebaud@gmail.com. Tuesday, July 2, 13
 L écosystème Hadoop Nicolas Thiébaud ni.thiebaud@gmail.com HUG France 250 membres sur la mailing liste 30 présentations 9 meetups organisés, de 20 à 100 invités Présence de Cloudera, MapR, Hortonworks,
L écosystème Hadoop Nicolas Thiébaud ni.thiebaud@gmail.com HUG France 250 membres sur la mailing liste 30 présentations 9 meetups organisés, de 20 à 100 invités Présence de Cloudera, MapR, Hortonworks,
AVRIL 2014. Au delà de Hadoop. Panorama des solutions NoSQL
 AVRIL 2014 Panorama des solutions NoSQL QUI SOMMES NOUS? Avril 2014 2 SMILE, EN QUELQUES CHIFFRES 1er INTÉGRATEUR EUROPÉEN DE SOLUTIONS OPEN SOURCE 3 4 NOS EXPERTISES ET NOS CONVICTIONS DANS NOS LIVRES
AVRIL 2014 Panorama des solutions NoSQL QUI SOMMES NOUS? Avril 2014 2 SMILE, EN QUELQUES CHIFFRES 1er INTÉGRATEUR EUROPÉEN DE SOLUTIONS OPEN SOURCE 3 4 NOS EXPERTISES ET NOS CONVICTIONS DANS NOS LIVRES
Business Intelligence, Etat de l art et perspectives. ICAM JP Gouigoux 10/2012
 Business Intelligence, Etat de l art et perspectives ICAM JP Gouigoux 10/2012 CONTEXTE DE LA BI Un peu d histoire Premières bases de données utilisées comme simple système de persistance du contenu des
Business Intelligence, Etat de l art et perspectives ICAM JP Gouigoux 10/2012 CONTEXTE DE LA BI Un peu d histoire Premières bases de données utilisées comme simple système de persistance du contenu des
Titre : La BI vue par l intégrateur Orange
 Titre : La BI vue par l intégrateur Orange Résumé : L entité Orange IT&L@bs, partenaire privilégié des entreprises et des collectivités dans la conception et l implémentation de SI Décisionnels innovants,
Titre : La BI vue par l intégrateur Orange Résumé : L entité Orange IT&L@bs, partenaire privilégié des entreprises et des collectivités dans la conception et l implémentation de SI Décisionnels innovants,
MapReduce et Hadoop. Alexandre Denis Alexandre.Denis@inria.fr. Inria Bordeaux Sud-Ouest France ENSEIRB PG306
 MapReduce et Hadoop Alexandre Denis Alexandre.Denis@inria.fr Inria Bordeaux Sud-Ouest France ENSEIRB PG306 Fouille de données Recherche & indexation de gros volumes Appliquer une opération simple à beaucoup
MapReduce et Hadoop Alexandre Denis Alexandre.Denis@inria.fr Inria Bordeaux Sud-Ouest France ENSEIRB PG306 Fouille de données Recherche & indexation de gros volumes Appliquer une opération simple à beaucoup
Organiser vos données - Big Data. Patrick Millart Senior Sales Consultant
 Organiser vos données - Big Data Patrick Millart Senior Sales Consultant The following is intended to outline our general product direction. It is intended for information purposes only, and may not be
Organiser vos données - Big Data Patrick Millart Senior Sales Consultant The following is intended to outline our general product direction. It is intended for information purposes only, and may not be
4 Exemples de problèmes MapReduce incrémentaux
 4 Exemples de problèmes MapReduce incrémentaux 1 / 32 Calcul des plus courtes distances à un noeud d un graphe Calcul des plus courts chemins entre toutes les paires de noeuds d un graphe Algorithme PageRank
4 Exemples de problèmes MapReduce incrémentaux 1 / 32 Calcul des plus courtes distances à un noeud d un graphe Calcul des plus courts chemins entre toutes les paires de noeuds d un graphe Algorithme PageRank
20 ans du Master SIAD de Toulouse - BigData par l exemple - Julien DULOUT - 22 mars 2013. 20 ans du SIAD -"Big Data par l'exemple" -Julien DULOUT
 20 ans du Master SIAD de Toulouse - BigData par l exemple - Julien DULOUT - 22 mars 2013 20 ans du SIAD -"BigData par l'exemple" -Julien DULOUT Qui a déjà entendu parler du phénomène BigData? Qui a déjà
20 ans du Master SIAD de Toulouse - BigData par l exemple - Julien DULOUT - 22 mars 2013 20 ans du SIAD -"BigData par l'exemple" -Julien DULOUT Qui a déjà entendu parler du phénomène BigData? Qui a déjà
Introduction aux algorithmes MapReduce. Mathieu Dumoulin (GRAAL), 14 Février 2014
, 14 Février 2014") Introduction aux algorithmes MapReduce Mathieu Dumoulin (GRAAL), 14 Février 2014 Plan Introduction de la problématique Tutoriel MapReduce Design d algorithmes MapReduce Tri, somme et calcul de moyenne
Introduction aux algorithmes MapReduce Mathieu Dumoulin (GRAAL), 14 Février 2014 Plan Introduction de la problématique Tutoriel MapReduce Design d algorithmes MapReduce Tri, somme et calcul de moyenne
BIG Data et R: opportunités et perspectives
 BIG Data et R: opportunités et perspectives Guati Rizlane 1 & Hicham Hajji 2 1 Ecole Nationale de Commerce et de Gestion de Casablanca, Maroc, rguati@gmail.com 2 Ecole des Sciences Géomatiques, IAV Rabat,
BIG Data et R: opportunités et perspectives Guati Rizlane 1 & Hicham Hajji 2 1 Ecole Nationale de Commerce et de Gestion de Casablanca, Maroc, rguati@gmail.com 2 Ecole des Sciences Géomatiques, IAV Rabat,
Les bases de données relationnelles
 Bases de données NO SQL et SIG : d un existant restreint à un avenir prometteur CHRISTIAN CAROLIN, AXES CONSEIL CAROLIN@AXES.FR - HTTP://WWW.AXES.FR Les bases de données relationnelles constituent désormais
Bases de données NO SQL et SIG : d un existant restreint à un avenir prometteur CHRISTIAN CAROLIN, AXES CONSEIL CAROLIN@AXES.FR - HTTP://WWW.AXES.FR Les bases de données relationnelles constituent désormais
Notes de cours Practical BigData
 Notes de cours Practical BigData Nguyen-Nhut DOAN 15 janvier 2015 Introduction Ces notes personnelles traduisent la deuxième partie du cours INF553 de l Ecole Polytechnique sur les bases de données et
Notes de cours Practical BigData Nguyen-Nhut DOAN 15 janvier 2015 Introduction Ces notes personnelles traduisent la deuxième partie du cours INF553 de l Ecole Polytechnique sur les bases de données et
Quels choix de base de données pour vos projets Big Data?
 Quels choix de base de données pour vos projets Big Data? Big Data? Le terme "big data" est très à la mode et naturellement un terme si générique est galvaudé. Beaucoup de promesses sont faites, et l'enthousiasme
Quels choix de base de données pour vos projets Big Data? Big Data? Le terme "big data" est très à la mode et naturellement un terme si générique est galvaudé. Beaucoup de promesses sont faites, et l'enthousiasme
OpenPaaS Le réseau social d'entreprise
 OpenPaaS Le réseau social d'entreprise Spécification des API datastore SP L2.3.1 Diffusion : Institut MinesTélécom, Télécom SudParis 1 / 12 1OpenPaaS DataBase API : ODBAPI...3 1.1Comparaison des concepts...3
OpenPaaS Le réseau social d'entreprise Spécification des API datastore SP L2.3.1 Diffusion : Institut MinesTélécom, Télécom SudParis 1 / 12 1OpenPaaS DataBase API : ODBAPI...3 1.1Comparaison des concepts...3
Document réalisé par Khadidjatou BAMBA
 Comprendre le BIG DATA Document réalisé par Khadidjatou BAMBA 1 Sommaire Avant propos. 3 Historique du Big Data.4 Introduction.....5 Chapitre I : Présentation du Big Data... 6 I. Généralités sur le Big
Comprendre le BIG DATA Document réalisé par Khadidjatou BAMBA 1 Sommaire Avant propos. 3 Historique du Big Data.4 Introduction.....5 Chapitre I : Présentation du Big Data... 6 I. Généralités sur le Big
Anticiper et prédire les sinistres avec une approche Big Data
 Anticiper et prédire les sinistres avec une approche Big Data Julien Cabot Directeur Big Data Analytics OCTO jcabot@octo.com @julien_cabot OCTO 2013 50, avenue des Champs-Elysées 75008 Paris - FRANCE Tél
Anticiper et prédire les sinistres avec une approche Big Data Julien Cabot Directeur Big Data Analytics OCTO jcabot@octo.com @julien_cabot OCTO 2013 50, avenue des Champs-Elysées 75008 Paris - FRANCE Tél
Catalogue des stages Ercom 2013
 Catalogue des stages Ercom 2013 Optimisations sur Modem LTE Poste basé à : Caen (14) Analyse et optimisation des performances des traitements réalisés dans un modem LTE. - Profiling et détermination des
Catalogue des stages Ercom 2013 Optimisations sur Modem LTE Poste basé à : Caen (14) Analyse et optimisation des performances des traitements réalisés dans un modem LTE. - Profiling et détermination des
Network Efficiency Monitoring - version 2
 École Polytechnique de l Université de Tours 64, Avenue Jean Portalis 37200 TOURS, FRANCE Tél. +33 (0)2 47 36 14 14 www.polytech.univ-tours.fr Département Informatique 5 e année 2012-2013 Projet de fin
École Polytechnique de l Université de Tours 64, Avenue Jean Portalis 37200 TOURS, FRANCE Tél. +33 (0)2 47 36 14 14 www.polytech.univ-tours.fr Département Informatique 5 e année 2012-2013 Projet de fin
Tables Rondes Le «Big Data»
 Tables Rondes Le «Big Data» 2012-2013 1 Plan Introduc9on 1 - Présenta9on Ingensi 2 - Le Big Data c est quoi? 3 - L histoire 4 - Le monde du libre : Hadoop 5 - Le système HDFS 6 - Les algorithmes distribués
Tables Rondes Le «Big Data» 2012-2013 1 Plan Introduc9on 1 - Présenta9on Ingensi 2 - Le Big Data c est quoi? 3 - L histoire 4 - Le monde du libre : Hadoop 5 - Le système HDFS 6 - Les algorithmes distribués
NoSQL - Systèmes de gestion de données distribués
 NoSQL - Systèmes de gestion de données distribués I. Mougenot mougenot@lirmm.fr Faculté des Sciences Université Montpellier 2 2014 I. Mougenot mougenot@lirmm.fr (UM2) GMIN332 C7 2014 1 / 73 Préambule NoSQL
NoSQL - Systèmes de gestion de données distribués I. Mougenot mougenot@lirmm.fr Faculté des Sciences Université Montpellier 2 2014 I. Mougenot mougenot@lirmm.fr (UM2) GMIN332 C7 2014 1 / 73 Préambule NoSQL
BIG DATA. Veille technologique. Malek Hamouda Nina Lachia Léo Valette. Commanditaire : Thomas Milon. Encadré: Philippe Vismara
 BIG DATA Veille technologique Malek Hamouda Nina Lachia Léo Valette Commanditaire : Thomas Milon Encadré: Philippe Vismara 1 2 Introduction Historique des bases de données : méthodes de stockage et d analyse
BIG DATA Veille technologique Malek Hamouda Nina Lachia Léo Valette Commanditaire : Thomas Milon Encadré: Philippe Vismara 1 2 Introduction Historique des bases de données : méthodes de stockage et d analyse
Hadoop / Big Data. Benjamin Renaut <renaut.benjamin@tokidev.fr> MBDS 2014-2015
 Hadoop / Big Data Benjamin Renaut MBDS 2014-2015 6 map/reduce et Hadoop: exemples plus avancés Exemple: parcours de graphe 6-1 On cherche à déterminer la profondeur maximale
Hadoop / Big Data Benjamin Renaut MBDS 2014-2015 6 map/reduce et Hadoop: exemples plus avancés Exemple: parcours de graphe 6-1 On cherche à déterminer la profondeur maximale
11/01/2014. Le Big Data Mining enjeux et approches techniques. Plan. Introduction. Introduction. Quelques exemples d applications
 Plan Le Big Data Mining enjeux et approches techniques Bernard Dousset Professeur des universités Institut de Recherche en Informatique de Toulouse UMR 5505 Université de Toulouse 118, Route de Narbonne,
Plan Le Big Data Mining enjeux et approches techniques Bernard Dousset Professeur des universités Institut de Recherche en Informatique de Toulouse UMR 5505 Université de Toulouse 118, Route de Narbonne,
Professeur superviseur ALAIN APRIL
 RAPPORT TECHNIQUE PRÉSENTÉ À L ÉCOLE DE TECHNOLOGIE SUPÉRIEURE DANS LE CADRE DU COURS LOG792 PROJET DE FIN D ÉTUDES EN GÉNIE LOGICIEL OPTIMISATION DE RECHERCHE GRÂCE À HBASE SOUS HADOOP ANNA KLOS KLOA22597907
RAPPORT TECHNIQUE PRÉSENTÉ À L ÉCOLE DE TECHNOLOGIE SUPÉRIEURE DANS LE CADRE DU COURS LOG792 PROJET DE FIN D ÉTUDES EN GÉNIE LOGICIEL OPTIMISATION DE RECHERCHE GRÂCE À HBASE SOUS HADOOP ANNA KLOS KLOA22597907
Le BigData, aussi par et pour les PMEs
 Parole d expert Le BigData, aussi par et pour les PMEs Stéphane MOUTON, CETIC Département Software and Services Technologies Avec le soutien de : LIEGE CREATIVE Le Big Data, aussi par et pour les PMEs
Parole d expert Le BigData, aussi par et pour les PMEs Stéphane MOUTON, CETIC Département Software and Services Technologies Avec le soutien de : LIEGE CREATIVE Le Big Data, aussi par et pour les PMEs
R+Hadoop = Rhadoop* Des logiciels libres complémentaires, une implémentation, une réponse au nouveau paradigme du bigdata!
 R+Hadoop = Rhadoop* * Des logiciels libres complémentaires, une implémentation, une réponse au nouveau paradigme du bigdata! 27 Janvier 2014 / Université Paul Sabatier / DTSI / David Tsang-Hin-Sun Big
R+Hadoop = Rhadoop* * Des logiciels libres complémentaires, une implémentation, une réponse au nouveau paradigme du bigdata! 27 Janvier 2014 / Université Paul Sabatier / DTSI / David Tsang-Hin-Sun Big
Importation et exportation de données dans HDFS
 1 Importation et exportation de données dans HDFS Introduction Dans une installation type, Hadoop se trouve au cœur d un flux de données complexe. Ces données proviennent souvent de systèmes disparates
1 Importation et exportation de données dans HDFS Introduction Dans une installation type, Hadoop se trouve au cœur d un flux de données complexe. Ces données proviennent souvent de systèmes disparates
Hadoop : une plate-forme d exécution de programmes Map-Reduce
 Hadoop : une plate-forme d exécution de programmes Map-Reduce Jonathan Lejeune UPMC 8 octobre 2013 PSIA 2013 Inspiré du cours des années précédentes de Luciana Arantes J. Lejeune (UPMC) Hadoop Map-Reduce
Hadoop : une plate-forme d exécution de programmes Map-Reduce Jonathan Lejeune UPMC 8 octobre 2013 PSIA 2013 Inspiré du cours des années précédentes de Luciana Arantes J. Lejeune (UPMC) Hadoop Map-Reduce
Déploiement d une architecture Hadoop pour analyse de flux. françois-xavier.andreu@renater.fr
 Déploiement d une architecture Hadoop pour analyse de flux françois-xavier.andreu@renater.fr 1 plan Introduction Hadoop Présentation Architecture d un cluster HDFS & MapReduce L architecture déployée Les
Déploiement d une architecture Hadoop pour analyse de flux françois-xavier.andreu@renater.fr 1 plan Introduction Hadoop Présentation Architecture d un cluster HDFS & MapReduce L architecture déployée Les
Hadoop, les clés du succès
 Hadoop, les clés du succès Didier Kirszenberg, Responsable des architectures Massive Data, HP France Copyright 2015 Hewlett-Packard Development Company, L.P. The information contained herein is subject
Hadoop, les clés du succès Didier Kirszenberg, Responsable des architectures Massive Data, HP France Copyright 2015 Hewlett-Packard Development Company, L.P. The information contained herein is subject
Bases de Données NoSQL
 Bases de Données NoSQL LI328 Technologies Web Mohamed-Amine Baazizi Transparents de Bernd Amann UPMC - LIP6 LI328 Technologies Web (B. Amann) 1 SGBD Universalité Systèmes «SQL» : Facilité d'utilisation
Bases de Données NoSQL LI328 Technologies Web Mohamed-Amine Baazizi Transparents de Bernd Amann UPMC - LIP6 LI328 Technologies Web (B. Amann) 1 SGBD Universalité Systèmes «SQL» : Facilité d'utilisation
M2 GL UE DOC «In memory analytics»
 M2 GL UE DOC «In memory analytics» Alexandre Termier 2014/2015 Sources Travaux Amplab, U.C. Berkeley Slides Ion Stoica Présentations Databricks Slides Pat McDonough Articles de M. Zaharia et al. sur les
M2 GL UE DOC «In memory analytics» Alexandre Termier 2014/2015 Sources Travaux Amplab, U.C. Berkeley Slides Ion Stoica Présentations Databricks Slides Pat McDonough Articles de M. Zaharia et al. sur les
Professeur-superviseur Alain April
 RAPPORT TECHNIQUE PRÉSENTÉ À L ÉCOLE DE TECHNOLOGIE SUPÉRIEURE DANS LE CADRE DU COURS GTI792 BASE DE DONNÉES DISTRIBUÉE APPLIQUÉE EN GÉNÉTIQUE DANS LE CADRE DE L'ANALYSE DE SÉQUENÇAGE GÉNOMIQUE JEAN-PHILIPPE
RAPPORT TECHNIQUE PRÉSENTÉ À L ÉCOLE DE TECHNOLOGIE SUPÉRIEURE DANS LE CADRE DU COURS GTI792 BASE DE DONNÉES DISTRIBUÉE APPLIQUÉE EN GÉNÉTIQUE DANS LE CADRE DE L'ANALYSE DE SÉQUENÇAGE GÉNOMIQUE JEAN-PHILIPPE
Hadoop : une plate-forme d exécution de programmes Map-Reduce
 Hadoop : une plate-forme d exécution de programmes Map-Reduce Jonathan Lejeune École des Mines de Nantes Janvier 2015 CODEL 2014/2015 J. Lejeune (École des Mines de Nantes) Hadoop Map-Reduce Janvier 2015
Hadoop : une plate-forme d exécution de programmes Map-Reduce Jonathan Lejeune École des Mines de Nantes Janvier 2015 CODEL 2014/2015 J. Lejeune (École des Mines de Nantes) Hadoop Map-Reduce Janvier 2015
Benjamin Cornu Florian Joyeux. Les choses à connaître pour (essayer) de concurrencer Facebook.
 de concurrencer Facebook.") Benjamin Cornu Florian Joyeux Les choses à connaître pour (essayer) de concurrencer Facebook. 1 Sommaire Présentation générale Historique Facebook La face cachée de l iceberg (back end) Architecture globale
Benjamin Cornu Florian Joyeux Les choses à connaître pour (essayer) de concurrencer Facebook. 1 Sommaire Présentation générale Historique Facebook La face cachée de l iceberg (back end) Architecture globale
Offre formation Big Data Analytics
 Offre formation Big Data Analytics OCTO 2014 50, avenue des Champs-Elysées 75008 Paris - FRANCE Tél : +33 (0)1 58 56 10 00 Fax : +33 (0)1 58 56 10 01 www.octo.com 1 Présentation d OCTO Technology 2 Une
Offre formation Big Data Analytics OCTO 2014 50, avenue des Champs-Elysées 75008 Paris - FRANCE Tél : +33 (0)1 58 56 10 00 Fax : +33 (0)1 58 56 10 01 www.octo.com 1 Présentation d OCTO Technology 2 Une
Livre. blanc. Solution Hadoop d entreprise d EMC. Stockage NAS scale-out Isilon et Greenplum HD. Février 2012
 Livre blanc Solution Hadoop d entreprise d EMC Stockage NAS scale-out Isilon et Greenplum HD Par Julie Lockner et Terri McClure, Analystes seniors Février 2012 Ce livre blanc d ESG, qui a été commandé
Livre blanc Solution Hadoop d entreprise d EMC Stockage NAS scale-out Isilon et Greenplum HD Par Julie Lockner et Terri McClure, Analystes seniors Février 2012 Ce livre blanc d ESG, qui a été commandé
NoSQL. Etat de l art et benchmark
 NoSQL Etat de l art et benchmark Travail de Bachelor réalisé en vue de l obtention du Bachelor HES par : Adriano Girolamo PIAZZA Conseiller au travail de Bachelor : David BILLARD, Professeur HES Genève,
NoSQL Etat de l art et benchmark Travail de Bachelor réalisé en vue de l obtention du Bachelor HES par : Adriano Girolamo PIAZZA Conseiller au travail de Bachelor : David BILLARD, Professeur HES Genève,
Cours 8 Not Only SQL
 Cours 8 Not Only SQL Cours 8 - NoSQL Qu'est-ce que le NoSQL? Cours 8 - NoSQL Qu'est-ce que le NoSQL? Catégorie de SGBD s'affranchissant du modèle relationnel des SGBDR. Mouvance apparue par le biais des
Cours 8 Not Only SQL Cours 8 - NoSQL Qu'est-ce que le NoSQL? Cours 8 - NoSQL Qu'est-ce que le NoSQL? Catégorie de SGBD s'affranchissant du modèle relationnel des SGBDR. Mouvance apparue par le biais des
Introduction Big Data
 Introduction Big Data SOMMAIRE Rédacteurs : Réf.: SH. Lazare / F. Barthélemy AXIO_BD_V1 QU'EST-CE QUE LE BIG DATA? ENJEUX TECHNOLOGIQUES ENJEUX STRATÉGIQUES BIG DATA ET RH ANNEXE Ce document constitue
Introduction Big Data SOMMAIRE Rédacteurs : Réf.: SH. Lazare / F. Barthélemy AXIO_BD_V1 QU'EST-CE QUE LE BIG DATA? ENJEUX TECHNOLOGIQUES ENJEUX STRATÉGIQUES BIG DATA ET RH ANNEXE Ce document constitue
Big Data. Les problématiques liées au stockage des données et aux capacités de calcul
 Big Data Les problématiques liées au stockage des données et aux capacités de calcul Les problématiques liées au Big Data La capacité de stockage - Traitement : Ponctuel ou permanent? - Cycle de vie des
Big Data Les problématiques liées au stockage des données et aux capacités de calcul Les problématiques liées au Big Data La capacité de stockage - Traitement : Ponctuel ou permanent? - Cycle de vie des
Hibernate vs. le Cloud Computing
 Hibernate vs. le Cloud Computing Qui suis-je? Julien Dubois Co-auteur de «Spring par la pratique» Ancien de SpringSource Directeur du consulting chez Ippon Technologies Suivez-moi sur Twitter : @juliendubois
Hibernate vs. le Cloud Computing Qui suis-je? Julien Dubois Co-auteur de «Spring par la pratique» Ancien de SpringSource Directeur du consulting chez Ippon Technologies Suivez-moi sur Twitter : @juliendubois
Introduc)on à Map- Reduce. Vincent Leroy
on à Map- Reduce. Vincent Leroy") Introduc)on à Map- Reduce Vincent Leroy Sources Apache Hadoop Yahoo! Developer Network Hortonworks Cloudera Prac)cal Problem Solving with Hadoop and Pig Les cours seront mis en ligne sur hhp://membres.liglab.fr/leroy/
Introduc)on à Map- Reduce Vincent Leroy Sources Apache Hadoop Yahoo! Developer Network Hortonworks Cloudera Prac)cal Problem Solving with Hadoop and Pig Les cours seront mis en ligne sur hhp://membres.liglab.fr/leroy/
Pentaho Business Analytics Intégrer > Explorer > Prévoir
 Pentaho Business Analytics Intégrer > Explorer > Prévoir Pentaho lie étroitement intégration de données et analytique. En effet, les services informatiques et les utilisateurs métiers peuvent accéder aux
Pentaho Business Analytics Intégrer > Explorer > Prévoir Pentaho lie étroitement intégration de données et analytique. En effet, les services informatiques et les utilisateurs métiers peuvent accéder aux
Le nouveau visage de la Dataviz dans MicroStrategy 10
 Le nouveau visage de la Dataviz dans MicroStrategy 10 Pour la première fois, MicroStrategy 10 offre une plateforme analytique qui combine une expérience utilisateur facile et agréable, et des capacités
Le nouveau visage de la Dataviz dans MicroStrategy 10 Pour la première fois, MicroStrategy 10 offre une plateforme analytique qui combine une expérience utilisateur facile et agréable, et des capacités
Introduction au Massive Data
 Introduction au Massive Data Didier Kirszenberg, Responsable des architectures Massive Data, HP France Copyright 2015 Hewlett-Packard Development Company, L.P. The information contained herein is subject
Introduction au Massive Data Didier Kirszenberg, Responsable des architectures Massive Data, HP France Copyright 2015 Hewlett-Packard Development Company, L.P. The information contained herein is subject
Présentation Windows Azure Hadoop Big Data - BI
 Présentation Windows Azure Hadoop Big Data - BI Sommaire 1. Architecture Hadoop dans Windows Azure... 3 2. Requête Hive avec Hadoop dans Windows Azure... 4 3. Cas d études... 5 3.1 Vue : Administrateur...
Présentation Windows Azure Hadoop Big Data - BI Sommaire 1. Architecture Hadoop dans Windows Azure... 3 2. Requête Hive avec Hadoop dans Windows Azure... 4 3. Cas d études... 5 3.1 Vue : Administrateur...
Big data et données géospatiales : Enjeux et défis pour la géomatique. Thierry Badard, PhD, ing. jr Centre de Recherche en Géomatique
 Big data et données géospatiales : Enjeux et défis pour la géomatique Thierry Badard, PhD, ing. jr Centre de Recherche en Géomatique Événement 25e anniversaire du CRG Université Laval, Qc, Canada 08 mai
Big data et données géospatiales : Enjeux et défis pour la géomatique Thierry Badard, PhD, ing. jr Centre de Recherche en Géomatique Événement 25e anniversaire du CRG Université Laval, Qc, Canada 08 mai
Stephan Hadinger, Sr. Mgr Solutions Architecture, AWS. Salon du Big Data 11 mars 2015
 Stephan Hadinger, Sr. Mgr Solutions Architecture, AWS Salon du Big Data 11 mars 2015 Accélération de l innovation +500 +280 Amazon EC2 Container Service +159 AWS Storage Gateway Amazon Elastic Transcoder
Stephan Hadinger, Sr. Mgr Solutions Architecture, AWS Salon du Big Data 11 mars 2015 Accélération de l innovation +500 +280 Amazon EC2 Container Service +159 AWS Storage Gateway Amazon Elastic Transcoder
Avant-propos. Organisation du livre
 Avant-propos Avec Hadoop par la pratique, les développeurs vont apprendre à maîtriser Hadoop et vont acquérir de nombreuses compétences sur la résolution de problèmes à l aide de ce framework. Ils vont
Avant-propos Avec Hadoop par la pratique, les développeurs vont apprendre à maîtriser Hadoop et vont acquérir de nombreuses compétences sur la résolution de problèmes à l aide de ce framework. Ils vont
Sécuristation du Cloud
 Schémas de recherche sur données chiffrées avancés Laboratoire de Cryptologie Thales Communications & Security 9 Avril 215 9/4/215 1 / 75 Contexte Introduction Contexte Objectif Applications Aujourd hui
Schémas de recherche sur données chiffrées avancés Laboratoire de Cryptologie Thales Communications & Security 9 Avril 215 9/4/215 1 / 75 Contexte Introduction Contexte Objectif Applications Aujourd hui
Differential Synchronization
 Differential Synchronization Neil Fraser Google 2009 BENA Pierrick CLEMENT Lucien DIARRA Thiemoko 2 Plan Introduction Stratégies de synchronisation Synchronisation différentielle Vue d ensemble Dual Shadow
Differential Synchronization Neil Fraser Google 2009 BENA Pierrick CLEMENT Lucien DIARRA Thiemoko 2 Plan Introduction Stratégies de synchronisation Synchronisation différentielle Vue d ensemble Dual Shadow
La dernière base de données de Teradata franchit le cap du big data grâce à sa technologie avancée
 Communiqué de presse Charles-Yves Baudet Twitter: Les clients de Teradata Teradata Corporation peuvent dan.conway@teradata.com tirer parti de plusieurs + 33 1 64 86 76 14 + 33 (0) 1 55 21 01 48/49 systèmes,
Communiqué de presse Charles-Yves Baudet Twitter: Les clients de Teradata Teradata Corporation peuvent dan.conway@teradata.com tirer parti de plusieurs + 33 1 64 86 76 14 + 33 (0) 1 55 21 01 48/49 systèmes,
Big Data? Big responsabilités! Paul-Olivier Gibert Digital Ethics
 Big Data? Big responsabilités! Paul-Olivier Gibert Digital Ethics Big data le Buzz Le Big Data? Tout le monde en parle sans trop savoir ce qu il signifie. Les médias high-tech en font la nouvelle panacée,
Big Data? Big responsabilités! Paul-Olivier Gibert Digital Ethics Big data le Buzz Le Big Data? Tout le monde en parle sans trop savoir ce qu il signifie. Les médias high-tech en font la nouvelle panacée,
Les enjeux du Big Data Innovation et opportunités de l'internet industriel. Datasio 2013
 Les enjeux du Big Data Innovation et opportunités de l'internet industriel François Royer froyer@datasio.com Accompagnement des entreprises dans leurs stratégies quantitatives Valorisation de patrimoine
Les enjeux du Big Data Innovation et opportunités de l'internet industriel François Royer froyer@datasio.com Accompagnement des entreprises dans leurs stratégies quantitatives Valorisation de patrimoine
 Préface Dunod Toute reproduction non autorisée est un délit. Les raisons de l émergence du Big Data sont bien connues. Elles sont d abord économiques et technologiques. La chute exponentielle des coûts
Préface Dunod Toute reproduction non autorisée est un délit. Les raisons de l émergence du Big Data sont bien connues. Elles sont d abord économiques et technologiques. La chute exponentielle des coûts
Change the game with smart innovation
 Change the game with smart innovation Master Thesis 2013 2014 Faculty of Science engineering 12/08/2012 Master Thesis proposal for the academic year 2013. TABLE OF CONTENTS Section Un Introduction... 3
Change the game with smart innovation Master Thesis 2013 2014 Faculty of Science engineering 12/08/2012 Master Thesis proposal for the academic year 2013. TABLE OF CONTENTS Section Un Introduction... 3
Bases de données documentaires et distribuées Cours NFE04
 Bases de données documentaires et distribuées Cours NFE04 Scalabilité Auteurs : Raphaël Fournier-S niehotta, Philippe Rigaux, Nicolas Travers prénom.nom@cnam.fr Département d informatique Conservatoire
Bases de données documentaires et distribuées Cours NFE04 Scalabilité Auteurs : Raphaël Fournier-S niehotta, Philippe Rigaux, Nicolas Travers prénom.nom@cnam.fr Département d informatique Conservatoire
Guide de commande Commander un certificat d identité numérique PersonalSign
 Guide de commande Commander un certificat d identité numérique PersonalSign 1 SOMMAIRE Commander un certificat PersonalSign 2 Pro (pour individus dans une organisation) Commander un certificat PersonalSign
Guide de commande Commander un certificat d identité numérique PersonalSign 1 SOMMAIRE Commander un certificat PersonalSign 2 Pro (pour individus dans une organisation) Commander un certificat PersonalSign
Paris Airports - Web API Airports Path finding
 Paris Airports - Web API Airports Path finding Hackathon A660 Version Version Date writer Comment 1.0 19/05/2015 Olivier MONGIN Document creation Rédacteur : Olivier.MONGIN@adp.fr Date : 19/05/2015 Approbateur
Paris Airports - Web API Airports Path finding Hackathon A660 Version Version Date writer Comment 1.0 19/05/2015 Olivier MONGIN Document creation Rédacteur : Olivier.MONGIN@adp.fr Date : 19/05/2015 Approbateur
affichage en français Nom de l'employeur *: Lions Village of Greater Edmonton Society
 LIONS VILLAGE of Greater Edmonton Society affichage en français Informations sur l'employeur Nom de l'employeur *: Lions Village of Greater Edmonton Society Secteur d'activité de l'employeur *: Développement
LIONS VILLAGE of Greater Edmonton Society affichage en français Informations sur l'employeur Nom de l'employeur *: Lions Village of Greater Edmonton Society Secteur d'activité de l'employeur *: Développement
Technologies Web. Ludovic Denoyer Sylvain Lamprier Mohamed Amine Baazizi Gabriella Contardo Narcisse Nya. Université Pierre et Marie Curie
 1 / 22 Technologies Web Ludovic Denoyer Sylvain Lamprier Mohamed Amine Baazizi Gabriella Contardo Narcisse Nya Université Pierre et Marie Curie Rappel 2 / 22 Problématique Quelles technologies utiliser
1 / 22 Technologies Web Ludovic Denoyer Sylvain Lamprier Mohamed Amine Baazizi Gabriella Contardo Narcisse Nya Université Pierre et Marie Curie Rappel 2 / 22 Problématique Quelles technologies utiliser
Le Big Data Vers de nouveaux usages! 18/03/2015
 Le Big Data Vers de nouveaux usages! 18/03/2015 Atos en bref est une société internationale spécialisée dans les services technologiques innovants, les services transactionnels à haute valeur et le conseil,
Le Big Data Vers de nouveaux usages! 18/03/2015 Atos en bref est une société internationale spécialisée dans les services technologiques innovants, les services transactionnels à haute valeur et le conseil,
Big Data et Graphes : Quelques pistes de recherche
 Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de Lyon/Université Claude Bernard Lyon 1/Université
Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de Lyon/Université Claude Bernard Lyon 1/Université
Analytics & Big Data. Focus techniques & nouvelles perspectives pour les actuaires. Université d Eté de l Institut des Actuaires Mardi 8 juillet 2014
 Analytics & Big Data Focus techniques & nouvelles perspectives pour les actuaires Local Optimization European Minded Université d Eté de l Institut des Actuaires Mardi 8 juillet 2014 Intervenants : Alexandre
Analytics & Big Data Focus techniques & nouvelles perspectives pour les actuaires Local Optimization European Minded Université d Eté de l Institut des Actuaires Mardi 8 juillet 2014 Intervenants : Alexandre