Chapitre 1 LE TEST DU KHI-DEUX
|
|
|
- Maximilien Morel
- il y a 8 ans
- Total affichages :
Transcription
1 Chapitre LE TEST DU KHI-DEUX I. Présentation de la statistique khi - carré ( χ²) Une somme de ν carré de variables indépendantes normalement distribuées de moyenne 0 et de variance suit une loi normale dite du khi-deux ou du khi-carré notée χ². Y Χ ν Y0Χ e avec Y 0 constante telle que l aire sous la courbe soit égale à ν nombre de degrés de liberté Figure : distributions χ² pour ν,, 4 et 8 II. Les tables du khi-deux Ces lois ont été tabulées pour ν variant de à 00. La table correspondant au nombre de degrés de liberté ν fournit le fractile d ordre p noté χ² p III. Le test du khi deux III.. Mode de calcul ( o e ) ( o e ) ( o p e p ) ( o e ) e e e p i e avec o i effectifs observés et e i effectifs théoriques i i

2 o e i N effectif total i On montre que ( ) ( ) o e o e ( o p e ) p ( oi ei ) e e e p e i oi e i N III.. Exemple de calcul de khi deux d ajustement Pour tester si un dé n est pas truqué, on le jette 50 fois et on note les résultats obtenus : En posant comme hypothèse nulle «le dé n est pas truqué», on s attend à ce que les effectifs observés ne diffèrent pas des effectifs théoriques, qui sont 5, 5, 5,, 5 (50 divisé par 6) χ observé ( 7 5) ( 6 5) ( 38 5) ( 5) ( 5 5) ( 5) ² 6² 38² ² 5² ² ou χ observé On fixe le seuil de significativité à 0% par exemple Le nombre de degrés de liberté est égal à 6-5 On lit dans la table : Χ 0.90 à ν 5 : 9.4 Si le Χ observé > 9.4, on rejette Si le Χ observé < 9.4, on ne peut pas rejeter H 0 (et on ne conclut pas) ; Dans notre cas, 0.08 > 9.4, on rejette H 0 (et on conclut que le dé est truqué) avec 0 chances sur 00 de se tromper. Si on travaille à 5%, on lit Χ 0.95 à ν 5 :. et dans ce cas 0.08 < 9.4, on ne peut rejeter H 0 (et on ne conclut pas). III. 3. Exemple de calcul de khi deux de croisement On travaille à partir du tableau de contingence qui sert à calculer les effectifs théoriques : A B totaux marginaux totaux de ligne X e e L Y e e L totaux marginaux totaux de colonne C C N e (L C )/N e (L C )/N

3 Exemple avec nombreuses modalités de variables Soit la répartition de 00 familles selon le nombre d enfants (X) et le nombre de pièces du lieu d habitation (Y). Testez à 5% l indépendance de ces deux variables nominales. Y X et + n. j et n i n.. 00 On inscrit en rouge les effectifs théoriques dans chacune des cases du tableau. Ho : il y a indépendance entre ces deux variables ( il n y a pas de lien entre le nombre d enfants et le nombre de pièces de l habitation) α 5% ν (5-)(5-) 6 χ² Si χ² observé > 6.3 Si χ² observé < 6.3 on rejette Ho on ne peut pas rejeter Ho χ observé < 6.3 donc on ne peut pas conclure à l indépendance entre les variables 3
 α 5% ν (5-)(5-) 6 χ² 0.95 6.3 Si χ² observé > 6.")
4 Mode de calcul pour le cas particulier de variables à modalités Dans ce cas particulier, on n a pas besoin de calculer les effectifs théoriques. X X totaux marginaux totaux de ligne Y a b n. Y c d n. totaux marginaux totaux de colonne n. n. n.. ab n.. cd n.. ( ad cb) χ ² n. n. n. n. n. n. n. n. IV. Conditions d application du khi-deux Les fréquences théoriques L indépendance des observations L inclusion des non-occurrences Khi-deux : test unilatéral ou bilatéral? V. Les mesures d association Exemples sur lesquels on va travailler (issus de Howell) ) relation entre tabagisme et sexe non-fumeurs fumeurs hommes femmes ( ) 000 χ
 ) relation entre tabagisme et sexe non-fumeurs fumeurs hommes 350 50 500 femmes 400 00 500")
5 ) relation entre responsabilité des courses alimentaires et sexe oui non hommes femmes χ ( ) C Le coefficient de contingence χ χ + N exemples : C. C Le coefficient Phi (Ø) Dans le cas des tables, le coefficient phi est une bonne mesure de corrélation entre deux variables dichotomiques. Φ χ N exemples : Φ. Φ Le coefficient Phi (ou V) de Cramèr (Ø c ) Φ c χ N ( k ) avec N taille de l échantillon et k plus petite valeur entre L (nbre de lignes) et C (nbre de colonnes) La mesure d accord : le kappa de Cohen (K) Cette statistique ne se base pas sur le khi-deux mais sur le tableau de contingence et sur le calcul des effectifs attendus. 5
 de Cramèr (Ø c ) Φ c χ N ( k ) avec N taille de l échantillon et k plus petite valeur entre L (nbre de lignes) et C (nbre de colonnes) La")
6 Exemple (Howell) : JUGE JUGE Pas de problèmes Intériorisation Extériorisation Pas de problèmes Intériorisation 3 6 Extériorisation On voit les accords : les entrées en diagonales (5, 3 et 3) Les désaccords se sont toutes les autres cases. JUGE JUGE Pas de problèmes Intériorisation Extériorisation Pas de problèmes 5 (0.67) 3 0 Intériorisation 3 (.) 6 Extériorisation 0 3 (.07) La formule du kappa est : ei oi ei κ avec o i les effectifs observés en diagonale N et e i les effectifs théoriques (attendus) en diagonale κ ( ) ( ) 30 ( )
 4 6 6 8 30 La formule du kappa est : ei oi ei κ avec o i les effectifs observés en diagonale N et e i les effectifs théoriques (attendus) en")
7 7

8 Chapitre COEFFICIENTS DE CORRELATION POUR VARIABLES ORDINALES I. Le coefficient rho de Spearman (ρ) Exemple : 5 copies d examen classées selon critères (X : cohérence argumentative et Y : nombre de connecteurs logiques utilisés) r X r Y Formule de rho : 6 d ρ N ( N ) ) Exemple : Calcul de rho : r X r Y r X -r Y d i ² Σ d i ² 30 ρ ² ( ) Remarques : Si les classements sont identiques : ρ Exemple de classements identiques : r X r Y r X -r Y d i ² ρ ( 6² ) 8

9 Si les classements sont inversés : ρ - r X r Y r X -r Y d i ² ρ ( 6² ) cas des ex-aequo Exemple : données brutes sur 7 individus selon deux critères X et Y ) on range X, on garde les couples ) on attribue des rangs aux données de X 3) on attribue des rangs aux données de Y 4) on calcule d 5) on calcule d² X i Y i X i rangés Y i r X r Y r X -r Y d i ² Σ d i ² 3.5 ρ ( 7² ) II. Le coefficient tau de Kendall (τ) Exemple : 5 individus statistiques classés selon critères X et Y r X r Y ère méthode ) on range par ordre croissant selon le premier critère ) on conserve les couples de données 3) on détermine les z ij 9
 Exemple : 5 individus statistiques classés selon critères X et Y r X 3 5 4 r Y 3 4 5 ère méthode ) on range par ordre croissant selon le premier critère ) on")
10 z ij si r yj > r yi z ij - si r yj r yi exemple : r X r Y r X rangés r Y rangés z. - z. 3 z 3. z Σz ij 6 z ij τ avec n nombre de sujets n( n ) τ (5 ) ème méthode ) on range par ordre croissant selon le premier critère ) on conserve les couples de données 3) on calcule pour chaque donnée rangée combien on a de données strictement supérieures à cette donnée (on compte point pour chaque donnée de rang supérieur) et combien on a de données de rang égal ou inférieur (on compte - à chaque fois) ; on fait la différence entre ces deux nombres et on l inscrit en dessous de la donnée. 4) On fait la somme de ces différences : S Exemple : r X r Y r X rangés r Y rangés / S 6 S 6 τ τ 0. 6 n( n ) 5(5 ) 0
 On fait la somme de ces différences : S Exemple : r X 3 5 4 r Y 3 4 5 r X rangés 3 4 5 r Y rangés 3 5 4 3 - / S 6 S 6 τ τ 0.")
11 Le cas des ex æquo τ n( n ) T S n( n ) X T Y avec T X t( t ) et T Y t( t ) t nombre d ex æquo dans chaque groupe Exemple : X i Y i X i rangés Y i r X r Y / 3 Tx ½ [ 3 (3-) + (-) ] 4 T Y ½ [ ( (-) ] τ n( n ) T S n( n ) X T Y τ (7 ) 4 7(7 ) Remarque : il y a plusieurs calculs de τ possibles, selon la position des r X ex aequo et les r Y correspondant. III. Le coefficient de concordance de Kendall (W) Exemple : 6 examinateurs classent 5 candidats E E E3 E4 E5 E6 r i C 3 C C C C
 Exemple : 6 examinateurs classent 5 candidats E E E3 E4 E5 E6 r i C 3 C 4 3 3 5 8 C3 5 5 4 5 5 4 8 C4 3 4 5 4 3")
12 n VarR W avec k nombre de juges et n nombre d individus k n ( n ) Exemple : E E E3 E4 E5 E6 r i r i ² C 3 C C C C Moy R 90/5 varr 84/5 (90/5)² W (5 ) 0.54 Remarque kw ρ k Le cas des ex æquo W nvarr k² n( n² ) k T n VarR (rappel : W ) k n ( n ) 3 avec T ( t t) t nombre d ex æquo dans chaque groupe d ex aequo Exemple : Soit 0 individus classés selon 3 critères. Les rangs sont les suivants : r X r Y r Z Σ r i r i ²

13 Tx / [ ( 3 -) + ( 3 -) ] T Y / [ ( 3 -) + ( 3 -) + ( 3 -) ].5 T Z / [ (4 3 4) + (3 3 3) ] 7 W W nvarr k² n( n² ) k T (0² ) 3 ( ) IV. Significativité des coefficients. Coefficient rho de Spearman Si 4 N 30 Table des valeurs critiques du ρ de Spearman 3

14 Si N 0 N La valeur t ρ est distribuée selon la loi de Student à ν N- degrés de liberté ρ Table de la loi de Student 4

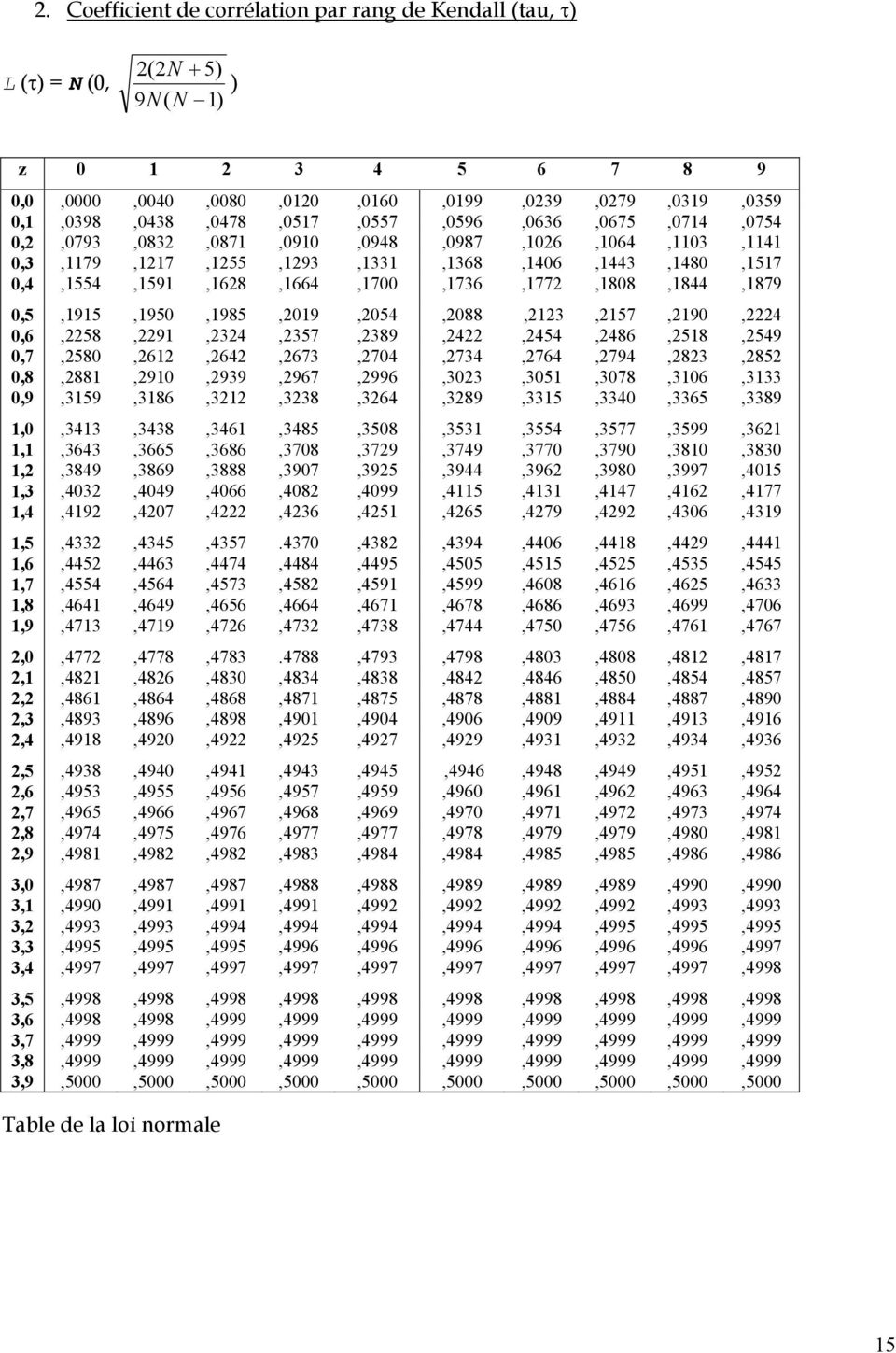
15 . Coefficient de corrélation par rang de Kendall (tau, τ) L (τ) N (0, (N + 5) 9N( N ) ) z ,0,0000,0040,0080,00,060,099,039,079,039,0359 0,,0398,0438,0478,057,0557,0596,0636,0675,074,0754 0,,0793,083,087,090,0948,0987,06,064,03,4 0,3,79,7,55,93,33,368,406,443,480,57 0,4,554,59,68,664,700,736,77,808,844,879 0,5,95,950,985,09,054,088,3,57,90,4 0,6,58,9,34,357,389,4,454,486,58,549 0,7,580,6,64,673,704,734,764,794,83,85 0,8,88,90,939,967,996,303,305,3078,306,333 0,9,359,386,3,338,364,389,335,3340,3365,3389,0,343,3438,346,3485,3508,353,3554,3577,3599,36,,3643,3665,3686,3708,379,3749,3770,3790,380,3830,,3849,3869,3888,3907,395,3944,396,3980,3997,405,3,403,4049,4066,408,4099,45,43,447,46,477,4,49,407,4,436,45,465,479,49,4306,439,5,433,4345, ,438,4394,4406,448,449,444,6,445,4463,4474,4484,4495,4505,455,455,4535,4545,7,4554,4564,4573,458,459,4599,4608,466,465,4633,8,464,4649,4656,4664,467,4678,4686,4693,4699,4706,9,473,479,476,473,4738,4744,4750,4756,476,4767,0,477,4778, ,4793,4798,4803,4808,48,487,,48,486,4830,4834,4838,484,4846,4850,4854,4857,,486,4864,4868,487,4875,4878,488,4884,4887,4890,3,4893,4896,4898,490,4904,4906,4909,49,493,496,4,498,490,49,495,497,499,493,493,4934,4936,5,4938,4940,494,4943,4945,4946,4948,4949,495,495,6,4953,4955,4956,4957,4959,4960,496,496,4963,4964,7,4965,4966,4967,4968,4969,4970,497,497,4973,4974,8,4974,4975,4976,4977,4977,4978,4979,4979,4980,498,9,498,498,498,4983,4984,4984,4985,4985,4986,4986 3,0,4987,4987,4987,4988,4988,4989,4989,4989,4990,4990 3,,4990,499,499,499,499,499,499,499,4993,4993 3,,4993,4993,4994,4994,4994,4994,4994,4995,4995,4995 3,3,4995,4995,4995,4996,4996,4996,4996,4996,4996,4997 3,4,4997,4997,4997,4997,4997,4997,4997,4997,4997,4998 3,5,4998,4998,4998,4998,4998,4998,4998,4998,4998,4998 3,6,4998,4998,4999,4999,4999,4999,4999,4999,4999,4999 3,7,4999,4999,4999,4999,4999,4999,4999,4999,4999,4999 3,8,4999,4999,4999,4999,4999,4999,4999,4999,4999,4999 3,9,5000,5000,5000,5000,5000,5000,5000,5000,5000,5000 Table de la loi normale 5
16 3. Coefficient de concordance de Kendall (W) N 7 On confronte nvar avec la valeur donnée dans une table pour k (nombre de juges) et n (nombre de sujets). Si la valeur calculée > valeur lue on rejette Ho N Valeurs supplémentaires pour N3 k k s Valeurs à Valeurs à Table des valeurs critiques de s (nvar) dans le coefficient de concordance de Kendall N > 7 L (k (n ) W) χ² ν n- 6
 dans le coefficient de concordance de Kendall N > 7 L (k (n ) W) χ² ν n- 6")
17 Chapitre 3 TESTS NON PARAMETRIQUES CAS D UN ECHANTILLON I. Le test binomial On utilise le test binomial lorsque la variable nominale présente modalités et que l effectif de l échantillon est petit. Exemple : La consigne d un expérimentateur propose au sujet de choisir entre deux options A et B (question fermée) ; 6 sujets répondent A : B : 4 Il pose donc comme hypothèse nulle qu il n y a pas de différence entre le nombre de réponses A et B (comme si on avait obtenu 8 et 8). Une table a été établie pour rejeter ou ne pas rejeter cette hypothèse nulle en fonction des résultats observés si N < 5 Voici la procédure : N nombre total de cas observés 6 x plus petit effectif (des deux) observés 4 on fixe le seuil : 0.05 On regarde dans la table la probabilité d apparition de cette valeur 4 ; elle est de <.05 donc on rejette l hypothèse nulle au risque de 5% Si on n avait que 0 sujets : N 0 A 8 B x proba lue.055 >.05 donc non significatif à 5% 7

18 x N Table of probabilities associated with values as small as observed values of x in the BINOMIAL TEST Given in the body of this table are one-tailed probabilities under Ho for the binomial test when P Q ½ II. Le test de Kolmogorov-Smirnov Ce test est un test d ajustement entre la distribution d une variable observée sur un échantillon et une distribution théorique. Il permet de dire si un échantillon peut raisonnablement être constitué comme provenant d une population présentant la distribution théorique. Il concerne les variables ordinales. Il porte sur la distribution cumulée des effectifs et permet de déterminer la probabilité de l écart entre l observé et le théorique. Exemple : observation d origine sociologique ; les noirs américains semblent préférer un teint clair (une couleur de peau) 0 personnes de couleur sont photographiées et chaque photo est tirée en 5 versions différentes en intensité de noir ; ces versions peuvent être rangées de à 5 (de la plus noire à la moins noire). Chaque sujet choisit sa propre photo parmi les 5 versions Si l hypothèse (les personnes de couleurs américaines préfèrent une couleur de peau plus claire) est fausse alors on ne devrait pas observer de différence entre les choix. Ces choix devraient se distribuer de façon égale avec la même probabilité d apparition. Ho : les effectifs des modalités des photos choisies sont égaux Seuil 5% N 0 8

19 rang de la modalité choisie o i o i S N (x) 0 /0 /0 6/0 0/0 e i e i F O (x) /0 4/0 6/0 8/0 0/0 F O (x) - S N (x) /0 3/0 5/0 /0 0 S N (x) fréquences observées cumulées croissantes F O (x) fréquences théoriques cumulées croissantes On calcule D sup F O (x) - S N (x) D 5/0 0.5 La table donne les valeurs de ce D en fonction du nombre de sujets et du seuil de significativité ; les valeurs lues peuvent être considérées comme des valeurs à ne pas dépasser si l on veut Ho ; si la valeur calculée est supérieure à la valeur lue, on rejette Ho. Dans notre exemple, on lit une valeur dans la table de > 0.40 donc on rejette Ho à 5% (et d ailleurs aussi à %) 9

20 N Au-delà de 35. N.36 N.63 N Table pour le test de Kolmogorov-Smirnov 0

21 III. Le test des séquences Exemple : Soient les séquences suivantes de pile ou face lors de 0 lancers successifs d une même pièce de monnaie par un même joueur : P F P P P F F P P F F F P F F P P F F P P P P P P P P P P P F F F F F F F F F F P F P F P F P F P F P F P F P F P F P F 0 P 0 F 0 P 0 F 0 P 0 F Un test permet de savoir si l ordre d apparition des piles et les faces est aléatoire ou non. Il repose sur le calcul du nombre de séquence (r) de symboles identiques. Exemple : ) r ) r 3) r 0 Exemple : un financier s intéresse à la variation du CAC 40 ; il note les résultats suivants +0. ; ; -0.5 ; +. ; +.3 ; -0.0 ; ; ; ; +.5 ; -0.3 ; -.8 ; -.49 ; -.3 ; -3.3 ; -.0 ; ; ; ; -0.0 Il s intéresse à une éventuelle structure de l ensemble de ces variations opposée à une variation aléatoire On notera n le nombre de + et n le nombre de. On relève r 8
22 Toute valeur r inférieure ou égale à celle trouvée dans la table (a) ou supérieure à celle trouvée dans la table (b) cause le rejet de Ho au seuil de 0.05 (a) n n (b) n n VALEURS CRITIQUES DE r DANS UN TEST DE SEQUENCES
23 Cas des petits échantillons : n et n 0 Pour ces échantillons, une table donne les valeurs permettant de rejeter Ho à 5% Si r r a (valeur de r donnée dans la table a) ou Si r r b (valeur de r donnée dans la table b) alors on rejette Ho à 5% Exemples : ) la pièce de monnaie : n et n 0 cas : r Ho à 5% cas : r rejet de Ho cas 3 : r 0 rejet de Ho ) le CAC 40 : n 9 n et n r 8 table a : 8 > 6 et 8 < 6 donc pas de rejet de Ho à 5% Cas des grands échantillons Si n ou n > 0, on ne peut plus utiliser la table. On sait qu une bonne approximation de la distribution de r est une loi normale : L () r nn N n + n + ; n n (nn n n ) ( n + n ) ( n + n ) Exemple : 50 personnes, 30 hommes et 0 femmes forment une file d attente Ho : il n y a pas de structure, l ordre MF est aléatoire dans cette file H : l ordre n est pas aléatoire dans cette file M F M F M M M F F M F M F M F M M M M F M F M F M M F F F M F M F M F M M F M M F M M M M F M F M M n 30 et n 0 r 35 Le centrage réduction de r donne : Ecart type 3.36 Moyenne z seuil 5%.98 >.96 donc rejet de Ho (l ordre n est pas aléatoire) 3
24 Chapitre 4 TESTS NON PARAMETRIQUES CAS DE DEUX ECHANTILLONS APPARIES I. Test de Mac Némar On utilise ce test lorsqu un ensemble de sujets est mesuré de façon ordinale ou nominale à deux moments séparés par un certain traitement (au sens large) : une formation, un lecture de texte, une visite d un établissement, une vision d un document, un apprentissage, etc. Ce test analyse le changement du sujet sur un certain point entre l avant et l après. t 0 t Après 0 A B avant 0 C D Le nombre d individus qui changent est A+D Sous l hypothèse nulle, l effectif théorique est (A+D)/ dans les deux cases qui nous intéressent. Χ A D + ( A + D) A + D A + D Χ A + D ( A + D) A + D ( A D A + D ) En fait, on applique une correction (par continuité) qui consiste à calculer : Χ ( A D A + D ) et on le confronte à la table du khi deux A + D Attention : si < 5 on utilise préférentiellement le test binomial avec N A+D x la plus petite valeur entre A et D 4
25 Exemples : er cas : 30 sujets 3 sujets ont donné la bonne réponse au pré test et au post test sujets se sont trompés lors du pré test sujets ont donné la bonne réponse au post test t 0 t Après 0 3 avant 0 t 0 t Après avant A 6 D 9 A+D 5 (5/ > 5 donc on utilise le test de Mac Némar) Ho : la probabilité de passer de 0 à est égale à celle de passer de à 0 (autrement dit 6 pas différent de 9 ; ou encore pas d effet d apprentissage) H : probabilité de passer d échec à réussite (de 0 à ) est supérieure à celle de passer de réussite à échec (autrement dit, 9 > 6, effet de l apprentissage) ν seuil 5% Χ ( 6 9 ) < 3.84, on ne peut pas rejeter Ho ème cas : 5 sujets t 0 t Après 0 avant A D 7 5 5
26 A + D 9 9/ < 5 test binomial N 9 x probabilité lue dans la table:.09 >.05 donc on ne peut pas rejeter Ho (pas d effet de l apprentissage) II. Test de signe On utilise le test de signe lorsque l on veut comparer des valeurs ordinales pour un couple de données. Il est utile lorsqu il n y a pas de quantification possible mais il faut évidemment pouvoir ordonner les valeurs. C est le cas lorsque l on veut savoir si un groupe préfère tel ou tel objet (sur une échelle ordinale), événement, traitement ou autre. Petit échantillon : N 5 Exemple : On demande à 5 enfants d une classe de juger les deux enseignants qui enseignent à mitemps. Ils utilisent une échelle graduée de à 0 pour chacun des deux enseignants. On attribue le signe + lorsque la valeur de la ère colonne est supérieure à celle de la seconde ; 0 ou lorsque les deux valeurs sont équivalentes. Melle X Melle Y Ho La fréquence d apparition de «+» est égale à la fréquence d apparition de «-» / 6
27 Remarque : les couples où il n y a pas de différence entre les deux valeurs comparées ne sont pas décomptés (on ne les prend pas en compte) car leur jugement ne sont ni à l avantage de l une, ni de l autre. Remarque : si on prédit une évaluation meilleure pour l une ou l autre, on effectuera un test unilatéral ; si on prédit une différence entre les deux, ce sera un test bilatéral. Dans cet exemple, on prédit une évaluation meilleure en faveur de Melle X ; donc test unilatéral. H La fréquence d apparition de «+» est supérieure à celle de «-» ( Melle X est plus appréciée par les élèves que Melle Y) On est dans les conditions d application du test binomial (nombre de modalités ; p q / ; N 5) : o Attention, on utilise pour N, le nombre total de couples moins le nombre de couples n ayant pas produit de différence ; cela signifie qu il faut avoir évaluer les écarts (en +, ou -) avant de savoir si on peut utiliser le test binomial ou non) N 5 3 o x est le plus petit des effectifs (ici c est le nombre de «-») x 4 o lecture : p.94 donc on ne peut pas conclure (on ne peut pas rejeter Ho) car.94 >.05 Grand échantillon : N > 5 On procède dans un er temps de la même manière, c est-à-dire on attribue les signes +, ou -. Puis on comptabilise le nombre de «+» que l on appelle R. On sait que L (Z) N (0, ) avec N ( R ± 0.5) Z N avec R si R N/ R 0.5 si R > N/ Exemple : La classe compte 35 élèves et que l on a obtenu les résultats suivants : N R R > N/ (4) donc on utilise la formule avec R 0.5 7
28 Z ( 0.5) Le test est unilatéral droit ; dans la table de la loi normale, z.46 correspond à.493 donc à un α de On rejette donc Ho au profit de l hypothèse alternative au seuil de.007, Melle X est plus appréciée par ses élèves que Melle Y. III. Test de Wilcoxon Dans l exemple précédent, on s est intéressé à la seule différence de jugement des deux enseignants pour chaque élève. On pourrait, de plus, vouloir connaître l importance de l écart entre les couples d évaluation. Pour ce faire, on utilise le test de Wilcoxon : on aura alors accès à la significativité de la différence éventuelle autant au niveau des signes que de la grandeur de l écart. Le test de Wilcoxon est plus puissant que le test de signe, car par exemple il donnera plus d importance à l avis de l élève qui a attribué 9 et 3, qu à l avis de celui qui a attribué 7 et 6. Petit échantillon N 5 Même exemple : Ho les deux enseignantes sont également appréciées Melle X est plus appréciée que Melle Y H Melle X Melle Y Rang en valeur absolue Rang positif Rang négatif / / / Σ + 45 Σ
29 ) on calcule la différence entre les deux valeurs pour chaque couple (en considérant toujours la ère colonne 9 7 ; 8 5 ; etc) ) on range ces différences en valeur absolue : on a deux fois ; on attribue donc deux fois le rang.5 on a ensuite +, -, +, + : on attribue à chacune de ces valeurs le rang 4.5 on a +3, -3 : rang 7.5 on a -4, +4 : rang 9.5 on a +6, -6 : rang.5 3) dans les deux colonnes suivantes, on redistribue les rangs en leur attribuant leur signe 4) On somme les rangs positifs et les rangs négatifs Ho se traduit par Σ rangs positifs Σ rangs négatifs T plus petite des deux valeurs en valeur absolue T 33 N nombre de rangs pris en compte (nombre total de paires moins nombre de paires n ayant pas produit de différence) N 9
30 α unil. α bil N Table de Wilcoxon pour séries appariées Si T calculé est inférieur ou égal au T lu, on rejette Ho Si T calculé supérieur au T lu, on ne peut pas conclure Dans notre exemple, pour N, on a T calculé (33) > à tout T lu ; donc on ne peut pas conclure (on garde Ho) Grand échantillon N > 5 On procède avec le même calcul mais on ne peut pas utiliser la table ; on sait que T suit une loi normale : L ( T ) N N ( ( N + ) ; 4 N( N + )(N + ) ) 4 Exemple : N 7 Σ rangs positifs 76 Σ rangs négatifs -0 30
31 T inf (76 ; -0 ) 0 µ T 7 (7 + ) 4 89 σ T 7 (7 + ) ( donc T suit la loi normale L (T) (89 ; 4.6) On calcule le rapport critique : 0 89 RC < donc rejet de Ho à 5% -.09 < -.96 donc rejet de Ho à % 3
32 Chapitre 5 TESTS NON PARAMETRIQUES CAS DE DEUX ECHANTILLONS INDEPENDANTS I. Test de Fischer On utilise le test de Fischer lorsque deux échantillons indépendants diffèrent quant à une variable discrète (nominale ou ordinale) qui ne prend que deux valeurs lorsque la somme des tailles des deux échantillons est inférieure ou égale à 30. Le test de Fischer apparaît comme se substituant au test du khi-deux dans le cas d une hypothèse d indépendance d une table avec (-)(-) degré de liberté. Mais dans ce test (contrairement au binomial) on prend en compte les 4 cases du tableau et les effectifs peuvent être très petits. Exemple : Dans une enquête, on veut savoir si les femmes et les hommes sont d accord sur certains items ; chaque item est présenté sous la forme d une question fermée de type «d accord ou pas d accord». Item : «les femmes au foyer doivent être rémunérées pour leur travail ménager» 4 femmes entre 0 et 30 ans 0 d accord 4 pas d accord hommes entre 0 et 30 ans 4 d accord 8 pas d accord X X Y (fem) 0 4 Y (hom) 4 8 Ho il n y a pas de différence de proportion de sujets d accord ou pas d accord dans l un ou l autre groupe H Il y a une différence Une table donne les significations des différences Notation : Utilisation de la table X X Y (fem) A (0) B (4) A+B (4) Y (hom) C (4) D (8) C+D () A+C (4) B+D () A+B+C+D (6) ) calculer A+B et C+D ) repérer la valeur de A+B dans la table, puis repérer la valeur C+D 3
33 3) parmi les valeurs données de B, repérer celle du tableau. Sur la même ligne, on lit les valeurs de D à dépasser si on ne veut pas rejeter Ho C est-à-dire, si la valeur de D est plus petite ou égale à la valeur lue dans le tableau, à un seuil donné, on peut rejeter Ho au seuil donné. 4) Si on ne trouve pas la valeur de B, on prend celle de A ; dans ce cas, le tableau donne la valeur de C qu il faut comparer à celle des nos résultats. Le niveau de significativité est donné pour un test unilatéral ; s il s agit d un test bilatéral, il faut doubler les seuils. Si on peut lire B, on aura les valeurs limites pour D Si on peut lire A, on aura les valeurs limites pour C Dans notre exemple : A+B 4 C+D B 4 on ne le trouve pas dans la table A 0 C devrait être (pour pouvoir rejeter Ho) inférieur ou égal à 3 (pour unilatéral à 5% ou bilatéral à 0%) Or, C 4, donc on ne peut pas rejeter Ho ; pas de conclusion Contrainte : Il faut que A+B 5 et C+D 5, sinon on ne peut pas lire la table. Si ce n est pas le cas, on inverse le tableau de contingence. Exemple : X X Y Y A+B 6 donc on ne pourra pas lire la table On inverse le tableau Y Y X 9 3 X A+B C+D On ne trouve pas B ; on lit A 9 ; on compare 9 à C (7) ; C devrait être 3 pour rejeter Ho, donc pas de conclusion 33
34 II. Le test de Mann Whitney Lorsque deux échantillons indépendants sont mesurés de façon ordinale, on utilise un test de Mann Whitney (le test U) pour tester le fait qu ils proviennent ou non d une même population. L hypothèse nulle est qu il n y a pas de différence entre les deux populations dont sont issus ces deux échantillons quant à la variable ordinale observée. La mise en œuvre du test diffère selon que : n et n 8 (cas A) 9 n et n 0 (cas B) n > 0 (cas C) avec n et n taille des deux échantillons, n < n n et n 8 Un psycholinguiste, travaillant sur la compréhension des consignes lors d exercices de mathématiques en classe de seconde, manipule la forme syntaxique de ces textes. Après il note la compréhension de l élève avec un score entre 0 et 50 Texte classique A Texte travaillé selon hypothèse linguistique B Ho : il n y a pas de différence de compréhension selon le texte H : il y a une meilleure compréhension dans le groupe B On applique un test unilatéral ; si bilatéral, on aurait posé comme H «il y a une différence de compréhension selon le type de texte.» α 5% o On range les deux échantillons confondus par ordre croissant en identifiant chacune des données (échantillons A ou B) A A A A A B B B B A A B B o Pour chaque note de A, on compte le nombre de notes de B inférieures ou égales à elle. On fait le total. C est U A A A A A B B B B A A B B / / / / 4 4 / / 8 34
35 o On lit une des tables appropriées Ici n 6 et n 7 (n toujours inférieur à n) U 8 Dans les tables, on lit directement la probabilité de U calculé quand n 8 ; si la probabilité lue est inférieure au seuil décidé, on rejette Ho. Dans la table, on lit une probabilité de <.05, donc on rejette Ho au seuil de 5% Si test bilatéral, on double la probabilité lue (.074), si α., rejet. Remarque : Si on avait compté pour chaque note de B le nombre de notes de A inférieures ou égales, on aurait obtenu : A A A A A B B B B A A B B / / / / / / / Cette valeur est notée U ; elle n apparaît pas dans la table Si vous avez commencé par calculer la valeur qui n apparaît pas dans la table, il est inutile de recommencer en comptant le nombre de l autre groupe. On sait que : U + U n n Donc si dans les tables, la valeur calculée est supérieure à la plus grande valeur de U donnée dans la table, c est que vous avez calculé U et il faut prendre pour U : U n n U 9 n, n 0 Même exemple mais plus de sujets Texte classique A Texte travaillé B n 9 n o On attribue un rang à chacune des valeurs, les deux échantillons étant confondus ; on fait la somme des rangs (R) des valeurs de l échantillon A ainsi que celle des valeurs de l échantillon B Pour des raisons pratiques, on calcule ainsi : 35
36 A B valeur rang valeur rang n R 99 n9 R o On calcule U et U : U n n n ( n + ) + R U n n n ( n + ) + R 9 0 U U U inf (U ; U) U 33 o On lit les tables Les tables donnent les valeurs maximales que doit prendre U pour pouvoir rejeter Ho. Dans notre exemple, on utilise un test unilatéral : ère table α.05 U lu 7 33 > 7 pas de rejet ème table α.05 U lu 3 3 ème table α.0 U lu 8 n > 0 Les tables sont inutilisables. n n nn ( n + n + ) L ( U ) N( ; ) U sera calculé avec R et on calcule le rapport critique. 36
37 Ex æquo L écart type de la distribution est : 3 n n ( n + n ) ( n + n ) T ( n + n )( n + n ) avec T Exemple 3 t t et t nombre d ex æquo pour une valeur valeur rang valeur rang n 349 n : fois Remarque : inutile de calculer la somme de n n ( n + ) 4 5 U n n + R
38 3 4 m 47 T 8 σ 3 4 (4 + ) (4 + ) 4 (4 )(4 ) RC < <.96 donc compris dans la zone où on ne rejette pas Ho ; donc pas de conclusion III. Le test médiane On utilise le test de la médiane lorsqu on veut tester la différence entre deux groupes indépendants quant à une variable ordinale ou par intervalle. Plus précisément, il s agit de tester l hypothèse selon laquelle les deux groupes proviennent de deux populations présentant la même médiane ou non. La procédure est la suivante : On détermine la médiane de l ensemble des valeurs prises par la variable On dichotomise l ensemble des valeurs prises par la variable dans chaque groupe en : o Valeur inférieure strictement à la médiane o Valeur supérieure strictement à la médiane On rassemble dans un tableau de la forme G G < méd A B A+B >méd C D C+D A+C B+D A+B+C+D n+nn Selon les effectifs, on applique le test du khi-deux d indépendance de deux variables nominales ou le test de Fischer Remarque : Si le nombre d individus présentant exactement la valeur médiane est petit par rapport à n+n, on les élimine (de l ordre de 0%). Si le nombre d individus présentant exactement la valeur médiane est plus important, on dichotomise de la sorte : médiane et > médiane 38
39 Exemples ) variable ordinale G : G : n9 n 3 On cherche la médiane de l ensemble ; on classe donc toutes les valeurs : L intervalle médian est (5 ; 6) ; la médiane est de 5.5 On fait le tableau suivant : on dénombre combien de valeurs < 5.5 et > dans le G, ainsi que dans le G. G G < > On applique le test de Fischer : A+B C+D B 5 donc D doit être <0 si on veut rejeter Ho D 8 donc pas de conclusion ) variable par intervalle Soient deux distributions X et Y x i n i n i [0 ; 5[ 3 3 [5 ; 0[ 8 [0 ; 5[ 0 [5 ; 0[ 7 8 [0 ; 5[
40 y i n i n i [0 ; 5[ [5 ; 0[ 3 4 [0 ; 5[ 9 3 [5 ; 0[ 5 [0 ; 5[ Il faut d abord calculer la médiane de l ensemble ; on refait donc un tableau en additionnant pour chaque intervalle les effectifs correspondant de X et de Y z i n i n i [0 ; 5[ 4 4 [5 ; 0[ 5 [0 ; 5[ 9 34 [5 ; 0[ 9 53 [0 ; 5[ La médiane se situe dans la classe [0 ; 5[ car 67/33.5 On fait une interpolation linéaire ; on associe 5 d effectif cumulé à 0, 34 à 5 et on cherche la valeur de la variable entre 0 et 5 correspondant à 33.5 : mé mé Donc la médiane de l ensemble est de 4.87 Il s agit maintenant de connaître exactement le nombre de sujets de chacun des groupes qui présentent une valeur < et > à 4.87 Pour cela, il faudra refaire des interpolations linéaires, avec un raisonnement inverse de celui que l on vient de faire : on connaît les valeurs de la variable, on cherche les effectifs cumulés correspondants. er groupe : x i n i n i [0 ; 5[ 3 3 [5 ; 0[ 8 [0 ; 5[ 0 [5 ; 0[ 7 8 [0 ; 5[ La mé de l ensemble est situé dans la classe [0 ; 5[ ; à la valeur 0 correspond sujets ( sujets ont un score strictement inférieur à 0) ; à la valeur 5 correspond sujets ; à combien de sujets correspond la valeur On va appeler A ce nombre de sujets : 40
41 A A Comme n 3, C ème groupe : y i n i n i [0 ; 5[ [5 ; 0[ 3 4 [0 ; 5[ 9 3 [5 ; 0[ 5 [0 ; 5[ La médiane de l ensemble est toujours dans la classe [0 ; 5[ ; on associe 0 à 4, 5 à 3 et on cherche 4.87 à combien? B B Comme n 35, D On peut maintenant faire le tableau : G G < > Χ ( ) ν Khi-deux lu à > 3.84 donc on rejette Ho au profit de H à 5% (S, p<.05) 4
42 Chapitre 6 ANALYSE DE LA VARIANCE I. Introduction Exemple : Soit l hypothèse selon laquelle le temps de réaction à un stimulus peut être affecté par la teneur de la consigne. C groupe contrôle : «Appuyez sur la touche le plus rapidement possible après l allumage de la lampe rouge.» C groupe expérimental «Appuyez sur la touche le plus rapidement possible après l allumage de la lampe rouge ; attention la lampe peut s allumer dans une autre couleur, n appuyez que si elle est rouge.» Σ m Gpe contrôle Gpe expé Temps en ms Variances intra et inter L idée générale est la suivante : on travaille non seulement sur l écart entre les deux moyennes, mais aussi sur la variabilité générale. La variabilité intra est mesurée par la variance intra qui donne une mesure de l erreur expérimentale (cf. cours ère année, variations aléatoires des mesures) ; elle explique les variations, pour une même situation expérimentale, du temps de réaction au sein d un même groupe de sujets (ou de plusieurs mesures pour un même sujet). Elle n atteint pas du tout la différence entre les deux situations. La variabilité inter est mesurée par la variance inter qui exprime l action éventuelle de la VI (variable indépendante) et celles de facteurs aléatoires (erreur expérimentale et fluctuation d échantillonnage) ; elle prend en compte les variations entre les deux situations (les deux groupes). On s intéresse au rapport : F cal Var int er c est l indice d effet de la VI Var int ra Si il n y a pas d effet de la VI : la var inter se réduit à l erreur expérimentale la var intra est, par définition, l erreur expérimentale et donc F cal 4
43 S il y a un effet de la VI : la var inter contient l erreur expérimentale mais quelque chose de chose en plus qui est bien plus important (en termes de quantité) que seule cette erreur la var intra est, par définition, l erreur expérimentale et donc F cal > Evidemment, c est la valeur de l écart entre F cal et qui sera ou non significatif. II. Notation Pour le moment, nous travaillons avec des groupes de même effectif. Un plan expérimental simple est noté S (A) S ensemble des individus statistiques pour un groupe cardinal de S S A ensemble des modalités prises par la VI cardinal de A A Dans notre exemple, on noterait S 0 (A ) On note : a une modalité de la VI (dans notre exemple, a ou, on attribue une modalité arbitraire car variable nominale) Y a s valeur de la variable (VD) pour un individu précis qui appartient à un groupe précis (donc pour une valeur précise de la VI) s S Y a. Y as somme des valeurs de la variable (VD) pour les individus s qui ont a pour modalité de la VI a A s S a s Y.. Yas somme de toutes les valeurs de la variable (VD) pour toutes les modalités de la VI Ya. M a. moyenne des valeurs de la variable VD pour une S modalité précise de la variable VI Y.. moyenne de toutes les valeurs de la variable VD SA pour toutes les modalités de la VI M.. Dans notre exemple : a groupe contrôle a groupe expérimental Y 4 Y 7 8 Y Y
44 Y.. Y. + Y. 450 M. 50/0 5 M. 00/0 0 M Les sommes des carrés Dans l anova, les variances inter (entre) et intra (dans) se ramènent à des sommes de carrés rapportées à des degrés de liberté. On travaille sur des écarts entre les valeurs de la variable et les moyennes. Y a s M.. (Y a s M a. ) + (M a. - M.. ) (Y a s M.. )² (Y a s M a. )² + (M a. - M.. )² + (Y a s M a. ) (M a. - M.. ) On veut la somme des carrés des écarts à la moyenne (cf. formule variance) a A s S a s a A s S a s (Y a s M.. )² a A s S a s a A s S a s (Y a s M a. )² + (Y a s M a. ) (M a. - M.. ) (M a. - M.. )² + or, on montre (cf Abdi Introduction au traitement statistique des données expérimentales), que la somme du dernier terme est nulle (car somme des Y a s somme des M a. ) on a donc a A s S a s a A s S a s (Y a s M.. )² a A s S a s (Y a s M a. )² + (M a. - M.. )² (Y a s M a. ) l écart entre un sujet et la moyenne dans son groupe ; donc la somme de tous ces écarts (donc pour tous les sujets) élevée au carré «représente ce qui se rapproche de la variance intra groupe» ; on l appelle SC dans (M a. - M.. ) écart entre la moyenne d un groupe et la moyenne générale ; la somme élevée au carré «représente ce qui se rapproche de la variance inter» ; on l appelle SC entre. (Y a s M.. ) écart entre le score d un individu et la moyenne générale ; la somme élevée au carré est SC tot donc on voit que SC tot SC dans + SC entre 44
45 somme des carrés totale somme des carrés dans les groupes + somme des carrés entre les groupes. Les degrés de liberté En regardant les formules précédentes, on s aperçoit qu elles dépendent du nombre de sujets (plus le nombre de sujets augmente, plus la somme des carré dans les groupes augmente). Si on veut comparer ces sommes, il faut les exprimer sur une même échelle ; il faut donc les normer selon le nombre de sujets, donc selon le degré de liberté. SC entre est calculé à partir des écarts des moyennes de groupes à la moyenne générale ; si nous avons A groupes, nous avons A moyennes donc : ddl entre A- SC dans est calculé à partir des écarts des scores de chaque groupe à la moyenne du groupe. Nous avons S observations par groupe (donc ddl S-) et nous avons une moyenne par groupe, donc A moyennes. ddl dans A (S-) AS A N A avec N nombre total de sujets SC tot se calcule à partir des écarts de chacun des scores à la moyenne générale ; nous avons N scores (ou S A) : ddl tot N Remarque : SC tot SC dans + SC entre ddl tot ddl dans + ddl entre N N A + A- Ces deux relations sont fondamentales dans l analyse de variance. Les carrés moyens On définit donc les carrés moyens comme le rapport des sommes des carrés sur le nombre de degrés de liberté correspondant : SC CM dans ddl dans dans SC CM entre ddl entre entre Attention CM tot CM dans + CM entre 45
46 Exemple : Σ Gpe contrôle Y. 50 Gpe expé Y. 00 m M. 5 M. 0 SC dans est la somme des écarts au carré entre les sujets et la moyenne de son groupe : SC dans (3-5)² + (4-5)² (7-5)² + (0-0)² + (5-0)² + + (9-0)² 37 SC entre est la somme des écarts entre la moyenne d un groupe et la moyenne générale (attention, pondérée par le nombre d individus dans chaque groupe) 450 M SC entre 0 (5-.5)² + 0 (0-.5)² 5 SC tot est la somme des écarts au carré entre le score d un individu et la moyenne générale : SC tot (3-.5)² (7-.5)² + (0-.5)² +. + (9-.5)² SC dans + SC entre ddl dans A (S-) AS A N A avec N nombre total de sujets 0 8 ddl entre A- - ddl tot N 9 SCentre 5 SC entre dans 37 CM 5 CM dans ddl ddl 8 entre dans III. L indice d effet F czl CM CM entre dans effet VI + erreur erreur exp exp 5 dans notre exemple : F cal Cet indice d effet suit une loi de Fisher-Snédécor à double degré de liberté : ν A c est le ddl du numérateur (ddl entre ) ν A (S-) N A c est le ddl du dénominateur (ddl dans ) Il y a donc autant de tables possibles que de couples de degré de liberté ; on se contente de travailler avec deux tables, celle du seuil de 5% et celle du seuil de %. 46
47 Si F cal F table Si F cal < F table rejet de Ho pas de conclusion L hypothèse nulle consiste à affirmer que, dans l ensemble de la population (rappel que les hypothèses ne concernent pas l échantillon considéré, mais la population dont provient l échantillon), la VI n a pas d effet sur la VD. La valeur observée du critère s attribue au hasard (erreur expérimentale). L hypothèse alternative considère que dans l ensemble de la population, la VI a un effet sur la VD. La valeur observée du critère s attribue à l effet de la VI sur la VD. Dans notre exemple : On regarde dans la table la valeur de F table à 5% pour ν et ν 8 ; on lit > 4.4 on rejette Ho Au seuil de %, on lit < 8.8 pas de conclusion IV. Présentation des résultats Les résultats sont classiquement représentés dans un tableau Source SC ddl CM F cal entre dans total (S, p<.05) * (S, p<.0) ** ns On trouve aussi une notation plus générale pour la première colonne qui rappelle le plan expérimental : A (ou encore «consigne») pour «entre» Renvoie à l ensemble des modalités prises par les groupes, donc au nombre de groupes ; c est donc bien la variabilité due aux groupes ; traduit l effet de la VI S (A) (ou encore «erreur») pour «dans» C est la variabilité dans les groupes ; c est le facteur sujet, l erreur expérimentale. Autre exemple : Hypothèse sur l utilisation d images mentales favorise la mémorisation. Apprentissage de paires de mots ; ensuite on donne le premier mot, le sujet doit donner le second. Deux groupes de 5 sujets : Groupe expérimental : consigne pour imager (lier les deux mots de la paire avec une même image : chat + cigare : imaginer un chat fumant un cigare) Groupe contrôle : mémoriser les couples de mots. 47
48 On relève le nombre de mots rappelés par sujet. GE GC Ho la VI n a pas d effet sur la VD La manipulation expérimentale n affecte pas le comportement des sujets L imagerie n influence pas la mémorisation Le GC et le GE ne diffèrent pas pour le nombre de mots rappelés ; seul le hasard responsable des différences observées Dans l ensemble de la population, la moyenne GC est égale à la moyenne GE est H La VI a un effet sur la VD Etc.. S 5 A SC entre ou SC A 70 SC dans ou SC S(A) 68 SC tot 338 ddl entre ddl A - ddl dans ddl S(A) 30-8 ddl tot 9 SC 70 entre SC dans 68 CM entre CM A 70 CM dans CM S ( A). 43 ddlentre ddldans 8 70 F cal.8.43 ν ν 8 à 5% on lit 4.0 à % on lit 7.64 source SC ddl CM F cal A S (A) total ** Avec SPSS : Analyse comparer les moyennes moyennes définir VD et VI choisir option tableau anova et êta 48
49 Tableau de bord VAR0000 VAR0000,00,00 Total Moyenne N Ecart-type 0,0000 5,6475 4,0000 5,4639 7, ,440 Tableau ANOVA VAR0000 * VAR0000 Inter-groupes Intra-classe Total Combiné Somme Moyenne des carrés df des carrés F Signification 70,000 70,000,76,000 68,000 8,49 338,000 9 V. Autres modes de calcul Mode Il est fondé sur le tableau suivant avec les «nombres dans le carré». source SC ddl CM F cal A A - A- A (entre) A- S (A) (dans) AS - A AS - A AS A AS-A total AS - AS - On calcule 7 quantités : Q «Grand total» Y.. somme de toutes les valeurs Q AS Σ Y.. ² somme du carré de toutes les valeurs Q3 A Σ Y a. ² /S on calcule la somme des valeurs des individus pour le er groupe ; on l élève au carré et on la divise par le nombre d individus dans le groupe ; on fait de même pour tous les groupes et on somme le tout. Q4 Y.. ²/AS Q²/AS Q5 SC tot AS Q - Q4 Q6 SC entre SC A A Q3 Q4 Q7 SC dans SC S(A) AS A Q Q3 49
50 Exemple : Deux méthodes pédagogiques I et II ; 5 étudiants dans chaque groupe ; même épreuve I II Q Y Q AS Σ Y.. ² 75² + 6² ² + 8² ² 5877 Q3 A Σ Y a. ² /S ( )² /5 + ( )² / 5 339²/5 + 46²/ Q4 Y.. ²/AS Q²/AS 755² / Q5 SC tot AS Q - Q Q6 SC entre SC A A Q3 Q Q7 SC dans SC S(A) AS A Q Q On vérifie que On calcule (ddl entre ; ddl dans 0-8) CM entre 59.9 / 59.9 CM dans 58.6 / F cal 59.9/ source SC ddl CM F cal A (entre) S (A) (dans) total * Mode On peut également simplifier les calculs en faisant une translation à la variable. Dans notre exemple, on pose Y Y 70 I II 5-0 Y AS Σ Y.. ² 5² + 8² + ² +. + ² + 0² 477 A Σ Y a. ² /S ( )² / 5 + ( )² / 5 -² + 66² /
51 Y.. ²/AS Q²/AS 55² / source SC ddl CM F cal A A A- A (entre) A S (A) (dans) AS A AS A AS A AS-A total AS AS /8 7.7 * Autre exemple : 3 groupes de 5 étudiants ; 3 méthodes de mémorisation selon consigne. Peut-on conclure à un effet de la consigne? image construite (définition du mot à mémoriser + dessin du mot à faire soi-même) image donnée (définition + dessin donné à recopier) contrôle (définition) On relève le nombre de mots mémorisés I Σ 6 II Σ 78 III Σ 56 Le plan expérimental est de la forme S (A) avec S 5 et A 3 Nous n avons qu un facteur de variation. Y AS Σ Y.. ² 3² + 9² ² + ² ² + 5² 469 A Σ Y a. ² /S (6² + 78² + 56²) / Y.. ²/AS 50² / source SC ddl CM F cal 5
52 A A (entre) S (A) AS A (dans) total AS A- AS A AS 4 A A AS A AS-A / ** VI. Lien entre l ANOVA et le test de Student Nous venons de comparer grâce à l ANOVA les moyennes de deux ou plusieurs groupes expérimentaux. L année dernière, nous avons vu que le T-test permet aussi de comparer deux groupes expérimentaux. Ce ne sont pas deux tests différents car le t cal est lié au F cal. Exemple : Deux groupes de 8 souris ; G produit supposé inhibiteur, G groupe contrôle ; on mesure le temps de passation dans une épreuve de labyrinthe. G G ) T-test Rappel: L ( X X ) St ( µ ν X X X X ; σ ) avec ns + ns + X X n + n n n σ et ν n + n -.5 4² + 5.5² ².5 x 5.9 σ ² + 8² ² 35.5 x 6.94 σ σ X X
T de Student Khi-deux Corrélation
 Les tests d inférence statistiques permettent d estimer le risque d inférer un résultat d un échantillon à une population et de décider si on «prend le risque» (si 0.05 ou 5 %) Une différence de moyennes
Les tests d inférence statistiques permettent d estimer le risque d inférer un résultat d un échantillon à une population et de décider si on «prend le risque» (si 0.05 ou 5 %) Une différence de moyennes
Relation entre deux variables : estimation de la corrélation linéaire
 CHAPITRE 3 Relation entre deux variables : estimation de la corrélation linéaire Parmi les analyses statistiques descriptives, l une d entre elles est particulièrement utilisée pour mettre en évidence
CHAPITRE 3 Relation entre deux variables : estimation de la corrélation linéaire Parmi les analyses statistiques descriptives, l une d entre elles est particulièrement utilisée pour mettre en évidence
TABLE DES MATIERES. C Exercices complémentaires 42
 TABLE DES MATIERES Chapitre I : Echantillonnage A - Rappels de cours 1. Lois de probabilités de base rencontrées en statistique 1 1.1 Définitions et caractérisations 1 1.2 Les propriétés de convergence
TABLE DES MATIERES Chapitre I : Echantillonnage A - Rappels de cours 1. Lois de probabilités de base rencontrées en statistique 1 1.1 Définitions et caractérisations 1 1.2 Les propriétés de convergence
Chapitre 6 Test de comparaison de pourcentages χ². José LABARERE
 UE4 : Biostatistiques Chapitre 6 Test de comparaison de pourcentages χ² José LABARERE Année universitaire 2010/2011 Université Joseph Fourier de Grenoble - Tous droits réservés. Plan I. Nature des variables
UE4 : Biostatistiques Chapitre 6 Test de comparaison de pourcentages χ² José LABARERE Année universitaire 2010/2011 Université Joseph Fourier de Grenoble - Tous droits réservés. Plan I. Nature des variables
Analyse de la variance Comparaison de plusieurs moyennes
 Analyse de la variance Comparaison de plusieurs moyennes Biostatistique Pr. Nicolas MEYER Laboratoire de Biostatistique et Informatique Médicale Fac. de Médecine de Strasbourg Mars 2011 Plan 1 Introduction
Analyse de la variance Comparaison de plusieurs moyennes Biostatistique Pr. Nicolas MEYER Laboratoire de Biostatistique et Informatique Médicale Fac. de Médecine de Strasbourg Mars 2011 Plan 1 Introduction
Principe d un test statistique
 Biostatistiques Principe d un test statistique Professeur Jean-Luc BOSSON PCEM2 - Année universitaire 2012/2013 Faculté de Médecine de Grenoble (UJF) - Tous droits réservés. Objectifs pédagogiques Comprendre
Biostatistiques Principe d un test statistique Professeur Jean-Luc BOSSON PCEM2 - Année universitaire 2012/2013 Faculté de Médecine de Grenoble (UJF) - Tous droits réservés. Objectifs pédagogiques Comprendre
Statistiques Descriptives à une dimension
 I. Introduction et Définitions 1. Introduction La statistique est une science qui a pour objectif de recueillir et de traiter les informations, souvent en très grand nombre. Elle regroupe l ensemble des
I. Introduction et Définitions 1. Introduction La statistique est une science qui a pour objectif de recueillir et de traiter les informations, souvent en très grand nombre. Elle regroupe l ensemble des
Chapitre 3. Les distributions à deux variables
 Chapitre 3. Les distributions à deux variables Jean-François Coeurjolly http://www-ljk.imag.fr/membres/jean-francois.coeurjolly/ Laboratoire Jean Kuntzmann (LJK), Grenoble University 1 Distributions conditionnelles
Chapitre 3. Les distributions à deux variables Jean-François Coeurjolly http://www-ljk.imag.fr/membres/jean-francois.coeurjolly/ Laboratoire Jean Kuntzmann (LJK), Grenoble University 1 Distributions conditionnelles
Tests de comparaison de moyennes. Dr Sahar BAYAT MASTER 1 année 2009-2010 UE «Introduction à la biostatistique»
 Tests de comparaison de moyennes Dr Sahar BAYAT MASTER 1 année 2009-2010 UE «Introduction à la biostatistique» Test de Z ou de l écart réduit Le test de Z : comparer des paramètres en testant leurs différences
Tests de comparaison de moyennes Dr Sahar BAYAT MASTER 1 année 2009-2010 UE «Introduction à la biostatistique» Test de Z ou de l écart réduit Le test de Z : comparer des paramètres en testant leurs différences
Seconde Généralités sur les fonctions Exercices. Notion de fonction.
 Seconde Généralités sur les fonctions Exercices Notion de fonction. Exercice. Une fonction définie par une formule. On considère la fonction f définie sur R par = x + x. a) Calculer les images de, 0 et
Seconde Généralités sur les fonctions Exercices Notion de fonction. Exercice. Une fonction définie par une formule. On considère la fonction f définie sur R par = x + x. a) Calculer les images de, 0 et
VI. Tests non paramétriques sur un échantillon
 VI. Tests non paramétriques sur un échantillon Le modèle n est pas un modèle paramétrique «TESTS du CHI-DEUX» : VI.1. Test d ajustement à une loi donnée VI.. Test d indépendance de deux facteurs 96 Différentes
VI. Tests non paramétriques sur un échantillon Le modèle n est pas un modèle paramétrique «TESTS du CHI-DEUX» : VI.1. Test d ajustement à une loi donnée VI.. Test d indépendance de deux facteurs 96 Différentes
UFR de Sciences Economiques Année 2008-2009 TESTS PARAMÉTRIQUES
 Université Paris 13 Cours de Statistiques et Econométrie I UFR de Sciences Economiques Année 2008-2009 Licence de Sciences Economiques L3 Premier semestre TESTS PARAMÉTRIQUES Remarque: les exercices 2,
Université Paris 13 Cours de Statistiques et Econométrie I UFR de Sciences Economiques Année 2008-2009 Licence de Sciences Economiques L3 Premier semestre TESTS PARAMÉTRIQUES Remarque: les exercices 2,
Annexe commune aux séries ES, L et S : boîtes et quantiles
 Annexe commune aux séries ES, L et S : boîtes et quantiles Quantiles En statistique, pour toute série numérique de données à valeurs dans un intervalle I, on définit la fonction quantile Q, de [,1] dans
Annexe commune aux séries ES, L et S : boîtes et quantiles Quantiles En statistique, pour toute série numérique de données à valeurs dans un intervalle I, on définit la fonction quantile Q, de [,1] dans
Introduction à la statistique non paramétrique
 Introduction à la statistique non paramétrique Catherine MATIAS CNRS, Laboratoire Statistique & Génome, Évry http://stat.genopole.cnrs.fr/ cmatias Atelier SFDS 27/28 septembre 2012 Partie 2 : Tests non
Introduction à la statistique non paramétrique Catherine MATIAS CNRS, Laboratoire Statistique & Génome, Évry http://stat.genopole.cnrs.fr/ cmatias Atelier SFDS 27/28 septembre 2012 Partie 2 : Tests non
NOTE SUR LA MODELISATION DU RISQUE D INFLATION
 NOTE SUR LA MODELISATION DU RISQUE D INFLATION 1/ RESUME DE L ANALYSE Cette étude a pour objectif de modéliser l écart entre deux indices d inflation afin d appréhender le risque à très long terme qui
NOTE SUR LA MODELISATION DU RISQUE D INFLATION 1/ RESUME DE L ANALYSE Cette étude a pour objectif de modéliser l écart entre deux indices d inflation afin d appréhender le risque à très long terme qui
TSTI 2D CH X : Exemples de lois à densité 1
 TSTI 2D CH X : Exemples de lois à densité I Loi uniforme sur ab ; ) Introduction Dans cette activité, on s intéresse à la modélisation du tirage au hasard d un nombre réel de l intervalle [0 ;], chacun
TSTI 2D CH X : Exemples de lois à densité I Loi uniforme sur ab ; ) Introduction Dans cette activité, on s intéresse à la modélisation du tirage au hasard d un nombre réel de l intervalle [0 ;], chacun
Chapitre 3 : Principe des tests statistiques d hypothèse. José LABARERE
 UE4 : Biostatistiques Chapitre 3 : Principe des tests statistiques d hypothèse José LABARERE Année universitaire 2010/2011 Université Joseph Fourier de Grenoble - Tous droits réservés. Plan I. Introduction
UE4 : Biostatistiques Chapitre 3 : Principe des tests statistiques d hypothèse José LABARERE Année universitaire 2010/2011 Université Joseph Fourier de Grenoble - Tous droits réservés. Plan I. Introduction
Tests paramétriques de comparaison de 2 moyennes Exercices commentés José LABARERE
 Chapitre 5 UE4 : Biostatistiques Tests paramétriques de comparaison de 2 moyennes Exercices commentés José LABARERE Année universitaire 2010/2011 Université Joseph Fourier de Grenoble - Tous droits réservés.
Chapitre 5 UE4 : Biostatistiques Tests paramétriques de comparaison de 2 moyennes Exercices commentés José LABARERE Année universitaire 2010/2011 Université Joseph Fourier de Grenoble - Tous droits réservés.
Biostatistiques : Petits effectifs
 Biostatistiques : Petits effectifs Master Recherche Biologie et Santé P. Devos DRCI CHRU de Lille EA2694 patrick.devos@univ-lille2.fr Plan Données Générales : Définition des statistiques Principe de l
Biostatistiques : Petits effectifs Master Recherche Biologie et Santé P. Devos DRCI CHRU de Lille EA2694 patrick.devos@univ-lille2.fr Plan Données Générales : Définition des statistiques Principe de l
distribution quelconque Signe 1 échantillon non Wilcoxon gaussienne distribution symétrique Student gaussienne position
 Arbre de NESI distribution quelconque Signe 1 échantillon distribution symétrique non gaussienne Wilcoxon gaussienne Student position appariés 1 échantillon sur la différence avec référence=0 2 échantillons
Arbre de NESI distribution quelconque Signe 1 échantillon distribution symétrique non gaussienne Wilcoxon gaussienne Student position appariés 1 échantillon sur la différence avec référence=0 2 échantillons
Introduction aux Statistiques et à l utilisation du logiciel R
 Introduction aux Statistiques et à l utilisation du logiciel R Christophe Lalanne Christophe Pallier 1 Introduction 2 Comparaisons de deux moyennes 2.1 Objet de l étude On a mesuré le temps de sommeil
Introduction aux Statistiques et à l utilisation du logiciel R Christophe Lalanne Christophe Pallier 1 Introduction 2 Comparaisons de deux moyennes 2.1 Objet de l étude On a mesuré le temps de sommeil
Estimation et tests statistiques, TD 5. Solutions
 ISTIL, Tronc commun de première année Introduction aux méthodes probabilistes et statistiques, 2008 2009 Estimation et tests statistiques, TD 5. Solutions Exercice 1 Dans un centre avicole, des études
ISTIL, Tronc commun de première année Introduction aux méthodes probabilistes et statistiques, 2008 2009 Estimation et tests statistiques, TD 5. Solutions Exercice 1 Dans un centre avicole, des études
Analyses de Variance à un ou plusieurs facteurs Régressions Analyse de Covariance Modèles Linéaires Généralisés
 Analyses de Variance à un ou plusieurs facteurs Régressions Analyse de Covariance Modèles Linéaires Généralisés Professeur Patrice Francour francour@unice.fr Une grande partie des illustrations viennent
Analyses de Variance à un ou plusieurs facteurs Régressions Analyse de Covariance Modèles Linéaires Généralisés Professeur Patrice Francour francour@unice.fr Une grande partie des illustrations viennent
Soit la fonction affine qui, pour représentant le nombre de mois écoulés, renvoie la somme économisée.
 ANALYSE 5 points Exercice 1 : Léonie souhaite acheter un lecteur MP3. Le prix affiché (49 ) dépasse largement la somme dont elle dispose. Elle décide donc d économiser régulièrement. Elle a relevé qu elle
ANALYSE 5 points Exercice 1 : Léonie souhaite acheter un lecteur MP3. Le prix affiché (49 ) dépasse largement la somme dont elle dispose. Elle décide donc d économiser régulièrement. Elle a relevé qu elle
Cours 9 : Plans à plusieurs facteurs
 Cours 9 : Plans à plusieurs facteurs Table des matières Section 1. Diviser pour regner, rassembler pour saisir... 3 Section 2. Définitions et notations... 3 2.1. Définitions... 3 2.2. Notations... 4 Section
Cours 9 : Plans à plusieurs facteurs Table des matières Section 1. Diviser pour regner, rassembler pour saisir... 3 Section 2. Définitions et notations... 3 2.1. Définitions... 3 2.2. Notations... 4 Section
Cours (7) de statistiques à distance, élaboré par Zarrouk Fayçal, ISSEP Ksar-Said, 2011-2012 LES STATISTIQUES INFERENTIELLES
 de statistiques à distance, élaboré par Zarrouk Fayçal, ISSEP Ksar-Said, 2011-2012 LES STATISTIQUES INFERENTIELLES") LES STATISTIQUES INFERENTIELLES (test de Student) L inférence statistique est la partie des statistiques qui, contrairement à la statistique descriptive, ne se contente pas de décrire des observations,
LES STATISTIQUES INFERENTIELLES (test de Student) L inférence statistique est la partie des statistiques qui, contrairement à la statistique descriptive, ne se contente pas de décrire des observations,
LES GENERATEURS DE NOMBRES ALEATOIRES
 LES GENERATEURS DE NOMBRES ALEATOIRES 1 Ce travail a deux objectifs : ====================================================================== 1. Comprendre ce que font les générateurs de nombres aléatoires
LES GENERATEURS DE NOMBRES ALEATOIRES 1 Ce travail a deux objectifs : ====================================================================== 1. Comprendre ce que font les générateurs de nombres aléatoires
FORMULAIRE DE STATISTIQUES
 FORMULAIRE DE STATISTIQUES I. STATISTIQUES DESCRIPTIVES Moyenne arithmétique Remarque: population: m xμ; échantillon: Mx 1 Somme des carrés des écarts "# FR MOYENNE(série) MOYENNE(série) NL GEMIDDELDE(série)
FORMULAIRE DE STATISTIQUES I. STATISTIQUES DESCRIPTIVES Moyenne arithmétique Remarque: population: m xμ; échantillon: Mx 1 Somme des carrés des écarts "# FR MOYENNE(série) MOYENNE(série) NL GEMIDDELDE(série)
Pratique de l analyse de données SPSS appliqué à l enquête «Identités et Capital social en Wallonie»
 Centre de recherche en démographie et sociétés UCL/IACCHOS/DEMO Pratique de l analyse de données SPSS appliqué à l enquête «Identités et Capital social en Wallonie» 1 2 3+ analyses univariées Type de variables
Centre de recherche en démographie et sociétés UCL/IACCHOS/DEMO Pratique de l analyse de données SPSS appliqué à l enquête «Identités et Capital social en Wallonie» 1 2 3+ analyses univariées Type de variables
Fluctuation d une fréquence selon les échantillons - Probabilités
 Fluctuation d une fréquence selon les échantillons - Probabilités C H A P I T R E 3 JE DOIS SAVOIR Calculer une fréquence JE VAIS ÊTRE C APABLE DE Expérimenter la prise d échantillons aléatoires de taille
Fluctuation d une fréquence selon les échantillons - Probabilités C H A P I T R E 3 JE DOIS SAVOIR Calculer une fréquence JE VAIS ÊTRE C APABLE DE Expérimenter la prise d échantillons aléatoires de taille
Lois de probabilité. Anita Burgun
 Lois de probabilité Anita Burgun Problème posé Le problème posé en statistique: On s intéresse à une population On extrait un échantillon On se demande quelle sera la composition de l échantillon (pourcentage
Lois de probabilité Anita Burgun Problème posé Le problème posé en statistique: On s intéresse à une population On extrait un échantillon On se demande quelle sera la composition de l échantillon (pourcentage
Introduction à l approche bootstrap
 Introduction à l approche bootstrap Irène Buvat U494 INSERM buvat@imedjussieufr 25 septembre 2000 Introduction à l approche bootstrap - Irène Buvat - 21/9/00-1 Plan du cours Qu est-ce que le bootstrap?
Introduction à l approche bootstrap Irène Buvat U494 INSERM buvat@imedjussieufr 25 septembre 2000 Introduction à l approche bootstrap - Irène Buvat - 21/9/00-1 Plan du cours Qu est-ce que le bootstrap?
IBM SPSS Statistics Base 20
 IBM SPSS Statistics Base 20 Remarque : Avant d utiliser ces informations et le produit qu elles concernent, lisez les informations générales sous Remarques sur p. 316. Cette version s applique à IBM SPSS
IBM SPSS Statistics Base 20 Remarque : Avant d utiliser ces informations et le produit qu elles concernent, lisez les informations générales sous Remarques sur p. 316. Cette version s applique à IBM SPSS
Probabilités sur un univers fini
 [http://mp.cpgedupuydelome.fr] édité le 7 août 204 Enoncés Probabilités sur un univers fini Evènements et langage ensembliste A quelle condition sur (a, b, c, d) ]0, [ 4 existe-t-il une probabilité P sur
[http://mp.cpgedupuydelome.fr] édité le 7 août 204 Enoncés Probabilités sur un univers fini Evènements et langage ensembliste A quelle condition sur (a, b, c, d) ]0, [ 4 existe-t-il une probabilité P sur
Continuité et dérivabilité d une fonction
 DERNIÈRE IMPRESSIN LE 7 novembre 014 à 10:3 Continuité et dérivabilité d une fonction Table des matières 1 Continuité d une fonction 1.1 Limite finie en un point.......................... 1. Continuité
DERNIÈRE IMPRESSIN LE 7 novembre 014 à 10:3 Continuité et dérivabilité d une fonction Table des matières 1 Continuité d une fonction 1.1 Limite finie en un point.......................... 1. Continuité
Une variable binaire prédictrice (VI) et une variable binaire observée (VD) (Comparaison de pourcentages sur 2 groupes indépendants)
 et une variable binaire observée (VD) (Comparaison de pourcentages sur 2 groupes indépendants)") CIVILITE-SES.doc - 1 - Une variable binaire prédictrice (VI) et une variable binaire observée (VD) (Comparaison de pourcentages sur 2 groupes indépendants) 1 PRÉSENTATION DU DOSSIER CIVILITE On s intéresse
CIVILITE-SES.doc - 1 - Une variable binaire prédictrice (VI) et une variable binaire observée (VD) (Comparaison de pourcentages sur 2 groupes indépendants) 1 PRÉSENTATION DU DOSSIER CIVILITE On s intéresse
Déroulement d un projet en DATA MINING, préparation et analyse des données. Walid AYADI
 1 Déroulement d un projet en DATA MINING, préparation et analyse des données Walid AYADI 2 Les étapes d un projet Choix du sujet - Définition des objectifs Inventaire des données existantes Collecte, nettoyage
1 Déroulement d un projet en DATA MINING, préparation et analyse des données Walid AYADI 2 Les étapes d un projet Choix du sujet - Définition des objectifs Inventaire des données existantes Collecte, nettoyage
LES DIFFERENTS TYPES DE MESURE
 LES DIFFERENTS TYPES DE MESURE Licence - Statistiques 2004/2005 REALITE ET DONNEES CHIFFREES Recherche = - mesure. - traduction d une réalité en chiffre - abouti à des tableaux, des calculs 1) Qu est-ce
LES DIFFERENTS TYPES DE MESURE Licence - Statistiques 2004/2005 REALITE ET DONNEES CHIFFREES Recherche = - mesure. - traduction d une réalité en chiffre - abouti à des tableaux, des calculs 1) Qu est-ce
Traitement des données avec Microsoft EXCEL 2010
 Traitement des données avec Microsoft EXCEL 2010 Vincent Jalby Septembre 2012 1 Saisie des données Les données collectées sont saisies dans une feuille Excel. Chaque ligne correspond à une observation
Traitement des données avec Microsoft EXCEL 2010 Vincent Jalby Septembre 2012 1 Saisie des données Les données collectées sont saisies dans une feuille Excel. Chaque ligne correspond à une observation
données en connaissance et en actions?
 1 Partie 2 : Présentation de la plateforme SPSS Modeler : Comment transformer vos données en connaissance et en actions? SPSS Modeler : l atelier de data mining Large gamme de techniques d analyse (algorithmes)
1 Partie 2 : Présentation de la plateforme SPSS Modeler : Comment transformer vos données en connaissance et en actions? SPSS Modeler : l atelier de data mining Large gamme de techniques d analyse (algorithmes)
Coefficients binomiaux
 Probabilités L2 Exercices Chapitre 2 Coefficients binomiaux 1 ( ) On appelle chemin une suite de segments de longueur 1, dirigés soit vers le haut, soit vers la droite 1 Dénombrer tous les chemins allant
Probabilités L2 Exercices Chapitre 2 Coefficients binomiaux 1 ( ) On appelle chemin une suite de segments de longueur 1, dirigés soit vers le haut, soit vers la droite 1 Dénombrer tous les chemins allant
Probabilités conditionnelles Loi binomiale
 Exercices 23 juillet 2014 Probabilités conditionnelles Loi binomiale Équiprobabilité et variable aléatoire Exercice 1 Une urne contient 5 boules indiscernables, 3 rouges et 2 vertes. On tire au hasard
Exercices 23 juillet 2014 Probabilités conditionnelles Loi binomiale Équiprobabilité et variable aléatoire Exercice 1 Une urne contient 5 boules indiscernables, 3 rouges et 2 vertes. On tire au hasard
Le Data Mining au service du Scoring ou notation statistique des emprunteurs!
 France Le Data Mining au service du Scoring ou notation statistique des emprunteurs! Comme le rappelle la CNIL dans sa délibération n 88-083 du 5 Juillet 1988 portant adoption d une recommandation relative
France Le Data Mining au service du Scoring ou notation statistique des emprunteurs! Comme le rappelle la CNIL dans sa délibération n 88-083 du 5 Juillet 1988 portant adoption d une recommandation relative
Baccalauréat ES Antilles Guyane 12 septembre 2014 Corrigé
 Baccalauréat ES Antilles Guyane 12 septembre 2014 Corrigé EXERCICE 1 5 points Commun à tous les candidats 1. Réponse c : ln(10)+2 ln ( 10e 2) = ln(10)+ln ( e 2) = ln(10)+2 2. Réponse b : n 13 0,7 n 0,01
Baccalauréat ES Antilles Guyane 12 septembre 2014 Corrigé EXERCICE 1 5 points Commun à tous les candidats 1. Réponse c : ln(10)+2 ln ( 10e 2) = ln(10)+ln ( e 2) = ln(10)+2 2. Réponse b : n 13 0,7 n 0,01
Probabilité. Table des matières. 1 Loi de probabilité 2 1.1 Conditions préalables... 2 1.2 Définitions... 2 1.3 Loi équirépartie...
 1 Probabilité Table des matières 1 Loi de probabilité 2 1.1 Conditions préalables........................... 2 1.2 Définitions................................. 2 1.3 Loi équirépartie..............................
1 Probabilité Table des matières 1 Loi de probabilité 2 1.1 Conditions préalables........................... 2 1.2 Définitions................................. 2 1.3 Loi équirépartie..............................
Lecture critique d article. Bio statistiques. Dr MARC CUGGIA MCU-PH Laboratoire d informatique médicale EA-3888
 Lecture critique d article Rappels Bio statistiques Dr MARC CUGGIA MCU-PH Laboratoire d informatique médicale EA-3888 Plan du cours Rappels fondamentaux Statistiques descriptives Notions de tests statistiques
Lecture critique d article Rappels Bio statistiques Dr MARC CUGGIA MCU-PH Laboratoire d informatique médicale EA-3888 Plan du cours Rappels fondamentaux Statistiques descriptives Notions de tests statistiques
BACCALAURÉAT GÉNÉRAL SESSION 2012 OBLIGATOIRE MATHÉMATIQUES. Série S. Durée de l épreuve : 4 heures Coefficient : 7 ENSEIGNEMENT OBLIGATOIRE
 BACCALAURÉAT GÉNÉRAL SESSION 2012 MATHÉMATIQUES Série S Durée de l épreuve : 4 heures Coefficient : 7 ENSEIGNEMENT OBLIGATOIRE Les calculatrices électroniques de poche sont autorisées, conformément à la
BACCALAURÉAT GÉNÉRAL SESSION 2012 MATHÉMATIQUES Série S Durée de l épreuve : 4 heures Coefficient : 7 ENSEIGNEMENT OBLIGATOIRE Les calculatrices électroniques de poche sont autorisées, conformément à la
Jeux mathématiques en maternelle. Activités clés. Jeu des maisons et des jardins (Yvette Denny PEMF)
") Activités clés NIVEAU : PS/MS Jeu des maisons et des jardins (Yvette Denny PEMF) Compétences Construire les premiers nombres dans leur aspect cardinal Construire des collections équipotentes Situation
Activités clés NIVEAU : PS/MS Jeu des maisons et des jardins (Yvette Denny PEMF) Compétences Construire les premiers nombres dans leur aspect cardinal Construire des collections équipotentes Situation
Exposing a test of homogeneity of chronological series of annual rainfall in a climatic area. with using, if possible, the regional vector Hiez.
 Test d homogéné$é Y. BRUNET-MORET Ingénieur hydrologue, Bureau Central Hydrologique Paris RÉSUMÉ Présentation d un test d homogénéi.té spécialement conçu pour vérijier Z homogénéité des suites chronologiques
Test d homogéné$é Y. BRUNET-MORET Ingénieur hydrologue, Bureau Central Hydrologique Paris RÉSUMÉ Présentation d un test d homogénéi.té spécialement conçu pour vérijier Z homogénéité des suites chronologiques
Probabilités. Rappel : trois exemples. Exemple 2 : On dispose d un dé truqué. On sait que : p(1) = p(2) =1/6 ; p(3) = 1/3 p(4) = p(5) =1/12
 = p(2) =1/6 ; p(3) = 1/3 p(4) = p(5) =1/12") Probabilités. I - Rappel : trois exemples. Exemple 1 : Dans une classe de 25 élèves, il y a 16 filles. Tous les élèves sont blonds ou bruns. Parmi les filles, 6 sont blondes. Parmi les garçons, 3 sont
Probabilités. I - Rappel : trois exemples. Exemple 1 : Dans une classe de 25 élèves, il y a 16 filles. Tous les élèves sont blonds ou bruns. Parmi les filles, 6 sont blondes. Parmi les garçons, 3 sont
Loi binomiale Lois normales
 Loi binomiale Lois normales Christophe ROSSIGNOL Année scolaire 204/205 Table des matières Rappels sur la loi binomiale 2. Loi de Bernoulli............................................ 2.2 Schéma de Bernoulli
Loi binomiale Lois normales Christophe ROSSIGNOL Année scolaire 204/205 Table des matières Rappels sur la loi binomiale 2. Loi de Bernoulli............................................ 2.2 Schéma de Bernoulli
Architecture des ordinateurs TD1 - Portes logiques et premiers circuits
 Architecture des ordinateurs TD1 - Portes logiques et premiers circuits 1 Rappel : un peu de logique Exercice 1.1 Remplir la table de vérité suivante : a b a + b ab a + b ab a b 0 0 0 1 1 0 1 1 Exercice
Architecture des ordinateurs TD1 - Portes logiques et premiers circuits 1 Rappel : un peu de logique Exercice 1.1 Remplir la table de vérité suivante : a b a + b ab a + b ab a b 0 0 0 1 1 0 1 1 Exercice
Cahiers de l IMA. Fascicule SPSS
 Octobre 2008 Numéro 41 Cahiers de l IMA Fascicule SPSS Ingrid Gilles Eva G. T. Green Paola Ricciardi Joos Régis Scheidegger Chiara Storari Thomas Tuescher Pascal Wagner-Egger Ricciardi-Joos Ricciardi-Joos
Octobre 2008 Numéro 41 Cahiers de l IMA Fascicule SPSS Ingrid Gilles Eva G. T. Green Paola Ricciardi Joos Régis Scheidegger Chiara Storari Thomas Tuescher Pascal Wagner-Egger Ricciardi-Joos Ricciardi-Joos
Statistique Descriptive Élémentaire
 Publications de l Institut de Mathématiques de Toulouse Statistique Descriptive Élémentaire (version de mai 2010) Alain Baccini Institut de Mathématiques de Toulouse UMR CNRS 5219 Université Paul Sabatier
Publications de l Institut de Mathématiques de Toulouse Statistique Descriptive Élémentaire (version de mai 2010) Alain Baccini Institut de Mathématiques de Toulouse UMR CNRS 5219 Université Paul Sabatier
Actuariat I ACT2121. septième séance. Arthur Charpentier. Automne 2012. charpentier.arthur@uqam.ca. http ://freakonometrics.blog.free.
 Actuariat I ACT2121 septième séance Arthur Charpentier charpentier.arthur@uqam.ca http ://freakonometrics.blog.free.fr/ Automne 2012 1 Exercice 1 En analysant le temps d attente X avant un certain événement
Actuariat I ACT2121 septième séance Arthur Charpentier charpentier.arthur@uqam.ca http ://freakonometrics.blog.free.fr/ Automne 2012 1 Exercice 1 En analysant le temps d attente X avant un certain événement
Recherche dans un tableau
 Chapitre 3 Recherche dans un tableau 3.1 Introduction 3.1.1 Tranche On appelle tranche de tableau, la donnée d'un tableau t et de deux indices a et b. On note cette tranche t.(a..b). Exemple 3.1 : 3 6
Chapitre 3 Recherche dans un tableau 3.1 Introduction 3.1.1 Tranche On appelle tranche de tableau, la donnée d'un tableau t et de deux indices a et b. On note cette tranche t.(a..b). Exemple 3.1 : 3 6
Biostatistiques Biologie- Vétérinaire FUNDP Eric Depiereux, Benoît DeHertogh, Grégoire Vincke
 www.fundp.ac.be/biostats Module 140 140 ANOVA A UN CRITERE DE CLASSIFICATION FIXE...2 140.1 UTILITE...2 140.2 COMPARAISON DE VARIANCES...2 140.2.1 Calcul de la variance...2 140.2.2 Distributions de référence...3
www.fundp.ac.be/biostats Module 140 140 ANOVA A UN CRITERE DE CLASSIFICATION FIXE...2 140.1 UTILITE...2 140.2 COMPARAISON DE VARIANCES...2 140.2.1 Calcul de la variance...2 140.2.2 Distributions de référence...3
CONCOURS D ENTREE A L ECOLE DE 2007 CONCOURS EXTERNE. Cinquième épreuve d admissibilité STATISTIQUE. (durée : cinq heures)
") CONCOURS D ENTREE A L ECOLE DE 2007 CONCOURS EXTERNE Cinquième épreuve d admissibilité STATISTIQUE (durée : cinq heures) Une composition portant sur la statistique. SUJET Cette épreuve est composée d un
CONCOURS D ENTREE A L ECOLE DE 2007 CONCOURS EXTERNE Cinquième épreuve d admissibilité STATISTIQUE (durée : cinq heures) Une composition portant sur la statistique. SUJET Cette épreuve est composée d un
Séries Statistiques Simples
 1. Collecte et Représentation de l Information 1.1 Définitions 1.2 Tableaux statistiques 1.3 Graphiques 2. Séries statistiques simples 2.1 Moyenne arithmétique 2.2 Mode & Classe modale 2.3 Effectifs &
1. Collecte et Représentation de l Information 1.1 Définitions 1.2 Tableaux statistiques 1.3 Graphiques 2. Séries statistiques simples 2.1 Moyenne arithmétique 2.2 Mode & Classe modale 2.3 Effectifs &
Baccalauréat ES/L Amérique du Sud 21 novembre 2013
 Baccalauréat ES/L Amérique du Sud 21 novembre 2013 A. P. M. E. P. EXERCICE 1 Commun à tous les candidats 5 points Une entreprise informatique produit et vend des clés USB. La vente de ces clés est réalisée
Baccalauréat ES/L Amérique du Sud 21 novembre 2013 A. P. M. E. P. EXERCICE 1 Commun à tous les candidats 5 points Une entreprise informatique produit et vend des clés USB. La vente de ces clés est réalisée
Probabilités sur un univers fini
 [http://mp.cpgedupuydelome.fr] édité le 10 août 2015 Enoncés 1 Proailités sur un univers fini Evènements et langage ensemliste A quelle condition sur (a,, c, d) ]0, 1[ 4 existe-t-il une proailité P sur
[http://mp.cpgedupuydelome.fr] édité le 10 août 2015 Enoncés 1 Proailités sur un univers fini Evènements et langage ensemliste A quelle condition sur (a,, c, d) ]0, 1[ 4 existe-t-il une proailité P sur
Mesures et incertitudes
 En physique et en chimie, toute grandeur, mesurée ou calculée, est entachée d erreur, ce qui ne l empêche pas d être exploitée pour prendre des décisions. Aujourd hui, la notion d erreur a son vocabulaire
En physique et en chimie, toute grandeur, mesurée ou calculée, est entachée d erreur, ce qui ne l empêche pas d être exploitée pour prendre des décisions. Aujourd hui, la notion d erreur a son vocabulaire
INF6304 Interfaces Intelligentes
 INF6304 Interfaces Intelligentes filtres collaboratifs 1/42 INF6304 Interfaces Intelligentes Systèmes de recommandations, Approches filtres collaboratifs Michel C. Desmarais Génie informatique et génie
INF6304 Interfaces Intelligentes filtres collaboratifs 1/42 INF6304 Interfaces Intelligentes Systèmes de recommandations, Approches filtres collaboratifs Michel C. Desmarais Génie informatique et génie
Premiers pas avec SES-Pegase (version 7.0) SES : Un Système Expert pour l analyse Statistique des données. Premiers pas avec SES-Pegase 1
 SES : Un Système Expert pour l analyse Statistique des données. Premiers pas avec SES-Pegase 1") Premiers pas avec SES-Pegase 1 Premiers pas avec SES-Pegase (version 7.0) SES : Un Système Expert pour l analyse Statistique des données www.delta-expert.com Mise à jour : Premiers pas avec SES-Pegase
Premiers pas avec SES-Pegase 1 Premiers pas avec SES-Pegase (version 7.0) SES : Un Système Expert pour l analyse Statistique des données www.delta-expert.com Mise à jour : Premiers pas avec SES-Pegase
LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING»
 LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING» Gilbert Saporta Professeur de Statistique Appliquée Conservatoire National des Arts et Métiers Dans leur quasi totalité, les banques et organismes financiers
LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING» Gilbert Saporta Professeur de Statistique Appliquée Conservatoire National des Arts et Métiers Dans leur quasi totalité, les banques et organismes financiers
PROJET DE GESTION PORTEFEUILLE. Evaluation d une Stratégie de Trading
 PROJET DE GESTION PORTEFEUILLE Evaluation d une Stratégie de Trading Encadré par M. Philippe Bernard Master 1 Economie Appliquée-Ingénierie Economique et Financière Taylan Kunal 2011-2012 Sommaire 1) Introduction
PROJET DE GESTION PORTEFEUILLE Evaluation d une Stratégie de Trading Encadré par M. Philippe Bernard Master 1 Economie Appliquée-Ingénierie Economique et Financière Taylan Kunal 2011-2012 Sommaire 1) Introduction
Lire ; Compter ; Tester... avec R
 Lire ; Compter ; Tester... avec R Préparation des données / Analyse univariée / Analyse bivariée Christophe Genolini 2 Table des matières 1 Rappels théoriques 5 1.1 Vocabulaire....................................
Lire ; Compter ; Tester... avec R Préparation des données / Analyse univariée / Analyse bivariée Christophe Genolini 2 Table des matières 1 Rappels théoriques 5 1.1 Vocabulaire....................................
LEÇON N 7 : Schéma de Bernoulli et loi binomiale. Exemples.
 LEÇON N 7 : Schéma de Bernoulli et loi binomiale. Exemples. Pré-requis : Probabilités : définition, calculs et probabilités conditionnelles ; Notion de variables aléatoires, et propriétés associées : espérance,
LEÇON N 7 : Schéma de Bernoulli et loi binomiale. Exemples. Pré-requis : Probabilités : définition, calculs et probabilités conditionnelles ; Notion de variables aléatoires, et propriétés associées : espérance,
Qu est-ce qu une probabilité?
 Chapitre 1 Qu est-ce qu une probabilité? 1 Modéliser une expérience dont on ne peut prédire le résultat 1.1 Ensemble fondamental d une expérience aléatoire Une expérience aléatoire est une expérience dont
Chapitre 1 Qu est-ce qu une probabilité? 1 Modéliser une expérience dont on ne peut prédire le résultat 1.1 Ensemble fondamental d une expérience aléatoire Une expérience aléatoire est une expérience dont
Le calcul du barème d impôt à Genève
 Le calcul du barème d impôt à Genève Plan : 1. Historique Passage d un système en escalier à une formule mathématique 2. Principe de l imposition Progressivité, impôt marginal / moyen ; barème couple/marié
Le calcul du barème d impôt à Genève Plan : 1. Historique Passage d un système en escalier à une formule mathématique 2. Principe de l imposition Progressivité, impôt marginal / moyen ; barème couple/marié
La survie nette actuelle à long terme Qualités de sept méthodes d estimation
 La survie nette actuelle à long terme Qualités de sept méthodes d estimation PAR Alireza MOGHADDAM TUTEUR : Guy HÉDELIN Laboratoire d Épidémiologie et de Santé publique, EA 80 Faculté de Médecine de Strasbourg
La survie nette actuelle à long terme Qualités de sept méthodes d estimation PAR Alireza MOGHADDAM TUTEUR : Guy HÉDELIN Laboratoire d Épidémiologie et de Santé publique, EA 80 Faculté de Médecine de Strasbourg
La problématique des tests. Cours V. 7 mars 2008. Comment quantifier la performance d un test? Hypothèses simples et composites
 La problématique des tests Cours V 7 mars 8 Test d hypothèses [Section 6.1] Soit un modèle statistique P θ ; θ Θ} et des hypothèses H : θ Θ H 1 : θ Θ 1 = Θ \ Θ Un test (pur) est une statistique à valeur
La problématique des tests Cours V 7 mars 8 Test d hypothèses [Section 6.1] Soit un modèle statistique P θ ; θ Θ} et des hypothèses H : θ Θ H 1 : θ Θ 1 = Θ \ Θ Un test (pur) est une statistique à valeur
1. Vocabulaire : Introduction au tableau élémentaire
 L1-S1 Lire et caractériser l'information géographique - Le traitement statistique univarié Statistique : le terme statistique désigne à la fois : 1) l'ensemble des données numériques concernant une catégorie
L1-S1 Lire et caractériser l'information géographique - Le traitement statistique univarié Statistique : le terme statistique désigne à la fois : 1) l'ensemble des données numériques concernant une catégorie
Exercices supplémentaires sur l introduction générale à la notion de probabilité 2009-2010
 Exercices supplémentaires sur l introduction générale à la notion de probabilité 2009-2010 Exercices fortement conseillés : 6, 10 et 14 1) Un groupe d étudiants est formé de 20 étudiants de première année
Exercices supplémentaires sur l introduction générale à la notion de probabilité 2009-2010 Exercices fortement conseillés : 6, 10 et 14 1) Un groupe d étudiants est formé de 20 étudiants de première année
Complément d information concernant la fiche de concordance
 Sommaire SAMEDI 0 DÉCEMBRE 20 Vous trouverez dans ce dossier les documents correspondants à ce que nous allons travailler aujourd hui : La fiche de concordance pour le DAEU ; Page 2 Un rappel de cours
Sommaire SAMEDI 0 DÉCEMBRE 20 Vous trouverez dans ce dossier les documents correspondants à ce que nous allons travailler aujourd hui : La fiche de concordance pour le DAEU ; Page 2 Un rappel de cours
Tableau 1 : Structure du tableau des données individuelles. INDIV B i1 1 i2 2 i3 2 i4 1 i5 2 i6 2 i7 1 i8 1
 UN GROUPE D INDIVIDUS Un groupe d individus décrit par une variable qualitative binaire DÉCRIT PAR UNE VARIABLE QUALITATIVE BINAIRE ANALYSER UN SOUS-GROUPE COMPARER UN SOUS-GROUPE À UNE RÉFÉRENCE Mots-clés
UN GROUPE D INDIVIDUS Un groupe d individus décrit par une variable qualitative binaire DÉCRIT PAR UNE VARIABLE QUALITATIVE BINAIRE ANALYSER UN SOUS-GROUPE COMPARER UN SOUS-GROUPE À UNE RÉFÉRENCE Mots-clés
Logiciel XLSTAT version 7.0. 40 rue Damrémont 75018 PARIS
 Logiciel XLSTAT version 7.0 Contact : Addinsoft 40 rue Damrémont 75018 PARIS 2005-2006 Plan Présentation générale du logiciel Statistiques descriptives Histogramme Discrétisation Tableau de contingence
Logiciel XLSTAT version 7.0 Contact : Addinsoft 40 rue Damrémont 75018 PARIS 2005-2006 Plan Présentation générale du logiciel Statistiques descriptives Histogramme Discrétisation Tableau de contingence
INTRODUCTION À L ANALYSE FACTORIELLE DES CORRESPONDANCES
 INTRODUCTION À L ANALYSE FACTORIELLE DES CORRESPONDANCES Dominique LAFFLY Maître de Conférences, Université de Pau Laboratoire Société Environnement Territoire UMR 5603 du CNRS et Université de Pau Domaine
INTRODUCTION À L ANALYSE FACTORIELLE DES CORRESPONDANCES Dominique LAFFLY Maître de Conférences, Université de Pau Laboratoire Société Environnement Territoire UMR 5603 du CNRS et Université de Pau Domaine
La classification automatique de données quantitatives
 La classification automatique de données quantitatives 1 Introduction Parmi les méthodes de statistique exploratoire multidimensionnelle, dont l objectif est d extraire d une masse de données des informations
La classification automatique de données quantitatives 1 Introduction Parmi les méthodes de statistique exploratoire multidimensionnelle, dont l objectif est d extraire d une masse de données des informations
Estimation: intervalle de fluctuation et de confiance. Mars 2012. IREM: groupe Proba-Stat. Fluctuation. Confiance. dans les programmes comparaison
 Estimation: intervalle de fluctuation et de confiance Mars 2012 IREM: groupe Proba-Stat Estimation Term.1 Intervalle de fluctuation connu : probabilité p, taille de l échantillon n but : estimer une fréquence
Estimation: intervalle de fluctuation et de confiance Mars 2012 IREM: groupe Proba-Stat Estimation Term.1 Intervalle de fluctuation connu : probabilité p, taille de l échantillon n but : estimer une fréquence
L analyse boursière avec Scilab
 L analyse boursière avec Scilab Introduction La Bourse est le marché sur lequel se traitent les valeurs mobilières. Afin de protéger leurs investissements et optimiser leurs résultats, les investisseurs
L analyse boursière avec Scilab Introduction La Bourse est le marché sur lequel se traitent les valeurs mobilières. Afin de protéger leurs investissements et optimiser leurs résultats, les investisseurs
Théorie et Codage de l Information (IF01) exercices 2013-2014. Paul Honeine Université de technologie de Troyes France
 exercices 2013-2014. Paul Honeine Université de technologie de Troyes France") Théorie et Codage de l Information (IF01) exercices 2013-2014 Paul Honeine Université de technologie de Troyes France TD-1 Rappels de calculs de probabilités Exercice 1. On dispose d un jeu de 52 cartes
Théorie et Codage de l Information (IF01) exercices 2013-2014 Paul Honeine Université de technologie de Troyes France TD-1 Rappels de calculs de probabilités Exercice 1. On dispose d un jeu de 52 cartes
Cours de Probabilités et de Statistique
 Cours de Probabilités et de Statistique Licence 1ère année 2007/2008 Nicolas Prioux Université Paris-Est Cours de Proba-Stat 2 L1.2 Science-Éco Chapitre Notions de théorie des ensembles 1 1.1 Ensembles
Cours de Probabilités et de Statistique Licence 1ère année 2007/2008 Nicolas Prioux Université Paris-Est Cours de Proba-Stat 2 L1.2 Science-Éco Chapitre Notions de théorie des ensembles 1 1.1 Ensembles
Statistiques Appliquées à l Expérimentation en Sciences Humaines. Christophe Lalanne, Sébastien Georges, Christophe Pallier
 Statistiques Appliquées à l Expérimentation en Sciences Humaines Christophe Lalanne, Sébastien Georges, Christophe Pallier Table des matières 1 Méthodologie expérimentale et recueil des données 6 1.1 Introduction.......................................
Statistiques Appliquées à l Expérimentation en Sciences Humaines Christophe Lalanne, Sébastien Georges, Christophe Pallier Table des matières 1 Méthodologie expérimentale et recueil des données 6 1.1 Introduction.......................................
Les probabilités. Chapitre 18. Tester ses connaissances
 Chapitre 18 Les probabilités OBJECTIFS DU CHAPITRE Calculer la probabilité d événements Tester ses connaissances 1. Expériences aléatoires Voici trois expériences : - Expérience (1) : on lance une pièce
Chapitre 18 Les probabilités OBJECTIFS DU CHAPITRE Calculer la probabilité d événements Tester ses connaissances 1. Expériences aléatoires Voici trois expériences : - Expérience (1) : on lance une pièce
UNE REPRESENTATION GRAPHIQUE DE LA LIAISON STATISTIQUE ENTRE DEUX VARIABLES ORDONNEES. Éric TÉROUANNE 1
 33 Math. Inf. Sci. hum., (33 e année, n 130, 1995, pp.33-42) UNE REPRESENTATION GRAPHIQUE DE LA LIAISON STATISTIQUE ENTRE DEUX VARIABLES ORDONNEES Éric TÉROUANNE 1 RÉSUMÉ Le stéréogramme de liaison est
33 Math. Inf. Sci. hum., (33 e année, n 130, 1995, pp.33-42) UNE REPRESENTATION GRAPHIQUE DE LA LIAISON STATISTIQUE ENTRE DEUX VARIABLES ORDONNEES Éric TÉROUANNE 1 RÉSUMÉ Le stéréogramme de liaison est
Évaluation de la régression bornée
 Thierry Foucart UMR 6086, Université de Poitiers, S P 2 M I, bd 3 téléport 2 BP 179, 86960 Futuroscope, Cedex FRANCE Résumé. le modèle linéaire est très fréquemment utilisé en statistique et particulièrement
Thierry Foucart UMR 6086, Université de Poitiers, S P 2 M I, bd 3 téléport 2 BP 179, 86960 Futuroscope, Cedex FRANCE Résumé. le modèle linéaire est très fréquemment utilisé en statistique et particulièrement
Correction du bac blanc CFE Mercatique
 Correction du bac blanc CFE Mercatique Exercice 1 (4,5 points) Le tableau suivant donne l évolution du nombre de bénéficiaires de minima sociaux en milliers : Année 2002 2003 2004 2005 2006 2007 2008 2009
Correction du bac blanc CFE Mercatique Exercice 1 (4,5 points) Le tableau suivant donne l évolution du nombre de bénéficiaires de minima sociaux en milliers : Année 2002 2003 2004 2005 2006 2007 2008 2009
CHAPITRE VIII : Les circuits avec résistances ohmiques
 CHAPITRE VIII : Les circuits avec résistances ohmiques VIII. 1 Ce chapitre porte sur les courants et les différences de potentiel dans les circuits. VIII.1 : Les résistances en série et en parallèle On
CHAPITRE VIII : Les circuits avec résistances ohmiques VIII. 1 Ce chapitre porte sur les courants et les différences de potentiel dans les circuits. VIII.1 : Les résistances en série et en parallèle On
FONCTION DE DEMANDE : REVENU ET PRIX
 FONCTION DE DEMANDE : REVENU ET PRIX 1. L effet d une variation du revenu. Les lois d Engel a. Conditions du raisonnement : prix et goûts inchangés, variation du revenu (statique comparative) b. Partie
FONCTION DE DEMANDE : REVENU ET PRIX 1. L effet d une variation du revenu. Les lois d Engel a. Conditions du raisonnement : prix et goûts inchangés, variation du revenu (statique comparative) b. Partie
Découverte du tableur CellSheet
 Découverte du tableur CellSheet l application pour TI-83 Plus et TI-84 Plus. Réalisé par Guy Juge Professeur de mathématiques et formateur IUFM de l académie de Caen Pour l équipe des formateurs T 3 Teachers
Découverte du tableur CellSheet l application pour TI-83 Plus et TI-84 Plus. Réalisé par Guy Juge Professeur de mathématiques et formateur IUFM de l académie de Caen Pour l équipe des formateurs T 3 Teachers
Baccalauréat ES Polynésie (spécialité) 10 septembre 2014 Corrigé
 10 septembre 2014 Corrigé") Baccalauréat ES Polynésie (spécialité) 10 septembre 2014 Corrigé A. P. M. E. P. Exercice 1 5 points 1. Réponse d. : 1 e Le coefficient directeur de la tangente est négatif et n est manifestement pas 2e
Baccalauréat ES Polynésie (spécialité) 10 septembre 2014 Corrigé A. P. M. E. P. Exercice 1 5 points 1. Réponse d. : 1 e Le coefficient directeur de la tangente est négatif et n est manifestement pas 2e
Méthode : On raisonnera tjs graphiquement avec 2 biens.
 Chapiittrre 1 : L uttiilliitté ((lles ménages)) Définitions > Utilité : Mesure le plaisir / la satisfaction d un individu compte tenu de ses goûts. (On s intéresse uniquement à un consommateur rationnel
Chapiittrre 1 : L uttiilliitté ((lles ménages)) Définitions > Utilité : Mesure le plaisir / la satisfaction d un individu compte tenu de ses goûts. (On s intéresse uniquement à un consommateur rationnel
Lecture graphique. Table des matières
 Lecture graphique Table des matières 1 Lecture d une courbe 2 1.1 Définition d une fonction.......................... 2 1.2 Exemple d une courbe........................... 2 1.3 Coût, recette et bénéfice...........................
Lecture graphique Table des matières 1 Lecture d une courbe 2 1.1 Définition d une fonction.......................... 2 1.2 Exemple d une courbe........................... 2 1.3 Coût, recette et bénéfice...........................
Algorithmique et Programmation, IMA
 Algorithmique et Programmation, IMA Cours 2 : C Premier Niveau / Algorithmique Université Lille 1 - Polytech Lille Notations, identificateurs Variables et Types de base Expressions Constantes Instructions
Algorithmique et Programmation, IMA Cours 2 : C Premier Niveau / Algorithmique Université Lille 1 - Polytech Lille Notations, identificateurs Variables et Types de base Expressions Constantes Instructions
A quels élèves profite l approche par les compétences de base? Etude de cas à Djibouti
 A quels élèves profite l approche par les compétences de base? Etude de cas à Djibouti Hamid Mohamed Aden, Directeur du CRIPEN, Djibouti Xavier Roegiers, Professeur à l Université de Louvain, Directeur
A quels élèves profite l approche par les compétences de base? Etude de cas à Djibouti Hamid Mohamed Aden, Directeur du CRIPEN, Djibouti Xavier Roegiers, Professeur à l Université de Louvain, Directeur
Probabilités Loi binomiale Exercices corrigés
 Probabilités Loi binomiale Exercices corrigés Sont abordés dans cette fiche : (cliquez sur l exercice pour un accès direct) Exercice 1 : épreuve de Bernoulli Exercice 2 : loi de Bernoulli de paramètre
Probabilités Loi binomiale Exercices corrigés Sont abordés dans cette fiche : (cliquez sur l exercice pour un accès direct) Exercice 1 : épreuve de Bernoulli Exercice 2 : loi de Bernoulli de paramètre
23. Interprétation clinique des mesures de l effet traitement
 23. Interprétation clinique des mesures de l effet traitement 23.1. Critères de jugement binaires Plusieurs mesures (indices) sont utilisables pour quantifier l effet traitement lors de l utilisation d
23. Interprétation clinique des mesures de l effet traitement 23.1. Critères de jugement binaires Plusieurs mesures (indices) sont utilisables pour quantifier l effet traitement lors de l utilisation d
Nouveau Barème W.B.F. de points de victoire 4 à 48 donnes
 Nouveau Barème W.B.F. de points de victoire 4 à 48 donnes Pages 4 à 48 barèmes 4 à 48 donnes Condensé en une page: Page 2 barèmes 4 à 32 ( nombre pair de donnes ) Page 3 Tous les autres barèmes ( PV de
Nouveau Barème W.B.F. de points de victoire 4 à 48 donnes Pages 4 à 48 barèmes 4 à 48 donnes Condensé en une page: Page 2 barèmes 4 à 32 ( nombre pair de donnes ) Page 3 Tous les autres barèmes ( PV de
Manuel d utilisation 26 juin 2011. 1 Tâche à effectuer : écrire un algorithme 2
 éducalgo Manuel d utilisation 26 juin 2011 Table des matières 1 Tâche à effectuer : écrire un algorithme 2 2 Comment écrire un algorithme? 3 2.1 Avec quoi écrit-on? Avec les boutons d écriture........
éducalgo Manuel d utilisation 26 juin 2011 Table des matières 1 Tâche à effectuer : écrire un algorithme 2 2 Comment écrire un algorithme? 3 2.1 Avec quoi écrit-on? Avec les boutons d écriture........