APPRENTISSAGE AUTOMATIQUE. Réduction de dimension
|
|
|
- Alphonse Milot
- il y a 8 ans
- Total affichages :
Transcription
1 APPRENTISSAGE AUTOMATIQUE Réduction de dimension

2 Malédiction de la dimensionalité Beaucoup de méthodes d apprentissage ne passent pas bien à l échelle pour des données de grandes dimensions: c est la malédiction de la dimensionnalité Gaussian Mixture Models : O(D 2 ) Plus proches voisins : O(nD) Beaucoup de méthodes d apprentissage ont leurs performances qui décroissent pour des données de grandes dimensions Pour une base d exemples donnée, il y a un nombre maximum de dimensions au delà duquel cela dégrade les performances de l algorithme

3 Intérêt de la réduction de dimension Identifier les attributs importants Motivations statistiques (e.g., supprimer du bruit) Réduction de la complexité de l algorithme d apprentissage Réduction de la complexité du classifieur : moins de paramètres Des classifieurs plus simples sont plus robustes sur des données moins volumineuses Motivations de visualisation: visualiser les données en 2D ou 3D La dimension intrinsèque des données peut en fait être faible

4 Classification de documents Pages web s Documents D 1 D 2 D M T 1 T 2. T N C Sports Travel Termes Jobs ACM Portal Internet IEEE Xplore Digital Libraries PubMed n n n But : Classifier des documents inconnus dans des catégories Challenge : des milliers de descripteurs Solution : Réduction de dimension 4

5 Gènes et puces à ADN Puce à ADN n n n But : Classer des nouvelles puces selon une maladie Challenge : des milliers de gènes, peu d instances Solution : réduction de dimension Expression de la puce à ADN 5

6 Autres données de grandes dimensions Visages Chiffres

7 Approches de la réduction de dimension La réduction de dimension peut désigner deux processus bien distincts : La sélection d attributs Parmi les D attributs existants, on cherche à sélectionner les D plus informatifs La construction d un espace de dimension réduite par extraction de nouveaux d attributs À partir des attributs existants, on cherche à créer une nouvelle représentation fidèle aux données initales, et dont les premières dimensions sont le plus informatives.! # # # # # # "# x 1 x 2 x D $ &! & # & # & '# & # & "# %& y 1 y 2 y D' (! $ *# & *# & *# & = f *# & *# %& # * )"# x 1 x 2 x D $ + &- &- &- &- &- & %& -,! # # # # # # "# x 1 x 2 x D $ &! & # & # & '# & # & "# %& y 1 y 2 y D' $ & & & & %&
\"# x 1 x 2 x D $ + &- &- &- &- &- & %& -,! # # # # # # \"# x 1 x 2 x D $ &!")
8 Sélection d attributs La sélection d un modèle passe également par la réduction du nombre de ses entrées Ceci consiste en la sélection d attributs pertinents : comment définir la pertinence? Définition : Un attribut est fortement pertinent si sa suppression entraîne la détérioration du taux de reconnaissance Définition : Un attribut X est faiblement pertinent s il n est pas fortement pertinent et s il existe un sous-ensemble d attributs S tel que le taux de reconnaissance du classifieur en utilisant S est plus élevé que celui obtenu en utilisant S {X}.

9 Buts de la sélection de variables Idéal : trouver le sous-ensemble minimal nécessaire et suffisant pour le classifieur Classique : sélectionner un sous ensemble de D attributs parmi un ensemble de D attributs (D <D) tel que la valeur d un critère donné soit optimale pour le sous-ensemble de taille D Augmentation du taux de reconnaissance : sélectionner un sous ensemble minimal d attributs qui augmente le taux de reconnaissance Approximation de la distribution des classes originales : sélectionner un sous ensemble minimal pour lequel la distribution des classes est aussi proche que possible de la distribution originale en utilisant tous les attributs

10 Composants de base Un algorithme de recherche d un sous ensemble (parcourir l espace des sous-ensembles d attributs qui est de taille 2 D -1) Une fonction d évaluation : associe une valeur numérique à un sous-ensemble d attributs (on veut maximiser cette fonction) Un inducteur : un algorithme permettant de générer un classifieur à partir de données d apprentissage Un critère d arrêt : détermine quand l algorithme de recherche doit se terminer Une procédure de validation : permet de déterminer si le sous-ensemble produit est valide.

11 Schéma récapitulatif

12 Les espaces de recherche Recherche exhaustive (à éviter) Recherche heuristique Méthodes séquentielles Forward : ajout de variables Backward : retrait de variables Stepwise : ajout possible après retrait Algorithme branch and bound Recherche aléatoire Procédés d échantillonnages aléatoire par algorithmes génétiques ou autres algorithmes évolutionnaires ou bio-inspirés

13 Les fonctions d évaluation But : fournir une fonction d évaluation qui puisse mesurer la capacité de discrimination d un ensemble d attributs Mesures de distance inter et intra classe Mesure de la théorie de l information Mesure du taux de reconnaissance d un classifieur Méthodes dépendantes du classifieur utilisé

14 Le graphe des sous-ensembles

15 Sélections Forward et Backward Forward Backward

16 Approche Filter et wrapper Suivant que l algorithme de recherche utilise ou non le taux de reconnaissance du classifieur comme fonction d évaluation, on peut répartir les algorithmes de sélection d attributs en deux catégories : Filter : filtrage des attributs avant l induction Wrapper : induction après chaque filtrage des attributs L approche filter est plus rapide, mais la sélection d attributs se fait de façon totalement indépendante du classifieur. L approche wrapper nécessite d effectuer un apprentissage pour chaque sous-ensemble à évaluer

17 Filter et Wrapper
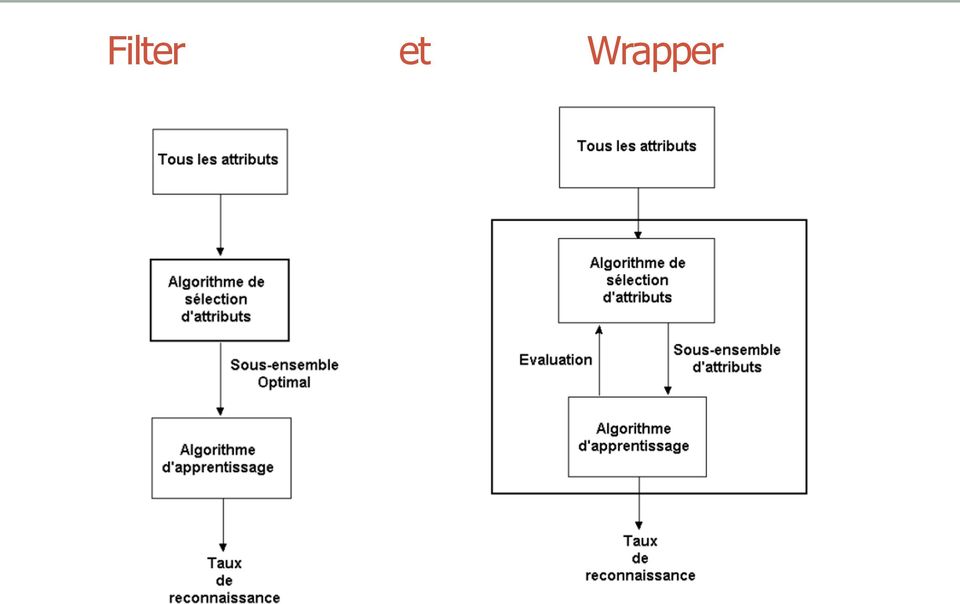
18 Filter : Mesure Wilks lambda On cherche à déterminer le pouvoir discriminant des variables Lambda de Wilks W : matrice de covariance intra-classe g # # j= 1 x! C ( ) ( ) l µ j l µ j W = x " x " B : matrice de covariance inter-classes g j= 1 l j t ( ) ( ) B = " n µ! µ µ! µ j j j t
 ( ) l µ j l µ j W = x \" x \" B : matrice de covariance")
19 Filter : Mesure Wilks lambda p attributs sélectionnés, g le nombre de groupes, n j le nombre d éléments de la classe C j, µ j la moyenne de la classe C j et µ la moyenne globale Critère d arrêt : D Arrêt si la p-ième variable n est pas significative Autre méthode : maximiser trace B ( ) trace W ( )
")
20 Méthodes d extraction d attributs Objectif: Détecter des structures de faibles dimensions dans un espace de très grandes dimensions Principe: Etant donné des données x i! " D, chercher une projection y = f (x) :! D "! D' avec D <D La projection y i! " D' doit préserver le plus d information de l espace original dans R D. Méthodes linéaires Analyse en composantes principales, LDA, MDS Non linéaires basées sur une analyse matricielle La structure de faible dimension est révélée par une décomposition en valeurs et vecteurs propres Liées à la théorie spectrale sur graphes Les matrices sont crées à partir de graphes

21 Réduction de dimension linéaire Beaucoup de méthodes réduction de dimension populaires sont linéaires! # # # # # # "# Trouver la transformation y=f(x) est guidé par la recherche d une fonction objectif à minimiser ou maximiser Suivant le critère choisi, on peut distinguer les méthodes linéaires selon un objectif de: Représentation du signal : le but de la réduction de dimension est de réduire efficacement la dimensionalité de la représentation Classification : le but est d augmenter la séparabilité des classes dans un espace de dimension réduit Parmi les méthodes linéaires, on distinguera: L Analyse en Composantes Principales (PCA) Objectif de représentation du signal L Analyse Discriminate Linéaire (LDA) Objectif de classification x 1 x 2 x D $ &! & # & # & '# & # & "# %& y 1 y 2 y D' $! & # & & = # # & # %& "# w 11 w 12 w 1D w D'1 w D'D! $ # &# &# &# &# %& # "# x 1 x 2 x D $ & & & & & & %&
22 L ACP : point de vue variance max L ACP (ou PCA) est une transformation qui préserve le plus possible la variance des données initiales La projection de x est z = w T x Trouver w qui maximise Var(z) Var(z) = Var(w T x) = E[(w T x E[w T x]) 2 ]=E[(w T x w T µ) 2 ] = E[(w T x w T µ)(w T x w T µ)] = E[w T (x µ)(x µ) T w] = w T E[(x µ)(x µ) T ]w = w T w avec E[(x µ)(x µ) T ] =
23 PCA : maximise la variance L ACP Maximise Var(z) s.t. w =1 max w w 1 T 1 Σw 1 α ( T w w 1) qui a un point stationaire si w 1 = αw 1, c-a-d si w 1 est un vecteur propre de La Variance est alors w T w=α La variance est maximisée si α est le vecteur propre de plus grande valeur propre Seconde composante principale : Max Var(z 2 ), s.t., w 2 =1 et orthogonal à w 1 max w 2 w 2 T!w 2 "! w 2 T w 2 "1 ( ) "! ( w T 2 w 1 " 0) w 2 = α w 2 c-a-d, w 2 est un autre vecteur propre de etc. 1 1
24 ACP : point de vue meilleure reconstruction linéaire Les données initiales sont On désire obtenir On peut représenter x comme une combinaison linéaire de D vecteurs orthogonaux! x i " R D avec i =1,...,n z i! R D' avec D' << D Avec les u d tels que où si et 0 sinon Les coefficients z d sont de la forme Ceci est une rotation de x vers les coordonnées z
25 ACP : point de vue meilleure reconstruction linéaire Si l on ne retient que D vecteurs de bases u d, on a L erreur d approximation est alors Que l on peut minimiser
26 ACP : point de vue meilleure reconstruction linéaire Pour trouver les valeurs optimales des b d, on met la dérivée par rapport aux b d à zéro, on obtient avec Ce qui donne, puisque avec la matrice de covariance
27 ACP : point de vue meilleure reconstruction linéaire Pour minimiser E D, relativement aux u d, on peut montrer ensuite que cela revient à avoir une base de vecteurs qui satisfait C-a-d, ce sont des vecteur propres de la matrice de covariance On peut réécrire ensuite E D par Cette erreur est minimale si l on enlève les plus petites valeurs propres Solution: retenir les vecteur propres de plus grandes valeurs propres de la matrice covariance (i.e., même solution que la maximisation de la variance)
28 Exemple On varie le nombre de vecteurs propres utilisés pour la reconstruction de l exemple Original D =1 D =10 D =50 D =250
29 PCA - Résumé 1) Centrer les données à l origine (i.e., enlever la moyenne) 2) Calculer la matrice de covariance 3) Décomposer la matrice de covariance en vecteurs/valeurs propres 4) Retenir uniquement quelques une des premières dimensions D
30 Interprétation/Propriétés Vecteurs propres Axes principaux de variance maximum Valeurs propres Variance projetée des entrées selon les axes principaux Dimension significative Le nombre de valeurs propres élevées et non négatives Pour Méthode de décomposition Pas de paramètres Non itératif Pas de minima local Contre Limité à des projections linéaires
31 Linear Discriminant Analysis - LDA LDA cherche à réduire la dimensionnalité en faisant en sorte que les classes soient bien séparées Il faut disposer d une mesure de séparation: on cherche une projection ou les exemples d une même classe ont une projection proche avec les moyennes des projections des classes qui soient éloignées Le Fisher LDA cherche à maximiser la différence entre entre les moyennes projetées normalisée par une mesure de dispersion intra classe (appelée scattering)
32 Fisher LDA Pour trouver l optimum w*, nous devons exprimer J(w) en fonction de w La dispersion dans l espace initial (within-class scatter) est S w est la matrice de dispersion intra-classe La dispersion de la projection y peut s exprimer en fonction de S w De même pour les moyennes S B est la matrice de dispersion inter-classe On obtient finalement La solution obtenue est alors
33 Fisher LDA multi-classes Au lieu d une projection 1D y, on cherche (C-1) projections par (C-1) vecteurs de projections arrangés dans une matrice W Within-class scatter: Between-class scatter: Trouver W* qui maximise Obtenu par les plus grands vecteurs propres de S W -1 S B 33
34 LDA vs PCA
35 LDA vs PCA
36 Metric Multidimensional Scaling Étant donné une matrice de distance entre des points de l espace de départ, trouver des vecteurs y tels que y i " y j # $ ij
37 MDS Le produit scalaire entre deux vecteurs de l espace initial est On cherche à minimiser une erreur afin de préserver les produits scalaires Solution obtenue par décomposition La projection retenue est alors une version tronquée rescalée des vecteurs propres
38 Problèmes PCA/LDA effectuent une transformation globale sur les données (translation/rotation/rescaling) Ces méthodent supposent que les données vivent dans un sous-espace linéaire Même pour des méthodes métriques comme MDS, cela ne préserve pas forcément bien les distances relativement à la variété sousjacente des données
39 ISOMAP Idées Une solution est de trouver une transformation qui préserve les distances géodésiques mesurées sur un graphe des données initiales Pour des exemples proches, la distance Euclidienne fournit une bonne approximation de la distance géodésique Pour des exemples éloignés, la distance géodésique peut être approximée par un calcul de plus court chemin Principe Utiliser des distance géodésiques à la place de distances Euclidiennes dans MDS Étant donné une matrice de distance entre des points de l espace de départ, trouver des vecteurs y tels que y i " y j # g ( $ ij ) 3 étapes Trouver les plus proches voisins de chaque exemple Trouver les plus courts chemins Appliquer MDS
40 Etapes Etape 1 Déterminer quels exemples de la variété sont voisins à partir d une distance d X (i,j) dans l espace initial Construire un graphe d adjacence (noeud=points, arêtes pour connecter les noeuds) pondéré par d X (i,j) Sélectionner les k plus proches voisins en s assurant que le graphe est connecté Le graphe obtenu est une approximation de la variété sous-jacente Etape 2 Estimer les distances géodésiques d M (i,j) entre toutes les paires d exemples par l algorithme de Dijkstra: D G Etape 3 Trouver la projection qui préserve le mieux les distances géodésiques estimées Effectuer MDS sur la matrice des distances géodésiques D G
41 Isomap - Algorithme
42 ISOMAP on Optdigits Optdigits after Isomap (with neighborhood graph)
43 Examples
44 Exemples
45 Isomap - Propriétés ISOMAP est garanti de découvrir la vraie dimensionnalité et géométrie d une certaine classe de variétés Euclidiennes Cette garantie provient du fait que lorsque le nombre d exemples augmente la distance D G mesurée sur le graphe est une bonne estimation de la distance géodésique D M ISOMAP est très sensible aux courts-circuits Ne necéssite qu un seul paramètre : la taille du voisinage
46 Locally Linear Embedding LLE utilise une stratégie différente d ISOMAP pour trouver la structure globale de la variété sous-jacente LLE exploite des distances mesurées sur des voisinages locaux linéaires Intuition Les exemples sont supposés provenir d un échantillonnage de la variété Si l on dispose de suffisamment de données (i.e., la variété est bien échantillonnée), on peut supposer que chaque exemple et ses voisins vivent sur un patch localement linéaire de la variété Approche LLE résout le problème en deux étapes Une combinaison linéaire approximant chaque exemple de l espace d entrée est calculée Trouver des coordonnées dans un espace réduit qui soient compatibles avec l approximation linéaire
47 Caracatérisation locale de la variété Le graphe doit être connecté Les voisinages locaux (appelés patchs) doivent refléter localement la structure des données Les poids caractérisent la structure locale de chaque voisinage : calculés par reconstruction linéaire des entrées à partir des voisins
48 LLE Partie 1 La géométrie locale des patchs est modélisée par des poids qui permettent de reconstruire chaque exemple par une combinaison linéaire de ses voisins Les erreurs de reconstruction sont mesurées par une fonction d erreur Les poids W ij mesurent la contribution du j ème exemple pour la reconstruction du i ème exemple Les poids W ij sont soumis à deux contraintes Chaque exemple est reconstruit à partir de ses voisins Les lignes de la matrice somment à un : Ces contraintes assurent que, pour chaque exemple, les poids sont invariants par translation, rotation, rescaling Les poids peuvent être obtenus par optimisation d un critère de moindres carrés
49 LLE Partie 2 Les poids de reconstruction reflètent les propriétés de la géométrie locale, ils doivent bien représenter les patchs locaux de la variété On cherche donc une projection Y de dimension d qui minimise la fonction de cout suivante Cette fonction de cout est similaire à la précédente, mais cette fois les poids W ij sont fixés et nous cherchons les Y i Pour que ce problème d optimisation soit bien posé, on ajoute deux contraintes Puisque les Y i peuvent être translatés sans modifier la fonction de cout, les Y i sont centrés Pour éviter des solutions dégénérées, on impose que les vecteurs de projection aient une matrice de covariance unitaire Ce problème de minimisation peut être résolu en retenant les d plus petits vecteurs propres de la matrice (I-W) T (I-W)
50 LLE - Résumé
51 Exemples
52 Exemples
53
54
55 LLE on Optdigits
56 Laplacian EigenMaps Idée Projeter des entrées proches vers des projections proches La proximité (ou similarité) est codée par les poids du graphe
57 LE - Principe Construction du graphe Pondérer le graphe Calculer les projections en imposant que deux exemple x i et x j dans l espace de départ donnent deux exemples y i et y j sont proches dans l espace de projection On cherche à minimiser le critère Ou bien
58 LE - Détails Nous savons que Cela revient donc à
59 LE - Résolution Le calcul de la projection se fait par décomposition et obtention des vecteurs propres Le Laplacien sur graphe est utilisé dans le calcul des poids : On retrouve donc la solution obtenue pour les ratio et Normalized Cuts
60 Comparaisons Voir pour un code matlab de comparaison
61 Comparaisons
62 PCA
63 LDA
64 MDS
65 ISOMAP
66 LLE
67 Kernel PCA Nous avons vu que l ACP permet de définir une projection linéaire des données Les données (M exemples) sont centrées On calcule la matrice de covariance Calculer vecteurs et valeurs propres de C : La projection finale est obtenue en retenant uniquement les D plus grands vecteur propres Le Kernel (Nonlinear) PCA consiste à déterminer la projection dans un espace d attributs implicite obtenu par un noyau de Mercer
68 Kernel PCA Pour définir le Kernel PCA Nous devons tout d abord projeter les données dans un espace de grandes dimensions F Nous devons définir la matrice de covariance dans cet espace Les données sont supposées centrées On calcule ensuite la décomposition de la matrice
69 Kernel PCA - Solution Comme nous l avons vu avec l ACP, les vecteur propres peuvent s exprimer comme une combinaison linéaire des exemples On multiplie par des deux cotés de Ce qui donne, combiné avec l expression précédente: Et après regroupement des termes:
70 Kernel PCA - Solution En définissant une matrice K de dimension M x M L expression précédente devient Ceci peut être résolu par Normalisation Pour assurer que les vecteurs propres sont orthogonaux, ils sont rescalés Comme les α sont des vecteurs propres de K, on a
71 Kernel PCA - Solution Pour trouver la projection d une nouvelle donnée x, on utilisera : Qui exprime une combinaison linéaire des vecteurs propres Ceci est le principe de l extension de Nyström qui permet de déterminer la projection de points qui n étaient pas parmi les exemples (nommé «out of sample extension») Le Kernel PCA généralise toutes les autres méthodes de réduction de dimension avec un noyau particulier
72 Centrer dans l espace F Nous avons supposé que les données étaient centrées dans l espace F: La matrice de covariance est alors et il faut résoudre En combinant les deux expressions, on obtient La matrice du noyau centrée peut donc être calculée à partir du noyau initial
73 Centrer dans l espace F Interprétation
74 Kernel PCA - Exemple Exemple simple avec 3 modes et 20 exemples par mode
75 Résultat de l ACP
76 Résultat du Kernel PCA
1 Complément sur la projection du nuage des individus
 TP 0 : Analyse en composantes principales (II) Le but de ce TP est d approfondir nos connaissances concernant l analyse en composantes principales (ACP). Pour cela, on reprend les notations du précédent
TP 0 : Analyse en composantes principales (II) Le but de ce TP est d approfondir nos connaissances concernant l analyse en composantes principales (ACP). Pour cela, on reprend les notations du précédent
L ANALYSE EN COMPOSANTES PRINCIPALES (A.C.P.) Pierre-Louis GONZALEZ
 Pierre-Louis GONZALEZ") L ANALYSE EN COMPOSANTES PRINCIPALES (A.C.P.) Pierre-Louis GONZALEZ INTRODUCTION Données : n individus observés sur p variables quantitatives. L A.C.P. permet d eplorer les liaisons entre variables et
L ANALYSE EN COMPOSANTES PRINCIPALES (A.C.P.) Pierre-Louis GONZALEZ INTRODUCTION Données : n individus observés sur p variables quantitatives. L A.C.P. permet d eplorer les liaisons entre variables et
Analyse de la vidéo. Chapitre 4.1 - La modélisation pour le suivi d objet. 10 mars 2015. Chapitre 4.1 - La modélisation d objet 1 / 57
 Analyse de la vidéo Chapitre 4.1 - La modélisation pour le suivi d objet 10 mars 2015 Chapitre 4.1 - La modélisation d objet 1 / 57 La représentation d objets Plan de la présentation 1 La représentation
Analyse de la vidéo Chapitre 4.1 - La modélisation pour le suivi d objet 10 mars 2015 Chapitre 4.1 - La modélisation d objet 1 / 57 La représentation d objets Plan de la présentation 1 La représentation
La classification automatique de données quantitatives
 La classification automatique de données quantitatives 1 Introduction Parmi les méthodes de statistique exploratoire multidimensionnelle, dont l objectif est d extraire d une masse de données des informations
La classification automatique de données quantitatives 1 Introduction Parmi les méthodes de statistique exploratoire multidimensionnelle, dont l objectif est d extraire d une masse de données des informations
Introduction au Data-Mining
 Introduction au Data-Mining Alain Rakotomamonjy - Gilles Gasso. INSA Rouen -Département ASI Laboratoire PSI Introduction au Data-Mining p. 1/25 Data-Mining : Kèkecé? Traduction : Fouille de données. Terme
Introduction au Data-Mining Alain Rakotomamonjy - Gilles Gasso. INSA Rouen -Département ASI Laboratoire PSI Introduction au Data-Mining p. 1/25 Data-Mining : Kèkecé? Traduction : Fouille de données. Terme
Analyse en Composantes Principales
 Analyse en Composantes Principales Anne B Dufour Octobre 2013 Anne B Dufour () Analyse en Composantes Principales Octobre 2013 1 / 36 Introduction Introduction Soit X un tableau contenant p variables mesurées
Analyse en Composantes Principales Anne B Dufour Octobre 2013 Anne B Dufour () Analyse en Composantes Principales Octobre 2013 1 / 36 Introduction Introduction Soit X un tableau contenant p variables mesurées
Laboratoire 4 Développement d un système intelligent
 DÉPARTEMENT DE GÉNIE LOGICIEL ET DES TI LOG770 - SYSTÈMES INTELLIGENTS ÉTÉ 2012 Laboratoire 4 Développement d un système intelligent 1 Introduction Ce quatrième et dernier laboratoire porte sur le développement
DÉPARTEMENT DE GÉNIE LOGICIEL ET DES TI LOG770 - SYSTÈMES INTELLIGENTS ÉTÉ 2012 Laboratoire 4 Développement d un système intelligent 1 Introduction Ce quatrième et dernier laboratoire porte sur le développement
Programmation linéaire
 1 Programmation linéaire 1. Le problème, un exemple. 2. Le cas b = 0 3. Théorème de dualité 4. L algorithme du simplexe 5. Problèmes équivalents 6. Complexité de l Algorithme 2 Position du problème Soit
1 Programmation linéaire 1. Le problème, un exemple. 2. Le cas b = 0 3. Théorème de dualité 4. L algorithme du simplexe 5. Problèmes équivalents 6. Complexité de l Algorithme 2 Position du problème Soit
Déroulement d un projet en DATA MINING, préparation et analyse des données. Walid AYADI
 1 Déroulement d un projet en DATA MINING, préparation et analyse des données Walid AYADI 2 Les étapes d un projet Choix du sujet - Définition des objectifs Inventaire des données existantes Collecte, nettoyage
1 Déroulement d un projet en DATA MINING, préparation et analyse des données Walid AYADI 2 Les étapes d un projet Choix du sujet - Définition des objectifs Inventaire des données existantes Collecte, nettoyage
Extraction d informations stratégiques par Analyse en Composantes Principales
 Extraction d informations stratégiques par Analyse en Composantes Principales Bernard DOUSSET IRIT/ SIG, Université Paul Sabatier, 118 route de Narbonne, 31062 Toulouse cedex 04 dousset@irit.fr 1 Introduction
Extraction d informations stratégiques par Analyse en Composantes Principales Bernard DOUSSET IRIT/ SIG, Université Paul Sabatier, 118 route de Narbonne, 31062 Toulouse cedex 04 dousset@irit.fr 1 Introduction
Exercice : la frontière des portefeuilles optimaux sans actif certain
 Exercice : la frontière des portefeuilles optimaux sans actif certain Philippe Bernard Ingénierie Economique & Financière Université Paris-Dauphine Février 0 On considère un univers de titres constitué
Exercice : la frontière des portefeuilles optimaux sans actif certain Philippe Bernard Ingénierie Economique & Financière Université Paris-Dauphine Février 0 On considère un univers de titres constitué
Arbres binaires de décision
 1 Arbres binaires de décision Résumé Arbres binaires de décision Méthodes de construction d arbres binaires de décision, modélisant une discrimination (classification trees) ou une régression (regression
1 Arbres binaires de décision Résumé Arbres binaires de décision Méthodes de construction d arbres binaires de décision, modélisant une discrimination (classification trees) ou une régression (regression
Programmation linéaire
 Programmation linéaire DIDIER MAQUIN Ecole Nationale Supérieure d Electricité et de Mécanique Institut National Polytechnique de Lorraine Mathématiques discrètes cours de 2ème année Programmation linéaire
Programmation linéaire DIDIER MAQUIN Ecole Nationale Supérieure d Electricité et de Mécanique Institut National Polytechnique de Lorraine Mathématiques discrètes cours de 2ème année Programmation linéaire
Filtrage stochastique non linéaire par la théorie de représentation des martingales
 Filtrage stochastique non linéaire par la théorie de représentation des martingales Adriana Climescu-Haulica Laboratoire de Modélisation et Calcul Institut d Informatique et Mathématiques Appliquées de
Filtrage stochastique non linéaire par la théorie de représentation des martingales Adriana Climescu-Haulica Laboratoire de Modélisation et Calcul Institut d Informatique et Mathématiques Appliquées de
Souad EL Bernoussi. Groupe d Analyse Numérique et Optimisation Rabat http ://www.fsr.ac.ma/ano/
 Recherche opérationnelle Les démonstrations et les exemples seront traités en cours Souad EL Bernoussi Groupe d Analyse Numérique et Optimisation Rabat http ://www.fsr.ac.ma/ano/ Table des matières 1 Programmation
Recherche opérationnelle Les démonstrations et les exemples seront traités en cours Souad EL Bernoussi Groupe d Analyse Numérique et Optimisation Rabat http ://www.fsr.ac.ma/ano/ Table des matières 1 Programmation
La programmation linéaire : une introduction. Qu est-ce qu un programme linéaire? Terminologie. Écriture mathématique
 La programmation linéaire : une introduction Qu est-ce qu un programme linéaire? Qu est-ce qu un programme linéaire? Exemples : allocation de ressources problème de recouvrement Hypothèses de la programmation
La programmation linéaire : une introduction Qu est-ce qu un programme linéaire? Qu est-ce qu un programme linéaire? Exemples : allocation de ressources problème de recouvrement Hypothèses de la programmation
Une comparaison de méthodes de discrimination des masses de véhicules automobiles
 p.1/34 Une comparaison de méthodes de discrimination des masses de véhicules automobiles A. Rakotomamonjy, R. Le Riche et D. Gualandris INSA de Rouen / CNRS 1884 et SMS / PSA Enquêtes en clientèle dans
p.1/34 Une comparaison de méthodes de discrimination des masses de véhicules automobiles A. Rakotomamonjy, R. Le Riche et D. Gualandris INSA de Rouen / CNRS 1884 et SMS / PSA Enquêtes en clientèle dans
Introduction au Data-Mining
 Introduction au Data-Mining Gilles Gasso, Stéphane Canu INSA Rouen -Département ASI Laboratoire LITIS 8 septembre 205. Ce cours est librement inspiré du cours DM de Alain Rakotomamonjy Gilles Gasso, Stéphane
Introduction au Data-Mining Gilles Gasso, Stéphane Canu INSA Rouen -Département ASI Laboratoire LITIS 8 septembre 205. Ce cours est librement inspiré du cours DM de Alain Rakotomamonjy Gilles Gasso, Stéphane
INTRODUCTION À L ANALYSE FACTORIELLE DES CORRESPONDANCES
 INTRODUCTION À L ANALYSE FACTORIELLE DES CORRESPONDANCES Dominique LAFFLY Maître de Conférences, Université de Pau Laboratoire Société Environnement Territoire UMR 5603 du CNRS et Université de Pau Domaine
INTRODUCTION À L ANALYSE FACTORIELLE DES CORRESPONDANCES Dominique LAFFLY Maître de Conférences, Université de Pau Laboratoire Société Environnement Territoire UMR 5603 du CNRS et Université de Pau Domaine
Laboratoire d Automatique et Productique Université de Batna, Algérie
 Anale. Seria Informatică. Vol. IX fasc. 2 Annals. Computer Science Series. 9 th Tome st Fasc. 2 La sélection de paramètres d un système industriel par les colonies de fourmis Ouahab Kadri, L. Hayet Mouss,
Anale. Seria Informatică. Vol. IX fasc. 2 Annals. Computer Science Series. 9 th Tome st Fasc. 2 La sélection de paramètres d un système industriel par les colonies de fourmis Ouahab Kadri, L. Hayet Mouss,
Traitement bas-niveau
 Plan Introduction L approche contour (frontière) Introduction Objectifs Les traitements ont pour but d extraire l information utile et pertinente contenue dans l image en regard de l application considérée.
Plan Introduction L approche contour (frontière) Introduction Objectifs Les traitements ont pour but d extraire l information utile et pertinente contenue dans l image en regard de l application considérée.
Apprentissage Automatique
 Apprentissage Automatique Introduction-I jean-francois.bonastre@univ-avignon.fr www.lia.univ-avignon.fr Définition? (Wikipedia) L'apprentissage automatique (machine-learning en anglais) est un des champs
Apprentissage Automatique Introduction-I jean-francois.bonastre@univ-avignon.fr www.lia.univ-avignon.fr Définition? (Wikipedia) L'apprentissage automatique (machine-learning en anglais) est un des champs
L analyse d images regroupe plusieurs disciplines que l on classe en deux catégories :
 La vision nous permet de percevoir et d interpreter le monde qui nous entoure. La vision artificielle a pour but de reproduire certaines fonctionnalités de la vision humaine au travers de l analyse d images.
La vision nous permet de percevoir et d interpreter le monde qui nous entoure. La vision artificielle a pour but de reproduire certaines fonctionnalités de la vision humaine au travers de l analyse d images.
Big Data et Graphes : Quelques pistes de recherche
 Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci http://liris.cnrs.fr/hamamache.kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de
Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci http://liris.cnrs.fr/hamamache.kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de
Contexte. Pour cela, elles doivent être très compliquées, c est-à-dire elles doivent être très différentes des fonctions simples,
 Non-linéarité Contexte Pour permettre aux algorithmes de cryptographie d être sûrs, les fonctions booléennes qu ils utilisent ne doivent pas être inversées facilement. Pour cela, elles doivent être très
Non-linéarité Contexte Pour permettre aux algorithmes de cryptographie d être sûrs, les fonctions booléennes qu ils utilisent ne doivent pas être inversées facilement. Pour cela, elles doivent être très
I. Polynômes de Tchebychev
 Première épreuve CCP filière MP I. Polynômes de Tchebychev ( ) 1.a) Tout réel θ vérifie cos(nθ) = Re ((cos θ + i sin θ) n ) = Re Cn k (cos θ) n k i k (sin θ) k Or i k est réel quand k est pair et imaginaire
Première épreuve CCP filière MP I. Polynômes de Tchebychev ( ) 1.a) Tout réel θ vérifie cos(nθ) = Re ((cos θ + i sin θ) n ) = Re Cn k (cos θ) n k i k (sin θ) k Or i k est réel quand k est pair et imaginaire
INF6304 Interfaces Intelligentes
 INF6304 Interfaces Intelligentes filtres collaboratifs 1/42 INF6304 Interfaces Intelligentes Systèmes de recommandations, Approches filtres collaboratifs Michel C. Desmarais Génie informatique et génie
INF6304 Interfaces Intelligentes filtres collaboratifs 1/42 INF6304 Interfaces Intelligentes Systèmes de recommandations, Approches filtres collaboratifs Michel C. Desmarais Génie informatique et génie
Intelligence Artificielle et Systèmes Multi-Agents. Badr Benmammar bbm@badr-benmammar.com
 Intelligence Artificielle et Systèmes Multi-Agents Badr Benmammar bbm@badr-benmammar.com Plan La première partie : L intelligence artificielle (IA) Définition de l intelligence artificielle (IA) Domaines
Intelligence Artificielle et Systèmes Multi-Agents Badr Benmammar bbm@badr-benmammar.com Plan La première partie : L intelligence artificielle (IA) Définition de l intelligence artificielle (IA) Domaines
Etat de l art de la Reconnaissance de Visage.
 Chapitre 2 2.1 Introduction De nos jours, il existe des ordinateurs capables d effectuer des tâches faites par l homme, qui demandent de l intelligence. Malgré tout ce progrès, la machine est toujours
Chapitre 2 2.1 Introduction De nos jours, il existe des ordinateurs capables d effectuer des tâches faites par l homme, qui demandent de l intelligence. Malgré tout ce progrès, la machine est toujours
Optimisation multi-critère pour l allocation de ressources sur Clouds distribués avec prise en compte de l énergie
 Optimisation multi-critère pour l allocation de ressources sur Clouds distribués avec prise en compte de l énergie 1 Présenté par: Yacine KESSACI Encadrement : N. MELAB E-G. TALBI 31/05/2011 Plan 2 Motivation
Optimisation multi-critère pour l allocation de ressources sur Clouds distribués avec prise en compte de l énergie 1 Présenté par: Yacine KESSACI Encadrement : N. MELAB E-G. TALBI 31/05/2011 Plan 2 Motivation
Exemples de problèmes et d applications. INF6953 Exemples de problèmes 1
 Exemples de problèmes et d applications INF6953 Exemples de problèmes Sommaire Quelques domaines d application Quelques problèmes réels Allocation de fréquences dans les réseaux radio-mobiles Affectation
Exemples de problèmes et d applications INF6953 Exemples de problèmes Sommaire Quelques domaines d application Quelques problèmes réels Allocation de fréquences dans les réseaux radio-mobiles Affectation
Annexe 6. Notions d ordonnancement.
 Annexe 6. Notions d ordonnancement. APP3 Optimisation Combinatoire: problèmes sur-contraints et ordonnancement. Mines-Nantes, option GIPAD, 2011-2012. Sophie.Demassey@mines-nantes.fr Résumé Ce document
Annexe 6. Notions d ordonnancement. APP3 Optimisation Combinatoire: problèmes sur-contraints et ordonnancement. Mines-Nantes, option GIPAD, 2011-2012. Sophie.Demassey@mines-nantes.fr Résumé Ce document
Projet SINF2275 «Data mining and decision making» Projet classification et credit scoring
 Projet SINF2275 «Data mining and decision making» Projet classification et credit scoring Année académique 2006-2007 Professeurs : Marco Saerens Adresse : Université catholique de Louvain Information Systems
Projet SINF2275 «Data mining and decision making» Projet classification et credit scoring Année académique 2006-2007 Professeurs : Marco Saerens Adresse : Université catholique de Louvain Information Systems
Big Data et Graphes : Quelques pistes de recherche
 Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de Lyon/Université Claude Bernard Lyon 1/Université
Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de Lyon/Université Claude Bernard Lyon 1/Université
Exercices Corrigés Premières notions sur les espaces vectoriels
 Exercices Corrigés Premières notions sur les espaces vectoriels Exercice 1 On considére le sous-espace vectoriel F de R formé des solutions du système suivant : x1 x 2 x 3 + 2x = 0 E 1 x 1 + 2x 2 + x 3
Exercices Corrigés Premières notions sur les espaces vectoriels Exercice 1 On considére le sous-espace vectoriel F de R formé des solutions du système suivant : x1 x 2 x 3 + 2x = 0 E 1 x 1 + 2x 2 + x 3
LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING»
 LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING» Gilbert Saporta Professeur de Statistique Appliquée Conservatoire National des Arts et Métiers Dans leur quasi totalité, les banques et organismes financiers
LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING» Gilbert Saporta Professeur de Statistique Appliquée Conservatoire National des Arts et Métiers Dans leur quasi totalité, les banques et organismes financiers
Objectifs. Clustering. Principe. Applications. Applications. Cartes de crédits. Remarques. Biologie, Génomique
 Objectifs Clustering On ne sait pas ce qu on veut trouver : on laisse l algorithme nous proposer un modèle. On pense qu il existe des similarités entre les exemples. Qui se ressemble s assemble p. /55
Objectifs Clustering On ne sait pas ce qu on veut trouver : on laisse l algorithme nous proposer un modèle. On pense qu il existe des similarités entre les exemples. Qui se ressemble s assemble p. /55
Enjeux mathématiques et Statistiques du Big Data
 Enjeux mathématiques et Statistiques du Big Data Mathilde Mougeot LPMA/Université Paris Diderot, mathilde.mougeot@univ-paris-diderot.fr Mathématique en Mouvements, Paris, IHP, 6 Juin 2015 M. Mougeot (Paris
Enjeux mathématiques et Statistiques du Big Data Mathilde Mougeot LPMA/Université Paris Diderot, mathilde.mougeot@univ-paris-diderot.fr Mathématique en Mouvements, Paris, IHP, 6 Juin 2015 M. Mougeot (Paris
Pourquoi l apprentissage?
 Pourquoi l apprentissage? Les SE sont basés sur la possibilité d extraire la connaissance d un expert sous forme de règles. Dépend fortement de la capacité à extraire et formaliser ces connaissances. Apprentissage
Pourquoi l apprentissage? Les SE sont basés sur la possibilité d extraire la connaissance d un expert sous forme de règles. Dépend fortement de la capacité à extraire et formaliser ces connaissances. Apprentissage
Chapitre 7. Statistique des échantillons gaussiens. 7.1 Projection de vecteurs gaussiens
 Chapitre 7 Statistique des échantillons gaussiens Le théorème central limite met en évidence le rôle majeur tenu par la loi gaussienne en modélisation stochastique. De ce fait, les modèles statistiques
Chapitre 7 Statistique des échantillons gaussiens Le théorème central limite met en évidence le rôle majeur tenu par la loi gaussienne en modélisation stochastique. De ce fait, les modèles statistiques
Chapitre 3. Les distributions à deux variables
 Chapitre 3. Les distributions à deux variables Jean-François Coeurjolly http://www-ljk.imag.fr/membres/jean-francois.coeurjolly/ Laboratoire Jean Kuntzmann (LJK), Grenoble University 1 Distributions conditionnelles
Chapitre 3. Les distributions à deux variables Jean-François Coeurjolly http://www-ljk.imag.fr/membres/jean-francois.coeurjolly/ Laboratoire Jean Kuntzmann (LJK), Grenoble University 1 Distributions conditionnelles
ProxiLens : Exploration interactive de données multidimensionnelles à partir de leur projection
 ProxiLens : Exploration interactive de données multidimensionnelles à partir de leur projection Nicolas HEULOT (CEA LIST) Michaël AUPETIT (CEA LIST) Jean-Daniel FEKETE (INRIA Saclay) Journées Big Data
ProxiLens : Exploration interactive de données multidimensionnelles à partir de leur projection Nicolas HEULOT (CEA LIST) Michaël AUPETIT (CEA LIST) Jean-Daniel FEKETE (INRIA Saclay) Journées Big Data
Introduction à l approche bootstrap
 Introduction à l approche bootstrap Irène Buvat U494 INSERM buvat@imedjussieufr 25 septembre 2000 Introduction à l approche bootstrap - Irène Buvat - 21/9/00-1 Plan du cours Qu est-ce que le bootstrap?
Introduction à l approche bootstrap Irène Buvat U494 INSERM buvat@imedjussieufr 25 septembre 2000 Introduction à l approche bootstrap - Irène Buvat - 21/9/00-1 Plan du cours Qu est-ce que le bootstrap?
Interception des signaux issus de communications MIMO
 Interception des signaux issus de communications MIMO par Vincent Choqueuse Laboratoire E 3 I 2, EA 3876, ENSIETA Laboratoire LabSTICC, UMR CNRS 3192, UBO 26 novembre 2008 Interception des signaux issus
Interception des signaux issus de communications MIMO par Vincent Choqueuse Laboratoire E 3 I 2, EA 3876, ENSIETA Laboratoire LabSTICC, UMR CNRS 3192, UBO 26 novembre 2008 Interception des signaux issus
Gestion des Clés Publiques (PKI)
") Chapitre 3 Gestion des Clés Publiques (PKI) L infrastructure de gestion de clés publiques (PKI : Public Key Infrastructure) représente l ensemble des moyens matériels et logiciels assurant la gestion des
Chapitre 3 Gestion des Clés Publiques (PKI) L infrastructure de gestion de clés publiques (PKI : Public Key Infrastructure) représente l ensemble des moyens matériels et logiciels assurant la gestion des
Cours de Mécanique du point matériel
 Cours de Mécanique du point matériel SMPC1 Module 1 : Mécanique 1 Session : Automne 2014 Prof. M. EL BAZ Cours de Mécanique du Point matériel Chapitre 1 : Complément Mathématique SMPC1 Chapitre 1: Rappels
Cours de Mécanique du point matériel SMPC1 Module 1 : Mécanique 1 Session : Automne 2014 Prof. M. EL BAZ Cours de Mécanique du Point matériel Chapitre 1 : Complément Mathématique SMPC1 Chapitre 1: Rappels
Objectifs du cours d aujourd hui. Informatique II : Cours d introduction à l informatique et à la programmation objet. Complexité d un problème (2)
") Objectifs du cours d aujourd hui Informatique II : Cours d introduction à l informatique et à la programmation objet Complexité des problèmes Introduire la notion de complexité d un problème Présenter
Objectifs du cours d aujourd hui Informatique II : Cours d introduction à l informatique et à la programmation objet Complexité des problèmes Introduire la notion de complexité d un problème Présenter
Une nouvelle approche de détection de communautés dans les réseaux sociaux
 UNIVERSITÉ DU QUÉBEC EN OUTAOUAIS Département d informatique et d ingénierie Une nouvelle approche de détection de communautés dans les réseaux sociaux Mémoire (INF 6021) pour l obtention du grade de Maîtrise
UNIVERSITÉ DU QUÉBEC EN OUTAOUAIS Département d informatique et d ingénierie Une nouvelle approche de détection de communautés dans les réseaux sociaux Mémoire (INF 6021) pour l obtention du grade de Maîtrise
Analyse dialectométrique des parlers berbères de Kabylie
 Saïd GUERRAB Analyse dialectométrique des parlers berbères de Kabylie Résumé de la thèse (pour affichage) Il est difficile de parler du berbère sans parler de la variation. Il y a d abord une variation
Saïd GUERRAB Analyse dialectométrique des parlers berbères de Kabylie Résumé de la thèse (pour affichage) Il est difficile de parler du berbère sans parler de la variation. Il y a d abord une variation
ACP Voitures 1- Méthode
 acp=princomp(voit,cor=t) ACP Voitures 1- Méthode Call: princomp(x = voit, cor = T) Standard deviations: Comp.1 Comp.2 Comp.3 Comp.4 Comp.5 Comp.6 2.1577815 0.9566721 0.4903373 0.3204833 0.2542759 0.1447788
acp=princomp(voit,cor=t) ACP Voitures 1- Méthode Call: princomp(x = voit, cor = T) Standard deviations: Comp.1 Comp.2 Comp.3 Comp.4 Comp.5 Comp.6 2.1577815 0.9566721 0.4903373 0.3204833 0.2542759 0.1447788
Resolution limit in community detection
 Introduction Plan 2006 Introduction Plan Introduction Introduction Plan Introduction Point de départ : un graphe et des sous-graphes. But : quantifier le fait que les sous-graphes choisis sont des modules.
Introduction Plan 2006 Introduction Plan Introduction Introduction Plan Introduction Point de départ : un graphe et des sous-graphes. But : quantifier le fait que les sous-graphes choisis sont des modules.
Programmation Linéaire - Cours 1
 Programmation Linéaire - Cours 1 P. Pesneau pierre.pesneau@math.u-bordeaux1.fr Université Bordeaux 1 Bât A33 - Bur 265 Ouvrages de référence V. Chvátal - Linear Programming, W.H.Freeman, New York, 1983.
Programmation Linéaire - Cours 1 P. Pesneau pierre.pesneau@math.u-bordeaux1.fr Université Bordeaux 1 Bât A33 - Bur 265 Ouvrages de référence V. Chvátal - Linear Programming, W.H.Freeman, New York, 1983.
TESTS PORTMANTEAU D ADÉQUATION DE MODÈLES ARMA FAIBLES : UNE APPROCHE BASÉE SUR L AUTO-NORMALISATION
 TESTS PORTMANTEAU D ADÉQUATION DE MODÈLES ARMA FAIBLES : UNE APPROCHE BASÉE SUR L AUTO-NORMALISATION Bruno Saussereau Laboratoire de Mathématiques de Besançon Université de Franche-Comté Travail en commun
TESTS PORTMANTEAU D ADÉQUATION DE MODÈLES ARMA FAIBLES : UNE APPROCHE BASÉE SUR L AUTO-NORMALISATION Bruno Saussereau Laboratoire de Mathématiques de Besançon Université de Franche-Comté Travail en commun
5. Apprentissage pour le filtrage collaboratif
 686 PARTIE 5 : Au-delà de l apprentissage supervisé 5. Apprentissage pour le filtrage collaboratif Il semble que le nombre de choix qui nous sont ouverts augmente constamment. Films, livres, recettes,
686 PARTIE 5 : Au-delà de l apprentissage supervisé 5. Apprentissage pour le filtrage collaboratif Il semble que le nombre de choix qui nous sont ouverts augmente constamment. Films, livres, recettes,
Fonctions de plusieurs variables
 Module : Analyse 03 Chapitre 00 : Fonctions de plusieurs variables Généralités et Rappels des notions topologiques dans : Qu est- ce que?: Mathématiquement, n étant un entier non nul, on définit comme
Module : Analyse 03 Chapitre 00 : Fonctions de plusieurs variables Généralités et Rappels des notions topologiques dans : Qu est- ce que?: Mathématiquement, n étant un entier non nul, on définit comme
Représentation des Nombres
 Chapitre 5 Représentation des Nombres 5. Representation des entiers 5.. Principe des représentations en base b Base L entier écrit 344 correspond a 3 mille + 4 cent + dix + 4. Plus généralement a n a n...
Chapitre 5 Représentation des Nombres 5. Representation des entiers 5.. Principe des représentations en base b Base L entier écrit 344 correspond a 3 mille + 4 cent + dix + 4. Plus généralement a n a n...
Régression linéaire. Nicolas Turenne INRA nicolas.turenne@jouy.inra.fr
 Régression linéaire Nicolas Turenne INRA nicolas.turenne@jouy.inra.fr 2005 Plan Régression linéaire simple Régression multiple Compréhension de la sortie de la régression Coefficient de détermination R
Régression linéaire Nicolas Turenne INRA nicolas.turenne@jouy.inra.fr 2005 Plan Régression linéaire simple Régression multiple Compréhension de la sortie de la régression Coefficient de détermination R
Mesure agnostique de la qualité des images.
 Mesure agnostique de la qualité des images. Application en biométrie Christophe Charrier Université de Caen Basse-Normandie GREYC, UMR CNRS 6072 Caen, France 8 avril, 2013 C. Charrier NR-IQA 1 / 34 Sommaire
Mesure agnostique de la qualité des images. Application en biométrie Christophe Charrier Université de Caen Basse-Normandie GREYC, UMR CNRS 6072 Caen, France 8 avril, 2013 C. Charrier NR-IQA 1 / 34 Sommaire
Théorèmes de Point Fixe et Applications 1
 Théorèmes de Point Fixe et Applications 1 Victor Ginsburgh Université Libre de Bruxelles et CORE, Louvain-la-Neuve Janvier 1999 Published in C. Jessua, C. Labrousse et D. Vitry, eds., Dictionnaire des
Théorèmes de Point Fixe et Applications 1 Victor Ginsburgh Université Libre de Bruxelles et CORE, Louvain-la-Neuve Janvier 1999 Published in C. Jessua, C. Labrousse et D. Vitry, eds., Dictionnaire des
Chapitre 5 : Flot maximal dans un graphe
 Graphes et RO TELECOM Nancy A Chapitre 5 : Flot maximal dans un graphe J.-F. Scheid 1 Plan du chapitre I. Définitions 1 Graphe Graphe valué 3 Représentation d un graphe (matrice d incidence, matrice d
Graphes et RO TELECOM Nancy A Chapitre 5 : Flot maximal dans un graphe J.-F. Scheid 1 Plan du chapitre I. Définitions 1 Graphe Graphe valué 3 Représentation d un graphe (matrice d incidence, matrice d
Première partie. Préliminaires : noyaux itérés. MPSI B 6 juin 2015
 Énoncé Soit V un espace vectoriel réel. L espace vectoriel des endomorphismes de V est désigné par L(V ). Lorsque f L(V ) et k N, on désigne par f 0 = Id V, f k = f k f la composée de f avec lui même k
Énoncé Soit V un espace vectoriel réel. L espace vectoriel des endomorphismes de V est désigné par L(V ). Lorsque f L(V ) et k N, on désigne par f 0 = Id V, f k = f k f la composée de f avec lui même k
Historique. Architecture. Contribution. Conclusion. Définitions et buts La veille stratégique Le multidimensionnel Les classifications
 L intelligence économique outil stratégique pour l entreprise Professeur Bernard DOUSSET dousset@irit.fr http://atlas.irit.fr Institut de Recherche en Informatique de Toulouse (IRIT) Equipe Systèmes d
L intelligence économique outil stratégique pour l entreprise Professeur Bernard DOUSSET dousset@irit.fr http://atlas.irit.fr Institut de Recherche en Informatique de Toulouse (IRIT) Equipe Systèmes d
de calibration Master 2: Calibration de modèles: présentation et simulation d
 Master 2: Calibration de modèles: présentation et simulation de quelques problèmes de calibration Plan de la présentation 1. Présentation de quelques modèles à calibrer 1a. Reconstruction d une courbe
Master 2: Calibration de modèles: présentation et simulation de quelques problèmes de calibration Plan de la présentation 1. Présentation de quelques modèles à calibrer 1a. Reconstruction d une courbe
Projet de traitement d'image - SI 381 reconstitution 3D d'intérieur à partir de photographies
 Projet de traitement d'image - SI 381 reconstitution 3D d'intérieur à partir de photographies Régis Boulet Charlie Demené Alexis Guyot Balthazar Neveu Guillaume Tartavel Sommaire Sommaire... 1 Structure
Projet de traitement d'image - SI 381 reconstitution 3D d'intérieur à partir de photographies Régis Boulet Charlie Demené Alexis Guyot Balthazar Neveu Guillaume Tartavel Sommaire Sommaire... 1 Structure
Programmation linéaire et Optimisation. Didier Smets
 Programmation linéaire et Optimisation Didier Smets Chapitre 1 Un problème d optimisation linéaire en dimension 2 On considère le cas d un fabricant d automobiles qui propose deux modèles à la vente, des
Programmation linéaire et Optimisation Didier Smets Chapitre 1 Un problème d optimisation linéaire en dimension 2 On considère le cas d un fabricant d automobiles qui propose deux modèles à la vente, des
Revue des algorithmes PCA, LDA et EBGM utilisés en reconnaissance 2D du visage pour la biométrie
 Revue des algorithmes PCA, LDA et EBGM utilisés en reconnaissance 2D du visage pour la biométrie Nicolas MORIZET, Thomas EA, Florence ROSSANT, Frédéric AMIEL, Amara AMARA Institut Supérieur d Électronique
Revue des algorithmes PCA, LDA et EBGM utilisés en reconnaissance 2D du visage pour la biométrie Nicolas MORIZET, Thomas EA, Florence ROSSANT, Frédéric AMIEL, Amara AMARA Institut Supérieur d Électronique
NON-LINEARITE ET RESEAUX NEURONAUX
 NON-LINEARITE ET RESEAUX NEURONAUX Vêlayoudom MARIMOUTOU Laboratoire d Analyse et de Recherche Economiques Université de Bordeaux IV Avenue. Leon Duguit, 33608 PESSAC, France tel. 05 56 84 85 77 e-mail
NON-LINEARITE ET RESEAUX NEURONAUX Vêlayoudom MARIMOUTOU Laboratoire d Analyse et de Recherche Economiques Université de Bordeaux IV Avenue. Leon Duguit, 33608 PESSAC, France tel. 05 56 84 85 77 e-mail
 Mémoire d Actuariat Tarification de la branche d assurance des accidents du travail Aymeric Souleau aymeric.souleau@axa.com 3 Septembre 2010 Plan 1 Introduction Les accidents du travail L assurance des
Mémoire d Actuariat Tarification de la branche d assurance des accidents du travail Aymeric Souleau aymeric.souleau@axa.com 3 Septembre 2010 Plan 1 Introduction Les accidents du travail L assurance des
Introduction au datamining
 Introduction au datamining Patrick Naïm janvier 2005 Définition Définition Historique Mot utilisé au départ par les statisticiens Le mot indiquait une utilisation intensive des données conduisant à des
Introduction au datamining Patrick Naïm janvier 2005 Définition Définition Historique Mot utilisé au départ par les statisticiens Le mot indiquait une utilisation intensive des données conduisant à des
Logiciel XLSTAT version 7.0. 40 rue Damrémont 75018 PARIS
 Logiciel XLSTAT version 7.0 Contact : Addinsoft 40 rue Damrémont 75018 PARIS 2005-2006 Plan Présentation générale du logiciel Statistiques descriptives Histogramme Discrétisation Tableau de contingence
Logiciel XLSTAT version 7.0 Contact : Addinsoft 40 rue Damrémont 75018 PARIS 2005-2006 Plan Présentation générale du logiciel Statistiques descriptives Histogramme Discrétisation Tableau de contingence
Une méthode de classification supervisée sans paramètre pour l apprentissage sur les grandes bases de données
 Une méthode de classification supervisée sans paramètre pour l apprentissage sur les grandes bases de données Marc Boullé Orange Labs 2 avenue Pierre Marzin 22300 Lannion marc.boulle@orange-ftgroup.com,
Une méthode de classification supervisée sans paramètre pour l apprentissage sur les grandes bases de données Marc Boullé Orange Labs 2 avenue Pierre Marzin 22300 Lannion marc.boulle@orange-ftgroup.com,
Optimisation non linéaire Irène Charon, Olivier Hudry École nationale supérieure des télécommunications
 Optimisation non linéaire Irène Charon, Olivier Hudry École nationale supérieure des télécommunications A. Optimisation sans contrainte.... Généralités.... Condition nécessaire et condition suffisante
Optimisation non linéaire Irène Charon, Olivier Hudry École nationale supérieure des télécommunications A. Optimisation sans contrainte.... Généralités.... Condition nécessaire et condition suffisante
Vérification audiovisuelle de l identité
 Vérification audiovisuelle de l identité Rémi Landais, Hervé Bredin, Leila Zouari, et Gérard Chollet École Nationale Supérieure des Télécommunications, Département Traitement du Signal et des Images, Laboratoire
Vérification audiovisuelle de l identité Rémi Landais, Hervé Bredin, Leila Zouari, et Gérard Chollet École Nationale Supérieure des Télécommunications, Département Traitement du Signal et des Images, Laboratoire
Évaluation de la régression bornée
 Thierry Foucart UMR 6086, Université de Poitiers, S P 2 M I, bd 3 téléport 2 BP 179, 86960 Futuroscope, Cedex FRANCE Résumé. le modèle linéaire est très fréquemment utilisé en statistique et particulièrement
Thierry Foucart UMR 6086, Université de Poitiers, S P 2 M I, bd 3 téléport 2 BP 179, 86960 Futuroscope, Cedex FRANCE Résumé. le modèle linéaire est très fréquemment utilisé en statistique et particulièrement
Plus courts chemins, programmation dynamique
 1 Plus courts chemins, programmation dynamique 1. Plus courts chemins à partir d un sommet 2. Plus courts chemins entre tous les sommets 3. Semi-anneau 4. Programmation dynamique 5. Applications à la bio-informatique
1 Plus courts chemins, programmation dynamique 1. Plus courts chemins à partir d un sommet 2. Plus courts chemins entre tous les sommets 3. Semi-anneau 4. Programmation dynamique 5. Applications à la bio-informatique
ESSEC. Cours «Management bancaire» Séance 3 Le risque de crédit Le scoring
 ESSEC Cours «Management bancaire» Séance 3 Le risque de crédit Le scoring Les méthodes d évaluation du risque de crédit pour les PME et les ménages Caractéristiques Comme les montants des crédits et des
ESSEC Cours «Management bancaire» Séance 3 Le risque de crédit Le scoring Les méthodes d évaluation du risque de crédit pour les PME et les ménages Caractéristiques Comme les montants des crédits et des
données en connaissance et en actions?
 1 Partie 2 : Présentation de la plateforme SPSS Modeler : Comment transformer vos données en connaissance et en actions? SPSS Modeler : l atelier de data mining Large gamme de techniques d analyse (algorithmes)
1 Partie 2 : Présentation de la plateforme SPSS Modeler : Comment transformer vos données en connaissance et en actions? SPSS Modeler : l atelier de data mining Large gamme de techniques d analyse (algorithmes)
Cours de Master Recherche
 Cours de Master Recherche Spécialité CODE : Résolution de problèmes combinatoires Christine Solnon LIRIS, UMR 5205 CNRS / Université Lyon 1 2007 Rappel du plan du cours 16 heures de cours 1 - Introduction
Cours de Master Recherche Spécialité CODE : Résolution de problèmes combinatoires Christine Solnon LIRIS, UMR 5205 CNRS / Université Lyon 1 2007 Rappel du plan du cours 16 heures de cours 1 - Introduction
Modèle de troncature gauche : Comparaison par simulation sur données indépendantes et dépendantes
 de troncature gauche : Comparaison par simulation sur données indépendantes et dépendantes Zohra Guessoum 1 & Farida Hamrani 2 1 Lab. MSTD, Faculté de mathématique, USTHB, BP n 32, El Alia, Alger, Algérie,zguessoum@usthb.dz
de troncature gauche : Comparaison par simulation sur données indépendantes et dépendantes Zohra Guessoum 1 & Farida Hamrani 2 1 Lab. MSTD, Faculté de mathématique, USTHB, BP n 32, El Alia, Alger, Algérie,zguessoum@usthb.dz
LA PHYSIQUE DES MATERIAUX. Chapitre 1 LES RESEAUX DIRECT ET RECIPROQUE
 LA PHYSIQUE DES MATERIAUX Chapitre 1 LES RESEAUX DIRECT ET RECIPROQUE Pr. A. Belayachi Université Mohammed V Agdal Faculté des Sciences Rabat Département de Physique - L.P.M belayach@fsr.ac.ma 1 1.Le réseau
LA PHYSIQUE DES MATERIAUX Chapitre 1 LES RESEAUX DIRECT ET RECIPROQUE Pr. A. Belayachi Université Mohammed V Agdal Faculté des Sciences Rabat Département de Physique - L.P.M belayach@fsr.ac.ma 1 1.Le réseau
Cours de méthodes de scoring
 UNIVERSITE DE CARTHAGE ECOLE SUPERIEURE DE STATISTIQUE ET D ANALYSE DE L INFORMATION Cours de méthodes de scoring Préparé par Hassen MATHLOUTHI Année universitaire 2013-2014 Cours de méthodes de scoring-
UNIVERSITE DE CARTHAGE ECOLE SUPERIEURE DE STATISTIQUE ET D ANALYSE DE L INFORMATION Cours de méthodes de scoring Préparé par Hassen MATHLOUTHI Année universitaire 2013-2014 Cours de méthodes de scoring-
Transmission d informations sur le réseau électrique
 Transmission d informations sur le réseau électrique Introduction Remarques Toutes les questions en italique devront être préparées par écrit avant la séance du TP. Les préparations seront ramassées en
Transmission d informations sur le réseau électrique Introduction Remarques Toutes les questions en italique devront être préparées par écrit avant la séance du TP. Les préparations seront ramassées en
Sujet proposé par Yves M. LEROY. Cet examen se compose d un exercice et de deux problèmes. Ces trois parties sont indépendantes.
 Promotion X 004 COURS D ANALYSE DES STRUCTURES MÉCANIQUES PAR LA MÉTHODE DES ELEMENTS FINIS (MEC 568) contrôle non classant (7 mars 007, heures) Documents autorisés : polycopié ; documents et notes de
Promotion X 004 COURS D ANALYSE DES STRUCTURES MÉCANIQUES PAR LA MÉTHODE DES ELEMENTS FINIS (MEC 568) contrôle non classant (7 mars 007, heures) Documents autorisés : polycopié ; documents et notes de
Modélisation et Simulation
 Cours de modélisation et simulation p. 1/64 Modélisation et Simulation G. Bontempi Département d Informatique Boulevard de Triomphe - CP 212 http://www.ulb.ac.be/di Cours de modélisation et simulation
Cours de modélisation et simulation p. 1/64 Modélisation et Simulation G. Bontempi Département d Informatique Boulevard de Triomphe - CP 212 http://www.ulb.ac.be/di Cours de modélisation et simulation
Exo7. Matrice d une application linéaire. Corrections d Arnaud Bodin.
 Exo7 Matrice d une application linéaire Corrections d Arnaud odin. Exercice Soit R muni de la base canonique = ( i, j). Soit f : R R la projection sur l axe des abscisses R i parallèlement à R( i + j).
Exo7 Matrice d une application linéaire Corrections d Arnaud odin. Exercice Soit R muni de la base canonique = ( i, j). Soit f : R R la projection sur l axe des abscisses R i parallèlement à R( i + j).
Sélection de Caractéristiques pour le Filtrage de Spams
 Sélection de Caractéristiques pour le Filtrage de Spams Kamilia MENGHOUR, Labiba SOUICI-MESLATI Laboratoire LRI, Université Badji Mokhtar, BP 12, 23000, Annaba, Algérie. k_menghour@yahoo.fr, souici_labiba@yahoo.fr
Sélection de Caractéristiques pour le Filtrage de Spams Kamilia MENGHOUR, Labiba SOUICI-MESLATI Laboratoire LRI, Université Badji Mokhtar, BP 12, 23000, Annaba, Algérie. k_menghour@yahoo.fr, souici_labiba@yahoo.fr
Le théorème des deux fonds et la gestion indicielle
 Le théorème des deux fonds et la gestion indicielle Philippe Bernard Ingénierie Economique& Financière Université Paris-Dauphine mars 2013 Les premiers fonds indiciels futent lancés aux Etats-Unis par
Le théorème des deux fonds et la gestion indicielle Philippe Bernard Ingénierie Economique& Financière Université Paris-Dauphine mars 2013 Les premiers fonds indiciels futent lancés aux Etats-Unis par
Une réponse (très) partielle à la deuxième question : Calcul des exposants critiques en champ moyen
 partielle à la deuxième question : Calcul des exposants critiques en champ moyen") Une réponse (très) partielle à la deuxième question : Calcul des exposants critiques en champ moyen Manière heuristique d'introduire l'approximation de champ moyen : on néglige les termes de fluctuations
Une réponse (très) partielle à la deuxième question : Calcul des exposants critiques en champ moyen Manière heuristique d'introduire l'approximation de champ moyen : on néglige les termes de fluctuations
FIMA, 7 juillet 2005
 F. Corset 1 S. 2 1 LabSAD Université Pierre Mendes France 2 Département de Mathématiques Université de Franche-Comté FIMA, 7 juillet 2005 Plan de l exposé plus court chemin Origine du problème Modélisation
F. Corset 1 S. 2 1 LabSAD Université Pierre Mendes France 2 Département de Mathématiques Université de Franche-Comté FIMA, 7 juillet 2005 Plan de l exposé plus court chemin Origine du problème Modélisation
CHAPITRE 5. Stratégies Mixtes
 CHAPITRE 5 Stratégies Mixtes Un des problèmes inhérents au concept d équilibre de Nash en stratégies pures est que pour certains jeux, de tels équilibres n existent pas. P.ex.le jeu de Pierre, Papier,
CHAPITRE 5 Stratégies Mixtes Un des problèmes inhérents au concept d équilibre de Nash en stratégies pures est que pour certains jeux, de tels équilibres n existent pas. P.ex.le jeu de Pierre, Papier,
Le risque Idiosyncrasique
 Le risque Idiosyncrasique -Pierre CADESTIN -Magali DRIGHES -Raphael MINATO -Mathieu SELLES 1 Introduction Risque idiosyncrasique : risque non pris en compte dans le risque de marché (indépendant des phénomènes
Le risque Idiosyncrasique -Pierre CADESTIN -Magali DRIGHES -Raphael MINATO -Mathieu SELLES 1 Introduction Risque idiosyncrasique : risque non pris en compte dans le risque de marché (indépendant des phénomènes
Gestion obligataire passive
 Finance 1 Université d Evry Séance 7 Gestion obligataire passive Philippe Priaulet L efficience des marchés Stratégies passives Qu est-ce qu un bon benchmark? Réplication simple Réplication par échantillonnage
Finance 1 Université d Evry Séance 7 Gestion obligataire passive Philippe Priaulet L efficience des marchés Stratégies passives Qu est-ce qu un bon benchmark? Réplication simple Réplication par échantillonnage
Data Mining. Vincent Augusto 2012-2013. École Nationale Supérieure des Mines de Saint-Étienne. Data Mining. V. Augusto.
 des des Data Mining Vincent Augusto École Nationale Supérieure des Mines de Saint-Étienne 2012-2013 1/65 des des 1 2 des des 3 4 Post-traitement 5 représentation : 6 2/65 des des Définition générale Le
des des Data Mining Vincent Augusto École Nationale Supérieure des Mines de Saint-Étienne 2012-2013 1/65 des des 1 2 des des 3 4 Post-traitement 5 représentation : 6 2/65 des des Définition générale Le
t 100. = 8 ; le pourcentage de réduction est : 8 % 1 t Le pourcentage d'évolution (appelé aussi taux d'évolution) est le nombre :
 est le nombre :") Terminale STSS 2 012 2 013 Pourcentages Synthèse 1) Définition : Calculer t % d'un nombre, c'est multiplier ce nombre par t 100. 2) Exemples de calcul : a) Calcul d un pourcentage : Un article coûtant
Terminale STSS 2 012 2 013 Pourcentages Synthèse 1) Définition : Calculer t % d'un nombre, c'est multiplier ce nombre par t 100. 2) Exemples de calcul : a) Calcul d un pourcentage : Un article coûtant
Echantillonnage Non uniforme
 Echantillonnage Non uniforme Marie CHABERT IRIT/INP-ENSEEIHT/ ENSEEIHT/TéSASA Patrice MICHEL et Bernard LACAZE TéSA 1 Plan Introduction Echantillonnage uniforme Echantillonnage irrégulier Comparaison Cas
Echantillonnage Non uniforme Marie CHABERT IRIT/INP-ENSEEIHT/ ENSEEIHT/TéSASA Patrice MICHEL et Bernard LACAZE TéSA 1 Plan Introduction Echantillonnage uniforme Echantillonnage irrégulier Comparaison Cas
MCMC et approximations en champ moyen pour les modèles de Markov
 MCMC et approximations en champ moyen pour les modèles de Markov Gersende FORT LTCI CNRS - TELECOM ParisTech En collaboration avec Florence FORBES (Projet MISTIS, INRIA Rhône-Alpes). Basé sur l article:
MCMC et approximations en champ moyen pour les modèles de Markov Gersende FORT LTCI CNRS - TELECOM ParisTech En collaboration avec Florence FORBES (Projet MISTIS, INRIA Rhône-Alpes). Basé sur l article:
Approximations variationelles des EDP Notes du Cours de M2
 Approximations variationelles des EDP Notes du Cours de M2 Albert Cohen Dans ce cours, on s intéresse à l approximation numérique d équations aux dérivées partielles linéaires qui admettent une formulation
Approximations variationelles des EDP Notes du Cours de M2 Albert Cohen Dans ce cours, on s intéresse à l approximation numérique d équations aux dérivées partielles linéaires qui admettent une formulation
Le théorème de Perron-Frobenius, les chaines de Markov et un célèbre moteur de recherche
 Le théorème de Perron-Frobenius, les chaines de Markov et un célèbre moteur de recherche Bachir Bekka Février 2007 Le théorème de Perron-Frobenius a d importantes applications en probabilités (chaines
Le théorème de Perron-Frobenius, les chaines de Markov et un célèbre moteur de recherche Bachir Bekka Février 2007 Le théorème de Perron-Frobenius a d importantes applications en probabilités (chaines
Travaux pratiques avec RapidMiner
 Travaux pratiques avec RapidMiner Master Informatique de Paris 6 Spécialité IAD Parcours EDOW Module Algorithmes pour la Fouille de Données Janvier 2012 Prise en main Généralités RapidMiner est un logiciel
Travaux pratiques avec RapidMiner Master Informatique de Paris 6 Spécialité IAD Parcours EDOW Module Algorithmes pour la Fouille de Données Janvier 2012 Prise en main Généralités RapidMiner est un logiciel
Programmes des classes préparatoires aux Grandes Ecoles
 Programmes des classes préparatoires aux Grandes Ecoles Filière : scientifique Voie : Biologie, chimie, physique et sciences de la Terre (BCPST) Discipline : Mathématiques Seconde année Préambule Programme
Programmes des classes préparatoires aux Grandes Ecoles Filière : scientifique Voie : Biologie, chimie, physique et sciences de la Terre (BCPST) Discipline : Mathématiques Seconde année Préambule Programme