Parallélisme et Répartition
|
|
|
- Nadine Favreau
- il y a 7 ans
- Total affichages :
Transcription
1 Parallélisme et Répartition Master Info Françoise Baude Université de Nice Sophia-Antipolis UFR Sciences Département Informatique web du cours : deptinfo.unice.fr/~baude Septembre 2008 Chapitre 1 : Introduction générale 1 Organisation 2h C x 7 2h TD x 7 2h TD Machine x 7 (F. Huet) Examen final Projet de programmation Devoir/exercices papier et/ou présentations De nombreux ouvrages+sites indiqués sur le site web du cours 2 1

2 Plan 1. Motivation 2. Un premier tour d horizon des architectures parallèles 3. Suite des cours 3 1. Introduction Justification de cet enseignement Thread = activité = fil/flot/chemin d exécution Ordonnancée sur une unité de traitement/calcul De plus en plus, un CPU contient plus d 1 unité (core) Car la puissance d une unité ne progresse plus Les architectures multi-cpu (parfois en réseau : grilles de calcul) sont aussi de + en + répandues Recourir systématiquement au Multi-threading avoir suffisamment de threads d exécution issues de l exécution d un programme afin d occuper le maximum d unités en parallèle Pour tout cela & pour «survivre à la révolution du software due à l avènement des CPUs multi-cœur»!: Savoir «penser une application en parallèle» Avoir les notions d architectures parallèles utiles Maitriser patterns et langages de programmation // éviter de tomber dans le piège «progr // en assembleur», cad prog multi-thread & multi-processus explicite 4 2

 Portable (sous Unix) Ce serait la même chose avec des threads Java!")
3 Un petit exemple: fibonacci Algo séquentiel pas performant On recalcule 2 fois fib(n-2) dans fib(n) Complexité est donc exponentielle mais ce n est pas le propos 5 Gestion explicite du multi-thread Ce programme utilise Pthread (Posix Threads) Portable (sous Unix) Ce serait la même chose avec des threads Java! Overhead incompressible dû à la gestion des threads C est très verbeux Sujet à plein d erreurs de programmation n a engendré que 2 threads Et si on veut profiter de X cœurs? Le réécrire pour avoir X+ threads 6 3

4 Qualité du code : Souhaits Extensibilité («scalability») Le nombre de threads effectif «s adapte» au nombre de cœurs cibles et bien sûr, la gestion du placement et ordonnancement de ces threads sur les cœurs n est pas à la charge du programme Simplicité du code La logique de l algorithme (seq ou //) doit rester visible Ne pas retomber dans de la programmation trop bas niveau d il y a 50 ans Ex. passage non typé des arguments des fonctions des threads Et n oublions pas la gestion de la concurrence des threads concernant le partage de données communes Mémoire commune synchro. des accès lect. et écriture Mémoire répartie échange de messages=valeurs données 7 Suite de l exemple (en Cilk) cilk_spawn crée une tache La plateforme gère autant de threads que le nombre de cœurs cibles Et schedule les taches sur les threads Le code est quasi identique à la version séquentielle Et même mieux : retrait des mots clés donne exactement la version séquentielle 8 4
 cilk_spawn crée une tache La plateforme gère autant de threads que le nombre de cœurs cibles Et")
5 En bref La raison d être du parallélisme, c est la performance de traitement (+vite, sur +gros) Mais à quel prix? Coût d achat (ou de location!) de la puissance de calcul Temps et difficulté de conception, de développement et d optimisation des applications Coût supplémentaire d exécution à cause de la présence d activités parallèles Comme toujours, c est une affaire de compromis Pour faire les bons, cela nécessite des connaissances théoriques, historiques, pratiques "Students graduating with a competence in engineering software for parallel systems will have a distinct advantage in the work force over those who do not." --- M. Oskin, The Revolution Inside the Box, Comm. ACM 51(7), July Un premier tour d horizon des architectures parallèles Comment exploiter le parallélisme dans un processeur 10 5
, July 2008 9 2.")

6 Pipeline (et donc parallélisme) au sein d une instruction 11 Processeurs super-scalaires : plusieurs instructions en parallèle Il faut que les instructions qui se suivent dans un code binaire soient le plus indépendantes possible c est en général le rôle du compilateur de tenter de réordonnancer les instructions 12 6


7 Processeurs vectoriels Exploitation de données multiples : un vecteur sur lesquelles appliquer le même traitement


8 Loi de Moore Source, cours CS194 U.Berkeley 15 et ses conséquences Source, cours CS194 U.Berkeley 16 8



9 Limite à la loi de Moore Source, cours CS194 U.Berkeley 17 Conséquences des Limites à la loi de Moore Source, cours CS194 U.Berkeley 18 9

10 Explosion des chip multicore Source, cours CS194 U.Berkeley 19 bien que ce ne soit pas la seule solution! 20 10

11 21 mais elles peuvent se combiner 22 11

12 Bilan: Exploitation du parallélisme intra-cpu Illustre (déjà!) toute la panoplie de méthodes d exploitation du parallélisme Parallélisme issu de la mise en pipeline Borné par la longueur du pipeline Parallélisme issu de données requérant un même traitement Borné par la dimension maximum autorisée pour une donnée (ex, la longueur d un registre vectoriel, 64 par ex) Parallélisme issu de la duplication de taches indépendantes Borné par le degré de duplication (de quoi?) : Des instructions que l on exécute en même temps : superscalaires Des unités de traitement (+ ou complètes) Multi-threading quand c est virtuel, entrelacement de plusieurs Un premier tour d horizon des architectures parallèles Comment exploiter le parallélisme dans un processeur Calculateur parallèle Comment exploiter du parallélisme en dupliquant les processeurs eux-mêmes Historiquement justifié par le besoin de traiter des problèmes plus gros, gourmands en temps Vieille histoire! Prémisses en

13

14
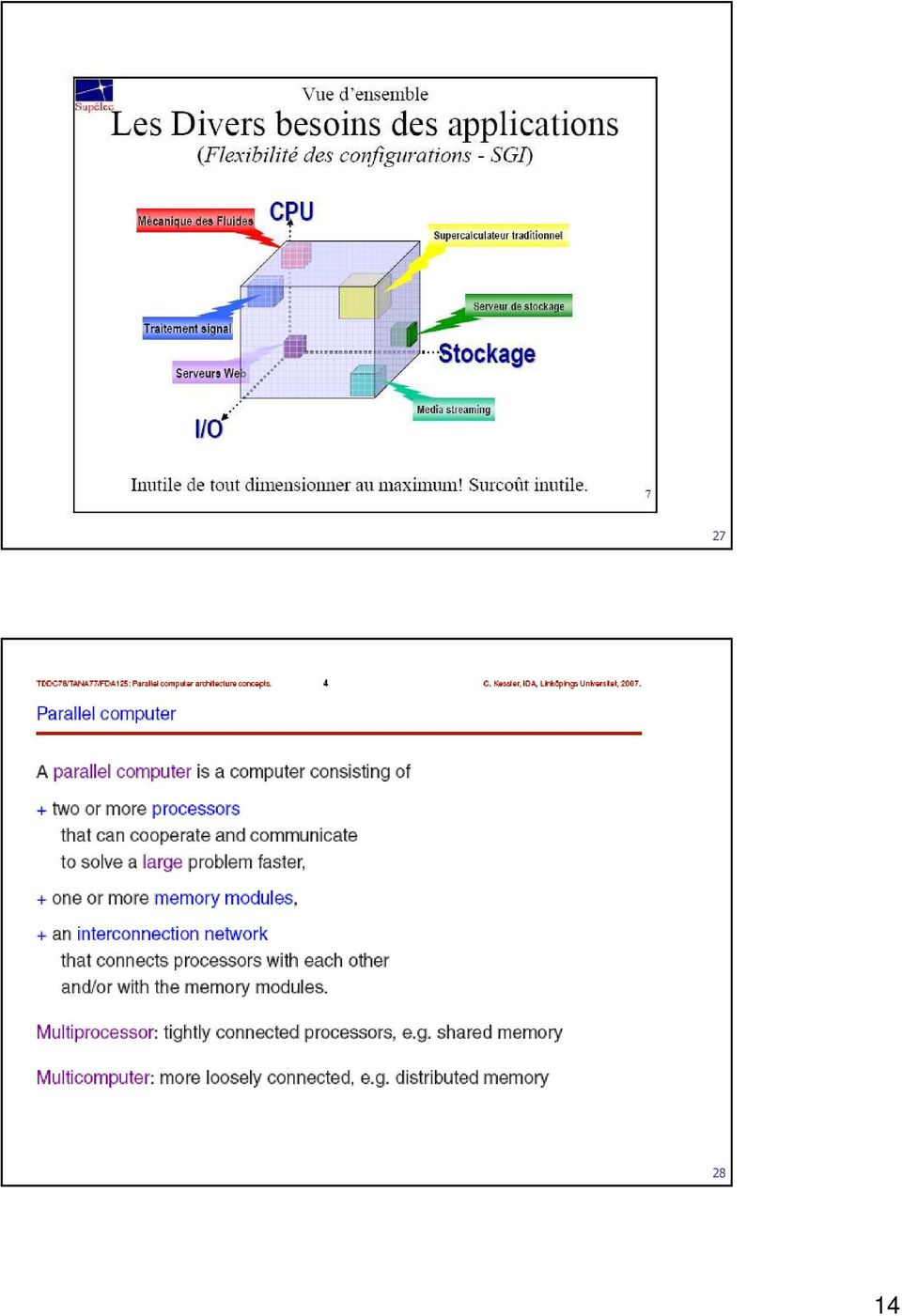
![Classifications de Flynn [1972] selon mémoire (+/-archi) SMP=Symmetric Multi Processing](/docs-images/39/18859591/images/15-0.jpg "CC-NUMA=CacheCoherent NonUniformMemoryAccess 29 Mémoire physique (virtuellement?")
15 Classifications de Flynn [1972] selon mémoire (+/-archi) SMP=Symmetric Multi Processing CC-NUMA=CacheCoherent NonUniformMemoryAccess 29 Mémoire physique (virtuellement?) partagée 30 15


16 Bilan: les supercalculateurs nombre de nœuds du cluster > potentialité de parallélisme au sein d un nœud Ex, SIMD 8 SPEs + 1 PPE du Cell Mise à jour, potentialité de parallélisme au sein d un nœud > nombre de nœuds => Et on ne parle même pas ici des Grilles de Calcul: «Internet wide Cluster» 31 L IBM Blue Gene/L SuperComputer Un ex. des multiples combinaisons One Cabinet 1024 PowerPC 700Mhz 256 Go RAM ( up to 2Go RAM per chip possible) 5.7 teraflops of processing power IBM version of a Linux Kernel on each processor Simple OS per chip MPI programming model 2x256MB 4MB de Mem. mem (cache) Partagée externe cohérente par soft, Recourir à un réseau interconnectant les chips (1 chip = 1 node sur figure 4), voir a) où chaque chip a 6 liens sur le tore 3D 32 16

17 Chip du Blue Gene/L 33 Top 500 Classement international des supercalculateurs Selon leurs performances en FLOPS Floating Point Operations Per Second sur un benchmark (Linpack : résolution d un système Ax=b) décrit les caractéristiques du 2eme en Juin 2008, une Blue Gene / L d IBM est la dernière liste est le 1er IBM Roadrunner Blade Center Cluster with IBM PowerXCell 8i + AMD Opteron, Voltaire infiniband 34 17

 et efficace 2 approches / écoles concernant les lges // proposés Partir des")
, fabrique des taches (ex.")
18 Top 500 vert des supercalculateurs La suite des cours : fil conducteur Comment programmer? Le plus simplement possible Tout en ayant des performances Et en ayant un programme portable, extensible («scalable») et efficace 2 approches / écoles concernant les lges // proposés Partir des spécificités du hardware, et essayer d abstraire Sélectionner un modèle de //sm générique, et espérer qu il sera implanté sur la + large gamme possible d architectures cibles Dans les 2 cas, délégation de nombreux pbms aux couches compil+os Le compilateur qui extrait automatiquement du parallélisme (ex. vectorisation), fabrique des taches (ex. à partir de boucles +/- agrégées) L OS qui sait placer et ordonnancer ces taches sur les threads système, voire les fusionner (load balancing versus work stealing) le + souvent, programmer d une manière qui génère des taches Au sein d une même application, et actives en même temps Difficultés car (données) dépendantes (données communes avec accès mémoire, ou envoi messages explicite) Eviter au minimum les blocages dus à la gestion concurrence Pertes de performances en cas de défaut de cache mémoire («cache miss») Rmq: on exclut ici les applications type «serveur» naturellement multithread (cf. cours Gestion concurrence L3) 36 18
, fabrique des taches (ex.")
19 Thèmes utiles à étudier Patterns d exploitation du parallélisme Introduction à OpenMP Notions d algorithmique PRAM Algorithmes parallèles classiques (en PRAM, OpenMP) Critères d évaluation de performances et optimisations En prenant en compte les modes d accès mémoire (NUMA) Introduction à MPI comme modèle de prog.// répartie Algorithmes parallèles et distribués classiques Tendances : émergence de nouvelles architectures parallèles et leur programmation IBM/Sony/Toshiba CELL NVIDIA GPUs permet de faire du «general purpose computing on graphical processing units»: GPGPU 37 En résume: cet enseignement est indispensable et de + en + dispensé 38 19

Eléments d architecture des machines parallèles et distribuées
 M2-RISE - Systèmes distribués et grille Eléments d architecture des machines parallèles et distribuées Stéphane Vialle Stephane.Vialle@supelec.fr http://www.metz.supelec.fr/~vialle Notions d architecture
M2-RISE - Systèmes distribués et grille Eléments d architecture des machines parallèles et distribuées Stéphane Vialle Stephane.Vialle@supelec.fr http://www.metz.supelec.fr/~vialle Notions d architecture
Architecture des ordinateurs
 Décoder la relation entre l architecture et les applications Violaine Louvet, Institut Camille Jordan CNRS & Université Lyon 1 Ecole «Découverte du Calcul» 2013 1 / 61 Simulation numérique... Physique
Décoder la relation entre l architecture et les applications Violaine Louvet, Institut Camille Jordan CNRS & Université Lyon 1 Ecole «Découverte du Calcul» 2013 1 / 61 Simulation numérique... Physique
Initiation au HPC - Généralités
 Initiation au HPC - Généralités Éric Ramat et Julien Dehos Université du Littoral Côte d Opale M2 Informatique 2 septembre 2015 Éric Ramat et Julien Dehos Initiation au HPC - Généralités 1/49 Plan du cours
Initiation au HPC - Généralités Éric Ramat et Julien Dehos Université du Littoral Côte d Opale M2 Informatique 2 septembre 2015 Éric Ramat et Julien Dehos Initiation au HPC - Généralités 1/49 Plan du cours
Limitations of the Playstation 3 for High Performance Cluster Computing
 Introduction Plan Limitations of the Playstation 3 for High Performance Cluster Computing July 2007 Introduction Plan Introduction Intérêts de la PS3 : rapide et puissante bon marché L utiliser pour faire
Introduction Plan Limitations of the Playstation 3 for High Performance Cluster Computing July 2007 Introduction Plan Introduction Intérêts de la PS3 : rapide et puissante bon marché L utiliser pour faire
Architecture des calculateurs
 Formation en Calcul Scientifique - LEM2I Architecture des calculateurs Violaine Louvet 1 1 Institut Camille jordan - CNRS 12-13/09/2011 Introduction Décoder la relation entre l architecture et les applications
Formation en Calcul Scientifique - LEM2I Architecture des calculateurs Violaine Louvet 1 1 Institut Camille jordan - CNRS 12-13/09/2011 Introduction Décoder la relation entre l architecture et les applications
Parallélisme et Répartition
 Parallélisme et Répartition Master Info Françoise Baude Université de Nice Sophia-Antipolis UFR Sciences Département Informatique baude@unice.fr web du cours : deptinfo.unice.fr/~baude Septembre 2009 Chapitre
Parallélisme et Répartition Master Info Françoise Baude Université de Nice Sophia-Antipolis UFR Sciences Département Informatique baude@unice.fr web du cours : deptinfo.unice.fr/~baude Septembre 2009 Chapitre
Quantification d incertitude et Tendances en HPC
 Quantification d incertitude et Tendances en HPC Laurence Viry E cole de Physique des Houches 7 Mai 2014 Laurence Viry Tendances en HPC 7 Mai 2014 1 / 47 Contents 1 Mode lisation, simulation et quantification
Quantification d incertitude et Tendances en HPC Laurence Viry E cole de Physique des Houches 7 Mai 2014 Laurence Viry Tendances en HPC 7 Mai 2014 1 / 47 Contents 1 Mode lisation, simulation et quantification
Systèmes et traitement parallèles
 Systèmes et traitement parallèles Mohsine Eleuldj Département Génie Informatique, EMI eleuldj@emi.ac.ma 1 Système et traitement parallèle Objectif Etude des architectures parallèles Programmation des applications
Systèmes et traitement parallèles Mohsine Eleuldj Département Génie Informatique, EMI eleuldj@emi.ac.ma 1 Système et traitement parallèle Objectif Etude des architectures parallèles Programmation des applications
Rapport 2014 et demande pour 2015. Portage de Méso-NH sur Machines Massivement Parallèles du GENCI Projet 2015 : GENCI GEN1605 & CALMIP-P0121
 Rapport 2014 et demande pour 2015 Portage de Méso-NH sur Machines Massivement Parallèles du GENCI Projet 2015 : GENCI GEN1605 & CALMIP-P0121 Rappel sur Méso-NH : Modélisation à moyenne échelle de l atmosphère
Rapport 2014 et demande pour 2015 Portage de Méso-NH sur Machines Massivement Parallèles du GENCI Projet 2015 : GENCI GEN1605 & CALMIP-P0121 Rappel sur Méso-NH : Modélisation à moyenne échelle de l atmosphère
Contrôle Non Destructif : Implantation d'algorithmes sur GPU et multi-coeurs. Gilles Rougeron CEA/LIST Département Imagerie Simulation et Contrôle
 Contrôle Non Destructif : Implantation d'algorithmes sur GPU et multi-coeurs Gilles Rougeron CEA/LIST Département Imagerie Simulation et Contrôle 1 CEA R & D for Nuclear Energy 5 000 people Nuclear systems
Contrôle Non Destructif : Implantation d'algorithmes sur GPU et multi-coeurs Gilles Rougeron CEA/LIST Département Imagerie Simulation et Contrôle 1 CEA R & D for Nuclear Energy 5 000 people Nuclear systems
Contexte et motivations Les techniques envisagées Evolution des processus Conclusion
 Vérification de logiciels par analyse statique Contexte et motivations Les techniques envisagées Evolution des processus Conclusion Contexte et motivations Specification Design architecture Revues and
Vérification de logiciels par analyse statique Contexte et motivations Les techniques envisagées Evolution des processus Conclusion Contexte et motivations Specification Design architecture Revues and
Les environnements de calcul distribué
 2 e Atelier CRAG, 3 au 8 Décembre 2012 Par Blaise Omer YENKE IUT, Université de Ngaoundéré, Cameroun. 4 décembre 2012 1 / 32 Calcul haute performance (HPC) High-performance computing (HPC) : utilisation
2 e Atelier CRAG, 3 au 8 Décembre 2012 Par Blaise Omer YENKE IUT, Université de Ngaoundéré, Cameroun. 4 décembre 2012 1 / 32 Calcul haute performance (HPC) High-performance computing (HPC) : utilisation
PACKZ System Requirements. Version: 2015-05-27. Version: 2015-05-27 Copyright 2015, PACKZ Software GmbH. 1
 PACKZ System Requirements Version: 2015-05-27 Copyright 2015, PACKZ Software GmbH. All rights reserved.this manual may not be copied, photocopied, reproduced, translated, or converted to any electronic
PACKZ System Requirements Version: 2015-05-27 Copyright 2015, PACKZ Software GmbH. All rights reserved.this manual may not be copied, photocopied, reproduced, translated, or converted to any electronic
Enseignant: Lamouchi Bassem Cours : Système à large échelle et Cloud Computing
 Enseignant: Lamouchi Bassem Cours : Système à large échelle et Cloud Computing Les Clusters Les Mainframes Les Terminal Services Server La virtualisation De point de vue naturelle, c est le fait de regrouper
Enseignant: Lamouchi Bassem Cours : Système à large échelle et Cloud Computing Les Clusters Les Mainframes Les Terminal Services Server La virtualisation De point de vue naturelle, c est le fait de regrouper
Équilibrage Dynamique de Charge pour des Calculs Parallèles sur Cluster Linux - Une Évaluation de l Environnement AMPI.
 Facultés Universitaires Notre-Dame de la Paix, Namur Institut d Informatique Année académique 2003-2004 Équilibrage Dynamique de Charge pour des Calculs Parallèles sur Cluster Linux - Une Évaluation de
Facultés Universitaires Notre-Dame de la Paix, Namur Institut d Informatique Année académique 2003-2004 Équilibrage Dynamique de Charge pour des Calculs Parallèles sur Cluster Linux - Une Évaluation de
Retour d exprience sur le cluster du CDS
 6 mai 2011 Sommaire 1 Généralités 2 Composant du cluster du CDS 3 Le cluster ALI 4 Retour d expérience Généralités Généralités Types de cluster Haute disponibilite Load balancing Cluster de calculs avec
6 mai 2011 Sommaire 1 Généralités 2 Composant du cluster du CDS 3 Le cluster ALI 4 Retour d expérience Généralités Généralités Types de cluster Haute disponibilite Load balancing Cluster de calculs avec
Métriques de performance pour les algorithmes et programmes parallèles
 Métriques de performance pour les algorithmes et programmes parallèles 11 18 nov. 2002 Cette section est basée tout d abord sur la référence suivante (manuel suggéré mais non obligatoire) : R. Miller and
Métriques de performance pour les algorithmes et programmes parallèles 11 18 nov. 2002 Cette section est basée tout d abord sur la référence suivante (manuel suggéré mais non obligatoire) : R. Miller and
Introduction aux systèmes temps réel. Iulian Ober IRIT ober@iut-blagnac.fr
 Introduction aux systèmes temps réel Iulian Ober IRIT ober@iut-blagnac.fr Définition Systèmes dont la correction ne dépend pas seulement des valeurs des résultats produits mais également des délais dans
Introduction aux systèmes temps réel Iulian Ober IRIT ober@iut-blagnac.fr Définition Systèmes dont la correction ne dépend pas seulement des valeurs des résultats produits mais également des délais dans
HPC by OVH.COM. Le bon calcul pour l innovation OVH.COM
 4 HPC by OVH.COM Le bon calcul pour l innovation 2 6 5 6 2 8 6 2 OVH.COM 5 2 HPC by OVH.COM 6 HPC pour High Performance Computing Utilisation de serveurs et de grappes de serveurs (clusters), configurés
4 HPC by OVH.COM Le bon calcul pour l innovation 2 6 5 6 2 8 6 2 OVH.COM 5 2 HPC by OVH.COM 6 HPC pour High Performance Computing Utilisation de serveurs et de grappes de serveurs (clusters), configurés
Exigences système Commercial & Digital Printing
 Exigences système OneVision Software AG Sommaire Speedflow Check 10.0, Speedflow Check Plus 10.0, Speedflow Edit 10.0 (Windows),... 2 Speedflow Recompose 10.0...2 Speedflow Edit 10.0 (Macintosh OSX)...2
Exigences système OneVision Software AG Sommaire Speedflow Check 10.0, Speedflow Check Plus 10.0, Speedflow Edit 10.0 (Windows),... 2 Speedflow Recompose 10.0...2 Speedflow Edit 10.0 (Macintosh OSX)...2
Tout savoir sur le matériel informatique
 Tout savoir sur le matériel informatique Thème de l exposé : Les Processeurs Date : 05 Novembre 2010 Orateurs : Hugo VIAL-JAIME Jérémy RAMBAUD Sommaire : 1. Introduction... 3 2. Historique... 4 3. Relation
Tout savoir sur le matériel informatique Thème de l exposé : Les Processeurs Date : 05 Novembre 2010 Orateurs : Hugo VIAL-JAIME Jérémy RAMBAUD Sommaire : 1. Introduction... 3 2. Historique... 4 3. Relation
Exposé de Pérennisation Comission de la Recherche 26 juin 2014
 Enseignant-Chercheur en informatique MINES ParisTech PSL Research University CRI (Centre de Recherche en Informatique) Exposé de Pérennisation Comission de la Recherche 26 juin 2014 2 Université de Rennes/IRISA
Enseignant-Chercheur en informatique MINES ParisTech PSL Research University CRI (Centre de Recherche en Informatique) Exposé de Pérennisation Comission de la Recherche 26 juin 2014 2 Université de Rennes/IRISA
Infrastructures Parallèles de Calcul
 Infrastructures Parallèles de Calcul Clusters Grids Clouds Stéphane Genaud 11/02/2011 Stéphane Genaud () 11/02/2011 1 / 8 Clusters - Grids - Clouds Clusters : assemblage de PCs + interconnexion rapide
Infrastructures Parallèles de Calcul Clusters Grids Clouds Stéphane Genaud 11/02/2011 Stéphane Genaud () 11/02/2011 1 / 8 Clusters - Grids - Clouds Clusters : assemblage de PCs + interconnexion rapide
Génération de code binaire pour application multimedia : une approche au vol
 Génération de binaire pour application multimedia : une approche au vol http://hpbcg.org/ Henri-Pierre Charles Université de Versailles Saint-Quentin en Yvelines 3 Octobre 2009 Présentation Présentation
Génération de binaire pour application multimedia : une approche au vol http://hpbcg.org/ Henri-Pierre Charles Université de Versailles Saint-Quentin en Yvelines 3 Octobre 2009 Présentation Présentation
Tivoli Endpoint Manager Introduction. 2011 IBM Corporation
 Tivoli Endpoint Manager Introduction Enjeux pour les départements IT Comment gérer : l inventaire la mise à jour la sécurité la conformité Sur des environnements hétérogènes OS : Windows, Mac, UNIX, Linux,
Tivoli Endpoint Manager Introduction Enjeux pour les départements IT Comment gérer : l inventaire la mise à jour la sécurité la conformité Sur des environnements hétérogènes OS : Windows, Mac, UNIX, Linux,
Chapitre 2 : Abstraction et Virtualisation
 Virtualisation et Cloud Computing Chapitre 2 : Abstraction et Virtualisation Objectifs Présenter la notion de niveaux d abstraction séparés par des interfaces bien définies Description des avantages et
Virtualisation et Cloud Computing Chapitre 2 : Abstraction et Virtualisation Objectifs Présenter la notion de niveaux d abstraction séparés par des interfaces bien définies Description des avantages et
INF6500 : Structures des ordinateurs. Sylvain Martel - INF6500 1
 INF6500 : Structures des ordinateurs Sylvain Martel - INF6500 1 Cours 4 : Multiprocesseurs Sylvain Martel - INF6500 2 Multiprocesseurs Type SISD SIMD MIMD Communication Shared memory Message-passing Groupe
INF6500 : Structures des ordinateurs Sylvain Martel - INF6500 1 Cours 4 : Multiprocesseurs Sylvain Martel - INF6500 2 Multiprocesseurs Type SISD SIMD MIMD Communication Shared memory Message-passing Groupe
CH.3 SYSTÈMES D'EXPLOITATION
 CH.3 SYSTÈMES D'EXPLOITATION 3.1 Un historique 3.2 Une vue générale 3.3 Les principaux aspects Info S4 ch3 1 3.1 Un historique Quatre générations. Préhistoire 1944 1950 ENIAC (1944) militaire : 20000 tubes,
CH.3 SYSTÈMES D'EXPLOITATION 3.1 Un historique 3.2 Une vue générale 3.3 Les principaux aspects Info S4 ch3 1 3.1 Un historique Quatre générations. Préhistoire 1944 1950 ENIAC (1944) militaire : 20000 tubes,
StruxureWare Power Monitoring v7.0. La nouvelle génération en matière de logiciel de gestion complète d énergie
 StruxureWare Power Monitoring v7.0 La nouvelle génération en matière de logiciel de gestion complète d énergie Évolution des deux plate-formes originales Power Monitoring v7.0 SMS ION Enterprise 2012 Struxureware
StruxureWare Power Monitoring v7.0 La nouvelle génération en matière de logiciel de gestion complète d énergie Évolution des deux plate-formes originales Power Monitoring v7.0 SMS ION Enterprise 2012 Struxureware
Fonctionnement et performance des processeurs
 Fonctionnement et performance des processeurs Eric Cariou Université de Pau et des Pays de l'adour Département Informatique Eric.Cariou@univ-pau.fr 1 Plan Fonctionnement des processeurs Unités de calcul
Fonctionnement et performance des processeurs Eric Cariou Université de Pau et des Pays de l'adour Département Informatique Eric.Cariou@univ-pau.fr 1 Plan Fonctionnement des processeurs Unités de calcul
Evolution des technologies et émergence du cloud computing Drissa HOUATRA, Orange Labs Issy
 Evolution des technologies et émergence du cloud computing Drissa HOUATRA, Orange Labs Issy Séminaire Aristote, 17 Déc. 2009 Ecole Polytechnique Palaiseau Plan L'univers du cloud Ressources Grilles, middleware
Evolution des technologies et émergence du cloud computing Drissa HOUATRA, Orange Labs Issy Séminaire Aristote, 17 Déc. 2009 Ecole Polytechnique Palaiseau Plan L'univers du cloud Ressources Grilles, middleware
Programmation parallèle et ordonnancement de tâches par vol de travail. Thierry Gautier thierry.gautier@inrialpes.fr MOAIS, INRIA, Grenoble
 Programmation parallèle et ordonnancement de tâches par vol de travail Thierry Gautier thierry.gautier@inrialpes.fr MOAIS, INRIA, Grenoble LyonCalcul 24/02/2014 Plan 1. Contexte technologique des architectures
Programmation parallèle et ordonnancement de tâches par vol de travail Thierry Gautier thierry.gautier@inrialpes.fr MOAIS, INRIA, Grenoble LyonCalcul 24/02/2014 Plan 1. Contexte technologique des architectures
Algorithmique I. Augustin.Lux@imag.fr Roger.Mohr@imag.fr Maud.Marchal@imag.fr. Algorithmique I 20-09-06 p.1/??
 Algorithmique I Augustin.Lux@imag.fr Roger.Mohr@imag.fr Maud.Marchal@imag.fr Télécom 2006/07 Algorithmique I 20-09-06 p.1/?? Organisation en Algorithmique 2 séances par semaine pendant 8 semaines. Enseignement
Algorithmique I Augustin.Lux@imag.fr Roger.Mohr@imag.fr Maud.Marchal@imag.fr Télécom 2006/07 Algorithmique I 20-09-06 p.1/?? Organisation en Algorithmique 2 séances par semaine pendant 8 semaines. Enseignement
Architecture des ordinateurs
 Architecture des ordinateurs Cours 4 5 novembre 2012 Archi 1/22 Micro-architecture Archi 2/22 Intro Comment assembler les différents circuits vus dans les cours précédents pour fabriquer un processeur?
Architecture des ordinateurs Cours 4 5 novembre 2012 Archi 1/22 Micro-architecture Archi 2/22 Intro Comment assembler les différents circuits vus dans les cours précédents pour fabriquer un processeur?
Contribution à la conception à base de composants logiciels d applications scientifiques parallèles.
 - École Normale Supérieure de LYON - Laboratoire de l Informatique du Parallélisme THÈSE en vue d obtenir le grade de Docteur de l École Normale Supérieure de Lyon - Université de Lyon Discipline : Informatique
- École Normale Supérieure de LYON - Laboratoire de l Informatique du Parallélisme THÈSE en vue d obtenir le grade de Docteur de l École Normale Supérieure de Lyon - Université de Lyon Discipline : Informatique
Exigences système Edition & Imprimeries de labeur
 Exigences système Edition & Imprimeries de labeur OneVision Software France Sommaire Asura 9.5, Asura Pro 9.5, Garda 5.0...2 PlugBALANCEin 6.5, PlugCROPin 6.5, PlugFITin 6.5, PlugRECOMPOSEin 6.5, PlugSPOTin
Exigences système Edition & Imprimeries de labeur OneVision Software France Sommaire Asura 9.5, Asura Pro 9.5, Garda 5.0...2 PlugBALANCEin 6.5, PlugCROPin 6.5, PlugFITin 6.5, PlugRECOMPOSEin 6.5, PlugSPOTin
Runtime. Gestion de la réactivité des communications réseau. François Trahay Runtime, LaBRI sous la direction d'alexandre Denis Université Bordeaux I
 Runtime Gestion de la réactivité des communications réseau François Trahay Runtime, LaBRI sous la direction d'alexandre Denis Université Bordeaux I 1 Le calcul hautes performances La tendance actuelle
Runtime Gestion de la réactivité des communications réseau François Trahay Runtime, LaBRI sous la direction d'alexandre Denis Université Bordeaux I 1 Le calcul hautes performances La tendance actuelle
Les clusters Linux. 4 août 2004 Benoît des Ligneris, Ph. D. benoit.des.ligneris@revolutionlinux.com. white-paper-cluster_fr.sxw, Version 74 Page 1
 Les clusters Linux 4 août 2004 Benoît des Ligneris, Ph. D. benoit.des.ligneris@revolutionlinux.com white-paper-cluster_fr.sxw, Version 74 Page 1 Table des matières Introduction....2 Haute performance (High
Les clusters Linux 4 août 2004 Benoît des Ligneris, Ph. D. benoit.des.ligneris@revolutionlinux.com white-paper-cluster_fr.sxw, Version 74 Page 1 Table des matières Introduction....2 Haute performance (High
Architectures d implémentation de Click&DECiDE NSI
 Architectures d implémentation de Click&DECiDE NSI de 1 à 300 millions de ligne de log par jour Dans ce document, nous allons étudier les différentes architectures à mettre en place pour Click&DECiDE NSI.
Architectures d implémentation de Click&DECiDE NSI de 1 à 300 millions de ligne de log par jour Dans ce document, nous allons étudier les différentes architectures à mettre en place pour Click&DECiDE NSI.
Linux embarqué: une alternative à Windows CE?
 embarqué: une alternative à Windows CE? : une alternative à Windows CE Présentation Mangrove Systems Distribution embarqué Perspective WinCe / Questions Mangrove systems Créé en 2001 Soutien Soutien Ministère
embarqué: une alternative à Windows CE? : une alternative à Windows CE Présentation Mangrove Systems Distribution embarqué Perspective WinCe / Questions Mangrove systems Créé en 2001 Soutien Soutien Ministère
Exigences système Edition & Imprimeries de labeur
 Exigences système Edition & Imprimeries de labeur OneVision Software France Sommaire Asura 10.2, Asura Pro 10.2, Garda 10.2...2 PlugBALANCEin10.2, PlugCROPin 10.2, PlugFITin 10.2, PlugRECOMPOSEin 10.2,
Exigences système Edition & Imprimeries de labeur OneVision Software France Sommaire Asura 10.2, Asura Pro 10.2, Garda 10.2...2 PlugBALANCEin10.2, PlugCROPin 10.2, PlugFITin 10.2, PlugRECOMPOSEin 10.2,
MODULE I1. Plan. Introduction. Introduction. Historique. Historique avant 1969. R&T 1ère année. Sylvain MERCHEZ
 MODULE I1 Plan Chapitre 1 Qu'est ce qu'un S.E? Introduction Historique Présentation d'un S.E Les principaux S.E R&T 1ère année Votre environnement Sylvain MERCHEZ Introduction Introduction Rôles et fonctions
MODULE I1 Plan Chapitre 1 Qu'est ce qu'un S.E? Introduction Historique Présentation d'un S.E Les principaux S.E R&T 1ère année Votre environnement Sylvain MERCHEZ Introduction Introduction Rôles et fonctions
Etude d architecture de consolidation et virtualisation
 BOUILLAUD Martin Stagiaire BTS Services Informatiques aux Organisations Janvier 2015 Etude d architecture de consolidation et virtualisation Projet : DDPP Table des matières 1. Objet du projet... 3 2.
BOUILLAUD Martin Stagiaire BTS Services Informatiques aux Organisations Janvier 2015 Etude d architecture de consolidation et virtualisation Projet : DDPP Table des matières 1. Objet du projet... 3 2.
Une dérivation du paradigme de réécriture de multiensembles pour l'architecture de processeur graphique GPU
 Une dérivation du paradigme de réécriture de multiensembles pour l'architecture de processeur graphique GPU Gabriel Antoine Louis Paillard Ce travail a eu le soutien de la CAPES, agence brésilienne pour
Une dérivation du paradigme de réécriture de multiensembles pour l'architecture de processeur graphique GPU Gabriel Antoine Louis Paillard Ce travail a eu le soutien de la CAPES, agence brésilienne pour
Rapport d activité. Mathieu Souchaud Juin 2007
 Rapport d activité Mathieu Souchaud Juin 2007 Ce document fait la synthèse des réalisations accomplies durant les sept premiers mois de ma mission (de novembre 2006 à juin 2007) au sein de l équipe ScAlApplix
Rapport d activité Mathieu Souchaud Juin 2007 Ce document fait la synthèse des réalisations accomplies durant les sept premiers mois de ma mission (de novembre 2006 à juin 2007) au sein de l équipe ScAlApplix
Outil d aide au choix Serveurs Lot 4 Marché Groupement de Recherche
 Outil d aide au choix Serveurs Lot 4 Marché Groupement de Recherche Serveurs DELL PowerEdge Tour Rack standard R310 T110II Rack de calcul Lames R815 M610 R410 R910 M620 R415 R510 T620 R620 R720/R720xd
Outil d aide au choix Serveurs Lot 4 Marché Groupement de Recherche Serveurs DELL PowerEdge Tour Rack standard R310 T110II Rack de calcul Lames R815 M610 R410 R910 M620 R415 R510 T620 R620 R720/R720xd
VMWare Infrastructure 3
 Ingénieurs 2000 Filière Informatique et réseaux Université de Marne-la-Vallée VMWare Infrastructure 3 Exposé système et nouvelles technologies réseau. Christophe KELLER Sommaire Sommaire... 2 Introduction...
Ingénieurs 2000 Filière Informatique et réseaux Université de Marne-la-Vallée VMWare Infrastructure 3 Exposé système et nouvelles technologies réseau. Christophe KELLER Sommaire Sommaire... 2 Introduction...
Systèmes Répartis. Pr. Slimane Bah, ing. PhD. Ecole Mohammadia d Ingénieurs. G. Informatique. Semaine 24.2. Slimane.bah@emi.ac.ma
 Ecole Mohammadia d Ingénieurs Systèmes Répartis Pr. Slimane Bah, ing. PhD G. Informatique Semaine 24.2 1 Semestre 4 : Fev. 2015 Grid : exemple SETI@home 2 Semestre 4 : Fev. 2015 Grid : exemple SETI@home
Ecole Mohammadia d Ingénieurs Systèmes Répartis Pr. Slimane Bah, ing. PhD G. Informatique Semaine 24.2 1 Semestre 4 : Fev. 2015 Grid : exemple SETI@home 2 Semestre 4 : Fev. 2015 Grid : exemple SETI@home
. Plan du cours. . Architecture: Fermi (2010-12), Kepler (12-?)
, Kepler (12-?)") Plan du cours Vision mate riel: architecture cartes graphiques NVIDIA INF 560 Calcul Paralle le et Distribue Cours 3 Vision logiciel: l abstraction logique de l architecture propose e par le langage CUDA
Plan du cours Vision mate riel: architecture cartes graphiques NVIDIA INF 560 Calcul Paralle le et Distribue Cours 3 Vision logiciel: l abstraction logique de l architecture propose e par le langage CUDA
Prise en compte des ressources dans les composants logiciels parallèles
 Prise en compte des ressources dans les composants logiciels parallèles Aperçus de l action RASC et du projet Concerto F. Guidec Frederic.Guidec@univ-ubs.fr Action RASC Plan de cet exposé Contexte Motivations
Prise en compte des ressources dans les composants logiciels parallèles Aperçus de l action RASC et du projet Concerto F. Guidec Frederic.Guidec@univ-ubs.fr Action RASC Plan de cet exposé Contexte Motivations
MapReduce. Malo Jaffré, Pablo Rauzy. 16 avril 2010 ENS. Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15
 MapReduce 16 avril 2010 1 / 15") MapReduce Malo Jaffré, Pablo Rauzy ENS 16 avril 2010 Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15 Qu est ce que c est? Conceptuellement Données MapReduce est un framework de calcul distribué
MapReduce Malo Jaffré, Pablo Rauzy ENS 16 avril 2010 Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15 Qu est ce que c est? Conceptuellement Données MapReduce est un framework de calcul distribué
Chapitre 4: Introduction au Cloud computing
 Virtualisation et Cloud Computing Chapitre 4: Introduction au Cloud computing L'évolution d'internet Virt. & Cloud 12/13 2 Définition Le cloud computing est une technologie permettant de délocaliser les
Virtualisation et Cloud Computing Chapitre 4: Introduction au Cloud computing L'évolution d'internet Virt. & Cloud 12/13 2 Définition Le cloud computing est une technologie permettant de délocaliser les
Catalogue des stages Ercom 2013
 Catalogue des stages Ercom 2013 Optimisations sur Modem LTE Poste basé à : Caen (14) Analyse et optimisation des performances des traitements réalisés dans un modem LTE. - Profiling et détermination des
Catalogue des stages Ercom 2013 Optimisations sur Modem LTE Poste basé à : Caen (14) Analyse et optimisation des performances des traitements réalisés dans un modem LTE. - Profiling et détermination des
Windows Server 2008. Chapitre 1: Découvrir Windows Server 2008
 Windows Server 2008 Chapitre 1: Découvrir Windows Server 2008 Objectives Identifier les caractéristiques de chaque édition de Windows Server 2008 Identifier les caractéristiques généraux de Windows Server
Windows Server 2008 Chapitre 1: Découvrir Windows Server 2008 Objectives Identifier les caractéristiques de chaque édition de Windows Server 2008 Identifier les caractéristiques généraux de Windows Server
Organiser vos données - Big Data. Patrick Millart Senior Sales Consultant
 Organiser vos données - Big Data Patrick Millart Senior Sales Consultant The following is intended to outline our general product direction. It is intended for information purposes only, and may not be
Organiser vos données - Big Data Patrick Millart Senior Sales Consultant The following is intended to outline our general product direction. It is intended for information purposes only, and may not be
«Clustering» et «Load balancing» avec Zope et ZEO
 «Clustering» et «Load balancing» avec Zope et ZEO IN53 Printemps 2003 1 Python : généralités 1989 : Guido Van Rossum, le «Python Benevolent Dictator for Life» Orienté objet, interprété, écrit en C Mêle
«Clustering» et «Load balancing» avec Zope et ZEO IN53 Printemps 2003 1 Python : généralités 1989 : Guido Van Rossum, le «Python Benevolent Dictator for Life» Orienté objet, interprété, écrit en C Mêle
Règles et paramètres d'exploitation de Caparmor 2 au 11/12/2009. Pôle de Calcul Intensif pour la mer, 11 Decembre 2009
 Règles et paramètres d'exploitation de Caparmor 2 au 11/12/2009 Pôle de Calcul Intensif pour la mer, 11 Decembre 2009 CAPARMOR 2 La configuration actuelle Les conditions d'accès à distance règles d'exploitation
Règles et paramètres d'exploitation de Caparmor 2 au 11/12/2009 Pôle de Calcul Intensif pour la mer, 11 Decembre 2009 CAPARMOR 2 La configuration actuelle Les conditions d'accès à distance règles d'exploitation
Programmation C. Apprendre à développer des programmes simples dans le langage C
 Programmation C Apprendre à développer des programmes simples dans le langage C Notes de cours sont disponibles sur http://astro.u-strasbg.fr/scyon/stusm (attention les majuscules sont importantes) Modalités
Programmation C Apprendre à développer des programmes simples dans le langage C Notes de cours sont disponibles sur http://astro.u-strasbg.fr/scyon/stusm (attention les majuscules sont importantes) Modalités
Cloud Computing. Introduction. ! Explosion du nombre et du volume de données
 Cloud Computing Frédéric Desprez LIP ENS Lyon/INRIA Grenoble Rhône-Alpes EPI GRAAL 25/03/2010! Introduction La transparence d utilisation des grandes plates-formes distribuées est primordiale Il est moins
Cloud Computing Frédéric Desprez LIP ENS Lyon/INRIA Grenoble Rhône-Alpes EPI GRAAL 25/03/2010! Introduction La transparence d utilisation des grandes plates-formes distribuées est primordiale Il est moins
Évaluation et implémentation des langages
 Évaluation et implémentation des langages Les langages de programmation et le processus de programmation Critères de conception et d évaluation des langages de programmation Les fondations de l implémentation
Évaluation et implémentation des langages Les langages de programmation et le processus de programmation Critères de conception et d évaluation des langages de programmation Les fondations de l implémentation
UNIVERSITÉ D ORLÉANS ÉCOLE DOCTORALE MIPTIS MATHÉMATIQUES, INFORMATIQUE, PHYSIQUE THÉORIQUE ET INGÉNIEURIE DES SYSTÈMES. THÈSE présentée par :
 UNIVERSITÉ D ORLÉANS ÉCOLE DOCTORALE MIPTIS MATHÉMATIQUES, INFORMATIQUE, PHYSIQUE THÉORIQUE ET INGÉNIEURIE DES SYSTÈMES Laboratoire d Informatique Fondamentale d Orléans THÈSE présentée par : Hélène COULLON
UNIVERSITÉ D ORLÉANS ÉCOLE DOCTORALE MIPTIS MATHÉMATIQUES, INFORMATIQUE, PHYSIQUE THÉORIQUE ET INGÉNIEURIE DES SYSTÈMES Laboratoire d Informatique Fondamentale d Orléans THÈSE présentée par : Hélène COULLON
Exécution des instructions machine
 Exécution des instructions machine Eduardo Sanchez EPFL Exemple: le processeur MIPS add a, b, c a = b + c type d'opération (mnémonique) destination du résultat lw a, addr opérandes sources a = mem[addr]
Exécution des instructions machine Eduardo Sanchez EPFL Exemple: le processeur MIPS add a, b, c a = b + c type d'opération (mnémonique) destination du résultat lw a, addr opérandes sources a = mem[addr]
Virtualisation & Sécurité
 Virtualisation & Sécurité Comment aborder la sécurité d une architecture virtualisée? Quels sont les principaux risques liés à la virtualisation? Peut-on réutiliser l expérience du monde physique? Quelles
Virtualisation & Sécurité Comment aborder la sécurité d une architecture virtualisée? Quels sont les principaux risques liés à la virtualisation? Peut-on réutiliser l expérience du monde physique? Quelles
Architecture distribuée
 Architecture distribuée Conception et développement d algorithmes distribués pour le moteur Baboukweb Jean-Christophe DALLEAU Département de Mathématiques et Informatique Université de La Réunion 26 juin
Architecture distribuée Conception et développement d algorithmes distribués pour le moteur Baboukweb Jean-Christophe DALLEAU Département de Mathématiques et Informatique Université de La Réunion 26 juin
Performances de la programmation multi-thread
 UFR Sciences et techniques de Franche-Comté Projet semestriel 2ème année de Master Informatique Performances de la programmation multi-thread Auteur(s) : Beuque Eric Moutenet Cyril Tuteur(s) : Philippe
UFR Sciences et techniques de Franche-Comté Projet semestriel 2ème année de Master Informatique Performances de la programmation multi-thread Auteur(s) : Beuque Eric Moutenet Cyril Tuteur(s) : Philippe
THÈSE. Pour obtenir le grade de. Spécialité : Informatique. Arrêté ministériel : 7 août 2006. Présentée et soutenue publiquement par.
 THÈSE Pour obtenir le grade de DOCTEUR DE L UNIVERSITÉ DE GRENOBLE Spécialité : Informatique Arrêté ministériel : 7 août 2006 Présentée et soutenue publiquement par Fabien GAUD le 02 Décembre 2010 ÉTUDE
THÈSE Pour obtenir le grade de DOCTEUR DE L UNIVERSITÉ DE GRENOBLE Spécialité : Informatique Arrêté ministériel : 7 août 2006 Présentée et soutenue publiquement par Fabien GAUD le 02 Décembre 2010 ÉTUDE
Guide de Tarification. Introduction Licence FD Entreprise Forfaits clé en main SaaS SaaS Dédié SaaS Partagé. Page 2 Page 3 Page 4 Page 5 Page 8
 Guide de Tarification Introduction Licence FD Entreprise Forfaits clé en main SaaS SaaS Dédié SaaS Partagé Page 2 Page 3 Page 4 Page 5 Page 8 Introduction Dexero FD est une application Web de gestion d
Guide de Tarification Introduction Licence FD Entreprise Forfaits clé en main SaaS SaaS Dédié SaaS Partagé Page 2 Page 3 Page 4 Page 5 Page 8 Introduction Dexero FD est une application Web de gestion d
AMBASSADE DE FRANCE EN ALLEMAGNE SERVICE POUR LA SCIENCE ET LA TECHNOLOGIE
 AMBASSADE DE FRANCE EN ALLEMAGNE SERVICE POUR LA SCIENCE ET LA TECHNOLOGIE Le Conseiller pour la Science et la Technologie SST/PR Berlin, le 23 novembre 2010 Etat des lieux comparatif dans le domaine des
AMBASSADE DE FRANCE EN ALLEMAGNE SERVICE POUR LA SCIENCE ET LA TECHNOLOGIE Le Conseiller pour la Science et la Technologie SST/PR Berlin, le 23 novembre 2010 Etat des lieux comparatif dans le domaine des
Chapitre 1. Infrastructures distribuées : cluster, grilles et cloud. Grid and Cloud Computing
 Chapitre 1. Infrastructures distribuées : cluster, grilles et cloud Grid and Cloud Computing Problématique Besoins de calcul croissants Simulations d'expériences coûteuses ou dangereuses Résolution de
Chapitre 1. Infrastructures distribuées : cluster, grilles et cloud Grid and Cloud Computing Problématique Besoins de calcul croissants Simulations d'expériences coûteuses ou dangereuses Résolution de
FOG : Free Open-Source Ghost. Solution libre de clonage et de déploiement de systèmes d'exploitation.
 FOG : Free Open-Source Ghost Solution libre de clonage et de déploiement de systèmes d'exploitation. JoSy-Plume 22 novembre 2010 Logiciel développé par Chuck Syperski et Jian Zhang, IT à l'université "DuPage"
FOG : Free Open-Source Ghost Solution libre de clonage et de déploiement de systèmes d'exploitation. JoSy-Plume 22 novembre 2010 Logiciel développé par Chuck Syperski et Jian Zhang, IT à l'université "DuPage"
GCOS 7 sur microprocesseur standard Diane Daniel POIRSON 14 octobre 2004 Matériels 64 / DPS 7 / DPS 7000 Architecture & Evolution - Daniel POIRSON 1
 sur microprocesseur standard Diane Daniel POIRSON 14 octobre 2004 Matériels 64 / DPS 7 / DPS 7000 Architecture & Evolution - Daniel POIRSON 1 Pourquoi aller vers les processeurs standard? Considérations
sur microprocesseur standard Diane Daniel POIRSON 14 octobre 2004 Matériels 64 / DPS 7 / DPS 7000 Architecture & Evolution - Daniel POIRSON 1 Pourquoi aller vers les processeurs standard? Considérations
Hétérogénéité pour atteindre une consommation énergétique proportionnelle dans les clouds
 Hétérogénéité pour atteindre une consommation énergétique proportionnelle dans les clouds Mardi Laurent Lefèvre LIP Inria/ENS Lyon Jean-Marc Pierson, Georges Da Costa, Patricia Stolf IRIT Toulouse Hétérogénéité
Hétérogénéité pour atteindre une consommation énergétique proportionnelle dans les clouds Mardi Laurent Lefèvre LIP Inria/ENS Lyon Jean-Marc Pierson, Georges Da Costa, Patricia Stolf IRIT Toulouse Hétérogénéité
vmware au CC-IN2P3 Déploiement rapide d une infrastructure destinée à de la formation et réflexions sur vsphere.
 vmware au CC-IN2P3 Déploiement rapide d une infrastructure destinée à de la formation et réflexions sur vsphere. Programme Partie 1 : Déploiement rapide de serveurs pour une formation administrateur grille
vmware au CC-IN2P3 Déploiement rapide d une infrastructure destinée à de la formation et réflexions sur vsphere. Programme Partie 1 : Déploiement rapide de serveurs pour une formation administrateur grille
Exigences système Commercial & Digital Printing
 Exigences système OneVision Software AG Sommaire 1 Speedflow Check 4.1 Speedflow Edit 4.1 (Windows, Macintosh OSX) Speedflow Recompose 4.1 Speedflow Impose 3.0 2 Speedflow Cockpit 3.1 Speedflow Control
Exigences système OneVision Software AG Sommaire 1 Speedflow Check 4.1 Speedflow Edit 4.1 (Windows, Macintosh OSX) Speedflow Recompose 4.1 Speedflow Impose 3.0 2 Speedflow Cockpit 3.1 Speedflow Control
<Insert Picture Here> Solaris pour la base de donnés Oracle
 Solaris pour la base de donnés Oracle Alain Chéreau Oracle Solution Center Agenda Compilateurs Mémoire pour la SGA Parallélisme RAC Flash Cache Compilateurs
Solaris pour la base de donnés Oracle Alain Chéreau Oracle Solution Center Agenda Compilateurs Mémoire pour la SGA Parallélisme RAC Flash Cache Compilateurs
Virtualisation des ressources serveur. Exemple : Systèmes partitionnés sous HP-UX et Oracle
 Virtualisation des ressources serveur Exemple : Systèmes partitionnés sous HP-UX et Oracle Sommaire 1 PRINCIPES DE LA VIRTUALISATION DES SERVEURS 3 2 PRINCIPES DE LA VIRTUALISATION DES SERVEURS PARTITIONNES
Virtualisation des ressources serveur Exemple : Systèmes partitionnés sous HP-UX et Oracle Sommaire 1 PRINCIPES DE LA VIRTUALISATION DES SERVEURS 3 2 PRINCIPES DE LA VIRTUALISATION DES SERVEURS PARTITIONNES
ORACLE 10g Découvrez les nouveautés. Jeudi 17 Mars Séminaire DELL/INTEL/ORACLE
 ORACLE 10g Découvrez les nouveautés Jeudi 17 Mars Séminaire DELL/INTEL/ORACLE Le Grid Computing d Entreprise Pourquoi aujourd hui? Principes et définitions appliqués au système d information Guy Ernoul,
ORACLE 10g Découvrez les nouveautés Jeudi 17 Mars Séminaire DELL/INTEL/ORACLE Le Grid Computing d Entreprise Pourquoi aujourd hui? Principes et définitions appliqués au système d information Guy Ernoul,
Protection de l Investissement Virtualisation, Efficacité énergétique
 Protection de l Investissement Virtualisation, Efficacité énergétique Conférence IDC France Secteur Public Les technologies au service de l efficacité publique 8 Avril 2008 AMD, Fabricant de Processeurs
Protection de l Investissement Virtualisation, Efficacité énergétique Conférence IDC France Secteur Public Les technologies au service de l efficacité publique 8 Avril 2008 AMD, Fabricant de Processeurs
BONJOURGRID : VERSION ORIENTÉE DONNÉE & MAPREDUCE SÉCURISÉ
 Laboratoire LaTICE Univ. de Tunis INRIA LYON Avalon Team Laboratoire d Informatique de Paris Nord (LIPN) BONJOURGRID : VERSION ORIENTÉE DONNÉE & MAPREDUCE SÉCURISÉ Heithem Abbes Heithem Abbes Rencontres
Laboratoire LaTICE Univ. de Tunis INRIA LYON Avalon Team Laboratoire d Informatique de Paris Nord (LIPN) BONJOURGRID : VERSION ORIENTÉE DONNÉE & MAPREDUCE SÉCURISÉ Heithem Abbes Heithem Abbes Rencontres
T. Gasc 1,2,3, F. De Vuyst 1, R. Motte 3, M. Peybernes 4, R. Poncet 5
 Modélisation de la performance et optimisation d un algorithme hydrodynamique de type Lagrange-Projection sur processeurs multi-cœurs T. Gasc 1,2,3, F. De Vuyst 1, R. Motte 3, M. Peybernes 4, R. Poncet
Modélisation de la performance et optimisation d un algorithme hydrodynamique de type Lagrange-Projection sur processeurs multi-cœurs T. Gasc 1,2,3, F. De Vuyst 1, R. Motte 3, M. Peybernes 4, R. Poncet
Big Data. Cyril Amsellem Consultant avant-vente. 16 juin 2011. Talend 2010 1
 Big Data Cyril Amsellem Consultant avant-vente 16 juin 2011 Talend 2010 1 Big Data Architecture globale Hadoop Les projets Hadoop (partie 1) Hadoop-Core : projet principal. HDFS : système de fichiers distribués
Big Data Cyril Amsellem Consultant avant-vente 16 juin 2011 Talend 2010 1 Big Data Architecture globale Hadoop Les projets Hadoop (partie 1) Hadoop-Core : projet principal. HDFS : système de fichiers distribués
THEME 1 : L ORDINATEUR ET SON ENVIRONNEMENT. Objectifs
 Architecture Matérielle des Systèmes Informatiques. S1 BTS Informatique de Gestion 1 ère année THEME 1 : L ORDINATEUR ET SON ENVIRONNEMENT Dossier 1 L environnement informatique. Objectifs Enumérer et
Architecture Matérielle des Systèmes Informatiques. S1 BTS Informatique de Gestion 1 ère année THEME 1 : L ORDINATEUR ET SON ENVIRONNEMENT Dossier 1 L environnement informatique. Objectifs Enumérer et
Cluster High Performance Computing. Dr. Andreas Koch, Cluster Specialist
 Cluster High Performance Computing Dr. Andreas Koch, Cluster Specialist TABLE DES MATIÈRES 1 RÉSUMÉ... 3 2 INTRODUCTION... 4 3 STRUCTURE D UN CLUSTER HPC... 6 3.1 INTRODUCTION... 6 3.2 MONTAGE SIMPLE...
Cluster High Performance Computing Dr. Andreas Koch, Cluster Specialist TABLE DES MATIÈRES 1 RÉSUMÉ... 3 2 INTRODUCTION... 4 3 STRUCTURE D UN CLUSTER HPC... 6 3.1 INTRODUCTION... 6 3.2 MONTAGE SIMPLE...
Exécutif temps réel Pierre-Yves Duval (cppm)
") Exécutif temps réel Pierre-Yves Duval (cppm) Ecole d informatique temps réel - La Londes les Maures 7-11 Octobre 2002 Plan Exécutif Tâches Evénements et synchronisation Partage de ressources Communications
Exécutif temps réel Pierre-Yves Duval (cppm) Ecole d informatique temps réel - La Londes les Maures 7-11 Octobre 2002 Plan Exécutif Tâches Evénements et synchronisation Partage de ressources Communications
Base de l'informatique. Généralité et Architecture Le système d'exploitation Les logiciels Le réseau et l'extérieur (WEB)
") Base de l'informatique Généralité et Architecture Le système d'exploitation Les logiciels Le réseau et l'extérieur (WEB) Généralité Comment fonctionne un ordinateur? Nous définirons 3 couches Le matériel
Base de l'informatique Généralité et Architecture Le système d'exploitation Les logiciels Le réseau et l'extérieur (WEB) Généralité Comment fonctionne un ordinateur? Nous définirons 3 couches Le matériel
Le groupe CSS. La société CEGI intervient depuis la Martinique au cœur des systèmes de gestion de nos clients. La société existe depuis 1973!
 La Virtualisation 1 Le groupe CSS La société CEGI intervient depuis la Martinique au cœur des systèmes de gestion de nos clients. La société existe depuis 1973! La société SASI est la filiale technologique
La Virtualisation 1 Le groupe CSS La société CEGI intervient depuis la Martinique au cœur des systèmes de gestion de nos clients. La société existe depuis 1973! La société SASI est la filiale technologique
4. Utilisation d un SGBD : le langage SQL. 5. Normalisation
 Base de données S. Lèbre slebre@unistra.fr Université de Strasbourg, département d informatique. Présentation du module Contenu général Notion de bases de données Fondements / Conception Utilisation :
Base de données S. Lèbre slebre@unistra.fr Université de Strasbourg, département d informatique. Présentation du module Contenu général Notion de bases de données Fondements / Conception Utilisation :
LXC : Une technologie de contextualisation ultra light intégrée au kernel Linux
 Benoît des Ligneris, Ph.D. P.D.G., bdl@rlnx.com Solutions Linux Open Source, 18 mars 2010 LXC : Une technologie de contextualisation ultra light intégrée au kernel Linux Révolution Linux 2010 Au menu Révolution
Benoît des Ligneris, Ph.D. P.D.G., bdl@rlnx.com Solutions Linux Open Source, 18 mars 2010 LXC : Une technologie de contextualisation ultra light intégrée au kernel Linux Révolution Linux 2010 Au menu Révolution
Découvrez les Nouveautés Février 2010 du Catalogue PC Pack PRO
 Découvrez les Nouveautés Février 2010 du Catalogue PC Pack PRO PC Acer Mini : 990 DH TTC Processeur Intel Core ATOM N270 Mémoire Vive 512Mo Disque Dur 8 Go Lecteur de cartes MEMOIRE 5-IN-1 Webcam intégré
Découvrez les Nouveautés Février 2010 du Catalogue PC Pack PRO PC Acer Mini : 990 DH TTC Processeur Intel Core ATOM N270 Mémoire Vive 512Mo Disque Dur 8 Go Lecteur de cartes MEMOIRE 5-IN-1 Webcam intégré
Architectures informatiques dans les nuages
 Architectures informatiques dans les nuages Cloud Computing : ressources informatiques «as a service» François Goldgewicht Consultant, directeur technique CCT CNES 18 mars 2010 Avant-propos Le Cloud Computing,
Architectures informatiques dans les nuages Cloud Computing : ressources informatiques «as a service» François Goldgewicht Consultant, directeur technique CCT CNES 18 mars 2010 Avant-propos Le Cloud Computing,
Systèmes d exploitation
 Systèmes d exploitation Virtualisation, Sécurité et Gestion des périphériques Gérard Padiou Département Informatique et Mathématiques appliquées ENSEEIHT Novembre 2009 Gérard Padiou Systèmes d exploitation
Systèmes d exploitation Virtualisation, Sécurité et Gestion des périphériques Gérard Padiou Département Informatique et Mathématiques appliquées ENSEEIHT Novembre 2009 Gérard Padiou Systèmes d exploitation
Fiche Technique. Cisco Security Agent
 Fiche Technique Cisco Security Agent Avec le logiciel de sécurité de point d extrémité Cisco Security Agent (CSA), Cisco offre à ses clients la gamme de solutions de protection la plus complète qui soit
Fiche Technique Cisco Security Agent Avec le logiciel de sécurité de point d extrémité Cisco Security Agent (CSA), Cisco offre à ses clients la gamme de solutions de protection la plus complète qui soit
Plan de la conférence. Virtualization. Définition. Historique. Technique. Abstraction matérielle
 Plan de la conférence Virtualization Microclub 7 mars 2008 Yves Masur - quelques définitions - technique utilisée - exemples d'émulations - la virtualisation x86 - VMWare - mise en oeuvre - conclusion
Plan de la conférence Virtualization Microclub 7 mars 2008 Yves Masur - quelques définitions - technique utilisée - exemples d'émulations - la virtualisation x86 - VMWare - mise en oeuvre - conclusion
Une bibliothèque de templates pour CUDA
 Une bibliothèque de templates pour CUDA Sylvain Collange, Marc Daumas et David Defour Montpellier, 16 octobre 2008 Types de parallèlisme de données Données indépendantes n threads pour n jeux de données
Une bibliothèque de templates pour CUDA Sylvain Collange, Marc Daumas et David Defour Montpellier, 16 octobre 2008 Types de parallèlisme de données Données indépendantes n threads pour n jeux de données
Master (filière Réseau) Parcours Recherche: Systèmes Informatiques et Réseaux (RTS)
 Parcours Recherche: Systèmes Informatiques et Réseaux (RTS)") Master (filière Réseau) Parcours Recherche: Systèmes Informatiques et Réseaux (RTS) Responsables: Tanguy Risset & Marine Minier Tanguy.Risset@insa-lyon.fr Marine.minier@insa-lyon.fr http://master-info.univ-lyon1.fr/m2rts/
Master (filière Réseau) Parcours Recherche: Systèmes Informatiques et Réseaux (RTS) Responsables: Tanguy Risset & Marine Minier Tanguy.Risset@insa-lyon.fr Marine.minier@insa-lyon.fr http://master-info.univ-lyon1.fr/m2rts/
Portage d applications sur le Cloud IaaS Portage d application
 s sur le Cloud IaaS Cécile Cavet cecile.cavet at apc.univ-paris7.fr Centre François Arago (FACe), Laboratoire AstroParticule et Cosmologie (APC), LabEx UnivEarthS APC, Univ. Paris Diderot, CNRS/IN2P3,
s sur le Cloud IaaS Cécile Cavet cecile.cavet at apc.univ-paris7.fr Centre François Arago (FACe), Laboratoire AstroParticule et Cosmologie (APC), LabEx UnivEarthS APC, Univ. Paris Diderot, CNRS/IN2P3,
Les mésocentres HPC àportée de clic des utilisateurs industriels
 Les mésocentres HPC àportée de clic des utilisateurs industriels Université de Reims Champagne-Ardenne (URCA) Centre de Calcul ROMEO Multidisciplinary university more than 22 000 students a wide initial
Les mésocentres HPC àportée de clic des utilisateurs industriels Université de Reims Champagne-Ardenne (URCA) Centre de Calcul ROMEO Multidisciplinary university more than 22 000 students a wide initial
Architecture de la grille
 1 2 Diversité des applications et des utilisateurs (profile, nombre,...) supposent des solutions différentes architectures différentes avec des services communs Services de base authentification: établir
1 2 Diversité des applications et des utilisateurs (profile, nombre,...) supposent des solutions différentes architectures différentes avec des services communs Services de base authentification: établir
Informatique UE 102. Jean-Yves Antoine. Architecture des ordinateurs et Algorithmique de base. UFR Sciences et Techniques Licence S&T 1ère année
 UFR Sciences et Techniques Licence S&T 1ère année Informatique UE 102 Architecture des ordinateurs et Algorithmique de base Jean-Yves Antoine http://www.info.univ-tours.fr/~antoine/ UFR Sciences et Techniques
UFR Sciences et Techniques Licence S&T 1ère année Informatique UE 102 Architecture des ordinateurs et Algorithmique de base Jean-Yves Antoine http://www.info.univ-tours.fr/~antoine/ UFR Sciences et Techniques