Certificat Big Data - Master MAthématiques
|
|
|
- Marie-Claude Robichaud
- il y a 10 ans
- Total affichages :
Transcription
1 1 / 1 Certificat Big Data - Master MAthématiques Master 2 Auteur : Sylvain Lamprier UPMC

2 Fouille de données et Medias Sociaux 2 / 1 Rich and big data: Millions d utilisateurs Millions de contenus Multimedia (texte, image, videos, etc...) Millions de connections et relations (de differents types) Preferences, tendences, opinions,... Analyse réseau social Traitements à large échelle Taille des données Complexité des données Dynamicité Données + Traitements distribués

3 Traitement Distribué 3 / 1 Hadoop Map Reduce API Java Echaînement de jobs Exemples de tâches MapReduce itérées Mise en oeuvre sur Hadoop Spark

4 Traitement distribué 4 / 1 Apache Hadoop Framework distribué Utilisé par de très nombreuses entreprises Traitements parallèles sur des clusters de machines Amener le code aux données Système de fichiers HDFS Système de fichiers virtuel de Hadoop Conçu pour stocker de très gros volumes de données sur un grand nombre de machines Permet l abstraction de l architecture physique de stockage Réplication des données

5 Map Reduce 5 / 1 Exécution d un problème de manière distribuée Découpage en sous-problèmes Execution des sous-problèmes sur les différentes machines du cluster Stratégie algorithmique dite du Divide and Conquer Deux étapes principales : Map: Emission de paires <clé,valeur> pour chaque donnée d entrée lue Reduce: Regroupement des valeurs de clé identique et application d un traitement sur ces valeurs de clé commune

6 Map Reduce 6 / 1 Composants d un processus Map Reduce: 1 Split: Divise les données d entrée en flux parallèles à fournir aux noeuds de calcul. 2 Read: Lit les flux de données en les découpant en unités à traiter. Par défaut à partir d un fichier texte: unité = ligne. 3 Map: Applique sur chaque unité envoyé par le Reader un traitement de transformation dont le résultat est stocké dans des paires <clé,valeur>. 4 Combine: Composant facultatif qui applique un traitement de reduction anticipé à des fins d optimisation. Cette étape ne doit pas perturber la logique de traitement. 5...

7 Map Reduce 7 / 1 Composants d un processus Map Reduce: Group: Regroupement (ou shuffle) des paires de clés communes. Réalisé par un tri distribué sur les différents noeuds du cluster. 3 Partition: Distribue les groupes de paires sur les différents noeuds de calcul pour préparer l opération de reduction. Généralement effectué par simple hashage et découpage en morceaux de données de tailles égales (dépend du nombre de noeuds Reduce). 4 Reduce: Applique un traitement de réduction à chaque liste de valeurs regroupées. 5 Write: Écrit le resultat du traitement dans le(s) fichier(s) résultats(s). On obtient autant de fichiers resultats que l on a de noeuds de reduction.
.")

8 Map Reduce 8 / 1

9 Map Reduce 9 / 1
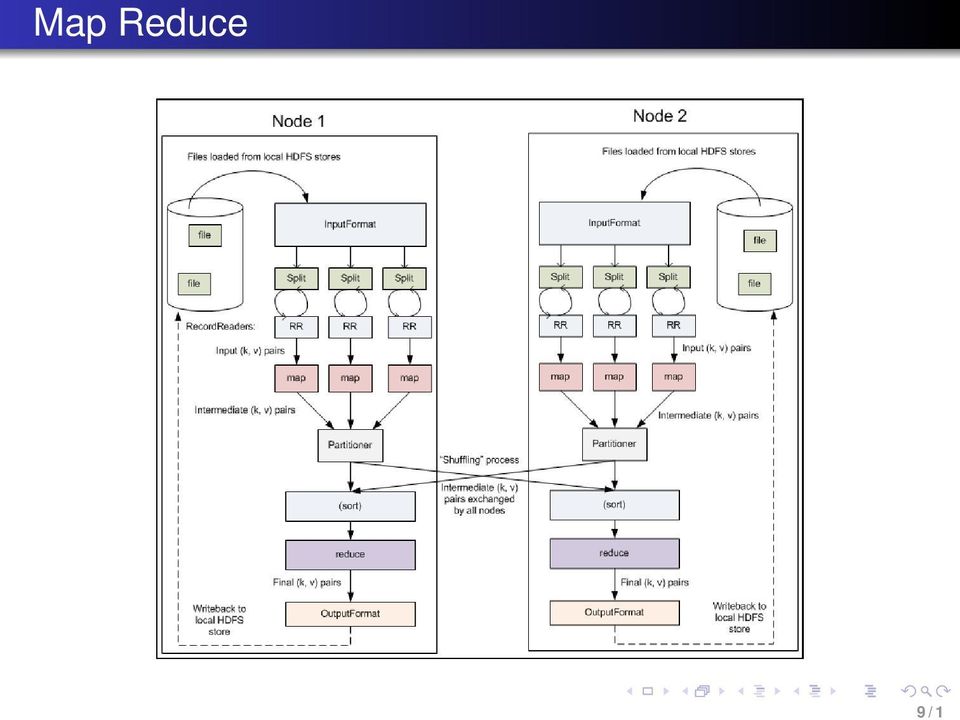
10 Hadoop Map Reduce 10 / 1 Hadoop : Framework Java Elements centraux: Interface Writable : types de données Class InputFormat<K,V> : format d entrée Class Mapper<KI,VI,KO,VO> : opération de Mapping Class Reducer<KI,VI,KO,VO> : opération de Reduction Class OutputFormat<K,V> : format de sortie

11 Map Reduce: Writable 11 / 1 Interface Writable : types de données Format d échange des différents composants MapReduce Hadoop nativement des classes d écriture pour les types primitifs int IntWritable long LongWritable float FloatWritable boolean BooleanWritable String Text... Pour les autres types : étendre soi-même Writable en redéfinissant readfields(datainput in) : définit la manière de lire la donnée dans un flux d entrée in write(dataoutput out) : définit la manière d écrire la donnée dans un flux de sortie out
 : définit la manière de lire la")
12 Hadoop Map Reduce: Writable 12 / 1 Exemple Writable : Point3D p u b l i c class Point3D implements W r i t a b l e { p u b l i c f l o a t x, y, z ; p u b l i c Point3D ( f l o a t x, f l o a t y, f l o a t z ) { t h i s. x = x ; t h i s. y = y ; t h i s. z = z ; } public void write ( DataOutput out ) throws IOException { out. w r i t e F l o a t ( x ) ; out. w r i t e F l o a t ( y ) ; out. w r i t e F l o a t ( z ) ; } } p u b l i c void readfields ( DataInput i n ) throws IOException { x = i n. readfloat ( ) ; y = i n. readfloat ( ) ; z = i n. readfloat ( ) ; }
 ; } } p u b l i c void readfields ( DataInput i n ) throws IOException { x = i n. readfloat ( ) ; y = i n.")
13 Hadoop Map Reduce: InputFormat 13 / 1 Class InputFormat<K,V> : format d entrée Les données d entrée sont découpées en unités de traitement Définit : Les fichiers à utiliser en entrée La manière de découper les données d entrée en blocs (définit le nombre de tâches map à executer) La manière de découper les blocs d entrée en unité de traitement (définit le nombre d itérations séquentielles de chaque tâche Map)

14 Hadoop Map Reduce: InputFormat 14 / 1 InputFormat standards : TextInputFormat: Données textuelles Découpage par ligne Clé: L offset de la line Valeur: La ligne textuelle KeyValueInputFormat Données textuelles Découpage par ligne Clé: Tout le texte qui précède la 1ière tabulation Valeur: Le reste de la line SequenceFileInputFormat Données binaires produites par Hadoop (SequenceFileOutputFormat) Découpage par couples définis dans le format Clé - Valeur: objets Writable sérialisés Les trois formats découpent les entrées en blocs de 64Mo Correspond à la taille des blocs sur HDFS Modifiable selon les paramètres mapred.min.split.size et mapred.max.split.size


15 Hadoop Map Reduce: InputFormat 15 / 1

16 Hadoop Map Reduce: InputFormat 16 / 1 Définition de FileInputFormat Personnalisés Hériter de FileInputFormat<K,V> Une méthode à redéfinir: createrecordreader(inputsplit,taskattemptcontext) : crée le lecteur d entrée Si on ne souhaite pas que le fichier soit découpé en plusieurs blocs : Redéfinir issplitable(jobcontext context, Path file) pour qu elle retourne false

 Le Reader termine la lecture de l unité sur le bloc suivant.")
17 Hadoop Map Reduce: RecordReader 17 / 1 Définit la manière dont on lit les entrées Un InputSplit est un bloc de traitement que l on doit lire par unités Problème : Les frontières des unités ne coincident pas toujours avec les frontières des blocs (ex: unité = ligne v.s. bloc=64mo) Le Reader termine la lecture de l unité sur le bloc suivant. Attention à bien respecter cette logique lors de la définition d un Reader personnalisé.
 Le Reader termine la lecture de l unité sur le bloc suivant.")
18 Hadoop Map Reduce: Mapper 18 / 1 Pour chaque unité de traitement Emission d une paire clé-valeur Hériter de Mapper<Kin,Vin,Kout,Vout> Exemple de Mapper: WordCount public class WordCountMapper extends Mapper<Object, Text, Text, IntWritable > { p r i v a t e s t a t i c f i n a l I n t W r i t a b l e ONE=new I n t W r i t a b l e ( 1 ) ; } protected void map( Object o f f s e t, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer tok=new StringTokenizer ( value. t o S t r i n g ( ), " " ) ; while ( tok. hasmoretokens ( ) ) { Text word=new Text ( tok. nexttoken ( ) ) ; context. w r i t e ( word, ONE) ; } }
, \" \" ) ; while ( tok. hasmoretokens ( ) ) { Text word=new Text ( tok. nexttoken ( ) ) ; context.")
19 Hadoop Map Reduce: Reducer 19 / 1 Pour chaque clé émise par le Mapper Réduction de la liste de valeurs associées Emission d un résultat Clé-Valeur Hériter de Reducer<Kin,Vin,Kout,Vout> Exemple de Reducer: WordCount public class WordCountReducer extends Reducer<Text, IntWritable, Text, Text > { public void reduce ( Text key, Iterable <IntWritable > values, Context context ) throws IOException, InterruptedException { I t e r a t o r < I n t W r i t a b l e > i =values. i t e r a t o r ( ) ; i n t count =0; while ( i. hasnext ( ) ) count+= i. next ( ). get ( ) ; context. w r i t e ( key, new Text ( count +" occurences. " ) ) ; } }
 ; i n t count =0; while ( i. hasnext ( ) ) count+= i. next ( ). get ( ) ; context. w r i t e ( key, new Text ( count +\" occurences.")
20 Hadoop Map Reduce: OutputFormat 20 / 1 Class OutputFormat<K,V> : format de sortie Les résultats du MapReduce sont écrites dans la sortie selon Le support de sortie Le format de sortie (texte, binaire, etc..) Le type de compression


21 Hadoop Map Reduce: OutputFormat 21 / 1
22 Hadoop Map Reduce: OutputFormat 22 / 1 Correspondance entre InputFormat et OuputFormat: TextOutputFormat KeyValueInputFormat SequenceOutputFormat SequenceInputFormat SequenceOutputFormat<K,V> Format de sortie du Mapper Permet de serialiser divers types d objects que l on pourra deserialiser par un SequenceInputFormat Différents types de compression permis (record ou block compression) Produit des fichiers facilement splittable améliore les performances d un traitement par un futur nouveau job MapReduce
23 Hadoop Map Reduce 23 / 1 Exemple de Création d un Job public s t a t i c Job createjob ( String in, String out ) throws IOException { Configuration conf=new Configuration ( ) ; Job job=job. getinstance (new Cluster ( conf ), conf ) ; job. setjarbyclass ( Test. class ) ; SequenceFileInputFormat. addinputpath ( job, new Path ( in ) ) ; job. setinputformatclass ( SequenceFileInputFormat. class ) ; job. setmapperclass ( TestMapper. class ) ; job. setmapoutputkeyclass ( Text. class ) ; job. setmapoutputvalueclass ( Point3D. class ) ; job. setcombinerclass ( TestReducer. class ) ; job. setreducerclass ( TestReducer. class ) ; job. setnumreducetasks ( 3 ) ; SequenceFileOutputFormat. setoutputpath ( job, new Path ( out ) ) ; job. setoutputformatclass ( SequenceFileOutputFormat. class ) ; job. setoutputkeyclass ( Text. class ) ; job. setoutputvalueclass ( Point3D. class ) ; r e t u r n job ; }
24 Hadoop Map Reduce 24 / 1 Exécution d un Job: Création du Driver p u b l i c class D r i v e r { p u b l i c s t a t i c void main ( S t r i n g [ ] args ) throws Exception { Job job=createjob ( args [ 0 ], args [ 1 ] ) ; job. setjarbyclass ( D r i v e r. class ) ; job. waitforcompletion ( t r u e ) ; } }
25 Hadoop Map Reduce: Echaînement de Jobs 25 / 1 Job submit() : Soumet le job waitforcompletion(boolean verbose) : Soumet le job et attend sa terminaison ControlledJob adddependingjob(controlledjob dependingjob) : ajoute une dépendence au job (attend la terminaison du job passé en paramètre pour commencer) submit() : Soumet le job JobControl addjob(controlledjob ajob) : ajoute un nouveau job au JobControl run() : lance les jobs allfinished() : retourne un booléen indiquant si tous les jobs lancés dans ce JobControl sont terminés
26 Hadoop Map Reduce: Echaînement de Jobs 26 / 1 Pour avoir un retour sur l execution while (! j o b C o n t r o l. a l l F i n i s h e d ( ) ) { System. out. p r i n t l n ( " Jobs i n w a i t i n g s t a t e : " + j o b C o n t r o l. g e t W a i t i n g J o b L i s t ( ). size ( ) ) ; System. out. p r i n t l n ( " Jobs i n ready s t a t e : " + j o b C o n t r o l. getreadyjobslist ( ). size ( ) ) ; System. out. p r i n t l n ( " Jobs i n running s t a t e : " + j o b C o n t r o l. getrunningjoblist ( ). size ( ) ) ; List <ControlledJob > successfuljoblist = jobcontrol. getsuccessfuljoblist ( ) ; System. out. p r i n t l n ( " Jobs i n success s t a t e : " + s u c c e s s f u l J o b L i s t. size ( ) ) ; List <ControlledJob > failedjoblist = jobcontrol. getfailedjoblist ( ) ; System. out. p r i n t l n ( " Jobs i n f a i l e d s t a t e : " + f a i l e d J o b L i s t. size ( ) ) ; }
Introduction à MapReduce/Hadoop et Spark
 1 / 36 Introduction à MapReduce/Hadoop et Spark Certificat Big Data Ludovic Denoyer et Sylvain Lamprier UPMC Plan 2 / 36 Contexte 3 / 36 Contexte 4 / 36 Data driven science: le 4e paradigme (Jim Gray -
1 / 36 Introduction à MapReduce/Hadoop et Spark Certificat Big Data Ludovic Denoyer et Sylvain Lamprier UPMC Plan 2 / 36 Contexte 3 / 36 Contexte 4 / 36 Data driven science: le 4e paradigme (Jim Gray -
Hadoop : une plate-forme d exécution de programmes Map-Reduce
 Hadoop : une plate-forme d exécution de programmes Map-Reduce Jonathan Lejeune UPMC 8 octobre 2013 PSIA 2013 Inspiré du cours des années précédentes de Luciana Arantes J. Lejeune (UPMC) Hadoop Map-Reduce
Hadoop : une plate-forme d exécution de programmes Map-Reduce Jonathan Lejeune UPMC 8 octobre 2013 PSIA 2013 Inspiré du cours des années précédentes de Luciana Arantes J. Lejeune (UPMC) Hadoop Map-Reduce
Hadoop : une plate-forme d exécution de programmes Map-Reduce
 Hadoop : une plate-forme d exécution de programmes Map-Reduce Jonathan Lejeune École des Mines de Nantes Janvier 2015 CODEL 2014/2015 J. Lejeune (École des Mines de Nantes) Hadoop Map-Reduce Janvier 2015
Hadoop : une plate-forme d exécution de programmes Map-Reduce Jonathan Lejeune École des Mines de Nantes Janvier 2015 CODEL 2014/2015 J. Lejeune (École des Mines de Nantes) Hadoop Map-Reduce Janvier 2015
API04 Contribution. Apache Hadoop: Présentation et application dans le domaine des Data Warehouses. Introduction. Architecture
 API04 Contribution Apache Hadoop: Présentation et application dans le domaine des Data Warehouses Introduction Cette publication a pour but de présenter le framework Java libre Apache Hadoop, permettant
API04 Contribution Apache Hadoop: Présentation et application dans le domaine des Data Warehouses Introduction Cette publication a pour but de présenter le framework Java libre Apache Hadoop, permettant
MapReduce et Hadoop. Alexandre Denis [email protected]. Inria Bordeaux Sud-Ouest France ENSEIRB PG306
 MapReduce et Hadoop Alexandre Denis [email protected] Inria Bordeaux Sud-Ouest France ENSEIRB PG306 Fouille de données Recherche & indexation de gros volumes Appliquer une opération simple à beaucoup
MapReduce et Hadoop Alexandre Denis [email protected] Inria Bordeaux Sud-Ouest France ENSEIRB PG306 Fouille de données Recherche & indexation de gros volumes Appliquer une opération simple à beaucoup
Cloud Computing MapReduce Année académique 2014/15
 Cloud Computing Année académique 2014/15 Qu'est-ce que le Big Data? Source: Paul Butler (Facebook) "Visualizing Friendships", https://www.facebook.com/note.php?note_id=469716398919 2 2015 Marcel Graf Qu'est-ce
Cloud Computing Année académique 2014/15 Qu'est-ce que le Big Data? Source: Paul Butler (Facebook) "Visualizing Friendships", https://www.facebook.com/note.php?note_id=469716398919 2 2015 Marcel Graf Qu'est-ce
Map-Reduce : un cadre de programmation parallèlle pour l analyse de grandes données. Stéphane Genaud ENSIIE
 Map-Reduce : un cadre de programmation parallèlle pour l analyse de grandes données Stéphane Genaud ENSIIE Traitement de données distribuées Google a introduit Map-Reduce [Dean and Ghemawat 2004] Ils s
Map-Reduce : un cadre de programmation parallèlle pour l analyse de grandes données Stéphane Genaud ENSIIE Traitement de données distribuées Google a introduit Map-Reduce [Dean and Ghemawat 2004] Ils s
Notes de cours Practical BigData
 Notes de cours Practical BigData Nguyen-Nhut DOAN 15 janvier 2015 Introduction Ces notes personnelles traduisent la deuxième partie du cours INF553 de l Ecole Polytechnique sur les bases de données et
Notes de cours Practical BigData Nguyen-Nhut DOAN 15 janvier 2015 Introduction Ces notes personnelles traduisent la deuxième partie du cours INF553 de l Ecole Polytechnique sur les bases de données et
Introduction à Hadoop & MapReduce
 Introduction à Hadoop & MapReduce Cours 2 Benjamin Renaut MOOC / FUN 2014-2015 5 Hadoop: présentation Apache Hadoop 5-1 Projet Open Source fondation Apache. http://hadoop.apache.org/
Introduction à Hadoop & MapReduce Cours 2 Benjamin Renaut MOOC / FUN 2014-2015 5 Hadoop: présentation Apache Hadoop 5-1 Projet Open Source fondation Apache. http://hadoop.apache.org/
4 Exemples de problèmes MapReduce incrémentaux
 4 Exemples de problèmes MapReduce incrémentaux 1 / 32 Calcul des plus courtes distances à un noeud d un graphe Calcul des plus courts chemins entre toutes les paires de noeuds d un graphe Algorithme PageRank
4 Exemples de problèmes MapReduce incrémentaux 1 / 32 Calcul des plus courtes distances à un noeud d un graphe Calcul des plus courts chemins entre toutes les paires de noeuds d un graphe Algorithme PageRank
MapReduce. Malo Jaffré, Pablo Rauzy. 16 avril 2010 ENS. Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15
 MapReduce 16 avril 2010 1 / 15") MapReduce Malo Jaffré, Pablo Rauzy ENS 16 avril 2010 Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15 Qu est ce que c est? Conceptuellement Données MapReduce est un framework de calcul distribué
MapReduce Malo Jaffré, Pablo Rauzy ENS 16 avril 2010 Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15 Qu est ce que c est? Conceptuellement Données MapReduce est un framework de calcul distribué
Programmation parallèle et distribuée (Master 1 Info 2015-2016)
") Programmation parallèle et distribuée (Master 1 Info 2015-2016) Hadoop MapReduce et HDFS Note bibliographique : ce cours est largement inspiré par le cours de Benjamin Renaut (Tokidev SAS) Introduction
Programmation parallèle et distribuée (Master 1 Info 2015-2016) Hadoop MapReduce et HDFS Note bibliographique : ce cours est largement inspiré par le cours de Benjamin Renaut (Tokidev SAS) Introduction
Programmation parallèle et distribuée
 Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2015) Marc Parizeau, Département de génie électrique et de génie informatique Plan Données massives («big data») Architecture Hadoop distribution
Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2015) Marc Parizeau, Département de génie électrique et de génie informatique Plan Données massives («big data») Architecture Hadoop distribution
MapReduce. Nicolas Dugué [email protected]. M2 MIAGE Systèmes d information répartis
 MapReduce Nicolas Dugué [email protected] M2 MIAGE Systèmes d information répartis Plan 1 Introduction Big Data 2 MapReduce et ses implémentations 3 MapReduce pour fouiller des tweets 4 MapReduce
MapReduce Nicolas Dugué [email protected] M2 MIAGE Systèmes d information répartis Plan 1 Introduction Big Data 2 MapReduce et ses implémentations 3 MapReduce pour fouiller des tweets 4 MapReduce
Programmation parallèle et distribuée
 Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2014) Marc Parizeau, Département de génie électrique et de génie informatique Plan Mégadonnées («big data») Architecture Hadoop distribution
Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2014) Marc Parizeau, Département de génie électrique et de génie informatique Plan Mégadonnées («big data») Architecture Hadoop distribution
Hadoop / Big Data. Benjamin Renaut <[email protected]> MBDS 2013-2014
 Hadoop / Big Data Benjamin Renaut MBDS 2013-2014 1 Introduction Programme Planning Objectifs TP/Évaluations Introduction 1-1 Benjamin Renaut Tokidev SAS - Bureau d'étude -
Hadoop / Big Data Benjamin Renaut MBDS 2013-2014 1 Introduction Programme Planning Objectifs TP/Évaluations Introduction 1-1 Benjamin Renaut Tokidev SAS - Bureau d'étude -
Introduc)on à Map- Reduce. Vincent Leroy
on à Map- Reduce. Vincent Leroy") Introduc)on à Map- Reduce Vincent Leroy Sources Apache Hadoop Yahoo! Developer Network Hortonworks Cloudera Prac)cal Problem Solving with Hadoop and Pig Les cours seront mis en ligne sur hhp://membres.liglab.fr/leroy/
Introduc)on à Map- Reduce Vincent Leroy Sources Apache Hadoop Yahoo! Developer Network Hortonworks Cloudera Prac)cal Problem Solving with Hadoop and Pig Les cours seront mis en ligne sur hhp://membres.liglab.fr/leroy/
7 Développement d une application de MapReduce
 7 Développement d une application de MapReduce Ecrire un programme d Hadoop demande un processus : écrire une fonction map, une fonction reduce et tester localement. Ecrire ensuite un programme pour lancer
7 Développement d une application de MapReduce Ecrire un programme d Hadoop demande un processus : écrire une fonction map, une fonction reduce et tester localement. Ecrire ensuite un programme pour lancer
Fouillez facilement dans votre système Big Data. Olivier TAVARD
 Fouillez facilement dans votre système Big Data Olivier TAVARD A propos de moi : Cofondateur de la société France Labs Développeur (principalement Java) Formateur en technologies de moteurs de recherche
Fouillez facilement dans votre système Big Data Olivier TAVARD A propos de moi : Cofondateur de la société France Labs Développeur (principalement Java) Formateur en technologies de moteurs de recherche
Programmation Par Objets
 Programmation Par Objets Structures de données package java.util B. Carré Polytech Lille 1 Tableaux et structures de données Tableaux «Objets» taille fixe type des éléments : primitif (homogène) ou objets
Programmation Par Objets Structures de données package java.util B. Carré Polytech Lille 1 Tableaux et structures de données Tableaux «Objets» taille fixe type des éléments : primitif (homogène) ou objets
Hadoop, Spark & Big Data 2.0. Exploiter une grappe de calcul pour des problème des données massives
 Hadoop, Spark & Big Data 2.0 Exploiter une grappe de calcul pour des problème des données massives Qui suis-je? Félix-Antoine Fortin Génie info. (B. Ing, M. Sc, ~PhD) Passionné de Python, Data Analytics,
Hadoop, Spark & Big Data 2.0 Exploiter une grappe de calcul pour des problème des données massives Qui suis-je? Félix-Antoine Fortin Génie info. (B. Ing, M. Sc, ~PhD) Passionné de Python, Data Analytics,
Hadoop / Big Data 2014-2015 MBDS. Benjamin Renaut <[email protected]>
 Hadoop / Big Data Benjamin Renaut MBDS 2014-2015 1 Introduction Programme Planning Objectifs TP/Évaluations Introduction 1-1 Benjamin Renaut Tokidev SAS - Bureau d'étude -
Hadoop / Big Data Benjamin Renaut MBDS 2014-2015 1 Introduction Programme Planning Objectifs TP/Évaluations Introduction 1-1 Benjamin Renaut Tokidev SAS - Bureau d'étude -
Implémentation parallèle de certains algorithmes de fouille de données avec le framework MapReduce
 Implémentation parallèle de certains algorithmes de fouille de données avec le framework MapReduce Algorithmes : K-means et Apriori Maria Malek LARIS-EISTI [email protected] 1 Cloud Computing et MapReduce
Implémentation parallèle de certains algorithmes de fouille de données avec le framework MapReduce Algorithmes : K-means et Apriori Maria Malek LARIS-EISTI [email protected] 1 Cloud Computing et MapReduce
Big Data Concepts et mise en oeuvre de Hadoop
 Introduction 1. Objectif du chapitre 9 2. Le Big Data 10 2.1 Introduction 10 2.2 Informatique connectée, objets "intelligents" et données collectées 11 2.3 Les unités de mesure dans le monde Big Data 12
Introduction 1. Objectif du chapitre 9 2. Le Big Data 10 2.1 Introduction 10 2.2 Informatique connectée, objets "intelligents" et données collectées 11 2.3 Les unités de mesure dans le monde Big Data 12
Introduction aux algorithmes MapReduce. Mathieu Dumoulin (GRAAL), 14 Février 2014
, 14 Février 2014") Introduction aux algorithmes MapReduce Mathieu Dumoulin (GRAAL), 14 Février 2014 Plan Introduction de la problématique Tutoriel MapReduce Design d algorithmes MapReduce Tri, somme et calcul de moyenne
Introduction aux algorithmes MapReduce Mathieu Dumoulin (GRAAL), 14 Février 2014 Plan Introduction de la problématique Tutoriel MapReduce Design d algorithmes MapReduce Tri, somme et calcul de moyenne
http://blog.khaledtannir.net
 Algorithme de parallélisations des traitements Khaled TANNIR Doctorant CIFRE LARIS/ESTI http://blog.khaledtannir.net [email protected] 2e SéRI 2010-2011 Jeudi 17 mars 2011 Présentation Doctorant CIFRE
Algorithme de parallélisations des traitements Khaled TANNIR Doctorant CIFRE LARIS/ESTI http://blog.khaledtannir.net [email protected] 2e SéRI 2010-2011 Jeudi 17 mars 2011 Présentation Doctorant CIFRE
Plan du cours. Historique du langage http://www.oracle.com/technetwork/java/index.html. Nouveautés de Java 7
 Université Lumière Lyon 2 Faculté de Sciences Economiques et Gestion KHARKIV National University of Economic Introduction au Langage Java Master Informatique 1 ère année Julien Velcin http://mediamining.univ-lyon2.fr/velcin
Université Lumière Lyon 2 Faculté de Sciences Economiques et Gestion KHARKIV National University of Economic Introduction au Langage Java Master Informatique 1 ère année Julien Velcin http://mediamining.univ-lyon2.fr/velcin
Auto-évaluation Programmation en Java
 Auto-évaluation Programmation en Java Document: f0883test.fm 22/01/2013 ABIS Training & Consulting P.O. Box 220 B-3000 Leuven Belgium TRAINING & CONSULTING INTRODUCTION AUTO-ÉVALUATION PROGRAMMATION EN
Auto-évaluation Programmation en Java Document: f0883test.fm 22/01/2013 ABIS Training & Consulting P.O. Box 220 B-3000 Leuven Belgium TRAINING & CONSULTING INTRODUCTION AUTO-ÉVALUATION PROGRAMMATION EN
Déploiement d une architecture Hadoop pour analyse de flux. franç[email protected]
 Déploiement d une architecture Hadoop pour analyse de flux franç[email protected] 1 plan Introduction Hadoop Présentation Architecture d un cluster HDFS & MapReduce L architecture déployée Les
Déploiement d une architecture Hadoop pour analyse de flux franç[email protected] 1 plan Introduction Hadoop Présentation Architecture d un cluster HDFS & MapReduce L architecture déployée Les
Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop
 Julien Gerlier Siman Chen Rapport de projet de fin d étude ASR 2010/2011 Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop Encadrants
Julien Gerlier Siman Chen Rapport de projet de fin d étude ASR 2010/2011 Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop Encadrants
Labs Hadoop Février 2013
 SOA - BRMS - ESB - BPM CEP BAM - High Performance Compute & Data Grid - Cloud Computing - Big Data NoSQL - Analytics Labs Hadoop Février 2013 Mathias Kluba Managing Consultant Responsable offres NoSQL
SOA - BRMS - ESB - BPM CEP BAM - High Performance Compute & Data Grid - Cloud Computing - Big Data NoSQL - Analytics Labs Hadoop Février 2013 Mathias Kluba Managing Consultant Responsable offres NoSQL
Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop
 Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop Soutenance de projet ASR 27/01/2011 Julien Gerlier Siman Chen Encadrés par Bruno
Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop Soutenance de projet ASR 27/01/2011 Julien Gerlier Siman Chen Encadrés par Bruno
Programmer en JAVA. par Tama ([email protected]( [email protected])
") Programmer en JAVA par Tama ([email protected]( [email protected]) Plan 1. Présentation de Java 2. Les bases du langage 3. Concepts avancés 4. Documentation 5. Index des mots-clés 6. Les erreurs fréquentes
Programmer en JAVA par Tama ([email protected]( [email protected]) Plan 1. Présentation de Java 2. Les bases du langage 3. Concepts avancés 4. Documentation 5. Index des mots-clés 6. Les erreurs fréquentes
Big Data. Cyril Amsellem Consultant avant-vente. 16 juin 2011. Talend 2010 1
 Big Data Cyril Amsellem Consultant avant-vente 16 juin 2011 Talend 2010 1 Big Data Architecture globale Hadoop Les projets Hadoop (partie 1) Hadoop-Core : projet principal. HDFS : système de fichiers distribués
Big Data Cyril Amsellem Consultant avant-vente 16 juin 2011 Talend 2010 1 Big Data Architecture globale Hadoop Les projets Hadoop (partie 1) Hadoop-Core : projet principal. HDFS : système de fichiers distribués
Cartographie des solutions BigData
 Cartographie des solutions BigData Panorama du marché et prospective 1 1 Solutions BigData Défi(s) pour les fournisseurs Quel marché Architectures Acteurs commerciaux Solutions alternatives 2 2 Quels Défis?
Cartographie des solutions BigData Panorama du marché et prospective 1 1 Solutions BigData Défi(s) pour les fournisseurs Quel marché Architectures Acteurs commerciaux Solutions alternatives 2 2 Quels Défis?
Développement Logiciel
 Développement Logiciel Éxamen session 1-2012-2013 (Vendedi 25 mai, 9h-11h) Seuls les documents liés directement au cours sont autorisés (comme dit sur le site) : sujets de TD, notes de cours, notes personnelles
Développement Logiciel Éxamen session 1-2012-2013 (Vendedi 25 mai, 9h-11h) Seuls les documents liés directement au cours sont autorisés (comme dit sur le site) : sujets de TD, notes de cours, notes personnelles
Java Licence Professionnelle 2009-2010. Cours 7 : Classes et méthodes abstraites
 Java Licence Professionnelle 2009-2010 Cours 7 : Classes et méthodes abstraites 1 Java Classes et méthodes abstraites - Le mécanisme des classes abstraites permet de définir des comportements (méthodes)
Java Licence Professionnelle 2009-2010 Cours 7 : Classes et méthodes abstraites 1 Java Classes et méthodes abstraites - Le mécanisme des classes abstraites permet de définir des comportements (méthodes)
Ricco Rakotomalala http://eric.univ-lyon2.fr/~ricco/cours/cours_programmation_r.html. R.R. Université Lyon 2
 Ricco Rakotomalala http://eric.univ-lyon2.fr/~ricco/cours/cours_programmation_r.html 1 Plan de présentation 1. L écosystème Hadoop 2. Principe de programmation MapReduce 3. Programmation des fonctions
Ricco Rakotomalala http://eric.univ-lyon2.fr/~ricco/cours/cours_programmation_r.html 1 Plan de présentation 1. L écosystème Hadoop 2. Principe de programmation MapReduce 3. Programmation des fonctions
NoSQL. Introduction 1/30. I NoSQL : Not Only SQL, ce n est pas du relationnel, et le contexte. I table d associations - Map - de couples (clef,valeur)
") 1/30 2/30 Anne-Cécile Caron Master MIAGE - SGBD 1er trimestre 2014-2015 I : Not Only SQL, ce n est pas du relationnel, et le contexte d utilisation n est donc pas celui des SGBDR. I Origine : recherche
1/30 2/30 Anne-Cécile Caron Master MIAGE - SGBD 1er trimestre 2014-2015 I : Not Only SQL, ce n est pas du relationnel, et le contexte d utilisation n est donc pas celui des SGBDR. I Origine : recherche
Acquisition des données - Big Data. Dario VEGA Senior Sales Consultant
 Acquisition des données - Big Data Dario VEGA Senior Sales Consultant The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated
Acquisition des données - Big Data Dario VEGA Senior Sales Consultant The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated
Introduction à Java. Matthieu Herrb CNRS-LAAS. Mars 2014. http://homepages.laas.fr/matthieu/cours/java/java.pdf
 Introduction à Java Matthieu Herrb CNRS-LAAS http://homepages.laas.fr/matthieu/cours/java/java.pdf Mars 2014 Plan 1 Concepts 2 Éléments du langage 3 Classes et objets 4 Packages 2/28 Histoire et motivations
Introduction à Java Matthieu Herrb CNRS-LAAS http://homepages.laas.fr/matthieu/cours/java/java.pdf Mars 2014 Plan 1 Concepts 2 Éléments du langage 3 Classes et objets 4 Packages 2/28 Histoire et motivations
Un ordonnanceur stupide
 Un ordonnanceur simple Université Paris Sud L objet des exercices qui suivent est de créer un ordonanceur implantant l algorithme du tourniquet ( round-robin scheduler ). La technique utilisée pour élire
Un ordonnanceur simple Université Paris Sud L objet des exercices qui suivent est de créer un ordonanceur implantant l algorithme du tourniquet ( round-robin scheduler ). La technique utilisée pour élire
Synchro et Threads Java TM
 Synchro et Threads Java TM NICOD JEAN-MARC Master 2 Informatique Université de Franche-Comté UFR des Sciences et Techniques septembre 2008 NICOD JEAN-MARC Synchro et Threads avec Java TM 1 / 32 Sommaire
Synchro et Threads Java TM NICOD JEAN-MARC Master 2 Informatique Université de Franche-Comté UFR des Sciences et Techniques septembre 2008 NICOD JEAN-MARC Synchro et Threads avec Java TM 1 / 32 Sommaire
Package Java.util Classe générique
 Package Java.util Classe générique 1 Classe Vector La taille est dynamique: dès qu un tableau vectoriel est plein, sa taille est doublée, triplée, etc. automatiquement Les cases sont de type Object add(object
Package Java.util Classe générique 1 Classe Vector La taille est dynamique: dès qu un tableau vectoriel est plein, sa taille est doublée, triplée, etc. automatiquement Les cases sont de type Object add(object
Programmation Réseau. Sécurité Java. [email protected]. UFR Informatique 2012-2013. jeudi 4 avril 13
 Programmation Réseau Sécurité Java [email protected] UFR Informatique 2012-2013 Java Sécurité? différentes sécurités disponibles et contrôlables intégrité contrôle d accès signature/authentification/cryptographie
Programmation Réseau Sécurité Java [email protected] UFR Informatique 2012-2013 Java Sécurité? différentes sécurités disponibles et contrôlables intégrité contrôle d accès signature/authentification/cryptographie
Logiciel Libre Cours 3 Fondements: Génie Logiciel
 Logiciel Libre Cours 3 Fondements: Génie Logiciel Stefano Zacchiroli [email protected] Laboratoire PPS, Université Paris Diderot 2013 2014 URL http://upsilon.cc/zack/teaching/1314/freesoftware/
Logiciel Libre Cours 3 Fondements: Génie Logiciel Stefano Zacchiroli [email protected] Laboratoire PPS, Université Paris Diderot 2013 2014 URL http://upsilon.cc/zack/teaching/1314/freesoftware/
Sommaire. 3. Les grands principes de GFS L architecture L accès de fichier en lecture L accès de fichier en écriture Bilan
 1 Sommaire 1. Google en chiffres 2. Les raisons d être de GFS 3. Les grands principes de GFS L architecture L accès de fichier en lecture L accès de fichier en écriture Bilan 4. Les Evolutions et Alternatives
1 Sommaire 1. Google en chiffres 2. Les raisons d être de GFS 3. Les grands principes de GFS L architecture L accès de fichier en lecture L accès de fichier en écriture Bilan 4. Les Evolutions et Alternatives
Les technologies du Big Data
 Les technologies du Big Data PRÉSENTÉ AU 40 E CONGRÈS DE L ASSOCIATION DES ÉCONOMISTES QUÉBÉCOIS PAR TOM LANDRY, CONSEILLER SENIOR LE 20 MAI 2015 WWW.CRIM.CA TECHNOLOGIES: DES DONNÉES JUSQU'À L UTILISATEUR
Les technologies du Big Data PRÉSENTÉ AU 40 E CONGRÈS DE L ASSOCIATION DES ÉCONOMISTES QUÉBÉCOIS PAR TOM LANDRY, CONSEILLER SENIOR LE 20 MAI 2015 WWW.CRIM.CA TECHNOLOGIES: DES DONNÉES JUSQU'À L UTILISATEUR
Polymorphisme, la classe Object, les package et la visibilité en Java... 1
 Polymorphisme, la classe Object, les package et la visibilité en Java. Polymorphisme, la classe Object, les package et la visibilité en Java.... 1 Polymorphisme.... 1 Le DownCast... 4 La Classe Object....
Polymorphisme, la classe Object, les package et la visibilité en Java. Polymorphisme, la classe Object, les package et la visibilité en Java.... 1 Polymorphisme.... 1 Le DownCast... 4 La Classe Object....
Traduction des Langages : Le Compilateur Micro Java
 BARABZAN Jean-René OUAHAB Karim TUCITO David 2A IMA Traduction des Langages : Le Compilateur Micro Java µ Page 1 Introduction Le but de ce projet est d écrire en JAVA un compilateur Micro-Java générant
BARABZAN Jean-René OUAHAB Karim TUCITO David 2A IMA Traduction des Langages : Le Compilateur Micro Java µ Page 1 Introduction Le but de ce projet est d écrire en JAVA un compilateur Micro-Java générant
La technologie Java Card TM
 Présentation interne au CESTI La technologie Java Card TM [email protected] http://dept-info.labri.u-bordeaux.fr/~sauveron 8 novembre 2002 Plan Qu est ce que Java Card? Historique Les avantages
Présentation interne au CESTI La technologie Java Card TM [email protected] http://dept-info.labri.u-bordeaux.fr/~sauveron 8 novembre 2002 Plan Qu est ce que Java Card? Historique Les avantages
BIG DATA en Sciences et Industries de l Environnement
 BIG DATA en Sciences et Industries de l Environnement François Royer www.datasio.com 21 mars 2012 FR Big Data Congress, Paris 2012 1/23 Transport terrestre Traçabilité Océanographie Transport aérien Télémétrie
BIG DATA en Sciences et Industries de l Environnement François Royer www.datasio.com 21 mars 2012 FR Big Data Congress, Paris 2012 1/23 Transport terrestre Traçabilité Océanographie Transport aérien Télémétrie
LMI 2. Programmation Orientée Objet POO - Cours 9. Said Jabbour. [email protected] www.cril.univ-artois.fr/~jabbour
 LMI 2 Programmation Orientée Objet POO - Cours 9 Said Jabbour [email protected] www.cril.univ-artois.fr/~jabbour CRIL UMR CNRS 8188 Faculté des Sciences - Univ. Artois Février 2011 Les collections
LMI 2 Programmation Orientée Objet POO - Cours 9 Said Jabbour [email protected] www.cril.univ-artois.fr/~jabbour CRIL UMR CNRS 8188 Faculté des Sciences - Univ. Artois Février 2011 Les collections
Département Informatique 5 e année 2013-2014. Hadoop: Optimisation et Ordonnancement
 École Polytechnique de l Université de Tours 64, Avenue Jean Portalis 37200 TOURS, FRANCE Tél. +33 (0)2 47 36 14 14 www.polytech.univ-tours.fr Département Informatique 5 e année 2013-2014 Hadoop: Optimisation
École Polytechnique de l Université de Tours 64, Avenue Jean Portalis 37200 TOURS, FRANCE Tél. +33 (0)2 47 36 14 14 www.polytech.univ-tours.fr Département Informatique 5 e année 2013-2014 Hadoop: Optimisation
Cours 8 Not Only SQL
 Cours 8 Not Only SQL Cours 8 - NoSQL Qu'est-ce que le NoSQL? Cours 8 - NoSQL Qu'est-ce que le NoSQL? Catégorie de SGBD s'affranchissant du modèle relationnel des SGBDR. Mouvance apparue par le biais des
Cours 8 Not Only SQL Cours 8 - NoSQL Qu'est-ce que le NoSQL? Cours 8 - NoSQL Qu'est-ce que le NoSQL? Catégorie de SGBD s'affranchissant du modèle relationnel des SGBDR. Mouvance apparue par le biais des
Panorama des solutions analytiques existantes
 Arnaud LAROCHE Julien DAMON Panorama des solutions analytiques existantes SFdS Méthodes et Logiciels - 16 janvier 2014 - Données Massives Ne sont ici considérés que les solutions autour de l environnement
Arnaud LAROCHE Julien DAMON Panorama des solutions analytiques existantes SFdS Méthodes et Logiciels - 16 janvier 2014 - Données Massives Ne sont ici considérés que les solutions autour de l environnement
INEX. Informatique en Nuage : Expérimentations et Vérification. Livrable n M2.1 ÉTUDE ET PARALLÉLISATION. Jérôme Richard
 INEX Informatique en Nuage : Expérimentations et Vérification Livrable n M2.1 ÉTUDE ET PARALLÉLISATION D ALGORITHMES POUR L ANALYSE DE GRANDS GRAPHES DE RÉSEAUX SOCIAUX Jérôme Richard Univ. Orléans, INSA
INEX Informatique en Nuage : Expérimentations et Vérification Livrable n M2.1 ÉTUDE ET PARALLÉLISATION D ALGORITHMES POUR L ANALYSE DE GRANDS GRAPHES DE RÉSEAUX SOCIAUX Jérôme Richard Univ. Orléans, INSA
Chapitre 10. Les interfaces Comparable et Comparator 1
 Chapitre 10: Les interfaces Comparable et Comparator 1/5 Chapitre 10 Les interfaces Comparable et Comparator 1 1 Ce chapitre a été extrait du document "Objets, Algorithmes, Patterns" de [René Lalement],
Chapitre 10: Les interfaces Comparable et Comparator 1/5 Chapitre 10 Les interfaces Comparable et Comparator 1 1 Ce chapitre a été extrait du document "Objets, Algorithmes, Patterns" de [René Lalement],
TP1 : Initiation à Java et Eclipse
 TP1 : Initiation à Java et Eclipse 1 TP1 : Initiation à Java et Eclipse Systèmes d Exploitation Avancés I. Objectifs du TP Ce TP est une introduction au langage Java. Il vous permettra de comprendre les
TP1 : Initiation à Java et Eclipse 1 TP1 : Initiation à Java et Eclipse Systèmes d Exploitation Avancés I. Objectifs du TP Ce TP est une introduction au langage Java. Il vous permettra de comprendre les
Hadoop / Big Data. Benjamin Renaut <[email protected]> MBDS 2014-2015
 Hadoop / Big Data Benjamin Renaut MBDS 2014-2015 6 map/reduce et Hadoop: exemples plus avancés Exemple: parcours de graphe 6-1 On cherche à déterminer la profondeur maximale
Hadoop / Big Data Benjamin Renaut MBDS 2014-2015 6 map/reduce et Hadoop: exemples plus avancés Exemple: parcours de graphe 6-1 On cherche à déterminer la profondeur maximale
Importation et exportation de données dans HDFS
 1 Importation et exportation de données dans HDFS Introduction Dans une installation type, Hadoop se trouve au cœur d un flux de données complexe. Ces données proviennent souvent de systèmes disparates
1 Importation et exportation de données dans HDFS Introduction Dans une installation type, Hadoop se trouve au cœur d un flux de données complexe. Ces données proviennent souvent de systèmes disparates
J2SE Threads, 1ère partie Principe Cycle de vie Création Synchronisation
 J2SE Threads, 1ère partie Principe Cycle de vie Création Synchronisation Cycle Ingénierie 2e année SIGL Dernière mise à jour : 19/10/2006 Christophe Porteneuve Threads Principes Cycle de vie Création java.lang.thread
J2SE Threads, 1ère partie Principe Cycle de vie Création Synchronisation Cycle Ingénierie 2e année SIGL Dernière mise à jour : 19/10/2006 Christophe Porteneuve Threads Principes Cycle de vie Création java.lang.thread
6 - Le système de gestion de fichiers F. Boyer, UJF-Laboratoire Lig, [email protected]
 6 - Le système de gestion de fichiers F. Boyer, UJF-Laboratoire Lig, [email protected] Interface d un SGF Implémentation d un SGF Gestion de la correspondance entre la structure logique et la structure
6 - Le système de gestion de fichiers F. Boyer, UJF-Laboratoire Lig, [email protected] Interface d un SGF Implémentation d un SGF Gestion de la correspondance entre la structure logique et la structure
HADOOP ET SON ÉCOSYSTÈME
 HADOOP ET SON ÉCOSYSTÈME Mars 2013 2012 Affini-Tech - Diffusion restreinte 1 AFFINI-TECH Méthodes projets Outils de reporting & Data-visualisation Business & Analyses BigData Modélisation Hadoop Technos
HADOOP ET SON ÉCOSYSTÈME Mars 2013 2012 Affini-Tech - Diffusion restreinte 1 AFFINI-TECH Méthodes projets Outils de reporting & Data-visualisation Business & Analyses BigData Modélisation Hadoop Technos
Projet gestion d'objets dupliqués
 Projet gestion d'objets dupliqués Daniel Hagimont [email protected] 1 Projet Service de gestion d'objets dupliqués Mise en cohérence lors de la prise d'un verrou sur un objet Pas de verrous imbriqués
Projet gestion d'objets dupliqués Daniel Hagimont [email protected] 1 Projet Service de gestion d'objets dupliqués Mise en cohérence lors de la prise d'un verrou sur un objet Pas de verrous imbriqués
Big Data : utilisation d un cluster Hadoop HDFS Map/Reduce HBase
 Big Data : utilisation d un cluster cluster Cécile Cavet cecile.cavet at apc.univ-paris7.fr Centre François Arago (FACe), Laboratoire APC, Université Paris Diderot LabEx UnivEarthS 14 Janvier 2014 C. Cavet
Big Data : utilisation d un cluster cluster Cécile Cavet cecile.cavet at apc.univ-paris7.fr Centre François Arago (FACe), Laboratoire APC, Université Paris Diderot LabEx UnivEarthS 14 Janvier 2014 C. Cavet
Remote Method Invocation (RMI)
") Remote Method Invocation (RMI) TP Réseau Université Paul Sabatier Master Informatique 1 ère Année Année 2006/2007 Plan Objectifs et Inconvénients de RMI Fonctionnement Définitions Architecture et principe
Remote Method Invocation (RMI) TP Réseau Université Paul Sabatier Master Informatique 1 ère Année Année 2006/2007 Plan Objectifs et Inconvénients de RMI Fonctionnement Définitions Architecture et principe
Bases de Données NoSQL
 Bases de Données NoSQL LI328 Technologies Web Mohamed-Amine Baazizi Transparents de Bernd Amann UPMC - LIP6 LI328 Technologies Web (B. Amann) 1 SGBD Universalité Systèmes «SQL» : Facilité d'utilisation
Bases de Données NoSQL LI328 Technologies Web Mohamed-Amine Baazizi Transparents de Bernd Amann UPMC - LIP6 LI328 Technologies Web (B. Amann) 1 SGBD Universalité Systèmes «SQL» : Facilité d'utilisation
Projet de programmation (IK3) : TP n 1 Correction
 : TP n 1 Correction") Projet de programmation (IK3) : TP n 1 Correction Semaine du 20 septembre 2010 1 Entrées/sorties, types de bases et structures de contrôle Tests et types de bases Tests et types de bases (entiers) public
Projet de programmation (IK3) : TP n 1 Correction Semaine du 20 septembre 2010 1 Entrées/sorties, types de bases et structures de contrôle Tests et types de bases Tests et types de bases (entiers) public
M2 GL UE DOC «In memory analytics»
 M2 GL UE DOC «In memory analytics» Alexandre Termier 2014/2015 Sources Travaux Amplab, U.C. Berkeley Slides Ion Stoica Présentations Databricks Slides Pat McDonough Articles de M. Zaharia et al. sur les
M2 GL UE DOC «In memory analytics» Alexandre Termier 2014/2015 Sources Travaux Amplab, U.C. Berkeley Slides Ion Stoica Présentations Databricks Slides Pat McDonough Articles de M. Zaharia et al. sur les
Formation Cloudera Data Analyst Utiliser Pig, Hive et Impala avec Hadoop
 Passez au niveau supérieur en termes de connaissance grâce à la formation Data Analyst de Cloudera. Public Durée Objectifs Analystes de données, business analysts, développeurs et administrateurs qui ont
Passez au niveau supérieur en termes de connaissance grâce à la formation Data Analyst de Cloudera. Public Durée Objectifs Analystes de données, business analysts, développeurs et administrateurs qui ont
L écosystème Hadoop Nicolas Thiébaud [email protected]. Tuesday, July 2, 13
 L écosystème Hadoop Nicolas Thiébaud [email protected] HUG France 250 membres sur la mailing liste 30 présentations 9 meetups organisés, de 20 à 100 invités Présence de Cloudera, MapR, Hortonworks,
L écosystème Hadoop Nicolas Thiébaud [email protected] HUG France 250 membres sur la mailing liste 30 présentations 9 meetups organisés, de 20 à 100 invités Présence de Cloudera, MapR, Hortonworks,
R+Hadoop = Rhadoop* Des logiciels libres complémentaires, une implémentation, une réponse au nouveau paradigme du bigdata!
 R+Hadoop = Rhadoop* * Des logiciels libres complémentaires, une implémentation, une réponse au nouveau paradigme du bigdata! 27 Janvier 2014 / Université Paul Sabatier / DTSI / David Tsang-Hin-Sun Big
R+Hadoop = Rhadoop* * Des logiciels libres complémentaires, une implémentation, une réponse au nouveau paradigme du bigdata! 27 Janvier 2014 / Université Paul Sabatier / DTSI / David Tsang-Hin-Sun Big
Web Tier : déploiement de servlets
 Web Tier : déploiement de servlets 1 / 35 Plan 1 Introduction 2 Servlet : Principe de fonctionnement 3 Création et développement sur un serveur JEE 4 Quelques méthodes de l API des servlets 5 Utilisation
Web Tier : déploiement de servlets 1 / 35 Plan 1 Introduction 2 Servlet : Principe de fonctionnement 3 Création et développement sur un serveur JEE 4 Quelques méthodes de l API des servlets 5 Utilisation
Fouille de données massives avec Hadoop
 Fouille de données massives avec Hadoop Sebastiao Correia [email protected] Talend 2013 AAFD'14 29-30 avril 2014 1 Agenda Présentation de Talend Définition du Big Data Le framework Hadoop 3 thématiques
Fouille de données massives avec Hadoop Sebastiao Correia [email protected] Talend 2013 AAFD'14 29-30 avril 2014 1 Agenda Présentation de Talend Définition du Big Data Le framework Hadoop 3 thématiques
Prénom : Matricule : Sigle et titre du cours Groupe Trimestre INF1101 Algorithmes et structures de données Tous H2004. Loc Jeudi 29/4/2004
 Questionnaire d'examen final INF1101 Sigle du cours Nom : Signature : Prénom : Matricule : Sigle et titre du cours Groupe Trimestre INF1101 Algorithmes et structures de données Tous H2004 Professeur(s)
Questionnaire d'examen final INF1101 Sigle du cours Nom : Signature : Prénom : Matricule : Sigle et titre du cours Groupe Trimestre INF1101 Algorithmes et structures de données Tous H2004 Professeur(s)
Corrigé des exercices sur les références
 Corrigé des exercices sur les références Exercice 3.1.1 dessin Pour cet exercice, vous allez dessiner des structures de données au moyen de petits schémas analogues à ceux du cours, comportant la pile
Corrigé des exercices sur les références Exercice 3.1.1 dessin Pour cet exercice, vous allez dessiner des structures de données au moyen de petits schémas analogues à ceux du cours, comportant la pile
as Architecture des Systèmes d Information
 Plan Plan Programmation - Introduction - Nicolas Malandain March 14, 2005 Introduction à Java 1 Introduction Présentation Caractéristiques Le langage Java 2 Types et Variables Types simples Types complexes
Plan Plan Programmation - Introduction - Nicolas Malandain March 14, 2005 Introduction à Java 1 Introduction Présentation Caractéristiques Le langage Java 2 Types et Variables Types simples Types complexes
Big Graph Data Forum Teratec 2013
 Big Graph Data Forum Teratec 2013 MFG Labs 35 rue de Châteaudun 75009 Paris, France www.mfglabs.com twitter: @mfg_labs Julien Laugel MFG Labs [email protected] @roolio SOMMAIRE MFG Labs Contexte
Big Graph Data Forum Teratec 2013 MFG Labs 35 rue de Châteaudun 75009 Paris, France www.mfglabs.com twitter: @mfg_labs Julien Laugel MFG Labs [email protected] @roolio SOMMAIRE MFG Labs Contexte
Livre. blanc. Solution Hadoop d entreprise d EMC. Stockage NAS scale-out Isilon et Greenplum HD. Février 2012
 Livre blanc Solution Hadoop d entreprise d EMC Stockage NAS scale-out Isilon et Greenplum HD Par Julie Lockner et Terri McClure, Analystes seniors Février 2012 Ce livre blanc d ESG, qui a été commandé
Livre blanc Solution Hadoop d entreprise d EMC Stockage NAS scale-out Isilon et Greenplum HD Par Julie Lockner et Terri McClure, Analystes seniors Février 2012 Ce livre blanc d ESG, qui a été commandé
Avant-propos. Organisation du livre
 Avant-propos Avec Hadoop par la pratique, les développeurs vont apprendre à maîtriser Hadoop et vont acquérir de nombreuses compétences sur la résolution de problèmes à l aide de ce framework. Ils vont
Avant-propos Avec Hadoop par la pratique, les développeurs vont apprendre à maîtriser Hadoop et vont acquérir de nombreuses compétences sur la résolution de problèmes à l aide de ce framework. Ils vont
Structure d un programme et Compilation Notions de classe et d objet Syntaxe
 Cours1 Structure d un programme et Compilation Notions de classe et d objet Syntaxe POO 1 Programmation Orientée Objet Un ensemble d objet qui communiquent Pourquoi POO Conception abstraction sur les types
Cours1 Structure d un programme et Compilation Notions de classe et d objet Syntaxe POO 1 Programmation Orientée Objet Un ensemble d objet qui communiquent Pourquoi POO Conception abstraction sur les types
RMI. Remote Method Invocation: permet d'invoquer des méthodes d'objets distants.
 RMI Remote Method Invocation: permet d'invoquer des méthodes d'objets distants. Méthode proche de RPC. Outils et classes qui rendent l'implantation d'appels de méthodes d'objets distants aussi simples
RMI Remote Method Invocation: permet d'invoquer des méthodes d'objets distants. Méthode proche de RPC. Outils et classes qui rendent l'implantation d'appels de méthodes d'objets distants aussi simples
Info0604 Programmation multi-threadée. Cours 5. Programmation multi-threadée en Java
 Info0604 Programmation multi-threadée Cours 5 Programmation multi-threadée en Java Pierre Delisle Université de Reims Champagne-Ardenne Département de Mathématiques et Informatique 18 février 2015 Plan
Info0604 Programmation multi-threadée Cours 5 Programmation multi-threadée en Java Pierre Delisle Université de Reims Champagne-Ardenne Département de Mathématiques et Informatique 18 février 2015 Plan
EPREUVE OPTIONNELLE d INFORMATIQUE CORRIGE
 EPREUVE OPTIONNELLE d INFORMATIQUE CORRIGE QCM Remarque : - A une question correspond au moins 1 réponse juste - Cocher la ou les bonnes réponses Barème : - Une bonne réponse = +1 - Pas de réponse = 0
EPREUVE OPTIONNELLE d INFORMATIQUE CORRIGE QCM Remarque : - A une question correspond au moins 1 réponse juste - Cocher la ou les bonnes réponses Barème : - Une bonne réponse = +1 - Pas de réponse = 0
Machines virtuelles fonctionnelles (suite) Compilation ML Java
 Compilation ML Java") Machines virtuelles fonctionnelles (suite) Compilation ML Java Cours de Compilation Avancée (MI190) Benjamin Canou Université Pierre et Maire Curie Année 2011/2012 Semaine 3 Machines virtuelles fonctionnelles
Machines virtuelles fonctionnelles (suite) Compilation ML Java Cours de Compilation Avancée (MI190) Benjamin Canou Université Pierre et Maire Curie Année 2011/2012 Semaine 3 Machines virtuelles fonctionnelles
Licence Bio Informatique Année 2004-2005. Premiers pas. Exercice 1 Hello World parce qu il faut bien commencer par quelque chose...
 Université Paris 7 Programmation Objet Licence Bio Informatique Année 2004-2005 TD n 1 - Correction Premiers pas Exercice 1 Hello World parce qu il faut bien commencer par quelque chose... 1. Enregistrez
Université Paris 7 Programmation Objet Licence Bio Informatique Année 2004-2005 TD n 1 - Correction Premiers pas Exercice 1 Hello World parce qu il faut bien commencer par quelque chose... 1. Enregistrez
WEBSERVICES. Michael Fortier. Master Informatique 2ème année. [email protected] A308, Université de Paris 13
 WEBSERVICES Michael Fortier Master Informatique 2ème année [email protected] A308, Université de Paris 13 https ://lipn.univ-paris13.fr/ fortier/enseignement/webservices/ Sommaire 1 Rappels
WEBSERVICES Michael Fortier Master Informatique 2ème année [email protected] A308, Université de Paris 13 https ://lipn.univ-paris13.fr/ fortier/enseignement/webservices/ Sommaire 1 Rappels
Environnements de développement (intégrés)
") Environnements de développement (intégrés) Tests unitaires, outils de couverture de code Patrick Labatut [email protected] http://www.di.ens.fr/~labatut/ Département d informatique École normale supérieure
Environnements de développement (intégrés) Tests unitaires, outils de couverture de code Patrick Labatut [email protected] http://www.di.ens.fr/~labatut/ Département d informatique École normale supérieure
TP3 : Manipulation et implantation de systèmes de fichiers 1
 École Normale Supérieure Systèmes et réseaux Année 2012-2013 TP3 : Manipulation et implantation de systèmes de fichiers 1 1 Répertoire de travail courant Le but de l exercice est d écrire une commande
École Normale Supérieure Systèmes et réseaux Année 2012-2013 TP3 : Manipulation et implantation de systèmes de fichiers 1 1 Répertoire de travail courant Le but de l exercice est d écrire une commande
Flux de données Lecture/Ecriture Fichiers
 Flux de données Lecture/Ecriture Fichiers 1 Un flux de données est un objet qui représente une suite d octets d un programme pour une certaine destination ou issus d une source pour un programme flux d
Flux de données Lecture/Ecriture Fichiers 1 Un flux de données est un objet qui représente une suite d octets d un programme pour une certaine destination ou issus d une source pour un programme flux d
Our experience in using Apache Giraph for computing the diameter of large graphs. Paul Bertot - Flavian Jacquot
 Our experience in using Apache Giraph for computing the diameter of large graphs Paul Bertot - Flavian Jacquot Plan 1. 2. 3. 4. 5. 6. Contexte Hadoop Giraph L étude Partitionnement ifub 2 1. Contexte -
Our experience in using Apache Giraph for computing the diameter of large graphs Paul Bertot - Flavian Jacquot Plan 1. 2. 3. 4. 5. 6. Contexte Hadoop Giraph L étude Partitionnement ifub 2 1. Contexte -
Technologies du Web. Ludovic DENOYER - [email protected]. Février 2014 UPMC
 Technologies du Web Ludovic DENOYER - [email protected] UPMC Février 2014 Ludovic DENOYER - [email protected] Technologies du Web Plan Retour sur les BDs Le service Search Un peu plus sur les
Technologies du Web Ludovic DENOYER - [email protected] UPMC Février 2014 Ludovic DENOYER - [email protected] Technologies du Web Plan Retour sur les BDs Le service Search Un peu plus sur les
Chapitre VI- La validation de la composition.
 Chapitre VI- La validation de la composition. Objectifs du chapitre : Expliquer les conséquences de l utilisation de règles de typage souples dans SEP. Présenter le mécanisme de validation des connexions
Chapitre VI- La validation de la composition. Objectifs du chapitre : Expliquer les conséquences de l utilisation de règles de typage souples dans SEP. Présenter le mécanisme de validation des connexions
Une introduction à Java
 Une introduction à Java IFT 287 (Semaine 1) UNIVERSITÉ DE SHERBROOKE 1 Java - Historique Développé par Sun Microsystems en 1994 Inventeur James Gosling (canadien!) Objectif langage sûr (fortement typé)
Une introduction à Java IFT 287 (Semaine 1) UNIVERSITÉ DE SHERBROOKE 1 Java - Historique Développé par Sun Microsystems en 1994 Inventeur James Gosling (canadien!) Objectif langage sûr (fortement typé)
Objets et Programmation. origine des langages orientés-objet
 Objets et Programmation origine des langages orientés-objet modularité, encapsulation objets, classes, messages exemples en Java héritage, liaison dynamique G. Falquet, Th. Estier CUI Université de Genève
Objets et Programmation origine des langages orientés-objet modularité, encapsulation objets, classes, messages exemples en Java héritage, liaison dynamique G. Falquet, Th. Estier CUI Université de Genève
Alfstore workflow framework Spécification technique
 Alfstore workflow framework Spécification technique Version 0.91 (2012-08-03) www.alfstore.com Email: [email protected] Alfstore workflow framework 2012-10-28 1/28 Historique des versions Version Date
Alfstore workflow framework Spécification technique Version 0.91 (2012-08-03) www.alfstore.com Email: [email protected] Alfstore workflow framework 2012-10-28 1/28 Historique des versions Version Date