Statistiques. Rappels de cours et travaux dirigés. Master 1 Biologie et technologie du végétal. Année
|
|
|
- Jean-Philippe Lessard
- il y a 8 ans
- Total affichages :
Transcription
1 Master 1 Biologie et technologie du végétal Année Statistiques Rappels de cours et travaux dirigés (Seul ce document sera autorisé en examen) auteur : Jean-Marc Labatte jean-marc.labatte@univ-angers.fr -1-

2 SOMMAIRE Table des matières Introduction...4 I STATISTIQUES DESCRIPTIVES...6 Fiche 1 Variable qualitative...7 Fiche Couple de variables qualitatives...8 Fiche 3 Variable quantitative...9 Fiche 4 Couple de variables quantitatives - Corrélation...11 Fiche 5 Couple variable quantitative variable qualitative...15 Fiche 6 Estimation ponctuelle d'une moyenne et d'un écart-type, Intervalle de confiance...16 Fiche 7 Estimation ponctuelle d'une fréquence, Intervalle de confiance...0 II TESTS ELEMENTAIRES SUR VARIABLES QUALITATIVES...1 Fiche 8 Comparaison d'une proportion à une référence...3 Fiche 9 Test de conformité à une distribution : test du Chi (génétique)...4 Fiche 10 Test d'indépendance : test du Chi...6 Fiche 11 Comparaison de deux ou plusieurs distributions : test du Chi...8 III TESTS ELEMENTAIRES SUR VARIABLES QUANTITATIVES...9 Fiche 1 Comparaison d'une moyenne à une valeur référence...30 Fiche 13 Comparaison de deux moyennes : t - test...33 Fiche 14 Comparaison de deux moyennes appariées : t-test apparié...35 Fiche 15 Comparaison de moyennes : tests non paramétriques de Mann Whitney - Wilcoxon. 37 Fiche 16 Comparaison de deux variances : Test F...38 Fiche 17 Test de conformité à une distribution : test du...40 Fiche 18 Normalité d'une distribution...41 Fiche 19 Test du coefficient de corrélation...43 IV COMPARAISON DE MOYENNES : ANOVA A UN FACTEUR...44 Fiche 0 Test ANOVA...54 Fiche Validation du modèle...58 Fiche 3 Robustesse de l'anova- Test de Kruskal Wallis...61 Fiche 4 Planification expérimentale...6 Fiche 5 Comparaisons multiples...65 V COMPARAISONS DE MOYENNES : ANOVA à FACTEURS...66 Fiche 6 Test ANOVA...67 Fiche 7 Validation...69 Fiche 8 Interaction entre facteurs...70 VI REGRESSION LINEAIRE SIMPLE...71 Fiche 9 Modèle de régression linéaire simple - Ajustement...7 Fiche 30 Validation du modèle de régression linéaire simple...75 Fiche 31 Remédiation par changement de variables...78 Fiche 3 Tests sur les paramètres - ANOVA...79 Fiche 33 Prédiction...81 Fiche 34 Diagnostics des points...8 VII REGRESSION LINEAIRE MULTIPLE...83 Fiche 35 Test d'un modèle...85 Fiche 36 Recherche du meilleur modèle : stepwise regression...86 Fiche 37 Validation du modèle...88 Annexe A : Lois de probabilités usuelles...90 Annexe B : Tables usuelles...9 Annexe C : Installation de R et quelques commandes
.")
3 Introduction Logiciel, R-commander, ade4 : Le cours et les TD seront illustrés à l'aide du logiciel, version libre du logiciel S-plus. Ce logiciel développé par des statisticiens pour des statisticiens est particulièrement bien adapté à l'analyse statistique descriptive, inférentielle et exploratoire. Pour faciliter son utilisation, nous utilisons un interface appelé R commander. Pour l'analyse factorielle nous recommandons l'usage de ade4 développé par l'université de Lyon. L'apprentissage de ce logiciel est sans doute plus délicat que les logiciels commerciaux mais permet à tous de disposer d'un outil gratuit, très performant, en perpétuelle évolution, exploitable dans toutes les circonstances et permettant à l'utilisateur une totale liberté dans ses choix d'analyse. Quelques liens en statistiques : : mathsv de l'université de Lyon reprend l'ensemble des bases de mathématiques, probabilités et statistiques que devraient posséder les étudiants de biologie. Présentation simple, rigoureuse, adaptée aux biologistes. : Site développé par l'université de Lyon1 sur l'utilisation des statistiques en Biologie, le meilleur site exploitant le logiciel R. : Plan de formation à la pratique statistique développé par la formation permanente de l'inra, bien adaptée à la biologie et pouvant être utilisé à différents niveaux. : Cours de statistiques appliqués assez complet : Ensemble de documents statistiques très intéressants appliqués principalement à l'agronomie. : Présentation simple et agréable / protocoles expérimentaux) Ouvrages en accès libre de Dagnelie (en particulier pour les Quelques références en statistiques Gibert Saporta : Probabilités, analyse des données et statistique, Technip, 006. DAGNELIE, Pierre (1998), Statistique théorique et appliquée. Statistique descriptive et bases de l'inférence statistique, tome 1, De Boeck Remerciements : Merci aux auteurs cités précédemment auxquels j'ai emprunté exemples et analyses. -3-

4 Méthodes présentées Une variable qualitative : test de conformité à une fréquence, test de conformité à une distribution ( ), Test du de comparaison de deux ou plusieurs distributions Deux variables qualitatives : Test du d'indépendance, AFC avec un grand tableau de contingence Une variable quantitative Test de conformité à une moyenne avec une population Test t de comparaison de moyennes avec deux populations ANOVA avec plusieurs populations Deux variables quantitatives ou plus Nuage de points, test de la corrélation entre les deux variables Régression linéaire simple avec deux variables Régression linéaire multiple, ACP, classification avec plus de deux variables Une variable quantitative et une variable ou plusieurs variables qualitatives ANOVA à un ou deux facteurs -4-

5 I STATISTIQUES DESCRIPTIVES Les statistiques descriptives recouvrent les différentes techniques de description des données, synthèse sous forme de paramètres ou de tableaux, représentations graphiques... Pour les grands tableaux, les techniques peuvent devenir plus complexes. Elles ne sont pas abordées ici. Pour mémoire, les principales méthodes d'analyse de données sont : Analyse en composantes principales (ACP) dans le cas de plusieurs variables quantitatives, Analyse des correspondances (AFC) dans le cas de grands tableaux de contingence, Classification (CAH) Les statistiques descriptives sont importantes pour présenter les données, communiquer, déterminer les hypothèses à tester, réaliser une première analyse et interprétation... On oppose les statistiques descriptives aux statistiques inférentielles dont l'objectif est de mettre en place des règles de décision afin de réaliser des tests statistiques. Nous aborderons ce domaine dans les chapitres suivants. Les données sous R et Rcmdr : En général, une ligne d'un tableau représente un individu. Les colonnes sont les variables qualitatives ou quantitatives, mesurées sur chaque individu. Dans ce cours, toutes les données sont avec les individus en ligne et les variables quantitatives et qualitatives (facteur) en colonne. Seuls les tableaux de contingence seront sous un autre format. Ces tableaux sont appelés dataframe sous R et ont des propriétés particulières. Une colonne de nombres est considérée comme une variable quantitative (numéric). Pour créer une variable qualitative (facteur) avec Rcmdr, il faut créer une colonne character en tapant des lettres ou des nombres. Pour saisir les données, on peut utiliser le tableur de Rcmdr : Données Nouveau jeu de données Pour récupérer un fichier déjà saisi sous tableur (csv ou txt), Données Importer des données Depuis un fichier txt (ou autre) -5-
 Les statistiques descriptives sont importantes pour présenter les données, communiquer, déterminer les hypothèses à tester, réaliser une")
6 Fiche 1 Variable qualitative Un caractère est dit qualitatif s'il est mesuré dans une échelle nominale (couleur, marque), les modalités ne sont pas hiérarchisées, s'il est mesuré dans une échelle ordinale (stades d'une maladie, classes d'âge...), les modalités sont alors hiérarchisées. Les graphiques et les tests dépendront de la nature des caractères. effectif observé Paramètre statistique Fréquence f = effectif total Réprésentations graphiques : nominale : diagramme circulaire (pie) ordinale : diagramme en bâton ou rectangle (barplot). Etude d'un exemple : Après inoculation d'un pathogène dans une plante, le stade de la maladie a été mesuré sur 5 plantes. Le stade est noté de I (aucun symptôme) à V (plante morte). Le résultat de l'étude est décrit dans le tableau suivant : stade I II III IV V Effectif Total fréquence a. Sous quelle forme étaient les données brutes? b. Créer un tableau patho1 contenant les données (rappel : une ligne = un individu) c. Calculer les fréquences. Statistiques Résumé Distribution des fréquences d. Représenter sous R graphiquement ce tableau. Graphes Graphe en barre : barplot ou en camenbert : pie 5 var1 4 3 Frequency var1 On peut ajouter un titre en tapant sous R : title(«distribution des fréquences») -6-
 à V (plante morte).")
 Compléter le tableau en ajoutant les fréquences ainsi que les effectifs marginaux. b) Construire le tableau sous l'hypothèse d'indépendance entre les deux caractères.")
7 Fiche Couple de variables qualitatives Etude d'un exemple : Le tableau résume la présence ou l'absence d'une infection bactérienne en fonction de l'utilisation ou non d'une antibiothérapie ou d'un placebo. a) Compléter le tableau en ajoutant les fréquences ainsi que les effectifs marginaux. b) Construire le tableau sous l'hypothèse d'indépendance entre les deux caractères. Tableau observé nij Antibio Placebo Total ni absence 75 7 présence 10 9 Total ni Tableau théorique sous l'hypothèse H 0 d'indépendance nij = ni n j n Antibio Placebo Total ni absence présence Total ni Statistiques Tables de contingence Remplir et analyser un tableau à double entrée saisir le tableau et cocher la case Imprimer attendues pour obtenir le tableau sous H 0. les fréquences Représentations graphiques On peut utiliser un diagramme en bâtons bidimensionnel ou comparer les distributions conditionnelles. par(mfrow=c(,1)) barplot(c(75,10)/85*100,ylim=c(0,100),main="antibio",names.arg=c("abs","pre")) barplot(c(7,9)/56*100,ylim=c(0,100),main="placebo",names.arg=c("abs","pre")) antibio abs pre placebo abs pre -7-


8 Fiche 3 Variable quantitative On appelle variable quantitative une variable qui se mesure dans une échelle discrète ou continue. 1. Tableau de répartition, calcul de fréquence, histogramme En présence d'une variable continue, les observations sont souvent regroupées par classe. Le nombre de classe N à construire est défini pour que les classes aient en général une amplitude identique et un effectif minimal suffisant. Ce nombre N peut être calculé empiriquement à partir de la règle de Sturge : N=1+ 3,3 log 10 n amplitude On détermine ensuite les classes [xi,xi+1[ avec xi+1 -xi =, en arrondissant si besoin. N Exemple hauteur : La mesure de la hauteur de 10 étudiants donne les résultats suivant : classe [165;170[ [170;175[ [175;180[ [180;185[ [185;190[ total effectif fréquence Données Gérer les variables dans le jeu de données actives Découper une variable numérique en classe. Paramètres de position et de dispersion La définition théorique de la moyenne x et de la variance S² est : n n x = xi S = x i x = et n i=1 n i=1 n n x i x i =1 Dans la pratique, on utilise un échantillon de la population pour estimer ces coefficients. On note x et s les estimateurs de ces paramètres. L'estimateur de la variance S calculé en divisant par n étant biaisé, on l'estime par s : n 1 x = xi n i =1 1 s = n 1 n x i x i =1 La médiane est le réel séparant la population en deux groupes de même effectif. On donne une définition analogue pour les quartiles, déciles... Exemple : Calculer à la main la moyenne, la médiane, les quartiles et l'écart-type de la hauteur des étudiants. -8-


9 Avec R: Statistiques Résumés Statistiques descriptives 3. Représentations graphiques : Histogramme, boxplot... Histogramme Graphe Histogramme Boxplots young h 185 Graphe Boîte de dispersion -9-

10 Fiche 4 Couple de variables quantitatives - Corrélation Sur chaque individu de l'échantillon sont mesurées maintenant deux variables quantitatives X et Y. Après un analyse de chacune de ces variables (fiche Variable quantitative), on procède à l'étude de la relation entre ces deux variables. Existe-t-il une liaison entre les deux variables? Cette relation est-elle linéaire ou non linéaire? La description de la liaison entre les deux variables se fait en premier lieu par un examen du nuage de points (xi,yi). L'observation du nuage permet de justifier la linéarité ou non de la relation (des tests existent mais nécessitent des conditions d'application rarement atteintes). relation fonctionnelle linéaire relation fonctionnelle non linéaire On procède dans le cas où la liaison est linéaire au calcul d'un paramètre de la liaison linéaire entre les deux variables, le coefficient de corrélation de Pearson : r= xi x yi y x y Ce coefficient est compris entre -1 et 1. Plus r est proche de +1, plus les variables sont positivement corrélées, lorsqu'une variable augmente l'autre a tendance à augmenter en parallèle. Plus r est proche de -1, plus les variables sont négativement corrélées, lorsqu'une variable augmente l'autre a tendance à diminuer en parallèle. Quand r est proche de 0, les variables ne sont pas significativement corrélées, les variations d'une variable n'apporte pas d'information sur les variations de l'autre variable. Il existe un test statistique permettant de tester l'hypothèse nulle H 0 «r = 0» (fiche #correlation) dans le cas d'une liaison linéaire. Dans le cas où H 0 est rejetée, on réalise en général une régression linéaire (chapitre III) de Y en X ou de X en Y
.")
 dans une population d arbres Age 1 3 4 5 6 7 Diamètre 3 5 10 11 17 18 0 Nuage de points Graphe Nuage de point -")
11 Quelques illustrations pour différentes valeurs de r : Etude de l'exemple arbre: Une étude de la liaison entre l âge (années) et le diamètre (cm) dans une population d arbres Age Diamètre Nuage de points Graphe Nuage de point


12 Calcul de la corrélation : Statistiques Résumé matrice de corrélation age cm age cm

13 Etude de l'exemple crabs (library MASS, fichier crabs) Données Données dans les package Lire les données dans les packages a. Etudier les relations entre les variables BD et CL CL 35 Matrice des nuages de points Graphe Nuage de point Graphe Matrice de nuages de points Corrélation et Matrice des corrélations Test du coefficient de corrélation Statistiques Résumés Matrice de corrélation Statistiques Résumés Test du coefficient BD CL CW FL BD CL CW FL BD t = ,df = 198, p-value <.e-16 H0 : Conclusion : alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: sample estimates: cor b. La relation est-elle similaire en fonction de l'espèce? Statistiques Résumés Descriptions statistiques sélectionner graphe par groupe mean sd 0% 5% 50% 75% 100% n B O sp B O 30 5 CL 35 Graphe Nuage de point 15 0 sélectionner graphe par groupe Graphe Graphe XY conditionnel sélectionner conditions BD

. L'objectif est donc ici d'observer d'éventuelles différences entre les populations (ou modalités d'un facteur).")
14 Fiche 5 Couple variable quantitative variable qualitative Il arrive fréquemment que l'on étudie une variable quantitative dans différentes populations ou en fonction d'un facteur (variable qualitative). L'objectif est donc ici d'observer d'éventuelles différences entre les populations (ou modalités d'un facteur). Exemple bébé: On considère étudie le poids des bébés en fonction du sexe et on obtient pour 5 filles.8 ; 3; 3 ; 3. ; 3.3 et pour 4 garçons 3; 3.; 3.4, 3.6. On souhaite étudier l'influence du sexe sur le poids des bébés. Statistiques Résumés Statistiques descriptives f m mean sd 0% 5% 50% 75% 100% n Boîte de dispersion Diagramme de la moyenne avec IC 95% Graphe Boîte de dispersion Graphe Graphe des moyennes


15 Fiche 6 Estimation ponctuelle d'une moyenne et d'un écarttype, Intervalle de confiance On dispose en général d'un échantillon prélevé dans une population pour laquelle la variable quantitative X a une moyenne µ et une variance inconnues. Règle pour l'estimation ponctuelle : Soit une variable quantitative X mesurée sur un échantillon de n individus, la moyenne est estimée par x = 1 n n xi i =1 n la variance est estimée par s X = 1 x x n 1 i = 1 i D'un échantillon à l'autre, les estimations ponctuelles vont varier d'autant plus que sa taille n est faible. Pour affiner l'estimation de ces paramètres, on détermine alors un intervalle de confiance dans lequel les valeurs réelles µ ou ont une probabilité déterminée à l'avance de se trouver. Cet intervalle de confiance, noté IC, permet ainsi de prendre en compte la variabilité de l'estimation ponctuelle. Simulation d'un exemple. n =50 et que l'on On suppose que la variable X suit la loi binomiale de paramètre p =0,01 et dispose d'un N-échantillon de 30 valeurs. Comment varie la moyenne estimée d'un échantillon? Distribution Distribution discrète Binomiale n=50, p=0,01 Graphe ou Echantillon Probability Mass Binomial Distribution: T rials = 50, Probability of success = Number of Successes Histogr am of apply(echantillonsbinomiaux, 1, mean) 0 5 F requency On obtient alors l'histogramme des 100 moyennes estimées (means) : apply(e chanti llonsb i nomiaux, 1, mean) Empiriquement, 95% des moyennes sur 30 échantillons tombent entre 6,4 et 8,4 (on a enlevé les 5 valeurs extrêmes sur les 100)

16 En théorie, on dispose de résultats plus précis dans les cas suivantes : On peut considérer que la variable X suit une loi normale. L'échantillon est suffisamment grand (>30) pour utiliser le théorème central limit. On peut alors considérer que la moyenne des échantillons suit une loi normale (mais pas forcément X). Théorème central limit : Soit X 1,, X n une suite de variables aléatoires indépendantes et identiquement distribuées, de même espérance et variance finies. La moyenne M n = loi normale N(, X 1 X n converge en loi vers la n ). n C'est bien ce que l'on observe par simulation dans l'exemple précédent. Propriétés de l'estimateur x cas 1 : n 30 et la variable X suit une loi normale (fiche #Normalité) x Si est connue, alors u = suit la loi normale centrée réduit n x Si est inconnue, alors t = s X suit la loi de Student à n 1 degrés de liberté. n Cas : Pour n 30 (application du théorème central limite) x t= s X suit la loi normale centrée réduite n Propriété de l'estimateur s X dans le cas où la variable X suit une loi normale Density Chi-Squared Distribution: df = 14 n 1 s X suit la loi du à n-1 ddl χ
. n C'est bien ce que l'on observe par simulation dans l'exemple précédent.")
17 Construction d'un intervalle de confiance pour la moyenne: x On recherche toutes les valeurs possibles de µ pour lesquelles t = s X soit compris entre tα / et t1-α / n t1-α / est le quantile de la loi normale ou de la loi de student à n-1 ddl pour laquelle P(t<t1-α / )=1-α/ donc P (tα / < t < t1-α /)=1- α (par symétrie tα / =- t1-α / ). On a alors l intervalle de confiance à 1-α pour : x -t1-α/ sx sx < µ < x +t1-α/ n n Pour = 5%, ce résultat signifie que "la vraie moyenne, μ", de la population a une probabilité de 95% d être dans cet intervalle. On notera par commodité cet intervalle de confiance IC 95. Construction d'un intervalle de confiance pour la variance : On recherche toutes les valeurs possibles de pour lesquelles et 1, n 1 n 1 s X soit compris entre, n 1 (ici il n'y a pas symétrie des quantiles). n 1 s X α <, n 1) = donc, n 1 est le quantile dans la table pour laquelle P( On a alors l intervalle de confiance à 1-α pour : n 1 s X / 1, n 1 < < n 1 s X /, n 1 Exemple hauteur : Reprendre l'exemple hauteur pour lequel x =177 et s X = 7 et en déduire un intervalle à 95% de et de. Calcul à la main de IC 95 :


18 Distribution de t : Chi-Squared Distribution: df = Density Density t Distribution: df = 14 5 t χ Quantile 0,975 : Distribution Distribution continue Distribution t Quantile On trouve les quantiles 0,05 ; 14 = 5,63 et 0,975 ; 14 = 6,11 Calcul avec R de IC 95 : Statistiques Moyenne t-test univarié data: hauteur$h t = , df = 14, p-value <.e-16 alternative hypothesis: true mean is not equal to 0 95 percent confidence interval: sample estimates: mean of x

19 Fiche 7 Estimation ponctuelle d'une fréquence, Intervalle de confiance Si une population contient une proportion f d individus possédant un caractère donné, l'estimateur de ce paramètre est la fréquence du caractère dans l'échantillon, noté f. Propriété de f pour n >100 et 0,1< f <0,9 f suit la loi normale N (f, f 1 f ) n Dans les autres cas, n<100 ou f < 0,1, il faut utiliser un modèle exact (binom.test dans R). Pour construire l'intervalle de confiance de f, on reprend un raisonnement analogue à la fiche précédente. Dans la pratique, comme on ne connaît pas f, on la remplace par f. Propriété : Pour un échantillon tel que n >100 et n f >10 et n(1- f )>10 : L intervalle de confiance à 1-α d une proportion est : ] f - u1-α / f 1n f ; f + u1-α / f 1n f [ où u1-α / représente le quantile de la loi normale centrée réduite. Pour =5%, u1-α /=1,96. Exemple : Un laboratoire d agronomie a effectué une étude sur le maintien du pouvoir germinatif des graines de Papivorus subquaticus après une conservation de 3 ans. Sur un lot de 80 graines, 47 ont germé. Calculer la probabilité de germination des graines de Papivorus subquaticus après trois ans de conservation avec un coefficient de confiance de 95%. Calcul à la main de IC 95 : Calcul avec R : prop.test(47,80) data: binom.test(47,80) 47 of 80, null probability 0.5 X-squared =.11,df=1, p-value = alternative hypothesis: equal to 0.5 true 95 percent confidence interval: sample estimates: p p is number of successes = 47, trials = 80, p-value = number of alternative hypothesis: true probability notof success is not equal to percent confidence interval: sample estimates: probability of success

.")
20 II TESTS ELEMENTAIRES SUR VARIABLES QUALITATIVES La majorité des tests élémentaires repose sur le principe suivant : 1. On définit une hypothèse nulle notée H 0 contre l'hypothèse alternative H (généralement H 0 n'est pas vérifiée). Le test a pour objectif d'accepter H 0 ou de rejeter H 0 avec un risque connu à partir des données dont on dispose. Les principales hypothèses nulles H 0 sont : Variables qualitatives «la fréquence observée est conforme à la fréquence attendue» prop.test «la distribution observée est conforme à la distribution attendue» «les distributions observées sont identiques» «les variables qualitatives sont indépendantes» Variables quantitatives «la moyenne observée est conforme à une valeur attendue» test t «les moyennes sont égales» test t «les moyennes appraiées sont égales» test t apparié «les variances sont égales» test F «les q moyennes sont égales» ANOVA, test F «les q variances sont égales» Test de Bartlett «Le coefficient de corrélation est nul» test de corrélation «La distribution de la variable suit une loi normale» test de shapiro. On détermine alors une statistique qui est une variable aléatoire construite à partir des données. Sous H 0, cette variable suit une loi de probabilité connue. On détermine alors l'intervalle dans lequel doit tomber la statistique avec une probabilité donnée, 95% le plus souvent. Unilatéral (test F, ) Bilatéral (test t ) - 0 -

21 3. On définit alors la règle de décision suivante : Si la statistique tombe dans l'intervalle, on accepte H 0. Attention, cela ne veut pas dire que H 0 est vraie, mais que les données et le test ne permettent pas de voir un écart significatif à H 0. Si la statistique ne tombe pas dans l'intervalle, on rejette H 0 avec un risque de première espèce connu de se tromper. On peut donc rejeter H 0 alors que H 0 est vraie, mais on connait le risque que l'on prend, p-value. En général, les ordinateurs calculent la valeur p -value de ce risque. On concluera alors que l'on rejette H 0 avec un risque de première espèce p -value. Plus p -value est faible (<0,05), plus le rejet est significatif. 4. La validité du test dépend souvent de certaines conditions sur les données, appelées conditions d'utilisation du test. Ces conditions doivent être vérifiées avant de pouvoir conclure. Pour la majorité des tests dits paramétriques (test t, ANOVA, régression), les conditions sont : Indépendance des individus. Les variables suivent des lois normales. Les variances sont stables. Pour les tests non paramétriques, seule l'hypothèse d'indépendance est nécessaire. Par exemple : On souhaite étudier le taux de cholestérol en fonction du sexe. On prend 30 hommes à Lille et 30 femmes à Marseille. On veut comparer le taux moyen en fonction du sexe mais le fait-on vraiment ici. Les individus ne sont pas choisis aléatoirement et on risque d'étudier autre chose que le sexe, l'alimentation par exemple (huile d'olive et beurre). L'indépendance est l'hypothèse la plus importante, sans elle les données ne servent à rien. Il faut donc bien réfléchir au préalable au protocole (risques de gradient, de facteurs cachés, tirage aléatoire, ). 5. Bilan Après avoir défini H 0 et le test en conséquence, on calcule la statistique et p-value la probabilité d'observer une valeur supérieure à cette statistique sous H 0 (en valeur absolue). La conclusion dépend alors de p-value : Si p> ( p>0,05), on accepte H 0 Si p < ( p <0,05), on rejette H 0 avec un risque de première espèce égal à (ou p). En conclusion d'un test, on utilise le terme significatif (rejet) ou non significatif (acceptation), par exemple : Si on accepte H 0 p 0,05 «les moyennes sont égales», on conclut les moyennes ne sont pas significativement différentes. Si on rejette H 0 p 0,05 «les moyennes sont égales», on conclut les moyennes sont significativement différentes avec un risque de première espèce égal à p-value
22 Fiche 8 Comparaison d'une proportion à une référence Objectif : Tester si une fréquence est conforme à une fréquence attendue. Soit une variable X prenant deux modalités (absence/présence). cas favorables Le but est de savoir si un échantillon de fréquence observée f =, estimateur de f, total appartient à une population de référence connue de fréquence f 0 ( H 0 vraie) ou à une autre population inconnue de fréquence f f 0 (H vraie). Données : Une variable qualitative avec deux modalités. Hypothèse nulle : La fréquence est f 0. Principe du test : f f 0 On calcule la statistique u= f o 1 f 0 qui suit sous H 0 la loi normale centrée réduite. n On calcule alors la probabilité p -value d'observer une valeur supérieure ou égale sous H 0 (en valeur absolue). Conditions d'utilisation : Le test est applicable si n f 0 10 et n(1- f 0) 10 Si cette condition n'est pas vérifiée, on utilise un test exact (binom.test). Les individus sont indépendants. (approximation par la loi normale). Test : On teste H 0 f = f 0 contre H f f 0. Si p >0,05, on accepte H 0. Si p <0,05, on rejette H 0 avec un risque de première espèce p. Exemple : On observe le sexe de 10 bébés : M F M M F F F F M F Cette proportion est-elle conforme à 0,5. Saisir le tableau et convertir en facteur, puis utiliser : Statistiques Proportion Porportion univarié Avec R : prop.test(4,10,p=0.5) ou binom.test(4,10,p=0,5) pour un petit effectif data: 4 out of 10, null probability 0.5 X-squared = 0.1, df = 1, p-value = alternative hypothesis: true p is not equal to percent confidence interval: sample estimates: p
23 Fiche 9 Test de conformité à une distribution : test du Chi (génétique) Objectif : On considère une variable X prenant k modalités, k > (pour k =, voir la fiche précédente). L'objectif du test est de vérifier que les modalités se distribuent suivant des probabilités attendues. On utilise un tel test en génétique par exemple pour vérifier : 1 1,, pour F) les lois de Mendel, (répartition le modèle de Hardy Weinberg. (répartition p1, p 1 p, p ). Données : Les données sont regroupées dans un tableau de contingence de la forme : Variable qualitative Modalité 1 Modalité... effectif n1obs nobs... Hypothèse nulle : H 0 «Les fréquences observées sont conformes aux probabilités attendues». Principe du test : Le principe du test du χ est d estimer à partir d une loi de probabilité connue (ou estimée à partir de l'échantillon), les effectifs théoriques pour les différentes modalités du caractère étudié et les comparer aux effectifs observés dans un échantillon. Deux cas peuvent se présenter : soit la loi de probabilité est spécifiée a priori car elle résulte par exemple d un modèle déterministe tel que la distribution mendélienne des caractères. soit la loi de probabilité théorique n est pas connue a priori et elle est déduite des caractéristiques statistiques mesurées sur l échantillon (estimation de p1 et p dans le cas du modèle de Hardy Weinberg). Le test du χ consiste à mesurer l écart qui existe entre la distribution théorique et la distribution observée et à tester si cet écart est suffisamment faible pour être imputable aux fluctuations d échantillonnage. On calcule les effectifs théoriques n1th eor, nth eor... attendus sous l'hypothèse où la distribution est conforme à celle attendue. On calcule ensuite la statistique : = k i =1 niobs nith eor n ith eor suit sous H 0 la loi du à degrés de liberté. On rejette alors H 0 dans le cas où dépasse la valeur seuil 1 (v)
24 Le nombre de ddl est k c, k représente le nombre de modalités et c celui des contraintes. Si la distribution théorique est entièrement connue a priori (lois mendeliennes), la seule contrainte est que la somme des probabilités vaut 1, donc = k 1. Sinon, il faut estimer des probabilités sur l'échantillon et augmenter d'autant les contraintes. Par exemple avec le modèle de Hardy Weinberg, la somme des probabilités vaut 1 et il faut estimer p1, soit c=, donc = k. Test : On teste l hypothèse H 0 (conforme à la distribution attendue) < 1 (v), on accepte H 0 -si -sinon on rejette H 0 avec un risque de première espèce α (ou p). i ( nth eor 5). Dans le cas contraire, on peut regrouper les classes les plus faibles, utiliser un test du corrigé, utiliser le test exact de Fisher... Conditions d'application : Les effectifs théoriques doivent être supérieurs à 5 Exemple Les résultats observés par Mendel sur le croisement de pois Jaune-Rond et Vert Ridé en F ont été : Jaune Ronde : 315 Jaune Ridée : 101 Verte Ronde : 108 Verte Ridée : 3 1. Quels sont les allèles dominants, le génotype en F1?. Les lois de Mendel sont-elles vérifiées? 3. Quels sont les effectifs attendus? Avec R : > chisq.test(c(315,101,108,3),p=c(9/16,3/16,3/16,1/16)) X-squared = 0.47, df = 3, p-value = H0 : Conclusion : - 4 -
25 Fiche 10 Test d'indépendance : test du Chi Objectif : Le test du χ est largement utilisé pour l'étude de l'indépendance entre deux caractères qualitatifs. La présentation des résultats se fait sous forme d'un tableau de contingence à deux entrées. Chaque entrée représente les modalités d'une des variables. On détermine alors le tableau attendu sous l'hypothèse d'indépendance (fiche #Couple de variables qualitatives) Données : Deux variables qualitatives sont mesurées sur n individus puis présentées sous forme d'un tableau de contingence (tableau à deux entrées) : Par exemple : c a n c e r présence tabac absence total présence absence total Hypothèse nulle H 0 : Les deux caractères sont indépendants L'indépendance entre deux caractères qualitatifs signifie que les modalités d'un caractère se distribuent de la même façon pour chacune des modalités de l'autre caractère. Par exemple, la couleur des yeux est-elle indépendante de la couleur des cheveux? Si oui, les caractères sont indépendants et on a autant de chance d'avoir les yeux bleus sachant qu'on a les cheveux blond ou qu'on a les cheveux brun. Ce test prend toute son importance dans la recherche des facteurs d'une maladie par exemple, indépendance entre cancer du poumon et le tabac, cancer du foie et alcool (travail et réussite) Principe du test : On calcule les effectifs théoriques sous l'hypothèse H 0. Les effectifs marginaux (totaux à la marge en ligne ou en colonne) et fréquences marginales du tableau restent inchangés. nijth eor = On calcule alors la statistique : ni obs n obsj n avec nijtheor l'effectif théorique, ni obs et n obsj les effectifs marginaux ligne et colonne, n l'effectif total. = ij nijobs nijth eor nijth eor Sous H 0, cette statistique suit la loi du à v= (l-1)(c-1) ddl avec l le nombre de lignes et c le nombre de colonnes
26 Test : On teste l hypothèse H 0 indépendance des deux caractères contre H dépendance entre les deux caractères : < 1 (v), on accepte H 0 -si -sinon on rejette H 0 avec un risque de première espèce α (ou p). Conditions d utilisation: L'effectif théorique calculé sous l'hypothèse H 0 doit être supérieur à 5. Remarque : Pour des effectifs faibles, il existe des corrections à ce test ou d'autres tests (test exact de Fisher). Exemple : Dans une formation végétale homogène, on choisit 38 points au hasard. En chaque point, on écoute pendant un temps fixé les oiseaux présents. On repère la pie Pica pica 17 fois et la corneille Corvus corone 19 fois. Sachant que les deux espèces ont été enregistrées simultanément 11 fois, peuton affirmer que la présence d une espèce influence la présence de l autre? Tableau de contingence observé : corneille présence absence P présence i absence e Sous l'hypothèse d'indépendance: corneille présence absence P présence i absence e Avec R : Statistiques Table de contingence Remplir un tableau à double entrée X-squared =.6611, df = 1, p-value = H0 : Conclusion : - 6 -
27 Fiche 11 Comparaison de deux ou plusieurs distributions : test du Chi Objectif : Soit une variable qualitative X prenant deux modalités (absence/présence) ou plusieurs modalités. Le but est de savoir si deux échantillons ou plusieurs échantillons ont une même distribution. Cet objectif revient à faire un test d'indépendance, la distribution entre les modalités est indépendante de la population dont est issu l'échantillon ( fiche Chi). Données : Les données sont regroupées dans un tableau de contingence de la forme : Variable qualitative Modalité 1 Modalité Effectif population 1 n11 obs n1 obs... Effectif population nijobs... Hypothèse nulle : La distribution est la même dans les différentes populations. Dans le cas où il n'y a que deux modalités, H 0 devient «la fréquence est la même dans les différentes populations». Principe du test : Le principe est le même que pour le test du ( fiche Chi). Test : On teste H 0, la distribution est la même dans les différentes populations contre H il existe des différence entre les populations. Si p >0,05, on accepte H 0. Si p <0,05, on rejette H 0 avec un risque de première espèce p. Conditions d'utilisation: L'effectif théorique doit être supérieur à 5. Exemple : La répartition des groupes sanguins dans trois communautés est présentée ci-dessous. Peut-on considérer que les proportions sont égales? A B AB O France Roumanie
28 III TESTS ELEMENTAIRES SUR VARIABLES QUANTITATIVES - 8 -
29 Fiche 1 Comparaison d'une moyenne à une valeur référence Objectif : L'objectif est de comparer une moyenne à une valeur de référence. On qualifie un tel test de test de conformité. Données : On dispose d'une variable quantitative X mesurée sur n individus. Hypothèse nulle H 0 : «= 0» Conditions d utilisation: - Un échantillon de n individus indépendants La variable suit une loi normale ou n >30. Principe du test : Pour une population de moyenne et variance inconnue, nous avons déjà vu que si les conditions sont respectées : x 0 t= sx suit sous H 0 une loi de Student à n-1 ddl. n Test bilatéral: On teste H 0 : «= 0» contre H : «0» si 0 - t 1 sinon on rejette H 0 avec un risque de première espèce (ou p) t Distribution: df = sx sx < x < 0 + t 1 on accepte H 0 n n Density -4-0 t - 9-4

30 Test unilatéral à droite : H 0 «µ>µ0» contre H «µ µ0» 0.4 t Distribution: df = 14 sinon on rejette H 0 avec un risque de première espèce α Density si x 0 t s, on accepte H 0 n t Test unilatéral à gauche : H 0 «µ<µ0» contre H «µ µ0» 0.4 t Distribution: df = 14 sinon on rejette H 0 avec un risque de première espèce α. 0.0 Density 0.1 si x 0 t s, on accepte H 0 n t Exemple hauteur : On reprend l'exemple de la hauteur avec x =177 et s X =7. Peut-on considérer la moyenne observée comme conforme à 17? inférieure à 180? Statistiques Moyenne T-test univarié t = , df = 14, p-value = alternative hypothesis: true mean percent confidence interval: sample estimates: mean of x 177 H0 : Conclusion : t = , df = 14, p-value = alternative hypothesis: true mean > percent confidence interval: Inf sample estimates: mean of x 177 H0 :
31 Conclusion :
32 Fiche 13 Comparaison de deux moyennes : t - test Objectif : Comparer les moyennes obtenues dans deux populations. Données : On dispose d'une variable quantitative mesurée sur n1 individus d'une population 1 et sur n individus d'une population. ind 1 ind... ind i X x1 x Population 1 xi X : variable quantitative Population : variable qualitative (facteur sous R) 1 Hypothèse nulle H 0 : «1 =» Principe du test : La variable d= x 1 x a pour variance estimée s d = n1 1 s 1 n 1 s n 1 n n1 n1. 1 Si les conditions sont respectées, la statistique t = x1 x suit sous H 0 une loi de Student à n1 n ddl. sd Test bilatéral: On teste H 0 : «1 =» contre H : «1» si - t 1 s d < d < t 1 s d, on accepte H 0 sinon on rejette H 0 avec un risque de première espèce (ou p-value). Test unilatéral: On teste H 0 : «1 >» contre H : «1» si d t 1 s d, on accepte H 0 sinon on rejette H 0 avec un risque de première espèce (ou p -value). Conditions d utilisation: Deux échantillons de n1 et n individus indépendants. La variable suit une loi normale dans chaque population ou n1 et n >30 : fiche Normalité La variable a la même variance dans les deux populations : fiche Test F - 3 -

33 Compléments: Pour comparer plusieurs populations dans les mêmes conditions : analyse de variance Si les hypothèses de normalités ou d'égalité des variances ne sont pas vérifiées, on utilise soit un test non-paramétrique fiche #Mann Whitney, soit un changement de variable fiche #Remédiation Exemple 1 : On a mesuré les dimensions d'une tumeur chez des souris traitées ou non avec une substance antitumorale. On a obtenu les résultats suivants : Souris témoins : n 1 = 0 x 1 =7,075 cm ² s 1 = 0,576 cm ² Souris traitées : n = 18 x = 5,850 cm ² s = 0,614 cm ² La différence observée est-elle significative? Quelles sont les hypothèses à vérifier? Exemple bébé : On considère étudie le poids des bébés en fonction du sexe et on obtient pour poids Saisir les colonnes poids et sexe, convertir le sexe en facteur, puis : filles.8 ; 3; 3 ; 3. ; 3.3 et pour 4 garçons 3; 3.; 3.4, 3.6. On suppose les variances égales et la distribution normale des poids..9 Statistiques Moyenne t-test indépendant f m sexe t = , df = 5.069, p-value = alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: sample estimates: mean in group f mean in group m H0-33 -
34 Fiche 14 Comparaison de deux moyennes appariées : t-test apparié Objectif : Comparer les moyennes obtenues dans le cas où les observations sont appariées (avantaprès sur un même individu, mesure par deux méthodes). Chaque individu est décrit par un couple de variables X 1, X. Données : On dispose de deux variables quantitatives X 1 et X mesurées sur n individus d'une population. ind 1 ind X1 x11 x1 X x 1 x Attention: les deux valeurs correspondent à un même individu donc sont sur une même ligne! Hypothèse nulle H 0 : «1 =» Principe du test : On construit une nouvelle variable Z = X X 1. Si les conditions sont respectées, la statistique z s z suit sous H 0 une loi de Student à n-1 ddl. n t= Test bilatéral: On teste H 0 : «1 =» contre H : «1» si - t 1 < t < t 1, on accepte H 0 sinon on rejette H 0 avec un risque de première espèce égal à (ou p ). Conditions d utilisation: Les individus sont indépendants. Les variables X 1 et X suivent une loi normale ou n >30 : fiche #Normalité Les variables ont la même variance : fiche #Test F Compléments: Si les hypothèses de normalités ou d'égalité des variances ne sont pas vérifiées, on utilise un test non-paramétrique (Wilcoxon, fiche #Wilcoxon) ou un changement de variable ( log X..., fiche #Remédiation)

35 Exemple : Une étude sur l'efficacité d'une crème amincissante conduite sur 10 hommes est présentée ci-dessous. On suppose que le poids suit une loi normale. Le régime est-il efficace? individu AV AP Z=AV-AP Avec R : Statistiques Moyenne T-test apparié t = 3.359, df = 9, p-value = alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: mean of the differences H0 : Conclusion :
.")
36 Fiche 15 Comparaison de moyennes : tests non paramétriques de Mann Whitney - Wilcoxon L'utilisation d'un test non paramétrique ne repose pas sur l'hypothèse d'une distribution particulière de la variable étudiée. Sa seule condition d'application est l'indépendance des individus. Ces tests sont en général moins puissants que les tests paramétriques lorsqu'ils existent (#t - test). La valeur de p est en effet plus grande avec ces tests. De plus les tests paramétriques permettent de tester des hypothèses en générale plus complexes (anova, comparaisons multiples...). On réalise donc préférentiellement un test paramétrique. On utilise donc de tels tests lorsque la distribution ne suit pas une loi normale, lorsque l'égalité des variances n'est pas vérifiée, en cas de faibles effectifs... La facilité d'exécution de ces tests avec un logiciel permet de confirmer en cas de doute sur les conditions d'application la signification du test paramétrique. Il ne faut pas hésiter à doubler le test paramétrique par un test non-paramétrique. Test de comparaison des moyennes de deux populations de Mann-Whitney Principe du test : Les données sont rangées dans l'ordre croissant. Dans l'hypothèse d'égalité des moyennes, les deux populations s'ordonnent aléatoirement. La statistique étudiée est la somme des rangs d'une des populations, W. Cette somme suit une loi normale sur laquelle repose la règle de décision. On note m1 l'effectif de la population 1 et m celui de la population, m1 et m >10, W la somme des rangs de la population 1. On a alors W = m 1 m 1 m 1 et W = m 1 m m 1 m 1 1 Exemple : Reprendre l'exemple bebe en fonction du sexe Statistiques Test non paramétrique Test Wilcoxon bivarié W = 5, p-value = H0 Conclusion : Test de comparaison des moyennes de données appariées de Wilcoxon Principe du test : Il repose sur le signe de la différence Exemple : Reprendre l'exemple des crèmes amincissantes Statistiques Test non paramétrique Test Wilcoxon apparié V = 4.5, p-value =
37 Fiche 16 Comparaison de deux variances : Test F Objectif : L'hypothèse d'égalité des variances est indispensable pour tester l'égalité de deux moyennes avec le test t (#t - test). Données : une variable quantitative X mesurée dans deux populations. Sous R, le tableau se présente sous la forme : X x1 x x3 Facteur 1 1 avec X la variable quantitative et Facteur la variable qualitative indiquant la population (facteur). Hypothèse nulle H 0 : Les variances sont égales «1 ² = ²» Conditions d utilisation: - Deux populations de moyennes et variances inconnues. Deux échantillons de n1 et n individus indépendants, Les variables suivent des lois normales ou chacun des effectifs est supérieur à 30 Principe du test : On souhaite tester l'égalité des variances de deux populations, H 0 est "σ1²=σ²" La statistique s 1 suit sous H 0 la loi de Fisher-Snedecor à n1-1 et n-1 ddl s Test : On teste l hypothèse H 0 ( 1 ² = ²) contre H ( 1 ² ²) s 1 F si < 1 (n1-1,n-1), on accepte H 0 s sinon on rejette H 0 avec un risque de première espèce égal à (ou p ). Compléments : Pour comparer plusieurs variances, on utilise le test de Bartlett ou de Lévène (chap V ANOVA). On peut appréhender les différences de variabilité à l'aide d'histogramme ou de boxplot

38 Exemple bébé : Reprendre l'exemple des bébés. Les variances sont elles les mêmes pour les sexes? poids Construction de la statistique : Calcul de s 1 et s : Test de H 0 : f m sexe Avec R : Statistiques Résumés Statistiques descriptives sélectionner mean résumer par groupe sd n f m Statistiques Variance Test F de deux variances F = 0.4, num df = 3, denom df = 3, p-value = alternative hypothesis: true ratio of variances is not equal to 1 sample estimates: ratio of variances 0.4 H0 Conclusion :
39 Fiche 17 Test de conformité à une distribution : test du Objectif : On considère une variable X quantitative. Si X est continue, les observations sont réparties par classes, assimilées à des modalités. Si X est discrète, chaque valeur est assimilée à une modalité. Dans le cas d'un nombre infini de valeurs, les valeurs peuvent également être réparties par classe. L'objectif est de tester si la répartition des individus dans les différentes classes est conforme à celle attendue pour une distribution théorique : cette distribution théorique peut être définie a priori, ou être estimée par rapport à l'échantillon. Dans le cas de la loi normale, on calcule la moyenne et l'écart-type de l'échantillon et on vérifie que l'échantillon se distribue suivant la loi normale de mêmes moyenne et écart-type. Données : Les données sont regroupées dans un tableau de la forme : Variable quantitative X classe 1 classe... effectif n1obs nobs... Hypothèse nulle : Les fréquences observées sont conformes aux probabilités attendues. Principe du test : Le principe du test du χ est d estimer à partir d une loi de probabilité connue (ou estimée à partir de l'échantillon), les effectifs théoriques pour les différentes classes du caractère étudié et les comparer aux effectifs observés dans un échantillon. Deux cas peuvent se présenter : soit la loi de probabilité est spécifiée a priori. Le nombre de ddl est alors le nombre de classes k moins 1, = k -1, soit la loi de probabilité théorique n est pas connue a priori et elle est déduite des caractéristiques statistiques mesurées sur l échantillon. Le nombre de ddl est alors le nombre de modalités moins un et moins le nombre de paramètres estimés. Pour l'adéquation à une loi normale inconnue, = k - 1. Test : On teste l hypothèse H 0 (conforme à la distribution attendue) < 1 (v), on accepte H 0 -si -sinon on rejette H 0 avec un risque de première espèce α (ou p). Conditions d'application : Il est impératif d'avoir n 50 et nith eor 5 Compléments : Pour tester la normalité d'une distribution, voir la fiche correspondante. Il existe aussi le test de Kolmogorov-Smirnov (>ks.test(x)). Ce test compare la fonction de répartition théorique supposée continue et entièrement déterminée avec la fonction de répartition de l'échantillon empirique. Exemple : On lance 60 fois un dé et on obtient 1 pour la face 1, 8 pour, 15 pour 3, 7 pour 4, 8 pour 5 et 10 pour 6. Le dé est-il pipé? (utiliser prop.test)
 notamment du fait des faibles effectifs souvent étudiés.")
40 Fiche 18 Normalité d'une distribution Objectif : La distribution suivant une loi normale d'une variable X est un pré-requis nécessaire à la majorité des tests paramétriques (ANOVA, régression...). Les méthodes de vérification ne sont pas entièrement satisfaisantes (faible puissance) notamment du fait des faibles effectifs souvent étudiés. On est donc conduit à croiser plusieurs approches, graphiques et tests, pour évaluer cette hypothèse. Exemple hauteur : Reprendre l'exemple hauteur Représentations graphiques : density Symétrie et unimodalité de la distribution On réalise ici un histogramme. L'existence de deux «pics» ou une forte dissymétrie est un bon indice d'une non normalité. On peut également représenter sur l'histogramme la fonction de densité de la loi normale correspondante et évaluer les écarts hauteur$h >x=seq(165,190,le=50) >lines(x,dnorm(x,mean(hauteur),sd(hauteur))) En pratique les tests ne sont pas très performants, en particulier pour les faibles échantillons. L'examen graphique, notamment la symétrie de la densit, est un bon indcateur.. Droite de Henry La droite de Henry représente les quantiles ( xi ) de la loi empirique en fonction des quantiles de la loi normale centrée réduite ( t i ). Si la loi empirique suit une loi normale, les points sont alignés x i = t i Les points doivent être alignés, à l'intérieur de l'enveloppe de confiance. 175 hauteur$h 185 Graphe Graphe quantile-quantile -1 0 norm quantiles
41 Tests statistiques : Il existe différents tests pour étudier la normalité : Test de Jarque Bera, Test d'adéquation du, test de Lilliefor (> library(nortest) > lillie.test(x)), test de shapiro Wilks. La multitude des tests indique qu'aucun n'est entièrement satisfaisant. Nous nous limiterons au dernier parmi les plus utilisés. Test de Shapiro & Wilks : On retiendra que le test de Shapiro et Wilks porte sur la corrélation au carré qu on voit sur un qqplot [qqnorm(x) sous R et graphique quantile-quantile sous R commander]. La corrélation est toujours très forte, la question est toujours l est-elle assez? La probabilité critique est la probabilité pour que la statistique soit inférieure ou égale à l observation. Statistiques Résumé Test de normalité de Shapiro Wilks W = , p-value = H0 Conclusion : Exemple bébé : W = 0.938, p-value = 0.59 Le test n'est pas correct ici car cette variable dépend du sexe. Il faut donc tester la normalité au sein de chaque sexe sinon on réalise le test sur un mélange de deux distributions. La limite du test est souvent lié au faible effectif dans chaque groupe. On ne peut donc pas vraiment tester la normalité avec un faible effectif sauf à observer des écarts extrêmes. On teste la normalité pour chacune des populations: attach(bebe) shapiro.test(kg[sexe=="m"]) W = 0.999, p-value = shapiro.test(kg[sexe=="f"]) W = , p-value = Examen des deux distributions > par(mfrow=c(,1)) >hist(kg[sexe=="m"],main="m", xlim=c(.5,4)) > hist(kg[sexe=="f"],main="f",xlim=c(.5,4))
.")
42 Fiche 19 Test du coefficient de corrélation Soient (X,Y) un couple de variables quantitatives. La description de la liaison entre les deux variables se fait préalablement par un examen du nuage de points (xi,yi). Voir la fiche #correlation Si le nuage de points décrit une relation linéaire entre les deux variables, on peut calculer comme indicateur de la liaison linéaire entre les deux variables, le coefficient de corrélation de Pearson : r= xi x yi y x y Si la relation entre les variables n'est pas linéaire, il est possible d'utiliser un autre coefficient de corrélation (par exemple le coefficient de corrélation de Spearman basé sur les rangs des observations). Objectif : La liaison linéaire entre les variables est significative si le coefficient de corrélation peut être considéré comme significativement non nul. Données : Un couple de variables quantitatives : X x1 x Y y1 y Hypothèse nulle : H0 "le coefficient de corrélation de Pearson est nul" ou "Les variables X et Y ne sont pas corrélées". Principe du test : Sous H 0, la statistique r suit une loi tabulée à n- ddl. On construit alors une zone d'acceptation centrée sur 0. Test : On teste H 0 «r= 0» contre H «r 0». Si p >0,05, on accepte H 0. Si p <0,05, on rejette H 0 avec un risque de première espèce p. Conditions d'application : Elles reposent sur la distribution multinormale du couple (X,Y). Exemple arbre : Test du coefficient de corrélation Statistiques Résumés Test du coefficient t = , df = 5, p-value = 5.70e-05 alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: sample estimates: cor H0 : - 4 -
43 IV COMPARAISON DE MOYENNES : ANOVA A UN FACTEUR Les données et objectifs : Cette technique s'applique à des tableaux décrivant pour chaque individu une variable quantitative Y en fonction d'un facteur. On appelle facteur une variable qualitative prenant plusieurs modalités dont on étudie l'influence sur la variable Y. Par exemple, le facteur peut être la variété, le dosage d'un apport nutritif, le type d'engrais, un traitement Le tableau type sous R est : Y y 11 y 1 y k Facteur A A B Facteur est une colonne déclarée en facteur k représente la répétition de la mesure pour la modalité L'objectif est d'évaluer si le facteur influence significativement la variable Y. Pour tester l'hypothèse nulle H 0 "toutes les moyennes sont égales", on a le plus souvent recours à l analyse de variance (ANOVA) développée par Fischer ( ). Le modèle linéaire pour un facteur En présence d'un seul facteur, on considère que la variable Y suit pour chaque modalité i une loi normale N(µi,σ²). yik = μ + αi + εik ou yik = μi + εik avec μ la moyenne générale de Y αi l'effet du la modalité i sur la moyenne (μ + αi = μi ) εik une variable aléatoire suivant une loi normale centrée N(0,σ²) On écrit alors : Ajustement du modèle: Les coefficients sont estimés en minimisant l'erreur quadratique moyenne : Critère des moindres carrés = 1 n y ik y i ik y ik = y i, Les différences entre les valeurs observées y ik et les valeurs prédites par le modèle notée y y s'appellent les résidus, notés eik = ik i Les estimations des coefficients sont : 1 y = y ik pour μ n ik 1 y i = n y ik pour μi i k s² = 1 n q yik yi soit ai = y i y pour αi pour σ² avec q le nombre de modalités ik
44 Exemple piece : Cinq pièces sont prélevées au hasard dans la production de trois machines, A, B et C. Chacune des pièces est ensuite mesurée par un seul opérateur. Les mesures sont présentées dans le tableau ci-dessous: facteur mesure A 5 A 7 A 6 A 9 A 13 B 8 B 14 B 7 B 1 B 9 Construire le fichier pieces et convertir le facteur. Boxplot Graphe des moyennes C 14 C 15 C 17 C 18 C 11 attach(pieces);stripchart(mes~fac,vert=t) mes mean of pieces$mes Plot of Means 1 3 fac 1 3 pieces$fac Calculer les moyennes Calculer les estimations i et s :
45 Bilan ANOVA
46 Fiche 0 Test ANOVA Objectif : L'objectif du test est de montrer l'existence de différences significatives entre les moyennes. Hypothèse nulle : H 0 «les moyennes sont toutes égales» contre H «les moyennes ne sont pas toutes égales». Il est important de comprendre que l'anova n'est pas un test permettant de «classer» des moyennes. On étudiera certains tests dits «tests de comparaison multiples» permettant de répondre à ce problème au paragraphe III. Principe du test : L'écart total et se décompose en un écart expliqué par le modèle, e B et un écart résiduel ew, soit : et eb ew = + y ik - y = ( y i y ) + ( y ik y i ) On utilise l'écriture anglosaxonne avec : B pour between groups (entre groupes) W pour within group (intra groupe) On montre que la somme des carrés des écarts se décompose en une somme intra et inter groupes SCE T = SCE B + SCE W y ik y = y i y + y ik y i ik ik ik En notant SCET la somme des carrés des écarts totaux, SCEB la somme des carrés des écarts intergroupes et SCEW la somme des carrés des écarts intra-groupe. On obtient les différentes variances, ou carrés moyens, en divisant les sommes de carrés d'écart par leurs degrés de liberté. Total: n 1 Inter : q 1 Intra : n q On vérifie que q 1 + n q = n 1. Les degrés de liberté se décomposent de manière additive comme les sommes de carrés d'écarts. On obtient alors les carrés moyens (mean squares) ou variances par les formules suivantes : CM T = SCE T n 1 CM B = SCE B q 1 CM W = SCE W n q avec n l'effectif total et qle nombre de modalités. On montre alors que la statistique F = CM B suit la loi de Fisher à (q-1;n-q) ddl sous H0. CM W Test : On teste H 0 «les moyennes sont toutes égales» contre H «les moyennes ne sont pas toutes égales si F < F1 (q-1,n-q), on accepte H 0 sinon on rejette H 0 avec un risque de première espèce égal à (ou p)
47 Tableau d'analyse de variance : les résultats du test se présente sous forme d'un tableau : Response: Y Sum Sq Df CM F p-value=pr(>f) facteur Residuals Construire le tableau d'analyse de variance pour l'exemple pièces Conditions d'utilisation : On retrouve les trois conditions : les observations sont indépendantes, la variable Y suit la loi normale au sein de chaque modalité, la variance de Y est la même pour toutes les modalités. Interprétation graphique :
48 Fiche 1 ANOVA avec R Remarque : Sous R il est préférable de mettre le témoin en premier dans le tableau. Les effets de chaque modalité seront ainsi calculés par rapport au témoin. Cas 1 : Sans examen des conditions d'application Statistiques Moyenne Anova à un facteur Df Sum Sq Mean Sq F value Pr(>F) var ** Residuals Signif. codes: A B C 0 '***' '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 mean sd n Cas : Avec examen des conditions d'application Statistiques Ajustement de modele modèle linéaire Residuals: Min 1Q Median Q Max 5 Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) e-05 *** var[t.b] var[t.c] ** Residual standard error:.944 on 1 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: 7.5 on and 1 DF, p-value: On peut alors afficher le tableau d'anova : Modèle Test d'hypothèse Table d'anova Response: poids Sum Sq Df F value Pr(>F) var ** Residuals Pour tester les conditions, construire les colonnes yi valeurs ajustées e et résidus i Modèle Ajouter les statistiques.. Table d'anova
, rôle de l'expérimentateur, du terrain.")
49 Fiche Validation du modèle L'hypothèse principale de cette méthode est l'indépendance des données. Cette propriété conduit à construire des protocoles expérimentaux permettant justement de contrôler d'éventuels biais : gradient (terrain, lumière), rôle de l'expérimentateur, du terrain... Ne pas respecter cette propriété conduit à mesurer et tester autre chose que l'effet étudié, autant dire les données deviennent inexploitables. La décomposition de la variance est toujours valable, quelle que soit la distribution des variables étudiées. Cependant, lorsqu'on réalise le test final (test F ), on admet la normalité des distributions (puisque le F est le rapport de deux khi-deux, qui sont des sommes de carrés de lois normales). L'ANOVA fait donc l'hypothèse de normalité. Elle est cependant assez robuste à la non normalité, ce qui permet de l'utiliser dans une grande variété de conditions. A l'opposé, l'anova fait une autre hypothèse très forte et moins évidente. Il est en effet nécessaire que la variance dans les différents groupes soit la même. C'est l'hypothèse d'homoscedasticité. L'ANOVA y est sensible. Il est donc nécessaire de la tester avant toute utilisation. L analyse des résidus e est particulièrement utile pour répondre aux hypothèses de normalité et d homoscédasticité. ij Pour éviter des erreurs, il vaut mieux réaliser les tests sur les résidus. 1. Indépendance L indépendance entre les différentes valeurs de la variable mesurée y est une condition essentielle à la réalisation de l analyse de variance. Les q échantillons comparés sont indépendants. L ensemble des n individus est réparti au hasard (randomisation) entre les q modalités du facteur contrôlé. ij On est conduit à construire des protocoles expérimentaux basés par exemple sur la construction de bloc, de carré latin... La cartographie des résidus est un moyen d'évaluer d'éventuels problèmes:

50 . Normalité La variable quantitative étudiée doit suivre une loi normale dans les q populations comparées. La normalité de la variable pourra être testée à l aide du test de Shapiro-Wilk si les effectifs sont suffisamment importants. Sinon le test non paramétrique de Lilliefors permet de tester l ajustement à loi normale lorsque les effectifs sont faibles. Observations graphiques : Graphe Histogramme ou Graphe indexé ou quantile-quantile Test de shapiro sur les résidus data: Shapiro-Wilk normality test pieces$linearmodel.1.residuals W = , p-value = Homoscédasticité de la variance En plus de l'examen graphique des boîtes de dispersion, on dispose de différents tests pour vérifier l'égalité de la variance dans les différentes populations : Le test de Lévène est le test le plus satisfaisant pour effectuer la comparaison multiple de variances mais sa réalisation est assez longue car il correspond à une ANOVA sur les résidus. Le test de Bartlett est dédié à la comparaison multiple de variances avec un nombre de répétitions ni différent selon les modalités i du facteur. Mais ce test est très sensible à l hypothèse de normalité des p populations (peu robuste). Le test de Hartley est dédié à la comparaison multiple de variances avec un nombre de répétitions ni identiques selon les modalités i du facteur. Mais ce test est très sensible à l hypothèse de normalité des p populations (peu robuste). Statistiques Variance Test de Bartlett ou Levene Faire le test sur les résidus bartlett.test(mes ~ fac, data=pieces) Bartlett's K-squared = 0.075, df =, p-value = levene.test(pieces$mes, pieces$fac) Df F value Pr(>F) group

51 Fiche 3 Robustesse de l'anova- Test de Kruskal Wallis De nombreux travaux ont étudié la robustesse de l ANOVA vis à vis des écarts aux hypothèses faites. Hypothèses Test Robustesse de l'anova Normalité de Y Test de Shapiro Wilk Très robuste si indépendance et égalité des variances Homoscédasticité des p distributions Test de Levène ou de Bartlett Très robuste à l inégalité des variances si mêmes effectifs Indépendance des p distributions Plan expérimental Pas robuste Remarque : L analyse de variance à un facteur contrôlé est relativement peu sensible à l inégalité des variances ainsi qu à la non normalité lorsque les échantillons comparés sont de grandes tailles. Dans le cas de forts écarts aux hypothèses de normalités ou d'homoscédasticité, on peut : Utiliser un changement de variables pour vérifier les hypothèses (fiche #Remédiation ).Par exemple si la normalité ou la stabilité de variance n'est pas vérifiée, on refait l'anova et le teste des conditions sur la nouvelle variable log(y) Données Gérer les variables actives dans le jeu de données Calculer une nouvelle variable Utiliser un test non-paramétrique comme le test de Kruskal Wallis pour comparer les moyennes. le test de Kruskal Wallis, qui est lui-même une extension du test non paramétrique de Wilcoxon Mann Whitney (du nom de ses trois auteurs). Ce test utilise des données du même type, mais se limite au cas "un facteur". Pour le cas à deux facteurs sans répétition, on peut envisager d'utiliser le test de Friedman. Test non paramétrique de Kruskal Wallis Statistiques Test non paramétrique Test Kruskal Wallis Kruskal-Wallis rank sum test Kruskal-Wallis chi-squared = , df =, p-value = H0 Conclusion
52 Fiche 4 Planification expérimentale Afin de tester l'effet d'un ou plusieurs facteurs, il est indispensable au préalable de planifier l'expérience. La planification expérimentale correspond aux choix à effectuer concernant : le nombre de facteurs à étudier et le nombre de niveaux par facteur, le nombre d'unités expérimentales, la façon de regrouper les unités. Le plan expérimental va dépendre naturellement du nombres d'unités possibles (coût, disponibilité en place) et donc limitera le choix des facteurs et des niveaux en conséquence. Le nombre d'unités conditionnent directement la puissance du test, à savoir la capacité du test statistiques à mettre en évidence une différence donnée. Il va de soit que la planification est l'étape la plus importante d'une expérimentation (après il est trop tard). Il est donc nécessaire de bien définir au préalable l'objectif de l'expérimentation, les dispositifs possibles, les contraintes, les biais possibles... La planification expérimentale repose sur trois principes : La randomisation : les niveaux des facteurs sont répartis au hasard dans les unités expérimentales afin de limiter des biais, par exemple : l'existence de gradient dans un champ, l'existence de gradient dans une serre (lumière, arrosage), l'influence du notateur s'il y a plusieurs expérimentateurs. Ces différents biais conduisent à mesurer un effet autre que le facteur étudié. Les répétitions : le nombre de répétitions augmentent sensiblement la puissance du test statistique. Ainsi une même différence pourra être non significative avec 5 répétitions mais significative avec 10 répétitions. Il existe des table permettant d'évaluer le nombre de répétitions nécessaires pour mettre en évidence une différence donnée. Le contrôle de l'erreur : L'erreur résiduelle doit être la plus faible possible en limitant ainsi l'effet de facteurs non contrôlés afin d'augmenter la puissance du test (le F). Par exemple, on choisira des unités expérimentales de petite taille regroupées au sein de blocs. Nous renvoyons à l'ouvrage de P. Dagnelie en libre accès internet pour une information complète et nous nous limiterons à présenter succintement deux plans expérimentaux : La méthode des blocs On désigne par blocs des ensembles dans lesquels sont regroupées les unités expérimentales de telle sorte qu elles soient aussi semblables que possible à l intérieur de chaque bloc. On peut s attendre ainsi à ce que l erreur expérimentale soit moindre que pour un même nombre d unités aléatoirement situées à l intérieur de la totalité de l espace expérimental. Les blocs sont généralement déterminés pour tenir compte, outre les causes contrôlables définies par les facteurs étudiés, d autres causes qu il peut être difficile, voire impossible, de maintenir constantes sur la totalité des unités expérimentales de l expérience. Les variations entre les blocs sont alors éliminés lorsque l on compare les effets des facteurs. Cette méthode peut être comparée à une analyse de variance à deux facteurs croisés. Le premier facteur étant le facteur étudié, le second se rapportant aux blocs. Si toutes les situations sont représentées dans l'expérience réalisée, on dit qu'on utilise un plan à blocs complets; si ce n'est pas le cas, c'est un plan à blocs incomplets. Exemple : si on compare le rendement de quatre variétés de maïs en les semant sur un lot de parcelle (six par exemple); les différences de fertilité de ces dernières vont introduire une variabilité parasite, nuisible pour la comparaison
53 L'idéal serait de découper chaque parcelle en quatre, de répartir aléatoirement chaque variété dans chaque quart pour comparer la productivité de chaque espèce de maïs au sein de chaque parcelle, et finalement résumer ces six comparaisons en une seule conclusion. Parcelle 1 (bloc 1) Rendement Rendement Rendement Rendement Maïs Maïs 1 Maïs 4 Maïs 3 Parcelle (bloc ) Rendement Rendement Rendement Rendement Maïs 1 Maïs 3 Maïs Maïs 4 Parcelle 3 (bloc 3) Rendement Rendement Rendement Rendement Maïs Maïs 3 Maïs 1 Maïs 4 Parcelle 4 (bloc 4) Rendement Rendement Rendement Rendement Maïs 4 Maïs Maïs 3 Maïs 1 Parcelle 5 (bloc 5) Rendement Rendement Rendement Rendement Maïs 3 Maïs 4 Maïs 1 Maïs Parcelle 6 (bloc 6) Rendement Rendement Rendement Rendement Maïs 1 Maïs 4 Maïs Maïs 3 Une analyse de variance à deux facteurs (le premier facteur correspond au rendement; le second à l'effet bloc) pourra nous dire si, après élimination des effets de bloc, il existe une différence significative entre les variétés de maïs. La méthode des carrés latins Le carré latin est un dispositif qui permet de contrôler l'hétérogénéité du matériel expérimental dans deux directions. Dans certaines expériences, il arrive qu'une série de k traitements soit donnée à des sujets à des moments différents (ou à des endroits différents du corps s'il s'agit de crèmes), et que l'ordre (ou le lieu d'application) dans lequel est donnée la séquence soit potentiellement important. Il est alors indispensable de tenir compte dans l'analyse d'un effet "ordre (ou lieu) d'administration" et faire attention à ce que chaque traitement soit donné de façon équilibrée en 1ère, ème,..., kème position. L'utilisation des carrés latins répond à cet impératif. Prenons l'exemple de 4 traitements donnés à 4 moments différents de la journée. Les sources d'erreur sont : - les moments de la journée - l'ordre d'administration Dans la figure suivante sont représentés par des lettres les 4 traitements. Les lignes du tableau représente les moments; les colonnes, l'ordre. A B C D B C D A C D A B D A B C Chaque traitement doit apparaître une fois dans chaque ligne et dans chaque colonne. Dans un carré latin, le nombre de lignes doit être égal au nombre de colonnes. Ainsi le carré latin sera toujours de type 3 x 3 ou 4 x 4 Pour un carré latin 3 x 3, il y a donc 1 configurations possibles; pour un carré latin 4 x 4, 576; pour un carré latin 5 x 5, combinaisons différentes La méthode des carrés latins est assimilée à une analyse de variance à trois facteurs. En effet, le premier facteur est le facteur traitement; les deux autres correspondent aux sources d'erreur (facteur ligne et facteur colonne)

54 Fiche 5 Comparaisons multiples Lorsqu'une ANOVA a rejeté l'hypothèse nulle à un certain niveau de risque α. Ce rejet se fait "en bloc", sans aucun détail sur les raisons qui l'ont provoqué. Lorsqu on planifie plusieurs comparaisons, il est nécessaire de prendre des mesures pour limiter le taux d erreur de l ensemble. Ainsi par exemple, il serait incorrect de réaliser des tests t classiques pour réaliser des comparaisons multiples car cela provoquerait une inflation très importante du risque de commettre au moins une erreur de première espèce. La méthode de Bonferroni consiste à fixer un taux d erreur par comparaison beaucoup plus sévère que α = 0,05 de telle sorte que le taux d erreur de l ensemble reste raisonnable. Pour k comparaisons, il suffit de prendre pour chaque test t de comparaison à le risque. Pour 3 populations, on aura par exemple k=3 (A-B,A-C,B-C) k D'autres tests (dits "post hoc", ou "a posteriori") ont été développés dans le but d'analyser plus finement la situation, et de comprendre ce qui a provoqué ce rejet. Par exemple : Le test de Dunnett s'intéresse à la situation où un des groupes est un groupe "témoin", et où l'on cherche à mettre en évidence le groupe dont la moyenne est significativement différente de celle du groupe témoin (typiquement, un groupe "placebo"). Le test de Newman-Keuls qui réduit le nombre de comparaisons deux-à-deux en garantissant comme non significatives les différences entre moyennes prises "en sandwich" entre deux moyennes dont les différences ne sont elles-mêmes pas significatives. Le test de Newman-Keuls est un test de comparaison de moyennes par paire, pratiqué à l issue d une ANOVA. Statistiques Moyenne Anova à un facteur Estimated Quantile = % family-wise confidence level 95% family-wise confidence level Linear Hypotheses: Estimate lwr upr B - A == C - A == C - B == B-A ( ) ( C-A > pairwise.t.test(y,fac,p.adj="bonf") Pairwise comparisons using t tests with pooled SD data: mes and fac P value adjustment method: holm C-B ) ( 0 ) 5 Linear Function 10
55 V COMPARAISONS DE MOYENNES : ANOVA à FACTEURS Objectif et données : On étudie maintenant une variable quantitative Y en fonction de deux facteurs, le rendement en fonction de la variété et de l'engrais utilisé par exemple. L'objectif est alors de tester la signification de l'effet moyen de chaque facteur et de leur intéraction. Le tableau de donnée se présente sous R sous la forme : Y Facteur I Facteur II y y 35 3 y ijk i j 5ème répétition de la combinaison -3 k ème répétition de la combinaison i j La construction du test est similaire à celle de l'anova à un facteur. Les modèles utilisés ici sont : Modèle sans répétition ou dispositif en bloc complets : yijk = μ + αi + βj + εijk avec μ la moyenne générale de Y αi l'effet du à la modalité i du facteur A sur la moyenne βj l'effet du à la modalité j du facteur B sur la moyenne εijk une variable aléatoire suivant une loi normale centrée N(0,σ²) Modèle avec répétition et interaction yijk = μ + αi + βj + γij + εijk avec μ la moyenne générale de Y α αi l'effet du à modalité i du facteur A βj l'effet du à modalité j du facteur B γij l'effet du à l'interaction de i et j εijk v.a. suivant une loi normale centrée N(0,σ²) Principe du test : On décompose la somme des carrés des écarts et à l'aide du test F on peut tester la signification de : l'effet moyen de chaque facteur, l'intraction entre les deux facteurs. Conditions d'utilisation : (fiche #Validation du modèle): Indépendance des observations Conditionnée par le protocole expérimental, test avec la cartographie des résidus Normalité des écarts résiduels test global sur les résidus et si effectifs suffisants test dans chaque groupe, Homoscédasticité test de Bartlett pour chaque facteur, test sur les combinaison de facteurs si effectifs suffisants Compléments : Parmi les méthodes qui découlent de l'anova, citons : les plans d'expériences avec facteurs emboîtés : l'influence d'un facteur dépend d'un autres facteurs (par exemple l'impact de différents traitements sur les individus d'une portée), Analyse de la covariance : la variable étudiée est influencée par des facteurs et d'autres variables quantitatives, Dispositifs factoriels : combinaisons de plusieurs facteurs
56 Fiche 6 Test ANOVA Test d'anova Le principe du test est similaire. On décompose la somme des carrés des écarts en fonction du facteur étudié et on construit une statistique qui suit la loi de Fisher. Il est ainsi possible de tester si une interaction est significative, si l'effet moyen d'un facteur est significatif Tableau d'analyse de variance Source ddl SCE CM F facteur 1 q1 1 SCE F1 SCE F1 q1 1 CM F1 CM res facteur q 1 SCE F SCE F q 1 CM F CM res Interaction q 1 1 q 1 SCE F1 F SCE F1 F q1 1 q 1 CM F1 F CM res résiduelles n q 1 q 1 SCE res SCE res n q 1 q 1 p value La signification de l'effet d'un facteur indique qu'en moyenne ce facteur à un effet significatif (il existe en moyenne une différence entre au moins deux modalités). La signification de l'interaction indique que les deux facteurs interagissent. L'analyse de ces résultats se fait avec un diagramme des interactions (voir la fiche). Exemple : On souhaite étudier le rendement d'une céréale en fonction de l'engrais et de la nature du terrain. On cultive p= types de terrain T1 et T et q=3 types d'engrais E1, E et E3. Chacune des combinaisons T*E est répétée 4 fois. (fichier rendement.txt ) Terrain T1 T1 T1 T1 T1 T1 T1 T1 T1 T1 T1 T1 T T T T T T T T T T T T Engrais E1 E1 E1 E1 E E E E E3 E3 E3 E3 E1 E1 E1 E1 E E E E E3 E3 E3 E3 Rendt Rendement Rendement Examen des données T1 E1 E E3 T Terrain Engrais

57 Statistiques Résumé Tableau statistique Moyennes croisées écarts type croisés Terrain Engrais T1 T E E E Terrain Engrais T1 T E E E Graphe Graphe des moyennes Diagramme des interactions 90 engrais$terrain T1 T mean of engrais$y Plot of M eans E1 E E3 engrais$engrais Modèle 1 deux facteurs avec interaction : Statistiques Ajustement de modele modele lineaire Modele Test d'hypothese Table d'anova Sum Sq Df F value Pr(>F) Engrais *** Terrain Engrais:Terrain Residuals H0 Conclusion Modele Resumé du modele Coefficients: (Intercept) Engrais[T.E] Engrais[T.E3] Terrain[T.T] Engrais[T.E]:Terrain[T.T] Engrais[T.E3]:Terrain[T.T] Estimate Std. Error t value Pr(> t ) e-08 ***

58 Fiche 7 Validation On valide les conditions sur les résidus du modèle : Modele y ijk ) Ajouter des statistiques (résidus eijk et fitted Distribution normale des résidus : Statistiques Resumes Test de normalité Shapiro W = 0.937, p-value = density engrais$residuals.linearmodel.4 Graphe Graphe indexé engrais$residuals.linearmodel.4 0 Index Homoscédasticité On ne peut comparer la variance entre les différentes combinaisons de facteurs, on peut néanmoins examiner si les résidus ont des variances comparables pour un facteur donné. > bartlett.test(rendement ~ Engrais, data=rendement) data: Rendement by Engrais Bartlett's K-squared = , df =, p-value = residuals.linearmodel.4 0 > bartlett.test(rendement ~ Terrain, data=rendement) data: Rendement by Terrain Bartlett's K-squared = , df = 1, p-value = fitted.linearmodel
59 Fiche 8 Interaction entre facteurs Interaction entre facteurs
, mais on recherche souvent à expliquer une des variables en fonction d'autres variables.")
60 VI REGRESSION LINEAIRE SIMPLE Objectif : La régression linéaire simple s'applique à des tableaux décrivant pour chaque individu deux variables quantitatives. L'analyse de ces tableaux peut se limiter à l'analyse des liaisons entre variables (corrélation, ACP), mais on recherche souvent à expliquer une des variables en fonction d'autres variables. On distingue alors la variable à expliquer Y (réponse) et les variables explicatives X i. Les variables explicatives peuvent être fixées par l'expérimentateur ou aléatoires. Dans tous les cas : la variable explicative X i est considérée comme exacte (à l'erreur de mesure près) la variable réponse Y est considérée comme une variable aléatoire avec une variabilité naturelle qui est décrite par un modèle dit modèle d'erreur (loi normale le plus souvent). le rôle des variables n'est donc pas symétrique et le choix de Y est le plus souvent naturel. Exemple : Choisir X i et Y 1. poids taille. poids frais poids sec 3. CO nb de voitures nb habitants L'objectif de la régression est de déterminer, si elle existe, une relation fonctionnelle entre la variable à expliquer Y et une ou plusieurs variables explicatives X1, X Données : individu 1 individu Y y1 y X1 x 11 x1 Représentation graphique : La première étape est d'observer le nuage de point pour déceler une éventuelle relation fonctionnelle. relation fonctionnelle linéaire relation fonctionnelle non linéaire Exemple : Sur un échantillon de 10 sujets d âges différents, on a recueilli l'âge et la concentration sanguine du cholestérol (en g/l) de 10 individus : age (xi) gl (yi) L'inverse a-t-il un sens? La relation fonctionnelle est-elle linéaire? Peut-on prévoir le taux de cholestérol attendu à 35 ans, 75 ans? Quels taux de cholestérol peuvent être considérés comme normaux à un âge donné?
61 Fiche 9 Modèle de régression linéaire simple - Ajustement On utilisera une régression linéaire simple dans le cas ou : la relation fonctionnelle peut être considérée comme linéaire entre Y et X (observation du nuage de points), la corrélation est significativement différente de 0 (fiche #correlation). Dans le cas contraire, il n'existe pas de relation (linéaire) significative entre Y et X et l'utilisation d'un modèle de régression linéaire n'a aucun intérêt. On réalisera donc toujours ces deux vérifications au préalable et dans l'ordre avant de se lancer dans une régression linéaire. Dans de nombreux cas, la relation fonctionnelle entre Y et X ne peut pas être considérée comme linéaire : on peut soit revenir à un modèle linéaire par changement de variables (fiche #Remédiation), soit utiliser une régression non linéaire (non abordé). Le modèle On définit ainsi un modèle stochastique : yi = f(xi)+ εi avec f la relation fonctionnelle entre X et Y εi une variable aléatoire décrivant la partie aléatoire de la variable Y Le modèle linéaire pour la régression linéaire simple est : yi = α + β xi+ εi ou yi = α + β1 x1i+ β xi + εi avec εi une variable aléatoire suivant une loi normale centrée N(0,σ²) L'intérêt du modèle linéaire est sa simplicité, son ubiquité et les différents outils statistiques qui s'y rattachent : diagnostic, intervalle de prédiction, test sur les coefficients Ajustement du modèle: On recherche dans une famille fixée de fonctions, la fonction f pour laquelle les yi sont les plus proches des f(xi). La proximité se mesure en général comme une erreur quadratique moyenne : n 1 Critère des moindres carrés = y i f x i n i=1-61 -
62 On parle alors de régression au sens des moindres carrés. Les différences entre les valeurs observées yi et les valeurs prédites par le modèle f x i, notée ei, s'appellent les résidus, notés ei. Ecart résiduel : ei= yi - f(xi) ou y i avec yi = f xi ei= yi - L'ajustement du modèle consiste donc à déterminer dans une famille de fonctions données, quelle est celle qui minimise l'erreur quadratique. Dans le cadre du modèle linéaire, on notera a, b, s² les estimations des paramètres α, β et σ². L'étude théorique conduit à : b= x i x yi y = x i x XY s X sy avec XY le coefficient de covariance de X et Y. a = y- b x s² = 1 n 1 y i y i = n e i Exemple : Reprendre l'exemple cholesterol et estimer les paramètres à la main et avec R x= y= XY = b= a= s = sx = sy =
63 Avec R : Statistiques Ajustement de modele Régression linéaire Attention Y est choisi en premier (Y~X) au contraire du nuage de point Residuals: Min 1Q Median Q Max Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) *** age e-05 *** Residual standard error: on 8 degrees of freedom Multiple R-Squared: , Adjusted R-squared: F-statistic: 8.9 on 1 and 8 DF, p-value: 1.748e-05 Illustration du principe d'ajustement attach(cholesterol) lm.chol <- lm(gl~age) attach(cholesterol) plot(age,gl) abline(lm.chol) segments(age,g.l,age,fitted(lm.chol))
.")
64 Fiche 30 Validation du modèle de régression linéaire simple On se place dans le cadre d'une relation linéaire entre deux variables (examen du nuage de points) et d'une liaison linéaire significative entre ces deux variables (coefficient de corrélation significativement non nul). Les hypothèses du modèle de régression linéaire simple nécessaire à la construction des principaux tests statistiques (inférence) sont : 1. indépendance des observations,. distribution normale centrée de l'écart résiduel, 3. homoscédasticité, à savoir que l'écart résiduel suit la même loi yi. indépendamment des valeurs de xi ou Dans le cas où ces hypothèses sont vérifiées, il est possible de construire des intervalles de confiances pour les paramètres estimés, des intervalles de confiance pour la prédiction, comparer les modèles,... La vérification de ces hypohèses n'est pas toujours évidente. Il est préférable de croiser différentes méthodes, graphiques et tests, pour évaluer l'existence d'écarts aux hypothèses. Aucune méthode n'est entièrement satisfaisante. Exemple cholesterol : Les analyses sont illustrées sur l'exemple cholesterol. On valide les conditions sur les résidus du modèle : Modele yi) Ajouter des statistiques (résidus ei et fitted 1. Indépendance des écarts résiduels Le problème d'indépendance est important notamment dans le cas de séries chronologiques pour lesquels il existe des modèles spécifiques (ARIMA ) gras$residuals.linearmodel.1 1. Observations graphiques : On observe sur l'ajustement du nuage par une droite ou sur le diagramme des écarts l'éventuelle apparition de tendances cycliques (saisons, cycles économiques,...), une relation non linéaire, une répartition non aléatoire des résidus (amplitude, signe).test de Durbin-Watson : On teste l'existence d'une relation autorégressive de type 4 6 Index
 Modele Diagnostic numérique Test de Durbin Watson data: gl ~ age DW =.1109, p-value = 0.")
65 . Test de Durbin-Watson : On teste l'existence d'une relation autorégressive de type : εi+1= ρ εi + τ avec τ ~N(0,σ²). n e i e i 1 On utilise la statistique i= n e i i= estimateur de (1-ρ) Modele Diagnostic numérique Test de Durbin Watson data: gl ~ age DW =.1109, p-value = alternative hypothesis: true autocorelation is not 0 H0 : Conclusion :. Homoscédasticité y i ou xi. Les y i ou xi mais Observations graphiques : On représente les écarts ei en fonction de écarts ne doivent pas croître en fonction de toujours rester du même ordre de grandeur. residuals.linearmodel.1 y i ou Un des problèmes récurrents est l'existence d'une relation entre l'écart résiduel et la valeur de y i ou xi. celle de xi. L'écart ei a parfois tendance à croître avec Il existe différents tests complémentaires concernant l'hypothèse H0 d'homoscédasticité fitted.linearmodel.1. Test de Breusch-Pagan : Ce test utilise la statistique nr² qui suit sous l'hypothèse H0 d'homoscédasticité un. Modele Diagnostic numérique Test de Breusch Pagan Breusch-Pagan test data: gl ~ age BP = , df = 1, p-value = : Conclusion : H0 Remarque : Il existe d'autres tests, test de White par exemple
66 3. Normalité des écarts résiduels gras$residuals.linearmodel gras$residuals.linearmodel frequency Observations graphiques : On peut utiliser les qqplot, histogramme, histogramme des résidus réduits gras$residuals.linearmodel Index norm quantiles. Test de shapiro : shapiro.test(cholesterol$res) Shapiro-Wilk normality test data: cholest$res W = , p-value = Quelques exemples
67 Fiche 31 Remédiation par changement de variables Il existe différentes techniques pour remédier aux violations de certaines hypothèses. Nous insisterons ici essentiellement sur le changement de variables qui permet par exemple de rendre linéaire une relation entre deux variables, de rendre normale la distribution des écarts résiduels ou de stabiliser la variance (homoscédasticité). Si un tel changement ne permet pas de corriger l'écart, on peut : pour une relation non-linéaire utiliser un modèle non linéaire, pour l'hétéroscédasticité, pondérer les observations, pour la non normalité, changer le modèle d'erreur... Pour certaines familles de fonctions, on transforme le problème de manière à se ramener à une régression linéaire. Voici quelques cas fréquents. Famille Fonctions Transformation Forme affine exponentielle puissance inverse logistique proportion y ' =arcsin y y est une proportion y ' = ax b
68 Fiche 3 Tests sur les paramètres - ANOVA Après vérification des hypothèses, il est possible d'envisager la construction de tests. Intervalle de confiance des paramètres Les estimateurs a, b, s des coefficients suivent des lois connues permettant de calculer des intervalles de confiance, de construire des tests Modele Resume du modele Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) *** age e-05 *** Residual standard error: on 8 degrees of freedom Multiple R-Squared: , Adjusted R-squared: F-statistic: 8.9 on 1 and 8 DF, p-value: 1.748e-05 Déterminer un intervalle de confiance à 99% des coefficients : Modele Intervalle de confiance 0.5 % 99.5 % (Intercept) age Analyse de variance Décomposition de la variance : L'écart total y i y se décompose en deux parties : l'écart expliqué par le modèle et l'écart résiduel. On a la relation : écart total = yi y écart expliqué yi y = + écart résiduel + yi yi On montre que les sommes des carrés des écarts (SCE) vérifient la même relation : La somme des carrés des écarts totale (SCtot) est égale à la somme des SC due au modèle (SCreg) et des SC des résidus (SCres) : SCEtot = n yi y i =1 SCEreg + n = y i y i = SCEres n + y i y i i =1
 ddl.")
69 Analyse de variance : Sous l'hypothèse H0 "b=0" (absence de liaison entre X et Y), on montre que SCE tot, n 1 SCE reg et 1 SCE res sont trois estimateurs sans biais de σ² qui suivent des lois du χ² à respectivement à n-1, 1 et nn ddl. On montre alors que la statistique F = SC reg SCres 1 suit la loi de Fisher à (1,n-) ddl. Il est alors n possible de construire un test pour tester H0 à l'aide de la distribution de F. Tableau d'analyse de variance : Modele Test d'hypothèse Table d'anova Response: gl Sum Sq Df F value Pr(>F) age e-05 *** Residuals Coefficient de détermination R²: Pour quantifier l'intérêt du modèle, on calcule le coefficient de détermination, noté R², égal au rapport de la somme des carrés des écarts expliqués par le modèle par la somme des carrés des écarts totaux : R²= SCE reg SCE tot On montre que ce coefficient est égal au coefficient de corrélation au carré : R²=r². Plus R² est proche de 1, plus le modèle permet d'expliquer une grande partie de la variabilité de Y. Coefficient de détermination ajusté R : Plus on utilise de variables pour expliquer Y plus on explique mécaniquement la variabilité sans que les variables n'aient forcément un rôle explicatif. Pour contrer cet effet, et donc éviter de surestimer le R, plusieurs auteurs ont proposé un R ajusté, qui tient compte du nombre de variables explicatives du modèle de régression. La formule la plus couramment utilisée est la suivante: = n 1 R p R n p 1 où n = nombre d'observations et p = nombre de variables explicatives Ce coefficient de détermination ajusté R est pertinent pour comparer la qualité de deux modèles, indépendamment du nombre de variables pris en compte. On prendra donc en compte son augmentation pour comparer deux modèles. Il existe d'autres critères AIC, BIC plus performants pour évaluer l'intérêt d'un modèle
70 Fiche 33 Prédiction yi : Le modèle de régression linéaire permet de construire des "enveloppes" de confiance pour yi ± s 1 xi x n s X t ou de prédiction pour pour y i : yi ± s 1 x x 1 i n sx t avec t la valeur du t de student correspondant à l'ic souhaité (prendre pour 95%). predc.col <- predict(lm.chol,int="confidence") predp.col <- predict(lm.chol,int="prediction") plot(chol,main="intervalle de confiance");abline(lm.chol) matlines(sort(age),predc.col[order(age),:3],lty=c(,),col="red") matlines(sort(age),predp.col[order(age),:3],lty=c(3,3),col="blue") gl Intervalle de confiance age
71 Fiche 34 Diagnostics des points Certains points apparaissent parfois très éloignés des valeurs attendues. Un examen graphique permet de les identifier et de vérifier alors la possibilité d'une erreur de saisie ou d'une valeur aberrante. Il existe également des techniques permettant d'identifier les points ayant une forte influence sur les coefficients de la droite. On appelle ces points, des points leviers. Une façon intuitive d'évaluer leur influence est de construire la droite de régression avec ou sans ce point et d'observer la différence entre les droites de régression obtenues. Distance de Cook : Cette distance calculée pour chaque point est d'autant plus grande que le point a une influence importante et/ou présente un écart important. hat values hii: Les hat values sont également des indicateurs des observations influentes. Modele Graphes Graphe d'influence des effets
, on peut étendre la méthode de régression linéaire simple à plusieurs variables")
72 VII REGRESSION LINEAIRE MULTIPLE Principe et objectifs : Il arrive qu'on veuille expliquer les variations d'une variable dépendante par l'action de plusieurs variables explicatives. Lorsqu'on a des raisons de penser que la relation entre ces variables est linéaire (faire des nuages de points), on peut étendre la méthode de régression linéaire simple à plusieurs variables explicatives. S'il y a deux variables explicatives, le résultat peut être visualisé sous la forme d'un plan de régression dont l'équation est : y i = a1 x1i + a xi + ei Graphes Graphe 3D nuage de points en 3D Le plan est ajusté selon le principe des moindres carrés où les sommes des carrés des erreurs d'estimation de la variable dépendante sont minimisées (construire un nuage 3D). La régression multiple peut être utilisée à plusieurs fins: Trouver la meilleure équation linéaire de prévision (modèle) et en évaluer la précision et la signification. Estimer la contribution relative de deux ou plusieurs variables explicatives sur la variation d'une variable à expliquer; déceler l'effet complémentaire ou, au contraire, antagoniste entre diverses variables explicatives. Juger de l'importance relative de plusieurs variables explicatives sur une variable dépendante en lien avec une théorie causale sous-jacente à la recherche (attention aux abus: une corrélation n'implique pas toujours une causalité; cette dernière doit être postulée a priori). Exemple : Fichier litters de la library DAAG décrivant la taille de la portée (litter size), le poids de l'animal (bodywt) et le poids du cerveau (brainwt). L'objectif est d'étudier le poids du cerveau en fonction des deux autres variables Matrice des nuages de points (scatterplot matrix) brainwt lsize 4 Matrice des corrélation : bodywt brainwt lsizebodywt bodywt brainwt lsize bodywt
 (Intercept) 0.17847 0.07533.366 0.03010 * bodywt 0.04306 0.006779 3.586 0.")
73 Modèles de régression : Il est possible de proposer trois modèles de régression linéaire pour expliquer brain wt. Statistiques Ajustement de modele lineaire régression lineaire Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) * bodywt ** lsize * Residual standard error: on 17 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: 15.8 on and 17 DF, p-value: Préciser les 3 modèles possibles et la valeur de R correspondant: Quel est le modèle le plus intéressant? Validation du modèle : La validation du modèle reste similaire : indépendance, homoscédasticité, normalité des résidus. Il est important de vérifier également la linéarité des relations à l'aide de nouveaux graphiques de contrôle (fiche validation). Compléments Régression sur variables centrées-réduites Une pratique courante en régression consiste à interpréter les coefficients de régression centrésréduits, c'est-à-dire ceux qu'on obtient en centrant-réduisant toutes les variables (y compris la variable dépendante). En exprimant toutes les variables en unités d'écart-type, on rend les coefficients de régression insensibles à l'étendue de variation des variables explicatives, leur permettant ainsi d'être interprétés directement en termes de "poids" relatif des variables explicatives. Notez aussi que la plupart des logiciels courants fournissent de toute manière les "coefficients de régression centrés réduits"(standardized regression coefficients) en plus des coefficients calculés pour les variables brutes. Régression sur les coordonnées principales. On réalise au préalable une analyse en composantes principales sur les variables explicatives. On construit ainsi de nouvelles variables non corrélées. Bibliographie Analyse de régression appliquée., Y Dodge V Rousson, Paris, Dunod nde ed., 004. Applied regression analysis., Draper N. R. Smith H. NY, J Wiley Sons, 3eme ed.,
74 Fiche 35 Test d'un modèle Test de signification globale du modèle de régression multiple La signification du modèle de régression multiple peut être testée par une statistique F qui, sous H0, est distribuée suivant la loi de Fisher à p et (n p-1) degrés de liberté, p désigne le nombre de variables explicatives. Les hypothèses du test sont: H 0 : la variable Y est linéairement indépendante des variables X k H : la variable Y est expliquée linéairement par au moins une des variables X k SCE reg p L'expression de F est : F= SCE res n p 1 On vérifie ainsi que le modèle est globalement significatif en comparant la valeur de F à celle de F 1 ( p,n-p-1). Test de signification des coefficients La question se pose ensuite de vérifier que chaque variable a une contribution significative. On teste la signification des coefficients relatifs à chaque variable à l'aide d'un test t de Student. Si le coefficient n'est pas significativement différent de 0, alors on supprime la variable du modèle. Exemple : On reprend l'exemple litters lm(formula = brainwt ~ bodywt + lsize, data = litters) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) * bodywt ** lsize * Residual standard error: on 17 degrees of freedom Multiple R-Squared: , Adjusted R-squared: F-statistic: 15.8 on and 17 DF, p-value: > step(regmodel.1) Start: AIC= Df Sum of Sq <none> - lsize - bodywt brainwt ~ bodywt + lsize RSS AIC lm(formula = brainwt ~ bodywt + lsize, data = litters) Coefficients: (Intercept) bodywt lsize
75 Fiche 36 Recherche du meilleur modèle : stepwise regression Pour déterminer la qualité d'un modèle et comparer les modèles entre eux, il est possible : d'étudier la valeur du coefficient de détermination ajusté qui doit être le plus élevé possible d'étudier le critère d'information d'akaike qui doit être le plus faible possible AIC = - Ln(L /Y) + k avec L la vraisemblance de l'observation et k le nombre de paramètres Sélection pas à pas (stepwise regression) On rencontre parfois des situations dans lesquelles on dispose de trop de variables explicatives, soit parce que le plan de recherche était trop vague au départ (on a mesuré beaucoup de variables "au cas où elles auraient un effet"), soit parce que le nombre d'observations (et donc de degrés de liberté) est trop faible par rapport au nombre de variables explicatives intéressantes. La séléction des variables pertinentes, la plus complète, consiste à faire entrer les variables l'une après l'autre dans le modèle par sélection progressive et à chaque étape : on retient la variable qui permet la plus forte augmentation du R ou la plus faible valeur d'aic, on vérifie que les coefficients relatifs à chaque variable sont significativement non nuls. Trois cas sont possibles : La dernière variable introduite a un coefficient non significativement non nul, on s'arrête au modèle précédent. Toutes les variables introduites ont un coefficient significativement non nul, on continue en ajoutant une nouvelle variable. Le coefficient d'une variable précédemment introduite a un coefficient non significativement non nul, on élimine cette variable et on reprend le stepwise. Etude d'un exemple : Utiliser les données oddbooks de la library DAAG. Nous allons étudier la variable weight en fonction des trois autres. 1 thick height breadth weight Premier pas : Recherche de la meilleure variable explicative breadth height thick weight breadth height thick weight breadth Examen du scatterplot : height weight Residual standard error: 86. on 10 degrees of Multiple R-Squared: , Adjusted R-squared: F-statistic: on 1 and 10 DF, p-value: 4.84e Estimate Std. Error t value Pr(> t ) (Intercept) * breadth e-06 *** 400 Modèle 1 : thick

76 Second pas : Recherche d'une seconde variable explicative lm(formula = weight ~ breadth + height, data = oddbooks) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) breadth * height Residual standard error: on 9 degrees of freedom Multiple R-Squared: 0.906, Adjusted R-squared: F-statistic: on and 9 DF, p-value:.369e-05 lm(formula = weight ~ breadth + thick, data = oddbooks) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) breadth *** thick Residual standard error: on 9 degrees of freedom Multiple R-Squared: , Adjusted R-squared: F-statistic: 43.5 on and 9 DF, p-value:.365e-05 Conclusion et vérification avec la fonction step de R: Modele Selection de modele pas à pas Direction: Criterion: forward AIC Start: AIC= brainwt ~ 1 Df Sum of Sq RSS AIC bodywt + lsize <none> Step: AIC= brainwt ~ bodywt + lsize <none> Df Sum of Sq RSS AIC Step: AIC= brainwt ~ bodywt + lsize Call: lm(formula = brainwt ~ bodywt + lsize, data = litters) Coefficients: (Intercept) bodywt lsize
 - Homosécdasticité - Indépendance des résidus - Linéarité des relations entre la variable dépendante Y et chacune des variables explicatives X k.")
77 Fiche 37 Validation du modèle La régression linéaire multiple est soumise aux mêmes contraintes que la régression linéaire simple: - Distribution normale de la variable dépendante (normalité des résidus) - Homosécdasticité - Indépendance des résidus - Linéarité des relations entre la variable dépendante Y et chacune des variables explicatives X k. On utilise le «ajouter statistiques» du modèle pour calculer les résidus RegModel.1.residuals e i et les yi : valeurs ajustées RegModel.1.fitted Exemple : Modèle litters 1. Normalité litters$regmodel.1.fitted 0.44 Shapiro-Wilk normality test data: litters$regmodel.1.residuals W = , p-value = norm quantiles On peut également vérifier que les résidus studentisés se retrouvent en majorité entre - et (4.).. Homoscédasticité RegModel.1.residuals Breusch-Pagan test data: brainwt ~ bodywt + lsize BP = 0.611, df = 1, p-value = RegModel.1.fitted
78 3. Indépendance litters$regmodel.1.rstudent Durbin-Watson test data: brainwt ~ bodywt + lsize DW = , p-value = 0.46 alter hyp: true autocorelation is not Index 4. Linéarité Added-Variable Plot bodywt lsize others Studentized Residuals 1 5. Influence des points Hat-Values bodywt others Component+Residual(brainwt) 0.5 Added-Variable Plot brainwt others (Intercept) others Component+Residual Plot Component+Residual(brainwt) brainwt others 0.03 Component+Residual Plot brainwt others 0.0 Added-Variable Plot lsize 10 1
79 Annexe A : Lois de probabilités usuelles Dans la majorité des processus étudiés, le résultat d'une étude peut se traduire par une grandeur mathématique (variable quantitative discrète ou continue, variable binaire). Cette grandeur est assimilée à une variable aléatoire réelle discrète ou continue. A partir de ces grandeurs, le statisticien construit des statistiques ( t du test de Student, du test du Khi Deux, F du test de Fisher, ) qui suivent des lois connues à partir desquelles sont construites les règles de décision. 1. Loi normale Dans de nombreux cas, les variables quantitatives se distribuent suivant une loi normale (courbe en cloche). Deux arguments expliquent ce phénomène : Une variable quantitative qui dépend d un grand nombre de causes indépendantes dont les effets s additionnent et dont aucune n est prépondérante suit une loi normale. Le théorème "central limit" conclut que la moyenne Sn de n variables quantitatives suivant une même loi de moyenne μ et d'écart-type σ converge vers la loi normale de mêmes paramètres. La loi normale est définie sur ℝ et a pour fonction de densité f(x) = 1 π σ ( x µ )² exp σ ². En particuliers, la loi normale centrée (moyenne nulle) réduite (variance unitaire) a pour fonction de densité f(x) = 1 π x² exp. Dans la pratique on revient toujours à cette loi en changeant la variable X en la variable Xcr = X µ σ Xcr est alors dite centrée réduite. 1. Tracer la fonction de densité Distribution Distribution continue Loi normale Graphe. Retrouver le quantile pour lequel la loi normale centrée réduite vérifie P(X < u0,975 ) = Distribution Distribution continue Loi normale quantile. Retrouver la probabilité pour laquelle la loi normale centrée réduite vérifie X > 3, Distribution Distribution continue Loi normale probabilité
80 . Loi de Pearson ou loi du La loi de Pearson ou loi du (Khi deux) trouve de nombreuses applications dans le cadre de la comparaison de proportions, des tests de conformité d une distribution observée à une distribution théorique et le test d indépendance de deux caractères qualitatifs. Définition : Soit Xcr1,, Xcrn, n variables normales centrées réduites indépendantes, on appelle la variable aléatoire définie par : = X cr X crn. Cette variable aléatoire suit la loi de Pearson (ou du ) à n degré de liberté (ddl). S'il existe k relations entre ces variables alors le nombre de ddl devient n-k. Par exemple, si les variables sont centrées (calcul de la moyenne), le nombre de ddl devient n-1. En utilisant R commander, étudier l'allure de la fonction de densité de la loi du en fonction du degré de liberté. Quel est le quantile, q, vérifiant P( X >q) =0.05 pour 1 ddl, ddl, 0 ddl? 3. Loi de Student La loi de Student est utilisée lors des tests de comparaison de paramètres comme la moyenne et dans l estimation de paramètres de la population à partir de données sur un échantillon (Test de Student). Définition : Soit U une variable aléatoire suivant une loi normale centrée réduite et V une loi du à n ddl. U et V étant indépendante on dit alors que t = U/ V n suit une loi de Student à n ddl. En utilisant R commander, étudier l'allure de la fonction de densité de la loi de Student en fonction du degré de liberté. Quel est le quantile, q, vérifiant P( X >q) =0.05 pour 1 ddl, ddl, 0 ddl. 4. Loi de Fisher-Snedecor La loi de Fisher-Snedecor est utilisée pour comparer deux variances observées et sert surtout dans les tests d analyse de variance et de covariance. Définition : Soit U et V deux variables aléatoires suivant des lois de Pearson respectivement à n et m ddl. U La statistique F = V n suit une loi de Fisher-Snedecor à (n,m) ddl. m En utilisant R commander, étudier l'allure de la fonction de densité de la loi de Fisher-Snedecor en fonction de n et m
81 Annexe B : Tables usuelles

82 - 8 -
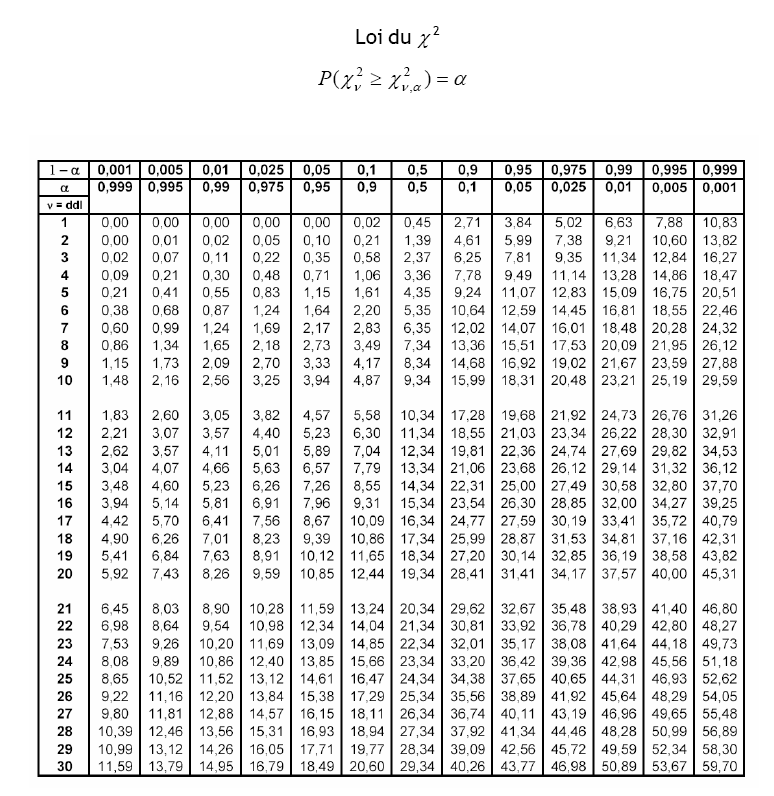
83 - 83 -
Analyse de la variance Comparaison de plusieurs moyennes
 Analyse de la variance Comparaison de plusieurs moyennes Biostatistique Pr. Nicolas MEYER Laboratoire de Biostatistique et Informatique Médicale Fac. de Médecine de Strasbourg Mars 2011 Plan 1 Introduction
Analyse de la variance Comparaison de plusieurs moyennes Biostatistique Pr. Nicolas MEYER Laboratoire de Biostatistique et Informatique Médicale Fac. de Médecine de Strasbourg Mars 2011 Plan 1 Introduction
Introduction aux Statistiques et à l utilisation du logiciel R
 Introduction aux Statistiques et à l utilisation du logiciel R Christophe Lalanne Christophe Pallier 1 Introduction 2 Comparaisons de deux moyennes 2.1 Objet de l étude On a mesuré le temps de sommeil
Introduction aux Statistiques et à l utilisation du logiciel R Christophe Lalanne Christophe Pallier 1 Introduction 2 Comparaisons de deux moyennes 2.1 Objet de l étude On a mesuré le temps de sommeil
Cours (7) de statistiques à distance, élaboré par Zarrouk Fayçal, ISSEP Ksar-Said, 2011-2012 LES STATISTIQUES INFERENTIELLES
 de statistiques à distance, élaboré par Zarrouk Fayçal, ISSEP Ksar-Said, 2011-2012 LES STATISTIQUES INFERENTIELLES") LES STATISTIQUES INFERENTIELLES (test de Student) L inférence statistique est la partie des statistiques qui, contrairement à la statistique descriptive, ne se contente pas de décrire des observations,
LES STATISTIQUES INFERENTIELLES (test de Student) L inférence statistique est la partie des statistiques qui, contrairement à la statistique descriptive, ne se contente pas de décrire des observations,
TABLE DES MATIERES. C Exercices complémentaires 42
 TABLE DES MATIERES Chapitre I : Echantillonnage A - Rappels de cours 1. Lois de probabilités de base rencontrées en statistique 1 1.1 Définitions et caractérisations 1 1.2 Les propriétés de convergence
TABLE DES MATIERES Chapitre I : Echantillonnage A - Rappels de cours 1. Lois de probabilités de base rencontrées en statistique 1 1.1 Définitions et caractérisations 1 1.2 Les propriétés de convergence
Lire ; Compter ; Tester... avec R
 Lire ; Compter ; Tester... avec R Préparation des données / Analyse univariée / Analyse bivariée Christophe Genolini 2 Table des matières 1 Rappels théoriques 5 1.1 Vocabulaire....................................
Lire ; Compter ; Tester... avec R Préparation des données / Analyse univariée / Analyse bivariée Christophe Genolini 2 Table des matières 1 Rappels théoriques 5 1.1 Vocabulaire....................................
distribution quelconque Signe 1 échantillon non Wilcoxon gaussienne distribution symétrique Student gaussienne position
 Arbre de NESI distribution quelconque Signe 1 échantillon distribution symétrique non gaussienne Wilcoxon gaussienne Student position appariés 1 échantillon sur la différence avec référence=0 2 échantillons
Arbre de NESI distribution quelconque Signe 1 échantillon distribution symétrique non gaussienne Wilcoxon gaussienne Student position appariés 1 échantillon sur la différence avec référence=0 2 échantillons
UFR de Sciences Economiques Année 2008-2009 TESTS PARAMÉTRIQUES
 Université Paris 13 Cours de Statistiques et Econométrie I UFR de Sciences Economiques Année 2008-2009 Licence de Sciences Economiques L3 Premier semestre TESTS PARAMÉTRIQUES Remarque: les exercices 2,
Université Paris 13 Cours de Statistiques et Econométrie I UFR de Sciences Economiques Année 2008-2009 Licence de Sciences Economiques L3 Premier semestre TESTS PARAMÉTRIQUES Remarque: les exercices 2,
Principe d un test statistique
 Biostatistiques Principe d un test statistique Professeur Jean-Luc BOSSON PCEM2 - Année universitaire 2012/2013 Faculté de Médecine de Grenoble (UJF) - Tous droits réservés. Objectifs pédagogiques Comprendre
Biostatistiques Principe d un test statistique Professeur Jean-Luc BOSSON PCEM2 - Année universitaire 2012/2013 Faculté de Médecine de Grenoble (UJF) - Tous droits réservés. Objectifs pédagogiques Comprendre
1. Vocabulaire : Introduction au tableau élémentaire
 L1-S1 Lire et caractériser l'information géographique - Le traitement statistique univarié Statistique : le terme statistique désigne à la fois : 1) l'ensemble des données numériques concernant une catégorie
L1-S1 Lire et caractériser l'information géographique - Le traitement statistique univarié Statistique : le terme statistique désigne à la fois : 1) l'ensemble des données numériques concernant une catégorie
TABLE DES MATIÈRES. Bruxelles, De Boeck, 2011, 736 p.
 STATISTIQUE THÉORIQUE ET APPLIQUÉE Tome 2 Inférence statistique à une et à deux dimensions Pierre Dagnelie TABLE DES MATIÈRES Bruxelles, De Boeck, 2011, 736 p. ISBN 978-2-8041-6336-5 De Boeck Services,
STATISTIQUE THÉORIQUE ET APPLIQUÉE Tome 2 Inférence statistique à une et à deux dimensions Pierre Dagnelie TABLE DES MATIÈRES Bruxelles, De Boeck, 2011, 736 p. ISBN 978-2-8041-6336-5 De Boeck Services,
Biostatistiques : Petits effectifs
 Biostatistiques : Petits effectifs Master Recherche Biologie et Santé P. Devos DRCI CHRU de Lille EA2694 patrick.devos@univ-lille2.fr Plan Données Générales : Définition des statistiques Principe de l
Biostatistiques : Petits effectifs Master Recherche Biologie et Santé P. Devos DRCI CHRU de Lille EA2694 patrick.devos@univ-lille2.fr Plan Données Générales : Définition des statistiques Principe de l
Statistiques Descriptives à une dimension
 I. Introduction et Définitions 1. Introduction La statistique est une science qui a pour objectif de recueillir et de traiter les informations, souvent en très grand nombre. Elle regroupe l ensemble des
I. Introduction et Définitions 1. Introduction La statistique est une science qui a pour objectif de recueillir et de traiter les informations, souvent en très grand nombre. Elle regroupe l ensemble des
Biostatistiques Biologie- Vétérinaire FUNDP Eric Depiereux, Benoît DeHertogh, Grégoire Vincke
 www.fundp.ac.be/biostats Module 140 140 ANOVA A UN CRITERE DE CLASSIFICATION FIXE...2 140.1 UTILITE...2 140.2 COMPARAISON DE VARIANCES...2 140.2.1 Calcul de la variance...2 140.2.2 Distributions de référence...3
www.fundp.ac.be/biostats Module 140 140 ANOVA A UN CRITERE DE CLASSIFICATION FIXE...2 140.1 UTILITE...2 140.2 COMPARAISON DE VARIANCES...2 140.2.1 Calcul de la variance...2 140.2.2 Distributions de référence...3
Introduction à la Statistique Inférentielle
 UNIVERSITE MOHAMMED V-AGDAL SCIENCES FACULTE DES DEPARTEMENT DE MATHEMATIQUES SMI semestre 4 : Probabilités - Statistique Introduction à la Statistique Inférentielle Prinemps 2013 0 INTRODUCTION La statistique
UNIVERSITE MOHAMMED V-AGDAL SCIENCES FACULTE DES DEPARTEMENT DE MATHEMATIQUES SMI semestre 4 : Probabilités - Statistique Introduction à la Statistique Inférentielle Prinemps 2013 0 INTRODUCTION La statistique
Introduction à l approche bootstrap
 Introduction à l approche bootstrap Irène Buvat U494 INSERM buvat@imedjussieufr 25 septembre 2000 Introduction à l approche bootstrap - Irène Buvat - 21/9/00-1 Plan du cours Qu est-ce que le bootstrap?
Introduction à l approche bootstrap Irène Buvat U494 INSERM buvat@imedjussieufr 25 septembre 2000 Introduction à l approche bootstrap - Irène Buvat - 21/9/00-1 Plan du cours Qu est-ce que le bootstrap?
Introduction à la statistique non paramétrique
 Introduction à la statistique non paramétrique Catherine MATIAS CNRS, Laboratoire Statistique & Génome, Évry http://stat.genopole.cnrs.fr/ cmatias Atelier SFDS 27/28 septembre 2012 Partie 2 : Tests non
Introduction à la statistique non paramétrique Catherine MATIAS CNRS, Laboratoire Statistique & Génome, Évry http://stat.genopole.cnrs.fr/ cmatias Atelier SFDS 27/28 septembre 2012 Partie 2 : Tests non
Exercices M1 SES 2014-2015 Ana Fermin (http:// fermin.perso.math.cnrs.fr/ ) 14 Avril 2015
 14 Avril 2015") Exercices M1 SES 214-215 Ana Fermin (http:// fermin.perso.math.cnrs.fr/ ) 14 Avril 215 Les exemples numériques présentés dans ce document d exercices ont été traités sur le logiciel R, téléchargeable par
Exercices M1 SES 214-215 Ana Fermin (http:// fermin.perso.math.cnrs.fr/ ) 14 Avril 215 Les exemples numériques présentés dans ce document d exercices ont été traités sur le logiciel R, téléchargeable par
Statistique : Résumé de cours et méthodes
 Statistique : Résumé de cours et méthodes 1 Vocabulaire : Population : c est l ensemble étudié. Individu : c est un élément de la population. Effectif total : c est le nombre total d individus. Caractère
Statistique : Résumé de cours et méthodes 1 Vocabulaire : Population : c est l ensemble étudié. Individu : c est un élément de la population. Effectif total : c est le nombre total d individus. Caractère
Lecture critique d article. Bio statistiques. Dr MARC CUGGIA MCU-PH Laboratoire d informatique médicale EA-3888
 Lecture critique d article Rappels Bio statistiques Dr MARC CUGGIA MCU-PH Laboratoire d informatique médicale EA-3888 Plan du cours Rappels fondamentaux Statistiques descriptives Notions de tests statistiques
Lecture critique d article Rappels Bio statistiques Dr MARC CUGGIA MCU-PH Laboratoire d informatique médicale EA-3888 Plan du cours Rappels fondamentaux Statistiques descriptives Notions de tests statistiques
Logiciel XLSTAT version 7.0. 40 rue Damrémont 75018 PARIS
 Logiciel XLSTAT version 7.0 Contact : Addinsoft 40 rue Damrémont 75018 PARIS 2005-2006 Plan Présentation générale du logiciel Statistiques descriptives Histogramme Discrétisation Tableau de contingence
Logiciel XLSTAT version 7.0 Contact : Addinsoft 40 rue Damrémont 75018 PARIS 2005-2006 Plan Présentation générale du logiciel Statistiques descriptives Histogramme Discrétisation Tableau de contingence
Feuille 6 : Tests. Peut-on dire que l usine a respecté ses engagements? Faire un test d hypothèses pour y répondre.
 Université de Nantes Année 2013-2014 L3 Maths-Eco Feuille 6 : Tests Exercice 1 On cherche à connaître la température d ébullition µ, en degrés Celsius, d un certain liquide. On effectue 16 expériences
Université de Nantes Année 2013-2014 L3 Maths-Eco Feuille 6 : Tests Exercice 1 On cherche à connaître la température d ébullition µ, en degrés Celsius, d un certain liquide. On effectue 16 expériences
Aide-mémoire de statistique appliquée à la biologie
 Maxime HERVÉ Aide-mémoire de statistique appliquée à la biologie Construire son étude et analyser les résultats à l aide du logiciel R Version 5(2) (2014) AVANT-PROPOS Les phénomènes biologiques ont cela
Maxime HERVÉ Aide-mémoire de statistique appliquée à la biologie Construire son étude et analyser les résultats à l aide du logiciel R Version 5(2) (2014) AVANT-PROPOS Les phénomènes biologiques ont cela
CONCOURS D ENTREE A L ECOLE DE 2007 CONCOURS EXTERNE. Cinquième épreuve d admissibilité STATISTIQUE. (durée : cinq heures)
") CONCOURS D ENTREE A L ECOLE DE 2007 CONCOURS EXTERNE Cinquième épreuve d admissibilité STATISTIQUE (durée : cinq heures) Une composition portant sur la statistique. SUJET Cette épreuve est composée d un
CONCOURS D ENTREE A L ECOLE DE 2007 CONCOURS EXTERNE Cinquième épreuve d admissibilité STATISTIQUE (durée : cinq heures) Une composition portant sur la statistique. SUJET Cette épreuve est composée d un
Chapitre 3. Les distributions à deux variables
 Chapitre 3. Les distributions à deux variables Jean-François Coeurjolly http://www-ljk.imag.fr/membres/jean-francois.coeurjolly/ Laboratoire Jean Kuntzmann (LJK), Grenoble University 1 Distributions conditionnelles
Chapitre 3. Les distributions à deux variables Jean-François Coeurjolly http://www-ljk.imag.fr/membres/jean-francois.coeurjolly/ Laboratoire Jean Kuntzmann (LJK), Grenoble University 1 Distributions conditionnelles
Analyses de Variance à un ou plusieurs facteurs Régressions Analyse de Covariance Modèles Linéaires Généralisés
 Analyses de Variance à un ou plusieurs facteurs Régressions Analyse de Covariance Modèles Linéaires Généralisés Professeur Patrice Francour francour@unice.fr Une grande partie des illustrations viennent
Analyses de Variance à un ou plusieurs facteurs Régressions Analyse de Covariance Modèles Linéaires Généralisés Professeur Patrice Francour francour@unice.fr Une grande partie des illustrations viennent
Estimation et tests statistiques, TD 5. Solutions
 ISTIL, Tronc commun de première année Introduction aux méthodes probabilistes et statistiques, 2008 2009 Estimation et tests statistiques, TD 5. Solutions Exercice 1 Dans un centre avicole, des études
ISTIL, Tronc commun de première année Introduction aux méthodes probabilistes et statistiques, 2008 2009 Estimation et tests statistiques, TD 5. Solutions Exercice 1 Dans un centre avicole, des études
FORMULAIRE DE STATISTIQUES
 FORMULAIRE DE STATISTIQUES I. STATISTIQUES DESCRIPTIVES Moyenne arithmétique Remarque: population: m xμ; échantillon: Mx 1 Somme des carrés des écarts "# FR MOYENNE(série) MOYENNE(série) NL GEMIDDELDE(série)
FORMULAIRE DE STATISTIQUES I. STATISTIQUES DESCRIPTIVES Moyenne arithmétique Remarque: population: m xμ; échantillon: Mx 1 Somme des carrés des écarts "# FR MOYENNE(série) MOYENNE(série) NL GEMIDDELDE(série)
Tests de comparaison de moyennes. Dr Sahar BAYAT MASTER 1 année 2009-2010 UE «Introduction à la biostatistique»
 Tests de comparaison de moyennes Dr Sahar BAYAT MASTER 1 année 2009-2010 UE «Introduction à la biostatistique» Test de Z ou de l écart réduit Le test de Z : comparer des paramètres en testant leurs différences
Tests de comparaison de moyennes Dr Sahar BAYAT MASTER 1 année 2009-2010 UE «Introduction à la biostatistique» Test de Z ou de l écart réduit Le test de Z : comparer des paramètres en testant leurs différences
Evaluation de la variabilité d'un système de mesure
 Evaluation de la variabilité d'un système de mesure Exemple 1: Diamètres des injecteurs de carburant Problème Un fabricant d'injecteurs de carburant installe un nouveau système de mesure numérique. Les
Evaluation de la variabilité d'un système de mesure Exemple 1: Diamètres des injecteurs de carburant Problème Un fabricant d'injecteurs de carburant installe un nouveau système de mesure numérique. Les
Chapitre 3 : Principe des tests statistiques d hypothèse. José LABARERE
 UE4 : Biostatistiques Chapitre 3 : Principe des tests statistiques d hypothèse José LABARERE Année universitaire 2010/2011 Université Joseph Fourier de Grenoble - Tous droits réservés. Plan I. Introduction
UE4 : Biostatistiques Chapitre 3 : Principe des tests statistiques d hypothèse José LABARERE Année universitaire 2010/2011 Université Joseph Fourier de Grenoble - Tous droits réservés. Plan I. Introduction
Annexe commune aux séries ES, L et S : boîtes et quantiles
 Annexe commune aux séries ES, L et S : boîtes et quantiles Quantiles En statistique, pour toute série numérique de données à valeurs dans un intervalle I, on définit la fonction quantile Q, de [,1] dans
Annexe commune aux séries ES, L et S : boîtes et quantiles Quantiles En statistique, pour toute série numérique de données à valeurs dans un intervalle I, on définit la fonction quantile Q, de [,1] dans
Exemples d application
 AgroParisTech Exemples d application du modèle linéaire E Lebarbier, S Robin Table des matières 1 Introduction 4 11 Avertissement 4 12 Notations 4 2 Régression linéaire simple 7 21 Présentation 7 211 Objectif
AgroParisTech Exemples d application du modèle linéaire E Lebarbier, S Robin Table des matières 1 Introduction 4 11 Avertissement 4 12 Notations 4 2 Régression linéaire simple 7 21 Présentation 7 211 Objectif
Statistique Descriptive Élémentaire
 Publications de l Institut de Mathématiques de Toulouse Statistique Descriptive Élémentaire (version de mai 2010) Alain Baccini Institut de Mathématiques de Toulouse UMR CNRS 5219 Université Paul Sabatier
Publications de l Institut de Mathématiques de Toulouse Statistique Descriptive Élémentaire (version de mai 2010) Alain Baccini Institut de Mathématiques de Toulouse UMR CNRS 5219 Université Paul Sabatier
Statistiques Appliquées à l Expérimentation en Sciences Humaines. Christophe Lalanne, Sébastien Georges, Christophe Pallier
 Statistiques Appliquées à l Expérimentation en Sciences Humaines Christophe Lalanne, Sébastien Georges, Christophe Pallier Table des matières 1 Méthodologie expérimentale et recueil des données 6 1.1 Introduction.......................................
Statistiques Appliquées à l Expérimentation en Sciences Humaines Christophe Lalanne, Sébastien Georges, Christophe Pallier Table des matières 1 Méthodologie expérimentale et recueil des données 6 1.1 Introduction.......................................
Tests paramétriques de comparaison de 2 moyennes Exercices commentés José LABARERE
 Chapitre 5 UE4 : Biostatistiques Tests paramétriques de comparaison de 2 moyennes Exercices commentés José LABARERE Année universitaire 2010/2011 Université Joseph Fourier de Grenoble - Tous droits réservés.
Chapitre 5 UE4 : Biostatistiques Tests paramétriques de comparaison de 2 moyennes Exercices commentés José LABARERE Année universitaire 2010/2011 Université Joseph Fourier de Grenoble - Tous droits réservés.
La survie nette actuelle à long terme Qualités de sept méthodes d estimation
 La survie nette actuelle à long terme Qualités de sept méthodes d estimation PAR Alireza MOGHADDAM TUTEUR : Guy HÉDELIN Laboratoire d Épidémiologie et de Santé publique, EA 80 Faculté de Médecine de Strasbourg
La survie nette actuelle à long terme Qualités de sept méthodes d estimation PAR Alireza MOGHADDAM TUTEUR : Guy HÉDELIN Laboratoire d Épidémiologie et de Santé publique, EA 80 Faculté de Médecine de Strasbourg
T de Student Khi-deux Corrélation
 Les tests d inférence statistiques permettent d estimer le risque d inférer un résultat d un échantillon à une population et de décider si on «prend le risque» (si 0.05 ou 5 %) Une différence de moyennes
Les tests d inférence statistiques permettent d estimer le risque d inférer un résultat d un échantillon à une population et de décider si on «prend le risque» (si 0.05 ou 5 %) Une différence de moyennes
INTRODUCTION À L ANALYSE FACTORIELLE DES CORRESPONDANCES
 INTRODUCTION À L ANALYSE FACTORIELLE DES CORRESPONDANCES Dominique LAFFLY Maître de Conférences, Université de Pau Laboratoire Société Environnement Territoire UMR 5603 du CNRS et Université de Pau Domaine
INTRODUCTION À L ANALYSE FACTORIELLE DES CORRESPONDANCES Dominique LAFFLY Maître de Conférences, Université de Pau Laboratoire Société Environnement Territoire UMR 5603 du CNRS et Université de Pau Domaine
Une introduction. Lionel RIOU FRANÇA. Septembre 2008
 Une introduction INSERM U669 Septembre 2008 Sommaire 1 Effets Fixes Effets Aléatoires 2 Analyse Classique Effets aléatoires Efficacité homogène Efficacité hétérogène 3 Estimation du modèle Inférence 4
Une introduction INSERM U669 Septembre 2008 Sommaire 1 Effets Fixes Effets Aléatoires 2 Analyse Classique Effets aléatoires Efficacité homogène Efficacité hétérogène 3 Estimation du modèle Inférence 4
Séries Statistiques Simples
 1. Collecte et Représentation de l Information 1.1 Définitions 1.2 Tableaux statistiques 1.3 Graphiques 2. Séries statistiques simples 2.1 Moyenne arithmétique 2.2 Mode & Classe modale 2.3 Effectifs &
1. Collecte et Représentation de l Information 1.1 Définitions 1.2 Tableaux statistiques 1.3 Graphiques 2. Séries statistiques simples 2.1 Moyenne arithmétique 2.2 Mode & Classe modale 2.3 Effectifs &
TESTS D'HYPOTHESES Etude d'un exemple
 TESTS D'HYPOTHESES Etude d'un exemple Un examinateur doit faire passer une épreuve type QCM à des étudiants. Ce QCM est constitué de 20 questions indépendantes. Pour chaque question, il y a trois réponses
TESTS D'HYPOTHESES Etude d'un exemple Un examinateur doit faire passer une épreuve type QCM à des étudiants. Ce QCM est constitué de 20 questions indépendantes. Pour chaque question, il y a trois réponses
t 100. = 8 ; le pourcentage de réduction est : 8 % 1 t Le pourcentage d'évolution (appelé aussi taux d'évolution) est le nombre :
 est le nombre :") Terminale STSS 2 012 2 013 Pourcentages Synthèse 1) Définition : Calculer t % d'un nombre, c'est multiplier ce nombre par t 100. 2) Exemples de calcul : a) Calcul d un pourcentage : Un article coûtant
Terminale STSS 2 012 2 013 Pourcentages Synthèse 1) Définition : Calculer t % d'un nombre, c'est multiplier ce nombre par t 100. 2) Exemples de calcul : a) Calcul d un pourcentage : Un article coûtant
Régression linéaire. Nicolas Turenne INRA nicolas.turenne@jouy.inra.fr
 Régression linéaire Nicolas Turenne INRA nicolas.turenne@jouy.inra.fr 2005 Plan Régression linéaire simple Régression multiple Compréhension de la sortie de la régression Coefficient de détermination R
Régression linéaire Nicolas Turenne INRA nicolas.turenne@jouy.inra.fr 2005 Plan Régression linéaire simple Régression multiple Compréhension de la sortie de la régression Coefficient de détermination R
LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING»
 LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING» Gilbert Saporta Professeur de Statistique Appliquée Conservatoire National des Arts et Métiers Dans leur quasi totalité, les banques et organismes financiers
LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING» Gilbert Saporta Professeur de Statistique Appliquée Conservatoire National des Arts et Métiers Dans leur quasi totalité, les banques et organismes financiers
Traitement des données avec Microsoft EXCEL 2010
 Traitement des données avec Microsoft EXCEL 2010 Vincent Jalby Septembre 2012 1 Saisie des données Les données collectées sont saisies dans une feuille Excel. Chaque ligne correspond à une observation
Traitement des données avec Microsoft EXCEL 2010 Vincent Jalby Septembre 2012 1 Saisie des données Les données collectées sont saisies dans une feuille Excel. Chaque ligne correspond à une observation
VI. Tests non paramétriques sur un échantillon
 VI. Tests non paramétriques sur un échantillon Le modèle n est pas un modèle paramétrique «TESTS du CHI-DEUX» : VI.1. Test d ajustement à une loi donnée VI.. Test d indépendance de deux facteurs 96 Différentes
VI. Tests non paramétriques sur un échantillon Le modèle n est pas un modèle paramétrique «TESTS du CHI-DEUX» : VI.1. Test d ajustement à une loi donnée VI.. Test d indépendance de deux facteurs 96 Différentes
Chapitre 6 Test de comparaison de pourcentages χ². José LABARERE
 UE4 : Biostatistiques Chapitre 6 Test de comparaison de pourcentages χ² José LABARERE Année universitaire 2010/2011 Université Joseph Fourier de Grenoble - Tous droits réservés. Plan I. Nature des variables
UE4 : Biostatistiques Chapitre 6 Test de comparaison de pourcentages χ² José LABARERE Année universitaire 2010/2011 Université Joseph Fourier de Grenoble - Tous droits réservés. Plan I. Nature des variables
La classification automatique de données quantitatives
 La classification automatique de données quantitatives 1 Introduction Parmi les méthodes de statistique exploratoire multidimensionnelle, dont l objectif est d extraire d une masse de données des informations
La classification automatique de données quantitatives 1 Introduction Parmi les méthodes de statistique exploratoire multidimensionnelle, dont l objectif est d extraire d une masse de données des informations
Tests du χ 2. on accepte H 0 bonne décision erreur de seconde espèce on rejette H 0 erreur de première espèce bonne décision
 Page n 1. Tests du χ 2 une des fonctions des statistiques est de proposer, à partir d observations d un phénomène aléatoire (ou modélisé comme tel) une estimation de la loi de ce phénomène. C est que nous
Page n 1. Tests du χ 2 une des fonctions des statistiques est de proposer, à partir d observations d un phénomène aléatoire (ou modélisé comme tel) une estimation de la loi de ce phénomène. C est que nous
TESTS D HYPOTHÈSE FONDÉS SUR LE χ². http://fr.wikipedia.org/wiki/eugénisme
 TESTS D HYPOTHÈSE FONDÉS SUR LE χ² http://fr.wikipedia.org/wiki/eugénisme Logo du Second International Congress of Eugenics 1921. «Comme un arbre, l eugénisme tire ses constituants de nombreuses sources
TESTS D HYPOTHÈSE FONDÉS SUR LE χ² http://fr.wikipedia.org/wiki/eugénisme Logo du Second International Congress of Eugenics 1921. «Comme un arbre, l eugénisme tire ses constituants de nombreuses sources
Cours de Tests paramétriques
 Cours de Tests paramétriques F. Muri-Majoube et P. Cénac 2006-2007 Licence Ce document est sous licence ALC TYPE 2. Le texte de cette licence est également consultable en ligne à l adresse http://www.librecours.org/cgi-bin/main?callback=licencetype2.
Cours de Tests paramétriques F. Muri-Majoube et P. Cénac 2006-2007 Licence Ce document est sous licence ALC TYPE 2. Le texte de cette licence est également consultable en ligne à l adresse http://www.librecours.org/cgi-bin/main?callback=licencetype2.
Relation entre deux variables : estimation de la corrélation linéaire
 CHAPITRE 3 Relation entre deux variables : estimation de la corrélation linéaire Parmi les analyses statistiques descriptives, l une d entre elles est particulièrement utilisée pour mettre en évidence
CHAPITRE 3 Relation entre deux variables : estimation de la corrélation linéaire Parmi les analyses statistiques descriptives, l une d entre elles est particulièrement utilisée pour mettre en évidence
Premiers pas avec SES-Pegase (version 7.0) SES : Un Système Expert pour l analyse Statistique des données. Premiers pas avec SES-Pegase 1
 SES : Un Système Expert pour l analyse Statistique des données. Premiers pas avec SES-Pegase 1") Premiers pas avec SES-Pegase 1 Premiers pas avec SES-Pegase (version 7.0) SES : Un Système Expert pour l analyse Statistique des données www.delta-expert.com Mise à jour : Premiers pas avec SES-Pegase
Premiers pas avec SES-Pegase 1 Premiers pas avec SES-Pegase (version 7.0) SES : Un Système Expert pour l analyse Statistique des données www.delta-expert.com Mise à jour : Premiers pas avec SES-Pegase
Statistiques descriptives
 Statistiques descriptives L3 Maths-Eco Université de Nantes Frédéric Lavancier F. Lavancier (Univ. Nantes) Statistiques descriptives 1 1 Vocabulaire de base F. Lavancier (Univ. Nantes) Statistiques descriptives
Statistiques descriptives L3 Maths-Eco Université de Nantes Frédéric Lavancier F. Lavancier (Univ. Nantes) Statistiques descriptives 1 1 Vocabulaire de base F. Lavancier (Univ. Nantes) Statistiques descriptives
Analyse de variance à deux facteurs (plan inter-sujets à deux facteurs) TP9
 TP9") Analyse de variance à deux facteurs (plan inter-sujets à deux facteurs) TP9 L analyse de variance à un facteur permet de vérifier, moyennant certaines hypothèses, si un facteur (un critère de classification,
Analyse de variance à deux facteurs (plan inter-sujets à deux facteurs) TP9 L analyse de variance à un facteur permet de vérifier, moyennant certaines hypothèses, si un facteur (un critère de classification,
Probabilité et Statistique pour le DEA de Biosciences. Avner Bar-Hen
 Probabilité et Statistique pour le DEA de Biosciences Avner Bar-Hen Université Aix-Marseille III 2000 2001 Table des matières 1 Introduction 3 2 Introduction à l analyse statistique 5 1 Introduction.................................
Probabilité et Statistique pour le DEA de Biosciences Avner Bar-Hen Université Aix-Marseille III 2000 2001 Table des matières 1 Introduction 3 2 Introduction à l analyse statistique 5 1 Introduction.................................
données en connaissance et en actions?
 1 Partie 2 : Présentation de la plateforme SPSS Modeler : Comment transformer vos données en connaissance et en actions? SPSS Modeler : l atelier de data mining Large gamme de techniques d analyse (algorithmes)
1 Partie 2 : Présentation de la plateforme SPSS Modeler : Comment transformer vos données en connaissance et en actions? SPSS Modeler : l atelier de data mining Large gamme de techniques d analyse (algorithmes)
STATISTIQUES. UE Modélisation pour la biologie
 STATISTIQUES UE Modélisation pour la biologie 2011 Cadre Général n individus: 1, 2,..., n Y variable à expliquer : Y = (y 1, y 2,..., y n ), y i R Modèle: Y = Xθ + ε X matrice du plan d expériences θ paramètres
STATISTIQUES UE Modélisation pour la biologie 2011 Cadre Général n individus: 1, 2,..., n Y variable à expliquer : Y = (y 1, y 2,..., y n ), y i R Modèle: Y = Xθ + ε X matrice du plan d expériences θ paramètres
Classe de première L
 Classe de première L Orientations générales Pour bon nombre d élèves qui s orientent en série L, la classe de première sera une fin d étude en mathématiques au lycée. On a donc voulu ici assurer à tous
Classe de première L Orientations générales Pour bon nombre d élèves qui s orientent en série L, la classe de première sera une fin d étude en mathématiques au lycée. On a donc voulu ici assurer à tous
Chapitre 3 : INFERENCE
 Chapitre 3 : INFERENCE 3.1 L ÉCHANTILLONNAGE 3.1.1 Introduction 3.1.2 L échantillonnage aléatoire 3.1.3 Estimation ponctuelle 3.1.4 Distributions d échantillonnage 3.1.5 Intervalles de probabilité L échantillonnage
Chapitre 3 : INFERENCE 3.1 L ÉCHANTILLONNAGE 3.1.1 Introduction 3.1.2 L échantillonnage aléatoire 3.1.3 Estimation ponctuelle 3.1.4 Distributions d échantillonnage 3.1.5 Intervalles de probabilité L échantillonnage
TABLE DES MATIÈRES. PRINCIPES D EXPÉRIMENTATION Planification des expériences et analyse de leurs résultats. Pierre Dagnelie
 PRINCIPES D EXPÉRIMENTATION Planification des expériences et analyse de leurs résultats Pierre Dagnelie TABLE DES MATIÈRES 2012 Presses agronomiques de Gembloux pressesagro.gembloux@ulg.ac.be www.pressesagro.be
PRINCIPES D EXPÉRIMENTATION Planification des expériences et analyse de leurs résultats Pierre Dagnelie TABLE DES MATIÈRES 2012 Presses agronomiques de Gembloux pressesagro.gembloux@ulg.ac.be www.pressesagro.be
IBM SPSS Statistics Base 20
 IBM SPSS Statistics Base 20 Remarque : Avant d utiliser ces informations et le produit qu elles concernent, lisez les informations générales sous Remarques sur p. 316. Cette version s applique à IBM SPSS
IBM SPSS Statistics Base 20 Remarque : Avant d utiliser ces informations et le produit qu elles concernent, lisez les informations générales sous Remarques sur p. 316. Cette version s applique à IBM SPSS
ANTISELECTION ET CHOIX D'ASSURANCE : LE CAS DU VOL EN HABITATION UNE APPROCHE DE LA MESURE DU PHENOMENE
 ANTISELECTION ET CHOIX D'ASSURANCE : LE CAS DU VOL EN HABITATION UNE APPROCHE DE LA MESURE DU PHENOMENE Yannick MACÉ Statisticien-Economiste Responsable du Secteur Analyses Techniques, Groupama (C.C.A.M.A.)
ANTISELECTION ET CHOIX D'ASSURANCE : LE CAS DU VOL EN HABITATION UNE APPROCHE DE LA MESURE DU PHENOMENE Yannick MACÉ Statisticien-Economiste Responsable du Secteur Analyses Techniques, Groupama (C.C.A.M.A.)
TSTI 2D CH X : Exemples de lois à densité 1
 TSTI 2D CH X : Exemples de lois à densité I Loi uniforme sur ab ; ) Introduction Dans cette activité, on s intéresse à la modélisation du tirage au hasard d un nombre réel de l intervalle [0 ;], chacun
TSTI 2D CH X : Exemples de lois à densité I Loi uniforme sur ab ; ) Introduction Dans cette activité, on s intéresse à la modélisation du tirage au hasard d un nombre réel de l intervalle [0 ;], chacun
Tableau 1 : Structure du tableau des données individuelles. INDIV B i1 1 i2 2 i3 2 i4 1 i5 2 i6 2 i7 1 i8 1
 UN GROUPE D INDIVIDUS Un groupe d individus décrit par une variable qualitative binaire DÉCRIT PAR UNE VARIABLE QUALITATIVE BINAIRE ANALYSER UN SOUS-GROUPE COMPARER UN SOUS-GROUPE À UNE RÉFÉRENCE Mots-clés
UN GROUPE D INDIVIDUS Un groupe d individus décrit par une variable qualitative binaire DÉCRIT PAR UNE VARIABLE QUALITATIVE BINAIRE ANALYSER UN SOUS-GROUPE COMPARER UN SOUS-GROUPE À UNE RÉFÉRENCE Mots-clés
Déroulement d un projet en DATA MINING, préparation et analyse des données. Walid AYADI
 1 Déroulement d un projet en DATA MINING, préparation et analyse des données Walid AYADI 2 Les étapes d un projet Choix du sujet - Définition des objectifs Inventaire des données existantes Collecte, nettoyage
1 Déroulement d un projet en DATA MINING, préparation et analyse des données Walid AYADI 2 Les étapes d un projet Choix du sujet - Définition des objectifs Inventaire des données existantes Collecte, nettoyage
Soit la fonction affine qui, pour représentant le nombre de mois écoulés, renvoie la somme économisée.
 ANALYSE 5 points Exercice 1 : Léonie souhaite acheter un lecteur MP3. Le prix affiché (49 ) dépasse largement la somme dont elle dispose. Elle décide donc d économiser régulièrement. Elle a relevé qu elle
ANALYSE 5 points Exercice 1 : Léonie souhaite acheter un lecteur MP3. Le prix affiché (49 ) dépasse largement la somme dont elle dispose. Elle décide donc d économiser régulièrement. Elle a relevé qu elle
CAPTEURS - CHAINES DE MESURES
 CAPTEURS - CHAINES DE MESURES Pierre BONNET Pierre Bonnet Master GSI - Capteurs Chaînes de Mesures 1 Plan du Cours Propriétés générales des capteurs Notion de mesure Notion de capteur: principes, classes,
CAPTEURS - CHAINES DE MESURES Pierre BONNET Pierre Bonnet Master GSI - Capteurs Chaînes de Mesures 1 Plan du Cours Propriétés générales des capteurs Notion de mesure Notion de capteur: principes, classes,
Le risque Idiosyncrasique
 Le risque Idiosyncrasique -Pierre CADESTIN -Magali DRIGHES -Raphael MINATO -Mathieu SELLES 1 Introduction Risque idiosyncrasique : risque non pris en compte dans le risque de marché (indépendant des phénomènes
Le risque Idiosyncrasique -Pierre CADESTIN -Magali DRIGHES -Raphael MINATO -Mathieu SELLES 1 Introduction Risque idiosyncrasique : risque non pris en compte dans le risque de marché (indépendant des phénomènes
Statistiques Décisionnelles L3 Sciences Economiques & Gestion Faculté d économie, gestion & AES Université Montesquieu - Bordeaux 4 2013-2014
 Tests du χ 2 Statistiques Décisionnelles L3 Sciences Economiques & Gestion Faculté d économie, gestion & AES Université Montesquieu - Bordeaux 4 2013-2014 A. Lourme http://alexandrelourme.free.fr Outline
Tests du χ 2 Statistiques Décisionnelles L3 Sciences Economiques & Gestion Faculté d économie, gestion & AES Université Montesquieu - Bordeaux 4 2013-2014 A. Lourme http://alexandrelourme.free.fr Outline
Table des matières. I Mise à niveau 11. Préface
 Table des matières Préface v I Mise à niveau 11 1 Bases du calcul commercial 13 1.1 Alphabet grec...................................... 13 1.2 Symboles mathématiques............................... 14 1.3
Table des matières Préface v I Mise à niveau 11 1 Bases du calcul commercial 13 1.1 Alphabet grec...................................... 13 1.2 Symboles mathématiques............................... 14 1.3
Comment se servir de cet ouvrage? Chaque chapitre présente une étape de la méthodologie
 Partie I : Séries statistiques descriptives univariées (SSDU) A Introduction Comment se servir de cet ouvrage? Chaque chapitre présente une étape de la méthodologie et tous sont organisés selon le même
Partie I : Séries statistiques descriptives univariées (SSDU) A Introduction Comment se servir de cet ouvrage? Chaque chapitre présente une étape de la méthodologie et tous sont organisés selon le même
Cours 9 : Plans à plusieurs facteurs
 Cours 9 : Plans à plusieurs facteurs Table des matières Section 1. Diviser pour regner, rassembler pour saisir... 3 Section 2. Définitions et notations... 3 2.1. Définitions... 3 2.2. Notations... 4 Section
Cours 9 : Plans à plusieurs facteurs Table des matières Section 1. Diviser pour regner, rassembler pour saisir... 3 Section 2. Définitions et notations... 3 2.1. Définitions... 3 2.2. Notations... 4 Section
Lois de probabilité. Anita Burgun
 Lois de probabilité Anita Burgun Problème posé Le problème posé en statistique: On s intéresse à une population On extrait un échantillon On se demande quelle sera la composition de l échantillon (pourcentage
Lois de probabilité Anita Burgun Problème posé Le problème posé en statistique: On s intéresse à une population On extrait un échantillon On se demande quelle sera la composition de l échantillon (pourcentage
SIG ET ANALYSE EXPLORATOIRE
 SIG ET ANALYSE EXPLORATOIRE VERS DE NOUVELLES PRATIQUES EN GÉOGRAPHIE Jean-Marc ORHAN Equipe P.A.R.I.S., URA 1243 du CNRS Paris Résumé L'offre actuelle dans le domaine des logiciels de type Système d'information
SIG ET ANALYSE EXPLORATOIRE VERS DE NOUVELLES PRATIQUES EN GÉOGRAPHIE Jean-Marc ORHAN Equipe P.A.R.I.S., URA 1243 du CNRS Paris Résumé L'offre actuelle dans le domaine des logiciels de type Système d'information
1 Complément sur la projection du nuage des individus
 TP 0 : Analyse en composantes principales (II) Le but de ce TP est d approfondir nos connaissances concernant l analyse en composantes principales (ACP). Pour cela, on reprend les notations du précédent
TP 0 : Analyse en composantes principales (II) Le but de ce TP est d approfondir nos connaissances concernant l analyse en composantes principales (ACP). Pour cela, on reprend les notations du précédent
Bureau : 238 Tel : 04 76 82 58 90 Email : dominique.muller@upmf-grenoble.fr
 Dominique Muller Laboratoire Inter-universitaire de Psychologie Bureau : 238 Tel : 04 76 82 58 90 Email : dominique.muller@upmf-grenoble.fr Supports de cours : webcom.upmf-grenoble.fr/lip/perso/dmuller/m2r/acm/
Dominique Muller Laboratoire Inter-universitaire de Psychologie Bureau : 238 Tel : 04 76 82 58 90 Email : dominique.muller@upmf-grenoble.fr Supports de cours : webcom.upmf-grenoble.fr/lip/perso/dmuller/m2r/acm/
LES GENERATEURS DE NOMBRES ALEATOIRES
 LES GENERATEURS DE NOMBRES ALEATOIRES 1 Ce travail a deux objectifs : ====================================================================== 1. Comprendre ce que font les générateurs de nombres aléatoires
LES GENERATEURS DE NOMBRES ALEATOIRES 1 Ce travail a deux objectifs : ====================================================================== 1. Comprendre ce que font les générateurs de nombres aléatoires
METHODOLOGIE GENERALE DE LA RECHERCHE EPIDEMIOLOGIQUE : LES ENQUETES EPIDEMIOLOGIQUES
 Enseignement du Deuxième Cycle des Etudes Médicales Faculté de Médecine de Toulouse Purpan et Toulouse Rangueil Module I «Apprentissage de l exercice médical» Coordonnateurs Pr Alain Grand Pr Daniel Rougé
Enseignement du Deuxième Cycle des Etudes Médicales Faculté de Médecine de Toulouse Purpan et Toulouse Rangueil Module I «Apprentissage de l exercice médical» Coordonnateurs Pr Alain Grand Pr Daniel Rougé
Probabilités sur un univers fini
 [http://mp.cpgedupuydelome.fr] édité le 7 août 204 Enoncés Probabilités sur un univers fini Evènements et langage ensembliste A quelle condition sur (a, b, c, d) ]0, [ 4 existe-t-il une probabilité P sur
[http://mp.cpgedupuydelome.fr] édité le 7 août 204 Enoncés Probabilités sur un univers fini Evènements et langage ensembliste A quelle condition sur (a, b, c, d) ]0, [ 4 existe-t-il une probabilité P sur
Pratique de l analyse de données SPSS appliqué à l enquête «Identités et Capital social en Wallonie»
 Centre de recherche en démographie et sociétés UCL/IACCHOS/DEMO Pratique de l analyse de données SPSS appliqué à l enquête «Identités et Capital social en Wallonie» 1 2 3+ analyses univariées Type de variables
Centre de recherche en démographie et sociétés UCL/IACCHOS/DEMO Pratique de l analyse de données SPSS appliqué à l enquête «Identités et Capital social en Wallonie» 1 2 3+ analyses univariées Type de variables
Programmes des classes préparatoires aux Grandes Ecoles
 Programmes des classes préparatoires aux Grandes Ecoles Filière : scientifique Voie : Biologie, chimie, physique et sciences de la Terre (BCPST) Discipline : Mathématiques Seconde année Préambule Programme
Programmes des classes préparatoires aux Grandes Ecoles Filière : scientifique Voie : Biologie, chimie, physique et sciences de la Terre (BCPST) Discipline : Mathématiques Seconde année Préambule Programme
Théorie des sondages : cours 5
 Théorie des sondages : cours 5 Camelia Goga IMB, Université de Bourgogne e-mail : camelia.goga@u-bourgogne.fr Master Besançon-2010 Chapitre 5 : Techniques de redressement 1. poststratification 2. l estimateur
Théorie des sondages : cours 5 Camelia Goga IMB, Université de Bourgogne e-mail : camelia.goga@u-bourgogne.fr Master Besançon-2010 Chapitre 5 : Techniques de redressement 1. poststratification 2. l estimateur
INF6304 Interfaces Intelligentes
 INF6304 Interfaces Intelligentes filtres collaboratifs 1/42 INF6304 Interfaces Intelligentes Systèmes de recommandations, Approches filtres collaboratifs Michel C. Desmarais Génie informatique et génie
INF6304 Interfaces Intelligentes filtres collaboratifs 1/42 INF6304 Interfaces Intelligentes Systèmes de recommandations, Approches filtres collaboratifs Michel C. Desmarais Génie informatique et génie
Exercices supplémentaires sur l introduction générale à la notion de probabilité 2009-2010
 Exercices supplémentaires sur l introduction générale à la notion de probabilité 2009-2010 Exercices fortement conseillés : 6, 10 et 14 1) Un groupe d étudiants est formé de 20 étudiants de première année
Exercices supplémentaires sur l introduction générale à la notion de probabilité 2009-2010 Exercices fortement conseillés : 6, 10 et 14 1) Un groupe d étudiants est formé de 20 étudiants de première année
Localisation des fonctions
 MODALISA 7 Localisation des fonctions Vous trouverez dans ce document la position des principales fonctions ventilées selon l organisation de Modalisa en onglets. Sommaire A. Fonctions communes à tous
MODALISA 7 Localisation des fonctions Vous trouverez dans ce document la position des principales fonctions ventilées selon l organisation de Modalisa en onglets. Sommaire A. Fonctions communes à tous
Probabilités conditionnelles Loi binomiale
 Exercices 23 juillet 2014 Probabilités conditionnelles Loi binomiale Équiprobabilité et variable aléatoire Exercice 1 Une urne contient 5 boules indiscernables, 3 rouges et 2 vertes. On tire au hasard
Exercices 23 juillet 2014 Probabilités conditionnelles Loi binomiale Équiprobabilité et variable aléatoire Exercice 1 Une urne contient 5 boules indiscernables, 3 rouges et 2 vertes. On tire au hasard
Un exemple de régression logistique sous
 Fiche TD avec le logiciel : tdr341 Un exemple de régression logistique sous A.B. Dufour & A. Viallefont Etude de l apparition ou non d une maladie cardiaque des coronaires 1 Présentation des données Les
Fiche TD avec le logiciel : tdr341 Un exemple de régression logistique sous A.B. Dufour & A. Viallefont Etude de l apparition ou non d une maladie cardiaque des coronaires 1 Présentation des données Les
Méthodes quantitatives en sciences humaines. 2 Pratique : 2 Étude personnelle : 2. BUREAU poste courriel ou site web
 360-300-RE HIVER 2008 MATHÉMATIQUES Plan de cours COURS : Méthodes quantitatives en sciences humaines PROGRAMME : 300.A0 Sciences humaines DISCIPLINE : Mathématiques Pondération : Théorie : 2 Pratique
360-300-RE HIVER 2008 MATHÉMATIQUES Plan de cours COURS : Méthodes quantitatives en sciences humaines PROGRAMME : 300.A0 Sciences humaines DISCIPLINE : Mathématiques Pondération : Théorie : 2 Pratique
Une variable binaire prédictrice (VI) et une variable binaire observée (VD) (Comparaison de pourcentages sur 2 groupes indépendants)
 et une variable binaire observée (VD) (Comparaison de pourcentages sur 2 groupes indépendants)") CIVILITE-SES.doc - 1 - Une variable binaire prédictrice (VI) et une variable binaire observée (VD) (Comparaison de pourcentages sur 2 groupes indépendants) 1 PRÉSENTATION DU DOSSIER CIVILITE On s intéresse
CIVILITE-SES.doc - 1 - Une variable binaire prédictrice (VI) et une variable binaire observée (VD) (Comparaison de pourcentages sur 2 groupes indépendants) 1 PRÉSENTATION DU DOSSIER CIVILITE On s intéresse
Évaluation de la régression bornée
 Thierry Foucart UMR 6086, Université de Poitiers, S P 2 M I, bd 3 téléport 2 BP 179, 86960 Futuroscope, Cedex FRANCE Résumé. le modèle linéaire est très fréquemment utilisé en statistique et particulièrement
Thierry Foucart UMR 6086, Université de Poitiers, S P 2 M I, bd 3 téléport 2 BP 179, 86960 Futuroscope, Cedex FRANCE Résumé. le modèle linéaire est très fréquemment utilisé en statistique et particulièrement
FPSTAT 2 í La dçecision statistique. 1. Introduction ça l'infçerence. 1
 INTRODUCTION ça L'INFçERENCE STATISTIQUE 1. Introduction 2. Notion de variable alçeatoire íprçesentation ívariables alçeatoires discrçetes ívariables alçeatoires continues 3. Reprçesentations d'une distribution
INTRODUCTION ça L'INFçERENCE STATISTIQUE 1. Introduction 2. Notion de variable alçeatoire íprçesentation ívariables alçeatoires discrçetes ívariables alçeatoires continues 3. Reprçesentations d'une distribution
Étude des flux d individus et des modalités de recrutement chez Formica rufa
 Étude des flux d individus et des modalités de recrutement chez Formica rufa Bruno Labelle Théophile Olivier Karl Lesiourd Charles Thevenin 07 Avril 2012 1 Sommaire Remerciements I) Introduction p3 Intérêt
Étude des flux d individus et des modalités de recrutement chez Formica rufa Bruno Labelle Théophile Olivier Karl Lesiourd Charles Thevenin 07 Avril 2012 1 Sommaire Remerciements I) Introduction p3 Intérêt
UNE REPRESENTATION GRAPHIQUE DE LA LIAISON STATISTIQUE ENTRE DEUX VARIABLES ORDONNEES. Éric TÉROUANNE 1
 33 Math. Inf. Sci. hum., (33 e année, n 130, 1995, pp.33-42) UNE REPRESENTATION GRAPHIQUE DE LA LIAISON STATISTIQUE ENTRE DEUX VARIABLES ORDONNEES Éric TÉROUANNE 1 RÉSUMÉ Le stéréogramme de liaison est
33 Math. Inf. Sci. hum., (33 e année, n 130, 1995, pp.33-42) UNE REPRESENTATION GRAPHIQUE DE LA LIAISON STATISTIQUE ENTRE DEUX VARIABLES ORDONNEES Éric TÉROUANNE 1 RÉSUMÉ Le stéréogramme de liaison est
Loi binomiale Lois normales
 Loi binomiale Lois normales Christophe ROSSIGNOL Année scolaire 204/205 Table des matières Rappels sur la loi binomiale 2. Loi de Bernoulli............................................ 2.2 Schéma de Bernoulli
Loi binomiale Lois normales Christophe ROSSIGNOL Année scolaire 204/205 Table des matières Rappels sur la loi binomiale 2. Loi de Bernoulli............................................ 2.2 Schéma de Bernoulli
DETERMINATION DE L INCERTITUDE DE MESURE POUR LES ANALYSES CHIMIQUES QUANTITATIVES
 Agence fédérale pour la Sécurité de la Chaîne alimentaire Administration des Laboratoires Procédure DETERMINATION DE L INCERTITUDE DE MESURE POUR LES ANALYSES CHIMIQUES QUANTITATIVES Date de mise en application
Agence fédérale pour la Sécurité de la Chaîne alimentaire Administration des Laboratoires Procédure DETERMINATION DE L INCERTITUDE DE MESURE POUR LES ANALYSES CHIMIQUES QUANTITATIVES Date de mise en application
Feuille d exercices 2 : Espaces probabilisés
 Feuille d exercices 2 : Espaces probabilisés Cours de Licence 2 Année 07/08 1 Espaces de probabilité Exercice 1.1 (Une inégalité). Montrer que P (A B) min(p (A), P (B)) Exercice 1.2 (Alphabet). On a un
Feuille d exercices 2 : Espaces probabilisés Cours de Licence 2 Année 07/08 1 Espaces de probabilité Exercice 1.1 (Une inégalité). Montrer que P (A B) min(p (A), P (B)) Exercice 1.2 (Alphabet). On a un
Résumé du Cours de Statistique Descriptive. Yves Tillé
 Résumé du Cours de Statistique Descriptive Yves Tillé 15 décembre 2010 2 Objectif et moyens Objectifs du cours Apprendre les principales techniques de statistique descriptive univariée et bivariée. Être
Résumé du Cours de Statistique Descriptive Yves Tillé 15 décembre 2010 2 Objectif et moyens Objectifs du cours Apprendre les principales techniques de statistique descriptive univariée et bivariée. Être
Statistique inférentielle TD 1 : Estimation
 POLYTECH LILLE Statistique inférentielle TD : Estimation Exercice : Maîtrise Statistique des Procédés Une entreprise de construction mécanique fabrique de pièces demoteurdevoiturepourungrandconstructeur
POLYTECH LILLE Statistique inférentielle TD : Estimation Exercice : Maîtrise Statistique des Procédés Une entreprise de construction mécanique fabrique de pièces demoteurdevoiturepourungrandconstructeur
Projet SINF2275 «Data mining and decision making» Projet classification et credit scoring
 Projet SINF2275 «Data mining and decision making» Projet classification et credit scoring Année académique 2006-2007 Professeurs : Marco Saerens Adresse : Université catholique de Louvain Information Systems
Projet SINF2275 «Data mining and decision making» Projet classification et credit scoring Année académique 2006-2007 Professeurs : Marco Saerens Adresse : Université catholique de Louvain Information Systems