Université Lumière Lyon 2 Département Informatique Statistique
|
|
|
- Ségolène Picard
- il y a 10 ans
- Total affichages :
Transcription
1 Université Lumière Lyon 2 Département Statistique M1 Rak Abdesselam Laboratoire ERIC - Bât.K Bureau K072 [email protected] rabdesselam/documents/ Année Universitaire

2 du 1 2 La régression Multiple 3 Chapitre 2 : Le 4 Chapitre 3 : (MCG) 5 Chapitre 4 : Détection et traitement de l'hétéroscédasticité et de l'autocorrélation 6 Bibliographie

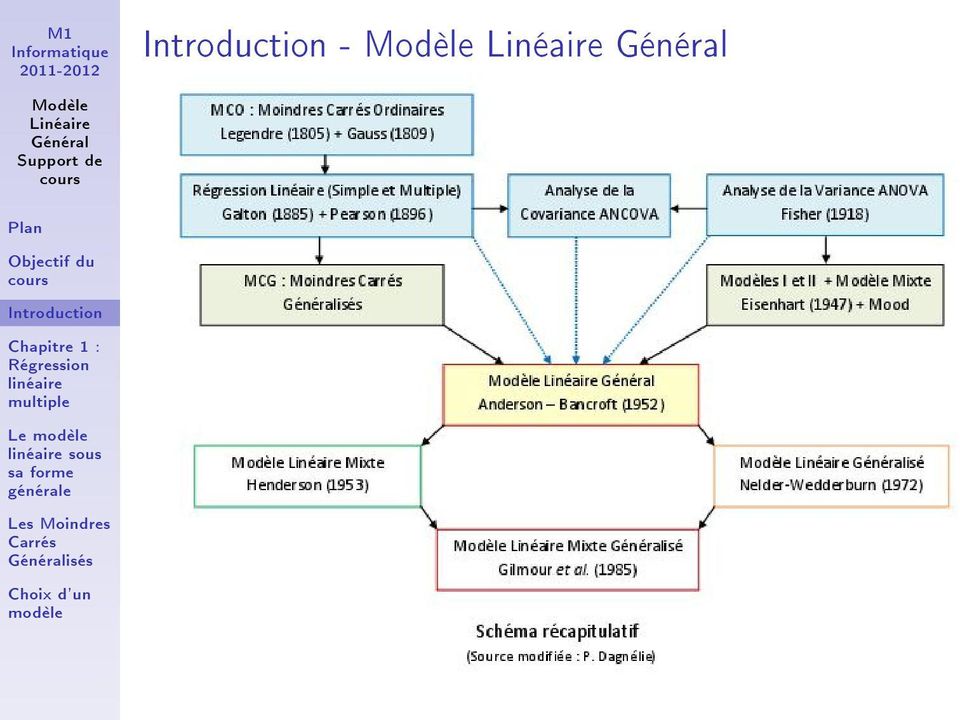
3 L'objet de ce est de présenter ce qu'est un en général ( ), en vue de mettre à disposition un outil statistique dont le pouvoir de représentation est extrêmement large. est l'un des outils essentiels de la statistique. On connaît l'existence de la régression simple-, de l'analyse de la variance ANOVA, de l'analyse de la covariance ANCOVA. Ces techniques associées à des s sont toutes des cas particuliers du général qui est par contre beaucoup moins connu.

4 La complexité du sujet ne provient pas de la diculté des calculs, car les formules de résolution sont en pratique les mêmes, mais plutôt de la diversité des approches possibles notamment faire la distinction entre et régression. C'est un outil de représentation. On ajuste des s, on estime des paramètres, on fait des tests statistiques, des intervalles et des régions de conance. Une large place est accordée dans ce aux exemples et exercices sur données réelles traités avec le logiciel SAS : Statistical Analysis System ou Système d'analyse Statistique.

5 Pré-requis : Quelques notions de Statistique & Probabilités et de Statistique inférentielle. Approche pédagogique : (5) séances de magistraux (durée 1h45 - salle L231) et (7) séances de travaux dirigés (durée 1h45 - salle ). Supports informatique : Tableur Excel, Logiciel SAS. Matériel pédagogique : (1) Polycopié de support de, (1) polycopié de travaux dirigés et (1) polycopié support SAS ainsi que de nombreux chiers de données réelles (Tables SAS - version 9.2.). Contrôle des connaissances : Un examen terminal (100%) - (salle - durée 1h30). Quelques références bibliographiques :
 Polycopié de support de, (1) polycopié de travaux dirigés et (1) polycopié support SAS ainsi que de nombreux chiers de")
6 -
7 Démarche dans l'élaboration d'un de régression Les données : n objets ou individus, i = 1,2,...,n Un ensemble des p variables explicatives (prédicteurs, exogènes) : x 1, x 2,..., x p, Une variable à expliquer (à prédire, endogène) : y. La régression permet de traiter de nombreux problèmes dans lesquels une variable à expliquer doit être exprimée en fonction de p (p > 1) variables explicatives. Géométriquement dans R p+1 : plan si p = 2 et un hyperplan si p > 2. La régression simple traite le cas particulier d'une seule variable explicative (p = 1). Géométriquement dans R 2 : droite

8 Démarche dans l'élaboration d'un de régression Cadre général de la régression Les valeurs observées relatives à un ensemble de n individus peuvent être désigné par x ij (i = 1,..., n et j = 1,..., p) pour les p variables explicatives (qui sont ment ment indépendantes) par une matrice X, y i (i = 1,..., n) pour la variable à expliquer par un vecteur-colonne y : X = x 11 x x 1p x 21 x x 2p : : : : x i 1 x i 2... x ip : : : : x n1 x n2... x np et y = On cherche alors à reconstruire y au moyen des x j par une forme : ŷ = b 0 + b 1 x 1 b b p x p et on désire que ŷ soit le plus proche possible de y. Le re à des notations matricielles s'impose. Le schèma de l'écriture matricielle du de régression sera présenté d'une façon un peu plus loin dans le cadre du général. y 1 y 2 : y i : y n

9 Démarche dans l'élaboration d'un de régression Cadre général de la régression Les p variables explicatives sont ment supposées être ment indépendantes, ne veut pas dire qu'elles sont statistiquement indépendantes (en particulier, elles peuvent être corélées). A éviter donc absolument l'abus de la terminologie : y variable dépendante et (x 1, x 2,..., x p ) variables indépendantes. Dans le cas de la régression X (n,p) est un tableau de données aléatoires, alors que dans le général X (n,p) est un tableau de données certaines.
 est un tableau de données aléatoires, alors que dans le général X (n,p) est un tableau de")
10 Démarche dans l'élaboration d'un de régression Cadre général de la régression Le terme n'est pas associé à l'idée de droite rectiligne, mais à celle de représentation des espérances des variables aléatoires à l'aide de combinaisons s de paramètres. En représentant par exemple l'espérance d'une variable aléatoire par l'équation : E(y i ) = b 0 + b 1 x i + b 2 x 2 i on se réfère à un (les espérances sont combinaisons s des trois paramètres b 0, b 1, b 2 ) même si la relation ici entre E(y) l'espérance de y et x est celle d'une parabole.
 même si la relation ici entre E(y) l'espérance de y et x")
11 Démarche dans l'élaboration d'un de régression Cadre général de la régression La forme du théorique s'énonce comme suit : y i = β 0 + β 1 x i β j x ij... + β px ip + ɛ i = β 0 + p j=1 β j x ij + ɛ i ou encore, y = β 0 + β 1 x β j x j... + β px p + ɛ = β 0 + p j=1 β j x j + ɛ - y i variable dépendante (ou expliquée) dont les valeurs sont conditionnées par celles des variables explicatives x i1, x i2,..., x ip et la composante ɛ i. - β 0, β 1,..., β p sont les (p+1) paramètres (inconnus) du, x ij (j = 1,..., p) représente la i me valeur des p variables explicatives (grandeurs certaines). - ɛ i dénote la uctuation aléatoire non observable attribuable à un ensemble de facteurs non pris en considération dans le ou que nous savons pas identier.
 paramètres (inconnus) du, x ij (j = 1,..., p) représente la i me valeur des p variables explicatives (grandeurs certaines).")
12 Démarche dans l'élaboration d'un de régression Hypothèses fondamentales du 1 Le terme ɛ i est supposé être une v.a. de moyenne nulle et de variance constante : E(ɛ i ) = 0, V (ɛ i ) = σ 2 i = 1,..., n. 2 Aucune corrélation entre les erreurs : Cov(ɛ i, ɛ k ) = 0 i, k i k. 3 Les variables explicatives x 1, x 2,..., x p sont des grandeurs certaines (non aléatoires, pouvant être observées sans erreur ou xées à des valeurs arbitraires). 4 Les uctuations des n v.a. indépendantes ɛ i sont normalement distribuées : ɛ i N(0, σ 2 ). σ 2 est donc aussi un paramètre (inconnu) du. Condition dans le but de construire des intervalles de conance et d'eectuer des tests d'hypothèses.... Il s'agit là de la forme d'un gaussien... La spécication de ces hypothèses permet de caractériser le comportement des y i dans le théorique. les observations y i sont indépendantes et normalement distribuées de moyenne E(y i ) = β 0 + β 1 x i β p x ip et de même variance V (y i ) = σ 2.
 du. Condition dans le but de construire des intervalles de conance et d'eectuer des tests d'hypothèses.... Il s'agit là de la forme d'un gaussien.")
13 Démarche dans l'élaboration d'un de régression Equation & Estimation des paramètres du théorique : y i = β 0 + β 1 x i β j x ij... + β px ip + ɛ i empirique ou ajusté : ŷ i = b 0 + b 1 x i b j x ij... + b px ip = b 0 + p j=1 b j x ij Estimations Equation de régression Moyenne des y i empirique E(y i ) = β 0 + β 1 x i β px ip ŷ i = b 0 + b 1 x i b px ip Variance des y i Variance des résidus V (y i ) = σ 2 s 2 = ni =1 (y i ŷ i ) 2 n (p+1) On utilisera ce ajusté pour faire de la prédiction d'un individu supplémentaire (anonyme) dont on ne connait que les valeurs des prédicteurs. La variance s 2 des résidus est une estimation ponctuelle de la variance des erreurs V (ɛ i ) = σ 2 On peut également présenter la moyenne et la variance des y i sous la forme : E(y i ) = E(y i /x 1,..., x p), V (y i ) = V (y i /x 1,..., x p) = σ 2

14 Démarche dans l'élaboration d'un de régression Paramètres du Tout comme dans le cas simple pour la droite de régression, nous avons re à la méthode des moindres carrés ordinaires (MCO) pour obtenir les estimations de diérents paramètres du : estimation des paramètres de l'hyperplan de régression. Estimation de la moyenne des y i : E(y i ) Les coecients b j du de régression minimisent la somme des carrés résiduelle : n i=1 (y i ŷ i ) 2, on doit résoudre le système d'équations normales en dérivant l'expression : n i=1 (y i ŷ i ) 2 = n i=1 (y i b 0 p j=1 (b j x ij ) 2 par rapport à b 0, b 1,..., b p et en annulant les dérivées premières. Il y a (p + 1) paramètres à estimer, ce qui conduit à un système de (p + 1) équations à (p + 1) inconnus (les coecients b j de la régression)
 2 = n i=1 (y i b 0 p j=1 (b j x ij ) 2 par rapport à b 0, b 1,..., b p et en annulant les dérivées premières.")
15 Paramètres du Démarche dans l'élaboration d'un de régression Estimation de la variance des y i : V (y i ) L'estimation de Var(y i ) = σ 2 s'obtient à partir de la variance résiduelle : s 2 = n i=1 (y i ŷ i ) 2 n (p+1) Dans le cas de p variables explicatives, où il faut estimer les (p + 1) paramètres β j du, nous perdons (p + 1) degrés de liberté, un pour chaque paramètre que l'on doit estimer.
 degrés de liberté, un pour chaque paramètre que l'on doit")
16 Démarche dans l'élaboration d'un de régression Tableau d'analyse de variance Source de Somme des Degrés de variation carrés liberté moyens Expliquée () SCReg = n i =1 (ŷ i y) 2 p CMReg = SCReg p Résiduelle SCRes = n i =1 (y i ŷ i ) 2 n - (p + 1) CMRes = SCRes n p 1 = s2 Totale SCTot = n i =1 (y i y) 2 n - 1 L'écart total est la somme de deux composantes : (y i y) = (ŷ i y) + (y i ŷ i ) SCTot = n i=1 (y i y) 2 = n i=1 (ŷ i y) 2 + n i=1 (y i ŷ i ) 2 = SCReg + SCRes
 = (ŷ i y) + (y i ŷ i ) SCTot = n i=1 (y i y) 2 = n i=1 (ŷ i y) 2 + n i=1 (y i ŷ i ) 2 = SCReg")
17 Démarche dans l'élaboration d'un de régression Coecient de détermination (ou d'explication) R 2 Permet d'évaluer la qualité de l'ajustement de l'équation de régression entre la variable dépendante y et l'ensemble des variables explicatives. R 2 = SCReg SCTot = ni =1 (ŷ i y) 2 ni =1 (y i y) 2 avec 0 R 2 1. Le Rajust 2 permet de comparer plusieurs s de régression comportant la même variable dépendante y mais dont ils dièrent soit par le nombre n d'observations, soit par le nombre p de variables explicatives, soit par les deux : R 2 ajust = 1 SCRes/(n p 1) SCTot/(n 1) = 1 (n 1)SCRes (n p 1)SCTot puisque SCRes SCTot = 1 R2 alors R 2 ajust = 1 (n 1) (n p 1) (1 R2 ). p = 1 p > 1 p n R 2 = Rajust 2 R 2 Rajust 2 R 2 Rajust 2
 SCTot/(n 1) = 1 (n 1)SCRes (n p 1)SCTot puisque SCRes SCTot = 1 R2 alors R 2 ajust = 1 (n 1) (n p 1) (1 R2 ).")
18 Démarche dans l'élaboration d'un de régression Inférence statistique en régression Tests d'hypothèses Dans l'élaboration d'un de régression, divers tests statistiques sont requis. Les plus fréquents permettent de répondre aux questions suivantes : 1 est-il signicatif dans son ensemble? 2 Est-ce que la contribution marginale de chaque variable explicative est signicative? Ce test permettra d'examiner si l'ajout d'une variable explicative à la suite d'autres variables explicatives déjà dans le apporte une contribution signicative dans l'explication de la variable y à expliquer. 3 Est-ce que le sous-ensemble de variables explicatives ont une inuence sur la variable y lorsqu'elles s'ajoutent au comportant déjà un certain nombre de variables explicatives?

19 Démarche dans l'élaboration d'un de régression est-il signicatif dans son ensemble? théorique : y = β 0 + β 1 x β j x j... + β p x p + ɛ = β 0 + p j=1 β jx j + ɛ Les hypothèses nulle et alternative sont alors : { H0 : β 1 =... = β p = 0 (aucune contribution signicative des x j ) H 1 : au moins un β j 0 (contribution signicative d'au moins une variable x j ) Pour eectuer ce test, on a re aux carrés moyens du tableau d'analyse de variance. On compare le carré moyen dû à la régression avec le carré moyen résiduel. La valeur observée du F de Fisher est donc : F = CMReg CMRes = SCReg/p SCRes/(n p 1) On obtient un rapport de deux variances. Sous l'hypothèse nulle H 0, F = CMReg CMRes F (p ; n p 1) est distribué selon une loi de Fisher à p et (n p 1) degrés de liberté. Au seuil de signication α choisi, la règle de décision : Rejeter H 0 si F > f (α ; p ; n p 1) (Cf. table statistique - loi de Fisher-Snedecor)

20 Démarche dans l'élaboration d'un de régression est-il signicatif dans son ensemble? La statistique F s'écrit sous la forme d'un rapport de deux variables aléatoires indépendantes distribuées selon la loi du khi-deux respectivement à p et n (p + 1) degrés de liberté : F = SCReg/σ2 / SCRes/σ2 = CMReg p (n p 1) CMRes F (p ; n p 1) On comprend ainsi, pourquoi la technique de comparaison de moyennes est appelée analyse de la variance : les sommes de carrés sont utilisées pour estimer des variances. On peut résumer les principaux résultats de l'analyse de régression comme suit dans le tableau d'analyse de variance (ou tableau ANOVA). Sources de Somme des Degrés de F variation carrés liberté moyens Expliquée SCReg = CMReg = Regression ni =1 (ŷ i y) 2 SCReg p p Non expliquée SCRes = CMRes = Résiduelle ni =1 (y i ŷ i ) 2 n - (p + 1) SCRes n p 1 = s2 Totale SCTot = n i =1 (y i y) 2 n - 1 CMReg CMRes
.")
21 Exemple d'application - Les données Démarche dans l'élaboration d'un de régression
22 Tableau ANOVA - Résultats SAS Démarche dans l'élaboration d'un de régression
23 Démarche dans l'élaboration d'un de régression Quelle est la distribution des coecients de régression? Avant d'aborder les tests individuels de chaque paramètre β j du, identions la distribution d'échantillonnage des coecients de régression b j : estimateurs (variables aléatoires) des paramètres inconnus β j. Sous l'hypothèse de normalité des erreurs ɛ i (ou de celle des y i ), la distribution d'échantillonnage du coecient b j (j = 0, 1,..., p) est celle d'une loi normale : b j N( E(b j ) = β j ; σ 2 (b j ) ). s(b j ) : écart-type (ou l'erreur-type) du coecient b j est une estimation ponctuelle de σ(b j ). Dans ce cas, les uctuations de l'écart-réduit : bj β j s(b j ) T (n p 1) d.d.l., c'est-à-dire, une loi de Student avec (n - p -1) degrés de liberté.
24 Démarche dans l'élaboration d'un de régression Quelle est la contribution marginale de chaque variable explicative? On va établir des tests de signication sur chaque paramètre β j du, ce qui revient à tester si la contribution marginale de chaque variable explicative x j est signicative dans le théorique : y = β 0 + β 1 x 1 + β 2 x β j x j... + β p x p + ɛ, au seuil de signication α. Il s'agit alors de tester les hypothèses suivantes : { H0 : β j = 0 (j = 0, 1,..., p) (contribution non signicative de la variable x j ) H 1 : β j 0 (contribution signicative de la variable x j ) Sous l'hypothèse nulle H 0, l'écart réduit bj β j s(b j ) devient t = bj s(b j ) qui est distribué selon une loi de Student avec (n p 1) degrés de liberté. Au seuil de signication α choisi, la règle de décision : Rejeter H 0 si t > t ( α 2 ; n p 1) Conclusion : si H 0 est rejetée, la contribution de la variable explicative x j est signicative au seuil α.
25 Exemple d'application - Résultats SAS Démarche dans l'élaboration d'un de régression
26 Démarche dans l'élaboration d'un de régression Test sur la nullité d'un sous-ensemble de paramètres D'une façon, pour eectuer ce test, il faut eectuer 2 analyses de régression, une avec le complet et une autre avec le réduit : réduit : y = β 0 + β 1 x β g x g + ɛ, complet : y = β 0 + β 1 x β g x g +β g+1 x g β p x p + ɛ, Hypothèses : { H0 : β g+1 = β g+2 =... = β p = 0 nullité des paramètres β j H 1 : au moins un des paramètres β j sous H 0 est diérent de 0 Quotient des carrés moyens : F = CReg(X 1,...,Xp) SCReg(X 1,...,Xg ) (p g) CRes(X 1,...,Xp) (n p g) où (p - g) représente le nombre de paramètres spéciés sous H 0.
27 Démarche dans l'élaboration d'un de régression Test sur la nullité d'un sous-ensemble de paramètres Hypothèses : { H0 : β g+1 = β g+2 =... = β p = 0 nullité des paramètres β j H 1 : au moins un des paramètres β j sous H 0 est diérent de 0 Règle de décision : Au seuil de signication α, on choisit de rejeter l'hypothèse nulle H 0 si F > F (α ; p g, n p 1). Si nous rejetons H 0, nous concluons que l'apport des variables x g+1,..., x p contribuent de façon signicative au de régression. Remarque : Dans le cas d'un à p variables explicatives, la contribution marginale de la variable x p, à la suite des (p 1) variables explicatives, se teste avec : F = t 2 = ( bp s(b p) )2 = CMReg(X 1,...,X p 1 ) CMRes(X 1,...,X p 1,X p). Ce rapport est appelé le "F partiel".
28 Démarche dans l'élaboration d'un de régression Rappels - Risques de 1ère et de 2ème espèce Un test statistique comporte 2 types d'erreur possibles : 1 Risque de première espèce : seuil de signication ; risque de rejeter à tort l'hypothèse nulle H 0 lorsque celle-ci est vraie : α = P( rejeter H 0 / H 0 vraie ). 2 Risque de deuxième espèce : risque de ne pas rejeter l'hypothèse nulle H 0 alors que l'hypothèse H 1 est vraie : β = P( ne pas rejeter H 0 / H 1 vraie ). Courbe d'ecacité du test : β en fonction des diverses valeurs du paramètre posées en H 1 que l'on suppose vraies. Puissance du test : 1 β = P( rejeter H 0 / H 1 vraie ). Courbe de puissance du test : (1 β) en fonction des diverses valeurs du paramètre posées en H 1. Les risques liés peuvent se résumer comme suit : Situation vraie : réalité H 0 est vraie H 1 est vraie Conclusion Non rejet de H 0 1 α : Bonne β : Mauvaise du test Rejet de H 0 α : Mauvaise 1 β : Bonne
29 Démarche dans l'élaboration d'un de régression Estimation par intervalle - Moyenne On peut également construire des intervalles de conance des paramètres du. Nous avons vu que l'estimation ponctuelle de E(y i ) pour toute observation i = 1, n, résulte du ajusté : ŷ i = b 0 + b 1 x i1 + b 2 x i b j x ij... + b p x ip. L'intervalle de conance de niveau (1 α)% de contenir la vraie moyenne E(y i ) s'écrit dans le cas d'un à p variables explicatives sur un échantillon de taille n : ŷ i t ( α 2 ; n p 1) s(ŷ i ) E(y i ) ŷ i + t ( α 2 ; n p 1) s(ŷ i ) L'expression de s(ŷ i ) est complexe (si on ne fait pas intervenir l'approche matricielle). Ainsi, par exemple, dans le cas d'un à p = 2 variables explicatives, l'estimation s 2 (ŷ i ) de la variance σ 2 (ŷ i ) s'obtient : s 2 (ŷ i ) = s 2 (b 0 ) + x 2 i1 s2 (b 1 ) + x 2 i2 s2 (b 2 ) + 2x i1 ĉov(b 0, b 1 ) + 2x i2 ĉov(b 0, b 2 ) + 2x i1 x i2 ĉov(b 1, b 2 ).
30 Exemple d'application - Résultats SAS Démarche dans l'élaboration d'un de régression
31 Démarche dans l'élaboration d'un de régression Intervalle de conance des paramètres du Sous l'hypothèse de normalité des erreurs ɛ i, la distribution d'échantillonnage du coecient b j (j = 0, 1,..., p) : b j N( E(b j ) = β j ; σ 2 (b j ) ). s(b j ) : écart-type (ou l'erreur-type) du coecient b j est une estimation ponctuelle de σ(b j ). Les uctuations de l'écart-réduit : loi de Student à (n - p -1) d.d.l.. bj β j s(b j ) T (n p 1) d.d.l., La procédure est similaire à celle d'un test d'égalité contre une diérence. Un intervalle de conance de niveau (1 α) d'un paramètre β j (j = 0,..., p) est déni par : b j t ( α 2 ; n p 1) s(b j ) β j b j + t ( α 2 ; n p 1) s(b j )
32 Exemple d'application - Résultats SAS Démarche dans l'élaboration d'un de régression
33 Démarche dans l'élaboration d'un de régression Intervalle de prédiction de y i Pour une nouvelle observation x i1, x i2,..., x ip, la prédiction la plus plausible est obtenue de l'équation de régression : ŷ i. Toutefois l'incertitude dans cette prédiction se détermine à l'aide de l'estimation de la variance de l'erreur de prédiction, soit : s 2 (d i ) = s 2 (ŷ i ) + s 2 où s 2 = CMRes de la régression à p variables explicatives. L'intervalle de prédiction de niveau de conance (1 α)% de contenir la vraie valeur de y i s'écrit : ŷ i t (α 2 ; n p 1) s(d i) y i ŷ i + t (α 2 ; n p 1) s(d i) où, s(d i )= s 2 (ŷ i ) + s 2, désigne l'écart-type de l'erreur de prédiction.
34 Exemple d'application - Résultats SAS Démarche dans l'élaboration d'un de régression
35 Démarche dans l'élaboration d'un de régression Elaboration du La démarche à suivre peut se résumer selon les étapes suivantes : 1 Identier les variables (dépendante et explicatives) qui font le sujet d'une étude de régression. 2 Spécier le de régression que l'on envisage d'analyser. 3 Prélever les observations sur les diverses variables en s'assurant que le nombre d'observations est supérieur au nombre de paramètres à estimer (n > p + 1). 4 Eectuer diverses tests statistiques sur les paramètres du pour ne retenir que les variables explicatives qui ont un eet signicatif. 5 Résumer les conclusions de l'analyse en indiquant l'équation de régression obtenue, les erreurs-types de chaque coecient, la table de variance ainsi que la valeur du coecient de détermination. 6 Eectuer à l'aide de l'équation résultante les estimations et prévisions requises.
36 Pour un théorique déterministe, la forme du général est donnée par : y i = β 0 x i0 + β 1 x i1 + β 2 x i β j x ij... + β p x ip + ɛ i i = 1,..., n Introduisons la notation matricielle an de pouvoir résoudre plus facilement le problème. Il s'agit de remplacer les n équations du par la seule équation matricielle : y = X β + ɛ. y 1 y 2 : : y i : : y n = 1 x 11 x x 1p 1 x 21 x x 2p 1 : : : : 1 : : : : 1 x i1 x i2... x ip 1 : : : : 1 : : : : 1 x n1 x n2... x np β 0 β 1 : β k : β p + ɛ 1 ɛ 2 : : ɛ i : : ɛ n
37 où y est le vecteur des n observations relatives à la variable expliquée, X (n,p+1) est la matrice relative aux p variables explicatives avec en plus une pseudo-variable ou variable instrumentale x 0 = 1 n, égale à 1 pour les n (n > p + 1) observations, qui correspond au paramètre indépendant β 0, β est le vecteur des paramètres inconnus à estimer et ɛ le vecteur des erreurs. Le problème consiste donc à estimer le vecteur β par un vecteur d'estimateurs b. On obtient les estimations b 0, b 1,..., b p en résolvant le système d'équations normales : ( t XX ) b = t Xy. La résolution de ce système s'obtient en inversant la matrice t XX et en multipliant cette inverse par la matrice t Xy. On obtient l'estimateur des moindres carrés : b = ( t XX ) 1 t Xy. La résolution de ce système d'équations normales est possible que si le déterminant de la matrice ( t XX ) est diérent de zéro.
38 Le vecteur ŷ = Xb = X ( t XX ) 1 t Xy des valeurs estimées ou ajustées et le vecteur e des résidus sont alors obtenus : ŷ = Xb = ŷ 1 : : ŷ i : : ŷ n = e = y ŷ = y Xb = 1 x 11 x x 1p 1 : : : : 1 : : : : 1 x i1 x i2... x ip 1 : : : : 1 : : : : 1 x n1 x n2... x np e 1 : : e i : : e n A ne pas confondre e i résidu calculé (observable) de la régression pour la i ème observation avec le terme aléatoire correspondant ɛ i erreur inobservable. b 0 b 1 : b k: b p
39 Hypothèses de base du Conditions d'application : Les hypothèses que doit respecter le et que l'on doit vérier : Hypothèses probabilistes : premières hypothèses pour l'inférence statistique sur les paramètres du. H 1 : Normalité des erreurs : ɛ i =1,...,n normalement distribués, H 2 : Les erreurs sont de moyenne nulle : E(ɛ i ) = 0 H 3 : Les erreurs ont la même variance (homoscédasticité - variance constante) : Var(ɛ i ) = σ 2 H 4 : Les covariances des erreurs sont nulles (indépendance) : Cov(ɛ i, ɛ i ) = 0 H 5 : Les erreurs sont indépendantes des variables explicatives (non aléatoires) ɛ i i.i.d. N(0, σ 2 ) Le vecteur aléatoire ɛ suit une loi multinormale de paramètres E(ɛ) = 0 et Var(ɛ) = σ 2 I n, où I n est la matrice identité d'ordre n et σ 2 une quantité inconnue : E(ɛ 1 ) E(ɛ 2 ) : E(ɛ n) = 0 0 : 0 ; Var(ɛ 1 ) Cov(ɛ 1, ɛ 2 )... Cov(ɛ 1, ɛ n) Cov(ɛ 2, ɛ 1 ) Var(ɛ 2 )... Cov(ɛ 2, ɛ n) : : : : Cov(ɛ n, ɛ 1 ) Cov(ɛ n, ɛ 2 )... Var(ɛ n) = σ σ : : : : σ 2 = σ2 I n
40 Hypothèses du Ces hypothèses reviennent à dire que le vecteur aléatoire y suit une loi multinormale : E(y) = X β et Var(y) = σ 2 I n les y i i.i.d. N(E(y i ) = β 0 + β 1 x i β p x ip, σ 2 ) A partir de ces hypothèses, on peut montrer que les estimateurs des moindres carrés b sont sans biais : E(b) = E[ ( t X X ) 1 t X y ] = ( t X X ) 1 t X E(y) = ( t X X ) 1 t X X β = β E(b j ) = β j j = 0,..., p Par ailleurs la matrice de variances-covariances de ces estimateurs : Var(b) = est donnée par : Var(b 0 ) Cov(b 0, b 1 )... Cov(b 0, b p) Cov(b 1, b 0 ) Var(b 1 )... Cov(b 1, b p) : : : : Cov(b p, b 0 ) Cov(b p, b 1 )... Var(b p) Var(b) = Var[ ( t X X ) 1 t X y ] = ( t X X ) 1 t X Var(y) t [( t X X ) 1 t X ] = σ 2 ( t X X ) 1 t X X ( t X X ) 1 = σ 2 ( t X X ) 1
41 Ecriture matricielle - Estimations Le principe des moindres carrés consiste à choisir les valeurs estimées b j qui minimisent la somme des carrés des résidus : t e e = t (y ŷ) (y ŷ) = t (y Xb) (y Xb) = t y y 2 t y X b + t b t X X b. = t y y 2 t y ŷ + t b ( t XX ) ( t XX ) 1 t Xy = t y y 2 t y ŷ + t b t Xy = t y y 2 t y ŷ + t (Xb)y = t y y t ŷ y On peut vérier matriciellement que les sommes de carrés : - totale : SCTot = t y y ny 2. - due à la régression : SCReg = t b t X y ny 2. - résiduelle : SCRes = t y y t b t X y.
42 Ecriture matricielle - Estimations sous SAS Estimations des variances Var(ɛ i ) = σ 2 variance des erreurs est estimée par : s 2 = t e e (n p 1). Var(b) var-covariances des estimateurs est estimée : s 2 (b) = s 2 ( t X X ) 1. Intervalle de conance de la moyenne E(y i ) : s 2 (ŷ i ) = t X i ( t X X ) 1 X i s 2. Das le cas de l'intervalle de prédiction de y i : s 2 (d i ) = s 2 (ŷ i ) + s 2. Application sous SAS Correspondance entre les symboles employés dans le et les paramètres correspondants de SAS. Symbole Instruction SAS ŷ i p ( t X X ) et t X y xpx ( t X X ) 1 i Matrice Var-Cov des estimateurs b j covb s(ŷ i ) stdp s(d i ) stdi Intervalle de conance de la moyenne E(y i ) clm Intervalle de prédiction de y i cli Tester un sous-ensemble de paramètres label: test nom-var1 = 0,...;
43 Vérication des hypothèses probabilistes Graphiques - tests statistiques : Les hypothèses probabilistes du : H 1 à H 5, font intervenir les termes d'erreur ɛ i qu'on estime par les résidus e i. Histogramme des résidus H 1 : Normalité des erreurs : superposer l'histogramme des résidus et la courbe de la fonction densité de probabilité d'une loi normale de même moyenne et de même écart-type.
44 Vérication des hypothèses probabilistes Le QQ-plot des résidus - H 1 : Normalité des erreurs : renomer les résidus par ordre décroissant, d'associer à un résidu e i le quantile q i = loi N(0, 1) puis de représenter les e i en fonction des q i. i (n+1) d'une Si les erreurs ɛ i sont normalement distribuées, les points sur le graphique doivent être à peu près alignés sur la droite e i = q i.
45 Vérication des hypothèses probabilistes Diagrammes des résidus en fonction des valeurs estimées ou des variables explicatives - H 2 : E(ɛ i ) = 0 : choisi est adéquat si les résidus sont répartis uniformément dans une bande horizontale du graphique. Sinon, le ne vérie pas cette hypothèse de base.
46 Vérication des hypothèses probabilistes H 1 : Normalité des résidus : Tests de Shapiro-Wilk ou de Kolmogorov-Smirnov. Principaux tests de normalité d'une variable : Shapiro-Wilk (le meilleur), Kolmogorov-Smirnov (le plus général), Cramer-von Mises et Anderson-Darling. Conclusion du test : l'hypothèse nulle H 0 : Normalité des résidus est acceptée si la probabilité Pr < W est supérieure au rique α = 5% choisi.
47 Vérication des hypothèses probabilistes H 1 : Normalité des résidus : Test graphique de Shapiro-Wilk
48 Vérication des hypothèses probabilistes H 3 : homoscédasticité - variance constante : test de White Si la variance n'est pas constante (hétéroscédasticité), les estimations des écart-types sont biaisées. Il en résulte que les résultats des tests statistiques sont biaisés et que les calculs des intervalles de conance et de prévision sont également biaisés. Cette hypothèse peut être vériée par le test de White : test d'indication des moments d'ordre 1 et 2, dont la règle de décision est basée sur la statistique du khi-deux. Conclusion du test : l'hypothèse nulle H 0 : homoscédasticité - variances constantes : si la probabilité Pr > ChiSq est supérieure au risque α = 5% choisi, on conclut que les variances sont égales (il y a homoscédasticité).
49 Vérication des hypothèses probabilistes H 3 : homoscédasticité : Test de Bartlett Conditions d'application : k échantillons de tailles n 1, n 2,..., n k prélevés au hasard et indépendamment de k populations normales de variances σ 2 1, σ2 2,..., σ2 k inconnues. En supposant H 0 : σ1 2 = σ2 2 =... = σ2 k vraie et selon les conditions mentionnées, la statistique de test de Bartlett : (n k) ln( ki =1 (n i 1)s i où, s i 2 = n i n i 1 s2 i n k 2 ) k i=1 (n i 1) ln(s i 2 ) χ 2 k 1 désigne l'estimation de la i me variance corrigée. Remarque 1 : dans le cas de deux échantillons (k = 2), Test de Fisher, la statistique adéquate et exacte est celle du rapport de deux variances, soit F = s 1 2 /σ 2 1 s 2 2 /σ 2 2 F (n1 1),(n 2 1). Remarque 2 : on peut également utiliser le test de Levene, c'est le meilleur car peu sensible à la non-normalité. Le test de Bartlett est meilleur si la distribution est normale. Le test de Fisher est le moins robuste en l'absence de normalité.
50 Application sous SAS Le tableau suivant résume la correspondance entre les hypothèses de base et la syntaxe du logiciel SAS pour pouvoir les vérier. Hypothèse - Critère Test Instruction SAS Procédure H 1 : Normalité des e i histogramme histogram residus / normal univariate H 1 : Normalité des e i Shapiro-Wilk normal univariate H 1 : Normalité des e i qq-plot des résidus qqplot residus / normal univariate H 1 : Normalité des e i pp-plot Shapiro-Wilk ppplot residus / normal capability H 2 : E(ɛ i ) = 0 diagramme de dispersion plot residus*x j residus*ŷ reg H 3 : homoscédasticité White model / spec reg H 3 : homoscédasticité Bartlett ou Levene means / hovtest = lmg
51 (MCG) D'une façon, la matrice des variances des erreurs ɛ i peut s'écrire sous la forme : Σ = Var(ɛ) = σ 2 M M : matrice symétrique dénie positive, connue, qui peut donc s'écrire sous la forme : M = T t T en posant T = U Λ 1 2 où, les colonnes de U sont les vecteurs propres de M et Λ la matrice diagonale des valeurs propres de M. Il s'en suit, le calcul des coecients du : b = ( t X M 1 X ) 1 ( t X M 1 y).
52 La méthode des Moindres 0rdinaires (MCO) suppose sur les erreurs les hypothèses H 3 : homoscédasticité (variance constante) et H 4 : Cov(ɛ i, ɛ i ) = 0 (Indépendance). Σ = Var(ɛ) = σ 2 I n, avec M = I n. La méthode des Moindres (MCG) considère le cas où l'hypothèse H 3 n'est pas vériée (hétéroscédasticité - variances diérentes). Parmi les diérentes formes possibles de la matrice M, une est particulièrement utilisée (méthode dite pondérée). Cette notion de MCG est essentiellement due à AITKEN (1935).
53 Méthode des Moindres Pondérés (MCP) La méthode des MCP consiste à appliquer une pondération sur les individus. On pose : M = Dw 1, où D w étant la matrice diagonale des poids w i > 0 diérents attribués aux individus. Σ = σ 2 1/w /w : : : : /w n = σ2 Dw 1 En posant la transformation : y w = W y ; X w = W X et ɛ w = W ɛ avec, W = w w : : : : wn On obtient le équivalent : y w = X w β + ɛ w tel que : t W W = D w Où, Var(ɛ w ) = Var(W ɛ) = WVar(ɛ) t W = σ 2 W Dw 1 t W = σ 2 I n Comme pour ce nouveau la variance des erreurs est constante, on pourra donc appliquer la méthode des MCO.
54 Méthode des moindres carrés pondérés On obtient le vecteur des estimateurs : b = ( t X w X w ) 1 t X w y w = ( t X t W W X ) 1 t X t W W y = ( t X D w X ) 1 ( t X D w y) = V 1 x V xy... si les données sont centrées... où, Vx 1 désigne la matrice inverse des variances-covariances des X et V xy la matrice des covariances des X avec y. Le vecteur des valeurs estimées pour y w = W y : ŷ w = X w b w = W X ( t X D w X ) 1 D w y. Le vecteur de valeurs estimées pour y = W 1 y w : ŷ = W 1 ŷ w = W 1 W X ( t X D w X ) 1 t X D w y = X b w. La variance σ 2 est quant à elle estimée par : sw 2 = 1 t (y n p 1 w ŷ w )(y w ŷ w )ŷ = 1 n p 1 t (y ŷ) t W W (y ŷ) = 1 n p 1 n i w i (y i ŷ i ) 2 s 2.
55 Comment remédier à l'hétéroscédasticité? Le premier remède recommandé est de remplacer les MCO par les MCP. Le second est de transformer une ou plusieurs variables et d'appliquer la méthode des MCO sur les données transformées. Le terme veut dire que y peut s'exprimer comme une combinaison des paramètres β j et des erreurs ɛ i du. Ceci n'impose donc aucune restriction sur les variables explicatives. Lorsque le n'est pas ou que la normalité des erreurs H 1 n'est pas vériée, un remède possible est de transformer une ou plusieurs des variables du an de rendre celui-ci.
56 Quelques transformations des variables Certaines transformations et s typiques : : y = β 0 + β 1 x 1 + β 2 x 2 + β 3 x 1 x 2 + β 4 x β 5x β 6 1 x 1 + ɛ que l'on peut réécrire : y = β 0 + β 1 x 1 + β 2 x 2 + β 3 x 3 + β 4 x 4 + β 5 x 5 + β 6 x 6 + ɛ en posant : x 3 = x 1 x 2, x 4 = x 2 1, x 5 = x 3 2, x 6 = 1 x 1. Les s non s : y = β 0 β x 1 ɛ ou y = β 0 x β 1 ɛ. que l'on peut remplacer par les s s équivalents : log(y) = log(β 0 ) + xlog(β 1 ) + log(ɛ) log(y) = log(β 0 ) + β 1 log(x) + log(ɛ). On utilise les variables log(x) et log(y) à la place des x et y (transformation logarithmique). On estime ensuite les paramètres log(β 0 ), log(β 1 ) et β 1 par la méthode des MCO.
57 Quelques transformations des variables Dans le cas les s : log(y) = β 0 + p j β j x j + ɛ ou log(y) = β 0 + p j β j log(x j ) + ɛ à la place du classique : y = β 0 + p j β j x j + ɛ. Lorsqu'il s'agit de transformer seulement la variable à expliquer y = β 0 + p j β j x j + ɛ. On peut par exemple remplacer y par : 1 log(y) ou y ou encore 1 (quand la variance augmente), exp(y) ou y 2 y (quand la variance diminue), 2 une nouvelle { variable zi(λ) (méthode de Box et Cox) dénie par : y λ i 1 z i (λ) = λỹ λ 1 (λ 0) ỹlog(y i ) (λ = 0) où, ỹ = n n i=1 y i est la moyenne géométrique des y i. le transformé s'écrit : z i (λ) = β 0 + p j β j x ij + ɛ i
58 Hypothèses stochastiques du Les problèmes d'estimation et d'inférence posés par l'autocorrélation et la colinéarité sont semblables à ceux dus à l'hétéroscédasticité. Examinons les eets de ces deux hypothèses supplémentaires du. H 6 : Absence d'autocorrélation des résidus : test de Durbin-Watson : les inconvénients d'une autocorrélation sont importants : les variances des paramètres et des résidus sont biaisées, ce qui engendre des biais lorsqu'on eectue des tests paramétriques ou lorsqu'on calcule des intervalles de conance ou de prévision. 1 On calcule sous l'hypothèse nulle H 0 : Absence d'autocorrélation des résidus (erreurs indépendants), la valeur D de la statistique de test de Durbin-Watson (rapport de variances): D = nt=2 (e t e t 1 ) 2 nt=2 et 2. 2 Puis on compare D avec des valeurs limites tabulées (d1 et d2). Ces valeurs dépendent de la taille de l'échantillon, du nombre de variables indépendantes du et du risque d'erreur choisi.
59 Hypothèses stochastiques du H 6 : Absence d'autocorrélation des résidus : Règle de décision : D < d 1 : présence d'autocorrélation positive. d 1 < D < d 2 : on ne peut rien conclure. D > d 2 : absence d'autocorrélation positive. 4 D < d 1 : présence d'autocorrélation négative. d 1 < 4 D < d 2 : on ne peut rien conclure. 4 D > d 2 : absence d'autocorrélation négative. D'une façon, D < 2 pour des autocorrélations positives, D > 2 pour des autocorrélations négatives, et doit être proche de 2 (disons entre 1.5 et 2.5) pour que l'autocorrélation soit acceptable.
60 Hypothèses stochastiques du H 7 : Absence de colinéarité : dans l'élaboration d'un à plusieurs variables explicatives, on est fréquemment confronté à la présence du phénomène de colinéarité : liaison entre deux voire plusieurs variables explicatives. Ce phénomène peut, dans une certaine mesure, être décelé par le calcul des coecients de corrélation entre les variables explicatives prises deux à deux.
61 Tests sur le coecient de corrélation Condition d'application : Le test sur le coecient de corrélation (Bravais-Pearson) est valable que si les distributions des variables x j et x k sont normales. En supposant H 0 : ρ(x j, x k ) = 0 : Indépendance vraie et selon les conditions mentionnées, la statistique de test : n 2 R(xj,x k ) 1 R 2 (x j,x k ) T n 2 d.d.l. où, R(x j, x k ) désigne l'estimateur du coecient de corrélation, l'estimation étant la valeur r(x j, x k ) du coecient de corrélation calculé sur l'échantillon. Ainsi, l'hypothèse nulle H 0 : La corrélation entre x j et x k n'est pas signicative, au seuil de signication α choisi, si : n 2 r(xj,x k ) 1 r 2 (x j,x k ) > t ( α 2,n 2)
62 Test sur le coecient de corrélation Conclusion du test : Non-rejet de H 0 si la probabilité Prob > r = 32.58% est supérieure à α = 5% choisi.
63 Les principales conséquences d'une forte colinéarité 1 Les estimations b j des coecients du deviennent très instables à mesure que la colinéarité devient de plus en plus forte. 2 La précision dans l'estimation des coecients du est grandement aectée. En eet, les variance s 2 (b j ) et ĉov(b j, b k ) seront beaucoup plus élevées que dans le cas d'absence d'une forte colinéarité. 3 Lorsque les s 2 (b j ) sont élevés, ceci peut avoir une conséquence directe de ne pas rejeter l'hypothèse nulle H 0 : β j = 0 avec le test de Student (contribution marginale) alors que le test sur l'ensemble des variables explicatives avec le F de Fisher s'est avéré signicatif. Une forte colinéarité présente donc des inconvénients au niveau de l'apport individuel des variables explicatives ainsi que sur les intervalles de conance des coecients du et sur les tests de signication.
64 Comment y remédier à l'eet de colinéarité? Faire un choix judicieux des variables explicatives à introduire dans le. En s'assurant au départ que le nombre d'observations n > p le nombre de variables explicatives (Hypothèse de structure). En retranchant une ou plusieurs variables explicatives; on portera une attention particulière aux variables explicatives dont les écarts-types s(b j ) des coecients sont très élevés. On retranchera toutefois qu'une variable à la fois (un nouveau devra être eectué à chaque fois que l'on retranche une variable). Re à des méthodes de type pas à pas ("Stepwise methods") : ne pas introduire ou retrancher du toute variable explicative fortement corrélée ment avec d'autres déjà incluses dans le.
65 Une étude peut comporter un nombre élevé de variables explicatives. Un des objectifs est de retenir que les variables qui présentent un apport signicatif à l'explication du comportement de la variable à expliquer ou encore celles qui permettent des estimations ou prédictions avec le plus de justesse possible. Diverses méthodes sont utilisées pour un choix pratique des variables explicatives (composantes du ) : - choix qui essaie de concillier la simplicité de l'utilisation du ajusté (faible nombre de variables explicatives), - et la qualité de l'ajustement (R 2 élevé, faible valeur du carré moyen résiduel, marge d'erreur acceptable dans les estimations par intervalle et les prédictions,...) Avec p + 1 variables explicatives (y compris la variable instrumentale x 0 = 1 n ), on peut construire 2 p+1 1 équations donc s possibles!!!
66 Les critères de sélection Il existe plusieurs critères pour sélectionner un certain nombre de variables explicatives parmi les p variables explicatives disponibles. Le critère du R 2 se révèle être le critère le plus utilisé. Le problème est qu'il augmente de façon systématique avec l'introduction de nouvelles variables explicatives dans le, même si celles-ci sont peu corrélées avec la varible à expliquer. Pour parer à cet inconvénient, on peut utiliser la statistique du R 2 ajust ou des critères : C p de Mallows ou encore le critère AIC, relatifs au biais, pouvant apparaître lors de l'estimation de s ne comprenant pas toutes les variables. Ces critères pénalisent explicitement le nombre de variables dans le.
67 Critères du R 2 et du R 2 ajust On a vu que le coecient de détermination R 2 = SCReg SCTot = 1 SCRes SCTot est une mesure qui permet d'évaluer le degré d'adéquation du. On a vu que : Rajust 2 = 1 (n 1) (n p 1) (1 R2 ) < R 2 permet de comparer plusieurs s qui dièrent soit par le nombre d'observations n, soit par le nombre p de variables explicatives introduites dans le. Le R 2 est une statistique calculée sur un échantillon alors que le R 2 ajust peut être considéré comme une estimation du R2 pour la population : R 2 pop.
68 Autres critères d'ajustement Critère de Mallows : La statistique C p de Mallows est une mesure standardisée du carré moyen résiduel pour un comportant p termes : C p = SCRes(p) (n 2(p + 1)). sk 2 Critère d'information de Akaike (Akaike Information Criterion) : AIC(p) = sy 2 (1 R 2 )e 2(p+1) n. Critère d'information de Schwartz (Bayesian Information Criterion) : BIC(p) = sy 2 (1 R 2 )n 2(p+1) n. Ces deux dernières mesures baissent également lorsque le R 2 augmente, mais se dégradent lorsque la taille du augmente. Il est plus convenable d'utiliser le logarithme de ces mesures.
69 Autres critères d'ajustement
70 Quelques procédures de sélection de variables Il existe plusieurs types de procédures de sélection de variables, en particulier les méthodes dites pas à pas. Bien qu'ecaces, il ne faut pas se er totalement aux résultats qu'elles fournissent. Il important d'y ajouter une part d'intuition, de déduction et de synthèse quant à la décision de supprimer ou d'ajouter une variable dans le, tout en tenant compte de l'objectif recherché. Par exemple, - Dans un but de prédiction (prévision), il est peut-être souhaitable d'avoir un avec un maximum de variables explicatives an d'augmenter le pouvoir explicatif. - Vu le coût élevé pour obtenir des informations pour un grand nombre de variables explicatives, il est peut-être souhaitable d'avoir un avec un minimum de variables explicatives. Quelques méthodes qui permettent d'obtenir un bon compromis parmi ces deux extrêmes.
71 Méthodes de sélection de variables La méthode d'élimination progressive "Backward method" considère le complet avec toutes les p variables explicatives. Puis élimine la variable la moins signicative du : celle qui entraine la plus faible diminution du R 2. Le processus est réitéré jusqu'à ce que toutes les variables restantes dans le soient signicatives avec un seuil de signication choisi. La méthode d'introduction progressive "Forward method" procède en sens inverse. A partir d'un sans aucune variable explicative puis ajouter la variable explicative la plus corrélée avec la variable à expliquer y. Elle réitère le processus d'introduction des autres variables tant que le R 2 augmente de façon signicative. La régression pas à pas "Stepwise method" combine les deux méthodes précédentes. La régression "Stagewise" est une variante de la méthode "Stepwise" avec deux seuils de signication diérents. Celui d'introduction est plus faible que celui d'élimination. Elle eectue d'abord la régression simple avec la variable explicative la plus corrélée avec y. Puis recherche pour introduire la variable, parmi les p 1 variables restantes, qui est la plus corrélée avec les résidus du précédent. Le processus est réitéré jusqu'à ce que plus aucune variable restante ne soit corrélée signicativement avec les résidus. Ces méthodes ne mènent pas forcément à la même solution et ne conduisent pas nécessairement au même choix de variables explicatives à retenir dans le.
72 Application sous SAS Le tableau suivant donne la correspondance entre les hypothèses, les méthodes et les tests présentés ainsi que la syntaxe des procédures SAS. Hypothèse - Critère - Méthode Test Instruction SAS Proc H 6 : Absence d'autocorrélation Durbin-Watson model / dw reg Hétéroscédasticité - MCP MCP weight variable (pondération) reg Corrélation Student pearson corr Coecient détermination ajusté Rajust 2 model / selection = rsquare reg Cp de Mallows C p model / selection = cp reg AIC Akaike model / selection = aic reg Pas à pas Stepwise method model / selection = stepwise reg progressive Forward method model / selection = forward reg Elimination progressive Backward method model / selection = backward reg