Algorithmes évolutionnaires sur. et GPU. Introduction : GPU et puissance calculatoire Principe du GPU : le pipeline
|
|
|
- Augustin Dubé
- il y a 8 ans
- Total affichages :
Transcription

1 Algorithmes évolutionnaires et GPU Introduction : GPU et puissance calculatoire Principe du GPU : le pipeline graphique Introduction au parallélisme de données Exemple de simulation Les langages de haut-niveau pour le GPU Accelerator, CUDA GPU et algorithmes évolutionnaires Programmation génétique sur GPU Algorithmes évolutionnaires sur GPU

2 Introduction Le GPU est devenu depuis années un processeur flexible, peu onéreux. Puissance Programmable Précision (float) Calculs dédiés 2

3 Motivation : puissance calculatoire Les GPUs sont puissants Intel Core 2 Duo 3,5 Ghz (Woodcrest Xeon) Peak Peak NVIDIA GeForce 8800 GTX Puissance 48 Gflops Bande passante21 Gbits/s Prix 900 Puissance 330 Gflops Mesuré Bande passante55,2 Gbits/s Mesuré Prix 600 Les GPUs sont de plus en plus rapides CPU : ~ x 1,4 /an GPU : ~ x 1,7 /an (pixels) à x 2,3 (vertex) 3
 à x 2,3")
4 Aperçu de la puissance calculatoire 4

5 Note Pourquoi les GPUs sont de plus en plus rapides? Intensité arithmétique Les calculs sont hyper-spécialisés et par conséquent les circuits sont simples (proches du RISC) Économie L'industrie du jeu vidéo pousse à l'innovation 5
 Économie L'industrie du jeu vidéo pousse à")
6 Motivations : flexibles et précis Les nouveaux GPUs sont programmables Programmation au niveau du pixel, du vertex et (bientôt) shader de géométrie Utilisation de langage de haut niveau Précision importante Précision des réels sur 32 bits dans tout le pipeline Suffisant pour la plupart des applications Bientôt en double précision 6

7 Problème : difficile à utiliser Les GPUs sont conçus pour les jeux vidéo L'architecture sous-jacente est : Modèle de programmation atypique Modèle de programmation très lié à la programmation graphique Basée sur le parallélisme de données En évolution rapide Relativement secrète! On ne peut pas faire simplement du portage de code 7

8 Le pipeline graphique Le pipeline graphique simplifié Hautement parallèle Beaucoup de caches, de FIFOs,... 8

9 Le pipeline graphique récent Processeur de vertex programmable (vertex shader) Pixel shader programmable 9
 Pixel")
10 Processeur de vertex But : Transformation sur les vertex Rotations Déplacements Changements d'échelles... Shaders programmables Éclairage Flou... Vertex shader de réflexion/réfractio 10

11 Le pipeline de vertex Fixe (ensemble de matrices Programmable à fournir) V0 à v15 : vertex 11
 V0 à v15 :")

12 GPU pipeline : rasterization Génération de primitives Conversion des vertex en primitives géométriques Rasterization (tramage) Génération de pixels à partir de la géométrie Pixels appelés plus généralement fragments (pixel avec données associées, profondeur, couleur,...) 12
 12")
13 Processeur de fragments But très simple : Le pixel pipeline reçoit un pixel, ainsi que quelques informations l'accompagnant (les coordonnées des textures, par exemple) Construire un pixel complet à partir de ces informations Le pipeline de pixels peut être fixe ou programmable (appelé pixel shader) 13

14 Exemple 14

15 Importance du data-parallélisme Les GPUs sont conçus pour le graphisme Traitement de vertex et de pixels indépendants Pas de données statiques ou partagées Traitement parallèle des données L'architecture des GPUs est basée sur une multiplications des ALUs Plusieurs processeurs de vertex et pixels La GeForce 8800 GTX a 128 ALUs 15

16 Applications idéales Intensité calculatoire importante Les applications doivent avoir: Ensemble important de données Beaucoup de parallélisme Très grande indépendance entre les données à traiter 16

17 Exemple : calcul sur une grille Programmation «classique» sur un GPU Les textures représentent la grille de calculs Beaucoup de calculs peuvent se projeter sur une grille Calcul matriciel Traitement d'images Simulation physique... 17

18 Vocabulaire Streams (ou grille de données) Ensemble de données nécessitant l'application du même traitement A la base du parallélisme de données Kernels Fonctions appliquées à chaque stream (transformations,...) Peu de dépendances entre les streams 18

19 Calcul sur GPU Calcul sur grille Réalisé en étapes Chaque étape met à jour la grille entière Chaque étape doit être terminée avant de passer à l'étape suivante La grille représente les streams, les étapes sont les kernels Algorithme de simulation de nuages 19

20 Ressources disponibles Processeurs programmables parallèles Processeurs de vertex et de fragments Ou conception unifiée ( GeForce 8800 GTX, ATI Xenos) Unité de texture Accès en lecture seule / écriture seule Optimisée pour l'accès en 2D 20

21 Processeur de vertex Programmable (SIMD) voire MIMD Traitement de vecteurs à 4 coordonnées (RGBA / XYZW) Peut réaliser un scatter mais pas un gather Peut changer la position d'un vertex Ne peut obtenir d'informations d'autres vertex Peut récupérer des informations des textures 21
22 Processeur de fragments Programmable en mode SIMD Traitement de vecteurs à 4 coordonnées (RGBA / XYZW) Note : la 8800 GTX est un processeur scalaire Accès en lecture aux textures Capable de gather - scatter limités? (mémoire partagée sur 8800 GTX) Adresse de sortie fixée à une adresse A priori plus utile que le processeur de vertex Plus de processeurs de fragments que de processeurs de vertex Sortie directe (sortie du pipeline) 22

23 CPU GPU analogies CPU GPU Stream / Tableau de donnés = Texture Lecture en mémoire = Lecture de texture 23
24 Kernels Kernel / Étape algorithmique = programmation du pixel shader 24
25 Retour de résultat Écriture du résultat = mise à jour de textures 25
26 Exemple N-body simulation N = 8192 corps N2 forces de gravitation 64 M forces/frame ~ 25 flops par force GeForce 8800 GTX Précision réel 16 bits : 73 fps, 122,5 Gflops Précision réel 32 bits : 39 fps, 65,4 Gflops 26
27 Calcul des forces gravitationnelles Chaque corps attire tous les autres corps N corps donc N2 forces Tampon de taille NxN Pixel(i,j) calcule la force entre le corps i et j Programme de fragment (pixel shader) très simple Limité par la taille maximale des textures 27

28 Calcul des forces gravitationnelles La force est proportionnelle à l'inverse du carré de la distance entre les corps 28

29 Calcul des forces gravitationnelles Les coordonnées (i,j) dans la texture gérant les forces sont utilisées pour récupérer la position des corps i et j 29
30 Calcul des forces gravitationnelles 30
31 Calcul de la force On dispose du tableau de force (i,j) On souhaite calculer la force totale soumise sur la particule i 31
32 Calcul de la force On dispose du tableau de force (i,j) On souhaite calculer la force totale soumise sur la particule i Sommation sur chaque colonne 32
33 Calcul de la force On dispose du tableau de force (i,j) On souhaite calculer la force totale soumise sur la particule i Sommation sur chaque colonne Réduction parallèle 33
34 Mise à jour des vitesses et positions Nous avons un tableau 1D de forces Une par corps Mise à jour de la vitesse u(i,t+dt) = u(i,t) + Ftotal(i)*dt Simple programme du pixel shader Mise à jour de la position x(i,t+dt) = x(i,t) + u(i,t)*dt Simple programme du pixel shader qui lit la position précédente et la vitesse et met à jour la nouvelle position 34
35 Langages de GPU de haut niveau 35
36 Langages de shader Cg, HLSL, OpenGL Shading Language Cg : HLSL : msdn.microsoft.com/library/default.asp?url=/libr ary/enus/directx9_c/directx/graphics/reference/h ighlevellanguageshaders.asp OpenGL Shading Language : pers/index.html 36
37 Langages de GPGPU Pourquoi? Rendre la programmation des GPU plus simples Connaissance d'opengl, directx,... inutiles Simplification des opérations communes Travail sur l'algorithme et non sur l'implémentation 37
38 Quelques exemples Accelerator Brook ATI/AMD CUDA Stanford University CTM Microsoft Reseach NVIDIA Peakstream RapidMind Version commerciale améliorée de sh 38
39 Accelerator Programmation data-parallèle du GPU Librairie data-parallèle à la disposition du programmeur Simple, haut niveau de programmation Compilateur JIT pour le CPU ou le GPU Fonctionne avec.net 39
40 Bibliothèque data-parallèle Conversion explicite entre tableaux DP et tableaux «classiques» Chaque opération produit un nouveau tableau DP Pas de pointeurs et d'accès aux éléments individuels 40
41 Tableaux data-parallèles 41

42 Conversion explicite 42
43 CUDA et calcul sur GPU 43
44 Présentation Programmation data-parallèle basée sur un système de threads Plusieurs milliers de threads possibles Cache de données data-parallèle Programmation en C Bibliothèques d'algèbre linéaire et de FFT disponibles Utilisable uniquement sur GPU de type nvidia 44
45 Exécution basée sur les threads Programme de threads Très grand nombre d'instructions Pas de limitation sur les alternatives et les boucles Allocation des threads suivant une logique 1D, 2D ou 3D Regroupement des threads en groupes logiques appelés blocs Mémoire partagée Les blocs sont exécutés en parallèle si des grilles de processeurs 45

46 Les blocs Les blocs sont exécutés en parallèles si des grilles de processeurs sont disponibles Aucun ordre sur les blocs n'est garanti 46
47 Mémoire partagée Mémoire dédiée Partagée entre les threads et utilisée pour la communication inter-threads Manipulée de manière explicite Aussi rapide que les registres 47
48 Mémoire globale Mémoire générale du GPU : allocation libération de mémoire Non typée (non limitée à la manipulation de texture) Support des pointeurs 48
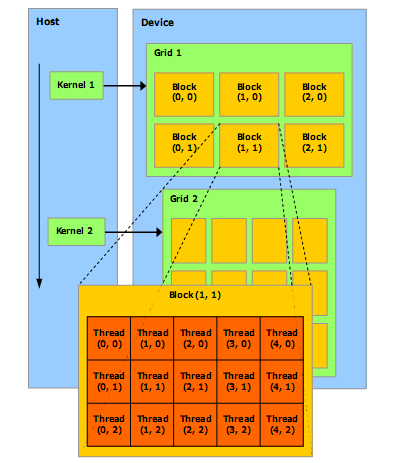
49 Modèle d'exécution 49
50 Exécution sur un GeForce 8800 GTX 768 Mo disponible 16 grilles de 8 processeurs 128 processeurs au total à 1,35 Ghz (675 Mhz) 16 ko par grille de mémoire partagée 32 threads minimum par bloc Cache de texture de 8 ko par grille À partir de 16 blocs, le parallélisme maximum est atteint (pour moins de 16 blocs, certaines grilles seront inoccupées) 50
51 Programmation C du GPU Assez simple à programmer, mais nécessite une connaissance approfondie pour une accélération optimale Extension de certains mots-clefs global void Kernelfunc(...); device int Globalvar; shared int Sharedvar; KernelFunc <<<500,128 >>>(...); 51
52 Mesure de temps sur GPU Exemple simple Utilisation d'une ou plusieurs grilles de multiprocesseurs ; Un fichier d'appel clock.cu exécuté sur le CPU ; Un fichier du kernel clock_kernel.cu exécuté sur le GPU 52
53 GPU et algorithmes évolutionnaires Wong ML, Wong TT, Fok KL: Parallel evolutionary algorithms on GPU, Proceedings of IEEE CEC 2005, vol 3, pp Wong ML, Wong TT, Fok KL: Evolutionary computing on consumer-level graphics hardware, IEEE Intelligent Sytems (to appear) Yu Q, Chen C., Pan Z. : Parallel Genetic Algorithms on Programmable Graphics Hardware, LNCS 3612, 2005 Ebner M., Reinhardt M., Albert J.: Evolution of vertex and pixel shaders, EuroGP 2005, pp Harding S., Banzhaf W.: Fast Genetic Programming on GPUs, EuroGP 2007, LNCS , pp
54 GP sur GPU Une unique (à ma connaissance) contribution partielle. Harding et Banzhaf 2007 Idée relativement simple Les arbres GP sont évalués pour chaque élément du jeu d'entraînement Application parallèle du jeu d'entraînement sur le GPU Pas de moteur d'évolution, l'évaluation de programmes aléatoires est réalisée sur le GPU Le tableau de jeu d'entraînement est transformé en texture et chargé sur le GPU Après l'évaluation, le résultat est transferé du 54 GPU vers le CPU
55 Expériences Expériences réalisées uniquement sur la phase d'évaluation Langage AcceleratorTM, parser GP écrit en C# et compilé avec Visual Studio 2005 GPU Nvidia GeForce 7300 GO (512 Mo) CPU Intel Centrino 1,83 Ghz 100 expressions générées aléatoirement pour calculer le facteur d'accélération (arbres a priori) Le programme du pixel shader correspond à un arbre 55
56 6 4 3 Fonction x 2x + x Nombre de cas de tests Longueur Maxi ,02 0,08 0,7 1, ,07 0,33 2,79 5, ,42 1,71 15,29 87, ,4 1,79 16,25 95,37 Facteur d'accélération 56
57 Classification (2 spirales) Jeu d'entraînement Taille de l'expression ,15 0,23 0,51 1, ,38 0,67 1,63 3, ,77 3,19 9,21 22, ,69 3,21 8,94 22,38 57
58 Conclusion Peu de gains pour des jeux d'entraînement de petite taille(surcoût de transfert non négligeable) Pour des jeux de taille importante, le gain est conséquent Question ouverte : A-t-on souvent en GP l'occasion de tester des jeux d'entraînement de cas ou plus? Coût de la compilation? 58
59 Travaux de Fok, Wong et Wong Il s'agit de programmation évolutionnaire sur GPU Les individus sont cha rgés dans les textures Pas de recombinaison, mutation indépendante sur chaque individu 59
60 Représentation des individus x1 x2 x3 x4 x5 x6 x7... x32 x1 x2 x3 x4 x5 x6 x7... x32 x1 x2 x1 x2 x5 x3 x4 x3 x4 x7 x6 x5 un individu de 32 gènes correspond à 8 pixels (r,g,b, ) La mémoire est mieux utilisée avec des multiples de 4 (stockage r,g,b, ) x6 x7 h w mémoire de texture 60
61 Réalisation de la mutation Mutation totalement parallélisable Pour chaque individu x x ' j =x j j R 0,1 1 ' j = j exp R j 0,1 2k Deux programmes de fragment un pour générer ' un pour générer x' 61
62 Visualisation 62
63 Évaluation du fitness Réalisation totalement parallèle de l'évaluation Le programme de shader calcule le déplacement correct pour le calcul du fitness 63
64 Compétition et sélection Sélection stochastique à travers un tournoi entre les individus de la nouvelle génération et les parents Compétition avec q individus générés aléatoirement Ces deux opérations sont réalisées sur le CPU pas de fonction aléatoire sur le GPU transfert coûteux entre le CPU et le GPU 64
65 Résultats GPU CPU , ,02 8, ,04 16,75 Expériences sur Pentium IV 2,4 Ghz GeForce 6800 Ultra avec 256 Mo Temps d'exécution par rapport à une exécution avec 400 individus 65
66 Travaux de Yu, Chen, Pan Travaux moins avancés que le précédent Évaluation parallèle du fitness Génération des nombres aléatoires à partir d'une matrice de texture aléatoire Réalisation de la recombinaison et de la mutation sur le GPU 66
67 Représentation de la population 4 gènes = 1 pixel au format (r,g,b, ) 1 grille 2D de texture correspond aux quatre premiers gènes de chaque individu Il y a donc n/4 grilles de texture 2D (pour une population de n individus) Une grille supplémentaire est utilisée pour le fitness 67
68 Visualisation 4N gènes M M*M chromosomes M N textures 2D GPU 68
69 Quelques résultats 1 x x x 2 1 x 4 1 Taille pop Opérations génétiques Fitness 1,4 0,3 5,8 1,4 11,8 7,9 17,9 15,4 20,1 17,1 GAIN f x =100 x 21 x x x 23 x
Initiation au HPC - Généralités
 Initiation au HPC - Généralités Éric Ramat et Julien Dehos Université du Littoral Côte d Opale M2 Informatique 2 septembre 2015 Éric Ramat et Julien Dehos Initiation au HPC - Généralités 1/49 Plan du cours
Initiation au HPC - Généralités Éric Ramat et Julien Dehos Université du Littoral Côte d Opale M2 Informatique 2 septembre 2015 Éric Ramat et Julien Dehos Initiation au HPC - Généralités 1/49 Plan du cours
Une bibliothèque de templates pour CUDA
 Une bibliothèque de templates pour CUDA Sylvain Collange, Marc Daumas et David Defour Montpellier, 16 octobre 2008 Types de parallèlisme de données Données indépendantes n threads pour n jeux de données
Une bibliothèque de templates pour CUDA Sylvain Collange, Marc Daumas et David Defour Montpellier, 16 octobre 2008 Types de parallèlisme de données Données indépendantes n threads pour n jeux de données
Eternelle question, mais attention aux arnaques Question qui est souvent mise en premier plan => ce n est pas une bonne idée
 Son PC portable 1 2 Eternelle question, mais attention aux arnaques Question qui est souvent mise en premier plan => ce n est pas une bonne idée Analysons d abord vos besoins Ensuite on n y reviendra 3
Son PC portable 1 2 Eternelle question, mais attention aux arnaques Question qui est souvent mise en premier plan => ce n est pas une bonne idée Analysons d abord vos besoins Ensuite on n y reviendra 3
Synthèse d'images I. Venceslas BIRI IGM Université de Marne La
 Synthèse d'images I Venceslas BIRI IGM Université de Marne La La synthèse d'images II. Rendu & Affichage 1. Introduction Venceslas BIRI IGM Université de Marne La Introduction Objectif Réaliser une image
Synthèse d'images I Venceslas BIRI IGM Université de Marne La La synthèse d'images II. Rendu & Affichage 1. Introduction Venceslas BIRI IGM Université de Marne La Introduction Objectif Réaliser une image
Segmentation d'images à l'aide d'agents sociaux : applications GPU
 Segmentation d'images à l'aide d'agents sociaux : applications GPU Richard MOUSSA Laboratoire Bordelais de Recherche en Informatique (LaBRI) - UMR 5800 Université de Bordeaux - France Laboratoire de recherche
Segmentation d'images à l'aide d'agents sociaux : applications GPU Richard MOUSSA Laboratoire Bordelais de Recherche en Informatique (LaBRI) - UMR 5800 Université de Bordeaux - France Laboratoire de recherche
Architecture des ordinateurs
 Décoder la relation entre l architecture et les applications Violaine Louvet, Institut Camille Jordan CNRS & Université Lyon 1 Ecole «Découverte du Calcul» 2013 1 / 61 Simulation numérique... Physique
Décoder la relation entre l architecture et les applications Violaine Louvet, Institut Camille Jordan CNRS & Université Lyon 1 Ecole «Découverte du Calcul» 2013 1 / 61 Simulation numérique... Physique
Introduction à CUDA. gael.guennebaud@inria.fr
 36 Introduction à CUDA gael.guennebaud@inria.fr 38 Comment programmer les GPU? Notion de kernel exemple (n produits scalaires): T ci =ai b ( ai, b : vecteurs 3D, ci for(int i=0;i
36 Introduction à CUDA gael.guennebaud@inria.fr 38 Comment programmer les GPU? Notion de kernel exemple (n produits scalaires): T ci =ai b ( ai, b : vecteurs 3D, ci for(int i=0;i
Limitations of the Playstation 3 for High Performance Cluster Computing
 Introduction Plan Limitations of the Playstation 3 for High Performance Cluster Computing July 2007 Introduction Plan Introduction Intérêts de la PS3 : rapide et puissante bon marché L utiliser pour faire
Introduction Plan Limitations of the Playstation 3 for High Performance Cluster Computing July 2007 Introduction Plan Introduction Intérêts de la PS3 : rapide et puissante bon marché L utiliser pour faire
M2-Images. Rendu Temps Réel - OpenGL 4 et compute shaders. J.C. Iehl. December 18, 2013
 Rendu Temps Réel - OpenGL 4 et compute shaders December 18, 2013 résumé des épisodes précédents... création des objets opengl, organisation des données, configuration du pipeline, draw,... opengl 4.3 :
Rendu Temps Réel - OpenGL 4 et compute shaders December 18, 2013 résumé des épisodes précédents... création des objets opengl, organisation des données, configuration du pipeline, draw,... opengl 4.3 :
Comme chaque ligne de cache a 1024 bits. Le nombre de lignes de cache contenu dans chaque ensemble est:
 Travaux Pratiques 3. IFT 1002/IFT 1005. Structure Interne des Ordinateurs. Département d'informatique et de génie logiciel. Université Laval. Hiver 2012. Prof : Bui Minh Duc. Tous les exercices sont indépendants.
Travaux Pratiques 3. IFT 1002/IFT 1005. Structure Interne des Ordinateurs. Département d'informatique et de génie logiciel. Université Laval. Hiver 2012. Prof : Bui Minh Duc. Tous les exercices sont indépendants.
Systèmes et traitement parallèles
 Systèmes et traitement parallèles Mohsine Eleuldj Département Génie Informatique, EMI eleuldj@emi.ac.ma 1 Système et traitement parallèle Objectif Etude des architectures parallèles Programmation des applications
Systèmes et traitement parallèles Mohsine Eleuldj Département Génie Informatique, EMI eleuldj@emi.ac.ma 1 Système et traitement parallèle Objectif Etude des architectures parallèles Programmation des applications
Outil d aide au choix Serveurs Lot 4 Marché Groupement de Recherche
 Outil d aide au choix Serveurs Lot 4 Marché Groupement de Recherche Serveurs DELL PowerEdge Tour Rack standard R310 T110II Rack de calcul Lames R815 M610 R410 R910 M620 R415 R510 T620 R620 R720/R720xd
Outil d aide au choix Serveurs Lot 4 Marché Groupement de Recherche Serveurs DELL PowerEdge Tour Rack standard R310 T110II Rack de calcul Lames R815 M610 R410 R910 M620 R415 R510 T620 R620 R720/R720xd
Contrôle Non Destructif : Implantation d'algorithmes sur GPU et multi-coeurs. Gilles Rougeron CEA/LIST Département Imagerie Simulation et Contrôle
 Contrôle Non Destructif : Implantation d'algorithmes sur GPU et multi-coeurs Gilles Rougeron CEA/LIST Département Imagerie Simulation et Contrôle 1 CEA R & D for Nuclear Energy 5 000 people Nuclear systems
Contrôle Non Destructif : Implantation d'algorithmes sur GPU et multi-coeurs Gilles Rougeron CEA/LIST Département Imagerie Simulation et Contrôle 1 CEA R & D for Nuclear Energy 5 000 people Nuclear systems
DE L ALGORITHME AU PROGRAMME INTRO AU LANGAGE C 51
 DE L ALGORITHME AU PROGRAMME INTRO AU LANGAGE C 51 PLAN DU COURS Introduction au langage C Notions de compilation Variables, types, constantes, tableaux, opérateurs Entrées sorties de base Structures de
DE L ALGORITHME AU PROGRAMME INTRO AU LANGAGE C 51 PLAN DU COURS Introduction au langage C Notions de compilation Variables, types, constantes, tableaux, opérateurs Entrées sorties de base Structures de
Hiérarchie matériel dans le monde informatique. Architecture d ordinateur : introduction. Hiérarchie matériel dans le monde informatique
 Architecture d ordinateur : introduction Dimitri Galayko Introduction à l informatique, cours 1 partie 2 Septembre 2014 Association d interrupteurs: fonctions arithmétiques élémentaires Elément «NON» Elément
Architecture d ordinateur : introduction Dimitri Galayko Introduction à l informatique, cours 1 partie 2 Septembre 2014 Association d interrupteurs: fonctions arithmétiques élémentaires Elément «NON» Elément
Évaluation et implémentation des langages
 Évaluation et implémentation des langages Les langages de programmation et le processus de programmation Critères de conception et d évaluation des langages de programmation Les fondations de l implémentation
Évaluation et implémentation des langages Les langages de programmation et le processus de programmation Critères de conception et d évaluation des langages de programmation Les fondations de l implémentation
Chapitre V : La gestion de la mémoire. Hiérarchie de mémoires Objectifs Méthodes d'allocation Simulation de mémoire virtuelle Le mapping
 Chapitre V : La gestion de la mémoire Hiérarchie de mémoires Objectifs Méthodes d'allocation Simulation de mémoire virtuelle Le mapping Introduction Plusieurs dizaines de processus doivent se partager
Chapitre V : La gestion de la mémoire Hiérarchie de mémoires Objectifs Méthodes d'allocation Simulation de mémoire virtuelle Le mapping Introduction Plusieurs dizaines de processus doivent se partager
Logiciel MAXPRO NVR SOLUTION D ENREGISTREMENT VIDÉO RÉSEAU
 SOLUTION D ENREGISTREMENT VIDÉO RÉSEAU Le logiciel MAXPRO NVR d Honeywell est un système IP ouvert de surveillance flexible et évolutif. Grâce à la prise en charge des caméras haute définition (HD) d Honeywell
SOLUTION D ENREGISTREMENT VIDÉO RÉSEAU Le logiciel MAXPRO NVR d Honeywell est un système IP ouvert de surveillance flexible et évolutif. Grâce à la prise en charge des caméras haute définition (HD) d Honeywell
Métriques de performance pour les algorithmes et programmes parallèles
 Métriques de performance pour les algorithmes et programmes parallèles 11 18 nov. 2002 Cette section est basée tout d abord sur la référence suivante (manuel suggéré mais non obligatoire) : R. Miller and
Métriques de performance pour les algorithmes et programmes parallèles 11 18 nov. 2002 Cette section est basée tout d abord sur la référence suivante (manuel suggéré mais non obligatoire) : R. Miller and
Exécution des instructions machine
 Exécution des instructions machine Eduardo Sanchez EPFL Exemple: le processeur MIPS add a, b, c a = b + c type d'opération (mnémonique) destination du résultat lw a, addr opérandes sources a = mem[addr]
Exécution des instructions machine Eduardo Sanchez EPFL Exemple: le processeur MIPS add a, b, c a = b + c type d'opération (mnémonique) destination du résultat lw a, addr opérandes sources a = mem[addr]
*Offre limitée au stock disponible - Prix affichés basés sur une TVA française de 19.6%.
 ASUS X54L-SX021V - Intel Pentium Dual-Core B940 4 Go 320 Go 15.6" LED Graveur DVD Wi-Fi N Webcam Windows 7 Premium 64 bits (garantie constructeur 1 ans) 499 TTC Le meilleur d'asus à prix optimisé! Choisissez
ASUS X54L-SX021V - Intel Pentium Dual-Core B940 4 Go 320 Go 15.6" LED Graveur DVD Wi-Fi N Webcam Windows 7 Premium 64 bits (garantie constructeur 1 ans) 499 TTC Le meilleur d'asus à prix optimisé! Choisissez
Une dérivation du paradigme de réécriture de multiensembles pour l'architecture de processeur graphique GPU
 Une dérivation du paradigme de réécriture de multiensembles pour l'architecture de processeur graphique GPU Gabriel Antoine Louis Paillard Ce travail a eu le soutien de la CAPES, agence brésilienne pour
Une dérivation du paradigme de réécriture de multiensembles pour l'architecture de processeur graphique GPU Gabriel Antoine Louis Paillard Ce travail a eu le soutien de la CAPES, agence brésilienne pour
Rendu temps réel de mer et de nuages
 Rendu temps réel de mer et de nuages Linares Antonin, Boyer Julien 17 décembre 2008 1 Résumé Nous allons traiter dans ce document les différentes méthodes explorées afin de parvenir à un rendu en temps
Rendu temps réel de mer et de nuages Linares Antonin, Boyer Julien 17 décembre 2008 1 Résumé Nous allons traiter dans ce document les différentes méthodes explorées afin de parvenir à un rendu en temps
Communications performantes par passage de message entre machines virtuelles co-hébergées
 Communications performantes par passage de message entre machines virtuelles co-hébergées François Diakhaté1,2 1 CEA/DAM Île de France 2 INRIA Bordeaux Sud Ouest, équipe RUNTIME Renpar 2009 1 Plan Introduction
Communications performantes par passage de message entre machines virtuelles co-hébergées François Diakhaté1,2 1 CEA/DAM Île de France 2 INRIA Bordeaux Sud Ouest, équipe RUNTIME Renpar 2009 1 Plan Introduction
Comparatif entre Matrox RT.X2 et Adobe Premiere Pro CS3 (logiciel seul)
") Comparatif entre et Adobe Premiere Pro CS3 (logiciel seul) offre la puissance de montage en temps réel et les outils de productivité supplémentaires dont vous avez besoin pour tirer pleinement parti d'adobe
Comparatif entre et Adobe Premiere Pro CS3 (logiciel seul) offre la puissance de montage en temps réel et les outils de productivité supplémentaires dont vous avez besoin pour tirer pleinement parti d'adobe
Pré-requis installation
 Pré-requis installation Version 2.5 TELELOGOS - 3, Avenue du Bois l'abbé - Angers Technopole - 49070 Beaucouzé - France Tel. +33 (0)2 4 22 70 00 - Fax. +33 (0)2 4 22 70 22 Web. www.telelogos.com - Email.
Pré-requis installation Version 2.5 TELELOGOS - 3, Avenue du Bois l'abbé - Angers Technopole - 49070 Beaucouzé - France Tel. +33 (0)2 4 22 70 00 - Fax. +33 (0)2 4 22 70 22 Web. www.telelogos.com - Email.
03/04/2007. Tâche 1 Tâche 2 Tâche 3. Système Unix. Time sharing
 3/4/27 Programmation Avancée Multimédia Multithreading Benoît Piranda Équipe SISAR Université de Marne La Vallée Besoin Programmes à traitements simultanés Réseau Réseau Afficher une animation en temps
3/4/27 Programmation Avancée Multimédia Multithreading Benoît Piranda Équipe SISAR Université de Marne La Vallée Besoin Programmes à traitements simultanés Réseau Réseau Afficher une animation en temps
en version SAN ou NAS
 tout-en-un en version SAN ou NAS Quand avez-vous besoin de virtualisation? Les opportunités de mettre en place des solutions de virtualisation sont nombreuses, quelque soit la taille de l'entreprise. Parmi
tout-en-un en version SAN ou NAS Quand avez-vous besoin de virtualisation? Les opportunités de mettre en place des solutions de virtualisation sont nombreuses, quelque soit la taille de l'entreprise. Parmi
Matériel & Logiciels (Hardware & Software)
") CHAPITRE 2 HARDWARE & SOFTWARE P. 1 Chapitre 2 Matériel & Logiciels (Hardware & Software) 2.1 Matériel (Hardware) 2.1.1 Présentation de l'ordinateur Un ordinateur est un ensemble de circuits électronique
CHAPITRE 2 HARDWARE & SOFTWARE P. 1 Chapitre 2 Matériel & Logiciels (Hardware & Software) 2.1 Matériel (Hardware) 2.1.1 Présentation de l'ordinateur Un ordinateur est un ensemble de circuits électronique
Choisir le bon ordinateur. et la bonne imprimante en 2013. avec. Les prix bas, la confiance en plus
 Choisir le bon ordinateur et la bonne imprimante en 2013 avec Les prix bas, la confiance en plus Comment bien choisir son laptop et son imprimante en 2013? Tour d horizon des nouveautés et des critères
Choisir le bon ordinateur et la bonne imprimante en 2013 avec Les prix bas, la confiance en plus Comment bien choisir son laptop et son imprimante en 2013? Tour d horizon des nouveautés et des critères
Portable Dell Alienware M18X
 Portable Dell Alienware M18X La meilleure expérience de jeu mobile de l univers Prenez le dessus sur vos ennemis grâce aux cartes graphiques mobiles les plus puissantes d Alienware. Des graphismes époustouflants
Portable Dell Alienware M18X La meilleure expérience de jeu mobile de l univers Prenez le dessus sur vos ennemis grâce aux cartes graphiques mobiles les plus puissantes d Alienware. Des graphismes époustouflants
Architecture des Ordinateurs. Partie II:
 Architecture des Ordinateurs Partie II: Le port Floppy permet le raccordement du lecteur de disquette àla carte mère. Remarque: Le lecteur de disquette a disparu il y a plus de 6 ans, son port suivra.
Architecture des Ordinateurs Partie II: Le port Floppy permet le raccordement du lecteur de disquette àla carte mère. Remarque: Le lecteur de disquette a disparu il y a plus de 6 ans, son port suivra.
Dell Vostro 3350/3450/3550/3750
 Dell Vostro 3350/3450/3550/3750 Installation et caractéristiques À propos des avertissements AVERTISSEMENT-test: un AVERTISSEMENT indique un risque d'endommagement du matériel, de blessure corporelle ou
Dell Vostro 3350/3450/3550/3750 Installation et caractéristiques À propos des avertissements AVERTISSEMENT-test: un AVERTISSEMENT indique un risque d'endommagement du matériel, de blessure corporelle ou
Pré-requis installation
 Pré-requis installation Version 2. TELELOGOS -, Avenue du Bois l'abbé - Angers Technopole - 9070 Beaucouzé - France Tel. + (0)2 22 70 00 - Fax. + (0)2 22 70 22 Web. www.telelogos.com - Email. support@telelogos.com
Pré-requis installation Version 2. TELELOGOS -, Avenue du Bois l'abbé - Angers Technopole - 9070 Beaucouzé - France Tel. + (0)2 22 70 00 - Fax. + (0)2 22 70 22 Web. www.telelogos.com - Email. support@telelogos.com
Intel Corporation Nicolas Biguet Business Development Manager Intel France
 Les serveurs pour l Entreprise Intel Corporation Nicolas Biguet Business Development Manager Intel France 1 Les orientations stratégiques Clients Réseaux Serveurs Fournir les les éléments de de base des
Les serveurs pour l Entreprise Intel Corporation Nicolas Biguet Business Development Manager Intel France 1 Les orientations stratégiques Clients Réseaux Serveurs Fournir les les éléments de de base des
Ordinateur portable Latitude E5410
 Ordinateur portable Latitude E5410 Dell Latitude E5410 Doté de fonctionnalités avancées pour gagner du temps et de l'argent, l'ordinateur portable Dell TM Latitude TM E5410 offre aux utilisateurs finaux
Ordinateur portable Latitude E5410 Dell Latitude E5410 Doté de fonctionnalités avancées pour gagner du temps et de l'argent, l'ordinateur portable Dell TM Latitude TM E5410 offre aux utilisateurs finaux
Documentation d information technique spécifique Education. PGI Open Line PRO
 Documentation d information technique spécifique Education PGI Open Line PRO EBP Informatique SA Rue de Cutesson - ZA du Bel Air BP 95 78513 Rambouillet Cedex www.ebp.com Equipe Education : 01 34 94 83
Documentation d information technique spécifique Education PGI Open Line PRO EBP Informatique SA Rue de Cutesson - ZA du Bel Air BP 95 78513 Rambouillet Cedex www.ebp.com Equipe Education : 01 34 94 83
Architecture des calculateurs
 Formation en Calcul Scientifique - LEM2I Architecture des calculateurs Violaine Louvet 1 1 Institut Camille jordan - CNRS 12-13/09/2011 Introduction Décoder la relation entre l architecture et les applications
Formation en Calcul Scientifique - LEM2I Architecture des calculateurs Violaine Louvet 1 1 Institut Camille jordan - CNRS 12-13/09/2011 Introduction Décoder la relation entre l architecture et les applications
Linux embarqué: une alternative à Windows CE?
 embarqué: une alternative à Windows CE? : une alternative à Windows CE Présentation Mangrove Systems Distribution embarqué Perspective WinCe / Questions Mangrove systems Créé en 2001 Soutien Soutien Ministère
embarqué: une alternative à Windows CE? : une alternative à Windows CE Présentation Mangrove Systems Distribution embarqué Perspective WinCe / Questions Mangrove systems Créé en 2001 Soutien Soutien Ministère
Parallélisme et Répartition
 Parallélisme et Répartition Master Info Françoise Baude Université de Nice Sophia-Antipolis UFR Sciences Département Informatique baude@unice.fr web du cours : deptinfo.unice.fr/~baude Septembre 2009 Chapitre
Parallélisme et Répartition Master Info Françoise Baude Université de Nice Sophia-Antipolis UFR Sciences Département Informatique baude@unice.fr web du cours : deptinfo.unice.fr/~baude Septembre 2009 Chapitre
CH.3 SYSTÈMES D'EXPLOITATION
 CH.3 SYSTÈMES D'EXPLOITATION 3.1 Un historique 3.2 Une vue générale 3.3 Les principaux aspects Info S4 ch3 1 3.1 Un historique Quatre générations. Préhistoire 1944 1950 ENIAC (1944) militaire : 20000 tubes,
CH.3 SYSTÈMES D'EXPLOITATION 3.1 Un historique 3.2 Une vue générale 3.3 Les principaux aspects Info S4 ch3 1 3.1 Un historique Quatre générations. Préhistoire 1944 1950 ENIAC (1944) militaire : 20000 tubes,
TVTools Cloud Edition
 NOS PACKS TVTOOLS CLOUD ÉDITION CONDITIONS TARIFAIRES TVTools Cloud Edition AU 1 ER NOVEMBRE 2014 Fourniture d un Pack TVTools Cloud Edition pour intégration dans un environnement informatique : Accès
NOS PACKS TVTOOLS CLOUD ÉDITION CONDITIONS TARIFAIRES TVTools Cloud Edition AU 1 ER NOVEMBRE 2014 Fourniture d un Pack TVTools Cloud Edition pour intégration dans un environnement informatique : Accès
Tests de performance du matériel
 3 Tests de performance du matériel Après toute la théorie du dernier chapitre, vous vous demandez certainement quelles sont les performances réelles de votre propre système. En fait, il y a plusieurs raisons
3 Tests de performance du matériel Après toute la théorie du dernier chapitre, vous vous demandez certainement quelles sont les performances réelles de votre propre système. En fait, il y a plusieurs raisons
Vers du matériel libre
 Février 2011 La liberté du logiciel n est qu une partie du problème. Winmodems Modem traditionnel Bon fonctionnement Plus cher Electronique propriétaire Blob sur DSP intégré au modem Bien reçu par les
Février 2011 La liberté du logiciel n est qu une partie du problème. Winmodems Modem traditionnel Bon fonctionnement Plus cher Electronique propriétaire Blob sur DSP intégré au modem Bien reçu par les
Institut Supérieure Aux Etudes Technologiques De Nabeul. Département Informatique
 Institut Supérieure Aux Etudes Technologiques De Nabeul Département Informatique Support de Programmation Java Préparé par Mlle Imene Sghaier 2006-2007 Chapitre 1 Introduction au langage de programmation
Institut Supérieure Aux Etudes Technologiques De Nabeul Département Informatique Support de Programmation Java Préparé par Mlle Imene Sghaier 2006-2007 Chapitre 1 Introduction au langage de programmation
TPs Architecture des ordinateurs DUT Informatique - M4104c SUJETS. R. Raffin Aix-Marseille Université romain.raffin-at-univ-amu.fr
 TPs Architecture des ordinateurs DUT Informatique - M4104c SUJETS R. Raffin Aix-Marseille Université romain.raffin-at-univ-amu.fr 2015 Table des matières 1 TP 1 : prise en main 2 1.1 Introduction.......................................................
TPs Architecture des ordinateurs DUT Informatique - M4104c SUJETS R. Raffin Aix-Marseille Université romain.raffin-at-univ-amu.fr 2015 Table des matières 1 TP 1 : prise en main 2 1.1 Introduction.......................................................
vbladecenter S! tout-en-un en version SAN ou NAS
 vbladecenter S! tout-en-un en version SAN ou NAS Quand avez-vous besoin de virtualisation? Les opportunités de mettre en place des solutions de virtualisation sont nombreuses, quelque soit la taille de
vbladecenter S! tout-en-un en version SAN ou NAS Quand avez-vous besoin de virtualisation? Les opportunités de mettre en place des solutions de virtualisation sont nombreuses, quelque soit la taille de
1 Architecture du cœur ARM Cortex M3. Le cœur ARM Cortex M3 sera présenté en classe à partir des éléments suivants :
 GIF-3002 SMI et Architecture du microprocesseur Ce cours discute de l impact du design du microprocesseur sur le système entier. Il présente d abord l architecture du cœur ARM Cortex M3. Ensuite, le cours
GIF-3002 SMI et Architecture du microprocesseur Ce cours discute de l impact du design du microprocesseur sur le système entier. Il présente d abord l architecture du cœur ARM Cortex M3. Ensuite, le cours
Poste de travail d enregistreur vidéo en réseau
 Poste de travail d enregistreur vidéo en réseau Les solutions de surveillance de bout en bout d Avigilon fournissent un degré de détail d image qu aucun autre système ne peut atteindre. Le logiciel Avigilon
Poste de travail d enregistreur vidéo en réseau Les solutions de surveillance de bout en bout d Avigilon fournissent un degré de détail d image qu aucun autre système ne peut atteindre. Le logiciel Avigilon
Tout savoir sur le matériel informatique
 Tout savoir sur le matériel informatique Thème de l exposé : Les Processeurs Date : 05 Novembre 2010 Orateurs : Hugo VIAL-JAIME Jérémy RAMBAUD Sommaire : 1. Introduction... 3 2. Historique... 4 3. Relation
Tout savoir sur le matériel informatique Thème de l exposé : Les Processeurs Date : 05 Novembre 2010 Orateurs : Hugo VIAL-JAIME Jérémy RAMBAUD Sommaire : 1. Introduction... 3 2. Historique... 4 3. Relation
Quantification d incertitude et Tendances en HPC
 Quantification d incertitude et Tendances en HPC Laurence Viry E cole de Physique des Houches 7 Mai 2014 Laurence Viry Tendances en HPC 7 Mai 2014 1 / 47 Contents 1 Mode lisation, simulation et quantification
Quantification d incertitude et Tendances en HPC Laurence Viry E cole de Physique des Houches 7 Mai 2014 Laurence Viry Tendances en HPC 7 Mai 2014 1 / 47 Contents 1 Mode lisation, simulation et quantification
Spécifications détaillées
 Hewlett Packard HP ProLiant ML110 G5 Serveur micro tour 4U 1 voie 1 x Xeon E3110 / 3 GHz RAM 1 Go Disque dur 1 x 250 Go DVD RW Gigabit Ethernet Moniteur : aucun(e) Le serveur HP ProLiant ML110 G5 offre
Hewlett Packard HP ProLiant ML110 G5 Serveur micro tour 4U 1 voie 1 x Xeon E3110 / 3 GHz RAM 1 Go Disque dur 1 x 250 Go DVD RW Gigabit Ethernet Moniteur : aucun(e) Le serveur HP ProLiant ML110 G5 offre
Le Programme SYGADE SYGADE 5.2. Besoins en équipement, logiciels et formation. UNCTAD/GID/DMFAS/Misc.6/Rev.7
 CONFÉRENCE DES NATIONS UNIES SUR LE COMMERCE ET LE DÉVELOPPEMENT UNITED NATIONS CONFERENCE ON TRADE AND DEVELOPMENT Le Programme SYGADE SYGADE 5.2 Besoins en équipement, logiciels et formation UNCTAD/GID/DMFAS/Misc.6/Rev.7
CONFÉRENCE DES NATIONS UNIES SUR LE COMMERCE ET LE DÉVELOPPEMENT UNITED NATIONS CONFERENCE ON TRADE AND DEVELOPMENT Le Programme SYGADE SYGADE 5.2 Besoins en équipement, logiciels et formation UNCTAD/GID/DMFAS/Misc.6/Rev.7
Techniques de stockage. Techniques de stockage, P. Rigaux p.1/43
 Techniques de stockage Techniques de stockage, P. Rigaux p.1/43 Techniques de stockage Contenu de ce cours : 1. Stockage de données. Supports, fonctionnement d un disque, technologie RAID 2. Organisation
Techniques de stockage Techniques de stockage, P. Rigaux p.1/43 Techniques de stockage Contenu de ce cours : 1. Stockage de données. Supports, fonctionnement d un disque, technologie RAID 2. Organisation
INITIATION AU LANGAGE C SUR PIC DE MICROSHIP
 COURS PROGRAMMATION INITIATION AU LANGAGE C SUR MICROCONTROLEUR PIC page 1 / 7 INITIATION AU LANGAGE C SUR PIC DE MICROSHIP I. Historique du langage C 1972 : naissance du C dans les laboratoires BELL par
COURS PROGRAMMATION INITIATION AU LANGAGE C SUR MICROCONTROLEUR PIC page 1 / 7 INITIATION AU LANGAGE C SUR PIC DE MICROSHIP I. Historique du langage C 1972 : naissance du C dans les laboratoires BELL par
Choix d'un serveur. Choix 1 : HP ProLiant DL380 G7 Base - Xeon E5649 2.53 GHz
 Choix d'un serveur Vous êtes responsable informatique d'une entreprise. Vous devez faire un choix pour l'achat d'un nouveau serveur. Votre prestataire informatique vous propose les choix ci-dessous Vous
Choix d'un serveur Vous êtes responsable informatique d'une entreprise. Vous devez faire un choix pour l'achat d'un nouveau serveur. Votre prestataire informatique vous propose les choix ci-dessous Vous
T E C S O F T 775,00 TTC 645,83 HT
 Chipset INTEL HM86 Processeur INTEL PENTIUM 3550 2,2 Ghz 4 Go mémoire DDRIII Ecran LED 15.6 WIDE 1366*768 Carte Vidéo intégré INTEL HD4600 2 ports USB 3.0, 2 port USB 2.0 Poids 2,2 Kg Dimensions 374 X
Chipset INTEL HM86 Processeur INTEL PENTIUM 3550 2,2 Ghz 4 Go mémoire DDRIII Ecran LED 15.6 WIDE 1366*768 Carte Vidéo intégré INTEL HD4600 2 ports USB 3.0, 2 port USB 2.0 Poids 2,2 Kg Dimensions 374 X
nom : Collège Ste Clotilde
 UNE CONFIGURATION INFORMATIQUE Objectif : Identifier les éléments principaux d une configuration L ordinateur enregistre des données qu il traite pour produire un résultat Sifflements 20 Notice 12 attache
UNE CONFIGURATION INFORMATIQUE Objectif : Identifier les éléments principaux d une configuration L ordinateur enregistre des données qu il traite pour produire un résultat Sifflements 20 Notice 12 attache
. Plan du cours. . Architecture: Fermi (2010-12), Kepler (12-?)
, Kepler (12-?)") Plan du cours Vision mate riel: architecture cartes graphiques NVIDIA INF 560 Calcul Paralle le et Distribue Cours 3 Vision logiciel: l abstraction logique de l architecture propose e par le langage CUDA
Plan du cours Vision mate riel: architecture cartes graphiques NVIDIA INF 560 Calcul Paralle le et Distribue Cours 3 Vision logiciel: l abstraction logique de l architecture propose e par le langage CUDA
Pré-requis installation
 Pré-requis installation Version 3.5.0 TELELOGOS - 3, Avenue du Bois l'abbé - Angers Technopole - 49070 Beaucouzé - France Tel. +33 (0)2 4 22 70 00 - Fax. +33 (0)2 4 22 70 22 Web. www.telelogos.com - Email.
Pré-requis installation Version 3.5.0 TELELOGOS - 3, Avenue du Bois l'abbé - Angers Technopole - 49070 Beaucouzé - France Tel. +33 (0)2 4 22 70 00 - Fax. +33 (0)2 4 22 70 22 Web. www.telelogos.com - Email.
Développement mobile MIDP 2.0 Mobile 3D Graphics API (M3G) JSR 184. Frédéric BERTIN fbertin@neotilus.com
 JSR 184. Frédéric BERTIN fbertin@neotilus.com") Développement mobile MIDP 2.0 Mobile 3D Graphics API (M3G) JSR 184 Frédéric BERTIN fbertin@neotilus.com Présentaion : Mobile 3D Graphics API JSR 184 M3G :présentation Package optionnel de l api J2ME. Prend
Développement mobile MIDP 2.0 Mobile 3D Graphics API (M3G) JSR 184 Frédéric BERTIN fbertin@neotilus.com Présentaion : Mobile 3D Graphics API JSR 184 M3G :présentation Package optionnel de l api J2ME. Prend
Argument-fetching dataflow machine de G.R. Gao et J.B. Dennis (McGill, 1988) = machine dataflow sans flux de données
 = machine dataflow sans flux de données") EARTH et Threaded-C: Éléments clés du manuel de références de Threaded-C Bref historique de EARTH et Threaded-C Ancêtres de l architecture EARTH: Slide 1 Machine à flux de données statique de J.B. Dennis
EARTH et Threaded-C: Éléments clés du manuel de références de Threaded-C Bref historique de EARTH et Threaded-C Ancêtres de l architecture EARTH: Slide 1 Machine à flux de données statique de J.B. Dennis
Le programme détaillé. Salle A07 Salle A06 Salle A04. Initiation à DirectX. Création de Mods Minecraft
 Le programme détaillé 14h30 Salle A07 Salle A06 Salle A04 D-Wod : Simulation de cheveux Initiation à DirectX Bruno Gaumétou Malek Bengougam http://www.d-wod.com/ 16h00 Wassa : Reconnaissance Faciale Création
Le programme détaillé 14h30 Salle A07 Salle A06 Salle A04 D-Wod : Simulation de cheveux Initiation à DirectX Bruno Gaumétou Malek Bengougam http://www.d-wod.com/ 16h00 Wassa : Reconnaissance Faciale Création
Présentation du module Base de données spatio-temporelles
 Présentation du module Base de données spatio-temporelles S. Lèbre slebre@unistra.fr Université de Strasbourg, département d informatique. Partie 1 : Notion de bases de données (12,5h ) Enjeux et principes
Présentation du module Base de données spatio-temporelles S. Lèbre slebre@unistra.fr Université de Strasbourg, département d informatique. Partie 1 : Notion de bases de données (12,5h ) Enjeux et principes
Introduction au calcul parallèle avec OpenCL
 Introduction au calcul parallèle avec OpenCL Julien Dehos Séminaire du 05/01/2012 Sommaire Introduction Le calculateur du CGR/LISIC/LMPA Généralités sur OpenCL Modèles Programmation Optimisation Conclusion
Introduction au calcul parallèle avec OpenCL Julien Dehos Séminaire du 05/01/2012 Sommaire Introduction Le calculateur du CGR/LISIC/LMPA Généralités sur OpenCL Modèles Programmation Optimisation Conclusion
Journée Utiliateurs 2015. Nouvelles du Pôle ID (Informatique) Pierre Neyron, LIG/CNRS
 Pierre Neyron, LIG/CNRS") Journée Utiliateurs 2015 Nouvelles du Pôle ID (Informatique) Pierre Neyron, LIG/CNRS 1 Pôle ID, Grid'5000 Ciment Une proximité des platesformes Autres sites G5K Grenoble + CIMENT Pôle ID = «Digitalis»
Journée Utiliateurs 2015 Nouvelles du Pôle ID (Informatique) Pierre Neyron, LIG/CNRS 1 Pôle ID, Grid'5000 Ciment Une proximité des platesformes Autres sites G5K Grenoble + CIMENT Pôle ID = «Digitalis»
Potentiels de la technologie FPGA dans la conception des systèmes. Avantages des FPGAs pour la conception de systèmes optimisés
 Potentiels de la technologie FPGA dans la conception des systèmes Avantages des FPGAs pour la conception de systèmes optimisés Gérard FLORENCE Lotfi Guedria Agenda 1. Le CETIC en quelques mots 2. Générateur
Potentiels de la technologie FPGA dans la conception des systèmes Avantages des FPGAs pour la conception de systèmes optimisés Gérard FLORENCE Lotfi Guedria Agenda 1. Le CETIC en quelques mots 2. Générateur
NVR Fusion IV. Pour quels marchés? Caractéristiques Matériel. Logiciel
 Le NVR Fusion IV est idéal pour les systèmes d enregistrement et de gestion de vidéosurveillance sur IP évolutifs. Un seul NVR Fusion IV permet la gestion en simultanée de l enregistrement, de la recherche
Le NVR Fusion IV est idéal pour les systèmes d enregistrement et de gestion de vidéosurveillance sur IP évolutifs. Un seul NVR Fusion IV permet la gestion en simultanée de l enregistrement, de la recherche
Rapport de stage Master 2
 Rapport de stage Master 2 Informatique Haute Performance et Simulation, 2 ème année Ecole Centrale Paris Accélération des méthodes statistiques sur GPU Auteur : CHAI Anchen. Responsables: Joel Falcou et
Rapport de stage Master 2 Informatique Haute Performance et Simulation, 2 ème année Ecole Centrale Paris Accélération des méthodes statistiques sur GPU Auteur : CHAI Anchen. Responsables: Joel Falcou et
GPGPU. Cours de MII 2
 GPGPU Cours de MII 2 1 GPGPU Objectif du cours : Comprendre les architectures GPU Comprendre la programmation parallèle sur GPU Maîtriser la programmation Cuda Contenu : 1 ou 2 cours magistraux 2 ou 3
GPGPU Cours de MII 2 1 GPGPU Objectif du cours : Comprendre les architectures GPU Comprendre la programmation parallèle sur GPU Maîtriser la programmation Cuda Contenu : 1 ou 2 cours magistraux 2 ou 3
Retour d expérience, portage de code Promes dans le cadre de l appel à projets CAPS-GENCI
 , portage de code Promes dans le cadre de l appel à projets CAPS-GENCI PROMES (UPR 8521 CNRS) Université de Perpignan France 29 juin 2011 1 Contexte 2 3 4 Sommaire Contexte 1 Contexte 2 3 4 Laboratoire
, portage de code Promes dans le cadre de l appel à projets CAPS-GENCI PROMES (UPR 8521 CNRS) Université de Perpignan France 29 juin 2011 1 Contexte 2 3 4 Sommaire Contexte 1 Contexte 2 3 4 Laboratoire
victor Logiciel de gestion pour une sécurité unifiée
 victor Logiciel de gestion pour une sécurité unifiée victor unifie la sécurité, la surveillance et la gestion des événements. À partir d une interface unique, vous pouvez gérer des données vidéo en direct
victor Logiciel de gestion pour une sécurité unifiée victor unifie la sécurité, la surveillance et la gestion des événements. À partir d une interface unique, vous pouvez gérer des données vidéo en direct
IN SYSTEM. Préconisations techniques pour Sage 100 Windows, MAC/OS, et pour Sage 100 pour SQL Server V16. Objectif :
 IN SYSTEM Préconisations techniques pour Sage 100 Windows, MAC/OS, et pour Sage 100 pour SQL V16 Objectif : En synthèse des manuels de référence de Sage Ligne 100, ce document vous présente les préconisations,
IN SYSTEM Préconisations techniques pour Sage 100 Windows, MAC/OS, et pour Sage 100 pour SQL V16 Objectif : En synthèse des manuels de référence de Sage Ligne 100, ce document vous présente les préconisations,
Université du Québec à Chicoutimi. Département d informatique et de mathématique. Plan de cours. Titre : Élément de programmation.
 Université du Québec à Chicoutimi Département d informatique et de mathématique Plan de cours Titre : Élément de programmation Sigle : 8inf 119 Session : Automne 2001 Professeur : Patrice Guérin Local
Université du Québec à Chicoutimi Département d informatique et de mathématique Plan de cours Titre : Élément de programmation Sigle : 8inf 119 Session : Automne 2001 Professeur : Patrice Guérin Local
FICHE PRODUIT 360 SPEECHMAGIC SDK
 Development FICHE PRODUIT 360 SPEECHMAGIC SDK PRINCIPAUX AVANTAGES Réduction du temps de traitement des comptes rendus Réduction des frais de transcription Amélioration des soins au patient grâce à un
Development FICHE PRODUIT 360 SPEECHMAGIC SDK PRINCIPAUX AVANTAGES Réduction du temps de traitement des comptes rendus Réduction des frais de transcription Amélioration des soins au patient grâce à un
á Surveillance en temps réel á Contrôle PTZ á Enregistrement
 &DPpUDV5pVHDX /RJLFLHOVG $GPLQLVWUDWLRQ *XLGHG XWLOLVDWLRQUDSLGH ,)RQFWLRQQDOLWpV $)RQFWLRQQDOLWpVGH%DVH á Surveillance en temps réel á Contrôle PTZ á Enregistrement %)RQFWLRQQDOLWpVVSpFLDOHV á Surveillance
&DPpUDV5pVHDX /RJLFLHOVG $GPLQLVWUDWLRQ *XLGHG XWLOLVDWLRQUDSLGH ,)RQFWLRQQDOLWpV $)RQFWLRQQDOLWpVGH%DVH á Surveillance en temps réel á Contrôle PTZ á Enregistrement %)RQFWLRQQDOLWpVVSpFLDOHV á Surveillance
Configuration système requise pour les grandes et moyennes entreprises
 Configuration système requise pour les grandes et moyennes entreprises Trend Micro Incorporated se réserve le droit de modifier sans préavis ce document et les produits décrits dans ce document. Avant
Configuration système requise pour les grandes et moyennes entreprises Trend Micro Incorporated se réserve le droit de modifier sans préavis ce document et les produits décrits dans ce document. Avant
Gestion de scène pour les moteurs 3D
 Gestion de scène pour les moteurs 3D Mémoire de recherche Nicolas Baillard Promotion : M2IRT 2009 Option : Ingiénerie des jeux vidéo (IJV) juillet 2009 ITIN 10, avenue de l Entreprise Parc Saint-Christophe
Gestion de scène pour les moteurs 3D Mémoire de recherche Nicolas Baillard Promotion : M2IRT 2009 Option : Ingiénerie des jeux vidéo (IJV) juillet 2009 ITIN 10, avenue de l Entreprise Parc Saint-Christophe
LA RECONNAISSANCE VOCALE INTEGREE
 Fiche produit LA RECONNAISSANCE VOCALE INTEGREE 360 SpeechMagic SDK Capturer l information médicale grâce à la reconnaissance vocale DÉFI : Comment optimiser la création des comptes rendus et la capture
Fiche produit LA RECONNAISSANCE VOCALE INTEGREE 360 SpeechMagic SDK Capturer l information médicale grâce à la reconnaissance vocale DÉFI : Comment optimiser la création des comptes rendus et la capture
Les tablettes. Présentation tablettes Descriptif Fournisseurs Caractéristiques Comparatifs Conseils Perspectives Démonstration
 Les Tablettes Les tablettes Présentation tablettes Descriptif Fournisseurs Caractéristiques Comparatifs Conseils Perspectives Démonstration Les tablettes Description: Appareil mobile positionné entre smartphone
Les Tablettes Les tablettes Présentation tablettes Descriptif Fournisseurs Caractéristiques Comparatifs Conseils Perspectives Démonstration Les tablettes Description: Appareil mobile positionné entre smartphone
Rapport 2014 et demande pour 2015. Portage de Méso-NH sur Machines Massivement Parallèles du GENCI Projet 2015 : GENCI GEN1605 & CALMIP-P0121
 Rapport 2014 et demande pour 2015 Portage de Méso-NH sur Machines Massivement Parallèles du GENCI Projet 2015 : GENCI GEN1605 & CALMIP-P0121 Rappel sur Méso-NH : Modélisation à moyenne échelle de l atmosphère
Rapport 2014 et demande pour 2015 Portage de Méso-NH sur Machines Massivement Parallèles du GENCI Projet 2015 : GENCI GEN1605 & CALMIP-P0121 Rappel sur Méso-NH : Modélisation à moyenne échelle de l atmosphère
Technologie de déduplication de Barracuda Backup. Livre blanc
 Technologie de déduplication de Barracuda Backup Livre blanc Résumé Les technologies de protection des données jouent un rôle essentiel au sein des entreprises et ce, quelle que soit leur taille. Toutefois,
Technologie de déduplication de Barracuda Backup Livre blanc Résumé Les technologies de protection des données jouent un rôle essentiel au sein des entreprises et ce, quelle que soit leur taille. Toutefois,
Séminaire RGE REIMS 17 février 2011
 Séminaire RGE REIMS 17 février 2011 ADACSYS Présentation des FPGA Agenda Spécificité et différences par rapport aux autres accélérateurs Nos atouts Applications Approche innovante Document confidentiel
Séminaire RGE REIMS 17 février 2011 ADACSYS Présentation des FPGA Agenda Spécificité et différences par rapport aux autres accélérateurs Nos atouts Applications Approche innovante Document confidentiel
Info0804. Cours 6. Optimisation combinatoire : Applications et compléments
 Recherche Opérationnelle Optimisation combinatoire : Applications et compléments Pierre Delisle Université de Reims Champagne-Ardenne Département de Mathématiques et Informatique 17 février 2014 Plan de
Recherche Opérationnelle Optimisation combinatoire : Applications et compléments Pierre Delisle Université de Reims Champagne-Ardenne Département de Mathématiques et Informatique 17 février 2014 Plan de
Initiation. àl algorithmique et à la programmation. en C
 Initiation àl algorithmique et à la programmation en C Initiation àl algorithmique et à la programmation en C Cours avec 129 exercices corrigés Illustration de couverture : alwyncooper - istock.com Dunod,
Initiation àl algorithmique et à la programmation en C Initiation àl algorithmique et à la programmation en C Cours avec 129 exercices corrigés Illustration de couverture : alwyncooper - istock.com Dunod,
Leçon 1 : Les principaux composants d un ordinateur
 Chapitre 2 Architecture d un ordinateur Leçon 1 : Les principaux composants d un ordinateur Les objectifs : o Identifier les principaux composants d un micro-ordinateur. o Connaître les caractéristiques
Chapitre 2 Architecture d un ordinateur Leçon 1 : Les principaux composants d un ordinateur Les objectifs : o Identifier les principaux composants d un micro-ordinateur. o Connaître les caractéristiques
T. Gasc 1,2,3, F. De Vuyst 1, R. Motte 3, M. Peybernes 4, R. Poncet 5
 Modélisation de la performance et optimisation d un algorithme hydrodynamique de type Lagrange-Projection sur processeurs multi-cœurs T. Gasc 1,2,3, F. De Vuyst 1, R. Motte 3, M. Peybernes 4, R. Poncet
Modélisation de la performance et optimisation d un algorithme hydrodynamique de type Lagrange-Projection sur processeurs multi-cœurs T. Gasc 1,2,3, F. De Vuyst 1, R. Motte 3, M. Peybernes 4, R. Poncet
Fonctionnement et performance des processeurs
 Fonctionnement et performance des processeurs Eric Cariou Université de Pau et des Pays de l'adour Département Informatique Eric.Cariou@univ-pau.fr 1 Plan Fonctionnement des processeurs Unités de calcul
Fonctionnement et performance des processeurs Eric Cariou Université de Pau et des Pays de l'adour Département Informatique Eric.Cariou@univ-pau.fr 1 Plan Fonctionnement des processeurs Unités de calcul
On distingue deux grandes catégories de mémoires : mémoire centrale (appelée également mémoire interne)
") Mémoire - espace destiné a recevoir, conserver et restituer des informations à traiter - tout composant électronique capable de stocker temporairement des données On distingue deux grandes catégories de
Mémoire - espace destiné a recevoir, conserver et restituer des informations à traiter - tout composant électronique capable de stocker temporairement des données On distingue deux grandes catégories de
Informatique industrielle A7-19571 Systèmes temps-réel J.F.Peyre. Partie I : Introduction
 Informatique industrielle A7-19571 Systèmes temps-réel J.F.Peyre Partie I : Introduction Plan de la première partie Quelques définitions Caractéristiques communes des applications temps-réel Exemples d
Informatique industrielle A7-19571 Systèmes temps-réel J.F.Peyre Partie I : Introduction Plan de la première partie Quelques définitions Caractéristiques communes des applications temps-réel Exemples d
DUT. Informatique, orientation Imagerie Numérique. Domaine : Sciences, Technologies, Santé. Mention : Informatique
 DUT Informatique, orientation Imagerie Numérique Domaine : Sciences, Technologies, Santé Mention : Informatique Organisation : Institut Universitaire de Technologie Lieu de formation : Le Puy en Velay
DUT Informatique, orientation Imagerie Numérique Domaine : Sciences, Technologies, Santé Mention : Informatique Organisation : Institut Universitaire de Technologie Lieu de formation : Le Puy en Velay
INTERSYSTEMS CACHÉ COMME ALTERNATIVE AUX BASES DE DONNÉES RÉSIDENTES EN MÉMOIRE
 I N T E RS Y S T E M S INTERSYSTEMS CACHÉ COMME ALTERNATIVE AUX BASES DE DONNÉES RÉSIDENTES EN MÉMOIRE David Kaaret InterSystems Corporation INTERSySTEMS CAChé CoMME ALTERNATIvE AUx BASES de données RéSIdENTES
I N T E RS Y S T E M S INTERSYSTEMS CACHÉ COMME ALTERNATIVE AUX BASES DE DONNÉES RÉSIDENTES EN MÉMOIRE David Kaaret InterSystems Corporation INTERSySTEMS CAChé CoMME ALTERNATIvE AUx BASES de données RéSIdENTES
Configuration matérielle et logicielle requise et prérequis de formation pour le SYGADE 6
 Configuration matérielle et logicielle requise et prérequis de formation pour le SYGADE 6 DMFAS6/HardwareSoftware/V4 Octobre 2013 2 Configuration matérielle et logicielle requise et prérequis de formation
Configuration matérielle et logicielle requise et prérequis de formation pour le SYGADE 6 DMFAS6/HardwareSoftware/V4 Octobre 2013 2 Configuration matérielle et logicielle requise et prérequis de formation
Ne laissez pas le stockage cloud pénaliser votre retour sur investissement
 Ne laissez pas le stockage cloud pénaliser votre retour sur investissement Préparé par : George Crump, analyste senior Préparé le : 03/10/2012 L investissement qu une entreprise fait dans le domaine de
Ne laissez pas le stockage cloud pénaliser votre retour sur investissement Préparé par : George Crump, analyste senior Préparé le : 03/10/2012 L investissement qu une entreprise fait dans le domaine de
Certificat Informatique et internet Niveau 1 TD D1. Domaine 1 : Travailler dans un environnement numérique évolutif. 1. Généralités : Filière
 Certificat Informatique et internet Niveau 1 Filière TD D1 Domaine 1 : Travailler dans un environnement numérique évolutif Nom N étudiant 1. Généralités : 1.1. Un ordinateur utilise des logiciels (aussi
Certificat Informatique et internet Niveau 1 Filière TD D1 Domaine 1 : Travailler dans un environnement numérique évolutif Nom N étudiant 1. Généralités : 1.1. Un ordinateur utilise des logiciels (aussi
Génération de code binaire pour application multimedia : une approche au vol
 Génération de binaire pour application multimedia : une approche au vol http://hpbcg.org/ Henri-Pierre Charles Université de Versailles Saint-Quentin en Yvelines 3 Octobre 2009 Présentation Présentation
Génération de binaire pour application multimedia : une approche au vol http://hpbcg.org/ Henri-Pierre Charles Université de Versailles Saint-Quentin en Yvelines 3 Octobre 2009 Présentation Présentation
PC Check & Tuning 2010 Optimisez et accélérez rapidement et simplement les performances de votre PC!
 PC Check & Tuning 2010 Optimisez et accélérez rapidement et simplement les performances de votre PC! MAGIX PC Check & Tuning 2010 est la solution logicielle complète pour l'analyse, la maintenance et l'accélération
PC Check & Tuning 2010 Optimisez et accélérez rapidement et simplement les performances de votre PC! MAGIX PC Check & Tuning 2010 est la solution logicielle complète pour l'analyse, la maintenance et l'accélération
Informatique Générale
 Informatique Générale Guillaume Hutzler Laboratoire IBISC (Informatique Biologie Intégrative et Systèmes Complexes) guillaume.hutzler@ibisc.univ-evry.fr Cours Dokeos 625 http://www.ens.univ-evry.fr/modx/dokeos.html
Informatique Générale Guillaume Hutzler Laboratoire IBISC (Informatique Biologie Intégrative et Systèmes Complexes) guillaume.hutzler@ibisc.univ-evry.fr Cours Dokeos 625 http://www.ens.univ-evry.fr/modx/dokeos.html
La programmation linéaire : une introduction. Qu est-ce qu un programme linéaire? Terminologie. Écriture mathématique
 La programmation linéaire : une introduction Qu est-ce qu un programme linéaire? Qu est-ce qu un programme linéaire? Exemples : allocation de ressources problème de recouvrement Hypothèses de la programmation
La programmation linéaire : une introduction Qu est-ce qu un programme linéaire? Qu est-ce qu un programme linéaire? Exemples : allocation de ressources problème de recouvrement Hypothèses de la programmation
4. Utilisation d un SGBD : le langage SQL. 5. Normalisation
 Base de données S. Lèbre slebre@unistra.fr Université de Strasbourg, département d informatique. Présentation du module Contenu général Notion de bases de données Fondements / Conception Utilisation :
Base de données S. Lèbre slebre@unistra.fr Université de Strasbourg, département d informatique. Présentation du module Contenu général Notion de bases de données Fondements / Conception Utilisation :