Introduction à Hadoop & MapReduce
|
|
|
- Corentin Paquette
- il y a 10 ans
- Total affichages :
Transcription
1 Introduction à Hadoop & MapReduce Cours 2 Benjamin Renaut <[email protected]> MOOC / FUN

2 5 Hadoop: présentation

3 Apache Hadoop 5-1 Projet Open Source fondation Apache. Développé en Java; portable. Assure l'exécution de tâches map/reduce; fourni le framework, en Java, pour leur développement. Autres langages supportés par le biais d'utilitaires internes.

4 Historique /2004: publication par Google de deux whitepapers, le premier sur GFS (un système de fichier distribué) et le second sur le paradigme Map/Reduce pour le calcul distribué : développement de la première version du framework qui deviendra Hadoop par Doug Cutting (archive.org) : Doug Cutting (désormais chez Yahoo) développe une première version exploitable de Apache Hadoop pour l'amélioration de l'indexation du moteur de recherche. Encore primitif (au maximum quelques machines, etc.).
 développe une première version exploitable de Apache Hadoop pour l'amélioration de")
5 Historique : développement maintenant très abouti, Hadoop utilisé chez Yahoo dans plusieurs départements : Hadoop désormais utilisé par de nombreuses autres entreprises et des universités, et le cluster Yahoo comporte machines et des centaines de peta-octets d'espace de stockage. Le nom lui-même n'est pas un acronyme: il s'agit du nom d'un éléphant en peluche du fils de l'auteur originel (Doug Cuttin) de Hadoop.


6 Qui utilise Hadoop 5-4 et des milliers d'entreprises et universités à travers le monde.

7 Le Big Data 5-5 La multiplication des données, dans un volume toujours plus important, et leur traitement, les problématiques posées et toutes les nouvelles possibilités et usages qui en découlent sont couverts par l'expression «Big Data». Hadoop est au coeur de ces problématiques; c'est (de très loin) le logiciel/framework le plus utilisé pour y répondre.
 le logiciel/framework le")
8 Avantages et inconvénients 5-6 Hadoop est: Simple à utiliser et à déployer. Portable (clusters hétérogènes). Indéfiniment scalable. Très extensible et interconnectable avec d'autres solutions. Il a également des inconvénients: overhead supérieur à une solution propriétaire spécifique dédiée à un problème; encore expérimental et en développement...

9 Conclusion 5-7 Hadoop n'utilise aucun principe foncièrement nouveau; il offre en revanche une très forte simplicité et souplesse de déploiement inconnues jusqu'à présent pour l'exécution facile de tâches parallèles variées. Grâce à Hadoop, même des structures limitées en taille/ressources peuvent facilement avoir accès à de fortes capacités de calcul: déploiement à bas coût de clusters en interne ou location de temps d'exécution via les services de cloud computing.

10 1 HDFS

11 Présentation 1-1 HDFS: Hadoop Distributed File System. Système de fichiers distribué associé à Hadoop. C'est là qu'on stocke données d'entrée, de sortie, etc. Caractéristiques: Distribué Redondé Conscient des caractéristiques physiques de l'emplacement des serveurs (racks) pour l'optimisation.

12 Architecture 1-2 Repose sur deux serveurs: Le NameNode, unique sur le cluster. Stocke les informations relative aux noms de fichiers et à leurs caractéristiques de manière centralisée. Le DataNode, plusieurs par cluster. Stocke le contenu des fichiers eux-même, fragmentés en blocs (64KB par défaut). Inspiré de GFS, lui-même issu de recherches de Google. «The Google File System», 2003.
.")
13 Architecture 1-3 Repose sur deux serveurs: Le NameNode, unique sur le cluster. Stocke les informations relative aux noms de fichiers et à leurs caractéristiques de manière centralisée. Le DataNode, plusieurs par cluster. Stocke le contenu des fichiers eux-même, fragmentés en blocs (64KB par défaut). Inspiré de GFS, lui-même issu de recherches de Google. «The Google File System», 2003.
.")
14 Écriture d'un fichier 1-4 Pour écrire un fichier: Le client contacte le NameNode du cluster, indiquant la taille du fichier et son nom. Le NameNode confirme la demande et indique au client de fragmenter le fichier en blocs, et d'envoyer tel ou tel bloc à tel ou tel DataNode. Le client envoie les fragments aux DataNode. Les DataNodes assurent ensuite la réplication des blocs.


15 Écriture d'un fichier 1-5

16 Lecture d'un fichier 1-6 Pour lire un fichier: Le client contacte le NameNode du cluster, indiquant le fichier qu'il souhaite obtenir. Le NameNode lui indique la taille, en blocs, du fichier, et pour chaque bloc une liste de DataNodes susceptibles de lui fournir. Le client contacte les DataNodes en question pour obtenir les blocs, qu'il reconstitue sous la forme du fichier. En cas de DataNode inaccessible/autre erreur pour un bloc, le client contacte un DataNode alternatif de la liste pour l'obtenir.


17 Lecture d'un fichier 1-7

18 En pratique 1-8 On utilise la commande console hadoop, depuis n'importe quelle machine du cluster. Sa syntaxe reprend celle des commandes Unix habituelles: $ hadoop fs -put data.txt /input/files/data.txt $ hadoop fs -get /input/files/data.txt data.txt $ hadoop fs -mkdir /output $ hadoop fs -rm /input/files/data.txt etc

19 Remarques 1-9 L'ensemble du système de fichier virtuel apparaît comme un disque «unique»: on ne se soucie pas de l'emplacement réel des données. Tolérant aux pannes: blocs répliqués. Plusieurs drivers FUSE existent pour monter le système de fichier HDFS d'une manière plus «directe».

20 Inconvénients 1-10 NameNode unique: si problème sur le serveur en question, HDFS est indisponible. Compensé par des architectures serveur active/standby. Optimisé pour des lectures concurrentes; sensiblement moins performant pour des écritures concurrentes.

21 Alternatives 1-11 D'autres systèmes de fichiers distribués (Amazon S3, Cloudstore ). Ponts d'interconnexion directe avec des systèmes de bases de données relationnelles (Oracle, MySQL, PostGreSQL). Autres ponts d'interconnexion (HTTP, FTP).
22 2 Hadoop: architecture
23 Architecture 1-1 Repose sur deux serveurs: Le JobTracker, unique sur le cluster. Reçoit les tâches map/reduce à exécuter (sous la forme d'une archive Java.jar), organise leur exécution sur le cluster. Le TaskTracker, plusieurs par cluster. Exécute le travail map/reduce lui-même (sous la forme de tâches map et reduce ponctuelles avec les données d'entrée associées). Chacun des TaskTrackers constitue une unité de calcul du cluster.
24 Architecture 1-2 Le serveur JobTracker est en communication avec HDFS; il sait où sont les données d'entrée du programme map/reduce et où doivent être stockées les données de sortie. Il peut ainsi optimiser la distribution des tâches selon les données associées. Pour exécuter un programme map/reduce, on devra donc: Écrire les données d'entrée sur HDFS. Soumettre le programme au JobTracker du cluster. Récupérer les données de sortie depuis HDFS.
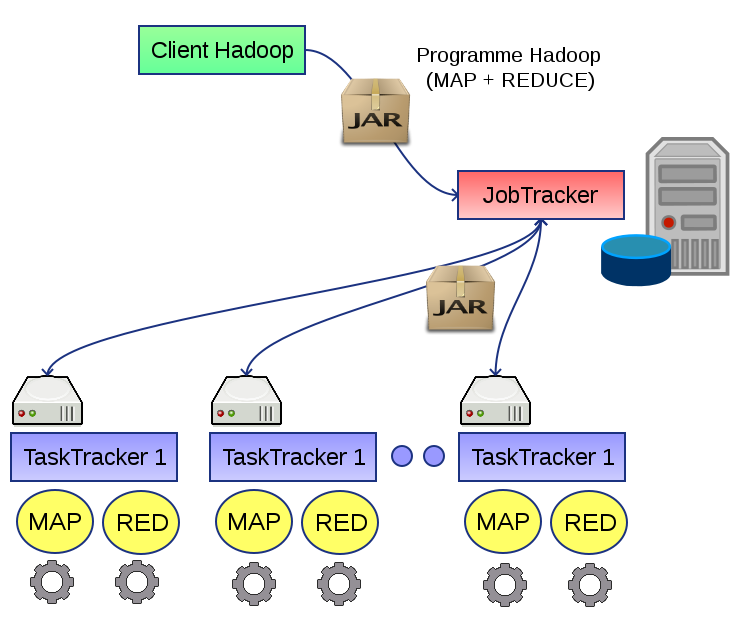
25 Architecture 1-3
26 Exécution d'une tâche 1-4 Tous les TaskTrackers signalent leur statut continuellement par le biais de paquets heartbeat. En cas de défaillance d'un TaskTracker (heartbeat manquant ou tâche échouée), le JobTracker avise en conséquence: redistribution de la tâche à un autre nœud, etc. Au cours de l'exécution d'une tâche, on peut obtenir des statistiques détaillées sur son évolution (étape actuelle, avancement, temps estimé avant completion, etc.), toujours par le biais du client console hadoop.
27 Autres considérations 1-5 Un seul JobTracker sur le serveur: point de défaillance unique. Là aussi, compensé par des architectures serveurs adaptées. Les deux serveurs «uniques» NameNode et JobTracker sont souvent actifs au sein d'une seule et même machine: le nœud maître du cluster. Tout changement dans la configuration du cluster est répliqué depuis le nœud maître sur l'intégralité du cluster.
28 Source: documentation Hadoop Architecture générale 1-6
29 3 Hadoop: installation
30 Objectif 3-1 Couvrir l'installation de Hadoop dans son environnement typique de déploiement (serveurs GNU/Linux ou similaires). Couvrir la configuration d'une instance Hadoop vous permettant d'expérimenter avec son utilisation et d'une manière plus générale avec map/reduce. Hadoop est capricieux sur environnement Windows; il est encore très expérimental => utiliser une machine virtuelle si nécessaire pour l'expérimentation.
31 Installation de Hadoop 3-2 Deux options: Par le biais de paquets adaptés à la distribution (.deb pour Debian/Ubuntu/etc.,.rpm pour Red Hat/Centos/etc.). Par le biais d'un tarball officiel de la fondation Apache: installation «manuelle».
32 Installation via paquet 3-3 Si disponible, utiliser les outils standards de la distribution: apt-get / yum. Alternativement, Cloudera, une entreprise phare de solutions Big Data / support et développement Hadoop, met à disposition sa propre distribution, CDH: h.html
33 Installation manuelle 3-4 Pré-requis: Distribution GNU/Linux moderne. Java (version Sun ou OpenJDK). On commence par créer le groupe et l'utilisateur qui seront spécifiques à Hadoop: # addgroup hadoop # adduser --ingroup hadoop hadoopuser # adduser hadoopuser
34 Installation manuelle 3-5 On télécharge ensuite Hadoop, en l'installant dans un répertoire au sein de /opt: # wget # tar vxzf hadoop-x.y.z.tar.gz -C /opt # cd /opt # ln -s /opt/hadoop-x.y.z /opt/hadoop # chown -R hadoopuser:hadoop /opt/hadoop* (remplacer l'url par un des miroirs et ajuster le numéro de version)
35 Installation manuelle 3-6 Il faut ensuite ajouter les différentes déclarations suivantes au sein du fichier.bashrc de l'utilisateur hadoopuser: # Variables Hadoop. Modifier l'emplacement du SDK java. export JAVA_HOME=/path/to/java/jdk export HADOOP_INSTALL=/opt/hadoop export PATH=$PATH:$HADOOP_INSTALL/bin export PATH=$PATH:$HADOOP_INSTALL/sbin export HADOOP_HOME=$HADOOP_INSTALL export HADOOP_MAPRED_HOME=$HADOOP_INSTALL export HADOOP_COMMON_HOME=$HADOOP_INSTALL export HADOOP_HDFS_HOME=$HADOOP_INSTALL export HADOOP_YARN_HOME=$HADOOP_INSTALL export HADOOP_CONF_DIR=$HADOOP_INSTALL/etc/hadoop
36 Installation manuelle 3-7 Enfin, il est aussi nécessaire d'indiquer l'emplacement du JDK Java dans le fichier /opt/hadoop/etc/hadoop/hadoopenv.sh. Localiser la ligne «export JAVA_HOME» au sein de ce fichier et l'éditer de telle sorte qu'elle pointe sur l'emplacement du JDK Java: export JAVA_HOME=/path/to/java/jdk Sauvegarder. Hadoop est désormais installé. Pour le confirmer, on peut par exemple utiliser la commande «hadoop version».
37 Installation manuelle Configuration 3-8 Il faut maintenant configurer Hadoop en mode nœud unique (pour l'expérimentation). Editer le fichier /opt/hadoop/etc/hadoop/core-site.xml, et insérer entre les deux balises <configuration> les lignes suivantes: <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property>
38 Installation manuelle Configuration 3-9 Editer maintenant le fichier /opt/hadoop/etc/hadoop/yarnsite.xml, et insérer entre les deux balises <configuration> les lignes suivantes: <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.shufflehandler</value> </property>
39 Installation manuelle Configuration 3-10 Renommer maintenant le fichier mapred-site.xml.template, au sein du même répertoire /opt/hadoop/etc/hadoop: $ cd /opt/hadoop/etc/hadoop $ mv mapred-site.xml.template mapred-site.xml Et ajouter les lignes suivantes entre les deux balises <configuration> au sein du fichier renommé mapredsite.xml: <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
40 Installation manuelle Configuration 3-11 Il faut maintenant créer les répertoires où seront stockés les données HDFS: # mkdir -p /opt/hdfs/namenode # mkdir -p /opt/hdfs/datanode # chown -R hadoopuser:hadoop /opt/hdfs Editer ensuite le fichier: /opt/hadoop/etc/hadoop/hdfs-site.xml
41 Installation manuelle Configuration 3-12 et insérer les lignes suivantes entre les deux balises <configuration>: <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/opt/hdfs/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/opt/hdfs/datanode</value> </property>
42 Installation manuelle Configuration 3-13 Il reste enfin à formater le système de fichiers HDFS local: $ hdfs namenode -format Hadoop est désormais correctement installé et configuré (un seul nœud). Le démarrer avec les commandes: $ start-dfs.sh $ start-yarn.sh Les commandes et codes présentés dans les sections successives du cours peuvent être testés sur une telle installation.
43 Machine virtuelle 3-14 Au besoin, une machine virtuelle associée au présent cours est par ailleurs disponible à l'adresse: (importable au sein de VirtualBox / VMWare).
44 4 Hadoop: utilisation (1)
45 API Java 4-1 Un programme Hadoop «natif» est développé en Java, en utilisant le SDK Hadoop, basé sur le mécanisme d'interfaces. Trois classes au minimum au sein d'un programme Hadoop: Classe Driver: Main du programme. Informe Hadoop des différents types et classes utilisés, des fichiers d'entrée/de sortie, etc. Classe Mapper: implémentation de la fonction MAP. Classe Reducer: implémentation de la fonction REDUCE.
46 API Java Classe Driver 4-2 La classe Driver doit au minimum: Passer à Hadoop des arguments «génériques» de la ligne de commande, par le biais d'un objet Configuration. Informer Hadoop des classes Driver, Mapper et Reducer par le biais d'un objet Job; et des types de clef et de valeur utilisés au sein du programme map/reduce par le biais du même objet. Spécifier à Hadoop l'emplacement des fichiers d'entrée sur HDFS; spécifier également l'emplacement où stocker les fichiers de sortie. Lancer l'exécution de la tâche map/reduce; recevoir son résultat.
47 En pratique 4-3 Création de l'objet Configuration: Configuration conf=new Configuration(); Passage à Hadoop de ses arguments «génériques»: String[] ourargs=new GenericOptionsParser(conf, args).getremainingargs(); On créé ensuite un nouvel objet Job: Job job=job.getinstance(conf, "Compteur de mots v1.0"); On indique à Hadoop les classes Driver, Mapper et Reducer: job.setjarbyclass(wcount.class); job.setmapperclass(wcountmap.class); job.setreducerclass(wcountreduce.class);
48 En pratique 4-4 On indique ensuite quels sont les types de clef/valeur utilisés au sein du programme: job.setoutputkeyclass(text.class); job.setoutputvalueclass(intwritable.class); il s'agit ici de types Hadoop. On spécifie l'emplacement des fichiers d'entrée/de sortie: FileInputFormat.addInputPath(job, new Path("/data/input.txt")); FileOutputFormat.setOutputPath(job, new Path("/data/results)); (ici via HDFS)
49 En pratique 4-5 Enfin, il reste à exécuter la tâche elle-même: if(job.waitforcompletion(true)) System.exit(0); System.exit(-1); Packages Java à importer depuis l'api Hadoop, dans cet exemple: org.apache.hadoop.mapreduce.job org.apache.hadoop.mapreduce.lib.input.fileinputformat org.apache.hadoop.mapreduce.lib.output.fileoutputformat org.apache.hadoop.conf.configuration org.apache.hadoop.util.genericoptionsparser org.apache.hadoop.fs.path org.apache.hadoop.io.text org.apache.hadoop.io.intwritable
50 Remarques 4-6 Il existe d'autres classes permettant de spécifier une source pour les données d'entrée/une destination pour les données de sortie; c'est la manière dont fonctionnent les alternatives à HDFS. On peut spécifier des types (clef;valeur) différents pour la sortie de l'opération MAP et la sortie de l'opération REDUCE (job.setmapoutputkeyclass / job.setmapoutputvalueclass). Il s'agit là du strict minimum pour une classe Driver; on aura généralement des implémentations plus complexes.
51 La classe Mapper 4-7 La classe Mapper est en charge de l'implémentation de la méthode map du programme map/reduce. Elle doit étendre la classe Hadoop org.apache.hadoop.mapreduce.mapper. Il s'agit d'une classe générique qui se paramétrise avec quatre types: Un type keyin: le type de clef d'entrée. Un type valuein: le type de valeur d'entrée. Un type keyout: le type de clef de sortie. Un type valueout: le type de valeur de sortie.
52 La classe Mapper 4-8 On déclarera une classe Mapper par exemple ainsi (ici pour l'exemple du compteur d'occurences de mots): public class WCountMap extends Mapper<Object, Text, Text, IntWritable> C'est la méthode map qu'on doit implémenter. Son prototype: protected void map(object key, Text value, Context context) throws IOException, InterruptedException Elle est appelée pour chaque couple (clef;valeur) d'entrée: respectivement les arguments key et value.
53 La classe Mapper 4-9 Le troisième argument, context, permet entre autres de renvoyer un couple (clef;valeur) en sortie de la méthode map. Par exemple: context.write("ciel", 1); il a d'autres usages possibles (passer un message à la classe Driver, etc.). Il faut évidemment que la clef et la valeur renvoyées ainsi correspondent aux types keyout et valueout de la classe Mapper.
54 La classe Mapper 4-10 Les différents packages Java à importer depuis l'api Hadoop: org.apache.hadoop.mapreduce.job org.apache.hadoop.io.text org.apache.hadoop.io.intwritable org.apache.hadoop.mapreduce.mapper
55 La classe Reducer 4-11 Similaire à la classe Mapper, elle implémente la méthode reduce du programme map/reduce. Elle doit étendre la classe Hadoop org.apache.hadoop.mapreduce.reducer. Il s'agit là aussi d'une classe générique qui se paramétrise avec les mêmes quatre types que pour la classe Mapper: keyin, valuein, keyout et valueout. A noter que contrairement à la classe Mapper, la classe Reducer recevra ses arguments sous la forme d'une clef unique et d'une liste de valeurs correspondant à cette clef.
56 La classe Reducer 4-12 On déclarera une classe Reducer par exemple ainsi: public class WCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> C'est la méthode reduce qu'on doit implémenter. Son prototype: public void reduce(text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException La fonction est appelée une fois par clef distincte. C'est l'argument key qui contient la clef distincte, et l'argument Iterable Java values qui contient la liste des valeurs correspondant à cette clef.
57 La classe Reducer 4-13 Là aussi, on peut renvoyer un couple (clef;valeur) en sortie de l'opération reduce par le biais de la méthode write de l'argument context: context.write("ciel", 5); Les différents packages Java à importer: org.apache.hadoop.mapreduce.job org.apache.hadoop.io.text org.apache.hadoop.io.intwritable import org.apache.hadoop.mapreduce.reducer;
58 Exemple Occurences de mots 4-14 // Le main du programme. public static void main(string[] args) throws Exception { // Créé un object de configuration Hadoop. Configuration conf=new Configuration(); // Permet à Hadoop de lire ses arguments génériques, // récupère les arguments restants dans ourargs. String[] ourargs=new GenericOptionsParser(conf, args).getremainingargs(); // Obtient un nouvel objet Job: une tâche Hadoop. On // fourni la configuration Hadoop ainsi qu'une description // textuelle de la tâche. Job job=job.getinstance(conf, "Compteur de mots v1.0");
59 Exemple Occurences de mots 4-15 // Défini les classes driver, map et reduce. job.setjarbyclass(wcount.class); job.setmapperclass(wcountmap.class); job.setreducerclass(wcountreduce.class); // Défini types clefs/valeurs de notre programme Hadoop. job.setoutputkeyclass(text.class); job.setoutputvalueclass(intwritable.class); // Défini les fichiers d'entrée du programme et le // répertoire des résultats. On se sert du premier et du // deuxième argument restants pour permettre à // l'utilisateur de les spécifier lors de l'exécution. FileInputFormat.addInputPath(job, new Path(ourArgs[0])); FileOutputFormat.setOutputPath(job, new Path(ourArgs[1]));
60 Exemple Occurences de mots 4-16 } // On lance la tâche Hadoop. Si elle s'est effectuée // correctement, on renvoie 0. Sinon, on renvoie -1. if(job.waitforcompletion(true)) System.exit(0); System.exit(-1);
61 Exemple Occurences de mots 4-17 private static final IntWritable ONE=new IntWritable(1); // La fonction MAP elle-même. protected void map(object offset, Text value, Context context) throws IOException, InterruptedException { // Un StringTokenizer va nous permettre de parcourir chacun des // mots de la ligne qui est passée à notre opération MAP. StringTokenizer tok=new StringTokenizer(value.toString(), " "); } while(tok.hasmoretokens()) { Text word=new Text(tok.nextToken()); // On renvoie notre couple (clef;valeur): le mot courant suivi // de la valeur 1 (définie dans la constante ONE). context.write(word, ONE); }
62 Exemple Occurences de mots 4-18 } // La fonction REDUCE elle-même. Les arguments: la clef key, un // Iterable de toutes les valeurs qui sont associées à la clef en // question, et le contexte Hadoop (un handle qui nous permet de // renvoyer le résultat à Hadoop). public void reduce(text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { // Pour parcourir toutes les valeurs associées à la clef fournie. Iterator<IntWritable> i=values.iterator(); int count=0; // Notre total pour le mot concerné. while(i.hasnext()) // Pour chaque valeur... count+=i.next().get(); //...on l'ajoute au total. // On renvoie le couple (clef;valeur) constitué de notre clef key // et du total, au format Text. context.write(key, new Text(count+" occurences.")); }
63 5 Hadoop: utilisation (2)
64 Exemple 2 Anagrammes / Driver 5-1 // Le main du programme. public static void main(string[] args) throws Exception { // Créé un object de configuration Hadoop. Configuration conf=new Configuration(); // Permet à Hadoop de lire ses arguments génériques, // récupère les arguments restants dans ourargs. String[] ourargs=new GenericOptionsParser(conf, args).getremainingargs(); // Obtient un nouvel objet Job: une tâche Hadoop. On // fourni la configuration Hadoop ainsi qu'une description // textuelle de la tâche. Job job=job.getinstance(conf, "Anagrammes v1.0");
65 Exemple 2 Anagrammes / Driver 5-2 job.setjarbyclass(anagrammes.class); job.setmapperclass(anagrammesmap.class); job.setreducerclass(anagrammesreduce.class); job.setoutputkeyclass(text.class); job.setoutputvalueclass(text.class); // Défini les fichiers d'entrée du programme et le // répertoire des résultats, depuis la ligne de commande. FileInputFormat.addInputPath(job, new Path(ourArgs[0])); FileOutputFormat.setOutputPath(job, new Path(ourArgs[1])); } // On lance la tâche Hadoop. Si elle s'est effectuée // correctement, on renvoie 0. Sinon, on renvoie -1. if(job.waitforcompletion(true)) System.exit(0); System.exit(-1);
66 Exemple 2 Anagrammes / Mapper 5-3 // Classe MAP public class AnagrammesMap extends Mapper<Object, Text, Text, Text> { // La fonction MAP elle-même. protected void map(object key, Text value, Context context) throws IOException, InterruptedException { // Ordonne les lettres de la valeur d'entrée par ordre alphabétique. // Il s'agira de la clef de sortie. char[] letters=value.tostring().tolowercase().tochararray(); Arrays.sort(letters); } } // On renvoie le couple (clef;valeur), en convertissant la clef //au type Hadoop (Text). context.write(new Text(new String(letters)), value);
67 Exemple 2 Anagrammes / Reducer 5-4 // La classe REDUCE. public class AnagrammesReduce extends Reducer<Text, Text, Text, Text> { public void reduce(text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { // Pour parcourir toutes les valeurs associées à la clef fournie. Iterator<Text> i=values.iterator(); String result=""; Boolean first=true; while(i.hasnext()) // Pour chaque valeur... { if(first) // Premier mot, donc on n'inclut pas le symbole " ". { // Notre chaîne de résultat contient initialement // le premier mot. result=i.next().tostring(); first=false; }
68 Exemple 2 Anagrammes / Reducer 5-5 } // Pas le premier: on concatene le mot à la chaîne de resultat. else result=result+" "+i.next().tostring(); } } // On renvoie le couple (clef;valeur) constitué de // notre clef key et de la chaîne concaténée. context.write(key, new Text(result));
69 Compilation 5-6 Un programme map/reduce Hadoop se compile comme tout programme Java «traditionnel». Il faut ensuite le compresser au sein d'un paquet Java.jar classique, en faisant par exemple: mkdir -p org/unice/hadoop/wordcount mv *.class org/unice/hadoop/wordcount jar -cvf unice_wcount.jar -C. org Avantage du.jar: on peut tout à fait y inclure plusieurs programmes map/reduce différent, et sélectionner celui qu'on souhaite à l'exécution.
70 Exécution 5-7 Là encore, on utilise le client console hadoop pour l'exécution. Synopsis: hadoop jar [JAR FILE] [DRIVER CLASS] [PARAMETERS] Par exemple: hadoop jar wcount_unice.jar org.unice.hadoop.wordcount.wcount \ /input/poeme.txt /results
71 Résultats 5-8 Hadoop stocke les résultats dans une série de fichiers dont le nom respecte le format: part-r-xxxx avec XXXX un compteur numérique incrémental. On a un fichier part-r par opération Reduce exécutée. Le «r» désigne le résultat de l'opération Reduce. On peut également demander la génération de la sortie des opérations map dans des fichiers part-m-*. En cas de succès, un fichier vide _SUCCESS est également créé.
72 Exécution 5-7 Là encore, on utilise le client console hadoop pour l'exécution. Synopsis: hadoop jar [JAR FILE] [DRIVER CLASS] [PARAMETERS] Par exemple: hadoop jar wcount_unice.jar org.unice.hadoop.wordcount.wcount \ /input/poeme.txt /results
73 6 Autres langages; autres outils Hadoop
74 Autres langages de programmation 6-1 Pour développer des programmes map/reduce Hadoop dans d'autres langages: utilitaire Streaming, distribué avec Hadoop. Il s'agit en réalité d'une application Hadoop Java classique capable d'invoquer un intépréteur/un binaire sur tous les nœuds du cluster. On spécifie à l'utilitaire deux arguments: le programme à exécuter pour l'opération map, et celui à exécuter pour l'opération reduce.
75 Autres langages de programmation 6-2 Synopsis: hadoop jar hadoop-streaming-x.y.z.jar -input [HDFS INPUT FILES] \ -output [HDFS OUTPUT FILES] \ -mapper [MAP PROGRAM] \ -reducer [REDUCE PROGRAM] Par exemple: hadoop jar hadoop-streaming-x.y.z.jar -input /poeme.txt \ -output /results -mapper./map.py -reducer./reduce.py
76 Dans le programme reduce, on est susceptible de recevoir plusieurs groupes, correspondant à plusieurs clefs distinctes, en entrée. Format des données 6-3 Pour passer les données d'entrée et recevoir les données de sortie, streaming fait appel aux flux standards respectifs stdin et stdout. Le format respecte le schéma suivant: CLEF[TABULATION]VALEUR avec un couple (clef;valeur) par ligne.
77 Exemple Occurences de mot, Python 6-4 Opération map: import sys # Pour chaque ligne d'entrée. for line in sys.stdin: # Supprimer les espaces autour de la ligne. line=line.strip() # Pour chaque mot de la ligne. words=line.split() for word in words: # Renvoyer couple clef;valeur: le mot comme clef, l'entier "1" comme # valeur. # On renvoie chaque couple sur une ligne, avec une tabulation entre # la clef et la valeur. print "%s\t%d" % (word, 1)
78 Exemple Occurences de mot, Python 6-5 Opération reduce: import sys total=0; # Notre total pour le mot courant. # Contient le dernier mot rencontré. lastword=none # Pour chaque ligne d'entrée. for line in sys.stdin: # Supprimer les espaces autour de la ligne. line=line.strip() # Récupérer la clef et la valeur, convertir la valeur en int. word, count=line.split('\t', 1) count=int(count)
79 Exemple Occurences de mot, Python 6-6 Opération reduce (suite): # On change de mot (test nécessaire parce qu'on est susceptible d'avoir # en entrée plusieurs clefs distinctes différentes pour une seule et # même exécution du programme Hadoop triera les couples par clef # distincte). if word!=lastword and lastword!=none: print "%s\t%d occurences" % (lastword, total) total=0; lastword=word total=total+count # Ajouter la valeur au total # Ecrire le dernier couple (clef;valeur). print "%s\t%d occurences" % (lastword, total)
80 Exemple Occurences de mot, Bash 6-7 Opération map: # Pour chaque ligne d'entrée. while read line; do # Supprimer les espaces autour de la ligne. line=$(echo "$line" sed 's/^\s*\(.\+\)\s*$/\1/') # Pour chaque mot de la ligne. for word in $line; do # Renvoyer couple clef;valeur: le mot comme clef, l'entier "1" comme # valeur. # On renvoie chaque couple sur une ligne, avec une tabulation entre # la clef et la valeur. echo -e $word"\t"1 done done
81 Exemple Occurences de mot, Bash 6-8 Opération reduce: lastword="" total=0 # Pour chaque ligne d'entrée. while read line; do # Supprimer les espaces autour de la ligne. line=$(echo "$line" sed 's/^\s*\(.\+\)\s*$/\1/') # Recuperer mot et occurrence (IE, clef et valeur) word=$(echo "$line" awk -F "\t" '{print $1}'); nb=$(echo "$line" awk -F "\t" '{print $2}');
82 Exemple Occurences de mot, Bash 6-9 Opération reduce (suite): # On change de mot (test nécessaire parce qu'on est susceptible d'avoir # en entrée plusieurs clefs distinctes différentes pour une seule et # même exécution du programme Hadoop triera les couples par clef # distincte). if [ "$word"!= "$lastword" ] && [ "$lastword"!= "" ]; then echo -e $lastword"\t"$total" occurences." total=0; fi lastword="$word" total=$[ $total + $nb ] done # Ajouter la valeur au total. # Ecrire le dernier couple (clef;valeur). echo -e $lastword"\t"$total" occurences."
83 et beaucoup d'autres Autres outils associés à Hadoop 6-10 Nombreux front-ends graphiques (projet Hue ). Apache Hive: outil d'analyse/recoupage/etc. de larges volumes de données, associé à un langage similaire à SQL: HiveQL. Apache Pig: outil permettant le développement de programmes map/reduce dans un langage simplifié et accessible (Piglatin). Sqoop: outil d'importation/exportation de données entre HDFS et de nombreux systèmes de gestion de bases de données classiques.
84 Conclusion 6-11 Le présent cours constitue une introduction. L'API Hadoop, et le framework en général, présentent de nombreuses autres possibilités. Se référer au guide de lectures, ou encore à la documentation Hadoop, pour approfondir le sujet. Expérimenter! Se familiariser avec l'approche map/reduce et l'utilisation de Hadoop nécessite de la pratique.
Hadoop / Big Data. Benjamin Renaut <[email protected]> MBDS 2013-2014
 Hadoop / Big Data Benjamin Renaut MBDS 2013-2014 1 Introduction Programme Planning Objectifs TP/Évaluations Introduction 1-1 Benjamin Renaut Tokidev SAS - Bureau d'étude -
Hadoop / Big Data Benjamin Renaut MBDS 2013-2014 1 Introduction Programme Planning Objectifs TP/Évaluations Introduction 1-1 Benjamin Renaut Tokidev SAS - Bureau d'étude -
Notes de cours Practical BigData
 Notes de cours Practical BigData Nguyen-Nhut DOAN 15 janvier 2015 Introduction Ces notes personnelles traduisent la deuxième partie du cours INF553 de l Ecole Polytechnique sur les bases de données et
Notes de cours Practical BigData Nguyen-Nhut DOAN 15 janvier 2015 Introduction Ces notes personnelles traduisent la deuxième partie du cours INF553 de l Ecole Polytechnique sur les bases de données et
MapReduce et Hadoop. Alexandre Denis [email protected]. Inria Bordeaux Sud-Ouest France ENSEIRB PG306
 MapReduce et Hadoop Alexandre Denis [email protected] Inria Bordeaux Sud-Ouest France ENSEIRB PG306 Fouille de données Recherche & indexation de gros volumes Appliquer une opération simple à beaucoup
MapReduce et Hadoop Alexandre Denis [email protected] Inria Bordeaux Sud-Ouest France ENSEIRB PG306 Fouille de données Recherche & indexation de gros volumes Appliquer une opération simple à beaucoup
Programmation parallèle et distribuée (Master 1 Info 2015-2016)
") Programmation parallèle et distribuée (Master 1 Info 2015-2016) Hadoop MapReduce et HDFS Note bibliographique : ce cours est largement inspiré par le cours de Benjamin Renaut (Tokidev SAS) Introduction
Programmation parallèle et distribuée (Master 1 Info 2015-2016) Hadoop MapReduce et HDFS Note bibliographique : ce cours est largement inspiré par le cours de Benjamin Renaut (Tokidev SAS) Introduction
Hadoop / Big Data 2014-2015 MBDS. Benjamin Renaut <[email protected]>
 Hadoop / Big Data Benjamin Renaut MBDS 2014-2015 1 Introduction Programme Planning Objectifs TP/Évaluations Introduction 1-1 Benjamin Renaut Tokidev SAS - Bureau d'étude -
Hadoop / Big Data Benjamin Renaut MBDS 2014-2015 1 Introduction Programme Planning Objectifs TP/Évaluations Introduction 1-1 Benjamin Renaut Tokidev SAS - Bureau d'étude -
API04 Contribution. Apache Hadoop: Présentation et application dans le domaine des Data Warehouses. Introduction. Architecture
 API04 Contribution Apache Hadoop: Présentation et application dans le domaine des Data Warehouses Introduction Cette publication a pour but de présenter le framework Java libre Apache Hadoop, permettant
API04 Contribution Apache Hadoop: Présentation et application dans le domaine des Data Warehouses Introduction Cette publication a pour but de présenter le framework Java libre Apache Hadoop, permettant
Introduc)on à Map- Reduce. Vincent Leroy
on à Map- Reduce. Vincent Leroy") Introduc)on à Map- Reduce Vincent Leroy Sources Apache Hadoop Yahoo! Developer Network Hortonworks Cloudera Prac)cal Problem Solving with Hadoop and Pig Les cours seront mis en ligne sur hhp://membres.liglab.fr/leroy/
Introduc)on à Map- Reduce Vincent Leroy Sources Apache Hadoop Yahoo! Developer Network Hortonworks Cloudera Prac)cal Problem Solving with Hadoop and Pig Les cours seront mis en ligne sur hhp://membres.liglab.fr/leroy/
Hadoop / Big Data. Benjamin Renaut <[email protected]> MBDS 2014-2015
 Hadoop / Big Data Benjamin Renaut MBDS 2014-2015 TP 1 Méthodologie Map/Reduce - programmation Hadoop. 1 Installer VirtualBox (https://www.virtualbox.org/). Importer la machine
Hadoop / Big Data Benjamin Renaut MBDS 2014-2015 TP 1 Méthodologie Map/Reduce - programmation Hadoop. 1 Installer VirtualBox (https://www.virtualbox.org/). Importer la machine
Certificat Big Data - Master MAthématiques
 1 / 1 Certificat Big Data - Master MAthématiques Master 2 Auteur : Sylvain Lamprier UPMC Fouille de données et Medias Sociaux 2 / 1 Rich and big data: Millions d utilisateurs Millions de contenus Multimedia
1 / 1 Certificat Big Data - Master MAthématiques Master 2 Auteur : Sylvain Lamprier UPMC Fouille de données et Medias Sociaux 2 / 1 Rich and big data: Millions d utilisateurs Millions de contenus Multimedia
7 Développement d une application de MapReduce
 7 Développement d une application de MapReduce Ecrire un programme d Hadoop demande un processus : écrire une fonction map, une fonction reduce et tester localement. Ecrire ensuite un programme pour lancer
7 Développement d une application de MapReduce Ecrire un programme d Hadoop demande un processus : écrire une fonction map, une fonction reduce et tester localement. Ecrire ensuite un programme pour lancer
Big Data Concepts et mise en oeuvre de Hadoop
 Introduction 1. Objectif du chapitre 9 2. Le Big Data 10 2.1 Introduction 10 2.2 Informatique connectée, objets "intelligents" et données collectées 11 2.3 Les unités de mesure dans le monde Big Data 12
Introduction 1. Objectif du chapitre 9 2. Le Big Data 10 2.1 Introduction 10 2.2 Informatique connectée, objets "intelligents" et données collectées 11 2.3 Les unités de mesure dans le monde Big Data 12
Hadoop / Big Data. Benjamin Renaut <[email protected]> MBDS 2014-2015
 Hadoop / Big Data Benjamin Renaut MBDS 2014-2015 TP 3 TP noté Méthodologie Map/Reduce - programmation Hadoop - Sqoop Préparation du TP 1 Importer la machine virtuelle.ova du
Hadoop / Big Data Benjamin Renaut MBDS 2014-2015 TP 3 TP noté Méthodologie Map/Reduce - programmation Hadoop - Sqoop Préparation du TP 1 Importer la machine virtuelle.ova du
Introduction à MapReduce/Hadoop et Spark
 1 / 36 Introduction à MapReduce/Hadoop et Spark Certificat Big Data Ludovic Denoyer et Sylvain Lamprier UPMC Plan 2 / 36 Contexte 3 / 36 Contexte 4 / 36 Data driven science: le 4e paradigme (Jim Gray -
1 / 36 Introduction à MapReduce/Hadoop et Spark Certificat Big Data Ludovic Denoyer et Sylvain Lamprier UPMC Plan 2 / 36 Contexte 3 / 36 Contexte 4 / 36 Data driven science: le 4e paradigme (Jim Gray -
Map-Reduce : un cadre de programmation parallèlle pour l analyse de grandes données. Stéphane Genaud ENSIIE
 Map-Reduce : un cadre de programmation parallèlle pour l analyse de grandes données Stéphane Genaud ENSIIE Traitement de données distribuées Google a introduit Map-Reduce [Dean and Ghemawat 2004] Ils s
Map-Reduce : un cadre de programmation parallèlle pour l analyse de grandes données Stéphane Genaud ENSIIE Traitement de données distribuées Google a introduit Map-Reduce [Dean and Ghemawat 2004] Ils s
Programmation parallèle et distribuée
 Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2014) Marc Parizeau, Département de génie électrique et de génie informatique Plan Mégadonnées («big data») Architecture Hadoop distribution
Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2014) Marc Parizeau, Département de génie électrique et de génie informatique Plan Mégadonnées («big data») Architecture Hadoop distribution
Programmation parallèle et distribuée
 Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2015) Marc Parizeau, Département de génie électrique et de génie informatique Plan Données massives («big data») Architecture Hadoop distribution
Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2015) Marc Parizeau, Département de génie électrique et de génie informatique Plan Données massives («big data») Architecture Hadoop distribution
Déploiement d une architecture Hadoop pour analyse de flux. franç[email protected]
 Déploiement d une architecture Hadoop pour analyse de flux franç[email protected] 1 plan Introduction Hadoop Présentation Architecture d un cluster HDFS & MapReduce L architecture déployée Les
Déploiement d une architecture Hadoop pour analyse de flux franç[email protected] 1 plan Introduction Hadoop Présentation Architecture d un cluster HDFS & MapReduce L architecture déployée Les
Fouillez facilement dans votre système Big Data. Olivier TAVARD
 Fouillez facilement dans votre système Big Data Olivier TAVARD A propos de moi : Cofondateur de la société France Labs Développeur (principalement Java) Formateur en technologies de moteurs de recherche
Fouillez facilement dans votre système Big Data Olivier TAVARD A propos de moi : Cofondateur de la société France Labs Développeur (principalement Java) Formateur en technologies de moteurs de recherche
MapReduce. Malo Jaffré, Pablo Rauzy. 16 avril 2010 ENS. Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15
 MapReduce 16 avril 2010 1 / 15") MapReduce Malo Jaffré, Pablo Rauzy ENS 16 avril 2010 Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15 Qu est ce que c est? Conceptuellement Données MapReduce est un framework de calcul distribué
MapReduce Malo Jaffré, Pablo Rauzy ENS 16 avril 2010 Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15 Qu est ce que c est? Conceptuellement Données MapReduce est un framework de calcul distribué
Cloud Computing MapReduce Année académique 2014/15
 Cloud Computing Année académique 2014/15 Qu'est-ce que le Big Data? Source: Paul Butler (Facebook) "Visualizing Friendships", https://www.facebook.com/note.php?note_id=469716398919 2 2015 Marcel Graf Qu'est-ce
Cloud Computing Année académique 2014/15 Qu'est-ce que le Big Data? Source: Paul Butler (Facebook) "Visualizing Friendships", https://www.facebook.com/note.php?note_id=469716398919 2 2015 Marcel Graf Qu'est-ce
Hadoop : une plate-forme d exécution de programmes Map-Reduce
 Hadoop : une plate-forme d exécution de programmes Map-Reduce Jonathan Lejeune UPMC 8 octobre 2013 PSIA 2013 Inspiré du cours des années précédentes de Luciana Arantes J. Lejeune (UPMC) Hadoop Map-Reduce
Hadoop : une plate-forme d exécution de programmes Map-Reduce Jonathan Lejeune UPMC 8 octobre 2013 PSIA 2013 Inspiré du cours des années précédentes de Luciana Arantes J. Lejeune (UPMC) Hadoop Map-Reduce
INTRODUCTION A JAVA. Fichier en langage machine Exécutable
 INTRODUCTION A JAVA JAVA est un langage orienté-objet pur. Il ressemble beaucoup à C++ au niveau de la syntaxe. En revanche, ces deux langages sont très différents dans leur structure (organisation du
INTRODUCTION A JAVA JAVA est un langage orienté-objet pur. Il ressemble beaucoup à C++ au niveau de la syntaxe. En revanche, ces deux langages sont très différents dans leur structure (organisation du
Big Data : utilisation d un cluster Hadoop HDFS Map/Reduce HBase
 Big Data : utilisation d un cluster cluster Cécile Cavet cecile.cavet at apc.univ-paris7.fr Centre François Arago (FACe), Laboratoire APC, Université Paris Diderot LabEx UnivEarthS 14 Janvier 2014 C. Cavet
Big Data : utilisation d un cluster cluster Cécile Cavet cecile.cavet at apc.univ-paris7.fr Centre François Arago (FACe), Laboratoire APC, Université Paris Diderot LabEx UnivEarthS 14 Janvier 2014 C. Cavet
Big Data. Cyril Amsellem Consultant avant-vente. 16 juin 2011. Talend 2010 1
 Big Data Cyril Amsellem Consultant avant-vente 16 juin 2011 Talend 2010 1 Big Data Architecture globale Hadoop Les projets Hadoop (partie 1) Hadoop-Core : projet principal. HDFS : système de fichiers distribués
Big Data Cyril Amsellem Consultant avant-vente 16 juin 2011 Talend 2010 1 Big Data Architecture globale Hadoop Les projets Hadoop (partie 1) Hadoop-Core : projet principal. HDFS : système de fichiers distribués
Hadoop / Big Data. Benjamin Renaut <[email protected]> MBDS 2014-2015
 Hadoop / Big Data Benjamin Renaut MBDS 2014-2015 6 map/reduce et Hadoop: exemples plus avancés Exemple: parcours de graphe 6-1 On cherche à déterminer la profondeur maximale
Hadoop / Big Data Benjamin Renaut MBDS 2014-2015 6 map/reduce et Hadoop: exemples plus avancés Exemple: parcours de graphe 6-1 On cherche à déterminer la profondeur maximale
Hadoop : une plate-forme d exécution de programmes Map-Reduce
 Hadoop : une plate-forme d exécution de programmes Map-Reduce Jonathan Lejeune École des Mines de Nantes Janvier 2015 CODEL 2014/2015 J. Lejeune (École des Mines de Nantes) Hadoop Map-Reduce Janvier 2015
Hadoop : une plate-forme d exécution de programmes Map-Reduce Jonathan Lejeune École des Mines de Nantes Janvier 2015 CODEL 2014/2015 J. Lejeune (École des Mines de Nantes) Hadoop Map-Reduce Janvier 2015
Ricco Rakotomalala http://eric.univ-lyon2.fr/~ricco/cours/cours_programmation_r.html. R.R. Université Lyon 2
 Ricco Rakotomalala http://eric.univ-lyon2.fr/~ricco/cours/cours_programmation_r.html 1 Plan de présentation 1. L écosystème Hadoop 2. Principe de programmation MapReduce 3. Programmation des fonctions
Ricco Rakotomalala http://eric.univ-lyon2.fr/~ricco/cours/cours_programmation_r.html 1 Plan de présentation 1. L écosystème Hadoop 2. Principe de programmation MapReduce 3. Programmation des fonctions
Plan du cours. Historique du langage http://www.oracle.com/technetwork/java/index.html. Nouveautés de Java 7
 Université Lumière Lyon 2 Faculté de Sciences Economiques et Gestion KHARKIV National University of Economic Introduction au Langage Java Master Informatique 1 ère année Julien Velcin http://mediamining.univ-lyon2.fr/velcin
Université Lumière Lyon 2 Faculté de Sciences Economiques et Gestion KHARKIV National University of Economic Introduction au Langage Java Master Informatique 1 ère année Julien Velcin http://mediamining.univ-lyon2.fr/velcin
Big Data. Les problématiques liées au stockage des données et aux capacités de calcul
 Big Data Les problématiques liées au stockage des données et aux capacités de calcul Les problématiques liées au Big Data La capacité de stockage - Traitement : Ponctuel ou permanent? - Cycle de vie des
Big Data Les problématiques liées au stockage des données et aux capacités de calcul Les problématiques liées au Big Data La capacité de stockage - Traitement : Ponctuel ou permanent? - Cycle de vie des
Formation Cloudera Data Analyst Utiliser Pig, Hive et Impala avec Hadoop
 Passez au niveau supérieur en termes de connaissance grâce à la formation Data Analyst de Cloudera. Public Durée Objectifs Analystes de données, business analysts, développeurs et administrateurs qui ont
Passez au niveau supérieur en termes de connaissance grâce à la formation Data Analyst de Cloudera. Public Durée Objectifs Analystes de données, business analysts, développeurs et administrateurs qui ont
CNAM 2010-2011. Déploiement d une application avec EC2 ( Cloud Amazon ) Auteur : Thierry Kauffmann Paris, Décembre 2010
 Auteur : Thierry Kauffmann Paris, Décembre 2010") CNAM 2010-2011 Déploiement d une application avec EC2 ( Cloud Amazon ) Auteur : Thierry Kauffmann Paris, Décembre 2010 Déploiement d une application dans le cloud. 1. Cloud Computing en 2010 2. Offre EC2
CNAM 2010-2011 Déploiement d une application avec EC2 ( Cloud Amazon ) Auteur : Thierry Kauffmann Paris, Décembre 2010 Déploiement d une application dans le cloud. 1. Cloud Computing en 2010 2. Offre EC2
Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop
 Julien Gerlier Siman Chen Rapport de projet de fin d étude ASR 2010/2011 Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop Encadrants
Julien Gerlier Siman Chen Rapport de projet de fin d étude ASR 2010/2011 Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop Encadrants
Labs Hadoop Février 2013
 SOA - BRMS - ESB - BPM CEP BAM - High Performance Compute & Data Grid - Cloud Computing - Big Data NoSQL - Analytics Labs Hadoop Février 2013 Mathias Kluba Managing Consultant Responsable offres NoSQL
SOA - BRMS - ESB - BPM CEP BAM - High Performance Compute & Data Grid - Cloud Computing - Big Data NoSQL - Analytics Labs Hadoop Février 2013 Mathias Kluba Managing Consultant Responsable offres NoSQL
Importation et exportation de données dans HDFS
 1 Importation et exportation de données dans HDFS Introduction Dans une installation type, Hadoop se trouve au cœur d un flux de données complexe. Ces données proviennent souvent de systèmes disparates
1 Importation et exportation de données dans HDFS Introduction Dans une installation type, Hadoop se trouve au cœur d un flux de données complexe. Ces données proviennent souvent de systèmes disparates
R+Hadoop = Rhadoop* Des logiciels libres complémentaires, une implémentation, une réponse au nouveau paradigme du bigdata!
 R+Hadoop = Rhadoop* * Des logiciels libres complémentaires, une implémentation, une réponse au nouveau paradigme du bigdata! 27 Janvier 2014 / Université Paul Sabatier / DTSI / David Tsang-Hin-Sun Big
R+Hadoop = Rhadoop* * Des logiciels libres complémentaires, une implémentation, une réponse au nouveau paradigme du bigdata! 27 Janvier 2014 / Université Paul Sabatier / DTSI / David Tsang-Hin-Sun Big
TP1. Outils Java Eléments de correction
 c sep. 2008, v2.1 Java TP1. Outils Java Eléments de correction Sébastien Jean Le but de ce TP, sur une séance, est de se familiariser avec les outils de développement et de documentation Java fournis par
c sep. 2008, v2.1 Java TP1. Outils Java Eléments de correction Sébastien Jean Le but de ce TP, sur une séance, est de se familiariser avec les outils de développement et de documentation Java fournis par
L écosystème Hadoop Nicolas Thiébaud [email protected]. Tuesday, July 2, 13
 L écosystème Hadoop Nicolas Thiébaud [email protected] HUG France 250 membres sur la mailing liste 30 présentations 9 meetups organisés, de 20 à 100 invités Présence de Cloudera, MapR, Hortonworks,
L écosystème Hadoop Nicolas Thiébaud [email protected] HUG France 250 membres sur la mailing liste 30 présentations 9 meetups organisés, de 20 à 100 invités Présence de Cloudera, MapR, Hortonworks,
27/11/12 Nature. SDK Python et Java pour le développement de services ACCORD Module(s)
") Propriétés du Document Source du Document SDK_accords.odt Titre du Document SDK Python et Java pour le développement de services ACCORD Module(s) PyaccordsSDK, JaccordsSDK Responsable Prologue Auteur(s)
Propriétés du Document Source du Document SDK_accords.odt Titre du Document SDK Python et Java pour le développement de services ACCORD Module(s) PyaccordsSDK, JaccordsSDK Responsable Prologue Auteur(s)
NoSQL. Introduction 1/30. I NoSQL : Not Only SQL, ce n est pas du relationnel, et le contexte. I table d associations - Map - de couples (clef,valeur)
") 1/30 2/30 Anne-Cécile Caron Master MIAGE - SGBD 1er trimestre 2014-2015 I : Not Only SQL, ce n est pas du relationnel, et le contexte d utilisation n est donc pas celui des SGBDR. I Origine : recherche
1/30 2/30 Anne-Cécile Caron Master MIAGE - SGBD 1er trimestre 2014-2015 I : Not Only SQL, ce n est pas du relationnel, et le contexte d utilisation n est donc pas celui des SGBDR. I Origine : recherche
Hadoop, Spark & Big Data 2.0. Exploiter une grappe de calcul pour des problème des données massives
 Hadoop, Spark & Big Data 2.0 Exploiter une grappe de calcul pour des problème des données massives Qui suis-je? Félix-Antoine Fortin Génie info. (B. Ing, M. Sc, ~PhD) Passionné de Python, Data Analytics,
Hadoop, Spark & Big Data 2.0 Exploiter une grappe de calcul pour des problème des données massives Qui suis-je? Félix-Antoine Fortin Génie info. (B. Ing, M. Sc, ~PhD) Passionné de Python, Data Analytics,
Tables Rondes Le «Big Data»
 Tables Rondes Le «Big Data» 2012-2013 1 Plan Introduc9on 1 - Présenta9on Ingensi 2 - Le Big Data c est quoi? 3 - L histoire 4 - Le monde du libre : Hadoop 5 - Le système HDFS 6 - Les algorithmes distribués
Tables Rondes Le «Big Data» 2012-2013 1 Plan Introduc9on 1 - Présenta9on Ingensi 2 - Le Big Data c est quoi? 3 - L histoire 4 - Le monde du libre : Hadoop 5 - Le système HDFS 6 - Les algorithmes distribués
Cartographie des solutions BigData
 Cartographie des solutions BigData Panorama du marché et prospective 1 1 Solutions BigData Défi(s) pour les fournisseurs Quel marché Architectures Acteurs commerciaux Solutions alternatives 2 2 Quels Défis?
Cartographie des solutions BigData Panorama du marché et prospective 1 1 Solutions BigData Défi(s) pour les fournisseurs Quel marché Architectures Acteurs commerciaux Solutions alternatives 2 2 Quels Défis?
Pharmed. gestion de pharmacie hospitalière. Installation / déploiement
 Pharmed gestion de pharmacie hospitalière Installation / déploiement Version 1.0 du 23/05/2006 Date Auteur Version Modification 23/05/06 Pierre CARLIER 1.0 14/06/06 Matthieu Laborie Table des matières
Pharmed gestion de pharmacie hospitalière Installation / déploiement Version 1.0 du 23/05/2006 Date Auteur Version Modification 23/05/06 Pierre CARLIER 1.0 14/06/06 Matthieu Laborie Table des matières
Avant-propos. Organisation du livre
 Avant-propos Avec Hadoop par la pratique, les développeurs vont apprendre à maîtriser Hadoop et vont acquérir de nombreuses compétences sur la résolution de problèmes à l aide de ce framework. Ils vont
Avant-propos Avec Hadoop par la pratique, les développeurs vont apprendre à maîtriser Hadoop et vont acquérir de nombreuses compétences sur la résolution de problèmes à l aide de ce framework. Ils vont
Programmer en JAVA. par Tama ([email protected]( [email protected])
") Programmer en JAVA par Tama ([email protected]( [email protected]) Plan 1. Présentation de Java 2. Les bases du langage 3. Concepts avancés 4. Documentation 5. Index des mots-clés 6. Les erreurs fréquentes
Programmer en JAVA par Tama ([email protected]( [email protected]) Plan 1. Présentation de Java 2. Les bases du langage 3. Concepts avancés 4. Documentation 5. Index des mots-clés 6. Les erreurs fréquentes
Introduction aux algorithmes MapReduce. Mathieu Dumoulin (GRAAL), 14 Février 2014
, 14 Février 2014") Introduction aux algorithmes MapReduce Mathieu Dumoulin (GRAAL), 14 Février 2014 Plan Introduction de la problématique Tutoriel MapReduce Design d algorithmes MapReduce Tri, somme et calcul de moyenne
Introduction aux algorithmes MapReduce Mathieu Dumoulin (GRAAL), 14 Février 2014 Plan Introduction de la problématique Tutoriel MapReduce Design d algorithmes MapReduce Tri, somme et calcul de moyenne
RMI le langage Java XII-1 JMF
 Remote Method Invocation (RMI) XII-1 Introduction RMI est un ensemble de classes permettant de manipuler des objets sur des machines distantes (objets distants) de manière similaire aux objets sur la machine
Remote Method Invocation (RMI) XII-1 Introduction RMI est un ensemble de classes permettant de manipuler des objets sur des machines distantes (objets distants) de manière similaire aux objets sur la machine
Chapitre I Notions de base et outils de travail
 Chapitre I Notions de base et outils de travail Objectifs Connaître les principes fondateurs et l historique du langage Java S informer des principales caractéristiques du langage Java Connaître l environnement
Chapitre I Notions de base et outils de travail Objectifs Connaître les principes fondateurs et l historique du langage Java S informer des principales caractéristiques du langage Java Connaître l environnement
HADOOP ET SON ÉCOSYSTÈME
 HADOOP ET SON ÉCOSYSTÈME Mars 2013 2012 Affini-Tech - Diffusion restreinte 1 AFFINI-TECH Méthodes projets Outils de reporting & Data-visualisation Business & Analyses BigData Modélisation Hadoop Technos
HADOOP ET SON ÉCOSYSTÈME Mars 2013 2012 Affini-Tech - Diffusion restreinte 1 AFFINI-TECH Méthodes projets Outils de reporting & Data-visualisation Business & Analyses BigData Modélisation Hadoop Technos
Java DataBaseConnectivity
 Java DataBaseConnectivity JDBC JDBC est une API Java (ensemble de classes et d interfaces défini par SUN et les acteurs du domaine des SGBD) permettant d accéder aux bases de données à l aide du langage
Java DataBaseConnectivity JDBC JDBC est une API Java (ensemble de classes et d interfaces défini par SUN et les acteurs du domaine des SGBD) permettant d accéder aux bases de données à l aide du langage
Titre: Version: Dernière modification: Auteur: Statut: Licence:
 Titre: Installation de WebObjects 5.3 Version: 2.1 Dernière modification: 2011/02/17 11:00 Auteur: Aurélien Minet Statut: version finale Licence: Creative Commons
Titre: Installation de WebObjects 5.3 Version: 2.1 Dernière modification: 2011/02/17 11:00 Auteur: Aurélien Minet Statut: version finale Licence: Creative Commons
Service WEB, BDD MySQL, PHP et réplication Heartbeat. Conditions requises : Dans ce TP, il est nécessaire d'avoir une machine Debian sous ProxMox
 Version utilisée pour la Debian : 7.7 Conditions requises : Dans ce TP, il est nécessaire d'avoir une machine Debian sous ProxMox Caractéristiques de bases : Un service web (ou service de la toile) est
Version utilisée pour la Debian : 7.7 Conditions requises : Dans ce TP, il est nécessaire d'avoir une machine Debian sous ProxMox Caractéristiques de bases : Un service web (ou service de la toile) est
Acquisition des données - Big Data. Dario VEGA Senior Sales Consultant
 Acquisition des données - Big Data Dario VEGA Senior Sales Consultant The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated
Acquisition des données - Big Data Dario VEGA Senior Sales Consultant The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated
Généralités sur le Langage Java et éléments syntaxiques.
 Généralités sur le Langage Java et éléments syntaxiques. Généralités sur le Langage Java et éléments syntaxiques....1 Introduction...1 Genéralité sur le langage Java....1 Syntaxe de base du Langage...
Généralités sur le Langage Java et éléments syntaxiques. Généralités sur le Langage Java et éléments syntaxiques....1 Introduction...1 Genéralité sur le langage Java....1 Syntaxe de base du Langage...
Les technologies du Big Data
 Les technologies du Big Data PRÉSENTÉ AU 40 E CONGRÈS DE L ASSOCIATION DES ÉCONOMISTES QUÉBÉCOIS PAR TOM LANDRY, CONSEILLER SENIOR LE 20 MAI 2015 WWW.CRIM.CA TECHNOLOGIES: DES DONNÉES JUSQU'À L UTILISATEUR
Les technologies du Big Data PRÉSENTÉ AU 40 E CONGRÈS DE L ASSOCIATION DES ÉCONOMISTES QUÉBÉCOIS PAR TOM LANDRY, CONSEILLER SENIOR LE 20 MAI 2015 WWW.CRIM.CA TECHNOLOGIES: DES DONNÉES JUSQU'À L UTILISATEUR
TP1 : Initiation à Java et Eclipse
 TP1 : Initiation à Java et Eclipse 1 TP1 : Initiation à Java et Eclipse Systèmes d Exploitation Avancés I. Objectifs du TP Ce TP est une introduction au langage Java. Il vous permettra de comprendre les
TP1 : Initiation à Java et Eclipse 1 TP1 : Initiation à Java et Eclipse Systèmes d Exploitation Avancés I. Objectifs du TP Ce TP est une introduction au langage Java. Il vous permettra de comprendre les
Rappel. Analyse de Données Structurées - Cours 12. Un langage avec des déclaration locales. Exemple d'un programme
 Rappel Ralf Treinen Université Paris Diderot UFR Informatique Laboratoire Preuves, Programmes et Systèmes [email protected] 6 mai 2015 Jusqu'à maintenant : un petit langage de programmation
Rappel Ralf Treinen Université Paris Diderot UFR Informatique Laboratoire Preuves, Programmes et Systèmes [email protected] 6 mai 2015 Jusqu'à maintenant : un petit langage de programmation
Professeur-superviseur Alain April
 RAPPORT TECHNIQUE PRÉSENTÉ À L ÉCOLE DE TECHNOLOGIE SUPÉRIEURE DANS LE CADRE DU COURS GTI792 BASE DE DONNÉES DISTRIBUÉE APPLIQUÉE EN GÉNÉTIQUE DANS LE CADRE DE L'ANALYSE DE SÉQUENÇAGE GÉNOMIQUE JEAN-PHILIPPE
RAPPORT TECHNIQUE PRÉSENTÉ À L ÉCOLE DE TECHNOLOGIE SUPÉRIEURE DANS LE CADRE DU COURS GTI792 BASE DE DONNÉES DISTRIBUÉE APPLIQUÉE EN GÉNÉTIQUE DANS LE CADRE DE L'ANALYSE DE SÉQUENÇAGE GÉNOMIQUE JEAN-PHILIPPE
Pour signifier qu'une classe fille hérite d'une classe mère, on utilise le mot clé extends class fille extends mère
 L'héritage et le polymorphisme en Java Pour signifier qu'une classe fille hérite d'une classe mère, on utilise le mot clé extends class fille extends mère En java, toutes les classes sont dérivée de la
L'héritage et le polymorphisme en Java Pour signifier qu'une classe fille hérite d'une classe mère, on utilise le mot clé extends class fille extends mère En java, toutes les classes sont dérivée de la
TP n 2 Concepts de la programmation Objets Master 1 mention IL, semestre 2 Le type Abstrait Pile
 TP n 2 Concepts de la programmation Objets Master 1 mention IL, semestre 2 Le type Abstrait Pile Dans ce TP, vous apprendrez à définir le type abstrait Pile, à le programmer en Java à l aide d une interface
TP n 2 Concepts de la programmation Objets Master 1 mention IL, semestre 2 Le type Abstrait Pile Dans ce TP, vous apprendrez à définir le type abstrait Pile, à le programmer en Java à l aide d une interface
Java Licence Professionnelle CISII, 2009-2010
 Licence Professionnelle CISII, 2009-2010 Cours 1 : Introduction à Java A. Belaïd [email protected] Cours disponible sur le site : http://www.loria.fr/~abelaid puis Teaching 1 Fonctionnement 12 séances :
Licence Professionnelle CISII, 2009-2010 Cours 1 : Introduction à Java A. Belaïd [email protected] Cours disponible sur le site : http://www.loria.fr/~abelaid puis Teaching 1 Fonctionnement 12 séances :
Initiation à la programmation en Python
 I-Conventions Initiation à la programmation en Python Nom : Prénom : Une commande Python sera écrite en caractère gras. Exemples : print 'Bonjour' max=input("nombre maximum autorisé :") Le résultat de
I-Conventions Initiation à la programmation en Python Nom : Prénom : Une commande Python sera écrite en caractère gras. Exemples : print 'Bonjour' max=input("nombre maximum autorisé :") Le résultat de
Java Licence Professionnelle CISII, 2009-10
 Java Licence Professionnelle CISII, 2009-10 Cours 4 : Programmation structurée (c) http://www.loria.fr/~tabbone/cours.html 1 Principe - Les méthodes sont structurées en blocs par les structures de la programmation
Java Licence Professionnelle CISII, 2009-10 Cours 4 : Programmation structurée (c) http://www.loria.fr/~tabbone/cours.html 1 Principe - Les méthodes sont structurées en blocs par les structures de la programmation
Info0101 Intro. à l'algorithmique et à la programmation. Cours 3. Le langage Java
 Info0101 Intro. à l'algorithmique et à la programmation Cours 3 Le langage Java Pierre Delisle, Cyril Rabat et Christophe Jaillet Université de Reims Champagne-Ardenne Département de Mathématiques et Informatique
Info0101 Intro. à l'algorithmique et à la programmation Cours 3 Le langage Java Pierre Delisle, Cyril Rabat et Christophe Jaillet Université de Reims Champagne-Ardenne Département de Mathématiques et Informatique
Anticiper et prédire les sinistres avec une approche Big Data
 Anticiper et prédire les sinistres avec une approche Big Data Julien Cabot Directeur Big Data Analytics OCTO [email protected] @julien_cabot OCTO 2013 50, avenue des Champs-Elysées 75008 Paris - FRANCE Tél
Anticiper et prédire les sinistres avec une approche Big Data Julien Cabot Directeur Big Data Analytics OCTO [email protected] @julien_cabot OCTO 2013 50, avenue des Champs-Elysées 75008 Paris - FRANCE Tél
NoSQL. Introduction 1/23. I NoSQL : Not Only SQL, ce n est pas du relationnel, et le contexte. I table d associations - Map - de couples (clef,valeur)
") 1/23 2/23 Anne-Cécile Caron Master MIAGE - BDA 1er trimestre 2013-2014 I : Not Only SQL, ce n est pas du relationnel, et le contexte d utilisation n est donc pas celui des SGBDR. I Origine : recherche
1/23 2/23 Anne-Cécile Caron Master MIAGE - BDA 1er trimestre 2013-2014 I : Not Only SQL, ce n est pas du relationnel, et le contexte d utilisation n est donc pas celui des SGBDR. I Origine : recherche
Structure d un programme et Compilation Notions de classe et d objet Syntaxe
 Cours1 Structure d un programme et Compilation Notions de classe et d objet Syntaxe POO 1 Programmation Orientée Objet Un ensemble d objet qui communiquent Pourquoi POO Conception abstraction sur les types
Cours1 Structure d un programme et Compilation Notions de classe et d objet Syntaxe POO 1 Programmation Orientée Objet Un ensemble d objet qui communiquent Pourquoi POO Conception abstraction sur les types
Initiation à JAVA et à la programmation objet. [email protected]
 Initiation à JAVA et à la programmation objet [email protected] O b j e c t i f s Découvrir un langage de programmation objet. Découvrir l'environnement java Découvrir les concepts de la programmation
Initiation à JAVA et à la programmation objet [email protected] O b j e c t i f s Découvrir un langage de programmation objet. Découvrir l'environnement java Découvrir les concepts de la programmation
TUTORIEL: INSTALLATION D'UN SERVEUR LOCAL SOUS WINDOWS 7 POUR APPINVENTOR version du 06/04/2013
 TUTORIEL: INSTALLATION D'UN SERVEUR LOCAL SOUS WINDOWS 7 POUR APPINVENTOR version du 06/04/2013 1. Téléchargement des sources AppInventor http://appinventor.mit.edu/appinventor-sources/ Télécharger ces
TUTORIEL: INSTALLATION D'UN SERVEUR LOCAL SOUS WINDOWS 7 POUR APPINVENTOR version du 06/04/2013 1. Téléchargement des sources AppInventor http://appinventor.mit.edu/appinventor-sources/ Télécharger ces
Le service FTP. M.BOUABID, 04-2015 Page 1 sur 5
 Le service FTP 1) Présentation du protocole FTP Le File Transfer Protocol (protocole de transfert de fichiers), ou FTP, est un protocole de communication destiné à l échange informatique de fichiers sur
Le service FTP 1) Présentation du protocole FTP Le File Transfer Protocol (protocole de transfert de fichiers), ou FTP, est un protocole de communication destiné à l échange informatique de fichiers sur
Introduction à Java. Matthieu Herrb CNRS-LAAS. Mars 2014. http://homepages.laas.fr/matthieu/cours/java/java.pdf
 Introduction à Java Matthieu Herrb CNRS-LAAS http://homepages.laas.fr/matthieu/cours/java/java.pdf Mars 2014 Plan 1 Concepts 2 Éléments du langage 3 Classes et objets 4 Packages 2/28 Histoire et motivations
Introduction à Java Matthieu Herrb CNRS-LAAS http://homepages.laas.fr/matthieu/cours/java/java.pdf Mars 2014 Plan 1 Concepts 2 Éléments du langage 3 Classes et objets 4 Packages 2/28 Histoire et motivations
Sommaire. 3. Les grands principes de GFS L architecture L accès de fichier en lecture L accès de fichier en écriture Bilan
 1 Sommaire 1. Google en chiffres 2. Les raisons d être de GFS 3. Les grands principes de GFS L architecture L accès de fichier en lecture L accès de fichier en écriture Bilan 4. Les Evolutions et Alternatives
1 Sommaire 1. Google en chiffres 2. Les raisons d être de GFS 3. Les grands principes de GFS L architecture L accès de fichier en lecture L accès de fichier en écriture Bilan 4. Les Evolutions et Alternatives
4. Utilisation d un SGBD : le langage SQL. 5. Normalisation
 Base de données S. Lèbre [email protected] Université de Strasbourg, département d informatique. Présentation du module Contenu général Notion de bases de données Fondements / Conception Utilisation :
Base de données S. Lèbre [email protected] Université de Strasbourg, département d informatique. Présentation du module Contenu général Notion de bases de données Fondements / Conception Utilisation :
Remote Method Invocation (RMI)
") Remote Method Invocation (RMI) TP Réseau Université Paul Sabatier Master Informatique 1 ère Année Année 2006/2007 Plan Objectifs et Inconvénients de RMI Fonctionnement Définitions Architecture et principe
Remote Method Invocation (RMI) TP Réseau Université Paul Sabatier Master Informatique 1 ère Année Année 2006/2007 Plan Objectifs et Inconvénients de RMI Fonctionnement Définitions Architecture et principe
Document réalisé par Khadidjatou BAMBA
 Comprendre le BIG DATA Document réalisé par Khadidjatou BAMBA 1 Sommaire Avant propos. 3 Historique du Big Data.4 Introduction.....5 Chapitre I : Présentation du Big Data... 6 I. Généralités sur le Big
Comprendre le BIG DATA Document réalisé par Khadidjatou BAMBA 1 Sommaire Avant propos. 3 Historique du Big Data.4 Introduction.....5 Chapitre I : Présentation du Big Data... 6 I. Généralités sur le Big
Professeur-superviseur Alain April
 RAPPORT TECHNIQUE PRÉSENTÉ À L ÉCOLE DE TECHNOLOGIE SUPÉRIEURE DANS LE CADRE DU COURS GTI792 PROJET DE FIN D'ÉTUDES EN GÉNIE DES TI BASE DE DONNÉES DISTRIBUÉE APPLIQUÉE À LA GÉNÉTIQUE DANS LE CADRE DE
RAPPORT TECHNIQUE PRÉSENTÉ À L ÉCOLE DE TECHNOLOGIE SUPÉRIEURE DANS LE CADRE DU COURS GTI792 PROJET DE FIN D'ÉTUDES EN GÉNIE DES TI BASE DE DONNÉES DISTRIBUÉE APPLIQUÉE À LA GÉNÉTIQUE DANS LE CADRE DE
La base de données XML exist. A. Belaïd
 La base de données XML exist Introduction Qu est-ce-que exist? C est une base de donnée native, entièrement écrite en Java XML n est pas une base de données en soi Bien qu il possède quelques caractéristiques
La base de données XML exist Introduction Qu est-ce-que exist? C est une base de donnée native, entièrement écrite en Java XML n est pas une base de données en soi Bien qu il possède quelques caractéristiques
Cours 1 : Introduction. Langages objets. but du module. contrôle des connaissances. Pourquoi Java? présentation du module. Présentation de Java
 Langages objets Introduction M2 Pro CCI, Informatique Emmanuel Waller, LRI, Orsay présentation du module logistique 12 blocs de 4h + 1 bloc 2h = 50h 1h15 cours, 45mn exercices table, 2h TD machine page
Langages objets Introduction M2 Pro CCI, Informatique Emmanuel Waller, LRI, Orsay présentation du module logistique 12 blocs de 4h + 1 bloc 2h = 50h 1h15 cours, 45mn exercices table, 2h TD machine page
Auto-évaluation Programmation en Java
 Auto-évaluation Programmation en Java Document: f0883test.fm 22/01/2013 ABIS Training & Consulting P.O. Box 220 B-3000 Leuven Belgium TRAINING & CONSULTING INTRODUCTION AUTO-ÉVALUATION PROGRAMMATION EN
Auto-évaluation Programmation en Java Document: f0883test.fm 22/01/2013 ABIS Training & Consulting P.O. Box 220 B-3000 Leuven Belgium TRAINING & CONSULTING INTRODUCTION AUTO-ÉVALUATION PROGRAMMATION EN
as Architecture des Systèmes d Information
 Plan Plan Programmation - Introduction - Nicolas Malandain March 14, 2005 Introduction à Java 1 Introduction Présentation Caractéristiques Le langage Java 2 Types et Variables Types simples Types complexes
Plan Plan Programmation - Introduction - Nicolas Malandain March 14, 2005 Introduction à Java 1 Introduction Présentation Caractéristiques Le langage Java 2 Types et Variables Types simples Types complexes
Sage 100 CRM Guide de l Import Plus avec Talend Version 8. Mise à jour : 2015 version 8
 Sage 100 CRM Guide de l Import Plus avec Talend Version 8 Mise à jour : 2015 version 8 Composition du progiciel Votre progiciel est composé d un boîtier de rangement comprenant : le cédérom sur lequel
Sage 100 CRM Guide de l Import Plus avec Talend Version 8 Mise à jour : 2015 version 8 Composition du progiciel Votre progiciel est composé d un boîtier de rangement comprenant : le cédérom sur lequel
Acronis Backup & Recovery 10 Advanced Server Virtual Edition. Guide de démarrage rapide
 Acronis Backup & Recovery 10 Advanced Server Virtual Edition Guide de démarrage rapide Ce document explique comment installer et utiliser Acronis Backup & Recovery 10 Advanced Server Virtual Edition. Copyright
Acronis Backup & Recovery 10 Advanced Server Virtual Edition Guide de démarrage rapide Ce document explique comment installer et utiliser Acronis Backup & Recovery 10 Advanced Server Virtual Edition. Copyright
20 ans du Master SIAD de Toulouse - BigData par l exemple - Julien DULOUT - 22 mars 2013. 20 ans du SIAD -"Big Data par l'exemple" -Julien DULOUT
 20 ans du Master SIAD de Toulouse - BigData par l exemple - Julien DULOUT - 22 mars 2013 20 ans du SIAD -"BigData par l'exemple" -Julien DULOUT Qui a déjà entendu parler du phénomène BigData? Qui a déjà
20 ans du Master SIAD de Toulouse - BigData par l exemple - Julien DULOUT - 22 mars 2013 20 ans du SIAD -"BigData par l'exemple" -Julien DULOUT Qui a déjà entendu parler du phénomène BigData? Qui a déjà
Langage Java. Classe de première SI
 Langage Java Table des matières 1. Premiers pas...2 1.1. Introduction...2 1.2. Mon premier programme...2 1.3. Les commentaires...2 2. Les variables et les opérateurs...2 3. La classe Scanner...3 4. Les
Langage Java Table des matières 1. Premiers pas...2 1.1. Introduction...2 1.2. Mon premier programme...2 1.3. Les commentaires...2 2. Les variables et les opérateurs...2 3. La classe Scanner...3 4. Les
http://blog.khaledtannir.net
 Algorithme de parallélisations des traitements Khaled TANNIR Doctorant CIFRE LARIS/ESTI http://blog.khaledtannir.net [email protected] 2e SéRI 2010-2011 Jeudi 17 mars 2011 Présentation Doctorant CIFRE
Algorithme de parallélisations des traitements Khaled TANNIR Doctorant CIFRE LARIS/ESTI http://blog.khaledtannir.net [email protected] 2e SéRI 2010-2011 Jeudi 17 mars 2011 Présentation Doctorant CIFRE
Livre. blanc. Solution Hadoop d entreprise d EMC. Stockage NAS scale-out Isilon et Greenplum HD. Février 2012
 Livre blanc Solution Hadoop d entreprise d EMC Stockage NAS scale-out Isilon et Greenplum HD Par Julie Lockner et Terri McClure, Analystes seniors Février 2012 Ce livre blanc d ESG, qui a été commandé
Livre blanc Solution Hadoop d entreprise d EMC Stockage NAS scale-out Isilon et Greenplum HD Par Julie Lockner et Terri McClure, Analystes seniors Février 2012 Ce livre blanc d ESG, qui a été commandé
SafeKit. Sommaire. Un livre blanc de Bull Evidian
 Un livre blanc de Bull Evidian SafeKit Une solution de haute disponibilité logicielle packageable avec n'importe quelle application Windows ou Unix Par Bruno Rochat Sommaire Novembre 2005 Haute disponibilité
Un livre blanc de Bull Evidian SafeKit Une solution de haute disponibilité logicielle packageable avec n'importe quelle application Windows ou Unix Par Bruno Rochat Sommaire Novembre 2005 Haute disponibilité
Hands on Openstack : Introduction
 Hands on Openstack : Introduction Tags : openstack cloud Alban Crommer 2013 Octopuce Connaître Openstack Niveau 0 : Connaissance des composants Connaître Openstack Niveau 1 : Utilisation des services et
Hands on Openstack : Introduction Tags : openstack cloud Alban Crommer 2013 Octopuce Connaître Openstack Niveau 0 : Connaissance des composants Connaître Openstack Niveau 1 : Utilisation des services et
INF2015 Développement de logiciels dans un environnement Agile. Examen intra 20 février 2014 17:30 à 20:30
 Examen intra 20 février 2014 17:30 à 20:30 Nom, prénom : Code permanent : Répondez directement sur le questionnaire. Question #1 5% Quelle influence peut avoir le typage dynamique sur la maintenabilité
Examen intra 20 février 2014 17:30 à 20:30 Nom, prénom : Code permanent : Répondez directement sur le questionnaire. Question #1 5% Quelle influence peut avoir le typage dynamique sur la maintenabilité
Cours intensif Java. 1er cours: de C à Java. Enrica DUCHI LIAFA, Paris 7. Septembre 2009. [email protected]
 . Cours intensif Java 1er cours: de C à Java Septembre 2009 Enrica DUCHI LIAFA, Paris 7 [email protected] LANGAGES DE PROGRAMMATION Pour exécuter un algorithme sur un ordinateur il faut le
. Cours intensif Java 1er cours: de C à Java Septembre 2009 Enrica DUCHI LIAFA, Paris 7 [email protected] LANGAGES DE PROGRAMMATION Pour exécuter un algorithme sur un ordinateur il faut le
ACTIVITÉ DE PROGRAMMATION
 ACTIVITÉ DE PROGRAMMATION The purpose of the Implementation Process is to realize a specified system element. ISO/IEC 12207 Sébastien Adam Une introduction 2 Introduction Ø Contenu Utilité de l ordinateur,
ACTIVITÉ DE PROGRAMMATION The purpose of the Implementation Process is to realize a specified system element. ISO/IEC 12207 Sébastien Adam Une introduction 2 Introduction Ø Contenu Utilité de l ordinateur,
Serveur d'archivage 2007 Installation et utilisation de la BD exist
 Type du document Procédure d'installation Auteur(s) Eric Bouladier Date de création 26/02/20007 Domaine de diffusion tous Validé par Equipe Versions Date Auteur(s) Modifications V1.00 26/02/2007 Eric Bouladier
Type du document Procédure d'installation Auteur(s) Eric Bouladier Date de création 26/02/20007 Domaine de diffusion tous Validé par Equipe Versions Date Auteur(s) Modifications V1.00 26/02/2007 Eric Bouladier
MapReduce. Nicolas Dugué [email protected]. M2 MIAGE Systèmes d information répartis
 MapReduce Nicolas Dugué [email protected] M2 MIAGE Systèmes d information répartis Plan 1 Introduction Big Data 2 MapReduce et ses implémentations 3 MapReduce pour fouiller des tweets 4 MapReduce
MapReduce Nicolas Dugué [email protected] M2 MIAGE Systèmes d information répartis Plan 1 Introduction Big Data 2 MapReduce et ses implémentations 3 MapReduce pour fouiller des tweets 4 MapReduce
Les journées SQL Server 2013
 Les journées SQL Server 2013 Un événement organisé par GUSS Les journées SQL Server 2013 Romain Casteres MVP SQL Server Consultant BI @PulsWeb Yazid Moussaoui Consultant Senior BI MCSA 2008/2012 Etienne
Les journées SQL Server 2013 Un événement organisé par GUSS Les journées SQL Server 2013 Romain Casteres MVP SQL Server Consultant BI @PulsWeb Yazid Moussaoui Consultant Senior BI MCSA 2008/2012 Etienne
Traitement de données
 Traitement de données Présentation du module TINI Présentation du module : Le module Tini se décline en plusieurs versions, il est constitué d une carte d application et d un module processeur : Les modules
Traitement de données Présentation du module TINI Présentation du module : Le module Tini se décline en plusieurs versions, il est constitué d une carte d application et d un module processeur : Les modules
Panorama des solutions analytiques existantes
 Arnaud LAROCHE Julien DAMON Panorama des solutions analytiques existantes SFdS Méthodes et Logiciels - 16 janvier 2014 - Données Massives Ne sont ici considérés que les solutions autour de l environnement
Arnaud LAROCHE Julien DAMON Panorama des solutions analytiques existantes SFdS Méthodes et Logiciels - 16 janvier 2014 - Données Massives Ne sont ici considérés que les solutions autour de l environnement