École d Hiver sur les applications de l informatique industrielle, réseaux et génie logiciel Décembre Data Mining.
|
|
|
- Gauthier Larochelle
- il y a 8 ans
- Total affichages :
Transcription
1 Data Mining Abdelmalek Amine Laboratoire GeCoDe - Universté de Saida


2 Disponibilité croissante de données données sur les clients données sur les entreprises numérisation de documents textuels, images, vidéos, voix, etc. Données en trop grandes quantités pour être traitées manuellement ou par des algorithmes classiques nombre d enregistrements en million ou milliard données de grandes dimensions (trop de champs/attributs/caractéristiques) Sources de données hétérogènes Augmentation constante du volume d'information Croissance exponentielle Émergence du Data Mining (fouille de données) 2
 Sources de données hétérogènes")
3 Data Mining (fouille de données) est un processus de découverte de règle, relations, corrélations et/ou dépendances à travers une grande quantité de données, grâce à des méthodes statistiques, mathématiques, de reconnaissances de formes,... Data Mining (fouille de données) se définit comme un processus analytique destiné a explorer de large quantité de données dans différents domaines, afin de dégager une certaine structure et/ou des relations systématiques entre variables, puis en validant les conclusions et appliquant les structures trouvées à de nouveaux groupes de données Data Mining (fouille de données) «un processus non-trivial d identification de structures inconnues, valides et potentiellement exploitables dans les bases de données» [Fayyad et al., 1996] 3
 «un")
4 Le Data Mining (fouille de données) renvoie à l ensemble des méthodes et algorithmes pour l exploration et l analyse de gros volumes de données (bases de données informatiques) dans la perspective d une aide à la prise de décision Le Data Mining (fouille de données) repose sur la mise en évidence de règles, de tendances invisibles pour un analyste humain 4


5 Data Mining (fouille de données) : convergence de plusieurs disciplines 5

 6")
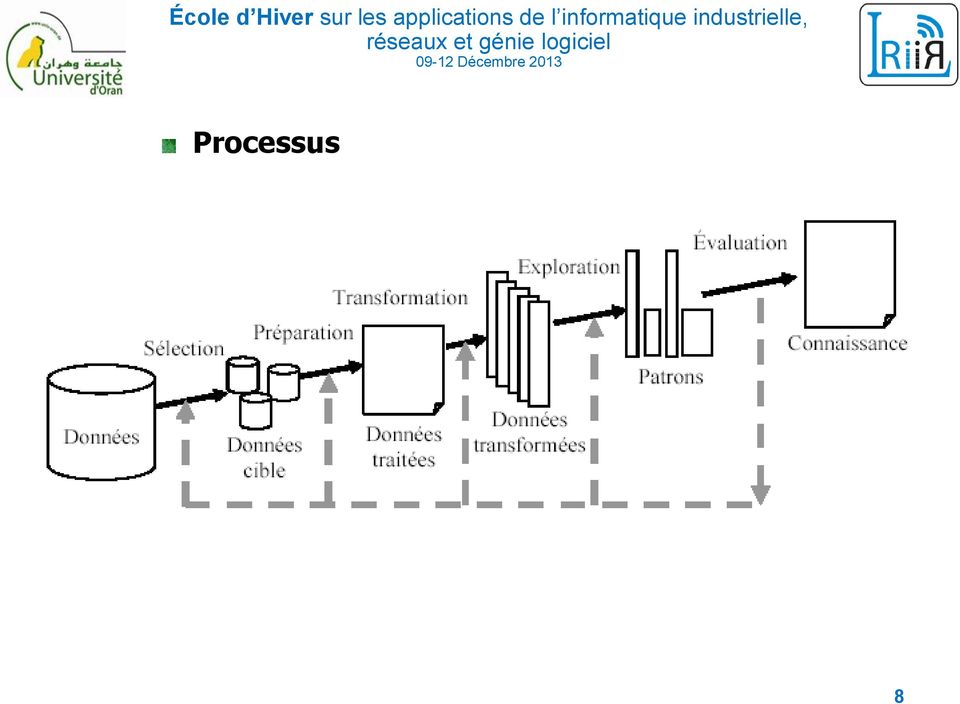
6 Processus du Data Mining (Étapes) 6
")
7 Processus 1. Identifier le problème cerner les objectifs 2. Préparer les données Collecter les données Nettoyer les données (suppression des doublons, des erreurs de saisie, traitement des informations manquantes,...) Enrichir les données Codage, normalisation 3. Fouille des données Choisir un type de modèle (classification, ) et une technique (arbres de décision,...) pour construire ce modèle Validation Évaluation (Erreurs, ) : par un expert ou statistique 4. Utiliser le modèle Voir les résultats du modèle sur les données, Appliquer le modèle pour prédire sur de nouvelles données,... 7
 et une technique (arbres de décision,.")
8 Processus 8
9 Taches du Data Mining (Types de modèles) 9

10 Selon les objectifs Classification examiner les caractéristiques d'un objet et lui attribuer une classe Prédiction prédire la valeur future d'un attribut en fonction d'autres attributs, par exemple prédire la "qualité" d'un client en fonction de son revenu Association consiste à déterminer les attributs qui sont corrélés : analyse du panier de la ménagère Segmentation consiste à former des groupes homogènes à l'intérieur d'une population. Tâche souvent faite avant les précédentes pour trouver les groupes sur lesquels appliquer la classification 10

11 Selon le type d'apprentissage Apprentissage supervisé processus dans lequel l'apprenant reçoit des exemples d'apprentissage comprenant à la fois des données d'entrée et de sortie classification, prédiction Apprentissage non supervisé processus dans lequel l'apprenant reçoit des exemples d'apprentissage ne comprenant que des données d'entrée Association, segmentation 11

12 Selon le type de modèles obtenus Modèles prédictifs utilisent les données avec des résultats connus pour développer des modèles permettant de prédire les valeurs d'autres données Exemple: modèle permettant de prédire les clients qui ne rembourseront pas leur crédit classification, prédiction modèles descriptifs proposent des descriptions des données pour aider à la prise de décision. Les modèles descriptifs aident à la construction de modèles prédictifs Association, segmentation 12

13 Quelques algorithmes (méthodes): - K-plus proches voisins (K-ppv ou Knn) - K-moyennes (K-means) - Naive Bayes - Régression linéaire - Réseau de neurones - Arbre de décision - Règles d association 13

14 Knn Calcul de similarité Entre le nouveau exemple et les exemples pré-classés Similarité(d1,d2) = cos(d1,d2) Trouve les k exemples les plus proches Recherche des catégories candidates Vote majoritaire des k exemples Somme des similarités > seuil Sélection d'une ou plusieurs catégories Plus grand nombre de votes Score supérieur à un seuil 14

15 K-means Calculer le centroïde pour chaque catégorie en utilisant les exemples (training set) Moyenner les vecteurs pour chaque catégorie Le vecteur centroïde est utilisé comme modèle de la catégorie Sélectionner les catégories Celles de plus haut score Avec un score plus grand qu'un seuil 15

16 Naïve Bayes Modèle probabiliste Basé sur l'observation de la présence des termes Suppose l'indépendance entre les termes La catégorie de plus grande probabilité est sélectionnée On peut utiliser un seuil pour en sélectionner plusieurs 16

17 Le modèle probabiliste pour un classifieur est le modèle conditionnel Où C est une variable de classe dépendante dont les instances ou classes sont peu nombreuses, conditionnée par plusieurs variables caractéristiques F1,, Fn À l'aide du théorème de Bayes, nous écrivons = = 17

18 Exemple Données Météo Perspective Température Humidité Vent Jouer Ensoleillé Chaude Elevée Faible Non Ensoleillé Chaude Elevée Fort Non Couvert Chaude Elevée Faible Oui Pluvieux Tiède Elevée Faible Oui Pluvieux Fraiche Normale Faible Oui Pluvieux Fraiche Normale Fort Non Couvert Fraiche Normale Fort Oui Ensoleillé Tiède Elevée Faible Non Ensoleillé Fraiche Normale Faible Oui Pluvieux Tiède Normale Faible Oui Ensoleillé Tiède Normale Fort Oui Couvert Tiède Elevée Fort Oui Couvert Chaude Normale Faible Oui Pluvieux Tiède Elevée Fort Non 18

19 Perspective Température Humidité Vent Jouer Ensoleillé Fraiche Elevée Fort? F1 F2 F3 F4 C Probabilité de (Jouer = Oui) = 2/9 * 3/9 * 3/9 * 3/9 * 9/14= 0,0053 Probabilité de (Jouer = Non) = 3/5 * 1/5 * 4/5 * 3/5 * 5/14= 0,0206 Pourcentage de Oui? Pourcentage de Non? 19
 = 3/5 * 1/5 * 4/5 *")
20 Attributs Numériques Pour les attributs numériques on va simplement listez les valeurs des instances, après on calcule L'espérance et la variance de chaque attribut numérique Espérance Variance 20

21 Exemple Données Météo Perspective Température Humidité Vent Jouer Ensoleillé Faible Non Ensoleillé Fort Non Couvert Faible Oui Pluvieux Faible Oui Pluvieux Faible Oui Pluvieux Fort Non Couvert Fort Oui Ensoleillé Faible Non Ensoleillé Faible Oui Pluvieux Faible Oui Ensoleillé Fort Oui Couvert Fort Oui Couvert Faible Oui Pluvieux Fort Non 21
22 Espérance de l attribut température pour Jouer = Oui Variance 22
23 Densité de probabilité 23
24 Perspective Température Humidité Vent Jouer Ensoleillé Fort? Probabilité de (Jouer = Oui) = 2/9 * 0,0340* 0,0221 * 3/9 * 9/14= 0, Probabilité de (Jouer = Non) = 3/5 * 0,0279 * 0,0381 * 3/5 * 5/14= 0, Pourcentage de Oui? Pourcentage de Non? 24
25 Arbre de Décision Méthode de classification Représentation graphique d une procédure de classification 25
26 Arbre de décision Chaque Nœud interne est un attribut Chaque Branche correspond à une valeur de l attribut Chaque Feuille représente une classe 26
27 Exemple Données Météo Perspective Température Humidité Vent Jouer Ensoleillé Chaude Elevée Faible Non Ensoleillé Chaude Elevée Fort Non Couvert Chaude Elevée Faible Oui Pluvieux Tiède Elevée Faible Oui Pluvieux Fraiche Normale Faible Oui Pluvieux Fraiche Normale Fort Non Couvert Fraiche Normale Fort Oui Ensoleillé Tiède Elevée Faible Non Ensoleillé Fraiche Normale Faible Oui Pluvieux Tiède Normale Faible Oui Ensoleillé Tiède Normale Fort Oui Couvert Tiède Elevée Fort Oui Couvert Chaude Normale Faible Oui Pluvieux Tiède Elevée Fort Non 27
28 Exemple Perspective Ensoleillé Couvert Pluvieux Humidité Oui Vent Elevée Normale Fort Faible Non Oui Non Oui 28
29 Arbre de décision Règles de classification Perspective Ensoleillé Couvert Pluvieux Une règle est générée pour chaque chemin de l arbre Elevée Humidité Oui Normale Fort Vent Faible Paire attribut valeur d un chemin forment une conjonction Non Oui Non Oui Nœud terminal représente la classe prédite Si Perspective=Ensoleillé et Humidité=Normale Alors jouer=oui 29
30 Plusieurs algorithmes pour les arbres de décision Algorithme de base - Construction récursive d un arbre de manière «diviser pour- régner» - Attributs considérés énumératifs Plusieurs variantes - ID3 - C4.5 - CART - CHAID - 30
31 Mesures de sélection d attributs - Gain d information ( ID3, C 4.5) - Indice Gini (CART) -Table de contingence statique x2 (CHAID) - 31
32 Arbre de décision obtenu avec ID3 Perspective Ensoleillé Température Chaude Humidité Elevée Vent Faible Tennis Non Perspective Ensoleillé Couvert Pluvieux Humidité OUI Vent Elevée Normale Fort Faible Non Oui Non Oui 32
33 Evaluation Exemple Mesures basés sur la table de contingences pré-étiqueté C1 pré-étiqueté C2 Affecté à C1 a b a+b Affecté à C2 c d c+d a+c b+d a+b+c+d Rappel : mesure la largeur de la classification ratio des données bien classées par rapport à l ensemble des données appartenant réellement à la classe. r=a/(a+c) Précision : mesure la qualité de la classification fraction des données bien classées sur toutes les données affectées à la classe. p=a/(a+b); bruit = 1-precision F-mesure : mesure le compromis entre r et p: F1=2r*p/(r+p) Plus la valeur de la F-mesure est grande, meilleure est la qualité de la classification 33

34 Text Mining 34
35 Structurées: 10% - augmentent de 4% par an Non structurées: 90% - augmentent de 6400% par an Le traitement des données non structurées constitue un enjeu colossal pour aujourd hui et plus encore pour demain 35
36 Lorsque les données considérées se présentent sous la forme de textes (qu ils soient non structurés ou semi-structurés) Données non structurées (textes bruts) : - Fichiers textes (TXT, RTF, DOC, ) - Pages web (article Wikipédia, blog, site institutionnel, ) Données semi-structurées : - SGML, XML, HTML - RDF, Text Mining (Text Data Mining) ou fouille de textes (fouille de données textuelles) 36
37 Text Mining (fouille de données textuelles) «l ensemble des tâches qui, par analyse de grandes quantités de textes et la détection de modèles fréquents, essaie d extraire de l information probablement utile» [Sebastiani, 2002]. 37
38 Le Text Mining est l ensemble des techniques et méthodes destinées au traitement automatique de données textuelles disponibles sous forme informatique (Internet, Intranet, bibliothèques numériques, DVD, ) en assez grande quantité, en vue d en dégager et structurer le contenu et les thèmes dans une perspective d analyse rapide, de découverte d informations cachées ou de prise automatique de décision. Le Text Mining est un procédé consistant à synthétiser (classer, structurer, résumer, ) les textes en analysant les relations, les patterns et les règles entre unités textuelles (mots, groupes, phrases, documents) 38
39 Data Mining Text Mining Objet Numérique & catégorique Textuel Structure des données Représentation des données Structuré Simple Non structuré ou semistructuré Complexe Dimension < Dizaine de Milliers > Dizaine de Milliers Méthodes Maturité Analyse de données, Apprentissage automatique, Statistique, Réseaux de neurones Nombreuses implémentations à partir de 1994 Text Mining versus Data Mining Data Mining, Recherche d information, NLP,... Nombreuses implémentations à partir de
40 La démarche du Text Mining ne se différencie pas de celle du Data Mining, elle est similaire Sa particularité réside dans les étapes spécifiques de préparation des données, qui permettent de passer du texte à la forme, et de la forme au nombre. 40
41 Définition du problème Traitement des données (Techniques de DataMining) Représentation graphique et connaissances Préparation des documents Traitement linguistique Etude lexicométrique Processus du Text Mining 41
42 Le processus du Text Mining comprend la succession d étapes suivantes: La définition du problème et identification des buts : Définition des buts attendus et des résultats souhaités. La préparation des données : Les textes doivent être recueillis en utilisant, par exemple, des outils automatique de récupération de l'information, ou de façon manuelle à partir de différentes sources. Le traitement linguistique : Les textes utilisés en entrée sont des textes en langue naturelle. Pour réussir un traitement juste de ces textes et extraire des connaissances à partir de ceux-ci, il faut qu ils passent des étapes appelées généralement prétraitement. L étape de prétraitement des textes appartient au domaine du traitement automatique de la langue naturelle. Elle comporte en général les phases suivantes : Détection de la langue du texte : Pour commencer le traitement il faut d abord savoir dans quelle langue chaque document est écrit et comment cette langue est encodée. Il est important de détecter avec précision la langue dans laquelle le texte est rédigé, car une erreur à ce niveau voue à l échec les étapes suivantes. Il existe deux familles d approches dans l identification de la langue : linguistique et statistique. Nettoyage des données : Habituellement, le nettoyage consiste à éliminer les mots vides (stopwords). Ces mots vides sont des mots ne jouant qu un rôle syntaxique, contribuant peu au sens des documents. On les élimine pour deux raisons : (a) Minimiser la taille du fichier traité (contrainte d espace). (b) Rendre le traitement plus rapide (contrainte de temps). Lemmatisation : La lemmatisation est l opération qui consiste à ramener les variantes (flexionnelles) d un même mot à une forme canonique, le lemme. Elle s appuie sur une analyse grammaticale des textes afin de remplacer les verbes par leur forme infinitive et les noms par leur forme au singulier. Cette opération permet de réduire le nombre de termes dans un index, ce qui est intéressant du point de vue du stockage des données. L étude lexicométrique : La lexicométrie est l étude quantitative du vocabulaire ; elle consiste à mesurer la fréquence d apparition des mots dans un même texte, et il en résulte une représentation mathématique du texte. Le traitement des données (techniques de Data Mining) : On choisit l une des techniques du Data Mining telles que les arbres de décisions, les algorithmes génétiques ou les réseaux de neurones, pour l appliquer aux textes transformés (représentation mathématique), ce qui permettra de réaliser plusieurs tâches telles que: la classification, la traduction automatique, l identification de la langue, etc. 42
43 1. Sélection du corpus de documents 2. Extraction des termes 3. Transformation 4. Traitement des données 5. Visualisation des résultats 6. Interprétation des résultats 43
44 Quelques «grands» noms : Claude Shannon ( ) - Fondateur de la théorie de l information - Entropie (définit la quantité d information contenue dans un document) Gerard Salton ( ) - Modèle d espaces vectoriels Karen Sparck Jones ( ) - IDF (Inverse Document Frequency) Cornelis Joost van Rijsbergen (1943) - Modèles probabilistes en recherche d information 44
45 Représentation des documents textuels 45
46 La plupart des algorithmes d apprentissage sont incapables de traiter directement des données non structurées Les documents textuels sont par nature sous un format non structuré Une étape préliminaire est indispensable dite de représentation La particularité du Text Mining réside dans les étapes spécifiques de préparation des données, qui permettent de passer : du texte à la forme au nombre 46
47 Hypothèse fondamentale des travaux sur l extraction et la sélection d informations : «le contenu textuel d un document discrimine le type et la valeur des informations qu il véhicule» Analyse de la fréquence d apparition des termes dans un texte (corpus de textes) 47
48 Terme Mot Phrase - Racine lexicale (Stem) n-gramme Concept - Lemme Document (texte) séquence de terme L'ensemble des documents - base documentaire - fonds documentaire - collection de documents - corpus 48
49 Deux modèles de représentation de textes pour le calcul de cette fréquence le modèle probabiliste le modèle vectoriel Le modèle vectoriel VSM pour Vector Space Model, ([Salton and McGill, 1983], [Salton et al., 1975]) le plus utilisé sert de base à la représentation des données textuelles par des vecteurs dans l'espace euclidien. Un document est représenté par un vecteur de termes. 49
50 L'étape d'indexation analyser les documents afin de créer une représentation de leur contenu textuel qui soit exploitable Chaque document est alors associé à un vecteur représenté par l'ensemble des termes d'indexation extraits (descripteurs) Fréquence Soit on associe un poids au terme soit on l'enregistre simplement comme «présent»/«non présent» dans le document courant valeur 1 s il est présent et 0 autrement 50
51 Transformation des textes forme analysable Modèle vectoriel Pondération (importance relative) w kj poids (fréquence ou importance) du terme t k dans le document d j Document d j vecteur des poids (w 1j,w 2j,...,w nj ) n : ensemble de termes Corpus (ensemble de documents=collection de textes) Documents Termes ou Descripteurs t k d 1 w 11 w 21 w w j1... w n1 d 2 w 12 w 22 w w j2... w n d m w 1m w 2m w 3m... w jm... w nm 51
52 Calcul du poids w kj (Pondération TFxIDF) Mesure l'importance d un terme dans un document relativement à l ensemble des documents TF IDF t k,d j Occ(t k,d j ) Log Nbre_ doc Nbre_ doc(t k ) Occ(t k, d j ): nombre d occurrences du terme t k dans le document d j Nbre_doc: nombre total de documents du corpus Nbre_doc(t k ): nombre de documents de cet ensemble dans lesquels apparaît au moins une fois le terme t k 52
53 Un terme qui apparait plusieurs fois dans un document est plus important qu un terme qui apparaît une seule fois Un terme qui apparaît dans peu de documents est un meilleur discriminant qu un terme qui apparaît dans tous les documents 53
54 Représentation en «sac de mots» consiste à transformer les textes en vecteurs dont chaque composante représente un mot Terme=mot 3 the TEXAS COMMERCE BANCSHARES <TCB> FILES PLAN Texas Commerce Bancshares Inc's Texas Commerce Bank-Houston said it filed an application with the Comptroller of the Currency in an effort to create the largest banking network in Harris County. The bank said the network would link 31 banks having 13.5 billion dlrs in assets and 7.5 billion dlrs in deposits county Texas billion 1 network 54
55 Représentation des textes par des phrases une sélection des phrases des séquences de mots se suivant dans le texte en privilégiant celles qui sont susceptibles de porter un sens important (pas l'unité lexicale «phrase» telle qu'on l entend habituellement) «the sweet little boy plays with a yellow ball» Les séquences : «sweet little boy», «yellow ball», «little boy» sont porteuses de sens. Les séquences : «the sweet», «a yellow» ne sont pas intéressantes 55
56 Représentation des textes avec des racines lexicales (stems) et des lemmes modèle «sac de mots» chaque flexion d'un mot est considérée comme un descripteur (terme) différent (Dimensionnalité) Stemming : considérer uniquement la racine des mots plutôt que les mots entiers (stem en anglais) le défaut principal des racines est de regrouper trop de mots différents sous une même racine lemmatisation : remplacer les verbes par leur forme infinitive et les noms par leur forme au singulier plus difficile à mettre en œuvre que la recherche de racines (stemming) elle nécessite une analyse grammaticale des textes 56
57 TEXAS COMMERCE BANCSHARES <TCB> FILES PLAN Texas Commerce Bancshares Inc's Texas Commerce Bank-Houston said it filed an application with the Comptroller of the Currency in an effort to create the largest banking network in Harris County. The bank said the network would link 31 banks having 13.5 billion dlrs in assets and 7.5 billion dlrs in deposits. Exemple de texte TEXA COMMERC BANCSHAR <TCB> FILE PLAN Texa Commerc Bancshar Inc's Texa Commerc Bank-Houston said it file an applic with the Comptrol of the Currenc in an effort to creat the largest bank network in Harri Counti. The bank said the network would link 31 bank have 13.5 billion dlr in asset and 7.5 billion dlr in deposit. Stemming : mots remplacés par leur racine (algorithme de Porter) TEXAS COMMERCE BANCSHARES LT TCB> FILE PLAN Texas Commerce Bancshares inc's Texas Commerce Bank Houston say it file an application with the comptroller of the currency in an effort to create the large banking network in Harris County The bank say the network would link bank billion dlrs in asset billion dlrs in deposit Lemmatisation : mots remplacés par lemme (algorithme TreeTagger) 57
58 Représentation des textes avec la méthode des n-grammes Un n-gramme peut désigner aussi bien un n-uplet de caractères (n-gramme de caractères) qu un n-uplet de mots (n-gramme de mots) Un n-gramme est une séquence de n caractères consécutifs. Pour un document quelconque, l ensemble des n-grammes que l on peut générer est le résultat que l on obtient en déplaçant une fenêtre de n cases sur le corps du texte. Ce déplacement se fait par étapes ; une étape correspond à un caractère pour les n- grammes de caractères, à un mot pour les n-grammes de mots 58
59 Exemple de n-grammes de mots dans la phrase «document clustering using ngrams» : - un-gramme: «document», «clustering», «using», «ngrams», - bi-grammes: «document clustering», «clustering using», «using ngrams», - tri-grammes: «document clustering using», «clustering using ngrams» Exemple de 5-grammes de caractères de la phrase «document clustering using ngrams» : «docum, ocume, cumen, ument, ment_, ent_c, nt_cl, t_clu, _clus, clust, luste, uster, steri, terin, ering, ring_, ing_u, ng_us, g_usi, _usin, using, sing_, ing_n, ng_ng, g_ngr, _ngra, ngram, grams» Le caractère «_» représente un blanc 59
60 Représentation par concepts Le processus de représentation ou d'indexation dans la majorité des systèmes actuels indexation classique basée sur les mots le sens des mots n'est pas pris en compte Concept termes synonymes Exemple : 60
61 Pour arriver à identifier les concepts des documents utilisation d'ontologies (abusivement) utilisation d un formalisme de représentation des connaissances (bases de données lexicales) domaines spécialisés Ressource lexicale Doc1 Vecteur du doc3 Vecteur du doc2 Vecteur du doc1 Exemple : WordNet est une base de données lexicales Concept synsets 61
62 Traitements complémentaires, Analyse et préparation - Corrections orthographiques (fautes de frappe ) processus de correction orthographique - Conversion de caractères majuscules en minuscules - conversion des caractères diacritiques - Reconnaissance de mots composés Utilisation d une table de mots composés du langage identifier ceux ne formant qu'un seul mot Ex : foot ball (foot et ball) - Elimination des mots-vides (mots-outils ou Stop-words) prépositions, at, of - les articles : the, an, a - les pronoms : her, him - les auxiliaires : be, have peut être étendu aux mots très fréquents au sein d'une collection de textes 62
63 Une liste de mots-vides : a, beaucoup, comment, encore, lequel, moyennant, près, ses, toujours, afin, ça, concernant, entre, les, ne, puis, sien, tous, ailleurs, ce, dans, et, lesquelles, ni, puisque, sienne, toute, ainsi, ceci, de, étaient, lesquels, non, quand, siennes, toutes, alors, cela, dedans, était, leur, nos, quant, siens, très, après, celle, dehors, étant, leurs, notamment, que, soi, trop, attendant, celles, déjà, etc, lors, notre, quel, soimême, tu, au, celui, delà, eux, lorsque, notres, quelle, soit, un, aucun, cependant, depuis, furent, lui, nôtre, quelqu un, sont, une, aucune, certain, des, grâce, ma, nôtres, quelqu une, suis, vos, au-dessous, certaine, desquelles, hormis, mais, nous, quelque, sur, votre, au-dessus, certaines, desquels, hors, malgré, nulle, quelquesunes, ta, vôtre, auprès, certains, dessus, ici, me, nulles, quelques-uns, tandis, vôtres, auquel, ces, dès, il, même, on, quels, tant, vous, aussi, cet, donc, ils, mêmes, ou, qui, te, vu, aussitôt, cette, donné, jadis, mes, où, quiconque, telle, y, autant, ceux, dont, je, mien, par, quoi, telles, autour, chacun, du, jusqu, mienne, parce, quoique, tes, aux, chacune, duquel, jusque, miennes, parmi, sa, tienne, auxquelles, chaque, durant, la, miens, plus, sans, tiennes, auxquels, chez, elle, laquelle, moins, plusieurs, sauf, tiens, avec, combien, elles, là, moment, pour, se, toi, à, comme, en, le, mon, pourquoi, selon, ton 63
64 Réduction de l espace de représentation Problème de la dimension (malédiction de la dimensionnalité) pour un corpus de taille raisonnable le nombre de descripteur plusieurs centaines de milliers Nécessité d utiliser une méthode statistique pour déterminer les mots utiles 64
65 Principe calculer pour chaque terme une valeur statistique qui représente son utilité (un score est associé à chaque terme) sélectionner les termes les plus importants (les attributs avec les scores les plus faibles seront éliminés) Il existe de nombreuses statistiques pour mesurer cette quantité d information un point commun à toutes ces statistiques est la nécessité de choisir un seuil Peu importe le critère choisi pour la sélection, il faut déterminer à partir de quelle valeur on élimine ou on conserve un terme 65
66 La Fréquence-document (Document Fréquency) L information mutuelle (mutual information) Le gain d information (information gain) Le Chi-deux La force du terme (term strength) 66
67 Similarité entre documents Document Vecteur Le nombre de termes présents dans les documents du corpus détermine la dimension de l espace Dans l espace vectoriel de dimension V, les vecteurs représentant les textes forment un faisceau de même origine Documents similaires les textes qui se ressemblent contiennent les mêmes termes ou des termes qui apparaissent dans les mêmes contextes (les termes qui ont des contextes identiques sont similaires) Vecteurs similaires dans l espace vectoriel, ils correspondent à des vecteurs proches 67
68 Le cosinus de l angle est souvent utilisé > cos( )<cos( ) d 2 est plus proche de d 1 que de d 3 Des vecteurs proches ont des directions quasi-identiques ou dont les extrémités sont proches documents similaires proches Permet de ranger les documents par pertinence 68
69 Similarité entre documents Estimée par une fonction calculant la distance entre les vecteurs de ces documents Quelques mesures: Distance du Cosinus Cos d i, d j tk TF IDF t, d TF IDF t, d k d i i 2 d j 2 k j Distance Euclidienne Euclidean(d,d ) i j 2 wki - wkj) n 1 ( Jaccard Sim(d i,d j) n ( 1 n wki w 1 1 n kj w ki. w n ( 1 kj ) w ki - w kj ) d = 1 s 69
70 Classification de documents La classification est la tâche la plus importante en Text Mining Application des méthodes classiques aux vecteurs de documents (Knn, Centroid, Naïve Bayes, SVM, Arbre de décision ) Segmentation des documents Evaluation 70
 Tanagra Rapid Miner YALE (Yet Another Learning Environment)")
71 Outils Weka (Waikato Environment for Knowledge Analysis) (Environnement Waikato pour l'analyse de connaissances) Tanagra Rapid Miner YALE (Yet Another Learning Environment) Orange 71
Apprentissage Automatique
 Apprentissage Automatique Introduction-I jean-francois.bonastre@univ-avignon.fr www.lia.univ-avignon.fr Définition? (Wikipedia) L'apprentissage automatique (machine-learning en anglais) est un des champs
Apprentissage Automatique Introduction-I jean-francois.bonastre@univ-avignon.fr www.lia.univ-avignon.fr Définition? (Wikipedia) L'apprentissage automatique (machine-learning en anglais) est un des champs
Introduction au Data-Mining
 Introduction au Data-Mining Alain Rakotomamonjy - Gilles Gasso. INSA Rouen -Département ASI Laboratoire PSI Introduction au Data-Mining p. 1/25 Data-Mining : Kèkecé? Traduction : Fouille de données. Terme
Introduction au Data-Mining Alain Rakotomamonjy - Gilles Gasso. INSA Rouen -Département ASI Laboratoire PSI Introduction au Data-Mining p. 1/25 Data-Mining : Kèkecé? Traduction : Fouille de données. Terme
Introduction au Data-Mining
 Introduction au Data-Mining Gilles Gasso, Stéphane Canu INSA Rouen -Département ASI Laboratoire LITIS 8 septembre 205. Ce cours est librement inspiré du cours DM de Alain Rakotomamonjy Gilles Gasso, Stéphane
Introduction au Data-Mining Gilles Gasso, Stéphane Canu INSA Rouen -Département ASI Laboratoire LITIS 8 septembre 205. Ce cours est librement inspiré du cours DM de Alain Rakotomamonjy Gilles Gasso, Stéphane
Introduction au datamining
 Introduction au datamining Patrick Naïm janvier 2005 Définition Définition Historique Mot utilisé au départ par les statisticiens Le mot indiquait une utilisation intensive des données conduisant à des
Introduction au datamining Patrick Naïm janvier 2005 Définition Définition Historique Mot utilisé au départ par les statisticiens Le mot indiquait une utilisation intensive des données conduisant à des
Intelligence Artificielle et Systèmes Multi-Agents. Badr Benmammar bbm@badr-benmammar.com
 Intelligence Artificielle et Systèmes Multi-Agents Badr Benmammar bbm@badr-benmammar.com Plan La première partie : L intelligence artificielle (IA) Définition de l intelligence artificielle (IA) Domaines
Intelligence Artificielle et Systèmes Multi-Agents Badr Benmammar bbm@badr-benmammar.com Plan La première partie : L intelligence artificielle (IA) Définition de l intelligence artificielle (IA) Domaines
Projet SINF2275 «Data mining and decision making» Projet classification et credit scoring
 Projet SINF2275 «Data mining and decision making» Projet classification et credit scoring Année académique 2006-2007 Professeurs : Marco Saerens Adresse : Université catholique de Louvain Information Systems
Projet SINF2275 «Data mining and decision making» Projet classification et credit scoring Année académique 2006-2007 Professeurs : Marco Saerens Adresse : Université catholique de Louvain Information Systems
Algorithmes d'apprentissage
 Algorithmes d'apprentissage 1 Agents qui apprennent à partir d'exemples La problématique : prise de décision automatisée à partir d'un ensemble d'exemples Diagnostic médical Réponse à une demande de prêt
Algorithmes d'apprentissage 1 Agents qui apprennent à partir d'exemples La problématique : prise de décision automatisée à partir d'un ensemble d'exemples Diagnostic médical Réponse à une demande de prêt
Big Data et Graphes : Quelques pistes de recherche
 Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci http://liris.cnrs.fr/hamamache.kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de
Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci http://liris.cnrs.fr/hamamache.kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de
Big Data et Graphes : Quelques pistes de recherche
 Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de Lyon/Université Claude Bernard Lyon 1/Université
Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de Lyon/Université Claude Bernard Lyon 1/Université
Laboratoire 4 Développement d un système intelligent
 DÉPARTEMENT DE GÉNIE LOGICIEL ET DES TI LOG770 - SYSTÈMES INTELLIGENTS ÉTÉ 2012 Laboratoire 4 Développement d un système intelligent 1 Introduction Ce quatrième et dernier laboratoire porte sur le développement
DÉPARTEMENT DE GÉNIE LOGICIEL ET DES TI LOG770 - SYSTÈMES INTELLIGENTS ÉTÉ 2012 Laboratoire 4 Développement d un système intelligent 1 Introduction Ce quatrième et dernier laboratoire porte sur le développement
EXTRACTION DE CONNAISSANCES À PARTIR DE DONNÉES TEXTUELLES VUE D ENSEMBLE
 ème Colloque National AIP PRIMECA La Plagne - 7- avril 7 EXTRACTION DE CONNAISSANCES À PARTIR DE DONNÉES TEXTUELLES VUE D ENSEMBLE Bruno Agard Département de Mathématiques et de Génie Industriel, École
ème Colloque National AIP PRIMECA La Plagne - 7- avril 7 EXTRACTION DE CONNAISSANCES À PARTIR DE DONNÉES TEXTUELLES VUE D ENSEMBLE Bruno Agard Département de Mathématiques et de Génie Industriel, École
INF6304 Interfaces Intelligentes
 INF6304 Interfaces Intelligentes filtres collaboratifs 1/42 INF6304 Interfaces Intelligentes Systèmes de recommandations, Approches filtres collaboratifs Michel C. Desmarais Génie informatique et génie
INF6304 Interfaces Intelligentes filtres collaboratifs 1/42 INF6304 Interfaces Intelligentes Systèmes de recommandations, Approches filtres collaboratifs Michel C. Desmarais Génie informatique et génie
Data Mining. Vincent Augusto 2012-2013. École Nationale Supérieure des Mines de Saint-Étienne. Data Mining. V. Augusto.
 des des Data Mining Vincent Augusto École Nationale Supérieure des Mines de Saint-Étienne 2012-2013 1/65 des des 1 2 des des 3 4 Post-traitement 5 représentation : 6 2/65 des des Définition générale Le
des des Data Mining Vincent Augusto École Nationale Supérieure des Mines de Saint-Étienne 2012-2013 1/65 des des 1 2 des des 3 4 Post-traitement 5 représentation : 6 2/65 des des Définition générale Le
Les algorithmes de fouille de données
 Février 2005 Les algorithmes de fouille de données DATAMINING Techniques appliquées à la vente, aux services client, interdictions. Cycle C Informatique Remerciements Je remercie les personnes, les universités
Février 2005 Les algorithmes de fouille de données DATAMINING Techniques appliquées à la vente, aux services client, interdictions. Cycle C Informatique Remerciements Je remercie les personnes, les universités
La classification automatique de données quantitatives
 La classification automatique de données quantitatives 1 Introduction Parmi les méthodes de statistique exploratoire multidimensionnelle, dont l objectif est d extraire d une masse de données des informations
La classification automatique de données quantitatives 1 Introduction Parmi les méthodes de statistique exploratoire multidimensionnelle, dont l objectif est d extraire d une masse de données des informations
LIVRE BLANC Décembre 2014
 PARSING MATCHING EQUALITY SEARCH LIVRE BLANC Décembre 2014 Introduction L analyse des tendances du marché de l emploi correspond à l évidence à une nécessité, surtout en période de tension comme depuis
PARSING MATCHING EQUALITY SEARCH LIVRE BLANC Décembre 2014 Introduction L analyse des tendances du marché de l emploi correspond à l évidence à une nécessité, surtout en période de tension comme depuis
De la modélisation linguistique aux applications logicielles: le rôle des Entités Nommées en Traitement Automatique des Langues
 De la modélisation linguistique aux applications logicielles: le rôle des Entités Nommées en Traitement Automatique des Langues Maud Ehrmann Joint Research Centre Ispra, Italie. Guillaume Jacquet Xerox
De la modélisation linguistique aux applications logicielles: le rôle des Entités Nommées en Traitement Automatique des Langues Maud Ehrmann Joint Research Centre Ispra, Italie. Guillaume Jacquet Xerox
Recherche d information en langue arabe : influence des paramètres linguistiques et de pondération de LSA
 RÉCITAL 2005, Dourdan, 6-10 juin 2005 Recherche d information en langue arabe : influence des paramètres linguistiques et de pondération de LSA Siham Boulaknadel (1,2), Fadoua Ataa-Allah (2) (1) LINA FRE
RÉCITAL 2005, Dourdan, 6-10 juin 2005 Recherche d information en langue arabe : influence des paramètres linguistiques et de pondération de LSA Siham Boulaknadel (1,2), Fadoua Ataa-Allah (2) (1) LINA FRE
Recherche d Information(RI): Fondements et illustration avec Apache Lucene. par Majirus Fansi @majirus
: Fondements et illustration avec Apache Lucene. par Majirus Fansi @majirus") 1 Recherche d Information(RI): Fondements et illustration avec Apache Lucene par Majirus Fansi @majirus Résumé Fondements de la Recherche d Information (RI) Noyau de toute application de RI Éléments à
1 Recherche d Information(RI): Fondements et illustration avec Apache Lucene par Majirus Fansi @majirus Résumé Fondements de la Recherche d Information (RI) Noyau de toute application de RI Éléments à
Spécificités, Applications et Outils
 Spécificités, Applications et Outils Ricco Rakotomalala Université Lumière Lyon 2 Laboratoire ERIC Laboratoire ERIC 1 Ricco Rakotomalala ricco.rakotomalala@univ-lyon2.fr http://chirouble.univ-lyon2.fr/~ricco/data-mining
Spécificités, Applications et Outils Ricco Rakotomalala Université Lumière Lyon 2 Laboratoire ERIC Laboratoire ERIC 1 Ricco Rakotomalala ricco.rakotomalala@univ-lyon2.fr http://chirouble.univ-lyon2.fr/~ricco/data-mining
Magister INFORMATIQUE. Présenté par. Soutenu en Février 2011 devant la commission du jury composée de :
 REPUBLIQUE ALGERIENNE DEMOCRATIQUE ET POPULAIRE MINISTERE DE L ENSEIGNEMENT SUPERIEUR ET DE LA RECHERCHE SCIENTIFIQUE UNIVERSITE ABOUBEKR BELKAID-TLEMCEN FACULTE DES SCIENCES DEPARTEMENT D INFORMATIQUE
REPUBLIQUE ALGERIENNE DEMOCRATIQUE ET POPULAIRE MINISTERE DE L ENSEIGNEMENT SUPERIEUR ET DE LA RECHERCHE SCIENTIFIQUE UNIVERSITE ABOUBEKR BELKAID-TLEMCEN FACULTE DES SCIENCES DEPARTEMENT D INFORMATIQUE
Introduction. Informatique décisionnelle et data mining. Data mining (fouille de données) Cours/TP partagés. Information du cours
 Cours/TP partagés. Information du cours") Information du cours Informatique décisionnelle et data mining www.lia.univ-avignon.fr/chercheurs/torres/cours/dm Juan-Manuel Torres juan-manuel.torres@univ-avignon.fr LIA/Université d Avignon Cours/TP
Information du cours Informatique décisionnelle et data mining www.lia.univ-avignon.fr/chercheurs/torres/cours/dm Juan-Manuel Torres juan-manuel.torres@univ-avignon.fr LIA/Université d Avignon Cours/TP
LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING»
 LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING» Gilbert Saporta Professeur de Statistique Appliquée Conservatoire National des Arts et Métiers Dans leur quasi totalité, les banques et organismes financiers
LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING» Gilbert Saporta Professeur de Statistique Appliquée Conservatoire National des Arts et Métiers Dans leur quasi totalité, les banques et organismes financiers
Christophe CANDILLIER Cours de DataMining mars 2004 Page 1
 Christophe CANDILLIER Cours de DataMining mars 2004 age 1 1. Introduction 2. rocessus du DataMining 3. Analyse des données en DataMining 4. Analyse en Ligne OLA 5. Logiciels 6. Bibliographie Christophe
Christophe CANDILLIER Cours de DataMining mars 2004 age 1 1. Introduction 2. rocessus du DataMining 3. Analyse des données en DataMining 4. Analyse en Ligne OLA 5. Logiciels 6. Bibliographie Christophe
données en connaissance et en actions?
 1 Partie 2 : Présentation de la plateforme SPSS Modeler : Comment transformer vos données en connaissance et en actions? SPSS Modeler : l atelier de data mining Large gamme de techniques d analyse (algorithmes)
1 Partie 2 : Présentation de la plateforme SPSS Modeler : Comment transformer vos données en connaissance et en actions? SPSS Modeler : l atelier de data mining Large gamme de techniques d analyse (algorithmes)
Pourquoi l apprentissage?
 Pourquoi l apprentissage? Les SE sont basés sur la possibilité d extraire la connaissance d un expert sous forme de règles. Dépend fortement de la capacité à extraire et formaliser ces connaissances. Apprentissage
Pourquoi l apprentissage? Les SE sont basés sur la possibilité d extraire la connaissance d un expert sous forme de règles. Dépend fortement de la capacité à extraire et formaliser ces connaissances. Apprentissage
Chapitre IX. L intégration de données. Les entrepôts de données (Data Warehouses) Motivation. Le problème
 Motivation. Le problème") Chapitre IX L intégration de données Le problème De façon très générale, le problème de l intégration de données (data integration) est de permettre un accès cohérent à des données d origine, de structuration
Chapitre IX L intégration de données Le problème De façon très générale, le problème de l intégration de données (data integration) est de permettre un accès cohérent à des données d origine, de structuration
Agenda de la présentation
 Le Data Mining Techniques pour exploiter l information Dan Noël 1 Agenda de la présentation Concept de Data Mining ou qu est-ce que le Data Mining Déroulement d un projet de Data Mining Place du Data Mining
Le Data Mining Techniques pour exploiter l information Dan Noël 1 Agenda de la présentation Concept de Data Mining ou qu est-ce que le Data Mining Déroulement d un projet de Data Mining Place du Data Mining
Trois approches du GREYC pour la classification de textes
 DEFT 2008, Avignon (associé à TALN 08) Trois approches du GREYC pour la classification de textes Thierry Charnois Antoine Doucet Yann Mathet François Rioult GREYC, Université de Caen, CNRS UMR 6072 Bd
DEFT 2008, Avignon (associé à TALN 08) Trois approches du GREYC pour la classification de textes Thierry Charnois Antoine Doucet Yann Mathet François Rioult GREYC, Université de Caen, CNRS UMR 6072 Bd
Pentaho Business Analytics Intégrer > Explorer > Prévoir
 Pentaho Business Analytics Intégrer > Explorer > Prévoir Pentaho lie étroitement intégration de données et analytique. En effet, les services informatiques et les utilisateurs métiers peuvent accéder aux
Pentaho Business Analytics Intégrer > Explorer > Prévoir Pentaho lie étroitement intégration de données et analytique. En effet, les services informatiques et les utilisateurs métiers peuvent accéder aux
I. Le déterminant Il détermine le nom. Le déterminant indique le genre, le
 I. Le déterminant Il détermine le nom. Le déterminant indique le genre, le nombre et le degré de détermination du nom. 1. L article le, la, les, l, d, au, aux, du, des, un, une, des, du, de l, de la, des.
I. Le déterminant Il détermine le nom. Le déterminant indique le genre, le nombre et le degré de détermination du nom. 1. L article le, la, les, l, d, au, aux, du, des, un, une, des, du, de l, de la, des.
MEMOIRE. Présenté par. Pour obtenir DIPLOME. Intitulé : B. Beldjilalii. B. Atmani. Encadreur : F. Barigou. S. Nait Bahloul. M.
 DEPARTEMENTT D'INFORMATIQUE MEMOIRE Présenté par B ARIGOU Baya Naouel Pour obtenir LE DIPLOME DE MAGISTER Spécialitéé Informatique Option : Automatique Informatique Intitulé : DÉTECTION DE COURRIELS INDÉSIRABLES
DEPARTEMENTT D'INFORMATIQUE MEMOIRE Présenté par B ARIGOU Baya Naouel Pour obtenir LE DIPLOME DE MAGISTER Spécialitéé Informatique Option : Automatique Informatique Intitulé : DÉTECTION DE COURRIELS INDÉSIRABLES
TRAITEMENT AUTOMATIQUE DES LANGUES. Licence d'informatique 2ème Année Semestre 1. Département d'informatique Université de Caen Basse-Normandie
 TRAITEMENT AUTOMATIQUE DES LANGUES Licence d'informatique 2ème Année Semestre 1 Département d'informatique Université de Caen Basse-Normandie https://dias.users.greyc.fr/?op=paginas/tal.html Plan Définition
TRAITEMENT AUTOMATIQUE DES LANGUES Licence d'informatique 2ème Année Semestre 1 Département d'informatique Université de Caen Basse-Normandie https://dias.users.greyc.fr/?op=paginas/tal.html Plan Définition
Programme. Matière : RECHERCHE D INFORMATION Crédit : 4 Cours : 1h30 TD : 1h30 Semestre : S1 du M1 Assuré par: Herzallah Abdelkarim
 Matière : RECHERCHE D INFORMATION Crédit : 4 Cours : 1h30 TD : 1h30 Semestre : S1 du M1 Assuré par: Herzallah Abdelkarim Programme 1-Introduction : Objectifs de la RI, Concepts de base : information, Besoin
Matière : RECHERCHE D INFORMATION Crédit : 4 Cours : 1h30 TD : 1h30 Semestre : S1 du M1 Assuré par: Herzallah Abdelkarim Programme 1-Introduction : Objectifs de la RI, Concepts de base : information, Besoin
Déroulement d un projet en DATA MINING, préparation et analyse des données. Walid AYADI
 1 Déroulement d un projet en DATA MINING, préparation et analyse des données Walid AYADI 2 Les étapes d un projet Choix du sujet - Définition des objectifs Inventaire des données existantes Collecte, nettoyage
1 Déroulement d un projet en DATA MINING, préparation et analyse des données Walid AYADI 2 Les étapes d un projet Choix du sujet - Définition des objectifs Inventaire des données existantes Collecte, nettoyage
Master d Informatique M1 Université Paris 7 - Denis Diderot Travail de Recherche Encadré Surf Bayesien
 Master d Informatique M1 Université Paris 7 - Denis Diderot Travail de Recherche Encadré Surf Bayesien Denis Cousineau Sous la direction de Roberto di Cosmo Juin 2005 1 Table des matières 1 Présentation
Master d Informatique M1 Université Paris 7 - Denis Diderot Travail de Recherche Encadré Surf Bayesien Denis Cousineau Sous la direction de Roberto di Cosmo Juin 2005 1 Table des matières 1 Présentation
JADT 2010-11/06/2010 Rome Utilisation de la visualisation en nuage arboré pour l'analyse littéraire
 JADT 2010-11/06/2010 Rome Utilisation de la visualisation en nuage arboré pour l'analyse littéraire Delphine Amstutz (CELLF Université Paris-Sorbonne Paris 4 / CNRS) Philippe Gambette (LIRMM Université
JADT 2010-11/06/2010 Rome Utilisation de la visualisation en nuage arboré pour l'analyse littéraire Delphine Amstutz (CELLF Université Paris-Sorbonne Paris 4 / CNRS) Philippe Gambette (LIRMM Université
t 100. = 8 ; le pourcentage de réduction est : 8 % 1 t Le pourcentage d'évolution (appelé aussi taux d'évolution) est le nombre :
 est le nombre :") Terminale STSS 2 012 2 013 Pourcentages Synthèse 1) Définition : Calculer t % d'un nombre, c'est multiplier ce nombre par t 100. 2) Exemples de calcul : a) Calcul d un pourcentage : Un article coûtant
Terminale STSS 2 012 2 013 Pourcentages Synthèse 1) Définition : Calculer t % d'un nombre, c'est multiplier ce nombre par t 100. 2) Exemples de calcul : a) Calcul d un pourcentage : Un article coûtant
Enjeux mathématiques et Statistiques du Big Data
 Enjeux mathématiques et Statistiques du Big Data Mathilde Mougeot LPMA/Université Paris Diderot, mathilde.mougeot@univ-paris-diderot.fr Mathématique en Mouvements, Paris, IHP, 6 Juin 2015 M. Mougeot (Paris
Enjeux mathématiques et Statistiques du Big Data Mathilde Mougeot LPMA/Université Paris Diderot, mathilde.mougeot@univ-paris-diderot.fr Mathématique en Mouvements, Paris, IHP, 6 Juin 2015 M. Mougeot (Paris
IODAA. de l 1nf0rmation à la Décision par l Analyse et l Apprentissage / 21
 IODAA de l 1nf0rmation à la Décision par l Analyse et l Apprentissage IODAA Informations générales 2 Un monde nouveau Des données numériques partout en croissance prodigieuse Comment en extraire des connaissances
IODAA de l 1nf0rmation à la Décision par l Analyse et l Apprentissage IODAA Informations générales 2 Un monde nouveau Des données numériques partout en croissance prodigieuse Comment en extraire des connaissances
Raisonnement probabiliste
 Plan Raisonnement probabiliste IFT-17587 Concepts avancés pour systèmes intelligents Luc Lamontagne Réseaux bayésiens Inférence dans les réseaux bayésiens Inférence exacte Inférence approximative 1 2 Contexte
Plan Raisonnement probabiliste IFT-17587 Concepts avancés pour systèmes intelligents Luc Lamontagne Réseaux bayésiens Inférence dans les réseaux bayésiens Inférence exacte Inférence approximative 1 2 Contexte
LOGO. Module «Big Data» Extraction de Connaissances à partir de Données. Claudia MARINICA MCF, ETIS UCP/ENSEA/CNRS Claudia.Marinica@u-cergy.
 Module «Big Data» Extraction de Connaissances à partir de Données Claudia MARINICA MCF, ETIS UCP/ENSEA/CNRS Claudia.Marinica@u-cergy.fr 14 Janvier 2015 Pourquoi l extraction de connaissances à partir de
Module «Big Data» Extraction de Connaissances à partir de Données Claudia MARINICA MCF, ETIS UCP/ENSEA/CNRS Claudia.Marinica@u-cergy.fr 14 Janvier 2015 Pourquoi l extraction de connaissances à partir de
L'intelligence d'affaires: la statistique dans nos vies de consommateurs
 L'intelligence d'affaires: la statistique dans nos vies de consommateurs Jean-François Plante, HEC Montréal Marc Fredette, HEC Montréal Congrès de l ACFAS, Université Laval, 6 mai 2013 Intelligence d affaires
L'intelligence d'affaires: la statistique dans nos vies de consommateurs Jean-François Plante, HEC Montréal Marc Fredette, HEC Montréal Congrès de l ACFAS, Université Laval, 6 mai 2013 Intelligence d affaires
Introduction au maillage pour le calcul scientifique
 Introduction au maillage pour le calcul scientifique CEA DAM Île-de-France, Bruyères-le-Châtel franck.ledoux@cea.fr Présentation adaptée du tutorial de Steve Owen, Sandia National Laboratories, Albuquerque,
Introduction au maillage pour le calcul scientifique CEA DAM Île-de-France, Bruyères-le-Châtel franck.ledoux@cea.fr Présentation adaptée du tutorial de Steve Owen, Sandia National Laboratories, Albuquerque,
Analyse de grandes bases de données en santé
 .. Analyse de grandes bases de données en santé Alain Duhamel Michaël Genin Mohamed Lemdani EA 2694 / CERIM Master 2 Recherche Biologie et Santé Journée Thématique Fouille de Données Plan. 1 Problématique.
.. Analyse de grandes bases de données en santé Alain Duhamel Michaël Genin Mohamed Lemdani EA 2694 / CERIM Master 2 Recherche Biologie et Santé Journée Thématique Fouille de Données Plan. 1 Problématique.
RapidMiner. Data Mining. 1 Introduction. 2 Prise en main. Master Maths Finances 2010/2011. 1.1 Présentation. 1.2 Ressources
 Master Maths Finances 2010/2011 Data Mining janvier 2011 RapidMiner 1 Introduction 1.1 Présentation RapidMiner est un logiciel open source et gratuit dédié au data mining. Il contient de nombreux outils
Master Maths Finances 2010/2011 Data Mining janvier 2011 RapidMiner 1 Introduction 1.1 Présentation RapidMiner est un logiciel open source et gratuit dédié au data mining. Il contient de nombreux outils
I.D.S. Systèmes de détection d intrusion - Link Analysis. par: FOUQUIN MATHIEU. responsable: AKLI ADJAOUTE DEVÈZE BENJAMIN.
 EPITA SCIA PROMO 2005 14-16 rue Voltaire 94270 Kremlin-Bicêtre I.D.S. Systèmes de détection d intrusion - Link Analysis Juillet 2004 par: DEVÈZE BENJAMIN FOUQUIN MATHIEU responsable: AKLI ADJAOUTE TABLE
EPITA SCIA PROMO 2005 14-16 rue Voltaire 94270 Kremlin-Bicêtre I.D.S. Systèmes de détection d intrusion - Link Analysis Juillet 2004 par: DEVÈZE BENJAMIN FOUQUIN MATHIEU responsable: AKLI ADJAOUTE TABLE
Bases de Données. Plan
 Université Mohammed V- Agdal Ecole Mohammadia d'ingénieurs Rabat Bases de Données Mr N.EL FADDOULI 2014-2015 Plan Généralités: Définition de Bases de Données Le modèle relationnel Algèbre relationnelle
Université Mohammed V- Agdal Ecole Mohammadia d'ingénieurs Rabat Bases de Données Mr N.EL FADDOULI 2014-2015 Plan Généralités: Définition de Bases de Données Le modèle relationnel Algèbre relationnelle
Techniques du Data Mining pour la prédiction de faillite des entreprises et la gestion du risque de crédit
 Techniques du Data Mining pour la prédiction de faillite des entreprises et la gestion du risque de crédit Adil Belhouari HEC - Montréal - Journées de l Optimisation 2005-09 Mai 2005 PLAN DE LA PRÉSENTATION
Techniques du Data Mining pour la prédiction de faillite des entreprises et la gestion du risque de crédit Adil Belhouari HEC - Montréal - Journées de l Optimisation 2005-09 Mai 2005 PLAN DE LA PRÉSENTATION
Une comparaison de méthodes de discrimination des masses de véhicules automobiles
 p.1/34 Une comparaison de méthodes de discrimination des masses de véhicules automobiles A. Rakotomamonjy, R. Le Riche et D. Gualandris INSA de Rouen / CNRS 1884 et SMS / PSA Enquêtes en clientèle dans
p.1/34 Une comparaison de méthodes de discrimination des masses de véhicules automobiles A. Rakotomamonjy, R. Le Riche et D. Gualandris INSA de Rouen / CNRS 1884 et SMS / PSA Enquêtes en clientèle dans
Travaux pratiques avec RapidMiner
 Travaux pratiques avec RapidMiner Master Informatique de Paris 6 Spécialité IAD Parcours EDOW Module Algorithmes pour la Fouille de Données Janvier 2012 Prise en main Généralités RapidMiner est un logiciel
Travaux pratiques avec RapidMiner Master Informatique de Paris 6 Spécialité IAD Parcours EDOW Module Algorithmes pour la Fouille de Données Janvier 2012 Prise en main Généralités RapidMiner est un logiciel
Le Data Mining au service du Scoring ou notation statistique des emprunteurs!
 France Le Data Mining au service du Scoring ou notation statistique des emprunteurs! Comme le rappelle la CNIL dans sa délibération n 88-083 du 5 Juillet 1988 portant adoption d une recommandation relative
France Le Data Mining au service du Scoring ou notation statistique des emprunteurs! Comme le rappelle la CNIL dans sa délibération n 88-083 du 5 Juillet 1988 portant adoption d une recommandation relative
La segmentation à l aide de EG-SAS. A.Bouhia Analyste principal à la Banque Nationale du Canada. Chargé de cours à l UQAM
 La segmentation à l aide de EG-SAS A.Bouhia Analyste principal à la Banque Nationale du Canada. Chargé de cours à l UQAM Définition de la segmentation - Au lieu de considérer une population dans son ensemble,
La segmentation à l aide de EG-SAS A.Bouhia Analyste principal à la Banque Nationale du Canada. Chargé de cours à l UQAM Définition de la segmentation - Au lieu de considérer une population dans son ensemble,
N. Paparoditis, Laboratoire MATIS
 N. Paparoditis, Laboratoire MATIS Contexte: Diffusion de données et services locaux STEREOPOLIS II Un véhicule de numérisation mobile terrestre Lasers Caméras Système de navigation/positionnement STEREOPOLIS
N. Paparoditis, Laboratoire MATIS Contexte: Diffusion de données et services locaux STEREOPOLIS II Un véhicule de numérisation mobile terrestre Lasers Caméras Système de navigation/positionnement STEREOPOLIS
Sélection d un moteur de recherche pour intranet : Les sept points à prendre en compte
 Sélection d un moteur de recherche pour intranet : Les sept points à prendre en compte 1Les bases : vos objectifs 2 Sélection d un moteur de recherche pour intranet : Les sept points à prendre en compte
Sélection d un moteur de recherche pour intranet : Les sept points à prendre en compte 1Les bases : vos objectifs 2 Sélection d un moteur de recherche pour intranet : Les sept points à prendre en compte
Entrepôt de données 1. Introduction
 Entrepôt de données 1 (data warehouse) Introduction 1 Présentation Le concept d entrepôt de données a été formalisé pour la première fois en 1990 par Bill Inmon. Il s agissait de constituer une base de
Entrepôt de données 1 (data warehouse) Introduction 1 Présentation Le concept d entrepôt de données a été formalisé pour la première fois en 1990 par Bill Inmon. Il s agissait de constituer une base de
TSTI 2D CH X : Exemples de lois à densité 1
 TSTI 2D CH X : Exemples de lois à densité I Loi uniforme sur ab ; ) Introduction Dans cette activité, on s intéresse à la modélisation du tirage au hasard d un nombre réel de l intervalle [0 ;], chacun
TSTI 2D CH X : Exemples de lois à densité I Loi uniforme sur ab ; ) Introduction Dans cette activité, on s intéresse à la modélisation du tirage au hasard d un nombre réel de l intervalle [0 ;], chacun
Identification de nouveaux membres dans des familles d'interleukines
 Identification de nouveaux membres dans des familles d'interleukines Nicolas Beaume Jérôme Mickolajczak Gérard Ramstein Yannick Jacques 1ère partie : Définition de la problématique Les familles de gènes
Identification de nouveaux membres dans des familles d'interleukines Nicolas Beaume Jérôme Mickolajczak Gérard Ramstein Yannick Jacques 1ère partie : Définition de la problématique Les familles de gènes
Intelligence Economique - Business Intelligence
 Intelligence Economique - Business Intelligence Notion de Business Intelligence Dès qu'il y a une entreprise, il y a implicitement intelligence économique (tout comme il y a du marketing) : quelle produit
Intelligence Economique - Business Intelligence Notion de Business Intelligence Dès qu'il y a une entreprise, il y a implicitement intelligence économique (tout comme il y a du marketing) : quelle produit
Linked Open Data. Le Web de données Réseau, usages, perspectives. Eric Charton. Eric Charton
 Linked Open Data Le Web de données Réseau, usages, perspectives Sommaire Histoire du Linked Open Data Structure et évolution du réseau Utilisations du Linked Open Data Présence sur le réseau LOD Futurs
Linked Open Data Le Web de données Réseau, usages, perspectives Sommaire Histoire du Linked Open Data Structure et évolution du réseau Utilisations du Linked Open Data Présence sur le réseau LOD Futurs
Introduction à la B.I. Avec SQL Server 2008
 Introduction à la B.I. Avec SQL Server 2008 Version 1.0 VALENTIN Pauline 2 Introduction à la B.I. avec SQL Server 2008 Sommaire 1 Présentation de la B.I. et SQL Server 2008... 3 1.1 Présentation rapide
Introduction à la B.I. Avec SQL Server 2008 Version 1.0 VALENTIN Pauline 2 Introduction à la B.I. avec SQL Server 2008 Sommaire 1 Présentation de la B.I. et SQL Server 2008... 3 1.1 Présentation rapide
Organisé par StatSoft France et animé par Dr Diego Kuonen, expert en techniques de data mining.
 2 jours : Mardi 15 et mercredi 16 novembre 2005 de 9 heures 30 à 17 heures 30 Organisé par StatSoft France et animé par Dr Diego Kuonen, expert en techniques de data mining. Madame, Monsieur, On parle
2 jours : Mardi 15 et mercredi 16 novembre 2005 de 9 heures 30 à 17 heures 30 Organisé par StatSoft France et animé par Dr Diego Kuonen, expert en techniques de data mining. Madame, Monsieur, On parle
Fast and furious decision tree induction
 Institut National des Sciences Appliquées de Rennes Rapport de pré-étude Encadrants : Nikolaos Parlavantzas - Christian Raymond Fast and furious decision tree induction Andra Blaj Nicolas Desfeux Emeline
Institut National des Sciences Appliquées de Rennes Rapport de pré-étude Encadrants : Nikolaos Parlavantzas - Christian Raymond Fast and furious decision tree induction Andra Blaj Nicolas Desfeux Emeline
SAS ENTERPRISE MINER POUR L'ACTUAIRE
 SAS ENTERPRISE MINER POUR L'ACTUAIRE Conférence de l Association des Actuaires I.A.R.D. 07 JUIN 2013 Sylvain Tremblay Spécialiste en formation statistique SAS Canada AGENDA Survol d Enterprise Miner de
SAS ENTERPRISE MINER POUR L'ACTUAIRE Conférence de l Association des Actuaires I.A.R.D. 07 JUIN 2013 Sylvain Tremblay Spécialiste en formation statistique SAS Canada AGENDA Survol d Enterprise Miner de
Sauvegarde collaborative entre pairs Ludovic Courtès LAAS-CNRS
 Sauvegarde collaborative entre pairs 1 Sauvegarde collaborative entre pairs Ludovic Courtès LAAS-CNRS Sauvegarde collaborative entre pairs 2 Introduction Pourquoi pair à pair? Utilisation de ressources
Sauvegarde collaborative entre pairs 1 Sauvegarde collaborative entre pairs Ludovic Courtès LAAS-CNRS Sauvegarde collaborative entre pairs 2 Introduction Pourquoi pair à pair? Utilisation de ressources
Data Mining. Master 1 Informatique - Mathématiques UAG
 Data Mining Master 1 Informatique - Mathématiques UAG 1.1 - Introduction Data Mining? On parle de Fouille de données Data Mining Extraction de connaissances à partir de données Knowledge Discovery in Data
Data Mining Master 1 Informatique - Mathématiques UAG 1.1 - Introduction Data Mining? On parle de Fouille de données Data Mining Extraction de connaissances à partir de données Knowledge Discovery in Data
Techniques d analyse et de conception d outils pour la gestion du processus de segmentation des abonnés des entreprises de télécommunication
 Techniques d analyse et de conception d outils pour la gestion du processus de segmentation des abonnés des entreprises de télécommunication R. Carlos Nana Mbinkeu 1,3, C. Tangha 1, A. Chomnoue 1, A. Kuete
Techniques d analyse et de conception d outils pour la gestion du processus de segmentation des abonnés des entreprises de télécommunication R. Carlos Nana Mbinkeu 1,3, C. Tangha 1, A. Chomnoue 1, A. Kuete
XML, PMML, SOAP. Rapport. EPITA SCIA Promo 2004 16 janvier 2003. Julien Lemoine Alexandre Thibault Nicolas Wiest-Million
 XML, PMML, SOAP Rapport EPITA SCIA Promo 2004 16 janvier 2003 Julien Lemoine Alexandre Thibault Nicolas Wiest-Million i TABLE DES MATIÈRES Table des matières 1 XML 1 1.1 Présentation de XML.................................
XML, PMML, SOAP Rapport EPITA SCIA Promo 2004 16 janvier 2003 Julien Lemoine Alexandre Thibault Nicolas Wiest-Million i TABLE DES MATIÈRES Table des matières 1 XML 1 1.1 Présentation de XML.................................
Grégoire de Lassence. Copyright 2006, SAS Institute Inc. All rights reserved.
 Grégoire de Lassence 1 Grégoire de Lassence Responsable Pédagogie et Recherche Département Académique Tel : +33 1 60 62 12 19 gregoire.delassence@fra.sas.com http://www.sas.com/france/academic SAS dans
Grégoire de Lassence 1 Grégoire de Lassence Responsable Pédagogie et Recherche Département Académique Tel : +33 1 60 62 12 19 gregoire.delassence@fra.sas.com http://www.sas.com/france/academic SAS dans
Dans cette définition, il y a trois notions clés: documents, requête, pertinence.
 Introduction à la RI 1. Définition Un système de recherche d'information (RI) est un système qui permet de retrouver les documents pertinents à une requête d'utilisateur, à partir d'une base de documents
Introduction à la RI 1. Définition Un système de recherche d'information (RI) est un système qui permet de retrouver les documents pertinents à une requête d'utilisateur, à partir d'une base de documents
N 334 - SIMON Anne-Catherine
 N 334 - SIMON Anne-Catherine RÉALISATION D UN CDROM/DVD CONTENANT DES DONNÉES DU LANGAGE ORAL ORGANISÉES EN PARCOURS DIDACTIQUES D INITIATION LINGUISTIQUE A PARTIR DES BASES DE DONNÉES VALIBEL Introduction
N 334 - SIMON Anne-Catherine RÉALISATION D UN CDROM/DVD CONTENANT DES DONNÉES DU LANGAGE ORAL ORGANISÉES EN PARCOURS DIDACTIQUES D INITIATION LINGUISTIQUE A PARTIR DES BASES DE DONNÉES VALIBEL Introduction
Travailler avec les télécommunications
 Travailler avec les télécommunications Minimiser l attrition dans le secteur des télécommunications Table des matières : 1 Analyse de l attrition à l aide du data mining 2 Analyse de l attrition de la
Travailler avec les télécommunications Minimiser l attrition dans le secteur des télécommunications Table des matières : 1 Analyse de l attrition à l aide du data mining 2 Analyse de l attrition de la
Chap 4: Analyse syntaxique. Prof. M.D. RAHMANI Compilation SMI- S5 2013/14 1
 Chap 4: Analyse syntaxique 1 III- L'analyse syntaxique: 1- Le rôle d'un analyseur syntaxique 2- Grammaires non contextuelles 3- Ecriture d'une grammaire 4- Les méthodes d'analyse 5- L'analyse LL(1) 6-
Chap 4: Analyse syntaxique 1 III- L'analyse syntaxique: 1- Le rôle d'un analyseur syntaxique 2- Grammaires non contextuelles 3- Ecriture d'une grammaire 4- Les méthodes d'analyse 5- L'analyse LL(1) 6-
Historique. Architecture. Contribution. Conclusion. Définitions et buts La veille stratégique Le multidimensionnel Les classifications
 L intelligence économique outil stratégique pour l entreprise Professeur Bernard DOUSSET dousset@irit.fr http://atlas.irit.fr Institut de Recherche en Informatique de Toulouse (IRIT) Equipe Systèmes d
L intelligence économique outil stratégique pour l entreprise Professeur Bernard DOUSSET dousset@irit.fr http://atlas.irit.fr Institut de Recherche en Informatique de Toulouse (IRIT) Equipe Systèmes d
Dan Istrate. Directeur de thèse : Eric Castelli Co-Directeur : Laurent Besacier
 Détection et reconnaissance des sons pour la surveillance médicale Dan Istrate le 16 décembre 2003 Directeur de thèse : Eric Castelli Co-Directeur : Laurent Besacier Thèse mené dans le cadre d une collaboration
Détection et reconnaissance des sons pour la surveillance médicale Dan Istrate le 16 décembre 2003 Directeur de thèse : Eric Castelli Co-Directeur : Laurent Besacier Thèse mené dans le cadre d une collaboration
Apprentissage Automatique pour la détection de relations d affaire
 Université de Montréal Apprentissage Automatique pour la détection de relations d affaire par Grâce CAPO-CHICHI Département d Informatique et de Recherche Opérationnelle Université de Montréal Mémoire
Université de Montréal Apprentissage Automatique pour la détection de relations d affaire par Grâce CAPO-CHICHI Département d Informatique et de Recherche Opérationnelle Université de Montréal Mémoire
Sujet proposé par Yves M. LEROY. Cet examen se compose d un exercice et de deux problèmes. Ces trois parties sont indépendantes.
 Promotion X 004 COURS D ANALYSE DES STRUCTURES MÉCANIQUES PAR LA MÉTHODE DES ELEMENTS FINIS (MEC 568) contrôle non classant (7 mars 007, heures) Documents autorisés : polycopié ; documents et notes de
Promotion X 004 COURS D ANALYSE DES STRUCTURES MÉCANIQUES PAR LA MÉTHODE DES ELEMENTS FINIS (MEC 568) contrôle non classant (7 mars 007, heures) Documents autorisés : polycopié ; documents et notes de
L apprentissage automatique
 L apprentissage automatique L apprentissage automatique L'apprentissage automatique fait référence au développement, à l analyse et à l implémentation de méthodes qui permettent à une machine d évoluer
L apprentissage automatique L apprentissage automatique L'apprentissage automatique fait référence au développement, à l analyse et à l implémentation de méthodes qui permettent à une machine d évoluer
Multi-catégorisation de textes juridiques et retour de pertinence
 Multi-catégorisation de textes juridiques et retour de pertinence Vincent Pisetta, Hakim Hacid et Djamel A. Zighed article paru dans G. Ritschard et C. Djeraba (eds), Extraction et gestion des Connaissances
Multi-catégorisation de textes juridiques et retour de pertinence Vincent Pisetta, Hakim Hacid et Djamel A. Zighed article paru dans G. Ritschard et C. Djeraba (eds), Extraction et gestion des Connaissances
Plan. Data mining (partie 2) Data Mining : Utilisateur ou Statisticien? Data Mining : Cocktail de techniques. Master MIAGE - ENITE.
 Data Mining : Utilisateur ou Statisticien? Data Mining : Cocktail de techniques. Master MIAGE - ENITE.") Plan Data mining (partie 2) Introduction 1. Les tâches du data mining 2. Le processus de data mining Master MIAGE - ENITE Spécialité ACSI 3. Les bases de l'analyse de données 4. Les modèles du data mining
Plan Data mining (partie 2) Introduction 1. Les tâches du data mining 2. Le processus de data mining Master MIAGE - ENITE Spécialité ACSI 3. Les bases de l'analyse de données 4. Les modèles du data mining
TEXT MINING. 10.6.2003 1 von 7
 TEXT MINING 10.6.2003 1 von 7 A LA RECHERCHE D'UNE AIGUILLE DANS UNE BOTTE DE FOIN Alors que le Data Mining recherche des modèles cachés dans de grandes quantités de données, le Text Mining se concentre
TEXT MINING 10.6.2003 1 von 7 A LA RECHERCHE D'UNE AIGUILLE DANS UNE BOTTE DE FOIN Alors que le Data Mining recherche des modèles cachés dans de grandes quantités de données, le Text Mining se concentre
Ressources lexicales au service de recherche et d indexation des images
 RECITAL 2011, Montpellier, 27 juin - 1er juillet 2011 Ressources lexicales au service de recherche et d indexation des images Inga Gheorghita 1,2 (1) ATILF-CNRS, Nancy-Université (UMR 7118), France (2)
RECITAL 2011, Montpellier, 27 juin - 1er juillet 2011 Ressources lexicales au service de recherche et d indexation des images Inga Gheorghita 1,2 (1) ATILF-CNRS, Nancy-Université (UMR 7118), France (2)
Rappels sur les suites - Algorithme
 DERNIÈRE IMPRESSION LE 14 septembre 2015 à 12:36 Rappels sur les suites - Algorithme Table des matières 1 Suite : généralités 2 1.1 Déition................................. 2 1.2 Exemples de suites............................
DERNIÈRE IMPRESSION LE 14 septembre 2015 à 12:36 Rappels sur les suites - Algorithme Table des matières 1 Suite : généralités 2 1.1 Déition................................. 2 1.2 Exemples de suites............................
Les 10 grands principes de l utilisation du data mining pour une gestion de la relation client réussie
 Les 10 grands principes de l utilisation du data mining pour une gestion de la relation client réussie Découvrir les stratégies ayant fait leurs preuves et les meilleures pratiques Points clés : Planifier
Les 10 grands principes de l utilisation du data mining pour une gestion de la relation client réussie Découvrir les stratégies ayant fait leurs preuves et les meilleures pratiques Points clés : Planifier
ACCÈS SÉMANTIQUE AUX BASES DE DONNÉES DOCUMENTAIRES
 ACCÈS SÉMANTIQUE AUX BASES DE DONNÉES DOCUMENTAIRES Techniques symboliques de traitement automatique du langage pour l indexation thématique et l extraction d information temporelle Thèse Défense publique
ACCÈS SÉMANTIQUE AUX BASES DE DONNÉES DOCUMENTAIRES Techniques symboliques de traitement automatique du langage pour l indexation thématique et l extraction d information temporelle Thèse Défense publique
COURS SYRRES RÉSEAUX SOCIAUX INTRODUCTION. Jean-Loup Guillaume
 COURS SYRRES RÉSEAUX SOCIAUX INTRODUCTION Jean-Loup Guillaume Le cours Enseignant : Jean-Loup Guillaume équipe Complex Network Page du cours : http://jlguillaume.free.fr/www/teaching-syrres.php Évaluation
COURS SYRRES RÉSEAUX SOCIAUX INTRODUCTION Jean-Loup Guillaume Le cours Enseignant : Jean-Loup Guillaume équipe Complex Network Page du cours : http://jlguillaume.free.fr/www/teaching-syrres.php Évaluation
! Text Encoding Initiative
 Format XML: suite! le contenu d un élément est la concaténation de! texte! et d éléments (imbrication)! => structure arborescente! pas de chevauchement de balises! => exemple : une analyse syntagmatique
Format XML: suite! le contenu d un élément est la concaténation de! texte! et d éléments (imbrication)! => structure arborescente! pas de chevauchement de balises! => exemple : une analyse syntagmatique
Homophones grammaticaux de catégories différentes. s y si ci
 GRAMMATICAUX DE CATÉGORIES DIFFÉRENTES S Y HOMOPHONES SI CI 1 Homophones grammaticaux de catégories différentes s y si ci s y : pronom personnel se (e élidé devant une voyelle) à la troisième personne
GRAMMATICAUX DE CATÉGORIES DIFFÉRENTES S Y HOMOPHONES SI CI 1 Homophones grammaticaux de catégories différentes s y si ci s y : pronom personnel se (e élidé devant une voyelle) à la troisième personne
Business & High Technology
 UNIVERSITE DE TUNIS INSTITUT SUPERIEUR DE GESTION DE TUNIS Département : Informatique Business & High Technology Chapitre 8 : ID : Informatique Décisionnelle BI : Business Intelligence Sommaire Introduction...
UNIVERSITE DE TUNIS INSTITUT SUPERIEUR DE GESTION DE TUNIS Département : Informatique Business & High Technology Chapitre 8 : ID : Informatique Décisionnelle BI : Business Intelligence Sommaire Introduction...
ricco.rakotomalala@univ-lyon2.fr http://chirouble.univ-lyon2.fr/~ricco/cours/ Publications, ressources, liens, logiciels,
 Université Lumière Lyon 2 Tutoriels Tanagra - http://tutoriels-data-mining.blogspot.fr/ 1 ricco.rakotomalala@univ-lyon2.fr http://chirouble.univ-lyon2.fr/~ricco/cours/ Publications, ressources, liens,
Université Lumière Lyon 2 Tutoriels Tanagra - http://tutoriels-data-mining.blogspot.fr/ 1 ricco.rakotomalala@univ-lyon2.fr http://chirouble.univ-lyon2.fr/~ricco/cours/ Publications, ressources, liens,
Arbres binaires de décision
 1 Arbres binaires de décision Résumé Arbres binaires de décision Méthodes de construction d arbres binaires de décision, modélisant une discrimination (classification trees) ou une régression (regression
1 Arbres binaires de décision Résumé Arbres binaires de décision Méthodes de construction d arbres binaires de décision, modélisant une discrimination (classification trees) ou une régression (regression
Didier MOUNIEN Samantha MOINEAUX
 Didier MOUNIEN Samantha MOINEAUX 08/01/2008 1 Généralisation des ERP ERP génère une importante masse de données Comment mesurer l impact réel d une décision? Comment choisir entre plusieurs décisions?
Didier MOUNIEN Samantha MOINEAUX 08/01/2008 1 Généralisation des ERP ERP génère une importante masse de données Comment mesurer l impact réel d une décision? Comment choisir entre plusieurs décisions?
1 Complément sur la projection du nuage des individus
 TP 0 : Analyse en composantes principales (II) Le but de ce TP est d approfondir nos connaissances concernant l analyse en composantes principales (ACP). Pour cela, on reprend les notations du précédent
TP 0 : Analyse en composantes principales (II) Le but de ce TP est d approfondir nos connaissances concernant l analyse en composantes principales (ACP). Pour cela, on reprend les notations du précédent
Coup de Projecteur sur les Réseaux de Neurones
 Coup de Projecteur sur les Réseaux de Neurones Les réseaux de neurones peuvent être utilisés pour des problèmes de prévision ou de classification. La représentation la plus populaire est le réseau multicouche
Coup de Projecteur sur les Réseaux de Neurones Les réseaux de neurones peuvent être utilisés pour des problèmes de prévision ou de classification. La représentation la plus populaire est le réseau multicouche
Le cinquième chapitre
 Le cinquième chapitre Objectif : présenter les supports matériels ou immatériels permettant d'étayer cette nouvelle approche de la fonction maintenance. I. Evolution du domaine technique - Différents domaines
Le cinquième chapitre Objectif : présenter les supports matériels ou immatériels permettant d'étayer cette nouvelle approche de la fonction maintenance. I. Evolution du domaine technique - Différents domaines
Algorithmes de Transmission et de Recherche de l Information dans les Réseaux de Communication. Philippe Robert INRIA Paris-Rocquencourt
 Algorithmes de Transmission et de Recherche de l Information dans les Réseaux de Communication Philippe Robert INRIA Paris-Rocquencourt Le 2 juin 2010 Présentation Directeur de recherche à l INRIA Institut
Algorithmes de Transmission et de Recherche de l Information dans les Réseaux de Communication Philippe Robert INRIA Paris-Rocquencourt Le 2 juin 2010 Présentation Directeur de recherche à l INRIA Institut
Annexe : La Programmation Informatique
 GLOSSAIRE Table des matières La Programmation...2 Les langages de programmation...2 Java...2 La programmation orientée objet...2 Classe et Objet...3 API et Bibliothèque Logicielle...3 Environnement de
GLOSSAIRE Table des matières La Programmation...2 Les langages de programmation...2 Java...2 La programmation orientée objet...2 Classe et Objet...3 API et Bibliothèque Logicielle...3 Environnement de
Principe de symétrisation pour la construction d un test adaptatif
 Principe de symétrisation pour la construction d un test adaptatif Cécile Durot 1 & Yves Rozenholc 2 1 UFR SEGMI, Université Paris Ouest Nanterre La Défense, France, cecile.durot@gmail.com 2 Université
Principe de symétrisation pour la construction d un test adaptatif Cécile Durot 1 & Yves Rozenholc 2 1 UFR SEGMI, Université Paris Ouest Nanterre La Défense, France, cecile.durot@gmail.com 2 Université
Les enjeux du Big Data Innovation et opportunités de l'internet industriel. Datasio 2013
 Les enjeux du Big Data Innovation et opportunités de l'internet industriel François Royer froyer@datasio.com Accompagnement des entreprises dans leurs stratégies quantitatives Valorisation de patrimoine
Les enjeux du Big Data Innovation et opportunités de l'internet industriel François Royer froyer@datasio.com Accompagnement des entreprises dans leurs stratégies quantitatives Valorisation de patrimoine
Classification Automatique de messages : une approche hybride
 RECIAL 2002, Nancy, 24-27 juin 2002 Classification Automatique de messages : une approche hybride O. Nouali (1) Laboratoire des Logiciels de base, CE.R.I.S., Rue des 3 frères Aïssiou, Ben Aknoun, Alger,
RECIAL 2002, Nancy, 24-27 juin 2002 Classification Automatique de messages : une approche hybride O. Nouali (1) Laboratoire des Logiciels de base, CE.R.I.S., Rue des 3 frères Aïssiou, Ben Aknoun, Alger,