Big Data, un nouveau paradigme et de nouveaux challenges
|
|
|
- Marie-Rose Monette
- il y a 10 ans
- Total affichages :
Transcription
1 Big Data, un nouveau paradigme et de nouveaux challenges Sebastiao Correia 21 Novembre 2014 Séminaire Thématique : Traitement et analyse statistique des données massives, Poitiers. 1

2 Présentation Sebastiao Correia Talend 2007 Directeur du développement du produit Data Quality Background : thèse en Physique Théorique Parcours Recherche opérationnelle : Optimisation, planification MDM & Business Intelligence Qualité des données 2

3 Objectifs du jour Mettre en évidence quelques changements de paradigmes Souligner l'importance de la qualité de données 3

4 Agenda Présentation de Talend Définition du Big Data Le framework Hadoop L'architecture lambda La qualité de données et le Big data Applications avec Talend Qualité de données Apprentissage automatique 4


5 Présentation de Talend 5
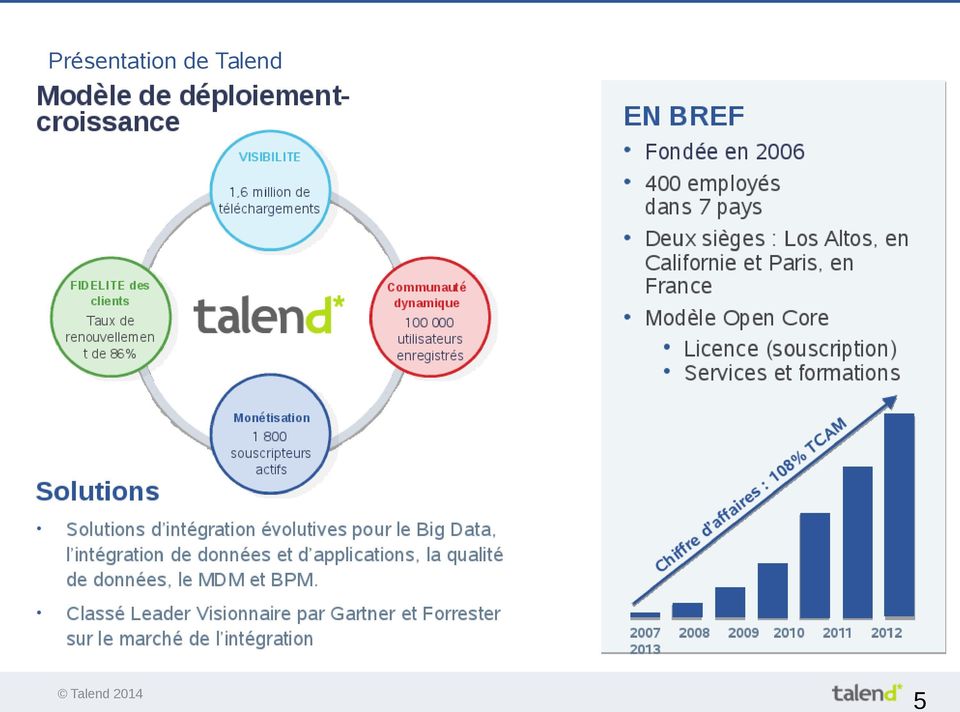
6 La plateforme Talend 6
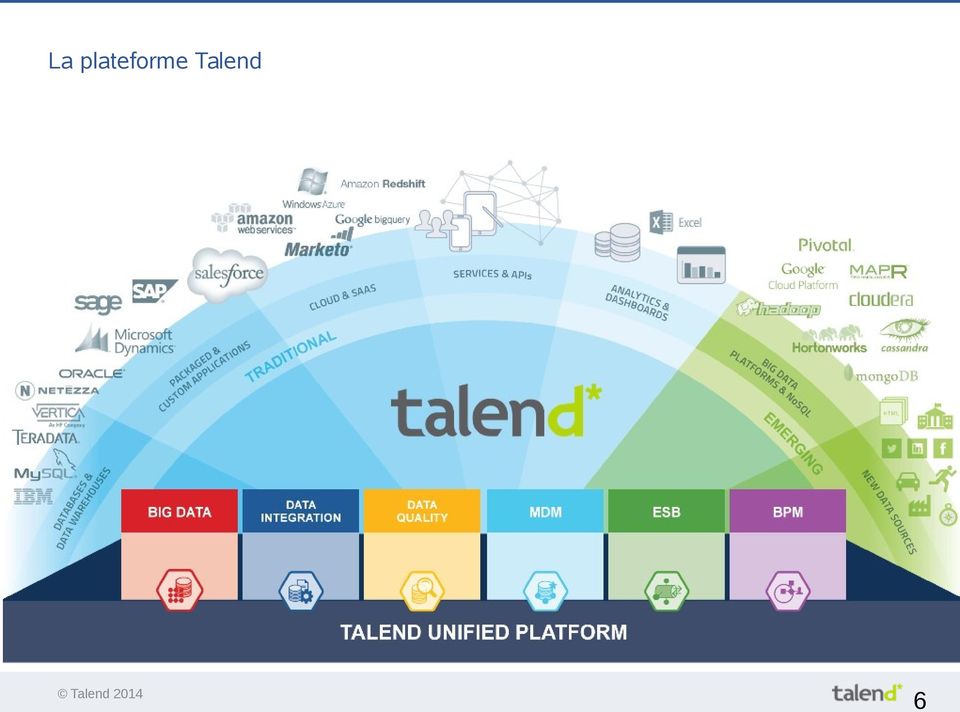

7 L'intégration de données (ETL) Studio de développement de jobs Talend 7


8 La gestion de la qualité des données Profilage des données Définir les critères de qualité Correction des données Suivi de la qualité dans le temps 8

9 Agenda Présentation de Talend Définition du Big Data Le framework Hadoop L'architecture lambda La qualité de données et le Big data Applications avec Talend Qualité de données Apprentissage automatique 9

10 Définition du Big Data Définition en cours d'élaboration en même temps que les techno évoluent Gartner : 3 V ou 5 V Intel : 300 TB de données générées par semaine Oracle : extraction de valeur des bases de données augmentées de sources de données non structurées Microsoft : ensembles de données complexes NIST: dépasse les capacités des systèmes actuels. Google trend: Big Data associé à Hadoop, NoSQL, Google, IBM et Oracle. 10

11 Croissance exponentielle des données En 2012, 90% des données ont été générées durant les 2 années précédentes. Chaque jour de 2012, 2.5 Exaoctets de données sont créés. 11

12 Quelques chiffres sur le déluge de données Par jour milliards d' millions tweets bits de contenu partagé sur Facebook. Par minute 72 heures (259,200 secondes) de video sont partagées sur YouTube. 2 millions de recherches sur Google likes des marques sur Facebook nouveaux posts sur Tumblr nouvelles photos sur Instagram. 571 nouveaux sites web 2.5 Petaoctects dans les bases de données Wal-Mart 40 To de données générées chaque secondes au LHC 25 Po de données stockées et analysées au LHC chaque année. 10 To produits par les capteurs des avions lors d'un vol pendant 30 minutes 1.25 To ce que peut contenir le cerveau humain Plus encore sur 12

13 Une révolution technologique : première étape En 2004, le stockage de 1Go coûtait moins de 1$. => Augmentation des capacités de stockage. Sources:

14 Une révolution technologique : deuxième étape Développement du Cloud. Salesforce 1999 Amazon Web Services 2002 Amazon Elastic Compute Cloud (EC2) 2006 Google Apps 2009 De nouvelles technologies sont apparues dès les années 2000 pour gérer la volumétrie et la variété des données : Hadoop HDFS Map Reduce 14

15 Agenda Présentation de Talend Définition du Big Data Le framework Hadoop L'architecture lambda La qualité de données et le Big data Applications avec Talend Qualité de données Apprentissage automatique 15

16 La naissance d'hadoop Quelques dates 2003 : The Google File System, Sanjay Ghemawat, Howard Gobioff, and ShunTak Leung : MapReduce: Simplified Data Processing on Large Clusters, Jeffrey Dean et Sanjay Ghemawat : Naissance d'hadoop chez Yahoo (HDFS et MapReduce), Doug Cutting et Mike Cafarella : Bigtable: A Distributed Storage System for Structured Data, Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, and Robert E. Gruber 16

17 Le framework Hadoop Hadoop projet opensource (Fondation Apache) dédié au calcul distribué, fiable et scalable Hypothèse de départ : les machines ne sont pas fiables Hadoop la haute disponibilité au niveau applicatif (redondance des données entre machines, pertes de connexions, plantages de machines,...) Modules HDFS : Hadoop Distributed File System (inspiré de GFS) MapReduce : système pour le traitement parallèle des gros volumes de données (inspiré de Google MapReduce) En version 2 : YARN : système de gestion et planification des ressources du cluster 17
 Modules HDFS : Hadoop Distributed File System (inspiré de GFS) MapReduce : système pour le traitement parallèle des gros volumes de données")
18 L'architecture Hadoop version 1 2 couches MapReduce HDFS En production depuis plus de 5 ans chez Yahoo, Ebay, Facebook... 18

19 L'architecture HDFS 1 Namenode pour l'adressage (Single-point-of-failure) Avec éventuellement un backupnode N datanodes pour le stockage 19

20 L'architecture MapReduce 1 Jobtracker : maître Découpe les jobs en tâches MR et les affecte aux tasktrackers N Tasktrackers : esclaves Exécute les mappers et reducers 20

21 Hadoop : un premier changement de paradigme Localité des Données Auparavant les données étaient déplacées dans une application pour être manipulées (SGBD, ETL, Applications...) Désormais, les applications (sous forme MapReduce) sont déplacées vers les données 21
22 Le modèle MapReduce Un programme MapReduce est composé de 2 fonctions Map() divise les données pour traiter des sous-problèmes Reduce() collecte et aggrège les résultats des sous-problèmes Fonctionne avec des données sous forme de paires (clé, valeur) Map(k1,v1) list(k2,v2) Reduce(k2, list (v2)) list(v3) 22

23 Le modèle MapReduce Exemple avec le décompte de mots 23
24 Un second paradigme : le système d'exploitation distribué YARN 24

25 L'architecture Hadoop version 2 Yarn : Sépare la planification des tâches de la gestion des ressources (jobtracker) ResourceManager composé de : Scheduler : alloue des ressources aux applications ApplicationsManager : accepte les demandes de tâches et les soumet à l'applicationmaster ApplicationMaster négocie les ressources ; exécute et suit les tâches dans un container NodeManager : suivi de l'utilisation des ressources d'une machine 25
26 L'écosystème autour de Hadoop Connexion aux SGBD externes Base de données orientée colonnes Couche SQL Machine learning Coordination du cluster Scripting Ecosystème exhaustif : 26
27 Les distributions Rôle d'une distribution Fournir un ensemble de composants cohérents fonctionnant ensemble Assurer la compatibilités et la mise à jour des composants Même principe que les distributions Linux D'autant plus important que les projets évoluent très rapidement De nouveaux composants sont créés D'autres sont améliorés... 27
28 L'écosystème Hadoop Contenu d'une distribution 28
29 Exemple de distribution avec Hortonworks 29
30 Les distributions 3 principales distributions : Hortonworks Cloudera fidèle à la distribution Apache et donc 100% open source. fidèle en grande partie sauf pour les outils d administration. MapR noyau Hadoop mais repackagé et enrichi de solutions propriétaires. 30
31 Agenda Présentation de Talend Définition du Big Data Le framework Hadoop L'architecture lambda La qualité de données et le Big data Applications avec Talend Qualité de données Apprentissage automatique 31
32 Nouveau paradigme architectural : l'architecture Lambda Nathan Marz de Twitter définit une architecture générique pour être robuste face aux erreurs humaines problèmes matériels Permettant des requêtes ad-hoc, une scalabilité en ajoutant des machines 32
33 Batch Layer Gère les données brutes Stockage HDFS, Immutabilité des données (pas de mise à jour, seulement des ajouts) Calcule les vues Batch Ces vues sont calculées sur l'ensemble des données grâce à un algorithme de recalcul Vue batch = fonction (toutes les data) Ou algorithme incrémental Vue batch = fonction(new data + old view) Robustesse (tolérance aux erreurs humaines) et scalabilité obtenue grâce à L'immutabilité des données Et la fonction de calcul sur l'ensemble des données 33
34 Serving Layer Cette couche Indexe les vues calculées par la couche batch Fournit un accès rapide aux données Mais les données ne sont pas récentes Longueur de calcul sur l'ensemble des données 34
35 Speed Layer Se concentre sur les données récentes Compense la forte latence des vues batch 2 approches : Avec latence Real time view = fonction(new data) Plus rapide car incrémentale Real time view = fonction(new data+real time view) 35
36 Exemple d'implémentation de l'architecture Lambda 36
37 Insert or Update : un changement de paradigme Dans cette architecture, les données sont immutables Conséquences : Toutes les données doivent avoir un timestamp Le suivi de l'évolution des données est plus simple. L'utilisation de langages de programmation fonctionnelle est possible La programmation fonctionnelle requiert des données immutables Le traitement parallèle des données est simplifié grâce aux langages de programmation fonctionnelle D'où le succès de Scala avec Spark 37
38 Paradigme du Schéma à la lecture Schéma fixe (schema-on-write) : les données doivent se conformer au schéma de base prédéfini Schéma à la lecture (schema-on-read) : les schéma sont créés par des vues sur les données Evolution de la structure des données difficile Pas de contrainte sur la structure des données ingérées par le système La structure de sortie est générée par le code 38
39 Agenda Présentation de Talend Définition du Big Data Le framework Hadoop L'architecture lambda La qualité de données et le Big data Applications avec Talend Qualité de données Apprentissage automatique 39
40 Les dimensions de la qualité de données La recherche a conduit à définir des critères concernant les données. Des Dimensions : L'exactitude : dans quelle mesure les données sont-elles correctes? La validité (ou pertinence) : dans quelle mesure les données répondent aux besoins des utilisateurs? La complétude : dans quelle mesure des données sont-elles manquantes? La cohérence : dans quelle mesure les données collectées de diverses manières à différents instants se recoupent-elles? L'actualité : les données sont-elles suffisamment «fraîches»? L'accessibilité (ou facilité d'utilisation) : l'information est-elle facilement accessible, suffisamment claire, documentée? On dénombre plus de 179 dimensions 40
41 La qualité des données dans le contexte Big Data 41
42 Les challenges de la qualité des données dans le contexte Big Data 42
43 Le partitionnement des données Le théorème CAP (théorème de Brewer) Dans un système partitionné, on peut garantir soit la disponibilité, soit la cohérence des données Au bout d'un temps, la cohérence est assurée (eventual consistency) Ce temps peut être suffisamment court pour passer inaperçu Néanmoins la cohérence est sacrifiée 43
44 Challenge : assurer la qualité des données Les dimensions particulièrement importantes La provenance (attention au Data Lake, conserver une traçabilité des données) La crédibilité (quelle confiance accorder aux données du web? ) La fraîcheur (en partie résolue par l'architecture lambda) L'obsolescence (doit-on définir un horizon des événements? ) L'unicité (Attention à la duplication d'information à des instants différents) La cohérence (théorème CAP) L'exactitude (certains algorithmes donnent une réponse probabiliste ) Projet Falcon pour la gouvernance des données (en incubation) 44
45 Challenge : Le couplage des données avec les algorithmes Schéma à la lecture => évolution des données en entrée Etape de création des vues Batch : Nettoyage des données Evolution de la structure des données du Master Dataset => adaptation des algorithmes de recalcul Cleaning 45
46 Agenda Présentation de Talend Définition du Big Data Le framework Hadoop L'architecture lambda La qualité de données et le Big data Applications avec Talend Qualité de données Apprentissage automatique 46
47 La qualité de données et le big data à Talend Quelques grandes étapes Profiler 2008 Déduplication Sur Hadoop 2011 Profilage Sur Hive 2012 Framework Map/Reduce Nettoyage
48 Profilage in situ avec Talend Le profilage est une étape importante de la qualité de données Echantillonner les données pour analyser la qualité? Qualité de l'échantillon? Représentativité? 1. Talend offre un profilage in situ de données sur HDFS en utilisant 1. Hive 2. Impala 2. Le profilage peut être fait au niveau des vues Batch ou Real Time 48
49 Exemple avec Hive Hive projet Apache initié par Facebook Langage de requêtage de type SQL Traduit les requêtes HiveQL en jobs map/reduce Hadoop. 49
50 Application du principe de Schema-on-read avec Hive Exemple de création d'une table Hive à partir d'un fichier csv Exemple de création d'une table Hive à partir d'un fichier de logs. CREATE EXTERNAL TABLE ACCESS_LOGS ( ip_address string, date_string string, request string, response string ) ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.regexserde' WITH SERDEPROPERTIES ("input.regex" = "^([\\d.]+) \\S+ \\S+ \\[(.+?)\\] \\\"(.+?)\\\" (\\d{3}) (\\d+)" ) LOCATION '/user/data/accesslogfixed'; 50

51 Exemple de profilage pour la détection de fraude Loi de Benford lignes nb étudiants/commune ou dépt ou pays Suspect OK 51

52 Exemple : Utilisation de Map Reduce pour le rapprochement de données Processus permettant d'identifier les enregistrements concernant les mêmes objets 52

53 Le rapprochement de données Optimisation en réduisant le nombre de comparaisons Stratégie de blocking partitionnement des données Exemple : nouveaux clients à comparer aux clients référencés => de comparaisons!! Blocking : 100 x blocs de 10 enregistrements en entrée à comparer à 100 blocs de 100 enregistrements. Nb comparaisons : 100 x (10 x 100) = Approche idéale pour Hadoop Map Reduce 53
54 Rapprochement avec Hadoop 54
55 Rapprochement avec Hadoop Map Splitting Mapping 55
56 Rapprochement avec Hadoop Shuffle 56
57 Rapprochement avec Hadoop Reduce 57
 Modèle quadratique dépend de la stratégie de blocking t ~ 16 +")
58 Rapprochement avec Talend Cluster 9 noeuds (Cloudera CDH 4.5 avec Yarn) Modèle quadratique dépend de la stratégie de blocking t ~ ,6x10-5 N + 2,5x10-11 N2 58
59 Outiller les data scientists l'apprentissage automatique Composants Mahout pour le clustering Composants Spark pour le filtrage collaboratif Implémenter son architecture lambda pour l'analytique Spark Streaming (micro-batch) Framework pour Storm Traiter des millions de tuples par seconde sur chaque noeud. Tolérance à la panne Garantit le traitement des données 59


60 Clustering Algorithmes disponibles (basés sur Mahout) Canopy (souvent utilisé pour initialiser les clusters du k-means) K-means Fuzzy k-means Dirichlet Et plusieurs distances Euclidienne Manhattan Chebyshev Cosinus 60
 Tourne sur un cluster Hadoop 2 100x plus rapide que")

61 Les futurs outils de fouille de données sur Hadoop - Spark Spark (projet Apache) Tourne sur un cluster Hadoop 2 100x plus rapide que Hadoop (en mémoire) Mllib K-means Régression linéaire Régression logistique Classification naïve bayesienne Descente de gradient stochastique 61
 Les données peuvent être conservées dans un cache Source : http://spark.apache.org/docs/latest/cluster-overview.html 62")
62 Spark Application Spark Programme principal : le Driver planifie l'exécution des tâches sur le cluster Connexion à plusieurs clusters managers (standalone ou Mesos/YARN) Le driver envoie des jobs (plusieurs tâches à exécuter) Les données peuvent être conservées dans un cache Source : 62

63 Recommandation de films avec Spark Apprentissage du modèle 63
64 Recommandation de films avec Spark 64
65 Conclusion 2 révolutions technologiques ont conduit à une explosion des données Prix du stockage de l'information, le cloud De nouveaux paradigmes Les algorithmes sont déplacés auprès des données Naissance d'un OS distribué autour des données avec Yarn/HDFS L'architecture lambda pour la robustesse et la scalabilité L'immutabilité des données permet une approche plus mathématique des transformations de donnnées Le schéma à la lecture (schema-on-read) relaxe les contraintes imposées sur les données en entrée 65
66 Conclusion Les challenges La gestion de la qualité des données La gestion des algorithmes (complexité) Construire les outils pour gérer cette évolution 66
Fouille de données massives avec Hadoop
 Fouille de données massives avec Hadoop Sebastiao Correia [email protected] Talend 2013 AAFD'14 29-30 avril 2014 1 Agenda Présentation de Talend Définition du Big Data Le framework Hadoop 3 thématiques
Fouille de données massives avec Hadoop Sebastiao Correia [email protected] Talend 2013 AAFD'14 29-30 avril 2014 1 Agenda Présentation de Talend Définition du Big Data Le framework Hadoop 3 thématiques
L écosystème Hadoop Nicolas Thiébaud [email protected]. Tuesday, July 2, 13
 L écosystème Hadoop Nicolas Thiébaud [email protected] HUG France 250 membres sur la mailing liste 30 présentations 9 meetups organisés, de 20 à 100 invités Présence de Cloudera, MapR, Hortonworks,
L écosystème Hadoop Nicolas Thiébaud [email protected] HUG France 250 membres sur la mailing liste 30 présentations 9 meetups organisés, de 20 à 100 invités Présence de Cloudera, MapR, Hortonworks,
HADOOP ET SON ÉCOSYSTÈME
 HADOOP ET SON ÉCOSYSTÈME Mars 2013 2012 Affini-Tech - Diffusion restreinte 1 AFFINI-TECH Méthodes projets Outils de reporting & Data-visualisation Business & Analyses BigData Modélisation Hadoop Technos
HADOOP ET SON ÉCOSYSTÈME Mars 2013 2012 Affini-Tech - Diffusion restreinte 1 AFFINI-TECH Méthodes projets Outils de reporting & Data-visualisation Business & Analyses BigData Modélisation Hadoop Technos
Big Data Concepts et mise en oeuvre de Hadoop
 Introduction 1. Objectif du chapitre 9 2. Le Big Data 10 2.1 Introduction 10 2.2 Informatique connectée, objets "intelligents" et données collectées 11 2.3 Les unités de mesure dans le monde Big Data 12
Introduction 1. Objectif du chapitre 9 2. Le Big Data 10 2.1 Introduction 10 2.2 Informatique connectée, objets "intelligents" et données collectées 11 2.3 Les unités de mesure dans le monde Big Data 12
Fouillez facilement dans votre système Big Data. Olivier TAVARD
 Fouillez facilement dans votre système Big Data Olivier TAVARD A propos de moi : Cofondateur de la société France Labs Développeur (principalement Java) Formateur en technologies de moteurs de recherche
Fouillez facilement dans votre système Big Data Olivier TAVARD A propos de moi : Cofondateur de la société France Labs Développeur (principalement Java) Formateur en technologies de moteurs de recherche
Tables Rondes Le «Big Data»
 Tables Rondes Le «Big Data» 2012-2013 1 Plan Introduc9on 1 - Présenta9on Ingensi 2 - Le Big Data c est quoi? 3 - L histoire 4 - Le monde du libre : Hadoop 5 - Le système HDFS 6 - Les algorithmes distribués
Tables Rondes Le «Big Data» 2012-2013 1 Plan Introduc9on 1 - Présenta9on Ingensi 2 - Le Big Data c est quoi? 3 - L histoire 4 - Le monde du libre : Hadoop 5 - Le système HDFS 6 - Les algorithmes distribués
BI dans les nuages. Olivier Bendavid, UM2 Prof. A. April, ÉTS
 BI dans les nuages Olivier Bendavid, UM2 Prof. A. April, ÉTS Table des matières Introduction Description du problème Les solutions Le projet Conclusions Questions? Introduction Quelles sont les défis actuels
BI dans les nuages Olivier Bendavid, UM2 Prof. A. April, ÉTS Table des matières Introduction Description du problème Les solutions Le projet Conclusions Questions? Introduction Quelles sont les défis actuels
Programmation parallèle et distribuée (Master 1 Info 2015-2016)
") Programmation parallèle et distribuée (Master 1 Info 2015-2016) Hadoop MapReduce et HDFS Note bibliographique : ce cours est largement inspiré par le cours de Benjamin Renaut (Tokidev SAS) Introduction
Programmation parallèle et distribuée (Master 1 Info 2015-2016) Hadoop MapReduce et HDFS Note bibliographique : ce cours est largement inspiré par le cours de Benjamin Renaut (Tokidev SAS) Introduction
Big Data : utilisation d un cluster Hadoop HDFS Map/Reduce HBase
 Big Data : utilisation d un cluster cluster Cécile Cavet cecile.cavet at apc.univ-paris7.fr Centre François Arago (FACe), Laboratoire APC, Université Paris Diderot LabEx UnivEarthS 14 Janvier 2014 C. Cavet
Big Data : utilisation d un cluster cluster Cécile Cavet cecile.cavet at apc.univ-paris7.fr Centre François Arago (FACe), Laboratoire APC, Université Paris Diderot LabEx UnivEarthS 14 Janvier 2014 C. Cavet
Introduction à MapReduce/Hadoop et Spark
 1 / 36 Introduction à MapReduce/Hadoop et Spark Certificat Big Data Ludovic Denoyer et Sylvain Lamprier UPMC Plan 2 / 36 Contexte 3 / 36 Contexte 4 / 36 Data driven science: le 4e paradigme (Jim Gray -
1 / 36 Introduction à MapReduce/Hadoop et Spark Certificat Big Data Ludovic Denoyer et Sylvain Lamprier UPMC Plan 2 / 36 Contexte 3 / 36 Contexte 4 / 36 Data driven science: le 4e paradigme (Jim Gray -
20 ans du Master SIAD de Toulouse - BigData par l exemple - Julien DULOUT - 22 mars 2013. 20 ans du SIAD -"Big Data par l'exemple" -Julien DULOUT
 20 ans du Master SIAD de Toulouse - BigData par l exemple - Julien DULOUT - 22 mars 2013 20 ans du SIAD -"BigData par l'exemple" -Julien DULOUT Qui a déjà entendu parler du phénomène BigData? Qui a déjà
20 ans du Master SIAD de Toulouse - BigData par l exemple - Julien DULOUT - 22 mars 2013 20 ans du SIAD -"BigData par l'exemple" -Julien DULOUT Qui a déjà entendu parler du phénomène BigData? Qui a déjà
Big Data. Cyril Amsellem Consultant avant-vente. 16 juin 2011. Talend 2010 1
 Big Data Cyril Amsellem Consultant avant-vente 16 juin 2011 Talend 2010 1 Big Data Architecture globale Hadoop Les projets Hadoop (partie 1) Hadoop-Core : projet principal. HDFS : système de fichiers distribués
Big Data Cyril Amsellem Consultant avant-vente 16 juin 2011 Talend 2010 1 Big Data Architecture globale Hadoop Les projets Hadoop (partie 1) Hadoop-Core : projet principal. HDFS : système de fichiers distribués
Groupe de Discussion Big Data Aperçu des technologies et applications. Stéphane MOUTON [email protected]
 Groupe de Discussion Big Data Aperçu des technologies et applications Stéphane MOUTON [email protected] Recherche appliquée et transfert technologique q Agréé «Centre Collectif de Recherche» par
Groupe de Discussion Big Data Aperçu des technologies et applications Stéphane MOUTON [email protected] Recherche appliquée et transfert technologique q Agréé «Centre Collectif de Recherche» par
Formation Cloudera Data Analyst Utiliser Pig, Hive et Impala avec Hadoop
 Passez au niveau supérieur en termes de connaissance grâce à la formation Data Analyst de Cloudera. Public Durée Objectifs Analystes de données, business analysts, développeurs et administrateurs qui ont
Passez au niveau supérieur en termes de connaissance grâce à la formation Data Analyst de Cloudera. Public Durée Objectifs Analystes de données, business analysts, développeurs et administrateurs qui ont
http://blog.khaledtannir.net
 Algorithme de parallélisations des traitements Khaled TANNIR Doctorant CIFRE LARIS/ESTI http://blog.khaledtannir.net [email protected] 2e SéRI 2010-2011 Jeudi 17 mars 2011 Présentation Doctorant CIFRE
Algorithme de parallélisations des traitements Khaled TANNIR Doctorant CIFRE LARIS/ESTI http://blog.khaledtannir.net [email protected] 2e SéRI 2010-2011 Jeudi 17 mars 2011 Présentation Doctorant CIFRE
MapReduce. Malo Jaffré, Pablo Rauzy. 16 avril 2010 ENS. Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15
 MapReduce 16 avril 2010 1 / 15") MapReduce Malo Jaffré, Pablo Rauzy ENS 16 avril 2010 Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15 Qu est ce que c est? Conceptuellement Données MapReduce est un framework de calcul distribué
MapReduce Malo Jaffré, Pablo Rauzy ENS 16 avril 2010 Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15 Qu est ce que c est? Conceptuellement Données MapReduce est un framework de calcul distribué
Cartographie des solutions BigData
 Cartographie des solutions BigData Panorama du marché et prospective 1 1 Solutions BigData Défi(s) pour les fournisseurs Quel marché Architectures Acteurs commerciaux Solutions alternatives 2 2 Quels Défis?
Cartographie des solutions BigData Panorama du marché et prospective 1 1 Solutions BigData Défi(s) pour les fournisseurs Quel marché Architectures Acteurs commerciaux Solutions alternatives 2 2 Quels Défis?
Panorama des solutions analytiques existantes
 Arnaud LAROCHE Julien DAMON Panorama des solutions analytiques existantes SFdS Méthodes et Logiciels - 16 janvier 2014 - Données Massives Ne sont ici considérés que les solutions autour de l environnement
Arnaud LAROCHE Julien DAMON Panorama des solutions analytiques existantes SFdS Méthodes et Logiciels - 16 janvier 2014 - Données Massives Ne sont ici considérés que les solutions autour de l environnement
Déploiement d une architecture Hadoop pour analyse de flux. franç[email protected]
 Déploiement d une architecture Hadoop pour analyse de flux franç[email protected] 1 plan Introduction Hadoop Présentation Architecture d un cluster HDFS & MapReduce L architecture déployée Les
Déploiement d une architecture Hadoop pour analyse de flux franç[email protected] 1 plan Introduction Hadoop Présentation Architecture d un cluster HDFS & MapReduce L architecture déployée Les
Les technologies du Big Data
 Les technologies du Big Data PRÉSENTÉ AU 40 E CONGRÈS DE L ASSOCIATION DES ÉCONOMISTES QUÉBÉCOIS PAR TOM LANDRY, CONSEILLER SENIOR LE 20 MAI 2015 WWW.CRIM.CA TECHNOLOGIES: DES DONNÉES JUSQU'À L UTILISATEUR
Les technologies du Big Data PRÉSENTÉ AU 40 E CONGRÈS DE L ASSOCIATION DES ÉCONOMISTES QUÉBÉCOIS PAR TOM LANDRY, CONSEILLER SENIOR LE 20 MAI 2015 WWW.CRIM.CA TECHNOLOGIES: DES DONNÉES JUSQU'À L UTILISATEUR
BIG DATA en Sciences et Industries de l Environnement
 BIG DATA en Sciences et Industries de l Environnement François Royer www.datasio.com 21 mars 2012 FR Big Data Congress, Paris 2012 1/23 Transport terrestre Traçabilité Océanographie Transport aérien Télémétrie
BIG DATA en Sciences et Industries de l Environnement François Royer www.datasio.com 21 mars 2012 FR Big Data Congress, Paris 2012 1/23 Transport terrestre Traçabilité Océanographie Transport aérien Télémétrie
 Préface Dunod Toute reproduction non autorisée est un délit. Les raisons de l émergence du Big Data sont bien connues. Elles sont d abord économiques et technologiques. La chute exponentielle des coûts
Préface Dunod Toute reproduction non autorisée est un délit. Les raisons de l émergence du Big Data sont bien connues. Elles sont d abord économiques et technologiques. La chute exponentielle des coûts
Vos experts Big Data. [email protected]. Le Big Data dans la pratique
 Vos experts Big Data [email protected] Le Big Data dans la pratique Expert Expert Infrastructure Data Science Spark MLLib Big Data depuis 2011 Expert Expert Hadoop / Spark NoSQL HBase Couchbase MongoDB
Vos experts Big Data [email protected] Le Big Data dans la pratique Expert Expert Infrastructure Data Science Spark MLLib Big Data depuis 2011 Expert Expert Hadoop / Spark NoSQL HBase Couchbase MongoDB
Programmation parallèle et distribuée
 Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2015) Marc Parizeau, Département de génie électrique et de génie informatique Plan Données massives («big data») Architecture Hadoop distribution
Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2015) Marc Parizeau, Département de génie électrique et de génie informatique Plan Données massives («big data») Architecture Hadoop distribution
Programmation parallèle et distribuée
 Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2014) Marc Parizeau, Département de génie électrique et de génie informatique Plan Mégadonnées («big data») Architecture Hadoop distribution
Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2014) Marc Parizeau, Département de génie électrique et de génie informatique Plan Mégadonnées («big data») Architecture Hadoop distribution
Les participants repartiront de cette formation en ayant une vision claire de la stratégie et de l éventuelle mise en œuvre d un Big Data.
 Big Data De la stratégie à la mise en oeuvre Description : La formation a pour objet de brosser sans concession le tableau du Big Data. Les participants repartiront de cette formation en ayant une vision
Big Data De la stratégie à la mise en oeuvre Description : La formation a pour objet de brosser sans concession le tableau du Big Data. Les participants repartiront de cette formation en ayant une vision
Organiser vos données - Big Data. Patrick Millart Senior Sales Consultant
 Organiser vos données - Big Data Patrick Millart Senior Sales Consultant The following is intended to outline our general product direction. It is intended for information purposes only, and may not be
Organiser vos données - Big Data Patrick Millart Senior Sales Consultant The following is intended to outline our general product direction. It is intended for information purposes only, and may not be
AVRIL 2014. Au delà de Hadoop. Panorama des solutions NoSQL
 AVRIL 2014 Panorama des solutions NoSQL QUI SOMMES NOUS? Avril 2014 2 SMILE, EN QUELQUES CHIFFRES 1er INTÉGRATEUR EUROPÉEN DE SOLUTIONS OPEN SOURCE 3 4 NOS EXPERTISES ET NOS CONVICTIONS DANS NOS LIVRES
AVRIL 2014 Panorama des solutions NoSQL QUI SOMMES NOUS? Avril 2014 2 SMILE, EN QUELQUES CHIFFRES 1er INTÉGRATEUR EUROPÉEN DE SOLUTIONS OPEN SOURCE 3 4 NOS EXPERTISES ET NOS CONVICTIONS DANS NOS LIVRES
Les quatre piliers d une solution de gestion des Big Data
 White Paper Les quatre piliers d une solution de gestion des Big Data Table des Matières Introduction... 4 Big Data : un terme très vaste... 4 Le Big Data... 5 La technologie Big Data... 5 Le grand changement
White Paper Les quatre piliers d une solution de gestion des Big Data Table des Matières Introduction... 4 Big Data : un terme très vaste... 4 Le Big Data... 5 La technologie Big Data... 5 Le grand changement
Les journées SQL Server 2013
 Les journées SQL Server 2013 Un événement organisé par GUSS Les journées SQL Server 2013 Romain Casteres MVP SQL Server Consultant BI @PulsWeb Yazid Moussaoui Consultant Senior BI MCSA 2008/2012 Etienne
Les journées SQL Server 2013 Un événement organisé par GUSS Les journées SQL Server 2013 Romain Casteres MVP SQL Server Consultant BI @PulsWeb Yazid Moussaoui Consultant Senior BI MCSA 2008/2012 Etienne
Analytics & Big Data. Focus techniques & nouvelles perspectives pour les actuaires. Université d Eté de l Institut des Actuaires Mardi 8 juillet 2014
 Analytics & Big Data Focus techniques & nouvelles perspectives pour les actuaires Local Optimization European Minded Université d Eté de l Institut des Actuaires Mardi 8 juillet 2014 Intervenants : Alexandre
Analytics & Big Data Focus techniques & nouvelles perspectives pour les actuaires Local Optimization European Minded Université d Eté de l Institut des Actuaires Mardi 8 juillet 2014 Intervenants : Alexandre
Offre formation Big Data Analytics
 Offre formation Big Data Analytics OCTO 2014 50, avenue des Champs-Elysées 75008 Paris - FRANCE Tél : +33 (0)1 58 56 10 00 Fax : +33 (0)1 58 56 10 01 www.octo.com 1 Présentation d OCTO Technology 2 Une
Offre formation Big Data Analytics OCTO 2014 50, avenue des Champs-Elysées 75008 Paris - FRANCE Tél : +33 (0)1 58 56 10 00 Fax : +33 (0)1 58 56 10 01 www.octo.com 1 Présentation d OCTO Technology 2 Une
Ricco Rakotomalala http://eric.univ-lyon2.fr/~ricco/cours/cours_programmation_r.html. R.R. Université Lyon 2
 Ricco Rakotomalala http://eric.univ-lyon2.fr/~ricco/cours/cours_programmation_r.html 1 Plan de présentation 1. L écosystème Hadoop 2. Principe de programmation MapReduce 3. Programmation des fonctions
Ricco Rakotomalala http://eric.univ-lyon2.fr/~ricco/cours/cours_programmation_r.html 1 Plan de présentation 1. L écosystème Hadoop 2. Principe de programmation MapReduce 3. Programmation des fonctions
NoSQL. Introduction 1/23. I NoSQL : Not Only SQL, ce n est pas du relationnel, et le contexte. I table d associations - Map - de couples (clef,valeur)
") 1/23 2/23 Anne-Cécile Caron Master MIAGE - BDA 1er trimestre 2013-2014 I : Not Only SQL, ce n est pas du relationnel, et le contexte d utilisation n est donc pas celui des SGBDR. I Origine : recherche
1/23 2/23 Anne-Cécile Caron Master MIAGE - BDA 1er trimestre 2013-2014 I : Not Only SQL, ce n est pas du relationnel, et le contexte d utilisation n est donc pas celui des SGBDR. I Origine : recherche
R+Hadoop = Rhadoop* Des logiciels libres complémentaires, une implémentation, une réponse au nouveau paradigme du bigdata!
 R+Hadoop = Rhadoop* * Des logiciels libres complémentaires, une implémentation, une réponse au nouveau paradigme du bigdata! 27 Janvier 2014 / Université Paul Sabatier / DTSI / David Tsang-Hin-Sun Big
R+Hadoop = Rhadoop* * Des logiciels libres complémentaires, une implémentation, une réponse au nouveau paradigme du bigdata! 27 Janvier 2014 / Université Paul Sabatier / DTSI / David Tsang-Hin-Sun Big
Hadoop, les clés du succès
 Hadoop, les clés du succès Didier Kirszenberg, Responsable des architectures Massive Data, HP France Copyright 2015 Hewlett-Packard Development Company, L.P. The information contained herein is subject
Hadoop, les clés du succès Didier Kirszenberg, Responsable des architectures Massive Data, HP France Copyright 2015 Hewlett-Packard Development Company, L.P. The information contained herein is subject
FORUM NTIC BIG DATA, OPEN DATA Big Data: les challenges, les défis
 FORUM NTIC BIG DATA, OPEN DATA Big Data: les challenges, les défis Joseph Salmon Télécom ParisTech Jeudi 6 Février Joseph Salmon (Télécom ParisTech) Big Data Jeudi 6 Février 1 / 18 Agenda Contexte et opportunités
FORUM NTIC BIG DATA, OPEN DATA Big Data: les challenges, les défis Joseph Salmon Télécom ParisTech Jeudi 6 Février Joseph Salmon (Télécom ParisTech) Big Data Jeudi 6 Février 1 / 18 Agenda Contexte et opportunités
Introduction aux algorithmes MapReduce. Mathieu Dumoulin (GRAAL), 14 Février 2014
, 14 Février 2014") Introduction aux algorithmes MapReduce Mathieu Dumoulin (GRAAL), 14 Février 2014 Plan Introduction de la problématique Tutoriel MapReduce Design d algorithmes MapReduce Tri, somme et calcul de moyenne
Introduction aux algorithmes MapReduce Mathieu Dumoulin (GRAAL), 14 Février 2014 Plan Introduction de la problématique Tutoriel MapReduce Design d algorithmes MapReduce Tri, somme et calcul de moyenne
NoSQL. Introduction 1/30. I NoSQL : Not Only SQL, ce n est pas du relationnel, et le contexte. I table d associations - Map - de couples (clef,valeur)
") 1/30 2/30 Anne-Cécile Caron Master MIAGE - SGBD 1er trimestre 2014-2015 I : Not Only SQL, ce n est pas du relationnel, et le contexte d utilisation n est donc pas celui des SGBDR. I Origine : recherche
1/30 2/30 Anne-Cécile Caron Master MIAGE - SGBD 1er trimestre 2014-2015 I : Not Only SQL, ce n est pas du relationnel, et le contexte d utilisation n est donc pas celui des SGBDR. I Origine : recherche
Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop
 Julien Gerlier Siman Chen Rapport de projet de fin d étude ASR 2010/2011 Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop Encadrants
Julien Gerlier Siman Chen Rapport de projet de fin d étude ASR 2010/2011 Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop Encadrants
Le BigData, aussi par et pour les PMEs
 Parole d expert Le BigData, aussi par et pour les PMEs Stéphane MOUTON, CETIC Département Software and Services Technologies Avec le soutien de : LIEGE CREATIVE Le Big Data, aussi par et pour les PMEs
Parole d expert Le BigData, aussi par et pour les PMEs Stéphane MOUTON, CETIC Département Software and Services Technologies Avec le soutien de : LIEGE CREATIVE Le Big Data, aussi par et pour les PMEs
Anticiper et prédire les sinistres avec une approche Big Data
 Anticiper et prédire les sinistres avec une approche Big Data Julien Cabot Directeur Big Data Analytics OCTO [email protected] @julien_cabot OCTO 2013 50, avenue des Champs-Elysées 75008 Paris - FRANCE Tél
Anticiper et prédire les sinistres avec une approche Big Data Julien Cabot Directeur Big Data Analytics OCTO [email protected] @julien_cabot OCTO 2013 50, avenue des Champs-Elysées 75008 Paris - FRANCE Tél
BIG Data et R: opportunités et perspectives
 BIG Data et R: opportunités et perspectives Guati Rizlane 1 & Hicham Hajji 2 1 Ecole Nationale de Commerce et de Gestion de Casablanca, Maroc, [email protected] 2 Ecole des Sciences Géomatiques, IAV Rabat,
BIG Data et R: opportunités et perspectives Guati Rizlane 1 & Hicham Hajji 2 1 Ecole Nationale de Commerce et de Gestion de Casablanca, Maroc, [email protected] 2 Ecole des Sciences Géomatiques, IAV Rabat,
Labs Hadoop Février 2013
 SOA - BRMS - ESB - BPM CEP BAM - High Performance Compute & Data Grid - Cloud Computing - Big Data NoSQL - Analytics Labs Hadoop Février 2013 Mathias Kluba Managing Consultant Responsable offres NoSQL
SOA - BRMS - ESB - BPM CEP BAM - High Performance Compute & Data Grid - Cloud Computing - Big Data NoSQL - Analytics Labs Hadoop Février 2013 Mathias Kluba Managing Consultant Responsable offres NoSQL
MapReduce. Nicolas Dugué [email protected]. M2 MIAGE Systèmes d information répartis
 MapReduce Nicolas Dugué [email protected] M2 MIAGE Systèmes d information répartis Plan 1 Introduction Big Data 2 MapReduce et ses implémentations 3 MapReduce pour fouiller des tweets 4 MapReduce
MapReduce Nicolas Dugué [email protected] M2 MIAGE Systèmes d information répartis Plan 1 Introduction Big Data 2 MapReduce et ses implémentations 3 MapReduce pour fouiller des tweets 4 MapReduce
Hadoop dans l entreprise: du concept à la réalité. Pourquoi et comment?
 Hadoop dans l entreprise: du concept à la réalité. Pourquoi et comment? Jean-Marc Spaggiari Cloudera [email protected] @jmspaggi Mai 2014 1 2 Avant qu on commence Agenda -Qu est-ce que Hadoop et pourquoi
Hadoop dans l entreprise: du concept à la réalité. Pourquoi et comment? Jean-Marc Spaggiari Cloudera [email protected] @jmspaggi Mai 2014 1 2 Avant qu on commence Agenda -Qu est-ce que Hadoop et pourquoi
Hadoop : une plate-forme d exécution de programmes Map-Reduce
 Hadoop : une plate-forme d exécution de programmes Map-Reduce Jonathan Lejeune École des Mines de Nantes Janvier 2015 CODEL 2014/2015 J. Lejeune (École des Mines de Nantes) Hadoop Map-Reduce Janvier 2015
Hadoop : une plate-forme d exécution de programmes Map-Reduce Jonathan Lejeune École des Mines de Nantes Janvier 2015 CODEL 2014/2015 J. Lejeune (École des Mines de Nantes) Hadoop Map-Reduce Janvier 2015
Les bases de données relationnelles
 Bases de données NO SQL et SIG : d un existant restreint à un avenir prometteur CHRISTIAN CAROLIN, AXES CONSEIL [email protected] - HTTP://WWW.AXES.FR Les bases de données relationnelles constituent désormais
Bases de données NO SQL et SIG : d un existant restreint à un avenir prometteur CHRISTIAN CAROLIN, AXES CONSEIL [email protected] - HTTP://WWW.AXES.FR Les bases de données relationnelles constituent désormais
Big Data et Graphes : Quelques pistes de recherche
 Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de Lyon/Université Claude Bernard Lyon 1/Université
Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de Lyon/Université Claude Bernard Lyon 1/Université
Surmonter les 5 défis opérationnels du Big Data
 Surmonter les 5 défis opérationnels du Big Data Jean-Michel Franco Talend Connect 9 octobre 2014 Talend 2014 1 Agenda Agenda Le Big Data depuis la découverte jusqu au temps réel en passant par les applications
Surmonter les 5 défis opérationnels du Big Data Jean-Michel Franco Talend Connect 9 octobre 2014 Talend 2014 1 Agenda Agenda Le Big Data depuis la découverte jusqu au temps réel en passant par les applications
Business Intelligence, Etat de l art et perspectives. ICAM JP Gouigoux 10/2012
 Business Intelligence, Etat de l art et perspectives ICAM JP Gouigoux 10/2012 CONTEXTE DE LA BI Un peu d histoire Premières bases de données utilisées comme simple système de persistance du contenu des
Business Intelligence, Etat de l art et perspectives ICAM JP Gouigoux 10/2012 CONTEXTE DE LA BI Un peu d histoire Premières bases de données utilisées comme simple système de persistance du contenu des
De l Etudiant à SBA à l Enseignant Chercheur à l ENSMA
 De l Etudiant à SBA à l Enseignant Chercheur à l ENSMA Ladjel BELLATRECHE [email protected] http://www.lias lab.fr/members/bellatreche Les déterminants de la motivation selon Rolland Viau Perception
De l Etudiant à SBA à l Enseignant Chercheur à l ENSMA Ladjel BELLATRECHE [email protected] http://www.lias lab.fr/members/bellatreche Les déterminants de la motivation selon Rolland Viau Perception
Le BIG DATA????? Big Buzz? Big Bang? Big Opportunity? Big hype? Big Business? Big Challenge? Big Hacking? Gérard Peliks planche 2
 Le BIG DATA????? Big Bang? Big hype? Big Challenge? Big Buzz? Big Opportunity? Big Business? Big Hacking? Gérard Peliks planche 2 Les quatre paradigmes de la science en marche Paradigme 1 : L empirisme
Le BIG DATA????? Big Bang? Big hype? Big Challenge? Big Buzz? Big Opportunity? Big Business? Big Hacking? Gérard Peliks planche 2 Les quatre paradigmes de la science en marche Paradigme 1 : L empirisme
Sommaire. 3. Les grands principes de GFS L architecture L accès de fichier en lecture L accès de fichier en écriture Bilan
 1 Sommaire 1. Google en chiffres 2. Les raisons d être de GFS 3. Les grands principes de GFS L architecture L accès de fichier en lecture L accès de fichier en écriture Bilan 4. Les Evolutions et Alternatives
1 Sommaire 1. Google en chiffres 2. Les raisons d être de GFS 3. Les grands principes de GFS L architecture L accès de fichier en lecture L accès de fichier en écriture Bilan 4. Les Evolutions et Alternatives
Bases de données documentaires et distribuées Cours NFE04
 Bases de données documentaires et distribuées Cours NFE04 Cloud et scalabilité Auteurs : Raphaël Fournier-S niehotta, Philippe Rigaux, Nicolas Travers pré[email protected] Département d informatique Conservatoire
Bases de données documentaires et distribuées Cours NFE04 Cloud et scalabilité Auteurs : Raphaël Fournier-S niehotta, Philippe Rigaux, Nicolas Travers pré[email protected] Département d informatique Conservatoire
Le cloud computing au service des applications cartographiques à haute disponibilité
 Le cloud computing au service des applications cartographiques à haute disponibilité Claude Philipona Les Rencontres de SIG-la-Lettre, Mai 2010 camptocamp SA / www.camptocamp.com / [email protected]
Le cloud computing au service des applications cartographiques à haute disponibilité Claude Philipona Les Rencontres de SIG-la-Lettre, Mai 2010 camptocamp SA / www.camptocamp.com / [email protected]
API04 Contribution. Apache Hadoop: Présentation et application dans le domaine des Data Warehouses. Introduction. Architecture
 API04 Contribution Apache Hadoop: Présentation et application dans le domaine des Data Warehouses Introduction Cette publication a pour but de présenter le framework Java libre Apache Hadoop, permettant
API04 Contribution Apache Hadoop: Présentation et application dans le domaine des Data Warehouses Introduction Cette publication a pour but de présenter le framework Java libre Apache Hadoop, permettant
4. Utilisation d un SGBD : le langage SQL. 5. Normalisation
 Base de données S. Lèbre [email protected] Université de Strasbourg, département d informatique. Présentation du module Contenu général Notion de bases de données Fondements / Conception Utilisation :
Base de données S. Lèbre [email protected] Université de Strasbourg, département d informatique. Présentation du module Contenu général Notion de bases de données Fondements / Conception Utilisation :
Document réalisé par Khadidjatou BAMBA
 Comprendre le BIG DATA Document réalisé par Khadidjatou BAMBA 1 Sommaire Avant propos. 3 Historique du Big Data.4 Introduction.....5 Chapitre I : Présentation du Big Data... 6 I. Généralités sur le Big
Comprendre le BIG DATA Document réalisé par Khadidjatou BAMBA 1 Sommaire Avant propos. 3 Historique du Big Data.4 Introduction.....5 Chapitre I : Présentation du Big Data... 6 I. Généralités sur le Big
Acquisition des données - Big Data. Dario VEGA Senior Sales Consultant
 Acquisition des données - Big Data Dario VEGA Senior Sales Consultant The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated
Acquisition des données - Big Data Dario VEGA Senior Sales Consultant The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated
M2 GL UE DOC «In memory analytics»
 M2 GL UE DOC «In memory analytics» Alexandre Termier 2014/2015 Sources Travaux Amplab, U.C. Berkeley Slides Ion Stoica Présentations Databricks Slides Pat McDonough Articles de M. Zaharia et al. sur les
M2 GL UE DOC «In memory analytics» Alexandre Termier 2014/2015 Sources Travaux Amplab, U.C. Berkeley Slides Ion Stoica Présentations Databricks Slides Pat McDonough Articles de M. Zaharia et al. sur les
Implémentation parallèle de certains algorithmes de fouille de données avec le framework MapReduce
 Implémentation parallèle de certains algorithmes de fouille de données avec le framework MapReduce Algorithmes : K-means et Apriori Maria Malek LARIS-EISTI [email protected] 1 Cloud Computing et MapReduce
Implémentation parallèle de certains algorithmes de fouille de données avec le framework MapReduce Algorithmes : K-means et Apriori Maria Malek LARIS-EISTI [email protected] 1 Cloud Computing et MapReduce
BIG DATA. Veille technologique. Malek Hamouda Nina Lachia Léo Valette. Commanditaire : Thomas Milon. Encadré: Philippe Vismara
 BIG DATA Veille technologique Malek Hamouda Nina Lachia Léo Valette Commanditaire : Thomas Milon Encadré: Philippe Vismara 1 2 Introduction Historique des bases de données : méthodes de stockage et d analyse
BIG DATA Veille technologique Malek Hamouda Nina Lachia Léo Valette Commanditaire : Thomas Milon Encadré: Philippe Vismara 1 2 Introduction Historique des bases de données : méthodes de stockage et d analyse
Cassandra et Spark pour gérer la musique On-line
 Cassandra et Spark pour gérer la musique On-line 16 Juin 2015 @ Paris Hammed RAMDANI Architecte SI 3.0 et BigData [email protected] +33 6 80 22 20 70 Appelez-moi Hammed ;-) (Sidi Mo)Hammed Ramdani @smramdani
Cassandra et Spark pour gérer la musique On-line 16 Juin 2015 @ Paris Hammed RAMDANI Architecte SI 3.0 et BigData [email protected] +33 6 80 22 20 70 Appelez-moi Hammed ;-) (Sidi Mo)Hammed Ramdani @smramdani
À PROPOS DE TALEND...
 WHITE PAPER Table des matières Résultats de l enquête... 4 Stratégie d entreprise Big Data... 5 Intégration des Big Data... 8 Les défis liés à la mise en œuvre des Big Data... 10 Les technologies pour
WHITE PAPER Table des matières Résultats de l enquête... 4 Stratégie d entreprise Big Data... 5 Intégration des Big Data... 8 Les défis liés à la mise en œuvre des Big Data... 10 Les technologies pour
NewPoint IT Consulting BIG DATA WHITE PAPER. NewPoint Information Technology Consulting
 NewPoint IT Consulting BIG DATA WHITE PAPER NewPoint Information Technology Consulting Contenu 1 Big Data: Défi et opportunité pour l'entreprise... 3 2 Les drivers techniques et d'entreprise de BIG DATA...
NewPoint IT Consulting BIG DATA WHITE PAPER NewPoint Information Technology Consulting Contenu 1 Big Data: Défi et opportunité pour l'entreprise... 3 2 Les drivers techniques et d'entreprise de BIG DATA...
Ecole des Hautes Etudes Commerciales HEC Alger. par Amina GACEM. Module Informatique 1ière Année Master Sciences Commerciales
 Ecole des Hautes Etudes Commerciales HEC Alger Évolution des SGBDs par Amina GACEM Module Informatique 1ière Année Master Sciences Commerciales Evolution des SGBDs Pour toute remarque, question, commentaire
Ecole des Hautes Etudes Commerciales HEC Alger Évolution des SGBDs par Amina GACEM Module Informatique 1ière Année Master Sciences Commerciales Evolution des SGBDs Pour toute remarque, question, commentaire
Les enjeux du Big Data Innovation et opportunités de l'internet industriel. Datasio 2013
 Les enjeux du Big Data Innovation et opportunités de l'internet industriel François Royer [email protected] Accompagnement des entreprises dans leurs stratégies quantitatives Valorisation de patrimoine
Les enjeux du Big Data Innovation et opportunités de l'internet industriel François Royer [email protected] Accompagnement des entreprises dans leurs stratégies quantitatives Valorisation de patrimoine
Big Data. Les problématiques liées au stockage des données et aux capacités de calcul
 Big Data Les problématiques liées au stockage des données et aux capacités de calcul Les problématiques liées au Big Data La capacité de stockage - Traitement : Ponctuel ou permanent? - Cycle de vie des
Big Data Les problématiques liées au stockage des données et aux capacités de calcul Les problématiques liées au Big Data La capacité de stockage - Traitement : Ponctuel ou permanent? - Cycle de vie des
MapReduce et Hadoop. Alexandre Denis [email protected]. Inria Bordeaux Sud-Ouest France ENSEIRB PG306
 MapReduce et Hadoop Alexandre Denis [email protected] Inria Bordeaux Sud-Ouest France ENSEIRB PG306 Fouille de données Recherche & indexation de gros volumes Appliquer une opération simple à beaucoup
MapReduce et Hadoop Alexandre Denis [email protected] Inria Bordeaux Sud-Ouest France ENSEIRB PG306 Fouille de données Recherche & indexation de gros volumes Appliquer une opération simple à beaucoup
Big Graph Data Forum Teratec 2013
 Big Graph Data Forum Teratec 2013 MFG Labs 35 rue de Châteaudun 75009 Paris, France www.mfglabs.com twitter: @mfg_labs Julien Laugel MFG Labs [email protected] @roolio SOMMAIRE MFG Labs Contexte
Big Graph Data Forum Teratec 2013 MFG Labs 35 rue de Châteaudun 75009 Paris, France www.mfglabs.com twitter: @mfg_labs Julien Laugel MFG Labs [email protected] @roolio SOMMAIRE MFG Labs Contexte
Hibernate vs. le Cloud Computing
 Hibernate vs. le Cloud Computing Qui suis-je? Julien Dubois Co-auteur de «Spring par la pratique» Ancien de SpringSource Directeur du consulting chez Ippon Technologies Suivez-moi sur Twitter : @juliendubois
Hibernate vs. le Cloud Computing Qui suis-je? Julien Dubois Co-auteur de «Spring par la pratique» Ancien de SpringSource Directeur du consulting chez Ippon Technologies Suivez-moi sur Twitter : @juliendubois
Big data et données géospatiales : Enjeux et défis pour la géomatique. Thierry Badard, PhD, ing. jr Centre de Recherche en Géomatique
 Big data et données géospatiales : Enjeux et défis pour la géomatique Thierry Badard, PhD, ing. jr Centre de Recherche en Géomatique Événement 25e anniversaire du CRG Université Laval, Qc, Canada 08 mai
Big data et données géospatiales : Enjeux et défis pour la géomatique Thierry Badard, PhD, ing. jr Centre de Recherche en Géomatique Événement 25e anniversaire du CRG Université Laval, Qc, Canada 08 mai
Présentation du module Base de données spatio-temporelles
 Présentation du module Base de données spatio-temporelles S. Lèbre [email protected] Université de Strasbourg, département d informatique. Partie 1 : Notion de bases de données (12,5h ) Enjeux et principes
Présentation du module Base de données spatio-temporelles S. Lèbre [email protected] Université de Strasbourg, département d informatique. Partie 1 : Notion de bases de données (12,5h ) Enjeux et principes
DEMARRER UN PROJET BIGDATA EN QUELQUES MINUTES GRACE AU CLOUD
 DEMARRER UN PROJET BIGDATA EN QUELQUES MINUTES GRACE AU CLOUD BIGDATA PARIS LE 1/4/2014 VINCENT HEUSCHLING @VHE74! 1 NOUS 100% Bigdata Infrastructure IT + Data Trouver vos opportunités Implémenter les
DEMARRER UN PROJET BIGDATA EN QUELQUES MINUTES GRACE AU CLOUD BIGDATA PARIS LE 1/4/2014 VINCENT HEUSCHLING @VHE74! 1 NOUS 100% Bigdata Infrastructure IT + Data Trouver vos opportunités Implémenter les
Département Informatique 5 e année 2013-2014. Hadoop: Optimisation et Ordonnancement
 École Polytechnique de l Université de Tours 64, Avenue Jean Portalis 37200 TOURS, FRANCE Tél. +33 (0)2 47 36 14 14 www.polytech.univ-tours.fr Département Informatique 5 e année 2013-2014 Hadoop: Optimisation
École Polytechnique de l Université de Tours 64, Avenue Jean Portalis 37200 TOURS, FRANCE Tél. +33 (0)2 47 36 14 14 www.polytech.univ-tours.fr Département Informatique 5 e année 2013-2014 Hadoop: Optimisation
Big Data et Graphes : Quelques pistes de recherche
 Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci http://liris.cnrs.fr/hamamache.kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de
Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci http://liris.cnrs.fr/hamamache.kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de
Transformez vos données en opportunités. avec Microsoft Big Data
 Transformez vos données en opportunités avec Microsoft Big Data 1 VOLUME Augmentation du volume de données tous les cinq ans Vélocité x10 4,3 Nombre d appareils connectés par adulte VARIÉTÉ 85% Part des
Transformez vos données en opportunités avec Microsoft Big Data 1 VOLUME Augmentation du volume de données tous les cinq ans Vélocité x10 4,3 Nombre d appareils connectés par adulte VARIÉTÉ 85% Part des
Pentaho Business Analytics Intégrer > Explorer > Prévoir
 Pentaho Business Analytics Intégrer > Explorer > Prévoir Pentaho lie étroitement intégration de données et analytique. En effet, les services informatiques et les utilisateurs métiers peuvent accéder aux
Pentaho Business Analytics Intégrer > Explorer > Prévoir Pentaho lie étroitement intégration de données et analytique. En effet, les services informatiques et les utilisateurs métiers peuvent accéder aux
4 Exemples de problèmes MapReduce incrémentaux
 4 Exemples de problèmes MapReduce incrémentaux 1 / 32 Calcul des plus courtes distances à un noeud d un graphe Calcul des plus courts chemins entre toutes les paires de noeuds d un graphe Algorithme PageRank
4 Exemples de problèmes MapReduce incrémentaux 1 / 32 Calcul des plus courtes distances à un noeud d un graphe Calcul des plus courts chemins entre toutes les paires de noeuds d un graphe Algorithme PageRank
Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop
 Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop Soutenance de projet ASR 27/01/2011 Julien Gerlier Siman Chen Encadrés par Bruno
Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop Soutenance de projet ASR 27/01/2011 Julien Gerlier Siman Chen Encadrés par Bruno
Tout savoir sur Hadoop : Vulgarisation de la technologie et les stratégies de certains acteurs
 Tout savoir sur Hadoop : Vulgarisation de la technologie et les stratégies de certains acteurs Hadoop suscite l'intérêt d'un nombre croissant d'entreprises. Dans ce guide, LeMagIT fait le tour des fonctionnalités
Tout savoir sur Hadoop : Vulgarisation de la technologie et les stratégies de certains acteurs Hadoop suscite l'intérêt d'un nombre croissant d'entreprises. Dans ce guide, LeMagIT fait le tour des fonctionnalités
Change the game with smart innovation
 Change the game with smart innovation Master Thesis 2013 2014 Faculty of Science engineering 12/08/2012 Master Thesis proposal for the academic year 2013. TABLE OF CONTENTS Section Un Introduction... 3
Change the game with smart innovation Master Thesis 2013 2014 Faculty of Science engineering 12/08/2012 Master Thesis proposal for the academic year 2013. TABLE OF CONTENTS Section Un Introduction... 3
Introduction au Data-Mining
 Introduction au Data-Mining Gilles Gasso, Stéphane Canu INSA Rouen -Département ASI Laboratoire LITIS 8 septembre 205. Ce cours est librement inspiré du cours DM de Alain Rakotomamonjy Gilles Gasso, Stéphane
Introduction au Data-Mining Gilles Gasso, Stéphane Canu INSA Rouen -Département ASI Laboratoire LITIS 8 septembre 205. Ce cours est librement inspiré du cours DM de Alain Rakotomamonjy Gilles Gasso, Stéphane
Le Big Data Vers de nouveaux usages! 18/03/2015
 Le Big Data Vers de nouveaux usages! 18/03/2015 Atos en bref est une société internationale spécialisée dans les services technologiques innovants, les services transactionnels à haute valeur et le conseil,
Le Big Data Vers de nouveaux usages! 18/03/2015 Atos en bref est une société internationale spécialisée dans les services technologiques innovants, les services transactionnels à haute valeur et le conseil,
Big Data On Line Analytics
 Fdil Fadila Bentayeb Lb Laboratoire ERIC Lyon 2 Big Data On Line Analytics ASD 2014 Hammamet Tunisie 1 Sommaire Sommaire Informatique décisionnelle (BI Business Intelligence) Big Data Big Data analytics
Fdil Fadila Bentayeb Lb Laboratoire ERIC Lyon 2 Big Data On Line Analytics ASD 2014 Hammamet Tunisie 1 Sommaire Sommaire Informatique décisionnelle (BI Business Intelligence) Big Data Big Data analytics
Le "tout fichier" Le besoin de centraliser les traitements des fichiers. Maitriser les bases de données. Historique
 Introduction à l informatique : Information automatisée Le premier ordinateur Définition disque dure, mémoire, carte mémoire, carte mère etc Architecture d un ordinateur Les constructeurs leader du marché
Introduction à l informatique : Information automatisée Le premier ordinateur Définition disque dure, mémoire, carte mémoire, carte mère etc Architecture d un ordinateur Les constructeurs leader du marché
BIG DATA et DONNéES SEO
 BIG DATA et DONNéES SEO Vincent Heuschling [email protected] @vhe74 2012 Affini-Tech - Diffusion restreinte 1 Agenda Affini-Tech SEO? Application Généralisation 2013 Affini-Tech - Diffusion restreinte
BIG DATA et DONNéES SEO Vincent Heuschling [email protected] @vhe74 2012 Affini-Tech - Diffusion restreinte 1 Agenda Affini-Tech SEO? Application Généralisation 2013 Affini-Tech - Diffusion restreinte
CNAM 2010-2011. Déploiement d une application avec EC2 ( Cloud Amazon ) Auteur : Thierry Kauffmann Paris, Décembre 2010
 Auteur : Thierry Kauffmann Paris, Décembre 2010") CNAM 2010-2011 Déploiement d une application avec EC2 ( Cloud Amazon ) Auteur : Thierry Kauffmann Paris, Décembre 2010 Déploiement d une application dans le cloud. 1. Cloud Computing en 2010 2. Offre EC2
CNAM 2010-2011 Déploiement d une application avec EC2 ( Cloud Amazon ) Auteur : Thierry Kauffmann Paris, Décembre 2010 Déploiement d une application dans le cloud. 1. Cloud Computing en 2010 2. Offre EC2
ETUDE ET IMPLÉMENTATION D UNE CACHE L2 POUR MOBICENTS JSLEE
 Mémoires 2010-2011 www.euranova.eu MÉMOIRES ETUDE ET IMPLÉMENTATION D UNE CACHE L2 POUR MOBICENTS JSLEE Contexte : Aujourd hui la plupart des serveurs d application JEE utilise des niveaux de cache L1
Mémoires 2010-2011 www.euranova.eu MÉMOIRES ETUDE ET IMPLÉMENTATION D UNE CACHE L2 POUR MOBICENTS JSLEE Contexte : Aujourd hui la plupart des serveurs d application JEE utilise des niveaux de cache L1
Hadoop : une plate-forme d exécution de programmes Map-Reduce
 Hadoop : une plate-forme d exécution de programmes Map-Reduce Jonathan Lejeune UPMC 8 octobre 2013 PSIA 2013 Inspiré du cours des années précédentes de Luciana Arantes J. Lejeune (UPMC) Hadoop Map-Reduce
Hadoop : une plate-forme d exécution de programmes Map-Reduce Jonathan Lejeune UPMC 8 octobre 2013 PSIA 2013 Inspiré du cours des années précédentes de Luciana Arantes J. Lejeune (UPMC) Hadoop Map-Reduce
Big Data. Concept et perspectives : la réalité derrière le "buzz"
 Big Data Concept et perspectives : la réalité derrière le "buzz" 2012 Agenda Concept & Perspectives Technologies & Acteurs 2 Pierre Audoin Consultants (PAC) Pierre Audoin Consultants (PAC) est une société
Big Data Concept et perspectives : la réalité derrière le "buzz" 2012 Agenda Concept & Perspectives Technologies & Acteurs 2 Pierre Audoin Consultants (PAC) Pierre Audoin Consultants (PAC) est une société
Introduction Big Data
 Introduction Big Data SOMMAIRE Rédacteurs : Réf.: SH. Lazare / F. Barthélemy AXIO_BD_V1 QU'EST-CE QUE LE BIG DATA? ENJEUX TECHNOLOGIQUES ENJEUX STRATÉGIQUES BIG DATA ET RH ANNEXE Ce document constitue
Introduction Big Data SOMMAIRE Rédacteurs : Réf.: SH. Lazare / F. Barthélemy AXIO_BD_V1 QU'EST-CE QUE LE BIG DATA? ENJEUX TECHNOLOGIQUES ENJEUX STRATÉGIQUES BIG DATA ET RH ANNEXE Ce document constitue
Stephan Hadinger, Sr. Mgr Solutions Architecture, AWS. Salon du Big Data 11 mars 2015
 Stephan Hadinger, Sr. Mgr Solutions Architecture, AWS Salon du Big Data 11 mars 2015 Accélération de l innovation +500 +280 Amazon EC2 Container Service +159 AWS Storage Gateway Amazon Elastic Transcoder
Stephan Hadinger, Sr. Mgr Solutions Architecture, AWS Salon du Big Data 11 mars 2015 Accélération de l innovation +500 +280 Amazon EC2 Container Service +159 AWS Storage Gateway Amazon Elastic Transcoder
La rencontre du Big Data et du Cloud
 La rencontre du Big Data et du Cloud Libérez le potentiel de toutes vos données Visualisez et exploitez plus rapidement les données de tous types, quelle que soit leur taille et indépendamment de leur
La rencontre du Big Data et du Cloud Libérez le potentiel de toutes vos données Visualisez et exploitez plus rapidement les données de tous types, quelle que soit leur taille et indépendamment de leur
Certificat Big Data - Master MAthématiques
 1 / 1 Certificat Big Data - Master MAthématiques Master 2 Auteur : Sylvain Lamprier UPMC Fouille de données et Medias Sociaux 2 / 1 Rich and big data: Millions d utilisateurs Millions de contenus Multimedia
1 / 1 Certificat Big Data - Master MAthématiques Master 2 Auteur : Sylvain Lamprier UPMC Fouille de données et Medias Sociaux 2 / 1 Rich and big data: Millions d utilisateurs Millions de contenus Multimedia
CENTAI : Big Data & Big Analytics Réunion DGPN / Thales Octobre 2013
 www.thalesgroup.com CENTAI : Big Data & Big Analytics Réunion DGPN / Thales Octobre 2013 2 / Sommaire CENTAI : Présentation du laboratoire Plate-forme OSINT LAB Détection de la fraude à la carte bancaire
www.thalesgroup.com CENTAI : Big Data & Big Analytics Réunion DGPN / Thales Octobre 2013 2 / Sommaire CENTAI : Présentation du laboratoire Plate-forme OSINT LAB Détection de la fraude à la carte bancaire
Machine Learning 9:HSMBKA=\WU\YX: Big Data et machine learning. Manuel du data scientist. InfoPro
 type d ouvrage se former retours d expérience Pirmin Lemberger, Marc Batty Médéric Morel, Jean-Luc Raffaëlli Management des systèmes d information applications métiers études, développement, intégration
type d ouvrage se former retours d expérience Pirmin Lemberger, Marc Batty Médéric Morel, Jean-Luc Raffaëlli Management des systèmes d information applications métiers études, développement, intégration
TRAVAUX DE RECHERCHE DANS LE
 TRAVAUX DE RECHERCHE DANS LE DOMAINE DE L'EXPLOITATION DES DONNÉES ET DES DOCUMENTS 1 Journée technologique " Solutions de maintenance prévisionnelle adaptées à la production Josiane Mothe, FREMIT, IRIT
TRAVAUX DE RECHERCHE DANS LE DOMAINE DE L'EXPLOITATION DES DONNÉES ET DES DOCUMENTS 1 Journée technologique " Solutions de maintenance prévisionnelle adaptées à la production Josiane Mothe, FREMIT, IRIT
Entreprise et Big Data
 Entreprise et Big Data Christophe Favart Chef Architecte, SAP Advanced Development, Business Information Technology Public Juin 2013 Agenda SAP Données d Entreprise Big Data en entreprise Solutions SAP
Entreprise et Big Data Christophe Favart Chef Architecte, SAP Advanced Development, Business Information Technology Public Juin 2013 Agenda SAP Données d Entreprise Big Data en entreprise Solutions SAP