Chaînes de Markov (version 0)
|
|
|
- Jules Clermont
- il y a 10 ans
- Total affichages :
Transcription
1 Chaînes de Markov (version 0) Yan Doumerc ECS1, lycée Gaston Berger, Lille 15 Mai 2014 Résumé Ce document accompagne une séance de formation destinée aux professeurs de classe préparatoire EC. Il s agit de présenter les fondamentaux des chaînes de Markov, thème qui fait son appartition dans les nouveaux programmes. L objectif est de donner les résultats théoriques majeurs ainsi que quelques preuves significatives, de présenter un panorama assez vaste d exemples qui peuvent servir d inspiration et de détailler les possibilités qu offre Scilab sur ce thème. Le contenu de ce document va au delà de ce qui est présentable à nos étudiants mais nous espérons qu il aidera ses lecteurs à avoir un bagage confortable et un recul suffisant pour enseigner le sujet. Table des matières 1 Introduction Motivations Les questions qui se posent Liste de notations Généralités Définitions Propriété de Markov En Scilab Structure linéaire 6 4 Structure topologique Communications entre états et classes Période Classification des états Transience, récurrence positive et récurrence nulle En Scilab Mesure invariante Définition, existence, unicité En Scilab Asymptotique Loi des grands nombres Convergence en loi de (X n ) Aspects matriciels dans le cas E fini 14 9 Analyse à un pas Temps d atteinte Probabilités et temps d absorption

2 10 Exemples La chaîne à deux états Bonus-malus en assurance Mobilité sociale Score au tennis Mots de taille 2 dans un pile ou face Ascension et rechutes Retenues lorsque l on pose une addition Collectionneur de coupons Sisyphe et les matrices compagnons Processus de vie et de mort et marches aléatoires Sur N Sur Z Sur [[0, s]. Ruine du joueur Marche aléatoire sur un graphe. Pagerank de Google. Cavalier sur un échiquier Marche aléatoire sur un groupe Urne d Ehrenfest Modèle de Wright-Fisher Processus de Galton-Watson Files d attente Un exemple non-homogène : urne de Polya Quelques preuves 30 1 Introduction 1.1 Motivations 1. Dans les nouveaux programmes, les chaînes de Markov constituent le thème 3 en ECS2 (6h) et ECT2 (4h), le thème 4 en ECE2 (6h). Elles mobilisent les compétences C2 (modéliser et simuler des phénomènes aléatoires ou déterministes et les traduire en langage mathématique) et C4 (représenter et interpréter les différentes convergences). 2. Les familles (X n ) n N de variables aléatoires indépendantes sont des objets fondamentaux en probabilités mais souvent trop «naïfs» pour décrire en pratique des phénomènes aléatoires. Les chaînes de Markov constituent un exemple fondamental de familles (X n ) de variables exhibant une dépendance suffisamment riche pour être pertinente et suffisamment simple pour se prêter à une étude détaillée. 3. Les chaînes de Markov sont le pendant aléatoire des suites récurrentes x n+1 = f(x n ). 4. Certains phénomènes se présentent spontanément comme des chaînes de Markov. Ce sont souvent des hypothèses d indépendance inhérentes au phénomène qui se transforment en propriété de Markov. Cf 10.5, 10.7, On peut aussi fabriquer une structure markovienne pour s adapter au plus près à la modélisation d une situation réelle. A ce titre, les chaînes de Markov constituent des approximations de la réalité dont il convient de mesurer ensuite la pertinence (notamment en termes de prédictions). Cf 10.3, 10.16, 10.15, 10.14, Notons que la structure markovienne à choisir peut être subtile : certains phénomènes ne sont pas directement markoviens en eux-mêmes mais proviennent d un processus markovien sous-jacent (chaîne de Markov cachée). 6. Enfin, les chaînes de Markov peuvent être utilisées comme outils dans des problèmes qui n ont a priori rien de markovien. Par exemple, les bonnes propriétés asymptotiques des chaînes de Markov peuvent permettre la simulation exacte ou approchée d une loi de probailité (algorithmes de Metropolis-Hastings et de Propp-Wilson) ou le calcul approché d une espérance sous cette loi (méthodes dites MCMC pour Monte Carlo Markov Chains). Elles peuvent aussi servir dans des problèmes d optimisation (algorithme de recuit simulé). 7. Pédagogiquement, les chaînes de Markov permettent de nouer un lien fort entre probabilités et algèbre linéaire. 2

3 8. Scilab a des commandes prévues pour les chaînes de Markov. Pour les comprendre, il faut avoir quelques connaissances mathématiques sur le sujet. 9. Ce document comporte quelques preuves que nous avons jugé utiles et significatives. Nous renvoyons à l abondante littérature sur le sujet. Notre bibliographie cîte des ouvrages et des articles publiés mais il existe aussi des cours très complets disponibles sur internet (il suffit de googliser «chaînes de Markov» ou «Markov chains» pour obtenir de nombreux cours de type L3 ou M1) 1.2 Les questions qui se posent En tant que généralisation des suites récurrentes x n+1 = f(x n ) et des suites de variables aléatoires indépendantes et de même loi, les chaînes de Markov soulèvent des questions naturelles. 1. Quels états la chaîne peut-elle visiter? Combien de fois la chaîne visite-t-elle ces états? 2. Existe-t-il des régions pièges telles que si la chaîne y entre, elle y reste? 3. Existence et unicité d un équilibre (analogue à un point fixe de f pour une suite x n+1 = f(x n ))? 4. Comportement asymptotique quand n + : loi des grands nombres pour f(x 1) + + f(x n ), n convergence de X n? 1.3 Liste de notations 1. L(Y )= loi de la variable aléatoire Y. 2. CM : chaîne de Markov. 3. CM(E, µ, Q) : chaîne de Markov à valeurs dans E, de loi initiale µ et de «matrice» de transition Q. On utilisera CM(E), CM(Q) ou CM(µ, Q) selon les situations. 4. P µ = loi de la chaîne X lorsque µ = L(X 0 ), P x = loi de la chaîne X lorsque X 0 = x, L µ (Y ) = loi de la variable aléatoire Y lorsque µ = L(X 0 ). 5. Si n N, X n+ = (X n+k ) k N = chaîne translatée de n. 6. Si A E, τ A = inf{n 0 X n A} = temps d atteinte de A, T A = inf{n > 0 X n A} temps positif d atteinte de A, τ x = τ {x}, T x = T {x}. 7. ρ xy = P x ( n N, X n = y) = P x (T y < + ) 8. N A = + n=0 1 X n A = nombre de passages de X en A. 3
 1.")
4 2 Généralités 2.1 Définitions 1. X = (X n ) n N suite de variables aléatoires à valeurs dans E (espace d états, fini ou dénombrable). X est une CM lorsque n N, (x 0,..., x n+1 ) E n+2, P (X n+1 = x n+1 (X 0,..., X n ) = (x 0,..., x n )) = P (X n+1 = x n+1 X n = x n ). 2. Une CM X est homogène lorsque P (X n+1 = y X n = x) ne dépend pas de n. On note Q xy := P (X n+1 = y X n = x) = P (X 1 = y X 0 = x) = probabilité de transition de x à y. 3. Q = (Q xy ) (x,y) E 2 := «matrice» de transition indicée par E 2 (Q xy 0, y E Q xy = 1). 4. Si µ = L(X 0 ) (loi de X 0 i.e. µ x = P (X 0 = x)) alors la loi de la chaîne X est entièrement déterminée par µ = L(X 0 ) et Q : P (X 0 = x 0, X 1 = x 1,..., X n = x n ) = µ x0 Q x0x 1 Q x1x 2 Q xn 1x n. 5. CM = suite récurrente aléatoire. Si (U n ) n N est une suite de variables aléatoires indépendantes et de même loi, indépendantes de X 0 et X n+1 = f(x n, U n+1 ) alors X est une CM de transitions données par Q xy = P (f(x, U) = y). Réciproquement, toute CM peut être réalisée ainsi. 2.2 Propriété de Markov 1. Propriété de Markov faible : conditionnellement à {X n = x}, la suite X n+ est une CM(δ x, Q) indépendante de (X 0,..., X n 1 ) i.e. n, A E n, B E N (B mesurable pour la tribu produit), P µ (X n+ B (X 0,..., X n 1 ) A, X n = x) = P x (X B). 2. La propriété de Markov forte permet de remplacer le n fixé de la propriété précédente par un temps T aléatoire lorsque c est un temps d arrêt i.e. lorsque, pour tout k N, {T = k} est dans la tribu F k engendrée par X 0,..., X k. On note alors F T = {A k N, A {T = k} F k } et la propriété de Markov forte dit alors que, conditionnellement à {T < + } {X T = x}, la suite X T + est une CM(δ x, Q) indépendante de F T. Cette formulation est très pratique mais nécessite des préalables (tribu engendrée par X 0,..., X k, temps d arrêt, tribu F T ) qu il me semble déraisonnable de présenter à nos étudiants de voie EC. Ainsi, je n utiliserai pas cette formulation. 2.3 En Scilab 1. La commande X=grand(n,"markov",Q,x0) renvoie une trajectoire X 1,..., X n de longueur n de la CM de matrice de transition Q de taille N, d espace d états [[1, N ] et d état initial x0 [[1, N ] 2. On peut simuler simultanément par la même commande m trajectoires de la chaîne en prenant pour x0 un vecteur de longueur m : Y est alors une matrice à m lignes et n colonnes, la i-ième ligne de cette matrice représentant une trajectoire de la chaîne issue de x0(i). 3. La commande Q=genmarkov(N,0) génère une matrice de transition aléatoire (irréductible, cf 4.1) de taille N. Cette commande admet d autres options (cf 5). -->Q=genmarkov(3,0) Q = >X=grand(10,"markov",Q,2) X =
 (loi de X 0 i.e. µ x = P (X 0 = x)) alors la loi de la chaîne X est entièrement déterminée par µ = L(X 0 ) et Q : P (X 0 = x 0, X 1 = x 1,.")
5 -->X=grand(10,"markov",Q,ones(1,4)) X = La commande X=grand(n, markov,q,x0) ne fonctionne que pour un espace d état fini. Une autre méthode est d utiliser une formule X n+1 = f(x n, U n+1 ) qui, modulo une boucle, réduit le problème à la simulation de variables aléatoires indépendantes et de même loi U n. 5. Parfois, les commandes matricielles de Scilab permettent d éviter une boucle et d écrire des codes très rapides (cf 10.12). 5

6 3 Structure linéaire 1. Une mesure (positive) µ sur E est vue comme un vecteur ligne (µ x ) x E indicé par E (à composantes 0). 2. Une fonction f sur E est vue comme un vecteur colonne (f(x)) x E indicé par E. 3. Lemme général de probabilités. Soit X, Y deux variables aléatoires à valeurs dans E, L(X), L(Y ) vecteurs lignes des lois de X et Y. On pose Q xy = P (Y = y X = x) et Q = (Q xy ) (x,y) E 2 matrice indicée par E 2. Alors Formule de transfert : E(f(X)) = L(X).f Formule des probabilités totales : L(Y ) = L(X).Q, où l on utilise les produits «matriciels» usuels (µ.q) y = x E µ xq xy, (Q.f) x = y E Q xyf(y). 4. Application à X CM(Q) : L(X n+1 ) = L(X n ).Q, L(X n ) = L(X 0 ).Q n E µ (f(x n )) = µ.q n.f, P x (X n = y) = Q n xy 5. En Scilab, on peut donc utiliser le produit matriciel pour calculer Q n, L(X 0 ).Q n ou µ.q n.f. A titre d exemple, si X est une CM([[1, N ], Q, ν) où N,Q sont connues et ν = U([[1, N ]), on peut calculer ainsi la loi de X 10 ou sa variance : L=(ones(1,N)/N)*Q^10 V=L*([1:N].^2)-(L*[1:N])^2 //renvoie vecteur ligne égal à la loi de X_10 //renvoie Var(X_10) 6. En Scilab, une façon rapide de stimuler l intérêt pour le comportement asymptotique d une CM est la séquence suivante : -->Q=genmarkov(5,0) Q = >Q^3 ans = >Q^100 ans = Pourquoi les lignes de Q n sont-elles égales? Cf 7.2 pour une réponse. 6
) = L(X).f Formule des probabilités totales : L(Y ) = L(X).Q, où l on utilise les produits «matriciels» usuels (µ.q) y = x E µ xq xy, (Q.f) x = y E Q xyf(y). 4.")
7 4 Structure topologique 4.1 Communications entre états et classes 1. Graphe orienté G associé à une CM(E, Q) : sommets = états ( E), arêtes : x y ssi Q xy > Si (x, y) E 2, les propriétés suivantes sont équivalentes : (a) P x ( n N, X n = y) > 0 (b) n N tel que Q n xy = P x (X n = y) > 0 (c) n N, x 1,..., x n 1 E tels que x x 1 x n 1 y i.e. Q xx1 Q x1x 2 Q xn 1y > 0 i.e. x, y sont reliés par un chemin dans le graphe orienté G. Si c est le cas, on dit que x mène à y et on note x y. C est une relation réflexive, transitive mais non-symétrique. 3. Lorsque x y et y x, on dit que x communique avec y et on note x y. est une relation d équivalence dont les classes d équivalence sont appelées simplement classes. 4. Une CM est irréductible si elle n a qu une seule classe i.e. si (x, y) E 2, x y. 5. Une partie F E est dite close si x F, y / F, Q xy = 0, ce qui équivaut à x F, P x ( n N, X n F ) = Un état x est absorbant lorsque {x} est close i.e. Q xx = Une classe n est pas toujours close : il peut exister des transitions entre deux classes mais uniquement dans un sens (sinon elles ne feraient qu une seule classe). 4.2 Période 1. Si x E, D x := {n N Q n xx > 0} et d x := pgcd D x = période de x (si D x ). 2. Si D x, on prouve que D x et d x N ne diffèrent que par un ensemble fini (utiliser Bezout et la stabilité de D x par somme). 3. Les états d une classe ont même période. 4. x est apériodique si d x = 1. Ceci équivaut à : k x N, n k x, Q n xx > 0. Une chaîne est apériodique si tous ses états le sont. 5. Une chaîne est irréductible et apériodique ssi (x, y) E 2, k xy N, n k xy, Q n xy > Ainsi, si E est fini, une CM(E, Q) est irréductible et apériodique ssi il existe k N tel que Q k ait tous ses coefficients positifs. 7. Si X CM(E, Q) est irréductible et de période d, il existe une partition E = E 0 E d 1 telle que (a) P (X n+k E i+k X n E i ) = 1 (avec E i+dj = E i ). (b) Q d a d classes E 0,..., E d 1 qui sont closes et apériodiques (pour Q d ). E 0,..., E d 1 sont les composantes cycliques de la chaîne CM(Q) et celle-ci les traverse successivement et de façon cyclique. 7

8 --]-i L--i - t_ I il --- i. L: =rl l =' :: 1- I tl 'i ri =- tl i -f-=r.-.i: F]_

9 5 Classification des états. 5.1 Transience, récurrence positive et récurrence nulle 1. Rappel : N x = n=0 1 {Xn=x}, ρ xy = P x ( n > 0, X n = y) = P x (T y < + ). 2. Un état x E vérifie soit les propriétés équivalentes du 2a, soit celles du 2b. (a) ρ xx = 1 P x (N x = + ) = 1 n Qn xx = + : x est alors dit récurrent ; (b) ρ xx < 1 k 1, P x (N x = k) = (1 ρ xx )ρ k 1 xx n Qn xx < + : x est alors dit transient. 3. Un état récurrent x est dit récurrent positif si E x (T x ) < + et récurrent nul si E x (T x ) = La récurrence est contagieuse : si x récurrent et x y alors y récurrent et ρ xy = ρ yx = 1. Ainsi, si x y et y x alors x est transient. 5. Transience, récurrence positive et récurrence nulle sont des propriétés de classe. 6. Toute classe récurrente est close. 7. Une CM(E) a au moins un état récurrent si E est fini. 8. Une classe récurrente finie est récurrente positive. 9. E est l union disjointe de classes ((RP i ) i I, (RN j ) j J, (T k ) i K ), I, J ou K pouvant être vides. Les RP i, RN j sont closes, les RN j sont infinies, les T k peuvent être infinies ou non, closes ou non. Mais si la chaîne sort d une T k, elle n y reviendra plus jamais. Si une T k est finie, la chaîne ne la visitera qu un nombre fini de fois. Il n y a qu un seul ordre dans lequel les T k peuvent être visitées. 10. Si E est fini, E est l union disjointe de classes ((RP i ) i I, (T k ) i K ), I. Les RP i sont closes. Les T k ne seront visitées qu un nombre fini de fois. La chaîne finira toujours par être absorbée par une des classes récurrentes. 11. Ainsi, si E est fini, on peut réordonner ses éléments de telle manière que la matrice de transition s écrive par blocs sous sa forme canonique : M M.. 2. Q = , (1) 0 0 M r 0 B 1 B r Q où les M 1,..., M r correspondent aux r classes récurrentes et la ligne B 1 B r Q correspond aux transitions démarrant dans l ensemble T des points transients. 5.2 En Scilab 1. La commande genmarkov([n1,n2,...,nr],nt) renvoie une matrice de transition écrite sous forme canonique (1) ayant r classes récurrentes de cardinaux respectifs n1,..., nr et une classe transiente contenant nt états. 2. La commande genmarkov([n1,n2,...,nr],nt, perm ) permute les états de manière que Q n apparaisse plus sous forme fondamentale. 3. La commande [perm,rec,tr,indsrec,indst]=classmarkov(q) permet de trouver le nombre d états transients (tr), les tailles des classes récurrentes (rec), les indices des états récurrents (indsrec) et transients (indst) ainsi qu une permutation (perm) de ces indices permettant de mettre la matrice de transition Q sous forme canonique. D où la session suivante : -->Q=genmarkov([2,1,1],2, perm ) Q =
 < + et récurrent nul si E x (T x ) = +. 4. La récurrence est contagieuse : si x récurrent et x y alors y récurrent et ρ xy = ρ yx = 1.")
10 >[perm,rec,tr,indsrec,indst]=classmarkov(q) indst = indsrec = tr = 2. rec = perm = >Q(perm,perm) ans = Pédagogiquement, si l on veut que les étudiants puissent générer une matrice de transition et s entraîner eux-mêmes à trouver les classes, la commande genmarkov([n1,n2,...,nr],nt, perm ) leur donne déjà les cardinaux des classes. On peut bricoler un générateur de matrices markoviennes avec des zéros en normalisant les lignes d une matrice d entiers aléatoires : function q=gene_mat_trans_avec_zer(n,p) // renvoie une matrice markovienne de taille n // p dans [0,1], proche de 1 pour qu il y ait beaucoup de 0 aux=0 while aux==0 // sert à ne pas diviser par 0 M=grand(n,n,"geom",p)-1 S=sum(M, c ) // sommes cumulées de M par lignes aux=prod(s) // produit des éléments de S end q=diag((1./s))*m // divise chaque ligne de M par sa somme endfunction Bien sûr, ce générateur a très peu d intérêt pour n = 2 ou 3. Exercice : on note Z le nombre de zéros dans la matrice ainsi générée et C le nombre de passages dans la boucle while. Quelles sont les lois de Z et C? Quel est le nombre moyen de zéros dans la matrice générée? Quel est le nombre moyen de zéros de passages dans la boucle? Quelle est la probabilité de passer plus d une fois dans la boucle? 9

11 6 Mesure invariante 6.1 Définition, existence, unicité 1. Une mesure µ sur E est invariante pour une CM(E, Q) lorsque µq = µ i.e. y E, µ x Q xy = µ y. x E Comme µ = 0 est toujours invariante, on sous-entendra dans la suite mesure non-nulle. 2. Interprétation probabiliste : soit µ une loi (i.e. une mesure de probabilté). Alors µ invariante n N, L µ (X n ) = µ n N, L µ (X) = L µ (X n+ ). 3. Une mesure invariante est un vecteur propre à gauche à composantes 0 de la matrice Q associé à la valeur propre Une mesure µ est réversible lorsque (x, y) E 2, µ x Q xy = µ y Q yx. Une mesure réversible est invariante (il n y a qu à sommer sur x E). 5. Une «matrice» de transition Q est bistochastique lorsque outre y E, x E Q xy = 1. Ceci signifie exactement que la mesure «constante» (µ x = 1 pour tout x E) est invariante. 6. Toute chaîne ayant au moins un état récurrent a au moins une mesure invariante. 7. Si µ est une mesure finie, invariante et si x un état transient alors µ x = Les mesures invariantes d une CM X irréductible et récurrente sont toutes proportionnelles. Elles vérifiet toutes µ y > 0 pour tout y E et on a la dichotomie suivante : (a) X est récurrente positive et toutes les mesures µ invariantes vérifient µ(e) < +. X possède alors une unique loi invariante donnée par x E, µ x = (E x (T x )) 1 > 0. (b) X est récurrente nulle et toutes les mesures invariantes vérifient µ(e) = +. X ne possède alors pas de loi invariante. 9. Ainsi, une chaîne admet une unique loi invariante ssi elle est irréductible, récurrente positive. 6.2 En Scilab 1. La fonction eigenmarkov(q) renvoie l unique loi stationnaire d une chaîne de Markov irréductible de matrice de transition Q. -->Q=[ ; ] Q = >eigenmarkov(q) ans = Si la chaîne comporte m classes récurrentes, eigenmarkov(q) renvoie une matrice à m lignes dont la i-ième ligne est la loi stationnaire correspondant à la i-ième classe récurrente. -->Q=[genmarkov(2,0) zeros(2,2); zeros(2,2) genmarkov(2,0)] Q =
 E 2, µ x Q xy = µ y Q yx. Une mesure réversible est invariante (il n y a qu à sommer sur x E). 5.")
12 >eigenmarkov(q) ans =

13 7 Asymptotique 7.1 Loi des grands nombres 1. Notons N n y = n k=1 1 X k =y le nombre de passages en y entre les instants 1 et n. Alors, pour tout chaîne X irréductible et toute loi initiale, y E, Ny n lim n + n = (E y(t y )) 1 presque-sûrement (avec (+ ) 1 = 0). (2) 2. Soit X une CM irréductible, récurrente nulle. Alors, pour toute loi initiale et toute fonction f intégrable par rapport à «la» mesure invariante, on a f(x 1 ) + + f(x n ) lim = 0 presque-sûrement. (3) n + n 3. Soit X une CM irréductible, récurrente positive. On note µ son unique loi invariante (µ x = (E x (T x )) 1 ) et on suppose que la fonction f est µ-intégrable. Alors, pour toute loi initiale, on a f(x 1 ) + + f(x n ) lim = µ.f presque-sûrement. (4) n + n 4. En Scilab, il suffit de simuler une seule trajectoire pour illustrer ces convergences car elles ont lieu avec probabilité un, quelle que soit la mesure initiale. A titre d exemple, si X CM(Q) est irréductible, récurrente positive de loi invariante µ, on pourra regarder les estimateurs ˆµ (n) N n x n (n) et ˆQ xy = 1 Nx n x = n 1 1 Xk =x,x k+1 =y. On pourra prouver qu ils convergent avec probabilité un k=0 respectivement vers µ x et Q xy (utiliser le fait que (X n, X n+1 ) est une CM irréductible, récurrente positive et de mesure invariante λ (x,y) = µ x Q xy ). On pourra les tester sur un exemple généré par genmarkov puis grand. 7.2 Convergence en loi de (X n ) 1. Pour une chaîne X irréductible, le théorème de convergence dominée permet de passer à l espérance sous P x dans (2) pour avoir x E, lim n + n k=1 Qk xy n = (E y (T y )) 1. (5) Ainsi la suite (P x (X n = y) = Q n xy) converge au sens de Césaro. Converge-t-elle au sens usuel? 2. Si y est transient ou récurrent nul, on a P x (X n = y) = Q n xy 0. n + ( ) Il existe des cas où la suite (P x (X n = y) = Q n xy) n a pas de limite (ex : Q =, Q 1 0 2n = I 2, Q 2n+1 = Q). C est un phénomène de périodicité qui fait obstacle à la convergence. 4. Soit X une CM irréductible, récurrente positive et apériodique. X a une unique loi invariante µ. Alors, pour toute loi initiale ν, la suite (X n ) converge en loi vers une variable aléatoire de loi µ : A E, lim P ν(x n A) = µ(a) et, en particulier, lim n + n + Qn xy = µ y = (E y (T y )) 1. (6) 5. En Scilab, pour illustrer ces convergences en loi, une seule trajectoire ne suffit plus. On peut fixer un n grand, simuler k trajectoires, obtenir des copies indépendantes Xn, 1..., Xn k et regarder la loi empirique associée µ k = 1 k δ k X i n qui approxime la loi de X n et donc la loi µ. La comparaison i=1 entre µ k et µ peut se faire à travers leurs histogramme ou à travers leurs fonctions de répartition si E R (F k (t) = 1 k 1 k X i n t d un côté et F (t) = µ(], t]) de l autre). i=1 12
) 1 ) et on suppose que la fonction f est µ-intégrable.")
14 6. En Scilab, une autre illustration possible est de calculer νq n par produit matriciel puis la distance en variation totale d V T (νq n, µ) = x E νqn (x) µ(x) et de représenter graphiquement d V T (νq n, µ) en fonction de n. 7. Supposons X CM(Q) irréductible, récurrente positive, de loi invariante µ, de période d et de composantes cycliques E 0,..., E d 1. Alors, pour tout 0 i d 1, µ(e i ) = 1/d et la chaîne (X nd+i ) n N converge en loi : A E, lim P d 1 ν(x nd+i A) = d ν(e j )µ(a E i+j ) n + et, en particulier pour (x, y) E j E i+j, j=0 lim n + Qnd+i xy = dµ y. 13
 = 1/d et la chaîne (X nd+i ) n N converge en loi : A E, lim P d 1 ν(x nd+i A) = d ν(e j )µ(a E i+j ) n + et,")
15 8 Aspects matriciels dans le cas E fini Soit X une CM(E, Q) avec E fini. Rappelons que, pour toute matrice, les valeurs propres à gauche et les valeurs propres à droite sont les mêmes avec même multiplicité algébrique (i.e. dans le polynôme caractéristique) et géométrique (i.e. dimension du sous-espace propre). On pourra donc parler des valeurs propres sans précision. 1. Les valeurs propres de Q sont toutes de module 1 et 1 est valeur propre. M M Si l on prend la forme canonique Q = , les valeurs propres sont celles 0 0 M r 0 B 1 B r Q de M 1,..., M r, Q. Chaque M i possède 1 comme valeur propre de multiplicité géométrique égale à 1. Les valeurs propres de Q sont de module < Ainsi, la dimension du sous-espace propre associé à 1 est égale au nombre de classes récurrentes. 4. Soit d k la période de M k. Les valeurs propres de module 1 de M k sont les racines d k -èmes de l unité. 5. Ainsi, si Q est irréductible et récurrente, elle est apériodique ssi 1 est la seule valeur propre de module Une loi invariante est un vecteur propre à gauche à composantes 0 et de somme 1. Chaque M k possède une unique loi invariante µ k et les lois invariantes sont toutes de la forme µ = r k=1 a kµ k où a k 0 et r k=1 a k = Si Q est irréductible (donc récurrente) et apériodique, la matrice Q n converge vers la matrice dont toutes les lignes sont égales à µ (l unique loi invariante). C est une matrice de projecteur de rang Soit Q de taille N = E irréductible dont l unique loi invariante est µ. On peut munir R E (ensemble des fonctions de E dans R vues comme vecteurs colonnes) du produit scalaire f, g = x E µ(x)f(x)g(x). On note 1 R E la fonction constante 1 si bien que µ.f = x µ(x)f(x) = f, 1. On confond Q avec l endomorphisme qu il induit canoniquement sur R E. Q est alors symétrique ssi µ est réversible. Dans ce cas, Q est diagonalisable dans une base orthonormée f 1,..., f N avec valeurs propres 1 = λ 1 > λ 2 λ N 1. L irréductibilité de Q se traduit par le fait que λ 1 = 1 soit valeur propre simple. Q est apériodique ssi λ N > 1. Ainsi, pour tout f R E N N N Q n f = f, f i Q n f i = f, f i λ n i f i = µ.f + f, f i λ n i f i. i=1 i=1 En notant c(x) = Q 2 xx/µ x et ρ = max(λ 2, λ N ) < 1, on peut prouver dans le cas apériodique que E x (f(x n )) µ.f 2 c(x)ρ 2n 2 f µ.f 2 et P x (X n A) µ(a) c(x)ρ2n 2, ce qui reprouve la convergence en loi de (X n ) et donne une vitesse de convergence. i=2 14

16 9 Analyse à un pas 9.1 Temps d atteinte 1. Rappel : si A E, τ A = inf{n 0 X n A} = temps d atteinte de A. 2. Posons φ A (x) = P x (τ A < + ). φ A est la solution minimale des équations suivantes : x A, φ A (x) = 1, x / A, φ A (x) = y E Q xy φ A (y). (7) 3. Si A B =, posons φ A,B (x) = P x (τ A < τ B ) pour tout x E. ψ est la solution minimale des équations suivantes : x A, φ A,B (x) = 1, x B, φ A,B (x) = 0, x / A B, φ A,B (x) = y A Q xy φ A,B (y). (8) 4. Posons ψ A (x) = E x (τ A ) pour tout x E. Alors ψ A est la solution minimale de l équation suivante : x A, ψ A (x) = 0, x / A, ψ A (x) = 1 + y / A Q xy ψ A (y). (9) Ainsi, en notant Q la matrice obtenue en supprimant les lignes et colonnes d indices dans A et en 1 introduisant les vecteurs colonnes de même taille ψ A = (ψ A (x)) x / A et J =., on a donc 1 ψ A = J + Qψ A i.e. (I Q)ψ A = J. (10) 9.2 Probabilités et temps d absorption M M Si E est fini, reprenons la forme canonique de Q = correspondant 0 0 M r 0 B 1 B r Q aux classes récurrentes (C 1,..., C r ) et à l ensemble T des points transients. Notons τ j le temps d atteinte de C j, τ = inf j τ j le temps d absorption dans une des classes récurrentes. On sait que τ est fini avec probabilité un et admet une espérance. Pour 1 j r et (x, y) T 2, les quantités d intérêt sont (a) E x (N y ) le nombre moyen de visites en y partant de x, (b) ψ(x) = E x (τ) le temps moyen d absorption partant de x, (c) φ j (x) = P x (τ j < + ) = P x (X τ C j ) la probabilité d être absorbée par C j partant de x. Introduisons les vecteurs colonnes ψ = (ψ(x)) x T, φ j = (φ j (x)) x T, J = t (1,..., 1) M T,1 (R) et J j = t (1,..., 1) M Cj,1(R). Posons aussi φ = (φ 1,..., φ r ) et B = (B 1 J 1,..., B r J r ) dans M T,r (R). Alors, on prouve que, on a I t Q est inversible et, si F = (I t Q) 1, on a : E x (N y ) = F xy, ψ = F J, φ = F B. (11) 2. Si E est fini, une CM(E, Q) est dite absorbante lorsque les classes récurrentes sont des singletons i.e. les états récurrents sont absorbants. Les calculs précédents sont alors tous valables. On a M 11 = = M rr = J 1 = = J r = 1, les B i sont des vecteurs colonnes et B = (B 1,..., B r ). 3. En Scilab, la commande [M,S]=eigenmarkov(Q) renvoie, en plus de la matrice M contenant dans sa j-ème ligne la loi invariante portée par C j, la matrice S est φ = F B i.e. S(x,j) est la probabilité de terminer dans la j-ième classe en démarrant en l état x. Cf 10.4 pour un exemple. 15
 = 0, x / A, ψ A (x) = 1 + y / A Q xy ψ A (y).")
17 10 Exemples 10.1 La chaîne à deux états ( 1 a a 1. Si E = {0, 1}, la matrice de transition est Q = b 1 b t (a, b).( 1, 1), rg(m) = 1. ) ( a a = I 2 +M où M = b b ) = 2. Le calcul de Q n est entièrement explicite et peut se faire dès la 1ère année de filière EC : soit par récurrence, soit par la formule du binôme en utilisant M k = ( a b) k 1 M pour k 1. En 2ème année, on peut faire ce calcul par diagonalisation explicite de M (facile car rg(m) = 1) puis de Q. La limite quand n + peut s étudier directement dans ce cas particulier. 3. La chaîne est irréductible ssi ab 0. Dans ce cas, elle est apériodique ssi a + b < 2. Le cas a = b = 1 est l archétype d une chaîne de période 2 qui donne si, par exemple, X n = 0 alors X 2n = 0 et X 2n+1 = 1 donc X n ne converge pas en loi Bonus-malus en assurance 1. E= ensemble des classes de tarifications = {1 (fort bonus), 2, 3, 4, 5, 6 (fort malus)}. 2. Evolution : si on n a aucun accident dans l année, on gagne en bonus (si possible) ; si on a au moins un accident dans l année, on passe à 6 (malus maximal). 3. p = probabilité de ne pas avoir d accident dans l année, q = 1 p. p q p q 4. Q = 0 p q 0 0 p 0 0 q p 0 q p q 5. Q est irréductible, récurrente positive et apériodique. En résolvant le système µq = Q, on voit que son unique loi invariante est µ = (p 5, qp 4, qp 3, qp 2, qp, q). D après 7.2.4, (X n ) converge en loi vers une variable aléatoire de loi µ. 6. Si le coût annuel de l assurance en classe i vaut f(i) alors le coût total pour un assuré sur n années vaut C n = f(x 1 ) + + f(x n ) et vérifie C n n( 6 x=1 f(x)µ(x)) avec probabilité un quand n Nous renvoyons à [L] ainsi qu à la page web http ://blogperso.univ-rennes1.fr/arthur.charpentier. 8. Voici une fonction qui simule une trajectoire de cette chaîne avec boucle for function x=simu_bonus_boucle(n,p) //simule trajectoire de longueur n de la chaîne bonus, p = proba de zéro accident x=ones(1,n) for i=2:n u=rand() x(i)=6+(max([1,x(i-1)-1])-6)*(u<p)// 6 si u>p et max(1,x(i-1)-1) si u<p end endfunction 9. Voici une fonction qui fabrique la matrice de cette chaîne. function m=mat_bonus(p) //calcule la mat de transition du bonus avec proba p de zéro accident q=1-p n=p*eye(5,5) n=[zeros(1,5);n] m=[n, q*ones(6,1)] 16

18 m(1,1)=p endfunction 10. Voici un code qui dessine plusieurs trajectoires de la chaîne. clf() n=input("longueur des trajectoires : ") k=input("nombre de trajectoires : ") p=input("proba de ne pas avoir d accident : ") y=grand(n, markov,mat_bonus(p),ones(1,k)) //y a k lignes contenant des trajectoires de longueur n y=[ones(1,k) y] //on ajoute les points de départ : y a k lignes et n+1 colonnes m=ones(k,1)*[1:n+1]-1//matrice à k lignes égales toutes à 0,1,2,...,n plot2d(m,y ) n1=string(n);p1=string(p);k1=string(k); xtitle([k1 trajectoires de longueur n1 de l évolution du bonus avec proba de ne pas avoir d accident p1], temps, états,boxed=1) 11. Voici un code qui dessine plusieurs trajectoires des moyennes empiriques des bonus. clf n=input("longueur des trajectoires : ") k=input("nombre de trajectoires : ") p=input("proba de ne pas avoir d accident : ") y=grand(n-1, markov,mat_bonus(p),ones(1,k)) //y a k lignes contenant des traj. de longueur n-1 y=[ones(1,k) y]//on ajoute les points de départ : y a k lignes et n colonnes y=cumsum(y, c )//on fait les sommes cumulées des trajectoires m=ones(k,1)*[1:n]//matrice à k lignes égales toutes à 1,2,...,n y=y./m// matrice à k lignes égales toutes à S_0/1, S_1/2, S_2/3,..., S_{n-1}/n mat=m-1// matrice à k lignes égales toutes à 0,1,2,...,n plot2d(mat,y ) n1=string(n);p1=string(p);k1=string(k); xtitle([ evolution des moy empiriques du bonus sur k1 trajectoires de longueur n1 avec proba de pas d accident p1], temps, moy empirique,boxed=1) 12. Voici un code qui représente les fréquences empiriques de visite des états sur une trajectoire et les compare à la loi invariante. clf n=input("longueur de la trajectoire : ") p=input("proba de ne pas avoir d accident : ") Q=mat_bonus(p) y=grand(n-1,"markov",q,1) //y =vecteur ligne contenant des trajectoires de longueur n-1 y=[1 y]//on ajoute les points de départ : y a 1 ligne et n colonnes histplot([0.5:6.5],y,style=5) plot2d([1:6],eigenmarkov(q),style=-5) n1=string(n);p1=string(p); 17
![des trajectoires de longueur n y=[ones(1,k) y] //on ajoute les points de départ : y a k lignes et n+1 colonnes m=ones(k,1)*[1:n+1]-1//matrice à k lignes égales toutes à 0,1,2,.](/docs-images/41/2484769/images/page_18.jpg "..,n plot2d(m,y ) n1=string(n);p1=string(p);k1=string(k); xtitle([k1 trajectoires de longueur n1 de l évolution du bonus avec proba de ne pas avoir d accident p1], temps, états,boxed=1) 11.")
19 xtitle([ Fréquence empirique de visite des états sur une trajectoire de longueur n1 avec proba de ne pas avoir d accident p1], états, fréq empirique,boxed=1) 13. Voici un code qui représente l a loi empirique de X n calculée sur plusieurs trajectoires. clf n=input("valeur de n : ") k=input("nombre de simulations : ") p=input("proba de ne pas avoir d accident : ") Q=mat_bonus(p) y=grand(n,"markov",q,ones(1,k)) //y a k lignes contenant des trajectoires de longueur n histplot([0.5:6.5],y(:,n),style=5) plot2d([1:6],eigenmarkov(q),style=-5) n1=string(n);p1=string(p);k1=string(k); xtitle([ Loi empirique de X_n calculée sur k1 simulations avec n= n1 et proba de ne pas avoir d accident p1], etats, freq empiriques,boxed=1) 10.3 Mobilité sociale 1. E= ensemble des catégories socio-professionnelles (CSP). 2. Supposons que la CSP évolue au fil des générations comme une chaîne de Markov homogène. Dans ce cas, les transitions Q xy = P (CSP du fils = y CSP du père = x) ne sont pas données a priori, elles doivet être évaluées par l observation. Sur une population donnée de taille N, on regarde n xy = nombre d individus de CSP y et dont le père est de CSP x, n x = y E n xy = nombre total d individus dont le père est de CSP x et on pose Q xy = n xy n x. Par construction, Q est une matrice de transition. 3. En pratique, Q est à coefficients strictement positifs donc irréductible et apériodique. La chaîne associée converge donc en loi vers son unique loi invariante. Cette loi représente l état d équilibre d une population dont la mobilité sociale a une structure correspondant à la matrice Q. 4. Bien sûr, l hypothèse d une évolution markovienne homogène est peu réaliste et doit être nuancée. Nous renvoyons à l article [T] pour une étude approfondie Score au tennis 1. E= ensemble des scores possibles dans un jeu au tennis opposant les joueurs A et B ( E = 18). 2. Evolution : on suppose les points indépendants les uns des autres et qu à chaque point A gagne avec probabilité a et perd avec probabilité b = 1 a. 3. La site (X n ) des scores est une CM. Les deux classes récurrentes sont les singletons absorbants {A gagne}, {B gagne}. {(40, 30), (40, 40), (30, 40)} est une classe transiente et les 13 autres classes transientes sont les singletons restants. 4. Voici une fonction qui génère la matrice de transition function m=mat_tennis(a) //calcule la mat de transition du tennis avec joueurs A et B // // a= proba que A gagne un point, 1-a = proba que B gagne un point //les états sont (score de A, score de B) et numérotés ainsi 1 : 0-0, // 2 : 0-15, 3 : 15-0, 4 : 30-0, 5 : 15-15, 6 : 0-30, 7 : 0-40, //8 : 15-30, 9 : 30-15, 10 : 40-0, 11 : : 30-30, 13 : 15-40, 18

20
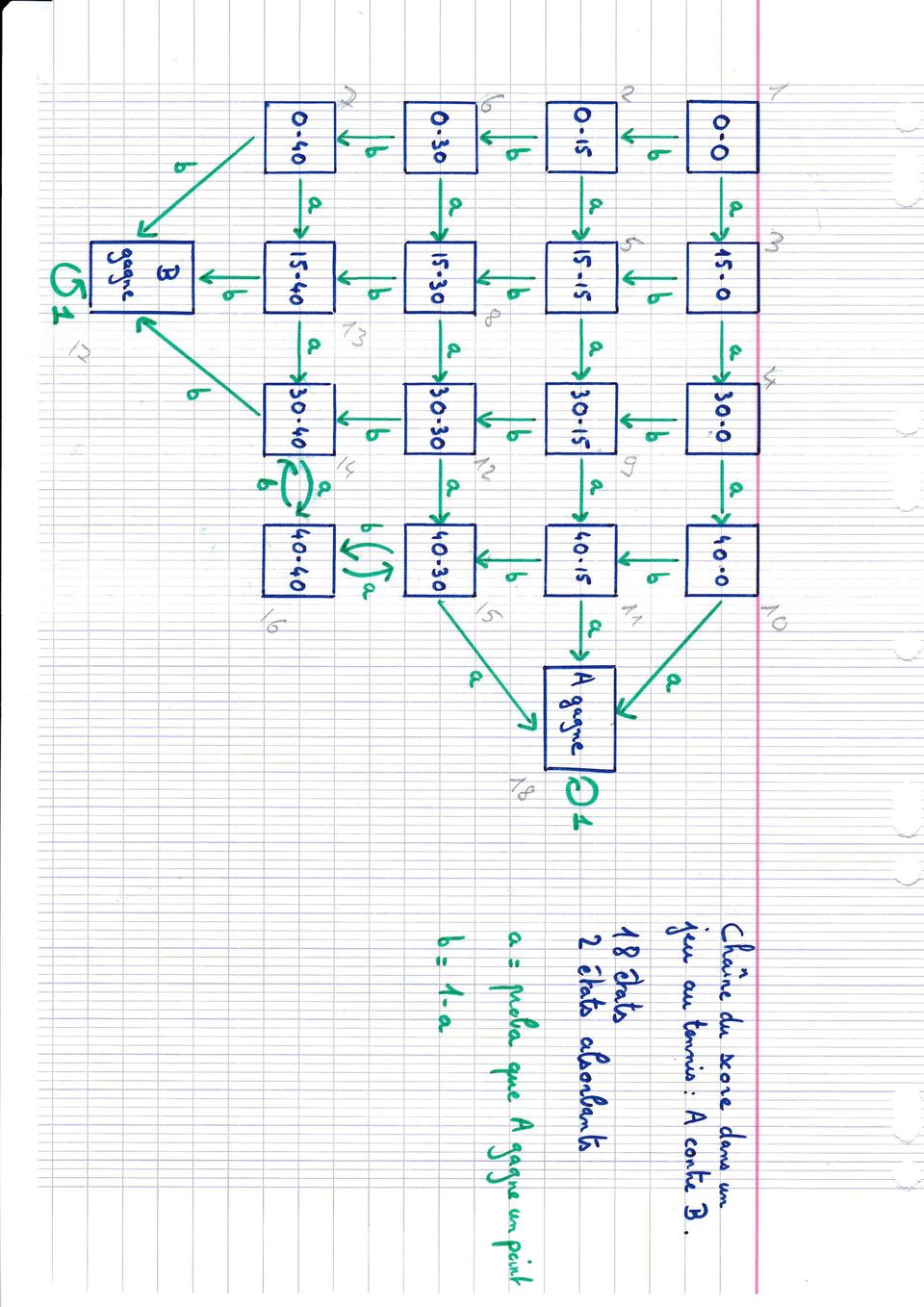
21 // 14 : 30-40, 15 : 40-30, 16 : 40-40, 17 : B gagne, 18 : A gagne m=zeros(18,18) m(1,2)=1-a ; m(1,3)=a ; m(2,5)=a ; m(2,6)=1-a ; m(3,4)=a ; m(3,5)=1-a ; m(4,9)=1-a ; m(4,10)=a ; m(5,8)=1-a ; m(5,9)=a ; m(6,7)=1-a ; m(6,8)=a ; m(7,13)=a ; m(7,17)=1-a ; m(8,12)=a ; m(8,13)=1-a ; m(9,11)=a ; m(9,12)=1-a ; m(10,11)=1-a ; m(10,18)=a ; m(11,15)=1-a ; m(11,18)=a ; m(12,14)=1-a ; m(12,15)=a ; m(13,14)=a ; m(13,17)=1-a ;m(14,16)=a ; m(14,17)=1-a ;m(15,16)=1-a ; m(15,18)=a ; m(16,14)=1-a ; m(16,15)=a ;m(17,17)=1 ; m(18,18)=1 ; endfunction Pour représenter graphiquement le score au cours d une partie, on représente la différence «score(a)- score(b)» avec un saut plus grand quand l un d eux gagne. Attention, cette différence est une fonction d une CM mais n est pas une CM en elle-même. Voici un code représentant une trajectoire de cette différence : //représente la différence score A -score B \in {-4,-3,-2,-1,0,1,2,3,4} //(4 = A gagne ; -4 = B gagne) au cours du temps de 0 à l // a= proba que A gagne un point ; l = longueur de la partie a=input( Proba que A gagne : ) l=input( Longueur de la partie : ) clf; m=mat_tennis(a); Y=grand(l,"markov",m,1); //Y vecteur ligne de taille l représentant 1 trajectoire de longueur l Z=(((Y==3) (Y==9)) (Y==15))+2*((Y==4) (Y==11))+3*(Y==10)+4*(Y==18)- ( (((Y==2) (Y==8)) (Y==14))+2*((Y==6) (Y==13))+3*(Y==7)+4*(Y==17)) //Z vecteur ligne detaille l représentant score A -score B au cours du temps plot2d([0:l],[0 Z],style=-11);plot2d([0:l],[0 Z],style=5) xtitle([ Evolution du score au cours d un jeu de tennis ], temps, score de A,boxed=1) Voici un code simulant n parties et calculant la durée moyenne consatée des parties i.e. le temps moyen empirique d absoprtion // simule n parties de longueur l de la chaîne du tennis // et calcule l esperance empirique du temps d absorption a=input( Proba que A gagne : ) l=input( Longueur de chaque partie : ) n=input( Nombre de parties simulées : ) m=mat_tennis(a); Y=grand(l,"markov",m,ones(1,n)); //Y =matrice à n lignes, l colonnes contenant les trajectoires Z=(Y>16)+0 // Z= matrice à n lignes, l colonnes enregistrant 0 si partie continue, 1 si finie [U,V]=max(Z,"c") // V colonne de taille n qui contient les temps d absorption des n parties t=mean(v) disp(t, la moy empirique du temps de jeu est ) 19
22 Voici un code simulant n parties et calculant la proportion de celles où A gagne i.e. la probabilité empirique que A gagne // simule n parties de longueur l de la chaîne du tennis //et calcule la proportion de fois où A gagne a=input( Proba que A gagne : ) l=input( Longueur de chaque partie : ) n=input( Nombre de parties simulées : ) m=mat_tennis(a); Y=grand(l,"markov",m,ones(1,n)); Z=Y(:,l) A=(Z==18) // Y = matrice à n lignes contenant les trajectoires de longueur l // colonne enregistrant qui a gagné chaque partie : 17 = B, 18 = A // colonne de booléens enregistrant si A gagne G=((Z==18)+(Z==17)-(Z==17).*(Z==18)) // G= colonne de booléens enregistrant s il y a eu gain p=sum(a)/sum(g) disp(p, la proba emipirique que A gagne est ) 5. La commande [M,S]=eigenmarkov(mat_tennis(a)) renverra la matrice S telle que S(x,j) est la probabilité de terminer dans la j-ème classe en démarrant en l état x. La probabilité que A gagne est donc S(1,1). 6. C est un exemple pédagogique car la probabilité théorique que A gagne se calcule explicitement en fonction de a et vaut p(a) = a 4 (1+4b+10b 2 )+20a 5 b 3 (1 2ab) 1 (laissé en exercice). On peut donc comparer la probabilité théorique que A gagne, celle calculée par eigenmarkov et la probabilité empirique calculée grâce au code précédent Mots de taille 2 dans un pile ou face 1. Cadre : jeu de pile ou face i.e. (Z n ) n N suite de variables aléatoires indépendantes et de même loi P (Z n = P ) = p, P (Z n = F ) = 1 p. 2. On s intéresse aux mots formés de deux lettres consécutives et, par exemple, au temps τ de 1ère apparition du mot P P ou du mot P F. 3. On note X n = (Z n, Z n+1 ). Alors (X n ) est une CM(E) où E = {P P, P F, F P, F F }. Ses transitions sont représentées sur le dessin suivant Q = 0 0 p q p q 0 0 p q 0 0. La chaîne est irréductible et 0 0 p q apériodique. 4. Notons τ le temps d atteinte de l état P P. Appliquons les résultats de Avec Q = J = 1 1 1, on a ψ = E P F (τ) E F P (τ) E F F (τ) = (I 3 Q) 1 J. 0 p q q p q Dans le jeu de pile ou face usuel (p = 1/2), il attendre 2 coups pour que la chaîne démarre avec la loi uniforme sur E donc E(τ ) = (E P P (τ) + E P F (τ) + E P F (τ) + E P F (τ)) = (0 + t J(I 3 Q) 1 J) = 6., 20
23 5. Remarque. Si X est CM(E) quelconque et Y n = (X n, X n+1,..., X n+k 1 ) alors (Y n ) est une CM(E k ). On peut ainsi calculer les temps d apparition de mots de taille k 2. Mais cette méthode demande l inversion d une matrice de taille 2 k. Une méthode de martingale donne le résultat plus directement Ascension et rechutes 1. On grimpe les barreaux d une échelle infinie. Lorsque l on a atteint le k-ème barreau, on parvient au suivant avec probabilité p k et on dégringole juqu au barreau 0 avec probabilité q k = 1 p k. 2. La suite (X n ) des barreaux atteints est une chaîne de Markov de «matrice» de transition Q = q 0 p q 1 0 p q p q n p n Si p k ]0, 1[ pour tout k N alors (X n ) est irréductible et apériodique. 4. Posons r 0 = 1 et r k = p 0 p 1 p k 1. Il est clair que P 0 (T 0 > k) = r k donc P 0 (T 0 = + ) = lim k + r k. Il est classique (en utilisant le logarithme) que cette limite est > 0 ssi la série i (1 p i ) = i q i converge. Ainsi, X est récurrente ssi i q i diverge. 5. Une mesure µ est invariante ssi µ 0 = + i=0 µ iq i et µ j = µ j 1 p j 1 i.e. µ j = µ 0 r j si j 0. En remplaçant, on a + + µ 0 = µ 0 r i q i = µ 0 (r i r i+1 ) = µ 0 (1 lim r k). k + i=0 i=1 Ainsi, si X est transiente, on a lim k + r k > 0 donc µ 0 = 0 donc la seule mesure invariante est nulle. Si X est récurrente, les mesures invariantes sont multiples de la mesure (r j ) j N. X est récurrente positive ssi j r j converge. 6. Si p k = p ]0, 1[ pour tout k N, cette chaîne modélise la longueur de la série actuelle des succès dans un jeu de pile ou face. i q diverge trivialement donc X est récurrente puis j r j = j pj converge donc X est récurrente positive, de loi invariante µ j = (1 p)p j (j N) (ceci est évident car dans ce cas X n a la loi de max(g 1, n + 1) où G G(1 p) et donc X n converge en loi vers G 1) Retenues lorsque l on pose une addition 1. Voici une addition de trois entiers à 5 chiffres en base 10 : les trois entiers sont en italiques, le résultat est souligné, les retenues sont en gras.. r 5 = 2 r 4 = 1 r 3 = 1 r 2 = 1 r 1 = 2 r 0 = Si on additionne n entiers au lieu de trois, les retenues sont dans [[0, n 1]. On peut aussi choisir une base b quelconque au lieu de b = Si l on choisit au hasard les chiffres des n entiers (indépendamment les uns des autres et de loi uniforme sur [[0, b 1]), le processus des retenues est une CM (homogène) à valeurs dans [[0, n 1] dont la matrice de transition Q b est explicite. Ces matrices Q b ont de magnifiques propriétés (leurs valeurs propres sont 1, b 1,..., b n+1 et les vecteurs propres associés sont entièrement explicites, indépendants de b et reliés à des objets de combinatoire des permutations, Q b Q c = Q bc, Q b est intimement liée à des procédures de mélanges de jeux de cartes). Nous renvoyons à [DF] pour de passionnants développements. 21
24 10.8 Collectionneur de coupons 1. Cadre : il existe k types de coupons numérotés de 1 à k. A chaque instant n, on reçoit un coupon de numéro U n. On suppose que les U n sont indépendantes et toutes de loi uniforme sur {1,..., k}. 2. On note X 0 = 0, X n = {U 1,..., U n } = nombre de numéros distincts obtenus à l instant n. Alors (X n ) est une CM([[0, k ]) de transitions 1 x si y = x + 1 k Q xy = x si y = x k 0 si y / {x, x + 1}. 3. L état k est absorbant et tous les autres sont transients. L objet d intérêt est souvent le temps τ nécessaire à l obtention de tous les numéros i.e. le temps d absorption de la chaîne (X n ) (qui est fini p.s. et intégrable). Les espérances E x (τ) peuvent se calculer grâce à aux équations de 9.2, la matrice fondamentale F étant explicite. On peut retrouver ces résultats de manière classique par addition de temps d attente successifs d obtention d un nouveau coupon suivant des lois géométriques de paramètres 1 i k (0 i k 1) Sisyphe et les matrices compagnons 1. Sisyphe pousse son rocher sur une pente où sont disposés de bas en haut les entiers 0, 1,..., n 1. A chaque instant, il avance d un cran. Arrivé au sommet, il chute en 0 avec probabilité a 0, en 1 avec probabilité a 1,..., en n 1 avec probabilité a n 1. La matrice de transition de cette chaîne est Q = a 0 a 1 a 2 a n 1 C est la matrice compagnon (ou sa transposée selon les conventions) du polynôme P (X) = X n a n 1 X n 1 a 1 X a Cette chaîne est irréductible ssi a 0 > 0. Dans ce cas, la période de la chaîne est le pgcd de {n k a k 0}. 3. Cet exemple permet de concevoir un exercice liant probabilité et algèbre linéaire (les matrices compagnons ont de nombreuses propriétés, par ex. les valeurs propres de Q sont les racines de P (X)) Processus de vie et de mort et marches aléatoires Sur N 1. Pour x N, on pose Q x,x+1 = p x, Q x,x 1 = q x, Q x,x = r x avec p x + r x + q x = 1 et q 0 = 0. Cette chaîne peut décrire l évolution d une population ou du nombre de personnes dans une file d attente (avec au plus une arrivée et un départ à chaque instant). 2. On suppose que x N, p x q x > 0 et p 0 > 0 ce qui rend la chaîne irréductible. Dans ce cas, s il existe x tel que r x > 0, la chaîne est apériodique. Sinon, la période vaut Le fait que Q xy = 0 si x y > 1 facilite les calculs. 4. Posons τ le temps d atteinte de 0 et φ(x) = P x (τ < ). ALors φ(0) = 1; x > 0, φ(x) = y E Q xy φ(y) = p x φ(x + 1) + r x φ(x) + q x φ(x 1). x Posons a x = q x /p x, b 0 = 1 et b x = a i. On a donc φ(x + 1) φ(x) = a x (φ(x) φ(x 1)) donc x 1 φ(x + 1) φ(x) = b x (φ(1) 1) puis φ(x) = 1 + (φ(1) 1) b i. Si i=1 22 i=0 i=0 b i = +, la condition
25 φ(x) 0 implique φ(1) = 1 puis P 0 (T 0 < ) = r 0 + p 0 φ(1) = r 0 + p 0 = 1. Donc la chaîne est récurrente. Si i=0 b i < +, la solution minimale est φ(x) = + i=x b i + i=0 b. i Donc φ(1) < 1 donc P 0 (T 0 < ) = r 0 + p 0 φ(1) < 1 et la chaîne est transiente. 5. Supposons la chaîne récurrente. Cherchons si elle est récurrente positive ou récurrente nulle. Une x p i 1 mesure µ est réversible ssi µ x+1 Q x+1,x = µ x Q x,x+1 i.e. µ x+1 = µ x p x /q x+1 i.e. µ x = µ 0. q i Comme la chaîne est irréductible et récurrente, il y a unicité de la mesure invariante (à multiplication près) et donc la chaîne est récurrente positive ssi x p i 1 < +. q i x i=1 6. Lorsque x N, (p x, q x, r x ) = (p, q, r) et q 0 = 0, la chaîne X est une marche aléatoire sur N avec réflexion en 0. Les résultats précédents assure que X est récurrent ssi (q/p) n diverge i.e. q p et récurent positif ssi ( (p/q) n converge i.e. q > p. Dans ce cas, l unique loi invariante de la chaîne est donnée par µ n = 1 p ) ( ) n p (n N). q q 7. Le cas particulier q x = 0, p x = p, r x = 1 p est le processus de Bernoulli qui peut se réaliser en prenant (U n ) indépendantes et toutes de loi de Bernoulli B(p) et X 0 = 0, X n = U U n Sur Z 1. Pour x Z, on pose Q x,x+1 = p x, Q x,x 1 = q x, Q x,x = r x avec p x + r x + q x = Pour passer de Z + à Z, la chaîne doit visiter 0. Donc la chaîne est récurrente ssi les suites (p x, q x ) x N q 1 q x et (q x, p x ) x N vérifient les propriétés de la partie précédente i.e. = + et p 1 p x x= 1 x= 1 p 1 p x q 1 q x p 0 p x+1 q 1 q x = +. De même, la chaîne est récurrente positive ssi < +. x=1 x=1 p 0 p x 1 q 1 q x i=1 < + et 3. Lorsque x Z, (p x, q x, r x ) = (p, q, r), la chaîne X est une marche aléatoire sur Z : elle peut se représenter comme X n = X 0 + n i=1 U i où les U i sont indépendantes et toutes de loi P (U i = 1) = p, P (U i = 1) = q, P (U i = 0) = r. Les résultats précédents assurent que X est récurrente nulle ssi p = q et transient ssi p q. Ceci se retrouve en utilisant la loi des grands nombres dans le cas p q car m = E(U 1 ) 0 et lim n + X n /n = m presque-sûrement. Dans le cas p = q, l analyse à un pas faite dans peut s écrire très simplement : si φ(x) = P x (τ < ) alors φ(x) = pφ(x + 1) + pφ(x 1) + (1 2p)φ(x) et les résultats sur les suites récurrentes d ordre 2 à coefficients constants donnent φ(x) = a + b x. 0 φ 1 entraîne b = 0 et φ(0) = 1 entraîne a = 1 i.e. φ(x) = 1 pour tout x Z, ce qui entraîne facilement la récurrence Sur [[0, s]. Ruine du joueur. 1. Si l on se place sur [[0, s], on prendra p x q x > 0 pour tout x [[1, s 1], p s = q 0 = 0 mais il faut spécifier r 0 et r s. 2. Si l on suppose ces états absorbants (r 0 = r s = 1), la chaîne a une classes transiente [[1, s 1] et deux classes absorbantes {0} et {s}. Elle sera absorbée en un temps fini τ et la partie...permet théoriquement de calculer P x (X τ = 0) et E x (τ) au prix de l inversion d une matrice tridiagonale. Lorsque (p x, q x, r x ) = (p, q, 0) pour tout x [[1, s 1], il s agit simplement de la ruine du joueur avec fortune totale s : il y a absorption lorsque l un des deux joueurs est ruiné (états 0 et s). Dans ce cas, l analyse à un pas se résout simplement et l on trouve... 23
26 3. Si l on suppose p 0 > 0 et q s > 0, la chaîne est irréductible, récurrente positive et son unique loi invariante est explicite (mêmes calculs que dans ). Cette chaîne représente le nombre de personnes dans une file d attente à capacité limitée (avec au plus une arrivée et un départ à chaue instant) Marche aléatoire sur un graphe. Pagerank de Google. Cavalier sur un échiquier. 1. Soit G un graphe orienté. On note x y lorsque le graphe a une flèche de x vers y. On note d x = {y G x y} et on suppose 0 < d x < Evolution : à chaque instant, on saute, avec équiprobabilité, vers l un des voisins s il en existe ou on 1 si d x 0 et x y d reste sur place sinon. Ceci donne une CM(G) de transitions Q xy = x 0 si d x 0 et x y 1 x=y si d x = 0 3. L irréductible de la chaîne est synonyme de connexité pour le graphe. 4. Application : le graphe du web a pour sommets les pages et pour flèches les hyperliens (x y lorsque la page x a un lien vers la page y). Google hiérarchise les pages grâce à un score de popularité (le pagerank). Comment attribuer un score à chaque page de telle manière qu une page a un score d autant plus élevé que d autres pages de scores élevés pointent vers elle? On sent bien que le vecteur des scores est défini par une équation de type vecteur propre i.e. mesure invariante. Précisément, le score d une page x sera lié à la probabilité qu un marcheur aléatoire sur le web se retrouve sur cette page x en temps grand. Mais les hypothèses du théorème de convergence ne sont pas vérifiées par le graphe du web (l irréductibilité tombe en défaut, il peut y avoir des classs récurrentes closes et des états transients ; il n y a pas apériodicité a priori). Pour remédier à ceci, on modifie l évolution du marcheur. Soit p ]0, 1[. A chaque instant, le lanceur lance une pièce truquée de paramètre p. S il obtient pile, il saute vers un voisin avec équiprobabilité ; sinon il saute vers l une quelconque des pages du web choisie avec équiprobabilité. Soit d le nombre de pages du web et J M d (R) la matrice dont tous les coefficients valent 1. La matrice de transition de la chaîne modifiée est donc Q = pq + 1 p J. Elle a tous ses coefficients positifs donc est irréductible et apériodique. Donc d elle possède une unique loi invariante µ et la loi de X n converge vers µ quand n +. Ainsi, µ x représente bien la probabilité que le marcheur X se retrouve sur cette page x quand n est grand. 5. Lorsque le graphe est non-orienté (i.e. x y ssi y x) alors la mesure donnée par x G, µ x = d x est réversible donc invariante. 6. Application : marche du cavalier sur un échiquier. Un cavalier part d un coin d un échiquier vide puis se déplace en choisissant à chaque fois un des déplacements possibles avec équiprobabilité. Quel temps moyen met-il pour revenir au coin d où il est parti? Solution : le cavalier effectue une marche aléatoire sur un graphe dont les sommets sont les cases et deux cases sont reliées si le cavalier peut légalement passer de l une à l autre. Ce graphe est non-orienté (vu qu un cavalier peut revenir en arrière) et irréductible (le cavalier peut aller partout). L unique loi invariante est donc µ x = d x /λ où λ = x d x = 2N, N = 168 nombre d arêtes du graphe (à calculer). Donc E x (T x ) = (µ x ) 1 = 2N/d x = N car d x = 2 si x est un coin. Exercice : même question avec une tour, avec un fou, avec une dame Marche aléatoire sur un groupe 1. Cadre : G un groupe de loi. et (U n ) n N une suite de variables aléatoires discrètes, indépendantes, à valeurs dans G et toutes de loi ν. 2. Evolution : X n = X n 1 U n = X 0 U 1 U n. 3. (X n ) est une CM(G) de transitions Q xy = P (U 1 = y x 1 ). 4. (X n ) est irréductible ssi G est le semi-groupe engendré par le support de la loi de U Toute marche aléatoire sur un groupe est bistochastique (cf 6.1.5) donc la mesure µ x = 1 est invariante. 6. Exemples. 24
27 (a) Si G = Z d et U 1 suit une loi uniforme sur l ensemble des 2d vecteurs {±e i, 1 i d} où (e i, 1 i d) est la base canonique de R d alors X est la marche aléatoire sur Z d aux plus proches voisins. Cette marche est récurrente nulle si d 2 et transiente si d 3. Ceci est un résultat dû à Pólya (1921) et peut s obtenir en examinant la convergence de la série P 0 (X n (d) = 0). En effet, P 0 (X (1) 2n+1 = 0) = 0, P 0(X (1) 2n = 0) = ( ) 2n n 2 2n (πn) 1/2 (formule de Stirling). Un astucieux argument de quart de tour donne P 0 (X (2) 2n = 0) = P 0(X (1) 2n une étude du plus grand coefficien trinomial montre P 0 (X (3) 2n = 0)2 (πn) 1. Ensuite, = 0) C( ) 2n n 2 2n n 1 Cn 3/2. Enfin, P 0 (X (d) 2n = 0) P 0(X (3) 2n = 0) si d 3. (b) Le processus de vie et de mort sur Z avec p n, q n, r n indépendants de n est une marche aléatoire sur Z. (c) Si G = S n, X modélise les étapes du mélange d un jeu de cartes. Cf sujet ESSEC, année 2011, option E. 7. Voici un code pour représenter k trajectoires d une marche aléatoire sur Z avec incrément P (U n = 1) = p, P (U n = 1) = 1 p. // dessine k trajectoires X_0,...,X_n de la marche aléatoire unidimensionnelle // simple démarrant en 0 clf(); n=input( longueur de la trajectoire : ) k=input( nombre de trajectoires : ) p=input( proba d ajouter 1 : ) u=grand(k,n,"def") //matrice à k lignes et n lignes contenant des uniformes [0,1[ s=[zeros(k,1) cumsum(2*(u<p)-1, c )]//trajectoires for i=1:k plot2d([0:n},s(i,:),pmodulo(i,8)+1) end n1=string(n);k1=string(k) xtitle([ Trajectoire de k1 trajectoires de n1 étapes d une marche aléatoire unidimensionnelle ], n, X_n,boxed=1) 8. Voici un code pour représenter k trajectoires d une marche aléatoire aux plus proches voisins sur Z 2 (incrément {(1, 0), ( 1, 0), (0, 1), (0, 1)}). // dessine k trajectoires X_1,...,X_n de la marche aléatoire plane avec // incrément (1,0) de proba droite, (-1,0) de proba gauche, (0,1) de proba // haut, (0,-1)de proba (1-droite-haut-gauche) démarrant en 0 clf(); n=input( longueur de la trajectoire : ) k=input( nombre de trajectoires : ) droite=input( proba d aller à droite : ) gauche=input( proba d aller à gauche : ) haut=input( proba d aller en haut : ) u=grand(k,n,"def") //matrice à k lignes et n lignes contenant des uniformes [0,1[ ab=2*(u<droite)-(u<droite+gauche) //vecteur ligne de n contenant les sauts en abscisses (1 ou -1) ord=-2*(u>droite+gauche+haut)+(u>droite+gauche) //vecteur ligne de n contenant les sauts en ordonnées (1 ou -1) ab=[zeros(k,1) cumsum(ab, c )] //on ajoute 0 état initial 25
28 ord=[zeros(k,1) cumsum(ord, c )] //on ajoute 0 état initial c=max([abs(ab),abs(ord)]) //détermine le carré d affichage graphique for i=1:k plot2d(ab(i,:),ord(i,:),pmodulo(i,5)+1,axesflag=4,rect=[-c,-c,c,c]) end n1=string(n);k1=string(k) xtitle([ Trajectoire de k1 trajectoires de n1 étapes d une marche Urne d Ehrenfest aléatoire plane ],boxed=1) 1. Modèle introduit en 1907 par les époux Ehrenfest dans un contexte de mécanique statistique (diffusion de molécules entre deux récipients qui communiquent). 2. Cadre : 2 urnes (n 0 et n 1) contenant au total d boules (n 1 à n d). 3. Evolution : à chaque instant, une boule est choisie au hasard et changée d urne. 4. Objet microscopique : X i n = n de l urne dans laquelle est la boule n i à l instant n. X n = (X 1 n, X 2 n,..., X d n) {0, 1} d (Z/2Z) d. X n+1 s obtient en choisissant une composante de X n et en changeant sa valeur i.e. X n+1 = X n + U n+1 où (U k ) est une suite de variables aléatoires indépendnates et toutes de loi uniforme sur {e 1,..., e d } où e i = (0,..., 0, 1, 0,..., 0). X peut donc être vue comme une marche aléatoire sur le groupe (Z/2Z) d ou comme la marche aléatoire sur le graphe non-orienté de l hypercube {0, 1} d (où x y lorsque i x i y i = 1). 5. Objet macroscopique : Y n = d i=1 Xi n= nombre de boules dans l urne 1. (Y n ) est une CM([[0, d]) de transitions d x si y = x + 1 d Q xy = x si y = x 1 d 0 si y / {x + 1, x 1}. 6. Les chaînes X et Y sont irréductibles, récurrentes (positives) et de période 2. Ainsi, la chaîne passe une infinité de fois par tout état. Si les boules représentent les molécules d air dans deux enceintes, ceci suggère qu il n y a qu à attendre pour qu une chambre à air crevée se remplisse spontanément. Mais regardons-y de plus près. La loi uniforme µ sur {0, 1} d est réversible (et donc invariante) pour X, c est la seule par irréductibilité et récurrence. Par conséquent, la loi binomiale µ = B(d, 1/2) (l image de µ par x {0, 1} d i x i) est invariante ( ) pour Y, c est la seule. Regardonc la chaîne d Y. Grâce à 6.1.8a, on a E x (T x ) = 1/µ x = 2 d /, ce qui est maximal pour x = 0 ou x = d, et x minimal pour x = d/2 (en supposant d pair). La formule de Stirling donne E d/2 (T d/2 ) πd/2 pour d + alors que E 0 (T 0 ) = E d (T d ) = 2 d. Ainsi, si ma chambre à air est initialement pleine, elle ne le redeviendra qu après un temps moyen de 2 d, ce qui est vertigineux lorsque d est de l ordre du nombre d Avogadro Ceci vient percuter le point de vue nâïf de la chambre qui se regonfle toute seule! En fait, on calcule facilement E x (Y 1 ) = ((d 2)/d)x + 1, ce qui donne E x (Y n ) = ((d 2)/d) n (x d/2) + d/2. Donc lim n + E x (Y n ) = d/2 (à vitesse géométrique). En moyenne, le nombre de boules tend à se répartir moitié-moitié dans chaque urne. On a même Y 2n et Y 2n+1 qui convergent en loi vers la loi uniforme sur les pairs et sur les impairs (selon la parité de l état initial). 7. Voici un code qui représente en histogrammes la mesure empirique sur une trajectoire ainsi que la loi invariante de la chaîne. //dessine en histogrammes la mesure empirique d une trajectoire Y_0,...,Y_n // de la chaîne d ehrenfest sur {0,...d} démarrant en Y0 \in {0,...d} clf d=input( Entrez le nombre de boules : ) X0=input( Entrez l etat initial : ) n=input( Entrez le n de (dirac(x_1)+...+dirac(x_n))/n : ) 26
29 p=zeros(d+1,d+1) for i=1:d p(i,i+1)=(d-i+1)/d p(i+1,i)=i/d end// p est la matrice de transition d ehrenfest traj=[x0,grand(n,"markov",p,x0+1)-1] // X0+1 est dans {1,...d+1}, grand simule chaîne sur {1,...d+1}, //on enlève 1 pour être sur {0,...d} classe=[-0.5:(d+0.5)] histplot(classe,traj,style=5) bibi=ones(1,d+1)/(2^d) for k=2:(d+1) bibi(k)=cdfbin("pq",k-1,d,0.5,0.5)-cdfbin("pq",k-2,d,0.5,0.5) end// contient les valeurs de la loi binomiale plot2d([0:d],bibi,-3) n1=string(n);d1=string(d) xtitle([ Mesure empirique d une trajectoire à n= n1 étapes de la chaîne d Ehrenfest avec d= d1 boules ], états, fréquence,boxed=1) legends([ loi binomiale B(d,1/2), histogrammes empiriques ],[-3,5],2) 8. Voici un code qui représente en histogrammes la loi empirique de X n calculée sur plusieurs simulations indépendantes ainsi que la loi invariante de la chaîne. Le résultat demande une explication... //dessine en histog. la loi de X_n (calculee sur k trajectoires indépendantes) // de la chaîne d ehrenfest sur {0,...d} démarrant en X0 \in {0,...d} clf d=input( Entrez le nombre de boules : ) X0=input( Entrez l etat initial : ) n=input( Entrez le n de X_n : ) k=input( Entrez le nombre de trajectoires simulées : ) p=zeros(d+1,d+1) for i=1:d p(i,i+1)=(d-i+1)/d p(i+1,i)=i/d end// p est la matrice de transition d ehrenfest I=(X0)*ones(1,k) traj=grand(n,"markov",p,i+1)-1 // X0+1 est dans {1,...d+1}, //grand simule la chaîne sur {1,...d+1}, on enlève 1 pour être sur {0,...d} classe=[-0.5:(d+0.5)] histplot(classe,traj(:,n),style=5) bibi=ones(1,d+1)/(2^d) for i=2:(d+1) bibi(i)=cdfbin("pq",i-1,d,0.5,0.5)-cdfbin("pq",i-2,d,0.5,0.5) end// contient les valeurs de la loi binomiale plot2d([0:d],bibi,-3) n1=string(n);d1=string(d);k1=string(k) xtitle([ Approximation (calculée sur k1 réalisations) de la loi de X_n avec n= n1 et d= d1 boules ], états, fréquence,boxed=1) 27
30 legends([ loi binomiale B(d,1/2), histogrammes empiriques ],[-3,5],2) Modèle de Wright-Fisher 1. Modèle de génétique introduit dans les années Cadre : population de d individus (d fixé) chacun de type A ou B. 3. Evolution : tous les individus d une génération meurent pour laisser place à ceux de la génération d après. Chaque individu de la génération n + 1 choisit un ancêtre dans la génération n et hérite de son type (A ou B). Les choix des divers ancêtres se font avec remise. 4. Objet : X n = nombre d individus de type A dans la génération n. X est une CM([[0, d]) de transitions données par : L(X n+1 X n = x) = B(d, x d ) i.e. ( ) d (x ) y ( Q xy = 1 x ) d y. y d d 5. 0 et d sont absorbants (donc récurrents). Les autres états sont transients. Notons φ(x) = P x (τ d < + ) la probabilité d être absorbé en d partant de x. Les résultats de 9 montrent que φ est l unique solution de φ(d) = 1, φ(0) = 0 et φ(x) = y Q xyφ(y) pour y / {0, d}. φ(x) = x/d est une solution (car la moyenne d une binomiale B(n, p) est np) donc c est la seule. Ainsi, partant de x, la probabilité d être absorbé en d est x/d et celle d être absorbé en 0 est (d x)/d. 6. X n converge p.s. (et donc en loi) vers X de loi sous P x égale à (x/d)δ d + ((d x)x/d)δ Variante : on peut souhaiter que les choix des divers ancêtres se fassent avec remise. Dans ce cas, il faut modifier le mécanisme d évolution (sinon la génération n + 1 serait identique à la génération n). On suppose la population de taille 2d, séparée en d couples. Chaque couple de la génération n + 1 choisit un individu de la génération n et hérite de son type. Les choix des différents couples se font sans remise. X n = nombre de couples de type A dans la génération n. X est une CM([[0, d]) de transitions données par : ( )( ) 2x 2d 2x y d y L(X n+1 X n = x) = H(d tirages, 2d objets au total dont 2x favorables) i.e. Q xy = ( ). 2d d 8. Généralisation : nombre quelconque k de types (au lieu de k = 2). La loi binomiale est à remplacer par une loi multinomiale, la loi hypergéométrique par une hypergéométrique multiple. 9. Le sujet Ecricome, année 2000, option S traitait de ce modèle dans un contexte de disquettes infectées ou saines Processus de Galton-Watson 1. Modèle introduit dans les années 1870 pour étudier la survie des noms de famille des lords de l Angleterre victorienne. 2. Cadre : une population dont la taille et la composition évoluent.chaque individu de la génératpopulation de d individus (d fixé) chacun de type A ou B. 3. Evolution : chaque individu de la génération n donne naissance à un nombre aléatoire (de loi µ dite loi de reproduction) de descendants puis meurt aussitôt. La génération n + 1 est composée de tous les descendants des individus de la génération n. Les naissances sont indépendantes entre elles. 4. Objet : X n = nombre d individus dans la génération n. X est une CM(N) de transitions données par : ( x ) L(X n+1 X n = x) = L Y i où les (Y i ) 1 i x sont indépendantes et de loi µ i=1 i.e. Q xy = µ x (y) = k 1,...,k x 0 k 1+ +k x=y µ k1 µ kx. 28
31 5. Les fonctions génératrices se prêtent mieux aux calculs car elles transforment le produit de convolution µ x en produit usuel : si G n (t) = E(t Xn ) et G(t) = E(t Y ) avec L(Y ) = µ alors G n+1 = G n G. 6. Si la loi de reproduction µ vaut δ 1, tous les états sont absorbants. Sinon, 0 est le seul état récurrent (il est même absorbant). Par conséquent, soit N N, n N, X n = 0 (extinction de la population), soit lim n + X n = +. Cf la séance...pour les probabilités avec lesquelles ces évènements se produisent Files d attente 1. Vaste théorie étudiant de nombreux modèles selon le nombre de serveurs, la discipline de service, les arrivées des clients, la capacité de la file, le temps discret ou continu, etc 2. Exemple : temps discret, un seul serveur, capacité d accueil illimitée, au maximum un client servi par instant. 3. Objet :X n = nombre de clients dans la file ou en service àl instant n 4. Evolution : entre les instants n et n + 1, Y n+1 clients arrivent et Z n+1 {0, 1} clients partent. On suppose (X 0, Y i, Z i ) i 1 indépendantes, (Y i ) i 1 de même loi, (Z i ) i 1 de même loi. Alors X n+1 = X n + Y n+1 1 Xn>0Z n+1 = f(x n, U n+1 ) où U n+1 = (Y n+1, Z n+1 ). X est donc une CM(N) Un exemple non-homogène : urne de Polya 1. Modèle introduit en 1923 par le mathématicien hongrois G. Pólya pour analyser un phénomène de contagion épidémique. 2. Cadre : une urne contient r bounes rouges et v boules vertes. 3. Evolution : à chaque tirage, on remet la boule tirée ainsi que c boules supplémentairs de la même couleur. Notons R n le nombre de boules rouges à l instant n. (R n ) est une chaîne de Markov sur N non-homogène de transitions i si j = i + c r + v + nc P (R n+1 = j R n = i) = i 1 si j = i r + v + nc 0 sinon. Cette probabilité dépend de n : la chaîne est non-homène. 4. La proportion X n de boules vertes après à l étape n converge presque-sûrement vers X qui suit Γ((r + v)/c) une loi bêta de paramètres v/c et r/c i.e. de densité Γ(v/c)Γ(r/c) x r c 1 (1 x) r c 1 1 [0,1] (x). Ceci peut être prouvé par un argument de martingale ((X n ) est une martingale positive) ou bien par application du théorème de De Finetti sur l échangeabilité. 29
32 11 Quelques preuves 1. Preuve du Définissons par récurrence Tx 1 = T x = inf{n > 0 X n = x} et Tx k = inf{n > X n = x} le temps du k-ème retour en x (éventuellement + ). T k 1 x P y (Tx k+1 < + ) = P y ( + i=1 [T x k = i, Tx k+1 < + ]) = P y (Tx k = i)p y (Tx k+1 < + Tx k = i) = = = i=1 i=1 i=1 i=1 i 1 P y (Tx k = i)p y (Tx k+1 < + X i = x, 1 Xj=x = k 1) j=1 i 1 P y (Tx k = i)p y (T x (X k+ ) < + X i = x, P y (T k x = i)p x (T x (X) < + ) j=1 1 Xj=x = k 1) [propriété de Markov faible] = P y (T k x < + )P x (T x (X) < + ) = P y (T k x < + )ρ xx. Par récurrence, il vient donc P y (Tx k < + ) = ρ yx ρ k 1 xx. Ainsi, si ρ xx = 1, P x (Tx k < + ) = 1 pour tout k. Par limite monotone,on a P x ( k Tx k < + ) = lim k + P x (Tx k < + ) = 1 i.e. P x (N x = + ) = 1. Si ρ xx < 1, P x ( Tx k < + ) = lim k + P x (Tx k < + ) = 0 i.e. P x (N x < + ) = 1. En outre, P x (N x = k) = P x (Tx k 1 < + ) P x (Tx k < + ) = (1 ρ xx )ρ k 1 xx si k 1. Ensuite, pour examiner la nature de la série n Qn xx, on utilise que E( + n=0 Z n) = + n=0 E(Z n) pour des variables aléatoires Z n positives et on conclut ainsi n=0 Q n xx = n=0 E x (1 Xn=x) = E x ( 1 Xn=x) = E x (N x ) = n=0 { + si ρxx = 1 (1 ρ xx ) 1 si ρ xx < 1. Si l on veut présenter cette preuve de façon compatible avec les programmes de classes EC, on peut k k introduire Nx k = 1 Xn=x et étudier S k = Q n xx = E x (Nx k ). Si ρ xx = 1, l inégalité de Markov n=0 assure S k ip x (Nx k i). Par limite monotone, ( + ) lim P x(nx k i) = P x {Nx k i} = P x (N x i) = 1. k + n=0 k=0 (S k ) est croissante donc a une limite et lim S k i. Ceci étant vrai pour tout i, on a lim S k = k + k + + i.e. n Qn xx diverge. Maintenant, si ρ xx < 1, on a Nx k N x donc S k = E(Nx k ) E(N x ) = (1 ρ xx ) 1 < +. La suite (S k ) est donc majorée i.e. n Qn xx converge. 2. Preuve du Soit x un état récurrent. On pose y E, ( Tx 1 ) ν y = E x = P x (X k = y, k < T x ). k=0 Alors, pour toute fonction f ( Tx 1 ) ν.q.f = ν.(qf) = E x (Qf)(X k ) = k=0 k=0 E x (1 Tx>kf(X k+1 )) = k=1 1 Xk =y k=0 ( Tx 1 = E x k=0 E Xk (f(x 1 )) ( Tx ) E x (1 Tx>k 1f(X k )) = E x f(x k ) k=1 ) = k=0 E x (1 Tx>kE Xk (f(x 1 ))) ( Tx 1 = E x k=0 f(x k ) ) = ν.f car P x (X 0 = X Tx ) = 1. Donc ν est invariante. Reste à voir que ν y < +. Si y x il existe n tel que Q n yx > 0. Comme νq n = ν, on ν y Q n yx ν x x = 1 donc ν y < +. Si y x alors x y (car x est récurrent) donc ν y = 0 < +. 30
33 3. Preuve du On admet l unicité (à multiplication près) dans le cas irréductible, récurrent. Notons ν x la mesure définie précédemment attachée à l état x. Alors ν x (E) = E x ( Tx 1 k=0 1 ) = E x (T x ). D où la dichotomie. Dans le cas récurrent positif, il y a une unique loi invariante µ. Par unicité, x E, µ = (ν x (E)) 1 ν x = (E x (T x )) 1 ν x = µ x = (E x (T x )) 1 ν x x = (E x (T x )) Preuve du Si y est transient alors Ny n N y = + k=1 1 X k =y < + donc Ny n /n 0 presquesûrement. Supposons maintenant y récurrent. Comme la chaîne est irréductible, il suffit de regarder la châine après son 1er passage en y et on peut donc supposer X 0 = y. Dans ce cas, si Ty k désigne le temps de k-ème retour en y (avec Ty 0 = 0, Ty 1 = T y ) alors les longueurs (Ty k+1 Ty k ) des excursions hors de y sont indépendantes et de même loi que T y. Donc la loi usuelle des grands nombres donne lim T y k /k = E y (T y ) presque-sûrement. Puis comme lim T y k = +, on fabrique la suite (k n ) k + k + telle que Ty kn n Ty kn+1. Alors k n T kn+1 y = N T y kn y Ty kn+1 N n y n N T kn+1 y y Ty kn+1 = k n + 1. Ty kn On conclut en utilisant que lim k n = + et lim T y k /k = E y (T y ). n + k + 5. Idée de la preuve du On s inspire de la preuve qui précède en regardant les V k = f(x T k y ) + + f(x T k+1 y 1 ) qui sont intégrables, indépendantes, de même loi et en décomposant f(x 1) + + f(x T k+1 y 1 ) = V V k puis en utilisant max 1 k n V k = o(n). 6. Preuve du dans le cas E fini. Soit (Q ij ) une matrice de transition markovienne. On suppose qu il existe m N tel que Q m ait tous ses coefficents strictement positifs. On note alors α = min i,j Q m ij > 0. Alors il existe des nombres π j > 0 tels que j π j = 1 et i, j, lim n + Qn ij = π j. En outre, la vitesse de convergence est au moins géométrique de raison 1 2α. L hypothèse du théorème équivaut (dans le cas fini) à l irréductibilité et l apériodicité. (a) Lemme. Soit (Q ij ) une matrice de transition markovienne. On notera Q n ij le coefficient d indice (i, j) de la matrice Q n, Mj n = max i Q n ij, mn j = min i Q n ij. Alors, pour tout j, la suite (Mj n) n N) est décroissante, la suite (m n j ) n N) est croissante. (b) Preuve du lemme. Q n+1 ij = k Q ik Q n kj k Q ik M n j = 1 M n j = M n j. On prend le max sur i pour avoir M n+1 j pour (m n j ) n N. M n j. Ainsi, (M n j ) n N est décroissante. De même (c) Preuve du théorème. Notons R = Q m, Mj n = max i Rij n, mn j = min i Rij n. Il existe un l (dépendant de n) tel que m n j = Rn lj. Alors R n+1 ij = k M n j R ik R n kj = k l R ik R n kj + R il m n j R ik + R il m n j = Mj n (1 R il ) + R il m n j k l On prend le max sur i pour avoir M n+1 j m n j α(m j n ). On ajoute pour obtenir mn j = M n j R il (M n j m n j ) M n j α(m n j m n j ) M n j α(m n j mn j M n+1 j m n+1 j (1 2α)(M n j m n j ). ). On trouve de même mn+1 j 31
34 Donc Mj n mn j (1 2α)n (Mj 0 m0 j ) = (1 2α)n. D après le lemme appliqué à R, les suites (Mj n) n N et (m n j ) n N sont adjacentes donc ont même limite π j. Comme (m n j ) n N est croissante et m 1 j α, on a π j α > 0. Maintenant, le lemme appliqué à Q prouve que (a n = max i Q n ij ) n N est décroissante, minorée par 0 donc converge. Comme la suite extraite (a mn ) n N converge vers π j d après le point précédent, la suite (a n ) converge elle-même vers π j. De même la suite (min i Q n ij ) n N converge aussi vers π j. Comme min i Q n ij Qn ij max i Q n ij, on conclut avec le théorème des gendarmes. 7. Preuve de Un produit par blocs prouve que Q n xy = Q n xy pour tout (x, y) T 2. Or y T est transient donc lim n + Qn xy = 0 (cf 2 du 7.2). Donc lim Q n = 0 donc toutes les valeurs propres de n + Q sont de module < 1 donc I t Q est inversible. Puis (x, y) T 2, E x (N y ) = k=0 E x (1 Xk =y) = k=0 Q k xy = k=0 Q k xy = F xy. Ensuite, l équation 10 appliquée avec A = i C i donne ψ = F J. Enfin, en utilsant φ j (x) = 1 si x C j, φ j (x) = 0 si x C k avec k j, l équation 7 avec A = C i donne : x T, φ j (x) = Q xy + Q xy φ j (y) i.e. φ j = B j J j + Qφ j i.e. φ j = F B i J i i.e. φ = F B. y C j y T Références [MPB] M. Benaïm et N. El Karoui. Promenade aléatoire : Chaînes de Markov et simulations ; martingales et stratégies. Ecole Polytechnique, [BC] B. Bercu et D. Chafaï. Modélisation stochastique et simulation. Dunod, [Du] R. Durrett. Probability : Theory and Examples. Duxbury Advanced Series, [DF] P. Diaconis et J. Fulman. Carries, Shuffling and an Amazing Matrix. American Mathematical Monthly, 2009, Vol 116, p [L] J. Lemaire. Bonus-Malus Systems in Automobile Insurance Springer, [MPB] L. Mazliak, P. Priouret et P. Baldi. Martingales et chaînes de Markov. Dunod, [P] E. Pardoux. Processus de Markov et applications. Dunod, [T] C. Torossian. Matrice intergénérationnelle et ordre de Bruhat dans le groupe symétrique. Disponible à l adresse torossian/. 32
Chapitre 3. Mesures stationnaires. et théorèmes de convergence
 Chapitre 3 Mesures stationnaires et théorèmes de convergence Christiane Cocozza-Thivent, Université de Marne-la-Vallée p.1 I. Mesures stationnaires Christiane Cocozza-Thivent, Université de Marne-la-Vallée
Chapitre 3 Mesures stationnaires et théorèmes de convergence Christiane Cocozza-Thivent, Université de Marne-la-Vallée p.1 I. Mesures stationnaires Christiane Cocozza-Thivent, Université de Marne-la-Vallée
Chaînes de Markov au lycée
 Journées APMEP Metz Atelier P1-32 du dimanche 28 octobre 2012 Louis-Marie BONNEVAL Chaînes de Markov au lycée Andreï Markov (1856-1922) , série S Problème 1 Bonus et malus en assurance automobile Un contrat
Journées APMEP Metz Atelier P1-32 du dimanche 28 octobre 2012 Louis-Marie BONNEVAL Chaînes de Markov au lycée Andreï Markov (1856-1922) , série S Problème 1 Bonus et malus en assurance automobile Un contrat
Probabilités sur un univers fini
 [http://mp.cpgedupuydelome.fr] édité le 7 août 204 Enoncés Probabilités sur un univers fini Evènements et langage ensembliste A quelle condition sur (a, b, c, d) ]0, [ 4 existe-t-il une probabilité P sur
[http://mp.cpgedupuydelome.fr] édité le 7 août 204 Enoncés Probabilités sur un univers fini Evènements et langage ensembliste A quelle condition sur (a, b, c, d) ]0, [ 4 existe-t-il une probabilité P sur
Texte Agrégation limitée par diffusion interne
 Page n 1. Texte Agrégation limitée par diffusion interne 1 Le phénomène observé Un fût de déchets radioactifs est enterré secrètement dans le Cantal. Au bout de quelques années, il devient poreux et laisse
Page n 1. Texte Agrégation limitée par diffusion interne 1 Le phénomène observé Un fût de déchets radioactifs est enterré secrètement dans le Cantal. Au bout de quelques années, il devient poreux et laisse
Simulation de variables aléatoires
 Chapter 1 Simulation de variables aléatoires Références: [F] Fishman, A first course in Monte Carlo, chap 3. [B] Bouleau, Probabilités de l ingénieur, chap 4. [R] Rubinstein, Simulation and Monte Carlo
Chapter 1 Simulation de variables aléatoires Références: [F] Fishman, A first course in Monte Carlo, chap 3. [B] Bouleau, Probabilités de l ingénieur, chap 4. [R] Rubinstein, Simulation and Monte Carlo
3 Approximation de solutions d équations
 3 Approximation de solutions d équations Une équation scalaire a la forme générale f(x) =0où f est une fonction de IR dans IR. Un système de n équations à n inconnues peut aussi se mettre sous une telle
3 Approximation de solutions d équations Une équation scalaire a la forme générale f(x) =0où f est une fonction de IR dans IR. Un système de n équations à n inconnues peut aussi se mettre sous une telle
Intégration et probabilités TD1 Espaces mesurés Corrigé
 Intégration et probabilités TD1 Espaces mesurés Corrigé 2012-2013 1 Petites questions 1 Est-ce que l ensemble des ouverts de R est une tribu? Réponse : Non, car le complémentaire de ], 0[ n est pas ouvert.
Intégration et probabilités TD1 Espaces mesurés Corrigé 2012-2013 1 Petites questions 1 Est-ce que l ensemble des ouverts de R est une tribu? Réponse : Non, car le complémentaire de ], 0[ n est pas ouvert.
Exercices - Polynômes : corrigé. Opérations sur les polynômes
 Opérations sur les polynômes Exercice 1 - Carré - L1/Math Sup - Si P = Q est le carré d un polynôme, alors Q est nécessairement de degré, et son coefficient dominant est égal à 1. On peut donc écrire Q(X)
Opérations sur les polynômes Exercice 1 - Carré - L1/Math Sup - Si P = Q est le carré d un polynôme, alors Q est nécessairement de degré, et son coefficient dominant est égal à 1. On peut donc écrire Q(X)
Programmes des classes préparatoires aux Grandes Ecoles
 Programmes des classes préparatoires aux Grandes Ecoles Filière : scientifique Voie : Biologie, chimie, physique et sciences de la Terre (BCPST) Discipline : Mathématiques Seconde année Préambule Programme
Programmes des classes préparatoires aux Grandes Ecoles Filière : scientifique Voie : Biologie, chimie, physique et sciences de la Terre (BCPST) Discipline : Mathématiques Seconde année Préambule Programme
Calcul matriciel. Définition 1 Une matrice de format (m,n) est un tableau rectangulaire de mn éléments, rangés en m lignes et n colonnes.
 est un tableau rectangulaire de mn éléments, rangés en m lignes et n colonnes.") 1 Définitions, notations Calcul matriciel Définition 1 Une matrice de format (m,n) est un tableau rectangulaire de mn éléments, rangés en m lignes et n colonnes. On utilise aussi la notation m n pour le
1 Définitions, notations Calcul matriciel Définition 1 Une matrice de format (m,n) est un tableau rectangulaire de mn éléments, rangés en m lignes et n colonnes. On utilise aussi la notation m n pour le
Moments des variables aléatoires réelles
 Chapter 6 Moments des variables aléatoires réelles Sommaire 6.1 Espérance des variables aléatoires réelles................................ 46 6.1.1 Définition et calcul........................................
Chapter 6 Moments des variables aléatoires réelles Sommaire 6.1 Espérance des variables aléatoires réelles................................ 46 6.1.1 Définition et calcul........................................
De même, le périmètre P d un cercle de rayon 1 vaut P = 2π (par définition de π). Mais, on peut démontrer (difficilement!) que
. Mais, on peut démontrer (difficilement!) que") Introduction. On suppose connus les ensembles N (des entiers naturels), Z des entiers relatifs et Q (des nombres rationnels). On s est rendu compte, depuis l antiquité, que l on ne peut pas tout mesurer
Introduction. On suppose connus les ensembles N (des entiers naturels), Z des entiers relatifs et Q (des nombres rationnels). On s est rendu compte, depuis l antiquité, que l on ne peut pas tout mesurer
I. Polynômes de Tchebychev
 Première épreuve CCP filière MP I. Polynômes de Tchebychev ( ) 1.a) Tout réel θ vérifie cos(nθ) = Re ((cos θ + i sin θ) n ) = Re Cn k (cos θ) n k i k (sin θ) k Or i k est réel quand k est pair et imaginaire
Première épreuve CCP filière MP I. Polynômes de Tchebychev ( ) 1.a) Tout réel θ vérifie cos(nθ) = Re ((cos θ + i sin θ) n ) = Re Cn k (cos θ) n k i k (sin θ) k Or i k est réel quand k est pair et imaginaire
Exo7. Matrice d une application linéaire. Corrections d Arnaud Bodin.
 Exo7 Matrice d une application linéaire Corrections d Arnaud odin. Exercice Soit R muni de la base canonique = ( i, j). Soit f : R R la projection sur l axe des abscisses R i parallèlement à R( i + j).
Exo7 Matrice d une application linéaire Corrections d Arnaud odin. Exercice Soit R muni de la base canonique = ( i, j). Soit f : R R la projection sur l axe des abscisses R i parallèlement à R( i + j).
Exercices - Fonctions de plusieurs variables : corrigé. Pour commencer
 Pour commencer Exercice 1 - Ensembles de définition - Première année - 1. Le logarithme est défini si x + y > 0. On trouve donc le demi-plan supérieur délimité par la droite d équation x + y = 0.. 1 xy
Pour commencer Exercice 1 - Ensembles de définition - Première année - 1. Le logarithme est défini si x + y > 0. On trouve donc le demi-plan supérieur délimité par la droite d équation x + y = 0.. 1 xy
Probabilités sur un univers fini
 [http://mp.cpgedupuydelome.fr] édité le 10 août 2015 Enoncés 1 Proailités sur un univers fini Evènements et langage ensemliste A quelle condition sur (a,, c, d) ]0, 1[ 4 existe-t-il une proailité P sur
[http://mp.cpgedupuydelome.fr] édité le 10 août 2015 Enoncés 1 Proailités sur un univers fini Evènements et langage ensemliste A quelle condition sur (a,, c, d) ]0, 1[ 4 existe-t-il une proailité P sur
Modèles à Événements Discrets. Réseaux de Petri Stochastiques
 Modèles à Événements Discrets Réseaux de Petri Stochastiques Table des matières 1 Chaînes de Markov Définition formelle Idée générale Discrete Time Markov Chains Continuous Time Markov Chains Propriétés
Modèles à Événements Discrets Réseaux de Petri Stochastiques Table des matières 1 Chaînes de Markov Définition formelle Idée générale Discrete Time Markov Chains Continuous Time Markov Chains Propriétés
L E Ç O N. Marches aléatoires. Niveau : Terminale S Prérequis : aucun
 9 L E Ç O N Marches aléatoires Niveau : Terminale S Prérequis : aucun 1 Chaînes de Markov Définition 9.1 Chaîne de Markov I Une chaîne de Markov est une suite de variables aléatoires (X n, n N) qui permet
9 L E Ç O N Marches aléatoires Niveau : Terminale S Prérequis : aucun 1 Chaînes de Markov Définition 9.1 Chaîne de Markov I Une chaîne de Markov est une suite de variables aléatoires (X n, n N) qui permet
Qu est-ce qu une probabilité?
 Chapitre 1 Qu est-ce qu une probabilité? 1 Modéliser une expérience dont on ne peut prédire le résultat 1.1 Ensemble fondamental d une expérience aléatoire Une expérience aléatoire est une expérience dont
Chapitre 1 Qu est-ce qu une probabilité? 1 Modéliser une expérience dont on ne peut prédire le résultat 1.1 Ensemble fondamental d une expérience aléatoire Une expérience aléatoire est une expérience dont
Chapitre 2 Le problème de l unicité des solutions
 Université Joseph Fourier UE MAT 127 Mathématiques année 2011-2012 Chapitre 2 Le problème de l unicité des solutions Ce que nous verrons dans ce chapitre : un exemple d équation différentielle y = f(y)
Université Joseph Fourier UE MAT 127 Mathématiques année 2011-2012 Chapitre 2 Le problème de l unicité des solutions Ce que nous verrons dans ce chapitre : un exemple d équation différentielle y = f(y)
Développement décimal d un réel
 4 Développement décimal d un réel On rappelle que le corps R des nombres réels est archimédien, ce qui permet d y définir la fonction partie entière. En utilisant cette partie entière on verra dans ce
4 Développement décimal d un réel On rappelle que le corps R des nombres réels est archimédien, ce qui permet d y définir la fonction partie entière. En utilisant cette partie entière on verra dans ce
Coefficients binomiaux
 Probabilités L2 Exercices Chapitre 2 Coefficients binomiaux 1 ( ) On appelle chemin une suite de segments de longueur 1, dirigés soit vers le haut, soit vers la droite 1 Dénombrer tous les chemins allant
Probabilités L2 Exercices Chapitre 2 Coefficients binomiaux 1 ( ) On appelle chemin une suite de segments de longueur 1, dirigés soit vers le haut, soit vers la droite 1 Dénombrer tous les chemins allant
La Licence Mathématiques et Economie-MASS Université de Sciences Sociales de Toulouse 1
 La Licence Mathématiques et Economie-MASS Université de Sciences Sociales de Toulouse 1 La licence Mathématiques et Economie-MASS de l Université des Sciences Sociales de Toulouse propose sur les trois
La Licence Mathématiques et Economie-MASS Université de Sciences Sociales de Toulouse 1 La licence Mathématiques et Economie-MASS de l Université des Sciences Sociales de Toulouse propose sur les trois
Exercice autour de densité, fonction de répatition, espérance et variance de variables quelconques.
 14-3- 214 J.F.C. p. 1 I Exercice autour de densité, fonction de répatition, espérance et variance de variables quelconques. Exercice 1 Densité de probabilité. F { ln x si x ], 1] UN OVNI... On pose x R,
14-3- 214 J.F.C. p. 1 I Exercice autour de densité, fonction de répatition, espérance et variance de variables quelconques. Exercice 1 Densité de probabilité. F { ln x si x ], 1] UN OVNI... On pose x R,
Le théorème de Perron-Frobenius, les chaines de Markov et un célèbre moteur de recherche
 Le théorème de Perron-Frobenius, les chaines de Markov et un célèbre moteur de recherche Bachir Bekka Février 2007 Le théorème de Perron-Frobenius a d importantes applications en probabilités (chaines
Le théorème de Perron-Frobenius, les chaines de Markov et un célèbre moteur de recherche Bachir Bekka Février 2007 Le théorème de Perron-Frobenius a d importantes applications en probabilités (chaines
ENS de Lyon TD 1 17-18 septembre 2012 Introduction aux probabilités. A partie finie de N
 ENS de Lyon TD 7-8 septembre 0 Introduction aux probabilités Exercice Soit (u n ) n N une suite de nombres réels. On considère σ une bijection de N dans N, de sorte que (u σ(n) ) n N est un réordonnement
ENS de Lyon TD 7-8 septembre 0 Introduction aux probabilités Exercice Soit (u n ) n N une suite de nombres réels. On considère σ une bijection de N dans N, de sorte que (u σ(n) ) n N est un réordonnement
Baccalauréat S Antilles-Guyane 11 septembre 2014 Corrigé
 Baccalauréat S ntilles-guyane 11 septembre 14 Corrigé EXERCICE 1 6 points Commun à tous les candidats Une entreprise de jouets en peluche souhaite commercialiser un nouveau produit et à cette fin, effectue
Baccalauréat S ntilles-guyane 11 septembre 14 Corrigé EXERCICE 1 6 points Commun à tous les candidats Une entreprise de jouets en peluche souhaite commercialiser un nouveau produit et à cette fin, effectue
LEÇON N 7 : Schéma de Bernoulli et loi binomiale. Exemples.
 LEÇON N 7 : Schéma de Bernoulli et loi binomiale. Exemples. Pré-requis : Probabilités : définition, calculs et probabilités conditionnelles ; Notion de variables aléatoires, et propriétés associées : espérance,
LEÇON N 7 : Schéma de Bernoulli et loi binomiale. Exemples. Pré-requis : Probabilités : définition, calculs et probabilités conditionnelles ; Notion de variables aléatoires, et propriétés associées : espérance,
Image d un intervalle par une fonction continue
 DOCUMENT 27 Image d un intervalle par une fonction continue La continuité d une fonction en un point est une propriété locale : une fonction est continue en un point x 0 si et seulement si sa restriction
DOCUMENT 27 Image d un intervalle par une fonction continue La continuité d une fonction en un point est une propriété locale : une fonction est continue en un point x 0 si et seulement si sa restriction
Exercices sur le chapitre «Probabilités»
 Arnaud de Saint Julien - MPSI Lycée La Merci 2014-2015 1 Pour démarrer Exercices sur le chapitre «Probabilités» Exercice 1 (Modélisation d un dé non cubique) On considère un parallélépipède rectangle de
Arnaud de Saint Julien - MPSI Lycée La Merci 2014-2015 1 Pour démarrer Exercices sur le chapitre «Probabilités» Exercice 1 (Modélisation d un dé non cubique) On considère un parallélépipède rectangle de
Travaux dirigés d introduction aux Probabilités
 Travaux dirigés d introduction aux Probabilités - Dénombrement - - Probabilités Élémentaires - - Variables Aléatoires Discrètes - - Variables Aléatoires Continues - 1 - Dénombrement - Exercice 1 Combien
Travaux dirigés d introduction aux Probabilités - Dénombrement - - Probabilités Élémentaires - - Variables Aléatoires Discrètes - - Variables Aléatoires Continues - 1 - Dénombrement - Exercice 1 Combien
3. Conditionnement P (B)
") Conditionnement 16 3. Conditionnement Dans cette section, nous allons rappeler un certain nombre de définitions et de propriétés liées au problème du conditionnement, c est à dire à la prise en compte
Conditionnement 16 3. Conditionnement Dans cette section, nous allons rappeler un certain nombre de définitions et de propriétés liées au problème du conditionnement, c est à dire à la prise en compte
Souad EL Bernoussi. Groupe d Analyse Numérique et Optimisation Rabat http ://www.fsr.ac.ma/ano/
 Recherche opérationnelle Les démonstrations et les exemples seront traités en cours Souad EL Bernoussi Groupe d Analyse Numérique et Optimisation Rabat http ://www.fsr.ac.ma/ano/ Table des matières 1 Programmation
Recherche opérationnelle Les démonstrations et les exemples seront traités en cours Souad EL Bernoussi Groupe d Analyse Numérique et Optimisation Rabat http ://www.fsr.ac.ma/ano/ Table des matières 1 Programmation
Chapitre 7. Statistique des échantillons gaussiens. 7.1 Projection de vecteurs gaussiens
 Chapitre 7 Statistique des échantillons gaussiens Le théorème central limite met en évidence le rôle majeur tenu par la loi gaussienne en modélisation stochastique. De ce fait, les modèles statistiques
Chapitre 7 Statistique des échantillons gaussiens Le théorème central limite met en évidence le rôle majeur tenu par la loi gaussienne en modélisation stochastique. De ce fait, les modèles statistiques
Couples de variables aléatoires discrètes
 Couples de variables aléatoires discrètes ECE Lycée Carnot mai Dans ce dernier chapitre de probabilités de l'année, nous allons introduire l'étude de couples de variables aléatoires, c'est-à-dire l'étude
Couples de variables aléatoires discrètes ECE Lycée Carnot mai Dans ce dernier chapitre de probabilités de l'année, nous allons introduire l'étude de couples de variables aléatoires, c'est-à-dire l'étude
* très facile ** facile *** difficulté moyenne **** difficile ***** très difficile I : Incontournable T : pour travailler et mémoriser le cours
 Exo7 Continuité (étude globale). Diverses fonctions Exercices de Jean-Louis Rouget. Retrouver aussi cette fiche sur www.maths-france.fr * très facile ** facile *** difficulté moyenne **** difficile *****
Exo7 Continuité (étude globale). Diverses fonctions Exercices de Jean-Louis Rouget. Retrouver aussi cette fiche sur www.maths-france.fr * très facile ** facile *** difficulté moyenne **** difficile *****
Feuille d exercices 2 : Espaces probabilisés
 Feuille d exercices 2 : Espaces probabilisés Cours de Licence 2 Année 07/08 1 Espaces de probabilité Exercice 1.1 (Une inégalité). Montrer que P (A B) min(p (A), P (B)) Exercice 1.2 (Alphabet). On a un
Feuille d exercices 2 : Espaces probabilisés Cours de Licence 2 Année 07/08 1 Espaces de probabilité Exercice 1.1 (Une inégalité). Montrer que P (A B) min(p (A), P (B)) Exercice 1.2 (Alphabet). On a un
Optimisation non linéaire Irène Charon, Olivier Hudry École nationale supérieure des télécommunications
 Optimisation non linéaire Irène Charon, Olivier Hudry École nationale supérieure des télécommunications A. Optimisation sans contrainte.... Généralités.... Condition nécessaire et condition suffisante
Optimisation non linéaire Irène Charon, Olivier Hudry École nationale supérieure des télécommunications A. Optimisation sans contrainte.... Généralités.... Condition nécessaire et condition suffisante
Calcul différentiel sur R n Première partie
 Calcul différentiel sur R n Première partie Université De Metz 2006-2007 1 Définitions générales On note L(R n, R m ) l espace vectoriel des applications linéaires de R n dans R m. Définition 1.1 (différentiabilité
Calcul différentiel sur R n Première partie Université De Metz 2006-2007 1 Définitions générales On note L(R n, R m ) l espace vectoriel des applications linéaires de R n dans R m. Définition 1.1 (différentiabilité
Correction de l examen de la première session
 de l examen de la première session Julian Tugaut, Franck Licini, Didier Vincent Si vous trouvez des erreurs de Français ou de mathématiques ou bien si vous avez des questions et/ou des suggestions, envoyez-moi
de l examen de la première session Julian Tugaut, Franck Licini, Didier Vincent Si vous trouvez des erreurs de Français ou de mathématiques ou bien si vous avez des questions et/ou des suggestions, envoyez-moi
Contents. 1 Introduction Objectifs des systèmes bonus-malus Système bonus-malus à classes Système bonus-malus : Principes
 Université Claude Bernard Lyon 1 Institut de Science Financière et d Assurances Système Bonus-Malus Introduction & Applications SCILAB Julien Tomas Institut de Science Financière et d Assurances Laboratoire
Université Claude Bernard Lyon 1 Institut de Science Financière et d Assurances Système Bonus-Malus Introduction & Applications SCILAB Julien Tomas Institut de Science Financière et d Assurances Laboratoire
Théorie et Codage de l Information (IF01) exercices 2013-2014. Paul Honeine Université de technologie de Troyes France
 exercices 2013-2014. Paul Honeine Université de technologie de Troyes France") Théorie et Codage de l Information (IF01) exercices 2013-2014 Paul Honeine Université de technologie de Troyes France TD-1 Rappels de calculs de probabilités Exercice 1. On dispose d un jeu de 52 cartes
Théorie et Codage de l Information (IF01) exercices 2013-2014 Paul Honeine Université de technologie de Troyes France TD-1 Rappels de calculs de probabilités Exercice 1. On dispose d un jeu de 52 cartes
Cours d Analyse. Fonctions de plusieurs variables
 Cours d Analyse Fonctions de plusieurs variables Licence 1ère année 2007/2008 Nicolas Prioux Université de Marne-la-Vallée Table des matières 1 Notions de géométrie dans l espace et fonctions à deux variables........
Cours d Analyse Fonctions de plusieurs variables Licence 1ère année 2007/2008 Nicolas Prioux Université de Marne-la-Vallée Table des matières 1 Notions de géométrie dans l espace et fonctions à deux variables........
La fonction exponentielle
 DERNIÈRE IMPRESSION LE 2 novembre 204 à :07 La fonction exponentielle Table des matières La fonction exponentielle 2. Définition et théorèmes.......................... 2.2 Approche graphique de la fonction
DERNIÈRE IMPRESSION LE 2 novembre 204 à :07 La fonction exponentielle Table des matières La fonction exponentielle 2. Définition et théorèmes.......................... 2.2 Approche graphique de la fonction
Cours 02 : Problème général de la programmation linéaire
 Cours 02 : Problème général de la programmation linéaire Cours 02 : Problème général de la Programmation Linéaire. 5 . Introduction Un programme linéaire s'écrit sous la forme suivante. MinZ(ou maxw) =
Cours 02 : Problème général de la programmation linéaire Cours 02 : Problème général de la Programmation Linéaire. 5 . Introduction Un programme linéaire s'écrit sous la forme suivante. MinZ(ou maxw) =
P1 : Corrigés des exercices
 P1 : Corrigés des exercices I Exercices du I I.2.a. Poker : Ω est ( l ensemble ) des parties à 5 éléments de l ensemble E des 52 cartes. Cardinal : 5 I.2.b. Bridge : Ω est ( l ensemble ) des parties à
P1 : Corrigés des exercices I Exercices du I I.2.a. Poker : Ω est ( l ensemble ) des parties à 5 éléments de l ensemble E des 52 cartes. Cardinal : 5 I.2.b. Bridge : Ω est ( l ensemble ) des parties à
CONCOURS D ENTREE A L ECOLE DE 2007 CONCOURS EXTERNE. Cinquième épreuve d admissibilité STATISTIQUE. (durée : cinq heures)
") CONCOURS D ENTREE A L ECOLE DE 2007 CONCOURS EXTERNE Cinquième épreuve d admissibilité STATISTIQUE (durée : cinq heures) Une composition portant sur la statistique. SUJET Cette épreuve est composée d un
CONCOURS D ENTREE A L ECOLE DE 2007 CONCOURS EXTERNE Cinquième épreuve d admissibilité STATISTIQUE (durée : cinq heures) Une composition portant sur la statistique. SUJET Cette épreuve est composée d un
Le modèle de Black et Scholes
 Le modèle de Black et Scholes Alexandre Popier février 21 1 Introduction : exemple très simple de modèle financier On considère un marché avec une seule action cotée, sur une période donnée T. Dans un
Le modèle de Black et Scholes Alexandre Popier février 21 1 Introduction : exemple très simple de modèle financier On considère un marché avec une seule action cotée, sur une période donnée T. Dans un
PROBABILITES ET STATISTIQUE I&II
 PROBABILITES ET STATISTIQUE I&II TABLE DES MATIERES CHAPITRE I - COMBINATOIRE ELEMENTAIRE I.1. Rappel des notations de la théorie des ensemble I.1.a. Ensembles et sous-ensembles I.1.b. Diagrammes (dits
PROBABILITES ET STATISTIQUE I&II TABLE DES MATIERES CHAPITRE I - COMBINATOIRE ELEMENTAIRE I.1. Rappel des notations de la théorie des ensemble I.1.a. Ensembles et sous-ensembles I.1.b. Diagrammes (dits
4 Distributions particulières de probabilités
 4 Distributions particulières de probabilités 4.1 Distributions discrètes usuelles Les variables aléatoires discrètes sont réparties en catégories selon le type de leur loi. 4.1.1 Variable de Bernoulli
4 Distributions particulières de probabilités 4.1 Distributions discrètes usuelles Les variables aléatoires discrètes sont réparties en catégories selon le type de leur loi. 4.1.1 Variable de Bernoulli
Exercices types Algorithmique et simulation numérique Oral Mathématiques et algorithmique Banque PT
 Exercices types Algorithmique et simulation numérique Oral Mathématiques et algorithmique Banque PT Ces exercices portent sur les items 2, 3 et 5 du programme d informatique des classes préparatoires,
Exercices types Algorithmique et simulation numérique Oral Mathématiques et algorithmique Banque PT Ces exercices portent sur les items 2, 3 et 5 du programme d informatique des classes préparatoires,
Probabilités et Statistiques. Feuille 2 : variables aléatoires discrètes
 IUT HSE Probabilités et Statistiques Feuille : variables aléatoires discrètes 1 Exercices Dénombrements Exercice 1. On souhaite ranger sur une étagère 4 livres de mathématiques (distincts), 6 livres de
IUT HSE Probabilités et Statistiques Feuille : variables aléatoires discrètes 1 Exercices Dénombrements Exercice 1. On souhaite ranger sur une étagère 4 livres de mathématiques (distincts), 6 livres de
Formes quadratiques. 1 Formes quadratiques et formes polaires associées. Imen BHOURI. 1.1 Définitions
 Formes quadratiques Imen BHOURI 1 Ce cours s adresse aux étudiants de niveau deuxième année de Licence et à ceux qui préparent le capes. Il combine d une façon indissociable l étude des concepts bilinéaires
Formes quadratiques Imen BHOURI 1 Ce cours s adresse aux étudiants de niveau deuxième année de Licence et à ceux qui préparent le capes. Il combine d une façon indissociable l étude des concepts bilinéaires
CCP PSI - 2010 Mathématiques 1 : un corrigé
 CCP PSI - 00 Mathématiques : un corrigé Première partie. Définition d une structure euclidienne sur R n [X]... B est clairement symétrique et linéaire par rapport à sa seconde variable. De plus B(P, P
CCP PSI - 00 Mathématiques : un corrigé Première partie. Définition d une structure euclidienne sur R n [X]... B est clairement symétrique et linéaire par rapport à sa seconde variable. De plus B(P, P
Fonctions de plusieurs variables
 Module : Analyse 03 Chapitre 00 : Fonctions de plusieurs variables Généralités et Rappels des notions topologiques dans : Qu est- ce que?: Mathématiquement, n étant un entier non nul, on définit comme
Module : Analyse 03 Chapitre 00 : Fonctions de plusieurs variables Généralités et Rappels des notions topologiques dans : Qu est- ce que?: Mathématiquement, n étant un entier non nul, on définit comme
Limites finies en un point
 8 Limites finies en un point Pour ce chapitre, sauf précision contraire, I désigne une partie non vide de R et f une fonction définie sur I et à valeurs réelles ou complees. Là encore, les fonctions usuelles,
8 Limites finies en un point Pour ce chapitre, sauf précision contraire, I désigne une partie non vide de R et f une fonction définie sur I et à valeurs réelles ou complees. Là encore, les fonctions usuelles,
Rappels sur les suites - Algorithme
 DERNIÈRE IMPRESSION LE 14 septembre 2015 à 12:36 Rappels sur les suites - Algorithme Table des matières 1 Suite : généralités 2 1.1 Déition................................. 2 1.2 Exemples de suites............................
DERNIÈRE IMPRESSION LE 14 septembre 2015 à 12:36 Rappels sur les suites - Algorithme Table des matières 1 Suite : généralités 2 1.1 Déition................................. 2 1.2 Exemples de suites............................
Filtrage stochastique non linéaire par la théorie de représentation des martingales
 Filtrage stochastique non linéaire par la théorie de représentation des martingales Adriana Climescu-Haulica Laboratoire de Modélisation et Calcul Institut d Informatique et Mathématiques Appliquées de
Filtrage stochastique non linéaire par la théorie de représentation des martingales Adriana Climescu-Haulica Laboratoire de Modélisation et Calcul Institut d Informatique et Mathématiques Appliquées de
www.h-k.fr/publications/objectif-agregation
 «Sur C, tout est connexe!» www.h-k.fr/publications/objectif-agregation L idée de cette note est de montrer que, contrairement à ce qui se passe sur R, «sur C, tout est connexe». Cet abus de langage se
«Sur C, tout est connexe!» www.h-k.fr/publications/objectif-agregation L idée de cette note est de montrer que, contrairement à ce qui se passe sur R, «sur C, tout est connexe». Cet abus de langage se
Suites numériques 3. 1 Convergence et limite d une suite
 Suites numériques 3 1 Convergence et limite d une suite Nous savons que les termes de certaines suites s approchent de plus en plus d une certaine valeur quand n augmente : par exemple, les nombres u n
Suites numériques 3 1 Convergence et limite d une suite Nous savons que les termes de certaines suites s approchent de plus en plus d une certaine valeur quand n augmente : par exemple, les nombres u n
Probabilités Loi binomiale Exercices corrigés
 Probabilités Loi binomiale Exercices corrigés Sont abordés dans cette fiche : (cliquez sur l exercice pour un accès direct) Exercice 1 : épreuve de Bernoulli Exercice 2 : loi de Bernoulli de paramètre
Probabilités Loi binomiale Exercices corrigés Sont abordés dans cette fiche : (cliquez sur l exercice pour un accès direct) Exercice 1 : épreuve de Bernoulli Exercice 2 : loi de Bernoulli de paramètre
aux différences est appelé équation aux différences d ordre n en forme normale.
 MODÉLISATION ET SIMULATION EQUATIONS AUX DIFFÉRENCES (I/II) 1. Rappels théoriques : résolution d équations aux différences 1.1. Équations aux différences. Définition. Soit x k = x(k) X l état scalaire
MODÉLISATION ET SIMULATION EQUATIONS AUX DIFFÉRENCES (I/II) 1. Rappels théoriques : résolution d équations aux différences 1.1. Équations aux différences. Définition. Soit x k = x(k) X l état scalaire
Probabilité. Table des matières. 1 Loi de probabilité 2 1.1 Conditions préalables... 2 1.2 Définitions... 2 1.3 Loi équirépartie...
 1 Probabilité Table des matières 1 Loi de probabilité 2 1.1 Conditions préalables........................... 2 1.2 Définitions................................. 2 1.3 Loi équirépartie..............................
1 Probabilité Table des matières 1 Loi de probabilité 2 1.1 Conditions préalables........................... 2 1.2 Définitions................................. 2 1.3 Loi équirépartie..............................
Théorème du point fixe - Théorème de l inversion locale
 Chapitre 7 Théorème du point fixe - Théorème de l inversion locale Dans ce chapitre et le suivant, on montre deux applications importantes de la notion de différentiabilité : le théorème de l inversion
Chapitre 7 Théorème du point fixe - Théorème de l inversion locale Dans ce chapitre et le suivant, on montre deux applications importantes de la notion de différentiabilité : le théorème de l inversion
Soit la fonction affine qui, pour représentant le nombre de mois écoulés, renvoie la somme économisée.
 ANALYSE 5 points Exercice 1 : Léonie souhaite acheter un lecteur MP3. Le prix affiché (49 ) dépasse largement la somme dont elle dispose. Elle décide donc d économiser régulièrement. Elle a relevé qu elle
ANALYSE 5 points Exercice 1 : Léonie souhaite acheter un lecteur MP3. Le prix affiché (49 ) dépasse largement la somme dont elle dispose. Elle décide donc d économiser régulièrement. Elle a relevé qu elle
Théorie de la Mesure et Intégration
 Université Pierre & Marie Curie (Paris 6) Licence de Mathématiques L3 UE LM364 Intégration 1 & UE LM365 Intégration 2 Année 2010 11 Théorie de la Mesure et Intégration Responsable des cours : Amaury LAMBERT
Université Pierre & Marie Curie (Paris 6) Licence de Mathématiques L3 UE LM364 Intégration 1 & UE LM365 Intégration 2 Année 2010 11 Théorie de la Mesure et Intégration Responsable des cours : Amaury LAMBERT
Capacité d un canal Second Théorème de Shannon. Théorie de l information 1/34
 Capacité d un canal Second Théorème de Shannon Théorie de l information 1/34 Plan du cours 1. Canaux discrets sans mémoire, exemples ; 2. Capacité ; 3. Canaux symétriques ; 4. Codage de canal ; 5. Second
Capacité d un canal Second Théorème de Shannon Théorie de l information 1/34 Plan du cours 1. Canaux discrets sans mémoire, exemples ; 2. Capacité ; 3. Canaux symétriques ; 4. Codage de canal ; 5. Second
Intégration et probabilités TD1 Espaces mesurés
 Intégration et probabilités TD1 Espaces mesurés 2012-2013 1 Petites questions 1) Est-ce que l ensemble des ouverts de R est une tribu? 2) Si F et G sont deux tribus, est-ce que F G est toujours une tribu?
Intégration et probabilités TD1 Espaces mesurés 2012-2013 1 Petites questions 1) Est-ce que l ensemble des ouverts de R est une tribu? 2) Si F et G sont deux tribus, est-ce que F G est toujours une tribu?
Intégrale de Lebesgue
 Intégrale de Lebesgue L3 Mathématiques Jean-Christophe Breton Université de Rennes 1 Septembre Décembre 2014 version du 2/12/14 Table des matières 1 Tribus (σ-algèbres) et mesures 1 1.1 Rappels ensemblistes..............................
Intégrale de Lebesgue L3 Mathématiques Jean-Christophe Breton Université de Rennes 1 Septembre Décembre 2014 version du 2/12/14 Table des matières 1 Tribus (σ-algèbres) et mesures 1 1.1 Rappels ensemblistes..............................
I. Introduction. 1. Objectifs. 2. Les options. a. Présentation du problème.
 I. Introduction. 1. Objectifs. Le but de ces quelques séances est d introduire les outils mathématiques, plus précisément ceux de nature probabiliste, qui interviennent dans les modèles financiers ; nous
I. Introduction. 1. Objectifs. Le but de ces quelques séances est d introduire les outils mathématiques, plus précisément ceux de nature probabiliste, qui interviennent dans les modèles financiers ; nous
Lois de probabilité. Anita Burgun
 Lois de probabilité Anita Burgun Problème posé Le problème posé en statistique: On s intéresse à une population On extrait un échantillon On se demande quelle sera la composition de l échantillon (pourcentage
Lois de probabilité Anita Burgun Problème posé Le problème posé en statistique: On s intéresse à une population On extrait un échantillon On se demande quelle sera la composition de l échantillon (pourcentage
Mesures gaussiennes et espaces de Fock
 Mesures gaussiennes et espaces de Fock Thierry Lévy Peyresq - Juin 2003 Introduction Les mesures gaussiennes et les espaces de Fock sont deux objets qui apparaissent naturellement et peut-être, à première
Mesures gaussiennes et espaces de Fock Thierry Lévy Peyresq - Juin 2003 Introduction Les mesures gaussiennes et les espaces de Fock sont deux objets qui apparaissent naturellement et peut-être, à première
Université Paris-Dauphine DUMI2E 1ère année, 2009-2010. Applications
 Université Paris-Dauphine DUMI2E 1ère année, 2009-2010 Applications 1 Introduction Une fonction f (plus précisément, une fonction réelle d une variable réelle) est une règle qui associe à tout réel x au
Université Paris-Dauphine DUMI2E 1ère année, 2009-2010 Applications 1 Introduction Une fonction f (plus précisément, une fonction réelle d une variable réelle) est une règle qui associe à tout réel x au
Équations non linéaires
 Équations non linéaires Objectif : trouver les zéros de fonctions (ou systèmes) non linéaires, c-à-d les valeurs α R telles que f(α) = 0. y f(x) α 1 α 2 α 3 x Equations non lineaires p. 1/49 Exemples et
Équations non linéaires Objectif : trouver les zéros de fonctions (ou systèmes) non linéaires, c-à-d les valeurs α R telles que f(α) = 0. y f(x) α 1 α 2 α 3 x Equations non lineaires p. 1/49 Exemples et
Résolution de systèmes linéaires par des méthodes directes
 Résolution de systèmes linéaires par des méthodes directes J. Erhel Janvier 2014 1 Inverse d une matrice carrée et systèmes linéaires Ce paragraphe a pour objet les matrices carrées et les systèmes linéaires.
Résolution de systèmes linéaires par des méthodes directes J. Erhel Janvier 2014 1 Inverse d une matrice carrée et systèmes linéaires Ce paragraphe a pour objet les matrices carrées et les systèmes linéaires.
Modélisation aléatoire en fiabilité des logiciels
 collection Méthodes stochastiques appliquées dirigée par Nikolaos Limnios et Jacques Janssen La sûreté de fonctionnement des systèmes informatiques est aujourd hui un enjeu économique et sociétal majeur.
collection Méthodes stochastiques appliquées dirigée par Nikolaos Limnios et Jacques Janssen La sûreté de fonctionnement des systèmes informatiques est aujourd hui un enjeu économique et sociétal majeur.
Probabilités conditionnelles Loi binomiale
 Exercices 23 juillet 2014 Probabilités conditionnelles Loi binomiale Équiprobabilité et variable aléatoire Exercice 1 Une urne contient 5 boules indiscernables, 3 rouges et 2 vertes. On tire au hasard
Exercices 23 juillet 2014 Probabilités conditionnelles Loi binomiale Équiprobabilité et variable aléatoire Exercice 1 Une urne contient 5 boules indiscernables, 3 rouges et 2 vertes. On tire au hasard
Continuité et dérivabilité d une fonction
 DERNIÈRE IMPRESSIN LE 7 novembre 014 à 10:3 Continuité et dérivabilité d une fonction Table des matières 1 Continuité d une fonction 1.1 Limite finie en un point.......................... 1. Continuité
DERNIÈRE IMPRESSIN LE 7 novembre 014 à 10:3 Continuité et dérivabilité d une fonction Table des matières 1 Continuité d une fonction 1.1 Limite finie en un point.......................... 1. Continuité
Programmation linéaire
 1 Programmation linéaire 1. Le problème, un exemple. 2. Le cas b = 0 3. Théorème de dualité 4. L algorithme du simplexe 5. Problèmes équivalents 6. Complexité de l Algorithme 2 Position du problème Soit
1 Programmation linéaire 1. Le problème, un exemple. 2. Le cas b = 0 3. Théorème de dualité 4. L algorithme du simplexe 5. Problèmes équivalents 6. Complexité de l Algorithme 2 Position du problème Soit
Introduction à l étude des Corps Finis
 Introduction à l étude des Corps Finis Robert Rolland (Résumé) 1 Introduction La structure de corps fini intervient dans divers domaines des mathématiques, en particulier dans la théorie de Galois sur
Introduction à l étude des Corps Finis Robert Rolland (Résumé) 1 Introduction La structure de corps fini intervient dans divers domaines des mathématiques, en particulier dans la théorie de Galois sur
Cours d analyse numérique SMI-S4
 ours d analyse numérique SMI-S4 Introduction L objet de l analyse numérique est de concevoir et d étudier des méthodes de résolution de certains problèmes mathématiques, en général issus de problèmes réels,
ours d analyse numérique SMI-S4 Introduction L objet de l analyse numérique est de concevoir et d étudier des méthodes de résolution de certains problèmes mathématiques, en général issus de problèmes réels,
Baccalauréat ES/L Métropole La Réunion 13 septembre 2013 Corrigé
 Baccalauréat S/L Métropole La Réunion 13 septembre 2013 Corrigé A. P. M.. P. XRCIC 1 Commun à tous les candidats Partie A 1. L arbre de probabilité correspondant aux données du problème est : 0,3 0,6 H
Baccalauréat S/L Métropole La Réunion 13 septembre 2013 Corrigé A. P. M.. P. XRCIC 1 Commun à tous les candidats Partie A 1. L arbre de probabilité correspondant aux données du problème est : 0,3 0,6 H
Chapitre VI - Méthodes de factorisation
 Université Pierre et Marie Curie Cours de cryptographie MM067-2012/13 Alain Kraus Chapitre VI - Méthodes de factorisation Le problème de la factorisation des grands entiers est a priori très difficile.
Université Pierre et Marie Curie Cours de cryptographie MM067-2012/13 Alain Kraus Chapitre VI - Méthodes de factorisation Le problème de la factorisation des grands entiers est a priori très difficile.
Eteindre. les. lumières MATH EN JEAN 2013-2014. Mme BACHOC. Elèves de seconde, première et terminale scientifiques :
 MTH EN JEN 2013-2014 Elèves de seconde, première et terminale scientifiques : Lycée Michel Montaigne : HERITEL ôme T S POLLOZE Hélène 1 S SOK Sophie 1 S Eteindre Lycée Sud Médoc : ROSIO Gauthier 2 nd PELGE
MTH EN JEN 2013-2014 Elèves de seconde, première et terminale scientifiques : Lycée Michel Montaigne : HERITEL ôme T S POLLOZE Hélène 1 S SOK Sophie 1 S Eteindre Lycée Sud Médoc : ROSIO Gauthier 2 nd PELGE
Calcul fonctionnel holomorphe dans les algèbres de Banach
 Chapitre 7 Calcul fonctionnel holomorphe dans les algèbres de Banach L objet de ce chapitre est de définir un calcul fonctionnel holomorphe qui prolonge le calcul fonctionnel polynômial et qui respecte
Chapitre 7 Calcul fonctionnel holomorphe dans les algèbres de Banach L objet de ce chapitre est de définir un calcul fonctionnel holomorphe qui prolonge le calcul fonctionnel polynômial et qui respecte
http://cermics.enpc.fr/scilab
 scilab à l École des Ponts ParisTech http://cermics.enpc.fr/scilab Introduction à Scilab Graphiques, fonctions Scilab, programmation, saisie de données Jean-Philippe Chancelier & Michel De Lara cermics,
scilab à l École des Ponts ParisTech http://cermics.enpc.fr/scilab Introduction à Scilab Graphiques, fonctions Scilab, programmation, saisie de données Jean-Philippe Chancelier & Michel De Lara cermics,
Programmation linéaire et Optimisation. Didier Smets
 Programmation linéaire et Optimisation Didier Smets Chapitre 1 Un problème d optimisation linéaire en dimension 2 On considère le cas d un fabricant d automobiles qui propose deux modèles à la vente, des
Programmation linéaire et Optimisation Didier Smets Chapitre 1 Un problème d optimisation linéaire en dimension 2 On considère le cas d un fabricant d automobiles qui propose deux modèles à la vente, des
Chapitre 5 : Flot maximal dans un graphe
 Graphes et RO TELECOM Nancy A Chapitre 5 : Flot maximal dans un graphe J.-F. Scheid 1 Plan du chapitre I. Définitions 1 Graphe Graphe valué 3 Représentation d un graphe (matrice d incidence, matrice d
Graphes et RO TELECOM Nancy A Chapitre 5 : Flot maximal dans un graphe J.-F. Scheid 1 Plan du chapitre I. Définitions 1 Graphe Graphe valué 3 Représentation d un graphe (matrice d incidence, matrice d
Introduction à la théorie des files d'attente. Claude Chaudet [email protected]
 Introduction à la théorie des files d'attente Claude Chaudet [email protected] La théorie des files d'attente... Principe: modélisation mathématique de l accès à une ressource partagée Exemples réseaux
Introduction à la théorie des files d'attente Claude Chaudet [email protected] La théorie des files d'attente... Principe: modélisation mathématique de l accès à une ressource partagée Exemples réseaux
Annexe commune aux séries ES, L et S : boîtes et quantiles
 Annexe commune aux séries ES, L et S : boîtes et quantiles Quantiles En statistique, pour toute série numérique de données à valeurs dans un intervalle I, on définit la fonction quantile Q, de [,1] dans
Annexe commune aux séries ES, L et S : boîtes et quantiles Quantiles En statistique, pour toute série numérique de données à valeurs dans un intervalle I, on définit la fonction quantile Q, de [,1] dans
Structures algébriques
 Structures algébriques 1. Lois de composition s Soit E un ensemble. Une loi de composition interne sur E est une application de E E dans E. Soient E et F deux ensembles. Une loi de composition externe
Structures algébriques 1. Lois de composition s Soit E un ensemble. Une loi de composition interne sur E est une application de E E dans E. Soient E et F deux ensembles. Une loi de composition externe
Introduction au Calcul des Probabilités
 Université des Sciences et Technologies de Lille U.F.R. de Mathématiques Pures et Appliquées Bât. M2, F-59655 Villeneuve d Ascq Cedex Introduction au Calcul des Probabilités Probabilités à Bac+2 et plus
Université des Sciences et Technologies de Lille U.F.R. de Mathématiques Pures et Appliquées Bât. M2, F-59655 Villeneuve d Ascq Cedex Introduction au Calcul des Probabilités Probabilités à Bac+2 et plus
Polynômes à plusieurs variables. Résultant
 Polynômes à plusieurs variables. Résultant Christophe Ritzenthaler 1 Relations coefficients-racines. Polynômes symétriques Issu de [MS] et de [Goz]. Soit A un anneau intègre. Définition 1.1. Soit a A \
Polynômes à plusieurs variables. Résultant Christophe Ritzenthaler 1 Relations coefficients-racines. Polynômes symétriques Issu de [MS] et de [Goz]. Soit A un anneau intègre. Définition 1.1. Soit a A \
La NP-complétude. Johanne Cohen. PRISM/CNRS, Versailles, France.
 La NP-complétude Johanne Cohen PRISM/CNRS, Versailles, France. Références 1. Algorithm Design, Jon Kleinberg, Eva Tardos, Addison-Wesley, 2006. 2. Computers and Intractability : A Guide to the Theory of
La NP-complétude Johanne Cohen PRISM/CNRS, Versailles, France. Références 1. Algorithm Design, Jon Kleinberg, Eva Tardos, Addison-Wesley, 2006. 2. Computers and Intractability : A Guide to the Theory of
Loi binomiale Lois normales
 Loi binomiale Lois normales Christophe ROSSIGNOL Année scolaire 204/205 Table des matières Rappels sur la loi binomiale 2. Loi de Bernoulli............................................ 2.2 Schéma de Bernoulli
Loi binomiale Lois normales Christophe ROSSIGNOL Année scolaire 204/205 Table des matières Rappels sur la loi binomiale 2. Loi de Bernoulli............................................ 2.2 Schéma de Bernoulli
Fonctions de plusieurs variables, intégrales multiples, et intégrales dépendant d un paramètre
 IUFM du Limousin 2009-10 PLC1 Mathématiques S. Vinatier Rappels de cours Fonctions de plusieurs variables, intégrales multiples, et intégrales dépendant d un paramètre 1 Fonctions de plusieurs variables
IUFM du Limousin 2009-10 PLC1 Mathématiques S. Vinatier Rappels de cours Fonctions de plusieurs variables, intégrales multiples, et intégrales dépendant d un paramètre 1 Fonctions de plusieurs variables
Que faire lorsqu on considère plusieurs variables en même temps?
 Chapitre 3 Que faire lorsqu on considère plusieurs variables en même temps? On va la plupart du temps se limiter à l étude de couple de variables aléatoires, on peut bien sûr étendre les notions introduites
Chapitre 3 Que faire lorsqu on considère plusieurs variables en même temps? On va la plupart du temps se limiter à l étude de couple de variables aléatoires, on peut bien sûr étendre les notions introduites
I - PUISSANCE D UN POINT PAR RAPPORT A UN CERCLE CERCLES ORTHOGONAUX POLES ET POLAIRES
 I - PUISSANCE D UN POINT PAR RAPPORT A UN CERCLE CERCLES ORTHOGONAUX POLES ET POLAIRES Théorème - Définition Soit un cercle (O,R) et un point. Une droite passant par coupe le cercle en deux points A et
I - PUISSANCE D UN POINT PAR RAPPORT A UN CERCLE CERCLES ORTHOGONAUX POLES ET POLAIRES Théorème - Définition Soit un cercle (O,R) et un point. Une droite passant par coupe le cercle en deux points A et
Baccalauréat ES Polynésie (spécialité) 10 septembre 2014 Corrigé
 10 septembre 2014 Corrigé") Baccalauréat ES Polynésie (spécialité) 10 septembre 2014 Corrigé A. P. M. E. P. Exercice 1 5 points 1. Réponse d. : 1 e Le coefficient directeur de la tangente est négatif et n est manifestement pas 2e
Baccalauréat ES Polynésie (spécialité) 10 septembre 2014 Corrigé A. P. M. E. P. Exercice 1 5 points 1. Réponse d. : 1 e Le coefficient directeur de la tangente est négatif et n est manifestement pas 2e
Dualité dans les espaces de Lebesgue et mesures de Radon finies
 Chapitre 6 Dualité dans les espaces de Lebesgue et mesures de Radon finies Nous allons maintenant revenir sur les espaces L p du Chapitre 4, à la lumière de certains résultats du Chapitre 5. Sauf mention
Chapitre 6 Dualité dans les espaces de Lebesgue et mesures de Radon finies Nous allons maintenant revenir sur les espaces L p du Chapitre 4, à la lumière de certains résultats du Chapitre 5. Sauf mention