BI = Business Intelligence Master Data-ScienceCours 7 - Data
|
|
|
- Victorien Alarie
- il y a 8 ans
- Total affichages :
Transcription
1 BI = Business Intelligence Master Data-Science Cours 7 - Data Mining Ludovic DENOYER - UPMC 30 mars 2015 Ludovic DENOYER -

2 Typologie des méthodes de Data Mining Différents types de méthodes : Méthodes descriptives : Permettent de décrire un ensemble de données pour une compréhension humaine Peuvent servir de socle au développement de modèles prédictifs Ex : Règles d association (voir cours précédent) Méthodes prédictives : Permettent de faire de la prédiction En support à la prise de décision Ex : Réseaux de neurones

3 Typologies des méthodes Source : Bernard Espinasse

4 Règles d association (rappel) Principe : Extraire à partir de données transactionnelles des règles de type A B où A et B sont des sous-ensembles des items en présence Algorithme APriori : Création des itemsets fréquents Création des règles à haute confiance à partir de ces itemsets Utilisation d algorithme greedy qui utilisent la propriété de monotonie

5 Arbres de décision Plan du cours : Arbres de décision (définition) Algorithme d apprentissage Forêts Aléatoires Forêts Extrêmement aléatoires

6 Arbres de décision Les arbres de décisions sont : Des modèles (d apprentissage/de fouille de données) supervisés utilisés pour la régression et/ou la classification Ce sont des modèles descriptifs mais aussi des modèles prédictifs Ils produisent un décision interprétable, sous forme d arbres

7 Arbres de décision C est une méthode appréciée en entreprise car : Elle obtient de bons résultats en terme de performance pure Le modèle appris est lisible par un expert. Cette caractéristique est très importante, car le travail de l analyste consiste aussi à faire comprendre ses résultats afin d emporter l adhésion des décideurs. Elle est capable de sélectionner les variables à utiliser. En ce sens, elle permet un travail exploratoire sur les grands volumes de données

8 Arbres de décision According to research in cognitive psychology (Miller 1956 ; Kahneman, Slovic, and Tversky 1982) the ability to conceptually grasp and manipulate multiple chunks of knowledge is limited by the physical and cognitive processing limitations of the shortterm memory portion of the brain. This places a premium on the utilization of dimensional manipulation and presentation techniques that are capable of preserving and reflecting high-dimensionality relationships in a readily comprehensible form so that the relationships can be more easily consumed and applied by humans.

9 Retour sur les règles d association Règles d association Les règles d association expriment une notion de lien entre objets de même type (ex : les produits vendus par un magasin). Attention : Une règle d association n exprime pas une corrélation Règles de production Les règles de production expliquent le lien entre une classe particulière et la valeur des caractéristiques de plusieurs objets Les deux types de règles ne véhiculent pas le même type d information.

10 Règles de production : Exemples Si crédit > 1/3 salaire mauvais Si crédit < 1/3 salaire ET charges > 4 mauvais Si crédit < 1/3 salaire ET charges < 4 ET propriétaire = oui bon Si crédit < 1/3 salaire ET charges < 4 ET propriétaire=non ET cadre=oui bon Si crédit < 1/3 salaire ET charges < 4 ET propriétaire=non ET cadre = non moyen


11 Arbres de décision Les règles de production peuvent être regroupées sous la forme d un arbre de décision En pratique, les systèmes construisent d abord les arbres d où ils dérivent les règles


12 Arbres de décision
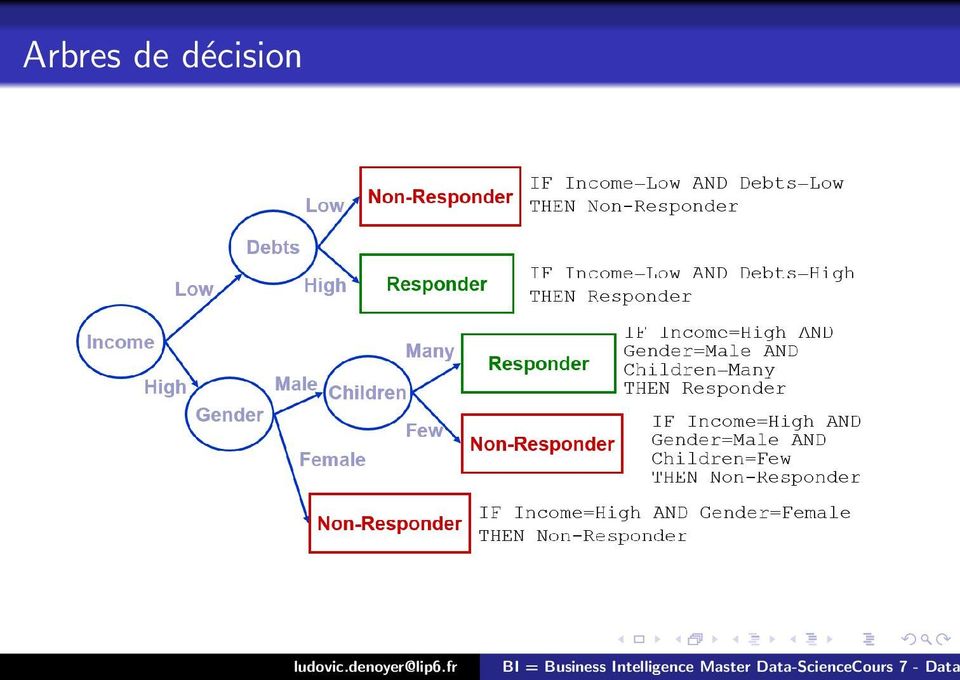

13 Arbres de décision

14 Exercice D onner les arbres de décisions qui expriment les fonctions booléennes suivantes : A et B A ou (B et C) A XOR B (A et B) ou (C et D)
 A XOR B (A et B)")
15 Algorithme L algorithme d inférence des arbres de décision est un algorithme de type Divide and Conquer Au début, tous les exemples sont à la racine de l arbre Partitionnement récursif des exemples

16 Algorithme Quelles règles trouvez vous pour savoir qui achète un ordinateur?

17 Algorithme

18 Algorithme

19 Algorithme

20 Algorithme

21 Algorithme
22 Algorithme Algorithme greedy qui prend la meilleure décision à chaque pas de temps L arbre est construit de haut en bas (top-down) de manière récursive (divide and conquer) Tous les exemples d apprentissage sont à la racine au début A chaque étape, les données sont partitionnées suivant la valeur d une variable La variable est sélectionnée par une mesure L algorithme s arrête quand : Toutes les données d un noeud sont dans la même catégorie Il n y a plus de variables disponibles pour continuer le partitionnement Il n y a pas de données dans un noeud

23 Critère de partitionnement Le critère usuellement de partitionnement est l entropie : Un ensemble aléatoire de données possède une entropie forte Un ensemble de basse entropie est un ensemble où la distribution de la variable de sortie possède un unique pic
24 Mesure de discrimination classique Utilisation de l entropie de Shannon : H S (C A) = i P(v i ) k P(c k v i ) log(p(c k v i )) Mesure issue de la théorie de l information initiée par C.E. Shannon en 1948 Mesure un taux de désordre
25 Construction de l arbre : cas général Algorithme d apprentissage 1 Calculer H(C A j ) pour tous les attributs A j 2 Choisir l attribut A j qui minimise H(C A j ) créer un nœud dans l arbre de décision 3 A l aide de A j, partitionner la base d apprentissage
26 Exemple
27 Exemple
28 Exemple
29 Exemple
30 Exercice Faire l arbre de décision la dessus : Num. exemple Att 1 Att 2 Att 3 Classe
31 Exercice attribut 1 : H(C A1) = 6( log log 0 3) 3 1 6( 3 log log 2 ) 3 ce qui donne H(C A1) = 0.5 (0 + 0) 0.5 ( ) = attribut 2 : H(C A2) = 6( log log 2 4) 2 2 6( 2 log log 0 ) 2 ce qui donne H(C A2) = 0.66 ( ) 0.33 (0 + 0) = attribut 3 : H(C A3) = 6( log log 1 4) 2 1 6( 2 log log 1 ) 2 ce qui donne H(C A2) = 0.66 ( ) 0.33 ( ) = 0.873
32 Exercice L attribut 1 est celui qui minimise l entropie et qui est donc choisi comme racine. Ensuite, on sépare la base d apprentissage en 2 selon les valeurs de A1. Les exemples qui ont la valeur 0 sont de la même classe, on arrête donc la construction de la branche de l arbre pour eux en créant une feuille dont la classe associée est +. Pour ceux qui ont la valeur 1 pour A1, on calcule les entropies de A2 et de A3 : attribut 2 : H(C A2) = 3( log log 2 2) 1 1 3( 1 log log 0 ) 1 ce qui donne H(C A2) = 0.66 (0 + 0) 0.33 (0 + 0) = 0.0 attribut 3 : H(C A3) = 3( log log 1 1) 2 1 3( 2 log log 1 ) 2 ce qui donne H(C A3) = 0.33 (0 + 0) 0.66 ( ) = 0.666
33 Exercice C est donc l attribut A2 qui minimise l entropie ici et qui est utilisé dans l arbre. L arbre final est donné dans la figure suivante : A A
34 Autres algorithmes
35 DT sur données continues Le choix des variables à utiliser est très important Algorithmes de discrétisation des variables
36 DT sur données continues
37 Sur-apprentissage
38 Sur-apprentissage Dans le cas extrême, on peut apprendre une branche par exemple d apprentissage Pré-élagage : Post-élagage : Arréter les développement d une branche avant que tous les exemples de cette branche soient bien classés Apprendre un arbre en entier, élaguer par la suite
39 Sur-Apprentissage Elagage à posteriori Idée : Elaguer après la construction de l arbre entier, en remplaçant les sous-arbres optimisant un critère d élagage par un noeud. Nombreuses méthodes. Encore beaucoup de recherches. Minimal Cost-Complexity Pruning (MCCP) (Breiman et al.,84) Reduced Error Pruning (REP) (Quinlan,87,93) Minimum Error Pruning (MEP) (Niblett & Bratko,86) Critical Value Pruning (CVP) (Mingers,87) Pessimistic Error Pruning (PEP) (Quinlan,87) Error-Based Pruning (EBP) (Quinlan,93) (utilisé dans C4.5)...
40 Forêts aléatoires Méthode introduite par Leo Breiman en Idées plus anciennes : Bagging (1996) Arbres de décisions CART (1984) Preuves de convergences récentes (2006,2008) Un site web utile : breiman/randomforests Idée Les forêts aléatoires consistent à faire tourner en parallèle un grand nombre d arbres de décisions construits aléatoirement, avant de les moyenner
41 Bagging d arbres Soit un ensemble X = x 1,...x n d apprentissage, et les étiquettes associées Y = y 1,..., y n. Le principe consiste à : Pour b = 1,...B : Tirer avec replacement n exemples d apprentissage de X, Y X b, Y b Apprendre un arbre de décision f b sur X b, Y b B Le classifieur final est : f (x) = 1 B f b (x) ou bien un vote b=1 majoritaire dans le cas catégoriel. Ce type d approche fait baisser la variance du modèle, sans augmenter son biais. Le nombre d arbres est souvent sélectionné par cross-validation.

42 Comment ça marche?

43 Comment ça marche?

44 Comment ça marche?
45 Random Forests Les random forests sont basées sur le même principe, avec une modification dans l algorithme d apprentissage des arbres de décision : A chaque noeud de l arbre, un sous-ensemble d attributs est sélectionné aléatoirement, le découpage s effectuant sur ce sous-ensemble d attributs Algorithme Pour b = 1,...B : Tirer avec replacement n exemples d apprentissage de X, Y X b, Y b Apprendre un arbre de décision f b sur X b, Y b, avec randomisation des variables B Le classifieur final est : f (x) = 1 B f b (x) ou bien un vote b=1 majoritaire dans le cas catégoriel.
46 Forêts extrêmement aléatoires Dans le cas précédent : La sélection du split se fait sur un critère de maximisation de gain d information, basé sur un sous-ensemble de candidats Pourquoi ne pas faire encore plus simple : L effort principal provien du calcul du gain d information On pourrait choisir un split aléatoire (sur un attribut aléatoire) dans chaque noeud arbre aléatoire
47 Arbre extrèmement aléatoire Random query pour chaque noeud de l arbre Les feuilles contiennent la distribution a posteriori des labels
48 Arbre extrèmement aléatoire Les forêts extrèmement aléatoires donnent des performances quasi similaires aux forêts aléatoires, mais au prix d un apprentissage beaucoup moins coûteux
49 Arbres de décision Modèles d apprentissage de règles de production Sur tous types de données Permet de sélectionner des variables discriminantes : il est donc utile aussi comme algorithme de prétraitement Performant Beaucoup d outils disponibles Par contre : Les performances se dégradent quand le nombre de classes est élevé L algorithme n est pas incrémental et il doit être re-appris à chaque fois que les données évoluent
Data Mining. Vincent Augusto 2012-2013. École Nationale Supérieure des Mines de Saint-Étienne. Data Mining. V. Augusto.
 des des Data Mining Vincent Augusto École Nationale Supérieure des Mines de Saint-Étienne 2012-2013 1/65 des des 1 2 des des 3 4 Post-traitement 5 représentation : 6 2/65 des des Définition générale Le
des des Data Mining Vincent Augusto École Nationale Supérieure des Mines de Saint-Étienne 2012-2013 1/65 des des 1 2 des des 3 4 Post-traitement 5 représentation : 6 2/65 des des Définition générale Le
Arbres binaires de décision
 1 Arbres binaires de décision Résumé Arbres binaires de décision Méthodes de construction d arbres binaires de décision, modélisant une discrimination (classification trees) ou une régression (regression
1 Arbres binaires de décision Résumé Arbres binaires de décision Méthodes de construction d arbres binaires de décision, modélisant une discrimination (classification trees) ou une régression (regression
Introduction au Data-Mining
 Introduction au Data-Mining Alain Rakotomamonjy - Gilles Gasso. INSA Rouen -Département ASI Laboratoire PSI Introduction au Data-Mining p. 1/25 Data-Mining : Kèkecé? Traduction : Fouille de données. Terme
Introduction au Data-Mining Alain Rakotomamonjy - Gilles Gasso. INSA Rouen -Département ASI Laboratoire PSI Introduction au Data-Mining p. 1/25 Data-Mining : Kèkecé? Traduction : Fouille de données. Terme
Algorithmes d'apprentissage
 Algorithmes d'apprentissage 1 Agents qui apprennent à partir d'exemples La problématique : prise de décision automatisée à partir d'un ensemble d'exemples Diagnostic médical Réponse à une demande de prêt
Algorithmes d'apprentissage 1 Agents qui apprennent à partir d'exemples La problématique : prise de décision automatisée à partir d'un ensemble d'exemples Diagnostic médical Réponse à une demande de prêt
Méthodes d apprentissage statistique «Machine Learning»
 Méthodes d apprentissage statistique «Machine Learning» Fabrice TAILLIEU, Sébastien DELUCINGE, Rémi BELLINA Le marché de l assurance a rarement été marqué par un environnement aussi difficile qu au cours
Méthodes d apprentissage statistique «Machine Learning» Fabrice TAILLIEU, Sébastien DELUCINGE, Rémi BELLINA Le marché de l assurance a rarement été marqué par un environnement aussi difficile qu au cours
Introduction au Data-Mining
 Introduction au Data-Mining Gilles Gasso, Stéphane Canu INSA Rouen -Département ASI Laboratoire LITIS 8 septembre 205. Ce cours est librement inspiré du cours DM de Alain Rakotomamonjy Gilles Gasso, Stéphane
Introduction au Data-Mining Gilles Gasso, Stéphane Canu INSA Rouen -Département ASI Laboratoire LITIS 8 septembre 205. Ce cours est librement inspiré du cours DM de Alain Rakotomamonjy Gilles Gasso, Stéphane
Une méthode de classification supervisée sans paramètre pour l apprentissage sur les grandes bases de données
 Une méthode de classification supervisée sans paramètre pour l apprentissage sur les grandes bases de données Marc Boullé Orange Labs 2 avenue Pierre Marzin 22300 Lannion marc.boulle@orange-ftgroup.com,
Une méthode de classification supervisée sans paramètre pour l apprentissage sur les grandes bases de données Marc Boullé Orange Labs 2 avenue Pierre Marzin 22300 Lannion marc.boulle@orange-ftgroup.com,
Techniques du Data Mining pour la prédiction de faillite des entreprises et la gestion du risque de crédit
 Techniques du Data Mining pour la prédiction de faillite des entreprises et la gestion du risque de crédit Adil Belhouari HEC - Montréal - Journées de l Optimisation 2005-09 Mai 2005 PLAN DE LA PRÉSENTATION
Techniques du Data Mining pour la prédiction de faillite des entreprises et la gestion du risque de crédit Adil Belhouari HEC - Montréal - Journées de l Optimisation 2005-09 Mai 2005 PLAN DE LA PRÉSENTATION
Fast and furious decision tree induction
 Institut National des Sciences Appliquées de Rennes Rapport de pré-étude Encadrants : Nikolaos Parlavantzas - Christian Raymond Fast and furious decision tree induction Andra Blaj Nicolas Desfeux Emeline
Institut National des Sciences Appliquées de Rennes Rapport de pré-étude Encadrants : Nikolaos Parlavantzas - Christian Raymond Fast and furious decision tree induction Andra Blaj Nicolas Desfeux Emeline
Projet SINF2275 «Data mining and decision making» Projet classification et credit scoring
 Projet SINF2275 «Data mining and decision making» Projet classification et credit scoring Année académique 2006-2007 Professeurs : Marco Saerens Adresse : Université catholique de Louvain Information Systems
Projet SINF2275 «Data mining and decision making» Projet classification et credit scoring Année académique 2006-2007 Professeurs : Marco Saerens Adresse : Université catholique de Louvain Information Systems
Pourquoi l apprentissage?
 Pourquoi l apprentissage? Les SE sont basés sur la possibilité d extraire la connaissance d un expert sous forme de règles. Dépend fortement de la capacité à extraire et formaliser ces connaissances. Apprentissage
Pourquoi l apprentissage? Les SE sont basés sur la possibilité d extraire la connaissance d un expert sous forme de règles. Dépend fortement de la capacité à extraire et formaliser ces connaissances. Apprentissage
L'intelligence d'affaires: la statistique dans nos vies de consommateurs
 L'intelligence d'affaires: la statistique dans nos vies de consommateurs Jean-François Plante, HEC Montréal Marc Fredette, HEC Montréal Congrès de l ACFAS, Université Laval, 6 mai 2013 Intelligence d affaires
L'intelligence d'affaires: la statistique dans nos vies de consommateurs Jean-François Plante, HEC Montréal Marc Fredette, HEC Montréal Congrès de l ACFAS, Université Laval, 6 mai 2013 Intelligence d affaires
Organisé par StatSoft France et animé par Dr Diego Kuonen, expert en techniques de data mining.
 2 jours : Mardi 15 et mercredi 16 novembre 2005 de 9 heures 30 à 17 heures 30 Organisé par StatSoft France et animé par Dr Diego Kuonen, expert en techniques de data mining. Madame, Monsieur, On parle
2 jours : Mardi 15 et mercredi 16 novembre 2005 de 9 heures 30 à 17 heures 30 Organisé par StatSoft France et animé par Dr Diego Kuonen, expert en techniques de data mining. Madame, Monsieur, On parle
Les algorithmes de fouille de données
 Février 2005 Les algorithmes de fouille de données DATAMINING Techniques appliquées à la vente, aux services client, interdictions. Cycle C Informatique Remerciements Je remercie les personnes, les universités
Février 2005 Les algorithmes de fouille de données DATAMINING Techniques appliquées à la vente, aux services client, interdictions. Cycle C Informatique Remerciements Je remercie les personnes, les universités
Big Data et Graphes : Quelques pistes de recherche
 Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci http://liris.cnrs.fr/hamamache.kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de
Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci http://liris.cnrs.fr/hamamache.kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de
Arbres de Décision. 1 Introduction
 Arbres de Décision Ricco RAKOTOMALALA Laboratoire ERIC Université Lumière Lyon 2 5, av. Mendés France 69676 BRON cedex e-mail : rakotoma@univ-lyon2.fr Résumé Après avoir détaillé les points clés de la
Arbres de Décision Ricco RAKOTOMALALA Laboratoire ERIC Université Lumière Lyon 2 5, av. Mendés France 69676 BRON cedex e-mail : rakotoma@univ-lyon2.fr Résumé Après avoir détaillé les points clés de la
La classification automatique de données quantitatives
 La classification automatique de données quantitatives 1 Introduction Parmi les méthodes de statistique exploratoire multidimensionnelle, dont l objectif est d extraire d une masse de données des informations
La classification automatique de données quantitatives 1 Introduction Parmi les méthodes de statistique exploratoire multidimensionnelle, dont l objectif est d extraire d une masse de données des informations
Apprentissage incrémental par sélection de données dans un flux pour une application de sécurité routière
 Apprentissage incrémental par sélection de données dans un flux pour une application de sécurité routière Nicolas Saunier INRETS Télécom Paris Sophie Midenet INRETS Alain Grumbach Télécom Paris Conférence
Apprentissage incrémental par sélection de données dans un flux pour une application de sécurité routière Nicolas Saunier INRETS Télécom Paris Sophie Midenet INRETS Alain Grumbach Télécom Paris Conférence
Big Data et Graphes : Quelques pistes de recherche
 Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de Lyon/Université Claude Bernard Lyon 1/Université
Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de Lyon/Université Claude Bernard Lyon 1/Université
Déroulement d un projet en DATA MINING, préparation et analyse des données. Walid AYADI
 1 Déroulement d un projet en DATA MINING, préparation et analyse des données Walid AYADI 2 Les étapes d un projet Choix du sujet - Définition des objectifs Inventaire des données existantes Collecte, nettoyage
1 Déroulement d un projet en DATA MINING, préparation et analyse des données Walid AYADI 2 Les étapes d un projet Choix du sujet - Définition des objectifs Inventaire des données existantes Collecte, nettoyage
INTRODUCTION AU DATA MINING
 INTRODUCTION AU DATA MINING 6 séances de 3 heures mai-juin 2006 EPF - 4 ème année - Option Ingénierie d Affaires et de Projets Bertrand LIAUDET TP DE DATA MINING Le TP et le projet consisteront à mettre
INTRODUCTION AU DATA MINING 6 séances de 3 heures mai-juin 2006 EPF - 4 ème année - Option Ingénierie d Affaires et de Projets Bertrand LIAUDET TP DE DATA MINING Le TP et le projet consisteront à mettre
Introduction au datamining
 Introduction au datamining Patrick Naïm janvier 2005 Définition Définition Historique Mot utilisé au départ par les statisticiens Le mot indiquait une utilisation intensive des données conduisant à des
Introduction au datamining Patrick Naïm janvier 2005 Définition Définition Historique Mot utilisé au départ par les statisticiens Le mot indiquait une utilisation intensive des données conduisant à des
LOGO. Module «Big Data» Extraction de Connaissances à partir de Données. Claudia MARINICA MCF, ETIS UCP/ENSEA/CNRS Claudia.Marinica@u-cergy.
 Module «Big Data» Extraction de Connaissances à partir de Données Claudia MARINICA MCF, ETIS UCP/ENSEA/CNRS Claudia.Marinica@u-cergy.fr 14 Janvier 2015 Pourquoi l extraction de connaissances à partir de
Module «Big Data» Extraction de Connaissances à partir de Données Claudia MARINICA MCF, ETIS UCP/ENSEA/CNRS Claudia.Marinica@u-cergy.fr 14 Janvier 2015 Pourquoi l extraction de connaissances à partir de
Data Mining. Bibliographie (1) Sites (1) Bibliographie (2) Plan du cours. Sites (2) Master 2 Informatique UAG
 Sites (1) Bibliographie (2) Plan du cours. Sites (2) Master 2 Informatique UAG") Data Mining Master 2 Informatique UAG Bibliographie (1) U. Fayyad, G. Piatetsky-Shapiro, P. Smyth, R. Uthurusamy, editors, Advances in Knowledge Discovery and Data Mining, AAAI/MIT Press, 1996 Gilbert
Data Mining Master 2 Informatique UAG Bibliographie (1) U. Fayyad, G. Piatetsky-Shapiro, P. Smyth, R. Uthurusamy, editors, Advances in Knowledge Discovery and Data Mining, AAAI/MIT Press, 1996 Gilbert
données en connaissance et en actions?
 1 Partie 2 : Présentation de la plateforme SPSS Modeler : Comment transformer vos données en connaissance et en actions? SPSS Modeler : l atelier de data mining Large gamme de techniques d analyse (algorithmes)
1 Partie 2 : Présentation de la plateforme SPSS Modeler : Comment transformer vos données en connaissance et en actions? SPSS Modeler : l atelier de data mining Large gamme de techniques d analyse (algorithmes)
Travaux pratiques avec RapidMiner
 Travaux pratiques avec RapidMiner Master Informatique de Paris 6 Spécialité IAD Parcours EDOW Module Algorithmes pour la Fouille de Données Janvier 2012 Prise en main Généralités RapidMiner est un logiciel
Travaux pratiques avec RapidMiner Master Informatique de Paris 6 Spécialité IAD Parcours EDOW Module Algorithmes pour la Fouille de Données Janvier 2012 Prise en main Généralités RapidMiner est un logiciel
Apprentissage. Intelligence Artificielle NFP106 Année 2012-2013. Plan. Apprentissage. Apprentissage
 Intelligence Artificielle NFP106 Année 2012-2013 Apprentissage! F.-Y. Villemin! Plan! Apprentissage! Induction! Règles d'inférence inductive! Apprentissage de concepts!! Arbres de décision! ID3! Analogie
Intelligence Artificielle NFP106 Année 2012-2013 Apprentissage! F.-Y. Villemin! Plan! Apprentissage! Induction! Règles d'inférence inductive! Apprentissage de concepts!! Arbres de décision! ID3! Analogie
Cours de Master Recherche
 Cours de Master Recherche Spécialité CODE : Résolution de problèmes combinatoires Christine Solnon LIRIS, UMR 5205 CNRS / Université Lyon 1 2007 Rappel du plan du cours 16 heures de cours 1 - Introduction
Cours de Master Recherche Spécialité CODE : Résolution de problèmes combinatoires Christine Solnon LIRIS, UMR 5205 CNRS / Université Lyon 1 2007 Rappel du plan du cours 16 heures de cours 1 - Introduction
Introduction. Informatique décisionnelle et data mining. Data mining (fouille de données) Cours/TP partagés. Information du cours
 Cours/TP partagés. Information du cours") Information du cours Informatique décisionnelle et data mining www.lia.univ-avignon.fr/chercheurs/torres/cours/dm Juan-Manuel Torres juan-manuel.torres@univ-avignon.fr LIA/Université d Avignon Cours/TP
Information du cours Informatique décisionnelle et data mining www.lia.univ-avignon.fr/chercheurs/torres/cours/dm Juan-Manuel Torres juan-manuel.torres@univ-avignon.fr LIA/Université d Avignon Cours/TP
Grandes lignes ASTRÉE. Logiciels critiques. Outils de certification classiques. Inspection manuelle. Definition. Test
 Grandes lignes Analyseur Statique de logiciels Temps RÉel Embarqués École Polytechnique École Normale Supérieure Mercredi 18 juillet 2005 1 Présentation d 2 Cadre théorique de l interprétation abstraite
Grandes lignes Analyseur Statique de logiciels Temps RÉel Embarqués École Polytechnique École Normale Supérieure Mercredi 18 juillet 2005 1 Présentation d 2 Cadre théorique de l interprétation abstraite
Spécificités, Applications et Outils
 Spécificités, Applications et Outils Ricco Rakotomalala Université Lumière Lyon 2 Laboratoire ERIC Laboratoire ERIC 1 Ricco Rakotomalala ricco.rakotomalala@univ-lyon2.fr http://chirouble.univ-lyon2.fr/~ricco/data-mining
Spécificités, Applications et Outils Ricco Rakotomalala Université Lumière Lyon 2 Laboratoire ERIC Laboratoire ERIC 1 Ricco Rakotomalala ricco.rakotomalala@univ-lyon2.fr http://chirouble.univ-lyon2.fr/~ricco/data-mining
$SSOLFDWLRQGXNULJHDJHSRXUOD FDOLEUDWLRQPRWHXU
 $SSOLFDWLRQGXNULJHDJHSRXUOD FDOLEUDWLRQPRWHXU Fabien FIGUERES fabien.figueres@mpsa.com 0RWVFOpV : Krigeage, plans d expériences space-filling, points de validations, calibration moteur. 5pVXPp Dans le
$SSOLFDWLRQGXNULJHDJHSRXUOD FDOLEUDWLRQPRWHXU Fabien FIGUERES fabien.figueres@mpsa.com 0RWVFOpV : Krigeage, plans d expériences space-filling, points de validations, calibration moteur. 5pVXPp Dans le
Resolution limit in community detection
 Introduction Plan 2006 Introduction Plan Introduction Introduction Plan Introduction Point de départ : un graphe et des sous-graphes. But : quantifier le fait que les sous-graphes choisis sont des modules.
Introduction Plan 2006 Introduction Plan Introduction Introduction Plan Introduction Point de départ : un graphe et des sous-graphes. But : quantifier le fait que les sous-graphes choisis sont des modules.
Le Data Mining au service du Scoring ou notation statistique des emprunteurs!
 France Le Data Mining au service du Scoring ou notation statistique des emprunteurs! Comme le rappelle la CNIL dans sa délibération n 88-083 du 5 Juillet 1988 portant adoption d une recommandation relative
France Le Data Mining au service du Scoring ou notation statistique des emprunteurs! Comme le rappelle la CNIL dans sa délibération n 88-083 du 5 Juillet 1988 portant adoption d une recommandation relative
Apprentissage statistique dans les graphes et les réseaux sociaux
 Apprentissage statistique dans les graphes et les réseaux sociaux Patrick Gallinari Collaboration : L. Denoyer, S. Peters Université Pierre et Marie Curie AAFD 2010 1 Plan Motivations et Problématique
Apprentissage statistique dans les graphes et les réseaux sociaux Patrick Gallinari Collaboration : L. Denoyer, S. Peters Université Pierre et Marie Curie AAFD 2010 1 Plan Motivations et Problématique
Why Software Projects Escalate: The Importance of Project Management Constructs
 Why Software Projects Escalate: The Importance of Project Management Constructs Why Software Projects Escalate: The Importance of Project Management Constructs 1. Introduction 2. Concepts de la gestion
Why Software Projects Escalate: The Importance of Project Management Constructs Why Software Projects Escalate: The Importance of Project Management Constructs 1. Introduction 2. Concepts de la gestion
Introduction aux outils BI de SQL Server 2014. Fouille de données avec SQL Server Analysis Services (SSAS)
") MIT820: Entrepôts de données et intelligence artificielle Introduction aux outils BI de SQL Server 2014 Fouille de données avec SQL Server Analysis Services (SSAS) Description générale Ce tutoriel a pour
MIT820: Entrepôts de données et intelligence artificielle Introduction aux outils BI de SQL Server 2014 Fouille de données avec SQL Server Analysis Services (SSAS) Description générale Ce tutoriel a pour
LES OUTILS D ALIMENTATION DU REFERENTIEL DE DB-MAIN
 LES OUTILS D ALIMENTATION DU REFERENTIEL DE DB-MAIN Les contenues de ce document sont la propriété exclusive de la société REVER. Ils ne sont transmis qu à titre d information et ne peuvent en aucun cas
LES OUTILS D ALIMENTATION DU REFERENTIEL DE DB-MAIN Les contenues de ce document sont la propriété exclusive de la société REVER. Ils ne sont transmis qu à titre d information et ne peuvent en aucun cas
BI = Business Intelligence Master Data-Science
 BI = Business Intelligence Master Data-Science UPMC 25 janvier 2015 Organisation Horaire Cours : Lundi de 13h30 à 15h30 TP : Vendredi de 13h30 à 17h45 Intervenants : Divers industriels (en cours de construction)
BI = Business Intelligence Master Data-Science UPMC 25 janvier 2015 Organisation Horaire Cours : Lundi de 13h30 à 15h30 TP : Vendredi de 13h30 à 17h45 Intervenants : Divers industriels (en cours de construction)
Introduction à l Informatique Décisionnelle - Business Intelligence (7)
") Introduction à l Informatique Décisionnelle - Business Intelligence (7) Bernard ESPINASSE Professeur à Aix-Marseille Université (AMU) Ecole Polytechnique Universitaire de Marseille Septembre 2013 Emergence
Introduction à l Informatique Décisionnelle - Business Intelligence (7) Bernard ESPINASSE Professeur à Aix-Marseille Université (AMU) Ecole Polytechnique Universitaire de Marseille Septembre 2013 Emergence
Entrepôt de données 1. Introduction
 Entrepôt de données 1 (data warehouse) Introduction 1 Présentation Le concept d entrepôt de données a été formalisé pour la première fois en 1990 par Bill Inmon. Il s agissait de constituer une base de
Entrepôt de données 1 (data warehouse) Introduction 1 Présentation Le concept d entrepôt de données a été formalisé pour la première fois en 1990 par Bill Inmon. Il s agissait de constituer une base de
Apprentissage Automatique
 Apprentissage Automatique Introduction-I jean-francois.bonastre@univ-avignon.fr www.lia.univ-avignon.fr Définition? (Wikipedia) L'apprentissage automatique (machine-learning en anglais) est un des champs
Apprentissage Automatique Introduction-I jean-francois.bonastre@univ-avignon.fr www.lia.univ-avignon.fr Définition? (Wikipedia) L'apprentissage automatique (machine-learning en anglais) est un des champs
Application de K-means à la définition du nombre de VM optimal dans un cloud
 Application de K-means à la définition du nombre de VM optimal dans un cloud EGC 2012 : Atelier Fouille de données complexes : complexité liée aux données multiples et massives (31 janvier - 3 février
Application de K-means à la définition du nombre de VM optimal dans un cloud EGC 2012 : Atelier Fouille de données complexes : complexité liée aux données multiples et massives (31 janvier - 3 février
chapitre 4 Nombres de Catalan
 chapitre 4 Nombres de Catalan I Dénitions Dénition 1 La suite de Catalan (C n ) n est la suite dénie par C 0 = 1 et, pour tout n N, C n+1 = C k C n k. Exemple 2 On trouve rapidement C 0 = 1, C 1 = 1, C
chapitre 4 Nombres de Catalan I Dénitions Dénition 1 La suite de Catalan (C n ) n est la suite dénie par C 0 = 1 et, pour tout n N, C n+1 = C k C n k. Exemple 2 On trouve rapidement C 0 = 1, C 1 = 1, C
Data 2 Business : La démarche de valorisation de la Data pour améliorer la performance de ses clients
 Data 2 Business : La démarche de valorisation de la Data pour améliorer la performance de ses clients Frédérick Vautrain, Dir. Data Science - Viseo Laurent Lefranc, Resp. Data Science Analytics - Altares
Data 2 Business : La démarche de valorisation de la Data pour améliorer la performance de ses clients Frédérick Vautrain, Dir. Data Science - Viseo Laurent Lefranc, Resp. Data Science Analytics - Altares
Intelligence Economique - Business Intelligence
 Intelligence Economique - Business Intelligence Notion de Business Intelligence Dès qu'il y a une entreprise, il y a implicitement intelligence économique (tout comme il y a du marketing) : quelle produit
Intelligence Economique - Business Intelligence Notion de Business Intelligence Dès qu'il y a une entreprise, il y a implicitement intelligence économique (tout comme il y a du marketing) : quelle produit
Conception d une Plateforme Open Source d Extraction et de Gestion des Connaissances
 Département d Informatique MEMOIRE Présenté par : KADEM Habib Pour obtenir LE DIPLOME DE MAGISTER Spécialité : Informatique Option : Informatique & Automatique Intitulé : Conception d une Plateforme Open
Département d Informatique MEMOIRE Présenté par : KADEM Habib Pour obtenir LE DIPLOME DE MAGISTER Spécialité : Informatique Option : Informatique & Automatique Intitulé : Conception d une Plateforme Open
Introduction à MapReduce/Hadoop et Spark
 1 / 36 Introduction à MapReduce/Hadoop et Spark Certificat Big Data Ludovic Denoyer et Sylvain Lamprier UPMC Plan 2 / 36 Contexte 3 / 36 Contexte 4 / 36 Data driven science: le 4e paradigme (Jim Gray -
1 / 36 Introduction à MapReduce/Hadoop et Spark Certificat Big Data Ludovic Denoyer et Sylvain Lamprier UPMC Plan 2 / 36 Contexte 3 / 36 Contexte 4 / 36 Data driven science: le 4e paradigme (Jim Gray -
DATAMINING C4.5 - DBSCAN
 14-16 rue Voltaire 94270 Kremlin Bicêtre Benjamin DEVÈZE Matthieu FOUQUIN PROMOTION 2005 SCIA DATAMINING C4.5 - DBSCAN Mai 2004 Responsable de spécialité SCIA : M. Akli Adjaoute Table des matières Table
14-16 rue Voltaire 94270 Kremlin Bicêtre Benjamin DEVÈZE Matthieu FOUQUIN PROMOTION 2005 SCIA DATAMINING C4.5 - DBSCAN Mai 2004 Responsable de spécialité SCIA : M. Akli Adjaoute Table des matières Table
Travaux pratiques. Compression en codage de Huffman. 1.3. Organisation d un projet de programmation
 Université de Savoie Module ETRS711 Travaux pratiques Compression en codage de Huffman 1. Organisation du projet 1.1. Objectifs Le but de ce projet est d'écrire un programme permettant de compresser des
Université de Savoie Module ETRS711 Travaux pratiques Compression en codage de Huffman 1. Organisation du projet 1.1. Objectifs Le but de ce projet est d'écrire un programme permettant de compresser des
BI = Business Intelligence Master Data-ScienceCours 2 - ETL
 BI = Business Intelligence Master Data-Science Cours 2 - ETL UPMC 1 er février 2015 Rappel L Informatique Décisionnelle (ID), en anglais Business Intelligence (BI), est l informatique à l usage des décideurs
BI = Business Intelligence Master Data-Science Cours 2 - ETL UPMC 1 er février 2015 Rappel L Informatique Décisionnelle (ID), en anglais Business Intelligence (BI), est l informatique à l usage des décideurs
Études des principaux algorithmes de data mining
 Études des principaux algorithmes de data mining Guillaume CALAS guillaume.calas@gmail.com Spécialisation Sciences Cognitives et Informatique Avancée 14-16 rue Voltaire, 94270 Le Kremlin-Bicêtre, France
Études des principaux algorithmes de data mining Guillaume CALAS guillaume.calas@gmail.com Spécialisation Sciences Cognitives et Informatique Avancée 14-16 rue Voltaire, 94270 Le Kremlin-Bicêtre, France
BIG DATA en Sciences et Industries de l Environnement
 BIG DATA en Sciences et Industries de l Environnement François Royer www.datasio.com 21 mars 2012 FR Big Data Congress, Paris 2012 1/23 Transport terrestre Traçabilité Océanographie Transport aérien Télémétrie
BIG DATA en Sciences et Industries de l Environnement François Royer www.datasio.com 21 mars 2012 FR Big Data Congress, Paris 2012 1/23 Transport terrestre Traçabilité Océanographie Transport aérien Télémétrie
République Algérienne Démocratique et Populaire
 République Algérienne Démocratique et Populaire وزارة التعليم العالي والبحث العلمي Ministère de l Enseignement Supérieur et de la Recherche Scientifique UNIVERSITE DES SCIENCES ET DE LA TECHNOLOGIE d ORAN
République Algérienne Démocratique et Populaire وزارة التعليم العالي والبحث العلمي Ministère de l Enseignement Supérieur et de la Recherche Scientifique UNIVERSITE DES SCIENCES ET DE LA TECHNOLOGIE d ORAN
ESIEA PARIS 2011-2012
 ESIEA PARIS 2011-2012 Examen MAT 5201 DATA MINING Mardi 08 Novembre 2011 Première Partie : 15 minutes (7 points) Enseignant responsable : Frédéric Bertrand Remarque importante : les questions de ce questionnaire
ESIEA PARIS 2011-2012 Examen MAT 5201 DATA MINING Mardi 08 Novembre 2011 Première Partie : 15 minutes (7 points) Enseignant responsable : Frédéric Bertrand Remarque importante : les questions de ce questionnaire
Formats d images. 1 Introduction
 Formats d images 1 Introduction Lorsque nous utilisons un ordinateur ou un smartphone l écran constitue un élément principal de l interaction avec la machine. Les images sont donc au cœur de l utilisation
Formats d images 1 Introduction Lorsque nous utilisons un ordinateur ou un smartphone l écran constitue un élément principal de l interaction avec la machine. Les images sont donc au cœur de l utilisation
Travailler avec les télécommunications
 Travailler avec les télécommunications Minimiser l attrition dans le secteur des télécommunications Table des matières : 1 Analyse de l attrition à l aide du data mining 2 Analyse de l attrition de la
Travailler avec les télécommunications Minimiser l attrition dans le secteur des télécommunications Table des matières : 1 Analyse de l attrition à l aide du data mining 2 Analyse de l attrition de la
Les participants repartiront de cette formation en ayant une vision claire de la stratégie et de l éventuelle mise en œuvre d un Big Data.
 Big Data De la stratégie à la mise en oeuvre Description : La formation a pour objet de brosser sans concession le tableau du Big Data. Les participants repartiront de cette formation en ayant une vision
Big Data De la stratégie à la mise en oeuvre Description : La formation a pour objet de brosser sans concession le tableau du Big Data. Les participants repartiront de cette formation en ayant une vision
TRS: Sélection des sous-graphes représentants par l intermédiaire des attributs topologiques et K-medoïdes
 TRS: Sélection des sous-graphes représentants par l intermédiaire des attributs topologiques et K-medoïdes Mohamed Moussaoui,Wajdi Dhifli,Sami Zghal,Engelbert Mephu Nguifo FSJEG, Université de Jendouba,
TRS: Sélection des sous-graphes représentants par l intermédiaire des attributs topologiques et K-medoïdes Mohamed Moussaoui,Wajdi Dhifli,Sami Zghal,Engelbert Mephu Nguifo FSJEG, Université de Jendouba,
AICp. Vincent Vandewalle. To cite this version: HAL Id: inria-00386678 https://hal.inria.fr/inria-00386678
 Sélection prédictive d un modèle génératif par le critère AICp Vincent Vandewalle To cite this version: Vincent Vandewalle. Sélection prédictive d un modèle génératif par le critère AICp. 41èmes Journées
Sélection prédictive d un modèle génératif par le critère AICp Vincent Vandewalle To cite this version: Vincent Vandewalle. Sélection prédictive d un modèle génératif par le critère AICp. 41èmes Journées
Data Mining. Master 1 Informatique - Mathématiques UAG
 Data Mining Master 1 Informatique - Mathématiques UAG 1.1 - Introduction Data Mining? On parle de Fouille de données Data Mining Extraction de connaissances à partir de données Knowledge Discovery in Data
Data Mining Master 1 Informatique - Mathématiques UAG 1.1 - Introduction Data Mining? On parle de Fouille de données Data Mining Extraction de connaissances à partir de données Knowledge Discovery in Data
Linked Open Data. Le Web de données Réseau, usages, perspectives. Eric Charton. Eric Charton
 Linked Open Data Le Web de données Réseau, usages, perspectives Sommaire Histoire du Linked Open Data Structure et évolution du réseau Utilisations du Linked Open Data Présence sur le réseau LOD Futurs
Linked Open Data Le Web de données Réseau, usages, perspectives Sommaire Histoire du Linked Open Data Structure et évolution du réseau Utilisations du Linked Open Data Présence sur le réseau LOD Futurs
Traitement et exploration du fichier Log du Serveur Web, pour l extraction des connaissances: Web Usage Mining
 Traitement et exploration du fichier Log du Serveur Web, pour l extraction des connaissances: Web Usage Mining Mostafa HANOUNE*, Fouzia BENABBOU* *Université Hassan II- Mohammedia, Faculté des sciences
Traitement et exploration du fichier Log du Serveur Web, pour l extraction des connaissances: Web Usage Mining Mostafa HANOUNE*, Fouzia BENABBOU* *Université Hassan II- Mohammedia, Faculté des sciences
ANGULAR JS AVEC GDE GOOGLE
 ANGULAR JS AVEC GDE GOOGLE JUIN 2015 BRINGING THE HUMAN TOUCH TO TECHNOLOGY 2015 SERIAL QUI SUIS-JE? ESTELLE USER EXPERIENCE DESIGNER BUSINESS ANALYST BRINGING THE HUMAN TOUCH TO TECHNOLOGY SERIAL.CH 2
ANGULAR JS AVEC GDE GOOGLE JUIN 2015 BRINGING THE HUMAN TOUCH TO TECHNOLOGY 2015 SERIAL QUI SUIS-JE? ESTELLE USER EXPERIENCE DESIGNER BUSINESS ANALYST BRINGING THE HUMAN TOUCH TO TECHNOLOGY SERIAL.CH 2
Apprentissage par renforcement (1a/3)
") Apprentissage par renforcement (1a/3) Bruno Bouzy 23 septembre 2014 Ce document est le chapitre «Apprentissage par renforcement» du cours d apprentissage automatique donné aux étudiants de Master MI, parcours
Apprentissage par renforcement (1a/3) Bruno Bouzy 23 septembre 2014 Ce document est le chapitre «Apprentissage par renforcement» du cours d apprentissage automatique donné aux étudiants de Master MI, parcours
Plan 1/9/2013. Génération et exploitation de données. CEP et applications. Flux de données et notifications. Traitement des flux Implémentation
 Complex Event Processing Traitement de flux de données en temps réel Romain Colle R&D Project Manager Quartet FS Plan Génération et exploitation de données CEP et applications Flux de données et notifications
Complex Event Processing Traitement de flux de données en temps réel Romain Colle R&D Project Manager Quartet FS Plan Génération et exploitation de données CEP et applications Flux de données et notifications
Le data mining et l assurance Mai 2004. Charles Dugas Président Marianne Lalonde Directrice, développement des affaires
 Le data mining et l assurance Mai 2004 Charles Dugas Président Marianne Lalonde Directrice, développement des affaires AGENDA Qu est-ce que le data mining? Le projet et les facteurs de réussite Les technologies
Le data mining et l assurance Mai 2004 Charles Dugas Président Marianne Lalonde Directrice, développement des affaires AGENDA Qu est-ce que le data mining? Le projet et les facteurs de réussite Les technologies
1 Modélisation d être mauvais payeur
 1 Modélisation d être mauvais payeur 1.1 Description Cet exercice est très largement inspiré d un document que M. Grégoire de Lassence de la société SAS m a transmis. Il est intitulé Guide de démarrage
1 Modélisation d être mauvais payeur 1.1 Description Cet exercice est très largement inspiré d un document que M. Grégoire de Lassence de la société SAS m a transmis. Il est intitulé Guide de démarrage
Agenda de la présentation
 Le Data Mining Techniques pour exploiter l information Dan Noël 1 Agenda de la présentation Concept de Data Mining ou qu est-ce que le Data Mining Déroulement d un projet de Data Mining Place du Data Mining
Le Data Mining Techniques pour exploiter l information Dan Noël 1 Agenda de la présentation Concept de Data Mining ou qu est-ce que le Data Mining Déroulement d un projet de Data Mining Place du Data Mining
SOCLE COMMUN - La Compétence 3 Les principaux éléments de mathématiques et la culture scientifique et technologique
 SOCLE COMMUN - La Compétence 3 Les principaux éléments de mathématiques et la culture scientifique et technologique DOMAINE P3.C3.D1. Pratiquer une démarche scientifique et technologique, résoudre des
SOCLE COMMUN - La Compétence 3 Les principaux éléments de mathématiques et la culture scientifique et technologique DOMAINE P3.C3.D1. Pratiquer une démarche scientifique et technologique, résoudre des
Data Mining et Statistique
 Data Mining et Statistique Philippe Besse, Caroline Le Gall, Nathalie Raimbault & Sophie Sarpy Résumé Cet article propose une introduction au Data Mining. Celle-ci prend la forme d une réflexion sur les
Data Mining et Statistique Philippe Besse, Caroline Le Gall, Nathalie Raimbault & Sophie Sarpy Résumé Cet article propose une introduction au Data Mining. Celle-ci prend la forme d une réflexion sur les
INF6304 Interfaces Intelligentes
 INF6304 Interfaces Intelligentes filtres collaboratifs 1/42 INF6304 Interfaces Intelligentes Systèmes de recommandations, Approches filtres collaboratifs Michel C. Desmarais Génie informatique et génie
INF6304 Interfaces Intelligentes filtres collaboratifs 1/42 INF6304 Interfaces Intelligentes Systèmes de recommandations, Approches filtres collaboratifs Michel C. Desmarais Génie informatique et génie
Coup de Projecteur sur les Réseaux de Neurones
 Coup de Projecteur sur les Réseaux de Neurones Les réseaux de neurones peuvent être utilisés pour des problèmes de prévision ou de classification. La représentation la plus populaire est le réseau multicouche
Coup de Projecteur sur les Réseaux de Neurones Les réseaux de neurones peuvent être utilisés pour des problèmes de prévision ou de classification. La représentation la plus populaire est le réseau multicouche
Les structures de données. Rajae El Ouazzani
 Les structures de données Rajae El Ouazzani Les arbres 2 1- Définition de l arborescence Une arborescence est une collection de nœuds reliés entre eux par des arcs. La collection peut être vide, cad l
Les structures de données Rajae El Ouazzani Les arbres 2 1- Définition de l arborescence Une arborescence est une collection de nœuds reliés entre eux par des arcs. La collection peut être vide, cad l
Filière Data Mining (Fouille de données) Pierre Morizet-Mahoudeaux
 Pierre Morizet-Mahoudeaux") Filière Data Mining (Fouille de données) Pierre Morizet-Mahoudeaux Plan Objectifs Débouchés Formation UVs spécifiques UVs connexes Enseignants et partenaires Structure générale des études à l UTC Règlement
Filière Data Mining (Fouille de données) Pierre Morizet-Mahoudeaux Plan Objectifs Débouchés Formation UVs spécifiques UVs connexes Enseignants et partenaires Structure générale des études à l UTC Règlement
Philippe BESSE*, Hélène MILHEM*, Olivier MESTRE*,**, Anne DUFOUR***, Vincent-Henri PEUCH*** Résumé
 Comparaison de techniques de «Data Mining» pour lʼadaptation statistique des prévisions dʼozone du modèle de chimie-transport MOCAGE A comparison of Data Mining techniques for the statistical adaptation
Comparaison de techniques de «Data Mining» pour lʼadaptation statistique des prévisions dʼozone du modèle de chimie-transport MOCAGE A comparison of Data Mining techniques for the statistical adaptation
Les algorithmes SLIQ et SSDM
 Les algorithmes SLIQ et SSDM Guillaume CALAS et Henri-François CHADEISSON guillaume.calas@gmail.com et chadei_h@epita.fr Spécialisation Sciences Cognitives et Informatique Avancée 14-16 rue Voltaire, 94270
Les algorithmes SLIQ et SSDM Guillaume CALAS et Henri-François CHADEISSON guillaume.calas@gmail.com et chadei_h@epita.fr Spécialisation Sciences Cognitives et Informatique Avancée 14-16 rue Voltaire, 94270
EXPLORATION DES BASES DE DONNÉES INDUSTRIELLES À L AIDE DU DATA MINING PERSPECTIVES
 EXPLORATION DES BASES DE DONNÉES INDUSTRIELLES À L AIDE DU DATA MINING PERSPECTIVES Bruno Agard (1), Andrew Kusiak (2) (1) Département de Mathématiques et de Génie Industriel, École Polytechnique de Montréal,
EXPLORATION DES BASES DE DONNÉES INDUSTRIELLES À L AIDE DU DATA MINING PERSPECTIVES Bruno Agard (1), Andrew Kusiak (2) (1) Département de Mathématiques et de Génie Industriel, École Polytechnique de Montréal,
Spécifications, Développement et Promotion. Ricco RAKOTOMALALA Université Lumière Lyon 2 Laboratoire ERIC
 Spécifications, Développement et Promotion Ricco RAKOTOMALALA Université Lumière Lyon 2 Laboratoire ERIC Ricco? Enseignant chercheur (CNU.27) En poste à l Université Lyon 2 Faculté de Sciences Eco. Recherche
Spécifications, Développement et Promotion Ricco RAKOTOMALALA Université Lumière Lyon 2 Laboratoire ERIC Ricco? Enseignant chercheur (CNU.27) En poste à l Université Lyon 2 Faculté de Sciences Eco. Recherche
Big data et données géospatiales : Enjeux et défis pour la géomatique. Thierry Badard, PhD, ing. jr Centre de Recherche en Géomatique
 Big data et données géospatiales : Enjeux et défis pour la géomatique Thierry Badard, PhD, ing. jr Centre de Recherche en Géomatique Événement 25e anniversaire du CRG Université Laval, Qc, Canada 08 mai
Big data et données géospatiales : Enjeux et défis pour la géomatique Thierry Badard, PhD, ing. jr Centre de Recherche en Géomatique Événement 25e anniversaire du CRG Université Laval, Qc, Canada 08 mai
Économétrie, causalité et analyse des politiques
 Économétrie, causalité et analyse des politiques Jean-Marie Dufour Université de Montréal October 2006 This work was supported by the Canada Research Chair Program (Chair in Econometrics, Université de
Économétrie, causalité et analyse des politiques Jean-Marie Dufour Université de Montréal October 2006 This work was supported by the Canada Research Chair Program (Chair in Econometrics, Université de
Jade. Projet Intelligence Artificielle «Devine à quoi je pense»
 Jade Projet Intelligence Artificielle «Devine à quoi je pense» Réalisé par Djénéba Djikiné, Alexandre Bernard et Julien Lafont EPSI CSII2-2011 TABLE DES MATIÈRES 1. Analyse du besoin a. Cahier des charges
Jade Projet Intelligence Artificielle «Devine à quoi je pense» Réalisé par Djénéba Djikiné, Alexandre Bernard et Julien Lafont EPSI CSII2-2011 TABLE DES MATIÈRES 1. Analyse du besoin a. Cahier des charges
Deuxième Licence en Informatique Data Warehousing et Data Mining La Classification - 1
 Deuxième Licence en Informatique Data Warehousing et Data Mining La Classification - 1 V. Fiolet Université de Mons-Hainaut 2006-2007 Nous allons aujourd hui nous intéresser à la tâche de classification
Deuxième Licence en Informatique Data Warehousing et Data Mining La Classification - 1 V. Fiolet Université de Mons-Hainaut 2006-2007 Nous allons aujourd hui nous intéresser à la tâche de classification
EXTRACTION DE CONNAISSANCES À PARTIR DE DONNÉES TEXTUELLES VUE D ENSEMBLE
 ème Colloque National AIP PRIMECA La Plagne - 7- avril 7 EXTRACTION DE CONNAISSANCES À PARTIR DE DONNÉES TEXTUELLES VUE D ENSEMBLE Bruno Agard Département de Mathématiques et de Génie Industriel, École
ème Colloque National AIP PRIMECA La Plagne - 7- avril 7 EXTRACTION DE CONNAISSANCES À PARTIR DE DONNÉES TEXTUELLES VUE D ENSEMBLE Bruno Agard Département de Mathématiques et de Génie Industriel, École
LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING»
 LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING» Gilbert Saporta Professeur de Statistique Appliquée Conservatoire National des Arts et Métiers Dans leur quasi totalité, les banques et organismes financiers
LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING» Gilbert Saporta Professeur de Statistique Appliquée Conservatoire National des Arts et Métiers Dans leur quasi totalité, les banques et organismes financiers
Prétraitement Supervisé des Variables Numériques pour la Fouille de Données Multi-Tables
 Prétraitement Supervisé des Variables Numériques pour la Fouille de Données Multi-Tables Dhafer Lahbib, Marc Boullé, Dominique Laurent France Télécom R&D - 2, avenue Pierre Marzin, 23300 Lannion dhafer.lahbib@orange-ftgroup.com
Prétraitement Supervisé des Variables Numériques pour la Fouille de Données Multi-Tables Dhafer Lahbib, Marc Boullé, Dominique Laurent France Télécom R&D - 2, avenue Pierre Marzin, 23300 Lannion dhafer.lahbib@orange-ftgroup.com
Etude d Algorithmes Parallèles de Data Mining
 REPUBLIQUE TUNISIENNE MINISTERE DE L ENSEIGNEMENT SUPERIEUR, DE LA TECHNOLOGIE ET DE LA RECHERCHE SCIENTIFIQUE UNIVERSITE DE TUNIS ELMANAR FACULTE DES SCIENCES DE TUNIS DEPARTEMENT DES SCIENCES DE L INFORMATIQUE
REPUBLIQUE TUNISIENNE MINISTERE DE L ENSEIGNEMENT SUPERIEUR, DE LA TECHNOLOGIE ET DE LA RECHERCHE SCIENTIFIQUE UNIVERSITE DE TUNIS ELMANAR FACULTE DES SCIENCES DE TUNIS DEPARTEMENT DES SCIENCES DE L INFORMATIQUE
TANAGRA : un logiciel gratuit pour l enseignement et la recherche
 TANAGRA : un logiciel gratuit pour l enseignement et la recherche Ricco Rakotomalala ERIC Université Lumière Lyon 2 5, av Mendès France 69676 Bron rakotoma@univ-lyon2.fr http://eric.univ-lyon2.fr/~ricco
TANAGRA : un logiciel gratuit pour l enseignement et la recherche Ricco Rakotomalala ERIC Université Lumière Lyon 2 5, av Mendès France 69676 Bron rakotoma@univ-lyon2.fr http://eric.univ-lyon2.fr/~ricco
Apprentissage Statistique
 Apprentissage Statistique Master DAC - Université Paris 6, patrick.gallinari@lip6.fr, http://www-connex.lip6.fr/~gallinar/ Année 2014-2015 Partie 1 Introduction Apprentissage Automatique Problématique
Apprentissage Statistique Master DAC - Université Paris 6, patrick.gallinari@lip6.fr, http://www-connex.lip6.fr/~gallinar/ Année 2014-2015 Partie 1 Introduction Apprentissage Automatique Problématique
Accélérer l agilité de votre site de e-commerce. Cas client
 Accélérer l agilité de votre site de e-commerce Cas client L agilité «outillée» devient nécessaire au delà d un certain facteur de complexité (clients x produits) Elevé Nombre de produits vendus Faible
Accélérer l agilité de votre site de e-commerce Cas client L agilité «outillée» devient nécessaire au delà d un certain facteur de complexité (clients x produits) Elevé Nombre de produits vendus Faible
Playzilla - Chargement par clé usb
 Juillet 2011 Version 001A SOMMAIRE I. UTILISATION SIMPLE... 3 Pré-requis... 4 Unité de stockage USB... 4 Configuration de playzilla... 4 1. MISE A JOUR DU CONTENU A PARTIR DE SCREEN COMPOSER... 6 1.1.
Juillet 2011 Version 001A SOMMAIRE I. UTILISATION SIMPLE... 3 Pré-requis... 4 Unité de stockage USB... 4 Configuration de playzilla... 4 1. MISE A JOUR DU CONTENU A PARTIR DE SCREEN COMPOSER... 6 1.1.
Introduction Big Data
 Introduction Big Data SOMMAIRE Rédacteurs : Réf.: SH. Lazare / F. Barthélemy AXIO_BD_V1 QU'EST-CE QUE LE BIG DATA? ENJEUX TECHNOLOGIQUES ENJEUX STRATÉGIQUES BIG DATA ET RH ANNEXE Ce document constitue
Introduction Big Data SOMMAIRE Rédacteurs : Réf.: SH. Lazare / F. Barthélemy AXIO_BD_V1 QU'EST-CE QUE LE BIG DATA? ENJEUX TECHNOLOGIQUES ENJEUX STRATÉGIQUES BIG DATA ET RH ANNEXE Ce document constitue
Objectifs. Clustering. Principe. Applications. Applications. Cartes de crédits. Remarques. Biologie, Génomique
 Objectifs Clustering On ne sait pas ce qu on veut trouver : on laisse l algorithme nous proposer un modèle. On pense qu il existe des similarités entre les exemples. Qui se ressemble s assemble p. /55
Objectifs Clustering On ne sait pas ce qu on veut trouver : on laisse l algorithme nous proposer un modèle. On pense qu il existe des similarités entre les exemples. Qui se ressemble s assemble p. /55
Laboratoire 4 Développement d un système intelligent
 DÉPARTEMENT DE GÉNIE LOGICIEL ET DES TI LOG770 - SYSTÈMES INTELLIGENTS ÉTÉ 2012 Laboratoire 4 Développement d un système intelligent 1 Introduction Ce quatrième et dernier laboratoire porte sur le développement
DÉPARTEMENT DE GÉNIE LOGICIEL ET DES TI LOG770 - SYSTÈMES INTELLIGENTS ÉTÉ 2012 Laboratoire 4 Développement d un système intelligent 1 Introduction Ce quatrième et dernier laboratoire porte sur le développement
La rencontre du Big Data et du Cloud
 La rencontre du Big Data et du Cloud Libérez le potentiel de toutes vos données Visualisez et exploitez plus rapidement les données de tous types, quelle que soit leur taille et indépendamment de leur
La rencontre du Big Data et du Cloud Libérez le potentiel de toutes vos données Visualisez et exploitez plus rapidement les données de tous types, quelle que soit leur taille et indépendamment de leur
Intelligence Artificielle et Robotique
 Intelligence Artificielle et Robotique Introduction à l intelligence artificielle David Janiszek david.janiszek@parisdescartes.fr http://www.math-info.univ-paris5.fr/~janiszek/ PRES Sorbonne Paris Cité
Intelligence Artificielle et Robotique Introduction à l intelligence artificielle David Janiszek david.janiszek@parisdescartes.fr http://www.math-info.univ-paris5.fr/~janiszek/ PRES Sorbonne Paris Cité
IODAA. de l 1nf0rmation à la Décision par l Analyse et l Apprentissage / 21
 IODAA de l 1nf0rmation à la Décision par l Analyse et l Apprentissage IODAA Informations générales 2 Un monde nouveau Des données numériques partout en croissance prodigieuse Comment en extraire des connaissances
IODAA de l 1nf0rmation à la Décision par l Analyse et l Apprentissage IODAA Informations générales 2 Un monde nouveau Des données numériques partout en croissance prodigieuse Comment en extraire des connaissances
Structure du cours : Il existe de nombreuses méthodes intéressantes qui couvrent l Analyse des Données
 Structure du cours : Il existe de nombreuses méthodes intéressantes qui couvrent l Analyse des Données et le Data Mining Nous suivons le plan suivant : Fonctionnement de Spad Catalogue des méthodes (statistiques
Structure du cours : Il existe de nombreuses méthodes intéressantes qui couvrent l Analyse des Données et le Data Mining Nous suivons le plan suivant : Fonctionnement de Spad Catalogue des méthodes (statistiques
Entrepôts de Données
 République Tunisienne Ministère de l Enseignement Supérieur Institut Supérieur des Etudes Technologique de Kef Support de Cours Entrepôts de Données Mention : Technologies de l Informatique (TI) Parcours
République Tunisienne Ministère de l Enseignement Supérieur Institut Supérieur des Etudes Technologique de Kef Support de Cours Entrepôts de Données Mention : Technologies de l Informatique (TI) Parcours
Master d Informatique M1 Université Paris 7 - Denis Diderot Travail de Recherche Encadré Surf Bayesien
 Master d Informatique M1 Université Paris 7 - Denis Diderot Travail de Recherche Encadré Surf Bayesien Denis Cousineau Sous la direction de Roberto di Cosmo Juin 2005 1 Table des matières 1 Présentation
Master d Informatique M1 Université Paris 7 - Denis Diderot Travail de Recherche Encadré Surf Bayesien Denis Cousineau Sous la direction de Roberto di Cosmo Juin 2005 1 Table des matières 1 Présentation