Modèles de prévision Partie 2 - séries temporelles # 2
|
|
|
- Ariane Corriveau
- il y a 8 ans
- Total affichages :
Transcription
1 Modèles de prévision Partie 2 - séries temporelles # 2 Arthur Charpentier charpentier.arthur@uqam.ca http ://freakonometrics.blog.free.fr/ Été 2014

2 Plan du cours Motivation et introduction aux séries temporelles Méthodes de lissage Modèles de régression (Buys-Ballot) Lissage(s) exponentiel(s) (Holt-Winters) Notions générales sur les processus stationnaires Les processus SARIM A Les modèles autorégressifs, AR(p), Φ(L)X t = ε t Les modèles moyennes mobiles, MA(q) (moving average), X t = Θ(L)ε t Les modèles autorégtressifs et moyenne mobiles, ARM A(p, q), Φ(L)X t = Θ(L)ε t Les modèles autorégtressifs, ARIMA(p, d, q), (1 L) d Φ(L)X t = Θ(L)ε t Les modèles autorégtressifs, SARIM A(p, d, q), (1 L) d (1 L s )Φ(L)X t = Θ(L)ε t Prévision avec un SARIMA, T XT +h
, (1 L) d Φ(L)X t = Θ(L)ε t Les modèles autorégtressifs, SARIM A(p, d, q), (1 L) d (1 L s )Φ(L)X t = Θ(L)ε t Prévision")
3 Le modèle AR(p) - autorégressif à l ordre p On appelle processus autoregressif d ordre p, noté AR (p), un processus stationnaire (X t ) vérifiant une relation du type X t p φ i X t i = ε t pour tout t Z, (1) i=1 où les φ i sont des réels et (ε t ) est un bruit blanc de variance σ 2. (1) est équivalent à l écriture Φ (L) X t = ε t où Φ (L) = I φ 1 L... φ p L p Remarque : En toute généralité, supposons Φ (L) X t = µ + ε t. Il est possible de se ramener à un processus (1) centré par une simple translation : on pose Y t = X t m où m = µ/φ (1). En effet, Φ (L) m = Φ (1) m.
 centré par une simple translation : on pose Y t = X t m où m = µ/φ (1).")
4 Le modèle AR(p) - autorégressif à l ordre p Si Φ(L) = 1 (ϕ 1 L + + ϕ p L) et que z 1 Φ(z) 0 (les racines de Φ sont de module strictement supérieur à 1 ), (X t ) admet une représentation MA( ) i.e. X t = + k=0 a k ε t k où a 0 = 1, a k R, + k=0 a k < +. On sait que Φ(L)X t = ε t, donc X t = Φ(L) 1 (ε t ).
X t = ε t, donc X t = Φ(L) 1 (ε t ).")
5 Autocorrélations d un processus AR(p), h ρ(h) Le processus (X t ) s écrit X t = φ 1 X t 1 + φ 2 X t φ p X t p + ε t. (2) En multipliant par X t, on obtient Xt 2 = φ 1 X t 1 X t + φ 2 X t 2 X t φ p X t p X t + ε t X t = φ 1 X t 1 X t + φ 2 X t 2 X t φ p X t p X t +ε t (φ 1 X t 1 + φ 2 X t φ p X t p + ε t ) = φ 1 X t 1 X t + φ 2 X t 2 X t φ p X t p X t + ε 2 t + [φ 1 X t 1 + φ 2 X t φ p X t p ] ε t, d où, en prenant l espérance γ (0) = φ 1 γ (1) + φ 2 γ (2) φ p γ (p) + σ 2.
 = φ 1 X t 1 X t + φ 2 X t 2 X t +... + φ p X t p X t + ε 2 t + [φ 1 X t 1 + φ 2 X t 2 +.")
6 Autocorrélations d un processus AR(p), h ρ(h) Le dernière terme étant nul E ([φ 1 X t 1 + φ 2 X t φ p X t p ] ε t ) = 0 car ε t est supposé indépendant du passé de X t, {X t 1, X t 2,..., X t p,...}. De plus, en multipliant (2) par X t h, en prenant l espérance et en divisant par γ (0), on obtient p ρ (h) φ i ρ (h i) = 0 pour tout h > 0. i=1
![.. + φ p X t p ] ε t ) = 0 car ε t est supposé indépendant du passé de X t, {X t 1, X t](/docs-images/41/6020472/images/page_6.jpg "2,..., X t p,...}.")
7 Autocorrélations d un processus AR(p), h ρ(h) Proposition 1. Soit (X t ) un processus AR (p) d autocorrélation ρ (h). Alors. ρ (1) 1 ρ (1) ρ (2).. ρ (p 1) ρ (2). ρ (1) 1 ρ (1).. ρ (p 2) ρ (3). ρ (2) ρ (1) 1.. ρ (p 3) = ρ (p 1) ρ (1) ρ (p) ρ (p 1) ρ (p 2) ρ (p 3) ρ (1) 1 φ 1 φ 2 φ 3. φ p 1 φ p Ce sont les équations de Yule-Walker. De plus les ρ(h) décroissent exponentiellement vers 0.
 ρ (p) ρ (p 1) ρ (p 2) ρ (p 3) ρ (1) 1 φ 1 φ 2 φ 3.")
8 Autocorrélations d un processus AR(p), h ρ(h) Preuve : h > 0, ρ(h) ϕ 1 ρ(h 1) ϕ p ρ(h p) = 0. Le polynôme caractéristique de cette relation de récurrence est : z p ϕ 1 z p 1 ϕ p 1 z ϕ p = z p ( 1 ϕ 1 z ϕ p 1 z p 1 ϕ p z p ) avec Φ(L)X t = ε t etφ(l) = 1 ϕ 1 L ϕ p L p. = z p Φ( 1 z ), Proposition 2. Pour un processus AR (p) les autocorrélations partielles ψ sont nulles au delà de rang p, ψ (h) = 0 pour h > p. Preuve : Si (X t ) est un processus AR(p) et si Φ(L)X t = µ + ε t est sa représentation canonique, en notant ψ(h) le coefficient de X t h dans EL(X t X t 1,..., X t h ) alors, X t = µ + ϕ 1 X t ϕ p X t p } {{ } L(1,X t,...,x t p ) L(1,X t,...,x t h ) + ε t
 est un processus AR(p) et si Φ(L)X t = µ + ε t est sa représentation canonique, en notant ψ(h) le coefficient de X t h dans EL(X t X t 1,.")
9 Autocorrélations d un processus AR(p), h ψ(h)... de telle sorte que EL(X t X t 1,..., X t h ) = µ + ϕ 1 X t ϕ p X t p + EL(ε t X t 1,..., X t h ) = µ + ϕ 1 X t ϕ p X t p + 0 Aussi, si h > p, le coefficient de X t h est 0. Et si h = p, le coefficient de X t p est ϕ p 0. Proposition 3. Pour un processus AR (p) les autocorrélations partielles ψ est non nulle au rang p, ψ (p) 0.

10 Le modèle AR(1) - autorégressif à l ordre 1 La forme général des processus de type AR (1) est X t φx t 1 = ε t pour tout t Z, où (ε t ) est un bruit blanc de variance σ 2. Remark si φ = ±1, le processus (X t ) n est pas stationnaire. Par exemple, pour φ = 1, X t = X t 1 + ε t peut s écrire X t X t h = ε t + ε t ε t h+1, et donc E (X t X t h ) 2 = hσ 2. Or pour un processus stationnaire, il est possible de montrer que E (X t X t h ) 2 4V (X t ). Puisqu il est impossible que pour tout h, hσ 2 4Var (X t ), le processus n est pas stationnaire. Ici, si φ = 1, (X t ) est une marche aléatoire.
 2 4V (X t ).")
11 Remark si φ < 1 alors on peut inverser le polynôme, et X t = (1 φl) 1 ε t = φ i ε t i (en fonction du passé de (ε t ) ). (3) i=0 Proposition 4. Si (X t ) est stationnaire, la fonction d autocorrélation est donnée par ρ (h) = φ h. Preuve : ρ (h) = φρ (h 1) > X=arima.sim(n = 240, list(ar = 0.8),sd = 1) > plot(x) > n=240; h=1 > plot(x[1:(n-h)],x[(1+h):n]) > library(ellipse) > lines(ellipse(0.8^h), type = l,col="red")
 = φρ (h 1) > X=arima.sim(n = 240, list(ar = 0.")
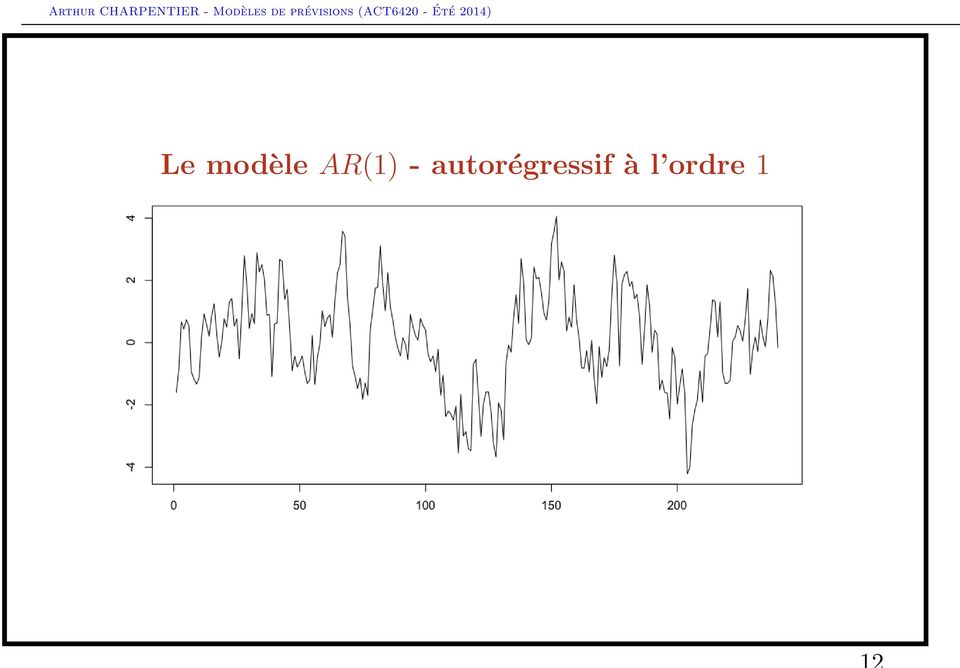
12 Le modèle AR(1) - autorégressif à l ordre 1
13 Le modèle AR(1), ρ(1) et ρ(2)
")
14 Le modèle AR(1), ρ(3) et ρ(4)
")
15 Le modèle AR(1) - autorégressif à l ordre 1 > X=arima.sim(n = 240, list(ar = -0.8),sd = 1)

16 Le modèle AR(1), ρ(1) et ρ(2)
")
17 Le modèle AR(1), ρ(3) et ρ(4)
")

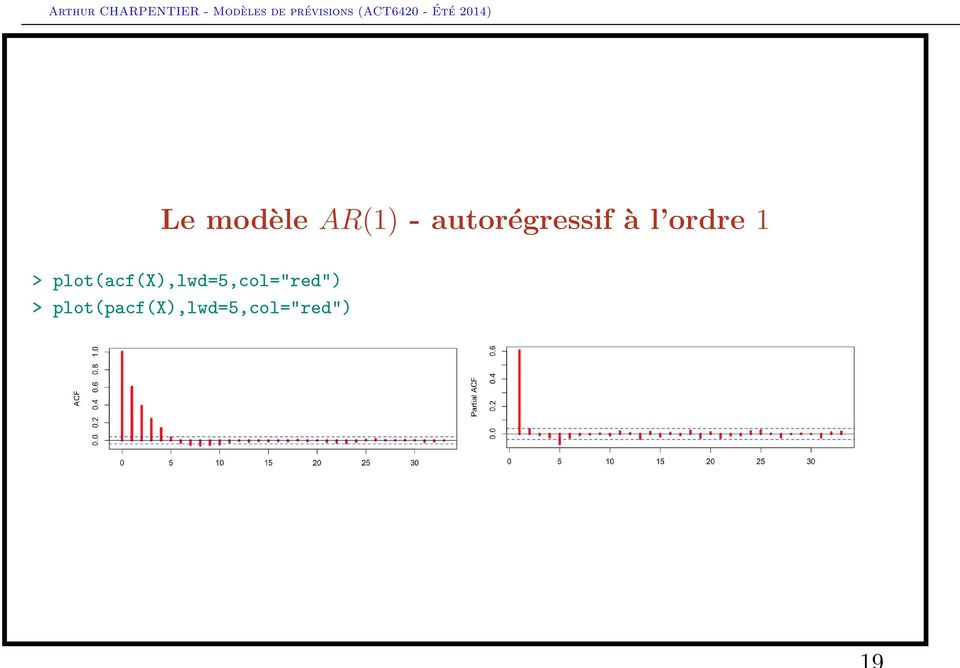
18 Le modèle AR(1) - autorégressif à l ordre 1 Considérons un processus AR(1) stationnaire avec φ 1 = 0.6. > X=arima.sim(n = 2400, list(ar = 0.6),sd = 1) > plot(x)

19 Le modèle AR(1) - autorégressif à l ordre 1 > plot(acf(x),lwd=5,col="red") > plot(pacf(x),lwd=5,col="red")

20 Le modèle AR(1) - autorégressif à l ordre 1 Considérons un processus AR(1) stationnaire avec φ 1 = 0.6. > X=arima.sim(n = 2400, list(ar = -0.6),sd = 1) > plot(x)

21 Le modèle AR(1) - autorégressif à l ordre 1 > plot(acf(x),lwd=5,col="red") > plot(pacf(x),lwd=5,col="red")
22 Le modèle AR(1) - autorégressif à l ordre 1 Considérons un processus AR(1) presque plus stationnaire avec φ 1 = > X=arima.sim(n = 2400, list(ar = 0.999),sd = 1) > plot(x)
23 Le modèle AR(1) - autorégressif à l ordre 1 > plot(acf(x),lwd=5,col="red") > plot(pacf(x),lwd=5,col="red")
24 Le modèle AR(2) - autorégressif à l ordre 2 Ces processus sont également appelés modèles de Yule, dont la forme générale est X t φ 1 X t 1 φ 2 X t 2 = ( 1 φ 1 L φ 2 L 2) X t = ε t pour tout t Z, où (ε t ) est un bruit blanc de variance σ 2, et où les racines du polynôme caractéristique Φ (z) = 1 φ 1 z φ 2 z 2 sont supposées à l extérieur du disque unité, de telle sorte que le processus soit stationnaire. Cette condition s écrit 1 φ 1 + φ 2 > φ 1 φ 2 > 0 φ φ 2 > 0,
25 Le modèle AR(2) - autorégressif à l ordre 2 La fonction d autocorrélation satisfait l équation de récurence ρ (h) = φ 1 ρ (h 1) + φ 2 ρ (h 2) pour h 2, et la fonction d autocorrélation partielle vérifie ρ (1) pour h = 1 [ ψ (h) = ρ (2) ρ (1) 2] [ / 1 ρ (1) 2] pour h = 2 0 pour h 3. À partir des équations de Yule Walker, la fonction d autocorrélation vérifie la relation de récurence ρ (0) = 1 et ρ (1) = φ 1 / (1 φ 2 ), ρ (h) = φ 1 ρ (h 1) + φ 2 ρ (h 2) pour h 2,
26 Le modèle AR(2) - autorégressif à l ordre 2 > X=arima.sim(n = 2400, list(ar = c(0.6,0.4)),sd = 1) > plot(acf(x),lwd=5,col="red") > plot(pacf(x),lwd=5,col="red")
27 Le modèle AR(2) - autorégressif à l ordre 2 > X=arima.sim(n = 2400, list(ar = c(0.6,-0.4)),sd = 1) > plot(acf(x),lwd=5,col="red") > plot(pacf(x),lwd=5,col="red")
28 Le modèle AR(2) - autorégressif à l ordre 2 > X=arima.sim(n = 2400, list(ar = c(-0.6,0.4)),sd = 1) > plot(acf(x),lwd=5,col="red") > plot(pacf(x),lwd=5,col="red")
29 Le modèle AR(2) - autorégressif à l ordre 2 > X=arima.sim(n = 2400, list(ar = c(-0.6,-0.4)),sd = 1) > plot(acf(x),lwd=5,col="red") > plot(pacf(x),lwd=5,col="red")
30 Le modèle MA(q) - moyenne mobile d ordre q On appelle processus moyenne mobile (moving average ) d ordre q, noté M A (q), un processus stationnaire (X t ) vérifiant une relation du type X t = ε t + q θ i ε t i pour tout t Z, (4) i=1 où les θ i sont des réels et (ε t ) est un bruit blanc de variance σ 2. (4) est équivalent à l écriture X t = Θ (L) ε t où Θ (L) = I + θ 1 L θ q L q. Remarque : Contrairement aux processus AR (p), les processus M A (q) sont toujours des processus stationnaires (si q < ou si la série des θ k est absolument convergente si q = ).
31 Le modèle MA(q) - moyenne mobile d ordre q La fonction d autocovarariance est donnée par γ (h) = E (X t X t h ) = E ([ε t + θ 1 ε t θ q ε t q ] [ε t h + θ 1 ε t h θ q ε t h q ]) [θ h + θ h+1 θ θ q θ q h ] σ 2 si 1 h q = 0 si h > q, avec, pour h = 0, la relation Cette dernière relation peut se réécrire γ (0) = [ 1 + θ θ θ 2 q] σ 2. γ (k) = σ 2 q θ j θ j+k avec la convention θ 0 = 1. j=0
32 Le modèle MA(q) - moyenne mobile d ordre q D où la fonction d autocovariance, ρ (h) = θ h + θ h+1 θ θ q θ q h 1 + θ θ θ2 q si 1 h q, et ρ (h) = 0 pour h > q. Proposition 5. Si (X t ) est un processus MA(q), γ (q) = σ 2 θ q 0, alors que γ (k) = 0 pour k > q.
33 Le modèle MA(1) - moyenne mobile d ordre 1 La forme générale des processus de type MA (1) est X t = ε t + θε t 1, pour tout t Z, où (ε t ) est un bruit blanc de variance σ 2. Les autocorrélations sont données par ρ (1) = θ, et ρ (h) = 0, pour h θ2 On peut noter que 1/2 ρ (1) 1/2 : les modèles MA (1) ne peuvent avoir de fortes autocorrélations à l ordre 1. > X=arima.sim(n = 240, list(ma = 0.8),sd = 1) > plot(x) > n=240;h=1 > plot(x[1:(n-h)],x[(1+h):n]) > library(ellipse) > lines(ellipse(.8/(1+.8^2)), type = l,col="red")
34 Le modèle MA(1) - moyenne mobile d ordre 1
35 Le modèle MA(1) - moyenne mobile d ordre 1
36 Le modèle MA(1) - moyenne mobile d ordre 1
37 Le modèle MA(1) - moyenne mobile d ordre 1 > X=arima.sim(n = 2400, list(ma =.7),sd = 1) > plot(acf(x),lwd=5,col="red") > plot(pacf(x),lwd=5,col="red")
38 Le modèle MA(1) - moyenne mobile d ordre 1 > X=arima.sim(n = 2400, list(ma = -0.7),sd = 1) > plot(acf(x),lwd=5,col="red") > plot(pacf(x),lwd=5,col="red")
39 Le modèle MA(2) - moyenne mobile d ordre 2 La forme générale de (X t ) suivant un processus MA (2) est X t = ε t + θ 1 ε t 1 + θ 2 ε t 2 pour tout t Z, où (ε t ) est un bruit blanc de variance σ 2. La fonction d autocorrélation est donnée par l expression suivante ρ (h) = θ 1 [1 + θ 2 ] / [ 1 + θ θ 2 2] pour h = 1 θ 2 / [ 1 + θ θ 2 2] pour h = 2 0 pour h 3,
40 Le modèle MA(2) - moyenne mobile d ordre 2 > X=arima.sim(n = 2400, list(ma = c(0.7,0.9)),sd = 1) > plot(acf(x),lwd=5,col="red") > plot(pacf(x),lwd=5,col="red")
41 Le modèle MA(2) - moyenne mobile d ordre 2 > X=arima.sim(n = 2400, list(ma = c(0.7,-0.9)),sd = 1) > plot(acf(x),lwd=5,col="red") > plot(pacf(x),lwd=5,col="red")
42 Le modèle MA(2) - moyenne mobile d ordre 2 > X=arima.sim(n = 2400, list(ma = c(0.7,-0.9)),sd = 1) > plot(acf(x),lwd=5,col="red") > plot(pacf(x),lwd=5,col="red")
43 Le modèle ARMA(p, q) On appelle processus ARMA (p, q), un processus stationnaire (X t ) vérifiant une relation du type X t p φ i X t i = ε t + i=1 q θ i ε t i pour tout t Z, (5) j=1 où les θ i sont des réels et (ε t ) est un bruit blanc de variance σ 2. (5) est équivalent à l écriture Θ (L) = I + θ 1 L θ q L q Φ (L) X t = Θ (L) ε t où Φ (L) = I φ 1 L... φ p L p On supposera de plus de les polyômes Φ et Θ n ont pas de racines en module strictement supérieures à 1, et n ont pas de racine commune. On supposera de plus que θ q 0 et φ p 0. On dira dans ce cas que cette écriture est la forme minimale.
44 Le modèle ARMA(p, q) Proposition 6. Soit (X t ) un processus ARMA (p, q), alors les autocovariances γ (h) satisfont p γ (h) φ i γ (h i) = 0 pour h q + 1. (6) i=1 Proposition 7. Soit (X t ) un processus ARMA (p, q), alors les autocorrélations γ (h) satisfont γ (h) p φ i γ (h i) = σ 2 [θ h + h 1 θ h h q h θ q ] pour 0 h q, (7) i=1 où les h i correspondent aux coefficients de la forme MA ( ) de (X t ), X t = + h j ε t j. j=0
45 Le modèle ARMA(p, q) Remarque : La variance de X t est donnée par Var (X t ) = γ (0) = 1 + θ θ 2 q + 2φ 1 θ φ h θ h 1 φ φ2 p σ 2 où h = min (p, q).
46 Le modèle ARMA(1, 1) Soit (X t ) un processus ARMA (1, 1) défini par X t φx t 1 = ε t + θε t 1, pour tout t, où φ 0, θ 0, φ < 1 et θ < 1. Ce processus peut de mettre sous forme AR ( ), puisque (1 φl) (1 + θl) 1 X t = Π (L) X t = ε t, où Π (L) = (1 φl) [ ] 1 θl + θ 2 L ( 1) h θ h L h +.., aussi Π (L) = + i=0 π i L i où π 0 = 1 π i = ( 1) i [φ + θ] θ i 1 pour i 1.
47 Le modèle ARMA(1, 1) La fonction d autocorrélation s écrit ρ (1) = (1 + φθ) (φ + θ) / [ 1 + θ 2 + 2φθ ] ρ (h) = φ h ρ (1) pour h 2, et la fonction d autocorrélations partielles a le même comportement qu une moyenne mobile, avec comme valeur initiale aψ (1) = ρ (1).
48 Le modèle ARMA(1, 1) > X=arima.sim(n = 2400, list(ar=0.6, ma = 0.7),sd = 1) > plot(acf(x),lwd=5,col="red") > plot(pacf(x),lwd=5,col="red")
49 Le modèle ARIMA(p, d, q) Définission l opérateur par X t = X t X t 1, i.e. X t = X t X t 1 = (1 L) X t d X t = (1 L) d X t Un processus (X t ) est un processus ARIMA (p, d, q) - autorégressif moyenne mobile intégré - s il vérifie une équation du type Φ (L) (1 L) d X t = Θ (L) ε t pour tout t 0 où Φ (L) = I φ 1 L φ 2 L φ p L p où φ p 0 Θ (L) = I + θ 1 L + θ 2 L θ q L q où θ q 0 sont des polynômes dont les racines sont de module supérieur à 1,...
50 ... et où les conditions initiales Le modèle ARIMA(p, d, q) Z 1 = {X 1,..., X p, ε 1,..., ε q } sont non-corrélées avec ε 0,..., ε t,... et où le processus (ε t ) est un bruit blanc de variance σ 2. Remarque : Si les processus ARMA peuvent être définis sur Z, il n en est pas de même pour les processus ARIMA qui doivent commencer à une certaine date (t = 0 par convention), avec des valeurs initiales (q valeurs pour les ε t, et p + d pour X t ). Proposition 8. Soit (X t ) un processus ARIMA (p, d, q) alors le processus ( d X t ) converge vers un processus ARMA (p, q) stationnaire.
51 Le modèle ARIMA(p, d, q) Proposition 9. Soit (X t ) un processus ARIMA (p, d, q) de valeurs initiales Z 1, alors (X t ) peut s écrire sous la forme suivante, fonction du passé du bruit, X t = t h j ε t j + h (t) Z 1, j=1 où les h j sont les coefficients de la division selon les puissances croissantes de Θ par Φ, et h (t) est un vecteur (ligne) de fonctions de t Proposition 10. Soit (X t ) un processus ARIMA (p, d, q) de valeurs initiales Z 1, alors (X t ) peut s écrire sous la forme suivante, fonction du passé de X t X t = t π j X t j + h (t) Z 1 + ε t, j=1 où les π j sont les coefficients (pour j 1) de la division selon les puissances croissantes de Φ par Θ, et h (t) est un vecteur (ligne) de fonctions de t quand tend vers 0 quand t.
52 Le(s) modèle(s) SARIMA(s, p, d, q) De façon générale, soient s 1,..., s n n entiers, alors un processus (X t ) est un processus SARIM A (p, d, q) - autorégressif moyenne mobile intégré saisonnier - s il vérifie une équation du type Φ (L) (1 L s 1 )... (1 L s n ) X t = Θ (L) (1 L) d ε t pour tout t 0 où Φ (L) = I φ 1 L φ 2 L φ p L p (où φ p 0) et Θ (L) = I + θ 1 L + θ 2 L θ q L q (où θ q 0) sont des polynômes dont les racines sont de module supérieur à 1, et où les conditions initiales Z 1 = {X 1,..., X p, ε 1,..., ε q } sont non-corrélées avec ε 0,..., ε t,... et où le processus (ε t ) est un bruit blanc de variance σ 2.
53 Le(s) modèle(s) SARIMA(s, p, d, q) Il est possible d avoir de la saisonalité, sans forcément avoir de racine unité saisonnière. Sous R, un modèle arima(p,d,q)(ps,ds,qs)[s] (sans constante) s écrit (1 L) d (1 L s ) ds Φ(L)Φ s (L s )X t = Θ(L)Θ s (L s ) avec deg(φ) =p, deg(θ) =q, deg(φ s ) =ps, et deg(θ) =qs. Par exemple arima(1,0,2)(1,0,0)[4] est un modèle (1 φl)(1 φ 4 L 4 )X t = (1 + θ 1 L + θ 2 L 2 )ε t
54 Le(s) modèle(s) SARIMA(s, p, d, q) Les deux formes les plus utilisées sont les suivantes, Φ (L) (1 L s ) X t = Θ (L) ε t pour tout t 0 Φ (L) (1 L s ) (1 L) d X t = Θ (L) ε t pour tout t 0
55 Le(s) modèle(s) SARIMA(s, p, d, q) Soit S N\{0} correspondant à la saisonnalité, et considérons le processus X t = (1 αl) ( 1 βl S) ε t = ε t αε t 1 βε t S + αβε t S 1. Les autocorrélations sont données par ρ (1) = α ( 1 + β 2) (1 + α 2 ) (1 + β 2 ) = α 1 + α 2, ρ (S 1) = αβ (1 + α 2 ) (1 + β 2 ), ρ (S) = β ( 1 + α 2) (1 + α 2 ) (1 + β 2 ) = β 1 + β 2, ρ (S + 1) = αβ (1 + α 2 ) (1 + β 2 ), et ρ (h) = 0 ailleurs. On peut noter que ρ (S 1) = ρ (S + 1) = ρ (1) ρ (S).
56 Le(s) modèle(s) SARIMA(s, p, d, q) Soit S N\{0} correspondant à la saisonnalité, et considérons le processus ( 1 φl S ) X t = (1 αl) ( 1 βl S) ε t ou X t φx t 1 = ε t αε t 1 βε t S +αβε t S 1. Les autocorrélations sont données par ρ (1) = α ( 1 + β 2) (1 + α 2 ) (1 + β 2 ) = α 1 + α 2, ρ (S 1) = α [β φ φ (β φ) 2 / ( 1 φ 2)] [ ], (1 + α 2 ) 1 + (β φ) 2 / (1 φ 2 ) ρ (S) = ( 1 + α 2) ρ S 1, α avec ρ (h) = 0 pour 2 h S 2, puis ρ (S + 1) = ρ (S 1) et ρ (h) = φρ (h S) pour h S + 2. En particulier ρ (ks) = φ k 1 ρ (S).
57 Le théorème de Wold Theorem 11. Tout processus (X t ), centré, et stationnaire au second ordre, peut être représenté sous une forme proche de la forme MA X t = θ j ε t j + η t, j=0 où (ε t ) est l innovation, au sens où ε t = X t EL (X t X t 1, X t 2,...), EL (ε t X t 1, X t 2,...) = 0, E (ε t X t j ) = 0, E (ε t ) = 0, E ( ) ε 2 t = σ 2 (indépendant de t) et E (ε t ε s ) = 0 pour t s, toutes les racines de Θ (L) sont à l extérieur du cercle unité : le polynome Θ est inversible, j=0 θ2 j < et θ 0 = 1, les coefficients θ j et le processus (ε t ) sont uniques, (η t ) vérifie η t = EL (η t X t 1, X t 2,...).
58 Estimation d un SARIMA : Box & Jenkins La méthdologie pour estimer un processus SARIMA est la suivante identification de l ordre d : poser Y t = (1 L) d X t identification de l ordre S : poser Z t = (1 L S )Y t identification de l ordre p, q tels que Φ p (L)Z t = Θ q (L)ε t estimer φ 1,, φ p et θ 1,, θ q construite la série ( ε t ), en déduire un estimateur de σ 2 vérifier que ( ε t ) est un bruit blanc
59 Identification de l ordre d d intégration Le test de Dickey & Fuller simple, H 0 : le processus suit une marche aléatoire contre l hypothèse alternative H 1 : le processus suit un modèle AR (1) (stationnaire). Y t = ρy t 1 + ε t : on teste H 0 : ρ = 1 (marche aléatoire sans dérive) Y t = α + ρy t 1 + ε t : on teste H 0 : α = 0 et ρ = 1 (marche aléatoire sans dérive) Y t = α + ρy t 1 + ε t : on teste H 0 : α 0 et ρ = 1 (marche aléatoire avec dérive) Y t = α + βt + ρy t 1 + ε t : on teste H 0 : α = 0, β = 0 et ρ = 1 (marche aléatoire sans dérive)
60 Identification de l ordre d d intégration Le test de Dickey & Fuller augmenté, H 0 : le processus suit une marche aléatoire contre l hypothèse alternative H 1 : le processus suit un modèle AR (p) (stationnaire). Φ (L) Y t = ε t : on teste H 0 : Φ (1) = 0 Φ (L) Y t = α + ε t : on teste H 0 : α = 0 et Φ (1) = 0 Φ (L) Y t = α + ε t : on teste H 0 : α 0 et Φ (1) = 0 Φ (L) Y t = α + βt + ε t : on teste H 0 : α = 0, β = 0 et Φ (1) = 0 Ces 4 cas peuvent être réécrits en introduisant les notations suivantes, Φ (L) = Φ (1) + (1 L) Φ (L) = Φ (1) [ p 1 i=0 α i L i ] (1 L) où α 0 = Φ (1) 1 et α i = α i 1 φ i = φ i φ p, pour i = 1,..., p.
61 Identification de l ordre d d intégration En posant ρ = 1 Φ (1), on peut réécrire les 4 cas en (1) Y t = ρy t 1 + α i y t i + ε t : on teste H 0 : ρ = 1 (2) Y t = α + ρy t 1 + α i y t i + ε t : on teste H 0 : α = 0 et ρ = 1 (3) Y t = α + ρy t 1 + α i y t i + ε t : on teste H 0 : α 0 et ρ = 1 (4) Y t = α + βt + ρy t 1 + α i y t i + ε t : on teste H 0 : α = 0, β = 0 et ρ = 1 > library(urca) > summary(ur.df(y=,lag=1,type="trend")) Il est aussi possible de laisser le logiciel choisir le nombre optimal de retard à considérer (à l aide du BIC, e.g.) > library(urca) > summary(ur.df(y=,lag=6,selectlags="bic",type="trend"))
62 Les tests de racine unité Dans le test de Dickey-Fuller (simple), on considère un modèle autorégressif (à l ordre 1), X t = α + βt + φx t 1 + ε t qui peut aussi s écrire X t X t 1 = X t = α + βt + φx t 1 + ε t, où ρ = φ 1 Une racine unité se traduit par φ = 1 ou encore ρ = 0, que l on peut tester par un test de Student. Considérons la série simulée suivante > set.seed(1) > E=rnorm(240) > X=cumsum(E) > plot(x,type="l")
63 63 Arthur CHARPENTIER - Modèles de prévisions (ACT Été 2014) > lags=0 > z=diff(x) > n=length(z) > z.diff=embed(z, lags+1)[,1]
64 > z.lag.1=x[(lags+1):n] > #z.diff.lag = x[, 2:lags] > summary(lm(z.diff~0+z.lag.1 )) Call: lm(formula = z.diff ~ 0 + z.lag.1) Coefficients: Estimate Std. Error t value Pr(> t ) z.lag Residual standard error: on 238 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 1 and 238 DF, p-value:
65 65 Arthur CHARPENTIER - Modèles de prévisions (ACT Été 2014) Les tests de racine unité > summary(lm(z.diff~0+z.lag.1 ))$coefficients[1,3] [1] > qnorm(c(.01,.05,.1)/2) [1] > library(urca) > df=ur.df(x,type="none",lags=0) > summary(df) Test regression none Residuals: Min 1Q Median 3Q Max Coefficients: Estimate Std. Error t value Pr(> t ) z.lag
66 Residual standard error: on 238 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 1 and 238 DF, p-value: Value of test-statistic is: Critical values for test statistics: 1pct 5pct 10pct tau
67 67 Arthur CHARPENTIER - Modèles de prévisions (ACT Été 2014) Les tests de racine unité Dans le test de Dickey-Fuller augmenté, on rajoute des retards dans la régression, > lags=1 > z=diff(x) > n=length(z) > z.diff=embed(z, lags+1)[,1] > z.lag.1=x[(lags+1):n] > k=lags+1 > z.diff.lag = embed(z, lags+1)[, 2:k] > summary(lm(z.diff~0+z.lag.1+z.diff.lag )) Call: lm(formula = z.diff ~ 0 + z.lag.1 + z.diff.lag) Coefficients: Estimate Std. Error t value Pr(> t ) z.lag z.diff.lag Residual standard error: on 236 degrees of freedom
68 Multiple R-squared: , Adjusted R-squared: F-statistic: on 2 and 236 DF, p-value: > summary(lm(z.diff~0+z.lag.1+z.diff.lag ))$coefficients[1,3] [1] > summary(df) ############################################### # Augmented Dickey-Fuller Test Unit Root Test # ############################################### Test regression none Value of test-statistic is: Critical values for test statistics: 1pct 5pct 10pct tau Et on peut rajouter autant de retards qu on le souhaite. Mais on peut aussi tester un modèle avec constante 68
69 69 Arthur CHARPENTIER - Modèles de prévisions (ACT Été 2014) > summary(lm(z.diff~1+z.lag.1+z.diff.lag )) Call: lm(formula = z.diff ~ 1 + z.lag.1 + z.diff.lag) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) * z.lag * z.diff.lag Signif. codes: 0 *** ** 0.01 * Residual standard error: on 235 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 2 and 235 DF, p-value: voire une tendance linéaire > temps=(lags+1):n > summary(lm(z.diff~1+temps+z.lag.1+z.diff.lag ))
70 Call: lm(formula = z.diff ~ 1 + temps + z.lag.1 + z.diff.lag) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) * temps z.lag * z.diff.lag Signif. codes: 0 *** ** 0.01 * Residual standard error: on 234 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: 1.91 on 3 and 234 DF, p-value: Dans le premier cas, les grandeurs d intérêt sont > summary(lm(z.diff~1+z.lag.1+z.diff.lag ))$coefficients[2,3] [1]
71 et pour le second > summary(lm(z.diff~1+temps+z.lag.1+z.diff.lag ))$coefficients[3,3] [1] Mais on peut aussi regarder si les spécifications de tendance ont du sens. Pour le modèle avec constante, on peut faire une analyse de la variance > anova(lm(z.diff ~ z.lag z.diff.lag),lm(z.diff ~ 0 + z.diff.lag)) Analysis of Variance Table Model 1: z.diff ~ z.lag z.diff.lag Model 2: z.diff ~ 0 + z.diff.lag Res.Df RSS Df Sum of Sq F Pr(>F) Signif. codes: 0 *** ** 0.01 * > anova(lm(z.diff ~ z.lag z.diff.lag), + lm(z.diff ~ 0 + z.diff.lag))$f[2] [1]
72 72 Arthur CHARPENTIER - Modèles de prévisions (ACT Été 2014) et dans le cas où on suppose qu il y a une tendance > anova(lm(z.diff ~ z.lag temps + z.diff.lag),lm(z.diff ~ 0 +z.diff.lag)) Analysis of Variance Table Model 1: z.diff ~ z.lag temps + z.diff.lag Model 2: z.diff ~ 0 + z.diff.lag Res.Df RSS Df Sum of Sq F Pr(>F) > anova(lm(z.diff ~ z.lag temps+ z.diff.lag),lm(z.diff ~ 0 + z.diff.lag))$f[2] [1] > anova(lm(z.diff ~ z.lag temps+ z.diff.lag),lm(z.diff ~ 1+z.diff.lag)) Analysis of Variance Table Model 1: z.diff ~ z.lag temps + z.diff.lag Model 2: z.diff ~ 1 + z.diff.lag Res.Df RSS Df Sum of Sq F Pr(>F)
73 73 Arthur CHARPENTIER - Modèles de prévisions (ACT Été 2014) Signif. codes: 0 *** ** 0.01 * > anova(lm(z.diff ~ z.lag temps+ z.diff.lag),lm(z.diff ~ 1+ z.diff.lag))$f[2] [1] La commande pour faire ces tests est ici > df=ur.df(x,type="drift",lags=1) > summary(df) ############################################### # Augmented Dickey-Fuller Test Unit Root Test # ############################################### Test regression drift Value of test-statistic is: Critical values for test statistics: 1pct 5pct 10pct tau phi
74 > df=ur.df(x,type="trend",lags=1) > summary(df) ############################################### # Augmented Dickey-Fuller Test Unit Root Test # ############################################### Test regression trend Value of test-statistic is: Critical values for test statistics: 1pct 5pct 10pct tau phi phi
75 Autres tests de racines unités, KPSS et PP Pour le test KPSS (Kwiatkowski - Phillips - Schmidt - Shin), il faut spécifier s il l on suppose que la srie est de moyenne constante, ou si une tendance doit être prise en compte. Si l on suppose une constante non-nulle, mais pas de tendance, on utilise > summary(ur.kpss(x,type="mu")) ####################### # KPSS Unit Root Test # ####################### Test is of type: mu with 4 lags. Value of test-statistic is: Critical value for a significance level of: 10pct 5pct 2.5pct 1pct critical values
76 et si on souhaite prendre en compte une tendance, > summary(ur.kpss(x,type="tau")) ####################### # KPSS Unit Root Test # ####################### Test is of type: tau with 4 lags. Value of test-statistic is: Critical value for a significance level of: 10pct 5pct 2.5pct 1pct critical values L hypothèse nulle correspond à l absence de racine unité : plus la statistique de test est grande, plus on s éloigne de la stationnarité (hypothèse nulle).
77 Autres tests de racines unités, KPSS et PP Pour le test PP de Philippes-Perron, on a un test de type Dickey-Fuller, > PP.test(X) Phillips-Perron Unit Root Test data: X Dickey-Fuller = , Trunc lag parameter = 4, p-value = 0.571
78 Modélisation de séries saisonnières Box & Jenkins (1970) ont introduit les processus ARIM A saisonniers, SARIM A, avec double saisonnalité, qui peuvent s approcher de la décomposition proposée par Harvey (1989), ou Hylleberg, Engle, Granger & Yoo (1990) un autre classe de modèle propose que les paramètres autoégressifs dépendent de la saisonnalité, ce qui donne les modèles ARIM A périodique, introduite par Franses & Paap (1996)
79 Petite digression, les modèles VAR On appelle processus vectoriel autoregressif d ordre p, noté V AR (p), un processus stationnaire (Y t ) = (Y 1,t,, Y d,t ) vérifiant une relation du type Y t p Φ i Y t i = ε t pour tout t Z, (8) i=1 où les Φ i sont des matrices (réelles) d d et (ε t ) est un bruit blanc de matrice de variance Σ, avec E(ε t ε t k ) = 0. Par exemple, un V AR(1), en dimension 2, est de la forme Y 1,t = φ 1,1 φ 1,2 Y 1,t 1 + ε 1,t Y 2,t φ 2,1 φ 2,2 Y 2,t 1 ε 2,t
80 Petite digression, les modèles VAR Remarque Tout processus V AR(p) peut se mettre sous une forme V AR(1). Considérons un processus V AR(2) en dimension 2 Y 1,t = a 1,1 a 1,2 Y 1,t 1 + b 1,1 b 2,1 Y 1,t 1 + ε 1,t Y 2,t a 2,1 a 2,2 Y 2,t 1 b 2,1 b 2,2 Y 2,t 1 ε 2,t On a un V AR(1) (contraint) en dimension 4 Y 1,t a 1,1 a 1,2 Y 2,t a Y = 2,1 a 2,2 1,t Y 2,t 1 b 1,1 b 2,1 Y 1,t 1 b 2,1 b 2,2 Y 2,t Y 1,t Y 2,t 2 + ε 1,t ε 2,t 0 0
81 Processus autorégressif périodique, P AR(1) Considerons un processus P AR(1) sur des données trimestrielles Y t = φ 1,s Y t 1 + ε t que l on pourrait écrire, en posant Y T = (Y 1,T, Y 2,T, Y 3,T, Y 4,T ), et en remplaçant le temps t par un couple (s, T ) (trimestre s = 1, 2, 3, 4 et année T = 1, 2,, n). Φ 0 Y T = Φ 1 Y T 1 + ε T avec Φ 0 = φ 1, φ 1, φ 1,4 1 et Φ 1 = φ 1,
82 Processus autorégressif périodique, P AR(1) On a une représentation avec des vecteurs de trimestres. L équation caractéristique s écrit Φ 0 Φ 1 z = (1 φ 1,1 φ 1,2 φ 1,3 φ 1,4 z) = 0 i.e. on a une racine unité si φ 1,1 φ 1,2 φ 1,3 φ 1,4 = 1.
83 Processus autorégressif périodique, P AR(2) Considerons un processus P AR(2) sur des données trimestrielles Y t = φ 1,s Y t 1 + φ 2,s Y t 2 + ε t que l on pourrait écrire, en posant Y T = (Y 1,T, Y 2,T, Y 3,T, Y 4,T ), et en remplaçant le temps t par un couple (s, T ) (trimestre s = 1, 2, 3, 4 et année T = 1, 2,, n). Φ 0 Y T = Φ 1 Y T 1 + ε T avec Φ 0 = φ 1, φ 2,3 φ 1, φ 2,4 φ 1,4 1 et Φ 1 = 0 0 φ 2,1 φ 1, φ 2,
84 Processus autorégressif périodique, P AR(p) On a une représentation avec des vecteurs de trimestres. Notons que pour un modèle P AR(p), i.e. Dans l exemple du P AR(2), Φ 0 Y T = Φ 1 Y T Φ p Y T p + ε T Y T = Φ 1 0 Φ 1Y T Φ 1 0 Φ py T p + Φ 1 0 ε T 19.8 L équation caractéristique s écrit Φ 1 0 = Φ 0 Φ 1 z Φ p z p = 0
85 Dans le cas d un processus P AR(2), 1 0 φ 2,1 z φ 1,1 z φ 1,2 1 0 φ 2,2 z Φ 0 Φ 1 z = φ 2,3 φ 1, φ 2,4 φ 4,1 1 Pour faire de la prévision avec un processus P AR(1), = 0 nŷ n+1 = E(Y n+1 ) = E(Φ 1 0 Φ 1Y n + Φ 1 0 ε n+1) = Φ 1 0 Φ 1Y n L erreur de prévision est ici nŷ n+1 Y n+1
86 De la saisonalité aux racines unités saisonnières Consiérons le cas de donnés trimestrielles. modèle à saisonnalité déterministe On suppose que X t = Z t k=0 γ k 1(t = k mod. 4) + ε t, i.e. X t = Z t + γ 1 1(t T 1 ) + γ 2 1(t T 2 ) + γ 3 1(t T 3 ) + γ 4 1(t T 4 ) + ε t modèle AR saisonnier stationnaire On suppose que X t = φ 4 X t 4 + ε t, ou plus généralement X t = φ 1 X t 4 + φ 2 X t φ p X t p 4 + ε t
87 De la saisonalité aux racines unités saisonnières > X=rep(rnorm(T)) > for(t in 13:T){X[t]=0.80*X[t-12]+E[t]} > acf(x[-(1:200)],lag=72,lwd=5)
88 De la saisonalité aux racines unités saisonnières > X=rep(rnorm(T)) > for(t in 13:T){X[t]=0.95*X[t-12]+E[t]} > acf(x[-(1:200)],lag=72,lwd=5)
89 De la saisonalité aux racines unités saisonnières modèle AR saisonnier non-stationnaire On suppose que X t = X t 4 + ε t, i.e. φ 4 = 1. > X=rep(rnorm(T)) > for(t in 13:T){X[t]=1.00*X[t-12]+E[t]} > acf(x[-(1:200)],lag=72,lwd=5)
90 De la saisonalité aux racines unités saisonnières Pour des données trimestrielles, le polynôme Φ(L) = (1 L 4 ) admet 4 racines (dans C), +1, +i, 1 et i, i.e. (1 L 4 ) = (1 L)(1 + L)(1 + L 2 ) = (1 L)(1 + L)(1 il)(1 + il) Pour des données mensuelle, le polynôme Φ(L) = (1 L 12 ) admet 12 racines ±1, ±i, ± 1 ± 3i 3 ± i et ± 2 2 ou encore e i 2kπ 12, avec k 1, 2,, 12. Remarque La racine k va indiquer le nombre de cycles par an.
91 De la saisonalité aux racines unités saisonnières Si la racine est d argument π, on a 1 cycle par an (sur 12 périodes) 6 Si la racine est d argument π, on a 2 cycle par an (sur 6 périodes) 3 Si la racine est d argument π, on a 3 cycle par an (sur 4 périodes) 2 Si la racine est d argument 2π 3 Si la racine est d argument 5π 6, on a 4 cycle par an (sur 3 périodes), on a 5 cycle par an
92 Les tests de racine unité saisonnière > source(" > plot(epilation)
93 Les tests de racine unité saisonnière > acf(epilation)
94 Les tests de racine unité saisonnière > library(uroot) > bbplot(epilation)
95 Les tests de racine unité saisonnière > bb3d(epilation)
96 Les tests de racine unité saisonnière Le test CH (de Canova & Hansen) suppose un modèle stationnaire, avec un cycle déterministe (hypothèse H 0, modèle stationnaire) X t = αx t 1 + s 1 k=0 γ k 1(t = k mod. s) + ε t Supposant que α < 1, on va tester la stabilité des coefficients γ k avec un test de type KPSS, i.e. X t = αx t 1 + s 1 k=0 γ k,t 1(t = k mod. s) + ε t avec γ k,t = γ k,t 1 + u t. On va tester si Var(u t ) = 0, par un test de rapport de vraisemblance.
97 Les tests de racine unité saisonnière > library(uroot) > CH.test(epilation) Null hypothesis: Stationarity. Alternative hypothesis: Unit root. Frequency of the tested cycles: pi/6, pi/3, pi/2, 2pi/3, 5pi/6, pi, L-statistic: Lag truncation parameter: 12 Critical values:
98 Les tests de racine unité saisonnière Le test HEGY suppose un modèle s X t = (1 L s )X t = où (pour des données trimestrielles) s 1 k=0 π k W k,t 1 + +ε t W 1,t = X t + X t 1 + X t 2 + X t 3 = (1 + L + L 2 + L 3 )X t = (1 + L)(1 + L 2 )X t W 2,t = X t X t 1 + X t 2 X t 3 = (1 L + L 2 L 3 )X t = (1 L)(1 + L 2 )X t W 3,t = X t X t 2 et W 4,t = X t 1 + X t 3 et on va tester (test de Fisher) si des π k sont nuls.
99 Les tests de racine unité saisonnière Si π k = 0 k = 1, 2, 3, 4, alors (X t ) est une marche aléatoire saisonnière Si π 1 = 0, alors Φ tel que Φ(L)X t = ε t admet +1 pour racine Φ(L) = (1 L 4 ) + π 2 (1 L)(1 + L 2 )L + π 3 (1 L)(1 + L)L 2 + π 4 (1 L)(1 + L)L (cf. test de Dickey-Fuller) Si π 2 = 0, alors Φ tel que Φ(L)X t = ε t admet 1 pour racine Φ(L) = (1 L 4 ) π 1 (1 + L)(1 + L 2 )L + π 3 (1 L)(1 + L)L 2 + π 4 (1 L)(1 + L)L (cycle semi-annuel). Si π 3 = 0 et π 4 = 0, alors Φ tel que Φ(L)X t = ε t admet ±i pour racines Φ(L) = (1 L 4 ) π 1 (1 + L)(1 + L 2 )L + π 2 (1 L)(1 + L 2 ) Si π k = 0 k = 2, 3, 4, alors Φ tel que Φ(L)X t = ε t admet 1, ±i pour racines
100 Les tests de racine unité saisonnière Remarque dans la version la plus générale, on peut rajouter une tendance, des cycles déterministes, et des retards (cf. Dickey Fuller augmenté) 12 X t = α + βt + s 1 k=0 γ k 1(t = k mod. s) + s 1 k=0 π k W k,t 1 + p φ k 12 X t k + ε t k=1
101 Les tests de racine unité saisonnière > library(uroot) > HEGY.test(epilation,itsd=c(1,1,c(1:11))) Null hypothesis: Unit root. Alternative hypothesis: Stationarity. Stat. p-value tpi_ tpi_ Fpi_3: Fpi_5: Fpi_7: Fpi_9: Fpi_11: Fpi_2: NA Fpi_1: NA Lag orders: Number of available observations: 83
102 Identification des ordres p et q d un ARMA(p, q) La règle la plus simple à utiliser est celle basée sur les propriétés des fonctions d autocorrélations pour les processus AR et M A pour un processus AR(p) ψ(p) 0 et ψ(h) = 0 pour h > p on cherche le plus grand p au delà duquel ψ(h) est non-significatif pour un processus MA(q) ρ(q) 0 et ρ(h) = 0 pour h > q on cherche le plus grand q au delà duquel ρ(h) est non-significatif
103 Identification des ordres p et q d un ARMA(p, q) > autoroute=read.table( +" + header=true,sep=";") > a7=autoroute$a007 > A7=ts(a7,start = c(1989, 9), frequency = 12) Il est possible d utiliser la fonction d autocorrélation étendue (EACF), introduite par Tsay & Tiao (1984),
104 Identification des ordres p et q d un ARMA(p, q) > EACF=eacf(A7,13,13) AR/MA x o o x x x x x o o x x x o 1 x x o o x x x o o o x x x x 2 o x o o o o x o o o o x x o 3 o x o x o o o o o o o x x x 4 x x x x o o o o o o o x o o 5 x x o o o x o o o o o x o x 6 x x o o o x o o o o o x o o 7 o x o o o x o o o o o x o o 8 o x o o o x o o o o o x o o 9 x x o o x o x o o o o x o o 10 x x o o x o x o o o o x o o 11 x x o o x x x o o o x x o o 12 x x o o o o o o o o o o o o 13 x x o o o o o o o o o o o o
105 Identification des ordres p et q d un ARMA(p, q) > EACF$eacf [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [1,] [2,] [3,] [4,] [5,] [6,] [7,] [8,] [9,] [10,] [11,] [12,] [13,] [14,]
106 Identification des ordres p et q d un ARMA(p, q) On cherche un coin à partir duquel les autocorrélations s annulent > library(rcolorbrewer) > CL=brewer.pal(6, "RdBu") > ceacf=matrix(as.numeric(cut(eacf$eacf, + ((-3):3)/3,labels=1:6)),nrow(EACF$eacf), + ncol(eacf$eacf)) > for(i in 1:ncol(EACF$eacf)){ + for(j in 1:nrow(EACF$eacf)){ + polygon(c(i-1,i-1,i,i)-.5,c(j-1,j,j,j-1)-.5, + col=cl[ceacf[j,i]]) + }}

107
108 Estimation des φ 1,, φ p, θ 1,, θ q Considérons un processus autorégressif, e.g. un AR(2) dont on souhaite estimer les paramètres, X t = φ 1 X t 1 + φ 2 X t 2 + ε t où (ε t ) est un bruit blanc de variance σ 2. > phi1=.5; phi2=-.4; sigma=1.5 > set.seed(1) > n=240 > WN=rnorm(n,sd=sigma) > Z=rep(NA,n) > Z[1:2]=rnorm(2,0,1) > for(t in 3:n){Z[t]=phi1*Z[t-1]+phi2*Z[t-2]+WN[t]}
109 109 Arthur CHARPENTIER - Modèles de prévisions (ACT Été 2014) utilisation les moindres carrés Estimation des φ 1,, φ p, θ 1,, θ q On peut réécrire la dynamique du processus sous forme matricielle, car Y 3 Y 2 Y 1 ε 3 Y 4 Y 3 Y 2. = φ 1 ε φ 2. Y t Y t 1 Y t 2 L estimation par moindres carrés (classiques) donne ici > base=data.frame(y=z[3:n],x1=z[2:(n-1)],x2=z[1:(n-2)]) > regression=lm(y~0+x1+x2,data=base) > summary(regression) ε t Call: lm(formula = Y ~ 0 + X1 + X2, data = base)
110 Residuals: Min 1Q Median 3Q Max Coefficients: Estimate Std. Error t value Pr(> t ) X e-13 *** X e-11 *** --- Signif. codes: 0 *** ** 0.01 * Residual standard error: on 236 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 2 and 236 DF, p-value: 6.949e-16 > regression$coefficients X1 X > summary(regression)$sigma [1]
111 Estimation des φ 1,, φ p, θ 1,, θ q utilisation les équations de Yule-Walker On a vu que les fonctions d autocorrélations et d autocovariance étaient liées par un système d équations, γ(1) = φ 1 γ(0) + φ 2 γ(1) i.e. γ(1) = γ(0) γ( 1) φ 1 γ(2) = φ 1 γ(1) + φ 2 γ(0) γ(2) γ(1) γ(0) φ 2 ou encore, 1 ρ( 1) φ 1 = ρ(1) 1 φ 2 ρ(1) i.e. ρ(2) φ 1 = φ 2 1 ρ( 1) ρ(1) 1 1 ρ(1) ρ(2)
112 Estimation des φ 1,, φ p, θ 1,, θ q > rho1=cor(z[1:(n-1)],z[2:n]) > rho2=cor(z[1:(n-2)],z[3:n]) > A=matrix(c(1,rho1,rho1,1),2,2) > b=matrix(c(rho1,rho2),2,1) > (PHI=solve(A,b)) [,1] [1,] [2,] On peut ensuite extraire le bruit, et calculer son écart-type afin d estimer σ 2 > estwn=base$y-(phi[1]*base$x1+phi[2]*base$x2) > sd(estwn) [1]
113 Estimation des φ 1,, φ p, θ 1,, θ q utilisation le maximum de vraisemblance (conditionnel) On va supposer ici que le bruit blanc est Gaussien, ε t N (0, σ 2 ), de telle sorte que X t X t 1, X t 2 N (φ 1 X t 1 + φ 2 X t 2, σ 2 ) La log-vraisemblance conditionnelle est alors > CondLogLik=function(A,TS){ + phi1=a[1]; phi2=a[2] + sigma=a[3] ; L=0 + for(t in 3:length(TS)){ + L=L+dnorm(TS[t],mean=phi1*TS[t-1]+ + phi2*ts[t-2],sd=sigma,log=true)} + return(-l)}
114 Estimation des φ 1,, φ p, θ 1,, θ q et on peut alors optimiser cette fonction > LogL=function(A) CondLogLik(A,TS=Z) > optim(c(0,0,1),logl) $par [1] $value [1]
115 Estimation d un modèle ARIM A On considère la série de vente de voitures au Québec, > source(" > X=as.numeric(quebec) > temps=1:length(x) > base=data.frame(temps,x) > reg=lm(x~temps) > T=1:200 > Xp=predict(reg,newdata=data.frame(temps=T)) > plot(temps,x,xlim=c(1,200),ylim=c(5000,30000),type="l") > lines(t,xp,col="red")
116 Estimation d un modèle ARIM A
117 Estimation d un modèle ARIM A > Y=X-predict(reg) > plot(temps,y,type="l",xlim=c(1,200))
118 Estimation d un modèle ARIM A > acf(y) > pacf(y)
119 Estimation d un modèle ARIM A > fit.ar12=arima(y,order=c(12,0,0),include.mean=false) > fit.ar12 Series: Y ARIMA(12,0,0) with non-zero mean Coefficients: ar1 ar2 ar3 ar4 ar5 ar6 ar s.e ar9 ar10 ar11 ar12 intercept s.e sigma^2 estimated as : log likelihood= AIC= AICc= BIC=
120 Estimation d un modèle ARIM A > acf(residuals(fit.ar12)) > pacf(residuals(fit.ar12))
121 Estimation d un modèle ARIM A > BP=function(h) Box.test(residuals(fit.ar12),lag=h, type= Box-Pierce )$p.value > plot(1:36,vectorize(bp)(1:36),type= b,col="red") > abline(h=.05,lty=2,col="blue")
122 En manque d inspiration? Estimation d un modèle ARIM A > library(caschrono) > armaselect(y,nbmod=5) p q sbc [1,] [2,] [3,] [4,] [5,]
123 Estimation d un modèle ARIM A > fit.arma12.1=arima(y,order=c(12,0,1),include.mean=false) > fit.arma12.1 Series: Y ARIMA(12,0,1) with non-zero mean Coefficients: ar1 ar2 ar3 ar4 ar5 ar6 ar s.e ar9 ar10 ar11 ar12 ma1 intercept s.e sigma^2 estimated as : log likelihood= AIC= AICc= BIC=
124 Estimation d un modèle ARIM A > acf(residuals(fit.arma12.1)) > pacf(residuals(fit.arma12.1))
125 Estimation d un modèle ARIM A > BP=function(h) Box.test(residuals(fit.arma12.1),lag=h, type= Box-Pierce )$p.value > plot(1:36,vectorize(bp)(1:36),type= b,col="red") > abline(h=.05,lty=2,col="blue")
126 Estimation d un modèle ARIM A > fit.ar14=arima(y,order=c(14,0,0),method="css",include.mean=false) > fit.ar14 Series: Y ARIMA(14,0,0) with non-zero mean Coefficients: ar1 ar2 ar3 ar4 ar5 ar6 ar s.e ar9 ar10 ar11 ar12 ar13 ar14 intercept s.e sigma^2 estimated as : part log likelihood=
127 Estimation d un modèle ARIM A > acf(residuals(fit.ar14)) > pacf(residuals(fit.ar14))
128 Estimation d un modèle ARIM A > BP=function(h) Box.test(residuals(fit.ar14),lag=h, type= Box-Pierce )$p.value > plot(1:36,vectorize(bp)(1:36),type= b,col="red") > abline(h=.05,lty=2,col="blue")
129 Estimation d un modèle SARIM A > fit.s=arima(y, order = c(p=0, d=0, q=0), + seasonal = list(order = c(0, 1, 0), period = 12)) > summary(fit.s) Series: Y ARIMA(0,0,0)(0,1,0)[12] sigma^2 estimated as : log likelihood= AIC= AICc= BIC= In-sample error measures: ME RMSE MAE MPE MAPE
130 Estimation d un modèle SARIM A > acf(residuals(fit.s)) > pacf(residuals(fit.s))
131 Estimation d un modèle SARIM A > BP=function(h) Box.test(residuals(fit.s),lag=h, type= Box-Pierce )$p.value > plot(1:36,vectorize(bp)(1:36),type= b,col="red") > abline(h=.05,lty=2,col="blue")
132 Envie de davantage d inspiration? Estimation d un modèle ARIM A > auto.arima(y,max.p=15, max.q=15) Series: Y ARIMA(2,0,3) with zero mean Coefficients: ar1 ar2 ma1 ma2 ma s.e sigma^2 estimated as : log likelihood= AIC= AICc= BIC=
133 Estimation d un modèle ARIM A > fit.arma2.3=arima(y, order = c(p=2, d=0, q=3),include.mean=false) > > summary(fit.arma2.3) Series: Y ARIMA(2,0,3) with zero mean Coefficients: ar1 ar2 ma1 ma2 ma s.e sigma^2 estimated as : log likelihood= AIC= AICc= BIC= In-sample error measures: ME RMSE MAE MPE MAPE
134 Estimation d un modèle ARIM A > acf(residuals(fit.arma2.3)) > pacf(residuals(fit.arma2.3))
135 Estimation d un modèle SARIMA(s, p, d, q) Nous avions vu que sous R, un modèle arima(p,d,q)(ps,ds,qs)[s] (sans constante) s écrit (1 L) d (1 L s ) ds Φ(L)Φ s (L s )X t = Θ(L)Θ s (L s ) avec deg(φ) =p, deg(θ) =q, deg(φ s ) =ps, et deg(θ) =qs. Par exemple arima(1,0,2)(1,0,0)[4] est un modèle (1 φl)(1 φ 4 L 4 )X t = (1 + θ 1 L + θ 2 L 2 )ε t L estimation se fait avec > arima(x,order=c(1,0,2),seasonal=list(order=c(1,0,0),period=4))
136 Estimation d un modèle SARIMA(s, p, d, q) > arima(x,order=c(1,0,2),seasonal=list(order=c(1,0,0),period=4)) Series: X ARIMA(1,0,2)(1,0,0)[4] with non-zero mean Coefficients: ar1 ma1 ma2 sar1 intercept s.e sigma^2 estimated as 1.026: log likelihood= AIC= AICc= BIC= i.e. ( L)( (0.0894) (0.0552) L4 )(X t ) = ( L (0.2186) (0.0851) avec σ 2 = 1.026, ou encore ( L)(1 0.7L 4 )X t = ( L 2 )ε t avec Var(ε t ) = 1. (0.0647) L2 )ε t
137 Prévision à l aide d un modèle ARIM A Pour finir, on veut faire de la prévision, i.e. pour h 1, construire T XT +h, prévision de X t+h, i.e. T X T +h = E(X t+h X T, X T 1,, X 1 ) et calculer Var( T XT +h X T, X T 1,, X 1 )).
138 Prévision T XT +h de X t+h On a observé {X 1,, X T }m modélisé par un processus ARIMA(p, d, q) si (X t ) est un processus autorégressif AR(p). On suppose que (X t ) vérifie X t = φ 1 X t φ p X t p + ε t ou Φ (L) X t = ε t La prévision optimale pour la date T + 1, faite à la date T est T X T +1 = EL (X T +1 X T, X T 1,...) = EL (X T +1 ε T, ε T 1,...) car (ε t ) est le processus d innovation. Aussi, T X T +1 = φ 1 X T φ p X T p +0
139 Prévision T XT +h de X t+h Pour un horizon h 1, T XT +h = EL (X T +h X T, X T 1,...) et donc, de façon récursive par X φ 1T XT +h φ h 1T XT +1 + φ h X T φ p X T +h p pour h p T T +h = φ 1T XT +h φ pt XT +h p pour h > p Par exemple pour un AR(1) (avec constante) T XT +1 = µ + φx T, T XT +2 = µ + φ T XT +1 = µ + φ [µ + φx T ] = µ [1 + φ] + φ 2 X T, T XT +3 = µ + φ T XT +2 = µ + φ [µ + φ [µ + φx T ]] = µ [ 1 + φ + φ 2] + φ 3 X T, et récursivement, on peut obtenir T XT +h de la forme T X T +h = µ + φ T XT +h 1 = µ [ 1 + φ + φ φ h 1] + φ h X T.
140 Prévision T XT +h de X t+h si (X t ) est un processus autorégressif MA(q). On suppose que (X t ) vérifie X t = ε t + θ 1 ε t θ q ε t q = Θ (L) ε t. La prévision optimale pour la date T + 1, faite à la date T est T X T +1 = EL (X T +1 X T, X T 1,...) = EL (X T +1 ε T, ε T 1,...) car (ε t ) est le processus d innovation. Aussi, T X T +1 = 0 + θ 1 ε T θ q ε T +1 q Plus généralement, X T T +h = EL (X T +h X T, X T 1,...) = EL (X T +h ε T, ε T 1,...), et donc X θ h ε T θ q ε T +h q pour h q T T +h = 0 pour h > q. (9)
141 Le soucis est qu il faut connaître (ε t ) (qui non observé). La stratégie est d inverser Θ (si c est possible), i.e. Si X t = Θ(L)ε t Θ(L) 1 X t = ε t X t = a k X t k + ε t et donc X t+h = k=1 a k X t+h k + ε t+h pour tout h 0 k=1 et donc, T XT +h peut être écrit de façon itérative T X T +h = h 1 k=1 a kt XT +h k + a k X t+h k k=h mais qui fait qui fait intervenir des valeurs non-observées (pour t 0). On
142 suppose alors que l on peut poser T X T +h = h 1 k=1 a kt XT +h k + T +h k=h a k X T +h k + k=t +h+1 a k X T +h k, } {{ } Négligeable (hyp.)
143 Erreur de prévision X t+h T XT +h Le plus simple est d utiliser une écriture MA(q), voire MA( ) (si c est possible) X T +h = θ i ε T +h i = T +h θ i ε T +h i + θ i ε T +h i, i=0 i=0 i=t +h+1 et donc T h = X t+h T XT +h h θ i ε T +h i. i=0 Sous l hypothèse de normalité des résidus (ε t ), i.e. ε t i.i.d., ε t N ( 0, σ 2), alors T h = X t+h T XT +h N ( h 0, σ 2 i=0 b 2 i ),
144 Erreur de prévision X t+h T XT +h... d où l intervalle de confiance pour X T +h au niveau 1 α T XT +h ± u 1 α/2 σ h où les θ i sont des estimateurs des coefficients de la forme moyenne mobile, et σ est un estimateur de la variance du résidu. i=0 θ 2 i,
145 Prévision T XT +h pour un AR(1) Considŕons le cas d un processus AR(1) (avec constante), X t = φ 1 X t 1 + µ + ε t. La prévision à horizon 1, faite à la date T, s écrit T X T +1 = E (X T +1 X T, X T 1,..., X 1 ) = φ 1 X T + µ, et de façon similaire, à horizon 2, T X T +2 = φ 1T XT +1 + µ = φ 2 1X T + [φ 1 + 1] µ. De façon plus générale, à horizon h 1, par récurence T X T +h = φ h 1X T + [ φ h φ ] µ. (10) Remarque A long terme (h ) T XT +h converge ver vers δ (1 φ 1 ) 1 (i.e. E(X t ).
146 Erreur de prévision X t+h T XT +h pour un AR(1) T h = T XT +h X T +h = T XT +h [φ 1 X T +h 1 + µ + ε T +h ] = T XT +h [ φ h 1X T + ( φ h φ ) µ + ε T +h + φ 1 ε T +h φ h 1 1 ε en substituant (10), on obtient qui possède la variance T h = ε T +h + φ 1 ε T +h φ h 1 1 ε T +1, Var( T h ) = [ 1 + φ φ φ 2h 2 ] 1 σ 2, où Var (ε t ) = σ 2. Remarque Var( T h ) Var( T h 1 )
MODELE A CORRECTION D ERREUR ET APPLICATIONS
 MODELE A CORRECTION D ERREUR ET APPLICATIONS Hélène HAMISULTANE Bibliographie : Bourbonnais R. (2000), Econométrie, DUNOD. Lardic S. et Mignon V. (2002), Econométrie des Séries Temporelles Macroéconomiques
MODELE A CORRECTION D ERREUR ET APPLICATIONS Hélène HAMISULTANE Bibliographie : Bourbonnais R. (2000), Econométrie, DUNOD. Lardic S. et Mignon V. (2002), Econométrie des Séries Temporelles Macroéconomiques
1 Définition de la non stationnarité
 Chapitre 2: La non stationnarité -Testsdedétection Quelques notes de cours (non exhaustives) 1 Définition de la non stationnarité La plupart des séries économiques sont non stationnaires, c est-à-direqueleprocessusquiles
Chapitre 2: La non stationnarité -Testsdedétection Quelques notes de cours (non exhaustives) 1 Définition de la non stationnarité La plupart des séries économiques sont non stationnaires, c est-à-direqueleprocessusquiles
2 TABLE DES MATIÈRES. I.8.2 Exemple... 38
 Table des matières I Séries chronologiques 3 I.1 Introduction................................... 3 I.1.1 Motivations et objectifs......................... 3 I.1.2 Exemples de séries temporelles.....................
Table des matières I Séries chronologiques 3 I.1 Introduction................................... 3 I.1.1 Motivations et objectifs......................... 3 I.1.2 Exemples de séries temporelles.....................
Exercices M1 SES 2014-2015 Ana Fermin (http:// fermin.perso.math.cnrs.fr/ ) 14 Avril 2015
 14 Avril 2015") Exercices M1 SES 214-215 Ana Fermin (http:// fermin.perso.math.cnrs.fr/ ) 14 Avril 215 Les exemples numériques présentés dans ce document d exercices ont été traités sur le logiciel R, téléchargeable par
Exercices M1 SES 214-215 Ana Fermin (http:// fermin.perso.math.cnrs.fr/ ) 14 Avril 215 Les exemples numériques présentés dans ce document d exercices ont été traités sur le logiciel R, téléchargeable par
TESTS PORTMANTEAU D ADÉQUATION DE MODÈLES ARMA FAIBLES : UNE APPROCHE BASÉE SUR L AUTO-NORMALISATION
 TESTS PORTMANTEAU D ADÉQUATION DE MODÈLES ARMA FAIBLES : UNE APPROCHE BASÉE SUR L AUTO-NORMALISATION Bruno Saussereau Laboratoire de Mathématiques de Besançon Université de Franche-Comté Travail en commun
TESTS PORTMANTEAU D ADÉQUATION DE MODÈLES ARMA FAIBLES : UNE APPROCHE BASÉE SUR L AUTO-NORMALISATION Bruno Saussereau Laboratoire de Mathématiques de Besançon Université de Franche-Comté Travail en commun
Température corporelle d un castor (une petite introduction aux séries temporelles)
") Température corporelle d un castor (une petite introduction aux séries temporelles) GMMA 106 GMMA 106 2014 2015 1 / 32 Cas d étude Temperature (C) 37.0 37.5 38.0 0 20 40 60 80 100 Figure 1: Temperature
Température corporelle d un castor (une petite introduction aux séries temporelles) GMMA 106 GMMA 106 2014 2015 1 / 32 Cas d étude Temperature (C) 37.0 37.5 38.0 0 20 40 60 80 100 Figure 1: Temperature
Modèle GARCH Application à la prévision de la volatilité
 Modèle GARCH Application à la prévision de la volatilité Olivier Roustant Ecole des Mines de St-Etienne 3A - Finance Quantitative Décembre 2007 1 Objectifs Améliorer la modélisation de Black et Scholes
Modèle GARCH Application à la prévision de la volatilité Olivier Roustant Ecole des Mines de St-Etienne 3A - Finance Quantitative Décembre 2007 1 Objectifs Améliorer la modélisation de Black et Scholes
Tests d indépendance en analyse multivariée et tests de normalité dans les modèles ARMA
 Tests d indépendance en analyse multivariée et tests de normalité dans les modèles ARMA Soutenance de doctorat, sous la direction de Pr. Bilodeau, M. et Pr. Ducharme, G. Université de Montréal et Université
Tests d indépendance en analyse multivariée et tests de normalité dans les modèles ARMA Soutenance de doctorat, sous la direction de Pr. Bilodeau, M. et Pr. Ducharme, G. Université de Montréal et Université
Analyse de la variance Comparaison de plusieurs moyennes
 Analyse de la variance Comparaison de plusieurs moyennes Biostatistique Pr. Nicolas MEYER Laboratoire de Biostatistique et Informatique Médicale Fac. de Médecine de Strasbourg Mars 2011 Plan 1 Introduction
Analyse de la variance Comparaison de plusieurs moyennes Biostatistique Pr. Nicolas MEYER Laboratoire de Biostatistique et Informatique Médicale Fac. de Médecine de Strasbourg Mars 2011 Plan 1 Introduction
CONCOURS D ENTREE A L ECOLE DE 2007 CONCOURS EXTERNE. Cinquième épreuve d admissibilité STATISTIQUE. (durée : cinq heures)
") CONCOURS D ENTREE A L ECOLE DE 2007 CONCOURS EXTERNE Cinquième épreuve d admissibilité STATISTIQUE (durée : cinq heures) Une composition portant sur la statistique. SUJET Cette épreuve est composée d un
CONCOURS D ENTREE A L ECOLE DE 2007 CONCOURS EXTERNE Cinquième épreuve d admissibilité STATISTIQUE (durée : cinq heures) Une composition portant sur la statistique. SUJET Cette épreuve est composée d un
Tests non-paramétriques de non-effet et d adéquation pour des covariables fonctionnelles
 Tests non-paramétriques de non-effet et d adéquation pour des covariables fonctionnelles Valentin Patilea 1 Cesar Sanchez-sellero 2 Matthieu Saumard 3 1 CREST-ENSAI et IRMAR 2 USC Espagne 3 IRMAR-INSA
Tests non-paramétriques de non-effet et d adéquation pour des covariables fonctionnelles Valentin Patilea 1 Cesar Sanchez-sellero 2 Matthieu Saumard 3 1 CREST-ENSAI et IRMAR 2 USC Espagne 3 IRMAR-INSA
Une introduction. Lionel RIOU FRANÇA. Septembre 2008
 Une introduction INSERM U669 Septembre 2008 Sommaire 1 Effets Fixes Effets Aléatoires 2 Analyse Classique Effets aléatoires Efficacité homogène Efficacité hétérogène 3 Estimation du modèle Inférence 4
Une introduction INSERM U669 Septembre 2008 Sommaire 1 Effets Fixes Effets Aléatoires 2 Analyse Classique Effets aléatoires Efficacité homogène Efficacité hétérogène 3 Estimation du modèle Inférence 4
I. Polynômes de Tchebychev
 Première épreuve CCP filière MP I. Polynômes de Tchebychev ( ) 1.a) Tout réel θ vérifie cos(nθ) = Re ((cos θ + i sin θ) n ) = Re Cn k (cos θ) n k i k (sin θ) k Or i k est réel quand k est pair et imaginaire
Première épreuve CCP filière MP I. Polynômes de Tchebychev ( ) 1.a) Tout réel θ vérifie cos(nθ) = Re ((cos θ + i sin θ) n ) = Re Cn k (cos θ) n k i k (sin θ) k Or i k est réel quand k est pair et imaginaire
Correction de l examen de la première session
 de l examen de la première session Julian Tugaut, Franck Licini, Didier Vincent Si vous trouvez des erreurs de Français ou de mathématiques ou bien si vous avez des questions et/ou des suggestions, envoyez-moi
de l examen de la première session Julian Tugaut, Franck Licini, Didier Vincent Si vous trouvez des erreurs de Français ou de mathématiques ou bien si vous avez des questions et/ou des suggestions, envoyez-moi
Données longitudinales et modèles de survie
 ANALYSE DU Données longitudinales et modèles de survie 5. Modèles de régression en temps discret André Berchtold Département des sciences économiques, Université de Genève Cours de Master ANALYSE DU Plan
ANALYSE DU Données longitudinales et modèles de survie 5. Modèles de régression en temps discret André Berchtold Département des sciences économiques, Université de Genève Cours de Master ANALYSE DU Plan
Formations EViews FORMATIONS GENERALES INTRODUCTIVES INTRO : INTRODUCTION A LA PRATIQUE DE L ECONOMETRIE AVEC EVIEWS
 Formations EViews FORMATIONS GENERALES INTRODUCTIVES DEB : DECOUVERTE DU LOGICIEL EVIEWS INTRO : INTRODUCTION A LA PRATIQUE DE L ECONOMETRIE AVEC EVIEWS FORMATIONS METHODES ECONOMETRIQUES VAR : MODELES
Formations EViews FORMATIONS GENERALES INTRODUCTIVES DEB : DECOUVERTE DU LOGICIEL EVIEWS INTRO : INTRODUCTION A LA PRATIQUE DE L ECONOMETRIE AVEC EVIEWS FORMATIONS METHODES ECONOMETRIQUES VAR : MODELES
3 Approximation de solutions d équations
 3 Approximation de solutions d équations Une équation scalaire a la forme générale f(x) =0où f est une fonction de IR dans IR. Un système de n équations à n inconnues peut aussi se mettre sous une telle
3 Approximation de solutions d équations Une équation scalaire a la forme générale f(x) =0où f est une fonction de IR dans IR. Un système de n équations à n inconnues peut aussi se mettre sous une telle
Introduction à l approche bootstrap
 Introduction à l approche bootstrap Irène Buvat U494 INSERM buvat@imedjussieufr 25 septembre 2000 Introduction à l approche bootstrap - Irène Buvat - 21/9/00-1 Plan du cours Qu est-ce que le bootstrap?
Introduction à l approche bootstrap Irène Buvat U494 INSERM buvat@imedjussieufr 25 septembre 2000 Introduction à l approche bootstrap - Irène Buvat - 21/9/00-1 Plan du cours Qu est-ce que le bootstrap?
MASTER ECONOMETRIE ET STATISTIQUE APPLIQUEE (ESA) Econométrie pour la Finance
 Econométrie pour la Finance") MASTER ECONOMETRIE ET STATISTIQUE APPLIQUEE (ESA) Université d Orléans Econométrie pour la Finance Modèles ARCH - GARCH Applications à la VaR Christophe Hurlin Documents et Supports Année Universitaire
MASTER ECONOMETRIE ET STATISTIQUE APPLIQUEE (ESA) Université d Orléans Econométrie pour la Finance Modèles ARCH - GARCH Applications à la VaR Christophe Hurlin Documents et Supports Année Universitaire
Correction du Baccalauréat S Amérique du Nord mai 2007
 Correction du Baccalauréat S Amérique du Nord mai 7 EXERCICE points. Le plan (P) a une pour équation cartésienne : x+y z+ =. Les coordonnées de H vérifient cette équation donc H appartient à (P) et A n
Correction du Baccalauréat S Amérique du Nord mai 7 EXERCICE points. Le plan (P) a une pour équation cartésienne : x+y z+ =. Les coordonnées de H vérifient cette équation donc H appartient à (P) et A n
Chapitre 2 Le problème de l unicité des solutions
 Université Joseph Fourier UE MAT 127 Mathématiques année 2011-2012 Chapitre 2 Le problème de l unicité des solutions Ce que nous verrons dans ce chapitre : un exemple d équation différentielle y = f(y)
Université Joseph Fourier UE MAT 127 Mathématiques année 2011-2012 Chapitre 2 Le problème de l unicité des solutions Ce que nous verrons dans ce chapitre : un exemple d équation différentielle y = f(y)
Souad EL Bernoussi. Groupe d Analyse Numérique et Optimisation Rabat http ://www.fsr.ac.ma/ano/
 Recherche opérationnelle Les démonstrations et les exemples seront traités en cours Souad EL Bernoussi Groupe d Analyse Numérique et Optimisation Rabat http ://www.fsr.ac.ma/ano/ Table des matières 1 Programmation
Recherche opérationnelle Les démonstrations et les exemples seront traités en cours Souad EL Bernoussi Groupe d Analyse Numérique et Optimisation Rabat http ://www.fsr.ac.ma/ano/ Table des matières 1 Programmation
NON-LINEARITE ET RESEAUX NEURONAUX
 NON-LINEARITE ET RESEAUX NEURONAUX Vêlayoudom MARIMOUTOU Laboratoire d Analyse et de Recherche Economiques Université de Bordeaux IV Avenue. Leon Duguit, 33608 PESSAC, France tel. 05 56 84 85 77 e-mail
NON-LINEARITE ET RESEAUX NEURONAUX Vêlayoudom MARIMOUTOU Laboratoire d Analyse et de Recherche Economiques Université de Bordeaux IV Avenue. Leon Duguit, 33608 PESSAC, France tel. 05 56 84 85 77 e-mail
Baccalauréat S Antilles-Guyane 11 septembre 2014 Corrigé
 Baccalauréat S ntilles-guyane 11 septembre 14 Corrigé EXERCICE 1 6 points Commun à tous les candidats Une entreprise de jouets en peluche souhaite commercialiser un nouveau produit et à cette fin, effectue
Baccalauréat S ntilles-guyane 11 septembre 14 Corrigé EXERCICE 1 6 points Commun à tous les candidats Une entreprise de jouets en peluche souhaite commercialiser un nouveau produit et à cette fin, effectue
Image d un intervalle par une fonction continue
 DOCUMENT 27 Image d un intervalle par une fonction continue La continuité d une fonction en un point est une propriété locale : une fonction est continue en un point x 0 si et seulement si sa restriction
DOCUMENT 27 Image d un intervalle par une fonction continue La continuité d une fonction en un point est une propriété locale : une fonction est continue en un point x 0 si et seulement si sa restriction
Les indices à surplus constant
 Les indices à surplus constant Une tentative de généralisation des indices à utilité constante On cherche ici en s inspirant des indices à utilité constante à définir un indice de prix de référence adapté
Les indices à surplus constant Une tentative de généralisation des indices à utilité constante On cherche ici en s inspirant des indices à utilité constante à définir un indice de prix de référence adapté
Probabilités III Introduction à l évaluation d options
 Probabilités III Introduction à l évaluation d options Jacques Printems Promotion 2012 2013 1 Modèle à temps discret 2 Introduction aux modèles en temps continu Limite du modèle binomial lorsque N + Un
Probabilités III Introduction à l évaluation d options Jacques Printems Promotion 2012 2013 1 Modèle à temps discret 2 Introduction aux modèles en temps continu Limite du modèle binomial lorsque N + Un
Direction des Études et Synthèses Économiques Département des Comptes Nationaux Division des Comptes Trimestriels
 Etab=MK3, Timbre=G430, TimbreDansAdresse=Vrai, Version=W2000/Charte7, VersionTravail=W2000/Charte7 Direction des Études et Synthèses Économiques Département des Comptes Nationaux Division des Comptes Trimestriels
Etab=MK3, Timbre=G430, TimbreDansAdresse=Vrai, Version=W2000/Charte7, VersionTravail=W2000/Charte7 Direction des Études et Synthèses Économiques Département des Comptes Nationaux Division des Comptes Trimestriels
Texte Agrégation limitée par diffusion interne
 Page n 1. Texte Agrégation limitée par diffusion interne 1 Le phénomène observé Un fût de déchets radioactifs est enterré secrètement dans le Cantal. Au bout de quelques années, il devient poreux et laisse
Page n 1. Texte Agrégation limitée par diffusion interne 1 Le phénomène observé Un fût de déchets radioactifs est enterré secrètement dans le Cantal. Au bout de quelques années, il devient poreux et laisse
Principe de symétrisation pour la construction d un test adaptatif
 Principe de symétrisation pour la construction d un test adaptatif Cécile Durot 1 & Yves Rozenholc 2 1 UFR SEGMI, Université Paris Ouest Nanterre La Défense, France, cecile.durot@gmail.com 2 Université
Principe de symétrisation pour la construction d un test adaptatif Cécile Durot 1 & Yves Rozenholc 2 1 UFR SEGMI, Université Paris Ouest Nanterre La Défense, France, cecile.durot@gmail.com 2 Université
Optimisation non linéaire Irène Charon, Olivier Hudry École nationale supérieure des télécommunications
 Optimisation non linéaire Irène Charon, Olivier Hudry École nationale supérieure des télécommunications A. Optimisation sans contrainte.... Généralités.... Condition nécessaire et condition suffisante
Optimisation non linéaire Irène Charon, Olivier Hudry École nationale supérieure des télécommunications A. Optimisation sans contrainte.... Généralités.... Condition nécessaire et condition suffisante
Programmes des classes préparatoires aux Grandes Ecoles
 Programmes des classes préparatoires aux Grandes Ecoles Filière : scientifique Voie : Biologie, chimie, physique et sciences de la Terre (BCPST) Discipline : Mathématiques Seconde année Préambule Programme
Programmes des classes préparatoires aux Grandes Ecoles Filière : scientifique Voie : Biologie, chimie, physique et sciences de la Terre (BCPST) Discipline : Mathématiques Seconde année Préambule Programme
Filtrage stochastique non linéaire par la théorie de représentation des martingales
 Filtrage stochastique non linéaire par la théorie de représentation des martingales Adriana Climescu-Haulica Laboratoire de Modélisation et Calcul Institut d Informatique et Mathématiques Appliquées de
Filtrage stochastique non linéaire par la théorie de représentation des martingales Adriana Climescu-Haulica Laboratoire de Modélisation et Calcul Institut d Informatique et Mathématiques Appliquées de
Chapitre 7. Statistique des échantillons gaussiens. 7.1 Projection de vecteurs gaussiens
 Chapitre 7 Statistique des échantillons gaussiens Le théorème central limite met en évidence le rôle majeur tenu par la loi gaussienne en modélisation stochastique. De ce fait, les modèles statistiques
Chapitre 7 Statistique des échantillons gaussiens Le théorème central limite met en évidence le rôle majeur tenu par la loi gaussienne en modélisation stochastique. De ce fait, les modèles statistiques
Exercices - Fonctions de plusieurs variables : corrigé. Pour commencer
 Pour commencer Exercice 1 - Ensembles de définition - Première année - 1. Le logarithme est défini si x + y > 0. On trouve donc le demi-plan supérieur délimité par la droite d équation x + y = 0.. 1 xy
Pour commencer Exercice 1 - Ensembles de définition - Première année - 1. Le logarithme est défini si x + y > 0. On trouve donc le demi-plan supérieur délimité par la droite d équation x + y = 0.. 1 xy
Séminaire TEST. 1 Présentation du sujet. October 18th, 2013
 Séminaire ES Andrés SÁNCHEZ PÉREZ October 8th, 03 Présentation du sujet Le problème de régression non-paramétrique se pose de la façon suivante : Supposons que l on dispose de n couples indépendantes de
Séminaire ES Andrés SÁNCHEZ PÉREZ October 8th, 03 Présentation du sujet Le problème de régression non-paramétrique se pose de la façon suivante : Supposons que l on dispose de n couples indépendantes de
TABLE DES MATIERES. C Exercices complémentaires 42
 TABLE DES MATIERES Chapitre I : Echantillonnage A - Rappels de cours 1. Lois de probabilités de base rencontrées en statistique 1 1.1 Définitions et caractérisations 1 1.2 Les propriétés de convergence
TABLE DES MATIERES Chapitre I : Echantillonnage A - Rappels de cours 1. Lois de probabilités de base rencontrées en statistique 1 1.1 Définitions et caractérisations 1 1.2 Les propriétés de convergence
Modèles pour données répétées
 Résumé Les données répétées, ou données longitudinales, constituent un domaine à la fois important et assez particulier de la statistique. On entend par données répétées des données telles que, pour chaque
Résumé Les données répétées, ou données longitudinales, constituent un domaine à la fois important et assez particulier de la statistique. On entend par données répétées des données telles que, pour chaque
Séries temporelles : régression, et modélisation ARIMA(p,d,q)
") Séries temporelles : régression, et modélisation ARIMA(p,d,q) 2 décembre 2012 Enseignant : Florin Avram Objectif : La prédiction des phénomènes spatio-temporaux est une des preoccupations principales dans
Séries temporelles : régression, et modélisation ARIMA(p,d,q) 2 décembre 2012 Enseignant : Florin Avram Objectif : La prédiction des phénomènes spatio-temporaux est une des preoccupations principales dans
CHAPITRE V SYSTEMES DIFFERENTIELS LINEAIRES A COEFFICIENTS CONSTANTS DU PREMIER ORDRE. EQUATIONS DIFFERENTIELLES.
 CHAPITRE V SYSTEMES DIFFERENTIELS LINEAIRES A COEFFICIENTS CONSTANTS DU PREMIER ORDRE EQUATIONS DIFFERENTIELLES Le but de ce chapitre est la résolution des deux types de systèmes différentiels linéaires
CHAPITRE V SYSTEMES DIFFERENTIELS LINEAIRES A COEFFICIENTS CONSTANTS DU PREMIER ORDRE EQUATIONS DIFFERENTIELLES Le but de ce chapitre est la résolution des deux types de systèmes différentiels linéaires
Exercices - Polynômes : corrigé. Opérations sur les polynômes
 Opérations sur les polynômes Exercice 1 - Carré - L1/Math Sup - Si P = Q est le carré d un polynôme, alors Q est nécessairement de degré, et son coefficient dominant est égal à 1. On peut donc écrire Q(X)
Opérations sur les polynômes Exercice 1 - Carré - L1/Math Sup - Si P = Q est le carré d un polynôme, alors Q est nécessairement de degré, et son coefficient dominant est égal à 1. On peut donc écrire Q(X)
Statistiques descriptives
 Statistiques descriptives L3 Maths-Eco Université de Nantes Frédéric Lavancier F. Lavancier (Univ. Nantes) Statistiques descriptives 1 1 Vocabulaire de base F. Lavancier (Univ. Nantes) Statistiques descriptives
Statistiques descriptives L3 Maths-Eco Université de Nantes Frédéric Lavancier F. Lavancier (Univ. Nantes) Statistiques descriptives 1 1 Vocabulaire de base F. Lavancier (Univ. Nantes) Statistiques descriptives
Le modèle de Black et Scholes
 Le modèle de Black et Scholes Alexandre Popier février 21 1 Introduction : exemple très simple de modèle financier On considère un marché avec une seule action cotée, sur une période donnée T. Dans un
Le modèle de Black et Scholes Alexandre Popier février 21 1 Introduction : exemple très simple de modèle financier On considère un marché avec une seule action cotée, sur une période donnée T. Dans un
Introduction aux Statistiques et à l utilisation du logiciel R
 Introduction aux Statistiques et à l utilisation du logiciel R Christophe Lalanne Christophe Pallier 1 Introduction 2 Comparaisons de deux moyennes 2.1 Objet de l étude On a mesuré le temps de sommeil
Introduction aux Statistiques et à l utilisation du logiciel R Christophe Lalanne Christophe Pallier 1 Introduction 2 Comparaisons de deux moyennes 2.1 Objet de l étude On a mesuré le temps de sommeil
Fonctions de plusieurs variables
 Module : Analyse 03 Chapitre 00 : Fonctions de plusieurs variables Généralités et Rappels des notions topologiques dans : Qu est- ce que?: Mathématiquement, n étant un entier non nul, on définit comme
Module : Analyse 03 Chapitre 00 : Fonctions de plusieurs variables Généralités et Rappels des notions topologiques dans : Qu est- ce que?: Mathématiquement, n étant un entier non nul, on définit comme
Introduction à l étude des Corps Finis
 Introduction à l étude des Corps Finis Robert Rolland (Résumé) 1 Introduction La structure de corps fini intervient dans divers domaines des mathématiques, en particulier dans la théorie de Galois sur
Introduction à l étude des Corps Finis Robert Rolland (Résumé) 1 Introduction La structure de corps fini intervient dans divers domaines des mathématiques, en particulier dans la théorie de Galois sur
CAPTEURS - CHAINES DE MESURES
 CAPTEURS - CHAINES DE MESURES Pierre BONNET Pierre Bonnet Master GSI - Capteurs Chaînes de Mesures 1 Plan du Cours Propriétés générales des capteurs Notion de mesure Notion de capteur: principes, classes,
CAPTEURS - CHAINES DE MESURES Pierre BONNET Pierre Bonnet Master GSI - Capteurs Chaînes de Mesures 1 Plan du Cours Propriétés générales des capteurs Notion de mesure Notion de capteur: principes, classes,
Espérance conditionnelle
 Espérance conditionnelle Samy Tindel Nancy-Université Master 1 - Nancy Samy T. (IECN) M1 - Espérance conditionnelle Nancy-Université 1 / 58 Plan 1 Définition 2 Exemples 3 Propriétés de l espérance conditionnelle
Espérance conditionnelle Samy Tindel Nancy-Université Master 1 - Nancy Samy T. (IECN) M1 - Espérance conditionnelle Nancy-Université 1 / 58 Plan 1 Définition 2 Exemples 3 Propriétés de l espérance conditionnelle
Exercice autour de densité, fonction de répatition, espérance et variance de variables quelconques.
 14-3- 214 J.F.C. p. 1 I Exercice autour de densité, fonction de répatition, espérance et variance de variables quelconques. Exercice 1 Densité de probabilité. F { ln x si x ], 1] UN OVNI... On pose x R,
14-3- 214 J.F.C. p. 1 I Exercice autour de densité, fonction de répatition, espérance et variance de variables quelconques. Exercice 1 Densité de probabilité. F { ln x si x ], 1] UN OVNI... On pose x R,
1 Complément sur la projection du nuage des individus
 TP 0 : Analyse en composantes principales (II) Le but de ce TP est d approfondir nos connaissances concernant l analyse en composantes principales (ACP). Pour cela, on reprend les notations du précédent
TP 0 : Analyse en composantes principales (II) Le but de ce TP est d approfondir nos connaissances concernant l analyse en composantes principales (ACP). Pour cela, on reprend les notations du précédent
Théorème du point fixe - Théorème de l inversion locale
 Chapitre 7 Théorème du point fixe - Théorème de l inversion locale Dans ce chapitre et le suivant, on montre deux applications importantes de la notion de différentiabilité : le théorème de l inversion
Chapitre 7 Théorème du point fixe - Théorème de l inversion locale Dans ce chapitre et le suivant, on montre deux applications importantes de la notion de différentiabilité : le théorème de l inversion
Exemples d application
 AgroParisTech Exemples d application du modèle linéaire E Lebarbier, S Robin Table des matières 1 Introduction 4 11 Avertissement 4 12 Notations 4 2 Régression linéaire simple 7 21 Présentation 7 211 Objectif
AgroParisTech Exemples d application du modèle linéaire E Lebarbier, S Robin Table des matières 1 Introduction 4 11 Avertissement 4 12 Notations 4 2 Régression linéaire simple 7 21 Présentation 7 211 Objectif
Peut-on encore stabiliser les prix des matières premières?
 DEA Analyse et Politique Économiques École des Hautes Études en Sciences Sociales, Paris Peut-on encore stabiliser les prix des matières premières? Étude d un mécanisme de lissage par moyenne mobile Sébastien
DEA Analyse et Politique Économiques École des Hautes Études en Sciences Sociales, Paris Peut-on encore stabiliser les prix des matières premières? Étude d un mécanisme de lissage par moyenne mobile Sébastien
Intégration et probabilités TD1 Espaces mesurés Corrigé
 Intégration et probabilités TD1 Espaces mesurés Corrigé 2012-2013 1 Petites questions 1 Est-ce que l ensemble des ouverts de R est une tribu? Réponse : Non, car le complémentaire de ], 0[ n est pas ouvert.
Intégration et probabilités TD1 Espaces mesurés Corrigé 2012-2013 1 Petites questions 1 Est-ce que l ensemble des ouverts de R est une tribu? Réponse : Non, car le complémentaire de ], 0[ n est pas ouvert.
NOTATIONS PRÉLIMINAIRES
 Pour le Jeudi 14 Octobre 2010 NOTATIONS Soit V un espace vectoriel réel ; l'espace vectoriel des endomorphismes de l'espace vectoriel V est désigné par L(V ). Soit f un endomorphisme de l'espace vectoriel
Pour le Jeudi 14 Octobre 2010 NOTATIONS Soit V un espace vectoriel réel ; l'espace vectoriel des endomorphismes de l'espace vectoriel V est désigné par L(V ). Soit f un endomorphisme de l'espace vectoriel
Régression linéaire. Nicolas Turenne INRA nicolas.turenne@jouy.inra.fr
 Régression linéaire Nicolas Turenne INRA nicolas.turenne@jouy.inra.fr 2005 Plan Régression linéaire simple Régression multiple Compréhension de la sortie de la régression Coefficient de détermination R
Régression linéaire Nicolas Turenne INRA nicolas.turenne@jouy.inra.fr 2005 Plan Régression linéaire simple Régression multiple Compréhension de la sortie de la régression Coefficient de détermination R
Un exemple de régression logistique sous
 Fiche TD avec le logiciel : tdr341 Un exemple de régression logistique sous A.B. Dufour & A. Viallefont Etude de l apparition ou non d une maladie cardiaque des coronaires 1 Présentation des données Les
Fiche TD avec le logiciel : tdr341 Un exemple de régression logistique sous A.B. Dufour & A. Viallefont Etude de l apparition ou non d une maladie cardiaque des coronaires 1 Présentation des données Les
3. Conditionnement P (B)
") Conditionnement 16 3. Conditionnement Dans cette section, nous allons rappeler un certain nombre de définitions et de propriétés liées au problème du conditionnement, c est à dire à la prise en compte
Conditionnement 16 3. Conditionnement Dans cette section, nous allons rappeler un certain nombre de définitions et de propriétés liées au problème du conditionnement, c est à dire à la prise en compte
Chapitre 2. Les Processus Aléatoires Non Stationnaires 1. Chapitre 2. Tests de Non Stationnarité et Processus Aléatoires Non Stationnaires
 Chapitre 2. Les Processus Aléatoires Non Stationnaires 1 Chapitre 2 Tests de Non Stationnarité et Processus Aléatoires Non Stationnaires Chapitre 2. Les Processus Aléatoires Non Stationnaires 2 Dans le
Chapitre 2. Les Processus Aléatoires Non Stationnaires 1 Chapitre 2 Tests de Non Stationnarité et Processus Aléatoires Non Stationnaires Chapitre 2. Les Processus Aléatoires Non Stationnaires 2 Dans le
Résolution d équations non linéaires
 Analyse Numérique Résolution d équations non linéaires Said EL HAJJI et Touria GHEMIRES Université Mohammed V - Agdal. Faculté des Sciences Département de Mathématiques. Laboratoire de Mathématiques, Informatique
Analyse Numérique Résolution d équations non linéaires Said EL HAJJI et Touria GHEMIRES Université Mohammed V - Agdal. Faculté des Sciences Département de Mathématiques. Laboratoire de Mathématiques, Informatique
Le Modèle Linéaire par l exemple :
 Publications du Laboratoire de Statistique et Probabilités Le Modèle Linéaire par l exemple : Régression, Analyse de la Variance,... Jean-Marc Azaïs et Jean-Marc Bardet Laboratoire de Statistique et Probabilités
Publications du Laboratoire de Statistique et Probabilités Le Modèle Linéaire par l exemple : Régression, Analyse de la Variance,... Jean-Marc Azaïs et Jean-Marc Bardet Laboratoire de Statistique et Probabilités
Le modèle de régression linéaire
 Chapitre 2 Le modèle de régression linéaire 2.1 Introduction L économétrie traite de la construction de modèles. Le premier point de l analyse consiste à se poser la question : «Quel est le modèle?». Le
Chapitre 2 Le modèle de régression linéaire 2.1 Introduction L économétrie traite de la construction de modèles. Le premier point de l analyse consiste à se poser la question : «Quel est le modèle?». Le
Cours 02 : Problème général de la programmation linéaire
 Cours 02 : Problème général de la programmation linéaire Cours 02 : Problème général de la Programmation Linéaire. 5 . Introduction Un programme linéaire s'écrit sous la forme suivante. MinZ(ou maxw) =
Cours 02 : Problème général de la programmation linéaire Cours 02 : Problème général de la Programmation Linéaire. 5 . Introduction Un programme linéaire s'écrit sous la forme suivante. MinZ(ou maxw) =
Simulation de variables aléatoires
 Chapter 1 Simulation de variables aléatoires Références: [F] Fishman, A first course in Monte Carlo, chap 3. [B] Bouleau, Probabilités de l ingénieur, chap 4. [R] Rubinstein, Simulation and Monte Carlo
Chapter 1 Simulation de variables aléatoires Références: [F] Fishman, A first course in Monte Carlo, chap 3. [B] Bouleau, Probabilités de l ingénieur, chap 4. [R] Rubinstein, Simulation and Monte Carlo
Actuariat I ACT2121. septième séance. Arthur Charpentier. Automne 2012. charpentier.arthur@uqam.ca. http ://freakonometrics.blog.free.
 Actuariat I ACT2121 septième séance Arthur Charpentier charpentier.arthur@uqam.ca http ://freakonometrics.blog.free.fr/ Automne 2012 1 Exercice 1 En analysant le temps d attente X avant un certain événement
Actuariat I ACT2121 septième séance Arthur Charpentier charpentier.arthur@uqam.ca http ://freakonometrics.blog.free.fr/ Automne 2012 1 Exercice 1 En analysant le temps d attente X avant un certain événement
Économetrie non paramétrique I. Estimation d une densité
 Économetrie non paramétrique I. Estimation d une densité Stéphane Adjemian Université d Évry Janvier 2004 1 1 Introduction 1.1 Pourquoi estimer une densité? Étudier la distribution des richesses... Proposer
Économetrie non paramétrique I. Estimation d une densité Stéphane Adjemian Université d Évry Janvier 2004 1 1 Introduction 1.1 Pourquoi estimer une densité? Étudier la distribution des richesses... Proposer
distribution quelconque Signe 1 échantillon non Wilcoxon gaussienne distribution symétrique Student gaussienne position
 Arbre de NESI distribution quelconque Signe 1 échantillon distribution symétrique non gaussienne Wilcoxon gaussienne Student position appariés 1 échantillon sur la différence avec référence=0 2 échantillons
Arbre de NESI distribution quelconque Signe 1 échantillon distribution symétrique non gaussienne Wilcoxon gaussienne Student position appariés 1 échantillon sur la différence avec référence=0 2 échantillons
Modèle de troncature gauche : Comparaison par simulation sur données indépendantes et dépendantes
 de troncature gauche : Comparaison par simulation sur données indépendantes et dépendantes Zohra Guessoum 1 & Farida Hamrani 2 1 Lab. MSTD, Faculté de mathématique, USTHB, BP n 32, El Alia, Alger, Algérie,zguessoum@usthb.dz
de troncature gauche : Comparaison par simulation sur données indépendantes et dépendantes Zohra Guessoum 1 & Farida Hamrani 2 1 Lab. MSTD, Faculté de mathématique, USTHB, BP n 32, El Alia, Alger, Algérie,zguessoum@usthb.dz
Exercice : la frontière des portefeuilles optimaux sans actif certain
 Exercice : la frontière des portefeuilles optimaux sans actif certain Philippe Bernard Ingénierie Economique & Financière Université Paris-Dauphine Février 0 On considère un univers de titres constitué
Exercice : la frontière des portefeuilles optimaux sans actif certain Philippe Bernard Ingénierie Economique & Financière Université Paris-Dauphine Février 0 On considère un univers de titres constitué
Continuité et dérivabilité d une fonction
 DERNIÈRE IMPRESSIN LE 7 novembre 014 à 10:3 Continuité et dérivabilité d une fonction Table des matières 1 Continuité d une fonction 1.1 Limite finie en un point.......................... 1. Continuité
DERNIÈRE IMPRESSIN LE 7 novembre 014 à 10:3 Continuité et dérivabilité d une fonction Table des matières 1 Continuité d une fonction 1.1 Limite finie en un point.......................... 1. Continuité
Chapitre 3. Les distributions à deux variables
 Chapitre 3. Les distributions à deux variables Jean-François Coeurjolly http://www-ljk.imag.fr/membres/jean-francois.coeurjolly/ Laboratoire Jean Kuntzmann (LJK), Grenoble University 1 Distributions conditionnelles
Chapitre 3. Les distributions à deux variables Jean-François Coeurjolly http://www-ljk.imag.fr/membres/jean-francois.coeurjolly/ Laboratoire Jean Kuntzmann (LJK), Grenoble University 1 Distributions conditionnelles
Exo7. Matrice d une application linéaire. Corrections d Arnaud Bodin.
 Exo7 Matrice d une application linéaire Corrections d Arnaud odin. Exercice Soit R muni de la base canonique = ( i, j). Soit f : R R la projection sur l axe des abscisses R i parallèlement à R( i + j).
Exo7 Matrice d une application linéaire Corrections d Arnaud odin. Exercice Soit R muni de la base canonique = ( i, j). Soit f : R R la projection sur l axe des abscisses R i parallèlement à R( i + j).
Chapitre 5 : Flot maximal dans un graphe
 Graphes et RO TELECOM Nancy A Chapitre 5 : Flot maximal dans un graphe J.-F. Scheid 1 Plan du chapitre I. Définitions 1 Graphe Graphe valué 3 Représentation d un graphe (matrice d incidence, matrice d
Graphes et RO TELECOM Nancy A Chapitre 5 : Flot maximal dans un graphe J.-F. Scheid 1 Plan du chapitre I. Définitions 1 Graphe Graphe valué 3 Représentation d un graphe (matrice d incidence, matrice d
Chapitre 1 : Évolution COURS
 Chapitre 1 : Évolution COURS OBJECTIFS DU CHAPITRE Savoir déterminer le taux d évolution, le coefficient multiplicateur et l indice en base d une évolution. Connaître les liens entre ces notions et savoir
Chapitre 1 : Évolution COURS OBJECTIFS DU CHAPITRE Savoir déterminer le taux d évolution, le coefficient multiplicateur et l indice en base d une évolution. Connaître les liens entre ces notions et savoir
Chapitre 1 Régime transitoire dans les systèmes physiques
 Chapitre 1 Régime transitoire dans les systèmes physiques Savoir-faire théoriques (T) : Écrire l équation différentielle associée à un système physique ; Faire apparaître la constante de temps ; Tracer
Chapitre 1 Régime transitoire dans les systèmes physiques Savoir-faire théoriques (T) : Écrire l équation différentielle associée à un système physique ; Faire apparaître la constante de temps ; Tracer
TP1 Méthodes de Monte Carlo et techniques de réduction de variance, application au pricing d options
 Université de Lorraine Modélisation Stochastique Master 2 IMOI 2014-2015 TP1 Méthodes de Monte Carlo et techniques de réduction de variance, application au pricing d options 1 Les options Le but de ce
Université de Lorraine Modélisation Stochastique Master 2 IMOI 2014-2015 TP1 Méthodes de Monte Carlo et techniques de réduction de variance, application au pricing d options 1 Les options Le but de ce
Fonctions de plusieurs variables, intégrales multiples, et intégrales dépendant d un paramètre
 IUFM du Limousin 2009-10 PLC1 Mathématiques S. Vinatier Rappels de cours Fonctions de plusieurs variables, intégrales multiples, et intégrales dépendant d un paramètre 1 Fonctions de plusieurs variables
IUFM du Limousin 2009-10 PLC1 Mathématiques S. Vinatier Rappels de cours Fonctions de plusieurs variables, intégrales multiples, et intégrales dépendant d un paramètre 1 Fonctions de plusieurs variables
Exercices Corrigés Premières notions sur les espaces vectoriels
 Exercices Corrigés Premières notions sur les espaces vectoriels Exercice 1 On considére le sous-espace vectoriel F de R formé des solutions du système suivant : x1 x 2 x 3 + 2x = 0 E 1 x 1 + 2x 2 + x 3
Exercices Corrigés Premières notions sur les espaces vectoriels Exercice 1 On considére le sous-espace vectoriel F de R formé des solutions du système suivant : x1 x 2 x 3 + 2x = 0 E 1 x 1 + 2x 2 + x 3
Équations non linéaires
 Équations non linéaires Objectif : trouver les zéros de fonctions (ou systèmes) non linéaires, c-à-d les valeurs α R telles que f(α) = 0. y f(x) α 1 α 2 α 3 x Equations non lineaires p. 1/49 Exemples et
Équations non linéaires Objectif : trouver les zéros de fonctions (ou systèmes) non linéaires, c-à-d les valeurs α R telles que f(α) = 0. y f(x) α 1 α 2 α 3 x Equations non lineaires p. 1/49 Exemples et
Méthodes de quadrature. Polytech Paris-UPMC. - p. 1/48
 Méthodes de Polytech Paris-UPMC - p. 1/48 Polynôme d interpolation de Preuve et polynôme de Calcul de l erreur d interpolation Étude de la formule d erreur Autres méthodes - p. 2/48 Polynôme d interpolation
Méthodes de Polytech Paris-UPMC - p. 1/48 Polynôme d interpolation de Preuve et polynôme de Calcul de l erreur d interpolation Étude de la formule d erreur Autres méthodes - p. 2/48 Polynôme d interpolation
Optimisation, traitement d image et éclipse de Soleil
 Kléber, PCSI1&3 014-015 I. Introduction 1/8 Optimisation, traitement d image et éclipse de Soleil Partie I Introduction Le 0 mars 015 a eu lieu en France une éclipse partielle de Soleil qu il était particulièrement
Kléber, PCSI1&3 014-015 I. Introduction 1/8 Optimisation, traitement d image et éclipse de Soleil Partie I Introduction Le 0 mars 015 a eu lieu en France une éclipse partielle de Soleil qu il était particulièrement
Densité de population et ingestion de nourriture chez un insecte vecteur de la maladie de Chagas
 Fiche TD avec le logiciel : tdr335 Densité de population et ingestion de nourriture chez un insecte vecteur de la maladie de Chagas F. Menu, A.B. Dufour, E. Desouhant et I. Amat La fiche permet de se familiariser
Fiche TD avec le logiciel : tdr335 Densité de population et ingestion de nourriture chez un insecte vecteur de la maladie de Chagas F. Menu, A.B. Dufour, E. Desouhant et I. Amat La fiche permet de se familiariser
CCP PSI - 2010 Mathématiques 1 : un corrigé
 CCP PSI - 00 Mathématiques : un corrigé Première partie. Définition d une structure euclidienne sur R n [X]... B est clairement symétrique et linéaire par rapport à sa seconde variable. De plus B(P, P
CCP PSI - 00 Mathématiques : un corrigé Première partie. Définition d une structure euclidienne sur R n [X]... B est clairement symétrique et linéaire par rapport à sa seconde variable. De plus B(P, P
UNIVERSITÉ DU QUÉBEC À MONTRÉAL TESTS EN ÉCHANTILLONS FINIS DU MEDAF SANS LA NORMALITÉ ET SANS LA CONVERGENCE
 UNIVERSITÉ DU QUÉBEC À MONTRÉAL TESTS EN ÉCHANTILLONS FINIS DU MEDAF SANS LA NORMALITÉ ET SANS LA CONVERGENCE MÉMOIRE PRÉSENTÉ COMME EXIGENCE PARTIELLE DE LA MAÎTRISE EN ÉCONOMIE PAR MATHIEU SISTO NOVEMBRE
UNIVERSITÉ DU QUÉBEC À MONTRÉAL TESTS EN ÉCHANTILLONS FINIS DU MEDAF SANS LA NORMALITÉ ET SANS LA CONVERGENCE MÉMOIRE PRÉSENTÉ COMME EXIGENCE PARTIELLE DE LA MAÎTRISE EN ÉCONOMIE PAR MATHIEU SISTO NOVEMBRE
Calcul différentiel sur R n Première partie
 Calcul différentiel sur R n Première partie Université De Metz 2006-2007 1 Définitions générales On note L(R n, R m ) l espace vectoriel des applications linéaires de R n dans R m. Définition 1.1 (différentiabilité
Calcul différentiel sur R n Première partie Université De Metz 2006-2007 1 Définitions générales On note L(R n, R m ) l espace vectoriel des applications linéaires de R n dans R m. Définition 1.1 (différentiabilité
Contexte. Pour cela, elles doivent être très compliquées, c est-à-dire elles doivent être très différentes des fonctions simples,
 Non-linéarité Contexte Pour permettre aux algorithmes de cryptographie d être sûrs, les fonctions booléennes qu ils utilisent ne doivent pas être inversées facilement. Pour cela, elles doivent être très
Non-linéarité Contexte Pour permettre aux algorithmes de cryptographie d être sûrs, les fonctions booléennes qu ils utilisent ne doivent pas être inversées facilement. Pour cela, elles doivent être très
Moments des variables aléatoires réelles
 Chapter 6 Moments des variables aléatoires réelles Sommaire 6.1 Espérance des variables aléatoires réelles................................ 46 6.1.1 Définition et calcul........................................
Chapter 6 Moments des variables aléatoires réelles Sommaire 6.1 Espérance des variables aléatoires réelles................................ 46 6.1.1 Définition et calcul........................................
aux différences est appelé équation aux différences d ordre n en forme normale.
 MODÉLISATION ET SIMULATION EQUATIONS AUX DIFFÉRENCES (I/II) 1. Rappels théoriques : résolution d équations aux différences 1.1. Équations aux différences. Définition. Soit x k = x(k) X l état scalaire
MODÉLISATION ET SIMULATION EQUATIONS AUX DIFFÉRENCES (I/II) 1. Rappels théoriques : résolution d équations aux différences 1.1. Équations aux différences. Définition. Soit x k = x(k) X l état scalaire
Licence MASS 2000-2001. (Re-)Mise à niveau en Probabilités. Feuilles de 1 à 7
Mise à niveau en Probabilités. Feuilles de 1 à 7") Feuilles de 1 à 7 Ces feuilles avec 25 exercices et quelques rappels historiques furent distribuées à des étudiants de troisième année, dans le cadre d un cours intensif sur deux semaines, en début d année,
Feuilles de 1 à 7 Ces feuilles avec 25 exercices et quelques rappels historiques furent distribuées à des étudiants de troisième année, dans le cadre d un cours intensif sur deux semaines, en début d année,
Étude des flux d individus et des modalités de recrutement chez Formica rufa
 Étude des flux d individus et des modalités de recrutement chez Formica rufa Bruno Labelle Théophile Olivier Karl Lesiourd Charles Thevenin 07 Avril 2012 1 Sommaire Remerciements I) Introduction p3 Intérêt
Étude des flux d individus et des modalités de recrutement chez Formica rufa Bruno Labelle Théophile Olivier Karl Lesiourd Charles Thevenin 07 Avril 2012 1 Sommaire Remerciements I) Introduction p3 Intérêt
IBM SPSS Forecasting. Créez des prévisions d'expert en un clin d'œil. Points clés. IBM Software Business Analytics
 IBM SPSS Statistics 19 IBM SPSS Forecasting Créez des prévisions d'expert en un clin d'œil Points clés Développer des prévisions fiables rapidement Réduire les erreurs de prévision Mettre à jour et gérer
IBM SPSS Statistics 19 IBM SPSS Forecasting Créez des prévisions d'expert en un clin d'œil Points clés Développer des prévisions fiables rapidement Réduire les erreurs de prévision Mettre à jour et gérer
Continuité en un point
 DOCUMENT 4 Continuité en un point En général, D f désigne l ensemble de définition de la fonction f et on supposera toujours que cet ensemble est inclus dans R. Toutes les fonctions considérées sont à
DOCUMENT 4 Continuité en un point En général, D f désigne l ensemble de définition de la fonction f et on supposera toujours que cet ensemble est inclus dans R. Toutes les fonctions considérées sont à
La problématique des tests. Cours V. 7 mars 2008. Comment quantifier la performance d un test? Hypothèses simples et composites
 La problématique des tests Cours V 7 mars 8 Test d hypothèses [Section 6.1] Soit un modèle statistique P θ ; θ Θ} et des hypothèses H : θ Θ H 1 : θ Θ 1 = Θ \ Θ Un test (pur) est une statistique à valeur
La problématique des tests Cours V 7 mars 8 Test d hypothèses [Section 6.1] Soit un modèle statistique P θ ; θ Θ} et des hypothèses H : θ Θ H 1 : θ Θ 1 = Θ \ Θ Un test (pur) est une statistique à valeur
* très facile ** facile *** difficulté moyenne **** difficile ***** très difficile I : Incontournable T : pour travailler et mémoriser le cours
 Exo7 Continuité (étude globale). Diverses fonctions Exercices de Jean-Louis Rouget. Retrouver aussi cette fiche sur www.maths-france.fr * très facile ** facile *** difficulté moyenne **** difficile *****
Exo7 Continuité (étude globale). Diverses fonctions Exercices de Jean-Louis Rouget. Retrouver aussi cette fiche sur www.maths-france.fr * très facile ** facile *** difficulté moyenne **** difficile *****
Résolution de systèmes linéaires par des méthodes directes
 Résolution de systèmes linéaires par des méthodes directes J. Erhel Janvier 2014 1 Inverse d une matrice carrée et systèmes linéaires Ce paragraphe a pour objet les matrices carrées et les systèmes linéaires.
Résolution de systèmes linéaires par des méthodes directes J. Erhel Janvier 2014 1 Inverse d une matrice carrée et systèmes linéaires Ce paragraphe a pour objet les matrices carrées et les systèmes linéaires.
Évaluation de la régression bornée
 Thierry Foucart UMR 6086, Université de Poitiers, S P 2 M I, bd 3 téléport 2 BP 179, 86960 Futuroscope, Cedex FRANCE Résumé. le modèle linéaire est très fréquemment utilisé en statistique et particulièrement
Thierry Foucart UMR 6086, Université de Poitiers, S P 2 M I, bd 3 téléport 2 BP 179, 86960 Futuroscope, Cedex FRANCE Résumé. le modèle linéaire est très fréquemment utilisé en statistique et particulièrement
Première partie. Préliminaires : noyaux itérés. MPSI B 6 juin 2015
 Énoncé Soit V un espace vectoriel réel. L espace vectoriel des endomorphismes de V est désigné par L(V ). Lorsque f L(V ) et k N, on désigne par f 0 = Id V, f k = f k f la composée de f avec lui même k
Énoncé Soit V un espace vectoriel réel. L espace vectoriel des endomorphismes de V est désigné par L(V ). Lorsque f L(V ) et k N, on désigne par f 0 = Id V, f k = f k f la composée de f avec lui même k
Programmation linéaire et Optimisation. Didier Smets
 Programmation linéaire et Optimisation Didier Smets Chapitre 1 Un problème d optimisation linéaire en dimension 2 On considère le cas d un fabricant d automobiles qui propose deux modèles à la vente, des
Programmation linéaire et Optimisation Didier Smets Chapitre 1 Un problème d optimisation linéaire en dimension 2 On considère le cas d un fabricant d automobiles qui propose deux modèles à la vente, des
ACTUARIAT 1, ACT 2121, AUTOMNE 2013 #12
 ACTUARIAT 1, ACT 2121, AUTOMNE 2013 #12 ARTHUR CHARPENTIER 1 Une compagnie d assurance modélise le montant de la perte lors d un accident par la variable aléatoire continue X uniforme sur l intervalle
ACTUARIAT 1, ACT 2121, AUTOMNE 2013 #12 ARTHUR CHARPENTIER 1 Une compagnie d assurance modélise le montant de la perte lors d un accident par la variable aléatoire continue X uniforme sur l intervalle
Le théorème des deux fonds et la gestion indicielle
 Le théorème des deux fonds et la gestion indicielle Philippe Bernard Ingénierie Economique& Financière Université Paris-Dauphine mars 2013 Les premiers fonds indiciels futent lancés aux Etats-Unis par
Le théorème des deux fonds et la gestion indicielle Philippe Bernard Ingénierie Economique& Financière Université Paris-Dauphine mars 2013 Les premiers fonds indiciels futent lancés aux Etats-Unis par