Programmation parallèle et distribuée
|
|
|
- Isabelle Boisvert
- il y a 8 ans
- Total affichages :
Transcription
1 Programmation parallèle et distribuée (GIF-4104/7104) Programmation massivement multifilaire sur GPU avec OpenCL (hiver 2013) Marc Parizeau, Département de génie électrique et de génie informatique

2 OpenCL Open Computing Language spécification ouverte et libre Initialement conçu par Apple proposé au Khronos Group en 2008 (version 1.0) consortium sans but lucratif, financé par diverses compagnies dont ATI, Intel, NVIDIA, SGI et Sun/Oracle Framework pour écrire des programmes qui s'exécutent à la fois sur des CPUs et GPUs CPU = Central Processing Unit GPU = Graphics Processing Unit GPGPU = General Purpose computing on Graphics Processing Unit Version actuelle: OpenCL 1.2 (nov. 2011) 2

3 Les GPUs sont caractérisés par des centaines de cœurs de traitement 3

4 Plan Architecture des GPUs ATI/AMD NVIDIA Cell OpenCL la plateforme les principales fonctions de l'api les étapes d'un programme la mémoire l'ordonnancement des fils d'exécution CUDA (Compute Unified Device Architecture) 4

5 CPU Beaucoup de surface investie en logique de contrôle optimisé pour réduire la latence des opérations unifilaires cache multi-niveau peu de registres réordonnancement des instructions pour alimenter les pipelines Control Logic ALU L2 Cache L1 Cache ~ 25GBPS System Memory L3 Cache A present day multicore CPU could have more than one ALU ( typically < 32) and some of the cache hierarchy is usually shared across cores Perhaad Mistry & Dana Schaa, Northeastern Univ Computer Architecture Research Lab, with Ben Gaster, AMD

6 GPU Beaucoup de cœurs moins de logique beaucoup de registres Beaucoup de fils d'exécution parallèles commutation à faible latence Beaucoup d'unités arithmétiques par cœur mémoire rapide permet d'alimenter toutes les unités arithmétiques Optimisé pour le débit Simple ALUs Cache High Bandwidth bus to ALUs On Board System Memory Perhaad Mistry & Dana Schaa, Northeastern Univ Computer Architecture Research Lab, with Ben Gaster, AMD

7 CPU vs. GPU - GFLOPs 7

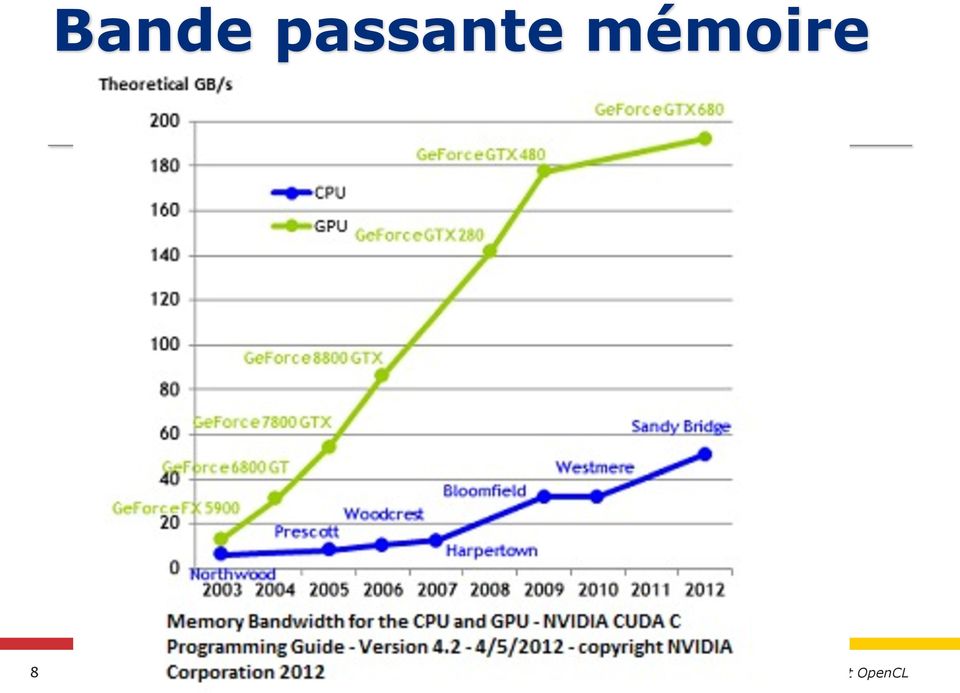
8 Bande passante mémoire 8
9 GPU AMD 9

10 Par exemple, la carte AMD Cypress 20 compute units 16 cœurs par unit 5 multiply-add par cœur 2.72 téraflops (simple précision) 544 gigaflops (double précision) 10
 544")
11 Moteur SIMD Un engin SIMD est aussi appelé «compute unit» un compute unit regroupe 16 cœurs un cœur peut effectuer jusqu'à 5 multiply-add par cycle les cœurs d'un même groupe exécutent tous les mêmes séquences d'instructions T-Processing Element One SIMD Engine One Stream Core Instruction and Control Flow General Purpose Registers Branch Execution Unit Processing Elements Source: AMD Accelerated Parallel Processing OpenCL Programming Guide 11

12 AMD et OpenCL Compute device un GPU physique Compute unit ensemble de processeurs élémentaires qui exécutent la même instruction Processing element un des coeurs (Stream Core) pouvant exécuter X opérations par cycle 12
 pouvant exécuter X opérations")
13 Architecture mémoire (AMD 5870) SIMD Engine LDS, Registers Compute Unit to Memory X-bar L2 Cache L1 Cache LDS Write Cache Atomic Path Perhaad Mistry & Dana Schaa, Northeastern Univ Computer Architecture Research Lab, with Ben Gaster, AMD 2011 Mémoire locale à chaque compute unit local data store (LDS) registres Cache L1 pour chaque compute unit Cache L2 partagée entre les compute units 13
 registres Cache L1 pour chaque compute unit Cache L2 partagée entre les compute")
14 AMD et OpenCL Une partie de la mémoire globale est exposée à OpenCL La mémoire locale correspond au LDS La mémoire privée utilise les registres La mémoire constante utilise la cache L1 Private Memory Workitem 1 Compute Unit 1 Local Memory Private Memory Workitem 1 Compute Device Global / Constant Memory Data Cache Global Memory Compute Device Memory Private Memory Workitem 1 Compute Unit N Local Memory Private Memory Workitem 1 14

15 GPU NVIDIA CUDA Core Dispatch Port Operand Collector FP Unit Int Unit Result Queue Par exemple, la carte GTX streaming multiprocessors (SM) chaque SM comporte 32 cœurs CUDA (processeurs élémentaires) total de 480 cœurs CUDA Un SM exécute des fils en groupe de 32 appelé «warp» Les cœurs CUDA comportent un ALU et un FPU chacun Warp Scheduler Core Core Core Core Core Core Core Core Dispatch Unit Core Core Core Core Core Core Core Core Instruction Cache Register File x 32bit Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Interconnect Memory LDST L1 Cache / 64kB Shared Memory L2 Cache Warp Scheduler Dispatch Unit LDST LDST LDST LDST LDST LDST LDST LDST LDST LDST LDST Perhaad Mistry & Dana Schaa, Northeastern Univ Computer Architecture Research Lab, with Ben Gaster, AMD 2011 SFU SFU SFU SFU 15

16 GPU NVIDIA 16

17 Architecture mémoire La Cache L1 est configurable pour chaque SM mémoire partagée mémoire globale La mémoire partagée sert entre les fils d'un même groupe Chaque SM possède aussi une banque de 32Ko pour les registres Registers Shared Memory Global Memory Thread Block L1 Cache L2 Cache Perhaad Mistry & Dana Schaa, Northeastern Univ Computer Architecture Research Lab, with Ben Gaster, AMD

18 NVIDIA et OpenCL Private Memory Workitem 1 Compute Unit 1 Local Memory Private Memory Workitem 1 Compute Device Global / Constant Memory Data Cache Global Memory Compute Device Memory Private Memory Workitem 1 Compute Unit N Local Memory Perhaad Mistry & Dana Schaa, Northeastern Univ Computer Architecture Research Lab, with Ben Gaster, AMD 2011 Private Memory Workitem 1 Comme pour AMD, un sous-ensemble de la mémoire est exposée à OpenCL La mémoire partagée configurable sert de mémoire locale pour chaque compute unit La mémoire privée utilise les registres 18

19 Cell SPE 0 SPE 1 SPE 2 SPE 3 Processeur de la PS3 1 processeurs PPC pour le host jusqu'à 8 processeurs «synergétiques» SPU LS LS = Local store per SPE of 256KB PPE SPU LS SPU LS 25 GBPS 25 GBPS 25 GBPS Element Interconnect ~ 200GBPS L1 and L2 Cache POWER PC SPU LS Memory & Interrupt Controller 25 GBPS 19

20 GPGPU en pratique Un usage efficace des GPUs, quels qu'ils soient, implique: la décomposition du problème en milliers de petites tâches indépendantes, de manière à pouvoir exploiter tout le matériel et minimiser la latence que ces tâches soit souvent les mêmes pour exploiter le modèle SIMD que les tâches soient surtout de nature arithmétique (éviter à tout prix la combinatoire) 20
")
21 Compilateur OpenCL OpenCL utilise la technologie de compilateur LLVM («low level virtual machine») pour compiler les noyaux (et pour GPU et pour CPU) Processus bourré d optimisations, différent selon le hardware OpenCL Compute Program LLVM IR LLVM Front-end Nvidia PTX AMD CAL IL x86 21
22 Plan Architecture des GPUs ATI/AMD NVIDIA Cell OpenCL la plateforme les principales fonctions de l'api les étapes d'un programme la mémoire l'ordonnancement des fils d'exécution CUDA 22
23 Architecture de OpenCL OpenCL est un environnement pour la programmation parallèle dans un contexte hétérogène CPU + GPU(s) Articulé autour de quatre modèles: plateforme exécution mémoire programmation 23
24 Plateformes Chaque implantation OpenCL définit la plateforme qui permet à l'hôte (CPU) d'interagir avec le ou les «devices» (GPUs) plusieurs plateformes différentes peuvent coexister un hôte + une ou plusieurs plateformes ex. : une implémentation d OpenCL fournie par NVidia pour parler à votre carte graphique, une autre par Intel pour le CPU ou pour utiliser votre carte graphique on-board 24
25 Chaque périphérique (compute device) contient plusieurs unités de calcul Chaque unité de calcul contient plusieurs processeurs élémentaires Chaque processeur élémentaire peut faire plusieurs opérations par cycle 25
26 26
27 27
28 Points saillants API des plateformes (sur l hôte) Couche d abstraction pour les ressources Interroger, choisir et initialiser des périphériques Créer des contextes d exécution et des files de travail (workqueues) API runtime (sur l hôte) Configurer et lancer l exécution de noyaux Gérer l allocation et les transferts de mémoire Langage OpenCL Noyaux de calcul qui seront exécutés sur le périphérique Langage basé sur le C Peut être compilé en ligne par votre programme ou hors ligne 28
29 Structure de base d un programme OpenCL 1. Identifier la/les plateformes et périphériques 2. Créer des contextes et des files 3. Créer et compiler des noyaux 4. Créer des objets mémoire 5. Initialiser les objets mémoire, y placer des données 6. Lancer l exécution des noyaux 7. Attendre la fin de l exécution 8. Récupérer le résultat 9. Répéter 5-8 tant qu il reste des traitements 29
30 Sélection d'une plateforme Permet d'obtenir une liste de plateformes disponibles num_entries spécifie le nombre d'entrées disponibles dans le tableau platforms num_platforms retourne le nombre total de plateformes disponibles 30
31 Information à propos d'une plateforme Retourne de l'information spécifique à propos de la plateforme platform 31
32 Sélection d'un device Permet d'obtenir une liste de devices pour la plateforme platform 32
33 Information sur un device Retourne de l'information à propos du device device des tonnes d'information sont disponibles! surtout à propos de ses capacités sert à optimiser le code... 33
34 Création d'un contexte Permet de créer un contexte OpenCL pour un ou plusieurs devices Permet de gérer dynamiquement le «runtime» de OpenCL la fonction pfn_notify sera appelée par OpenCL en cas d'erreur pour ce contexte 34
35 Information sur le contexte Retourne de l'information concernant le contexte context 35
36 Création d'une file de commandes Permet de créer une file de commandes sert à enfiler des opérations à effectuer sur le GPU on peut créer plusieurs files de commande dans un même contexte chaque file sera indépendante; aucune synchronisation nécessaire 36
37 Information sur une file Retourne des information spécifiques sur la file de commandes command_queue 37
38 Création d'un buffer Permet de créer un buffer dans la mémoire du GPU pour transférer des données dans le contexte context le CPU est responsable d allouer la mémoire sur le GPU tous les transferts entre le CPU et le GPU doivent être explicites copie les données dans host_ptr en même temps 38
39 Lecture d'un buffer Insère une opération de lecture dans la file command_queue permet de transférer le contenu d'un buffer vers la mémoire du CPU encore une fois, opération initiée par le CPU 39
40 Écriture d'un buffer Insère une opération d'écriture dans la file command_queue permet de transférer de l'information depuis la mémoire du CPU vers un buffer du GPU 40
41 Copie d'un buffer Permet de copier le contenu d'un buffer vers un autre buffer 41
42 Création d'une image 2D Permet la création d'un objet image de dimension: image_width (pixels) image_height (pixels) image_row_pitch (octets) Format 3D également. 42
43 Images Types supportés : R, RG, RBG, RGBA, luminance, etc. 8 / 16 / 32 bits signés/non-signés, floats Interpolation linéaire, gestion des effets de bord Pourquoi? Accès mémoire accéléré par le hardware sur le GPU Permet réutilisation de features existants dans les GPUs pour les textures Désavantages L écriture est plus lente Limite au niveau des formats supportés 43
44 Formats d'image 44
45 45
46 Formats d'image supportés Permet d'obtenir la liste des formats d'image supportés pour une certaine plateforme 46
47 Les formats suivants sont toujours supportés: On peut lire, écrire et copier des images: clenqueuereadimage() clenqueuewriteimage() clenqueuecopyimage() 47
48 Création d'un programme Permet de créer un noyau qui s'exécutera sur le GPU à partir de code source les lignes du code sont contenues dans strings elles sont terminées par des zéros sinon les longueurs des lignes sont spécifiées par lengths 48
49 Compilation d'un programme Permet de compiler et de linker le code source d'un programme on peut spécifier plusieurs devices si non nul, la fonction pfn_notify est appelée pour signaler la fin de l'opération 49
50 Création d'un noyau Création d'un objet noyau à partir du programme program le programme doit avoir été compilé préalablement le noyau kernel_name doit avoir été déclaré dans le programme avec le qualificatif «kernel» c est l objet qu on va exécuter 50
51 Permet de créer tous les noyaux déclarés dans le programme program Permet de spécifier les arguments d'un noyau 51
52 Exécution d'un noyau Permet d'exécuter un noyau sur un device en utilisant work_dim dimensions le nombre total de «work-items» (le «local_work_size») doit être inférieur ou égal à CL_DEVICE_MAX_WORK_GROUP_SIZE le global_work_size doit être divisible par le local_work_size la commande attend la fin des événements de la event_wait_list 52
53 Exemple - vecadd Addition de deux vecteurs de valeurs flottantes 53
54 Cas à 2 dimensions indices locaux: sx et sy indices globaux: gx et gy 54
55 Modèle d'exécution L'exécution d'un noyau provoque la définition d'un espace d'indices NDRange = «N Dimensional Range» Une instance de noyau = 1 «work-item» correspond à 1 point dans l'espace d'exécution c'est la granularité la plus fine Les «work-items» sont organisés en groupes correspond à 1 point dans l'espace des «compute-units» tous les «work-items» d'un même groupe s'exécutent à l'intérieur du même «compute unit» c'est un deuxième niveau de granularité Les instances de «work-group» s'exécutent en parallèle sur les «compute-units» disponibles 55
56 Fonction diverses uint get_work_dim (): retourne le nombre de dimensions du NDRange size_t get_global_size (uint dimindx): retourne le nombre global de fils dans la dimension dimindx size_t get_global_id (uint dimindx): retourne l'indice global du fil d'exécution appelant, dans la dimension dimindx les gx et gy de tout à l heure size_t get_local_size (uint dimindx): retourne le nombre de fils par groupe dans la dimension dimindx 56
57 size_t get_local_id (uint dimindx): retourne l'indice local du fil d'exécution appelant, pour la dimension dimindx les sx et sy de tout à l heure size_t get_num_groups (uint dimindx): retourne le nombre de groupes dans la dimension dimindx size_t get_group_id (uint dimindx): retourne l'indice du groupe dans la dimension dimindx 57
58 Types de mémoire 58
59 59
60 Ce sont à peu près les mêmes étapes qui doivent être effectuées, peu importe l'application c'est donc ardu, mais pas nécessairement difficile OpenCL nous permet tout de même d'exploiter du matériel hétérogène à l'aide d'un même programme exécutable on peut aussi exploiter plusieurs GPUs sans changer le programme il faut donc accepter de faire un certain nombre d'initialisations Avec le wrapper C++ d OpenCL on réduit la quantité de poutine requise. 60
61 Restrictions Pour les noyaux: pas d'appels récursifs librairie de fonctions standards peut fonctionner avec CPUs Group_size: au moins la dimension d'un «warp» (NVIDIA) ou d'un «wavefront» (AMD) idéalement une puissance de 2 61
62 Plateformes de développement Apple: OpenCL est installé par défaut avec les outils de développement (Xcode) AMD: DOWNLOADS/Pages/default.aspx NVIDIA: 62
63 Structure de base d un programme OpenCL 1. Initialiser plateformes, périphériques, contextes, files d opérations 2. Créer et compiler des noyaux 3. Créer des objets mémoire, les remplir (clenqueuewritebuffer) 4. Lancer l exécution des noyaux (clenqueuendrangekernel) 5. Attendre la fin de l exécution 6. Récupérer le résultat (clenqueuereadbuffer) 7. Répéter 3-6 tant qu il reste des traitements 63
64 64
65 Cas à 2 dimensions indices locaux: sx et sy indices globaux: gx et gy 65
66 Contrôle du flot dans un work-group Instruction SIMD division du programme en warps (nvidia) ou wavefronts (amd) exécution d une même instruction pour tous les processeurs du compute unit (appelé lockstep execution) Malgré le lockstep, chaque work-item peut prendre un chemin d exécution différent les instructions des deux chemins doivent être lancées pour tous les threads les processeurs qui n ont pas pris le branchement attendent Une façon optimale d exploiter les branchement et de les utiliser avec une granularité correspondant au work-groups 66
67 Définir la taille des workgroups global_size = global_size_0 * global_size_1 *... Le choix optimal des local_work_size dépendra de l architecture de la carte. le nombre de threads éxécutant les mêmes instructions en parallèle pour chaque Compute Unit est différent (32 pour nvidia, 64 pour ATI) cela dépend du nombre de coeurs dans chaque Compute Unit Utiliser un multiple de ce chiffre, sinon des coeurs seront inutilisés. Truc simple, puissance de 2 : nvidia : 32, 64, 128, 256, 512 amd : 64, 128, 256, 512 les local_size_i doivent être un multiple des global_size_i (possible de tricher) Tenir compte des besoins en mémoire (locale et privée) de vos work-groups, si ceux-ci sont gourmands, utiliser des valeurs plus petites 67
68 L occupation (occupancy) Les work-groups sont assignés aux compute units Lorsqu un work-group est assigné à un compute unit, il ne peut pas être swappé avant d avant terminé l exécution de ses threads S il y a suffisamment de ressources, plusieurs work-groups peuvent s exécuter sur un même compute unit en alternance permet de cacher la latence des accès mémoire Le terme occupation est utilisé pour décrire combien les ressources d un compute unit sont utilisées 68
69 L occupation - registres La disponibilité des registres et un facteur limitatif Le nombre maximum de registres demandés par votre noyau doit être disponible pour tous les threads du work-group ex: GPU avec registres par compute unit roulant un noyau qui nécessite 35 registres par thread Chaque compute unit peut exécuter combien de threads au maximum? Qu est-ce que ça implique pour la taille du work-group? 69
70 L occupation - autre facteurs Mémoire locale KB pour un même compute unit tous les work-group doivent se partager cette mémoire Nb. max de threads Les cartes ont un nombre maximum de threads pouvant être actifs en même temps Varie selon la carte, selon le fabricant. NVidia : limite par Compute Unit. AMD : limite globale pour le GPU au complet + limite locale. 70
71 Autres outils pour noyaux Types vecteur : typen, où n est une puissance de 2 (e.g., float2, float4,...) n = 3 est supporté, aligné en mémoire comme n=4 Fonctions built-ins math pour valeurs continues ou discrètes sin, asin, log, exp, etc., pour tous les types incluant vecteurs fonctions spéciales pour entiers, supportant le bit-shifting, la troncation et bien d autres. Exemple : upsample(int hi, int lo) // retourne (hi << 8) lo fonctions géométriques: produit scalaire, produit vectoriel, norme de vecteurs, calcul de distances 71
72 Produit de matrices Problème à 2 dimensions Chaque fil permet de calculer un élément du résultat le global size correspond au nombre d'éléments dans la matrice 72
73 Solution séquentielle // A(NxP) * B(PxM) = C(NxM) // Iterate over the rows of Matrix A for(int n = 0; n < N; n++) { // Iterate over the columns of Matrix B for(int m = 0; m < M; m++) { C[n*M + m] = 0; // Multiply and accumulate the values in the current row // of A and column of B for(int p = 0; p < P; p++) { C[n*M + m] += A[n*P + p] * B[p*M + m]; } } } 73
74 kernel void mmul(const int M, const int N, const int P, global float* A, global float* B, global float* C) { int p; int col = get_global_id(0); int row = get_global_id(1); float tmp; if((row < N) && (col < M)) { tmp = 0.0; for(p=0; p<p; p++) tmp += A[row*P + p] * B[p*M + col]; } C[row*M+col] = tmp; } 74
75 Temps d exécution Multiplication de deux matrices 1000x s pour le code GPU (GTX Nvidia 660 Ti) 2.59s pour une variante avec OMP (Intel Core i5, 4 coeurs sans hyperthreading) 7.20s pour un seul processeur (même CPU) Speedup GPU-séquentiel : 165 GPU-OpenMP : 60 Pour être équitable, il manquerait une comparaison avec opérations SSE 75
76 Problème? on accède plusieurs fois aux éléments des matrices qui sont stockées dans la mémoire globale la mémoire globale est lente surtout lorsqu'elle doit fournir beaucoup de fils d'exécution Solution? copier les matrices dans la mémoire locale chaque fil doit participer à la recopie compliqué, donc s assurer qu on a besoin d un telle optimisation 76
77 #define BLOCK_SIZE 8 kernel attribute ((reqd_work_group_size(block_size, BLOCK_SIZE, 1))) void floatmatrixmultlocals( global float * MResp, global float * M1, global float * M2, global int * q) { //Identification of this workgroup int i = get_group_id(0); int j = get_group_id(1); } //Identification of work-item int idx = get_local_id(0); int idy = get_local_id(1); //matrixes dimensions int p = get_global_size(0); int r = get_global_size(1); int qq = q[0]; //Number of submatrixes to be processed by each worker (Q dimension) int numsubmat = qq/block_size; float4 resp = (float4)(0,0,0,0); local float A[BLOCK_SIZE][BLOCK_SIZE]; local float B[BLOCK_SIZE][BLOCK_SIZE]; for (int k=0; k<numsubmat; k++) { //Copy submatrixes to local memory. Each worker copies one element //Notice that A[i,k] accesses elements starting from M[BLOCK_SIZE*i, BLOCK_SIZE*j] A[idX][idY] = M1[BLOCK_SIZE*i + idx + p*(block_size*k+idy)]; B[idX][idY] = M2[BLOCK_SIZE*k + idx + qq*(block_size*j+idy)]; barrier(clk_local_mem_fence); for (int k2 = 0; k2 < BLOCK_SIZE; k2+=4) { float4 temp1=(float4)(a[idx][k2], A[idX][k2+1], A[idX][k2+2], A[idX][k2+3]); float4 temp2=(float4)(b[k2][idy], B[k2+1][idY], B[k2+2][idY], B[k2+3][idY]); resp += temp1 * temp2; } barrier(clk_local_mem_fence); } MResp[BLOCK_SIZE*i + idx + p*(block_size*j+idy)] = resp.x+resp.y+resp.z+resp.w; 77
78 Mémoire locale Accessible pour tous les work-items d un work-group Définition dans le noyau directement, ou passé comme paramètre préfixe local Il faut synchroniser les accès pour s assurer que l écriture est bien acheminée (même si parfois la connaissance du hardware nous permettrait de sauter cette étape) Utilisation de barrières (local, global) 78
79 Voici un exemple de programme avec mémoire locale: kernel void localaccess( global float* A, global float* B, local float* C ) { local float alocalarray[1]; if( get_local_id(0) == 0 ) { alocalarray[0] = A[0]; } } C[get_local_id(0)] = A[get_global_id(0)]; barrier( CLK_LOCAL_MEM_FENCE ); float neighborsum = C[get_local_id(0)] + alocalarray[0]; if( get_local_id(0) > 0 ) neighborsum = neighborsum + C[get_local_id(0)-1]; B[get_global_id(0)] = neighborsum; Allocation du paramètre local err = clsetkernelarg(kernel_object, 3, sizeof(float)*len_c, NULL); 79
80
81 Accès à la mémoire Soit un tableau d'entiers x (32 bits) X: 0x Un fil veut accéder à l'élément x[0] int temp = x[0]; x x x
82 Problème... Les bus de mémoire sur les GPUs sont très larges par exemple 256 bits (32 octets) permet des bandes passantes plus élevées Les accès en mémoire doivent cependant être alignés avec la largeur du bus: Desired address: 0x Bus mask: 0xFFFFFFE0 Bus access: 0x Tous les accès de 0x à 0x F produiront l'adresse 0x
83 Histogramme Statistiques sur un ensemble de données Pratique pour faire des statistiques, mesures des quantiles, etc. 83
84 Histogramme Solution séquentielle : for (int i = 0; i < BIN_COUNT; i++) result[i] = 0; for (int i = 0; i < data.size(); i++) result[computebin(data[i])]++; Comment paralléliser? Est-ce qu on peut lancer un thread pour chaque point dans data? 84
85 Version naïve kernel void naive_histo( global int *d_bins, const int *d_in, const int BIN_COUNT) { int myid = get_global_id(0); int myitem = d_in[myid]; int mybin = myitem % BIN_COUNT; d_bins[mybins]++; } 85
86 Version naïve (fixed) kernel void naive_histo( global int *d_bins, const int *d_in, const int BIN_COUNT) { int myid = get_global_id(0); int myitem = d_in[myid]; int mybin = myitem % BIN_COUNT; atomic_inc(&d_bins[mybins]); } Fonctionne, mais sous-optimal à cause de l accès atomique Un seul thread incrémente un bin à la fois.. presque séquentiel pour un petit nombre de bins le GPU cache la latence en switchant à d autres blocs de threads pour calculer, mais pas grand chose à calculer dans ce cas-ci... Solution : calculer un histogramme local sur chaque work-group 86
87 Histogramme local Supposons que nos données sont une image : histogramme sur les couleurs 87
88 Histogramme local Opération de réduction requise à la fin réalisable en parallèle 88
89 Paramètres pour l exécution Nombre de work-groups : Choisir un nombre le plus petit possible Idéalement, nb work-groups = nb compute units Limite la complexité de l opération de réduction à la fin Nombre de work-items par work-group Le premier défini le second (ou vice versa) De ce côté, les critères définis précédemment sont encore bons Avoir 2-4 fois le nombre de threads habituellement dans un warp ou wavefront permet d utiliser le compute unit plus efficacement Compromis à faire 89
90 Optimisation des accès mémoire L opération histogramme ne dépend pas de l ordre des données Faire une seule lecture à la fois est inefficace (e.g., data[0]) Supposant un GPU AMD : lecture de 128 bit sur chaque work-item le hardware est optimisé pour faire la lecture de pixels à quatre composantes 32 bits, donne la meilleure performance lecture de vecteurs de taille 4 90
91 Accès mémoire Accès mémoires consécutifs pour work-items consécutifs : uint g_id = get_global_id(0); uint stride = get_global_size(0); for (i=0, idx=g_id; i<n4vectorsperworkitem; i++, idx += stride) { uint4 temp = Image[idx];... Chaque work-item lit ses pixels en série : uint g_id = get_global_id(0); for (i=0, idx=g_id*n4vectorsperworkitem; I<n4Vectors PerWorkItem; i++, idx++) { uint4 temp = Image[idx]; 91
92 Accès mémoire (illustré) 92
93 Remplissage des histogrammes locaux Encore une fois, opération atomiques (évite les courses critiques) uint4 px = read_imageui(img, flags, uint2(idx, y)); atom_inc(&tmp_histogram[px.x]); atom_inc(&tmp_histogram[256+px.y]); atom_inc(&tmp_histogram[512+px.z]); 93
94 Réduction Concatener les résultats : opération standard de réduction Définir pour un histogramme avec NUM_BINS * 3 valeurs (3 couleurs) il faut voir ces 3 histogrammes comme un long vecteur réduction (addition) sur global_work_size vecteurs de NUM_BINS*3 valeurs 94
95 Réduction simple Comment? Supposons une réduction simple (somme) pour un vecteur d entiers (plutôt qu un vecteur de vecteurs) Paramètres : {1, 2, 3, 4}, + Résultat : = 10 En parallèle : (1 + 2) + (3 + 4) Pour de très grands vecteurs, possible de procéder en deux phases 95
96 Réduction d histogrammes Noyau exécutant la somme de tous les histogrammes partiels/locaux créés dans la première étape Un thread par bin (boîte), effectue la somme de tous les histogrammes locaux pour une seule tranche opération assez simple, car besoins différents... il s agit d un cas spécial de réduction. lorsqu on a plus de données, on va plutôt dans l autre sens imaginer un vecteur de 2^20 données 96
97 Résultat Histogramme pour image 1920x1080 Temps d exécution séquentiel ~ 17.3ms Temps d exécution parallèle ~ 0.453ms Possible d aller optimiser encore plus en utilisant d autres stratégies... Il y a des conflits dans la mémoire locale, au niveau des opérations atomiques Utiliser plusieurs histogrammes locaux par work-group, effectuer un reduce de plus (temps requis minimal) Dépend du nombre de bins encore une fois, plus il est petit, plus ça sera intéressant (car plus de conflits) 97
98 Analyser la performance Profilage de la performance avec les évènements Doit être activé préalablement dans la queue Permet de savoir quand une tâche (read, write, kernel) a été mise dans la file, lancée, terminée. Activation : queue = clcreatecommandqueue( context, device, CL_QUEUE_PROFILING_ENABLE, &err); Pour la suite, on passe un objet event à chaque appel de fonction : err = clenqueuendrangekernel(queue, kernel,..., &event); 98
99 Analyser la performance Pour récuperer l info : cl_int clgeteventprofilinginfo (cl_event event, "cl_profiling_info param_name, "size_t param_value_size, "void *param_value, "size_t *param_value_size_ret) enum cl_profiling_info: CL_PROFILING_COMMAND_QUEUED, CL_PROFILING_COMMAND_SUBMIT, CL_PROFILING_COMMAND_START, CL_PROFILING_COMMAND_END Retourne une valeur de temps absolue en ns 99
100 AMD Accelerated parallel processing profiler (APP) Deux modes d utilisation: plug-in pour Visual Studio 2008/2010 outil ligne de commande pour Windows/Linux Essentiellement, le plug-in lit la sortie de l outil ligne de commande et le dessine plus élégamment Permet de déterminer si votre application est limitée par l exécution du noyau ou bien les transferts de données 100
101 CHAPTER 12 OpenCL profiling and debugging APP (visualisation) 101FIGURE 12.1
102 Débugger votre code Il existe un debugger : gdebugger fonctionne pour OpenCL et OpenGL à vous de voir si vous voulez vous en servir Plus simple : extension AMD printf attention, un printf dans un noyau va imprimer pour chaque work_item ceci étant dit, on l active comme suit : #pragma OPENCL EXTENSION cl_amd_printf : enable 102
103 Autres façons de faire du GPGPU Utilisation de primitives OpenGL, du pipeline de rendu graphique il faut programmer des shaders en GLSL Exploiter les textures, les viewports Demande de réfléchir beaucoup avant de trouver une solution (ex. comment faire une FFT avec des triangles?) 103
104 Exemple : réduction avec OpenGL Stocker les données dans une texture 2D Effectuer le rendu d un carré sur lequel la texture est appliquée Aligner le carré avec la caméra Le carré doit faire le 1/4 de la taille de la texture, cela va forcer une interpolation Utiliser la sortie (le rendu) de ce carré comme entrée pour la passe suivante Répéter jusqu à la fin 104
105 Shader résultant uniform sampler2d u_data; in vec2 fs_texcoords; out float out_maxvalue; void main(void) { float v0 = texture(u_data, fs_texcoords).r; float v1 = textureoffset(u_data, fs_texcoords, ivec2(0, 1)).r; float v2 = textureoffset(u_data, fs_texcoords, ivec2(1, 0)).r; float v3 = textureoffset(u_data, fs_texcoords, ivec2(1, 1)).r; out_maxvalue = max(max(v0, v1), max(v2, v3)); } Intéressant, mais compliqué. Plus simple avec OpenCL 105
106 CUDA À peu de choses près, fonctionne de la même façon les GPU NVidia sont très similaires à ceux d AMD Un compilateur externe vient remplacer le compilateur c standard. nvcc Permet d avoir les noyaux dans le même fichier source que votre programme principal (le compilateur reconnaît les attributs et traite le code différemment) Ne fonctionne pas sur des CPUs on ne parle plus de calcul hétérogène, mais strictement de GPGPU (pour cartes NVidia). 106
107 Comparaison avec CUDA CUDA OpenCL 107
108 Programme CUDA (noyau) global void vectoradd(const float *A, const float *B, float *C, int numelements) { int i = blockdim.x * blockidx.x + threadidx.x; } if (i < numelements) { C[i] = A[i] + B[i]; } Différence dans les indices de thread 108
109 Programme CUDA (host) Fichier
110 Programme CUDA Beaucoup moins de gestion requise dans le programme hôte On sait à quoi s attendre... le compilateur fait également une bonne partie du travail Remarquez que le noyau est pratiquement identique 110
111 Conclusion OpenCL permet d'exploiter la puissance de calcul des GPGPUs de manière indépendante de la plateforme définir le contexte (device + queue) définir le programme et les noyaux spécifier les paramètres des noyaux exécuter un NDRange (dimension du problème + dimension du groupe de travail Attention à la mémoire avec des centaines de fils d'exécution parallèles, la mémoire globale devient vite un goulot d'étranglement 111
112 Documents et information: opencl-1.1.pdf Tutoriels: universities/pages/default.aspx? cmpid=devbanner_univkit %20Tutorials%20-%
M2-Images. Rendu Temps Réel - OpenGL 4 et compute shaders. J.C. Iehl. December 18, 2013
 Rendu Temps Réel - OpenGL 4 et compute shaders December 18, 2013 résumé des épisodes précédents... création des objets opengl, organisation des données, configuration du pipeline, draw,... opengl 4.3 :
Rendu Temps Réel - OpenGL 4 et compute shaders December 18, 2013 résumé des épisodes précédents... création des objets opengl, organisation des données, configuration du pipeline, draw,... opengl 4.3 :
Introduction au calcul parallèle avec OpenCL
 Introduction au calcul parallèle avec OpenCL Julien Dehos Séminaire du 05/01/2012 Sommaire Introduction Le calculateur du CGR/LISIC/LMPA Généralités sur OpenCL Modèles Programmation Optimisation Conclusion
Introduction au calcul parallèle avec OpenCL Julien Dehos Séminaire du 05/01/2012 Sommaire Introduction Le calculateur du CGR/LISIC/LMPA Généralités sur OpenCL Modèles Programmation Optimisation Conclusion
Introduction à CUDA. gael.guennebaud@inria.fr
 36 Introduction à CUDA gael.guennebaud@inria.fr 38 Comment programmer les GPU? Notion de kernel exemple (n produits scalaires): T ci =ai b ( ai, b : vecteurs 3D, ci for(int i=0;i
36 Introduction à CUDA gael.guennebaud@inria.fr 38 Comment programmer les GPU? Notion de kernel exemple (n produits scalaires): T ci =ai b ( ai, b : vecteurs 3D, ci for(int i=0;i
. Plan du cours. . Architecture: Fermi (2010-12), Kepler (12-?)
, Kepler (12-?)") Plan du cours Vision mate riel: architecture cartes graphiques NVIDIA INF 560 Calcul Paralle le et Distribue Cours 3 Vision logiciel: l abstraction logique de l architecture propose e par le langage CUDA
Plan du cours Vision mate riel: architecture cartes graphiques NVIDIA INF 560 Calcul Paralle le et Distribue Cours 3 Vision logiciel: l abstraction logique de l architecture propose e par le langage CUDA
Une bibliothèque de templates pour CUDA
 Une bibliothèque de templates pour CUDA Sylvain Collange, Marc Daumas et David Defour Montpellier, 16 octobre 2008 Types de parallèlisme de données Données indépendantes n threads pour n jeux de données
Une bibliothèque de templates pour CUDA Sylvain Collange, Marc Daumas et David Defour Montpellier, 16 octobre 2008 Types de parallèlisme de données Données indépendantes n threads pour n jeux de données
Initiation au HPC - Généralités
 Initiation au HPC - Généralités Éric Ramat et Julien Dehos Université du Littoral Côte d Opale M2 Informatique 2 septembre 2015 Éric Ramat et Julien Dehos Initiation au HPC - Généralités 1/49 Plan du cours
Initiation au HPC - Généralités Éric Ramat et Julien Dehos Université du Littoral Côte d Opale M2 Informatique 2 septembre 2015 Éric Ramat et Julien Dehos Initiation au HPC - Généralités 1/49 Plan du cours
Segmentation d'images à l'aide d'agents sociaux : applications GPU
 Segmentation d'images à l'aide d'agents sociaux : applications GPU Richard MOUSSA Laboratoire Bordelais de Recherche en Informatique (LaBRI) - UMR 5800 Université de Bordeaux - France Laboratoire de recherche
Segmentation d'images à l'aide d'agents sociaux : applications GPU Richard MOUSSA Laboratoire Bordelais de Recherche en Informatique (LaBRI) - UMR 5800 Université de Bordeaux - France Laboratoire de recherche
Introduction à la programmation des GPUs
 Introduction à la programmation des GPUs Anne-Sophie Mouronval Mesocentre de calcul de l Ecole Centrale Paris Laboratoire MSSMat Avril 2013 Anne-Sophie Mouronval Introduction à la programmation des GPUs
Introduction à la programmation des GPUs Anne-Sophie Mouronval Mesocentre de calcul de l Ecole Centrale Paris Laboratoire MSSMat Avril 2013 Anne-Sophie Mouronval Introduction à la programmation des GPUs
Architecture des calculateurs
 Formation en Calcul Scientifique - LEM2I Architecture des calculateurs Violaine Louvet 1 1 Institut Camille jordan - CNRS 12-13/09/2011 Introduction Décoder la relation entre l architecture et les applications
Formation en Calcul Scientifique - LEM2I Architecture des calculateurs Violaine Louvet 1 1 Institut Camille jordan - CNRS 12-13/09/2011 Introduction Décoder la relation entre l architecture et les applications
1 Architecture du cœur ARM Cortex M3. Le cœur ARM Cortex M3 sera présenté en classe à partir des éléments suivants :
 GIF-3002 SMI et Architecture du microprocesseur Ce cours discute de l impact du design du microprocesseur sur le système entier. Il présente d abord l architecture du cœur ARM Cortex M3. Ensuite, le cours
GIF-3002 SMI et Architecture du microprocesseur Ce cours discute de l impact du design du microprocesseur sur le système entier. Il présente d abord l architecture du cœur ARM Cortex M3. Ensuite, le cours
Rappels d architecture
 Assembleur Rappels d architecture Un ordinateur se compose principalement d un processeur, de mémoire. On y attache ensuite des périphériques, mais ils sont optionnels. données : disque dur, etc entrée
Assembleur Rappels d architecture Un ordinateur se compose principalement d un processeur, de mémoire. On y attache ensuite des périphériques, mais ils sont optionnels. données : disque dur, etc entrée
Architecture des ordinateurs
 Décoder la relation entre l architecture et les applications Violaine Louvet, Institut Camille Jordan CNRS & Université Lyon 1 Ecole «Découverte du Calcul» 2013 1 / 61 Simulation numérique... Physique
Décoder la relation entre l architecture et les applications Violaine Louvet, Institut Camille Jordan CNRS & Université Lyon 1 Ecole «Découverte du Calcul» 2013 1 / 61 Simulation numérique... Physique
Calcul multi GPU et optimisation combinatoire
 Année universitaire 2010 2011 Master recherche EEA Spécialité : SAID Systèmes Automatiques, Informatiques et Décisionnels Parcours : Systèmes Automatiques Calcul multi GPU et optimisation combinatoire
Année universitaire 2010 2011 Master recherche EEA Spécialité : SAID Systèmes Automatiques, Informatiques et Décisionnels Parcours : Systèmes Automatiques Calcul multi GPU et optimisation combinatoire
Contrôle Non Destructif : Implantation d'algorithmes sur GPU et multi-coeurs. Gilles Rougeron CEA/LIST Département Imagerie Simulation et Contrôle
 Contrôle Non Destructif : Implantation d'algorithmes sur GPU et multi-coeurs Gilles Rougeron CEA/LIST Département Imagerie Simulation et Contrôle 1 CEA R & D for Nuclear Energy 5 000 people Nuclear systems
Contrôle Non Destructif : Implantation d'algorithmes sur GPU et multi-coeurs Gilles Rougeron CEA/LIST Département Imagerie Simulation et Contrôle 1 CEA R & D for Nuclear Energy 5 000 people Nuclear systems
Limitations of the Playstation 3 for High Performance Cluster Computing
 Introduction Plan Limitations of the Playstation 3 for High Performance Cluster Computing July 2007 Introduction Plan Introduction Intérêts de la PS3 : rapide et puissante bon marché L utiliser pour faire
Introduction Plan Limitations of the Playstation 3 for High Performance Cluster Computing July 2007 Introduction Plan Introduction Intérêts de la PS3 : rapide et puissante bon marché L utiliser pour faire
INF6500 : Structures des ordinateurs. Sylvain Martel - INF6500 1
 INF6500 : Structures des ordinateurs Sylvain Martel - INF6500 1 Cours 4 : Multiprocesseurs Sylvain Martel - INF6500 2 Multiprocesseurs Type SISD SIMD MIMD Communication Shared memory Message-passing Groupe
INF6500 : Structures des ordinateurs Sylvain Martel - INF6500 1 Cours 4 : Multiprocesseurs Sylvain Martel - INF6500 2 Multiprocesseurs Type SISD SIMD MIMD Communication Shared memory Message-passing Groupe
Génération de code binaire pour application multimedia : une approche au vol
 Génération de binaire pour application multimedia : une approche au vol http://hpbcg.org/ Henri-Pierre Charles Université de Versailles Saint-Quentin en Yvelines 3 Octobre 2009 Présentation Présentation
Génération de binaire pour application multimedia : une approche au vol http://hpbcg.org/ Henri-Pierre Charles Université de Versailles Saint-Quentin en Yvelines 3 Octobre 2009 Présentation Présentation
Fonctionnement et performance des processeurs
 Fonctionnement et performance des processeurs Eric Cariou Université de Pau et des Pays de l'adour Département Informatique Eric.Cariou@univ-pau.fr 1 Plan Fonctionnement des processeurs Unités de calcul
Fonctionnement et performance des processeurs Eric Cariou Université de Pau et des Pays de l'adour Département Informatique Eric.Cariou@univ-pau.fr 1 Plan Fonctionnement des processeurs Unités de calcul
Vers du matériel libre
 Février 2011 La liberté du logiciel n est qu une partie du problème. Winmodems Modem traditionnel Bon fonctionnement Plus cher Electronique propriétaire Blob sur DSP intégré au modem Bien reçu par les
Février 2011 La liberté du logiciel n est qu une partie du problème. Winmodems Modem traditionnel Bon fonctionnement Plus cher Electronique propriétaire Blob sur DSP intégré au modem Bien reçu par les
Exécution des instructions machine
 Exécution des instructions machine Eduardo Sanchez EPFL Exemple: le processeur MIPS add a, b, c a = b + c type d'opération (mnémonique) destination du résultat lw a, addr opérandes sources a = mem[addr]
Exécution des instructions machine Eduardo Sanchez EPFL Exemple: le processeur MIPS add a, b, c a = b + c type d'opération (mnémonique) destination du résultat lw a, addr opérandes sources a = mem[addr]
Argument-fetching dataflow machine de G.R. Gao et J.B. Dennis (McGill, 1988) = machine dataflow sans flux de données
 = machine dataflow sans flux de données") EARTH et Threaded-C: Éléments clés du manuel de références de Threaded-C Bref historique de EARTH et Threaded-C Ancêtres de l architecture EARTH: Slide 1 Machine à flux de données statique de J.B. Dennis
EARTH et Threaded-C: Éléments clés du manuel de références de Threaded-C Bref historique de EARTH et Threaded-C Ancêtres de l architecture EARTH: Slide 1 Machine à flux de données statique de J.B. Dennis
Calcul scientifique précis et efficace sur le processeur CELL
 Université P. et M. Curie Master spécialité informatique Calcul scientifique précis et efficace sur le processeur CELL NGUYEN Hong Diep Rapport de stage recherche de master 2 effectué au laboratoire LIP6
Université P. et M. Curie Master spécialité informatique Calcul scientifique précis et efficace sur le processeur CELL NGUYEN Hong Diep Rapport de stage recherche de master 2 effectué au laboratoire LIP6
Potentiels de la technologie FPGA dans la conception des systèmes. Avantages des FPGAs pour la conception de systèmes optimisés
 Potentiels de la technologie FPGA dans la conception des systèmes Avantages des FPGAs pour la conception de systèmes optimisés Gérard FLORENCE Lotfi Guedria Agenda 1. Le CETIC en quelques mots 2. Générateur
Potentiels de la technologie FPGA dans la conception des systèmes Avantages des FPGAs pour la conception de systèmes optimisés Gérard FLORENCE Lotfi Guedria Agenda 1. Le CETIC en quelques mots 2. Générateur
Une dérivation du paradigme de réécriture de multiensembles pour l'architecture de processeur graphique GPU
 Une dérivation du paradigme de réécriture de multiensembles pour l'architecture de processeur graphique GPU Gabriel Antoine Louis Paillard Ce travail a eu le soutien de la CAPES, agence brésilienne pour
Une dérivation du paradigme de réécriture de multiensembles pour l'architecture de processeur graphique GPU Gabriel Antoine Louis Paillard Ce travail a eu le soutien de la CAPES, agence brésilienne pour
Concept de machine virtuelle
 Concept de machine virtuelle Chap. 5: Machine virtuelle Alain Sandoz Semestre été 2007 1 Introduction: Java Virtual Machine Machine Virtuelle Java: qu est-ce que c est? c est la spécification d une machine
Concept de machine virtuelle Chap. 5: Machine virtuelle Alain Sandoz Semestre été 2007 1 Introduction: Java Virtual Machine Machine Virtuelle Java: qu est-ce que c est? c est la spécification d une machine
Architecture des Ordinateurs. Partie II:
 Architecture des Ordinateurs Partie II: Le port Floppy permet le raccordement du lecteur de disquette àla carte mère. Remarque: Le lecteur de disquette a disparu il y a plus de 6 ans, son port suivra.
Architecture des Ordinateurs Partie II: Le port Floppy permet le raccordement du lecteur de disquette àla carte mère. Remarque: Le lecteur de disquette a disparu il y a plus de 6 ans, son port suivra.
Parallélisme et Répartition
 Parallélisme et Répartition Master Info Françoise Baude Université de Nice Sophia-Antipolis UFR Sciences Département Informatique baude@unice.fr web du cours : deptinfo.unice.fr/~baude Septembre 2009 Chapitre
Parallélisme et Répartition Master Info Françoise Baude Université de Nice Sophia-Antipolis UFR Sciences Département Informatique baude@unice.fr web du cours : deptinfo.unice.fr/~baude Septembre 2009 Chapitre
Métriques de performance pour les algorithmes et programmes parallèles
 Métriques de performance pour les algorithmes et programmes parallèles 11 18 nov. 2002 Cette section est basée tout d abord sur la référence suivante (manuel suggéré mais non obligatoire) : R. Miller and
Métriques de performance pour les algorithmes et programmes parallèles 11 18 nov. 2002 Cette section est basée tout d abord sur la référence suivante (manuel suggéré mais non obligatoire) : R. Miller and
La technologie Java Card TM
 Présentation interne au CESTI La technologie Java Card TM sauveron@labri.u-bordeaux.fr http://dept-info.labri.u-bordeaux.fr/~sauveron 8 novembre 2002 Plan Qu est ce que Java Card? Historique Les avantages
Présentation interne au CESTI La technologie Java Card TM sauveron@labri.u-bordeaux.fr http://dept-info.labri.u-bordeaux.fr/~sauveron 8 novembre 2002 Plan Qu est ce que Java Card? Historique Les avantages
<Insert Picture Here> Solaris pour la base de donnés Oracle
 Solaris pour la base de donnés Oracle Alain Chéreau Oracle Solution Center Agenda Compilateurs Mémoire pour la SGA Parallélisme RAC Flash Cache Compilateurs
Solaris pour la base de donnés Oracle Alain Chéreau Oracle Solution Center Agenda Compilateurs Mémoire pour la SGA Parallélisme RAC Flash Cache Compilateurs
TP n 2 Concepts de la programmation Objets Master 1 mention IL, semestre 2 Le type Abstrait Pile
 TP n 2 Concepts de la programmation Objets Master 1 mention IL, semestre 2 Le type Abstrait Pile Dans ce TP, vous apprendrez à définir le type abstrait Pile, à le programmer en Java à l aide d une interface
TP n 2 Concepts de la programmation Objets Master 1 mention IL, semestre 2 Le type Abstrait Pile Dans ce TP, vous apprendrez à définir le type abstrait Pile, à le programmer en Java à l aide d une interface
Plan du cours 2014-2015. Cours théoriques. 29 septembre 2014
 numériques et Institut d Astrophysique et de Géophysique (Bât. B5c) Bureau 0/13 email:.@ulg.ac.be Tél.: 04-3669771 29 septembre 2014 Plan du cours 2014-2015 Cours théoriques 16-09-2014 numériques pour
numériques et Institut d Astrophysique et de Géophysique (Bât. B5c) Bureau 0/13 email:.@ulg.ac.be Tél.: 04-3669771 29 septembre 2014 Plan du cours 2014-2015 Cours théoriques 16-09-2014 numériques pour
Introduction à la Programmation Parallèle: MPI
 Introduction à la Programmation Parallèle: MPI Frédéric Gava et Gaétan Hains L.A.C.L Laboratoire d Algorithmique, Complexité et Logique Cours du M2 SSI option PSSR Plan 1 Modèle de programmation 2 3 4
Introduction à la Programmation Parallèle: MPI Frédéric Gava et Gaétan Hains L.A.C.L Laboratoire d Algorithmique, Complexité et Logique Cours du M2 SSI option PSSR Plan 1 Modèle de programmation 2 3 4
THEME 1 : L ORDINATEUR ET SON ENVIRONNEMENT. Objectifs
 Architecture Matérielle des Systèmes Informatiques. S1 BTS Informatique de Gestion 1 ère année THEME 1 : L ORDINATEUR ET SON ENVIRONNEMENT Dossier 1 L environnement informatique. Objectifs Enumérer et
Architecture Matérielle des Systèmes Informatiques. S1 BTS Informatique de Gestion 1 ère année THEME 1 : L ORDINATEUR ET SON ENVIRONNEMENT Dossier 1 L environnement informatique. Objectifs Enumérer et
td3a correction session7az
 td3a correction session7az August 19, 2015 1 Séance 7 : PIG et JSON et streaming avec les données vélib (correction avec Azure) Plan Récupération des données Connexion au cluster et import des données
td3a correction session7az August 19, 2015 1 Séance 7 : PIG et JSON et streaming avec les données vélib (correction avec Azure) Plan Récupération des données Connexion au cluster et import des données
Cahier des charges. driver WIFI pour chipset Ralink RT2571W. sur hardware ARM7
 Cahier des charges driver WIFI pour chipset Ralink RT2571W sur hardware ARM7 RevA 13/03/2006 Création du document Sylvain Huet RevB 16/03/2006 Fusion des fonctions ARP et IP. SH Modification des milestones
Cahier des charges driver WIFI pour chipset Ralink RT2571W sur hardware ARM7 RevA 13/03/2006 Création du document Sylvain Huet RevB 16/03/2006 Fusion des fonctions ARP et IP. SH Modification des milestones
TPs Architecture des ordinateurs DUT Informatique - M4104c SUJETS. R. Raffin Aix-Marseille Université romain.raffin-at-univ-amu.fr
 TPs Architecture des ordinateurs DUT Informatique - M4104c SUJETS R. Raffin Aix-Marseille Université romain.raffin-at-univ-amu.fr 2015 Table des matières 1 TP 1 : prise en main 2 1.1 Introduction.......................................................
TPs Architecture des ordinateurs DUT Informatique - M4104c SUJETS R. Raffin Aix-Marseille Université romain.raffin-at-univ-amu.fr 2015 Table des matières 1 TP 1 : prise en main 2 1.1 Introduction.......................................................
Conception de circuits numériques et architecture des ordinateurs
 Conception de circuits numériques et architecture des ordinateurs Frédéric Pétrot Année universitaire 2014-2015 Structure du cours C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 C11 Codage des nombres en base 2, logique
Conception de circuits numériques et architecture des ordinateurs Frédéric Pétrot Année universitaire 2014-2015 Structure du cours C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 C11 Codage des nombres en base 2, logique
La mémoire. Un ordinateur. L'octet. Le bit
 Introduction à l informatique et à la programmation Un ordinateur Un ordinateur est une machine à calculer composée de : un processeur (ou unité centrale) qui effectue les calculs une mémoire qui conserve
Introduction à l informatique et à la programmation Un ordinateur Un ordinateur est une machine à calculer composée de : un processeur (ou unité centrale) qui effectue les calculs une mémoire qui conserve
03/04/2007. Tâche 1 Tâche 2 Tâche 3. Système Unix. Time sharing
 3/4/27 Programmation Avancée Multimédia Multithreading Benoît Piranda Équipe SISAR Université de Marne La Vallée Besoin Programmes à traitements simultanés Réseau Réseau Afficher une animation en temps
3/4/27 Programmation Avancée Multimédia Multithreading Benoît Piranda Équipe SISAR Université de Marne La Vallée Besoin Programmes à traitements simultanés Réseau Réseau Afficher une animation en temps
ASR1 TD7 : Un microprocesseur RISC 16 bits
 {Â Ö Ñ º ØÖ Ý,È ØÖ ºÄÓ Ù,Æ ÓÐ ºÎ ÝÖ Ø¹ ÖÚ ÐÐÓÒ} Ò ¹ÐÝÓÒº Ö ØØÔ»»Ô Ö Óº Ò ¹ÐÝÓÒº Ö» Ö Ñ º ØÖ Ý»¼ Ö½» ASR1 TD7 : Un microprocesseur RISC 16 bits 13, 20 et 27 novembre 2006 Présentation générale On choisit
{Â Ö Ñ º ØÖ Ý,È ØÖ ºÄÓ Ù,Æ ÓÐ ºÎ ÝÖ Ø¹ ÖÚ ÐÐÓÒ} Ò ¹ÐÝÓÒº Ö ØØÔ»»Ô Ö Óº Ò ¹ÐÝÓÒº Ö» Ö Ñ º ØÖ Ý»¼ Ö½» ASR1 TD7 : Un microprocesseur RISC 16 bits 13, 20 et 27 novembre 2006 Présentation générale On choisit
1. Structure d un programme C. 2. Commentaire: /*..texte */ On utilise aussi le commentaire du C++ qui est valable pour C: 3.
 1. Structure d un programme C Un programme est un ensemble de fonctions. La fonction "main" constitue le point d entrée pour l exécution. Un exemple simple : #include int main() { printf ( this
1. Structure d un programme C Un programme est un ensemble de fonctions. La fonction "main" constitue le point d entrée pour l exécution. Un exemple simple : #include int main() { printf ( this
DE L ALGORITHME AU PROGRAMME INTRO AU LANGAGE C 51
 DE L ALGORITHME AU PROGRAMME INTRO AU LANGAGE C 51 PLAN DU COURS Introduction au langage C Notions de compilation Variables, types, constantes, tableaux, opérateurs Entrées sorties de base Structures de
DE L ALGORITHME AU PROGRAMME INTRO AU LANGAGE C 51 PLAN DU COURS Introduction au langage C Notions de compilation Variables, types, constantes, tableaux, opérateurs Entrées sorties de base Structures de
TP 1. Prise en main du langage Python
 TP. Prise en main du langage Python Cette année nous travaillerons avec le langage Python version 3. ; nous utiliserons l environnement de développement IDLE. Étape 0. Dans votre espace personnel, créer
TP. Prise en main du langage Python Cette année nous travaillerons avec le langage Python version 3. ; nous utiliserons l environnement de développement IDLE. Étape 0. Dans votre espace personnel, créer
Machines Virtuelles. et bazard autour. Rémi Forax
 Machines Virtuelles et bazard autour Rémi Forax Avant propos Quelle est la complexité du code ci-dessous? Avec un processeur à 1Ghz, combien de temps le calcul prendra t'il? public static void main(string[]
Machines Virtuelles et bazard autour Rémi Forax Avant propos Quelle est la complexité du code ci-dessous? Avec un processeur à 1Ghz, combien de temps le calcul prendra t'il? public static void main(string[]
Structure d un programme et Compilation Notions de classe et d objet Syntaxe
 Cours1 Structure d un programme et Compilation Notions de classe et d objet Syntaxe POO 1 Programmation Orientée Objet Un ensemble d objet qui communiquent Pourquoi POO Conception abstraction sur les types
Cours1 Structure d un programme et Compilation Notions de classe et d objet Syntaxe POO 1 Programmation Orientée Objet Un ensemble d objet qui communiquent Pourquoi POO Conception abstraction sur les types
Cours Programmation Système
 Cours Programmation Système Filière SMI Semestre S6 El Mostafa DAOUDI Département de Mathématiques et d Informatique, Faculté des Sciences Université Mohammed Premier Oujda m.daoudi@fso.ump.ma Février
Cours Programmation Système Filière SMI Semestre S6 El Mostafa DAOUDI Département de Mathématiques et d Informatique, Faculté des Sciences Université Mohammed Premier Oujda m.daoudi@fso.ump.ma Février
EPREUVE OPTIONNELLE d INFORMATIQUE CORRIGE
 EPREUVE OPTIONNELLE d INFORMATIQUE CORRIGE QCM Remarque : - A une question correspond au moins 1 réponse juste - Cocher la ou les bonnes réponses Barème : - Une bonne réponse = +1 - Pas de réponse = 0
EPREUVE OPTIONNELLE d INFORMATIQUE CORRIGE QCM Remarque : - A une question correspond au moins 1 réponse juste - Cocher la ou les bonnes réponses Barème : - Une bonne réponse = +1 - Pas de réponse = 0
Programmation parallèle et ordonnancement de tâches par vol de travail. Thierry Gautier thierry.gautier@inrialpes.fr MOAIS, INRIA, Grenoble
 Programmation parallèle et ordonnancement de tâches par vol de travail Thierry Gautier thierry.gautier@inrialpes.fr MOAIS, INRIA, Grenoble LyonCalcul 24/02/2014 Plan 1. Contexte technologique des architectures
Programmation parallèle et ordonnancement de tâches par vol de travail Thierry Gautier thierry.gautier@inrialpes.fr MOAIS, INRIA, Grenoble LyonCalcul 24/02/2014 Plan 1. Contexte technologique des architectures
ARDUINO DOSSIER RESSOURCE POUR LA CLASSE
 ARDUINO DOSSIER RESSOURCE POUR LA CLASSE Sommaire 1. Présentation 2. Exemple d apprentissage 3. Lexique de termes anglais 4. Reconnaître les composants 5. Rendre Arduino autonome 6. Les signaux d entrée
ARDUINO DOSSIER RESSOURCE POUR LA CLASSE Sommaire 1. Présentation 2. Exemple d apprentissage 3. Lexique de termes anglais 4. Reconnaître les composants 5. Rendre Arduino autonome 6. Les signaux d entrée
MapReduce. Malo Jaffré, Pablo Rauzy. 16 avril 2010 ENS. Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15
 MapReduce 16 avril 2010 1 / 15") MapReduce Malo Jaffré, Pablo Rauzy ENS 16 avril 2010 Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15 Qu est ce que c est? Conceptuellement Données MapReduce est un framework de calcul distribué
MapReduce Malo Jaffré, Pablo Rauzy ENS 16 avril 2010 Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15 Qu est ce que c est? Conceptuellement Données MapReduce est un framework de calcul distribué
Systèmes et traitement parallèles
 Systèmes et traitement parallèles Mohsine Eleuldj Département Génie Informatique, EMI eleuldj@emi.ac.ma 1 Système et traitement parallèle Objectif Etude des architectures parallèles Programmation des applications
Systèmes et traitement parallèles Mohsine Eleuldj Département Génie Informatique, EMI eleuldj@emi.ac.ma 1 Système et traitement parallèle Objectif Etude des architectures parallèles Programmation des applications
Programmation système I Les entrées/sorties
 Programmation système I Les entrées/sorties DUT 1 re année Université de Marne La vallée Les entrées-sorties : E/O Entrées/Sorties : Opérations d échanges d informations dans un système informatique. Les
Programmation système I Les entrées/sorties DUT 1 re année Université de Marne La vallée Les entrées-sorties : E/O Entrées/Sorties : Opérations d échanges d informations dans un système informatique. Les
Hiérarchie matériel dans le monde informatique. Architecture d ordinateur : introduction. Hiérarchie matériel dans le monde informatique
 Architecture d ordinateur : introduction Dimitri Galayko Introduction à l informatique, cours 1 partie 2 Septembre 2014 Association d interrupteurs: fonctions arithmétiques élémentaires Elément «NON» Elément
Architecture d ordinateur : introduction Dimitri Galayko Introduction à l informatique, cours 1 partie 2 Septembre 2014 Association d interrupteurs: fonctions arithmétiques élémentaires Elément «NON» Elément
Cours intensif Java. 1er cours: de C à Java. Enrica DUCHI LIAFA, Paris 7. Septembre 2009. Enrica.Duchi@liafa.jussieu.fr
 . Cours intensif Java 1er cours: de C à Java Septembre 2009 Enrica DUCHI LIAFA, Paris 7 Enrica.Duchi@liafa.jussieu.fr LANGAGES DE PROGRAMMATION Pour exécuter un algorithme sur un ordinateur il faut le
. Cours intensif Java 1er cours: de C à Java Septembre 2009 Enrica DUCHI LIAFA, Paris 7 Enrica.Duchi@liafa.jussieu.fr LANGAGES DE PROGRAMMATION Pour exécuter un algorithme sur un ordinateur il faut le
Module.NET 3 Les Assemblys.NET
 Module.NET Chapitre 3 Les Assemblys.NET 2011/2012 Page 1 sur 13 Contenu Cours... 3 3.1 - Définition d un assembly.net... 3 3.2 - Private assembly ou assembly privé.... 3 3.3 - Shared assembly ou assembly
Module.NET Chapitre 3 Les Assemblys.NET 2011/2012 Page 1 sur 13 Contenu Cours... 3 3.1 - Définition d un assembly.net... 3 3.2 - Private assembly ou assembly privé.... 3 3.3 - Shared assembly ou assembly
TP SIN Traitement d image
 TP SIN Traitement d image Pré requis (l élève doit savoir): - Utiliser un ordinateur Objectif terminale : L élève doit être capable de reconnaître un format d image et d expliquer les différents types
TP SIN Traitement d image Pré requis (l élève doit savoir): - Utiliser un ordinateur Objectif terminale : L élève doit être capable de reconnaître un format d image et d expliquer les différents types
TP1 : Initiation à Java et Eclipse
 TP1 : Initiation à Java et Eclipse 1 TP1 : Initiation à Java et Eclipse Systèmes d Exploitation Avancés I. Objectifs du TP Ce TP est une introduction au langage Java. Il vous permettra de comprendre les
TP1 : Initiation à Java et Eclipse 1 TP1 : Initiation à Java et Eclipse Systèmes d Exploitation Avancés I. Objectifs du TP Ce TP est une introduction au langage Java. Il vous permettra de comprendre les
Principes. 2A-SI 3 Prog. réseau et systèmes distribués 3. 3 Programmation en CORBA. Programmation en Corba. Stéphane Vialle
 2A-SI 3 Prog. réseau et systèmes distribués 3. 3 Programmation en CORBA Stéphane Vialle Stephane.Vialle@supelec.fr http://www.metz.supelec.fr/~vialle 1 Principes 2 Architecture 3 4 Aperçu d utilisation
2A-SI 3 Prog. réseau et systèmes distribués 3. 3 Programmation en CORBA Stéphane Vialle Stephane.Vialle@supelec.fr http://www.metz.supelec.fr/~vialle 1 Principes 2 Architecture 3 4 Aperçu d utilisation
Introduction à MATLAB R
 Introduction à MATLAB R Romain Tavenard 10 septembre 2009 MATLAB R est un environnement de calcul numérique propriétaire orienté vers le calcul matriciel. Il se compose d un langage de programmation, d
Introduction à MATLAB R Romain Tavenard 10 septembre 2009 MATLAB R est un environnement de calcul numérique propriétaire orienté vers le calcul matriciel. Il se compose d un langage de programmation, d
Modélisation des interfaces matériel/logiciel
 Modélisation des interfaces matériel/logiciel Présenté par Frédéric Pétrot Patrice Gerin Alexandre Chureau Hao Shen Aimen Bouchhima Ahmed Jerraya 1/28 TIMA Laboratory SLS Group 46 Avenue Félix VIALLET
Modélisation des interfaces matériel/logiciel Présenté par Frédéric Pétrot Patrice Gerin Alexandre Chureau Hao Shen Aimen Bouchhima Ahmed Jerraya 1/28 TIMA Laboratory SLS Group 46 Avenue Félix VIALLET
SYSTÈME DE GESTION DE FICHIERS
 SYSTÈME DE GESTION DE FICHIERS - DISQUE 1 Les couches logiciels réponse requête Requêtes E/S Système E/S Pilote E/S Interruptions utilisateur traitement S.E. commandes S.E. S.E. matériel Contrôleur E/S
SYSTÈME DE GESTION DE FICHIERS - DISQUE 1 Les couches logiciels réponse requête Requêtes E/S Système E/S Pilote E/S Interruptions utilisateur traitement S.E. commandes S.E. S.E. matériel Contrôleur E/S
Table des matières PRESENTATION DU LANGAGE DS2 ET DE SES APPLICATIONS. Introduction
 PRESENTATION DU LANGAGE DS2 ET DE SES APPLICATIONS Depuis SAS 9.2 TS2M3, SAS propose un nouveau langage de programmation permettant de créer et gérer des tables SAS : le DS2 («Data Step 2»). Ces nouveautés
PRESENTATION DU LANGAGE DS2 ET DE SES APPLICATIONS Depuis SAS 9.2 TS2M3, SAS propose un nouveau langage de programmation permettant de créer et gérer des tables SAS : le DS2 («Data Step 2»). Ces nouveautés
Choix d'un serveur. Choix 1 : HP ProLiant DL380 G7 Base - Xeon E5649 2.53 GHz
 Choix d'un serveur Vous êtes responsable informatique d'une entreprise. Vous devez faire un choix pour l'achat d'un nouveau serveur. Votre prestataire informatique vous propose les choix ci-dessous Vous
Choix d'un serveur Vous êtes responsable informatique d'une entreprise. Vous devez faire un choix pour l'achat d'un nouveau serveur. Votre prestataire informatique vous propose les choix ci-dessous Vous
Projet de développement
 Projet de développement Introduction à Eclipse Philippe Collet Licence 3 MIAGE S6 2012-2013 http://miageprojet2.unice.fr/index.php?title=user:philippecollet/projet_de_développement_2012-2013 Plan r Application
Projet de développement Introduction à Eclipse Philippe Collet Licence 3 MIAGE S6 2012-2013 http://miageprojet2.unice.fr/index.php?title=user:philippecollet/projet_de_développement_2012-2013 Plan r Application
Exécutif temps réel Pierre-Yves Duval (cppm)
") Exécutif temps réel Pierre-Yves Duval (cppm) Ecole d informatique temps réel - La Londes les Maures 7-11 Octobre 2002 Plan Exécutif Tâches Evénements et synchronisation Partage de ressources Communications
Exécutif temps réel Pierre-Yves Duval (cppm) Ecole d informatique temps réel - La Londes les Maures 7-11 Octobre 2002 Plan Exécutif Tâches Evénements et synchronisation Partage de ressources Communications
Analyse de sécurité de logiciels système par typage statique
 Contexte Modélisation Expérimentation Conclusion Analyse de sécurité de logiciels système par typage statique Application au noyau Linux Étienne Millon UPMC/LIP6 Airbus Group Innovations Sous la direction
Contexte Modélisation Expérimentation Conclusion Analyse de sécurité de logiciels système par typage statique Application au noyau Linux Étienne Millon UPMC/LIP6 Airbus Group Innovations Sous la direction
Surveillance de Scripts LUA et de réception d EVENT. avec LoriotPro Extended & Broadcast Edition
 Surveillance de Scripts LUA et de réception d EVENT avec LoriotPro Extended & Broadcast Edition L objectif de ce document est de présenter une solution de surveillance de processus LUA au sein de la solution
Surveillance de Scripts LUA et de réception d EVENT avec LoriotPro Extended & Broadcast Edition L objectif de ce document est de présenter une solution de surveillance de processus LUA au sein de la solution
Big Data et Graphes : Quelques pistes de recherche
 Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de Lyon/Université Claude Bernard Lyon 1/Université
Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de Lyon/Université Claude Bernard Lyon 1/Université
Licence Bio Informatique Année 2004-2005. Premiers pas. Exercice 1 Hello World parce qu il faut bien commencer par quelque chose...
 Université Paris 7 Programmation Objet Licence Bio Informatique Année 2004-2005 TD n 1 - Correction Premiers pas Exercice 1 Hello World parce qu il faut bien commencer par quelque chose... 1. Enregistrez
Université Paris 7 Programmation Objet Licence Bio Informatique Année 2004-2005 TD n 1 - Correction Premiers pas Exercice 1 Hello World parce qu il faut bien commencer par quelque chose... 1. Enregistrez
1-Introduction 2. 2-Installation de JBPM 3. 2-JBPM en action.7
 Sommaire 1-Introduction 2 1-1- BPM (Business Process Management)..2 1-2 J-Boss JBPM 2 2-Installation de JBPM 3 2-1 Architecture de JOBSS JBPM 3 2-2 Installation du moteur JBoss JBPM et le serveur d application
Sommaire 1-Introduction 2 1-1- BPM (Business Process Management)..2 1-2 J-Boss JBPM 2 2-Installation de JBPM 3 2-1 Architecture de JOBSS JBPM 3 2-2 Installation du moteur JBoss JBPM et le serveur d application
Analyse de performance, monitoring
 Analyse de performance, monitoring Plan Principes de profilage Projet TPTP dans Eclipse Utilisation des profiling tools de TPTP Philippe Collet Master 1 Informatique 2009-2010 http://deptinfo.unice.fr/twiki/bin/view/minfo/gl
Analyse de performance, monitoring Plan Principes de profilage Projet TPTP dans Eclipse Utilisation des profiling tools de TPTP Philippe Collet Master 1 Informatique 2009-2010 http://deptinfo.unice.fr/twiki/bin/view/minfo/gl
Brefs rappels sur la pile et le tas (Stack. / Heap) et les pointeurs
 et les pointeurs") Brefs rappels sur la pile et le tas (Stack / Heap) et les pointeurs (exemples en C) v1.11 - Olivier Carles 1 Pile et Tas Mémoire allouée de manière statique Mémoire Allouée Dynamiquement variables locales
Brefs rappels sur la pile et le tas (Stack / Heap) et les pointeurs (exemples en C) v1.11 - Olivier Carles 1 Pile et Tas Mémoire allouée de manière statique Mémoire Allouée Dynamiquement variables locales
Pour signifier qu'une classe fille hérite d'une classe mère, on utilise le mot clé extends class fille extends mère
 L'héritage et le polymorphisme en Java Pour signifier qu'une classe fille hérite d'une classe mère, on utilise le mot clé extends class fille extends mère En java, toutes les classes sont dérivée de la
L'héritage et le polymorphisme en Java Pour signifier qu'une classe fille hérite d'une classe mère, on utilise le mot clé extends class fille extends mère En java, toutes les classes sont dérivée de la
Exigences système Edition & Imprimeries de labeur
 Exigences système Edition & Imprimeries de labeur OneVision Software France Sommaire Asura 9.5, Asura Pro 9.5, Garda 5.0...2 PlugBALANCEin 6.5, PlugCROPin 6.5, PlugFITin 6.5, PlugRECOMPOSEin 6.5, PlugSPOTin
Exigences système Edition & Imprimeries de labeur OneVision Software France Sommaire Asura 9.5, Asura Pro 9.5, Garda 5.0...2 PlugBALANCEin 6.5, PlugCROPin 6.5, PlugFITin 6.5, PlugRECOMPOSEin 6.5, PlugSPOTin
Cours Informatique 1. Monsieur SADOUNI Salheddine
 Cours Informatique 1 Chapitre 2 les Systèmes Informatique Monsieur SADOUNI Salheddine Un Système Informatique lesystème Informatique est composé de deux parties : -le Matériel : constitué de l unité centrale
Cours Informatique 1 Chapitre 2 les Systèmes Informatique Monsieur SADOUNI Salheddine Un Système Informatique lesystème Informatique est composé de deux parties : -le Matériel : constitué de l unité centrale
Programmation parallèle et distribuée
 Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2014) Marc Parizeau, Département de génie électrique et de génie informatique Plan Mégadonnées («big data») Architecture Hadoop distribution
Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2014) Marc Parizeau, Département de génie électrique et de génie informatique Plan Mégadonnées («big data») Architecture Hadoop distribution
imvision System Manager
 SYSTIMAX Solutions imvision System Manager Logiciel de Gestion de l Infrastructure www.commscope.com imvision System Manager Vision imvision System Manager peut vous donner une vue complète de votre infrastructure
SYSTIMAX Solutions imvision System Manager Logiciel de Gestion de l Infrastructure www.commscope.com imvision System Manager Vision imvision System Manager peut vous donner une vue complète de votre infrastructure
Temps Réel. Jérôme Pouiller <j.pouiller@sysmic.org> Septembre 2011
 Temps Réel Jérôme Pouiller Septembre 2011 Sommaire Problèmatique Le monotâche Le multitâches L ordonnanement Le partage de ressources Problèmatiques des OS temps réels J. Pouiller
Temps Réel Jérôme Pouiller Septembre 2011 Sommaire Problèmatique Le monotâche Le multitâches L ordonnanement Le partage de ressources Problèmatiques des OS temps réels J. Pouiller
Software and Hardware Datasheet / Fiche technique du logiciel et du matériel
 Software and Hardware Datasheet / Fiche technique du logiciel et du matériel 1 System requirements Windows Windows 98, ME, 2000, XP, Vista 32/64, Seven 1 Ghz CPU 512 MB RAM 150 MB free disk space 1 CD
Software and Hardware Datasheet / Fiche technique du logiciel et du matériel 1 System requirements Windows Windows 98, ME, 2000, XP, Vista 32/64, Seven 1 Ghz CPU 512 MB RAM 150 MB free disk space 1 CD
Tests de performance du matériel
 3 Tests de performance du matériel Après toute la théorie du dernier chapitre, vous vous demandez certainement quelles sont les performances réelles de votre propre système. En fait, il y a plusieurs raisons
3 Tests de performance du matériel Après toute la théorie du dernier chapitre, vous vous demandez certainement quelles sont les performances réelles de votre propre système. En fait, il y a plusieurs raisons
Formation IPICO du 10/11 Février 2011 :
 Formation IPICO du 10/11 Février 2011 : Tapis défectueux : Etablir une liste recensant les tapis défectueux (n de série, couleur) et envoyer cette liste à Larry. Ensuite envoyer les tapis à TI Group à
Formation IPICO du 10/11 Février 2011 : Tapis défectueux : Etablir une liste recensant les tapis défectueux (n de série, couleur) et envoyer cette liste à Larry. Ensuite envoyer les tapis à TI Group à
UEO11 COURS/TD 1. nombres entiers et réels codés en mémoire centrale. Caractères alphabétiques et caractères spéciaux.
 UEO11 COURS/TD 1 Contenu du semestre Cours et TDs sont intégrés L objectif de ce cours équivalent a 6h de cours, 10h de TD et 8h de TP est le suivant : - initiation à l algorithmique - notions de bases
UEO11 COURS/TD 1 Contenu du semestre Cours et TDs sont intégrés L objectif de ce cours équivalent a 6h de cours, 10h de TD et 8h de TP est le suivant : - initiation à l algorithmique - notions de bases
Comme chaque ligne de cache a 1024 bits. Le nombre de lignes de cache contenu dans chaque ensemble est:
 Travaux Pratiques 3. IFT 1002/IFT 1005. Structure Interne des Ordinateurs. Département d'informatique et de génie logiciel. Université Laval. Hiver 2012. Prof : Bui Minh Duc. Tous les exercices sont indépendants.
Travaux Pratiques 3. IFT 1002/IFT 1005. Structure Interne des Ordinateurs. Département d'informatique et de génie logiciel. Université Laval. Hiver 2012. Prof : Bui Minh Duc. Tous les exercices sont indépendants.
Centre CPGE TSI - Safi 2010/2011. Algorithmique et programmation :
 Algorithmique et programmation : STRUCTURES DE DONNÉES A. Structure et enregistrement 1) Définition et rôle des structures de données en programmation 1.1) Définition : En informatique, une structure de
Algorithmique et programmation : STRUCTURES DE DONNÉES A. Structure et enregistrement 1) Définition et rôle des structures de données en programmation 1.1) Définition : En informatique, une structure de
Windows Server 2008. Chapitre 1: Découvrir Windows Server 2008
 Windows Server 2008 Chapitre 1: Découvrir Windows Server 2008 Objectives Identifier les caractéristiques de chaque édition de Windows Server 2008 Identifier les caractéristiques généraux de Windows Server
Windows Server 2008 Chapitre 1: Découvrir Windows Server 2008 Objectives Identifier les caractéristiques de chaque édition de Windows Server 2008 Identifier les caractéristiques généraux de Windows Server
Eléments d architecture des machines parallèles et distribuées
 M2-RISE - Systèmes distribués et grille Eléments d architecture des machines parallèles et distribuées Stéphane Vialle Stephane.Vialle@supelec.fr http://www.metz.supelec.fr/~vialle Notions d architecture
M2-RISE - Systèmes distribués et grille Eléments d architecture des machines parallèles et distribuées Stéphane Vialle Stephane.Vialle@supelec.fr http://www.metz.supelec.fr/~vialle Notions d architecture
Vulgarisation Java EE Java EE, c est quoi?
 Paris, le 1 Février 2012 Vulgarisation Java EE Java EE, c est quoi? Sommaire Qu est ce que Java? Types d applications Java Environnements Java Versions de Java Java EE, c est quoi finalement? Standards
Paris, le 1 Février 2012 Vulgarisation Java EE Java EE, c est quoi? Sommaire Qu est ce que Java? Types d applications Java Environnements Java Versions de Java Java EE, c est quoi finalement? Standards
Chapitre V : La gestion de la mémoire. Hiérarchie de mémoires Objectifs Méthodes d'allocation Simulation de mémoire virtuelle Le mapping
 Chapitre V : La gestion de la mémoire Hiérarchie de mémoires Objectifs Méthodes d'allocation Simulation de mémoire virtuelle Le mapping Introduction Plusieurs dizaines de processus doivent se partager
Chapitre V : La gestion de la mémoire Hiérarchie de mémoires Objectifs Méthodes d'allocation Simulation de mémoire virtuelle Le mapping Introduction Plusieurs dizaines de processus doivent se partager
Programmation parallèle et distribuée
 Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2015) Marc Parizeau, Département de génie électrique et de génie informatique Plan Données massives («big data») Architecture Hadoop distribution
Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2015) Marc Parizeau, Département de génie électrique et de génie informatique Plan Données massives («big data») Architecture Hadoop distribution
INTRODUCTION A JAVA. Fichier en langage machine Exécutable
 INTRODUCTION A JAVA JAVA est un langage orienté-objet pur. Il ressemble beaucoup à C++ au niveau de la syntaxe. En revanche, ces deux langages sont très différents dans leur structure (organisation du
INTRODUCTION A JAVA JAVA est un langage orienté-objet pur. Il ressemble beaucoup à C++ au niveau de la syntaxe. En revanche, ces deux langages sont très différents dans leur structure (organisation du
SYSTÈME DE GESTION DE FICHIERS SGF - DISQUE
 SYSTÈME DE GESTION DE FICHIERS SGF - DISQUE C.Crochepeyre MPS_SGF 2000-20001 Diapason 1 Les couches logiciels réponse SGF requête matériel matériel Requêtes E/S Système E/S Pilote E/S Interruptions Contrôleur
SYSTÈME DE GESTION DE FICHIERS SGF - DISQUE C.Crochepeyre MPS_SGF 2000-20001 Diapason 1 Les couches logiciels réponse SGF requête matériel matériel Requêtes E/S Système E/S Pilote E/S Interruptions Contrôleur
UE Programmation Impérative Licence 2ème Année 2014 2015
 UE Programmation Impérative Licence 2 ème Année 2014 2015 Informations pratiques Équipe Pédagogique Florence Cloppet Neilze Dorta Nicolas Loménie prenom.nom@mi.parisdescartes.fr 2 Programmation Impérative
UE Programmation Impérative Licence 2 ème Année 2014 2015 Informations pratiques Équipe Pédagogique Florence Cloppet Neilze Dorta Nicolas Loménie prenom.nom@mi.parisdescartes.fr 2 Programmation Impérative
Compilation (INF 564)
") Présentation du cours Le processeur MIPS Programmation du MIPS 1 Compilation (INF 564) Introduction & architecture MIPS François Pottier 10 décembre 2014 Présentation du cours Le processeur MIPS Programmation
Présentation du cours Le processeur MIPS Programmation du MIPS 1 Compilation (INF 564) Introduction & architecture MIPS François Pottier 10 décembre 2014 Présentation du cours Le processeur MIPS Programmation
Bases Java - Eclipse / Netbeans
 Institut Galilée PDJ Année 2014-2015 Master 1 Environnements Java T.P. 1 Bases Java - Eclipse / Netbeans Il existe plusieurs environnements Java. Il est ESSENTIEL d utiliser la bonne version, et un environnement
Institut Galilée PDJ Année 2014-2015 Master 1 Environnements Java T.P. 1 Bases Java - Eclipse / Netbeans Il existe plusieurs environnements Java. Il est ESSENTIEL d utiliser la bonne version, et un environnement
Conventions d écriture et outils de mise au point
 Logiciel de base Première année par alternance Responsable : Christophe Rippert Christophe.Rippert@Grenoble-INP.fr Introduction Conventions d écriture et outils de mise au point On va utiliser dans cette
Logiciel de base Première année par alternance Responsable : Christophe Rippert Christophe.Rippert@Grenoble-INP.fr Introduction Conventions d écriture et outils de mise au point On va utiliser dans cette
Gestionde la conformité des licenses
 Gestionde la conformité des licenses CA ITAM CA Technologies Le 3 octobre 2013 Agenda Introduction et concepts de la gestion de conformité Présentation de la solution Démonstration Point de vue : Natixis
Gestionde la conformité des licenses CA ITAM CA Technologies Le 3 octobre 2013 Agenda Introduction et concepts de la gestion de conformité Présentation de la solution Démonstration Point de vue : Natixis
INITIATION AU LANGAGE C SUR PIC DE MICROSHIP
 COURS PROGRAMMATION INITIATION AU LANGAGE C SUR MICROCONTROLEUR PIC page 1 / 7 INITIATION AU LANGAGE C SUR PIC DE MICROSHIP I. Historique du langage C 1972 : naissance du C dans les laboratoires BELL par
COURS PROGRAMMATION INITIATION AU LANGAGE C SUR MICROCONTROLEUR PIC page 1 / 7 INITIATION AU LANGAGE C SUR PIC DE MICROSHIP I. Historique du langage C 1972 : naissance du C dans les laboratoires BELL par