Cours d'architecture parallèle
|
|
|
- Yolande Michel
- il y a 10 ans
- Total affichages :
Transcription
1 Cours d'architecture parallèle Denis Barthou 1

2 1- Parallélisme De nombreux services et machines sont déjà parallèles Internet et infrastructure de serveurs Bases de données Jeux en réseau Réseaux de senseurs (automobile, équipements embarqués, )... Quoi de neuf? 2
... Quoi de neuf?")
3 1- Parallélisme De nombreux services et machines sont déjà parallèles Internet et infrastructure de serveurs Bases de données Jeux en réseau Réseaux de senseurs (automobile, équipements embarqués, )... Quoi de neuf? Parallélisme à tous les niveaux, au niveau architecture Augmentation du nombre de coeurs 3

4 4 Nvidia Fermi: 192 cores 7,1 milliards de transistors 1- Parallélisme multicore/manycore Many core déjà présent. Intel Tera chip, 2007 (80 cores) Intel SCC, 2010 (48 cores) Many Integrated Chips (MIC) Puce KnightCorner Intel (50 cores)
 Many Integrated Chips (MIC) Puce KnightCorner Intel")
5 1- Pourquoi on en est là? Loi de Moore Tous les 18 mois, le nombre de transistors double, à prix constant (1965) Une loi exponentielle s'applique également sur: les performances des processeurs, la capacité mémoire, disque la taille de la gravure (de plus en plus petite) la dissipation d'énergie 5

6 1- Loi de Moore, facteur limitant: W W = CV 2 f 6

7 1- Impacts La fréquence ne croit plus (augmente dissipation) Le nombre de coeurs augmente 7
 Le nombre")
8 1- Impacts Puissance dissipée ralentie (la cause) Performances/coeur ralenties 8

9 1- Choix des multicoeurs Choix technologique par défaut, pas une révolution choisie Besoin d'avancées décisives pour le logiciel Cacher la complexité de l'architecture Trouver du parallélisme, efficacement Toutes les applications devront tourner sur une machine parallèle Machines // pour HPC: accepte de tuner performances longtemps, d'analyser problèmes Machines pour les vrais utilisateurs: doit fonctionner, convaincre qu'il y a un intérêt au parallélisme. 9

10 1- Ne pas oublier: loi d'amdahl Métriques Speed-up: T1 / Tp Efficacité: T1 / (p.tp) Loi d'amdahl: f fraction de code parallèle, speed up max sur p proc. est: 1 / ((1 f) + f/p) En réalité, scalabilité pas si bonne et perf décroissent quand p augmente... 10

11 1- Ne pas oublier: interactions soft+hard Les performances sont le résultat des interactions entre Le compilateur, l'os Les bibliothèques, le support runtime Le matériel 11

12 1- Objectifs de ce cours Analyser et comprendre le fonctionnement d'une machine parallèle Etudier les machines parallèles actuelles Utiliser ces connaissances pour mieux optimiser des codes applicatifs 12

13 Tendances sur les performances Performances pour multicoeurs et machines parallèles sur code scientifique 13

14 Tendances sur les performances Performances pour multicoeurs et machines parallèles sur code scientifique 14

15 2- Fonctionnement unicoeur Processeurs actuels: ~1 milliard de transistors Clairement, travaillent en parallèle Comment le hardware organise/exprime le parallélisme? Trouve le parallélisme entre instructions (ILP) But des architectes jusqu'en 2002 Cacher ce parallélisme à tout le monde (utilisateur, compilateur, runtime) 15
 But des architectes jusqu'en 2002")
16 2- Fonctionnement unicoeur Exemples de mécanismes pour trouver/exprimer l'ilp Pipeline: découpe l'exécution en plusieurs étapes Superscalaire: exécute plusieurs instructions à la fois VLIW: exécute des instructions composites Exécution vectorielle: une instruction opère sur plusieurs données Out of order execution: les instructions indépendantes peuvent s'exécuter en parallèle 16

17 2-a Pipeline Exemple de la laverie (D. Patterson) 30min lavage, 40min sechage, 20min pliage. Non pipeliné: 90min/pers., Bande passante: 1pers/90min Pipeliné: 120min/pers., Bande passante: 1pers/40min. Chaque étape prend le temps de l'étape la plus longue. Speed-up: augmente avec nombre d'étages. 17

18 2-a Pipeline Pipeline en 5 étages du MIPS (IF/ID/Ex/Mem/WB) 18
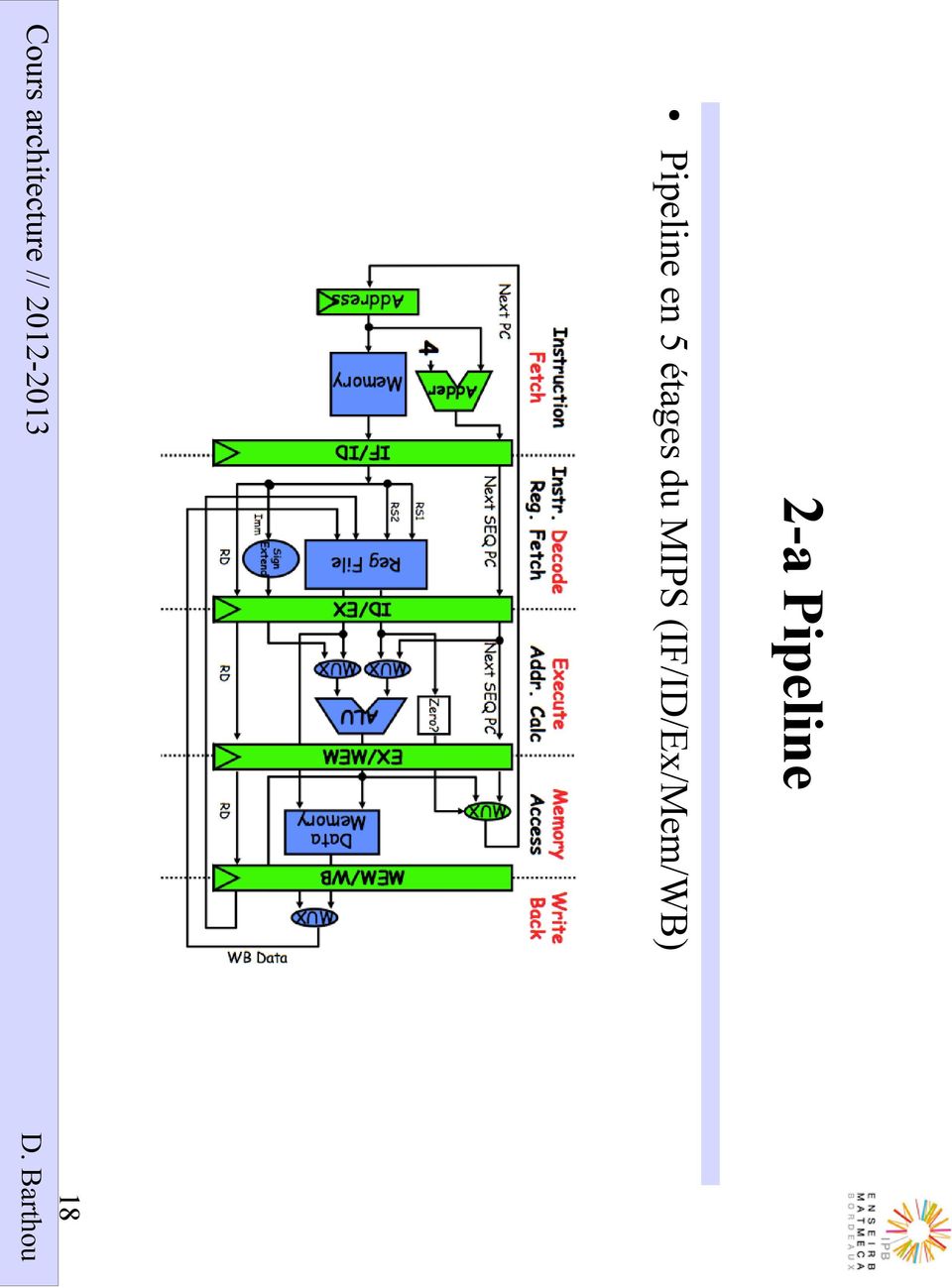
19 2-a Pipeline Idéalement, 1 cycle/instruction Superscalaire: moins d'1 cycle/instruction 19

20 2-a Pipeline Difficultés pour un pipeline (hazards) Dépendances de données: la valeur calculée par une instruction doit être utilisée par une autre instruction, mais l'utilisation a lieu avant le calcul... Branchements Solutions: Forwarding: passe la valeur disponible à un étage à un autre étage Stall Speculation 20

21 2-a Pipeline Dépendances, forwarding et stall Superscalaire: augmente la probabilité de hazard 21
22 2-b Out of order Idée principale: permettre aux instructions qui suivent une instruction qui stall de s'exécuter sans attendre. Problèmes de l'ooo: Interruptions? Ordre de completion des instructions et effets de bord? 22
23 2-b Out of order: exemple du MIPS 10k 23
24 2-b Out of Order: algorithme de Tomasulo 5 étapes: Dispatch: prend une instruction d'une file d'attente et la place dans un emplacement libre du ROB. Mise à jour des registres écrits Issue: attend que les opérandes de l'instruction soient prêts Execute: l'instruction part dans le pipeline Write result (WB): ecrit le resultat sur un Common Data Bus pour mettre à jour la valeur écrite et débloquer d'autres instructions Commit: met à jour le registre avec la valeur du ROB. Quand l'instruction à la tête du ROB (une file) est finie, fait sa mise à jour et enlève l'instruction 24
25 2-b Out of order: mise en place Besoin matériel: Buffer pour les instructions non terminées: reorder buffer (rob) Les registres ecrits sont renommés (évite WAR,WAW) 25
26 26
27 27
28 28
29 29
30 30
31 31
32 32
33 33
34 34
35 35
36 36
37 37
38 Plan 1. Introduction, contexte 2. Architecture unicoeur Pipeline, OoO, superscalaire, VLIW, prediction des branchements, limites à l'ilp 3. Architecture vectorielle 4. Mémoire et caches Définition, vectorisation Principe, caches, caches en multicoeur, optimisation 5. Nouvelles architectures et accélérateurs 38
39 2-b Out of order Actuellement Pipelines de plus de 10 étages 6-8 instructions lues / cycle => beaucoup d'instructions en vol OoO et ILP: calcul des dépendances, reordonnancement dynamique, renommage de registres. ROB et dispatch buffer: faire comme si instructions exécutées dans ordre séquentiel Pour éviter stalls: Spéculation, Gestion spéculative des branchements, delay slot Complexité du mécanisme: quadratique en nombre d'instructions... 39
40 2- Superscalaire / VLIW Pipeline scalaire Superscalaire et VLIW 40
41 2-c Architecture Superscalaire Caractéristiques Plusieurs instructions lancées en même temps Multiples unités fonctionnelles (y compris décodage) Adaptations par rapport pipeline simple Risques élevés de dépendances Tout est plus compliqué! Pénalité importante si bulle dans pipeline Mécanismes hardware additionnels Renommage de registres, OoO Prédiction de branchement 41
42 2-d Very Large Instruction Word Caractéristiques Les instructions sont regroupées statiquement, dans le code asm, en paquet, un paquet est exécuté par cycle Le nombre d'instruction par paquet est fixé (au max) Le compilateur fait les paquets 42
43 2-d VLIW Regroupe les instructions par paquets prédéfinis Le soft doit garantir: latence entre instructions suffisante pour satisfaire dépendances Pas d'instructions dont données non prêtes 43
44 2-d VLIW VLIW requiert support spécial du compilateur Paquets: bundle sur IA64, molecule sur Transmeta Le compilateur trouve le parallélisme Peut nécessiter recompilation quand change d'architecture 44
45 2-d VLIW Déroulage d'instructions: 45
46 2-d VLIW: exemple de l'itanium 46
47 2-d VLIW: registres Itanium 47
48 2-d VLIW: exemple de l'itanium Exécution: Les bundles sont lus jusqu'à saturation des unités fonctionnelles Au max, 2 bundles exécutés en parallèle (taille max fenêtre d'exécution) 48
49 2-d VLIW: exemple de l'itanium Exécution Tous les cycles: une nouvelle fenêtre Limitation du parallélisme: Nombre d'unités fonctionnelles Longueur du groupe d'instructions 49
50 2-d VLIW: exemple de l'itanium Exécution Tous les cycles: une nouvelle fenêtre Limitation du parallélisme: Nombre d'unités fonctionnelles Longueur du groupe d'instructions 50
51 2-d VLIW: exemple de l'itanium Mécanismes pour assurer un bon niveau de parallélisme Pas les mêmes que le superscalaire, ni OoO ni renommage de registres Les mécanismes proposés permettent au compilateur d'exprimer du parallélisme Problèmes de branchement: Prédiction statique des branchements: instructions différentes de branchement suivant probabilité de faire le branchement Prédication Dépendances (entre cases mémoire, entre un load et un store par ex.) Spéculation D'autres mécanismes complètent la panoplie: registres tournants, grand nombre de registres,... 51
52 2-d VLIW: Prédication sur Itanium Principe: Remplacer les branchements par instructions conditionnées (prédicatées) Les deux branches du if..then..else sont exécutées, en parallèle! 52
53 2-d VLIW: Prédication sur Itanium Prédication + Plus de stall dus aux branchements! Plus de branchement! + Augmente le parallélisme, très bien pour un VLIW - Beaucoup d'instructions sont des nop au final... Pas rentable pour des if..then..else contenant de longues séquences d'instructions 53
54 2-d VLIW: Spéculation Problème de dépendances: store (r1), r2 stocke la valeur de r2 à l'adresse r1 load r3, (r4) lit la valeur à l'adresse r4 et la place dans r3 Possible dépendance si r1 == r4 Les instructions ne peuvent pas être mises en parallèle, stall... Spéculation load.a r3,(r4) load spéculatif: on suppose qu'il n'y a pas de dépendance store (r1), r2 le load peut être fait bien avant le store... check.a r4 vérifie que la spéculation était légale 54
55 2-d VLIW: Spéculation Spéculation + Permet d'exprimer plus de parallélisme et diminuer les dépendances couteuses - Si spéculation erronée, exécute code de correction... - Au final, difficulté du compilateur et des optimisations à bien utiliser ce type de spéculation 55
56 2-e Prédiction de branchements Objectif: prédire le plus tot possible si L'instruction est un branchement branch predictor L'adresse du branchement branch target predictor (un cache, BTB) Idée: Prédire le futur avec le passé Etre sur de pouvoir revenir en arrière en cas de mauvaise prédiction 56
57 2-e Prédiction de branchements Algorithmes de prédiction de branchement Ultrasimple: Prédire toujours la même chose (pas pris si en avant, pris si en arrière, ) L'utilisateur prédit en choisissant l'instruction asm A 1 bit: se base sur le dernier branchement. Si branchement pris la dernière fois, prédit qu'on le prendra. Si branchement pas pris, alors prédit pas pris. Prédiction très tot: étage décodage (fetch)! 57
58 2-e Prédiction de branchements Algorithmes de prédiction A 2bits: se base sur les 2 derniers branchements. Prédiction suivant valeur des deux bits: 0 et 1: branchement pris 2 et 3: branchement pas pris Mise à jour Si pris, décrémente compteur (si 0, reste à 0) Si pas pris: incrémente compteur (si 3, reste à 3) 58
59 2-e Prédiction de branchements Corrélation entre branchements (Yeh, Patt, 1992) If (x[i]>5) y=y+4; If (x[i]>3) c=2; Si le premier branchement est pris, le deuxième aussi les 2 branchements sont corrélés Historique des branchements: garde la trace des résultats des h derniers branchements Indexé par le PC (program counter) Depuis pentium Pro: garde sur 2 bits les 2 derniers branchements 59
60 2-e Prédiction de branchements K dernières valeurs k entrées Prédicteur global, pour tous les branchements Ou prédicteur local, pour l'historique d'1 branchement Automate pris/pas pris 60
61 2-e Prédiction de branchement Limites théoriques de la prédiction de branchement: Pas possible de prédire bruit Limite pratique: Taille de l'historique Arbitre entre méthodes de prédiction 61
62 2-f Limites au parallélisme d'instructions Pour une machine idéale: Nombre de registres infini Fenêtre d'instructions infinie Nombre d'instructions/cycle infini Prédiction de branchement parfaite 62
63 2-f Limites au parallélisme d'instructions Machine plus réaliste: Fenêtre limitée (2048 instructions) Prédicteur de branchement 64 instructions/cycle max. 63
64 2-f Limites au parallélisme d'instructions Pour passer de 6 à 12 instructions/cycle, estimation: 3-4 accès mémoire/cycle 2-3 branchements/cycle Renommer plus de 20 registres/cycle Chercher 12 à 24 instructions/cycle Augmentation de la complexité limite la fréquence Ex: Itanium2, 6 instructions/cycle, large fenêtre d'exécution. Consomme beaucoup, faible fréquence. 64
65 2- VLIW/Superscalaire Conclusion VLIW et superscalaire Limites au parallélisme d'instruction (ILP) Matériel: pour le OoO, nombre de transistors croit exponentiellement avec nombre d'instructions à mettre en parallèles Logiciel: difficile de trouver des séquences de plus de 6 instructions parallèles dans les codes (même en optimisant) Gains de performances apportés par l'ilp Out of order can buy you 5 cycles, not 200 cycles (D.Levinthal, Intel) Gains au max d'un facteur 6, sur des codes très simples Ne permet pas de résoudre les longues latences mémoire (cf apres) 65
66 3- Vectoriel a) Le vectoriel, c'est quoi? Une instruction (vectorielle), appliquée sur plusieurs données (un vecteur de données) SIMD: single instruction, multiple data b) Comment l'utiliser? 66
67 3-a Vectoriel: c'est quoi? Caractéristiques Ne convient pas à tous les codes, toutes les instructions Instructions types: multimédia, calcul 3D (cartes graphiques), calcul scientifique, simulations physiques Multimédia = marché de masse (rentabilise développements) Extensions jeu d'instructions vectorielles pour toutes les architectures Intel: MMX, SSE, AVX, AVX2 IBM: Altivec ARM: Neon Sparc: Visual Instruction Set Certains processeurs vectoriels: Cray, GPUs,... 67
68 3-a Vectoriel Exemple type de code vectorisable For (i=0; i<n; i++) A[i] = B[i] + C[i]; Toutes les itérations peuvent être faites simultanément. Addition élément par élément des vecteurs B et C 68
69 3-a Vectoriel Calculs vectoriels et longueur du vecteur 69
70 3-a Vectoriel: exemple SSE Registre vectoriel (SSE) %xmm Peut être vu comme 1 valeur 128 bits, 2 valeurs 64 bits, 4 valeur 32 bits... Longueur des valeurs spécifié par l'instruction La longueur du vecteur est toujours de 128 bits Accès mémoire en 1 instruction (en load et store) 70
71 3-a Vectoriel: exemple SSE Exemple type d'instruction vectorielle (SSE) Registres vectoriel: contient différentes valeurs indépendantes (ici, 4) Les opérations sont les mêmes sur les 4 valeurs 71
72 3-a Vectoriel: exemple de AVX Extension de SSE sur 256 bits Instructions 3 adresses possibles x = y op z Contraintes d'alignement sur 256 bits pour le chargement mémoire (non alignement ralentissement) A venir: Plus de 256 bits 72
73 3-a Vectoriel: exemple Itanium Exemple d'instruction plus compliqué: psad for (i=0; i<7; i++) s+=abs(a[i]-b[i]); Calcule ⅼAi-Biⅼ Aucune chance pour le compilateur de la sélectionner! 73
74 3-a Vectoriel Jeu d'instruction vectoriel Actuellement, sur petits registres (128, 256 bits). Avant, sur Cray, registres très longs. Jeux d'instructions très riche (1400 pages juste pour décrire SSE) Utilisation des instructions vectorielles Responsabilité compilateur: nécessite vectoriseur. Difficile prise en compte de la richesse des instructions Responsabilité utilisateur: codage en utilisant l'assembleur, ou les fonctions intrinsèques (correspond à une instruction asm) Le hardware ne vectorise pas! 74
75 3-b Vectorisation Est-ce que c'est facile de vectoriser? Le compilateur peut vectoriser L'utilisateur peut vectoriser Intrinsics Attributs de type (gcc/icc) Transformations de code pour aider la vectorisation (pragmas, transformations de code, ) Est-ce que c'est intéressant de vectoriser? 75
76 3-b Vectorisation: difficile! Extrait de la documentation IBM programmeur pour Blue Gene/L 76
77 3-b Vectorisation par le compilateur Lire la documentation! La plupart des compilateurs font de l'auto-vectorisation Gcc: Donnent un rapport de vectorisation expliquant si il a vectorisé une boucle, si non pourquoi. Contraintes à la vectorisation automatique Nécessite une bonne analyse de dépendance Certaines transformations de code peuvent perdre le compilo Contraintes d'alignement (ne pas perdre de performance, ou ne pas faire bus error...) Données contigues en mémoire (pas de trou, ou de stride >1) Problème de transfert unités vectorielles unités scalaires. Il faut en général que le calcul soit entièrement vectoriel. 77
78 3-b Vectorisation à la main Quand ça ne suffit pas...il faut mettre les mains dedans En général, code non portable Eviter l'asm autant qu'on peut Solution 1: intrinsics Solution non portable pour utiliser instructions vectorielles en C/C++ Une fonction instrinsic = une instruction asm codée en C Le compilateur s'occupe de l'allocation des registres, peu d'optimisations à espérer 78
79 3-b Vectorisation Solution 1: intrinsics (extrait calcul de mandelbrot, site Intel) #include <immintrin.h>. m256 ymm13 = _mm256_mul_ps(ymm11,ymm11); // xi*xi m256 ymm14 = _mm256_mul_ps(ymm12,ymm12); // yi*yi m256 ymm15 = _mm256_add_ps(ymm13,ymm14); // xi*xi+yi*yi // xi*xi+yi*yi < 4 in each slot ymm15 = _mm256_cmp_ps(ymm15,ymm5, _CMP_LT_OQ); // now ymm15 has all 1s in the non overflowed locations test = _mm256_movemask_ps(ymm15)&255; // lower 8 bits are comparisons ymm15 = _mm256_and_ps(ymm15,ymm4); // get 1.0f or 0.0f in each field as counters // counters for each pixel iteration ymm10 = _mm256_add_ps(ymm10,ymm15); ymm15 = _mm256_mul_ps(ymm11,ymm12); // xi*yi ymm11 = _mm256_sub_ps(ymm13,ymm14); // xi*xi-yi*yi ymm11 = _mm256_add_ps(ymm11,ymm8); // xi <- xi*xi-yi*yi+x0 done! ymm12 = _mm256_add_ps(ymm15,ymm15); // 2*xi*yi ymm12 = _mm256_add_ps(ymm12,ymm9); // yi <- 2*xi*yi+y0 79
80 3-b Vectorisation Exemple de speed-up: Sur calcul fractal (trivialement vectoriel, //) Max théorique: facteur d'accélération 8 Caractéristiques du calcul: Dominé par les calculs (pas les accès mémoire) 80
81 3-b Vectorisation Solution 2: attributs de type vecteur Extensions gcc, supportées par icc. Par ex: typedef int vec attribute ((vector_size (N))); Possible d'écrire les calculs comme des types de base (+,*,/,...), génère un code vectoriel. N doit être une constante immédiate + Le compilateur se charge de la génération de code, de la vectorisation, de l'allocation des registres. - Ne permet pas l'utilisation de manipulation complexes d'éléments de vecteur 81
82 3-b Vectorisation Solution 3: Modifier son code pour que le compilateur vectorise. Quelques transformations: Choisir/recopier ses structures pour avoir des données contigues A[B[i]] recopier dans A'[i] tableau de structures structure de tableaux si besoin Eviter le controle (if...) et le transformer en expressions? Aligner ses structures (valloc, mem_align) Faire des boucles avec peu d'instructions (fissionner) 82
83 3-b Vectorisation Est-ce que c'est rentable de vectoriser? La vectorisation améliore les calculs (moins d'instructions), les opérations mémoire (moins d'instructions) La vectorisation ne change pas la latence mémoire code memory-bound : vectorisation probablement aucun effet 83
84 3- Conclusion vectorisation Important facteur pour les performances actuellement. Utiliser le compilateur au mieux Vérifier qu'il vectorise correctement (asm) Faire des transformations de code pour l'aider En dernier recours, vectoriser à la main 84
85 4- Mémoire CPU Memory Performance limitée par les accès mémoire Bande passante (quantité d'octets/cycle) Si m est la fraction moyenne d'accès mémoire dans le code, il faut 1+m accès par instruction Latence (cycles pour un accès) Temps d'un accès >> 1 cycle 85
86 4- Mémoire a) Principe général b) Fonctionnement des caches c) Caches en multicoeur d) Optimisation mémoire de codes 86
87 4-a La technologie des mémoires Dynamic RAM La mémoire principale + Faible consommation + Faible taille - Nécessite amplification Chaque lecture affaibli le signal - Signal pas carré (capacité) 1-T DRAM Cell word access transistor VREF bit Storage capacitor (FET gate, trench, stack) 87
88 88 Data D N+M M Column Decoder & Sense Amplifiers Memory cell (one bit) M bits pour cols. N bits pour lignes Row Address Decoder Row 2 N N Adresse sur N+M bits Tableaux 2D Col. 1 bit lines Col. word lines 2 M Row 1 Organisation par tableau de bits 4-a La technologie des mémoires
89 4-a Problème de la mémoire Ecart entre processeur/mémoire: +50%/an Pour un processeur superscalaire à 2Ghz 4 instructions/cycle, une DRAM à 100ns l'accès => 800 instructions pour un accès! 89
90 4-b Accès types aux données Address n loop iterations Instruction fetches Stack accesses subroutine call argument access subroutine return Data accesses Time 90
91 4-b Localité Accès mémoire suivent souvent une régularité prédictible Localité temporelle: si une cellule mémoire est accédée, il est probable qu'elle soit accédée dans un futur proche Localité spatiale: si une cellule mémoire est accédée, il est probable qu'une cellule mémoire proche soit accédée dans un futur proche Exemple de localité temporelle: les instructions dans une boucle sont accédées plusieurs fois Exemple de localité spatiale: les instructions dans une séquence sont accédées les uns après les autres. 91
92 4-b Localité spatiale et temporelle 92
93 4-b Localité spatiale et temporelle Dans une boucle for (i-0; i<n; i++) { S1 = A[i] S2 = A[i + K] } Combien d'itérations séparent deux utilisations successives d'un même élément de tableau? K Idée principale Garder A[i] lu en S1 dans une mémoire rapide jusqu'à sa prochaine réutilisation par S2 K itérations plus tard. Si stocké dans registres, nécessaire au moins K registres 93
94 4-b Cache Les caches exploitent les deux types de localité Localité temporelle: se rapellent les éléments recemment utilisés Localité spatiale: récupèrent des blocs de données voisins de celles utilisées Utilise une autre technologie: Static RAM CPU A Small, B Fast Memory (RF, SRAM) holds frequently used data Big, Slow Memory (DRAM) 94
95 4-b Cache A chaque accès mémoire: Vérifie si l'élément est dans le cache: si oui, c'est un cache hit (faible latence), Sinon c'est un cache miss (grosse latence), le chercher en mémoire. Le placer dans le cache ainsi que ses voisins. Gain attendu: T1 latence pour un hit, T2 latence pour un miss (et accès mémoire) h: fraction des références mémoires faisant un hit (hit ratio) Latence moyenne = h.t1 + (1 - h). T2 Si h=0,5, au mieux latence moyenne = ½ T2... Gain d'un facteur 2 seulement, quelque soit la vitesse du cache!! => Besoin d'avoir h proche de 1 95
96 4-b Fonctionnement du cache Points clés sur le fonctionnement Identification: comment on trouve une donnée dans le cache? Placement: où sont placées les données dans le cache? Politique de remplacement: comment faire de la place pour de nouvelles données? Politique d'écriture: comment propager les changements de données? Quelles autres stratégies pour améliorer le hit ratio? 96
97 4-b Structure du cache et identification Ligne de cache: bloc de données correspondant à un bloc de données consécutives en mémoire (par ex., 128 octets = 1 ligne) Les lignes de cache sont organisées en ensembles de lignes (sets) Associativité: nombre de lignes d'un set (identique pour tous les sets) Correspondance adresse mémoire et place dans le cache: Une partie est gardée, l' address tag, pour pouvoir l'identifier Une partie de l'adresse va correspondre au numéro de set La dernière partie de l'adresse correspond à la position de la donnée dans la ligne de cache 97
98 4-b Placement Où placer dans le cache la donnée venant de l'adresse 12? 98
99 4-b Placement 99
100 4-b Placement Associativité Une donnée peut être placée Dans n'importe quelle ligne de cache d'un set Et dans un seul set Cas extrêmes: complètement associatif (un set) ou direct map (un set=une ligne de cache). La donnée contenue à une adresse est-elle dans le cache? Calcul du set où devrait être la donnée, en fonction de l'adresse Pour chaque ligne de cache: (en parallèle) Vérification du tag avec l'adresse cherchée 100
101 4-b Remplacement: caches associatifs Quand un set est plein, quelle ligne du set remplacer? Au hasard La donnée la moins récemment utilisée (Least Recently Used, LRU) A chaque accès, on doit mettre à jour un indice de fraicheur de la donnée et des autres données du set Utilisé sur caches avec petite associativité (2,4,8) Une ligne, à tour de rôle (méthode round robin). Utilisé sur caches avec grande associativité Least Frequently Used (LFU) 101
102 4-b Politique d'écriture Quelle mise à jour du cache si on écrit une donnée vers la mémoire? Cache hit: Write through: On écrit dans le cache et la mémoire. Reste simple même si augmente l'utilisation de la bande passante mémoire Write back: On écrit dans le cache. La donnée est écrite en mémoire seulement si enlevée du cache. Un bit (appelé dirty bit) permet d'éviter copie vers mémoire si donnée pas écrite. Cache miss (pour une écriture): No write allocate: ne pas ramener la donnée écrite en cache Write allocate: ramène la donnée en cache Combinaisons possibles: write through et no write allocate 102
103 4-b Causes de cache miss Cache miss obligatoire (compulsory miss): on accède pour la première fois à la donnée Cache miss de capacité (capacity miss): La donnée a déjà été accédée mais a été enlevée du cache car le volume de données accédé depuis excède la taille du cache Cache miss de conflit (conflict miss): La donnée a déjà été accédée mais a été enlevée du cache car d'autres données l'ont évincée de son set. Il est possible qu'il reste de la place ailleurs dans le cache (problème dû à la politique de placement) 103
104 4-b Hiérarchie mémoire Généralisation à plusieurs niveaux de cache 104
105 4-b Hiérarchie mémoire Influence de la présence du L2 sur le L1 Utilise un plus petit L1 Améliore temps d'accès en cas de hit Réduit cout énergétique d'un accès (en moyenne) Utilise un L1 write-through (plus simple) et un L2 write-back sur la puce Le L2 write back absorbe le trafic mémoire sortant 105
106 4-b Hiérarchie mémoire Inclusion Cache inclusif Cache interne a une copie de lignes du cache externe Accès externe: juste besoin vérifier L2 Le plus courant Cache exclusif Cache interne peut avoir des lignes qui ne sont pas dans cache externe Echange les lignes entre caches si miss du cache interne 106
107 4-b Reduction du coût de l'associativité Associativité: Reduit le nombre de miss de conflit Coute cher à faire (surface, energie, delai) Optimisation pour contrebalancer une associativité limitée: Victim cache Way prediction 107
108 4-b Victim cache CPU RF L1 Data Cache Direct Map. (HP 7200) Victim Cache Fully Assoc. 4 blocks Evicted data from L1 Unified L2 Cache where? Victim cache: petit cache associatif qui sert de back-up à un cache direct map (Jouppi 1990) D'abord cherche donnée dans cache DM, si miss, cherche dans VC Si hit, échange donnée DM/VC. Si Miss, DM VC, VC? 108
109 4-b Victim cache Avantage du victim cache: Temps d'accès rapide (DM) Nombre réduit de conflict miss 109
110 4-b Way Predicting Instruction Cache Jump control Jump target 0x4 Add Dec Alpha21264 PC addr inst Primary Instruction way Cache Sequential Way Branch Target Way 110
111 4-b Way Prediction Cache Utilise une table de prédiction basé sur l'adresse pour prédire le way Lit la table et cherche ce way (MIPS R10000 L2) HIT MISS Return copy of data from cache Look in other way SLOW HIT (change entry in prediction table) MISS Read block of data from next level of cache 111
112 4-c Organisation des caches en multicoeurs L1: pas partagé, trop critique pour performances Partage du L2 ou L3 + Meilleure communication entre les coeurs, via le cache - Contention mémoire cache (bande passante partagée, taille du cache partagée) Pas de partage - Communication entre coeurs seulement par la mémoire + Pas de contention mémoire cache Dans tous les cas, mémoire partagée: - Partage bande passante vers la mémoire (interface de la puce) 112
113 4-c Write back/write Through Write Through Toute écriture par un processeur Mise a jour cache local Ecriture sur le bus global: maj mémoire et invalide/maj des autres caches Avantage: simple à implémenter Inconvénient: avec ~15% des accès mémoire des écritures, consomme beaucoup de bande passante. Ne scale pas avec le nombre de processeurs... Nécessite un tagging dual-way 113
114 4-c Write back/ Write Through Write back Quand cache propriétaire d'une donnée, écriture n'entraine pas écriture sur le bus Préserve bande passante Actuellement utilisé par la plupart multicores 114
115 4-c Caches et mémoire partagée Pour limiter trafic mémoire, utile d'avoir plusieurs copies des mêmes données (venant des mêmes adresses) dans les différents caches Données en lecture seule: tout va bien Ecriture d'une donnée présente dans plusieurs cache: Il faut mettre à jour les autres copies! S'appelle un problème de cohérence de cache Problème similaire avec DMA. L'unité mémoire en cache est la ligne de cache Mêmes lignes dans les caches, même si les coeurs n'ont pas accédé aux mêmes adresses! S'appelle du Faux Partage 115
116 4-c Caches et IO Address (A) Memory Bus Physical Memory Proc. Data (D) Cache R/W Either Cache or DMA can be the Bus Master and effect transfers A D R/W Page transfers occur while the Processor is running DMA DISK 116
117 4-c Caches et IO Proc. Cached portions of page Cache Memory Bus Physical Memory DMA transfers DMA DISK 117
118 4-c Cohérence de cache Pour maintenir la cohérence: Un seul processeur doit pouvoir modifier une donnée à la fois Informer des modifications Informer tous les processeurs d'une modification (snoop) Ou informer les processeurs possédant une copie d'une modification (directory) Après une modification, faire quelque chose des autres copies Invalidation: toutes les copies sont invalidées Ou Mise à jour: toutes les copies sont mises à jour 118
119 4-c Snoopy cache Nécessite cache write through. La mémoire a toujours les valeurs les plus à jour Toutes les mises à jour circulent sur bus mémoire Principe: Les caches espionnent les valeurs qui circulent sur le bus (snoopy cache) Si une valeur est écrite à une adresse mémoire, les caches vérifient qu'ils n'ont pas cette valeur. Si oui invalider leur valeur ou la mettre à jour Si un cache fait un miss sur une adresse, les caches vérifient s'ils n'ont pas cette adresse. Si oui fournir la valeur. 119
120 4-c Snoopy cache Memory Bus M1 Snoopy Cache Physical Memory M2 Snoopy Cache M3 Snoopy Cache DMA DISKS 120
121 4-c Répertoire central Principe: Pour un cache partagé, Le répertoire garde, pour chaque ligne dans les caches, les infos sur les caches qui ont la ligne Mis à jour à chaque accès à la mémoire. Permet mise à jour des caches. 121
122 4-c Répertoire central Réalisation: Avec chaque ligne, un bit par cache pour savoir si présent ou pas dans le cache + Accès à l'info importante en un endroit - Les mises à jour nécessitent d'abord de consulter le répertoire - Contention mémoire sur le répertoire - Coût en espace mémoire Des versions de répertoire existent, distribuées dans les caches. 122
123 4-c Protocole de cohérence: MSI Each cache line has a tag state bits Address tag M: Modified S: Shared I: Invalid Read miss Read by any processor M S I Other processor intent to write Write miss Other processor intent to write 123 P1 intent to write Other processor reads writes back P1 P1 reads or writes Cache state in processor P 1
124 4-c Protocole de cohérence: MESI Each cache line has a tag state bits Address tag M: Modified Exclusive E: Exclusive, unmodified S: Shared I: Invalid P1 write or read Other processor reads writes back P1 Read miss, shared Read by any processor P1 write M E S I Other processor intent to write P1 read Write miss Other processor intent to write Cache state in processor P P1 intent to write Read miss, not shared
125 4-c Quelques résultats de benchmark: Nehalem 125
126 4-c Quelques résultats de benchmark: Nehalem 126
127 4-c Quelques résultats de benchmark: Nehalem Pour des données dans l'état M: Nécessaire de faire un writeback en L3 et en mémoire? Si données dans le L1/L2 d'un autre coeur, write back L3, puis lecture à partir du L3 les performances en L1 sont plus mauvaises que celles en mémoire et bien plus mauvaise qu'en L3! 127
128 4-c Cache Nehalem en détails Cache L2: 256 KB, 8-way assoc. 1 L2 privé pour chacun des 4 coeurs de la puce 128
129 4-c Cache Nehalem en détails Cache L3: Partagé entre les 4 coeurs 8MB, 16 way, inclusif Arbitre: sérialise les requêtes au L3, en provenance des différents L2 129
130 4-c Cache Nehalem en détails Fonctionnement du cache L2 (snoopy) Traite les requêtes des autres L2: invalidation automatique, write back au L3 Etat F (forward): etat additionnel pour le S, une seule copie de la ligne en F. Le cache qui a la copie F repond aux requêtes des autres caches, pas ceux avec une copie en S. 130
131 4-c Cache Nehalem en détails Cache L3: Tient la liste des caches L2 ayant une copie des données en L3 (dans un vecteur de bits) Minimise le trafic Techniques de directory 131
132 4-c Cache Nehalem en détails Gestion cohérence L3 Arbitrage entre les L2 Maintient à jour la liste des L2 ayant les données 132
133 4-c Quelques résultats: Nehalem Ecriture de données dans l'etat E: Invalidation des données dans l'état E, transfert entre caches L2 Utilisation du snoop 133
134 4-c Quelques benchmarks: Nehalem Ecriture de données dans l'état M: Même problème que pour la lecture Performances les moins bonnes quand les données tiennent dans le L
135 4-c Quelques benchmarks Dunnington Dunnington: machine IBM EX4, 96 coeurs regroupés en 4 noeuds, chacun 4 sockets de 6 coeurs L1 privé (32KB), L2 partagé entre 2 coeurs (3MB), L3 partagé (16MB) entre 6 coeurs Un L4 entre puces d'un même noeud (memoire) 135
136 4-c Quelques benchmarks: Dunnington En lecture: Performances similaires que pour Nehalem Perte de perf quand on lit une donnée modifiée présente dans un autre L1 136
137 4-c Quelques benchmarks: Dunnington En écriture: Très mauvaises performances Plus mauvaises quand les données sont dans son cache que dans celui du coeur voisin! Même chose pour etat M ou S Mieux vaut éviter d'écrire des données sur cette machine... Gros impact sur les performances de certains codes 137
138 4-c Faux partage La ligne de cache: taille minimale d'info stockée dans les caches Toute la ligne est chargée, invalidée, On peut faire grandir la ligne sans rajouter des tags diminue le cout relatif des tags Inconvénient: protocole de cohérence sur toute la ligne. Si données pour coeurs différents sur la même ligne, faux partage. 138
139 4-c Faux partage A[0] et A[1] dans la même ligne de cache. CPU 1 écrit A[0], CPU 2 écrit A[1] chaque écriture invalide la ligne de cache de l'autre CPU Faux partage: ligne de cache partagée, mais pas de données communes entre les CPUs! Très mauvais pour localité temporelle CPU cache CPU 1 CPU 2 Store 1,A[0] A[0]=1 CPU cache A[0] invalide CPU cache CPU cache A[0] invalide Store 2,A[1] A[1]=2 Store 3, A[0] A[0]=1 A[1] invalide Store 0,A[1] A[1]=0 139
140 4-c Prefetching Le hardware peut précharger des données en cache, basé sur la régularité des accès précédents. Spécule sur les futures données/instructions utiles et les charge dans le cache Le prefetch d'instruction est plus facile Types de prefetch Hardware Software (compilateur ou utilisateur) Quel type de miss évite le prefetch?? 140
141 4-c Prefetching hardware Prefetch sur un miss Precharge le bloc b+1 quand on miss sur le bloc b One Block Lookahead (OBL) mecanisme Commence le prefetch du bloc b+k quand on accède au bloc b (k paramètre du prefetch) Prefetch avec stride Détecte les régularités d'accès: si on accède aux blocs b, b+n, b+2n, prefetch le bloc b+3n Ex: IBM Power5: prefetch 8 flux indépendants basés sur les strides, précharge 12 lignes d'avance. 141
142 4-c Prefetching hardware Instruction prefetch sur architecture Alpha AXP Prefetch 2 blocs sur un miss (le bloc demandé et le suivant) Bloc suivant placé dans stream buffer Si miss L1, regarde stream buffer et prefetch bloc suivant CPU RF Req block Stream Buffer L1 Instruction Prefetched instruction block Req block Unified L2 Cache 142
143 4-c Prefetching hardware Limites Comment faire la différence entre un accès régulier avec un large stride et des accès à des données qui n'ont rien à voir? Prefetch par stride limité sur la taille du stride. Au delà d'une valeur de stride, considère que les accès sont irréguliers Importance de choisir des structures de données appropriées Importance de l'ordre de parcours des dimensions de tableau 143
144 4-d Optimisations pour le cache Transformations du code source ou asm Changer le code pour améliorer la localité spaciale ou temporelle Réordonnancer les instructions: tiling, fusion, fission, loop interchange,...verifier les dépendances! Changer les structures de données: copie de données, refaire des calculs (plutot que de charger des données) Ne charger que ce qui est nécessaire dans le cache: streaming (explicitement ne pas charger des données en cache, en lecture ou ecriture) pour données lues/écrites une fois, prefetch software 144
145 4-d Permutation de boucle for(j=0; j < N; j++) { for(i=0; i < M; i++) { x[i][j] = 2 * x[i][j]; } } for(i=0; i < M; i++) { for(j=0; j < N; j++) { x[i][j] = 2 * x[i][j]; } } Loop interchange: quelle amélioration? 145
146 4-d Fusion de boucles for(i=0; i < N; i++) a[i] = b[i] * c[i]; for(i=0; i < N; i++) d[i] = a[i] * c[i]; for(i=0; i < N; i++) { a[i] = b[i] * c[i]; d[i] = a[i] * c[i]; } Loop fusion: quelle amélioration? 146
147 4-d Fission de boucles for(i=0; i < N; i++) a[i] = b[i] * c[i]; d[i] = e[i] * f[i]; for(i=0; i < N; i++) a[i] = b[i] * c[i]; for(i=0; i < N; i++) d[i] = e[i] * f[i]; Loop fission: quelle amélioration? 147
148 4-d Tuilage for(i=0; i < N; i++) for(j=0; j < N; j++) for (k=0; k<n; k++) c[i][j] = c[i][j]+a[i][k]*b[k][j] for(i=0; i < N; i=i+b) for(j=0; j < N; j=j+b) for(k=0; k < N; k++) for(ii=i; i < min(i+b,n); i++) for(jj=j; jj < min(j+b,n); jj++) c[ii][jj] = c[ii][jj]+a[ii][k]*b[k][jj] Tuilage: quel avantage pour le cache? Quelle taille pour B?? 148
149 4-d Tuilage pour code de calcul LU Effets de cohérence sur Nehalem Ne pas prendre bloc trop petit (pas en cache L1) Faire du tuilage pour le L3 149
150 4-d Tuilage pour code de calcul LU 150
151 4-d Prefetch software for(i=0; i < N; i++) { prefetch( &a[i + k] ); prefetch( &b[i + k] ); SUM = SUM + a[i] * b[i]; } Prefetch soft: quand prefetcher? (valeur de k) Trop court: pas le bénéfice du prefetch Trop loin: page miss, pollution de cache possible, ne doit pas dépasser taille de cache. 151
152 4-d Fusion de tableaux int value[size], key[size]; struct merged { int value,key; }; struct merged array_merged[size] Quel avantage pour le cache? 152
153 4-d Un exemple: le produit matriciel for (i=0; i<m; i++) for (j=0; j<n; j++) for (k=0; k<p; k++) C[i][j] += A[i][k]*B[k][j] A P N K M K Produit matriciel Opération au coeur de nombreux solveurs Bon profil pour le cache: 3*N 2 données, N 3 opérations Les matrices sont trop grosses pour tenir dans les caches Beaucoup d'opportunités pour optimiser B C 153
154 4-d Un exemple: le produit matriciel for (i=0; i<m; i++) for (j=0; j<n; j++) for (k=0; k<p; k++) C[i][j] += A[i][k]*B[k][j] M A P K N K B C Optimisations (dépendant taille matrice) Tuilage pour les différents niveaux de cache, pour les registres Prefetching, Ordonnancement des instructions, unrolling Vectorisation 154
155 4-d Un exemple: le produit matriciel for (i=0; i<m; i++) for (j=0; j<n; j++) for (k=0; k<p; k++) C[i][j] += A[i][k]*B[k][j] M A P K N K B C ATLAS: Auto-Tuning Linear Algebra System Générateur de bibliothèque de calcul d'algèbre linéaire Génère de multiples versions de code optimisés Les tests et prend les meilleurs (auto-tuning, compilation itérative) 155
156 C[i][j] += A[i][k] * B[k][j] 156 A C for (int k = 0; k < NB; k++) NB M for (int j = 0; j < NB; j++) for (int i = 0; i < NB; i++) Code Mini-MMM K N B Paramètre: NB K Objectif: faire rentrer les tuiles dans le L1 ou L2 Seulement avec des tuiles carrées NB Tuilage dans ATLAS: 4-d ATLAS: produit matriciel
157 store C[i..i+MU-1, j..j+nu-1] 157 A C multiply A s and B s and add to C s K NB MU for (int k = 0; k < NB; k++) load A[i..i+MU-1,k] into registers KU times load B[k,j..j+NU-1] into registers load C[i..i+MU-1, j..j+nu-1] into registers for (int i = 0; i < NB; i += MU) NB for (int j = 0; j < NB; j += NU) B Code en plus si NB n'est pas multiple de NU/MU/KU Faire tenir ces blocs dans les registres K Paramètres: NU, MU, KU NU Tuilage pour les registres 4-d ATLAS: produit matriciel
158 4-d ATLAS: produit matriciel Paramètres à rechercher (en fonction taille matrice, architecture) NU,MU,KU, NB Prefetch distance Ordonnancement des instructions à l'intérieur des boucles Plusieurs méthodes: Recherche exhaustive, en bornant a priori ces valeurs Modéliser le cache et l'architecture, trouver ces valeurs Variante: faire un peu de recherche exhaustive autour des valeurs prévues Améliorer le code à la main (unleashed version of ATLAS) 158
159 4-d ATLAS: produit matriciel Méthode par modèle très proche méthode par recherche exhaustive Temps d'obtention d'un bon code très court Encore un écart avec code fait main nécessite un peu d'expertise, possible par méthode d'apprentissage Avantage d'atlas: Complètement automatique S'adapte aux nouvelles architectures 159
160 4-d Compilation itérative et méthodes par apprentissage Généralisation des méthodes par auto-tuning Recherche des meilleurs paramètres d'optimisation automatiquement Limiter la zone de recherche par apprentissage, par modèle Recherche des meilleurs combinaisons d'algorithmes pour une architecture SPIRAL et FFTW: générateurs de bibliothèques pour traitement du signal Dans les compilateurs Milepost pour gcc: apprentissage des optimisations qui sont efficaces sur des types de codes 160
161 5- Architectures pour l'exascale 161
162 5- Architectures pour l'exascale Quels besoins pour l'exascale? Climate Science, High Energy Physics, Nuclear Physics Fusion Energy Nuclear Energy Biology Material Science and Chemistry National Security Workshop sur les Grand Challenges Quelle roadmap? IESP: International Exascale Software Industriels, universitaires, agences Deux scenarios possibles: Large nombre de petits processeurs: 1000 cores/chip, 1 million de puces Processeurs hybrides: ex 1Ghz processeur, 10K FPU/socket, 100K sockets/system 10^9 threads d'exécution 162
163 5- Ce qui a conduit au petaflop... La loi de Moore continue! 22nm: 37% de gain en basse consommation 163
164 5- Prévisions pour l'exaflop <7nm: problemes quantiques (c) Intel 164
165 5- Projection pour l'exaflop Prévision du DoE 5 changements majeurs: a- Changement des hiérarchies mémoire b- Tolérance aux pannes c- Efficacité energétique d- Hétérogénéité e- Echelle 165
166 5-a Changements hiérarchies mémoire Déplacer des données: consomme une part importante de l'énergie Calcul gratuit, bande passante chère Hiérarchies mémoire Puces 3D Interconnexions photoniques Processeurs dataflow 166
167 5-a Empilement mémoire 3D Projet Eurocloud FP7, 167
168 5-a Empilement mémoire 3D Empilement vertical de many-core et de DRAM meilleure bande passante, et meilleure efficacité energétique Samsung 3D RAM 168
169 5-a Intégration réseau photonique 169
170 5-a Intégration réseau photonique Carte pour un supercalculateur photonique Bande passante: 10TB/s, off et on-chip 170
171 5-a Architectures dataflow Principe: réduire la mémoire sur le puce en connectant directement les unités fonctionnelles entre elles. FPGA ou many-core connectés en grille diminue fortement la consommation (5W) (c) MPPA Kalray (c) Maxeler 171
172 5-b Tolérances aux pannes Cause: Réduction de la finesse de gravure Grand nombre d'unités Voltage très bas (rapport signal/bruit faible) (c) Intel 172
173 5-b Tolérances aux pannes Schéma classique de checkpoint/restart: Sauvegarde régulière des données Requiert opérations I/O globales Le MTBF doit être > au temps de sauvegarde... A définir: nouveaux algorithmes avec sauvegarde mieux intégrée, Restart plus facile. (c) Intel Sauvegarde et synchro 173
174 5-c Efficacité energétique Améliorations hardware: ne suffira pas - Définir nouveaux algorithmes pour diminer consommation - Eteindre certains composants non utilisés - Réduire la fréquence lors le code devient mémory bound - Améliorer les algos de cache, mieux utiliser le cache - Compromis calcul / mouvements de données: refaire des calculs, changer la précision,
175 5-c Efficacité énergétique 175
176 5-c Efficacité énergétique ARM Kal el 4 cores rapides 1 core plus lent 176
177 5-d Hétérogénéité Causes: Type multiple de coeurs: accélérateurs, GPUs Réseau d'interconnection Type de mémoire, connection des caches Software: programmation, os, outils Parmi ceux que vous connaissez MPI, OpenMP, OpenCL,
178 5-d Hétérogénéité hardware 178
179 5-d Hétérogénéité software Un exemple de code MPI/OpenMP/Cuda
180 5- Implications Nouveaux modèles de programmation requis! Besoin de gagner en sémantique pour exprimer parallélisme Besoin de technique de compilation/ auto-tuning Code portable Besoin de techniques de runtime Adaptation dynamique du code aux données de l'appli et au hardware Besoin d'outils d'analyse de performance pour comprendre sur quels paramètres jouer A développer dans le cadre d'applications Beaucoup de travail reste à faire! 180
Exécution des instructions machine
 Exécution des instructions machine Eduardo Sanchez EPFL Exemple: le processeur MIPS add a, b, c a = b + c type d'opération (mnémonique) destination du résultat lw a, addr opérandes sources a = mem[addr]
Exécution des instructions machine Eduardo Sanchez EPFL Exemple: le processeur MIPS add a, b, c a = b + c type d'opération (mnémonique) destination du résultat lw a, addr opérandes sources a = mem[addr]
Architecture des ordinateurs
 Décoder la relation entre l architecture et les applications Violaine Louvet, Institut Camille Jordan CNRS & Université Lyon 1 Ecole «Découverte du Calcul» 2013 1 / 61 Simulation numérique... Physique
Décoder la relation entre l architecture et les applications Violaine Louvet, Institut Camille Jordan CNRS & Université Lyon 1 Ecole «Découverte du Calcul» 2013 1 / 61 Simulation numérique... Physique
Initiation au HPC - Généralités
 Initiation au HPC - Généralités Éric Ramat et Julien Dehos Université du Littoral Côte d Opale M2 Informatique 2 septembre 2015 Éric Ramat et Julien Dehos Initiation au HPC - Généralités 1/49 Plan du cours
Initiation au HPC - Généralités Éric Ramat et Julien Dehos Université du Littoral Côte d Opale M2 Informatique 2 septembre 2015 Éric Ramat et Julien Dehos Initiation au HPC - Généralités 1/49 Plan du cours
Fonctionnement et performance des processeurs
 Fonctionnement et performance des processeurs Eric Cariou Université de Pau et des Pays de l'adour Département Informatique [email protected] 1 Plan Fonctionnement des processeurs Unités de calcul
Fonctionnement et performance des processeurs Eric Cariou Université de Pau et des Pays de l'adour Département Informatique [email protected] 1 Plan Fonctionnement des processeurs Unités de calcul
Chapitre V : La gestion de la mémoire. Hiérarchie de mémoires Objectifs Méthodes d'allocation Simulation de mémoire virtuelle Le mapping
 Chapitre V : La gestion de la mémoire Hiérarchie de mémoires Objectifs Méthodes d'allocation Simulation de mémoire virtuelle Le mapping Introduction Plusieurs dizaines de processus doivent se partager
Chapitre V : La gestion de la mémoire Hiérarchie de mémoires Objectifs Méthodes d'allocation Simulation de mémoire virtuelle Le mapping Introduction Plusieurs dizaines de processus doivent se partager
1 Architecture du cœur ARM Cortex M3. Le cœur ARM Cortex M3 sera présenté en classe à partir des éléments suivants :
 GIF-3002 SMI et Architecture du microprocesseur Ce cours discute de l impact du design du microprocesseur sur le système entier. Il présente d abord l architecture du cœur ARM Cortex M3. Ensuite, le cours
GIF-3002 SMI et Architecture du microprocesseur Ce cours discute de l impact du design du microprocesseur sur le système entier. Il présente d abord l architecture du cœur ARM Cortex M3. Ensuite, le cours
Architecture des calculateurs
 Formation en Calcul Scientifique - LEM2I Architecture des calculateurs Violaine Louvet 1 1 Institut Camille jordan - CNRS 12-13/09/2011 Introduction Décoder la relation entre l architecture et les applications
Formation en Calcul Scientifique - LEM2I Architecture des calculateurs Violaine Louvet 1 1 Institut Camille jordan - CNRS 12-13/09/2011 Introduction Décoder la relation entre l architecture et les applications
Tout savoir sur le matériel informatique
 Tout savoir sur le matériel informatique Thème de l exposé : Les Processeurs Date : 05 Novembre 2010 Orateurs : Hugo VIAL-JAIME Jérémy RAMBAUD Sommaire : 1. Introduction... 3 2. Historique... 4 3. Relation
Tout savoir sur le matériel informatique Thème de l exposé : Les Processeurs Date : 05 Novembre 2010 Orateurs : Hugo VIAL-JAIME Jérémy RAMBAUD Sommaire : 1. Introduction... 3 2. Historique... 4 3. Relation
Génération de code binaire pour application multimedia : une approche au vol
 Génération de binaire pour application multimedia : une approche au vol http://hpbcg.org/ Henri-Pierre Charles Université de Versailles Saint-Quentin en Yvelines 3 Octobre 2009 Présentation Présentation
Génération de binaire pour application multimedia : une approche au vol http://hpbcg.org/ Henri-Pierre Charles Université de Versailles Saint-Quentin en Yvelines 3 Octobre 2009 Présentation Présentation
Systèmes et traitement parallèles
 Systèmes et traitement parallèles Mohsine Eleuldj Département Génie Informatique, EMI [email protected] 1 Système et traitement parallèle Objectif Etude des architectures parallèles Programmation des applications
Systèmes et traitement parallèles Mohsine Eleuldj Département Génie Informatique, EMI [email protected] 1 Système et traitement parallèle Objectif Etude des architectures parallèles Programmation des applications
Limitations of the Playstation 3 for High Performance Cluster Computing
 Introduction Plan Limitations of the Playstation 3 for High Performance Cluster Computing July 2007 Introduction Plan Introduction Intérêts de la PS3 : rapide et puissante bon marché L utiliser pour faire
Introduction Plan Limitations of the Playstation 3 for High Performance Cluster Computing July 2007 Introduction Plan Introduction Intérêts de la PS3 : rapide et puissante bon marché L utiliser pour faire
Architecture des Ordinateurs. Partie II:
 Architecture des Ordinateurs Partie II: Le port Floppy permet le raccordement du lecteur de disquette àla carte mère. Remarque: Le lecteur de disquette a disparu il y a plus de 6 ans, son port suivra.
Architecture des Ordinateurs Partie II: Le port Floppy permet le raccordement du lecteur de disquette àla carte mère. Remarque: Le lecteur de disquette a disparu il y a plus de 6 ans, son port suivra.
Mesure de performances. [Architecture des ordinateurs, Hennessy & Patterson, 1996]
![Mesure de performances. [Architecture des ordinateurs, Hennessy & Patterson, 1996]](/thumbs/23/1769821.jpg "Mesure de performances. [Architecture des ordinateurs, Hennessy & Patterson, 1996]") Mesure de performances [Architecture des ordinateurs, Hennessy & Patterson, 1996] Croissance des performances des microprocesseurs Avant le milieu des années 80, le gain dépendait de la technologie. Après,
Mesure de performances [Architecture des ordinateurs, Hennessy & Patterson, 1996] Croissance des performances des microprocesseurs Avant le milieu des années 80, le gain dépendait de la technologie. Après,
GESTION DE LA MEMOIRE
 GESTION DE LA MEMOIRE MEMOIRE CENTRALE (MC) MEMOIRE SECONDAIRE (MS) 1. HIÉRARCHIE ET DIFFÉRENTS TYPES DE MÉMOIRE... 2 2. MÉMOIRE CACHE... 3 3. MODÈLE D'ALLOCATION CONTIGUË (MC OU MS)... 5 3.1. STRATÉGIE
GESTION DE LA MEMOIRE MEMOIRE CENTRALE (MC) MEMOIRE SECONDAIRE (MS) 1. HIÉRARCHIE ET DIFFÉRENTS TYPES DE MÉMOIRE... 2 2. MÉMOIRE CACHE... 3 3. MODÈLE D'ALLOCATION CONTIGUË (MC OU MS)... 5 3.1. STRATÉGIE
Conception de circuits numériques et architecture des ordinateurs
 Conception de circuits numériques et architecture des ordinateurs Frédéric Pétrot Année universitaire 2014-2015 Structure du cours C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 C11 Codage des nombres en base 2, logique
Conception de circuits numériques et architecture des ordinateurs Frédéric Pétrot Année universitaire 2014-2015 Structure du cours C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 C11 Codage des nombres en base 2, logique
Architecture des ordinateurs
 Architecture des ordinateurs Cours 4 5 novembre 2012 Archi 1/22 Micro-architecture Archi 2/22 Intro Comment assembler les différents circuits vus dans les cours précédents pour fabriquer un processeur?
Architecture des ordinateurs Cours 4 5 novembre 2012 Archi 1/22 Micro-architecture Archi 2/22 Intro Comment assembler les différents circuits vus dans les cours précédents pour fabriquer un processeur?
Conception de circuits numériques et architecture des ordinateurs
 Conception de circuits numériques et architecture des ordinateurs Frédéric Pétrot et Sébastien Viardot Année universitaire 2011-2012 Structure du cours C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 C11 C12 Codage des
Conception de circuits numériques et architecture des ordinateurs Frédéric Pétrot et Sébastien Viardot Année universitaire 2011-2012 Structure du cours C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 C11 C12 Codage des
Structure fonctionnelle d un SGBD
 Fichiers et Disques Structure fonctionnelle d un SGBD Requetes Optimiseur de requetes Operateurs relationnels Methodes d acces Gestion de tampon Gestion de disque BD 1 Fichiers et Disques Lecture : Transfert
Fichiers et Disques Structure fonctionnelle d un SGBD Requetes Optimiseur de requetes Operateurs relationnels Methodes d acces Gestion de tampon Gestion de disque BD 1 Fichiers et Disques Lecture : Transfert
Matériel & Logiciels (Hardware & Software)
") CHAPITRE 2 HARDWARE & SOFTWARE P. 1 Chapitre 2 Matériel & Logiciels (Hardware & Software) 2.1 Matériel (Hardware) 2.1.1 Présentation de l'ordinateur Un ordinateur est un ensemble de circuits électronique
CHAPITRE 2 HARDWARE & SOFTWARE P. 1 Chapitre 2 Matériel & Logiciels (Hardware & Software) 2.1 Matériel (Hardware) 2.1.1 Présentation de l'ordinateur Un ordinateur est un ensemble de circuits électronique
M2-Images. Rendu Temps Réel - OpenGL 4 et compute shaders. J.C. Iehl. December 18, 2013
 Rendu Temps Réel - OpenGL 4 et compute shaders December 18, 2013 résumé des épisodes précédents... création des objets opengl, organisation des données, configuration du pipeline, draw,... opengl 4.3 :
Rendu Temps Réel - OpenGL 4 et compute shaders December 18, 2013 résumé des épisodes précédents... création des objets opengl, organisation des données, configuration du pipeline, draw,... opengl 4.3 :
Techniques de stockage. Techniques de stockage, P. Rigaux p.1/43
 Techniques de stockage Techniques de stockage, P. Rigaux p.1/43 Techniques de stockage Contenu de ce cours : 1. Stockage de données. Supports, fonctionnement d un disque, technologie RAID 2. Organisation
Techniques de stockage Techniques de stockage, P. Rigaux p.1/43 Techniques de stockage Contenu de ce cours : 1. Stockage de données. Supports, fonctionnement d un disque, technologie RAID 2. Organisation
Gestion de mémoire secondaire F. Boyer, Laboratoire Sardes [email protected]
 Gestion de mémoire secondaire F. Boyer, Laboratoire Sardes [email protected] 1- Structure d un disque 2- Ordonnancement des requêtes 3- Gestion du disque - formatage - bloc d amorçage - récupération
Gestion de mémoire secondaire F. Boyer, Laboratoire Sardes [email protected] 1- Structure d un disque 2- Ordonnancement des requêtes 3- Gestion du disque - formatage - bloc d amorçage - récupération
EPREUVE OPTIONNELLE d INFORMATIQUE CORRIGE
 EPREUVE OPTIONNELLE d INFORMATIQUE CORRIGE QCM Remarque : - A une question correspond au moins 1 réponse juste - Cocher la ou les bonnes réponses Barème : - Une bonne réponse = +1 - Pas de réponse = 0
EPREUVE OPTIONNELLE d INFORMATIQUE CORRIGE QCM Remarque : - A une question correspond au moins 1 réponse juste - Cocher la ou les bonnes réponses Barème : - Une bonne réponse = +1 - Pas de réponse = 0
Métriques de performance pour les algorithmes et programmes parallèles
 Métriques de performance pour les algorithmes et programmes parallèles 11 18 nov. 2002 Cette section est basée tout d abord sur la référence suivante (manuel suggéré mais non obligatoire) : R. Miller and
Métriques de performance pour les algorithmes et programmes parallèles 11 18 nov. 2002 Cette section est basée tout d abord sur la référence suivante (manuel suggéré mais non obligatoire) : R. Miller and
Tests de performance du matériel
 3 Tests de performance du matériel Après toute la théorie du dernier chapitre, vous vous demandez certainement quelles sont les performances réelles de votre propre système. En fait, il y a plusieurs raisons
3 Tests de performance du matériel Après toute la théorie du dernier chapitre, vous vous demandez certainement quelles sont les performances réelles de votre propre système. En fait, il y a plusieurs raisons
Chapitre 4 : Les mémoires
 1. Introduction: Chapitre 4 : Les mémoires Nous savons que dans un ordinateur toutes les informations : valeur numérique, instruction, adresse, symbole (chiffre, lettre,... etc.) sont manipulées sous une
1. Introduction: Chapitre 4 : Les mémoires Nous savons que dans un ordinateur toutes les informations : valeur numérique, instruction, adresse, symbole (chiffre, lettre,... etc.) sont manipulées sous une
Caches web. Olivier Aubert 1/35
 Caches web Olivier Aubert 1/35 Liens http://mqdoc.lasat.com/online/courses/caching/ (prise en compte des caches dans la conception de sites) http://mqdoc.lasat.com/online/courses/proxyserver http://www.web-caching.com/mnot_tutorial/
Caches web Olivier Aubert 1/35 Liens http://mqdoc.lasat.com/online/courses/caching/ (prise en compte des caches dans la conception de sites) http://mqdoc.lasat.com/online/courses/proxyserver http://www.web-caching.com/mnot_tutorial/
T. Gasc 1,2,3, F. De Vuyst 1, R. Motte 3, M. Peybernes 4, R. Poncet 5
 Modélisation de la performance et optimisation d un algorithme hydrodynamique de type Lagrange-Projection sur processeurs multi-cœurs T. Gasc 1,2,3, F. De Vuyst 1, R. Motte 3, M. Peybernes 4, R. Poncet
Modélisation de la performance et optimisation d un algorithme hydrodynamique de type Lagrange-Projection sur processeurs multi-cœurs T. Gasc 1,2,3, F. De Vuyst 1, R. Motte 3, M. Peybernes 4, R. Poncet
Optimisation multi-critère pour l allocation de ressources sur Clouds distribués avec prise en compte de l énergie
 Optimisation multi-critère pour l allocation de ressources sur Clouds distribués avec prise en compte de l énergie 1 Présenté par: Yacine KESSACI Encadrement : N. MELAB E-G. TALBI 31/05/2011 Plan 2 Motivation
Optimisation multi-critère pour l allocation de ressources sur Clouds distribués avec prise en compte de l énergie 1 Présenté par: Yacine KESSACI Encadrement : N. MELAB E-G. TALBI 31/05/2011 Plan 2 Motivation
Guide Mémoire NETRAM
 Guide Mémoire NETRAM Types de mémoires vives On distingue généralement deux grandes catégories de mémoires vives : Mémoires dynamiques (DRAM, Dynamic Random Access Module), peu coûteuses. Elles sont principalement
Guide Mémoire NETRAM Types de mémoires vives On distingue généralement deux grandes catégories de mémoires vives : Mémoires dynamiques (DRAM, Dynamic Random Access Module), peu coûteuses. Elles sont principalement
Cours Informatique Master STEP
 Cours Informatique Master STEP Bases de la programmation: Compilateurs/logiciels Algorithmique et structure d'un programme Programmation en langage structuré (Fortran 90) Variables, expressions, instructions
Cours Informatique Master STEP Bases de la programmation: Compilateurs/logiciels Algorithmique et structure d'un programme Programmation en langage structuré (Fortran 90) Variables, expressions, instructions
Une méthode de conception de systèmes sur puce
 École thématique ARCHI 05 Une méthode de conception de systèmes sur puce (de l intégration d applications) Frédéric PÉTROT Laboratoire TIMA Institut National Polytechnique de Grenoble Frédéric Pétrot/TIMA/INPG
École thématique ARCHI 05 Une méthode de conception de systèmes sur puce (de l intégration d applications) Frédéric PÉTROT Laboratoire TIMA Institut National Polytechnique de Grenoble Frédéric Pétrot/TIMA/INPG
SECURIDAY 2012 Pro Edition
 SECURINETS CLUB DE LA SECURITE INFORMATIQUE INSAT SECURIDAY 2012 Pro Edition [LOAD BALANCING] Chef Atelier : Asma JERBI (rt5) Hajer MEHRZI(rt3) Rania FLISS (rt3) Ibtissem OMAR (rt3) Asma Tounsi (rt3la)
SECURINETS CLUB DE LA SECURITE INFORMATIQUE INSAT SECURIDAY 2012 Pro Edition [LOAD BALANCING] Chef Atelier : Asma JERBI (rt5) Hajer MEHRZI(rt3) Rania FLISS (rt3) Ibtissem OMAR (rt3) Asma Tounsi (rt3la)
Eléments d architecture des machines parallèles et distribuées
 M2-RISE - Systèmes distribués et grille Eléments d architecture des machines parallèles et distribuées Stéphane Vialle [email protected] http://www.metz.supelec.fr/~vialle Notions d architecture
M2-RISE - Systèmes distribués et grille Eléments d architecture des machines parallèles et distribuées Stéphane Vialle [email protected] http://www.metz.supelec.fr/~vialle Notions d architecture
Mise en oeuvre TSM 6.1
 Mise en oeuvre TSM 6.1 «Bonnes pratiques» pour la base de données TSM DB2 Powered by Qui sommes nous? Des spécialistes dans le domaine de la sauvegarde et de la protection des données 10 ans d expertise
Mise en oeuvre TSM 6.1 «Bonnes pratiques» pour la base de données TSM DB2 Powered by Qui sommes nous? Des spécialistes dans le domaine de la sauvegarde et de la protection des données 10 ans d expertise
Contrôle Non Destructif : Implantation d'algorithmes sur GPU et multi-coeurs. Gilles Rougeron CEA/LIST Département Imagerie Simulation et Contrôle
 Contrôle Non Destructif : Implantation d'algorithmes sur GPU et multi-coeurs Gilles Rougeron CEA/LIST Département Imagerie Simulation et Contrôle 1 CEA R & D for Nuclear Energy 5 000 people Nuclear systems
Contrôle Non Destructif : Implantation d'algorithmes sur GPU et multi-coeurs Gilles Rougeron CEA/LIST Département Imagerie Simulation et Contrôle 1 CEA R & D for Nuclear Energy 5 000 people Nuclear systems
Cours 1 : La compilation
 /38 Interprétation des programmes Cours 1 : La compilation Yann Régis-Gianas [email protected] PPS - Université Denis Diderot Paris 7 2/38 Qu est-ce que la compilation? Vous avez tous déjà
/38 Interprétation des programmes Cours 1 : La compilation Yann Régis-Gianas [email protected] PPS - Université Denis Diderot Paris 7 2/38 Qu est-ce que la compilation? Vous avez tous déjà
6 - Le système de gestion de fichiers F. Boyer, UJF-Laboratoire Lig, [email protected]
 6 - Le système de gestion de fichiers F. Boyer, UJF-Laboratoire Lig, [email protected] Interface d un SGF Implémentation d un SGF Gestion de la correspondance entre la structure logique et la structure
6 - Le système de gestion de fichiers F. Boyer, UJF-Laboratoire Lig, [email protected] Interface d un SGF Implémentation d un SGF Gestion de la correspondance entre la structure logique et la structure
SYSTÈME DE GESTION DE FICHIERS
 SYSTÈME DE GESTION DE FICHIERS - DISQUE 1 Les couches logiciels réponse requête Requêtes E/S Système E/S Pilote E/S Interruptions utilisateur traitement S.E. commandes S.E. S.E. matériel Contrôleur E/S
SYSTÈME DE GESTION DE FICHIERS - DISQUE 1 Les couches logiciels réponse requête Requêtes E/S Système E/S Pilote E/S Interruptions utilisateur traitement S.E. commandes S.E. S.E. matériel Contrôleur E/S
Quantification d incertitude et Tendances en HPC
 Quantification d incertitude et Tendances en HPC Laurence Viry E cole de Physique des Houches 7 Mai 2014 Laurence Viry Tendances en HPC 7 Mai 2014 1 / 47 Contents 1 Mode lisation, simulation et quantification
Quantification d incertitude et Tendances en HPC Laurence Viry E cole de Physique des Houches 7 Mai 2014 Laurence Viry Tendances en HPC 7 Mai 2014 1 / 47 Contents 1 Mode lisation, simulation et quantification
Base de l'informatique. Généralité et Architecture Le système d'exploitation Les logiciels Le réseau et l'extérieur (WEB)
") Base de l'informatique Généralité et Architecture Le système d'exploitation Les logiciels Le réseau et l'extérieur (WEB) Généralité Comment fonctionne un ordinateur? Nous définirons 3 couches Le matériel
Base de l'informatique Généralité et Architecture Le système d'exploitation Les logiciels Le réseau et l'extérieur (WEB) Généralité Comment fonctionne un ordinateur? Nous définirons 3 couches Le matériel
Guide d'installation et de configuration de Pervasive.SQL 7 dans un environnement réseau Microsoft Windows NT
 Guide d'installation et de configuration de Pervasive.SQL 7 dans un environnement réseau Microsoft Windows NT Ce guide explique les différentes étapes de l installation et de la configuration des composantes
Guide d'installation et de configuration de Pervasive.SQL 7 dans un environnement réseau Microsoft Windows NT Ce guide explique les différentes étapes de l installation et de la configuration des composantes
Complexité. Licence Informatique - Semestre 2 - Algorithmique et Programmation
 Complexité Objectifs des calculs de complexité : - pouvoir prévoir le temps d'exécution d'un algorithme - pouvoir comparer deux algorithmes réalisant le même traitement Exemples : - si on lance le calcul
Complexité Objectifs des calculs de complexité : - pouvoir prévoir le temps d'exécution d'un algorithme - pouvoir comparer deux algorithmes réalisant le même traitement Exemples : - si on lance le calcul
SYSTÈME DE GESTION DE FICHIERS SGF - DISQUE
 SYSTÈME DE GESTION DE FICHIERS SGF - DISQUE C.Crochepeyre MPS_SGF 2000-20001 Diapason 1 Les couches logiciels réponse SGF requête matériel matériel Requêtes E/S Système E/S Pilote E/S Interruptions Contrôleur
SYSTÈME DE GESTION DE FICHIERS SGF - DISQUE C.Crochepeyre MPS_SGF 2000-20001 Diapason 1 Les couches logiciels réponse SGF requête matériel matériel Requêtes E/S Système E/S Pilote E/S Interruptions Contrôleur
Introduction à la Programmation Parallèle: MPI
 Introduction à la Programmation Parallèle: MPI Frédéric Gava et Gaétan Hains L.A.C.L Laboratoire d Algorithmique, Complexité et Logique Cours du M2 SSI option PSSR Plan 1 Modèle de programmation 2 3 4
Introduction à la Programmation Parallèle: MPI Frédéric Gava et Gaétan Hains L.A.C.L Laboratoire d Algorithmique, Complexité et Logique Cours du M2 SSI option PSSR Plan 1 Modèle de programmation 2 3 4
Le Network File System de Sun (NFS)
") 1 sur 5 Le Network File System de Sun (NFS) Le Network File System de Sun (NFS) Architecture Protocoles Mounting Automounting vs Static mounting Directory et accès aux fichiers Problèmes Implémentation
1 sur 5 Le Network File System de Sun (NFS) Le Network File System de Sun (NFS) Architecture Protocoles Mounting Automounting vs Static mounting Directory et accès aux fichiers Problèmes Implémentation
4. Utilisation d un SGBD : le langage SQL. 5. Normalisation
 Base de données S. Lèbre [email protected] Université de Strasbourg, département d informatique. Présentation du module Contenu général Notion de bases de données Fondements / Conception Utilisation :
Base de données S. Lèbre [email protected] Université de Strasbourg, département d informatique. Présentation du module Contenu général Notion de bases de données Fondements / Conception Utilisation :
PROBLEMES D'ORDONNANCEMENT AVEC RESSOURCES
 Leçon 11 PROBLEMES D'ORDONNANCEMENT AVEC RESSOURCES Dans cette leçon, nous retrouvons le problème d ordonnancement déjà vu mais en ajoutant la prise en compte de contraintes portant sur les ressources.
Leçon 11 PROBLEMES D'ORDONNANCEMENT AVEC RESSOURCES Dans cette leçon, nous retrouvons le problème d ordonnancement déjà vu mais en ajoutant la prise en compte de contraintes portant sur les ressources.
Éléments d'architecture des ordinateurs
 Chapitre 1 Éléments d'architecture des ordinateurs Machines take me by surprise with great frequency. Alan Turing 1.1 Le Hardware Avant d'attaquer la programmation, il est bon d'avoir quelques connaissances
Chapitre 1 Éléments d'architecture des ordinateurs Machines take me by surprise with great frequency. Alan Turing 1.1 Le Hardware Avant d'attaquer la programmation, il est bon d'avoir quelques connaissances
MapReduce. Malo Jaffré, Pablo Rauzy. 16 avril 2010 ENS. Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15
 MapReduce 16 avril 2010 1 / 15") MapReduce Malo Jaffré, Pablo Rauzy ENS 16 avril 2010 Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15 Qu est ce que c est? Conceptuellement Données MapReduce est un framework de calcul distribué
MapReduce Malo Jaffré, Pablo Rauzy ENS 16 avril 2010 Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15 Qu est ce que c est? Conceptuellement Données MapReduce est un framework de calcul distribué
Plan global Outils de développement et compilation. Plan. Objectifs des outils présentés. IDE, GCC/Clang, ASAN, perf, valgrind, GDB.
 global Outils de développement et compilation IDE, GCC/Clang, ASAN, perf, valgrind, GDB Timothée Ravier LIFO, INSA-CVL, LIPN 1 re année cycle ingénieur STI 2013 2014 1 / 36 Objectifs des outils présentés
global Outils de développement et compilation IDE, GCC/Clang, ASAN, perf, valgrind, GDB Timothée Ravier LIFO, INSA-CVL, LIPN 1 re année cycle ingénieur STI 2013 2014 1 / 36 Objectifs des outils présentés
Choix d'un serveur. Choix 1 : HP ProLiant DL380 G7 Base - Xeon E5649 2.53 GHz
 Choix d'un serveur Vous êtes responsable informatique d'une entreprise. Vous devez faire un choix pour l'achat d'un nouveau serveur. Votre prestataire informatique vous propose les choix ci-dessous Vous
Choix d'un serveur Vous êtes responsable informatique d'une entreprise. Vous devez faire un choix pour l'achat d'un nouveau serveur. Votre prestataire informatique vous propose les choix ci-dessous Vous
On distingue deux grandes catégories de mémoires : mémoire centrale (appelée également mémoire interne)
") Mémoire - espace destiné a recevoir, conserver et restituer des informations à traiter - tout composant électronique capable de stocker temporairement des données On distingue deux grandes catégories de
Mémoire - espace destiné a recevoir, conserver et restituer des informations à traiter - tout composant électronique capable de stocker temporairement des données On distingue deux grandes catégories de
Rappels d architecture
 Assembleur Rappels d architecture Un ordinateur se compose principalement d un processeur, de mémoire. On y attache ensuite des périphériques, mais ils sont optionnels. données : disque dur, etc entrée
Assembleur Rappels d architecture Un ordinateur se compose principalement d un processeur, de mémoire. On y attache ensuite des périphériques, mais ils sont optionnels. données : disque dur, etc entrée
INF6500 : Structures des ordinateurs. Sylvain Martel - INF6500 1
 INF6500 : Structures des ordinateurs Sylvain Martel - INF6500 1 Cours 4 : Multiprocesseurs Sylvain Martel - INF6500 2 Multiprocesseurs Type SISD SIMD MIMD Communication Shared memory Message-passing Groupe
INF6500 : Structures des ordinateurs Sylvain Martel - INF6500 1 Cours 4 : Multiprocesseurs Sylvain Martel - INF6500 2 Multiprocesseurs Type SISD SIMD MIMD Communication Shared memory Message-passing Groupe
SGM. Master S.T.S. mention informatique, première année. Isabelle Puaut. Septembre 2011. Université de Rennes I - IRISA
 SGM Master S.T.S. mention informatique, première année Isabelle Puaut Université de Rennes I - IRISA Septembre 2011 Isabelle Puaut SGM 2 / 1 Organisation de l enseignement Semestre 1 : processus, synchronisation
SGM Master S.T.S. mention informatique, première année Isabelle Puaut Université de Rennes I - IRISA Septembre 2011 Isabelle Puaut SGM 2 / 1 Organisation de l enseignement Semestre 1 : processus, synchronisation
Compilation (INF 564)
") Présentation du cours Le processeur MIPS Programmation du MIPS 1 Compilation (INF 564) Introduction & architecture MIPS François Pottier 10 décembre 2014 Présentation du cours Le processeur MIPS Programmation
Présentation du cours Le processeur MIPS Programmation du MIPS 1 Compilation (INF 564) Introduction & architecture MIPS François Pottier 10 décembre 2014 Présentation du cours Le processeur MIPS Programmation
INITIATION AU LANGAGE C SUR PIC DE MICROSHIP
 COURS PROGRAMMATION INITIATION AU LANGAGE C SUR MICROCONTROLEUR PIC page 1 / 7 INITIATION AU LANGAGE C SUR PIC DE MICROSHIP I. Historique du langage C 1972 : naissance du C dans les laboratoires BELL par
COURS PROGRAMMATION INITIATION AU LANGAGE C SUR MICROCONTROLEUR PIC page 1 / 7 INITIATION AU LANGAGE C SUR PIC DE MICROSHIP I. Historique du langage C 1972 : naissance du C dans les laboratoires BELL par
Julien MATHEVET Alexandre BOISSY GSID 4. Rapport RE09. Load Balancing et migration
 Julien MATHEVET Alexandre BOISSY GSID 4 Rapport Load Balancing et migration Printemps 2001 SOMMAIRE INTRODUCTION... 3 SYNTHESE CONCERNANT LE LOAD BALANCING ET LA MIGRATION... 4 POURQUOI FAIRE DU LOAD BALANCING?...
Julien MATHEVET Alexandre BOISSY GSID 4 Rapport Load Balancing et migration Printemps 2001 SOMMAIRE INTRODUCTION... 3 SYNTHESE CONCERNANT LE LOAD BALANCING ET LA MIGRATION... 4 POURQUOI FAIRE DU LOAD BALANCING?...
<Insert Picture Here> Solaris pour la base de donnés Oracle
 Solaris pour la base de donnés Oracle Alain Chéreau Oracle Solution Center Agenda Compilateurs Mémoire pour la SGA Parallélisme RAC Flash Cache Compilateurs
Solaris pour la base de donnés Oracle Alain Chéreau Oracle Solution Center Agenda Compilateurs Mémoire pour la SGA Parallélisme RAC Flash Cache Compilateurs
Parallélisme et Répartition
 Parallélisme et Répartition Master Info Françoise Baude Université de Nice Sophia-Antipolis UFR Sciences Département Informatique [email protected] web du cours : deptinfo.unice.fr/~baude Septembre 2009 Chapitre
Parallélisme et Répartition Master Info Françoise Baude Université de Nice Sophia-Antipolis UFR Sciences Département Informatique [email protected] web du cours : deptinfo.unice.fr/~baude Septembre 2009 Chapitre
Informatique Industrielle Année 2004-2005. Architecture des ordinateurs Note de cours T.Dumartin
 Informatique Industrielle Année 2004-2005 Architecture des ordinateurs Note de cours T.Dumartin 1 GENERALITES 5 1.1 INTRODUCTION 5 1.2 QU ENTEND-T-ON PAR ARCHITECTURE? 5 1.3 QU EST CE QU UN MICROPROCESSEUR?
Informatique Industrielle Année 2004-2005 Architecture des ordinateurs Note de cours T.Dumartin 1 GENERALITES 5 1.1 INTRODUCTION 5 1.2 QU ENTEND-T-ON PAR ARCHITECTURE? 5 1.3 QU EST CE QU UN MICROPROCESSEUR?
IV- Comment fonctionne un ordinateur?
 1 IV- Comment fonctionne un ordinateur? L ordinateur est une alliance du hardware (le matériel) et du software (les logiciels). Jusqu à présent, nous avons surtout vu l aspect «matériel», avec les interactions
1 IV- Comment fonctionne un ordinateur? L ordinateur est une alliance du hardware (le matériel) et du software (les logiciels). Jusqu à présent, nous avons surtout vu l aspect «matériel», avec les interactions
COMPOSANTS DE L ARCHITECTURE D UN SGBD. Chapitre 1
 1 COMPOSANTS DE L ARCHITECTURE D UN SGBD Chapitre 1 Généralité 2 Les composants principaux de l architecture d un SGBD Sont: Les processus Les structures mémoires Les fichiers P1 P2 Pn SGA Fichiers Oracle
1 COMPOSANTS DE L ARCHITECTURE D UN SGBD Chapitre 1 Généralité 2 Les composants principaux de l architecture d un SGBD Sont: Les processus Les structures mémoires Les fichiers P1 P2 Pn SGA Fichiers Oracle
Cours 13. RAID et SAN. 2004, Marc-André Léger
 Cours 13 RAID et SAN Plan Mise en contexte Storage Area Networks Architecture Fibre Channel Network Attached Storage Exemple d un serveur NAS EMC2 Celerra Conclusion Démonstration Questions - Réponses
Cours 13 RAID et SAN Plan Mise en contexte Storage Area Networks Architecture Fibre Channel Network Attached Storage Exemple d un serveur NAS EMC2 Celerra Conclusion Démonstration Questions - Réponses
Cours 1 : Qu est-ce que la programmation?
 1/65 Introduction à la programmation Cours 1 : Qu est-ce que la programmation? Yann Régis-Gianas [email protected] Université Paris Diderot Paris 7 2/65 1. Sortez un appareil qui peut se rendre
1/65 Introduction à la programmation Cours 1 : Qu est-ce que la programmation? Yann Régis-Gianas [email protected] Université Paris Diderot Paris 7 2/65 1. Sortez un appareil qui peut se rendre
Hétérogénéité pour atteindre une consommation énergétique proportionnelle dans les clouds
 Hétérogénéité pour atteindre une consommation énergétique proportionnelle dans les clouds Mardi Laurent Lefèvre LIP Inria/ENS Lyon Jean-Marc Pierson, Georges Da Costa, Patricia Stolf IRIT Toulouse Hétérogénéité
Hétérogénéité pour atteindre une consommation énergétique proportionnelle dans les clouds Mardi Laurent Lefèvre LIP Inria/ENS Lyon Jean-Marc Pierson, Georges Da Costa, Patricia Stolf IRIT Toulouse Hétérogénéité
Concept de machine virtuelle
 Concept de machine virtuelle Chap. 5: Machine virtuelle Alain Sandoz Semestre été 2007 1 Introduction: Java Virtual Machine Machine Virtuelle Java: qu est-ce que c est? c est la spécification d une machine
Concept de machine virtuelle Chap. 5: Machine virtuelle Alain Sandoz Semestre été 2007 1 Introduction: Java Virtual Machine Machine Virtuelle Java: qu est-ce que c est? c est la spécification d une machine
Contributions à l expérimentation sur les systèmes distribués de grande taille
 Contributions à l expérimentation sur les systèmes distribués de grande taille Lucas Nussbaum Soutenance de thèse 4 décembre 2008 Lucas Nussbaum Expérimentation sur les systèmes distribués 1 / 49 Contexte
Contributions à l expérimentation sur les systèmes distribués de grande taille Lucas Nussbaum Soutenance de thèse 4 décembre 2008 Lucas Nussbaum Expérimentation sur les systèmes distribués 1 / 49 Contexte
Rapport 2014 et demande pour 2015. Portage de Méso-NH sur Machines Massivement Parallèles du GENCI Projet 2015 : GENCI GEN1605 & CALMIP-P0121
 Rapport 2014 et demande pour 2015 Portage de Méso-NH sur Machines Massivement Parallèles du GENCI Projet 2015 : GENCI GEN1605 & CALMIP-P0121 Rappel sur Méso-NH : Modélisation à moyenne échelle de l atmosphère
Rapport 2014 et demande pour 2015 Portage de Méso-NH sur Machines Massivement Parallèles du GENCI Projet 2015 : GENCI GEN1605 & CALMIP-P0121 Rappel sur Méso-NH : Modélisation à moyenne échelle de l atmosphère
Windows Server 2008. Chapitre 1: Découvrir Windows Server 2008
 Windows Server 2008 Chapitre 1: Découvrir Windows Server 2008 Objectives Identifier les caractéristiques de chaque édition de Windows Server 2008 Identifier les caractéristiques généraux de Windows Server
Windows Server 2008 Chapitre 1: Découvrir Windows Server 2008 Objectives Identifier les caractéristiques de chaque édition de Windows Server 2008 Identifier les caractéristiques généraux de Windows Server
Disponibilité et fiabilité des services et des systèmes
 Disponibilité et fiabilité des services et des systèmes Anthony Busson Introduction Un site Web commercial perd de l argent lorsque leur site n est plus disponible L activité d une entreprise peut être
Disponibilité et fiabilité des services et des systèmes Anthony Busson Introduction Un site Web commercial perd de l argent lorsque leur site n est plus disponible L activité d une entreprise peut être
TP n 2 Concepts de la programmation Objets Master 1 mention IL, semestre 2 Le type Abstrait Pile
 TP n 2 Concepts de la programmation Objets Master 1 mention IL, semestre 2 Le type Abstrait Pile Dans ce TP, vous apprendrez à définir le type abstrait Pile, à le programmer en Java à l aide d une interface
TP n 2 Concepts de la programmation Objets Master 1 mention IL, semestre 2 Le type Abstrait Pile Dans ce TP, vous apprendrez à définir le type abstrait Pile, à le programmer en Java à l aide d une interface
Gestion répartie de données - 1
 Gestion répartie de données - 1 Sacha Krakowiak Université Joseph Fourier Projet Sardes (INRIA et IMAG-LSR) http://sardes.inrialpes.fr/~krakowia Gestion répartie de données Plan de la présentation Introduction
Gestion répartie de données - 1 Sacha Krakowiak Université Joseph Fourier Projet Sardes (INRIA et IMAG-LSR) http://sardes.inrialpes.fr/~krakowia Gestion répartie de données Plan de la présentation Introduction
Evaluation des performances de programmes parallèles haut niveau à base de squelettes
 Evaluation des performances de programmes parallèles haut niveau à base de squelettes Enhancing the Performance Predictability of Grid Applications with Patterns and Process Algebras A. Benoit, M. Cole,
Evaluation des performances de programmes parallèles haut niveau à base de squelettes Enhancing the Performance Predictability of Grid Applications with Patterns and Process Algebras A. Benoit, M. Cole,
Partie 7 : Gestion de la mémoire
 INF3600+INF2610 Automne 2006 Partie 7 : Gestion de la mémoire Exercice 1 : Considérez un système disposant de 16 MO de mémoire physique réservée aux processus utilisateur. La mémoire est composée de cases
INF3600+INF2610 Automne 2006 Partie 7 : Gestion de la mémoire Exercice 1 : Considérez un système disposant de 16 MO de mémoire physique réservée aux processus utilisateur. La mémoire est composée de cases
Évaluation et implémentation des langages
 Évaluation et implémentation des langages Les langages de programmation et le processus de programmation Critères de conception et d évaluation des langages de programmation Les fondations de l implémentation
Évaluation et implémentation des langages Les langages de programmation et le processus de programmation Critères de conception et d évaluation des langages de programmation Les fondations de l implémentation
Vers du matériel libre
 Février 2011 La liberté du logiciel n est qu une partie du problème. Winmodems Modem traditionnel Bon fonctionnement Plus cher Electronique propriétaire Blob sur DSP intégré au modem Bien reçu par les
Février 2011 La liberté du logiciel n est qu une partie du problème. Winmodems Modem traditionnel Bon fonctionnement Plus cher Electronique propriétaire Blob sur DSP intégré au modem Bien reçu par les
Pascale Borla-Salamet Consultante Avant Vente Oracle France. Oracle Exadata Performance et Optimisation de votre Datawarehouse
 Pascale Borla-Salamet Consultante Avant Vente Oracle France Oracle Exadata Performance et Optimisation de votre Datawarehouse Agenda Les nouveaux challenges Exadata Storage Server Oracle Database Machine
Pascale Borla-Salamet Consultante Avant Vente Oracle France Oracle Exadata Performance et Optimisation de votre Datawarehouse Agenda Les nouveaux challenges Exadata Storage Server Oracle Database Machine
SQL Server 2008 et YourSqlDba
 SQL Server 2008 et YourSqlDba Le futur de la maintenance des bases de données et la haute-disponibilité Par : Maurice Pelchat Société GRICS Survol du sujet Haute disponibilité (HD) Assurer la disponibilité
SQL Server 2008 et YourSqlDba Le futur de la maintenance des bases de données et la haute-disponibilité Par : Maurice Pelchat Société GRICS Survol du sujet Haute disponibilité (HD) Assurer la disponibilité
Sanity Check. bgcolor mgcolor fgcolor
 Sanity Check bgcolor mgcolor fgcolor 0 1 2 3 4 5 6 7 8 9 10 Compilation pour cibles hétérogènes: automatisation des analyses, transformations et décisions nécessaires, François Irigoin et Ronan Keryell
Sanity Check bgcolor mgcolor fgcolor 0 1 2 3 4 5 6 7 8 9 10 Compilation pour cibles hétérogènes: automatisation des analyses, transformations et décisions nécessaires, François Irigoin et Ronan Keryell
TASCAM MX-2424. Utilisation du SCSI
 TASCAM MX-2424 Utilisation du SCSI 1. TERMINOLOGIE SCSI...3 2. CABLES ET BOUCHONS SCSI...4 3. BOITIERS SCSI EXTERNES...4 4. PERIPHERIQUES SUPPORTES...5 4.1 Disques durs SCSI...5 4.2 Lecteurs de sauvegarde
TASCAM MX-2424 Utilisation du SCSI 1. TERMINOLOGIE SCSI...3 2. CABLES ET BOUCHONS SCSI...4 3. BOITIERS SCSI EXTERNES...4 4. PERIPHERIQUES SUPPORTES...5 4.1 Disques durs SCSI...5 4.2 Lecteurs de sauvegarde
Systemes d'exploitation des ordinateurs
 ! " #$ % $ &' ( $ plan_ch6_m1 Systemes d'exploitation des ordinateurs Conception de Systèmes de Gestion de la Mémoire Centrale Objectifs 1. Conception de systèmes paginés 2. Conception des systèmes segmentés
! " #$ % $ &' ( $ plan_ch6_m1 Systemes d'exploitation des ordinateurs Conception de Systèmes de Gestion de la Mémoire Centrale Objectifs 1. Conception de systèmes paginés 2. Conception des systèmes segmentés
Technologie de déduplication de Barracuda Backup. Livre blanc
 Technologie de déduplication de Barracuda Backup Livre blanc Résumé Les technologies de protection des données jouent un rôle essentiel au sein des entreprises et ce, quelle que soit leur taille. Toutefois,
Technologie de déduplication de Barracuda Backup Livre blanc Résumé Les technologies de protection des données jouent un rôle essentiel au sein des entreprises et ce, quelle que soit leur taille. Toutefois,
 Licence ST Université Claude Bernard Lyon I LIF1 : Algorithmique et Programmation C Bases du langage C 1 Conclusion de la dernière fois Introduction de l algorithmique générale pour permettre de traiter
Licence ST Université Claude Bernard Lyon I LIF1 : Algorithmique et Programmation C Bases du langage C 1 Conclusion de la dernière fois Introduction de l algorithmique générale pour permettre de traiter
Institut Supérieure Aux Etudes Technologiques De Nabeul. Département Informatique
 Institut Supérieure Aux Etudes Technologiques De Nabeul Département Informatique Support de Programmation Java Préparé par Mlle Imene Sghaier 2006-2007 Chapitre 1 Introduction au langage de programmation
Institut Supérieure Aux Etudes Technologiques De Nabeul Département Informatique Support de Programmation Java Préparé par Mlle Imene Sghaier 2006-2007 Chapitre 1 Introduction au langage de programmation
Eléments de spécification des systèmes temps réel Pierre-Yves Duval (cppm)
") Eléments de spécification des systèmes temps réel Pierre-Yves Duval (cppm) Ecole d informatique temps réel - La Londes les Maures 7-11 Octobre 2002 - Evénements et architectures - Spécifications de performances
Eléments de spécification des systèmes temps réel Pierre-Yves Duval (cppm) Ecole d informatique temps réel - La Londes les Maures 7-11 Octobre 2002 - Evénements et architectures - Spécifications de performances
Comme chaque ligne de cache a 1024 bits. Le nombre de lignes de cache contenu dans chaque ensemble est:
 Travaux Pratiques 3. IFT 1002/IFT 1005. Structure Interne des Ordinateurs. Département d'informatique et de génie logiciel. Université Laval. Hiver 2012. Prof : Bui Minh Duc. Tous les exercices sont indépendants.
Travaux Pratiques 3. IFT 1002/IFT 1005. Structure Interne des Ordinateurs. Département d'informatique et de génie logiciel. Université Laval. Hiver 2012. Prof : Bui Minh Duc. Tous les exercices sont indépendants.
ARDUINO DOSSIER RESSOURCE POUR LA CLASSE
 ARDUINO DOSSIER RESSOURCE POUR LA CLASSE Sommaire 1. Présentation 2. Exemple d apprentissage 3. Lexique de termes anglais 4. Reconnaître les composants 5. Rendre Arduino autonome 6. Les signaux d entrée
ARDUINO DOSSIER RESSOURCE POUR LA CLASSE Sommaire 1. Présentation 2. Exemple d apprentissage 3. Lexique de termes anglais 4. Reconnaître les composants 5. Rendre Arduino autonome 6. Les signaux d entrée
Analyse de performance, monitoring
 Analyse de performance, monitoring Plan Principes de profilage Projet TPTP dans Eclipse Utilisation des profiling tools de TPTP Philippe Collet Master 1 Informatique 2009-2010 http://deptinfo.unice.fr/twiki/bin/view/minfo/gl
Analyse de performance, monitoring Plan Principes de profilage Projet TPTP dans Eclipse Utilisation des profiling tools de TPTP Philippe Collet Master 1 Informatique 2009-2010 http://deptinfo.unice.fr/twiki/bin/view/minfo/gl
<Insert Picture Here> Exadata Storage Server et DB Machine V2
 Exadata Storage Server et DB Machine V2 Croissance de la Volumétrie des Données Volumes multipliés par 3 tous les 2 ans Evolution des volumes de données 1000 Terabytes (Données) 800
Exadata Storage Server et DB Machine V2 Croissance de la Volumétrie des Données Volumes multipliés par 3 tous les 2 ans Evolution des volumes de données 1000 Terabytes (Données) 800
en version SAN ou NAS
 tout-en-un en version SAN ou NAS Quand avez-vous besoin de virtualisation? Les opportunités de mettre en place des solutions de virtualisation sont nombreuses, quelque soit la taille de l'entreprise. Parmi
tout-en-un en version SAN ou NAS Quand avez-vous besoin de virtualisation? Les opportunités de mettre en place des solutions de virtualisation sont nombreuses, quelque soit la taille de l'entreprise. Parmi
Sommaire. 3. Les grands principes de GFS L architecture L accès de fichier en lecture L accès de fichier en écriture Bilan
 1 Sommaire 1. Google en chiffres 2. Les raisons d être de GFS 3. Les grands principes de GFS L architecture L accès de fichier en lecture L accès de fichier en écriture Bilan 4. Les Evolutions et Alternatives
1 Sommaire 1. Google en chiffres 2. Les raisons d être de GFS 3. Les grands principes de GFS L architecture L accès de fichier en lecture L accès de fichier en écriture Bilan 4. Les Evolutions et Alternatives
Info0804. Cours 6. Optimisation combinatoire : Applications et compléments
 Recherche Opérationnelle Optimisation combinatoire : Applications et compléments Pierre Delisle Université de Reims Champagne-Ardenne Département de Mathématiques et Informatique 17 février 2014 Plan de
Recherche Opérationnelle Optimisation combinatoire : Applications et compléments Pierre Delisle Université de Reims Champagne-Ardenne Département de Mathématiques et Informatique 17 février 2014 Plan de
Chapitre 1 : Introduction aux bases de données
 Chapitre 1 : Introduction aux bases de données Les Bases de Données occupent aujourd'hui une place de plus en plus importante dans les systèmes informatiques. Les Systèmes de Gestion de Bases de Données
Chapitre 1 : Introduction aux bases de données Les Bases de Données occupent aujourd'hui une place de plus en plus importante dans les systèmes informatiques. Les Systèmes de Gestion de Bases de Données
Installation et prise en main
 TP1 Installation et prise en main Android est le système d'exploitation pour smartphones, tablettes et autres appareils développé par Google. Pour permettre aux utilisateurs d'installer des applications
TP1 Installation et prise en main Android est le système d'exploitation pour smartphones, tablettes et autres appareils développé par Google. Pour permettre aux utilisateurs d'installer des applications
vbladecenter S! tout-en-un en version SAN ou NAS
 vbladecenter S! tout-en-un en version SAN ou NAS Quand avez-vous besoin de virtualisation? Les opportunités de mettre en place des solutions de virtualisation sont nombreuses, quelque soit la taille de
vbladecenter S! tout-en-un en version SAN ou NAS Quand avez-vous besoin de virtualisation? Les opportunités de mettre en place des solutions de virtualisation sont nombreuses, quelque soit la taille de
Leçon 1 : Les principaux composants d un ordinateur
 Chapitre 2 Architecture d un ordinateur Leçon 1 : Les principaux composants d un ordinateur Les objectifs : o Identifier les principaux composants d un micro-ordinateur. o Connaître les caractéristiques
Chapitre 2 Architecture d un ordinateur Leçon 1 : Les principaux composants d un ordinateur Les objectifs : o Identifier les principaux composants d un micro-ordinateur. o Connaître les caractéristiques
1/24. I passer d un problème exprimé en français à la réalisation d un. I expressions arithmétiques. I structures de contrôle (tests, boucles)
") 1/4 Objectif de ce cours /4 Objectifs de ce cours Introduction au langage C - Cours Girardot/Roelens Septembre 013 Du problème au programme I passer d un problème exprimé en français à la réalisation d
1/4 Objectif de ce cours /4 Objectifs de ce cours Introduction au langage C - Cours Girardot/Roelens Septembre 013 Du problème au programme I passer d un problème exprimé en français à la réalisation d