DESS ID JUIN Tinseaux Benoit
|
|
|
- Valentin Rochon
- il y a 10 ans
- Total affichages :
Transcription
1 DESS ID JUIN 2004 Tinseaux Benoit

2 Concept Données Data «Ce qui est donné, connu, déterminé à l avance dans l énoncé d un problème, et qui sert à découvrir ce qui est inconnu» «Ce qui est admis, connu ou reconnu et qui sert de base à un raisonnement, de point de départ pour une recherche, une étude» Source : Le Petit Robert Le concept de datamining est né de la nécessité de rechercher dans des bases de données toujours plus importante, des informations pertinentes mais aussi non triviales. Le datamining n est ni une technologie, ni un outil informatique, il s agit véritablement d un concept. L émergence de l informatique au sein des entreprises ainsi que la chute du prix des modules de stockage ont convaincu les sociétés de se constituer des bases de données clientes. Ces bases de données se révèlent être de véritables mines d or pour peu qu on sache les exploiter convenablement, c est de ce besoin qu est né le concept de datamining. Présentation Introduction Le datamining ou «fouille de données» est une étape de l ECD (Extraction de Connaissances à partir de données) ou KDD (Knowledge Discovery in Databases), l ECD est un processus qui inclut des étapes préalables à la fouille elle même : - Accès aux données, souvent disséminées dans plusieurs bases de données, - Nettoyage pour corriger les erreurs, les doublons, - Mise en forme et codage des données souvent diverses : numériques, symboliques, images, textes, sons, - Sélection, ou construction, d attributs (variables) et d instances. L ECD inclut aussi des étapes ultérieures de valorisation et de communication des résultats, telles que la visualisation. La fouille elle même (le datamining) opère sur des tableaux bi-dimensionnels ad hoc, souvent appelés datamarts.

3 Le datamining est un sujet qui dépasse aujourd hui le cercle restreint de la communauté scientifique pour susciter un vif intérêt dans le monde des affaires. Plusieurs définitions du datamining sont désormais employées : - «L extraction d informations originales, auparavant inconnues, potentiellement utiles à partir de données» - «La découverte de nouvelles corrélations, tendances et modèles par le tamisage d un large volume de données» - «Un processus d aide à la décision où les utilisateurs cherchent des modèles d interprétation dans les données» - ou bien encore des choses plus poétiques mais poins explicites du style «torturer l information disponible jusqu à ce qu elle avoue» Le processus du datamining Plus précisément, le datamining peut se décomposer en 8 étapes : 1. Poser le problème 2. Rechercher des données 3. Sélectionner les données pertinentes 4. Nettoyer des données 5. Transformer les variables 6. Rechercher le modèle 7. Evaluer le résultat 8. Intégrer la connaissance Les principaux algorithmes du datamining On dénombre sept techniques principales dans le domaine du datamining : 1. Apprentissage fondé sur l explication (EBL ou Explanation Based Learning) : Apprentissage formé sur des explications dérivées d une théorie (généralement incomplète) fournie en entrée. Cette forme d apprentissage repose sur des déductions pour expliquer les données à partir de la théorie et sur des arbres de décision pour générer de la nouvelle connaissance. 2. Apprentissage statistique (STL pour Statistical Learning) : Cet apprentissage repose sur des opérations statistiques telles que la classification bayésienne ou la régression pour apprendre à partir de données.

4 3. Apprentissage par réseaux neuronaux (NNL pour Neural Network Learning) : Un réseau de neurones est défini par un ensemble d unités de traitement qui peuvent être des unités soit d entrée, soit de sortie, soit cachées. L apprentissage s effectue par l injection de cas en entrée et par la mesure des conclusions en sortie. 4. Apprentissage algorithme génétique (GAL pour Genetic Algorithm Learning) : Les algorithmes génétiques sont des procédures de recherche fondées sur la dynamique de la génétique biologique. Ils comportent trois opérateurs, la sélection, la combinaison et la mutation, qui sont appliqués à des générations successives d ensemble de données. Les meilleures combinaisons survivent et produisent, par exemple, des plannings, des règles 5. Apprentissage par similarité (SBL pour Similarity Based Learning) : Ces techniques utilisent des indicateurs de similarité pour regrouper des données ou des observations et pour définir des règles. 6. Apprentissage symbolique empirique (SEL pour Symbolic Empirical Learning) : Cette forme d apprentissage extrait des règles symboliques compréhensibles par l utilisateur à partir de données. On retrouve dans cette catégorie les algorithmes ID3/C4.5 et CN2 notamment. 7. Apprentissage par analogie (ANL pour Analogy Learning) : L apprentissage s appuie sur l analogie entre un nouveau cas et des cas ressemblants soumis préalablement. Les domaines d application Voici un liste non exhaustive des applications possibles du datamining par secteur d activités : - Grande distribution et VPC : Analyse des comportements des consommateurs, recherche des similarités des consommateurs en fonction de critères géographiques ou socio-démographiques, prédiction des taux de réponse en marketing direct, vente croisée et activation sélective dans le domaine des cartes de fidélité, optimisation des réapprovisionnements. - Laboratoires pharmaceutiques : Modélisation comportementale et prédiction de médications ou de visites, optimisation des plans d action des visiteurs médicaux pour le lancement de nouvelles molécules, identification des meilleures thérapies pour différentes maladies. - Banques : Modélisation prédictive des clients partants, détermination de pré-autorisations de crédit. - Assurance : Modèles de sélection et de tarification, analyse des sinistres, recherche des critères explicatifs du risque ou de la fraude, prévision d appel sur les plates-formes d assurance directe.

5 - Aéronautique, automobile et industries : Contrôle qualité et anticipation des défauts, prévision des ventes, dépouillement d enquêtes de satisfaction. - Transport et voyagistes : Optimisation des tournées, prédiction de carnets de commande, marketing relationnel dans le cadre de programmes de fidélité. - Télécommunications, eau, énergie : Simulation de tarifs, détection de formes de consommation frauduleuses, classification des clients selon la forme de l utilisation des services, prévision de ventes. Comme on peut le voir, le datamining peut s appliquer à tous les domaines. Enjeux En préambule, les résultats du datamining doivent, s ils veulent prouver leur rentabilité, être intégrés selon les cas, soit dans l informatique de l entreprise, soit dans ses procédures. Ainsi, après avoir, par exemple, élaboré un modèle prédictif du départ d un client à la concurrence, il faudra soit mettre en place des programmes pour calculer le risque de départ, de chaque client, soit diffuser une procédure pour que les commerciaux appliquent manuellement ces règles et prennent les mesures adaptées. Cela étant posé, les opérations de datamining se soldent généralement par des gains significatifs tant en termes absolus (les gains) qu en termes relatifs (les retours sur investissement). A titre indicatif, il n est pas rare que les premières applications de datamining génèrent plus de 10 fois l investissement qu elles auront nécessité, soit un retour sur investissement de l ordre du mois! Afin d illustrer ce potentiel, voici deux cas concrets : - Une banque veut améliorer son taux de transformation de rendez vous commerciaux en vente de produits financiers : 60 millions de retour pour un investissement de 2 millions, soit une durée de retour sur investissement de l opération de datamining en 12 jours - Une entreprise de vente par correspondance (VPC) cherche à améliorer le taux de rendement sur l envoi de catalogue spécialisé : 1 millions de retour sur un investissement de francs soit une durée de retour sur investissement d environ 30 jours.

6 Comme on peut le voir le datamining permet de générer des gains important avec finalement peu de moyens. De plus, le datamining qui traite sur des grands volumes de données permet de découvrir des pépites impossibles à dénicher par d autres moyens, il est donc devenu un outil indispensable aux entreprises. Du datamining à l analyse de données symboliques Présentation de l analyse de données symboliques L augmentation de la taille des bases de données, la diversité de formats des données ainsi que la précision de celles ci dans tous les domaines d activité sont de véritables gisements dans lesquelles les entreprises ont la possibilité de puiser pour en retirer de la connaissance. Ces connaissances sont disponibles mais ne sont pas toujours évidentes à extraire et à représenter. Résumer ces données grâce à des concepts sous jacents comme des pays, des marques, des catégorie socioprofessionnelles etc ) représente un enjeu très important pour les industrie. En effet, ces concepts, contrairement à des données individuelles, peuvent être décrits par des données plus complexes que celle utilisées dans l analyse de données classique. Ces données sont dites symboliques car elles expriment la variation interne inéluctable des concepts et sont structurées. L analyse de données symbolique est basée sur la vision du monde telle qu il est réellement, ainsi, le monde est constitué d individus (par exemple des produits, ou bien encore des employés ou des clients) et de concepts (par exemple, les concepts correspondant aux individus précédents pourraient être des catégorie de produit (boissons gazeuses, eau minérales plates, ), des statuts d employés (cadres, techniciens, ouvriers, ) ou bien encore des localisations géographiques des clients (pays, département, ). "L'extension" d'un concept est l'ensemble des individus qui satisfont ses propriétés caractéristiques appelées "intention". Par exemple, l extension du concept «eau minérale plate» décrit l ensemble des individus possédant les caractéristiques du concept (un certain taux de minéraux, pas de nitrates, pas de bulles, ). Tous les individus possèdent un certain nombre d attributs qui les décrivent, par exemple, dans le cas de personnes, la taille, le poids, le sexe, la catégorie socioprofessionnelle etc Une description est constituée d'un ou plusieurs produits cartésiens exprimant ces propriétés par leur domaine de variation pour l'individu considéré. Une classe d'individus est modélisée dans l'espace des descriptions à l'aide d'un opérateur utilisant les descriptions des individus qui la constituent (l'intervalle de variation ou l'histogramme de leur âge, de leur taille, etc.). Chaque individu est considéré comme un cas particulier de classe d'individus et donc aussi bien les classes que les individus peuvent être modélisés dans le même espace de description. Les concepts sont modélisés dans un espace dit des "objets symboliques". Ainsi, chaque concept est modélisé par "un objet symbolique" qui représente son intention et se définit par un triplet: la "description" d'une classe d'individus appartenant à l'extension du concept, un "opérateur de comparaison" entre deux descriptions, une "fonction de reconnaissance". Comme les concepts, les objets symboliques ont une extension qui se calcule à l'aide de leur fonction de reconnaissance.

7 Le premier grand principe de l'ads consiste à analyser un ensemble d'individus tout en prenant en compte la statistique propre, les données répétées, la variation interne de chacun d'entre eux, considéré d'abord comme un cas unique. Ainsi, quand cette variation n'est pas prise en compte on se trouve dans le cas de l'analyse des Données (AD) classique. Il en résulte, que toute méthode d'ads doit avoir comme cas particulier une méthode d'ad classique. Le second grand principe qui dérive naturellement du premier est que les résultats obtenus doivent eux-mêmes s'interpréter en termes de données symboliques ou d'objets symboliques, autrement dit, dans des termes plus riches que ceux utilisés en AD classique mais aussi intelligibles par l'expert puisque ce sont ceux qu'il a utilisé en entrée. Le premier principe conduit à utiliser en entrée d'une ADS la définition de données dites "symboliques" (i.e. "non purement numériques") qui prennent en compte la variation interne aux individus et leur complexité. Ainsi, un "tableau de données symboliques" autorise plusieurs valeurs par case, ces valeurs étant parfois pondérées et liées entre elles par des règles et des taxonomies. On peut montrer que de telles données ne sont pas réductibles, sans perte d'informations, à des données standard. Plusieurs grandes sources d'unités statistiques (i.e. "individus de second ordre") munies de variation interne sont évoquées comme les bases de données, les données stochastiques, les séries chronologiques, les données confidentielles. En sortie d'une ADS on peut obtenir des objets symboliques. On les définit, on introduit les trois opérateurs de généralisation, de comparaison et d'agrégation qui permettent de les construire. Apports de l analyse de données symboliques L analyse de données symboliques est intéressante à plus d un titre : - Les objets symboliques permettent la description d objets plus complexes que la structure standard de tableau de données, et d y ajouter de la connaissance a priori sur les données (par exemple en définissant des hiérarchies sur les domaines de valeurs des caractéristiques décrites). - La structure proposée n est pas trop complexe, et permet d étendre sans problème les méthodes standard d analyse statistique des données. - Les objets symboliques constituent en eux mêmes des résumés d un tableau de données, puisqu ils décrivent des groupes d individus au lieu d individus élémentaires. Le logiciel d analyse de données symboliques SODAS Présentation générale

8 La méthodologie proposée est basée sur les principes suivants : Chaque objet symbolique permettant de décrire un groupe d individus, hypothèse est faite que la base de données contient à la fois la description des individus élémentaires, leur appartenance aux groupes définissant les objets symboliques, ainsi que les connaissances a priori sur les données (hiérarchies sur les domaines des attributs). La présence d un schéma conceptuel (par exemple en entité-relation) aurait grandement facilité la spécification de l extraction des objets symboliques à partir d une base de données relationnelle. Cependant, ce schéma conceptuel n étant que rarement disponible (et les outils de rétro-engineering étant lourds à mettre en œuvre), le choix s est porté sur la spécification de requêtes type, associées à une sémantique particulière, que l utilisateur doit écrire en fonction de sa connaissance du schéma relationnel de la base de données. Un exemple de requête type est la requête où la première colonne représente l identifiant des individus, la seconde l identifiant des groupes, et les autres colonnes représentent des caractéristiques des individus. Ainsi, la spécification de la sémantique des données est reportée sur les connaissances de l utilisateur. Exemples d objets symboliques générés à partir de cette base de données
 aurait grandement facilité la spécification de l extraction des objets symboliques à partir d une base de données relationnelle.")
9 Une fois les différentes requêtes spécifiées par l utilisateur, des fonctions de généralisation sont appliquées pour construire les descriptions des groupes d individus à partir des descriptions des individus extraits de la base de donnée. Les objets symboliques générés par généralisation sont ensuite simplifiés en éliminant les individus atypiques qui conduisent à des descriptions peu interprétables. Cette méthodologie a été mise en oeuvre sous la forme d un module (DB2SO) du logiciel SODAS, qui s est avéré essentiel. Une attention particulière a été portée aux performances de ce module en terme de temps de réponse. En particulier, les objets symboliques peuvent être construits à partir d un échantillon des individus extraits de la base au lieu de l ensemble des individus, si la taille du résultat de la requête est importante. Ces travaux contribuent à valoriser les informations stockées dans les bases de données relationnelles pour les raisons suivantes : Les objets symboliques construits constituent des résumés des bases de données, en supprimant les informations individuelles qui sont souvent sensibles et difficiles à diffuser. Ils sont donc des objets de diffusion de la connaissance contenue dans les systèmes d information des entreprises. Les objets symboliques peuvent être analysés par les méthodes d analyse statistique de données étendues aux objets symboliques dans le projet SODAS. Par leurs capacités de synthèse et de prédiction de comportements, ces méthodes permettent de donner une valeur aux données de l entreprise. Présentation DB2SO DB2SO est le module d importation et de transformation de base de données de SODAS, il est accessible par le menu «SODAS File» -> «Import» -> «Importation (DB2SO)» Vue générale :
 du logiciel SODAS, qui s est avéré essentiel.")

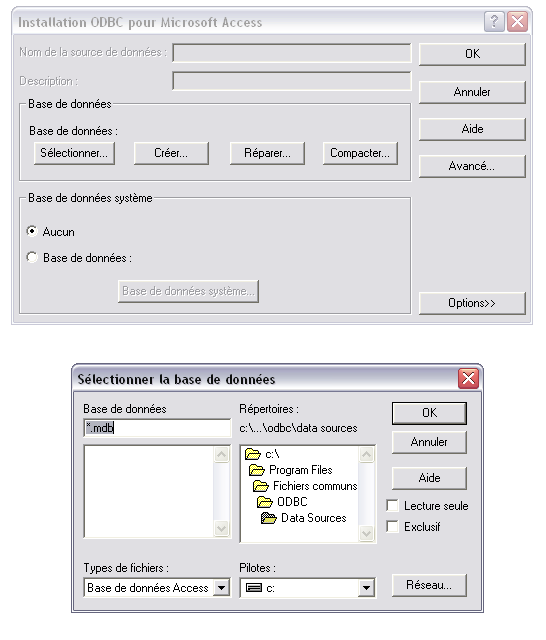
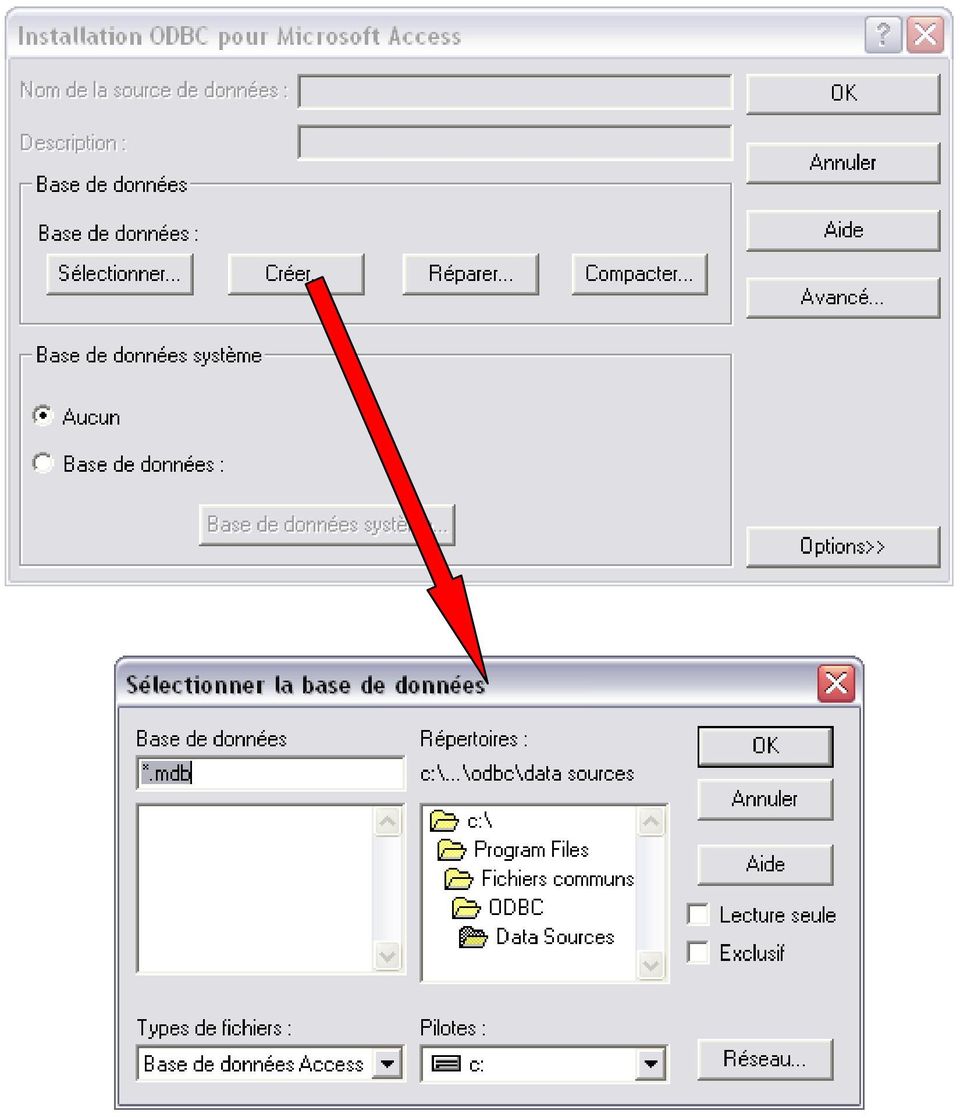
10 Dans ce menu, il faut choisir la source de données, pour en créer une nouvelle, il faut continuer en cliquant sur le bouton «Nouveau», s ouvre alors une 2 ème fenêtre dans laquelle il faut choisir le type de base de données que l on souhaite importer dans DB2SO. Dans le cas présent, il s agira d une base Access.


11 Il faut ensuite indiquer le nom dans laquelle la nouvelle base de données sera sauvée, ici elle sera sauvée sous le nom «Tennis1.mdb.dsn»

12

13 Il faut ensuite choisir la base de données à partir de laquelle DB2SO va créer la nouvelle base de données. Il ne reste alors plus qu à faire la requête SQL pour récupérer les données voulues à partir de la base de données, ici on récupérera toutes les données de la table tennis dans la base de données. DB2SO nous donnes alors quelques infos sur les données qu il a importé, ici il a récupéré 50 individus ayant chacun 23 attributs : 9 qualitatifs et 14 quantitatifs.

14 Ajout d une variable à expliquer Pour ajouter une variable à expliquer, il existe une fonction spéciale dans DB2SO appelée «Add Single», cette fonction va permettre de créer une requête SQL et ainsi d importer la variable à expliquer. Analyse d une base de données à l aide de SODAS Présentation de la base de données à étudier Nous allons faire une étude à l aide du logiciel SODAS afin de mieux appréhender le concept d objet symbolique. La base de données étudiée a été constituée entièrement à la main sous access, à partir de site donnant des statistiques sur les joueurs de tennis, les principaux sites utilisés ont été ceux de la fédération internationale de tennis et le site de l ATP. Cette base de données contient des informations sur les 50 premiers joueurs au classement «the race» de décembre On pourra noter que par souci de simplicité pour les requêtes, seul la table «tennis» qui contient toutes informations nécessaires est utilisée dans ce rapport, ainsi que la table pays pour l ajout d une variable «add single» ; de même on pourra remarquer que certains attributs présents dans la table ne sont pas utilisés, ils ont néanmoins servi a nombreux tests même s ils ne sont pas présents dans cette étude. Les requêtes ne sont pas données car elles sont très simples, le choix des variables se faisant principalement au niveau de SODAS lui-même, ce qui permet une plus grande flexibilité dans ce même choix des variables, ainsi que de faire de plus nombreuses analyses sans avoir a recharger une base de données. Utilisation des différentes méthodes présentes dans SODAS SOE La méthode SOE ( Symbolic Object Editor) permet de voir les objets symboliques crées, et cela sous forme de tableau ou bien d étoile, les étoiles permettent notamment de voir et de comparer des répartitions entre différents objet symboliques.

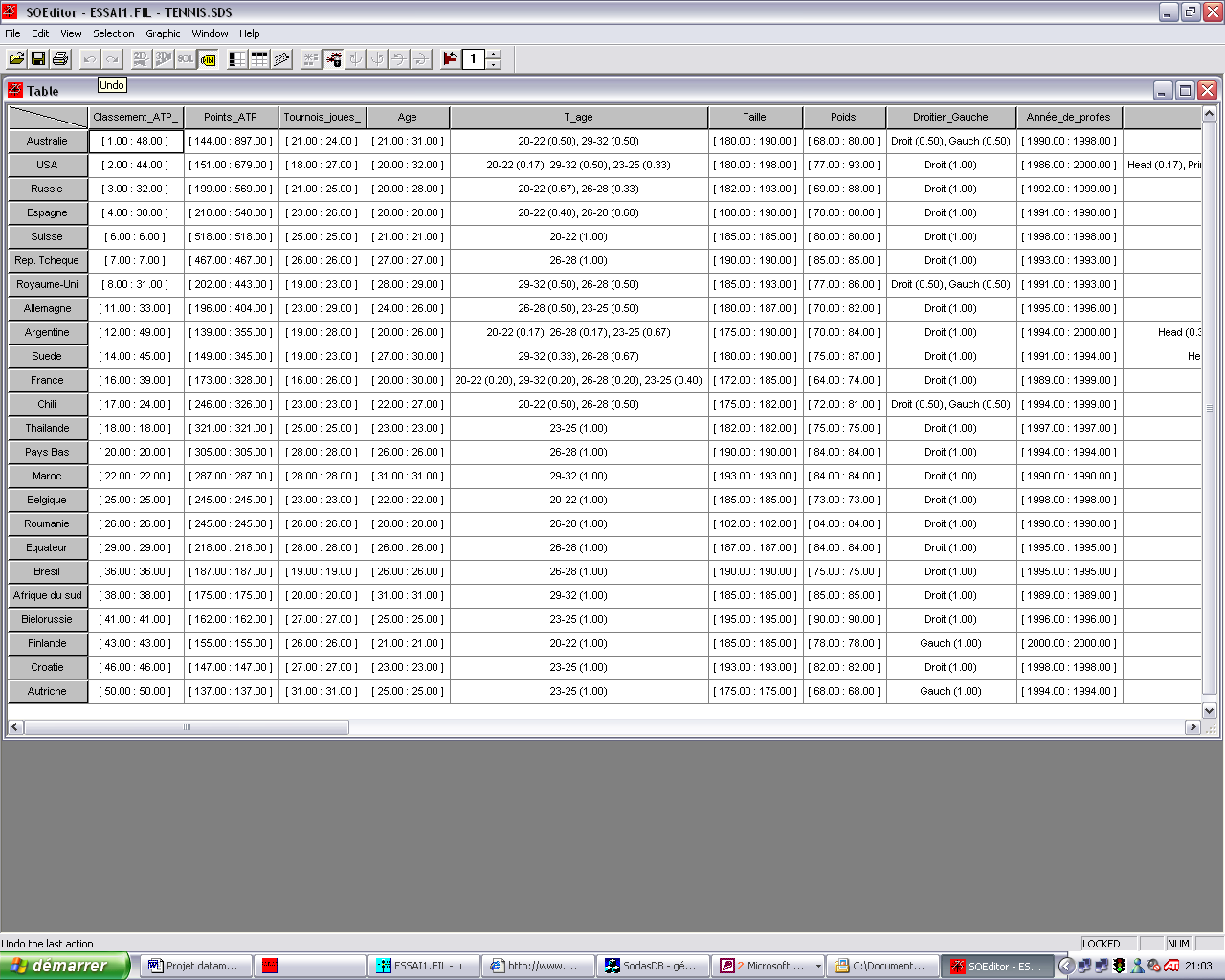
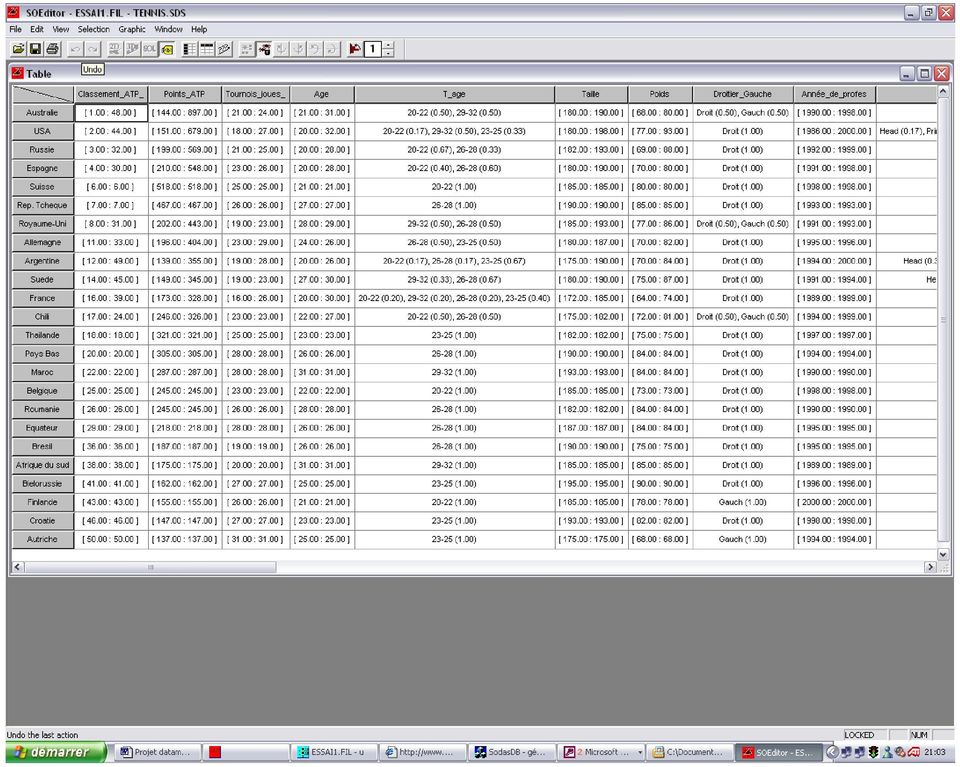
15 Un exemple de tableau, on y voit notamment que les concepts sont les pays et les écarts de quelques variables sur ces différents concepts comme la taille, le poids etc

16
17 Voici quelques exemples d étoiles et qui nous donnent des informations intéressantes : On voit par exemple sur ces 2 étoiles qui nous permettent de comparer le poids, la taille, le nombre de titres, les gains et la surface de prédilection des joueurs Américains faces aux joueurs Espagnols. Il en ressort tout de suite que les joueurs Américains sont globalement plus grands et surtout plus lourds que les Espagnols, le nombre de titres gagnés est a peu près similaire puisqu il va de 0 à 5 chez les Américains et de 0 à 4 chez les Espagnols, de la même manière, les gains sont à peu près similaires. Par contre on voit que chez 100% des Espagnols la surface de prédilection est terre battue alors que les Américains privilégient plutôt les surfaces dites «rapides» que sont l herbe et le dur. On peut donc trouver une corrélation entre la surface de prédilection et le rapport poids/taille : les surfaces rapides sont plutôt destinées aux joueurs puissants que sont les «frappeurs» alors que la terre battue qui est la surface la plus lente privilégie plutôt les joueurs techniques et moins puissants.

18
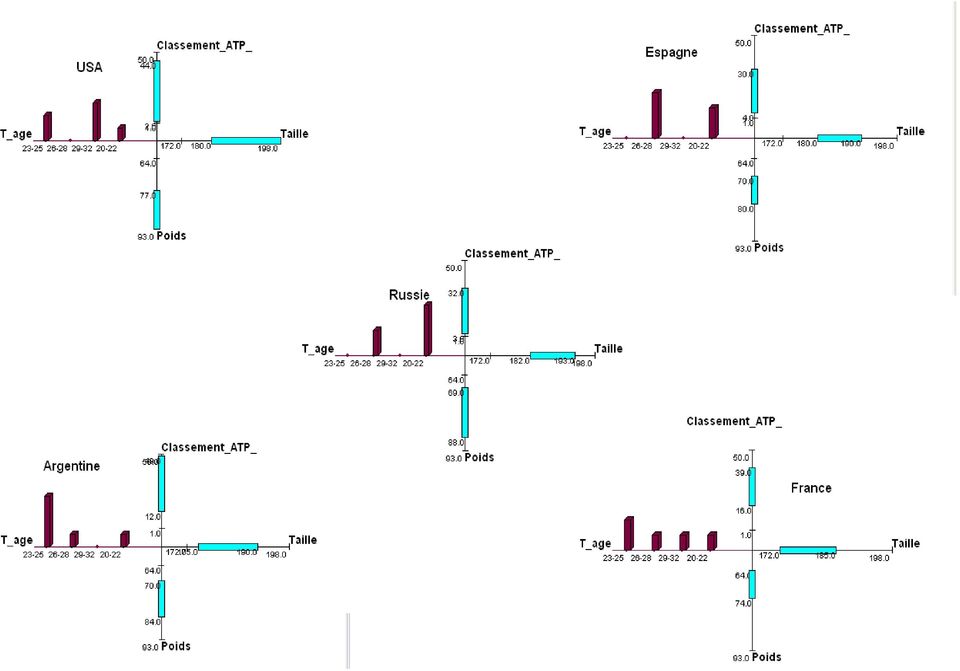
19 Sur ces étoiles on peu tout de suite faire une comparaison de la taille, du poids, du classement et de l age des joueurs des pays qui ont le plus de joueurs classés dans le top 50. Concernant l age, on voit tout de suite que l Argentine est le pays qui a le plus de jeunes talents, vient ensuite la Russie alors que les américains et les Espagnols sont beaucoup plus âgés, la France est le pays où l âge des joueurs est le plus réparti. Concernant la taille, les russes, les espagnols et surtout les américains sont les plus grands, la France est le pays où les joueurs sont les plus petits. Ensuite, il est intéressant de noter que malgré une répartition de taille assez similaire chez les russes, les espagnols et les américains, les espagnols sont beaucoup plus légers que les américains et les russes. Concernant le classement ATP, bien que la répartition soit à peu près la même partout, on peut noter que seul l Argentine et la France ne possèdent pas de joueur dans le top 10. STAT La méthode STAT ( Elementary Statistics On Symbolic Objects) étend aux objets symboliques, représentés par leur description, plusieurs méthodes de statistique élémentaire limitées aux données. C est un composant de SODAS et donc il fonctionne dans SODAS avec les bases de données de SODAS. Les méthodes dépendent du type des variables de la base et sont filtrées en fonction de la méthode de travail : - fréquences relatives pour variables multimodales (a) - fréquences relatives pour variables intervalles (b) - capacités et min/max/mean pour variables multimodales probabilistes - biplot pour variables intervalles (d) - objet central.


20 On voit par exemple sur ce graphique que la plupart des joueurs remportent entre 1 et 2 titres, les joueurs remportant plus de 2 titre ne représentent que 22% des joueurs, et seuls 5 % des joueurs ont remportés plus de 4 titres.


21 Concernant la date de professionnalisation des joueurs, on remarque que presque 60% des joueurs classés au top 50 on commencé leur carrière professionnelle entre 1992 et 1996, ce qui veut dire qu ils ont entre 6 et 10 ans de carrière professionnelle, l expérience semble donc être in facteur essentiel de la réussite au tennis. Par contre on voit que au delà de 11 années de carrière, le nombre de joueurs bien classés diminue très fortement, et de la même manière, le nombre de joueurs bien classés ayant moins de 2 ans de carrière est très faible, on peut donc considérer que le tennis est un sport dans lequel l apogée de la carrière se fait au bout de 6 à 10 ans mais que ce succès est très éphémère et ne dure pas plus de 4-5 ans.
22 sur ce biplot on voit que les espagnols sont un peu moins grands mais ont un pourcentage de victoire sur herbe beaucoup plus faible que les anglais, on peut supposer que cela est du au fait la majorité des courts de tennis en Angleterre est en herbe alors qu en Espagne, le climat ne favorise pas ce genre de terrain dont l entretien serait très couteux.
23 DIV La méthode DIv (Divisive Clustering) est une méthode de classification hiérarchique qui effectue des division successives sur tous les objets d une classe. A chaque nœud, les classes sont divisées en 2 nouvelles classes selon qu elles répondent ou on à la «question» du nœud.. Cette question binaire induit le meilleur partage en deux classes selon une extension du critère de l inertie. L algorithme se termine après k-1 divisions, où k représente le nombre de classes données comme inputs par l utilisateur BASE=C:\SODAS\Tmp\BKEU1W01.CMD nind=24 nvar=23 nvarsel=2 METHOD=DIVISIVE CLUSTERING VARIANCE OF THE SELECTED VARIABLES : Taille : Poids : PARTITION IN 2 CLUSTERS : : Cluster 1 (n=14) : "Australie" "Russie" "Espagne" "Suisse" "Allemagne" "Argentine" "Suede" "France" "Chili" "Thailande" "Belgique" "Bresil" "Finlande" "Autriche" Cluster 2 (n=10) : "USA" "Rep. Tcheque" "Royaume-Uni" "Pays Bas" "Maroc" "Roumanie" "Equateur" "Afrique du sud" "Bielorussie" "Croatie" Explicated inertia : PARTITION IN 3 CLUSTERS :
24 : Cluster 1 (n=2) : "France" "Autriche" Cluster 2 (n=10) : "USA" "Rep. Tcheque" "Royaume-Uni" "Pays Bas" "Maroc" "Roumanie" "Equateur" "Afrique du sud" "Bielorussie" "Croatie" Cluster 3 (n=12) : "Australie" "Russie" "Espagne" "Suisse" "Allemagne" "Argentine" "Suede" "Chili" "Thailande" "Belgique" "Bresil" "Finlande" Explicated inertia : PARTITION IN 4 CLUSTERS : : Cluster 1 (n=2) : "France" "Autriche" Cluster 2 (n=5) : "USA" "Royaume-Uni" "Roumanie" "Equateur" "Afrique du sud" Cluster 3 (n=12) : "Australie" "Russie" "Espagne" "Suisse" "Allemagne" "Argentine" "Suede" "Chili" "Thailande" "Belgique" "Bresil" "Finlande" Cluster 4 (n=5) :
25 "Rep. Tcheque" "Pays Bas" "Maroc" "Bielorussie" "Croatie" Explicated inertia : THE CLUSTERING TREE : the number noted at each node indicates the order of the divisions - Ng <-> yes and Nd <-> no Classe 1 (Ng=2)!! [Poids <= ]!!! Classe 3 (Nd=12)!! [Poids <= ]!! Classe 2 (Ng=5)!!! [Taille <= ]! Classe 4 (Nd=5) Les variables utilisées sont la taille et le poids, on voit que 14 pays ont des joueurs dont le poids moyen est inférieur à 81,25 kilos et parmis ces pays, seuls 2 ont des joueurs dont le poids moyen est inférieur à 71 kilos. Parmis les autres pays (ceux dont les joueurs font plus de 81 kilos) on voit que la moitié de ceux-ci ont des joueurs très grands, dont la taille dépasse 190. Pour cet exemple, peu de partition (4) a été sélectionné, car le fichier résultat devient vite très grand.
26 PCM La méthode PCM (Principal Component Analisys), c est une extension de la méthode d analyse en composante principale classique Dans cette analyse, la variable choisie est le pourcentage de victoire sur terre battue, on y voit tout de suite les disparités entre les différents pays.
27 TREE La méthode TREE est une méthode qui crée un arbre de décision. Dans l exemple qui suit, la «variable class identifier» est la surface de prédilection de chaque pays et les variables prédictives sont la taille et le poids des joueurs. RESULTS BY SYMBOLIC OBJECT ==================================================================================================== No Nom Leaf Class Herbe Terre Moquet Dur criterion No true assig. ( 1) ( 2) ( 3) ( 4) ==================================================================================================== 1 "Australie" (*) "USA" (*) "Russie" (*) "Espagne" "Suisse" "Rep. Tcheque" (*) "Royaume-Uni" "Allemagne" (*) "Argentine" "Suede" "France" (*) "Chili" "Thailande" (*) "Pays Bas" (*) "Maroc" "Belgique" "Roumanie" "Equateur" "Bresil" "Afrique du sud" "Bielorussie" "Finlande" "Croatie" "Autriche" ====================================================================================================
28 ================================== EDITION OF DECISION TREE ================================== PARAMETERS : Learning Set : 24 Number of variables : 3 Max. number of nodes: 15 Soft Assign : ( 1 ) FUZZY Criterion coding : ( 3 ) LOG-LIKELIHOOD Min. number of object by node : 5 Min. size of no-majority classes : 2 Min. size of descendant nodes : 1.00 Frequency of test set : IF ASSERTION IS TRUE (up)! --- x [ ASSERTION ]! IF ASSERTION IS FALSE (down)
29 +---- [ 8 ]Terre Battue ( )!!----4[ Taille <= ]!!! [ 9 ]Terre Battue ( )!!----2[ Poids <= ]!!! [ 5 ]Moquette ( )!!----1[ Age <= ]!! [ 6 ]Dur ( )!!!----3[ Taille <= ]!! [ 56 ]Terre Battue ( )!!!!---28[ Age <= ]!!!!! [ 57 ]Herbe ( )!!!!---14[ Age <= ]!!!!! [ 29 ]Terre Battue ( )!!!----7[ Poids <= ]! [ 15 ]Herbe ( ) Conclusion
Datamining. Université Paris Dauphine DESS ID 2004/2005. Séries télévisées nominées aux oscars. Enseignant : Réalisé par : Mars 2005. Mr E.
 Université Paris Dauphine DESS ID 2004/2005 Datamining Séries télévisées nominées aux oscars Mars 2005 Enseignant : Mr E. DIDAY Réalisé par : Mounia CHERRAD Anne-Sophie REGOTTAZ Sommaire Introduction...
Université Paris Dauphine DESS ID 2004/2005 Datamining Séries télévisées nominées aux oscars Mars 2005 Enseignant : Mr E. DIDAY Réalisé par : Mounia CHERRAD Anne-Sophie REGOTTAZ Sommaire Introduction...
Introduction au datamining
 Introduction au datamining Patrick Naïm janvier 2005 Définition Définition Historique Mot utilisé au départ par les statisticiens Le mot indiquait une utilisation intensive des données conduisant à des
Introduction au datamining Patrick Naïm janvier 2005 Définition Définition Historique Mot utilisé au départ par les statisticiens Le mot indiquait une utilisation intensive des données conduisant à des
Introduction au Data-Mining
 Introduction au Data-Mining Alain Rakotomamonjy - Gilles Gasso. INSA Rouen -Département ASI Laboratoire PSI Introduction au Data-Mining p. 1/25 Data-Mining : Kèkecé? Traduction : Fouille de données. Terme
Introduction au Data-Mining Alain Rakotomamonjy - Gilles Gasso. INSA Rouen -Département ASI Laboratoire PSI Introduction au Data-Mining p. 1/25 Data-Mining : Kèkecé? Traduction : Fouille de données. Terme
Projet SINF2275 «Data mining and decision making» Projet classification et credit scoring
 Projet SINF2275 «Data mining and decision making» Projet classification et credit scoring Année académique 2006-2007 Professeurs : Marco Saerens Adresse : Université catholique de Louvain Information Systems
Projet SINF2275 «Data mining and decision making» Projet classification et credit scoring Année académique 2006-2007 Professeurs : Marco Saerens Adresse : Université catholique de Louvain Information Systems
Quel est le temps de travail des enseignants?
 Quel est le temps de travail des enseignants? Dans les établissements publics, les enseignants donnent, en moyenne et par an, 779 heures de cours dans l enseignement primaire, 701 heures de cours dans
Quel est le temps de travail des enseignants? Dans les établissements publics, les enseignants donnent, en moyenne et par an, 779 heures de cours dans l enseignement primaire, 701 heures de cours dans
Introduction à la B.I. Avec SQL Server 2008
 Introduction à la B.I. Avec SQL Server 2008 Version 1.0 VALENTIN Pauline 2 Introduction à la B.I. avec SQL Server 2008 Sommaire 1 Présentation de la B.I. et SQL Server 2008... 3 1.1 Présentation rapide
Introduction à la B.I. Avec SQL Server 2008 Version 1.0 VALENTIN Pauline 2 Introduction à la B.I. avec SQL Server 2008 Sommaire 1 Présentation de la B.I. et SQL Server 2008... 3 1.1 Présentation rapide
Christophe CANDILLIER Cours de DataMining mars 2004 Page 1
 Christophe CANDILLIER Cours de DataMining mars 2004 age 1 1. Introduction 2. rocessus du DataMining 3. Analyse des données en DataMining 4. Analyse en Ligne OLA 5. Logiciels 6. Bibliographie Christophe
Christophe CANDILLIER Cours de DataMining mars 2004 age 1 1. Introduction 2. rocessus du DataMining 3. Analyse des données en DataMining 4. Analyse en Ligne OLA 5. Logiciels 6. Bibliographie Christophe
DATA MINING - Analyses de données symboliques sur les restaurants
 Master 2 Professionnel - Informatique Décisionnelle DATA MINING - Analyses de données symboliques sur les restaurants Etudiants : Enseignant : Vincent RICHARD Edwin DIDAY Seghir SADAOUI SOMMAIRE I Introduction...
Master 2 Professionnel - Informatique Décisionnelle DATA MINING - Analyses de données symboliques sur les restaurants Etudiants : Enseignant : Vincent RICHARD Edwin DIDAY Seghir SADAOUI SOMMAIRE I Introduction...
La classification automatique de données quantitatives
 La classification automatique de données quantitatives 1 Introduction Parmi les méthodes de statistique exploratoire multidimensionnelle, dont l objectif est d extraire d une masse de données des informations
La classification automatique de données quantitatives 1 Introduction Parmi les méthodes de statistique exploratoire multidimensionnelle, dont l objectif est d extraire d une masse de données des informations
données en connaissance et en actions?
 1 Partie 2 : Présentation de la plateforme SPSS Modeler : Comment transformer vos données en connaissance et en actions? SPSS Modeler : l atelier de data mining Large gamme de techniques d analyse (algorithmes)
1 Partie 2 : Présentation de la plateforme SPSS Modeler : Comment transformer vos données en connaissance et en actions? SPSS Modeler : l atelier de data mining Large gamme de techniques d analyse (algorithmes)
Projet de Datamining Supervisé (SODAS) Analyse des régions françaises
 Analyse des régions françaises") Master 2 ème Année Ingénierie Statistique et financière Projet de Datamining Supervisé (SODAS) Analyse des régions françaises Réalisé par : Nicolas CHAIGNEAUD Nora SLIMANI Année universitaire 2007-2008
Master 2 ème Année Ingénierie Statistique et financière Projet de Datamining Supervisé (SODAS) Analyse des régions françaises Réalisé par : Nicolas CHAIGNEAUD Nora SLIMANI Année universitaire 2007-2008
Université Paris IX DAUPHINE DATE : 24/04/06
 Master Informatique Décisionnelle Application des outils de l'informatique Décisionnelle en entreprise ETUDE SUR LES MARQUES ET LES CONTRUCTEUR DES VÉHICULES APPARTENANT AUX CLIENTS D UNE COMPAGNIE D ASSURANCE
Master Informatique Décisionnelle Application des outils de l'informatique Décisionnelle en entreprise ETUDE SUR LES MARQUES ET LES CONTRUCTEUR DES VÉHICULES APPARTENANT AUX CLIENTS D UNE COMPAGNIE D ASSURANCE
L apprentissage automatique
 L apprentissage automatique L apprentissage automatique L'apprentissage automatique fait référence au développement, à l analyse et à l implémentation de méthodes qui permettent à une machine d évoluer
L apprentissage automatique L apprentissage automatique L'apprentissage automatique fait référence au développement, à l analyse et à l implémentation de méthodes qui permettent à une machine d évoluer
Analyse de grandes bases de données en santé
 .. Analyse de grandes bases de données en santé Alain Duhamel Michaël Genin Mohamed Lemdani EA 2694 / CERIM Master 2 Recherche Biologie et Santé Journée Thématique Fouille de Données Plan. 1 Problématique.
.. Analyse de grandes bases de données en santé Alain Duhamel Michaël Genin Mohamed Lemdani EA 2694 / CERIM Master 2 Recherche Biologie et Santé Journée Thématique Fouille de Données Plan. 1 Problématique.
Introduction au Data-Mining
 Introduction au Data-Mining Gilles Gasso, Stéphane Canu INSA Rouen -Département ASI Laboratoire LITIS 8 septembre 205. Ce cours est librement inspiré du cours DM de Alain Rakotomamonjy Gilles Gasso, Stéphane
Introduction au Data-Mining Gilles Gasso, Stéphane Canu INSA Rouen -Département ASI Laboratoire LITIS 8 septembre 205. Ce cours est librement inspiré du cours DM de Alain Rakotomamonjy Gilles Gasso, Stéphane
Chapitre 9 : Informatique décisionnelle
 Chapitre 9 : Informatique décisionnelle Sommaire Introduction... 3 Définition... 3 Les domaines d application de l informatique décisionnelle... 4 Architecture d un système décisionnel... 5 L outil Oracle
Chapitre 9 : Informatique décisionnelle Sommaire Introduction... 3 Définition... 3 Les domaines d application de l informatique décisionnelle... 4 Architecture d un système décisionnel... 5 L outil Oracle
Manuel de Trading Bienvenue dans le monde palpitant du trading des options binaires!
 Manuel de Trading Bienvenue dans le monde palpitant du trading des options binaires! Ce manuel vous expliquera exactement ce que sont les options binaires, comment les trader et comment utiliser notre
Manuel de Trading Bienvenue dans le monde palpitant du trading des options binaires! Ce manuel vous expliquera exactement ce que sont les options binaires, comment les trader et comment utiliser notre
Apprentissage Automatique
 Apprentissage Automatique Introduction-I [email protected] www.lia.univ-avignon.fr Définition? (Wikipedia) L'apprentissage automatique (machine-learning en anglais) est un des champs
Apprentissage Automatique Introduction-I [email protected] www.lia.univ-avignon.fr Définition? (Wikipedia) L'apprentissage automatique (machine-learning en anglais) est un des champs
WEBSELL. Projet DATAMINING
 WEBSELL Projet DATAMINING Analyse des données dans le cadre d une étude de banchmarking DESS ID Session 2005/2006 Mariam GASPARIAN [ Page 1 ] SOMMAIRE 1. INTRODUCTION... 3 2. METHODES ET OUTILS... 4 2.1.
WEBSELL Projet DATAMINING Analyse des données dans le cadre d une étude de banchmarking DESS ID Session 2005/2006 Mariam GASPARIAN [ Page 1 ] SOMMAIRE 1. INTRODUCTION... 3 2. METHODES ET OUTILS... 4 2.1.
Quelle part de leur richesse nationale les pays consacrent-ils à l éducation?
 Indicateur Quelle part de leur richesse nationale les pays consacrent-ils à l éducation? En 2008, les pays de l OCDE ont consacré 6.1 % de leur PIB cumulé au financement de leurs établissements d enseignement.
Indicateur Quelle part de leur richesse nationale les pays consacrent-ils à l éducation? En 2008, les pays de l OCDE ont consacré 6.1 % de leur PIB cumulé au financement de leurs établissements d enseignement.
Actifs des fonds de pension et des fonds de réserve publics
 Extrait de : Panorama des pensions 2013 Les indicateurs de l'ocde et du G20 Accéder à cette publication : http://dx.doi.org/10.1787/pension_glance-2013-fr Actifs des fonds de pension et des fonds de réserve
Extrait de : Panorama des pensions 2013 Les indicateurs de l'ocde et du G20 Accéder à cette publication : http://dx.doi.org/10.1787/pension_glance-2013-fr Actifs des fonds de pension et des fonds de réserve
Didier MOUNIEN Samantha MOINEAUX
 Didier MOUNIEN Samantha MOINEAUX 08/01/2008 1 Généralisation des ERP ERP génère une importante masse de données Comment mesurer l impact réel d une décision? Comment choisir entre plusieurs décisions?
Didier MOUNIEN Samantha MOINEAUX 08/01/2008 1 Généralisation des ERP ERP génère une importante masse de données Comment mesurer l impact réel d une décision? Comment choisir entre plusieurs décisions?
Étude EcoVadis - Médiation Inter-Entreprises COMPARATIF DE LA PERFORMANCE RSE DES ENTREPRISES FRANCAISES AVEC CELLE DES PAYS DE L OCDE ET DES BRICS
 Étude EcoVadis - Médiation Inter-Entreprises COMPARATIF DE LA PERFORMANCE RSE DES ENTREPRISES FRANCAISES AVEC CELLE DES PAYS DE L OCDE ET DES BRICS 23 mars 2015 Synthèse Avec plus de 12.000 évaluations
Étude EcoVadis - Médiation Inter-Entreprises COMPARATIF DE LA PERFORMANCE RSE DES ENTREPRISES FRANCAISES AVEC CELLE DES PAYS DE L OCDE ET DES BRICS 23 mars 2015 Synthèse Avec plus de 12.000 évaluations
Entrepôt de données 1. Introduction
 Entrepôt de données 1 (data warehouse) Introduction 1 Présentation Le concept d entrepôt de données a été formalisé pour la première fois en 1990 par Bill Inmon. Il s agissait de constituer une base de
Entrepôt de données 1 (data warehouse) Introduction 1 Présentation Le concept d entrepôt de données a été formalisé pour la première fois en 1990 par Bill Inmon. Il s agissait de constituer une base de
REGARDS SUR L ÉDUCATION 2013 : POINTS SAILLANTS POUR LE CANADA
 REGARDS SUR L ÉDUCATION 2013 : POINTS SAILLANTS POUR LE CANADA Regards sur l éducation est un rapport annuel publié par l Organisation de coopération et de développement économiques (OCDE) et portant sur
REGARDS SUR L ÉDUCATION 2013 : POINTS SAILLANTS POUR LE CANADA Regards sur l éducation est un rapport annuel publié par l Organisation de coopération et de développement économiques (OCDE) et portant sur
INF6304 Interfaces Intelligentes
 INF6304 Interfaces Intelligentes filtres collaboratifs 1/42 INF6304 Interfaces Intelligentes Systèmes de recommandations, Approches filtres collaboratifs Michel C. Desmarais Génie informatique et génie
INF6304 Interfaces Intelligentes filtres collaboratifs 1/42 INF6304 Interfaces Intelligentes Systèmes de recommandations, Approches filtres collaboratifs Michel C. Desmarais Génie informatique et génie
La segmentation à l aide de EG-SAS. A.Bouhia Analyste principal à la Banque Nationale du Canada. Chargé de cours à l UQAM
 La segmentation à l aide de EG-SAS A.Bouhia Analyste principal à la Banque Nationale du Canada. Chargé de cours à l UQAM Définition de la segmentation - Au lieu de considérer une population dans son ensemble,
La segmentation à l aide de EG-SAS A.Bouhia Analyste principal à la Banque Nationale du Canada. Chargé de cours à l UQAM Définition de la segmentation - Au lieu de considérer une population dans son ensemble,
Créer le schéma relationnel d une base de données ACCESS
 Utilisation du SGBD ACCESS Polycopié réalisé par Chihab Hanachi et Jean-Marc Thévenin Créer le schéma relationnel d une base de données ACCESS GENERALITES SUR ACCESS... 1 A PROPOS DE L UTILISATION D ACCESS...
Utilisation du SGBD ACCESS Polycopié réalisé par Chihab Hanachi et Jean-Marc Thévenin Créer le schéma relationnel d une base de données ACCESS GENERALITES SUR ACCESS... 1 A PROPOS DE L UTILISATION D ACCESS...
Agenda de la présentation
 Le Data Mining Techniques pour exploiter l information Dan Noël 1 Agenda de la présentation Concept de Data Mining ou qu est-ce que le Data Mining Déroulement d un projet de Data Mining Place du Data Mining
Le Data Mining Techniques pour exploiter l information Dan Noël 1 Agenda de la présentation Concept de Data Mining ou qu est-ce que le Data Mining Déroulement d un projet de Data Mining Place du Data Mining
Manipulation de données avec SAS Enterprise Guide et modélisation prédictive avec SAS Enterprise Miner
 Le cas Orion Star Manipulation de données avec SAS Enterprise Guide et modélisation prédictive avec SAS Enterprise Miner Le cas Orion Star... 1 Manipulation de données avec SAS Enterprise Guide et modélisation
Le cas Orion Star Manipulation de données avec SAS Enterprise Guide et modélisation prédictive avec SAS Enterprise Miner Le cas Orion Star... 1 Manipulation de données avec SAS Enterprise Guide et modélisation
Mémo technique LE DATAMINING
 Mémo technique LE DATAMINING 46, rue de la Tour 75116 Paris France Tél : 00 33 (0)1 73 00 55 00 Fax : 00 33 (0)1 73 00 55 01 http://www.softcomputing.com Février 01 SOMMAIRE 1 SYNTHESE : CE QU IL FAUT
Mémo technique LE DATAMINING 46, rue de la Tour 75116 Paris France Tél : 00 33 (0)1 73 00 55 00 Fax : 00 33 (0)1 73 00 55 01 http://www.softcomputing.com Février 01 SOMMAIRE 1 SYNTHESE : CE QU IL FAUT
LIVRE BLANC Décembre 2014
 PARSING MATCHING EQUALITY SEARCH LIVRE BLANC Décembre 2014 Introduction L analyse des tendances du marché de l emploi correspond à l évidence à une nécessité, surtout en période de tension comme depuis
PARSING MATCHING EQUALITY SEARCH LIVRE BLANC Décembre 2014 Introduction L analyse des tendances du marché de l emploi correspond à l évidence à une nécessité, surtout en période de tension comme depuis
Le coût du rachat de trimestres pour carrière à l étranger multiplié par 4 au plus tard le 1 er janvier 2011
 Le coût du rachat de trimestres pour carrière à l étranger multiplié par 4 au plus tard le 1 er janvier 2011 Un article de la loi de financement de la sécurité sociale 2010 aligne le coût de ce rachat
Le coût du rachat de trimestres pour carrière à l étranger multiplié par 4 au plus tard le 1 er janvier 2011 Un article de la loi de financement de la sécurité sociale 2010 aligne le coût de ce rachat
Travaux pratiques avec RapidMiner
 Travaux pratiques avec RapidMiner Master Informatique de Paris 6 Spécialité IAD Parcours EDOW Module Algorithmes pour la Fouille de Données Janvier 2012 Prise en main Généralités RapidMiner est un logiciel
Travaux pratiques avec RapidMiner Master Informatique de Paris 6 Spécialité IAD Parcours EDOW Module Algorithmes pour la Fouille de Données Janvier 2012 Prise en main Généralités RapidMiner est un logiciel
DÉPLOIEMENT DE QLIKVIEW POUR DES ANALYSES BIG DATA CHEZ KING.COM
 DÉPLOIEMENT DE QLIKVIEW POUR DES ANALYSES BIG DATA CHEZ KING.COM Étude de cas technique QlikView : Big Data Juin 2012 qlikview.com Introduction La présente étude de cas technique QlikView se consacre au
DÉPLOIEMENT DE QLIKVIEW POUR DES ANALYSES BIG DATA CHEZ KING.COM Étude de cas technique QlikView : Big Data Juin 2012 qlikview.com Introduction La présente étude de cas technique QlikView se consacre au
Critères pour avoir la meilleure équipe!
 PROJET DATAMINING Basket-ball professionnel "NBA" : Critères pour avoir la meilleure équipe! Réalisé par : Anasse LAHLOU KASSI Houssam Eddine HOUBAINE DESS TIO DESS ID Année Scolaire : SOMMAIRE INTRODUCTION...
PROJET DATAMINING Basket-ball professionnel "NBA" : Critères pour avoir la meilleure équipe! Réalisé par : Anasse LAHLOU KASSI Houssam Eddine HOUBAINE DESS TIO DESS ID Année Scolaire : SOMMAIRE INTRODUCTION...
Le scoring est-il la nouvelle révolution du microcrédit?
 Retour au sommaire Le scoring est-il la nouvelle révolution du microcrédit? BIM n 32-01 octobre 2002 Frédéric DE SOUSA-SANTOS Le BIM de cette semaine se propose de vous présenter un ouvrage de Mark Schreiner
Retour au sommaire Le scoring est-il la nouvelle révolution du microcrédit? BIM n 32-01 octobre 2002 Frédéric DE SOUSA-SANTOS Le BIM de cette semaine se propose de vous présenter un ouvrage de Mark Schreiner
Structure du cours : Il existe de nombreuses méthodes intéressantes qui couvrent l Analyse des Données
 Structure du cours : Il existe de nombreuses méthodes intéressantes qui couvrent l Analyse des Données et le Data Mining Nous suivons le plan suivant : Fonctionnement de Spad Catalogue des méthodes (statistiques
Structure du cours : Il existe de nombreuses méthodes intéressantes qui couvrent l Analyse des Données et le Data Mining Nous suivons le plan suivant : Fonctionnement de Spad Catalogue des méthodes (statistiques
RapidMiner. Data Mining. 1 Introduction. 2 Prise en main. Master Maths Finances 2010/2011. 1.1 Présentation. 1.2 Ressources
 Master Maths Finances 2010/2011 Data Mining janvier 2011 RapidMiner 1 Introduction 1.1 Présentation RapidMiner est un logiciel open source et gratuit dédié au data mining. Il contient de nombreux outils
Master Maths Finances 2010/2011 Data Mining janvier 2011 RapidMiner 1 Introduction 1.1 Présentation RapidMiner est un logiciel open source et gratuit dédié au data mining. Il contient de nombreux outils
1. Introduction...2. 2. Création d'une requête...2
 1. Introduction...2 2. Création d'une requête...2 3. Définition des critères de sélection...5 3.1 Opérateurs...5 3.2 Les Fonctions...6 3.3 Plusieurs critères portant sur des champs différents...7 3.4 Requête
1. Introduction...2 2. Création d'une requête...2 3. Définition des critères de sélection...5 3.1 Opérateurs...5 3.2 Les Fonctions...6 3.3 Plusieurs critères portant sur des champs différents...7 3.4 Requête
Data Mining. Vincent Augusto 2012-2013. École Nationale Supérieure des Mines de Saint-Étienne. Data Mining. V. Augusto.
 des des Data Mining Vincent Augusto École Nationale Supérieure des Mines de Saint-Étienne 2012-2013 1/65 des des 1 2 des des 3 4 Post-traitement 5 représentation : 6 2/65 des des Définition générale Le
des des Data Mining Vincent Augusto École Nationale Supérieure des Mines de Saint-Étienne 2012-2013 1/65 des des 1 2 des des 3 4 Post-traitement 5 représentation : 6 2/65 des des Définition générale Le
et les Systèmes Multidimensionnels
 Le Data Warehouse et les Systèmes Multidimensionnels 1 1. Définition d un Datawarehouse (DW) Le Datawarehouse est une collection de données orientées sujet, intégrées, non volatiles et historisées, organisées
Le Data Warehouse et les Systèmes Multidimensionnels 1 1. Définition d un Datawarehouse (DW) Le Datawarehouse est une collection de données orientées sujet, intégrées, non volatiles et historisées, organisées
Exploitation et analyse des données appliquées aux techniques d enquête par sondage. Introduction.
 Exploitation et analyse des données appliquées aux techniques d enquête par sondage. Introduction. Etudes et traitements statistiques des données : le cas illustratif de la démarche par sondage INTRODUCTION
Exploitation et analyse des données appliquées aux techniques d enquête par sondage. Introduction. Etudes et traitements statistiques des données : le cas illustratif de la démarche par sondage INTRODUCTION
Les Entrepôts de Données
 Les Entrepôts de Données Grégory Bonnet Abdel-Illah Mouaddib GREYC Dépt Dépt informatique :: GREYC Dépt Dépt informatique :: Cours Cours SIR SIR Systèmes d information décisionnels Nouvelles générations
Les Entrepôts de Données Grégory Bonnet Abdel-Illah Mouaddib GREYC Dépt Dépt informatique :: GREYC Dépt Dépt informatique :: Cours Cours SIR SIR Systèmes d information décisionnels Nouvelles générations
à la Consommation dans le monde à fin 2012
 Le Crédit à la Consommation dans le monde à fin 2012 Introduction Pour la 5 ème année consécutive, le Panorama du Crédit Conso de Crédit Agricole Consumer Finance publie son étude annuelle sur l état du
Le Crédit à la Consommation dans le monde à fin 2012 Introduction Pour la 5 ème année consécutive, le Panorama du Crédit Conso de Crédit Agricole Consumer Finance publie son étude annuelle sur l état du
Transmission d informations sur le réseau électrique
 Transmission d informations sur le réseau électrique Introduction Remarques Toutes les questions en italique devront être préparées par écrit avant la séance du TP. Les préparations seront ramassées en
Transmission d informations sur le réseau électrique Introduction Remarques Toutes les questions en italique devront être préparées par écrit avant la séance du TP. Les préparations seront ramassées en
Pourquoi l apprentissage?
 Pourquoi l apprentissage? Les SE sont basés sur la possibilité d extraire la connaissance d un expert sous forme de règles. Dépend fortement de la capacité à extraire et formaliser ces connaissances. Apprentissage
Pourquoi l apprentissage? Les SE sont basés sur la possibilité d extraire la connaissance d un expert sous forme de règles. Dépend fortement de la capacité à extraire et formaliser ces connaissances. Apprentissage
Améliorer les performances du site par l'utilisation de techniques de Web Mining
 Améliorer les performances du site par l'utilisation de techniques de Web Mining CLUB SAS 2001 17/18 octobre 2001 Stéfan Galissie LINCOLN [email protected] [email protected] 2001 Sommaire
Améliorer les performances du site par l'utilisation de techniques de Web Mining CLUB SAS 2001 17/18 octobre 2001 Stéfan Galissie LINCOLN [email protected] [email protected] 2001 Sommaire
Encryptions, compression et partitionnement des données
 Encryptions, compression et partitionnement des données Version 1.0 Grégory CASANOVA 2 Compression, encryption et partitionnement des données Sommaire 1 Introduction... 3 2 Encryption transparente des
Encryptions, compression et partitionnement des données Version 1.0 Grégory CASANOVA 2 Compression, encryption et partitionnement des données Sommaire 1 Introduction... 3 2 Encryption transparente des
INTRODUCTION AU DATA MINING
 INTRODUCTION AU DATA MINING 6 séances de 3 heures mai-juin 2006 EPF - 4 ème année - Option Ingénierie d Affaires et de Projets Bertrand LIAUDET TP DE DATA MINING Le TP et le projet consisteront à mettre
INTRODUCTION AU DATA MINING 6 séances de 3 heures mai-juin 2006 EPF - 4 ème année - Option Ingénierie d Affaires et de Projets Bertrand LIAUDET TP DE DATA MINING Le TP et le projet consisteront à mettre
La nouvelle planification de l échantillonnage
 La nouvelle planification de l échantillonnage Pierre-Arnaud Pendoli Division Sondages Plan de la présentation Rappel sur le Recensement de la population (RP) en continu Description de la base de sondage
La nouvelle planification de l échantillonnage Pierre-Arnaud Pendoli Division Sondages Plan de la présentation Rappel sur le Recensement de la population (RP) en continu Description de la base de sondage
Le point sur les marchés des pensions. des pays de l OCDE OCDE
 CONSEIL D ORIENTATION DES RETRAITES Séance plénière du 17 décembre 2013 à 14h30 «Etat des lieux sur l épargne en prévision de la retraite» Document N 13 Document de travail, n engage pas le Conseil Le
CONSEIL D ORIENTATION DES RETRAITES Séance plénière du 17 décembre 2013 à 14h30 «Etat des lieux sur l épargne en prévision de la retraite» Document N 13 Document de travail, n engage pas le Conseil Le
Spécificités, Applications et Outils
 Spécificités, Applications et Outils Ricco Rakotomalala Université Lumière Lyon 2 Laboratoire ERIC Laboratoire ERIC 1 Ricco Rakotomalala [email protected] http://chirouble.univ-lyon2.fr/~ricco/data-mining
Spécificités, Applications et Outils Ricco Rakotomalala Université Lumière Lyon 2 Laboratoire ERIC Laboratoire ERIC 1 Ricco Rakotomalala [email protected] http://chirouble.univ-lyon2.fr/~ricco/data-mining
Sciences de Gestion Spécialité : SYSTÈMES D INFORMATION DE GESTION
 Sciences de Gestion Spécialité : SYSTÈMES D INFORMATION DE GESTION Classe de terminale de la série Sciences et Technologie du Management et de la Gestion Préambule Présentation Les technologies de l information
Sciences de Gestion Spécialité : SYSTÈMES D INFORMATION DE GESTION Classe de terminale de la série Sciences et Technologie du Management et de la Gestion Préambule Présentation Les technologies de l information
Introduction. Informatique décisionnelle et data mining. Data mining (fouille de données) Cours/TP partagés. Information du cours
 Cours/TP partagés. Information du cours") Information du cours Informatique décisionnelle et data mining www.lia.univ-avignon.fr/chercheurs/torres/cours/dm Juan-Manuel Torres [email protected] LIA/Université d Avignon Cours/TP
Information du cours Informatique décisionnelle et data mining www.lia.univ-avignon.fr/chercheurs/torres/cours/dm Juan-Manuel Torres [email protected] LIA/Université d Avignon Cours/TP
Etude d un cas industriel : Optimisation de la modélisation de paramètre de production
 Revue des Sciences et de la Technologie RST- Volume 4 N 1 /janvier 2013 Etude d un cas industriel : Optimisation de la modélisation de paramètre de production A.F. Bernate Lara 1, F. Entzmann 2, F. Yalaoui
Revue des Sciences et de la Technologie RST- Volume 4 N 1 /janvier 2013 Etude d un cas industriel : Optimisation de la modélisation de paramètre de production A.F. Bernate Lara 1, F. Entzmann 2, F. Yalaoui
L indice de SEN, outil de mesure de l équité des systèmes éducatifs. Une comparaison à l échelle européenne
 L indice de SEN, outil de mesure de l équité des systèmes éducatifs. Une comparaison à l échelle européenne Sophie Morlaix To cite this version: Sophie Morlaix. L indice de SEN, outil de mesure de l équité
L indice de SEN, outil de mesure de l équité des systèmes éducatifs. Une comparaison à l échelle européenne Sophie Morlaix To cite this version: Sophie Morlaix. L indice de SEN, outil de mesure de l équité
CentreRH. Logiciel de gestion de centre de formation. Mise à jour version 15. AppliRH
 CentreRH Logiciel de gestion de centre de formation Mise à jour version 15 AppliRH Table des matie res 1. Création de devis à partir d une session... 2 2. Visualisation des sessions confirmées sur les
CentreRH Logiciel de gestion de centre de formation Mise à jour version 15 AppliRH Table des matie res 1. Création de devis à partir d une session... 2 2. Visualisation des sessions confirmées sur les
Introduction aux outils BI de SQL Server 2014. Fouille de données avec SQL Server Analysis Services (SSAS)
") MIT820: Entrepôts de données et intelligence artificielle Introduction aux outils BI de SQL Server 2014 Fouille de données avec SQL Server Analysis Services (SSAS) Description générale Ce tutoriel a pour
MIT820: Entrepôts de données et intelligence artificielle Introduction aux outils BI de SQL Server 2014 Fouille de données avec SQL Server Analysis Services (SSAS) Description générale Ce tutoriel a pour
BASE. Vous avez alors accès à un ensemble de fonctionnalités explicitées ci-dessous :
 BASE BioArray Software Environment (BASE) est une base de données permettant de gérer l importante quantité de données générées par des analyses de bio-puces. BASE gère les informations biologiques, les
BASE BioArray Software Environment (BASE) est une base de données permettant de gérer l importante quantité de données générées par des analyses de bio-puces. BASE gère les informations biologiques, les
NF26 Data warehouse et Outils Décisionnels Printemps 2010
 NF26 Data warehouse et Outils Décisionnels Printemps 2010 Rapport Modélisation Datamart VU Xuan Truong LAURENS Francis Analyse des données Avant de proposer un modèle dimensionnel, une analyse exhaustive
NF26 Data warehouse et Outils Décisionnels Printemps 2010 Rapport Modélisation Datamart VU Xuan Truong LAURENS Francis Analyse des données Avant de proposer un modèle dimensionnel, une analyse exhaustive
GROUPE DE TRAVAIL «ARTICLE 29» SUR LA PROTECTION DES DONNÉES
 GROUPE DE TRAVAIL «ARTICLE 29» SUR LA PROTECTION DES DONNÉES 00727/12/FR WP 192 Avis 02/2012 sur la reconnaissance faciale dans le cadre des services en ligne et mobiles Adopté le 22 mars 2012 Le groupe
GROUPE DE TRAVAIL «ARTICLE 29» SUR LA PROTECTION DES DONNÉES 00727/12/FR WP 192 Avis 02/2012 sur la reconnaissance faciale dans le cadre des services en ligne et mobiles Adopté le 22 mars 2012 Le groupe
IBM SPSS Modeler Social Network Analysis 15 Guide de l utilisateur
 IBM SPSS Modeler Social Network Analysis 15 Guide de l utilisateur Remarque : Avant d utiliser ces informations et le produit qu elles concernent, lisez les informations générales sous Avis sur p. 24.
IBM SPSS Modeler Social Network Analysis 15 Guide de l utilisateur Remarque : Avant d utiliser ces informations et le produit qu elles concernent, lisez les informations générales sous Avis sur p. 24.
Le creusement des inégalités touche plus particulièrement les jeunes et les pauvres
 LE POINT SUR LES INÉGALITÉS DE REVENU Le creusement des inégalités touche plus particulièrement les jeunes et les pauvres Résultats issus de la Base de données de l OCDE sur la distribution des revenus
LE POINT SUR LES INÉGALITÉS DE REVENU Le creusement des inégalités touche plus particulièrement les jeunes et les pauvres Résultats issus de la Base de données de l OCDE sur la distribution des revenus
LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING»
 LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING» Gilbert Saporta Professeur de Statistique Appliquée Conservatoire National des Arts et Métiers Dans leur quasi totalité, les banques et organismes financiers
LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING» Gilbert Saporta Professeur de Statistique Appliquée Conservatoire National des Arts et Métiers Dans leur quasi totalité, les banques et organismes financiers
Pentaho Business Analytics Intégrer > Explorer > Prévoir
 Pentaho Business Analytics Intégrer > Explorer > Prévoir Pentaho lie étroitement intégration de données et analytique. En effet, les services informatiques et les utilisateurs métiers peuvent accéder aux
Pentaho Business Analytics Intégrer > Explorer > Prévoir Pentaho lie étroitement intégration de données et analytique. En effet, les services informatiques et les utilisateurs métiers peuvent accéder aux
UNE EXPERIENCE, EN COURS PREPARATOIRE, POUR FAIRE ORGANISER DE L INFORMATION EN TABLEAU
 Odile VERBAERE UNE EXPERIENCE, EN COURS PREPARATOIRE, POUR FAIRE ORGANISER DE L INFORMATION EN TABLEAU Résumé : Cet article présente une réflexion sur une activité de construction de tableau, y compris
Odile VERBAERE UNE EXPERIENCE, EN COURS PREPARATOIRE, POUR FAIRE ORGANISER DE L INFORMATION EN TABLEAU Résumé : Cet article présente une réflexion sur une activité de construction de tableau, y compris
Didacticiel Études de cas. Description succincte de Pentaho Data Integration Community Edition (Kettle).
.") 1 Objectif Description succincte de Pentaho Data Integration Community Edition (Kettle). L informatique décisionnelle («Business Intelligence BI» en anglais, ça fait tout de suite plus glamour) fait référence
1 Objectif Description succincte de Pentaho Data Integration Community Edition (Kettle). L informatique décisionnelle («Business Intelligence BI» en anglais, ça fait tout de suite plus glamour) fait référence
Plan d action SMB d une Approche Agile de la BITM Pour les PME
 Plan d action SMB d une Approche Agile de la BITM Pour les PME Personnel, processus et technologie nécessaires pour élaborer une solution rapide, souple et économique Copyright 2013 Pentaho Corporation.
Plan d action SMB d une Approche Agile de la BITM Pour les PME Personnel, processus et technologie nécessaires pour élaborer une solution rapide, souple et économique Copyright 2013 Pentaho Corporation.
La coordination des soins de santé en Europe
 La coordination des soins de santé en Europe Droits des personnes assurées et des membres de leur famille selon les règlements (CE) n 883/2004 et (CE) n 987/2009 La coordination des soins de santé en
La coordination des soins de santé en Europe Droits des personnes assurées et des membres de leur famille selon les règlements (CE) n 883/2004 et (CE) n 987/2009 La coordination des soins de santé en
4. Résultats et discussion
 17 4. Résultats et discussion La signification statistique des gains et des pertes bruts annualisés pondérés de superficie forestière et du changement net de superficie forestière a été testée pour les
17 4. Résultats et discussion La signification statistique des gains et des pertes bruts annualisés pondérés de superficie forestière et du changement net de superficie forestière a été testée pour les
Market Data Feed. Maîtrisez le flux.
 Market Data Feed Maîtrisez le flux. Market Data Feed (MDF) est un service très performant de diffusion de données de marché en temps réel permettant une importante personnalisation dans leur sélection.
Market Data Feed Maîtrisez le flux. Market Data Feed (MDF) est un service très performant de diffusion de données de marché en temps réel permettant une importante personnalisation dans leur sélection.
Disparités entre les cantons dans tous les domaines examinés
 Office fédéral de la statistique Bundesamt für Statistik Ufficio federale di statistica Uffizi federal da statistica Swiss Federal Statistical Office EMBARGO: 02.05.2005, 11:00 COMMUNIQUÉ DE PRESSE MEDIENMITTEILUNG
Office fédéral de la statistique Bundesamt für Statistik Ufficio federale di statistica Uffizi federal da statistica Swiss Federal Statistical Office EMBARGO: 02.05.2005, 11:00 COMMUNIQUÉ DE PRESSE MEDIENMITTEILUNG
Intelligence Artificielle et Systèmes Multi-Agents. Badr Benmammar [email protected]
 Intelligence Artificielle et Systèmes Multi-Agents Badr Benmammar [email protected] Plan La première partie : L intelligence artificielle (IA) Définition de l intelligence artificielle (IA) Domaines
Intelligence Artificielle et Systèmes Multi-Agents Badr Benmammar [email protected] Plan La première partie : L intelligence artificielle (IA) Définition de l intelligence artificielle (IA) Domaines
Vision prospective et obstacles à surmonter pour les assureurs
 smart solutions for smart leaders Le «Big Data» assurément Rédigé par Pascal STERN Architecte d Entreprise Vision prospective et obstacles à surmonter pour les assureurs Un avis rendu par la cour de justice
smart solutions for smart leaders Le «Big Data» assurément Rédigé par Pascal STERN Architecte d Entreprise Vision prospective et obstacles à surmonter pour les assureurs Un avis rendu par la cour de justice
PRÉSENTATION PRODUIT. Plus qu un logiciel, la méthode plus efficace de réconcilier.
 PRÉSENTATION PRODUIT Plus qu un logiciel, la méthode plus efficace de réconcilier. Automatiser les réconciliations permet d optimiser l utilisation des ressources et de générer plus de rentabilité dans
PRÉSENTATION PRODUIT Plus qu un logiciel, la méthode plus efficace de réconcilier. Automatiser les réconciliations permet d optimiser l utilisation des ressources et de générer plus de rentabilité dans
les étudiants d assas au service des professionnels
 les étudiants d assas au service des professionnels 2 3 Présentation Générale Les avantages de l Association Pour les professionnels QUI SOMMES-NOUS? Assas Junior Conseil est une association à caractère
les étudiants d assas au service des professionnels 2 3 Présentation Générale Les avantages de l Association Pour les professionnels QUI SOMMES-NOUS? Assas Junior Conseil est une association à caractère
MASTER SIS PRO : logique et sécurité DÉTECTION D INTRUSIONS. Odile PAPINI, LSIS. Université de Toulon et du Var. papini@univ-tln.
 MASTER SIS PRO : logique et sécurité DÉTECTION D INTRUSIONS Odile PAPINI, LSIS. Université de Toulon et du Var. [email protected] Plan Introduction Généralités sur les systèmes de détection d intrusion
MASTER SIS PRO : logique et sécurité DÉTECTION D INTRUSIONS Odile PAPINI, LSIS. Université de Toulon et du Var. [email protected] Plan Introduction Généralités sur les systèmes de détection d intrusion
Créer et partager des fichiers
 Créer et partager des fichiers Le rôle Services de fichiers... 246 Les autorisations de fichiers NTFS... 255 Recherche de comptes d utilisateurs et d ordinateurs dans Active Directory... 262 Délégation
Créer et partager des fichiers Le rôle Services de fichiers... 246 Les autorisations de fichiers NTFS... 255 Recherche de comptes d utilisateurs et d ordinateurs dans Active Directory... 262 Délégation
Principaux partenaires commerciaux de l UE, 2002-2014 (Part dans le total des échanges de biens extra-ue, sur la base de la valeur commerciale)
") 55/2015-27 mars 2015 Commerce international de biens en 2014 Principaux partenaires commerciaux de l UE en 2014: les États-Unis pour les exportations, la Chine pour les importations Le commerce entre États
55/2015-27 mars 2015 Commerce international de biens en 2014 Principaux partenaires commerciaux de l UE en 2014: les États-Unis pour les exportations, la Chine pour les importations Le commerce entre États
Sommaire. Rentabilité du retour d une franchise de baseball de la Ligue majeure de baseball à Montréal (les «Expos»)
") Sommaire Rentabilité du retour d une franchise de baseball de la Ligue majeure de baseball à Montréal (les «Expos») Novembre 2013 Table des matières 1. CONTEXTE ET OBJECTIFS... 3 2. MÉTHODES DE RECHERCHE...
Sommaire Rentabilité du retour d une franchise de baseball de la Ligue majeure de baseball à Montréal (les «Expos») Novembre 2013 Table des matières 1. CONTEXTE ET OBJECTIFS... 3 2. MÉTHODES DE RECHERCHE...
Comité du développement et de la propriété intellectuelle (CDIP)
") F CDIP/12/INF/4 ORIGINAL : ANGLAIS DATE : 3 OCTOBRE 2013 Comité du développement et de la propriété intellectuelle (CDIP) Douzième session Genève, 18 21 novembre 2013 RÉSUMÉ DE L ÉTUDE SUR LA PROPRIÉTÉ
F CDIP/12/INF/4 ORIGINAL : ANGLAIS DATE : 3 OCTOBRE 2013 Comité du développement et de la propriété intellectuelle (CDIP) Douzième session Genève, 18 21 novembre 2013 RÉSUMÉ DE L ÉTUDE SUR LA PROPRIÉTÉ
Gènes Diffusion - EPIC 2010
 Gènes Diffusion - EPIC 2010 1. Contexte. 2. Notion de génétique animale. 3. Profil de l équipe plateforme. 4. Type et gestion des données biologiques. 5. Environnement Matériel et Logiciel. 6. Analyses
Gènes Diffusion - EPIC 2010 1. Contexte. 2. Notion de génétique animale. 3. Profil de l équipe plateforme. 4. Type et gestion des données biologiques. 5. Environnement Matériel et Logiciel. 6. Analyses
Âge effectif de sortie du marché du travail
 Extrait de : Panorama des pensions 2013 Les indicateurs de l'ocde et du G20 Accéder à cette publication : http://dx.doi.org/10.1787/pension_glance-2013-fr Âge effectif de sortie du marché du travail Merci
Extrait de : Panorama des pensions 2013 Les indicateurs de l'ocde et du G20 Accéder à cette publication : http://dx.doi.org/10.1787/pension_glance-2013-fr Âge effectif de sortie du marché du travail Merci
ORACLE TUNING PACK 11G
 ORACLE TUNING PACK 11G PRINCIPALES CARACTÉRISTIQUES : Conseiller d'optimisation SQL (SQL Tuning Advisor) Mode automatique du conseiller d'optimisation SQL Profils SQL Conseiller d'accès SQL (SQL Access
ORACLE TUNING PACK 11G PRINCIPALES CARACTÉRISTIQUES : Conseiller d'optimisation SQL (SQL Tuning Advisor) Mode automatique du conseiller d'optimisation SQL Profils SQL Conseiller d'accès SQL (SQL Access
AssetCenter Notes de version
 Peregrine AssetCenter Notes de version PART NUMBER AC-4.1.0-FRE-01015-00189 AssetCenter Copyright 2002 Peregrine Systems, Inc. Tous droits réservés. Les informations contenues dans ce document sont la
Peregrine AssetCenter Notes de version PART NUMBER AC-4.1.0-FRE-01015-00189 AssetCenter Copyright 2002 Peregrine Systems, Inc. Tous droits réservés. Les informations contenues dans ce document sont la
Calc 2 Avancé. OpenOffice.org. Guide de formation avec exercices et cas pratiques. Philippe Moreau
 OpenOffice.org Calc 2 Avancé Guide de formation avec exercices et cas pratiques Philippe Moreau Tsoft et Groupe Eyrolles, 2007, ISBN : 2-212-12036-2, ISBN 13 : 978-2-212-12036-3 4 - Plages de données 4
OpenOffice.org Calc 2 Avancé Guide de formation avec exercices et cas pratiques Philippe Moreau Tsoft et Groupe Eyrolles, 2007, ISBN : 2-212-12036-2, ISBN 13 : 978-2-212-12036-3 4 - Plages de données 4
Sciences de Gestion Spécialité : GESTION ET FINANCE
 Sciences de Gestion Spécialité : GESTION ET FINANCE Classe de terminale de la série Sciences et Technologie du Management et de la Gestion I. PRESENTATION GENERALE 1. Les objectifs du programme Le système
Sciences de Gestion Spécialité : GESTION ET FINANCE Classe de terminale de la série Sciences et Technologie du Management et de la Gestion I. PRESENTATION GENERALE 1. Les objectifs du programme Le système
basée sur le cours de Bertrand Legal, maître de conférences à l ENSEIRB www.enseirb.fr/~legal Olivier Augereau Formation UML
 basée sur le cours de Bertrand Legal, maître de conférences à l ENSEIRB www.enseirb.fr/~legal Olivier Augereau Formation UML http://olivier-augereau.com Sommaire Introduction I) Les bases II) Les diagrammes
basée sur le cours de Bertrand Legal, maître de conférences à l ENSEIRB www.enseirb.fr/~legal Olivier Augereau Formation UML http://olivier-augereau.com Sommaire Introduction I) Les bases II) Les diagrammes
«Manuel Pratique» Gestion budgétaire
 11/06/01 B50/v2.31/F/MP005.01 «Manuel Pratique» Gestion budgétaire Finance A l usage des utilisateurs de Sage BOB 50 Solution Sage BOB 50 2 L éditeur veille à la fiabilité des informations publiées, lesquelles
11/06/01 B50/v2.31/F/MP005.01 «Manuel Pratique» Gestion budgétaire Finance A l usage des utilisateurs de Sage BOB 50 Solution Sage BOB 50 2 L éditeur veille à la fiabilité des informations publiées, lesquelles
Big Data et Graphes : Quelques pistes de recherche
 Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de Lyon/Université Claude Bernard Lyon 1/Université
Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de Lyon/Université Claude Bernard Lyon 1/Université
1 Introduction et installation
 TP d introduction aux bases de données 1 TP d introduction aux bases de données Le but de ce TP est d apprendre à manipuler des bases de données. Dans le cadre du programme d informatique pour tous, on
TP d introduction aux bases de données 1 TP d introduction aux bases de données Le but de ce TP est d apprendre à manipuler des bases de données. Dans le cadre du programme d informatique pour tous, on
Nos Solutions PME VIPDev sont les Atouts Business de votre entreprise.
 Solutions PME VIPDev Nos Solutions PME VIPDev sont les Atouts Business de votre entreprise. Cette offre est basée sur la mise à disposition de l ensemble de nos compétences techniques et créatives au service
Solutions PME VIPDev Nos Solutions PME VIPDev sont les Atouts Business de votre entreprise. Cette offre est basée sur la mise à disposition de l ensemble de nos compétences techniques et créatives au service
Utiliser Access ou Excel pour gérer vos données
 Page 1 of 5 Microsoft Office Access Utiliser Access ou Excel pour gérer vos données S'applique à : Microsoft Office Access 2007 Masquer tout Les programmes de feuilles de calcul automatisées, tels que
Page 1 of 5 Microsoft Office Access Utiliser Access ou Excel pour gérer vos données S'applique à : Microsoft Office Access 2007 Masquer tout Les programmes de feuilles de calcul automatisées, tels que
PROGRAMME INTERNATIONAL POUR LE SUIVI DES ACQUIS DES ÉLÈVES QUESTIONS ET RÉPONSES DE L ÉVALUATION PISA 2012 DE LA CULTURE FINANCIÈRE
 PROGRAMME INTERNATIONAL POUR LE SUIVI DES ACQUIS DES ÉLÈVES QUESTIONS ET RÉPONSES DE L ÉVALUATION PISA 2012 DE LA CULTURE FINANCIÈRE TABLE DES MATIÈRES INTRODUCTION... 3 QUESTION NIVEAU 1: FACTURE... 4
PROGRAMME INTERNATIONAL POUR LE SUIVI DES ACQUIS DES ÉLÈVES QUESTIONS ET RÉPONSES DE L ÉVALUATION PISA 2012 DE LA CULTURE FINANCIÈRE TABLE DES MATIÈRES INTRODUCTION... 3 QUESTION NIVEAU 1: FACTURE... 4
Logiciel XLSTAT version 7.0. 40 rue Damrémont 75018 PARIS
 Logiciel XLSTAT version 7.0 Contact : Addinsoft 40 rue Damrémont 75018 PARIS 2005-2006 Plan Présentation générale du logiciel Statistiques descriptives Histogramme Discrétisation Tableau de contingence
Logiciel XLSTAT version 7.0 Contact : Addinsoft 40 rue Damrémont 75018 PARIS 2005-2006 Plan Présentation générale du logiciel Statistiques descriptives Histogramme Discrétisation Tableau de contingence
Le modèle de données
 Le modèle de données Introduction : Une fois que l étude des besoins est complétée, deux points importants sont à retenir : Les données du système étudié Les traitements effectués par le système documentaire.
Le modèle de données Introduction : Une fois que l étude des besoins est complétée, deux points importants sont à retenir : Les données du système étudié Les traitements effectués par le système documentaire.