CH 3 : Classification
|
|
|
- Marie Desjardins
- il y a 8 ans
- Total affichages :
Transcription
1 CH 3 : Classification A- Généralités B- Mesure d éloignement C- Critère d homogénéité D- Choix d une méthode E- Mesures de la qualité F- Interprétation G- ACP/Classification H- Exemple



2

3 A- Généralités Données= tableau n*p individus*variables Objectif = recherche d une typologie ou segmentation, c est à dire d une partition ou répartition des n individus dans des classes, sur la base de l'observation de p descripteurs Moyen= chaque classe doit être la plus homogène possible et, entre elles, les plus distinctes possibles, au sens d un critère à définir.


4 A- Généralités

5 A- Généralités Mise en œuvre d une classification : Choix de la mesure d éloignement (dissimilarité, distance) entre individus (généralement distance euclidienne) Choix du critère d homogénéité des classes à optimiser (généralement inertie). Choix de la méthode utilisée : la Classification Ascendante Hiérarchique (CAH) ou celle par réallocation dynamique sont les plus utilisées Mesure de la qualité de la classification Choix du nombre de classes et leur interprétation
 ou celle par réallocation dynamique")
6 B- Mesure d éloignement Ensemble des individus On définit d / (1) d( e, e ) = 0 i i (2) d( e, e ) = d( e, e ) i j j i (3) d( e, e ) = 0 e = e i j i j (4) d( e, e ) d( e, e ) + d( e, e ) i j i k k j (5) d( e, e ) max( d( e, e ), d( e, e )) i j i k k j Indice de dissimilarité : (1) (2) E = ( e 1,... e i,... e n ) Indice de distance : (1) (2) (3) ; Distance : (1) (2) (3) (4) Distance ultramétrique : (1) (2) (3) (4) (5)
 Indice de distance : (1) (2) (3) ; Distance : (1) (2) (3) (4) Distance ultramétrique : (1) (2)")
7 B- Mesure d éloignement Le choix d'une mesure dépend de la nature des descripteurs. Le plus souvent, le choix se porte sur une distance euclidienne (i.e. engendrée par un produit scalaire) appropriée. Variables quantitatives : M de produit scalaire sur l espace des variables: (1) M = I p (2) M = D 1 σ (3) M = V 1 d( e, e ) = i j (1) variables homogènes, (2) hétérogènes, (3) corrélées 2 e e e = ' Me i j M i j
 M = V 1 d( e, e ) = i j (1) variables homogènes, (2) hétérogènes, (3) corrélées 2 e e e = ' Me i j")
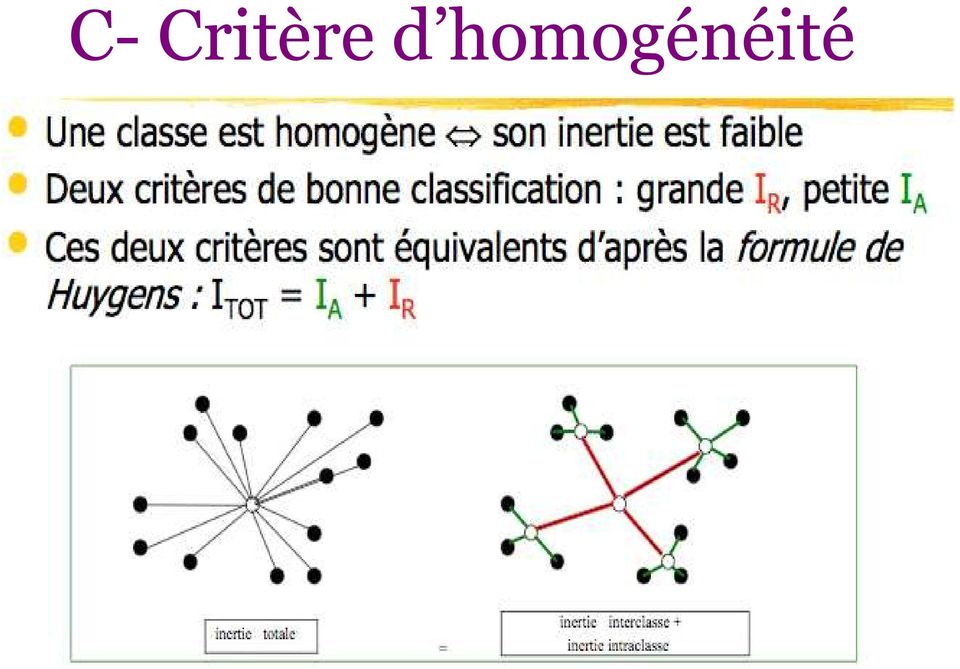
8 C- Critère d homogénéité Si l'ensemble des points est regroupé en K classes Nk ~ ( Gk, Pk ) Inertie intra-classes : Inertie inter-classes : K K I = I = p X G W k i i k k= 1 k= 1 e N K 2 IB = Pk Gk G k = 1 i k ² I = I + I W B Critère le plus utilisé ( variables quantitatives)= K fixé min N I k W
= K fixé min")
9 C- Critère d homogénéité


10 D- Les méthodes

11 D- 1 Algorithmes de partitionnement Principe : on part d'une partition arbitraire en K classes (K choisi) que l on améliore itérativement jusqu à la convergence du critère choisi. - Méthode des centres mobiles - Méthode des k-means - Méthode des «nuées dynamiques»

12 Centres mobiles (Forgy): D- 1 Algorithmes de partitionnement Initialisation : Choix aléatoire de k points de l espace (centres des classes) Itérer les deux étapes suivantes jusqu à ce que le critère à minimiser (inertie intraclasses) ne décroisse plus de manière significative (minimum local), ou bien jusqu à atteindre un nombre d itérations fixées: Tous les individus sont affectés à la classe dont le centre est le plus proche au sens de la distance choisie. On construit ainsi k classes d individus On calcule les barycentres des classes créées qui deviennent les k nouveaux centres

13 D- 1 Algorithmes de partitionnement

14 D- 1 Algorithmes de partitionnement «k-means» (Mc Queen): les barycentres des classes ne sont pas recalculés à la fin des affectations, mais à la fin de chaque allocation d un individu à une classe. L algorithme est ainsi plus rapide, mais l'ordre d'apparition des individus dans le fichier n'est pas neutre. «nuées dynamiques» (Diday): ce n'est plus un seul point qui représente une classe mais un noyau de points constitués d éléments représentatifs de la classe. Cela permet de corriger l influence d éventuelles valeurs extrêmes sur le calcul du barycentre.
: ce n'est plus un seul point qui représente une classe mais un noyau de points constitués d éléments")
15 Remarques sur la méthode : D- 1 Algorithmes de partitionnement On peut montrer que l algorithme fait diminuer l inertie interclasses à chaque itération donc l algorithme converge L expérience montre que le nombre d itérations nécessaires est très faible Inconvénients des algorithmes de partitionnement: Instabilité : Le minimum obtenu est un minimum local: la répartition en classes dépend du choix initial des centres (faire tourner l algorithme plusieurs fois pour identifier des formes fortes) Le nombre de classes est fixé par avance (on peut s aider d une ACP pour le déterminer)
 Le nombre de classes est fixé par avance (on peut s aider d une ACP pour le")
16 D- 1 Algorithmes de partitionnement Programmation sous R : >km=kmeans(x, centers=, iter.max=, algorithm=) centers=soit un vecteur indiquant les centres de départ, soit le nombre de classes choisies iter.max= nombre d itérations maximale; jusqu à convergence par défaut algorithm=«forgy» pour centres mobiles, «MacQueen» pour k- means, nuées dynamiques par défaut

17 D- 1 Algorithmes de partitionnement >names(km) [1] "cluster" "centers" "withinss" "size" cluster: vecteur d entier indiquant le numero de classe de chaque individu. centers: matrice des coordonnées des centres de gravité des classes (valeurs moyennes des variables pour chaque classe). withinss: vecteur somme des carrés des écarts intra-classes pour chaque classe (=Ik*n lorsque les poids sont égaux). size: vecteur de l effectifs dans chaque classe.
.")
18 D-2 Classification ascendante hiérarchique (CAH) Principe: Fournir un ensemble de partitions de moins en moins fines obtenus par regroupement successifs de parties. Une fois cet algorithme terminé, on ne récupère donc pas Une fois cet algorithme terminé, on ne récupère donc pas directement une partition, mais une hiérarchie de partitions en n, 1 classes, avec diminution de l inertie inter-classes à chaque agrégation

19 D-2 Classification ascendante hiérarchique (CAH) Algorithme : Initialisation : les classes initiales sont les n singletonsindividus. Calculer la matrice de leurs distances deux à deux Itérer les deux étapes suivantes jusqu à l agrégation en une seule classe : Regrouper les deux éléments (classes) les plus proches au sens de la distance entre groupes choisie Mettre à jour le tableau de distances en remplaçant les deux classes regroupées par la nouvelle et en calculant sa distance avec chacune des autres classes
 les plus proches au sens de la distance entre groupes choisie Mettre à jour le tableau de")
20 D-2 Classification ascendante hiérarchique (CAH) Nécessité de définir une distance entre groupes d individus (appelé stratégie d agrégation). Nécessite de choisir le nombre de classes à retenir

21 D-2 Classification ascendante hiérarchique (CAH) Stratégies d agrégation : stratégie du saut minimum ou single linkage (la distance entre parties est la plus petite distance entre éléments des deux parties): ( A, B ) = min d ( i, j ) i A, j B stratégie du saut maximum ou du diamètre ou complete linkage (la distance entre parties est la plus grande distance entre éléments des deux parties): ( A, B) = max d( i, j) i A, j B
22 D-2 Classification ascendante hiérarchique (CAH) Méthode du saut Ward (en espace euclidien, option par défaut de SAS) p p ( A, B) = A B d²( G, G ) p + p A B A B A chaque itération, on agrège de manière à avoir une gain minimum d inertie intra-classe :( A, B) = perte d inertie interclasse due à cette agrégation
23 D-2 Classification ascendante hiérarchique (CAH) Remarques sur les méthode : Avec la méthode de Ward, on agrège a chaque itération les classes dont l'agrégation fait perdre le moins d'inertie interclasse il s'agit donc d'une optimisation pas-a-pas, qui ne dépend pas d'un choix initial arbitraire Inconvénients Tourne lentement Vraisemblablement assez éloigné d'un optimum si le nombre de pas n p est trop élevé La CAH est peu robuste: il suffit de modifier une distance pour que le saut change (sensibilité aux valeurs extrêmes).
24 D-2 Classification ascendante hiérarchique (CAH) La méthode du single linkage occasionne des problème de chaînage : Très souvent, en effet, on se retrouve avec un groupe démesurément gros et plusieurs petits groupes satellites. Le complete linkage ne présente pas ce problème. Il tend, au Le complete linkage ne présente pas ce problème. Il tend, au contraire à former des groupes de taille égale. Cependant, la méthode est très sensible aux points aberrants et est peu utilisée en pratique.
25 D-2 Classification ascendante hiérarchique (CAH) Choix du nombre de classes: On décidera de retenir la partition qui semble la meilleure, généralement celle qui précède une valeur de la distance inter brutalement plus faible (à chaque agrégation, on perd de la distance entre les groupes) celle telle que les partitions ont un sens «naturel».
26 D-2 Classification ascendante hiérarchique (CAH) Graphiques utiles au choix du nombre de classes: Graphique représentant la perte de distance (resp. gain) en fonction du nombre de d iterations (resp. de classes). La i itération correspond au passage de n-i+1 à n-i classes. On coupe l arbre avant une perte trop importante de de distance (inertie inter pour ward). I B De facon équivalente, on peut aussi utiliser le graphe du R- square semi-partiel :
27 D-2 Classification ascendante hiérarchique (CAH) Semi-partial R-squared (SPRSQ)= mesure la perte d inertie interclasse (ou de distance) provoquée en regroupant 2 classes. Le but étant d avoir une inertie interclasse maximum, on recherche un faible SPRSQ suivi d un fort SPRSQ à l agrégation suivante : un pic pour k classes et un creux pour k+1 classes indique une bonne classification en k+1 classes SPRSQ = I SPRSQ = I B I
28 D-2 Classification ascendante hiérarchique (CAH) Dendogramme = représentation graphique sous forme d arbre binaire, d agrégations successives jusqu à réunion en une seule classe de tous les individus. La hauteur d une branche est proportionnelle à la distance entre les deux objets regroupés. Dans le cas du saut de Ward, à la perte d inertie interclasses. On coupe avant une forte perte d inertie inter : La coupure fournit dans chaque sous-arbre, la répartition des individus en classes
29 D-2 Classification ascendante hiérarchique (CAH) Programmation sous R: >hc=hclust(d, method=) d= un tableau de distances comme produit par dist() method= méthode d agrégation: "ward", 'single", "complete«(méthode par défaut) fonction dist(x, method=): x= tableau sur lequel calculer la distance method='"euclidean"', '"maximum"', '"manhattan"', '"canberra"', '"binary"' or '"minkowski"'. Par défaut, euclidienne
30 D-2 Classification ascendante hiérarchique (CAH) >names (hc) [1] "merge" "height" "order" "labels" "method" [6] "call" "dist.method«>plot(hc, hang=, cex=) # dessine le dendogramme, hang=-1 pour mettre tous le noms des individus au même niveau, cex pour baisser la casse >cutree(hc,k=) #attribue la classe de chaque individu lorsqu on coupe à k classes >rect.hclust(hc, k=, border=«red») #dessine les classes sur le dendogramme
31 D-2 Classification ascendante hiérarchique (CAH) merge: an n-1 by 2 matrix. Row i of 'merge' describes the merging of clusters at step i of the clustering. height: a set of n-1 non-decreasing real values. The clustering _height_: that is, the value of the criterion associated with the clustering 'method' for the particular agglomeration. order: a vector giving the permutation of the original observations suitable for plotting, in the sense that a cluster plot using this ordering and matrix 'merge' will not have crossings of the branches. labels: labels for each of the objects being clustered. call: the call which produced the result. method: the cluster method that has been used. dist.method: the distance that has been used to create 'd'
32 D-2 Classification ascendante hiérarchique (CAH) Ce que font ces fonctions en pratique : >m=matrix(1:16,4,4) > m [,1] [,2] [,3] [,4] [1,] [2,] [3,] [4,] >dist(m)^2 #il vaut mieux utiliser le carré, plus proche de la perte d inertie à # chaque agrégation, qui est proportionnelle à une distance² * *= carré de la distance euclidienne entre lignes 1 et 2 de la matrice=(2-1)²+(6-5)²+(10-9)²+(14-13)²=4
33 D-2 Classification ascendante hiérarchique (CAH) > hc=hclust(dist(m)^2,method="ward") Donne les agrégations successives, faites de manière à perdre le moins possible d inertie inter-classe (i.e. les éléments les plus proches à chaque agrégation au sens de la distance de Ward : p 2 p ( A, B) = A B G B G p + p A A B > hc$merge [,1] [,2] [1,] -1-2 [2,] -3-4 [3,] 1 2 $merge donne les agrégations faites à chaque pas, que l on va détailler:
34 D-2 Classification ascendante hiérarchique (CAH) 1 agrégation : on part de la matrice des distances de Ward, à ce stade =d²(ei,ej)/8 >de1=dist(m)^2/8 >de On agrège 1 et 2 en cl1: delta(1,2)=0.5, min. (on aurait pu aussi regrouper 2 et 3 ou 3 et 4) 2 agrégation : nouveaux éléments et calcul de la nouvelle matrice de distance de ward >cl1=apply(m[1:2,],2,mean) >m2=rbind(cl1,m[3:4,]) >rownames(m2)=c("cl1",3,4) > m2 [,1] [,2] [,3] [,4] cl
35 D-2 Classification ascendante hiérarchique (CAH) > d2=dist(m2,diag=t,upper=t)^2 cl1 3 4 cl > de2=matrix(c(0, (2/12)*9, (2/12)*25,(2/12)*9,0, (1/8)*4,(2/12)*25,(1/8)*4,0),3,3,byrow=T) > rownames(de2)=c("cl1",3,4) > colnames(de2)=c("cl1",3,4) > de2 cl1 3 4 cl
36 D-2 Classification ascendante hiérarchique (CAH) On agrège 3 et 4 en cl2: delta(3,4)=0.5, minimal 3 agrégation: nouveaux éléments et nouvelle matrice de Ward >cl2=apply(m2[2:3,],2,mean) >m3=rbind(cl1,cl2) > m3 [,1] [,2] [,3] [,4] cl cl > de3=dist(m3)^2/4 [1] 4 On retrouve bien les résultats de $merge. Par ailleurs, le vecteur des distances de Ward (perte d inertie inter à chaque agrégation est : dib=[0.5,0.5,4 ](on vérifie que la somme des composantes=inertie totale du tableau). La fonction $height donne le vecteur 2*n*dib >hc$height [1]
37 D- 3 Méthode mixte Combinent efficacement les avantages des deux types de méthodes vues précédemment et permettent d'en annuler les inconvénients CAH, suivie mais aussi parfois précédée d'une méthode de type centres mobiles Si le nombre d'individus n est élevé (plusieurs milliers), lancer plusieurs fois un algorithme de type centres mobiles, en faisant varier le choix des K points de départ : le produit des partitions obtenues permet d'obtenir les groupes d'individus toujours classés ensemble : les formes fortes.
38 D- 3 Méthode mixte On lance une CAH sur les centres de ces formes fortes, avec la méthode de Ward : on chemine ainsi vers une partition en K classes, en minimisant a chaque pas la perte d'inertie interclasse. On lance les centres mobiles sur la partition issue de la CAH, avec pour points de départ les barycentres des K classes : on est ainsi assure d'aboutir a un optimum local,en autorisant quelques reaffectations individuelles
39 E- Mesure de la qualité (toute classification) R² = proportion de la variance expliquée par les classes R 2 = I B I - doit être le plus proche possible de 1 sans avoir trop de classes - s arrêter après le dernier saut important Pseudo F = mesure la séparation entre toutes les classes - n=observations; k=classes - doit être grand F = R 2 /k 1 (1 R 2 )/n k
40 E- Mesure de la qualité (toute classification) Cubic clustering criterion CCC (valable sous SAS) permet de tester H0 = Les données sont issues d une distribution uniforme (pas de classes) où K est une constante (voir Sarle (1983)) - CCC > 2 : bonne classification - 0< CCC<2 : classification peut être OK mais à vérifier - CCC< 0 : présence d outliers gênants (surtout si CCC < -30) On trace CCC versus le nombre de classes. Un creux pour k classes suivi d un pic pour k+1 classes indique une bonne classification en k+1 classes (surtout si on a une croissance ou décroissance douce à partir de k+2 classes) Rq : ne pas utiliser CCC et F en single linkage
41 F- Caractérisation des classes Chaque classe est décrite grâce aux variables actives - celles sur lesquelles on a souhaité différencier les classes ; mais aussi avec toute autre variable supplémentaire (quel qu'en soit le type) dont on connaît les valeurs sur notre population de n individus. Généralement, on commence par calculer la distance entre le barycentre de chaque classe et le barycentre global, afin de connaître l'excentricité globale de chaque groupe. Ensuite, on peut comparer, pour chaque variable, sa distribution sur chaque classe et sur l'ensemble de la population. Lorsque les variables sont numériques, on compare généralement leurs moyennes sur les différents groupes(en tenant compte des effectifs et des variances respectifs), à l aide de tests statistiques.
42 F- Caractérisation des classes On peut aussi quantifier la force discriminante de chaque variable sur la classification dans son ensemble, afin de déterminer quelles sont les caractéristiques expliquant le plus les différenciations construites. En fin de course, il est fréquent de «nommer» chacune des classes obtenues par un qualificatif résumant la caractérisation. Pour illustrer ce qui caractérise une classe, on peut aussi rechercher l'individu le plus typique (ou central) de la classe, ou bien encore un noyau d'individus la représentant bien.
43 F- Caractérisation des classes Les tests utilisés sont ceux utilisés en analyse de variance à un facteur (test de Fisher, test de Student, test de Scheffe, test de Bartlett ) La force discriminante est la statistique de fisher : (variance La force discriminante est la statistique de fisher : (variance inter/k-1)/(variance intra/n-k)
44 G- Complémentarité ACP/Classification ACP = outil puissant pour analyser les corrélations entre plusieurs variables. Permet d'obtenir de nouvelles variables non corrélées à forte variance (i.e. à fort pouvoir informatif). Limites de l ACP: - l'acp permet de visualiser la structure des corrélations, mais ces visualisations ne sont réalisables que sur des plans, ce qui limite la perception précise des phénomènes si les variables sont nombreuses et leurs relations complexes - la contrainte d'orthogonalité des axes rend souvent l'interprétation délicate au-delà du premier plan factoriel, car les informations délivrées sont alors résiduelles, sachant les proximités déjà observées sur les axes précédents.
45 G- Complémentarité ACP/Classification En comparaison, les méthodes de classification prennent en compte l'ensemble des dimensions du nuage, et corrigent donc les distorsions des projections factorielles, en appréhendant les individus tels qu'ils sont en réalité, et non tels qu'ils apparaissent en projection. Une solution : faire figurer sur les projections factorielles du nuage des individus la partition obtenue par classification : on fait figurer ces classes par leur barycentre, et/ou par leur enveloppe, voire en remplaçant chaque point projeté par le code de sa classe d'appartenance, si le nombre de points est assez restreint.
46 G- Complémentarité ACP/Classification Exemples de programmes R pour la représentation des classes sur les axes factoriels Programme 1 : k= #nombre de classes choisies p =princomp(don) #don=tableau de données u = p$loadings x =(t(u) %*% t(don))[1:2,] x = t(x) plot(x, col="red") c =hc$merge y =NULL n = NULL
47 for (i in (1:(length(don[,1])-1))) { if( c[i,1]>0 ){ a =y[ c[i,1], ] a.n = n[ c[i,1] ] } else { a =x[ -c[i,1], ] a.n = 1 } if( c[i,2]>0 ){ b = y[ c[i,2], ] b.n = n[ c[i,2] ] } else { b =x[ -c[i,2], ] b.n =1 } n = append(n, a.n+b.n) m = ( a.n * a + b.n * b )/( a.n + b.n ) G- Complémentarité ACP/Classification
48 G- Complémentarité ACP/Classification y =rbind(y, m) segments( m[1], m[2], a[1], a[2], col= "red" ) segments( m[1], m[2], b[1], b[2], col= "red" ) if( i> length(voit[,1])-1-k ){ op=par(ps=20) text( m[1], m[2], paste(length(don[,1])-i), col= " blue" ) par(op) } } text( x[,1], x[,2], attr(x, "dimnames")[[1]], col=cutree(cl,k),cex=0.7)
49 Programme 2 (plus simple): don= k= G- Complémentarité ACP/Classification p =princomp(don,corr=t) u =p$loadings x =(t(u) %*% t(don))[1:2,] x = t(x) par(pch ="*" ) plot(x, col=cutree(cl,k), pch=, lwd=3 ) text( x[,1], x[,2], attr(x, "dimnames")[[1]],cex=0.7,col=cutree(cl,k) )
50 G- Complémentarité ACP/Classification Programme 3 (avec les kmeans): k= cl <- kmeans(don, k, 20) p <- princomp(don) u <- p$loadings x <- (t(u) %*% t(don))[1:2,] x <- t(x) plot(x, col=cl$cluster, pch=3, lwd=3) c <- (t(u) %*% t(cl$center))[1:2,] c <- t(c) points(c, col = 1:k, pch=7, lwd=3) for (i in 1:k) { print(paste("cluster", i)) for (j in (1:length(don[,1]))[cl$cluster==i]) { segments( x[j,1], x[j,2], c[i,1], c[i,2], col=i ) } } text( x[,1], x[,2], attr(x, "dimnames")[[1]],col=cl$cluster,cex=0.7 )
51 H- Exemple >crimer=scale(crime)*sqrt(20/19) > kmr=kmeans(crimer,4) > kmr K-means clustering with 4 clusters of sizes 4, 2, 6, 8 Cluster means: Meurtre Rapt vol attaque viol larcin
52 H- Exemple Clustering vector: Alabama Alaska Arizona Arkansas California Colorado Connecticut Delaware Florida Georgia Hawaii Idaho Illinois Indiana Iowa Kansas Kentucky Louisiana Maine Maryland 4 3 Within cluster sum of squares by cluster: [1] Available components: [1] "cluster" "centers" "withinss" "size"
53 H- Exemple Remarques : I=p=6 Ik=km$withinss/20 Iw=sum(Ik) Ib=sum(km$size*(km$centers)^2)/20 Ib+Iw=I Excentricité= apply(kmr$centers^2,1,sum)
54 représentation dans les axes d'une ACP(programme3) Louisiana Alabama delits mineurs -----delits majeurs California Alaska Maryland Florida Colorado Arizona Georgia Illinois Delaw are Haw aii Kentucky Arkansas Indiana Kansas Idaho Connecticut Maine Iow a forte criminalite ---- faible criminalite
55 H- Exemple cl=hclust(dist(crimer)^2,method="ward") dib=cl$height/(2*20); sprs=dib/6; sprs [1] [7] [13] [19] plot(sprs type=«o", main="r² partiel",xlab="nombre d'iterations«plot(dib,type="b", main=«perte d inertie inter",xlab="nombre d'iterations") On perd au passage de 15 (pic,5 classes) à 14 (creux, 6 classes) itérations. On garde 6 classes. Le R2 vaut alors 78%. Ou au passage de 17 à 16 (3 à 4 classes). On garde 4 classes. Le R2 vaut 66%. r2= (6-cumsum(dib))/6; r2[14]; r2[16] plot(r2, type="o", main="r²",xlab="nombre d'iterations")
56 H- Exemple
57 H- Exemple
58 H- Exemple
59 H- Exemple > plot(cl, hang=-1) > rect.hclust(cl, k=4, border="red") > class=cutree(cl, 4);class Alabama Alaska Arizona Arkansas California Colorado Connecticut Delaware Florida Georgia Hawaii Idaho Illinois Indiana Iowa Kansas Kentucky Louisiana Maine Maryland
60
61 H- Exemple k=4 p =princomp(crimer,corr=t) u =p$loadings x =(t(u) %*% t(crimer))[1:2,] x = t(x) par(pch ="*" ) plot(x, col=cutree(cl,k), pch="", lwd=3,xlab="forte criminalité criminalité", ylab="faible gravité forte gravité" ) text( x[,1], x[,2], attr(x, "dimnames")[[1]],cex=0.7,col=cutree(cl,k) ) faible
62
63 H- Exemple cr=cbind(crimer, class) cbind(apply(cr[class==1,],2,mean),apply(cr[class==2,],2,mean),apply(cr[class==3,],2,mean),apply(cr[class==4,],2,mean)) [,1] [,2] [,3] [,4] Meutre Rapt Vol Attaque Viol Larcin class NOIR ROUGE VERT BLEU
ACP Voitures 1- Méthode
 acp=princomp(voit,cor=t) ACP Voitures 1- Méthode Call: princomp(x = voit, cor = T) Standard deviations: Comp.1 Comp.2 Comp.3 Comp.4 Comp.5 Comp.6 2.1577815 0.9566721 0.4903373 0.3204833 0.2542759 0.1447788
acp=princomp(voit,cor=t) ACP Voitures 1- Méthode Call: princomp(x = voit, cor = T) Standard deviations: Comp.1 Comp.2 Comp.3 Comp.4 Comp.5 Comp.6 2.1577815 0.9566721 0.4903373 0.3204833 0.2542759 0.1447788
La classification automatique de données quantitatives
 La classification automatique de données quantitatives 1 Introduction Parmi les méthodes de statistique exploratoire multidimensionnelle, dont l objectif est d extraire d une masse de données des informations
La classification automatique de données quantitatives 1 Introduction Parmi les méthodes de statistique exploratoire multidimensionnelle, dont l objectif est d extraire d une masse de données des informations
Stéphane Tufféry DATA MINING & STATISTIQUE DÉCISIONNELLE. 04/04/2008 Stéphane Tufféry - Data Mining - http://data.mining.free.fr
 Stéphane Tufféry DATA MINING & STATISTIQUE DÉCISIONNELLE 1 Plan du cours Qu est-ce que le data mining? A quoi sert le data mining? Les 2 grandes familles de techniques Le déroulement d un projet de data
Stéphane Tufféry DATA MINING & STATISTIQUE DÉCISIONNELLE 1 Plan du cours Qu est-ce que le data mining? A quoi sert le data mining? Les 2 grandes familles de techniques Le déroulement d un projet de data
COURS DE DATA MINING 4 : MODELISATION NON-SUPERVISEE CLASSIFICATIONS AUTOMATIQUES
 COURS DE DATA MINING 4 : MODELISATION NON-SUPERVISEE CLASSIFICATIONS AUTOMATIQUES EPF 4/ 5 ème année - Option Ingénierie d Affaires et de Projets - Finance Bertrand LIAUDET 4 : Modélisation non-supervisée
COURS DE DATA MINING 4 : MODELISATION NON-SUPERVISEE CLASSIFICATIONS AUTOMATIQUES EPF 4/ 5 ème année - Option Ingénierie d Affaires et de Projets - Finance Bertrand LIAUDET 4 : Modélisation non-supervisée
Arbres binaires de décision
 1 Arbres binaires de décision Résumé Arbres binaires de décision Méthodes de construction d arbres binaires de décision, modélisant une discrimination (classification trees) ou une régression (regression
1 Arbres binaires de décision Résumé Arbres binaires de décision Méthodes de construction d arbres binaires de décision, modélisant une discrimination (classification trees) ou une régression (regression
Classification non supervisée
 AgroParisTech Classification non supervisée E. Lebarbier, T. Mary-Huard Table des matières 1 Introduction 4 2 Méthodes de partitionnement 5 2.1 Mesures de similarité et de dissimilarité, distances.................
AgroParisTech Classification non supervisée E. Lebarbier, T. Mary-Huard Table des matières 1 Introduction 4 2 Méthodes de partitionnement 5 2.1 Mesures de similarité et de dissimilarité, distances.................
Historique. Architecture. Contribution. Conclusion. Définitions et buts La veille stratégique Le multidimensionnel Les classifications
 L intelligence économique outil stratégique pour l entreprise Professeur Bernard DOUSSET dousset@irit.fr http://atlas.irit.fr Institut de Recherche en Informatique de Toulouse (IRIT) Equipe Systèmes d
L intelligence économique outil stratégique pour l entreprise Professeur Bernard DOUSSET dousset@irit.fr http://atlas.irit.fr Institut de Recherche en Informatique de Toulouse (IRIT) Equipe Systèmes d
Agrégation des portefeuilles de contrats d assurance vie
 Agrégation des portefeuilles de contrats d assurance vie Est-il optimal de regrouper les contrats en fonction de l âge, du genre, et de l ancienneté des assurés? Pierre-O. Goffard Université d été de l
Agrégation des portefeuilles de contrats d assurance vie Est-il optimal de regrouper les contrats en fonction de l âge, du genre, et de l ancienneté des assurés? Pierre-O. Goffard Université d été de l
Séance 11 : Typologies
 Séance 11 : Typologies Sommaire Proc CLUSTER : Typologie hiérarchique... 3 Proc FASTCLUS : Typologie nodale... 8 Proc MODECLUS : Typologie non paramétrique... 11 - Les phénomènes observés (attitudes, comportements,
Séance 11 : Typologies Sommaire Proc CLUSTER : Typologie hiérarchique... 3 Proc FASTCLUS : Typologie nodale... 8 Proc MODECLUS : Typologie non paramétrique... 11 - Les phénomènes observés (attitudes, comportements,
La segmentation à l aide de EG-SAS. A.Bouhia Analyste principal à la Banque Nationale du Canada. Chargé de cours à l UQAM
 La segmentation à l aide de EG-SAS A.Bouhia Analyste principal à la Banque Nationale du Canada. Chargé de cours à l UQAM Définition de la segmentation - Au lieu de considérer une population dans son ensemble,
La segmentation à l aide de EG-SAS A.Bouhia Analyste principal à la Banque Nationale du Canada. Chargé de cours à l UQAM Définition de la segmentation - Au lieu de considérer une population dans son ensemble,
1 - PRESENTATION GENERALE...
 Contenu PREAMBULE... 2 INTRODUCTION... 2 1 - PRESENTATION GENERALE... 4 Qualité et optimalité... 8 2 - AGREGATION AUTOUR DE CENTRES MOBILES... 9 2.1 LES BASES DE L'ALGORITHME... 10 2.2 TECHNIQUES CONNEXES...
Contenu PREAMBULE... 2 INTRODUCTION... 2 1 - PRESENTATION GENERALE... 4 Qualité et optimalité... 8 2 - AGREGATION AUTOUR DE CENTRES MOBILES... 9 2.1 LES BASES DE L'ALGORITHME... 10 2.2 TECHNIQUES CONNEXES...
L ANALYSE EN COMPOSANTES PRINCIPALES (A.C.P.) Pierre-Louis GONZALEZ
 Pierre-Louis GONZALEZ") L ANALYSE EN COMPOSANTES PRINCIPALES (A.C.P.) Pierre-Louis GONZALEZ INTRODUCTION Données : n individus observés sur p variables quantitatives. L A.C.P. permet d eplorer les liaisons entre variables et
L ANALYSE EN COMPOSANTES PRINCIPALES (A.C.P.) Pierre-Louis GONZALEZ INTRODUCTION Données : n individus observés sur p variables quantitatives. L A.C.P. permet d eplorer les liaisons entre variables et
Recherche dans un tableau
 Chapitre 3 Recherche dans un tableau 3.1 Introduction 3.1.1 Tranche On appelle tranche de tableau, la donnée d'un tableau t et de deux indices a et b. On note cette tranche t.(a..b). Exemple 3.1 : 3 6
Chapitre 3 Recherche dans un tableau 3.1 Introduction 3.1.1 Tranche On appelle tranche de tableau, la donnée d'un tableau t et de deux indices a et b. On note cette tranche t.(a..b). Exemple 3.1 : 3 6
Analyse en Composantes Principales
 Analyse en Composantes Principales Anne B Dufour Octobre 2013 Anne B Dufour () Analyse en Composantes Principales Octobre 2013 1 / 36 Introduction Introduction Soit X un tableau contenant p variables mesurées
Analyse en Composantes Principales Anne B Dufour Octobre 2013 Anne B Dufour () Analyse en Composantes Principales Octobre 2013 1 / 36 Introduction Introduction Soit X un tableau contenant p variables mesurées
INTRODUCTION À L ANALYSE FACTORIELLE DES CORRESPONDANCES
 INTRODUCTION À L ANALYSE FACTORIELLE DES CORRESPONDANCES Dominique LAFFLY Maître de Conférences, Université de Pau Laboratoire Société Environnement Territoire UMR 5603 du CNRS et Université de Pau Domaine
INTRODUCTION À L ANALYSE FACTORIELLE DES CORRESPONDANCES Dominique LAFFLY Maître de Conférences, Université de Pau Laboratoire Société Environnement Territoire UMR 5603 du CNRS et Université de Pau Domaine
Introduction au Data-Mining
 Introduction au Data-Mining Alain Rakotomamonjy - Gilles Gasso. INSA Rouen -Département ASI Laboratoire PSI Introduction au Data-Mining p. 1/25 Data-Mining : Kèkecé? Traduction : Fouille de données. Terme
Introduction au Data-Mining Alain Rakotomamonjy - Gilles Gasso. INSA Rouen -Département ASI Laboratoire PSI Introduction au Data-Mining p. 1/25 Data-Mining : Kèkecé? Traduction : Fouille de données. Terme
Scénario: Données bancaires et segmentation de clientèle
 Résumé Scénario: Données bancaires et segmentation de clientèle Exploration de données bancaires par des méthodes uni, bi et multidimensionnelles : ACP, AFCM k-means, CAH. 1 Présentation Le travail proposé
Résumé Scénario: Données bancaires et segmentation de clientèle Exploration de données bancaires par des méthodes uni, bi et multidimensionnelles : ACP, AFCM k-means, CAH. 1 Présentation Le travail proposé
PLAN. Ricco Rakotomalala Tutoriels Tanagra - http://tutoriels-data-mining.blogspot.fr/ 2
 Apprentissage non-supervisé ou apprentissage multi-supervisé? Ricco RAKOTOMALALA Tutoriels Tanagra - http://tutoriels-data-mining.blogspot.fr/ PLAN. Classification automatique, typologie, etc.. Interprétation
Apprentissage non-supervisé ou apprentissage multi-supervisé? Ricco RAKOTOMALALA Tutoriels Tanagra - http://tutoriels-data-mining.blogspot.fr/ PLAN. Classification automatique, typologie, etc.. Interprétation
Exemple PLS avec SAS
 Exemple PLS avec SAS This example, from Umetrics (1995), demonstrates different ways to examine a PLS model. The data come from the field of drug discovery. New drugs are developed from chemicals that
Exemple PLS avec SAS This example, from Umetrics (1995), demonstrates different ways to examine a PLS model. The data come from the field of drug discovery. New drugs are developed from chemicals that
Big Data et Graphes : Quelques pistes de recherche
 Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de Lyon/Université Claude Bernard Lyon 1/Université
Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de Lyon/Université Claude Bernard Lyon 1/Université
Initiation à l analyse en composantes principales
 Fiche TD avec le logiciel : tdr601 Initiation à l analyse en composantes principales A.B. Dufour & J.R. Lobry Une première approche très intuitive et interactive de l ACP. Centrage et réduction des données.
Fiche TD avec le logiciel : tdr601 Initiation à l analyse en composantes principales A.B. Dufour & J.R. Lobry Une première approche très intuitive et interactive de l ACP. Centrage et réduction des données.
Logiciel XLSTAT version 7.0. 40 rue Damrémont 75018 PARIS
 Logiciel XLSTAT version 7.0 Contact : Addinsoft 40 rue Damrémont 75018 PARIS 2005-2006 Plan Présentation générale du logiciel Statistiques descriptives Histogramme Discrétisation Tableau de contingence
Logiciel XLSTAT version 7.0 Contact : Addinsoft 40 rue Damrémont 75018 PARIS 2005-2006 Plan Présentation générale du logiciel Statistiques descriptives Histogramme Discrétisation Tableau de contingence
Déroulement d un projet en DATA MINING, préparation et analyse des données. Walid AYADI
 1 Déroulement d un projet en DATA MINING, préparation et analyse des données Walid AYADI 2 Les étapes d un projet Choix du sujet - Définition des objectifs Inventaire des données existantes Collecte, nettoyage
1 Déroulement d un projet en DATA MINING, préparation et analyse des données Walid AYADI 2 Les étapes d un projet Choix du sujet - Définition des objectifs Inventaire des données existantes Collecte, nettoyage
Objectifs. Clustering. Principe. Applications. Applications. Cartes de crédits. Remarques. Biologie, Génomique
 Objectifs Clustering On ne sait pas ce qu on veut trouver : on laisse l algorithme nous proposer un modèle. On pense qu il existe des similarités entre les exemples. Qui se ressemble s assemble p. /55
Objectifs Clustering On ne sait pas ce qu on veut trouver : on laisse l algorithme nous proposer un modèle. On pense qu il existe des similarités entre les exemples. Qui se ressemble s assemble p. /55
Projet SINF2275 «Data mining and decision making» Projet classification et credit scoring
 Projet SINF2275 «Data mining and decision making» Projet classification et credit scoring Année académique 2006-2007 Professeurs : Marco Saerens Adresse : Université catholique de Louvain Information Systems
Projet SINF2275 «Data mining and decision making» Projet classification et credit scoring Année académique 2006-2007 Professeurs : Marco Saerens Adresse : Université catholique de Louvain Information Systems
Individus et informations supplémentaires
 ADE-4 Individus et informations supplémentaires Résumé La fiche décrit l usage des individus supplémentaires dans des circonstances variées. En particulier, cette pratique est étendue aux analyses inter
ADE-4 Individus et informations supplémentaires Résumé La fiche décrit l usage des individus supplémentaires dans des circonstances variées. En particulier, cette pratique est étendue aux analyses inter
Once the installation is complete, you can delete the temporary Zip files..
 Sommaire Installation... 2 After the download... 2 From a CD... 2 Access codes... 2 DirectX Compatibility... 2 Using the program... 2 Structure... 4 Lier une structure à une autre... 4 Personnaliser une
Sommaire Installation... 2 After the download... 2 From a CD... 2 Access codes... 2 DirectX Compatibility... 2 Using the program... 2 Structure... 4 Lier une structure à une autre... 4 Personnaliser une
I. Programmation I. 1 Ecrire un programme en Scilab traduisant l organigramme montré ci-après (on pourra utiliser les annexes):
:") Master Chimie Fondamentale et Appliquée : spécialité «Ingénierie Chimique» Examen «Programmation, Simulation des procédés» avril 2008a Nom : Prénom : groupe TD : I. Programmation I. 1 Ecrire un programme
Master Chimie Fondamentale et Appliquée : spécialité «Ingénierie Chimique» Examen «Programmation, Simulation des procédés» avril 2008a Nom : Prénom : groupe TD : I. Programmation I. 1 Ecrire un programme
Big Data et Graphes : Quelques pistes de recherche
 Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci http://liris.cnrs.fr/hamamache.kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de
Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci http://liris.cnrs.fr/hamamache.kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de
Baccalauréat L spécialité, Métropole et Réunion, 19 juin 2009 Corrigé.
 Baccalauréat L spécialité, Métropole et Réunion, 19 juin 2009 Corrigé. L usage d une calculatrice est autorisé Durée : 3heures Deux annexes sont à rendre avec la copie. Exercice 1 5 points 1_ Soit f la
Baccalauréat L spécialité, Métropole et Réunion, 19 juin 2009 Corrigé. L usage d une calculatrice est autorisé Durée : 3heures Deux annexes sont à rendre avec la copie. Exercice 1 5 points 1_ Soit f la
Enjeux mathématiques et Statistiques du Big Data
 Enjeux mathématiques et Statistiques du Big Data Mathilde Mougeot LPMA/Université Paris Diderot, mathilde.mougeot@univ-paris-diderot.fr Mathématique en Mouvements, Paris, IHP, 6 Juin 2015 M. Mougeot (Paris
Enjeux mathématiques et Statistiques du Big Data Mathilde Mougeot LPMA/Université Paris Diderot, mathilde.mougeot@univ-paris-diderot.fr Mathématique en Mouvements, Paris, IHP, 6 Juin 2015 M. Mougeot (Paris
Principe de symétrisation pour la construction d un test adaptatif
 Principe de symétrisation pour la construction d un test adaptatif Cécile Durot 1 & Yves Rozenholc 2 1 UFR SEGMI, Université Paris Ouest Nanterre La Défense, France, cecile.durot@gmail.com 2 Université
Principe de symétrisation pour la construction d un test adaptatif Cécile Durot 1 & Yves Rozenholc 2 1 UFR SEGMI, Université Paris Ouest Nanterre La Défense, France, cecile.durot@gmail.com 2 Université
Introduction au datamining
 Introduction au datamining Patrick Naïm janvier 2005 Définition Définition Historique Mot utilisé au départ par les statisticiens Le mot indiquait une utilisation intensive des données conduisant à des
Introduction au datamining Patrick Naïm janvier 2005 Définition Définition Historique Mot utilisé au départ par les statisticiens Le mot indiquait une utilisation intensive des données conduisant à des
1 de 46. Algorithmique. Trouver et Trier. Florent Hivert. Mél : Florent.Hivert@lri.fr Page personnelle : http://www.lri.fr/ hivert
 1 de 46 Algorithmique Trouver et Trier Florent Hivert Mél : Florent.Hivert@lri.fr Page personnelle : http://www.lri.fr/ hivert 2 de 46 Algorithmes et structures de données La plupart des bons algorithmes
1 de 46 Algorithmique Trouver et Trier Florent Hivert Mél : Florent.Hivert@lri.fr Page personnelle : http://www.lri.fr/ hivert 2 de 46 Algorithmes et structures de données La plupart des bons algorithmes
Introduction à MATLAB R
 Introduction à MATLAB R Romain Tavenard 10 septembre 2009 MATLAB R est un environnement de calcul numérique propriétaire orienté vers le calcul matriciel. Il se compose d un langage de programmation, d
Introduction à MATLAB R Romain Tavenard 10 septembre 2009 MATLAB R est un environnement de calcul numérique propriétaire orienté vers le calcul matriciel. Il se compose d un langage de programmation, d
INTRODUCTION AU DATA MINING
 INTRODUCTION AU DATA MINING 6 séances de 3 heures mai-juin 2006 EPF - 4 ème année - Option Ingénierie d Affaires et de Projets Bertrand LIAUDET TP DE DATA MINING Le TP et le projet consisteront à mettre
INTRODUCTION AU DATA MINING 6 séances de 3 heures mai-juin 2006 EPF - 4 ème année - Option Ingénierie d Affaires et de Projets Bertrand LIAUDET TP DE DATA MINING Le TP et le projet consisteront à mettre
M2-Images. Rendu Temps Réel - OpenGL 4 et compute shaders. J.C. Iehl. December 18, 2013
 Rendu Temps Réel - OpenGL 4 et compute shaders December 18, 2013 résumé des épisodes précédents... création des objets opengl, organisation des données, configuration du pipeline, draw,... opengl 4.3 :
Rendu Temps Réel - OpenGL 4 et compute shaders December 18, 2013 résumé des épisodes précédents... création des objets opengl, organisation des données, configuration du pipeline, draw,... opengl 4.3 :
PREPROCESSING PAR LISSAGE LOESS POUR ACP LISSEE
 PREPROCESSING PAR LISSAGE LOESS POUR ACP LISSEE Jean-Paul Valois, Claude Mouret & Nicolas Pariset Total, 64018 Pau Cédex MOTS CLEFS : Analyse spatiale, ACP, Lissage, Loess PROBLEMATIQUE En analyse multivariée,
PREPROCESSING PAR LISSAGE LOESS POUR ACP LISSEE Jean-Paul Valois, Claude Mouret & Nicolas Pariset Total, 64018 Pau Cédex MOTS CLEFS : Analyse spatiale, ACP, Lissage, Loess PROBLEMATIQUE En analyse multivariée,
Travaux pratiques avec RapidMiner
 Travaux pratiques avec RapidMiner Master Informatique de Paris 6 Spécialité IAD Parcours EDOW Module Algorithmes pour la Fouille de Données Janvier 2012 Prise en main Généralités RapidMiner est un logiciel
Travaux pratiques avec RapidMiner Master Informatique de Paris 6 Spécialité IAD Parcours EDOW Module Algorithmes pour la Fouille de Données Janvier 2012 Prise en main Généralités RapidMiner est un logiciel
Kit de dépistage et de déclaration du virus Ebola (CARE)
") C A R E Kit de dépistage et de déclaration du virus Ebola (CARE) Si vous tombez malade, faites-vous soigner dès que possible pour avoir les meilleures chances de guérison! Cher voyageur, Que vous rentriez
C A R E Kit de dépistage et de déclaration du virus Ebola (CARE) Si vous tombez malade, faites-vous soigner dès que possible pour avoir les meilleures chances de guérison! Cher voyageur, Que vous rentriez
Qualité du logiciel: Méthodes de test
 Qualité du logiciel: Méthodes de test Matthieu Amiguet 2004 2005 Analyse statique de code Analyse statique de code Étudier le programme source sans exécution Généralement réalisée avant les tests d exécution
Qualité du logiciel: Méthodes de test Matthieu Amiguet 2004 2005 Analyse statique de code Analyse statique de code Étudier le programme source sans exécution Généralement réalisée avant les tests d exécution
SEMIN- Gestion des couleurs sous R. Michel BAYLAC. MNHN Département Systématique et Evolution OSEB baylac@mnhn.fr
 SEMIN- Gestion des couleurs sous R Michel BAYLAC MNHN Département Systématique et Evolution OSEB baylac@mnhn.fr SEMIN-R du MNHN 08 Janvier 2008 Sémin R du MNHN : 8 janvier 2008 Gestion des couleurs sous
SEMIN- Gestion des couleurs sous R Michel BAYLAC MNHN Département Systématique et Evolution OSEB baylac@mnhn.fr SEMIN-R du MNHN 08 Janvier 2008 Sémin R du MNHN : 8 janvier 2008 Gestion des couleurs sous
Cours 7 : Utilisation de modules sous python
 Cours 7 : Utilisation de modules sous python 2013/2014 Utilisation d un module Importer un module Exemple : le module random Importer un module Exemple : le module random Importer un module Un module est
Cours 7 : Utilisation de modules sous python 2013/2014 Utilisation d un module Importer un module Exemple : le module random Importer un module Exemple : le module random Importer un module Un module est
VISUALISATION DES DISTANCES ENTRE LES CLASSES DE LA CARTE DE KOHONEN POUR LE DEVELOPPEMENT D'UN OUTIL D'ANALYSE ET DE REPRESENTATION DES DONNEES
 VISUALISATION DES DISTANCES ENTRE LES CLASSES DE LA CARTE DE KOHONEN POUR LE DEVELOPPEMENT D'UN OUTIL D'ANALYSE ET DE REPRESENTATION DES DONNEES Patrick Rousset 1,2 et Christiane Guinot 3 1 CEREQ, Service
VISUALISATION DES DISTANCES ENTRE LES CLASSES DE LA CARTE DE KOHONEN POUR LE DEVELOPPEMENT D'UN OUTIL D'ANALYSE ET DE REPRESENTATION DES DONNEES Patrick Rousset 1,2 et Christiane Guinot 3 1 CEREQ, Service
L'analyse des données à l usage des non mathématiciens
 Montpellier L'analyse des données à l usage des non mathématiciens 2 ème Partie: L'analyse en composantes principales AGRO.M - INRA - Formation Permanente Janvier 2006 André Bouchier Analyses multivariés.
Montpellier L'analyse des données à l usage des non mathématiciens 2 ème Partie: L'analyse en composantes principales AGRO.M - INRA - Formation Permanente Janvier 2006 André Bouchier Analyses multivariés.
Transmission d informations sur le réseau électrique
 Transmission d informations sur le réseau électrique Introduction Remarques Toutes les questions en italique devront être préparées par écrit avant la séance du TP. Les préparations seront ramassées en
Transmission d informations sur le réseau électrique Introduction Remarques Toutes les questions en italique devront être préparées par écrit avant la séance du TP. Les préparations seront ramassées en
Instructions pour mettre à jour un HFFv2 v1.x.yy v2.0.00
 Instructions pour mettre à jour un HFFv2 v1.x.yy v2.0.00 HFFv2 1. OBJET L accroissement de la taille de code sur la version 2.0.00 a nécessité une évolution du mapping de la flash. La conséquence de ce
Instructions pour mettre à jour un HFFv2 v1.x.yy v2.0.00 HFFv2 1. OBJET L accroissement de la taille de code sur la version 2.0.00 a nécessité une évolution du mapping de la flash. La conséquence de ce
Pourquoi l apprentissage?
 Pourquoi l apprentissage? Les SE sont basés sur la possibilité d extraire la connaissance d un expert sous forme de règles. Dépend fortement de la capacité à extraire et formaliser ces connaissances. Apprentissage
Pourquoi l apprentissage? Les SE sont basés sur la possibilité d extraire la connaissance d un expert sous forme de règles. Dépend fortement de la capacité à extraire et formaliser ces connaissances. Apprentissage
données en connaissance et en actions?
 1 Partie 2 : Présentation de la plateforme SPSS Modeler : Comment transformer vos données en connaissance et en actions? SPSS Modeler : l atelier de data mining Large gamme de techniques d analyse (algorithmes)
1 Partie 2 : Présentation de la plateforme SPSS Modeler : Comment transformer vos données en connaissance et en actions? SPSS Modeler : l atelier de data mining Large gamme de techniques d analyse (algorithmes)
Filtrage stochastique non linéaire par la théorie de représentation des martingales
 Filtrage stochastique non linéaire par la théorie de représentation des martingales Adriana Climescu-Haulica Laboratoire de Modélisation et Calcul Institut d Informatique et Mathématiques Appliquées de
Filtrage stochastique non linéaire par la théorie de représentation des martingales Adriana Climescu-Haulica Laboratoire de Modélisation et Calcul Institut d Informatique et Mathématiques Appliquées de
LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING»
 LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING» Gilbert Saporta Professeur de Statistique Appliquée Conservatoire National des Arts et Métiers Dans leur quasi totalité, les banques et organismes financiers
LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING» Gilbert Saporta Professeur de Statistique Appliquée Conservatoire National des Arts et Métiers Dans leur quasi totalité, les banques et organismes financiers
Introduction au Data-Mining
 Introduction au Data-Mining Gilles Gasso, Stéphane Canu INSA Rouen -Département ASI Laboratoire LITIS 8 septembre 205. Ce cours est librement inspiré du cours DM de Alain Rakotomamonjy Gilles Gasso, Stéphane
Introduction au Data-Mining Gilles Gasso, Stéphane Canu INSA Rouen -Département ASI Laboratoire LITIS 8 septembre 205. Ce cours est librement inspiré du cours DM de Alain Rakotomamonjy Gilles Gasso, Stéphane
Théorie et Codage de l Information (IF01) exercices 2013-2014. Paul Honeine Université de technologie de Troyes France
 exercices 2013-2014. Paul Honeine Université de technologie de Troyes France") Théorie et Codage de l Information (IF01) exercices 2013-2014 Paul Honeine Université de technologie de Troyes France TD-1 Rappels de calculs de probabilités Exercice 1. On dispose d un jeu de 52 cartes
Théorie et Codage de l Information (IF01) exercices 2013-2014 Paul Honeine Université de technologie de Troyes France TD-1 Rappels de calculs de probabilités Exercice 1. On dispose d un jeu de 52 cartes
Improving the breakdown of the Central Credit Register data by category of enterprises
 Improving the breakdown of the Central Credit Register data by category of enterprises Workshop on Integrated management of micro-databases Deepening business intelligence within central banks statistical
Improving the breakdown of the Central Credit Register data by category of enterprises Workshop on Integrated management of micro-databases Deepening business intelligence within central banks statistical
Algorithmes d'apprentissage
 Algorithmes d'apprentissage 1 Agents qui apprennent à partir d'exemples La problématique : prise de décision automatisée à partir d'un ensemble d'exemples Diagnostic médical Réponse à une demande de prêt
Algorithmes d'apprentissage 1 Agents qui apprennent à partir d'exemples La problématique : prise de décision automatisée à partir d'un ensemble d'exemples Diagnostic médical Réponse à une demande de prêt
ESIEA PARIS 2011-2012
 ESIEA PARIS 2011-2012 Examen MAT 5201 DATA MINING Mardi 08 Novembre 2011 Première Partie : 15 minutes (7 points) Enseignant responsable : Frédéric Bertrand Remarque importante : les questions de ce questionnaire
ESIEA PARIS 2011-2012 Examen MAT 5201 DATA MINING Mardi 08 Novembre 2011 Première Partie : 15 minutes (7 points) Enseignant responsable : Frédéric Bertrand Remarque importante : les questions de ce questionnaire
Encryptions, compression et partitionnement des données
 Encryptions, compression et partitionnement des données Version 1.0 Grégory CASANOVA 2 Compression, encryption et partitionnement des données Sommaire 1 Introduction... 3 2 Encryption transparente des
Encryptions, compression et partitionnement des données Version 1.0 Grégory CASANOVA 2 Compression, encryption et partitionnement des données Sommaire 1 Introduction... 3 2 Encryption transparente des
$SSOLFDWLRQGXNULJHDJHSRXUOD FDOLEUDWLRQPRWHXU
 $SSOLFDWLRQGXNULJHDJHSRXUOD FDOLEUDWLRQPRWHXU Fabien FIGUERES fabien.figueres@mpsa.com 0RWVFOpV : Krigeage, plans d expériences space-filling, points de validations, calibration moteur. 5pVXPp Dans le
$SSOLFDWLRQGXNULJHDJHSRXUOD FDOLEUDWLRQPRWHXU Fabien FIGUERES fabien.figueres@mpsa.com 0RWVFOpV : Krigeage, plans d expériences space-filling, points de validations, calibration moteur. 5pVXPp Dans le
Data Mining. Vincent Augusto 2012-2013. École Nationale Supérieure des Mines de Saint-Étienne. Data Mining. V. Augusto.
 des des Data Mining Vincent Augusto École Nationale Supérieure des Mines de Saint-Étienne 2012-2013 1/65 des des 1 2 des des 3 4 Post-traitement 5 représentation : 6 2/65 des des Définition générale Le
des des Data Mining Vincent Augusto École Nationale Supérieure des Mines de Saint-Étienne 2012-2013 1/65 des des 1 2 des des 3 4 Post-traitement 5 représentation : 6 2/65 des des Définition générale Le
Caroline Hurault-Delarue 1, Cécile Chouquet 2, Nicolas Savy 2, Isabelle Lacroix 1, Christine Damase- Michel 1
 Trajectoires individuelles d'exposition aux psychotropes au cours de la grossesse et partitionnement en fonction du profil d'exposition : utilisation des K-means pour données longitudinales Caroline Hurault-Delarue
Trajectoires individuelles d'exposition aux psychotropes au cours de la grossesse et partitionnement en fonction du profil d'exposition : utilisation des K-means pour données longitudinales Caroline Hurault-Delarue
REVISION DE LA DIRECTIVE ABUS DE MARCHE
 REVISION DE LA DIRECTIVE ABUS DE MARCHE Principaux changements attendus 1 Le contexte La directive Abus de marché a huit ans (2003) Régimes de sanctions disparates dans l Union Harmonisation nécessaire
REVISION DE LA DIRECTIVE ABUS DE MARCHE Principaux changements attendus 1 Le contexte La directive Abus de marché a huit ans (2003) Régimes de sanctions disparates dans l Union Harmonisation nécessaire
Info0804. Cours 6. Optimisation combinatoire : Applications et compléments
 Recherche Opérationnelle Optimisation combinatoire : Applications et compléments Pierre Delisle Université de Reims Champagne-Ardenne Département de Mathématiques et Informatique 17 février 2014 Plan de
Recherche Opérationnelle Optimisation combinatoire : Applications et compléments Pierre Delisle Université de Reims Champagne-Ardenne Département de Mathématiques et Informatique 17 février 2014 Plan de
Le Data Mining au service du Scoring ou notation statistique des emprunteurs!
 France Le Data Mining au service du Scoring ou notation statistique des emprunteurs! Comme le rappelle la CNIL dans sa délibération n 88-083 du 5 Juillet 1988 portant adoption d une recommandation relative
France Le Data Mining au service du Scoring ou notation statistique des emprunteurs! Comme le rappelle la CNIL dans sa délibération n 88-083 du 5 Juillet 1988 portant adoption d une recommandation relative
Cette Leçon va remplir ces attentes spécifiques du curriculum :
 Dev4Plan1 Le Plan De Leçon 1. Information : Course : Français Cadre Niveau : Septième Année Unité : Mes Relations Interpersonnelles Thème du Leçon : Les Adjectifs Descriptifs Date : Temps : 55 minutes
Dev4Plan1 Le Plan De Leçon 1. Information : Course : Français Cadre Niveau : Septième Année Unité : Mes Relations Interpersonnelles Thème du Leçon : Les Adjectifs Descriptifs Date : Temps : 55 minutes
TRAITEMENT DES DONNEES MANQUANTES AU MOYEN DE L ALGORITHME DE KOHONEN
 TRAITEMENT DES DONNEES MANQUANTES AU MOYEN DE L ALGORITHME DE KOHONEN Marie Cottrell, Smaïl Ibbou, Patrick Letrémy SAMOS-MATISSE UMR 8595 90, rue de Tolbiac 75634 Paris Cedex 13 Résumé : Nous montrons
TRAITEMENT DES DONNEES MANQUANTES AU MOYEN DE L ALGORITHME DE KOHONEN Marie Cottrell, Smaïl Ibbou, Patrick Letrémy SAMOS-MATISSE UMR 8595 90, rue de Tolbiac 75634 Paris Cedex 13 Résumé : Nous montrons
Etudes marketing et connaissance client
 Master deuxième année Mention : Statistique et Traitement de Données Etudes marketing et connaissance client Imane Hammouali Tuteur de stage: M. Sébastien Confesson Stage effectué au Service Etudes Marketing
Master deuxième année Mention : Statistique et Traitement de Données Etudes marketing et connaissance client Imane Hammouali Tuteur de stage: M. Sébastien Confesson Stage effectué au Service Etudes Marketing
Souad EL Bernoussi. Groupe d Analyse Numérique et Optimisation Rabat http ://www.fsr.ac.ma/ano/
 Recherche opérationnelle Les démonstrations et les exemples seront traités en cours Souad EL Bernoussi Groupe d Analyse Numérique et Optimisation Rabat http ://www.fsr.ac.ma/ano/ Table des matières 1 Programmation
Recherche opérationnelle Les démonstrations et les exemples seront traités en cours Souad EL Bernoussi Groupe d Analyse Numérique et Optimisation Rabat http ://www.fsr.ac.ma/ano/ Table des matières 1 Programmation
Analyses multivariées avec R Commander (via le package FactoMineR) Qu est ce que R? Introduction à R Qu est ce que R?
 Qu est ce que R? Introduction à R Qu est ce que R?") Analyses multivariées avec R Commander Analyses multivariées avec R Commander (via le package FactoMineR) Plate-forme de Support en Méthodologie et Calcul Statistique (SMCS) - UCL 1 Introduction à R 2
Analyses multivariées avec R Commander Analyses multivariées avec R Commander (via le package FactoMineR) Plate-forme de Support en Méthodologie et Calcul Statistique (SMCS) - UCL 1 Introduction à R 2
Modèles pour données répétées
 Résumé Les données répétées, ou données longitudinales, constituent un domaine à la fois important et assez particulier de la statistique. On entend par données répétées des données telles que, pour chaque
Résumé Les données répétées, ou données longitudinales, constituent un domaine à la fois important et assez particulier de la statistique. On entend par données répétées des données telles que, pour chaque
L'analyse de données. Polycopié de cours ENSIETA - Réf. : 1463. Arnaud MARTIN
 L'analyse de données Polycopié de cours ENSIETA - Réf : 1463 Arnaud MARTIN Septembre 2004 Table des matières 1 Introduction 1 11 Domaines d'application 2 12 Les données 2 13 Les objectifs 3 14 Les méthodes
L'analyse de données Polycopié de cours ENSIETA - Réf : 1463 Arnaud MARTIN Septembre 2004 Table des matières 1 Introduction 1 11 Domaines d'application 2 12 Les données 2 13 Les objectifs 3 14 Les méthodes
1 Modélisation d être mauvais payeur
 1 Modélisation d être mauvais payeur 1.1 Description Cet exercice est très largement inspiré d un document que M. Grégoire de Lassence de la société SAS m a transmis. Il est intitulé Guide de démarrage
1 Modélisation d être mauvais payeur 1.1 Description Cet exercice est très largement inspiré d un document que M. Grégoire de Lassence de la société SAS m a transmis. Il est intitulé Guide de démarrage
Datamining. Université Paris Dauphine DESS ID 2004/2005. Séries télévisées nominées aux oscars. Enseignant : Réalisé par : Mars 2005. Mr E.
 Université Paris Dauphine DESS ID 2004/2005 Datamining Séries télévisées nominées aux oscars Mars 2005 Enseignant : Mr E. DIDAY Réalisé par : Mounia CHERRAD Anne-Sophie REGOTTAZ Sommaire Introduction...
Université Paris Dauphine DESS ID 2004/2005 Datamining Séries télévisées nominées aux oscars Mars 2005 Enseignant : Mr E. DIDAY Réalisé par : Mounia CHERRAD Anne-Sophie REGOTTAZ Sommaire Introduction...
Chapitre 3. Mesures stationnaires. et théorèmes de convergence
 Chapitre 3 Mesures stationnaires et théorèmes de convergence Christiane Cocozza-Thivent, Université de Marne-la-Vallée p.1 I. Mesures stationnaires Christiane Cocozza-Thivent, Université de Marne-la-Vallée
Chapitre 3 Mesures stationnaires et théorèmes de convergence Christiane Cocozza-Thivent, Université de Marne-la-Vallée p.1 I. Mesures stationnaires Christiane Cocozza-Thivent, Université de Marne-la-Vallée
I. Polynômes de Tchebychev
 Première épreuve CCP filière MP I. Polynômes de Tchebychev ( ) 1.a) Tout réel θ vérifie cos(nθ) = Re ((cos θ + i sin θ) n ) = Re Cn k (cos θ) n k i k (sin θ) k Or i k est réel quand k est pair et imaginaire
Première épreuve CCP filière MP I. Polynômes de Tchebychev ( ) 1.a) Tout réel θ vérifie cos(nθ) = Re ((cos θ + i sin θ) n ) = Re Cn k (cos θ) n k i k (sin θ) k Or i k est réel quand k est pair et imaginaire
BIG Data et R: opportunités et perspectives
 BIG Data et R: opportunités et perspectives Guati Rizlane 1 & Hicham Hajji 2 1 Ecole Nationale de Commerce et de Gestion de Casablanca, Maroc, rguati@gmail.com 2 Ecole des Sciences Géomatiques, IAV Rabat,
BIG Data et R: opportunités et perspectives Guati Rizlane 1 & Hicham Hajji 2 1 Ecole Nationale de Commerce et de Gestion de Casablanca, Maroc, rguati@gmail.com 2 Ecole des Sciences Géomatiques, IAV Rabat,
Judge Group: P Title: Quel est meilleur: le compost ou le fertilisant chimique? Student(s): Emma O'Shea Grade: 6
: Emma O'Shea Grade: 6") Project No.1114 Title: Quel est meilleur: le compost ou le fertilisant chimique? Level: Student(s): Emma O'Shea Grade: 6 This progect compares the results of compost, chemical fertilizer and normal earth
Project No.1114 Title: Quel est meilleur: le compost ou le fertilisant chimique? Level: Student(s): Emma O'Shea Grade: 6 This progect compares the results of compost, chemical fertilizer and normal earth
Gnuplot. Chapitre 3. 3.1 Lancer Gnuplot. 3.2 Options des graphes
 Chapitre 3 Gnuplot Le langage C ne permet pas directement de dessiner des courbes et de tracer des plots. Il faut pour cela stocker résultats dans des fichier, et, dans un deuxième temps utiliser un autre
Chapitre 3 Gnuplot Le langage C ne permet pas directement de dessiner des courbes et de tracer des plots. Il faut pour cela stocker résultats dans des fichier, et, dans un deuxième temps utiliser un autre
ISFA 2 année 2002-2003. Les questions sont en grande partie indépendantes. Merci d utiliser l espace imparti pour vos réponses.
 On considère la matrice de données : ISFA 2 année 22-23 Les questions sont en grande partie indépendantes Merci d utiliser l espace imparti pour vos réponses > ele JCVGE FM1 GM JCRB FM2 JMLP Paris 61 29
On considère la matrice de données : ISFA 2 année 22-23 Les questions sont en grande partie indépendantes Merci d utiliser l espace imparti pour vos réponses > ele JCVGE FM1 GM JCRB FM2 JMLP Paris 61 29
Chapitre 3. Les distributions à deux variables
 Chapitre 3. Les distributions à deux variables Jean-François Coeurjolly http://www-ljk.imag.fr/membres/jean-francois.coeurjolly/ Laboratoire Jean Kuntzmann (LJK), Grenoble University 1 Distributions conditionnelles
Chapitre 3. Les distributions à deux variables Jean-François Coeurjolly http://www-ljk.imag.fr/membres/jean-francois.coeurjolly/ Laboratoire Jean Kuntzmann (LJK), Grenoble University 1 Distributions conditionnelles
FORMULAIRE DE STATISTIQUES
 FORMULAIRE DE STATISTIQUES I. STATISTIQUES DESCRIPTIVES Moyenne arithmétique Remarque: population: m xμ; échantillon: Mx 1 Somme des carrés des écarts "# FR MOYENNE(série) MOYENNE(série) NL GEMIDDELDE(série)
FORMULAIRE DE STATISTIQUES I. STATISTIQUES DESCRIPTIVES Moyenne arithmétique Remarque: population: m xμ; échantillon: Mx 1 Somme des carrés des écarts "# FR MOYENNE(série) MOYENNE(série) NL GEMIDDELDE(série)
DOCUMENTATION - FRANCAIS... 2
 DOCUMENTATION MODULE SHOPDECORATION MODULE PRESTASHOP CREE PAR PRESTACREA INDEX : DOCUMENTATION - FRANCAIS... 2 INSTALLATION... 2 Installation automatique... 2 Installation manuelle... 2 Résolution des
DOCUMENTATION MODULE SHOPDECORATION MODULE PRESTASHOP CREE PAR PRESTACREA INDEX : DOCUMENTATION - FRANCAIS... 2 INSTALLATION... 2 Installation automatique... 2 Installation manuelle... 2 Résolution des
Masters Spécialisés «Actuariat et Prévoyance» et «Actuariat et Finance»
 Masters Spécialisés «Actuariat et Prévoyance» et «Actuariat et Finance» Introduction au Data Mining K. EL HIMDI elhimdi@menara.ma 1 Sommaire du MODULE Partie 1 : Introduction au Data Mining Partie 2 :
Masters Spécialisés «Actuariat et Prévoyance» et «Actuariat et Finance» Introduction au Data Mining K. EL HIMDI elhimdi@menara.ma 1 Sommaire du MODULE Partie 1 : Introduction au Data Mining Partie 2 :
First Nations Assessment Inspection Regulations. Règlement sur l inspection aux fins d évaluation foncière des premières nations CONSOLIDATION
 CANADA CONSOLIDATION CODIFICATION First Nations Assessment Inspection Regulations Règlement sur l inspection aux fins d évaluation foncière des premières nations SOR/2007-242 DORS/2007-242 Current to September
CANADA CONSOLIDATION CODIFICATION First Nations Assessment Inspection Regulations Règlement sur l inspection aux fins d évaluation foncière des premières nations SOR/2007-242 DORS/2007-242 Current to September
Cours Informatique Master STEP
 Cours Informatique Master STEP Bases de la programmation: Compilateurs/logiciels Algorithmique et structure d'un programme Programmation en langage structuré (Fortran 90) Variables, expressions, instructions
Cours Informatique Master STEP Bases de la programmation: Compilateurs/logiciels Algorithmique et structure d'un programme Programmation en langage structuré (Fortran 90) Variables, expressions, instructions
2015 kmeans. September 3, 2015
 2015 kmeans September 3, 2015 1 Kmeans avec PIG auteurs : P. Atalaya, M. Gubri M k-means est un algorithme de clustering relativement simple qu on cherche à paralléliser. In [1]: import pyensae %nb_menu
2015 kmeans September 3, 2015 1 Kmeans avec PIG auteurs : P. Atalaya, M. Gubri M k-means est un algorithme de clustering relativement simple qu on cherche à paralléliser. In [1]: import pyensae %nb_menu
RapidMiner. Data Mining. 1 Introduction. 2 Prise en main. Master Maths Finances 2010/2011. 1.1 Présentation. 1.2 Ressources
 Master Maths Finances 2010/2011 Data Mining janvier 2011 RapidMiner 1 Introduction 1.1 Présentation RapidMiner est un logiciel open source et gratuit dédié au data mining. Il contient de nombreux outils
Master Maths Finances 2010/2011 Data Mining janvier 2011 RapidMiner 1 Introduction 1.1 Présentation RapidMiner est un logiciel open source et gratuit dédié au data mining. Il contient de nombreux outils
Analyse de grandes bases de données en santé
 .. Analyse de grandes bases de données en santé Alain Duhamel Michaël Genin Mohamed Lemdani EA 2694 / CERIM Master 2 Recherche Biologie et Santé Journée Thématique Fouille de Données Plan. 1 Problématique.
.. Analyse de grandes bases de données en santé Alain Duhamel Michaël Genin Mohamed Lemdani EA 2694 / CERIM Master 2 Recherche Biologie et Santé Journée Thématique Fouille de Données Plan. 1 Problématique.
Parallélisation de l algorithme des k-médoïdes. Application au clustering de courbes.
 Parallélisation de l algorithme des k-médoïdes. Application au clustering de courbes. Benjamin Auder 1 & Jairo Cugliari 2 1 Laboratoire LMO. Université Paris-Sud. Bât 425. 91405 Orsay Cedex, France. benjamin.auder@math.u-psud.fr
Parallélisation de l algorithme des k-médoïdes. Application au clustering de courbes. Benjamin Auder 1 & Jairo Cugliari 2 1 Laboratoire LMO. Université Paris-Sud. Bât 425. 91405 Orsay Cedex, France. benjamin.auder@math.u-psud.fr
DATAMINING C4.5 - DBSCAN
 14-16 rue Voltaire 94270 Kremlin Bicêtre Benjamin DEVÈZE Matthieu FOUQUIN PROMOTION 2005 SCIA DATAMINING C4.5 - DBSCAN Mai 2004 Responsable de spécialité SCIA : M. Akli Adjaoute Table des matières Table
14-16 rue Voltaire 94270 Kremlin Bicêtre Benjamin DEVÈZE Matthieu FOUQUIN PROMOTION 2005 SCIA DATAMINING C4.5 - DBSCAN Mai 2004 Responsable de spécialité SCIA : M. Akli Adjaoute Table des matières Table
Differential Synchronization
 Differential Synchronization Neil Fraser Google 2009 BENA Pierrick CLEMENT Lucien DIARRA Thiemoko 2 Plan Introduction Stratégies de synchronisation Synchronisation différentielle Vue d ensemble Dual Shadow
Differential Synchronization Neil Fraser Google 2009 BENA Pierrick CLEMENT Lucien DIARRA Thiemoko 2 Plan Introduction Stratégies de synchronisation Synchronisation différentielle Vue d ensemble Dual Shadow
2 Serveurs OLAP et introduction au Data Mining
 2-1 2 Serveurs OLAP et introduction au Data Mining 2-2 Création et consultation des cubes en mode client-serveur Serveur OLAP Clients OLAP Clients OLAP 2-3 Intérêt Systèmes serveurs et clients Fonctionnalité
2-1 2 Serveurs OLAP et introduction au Data Mining 2-2 Création et consultation des cubes en mode client-serveur Serveur OLAP Clients OLAP Clients OLAP 2-3 Intérêt Systèmes serveurs et clients Fonctionnalité
Mémo d utilisation de ADE-4
 Mémo d utilisation de ADE-4 Jérôme Mathieu http://www.jerome.mathieu.freesurf.fr 2003 ADE-4 est un logiciel d analyses des communautés écologiques créé par l équipe de biostatistiques de Lyon. Il propose
Mémo d utilisation de ADE-4 Jérôme Mathieu http://www.jerome.mathieu.freesurf.fr 2003 ADE-4 est un logiciel d analyses des communautés écologiques créé par l équipe de biostatistiques de Lyon. Il propose
Probabilités sur un univers fini
 [http://mp.cpgedupuydelome.fr] édité le 7 août 204 Enoncés Probabilités sur un univers fini Evènements et langage ensembliste A quelle condition sur (a, b, c, d) ]0, [ 4 existe-t-il une probabilité P sur
[http://mp.cpgedupuydelome.fr] édité le 7 août 204 Enoncés Probabilités sur un univers fini Evènements et langage ensembliste A quelle condition sur (a, b, c, d) ]0, [ 4 existe-t-il une probabilité P sur
Programmation linéaire
 1 Programmation linéaire 1. Le problème, un exemple. 2. Le cas b = 0 3. Théorème de dualité 4. L algorithme du simplexe 5. Problèmes équivalents 6. Complexité de l Algorithme 2 Position du problème Soit
1 Programmation linéaire 1. Le problème, un exemple. 2. Le cas b = 0 3. Théorème de dualité 4. L algorithme du simplexe 5. Problèmes équivalents 6. Complexité de l Algorithme 2 Position du problème Soit
Solutions du chapitre 4
 Solutions du chapitre 4 Structures de contrôle: première partie 4.9 Identifiez et corrigez les erreurs (il peut y en avoir plus d une par segment de code) de chacune des proposition suivantes: a) if (
Solutions du chapitre 4 Structures de contrôle: première partie 4.9 Identifiez et corrigez les erreurs (il peut y en avoir plus d une par segment de code) de chacune des proposition suivantes: a) if (
Chapitre 2 Le problème de l unicité des solutions
 Université Joseph Fourier UE MAT 127 Mathématiques année 2011-2012 Chapitre 2 Le problème de l unicité des solutions Ce que nous verrons dans ce chapitre : un exemple d équation différentielle y = f(y)
Université Joseph Fourier UE MAT 127 Mathématiques année 2011-2012 Chapitre 2 Le problème de l unicité des solutions Ce que nous verrons dans ce chapitre : un exemple d équation différentielle y = f(y)
ESSEC. Cours «Management bancaire» Séance 3 Le risque de crédit Le scoring
 ESSEC Cours «Management bancaire» Séance 3 Le risque de crédit Le scoring Les méthodes d évaluation du risque de crédit pour les PME et les ménages Caractéristiques Comme les montants des crédits et des
ESSEC Cours «Management bancaire» Séance 3 Le risque de crédit Le scoring Les méthodes d évaluation du risque de crédit pour les PME et les ménages Caractéristiques Comme les montants des crédits et des
Chp. 4. Minimisation d une fonction d une variable
 Chp. 4. Minimisation d une fonction d une variable Avertissement! Dans tout ce chapître, I désigne un intervalle de IR. 4.1 Fonctions convexes d une variable Définition 9 Une fonction ϕ, partout définie
Chp. 4. Minimisation d une fonction d une variable Avertissement! Dans tout ce chapître, I désigne un intervalle de IR. 4.1 Fonctions convexes d une variable Définition 9 Une fonction ϕ, partout définie
Probabilités conditionnelles Exercices corrigés
 Terminale S Probabilités conditionnelles Exercices corrigés Exercice : (solution Une compagnie d assurance automobile fait un bilan des frais d intervention, parmi ses dossiers d accidents de la circulation.
Terminale S Probabilités conditionnelles Exercices corrigés Exercice : (solution Une compagnie d assurance automobile fait un bilan des frais d intervention, parmi ses dossiers d accidents de la circulation.
Compression et Transmission des Signaux. Samson LASAULCE Laboratoire des Signaux et Systèmes, Gif/Yvette
 Compression et Transmission des Signaux Samson LASAULCE Laboratoire des Signaux et Systèmes, Gif/Yvette 1 De Shannon à Mac Donalds Mac Donalds 1955 Claude Elwood Shannon 1916 2001 Monsieur X 1951 2 Où
Compression et Transmission des Signaux Samson LASAULCE Laboratoire des Signaux et Systèmes, Gif/Yvette 1 De Shannon à Mac Donalds Mac Donalds 1955 Claude Elwood Shannon 1916 2001 Monsieur X 1951 2 Où