Architecture en couche d un SGBD. Modèles de stockage et d indexation. Hiérarchie mémoire. Modèle de stockage: plan du cours
|
|
|
- Arthur Bertrand
- il y a 8 ans
- Total affichages :
Transcription
1 Architecture en couche d un SGBD Interface Modèles de stockage et d indexation Analyseur sémantique Optimiseur Moteur d exécution Opérations relationnelles Méthodes d accès aux données By courtesy of N. Anciaux, L. Bouganim, P. Pucheral, P. Bonnet, D. Shasha, M. J. Zaki Gestion de Mémoire Gestion de Verrous Gestion des Journaux Système d exploitation 1 2 Modèle de stockage: plan du cours Hiérarchie mémoire Introduction à la hiérarchie mémoire Cache CPU, RAM, disques, Flash Ratio Prix (approx) Accès (ns) Débit (Mo/s) Organisation des données Format des attributs, tuples, pages, fichiers, index Modèle de stockage Organisation des index Type d index Modèle d indexation Deux exemples concrets Oracle Key-Value Store: Cassandra Cache processeur RAM Disques Bandes / Disques optiques ms qq sec 10 Go/s 1 Go/s (x10-1 ) 100 Mo/s (x10-2 ) 10 Mo/s (x10-3 ) 3 4
 Accès (ns) Débit (Mo/s) Organisation des données Format des attributs, tuples, pages, fichiers, index Modèle de stockage Organisation des index Type d index Modèle")
2 Disques Magnétiques Optimisations logicielles Progression moyenne des disques Capacité + 60% par an Latence stable contraintes mécaniques Débit + 40% par an Tête de lecture Arbre Pistes Prefetching Le SGBD peut anticiper les patterns d accès aux données Ainsi, il peut pré-charger (prefetch) des données en RAM NB: le prefetching doit être géré au niveau du SGBD (vs. OS) piste plateau levier Contrôleur arbre tête de lecture bras Mouvement du bras Bras Plateaux Secteur Clustering Regroupement physique des données fréquemment utilisées ensemble dans les mêmes blocs/pages de données Placement de ces blocs sur La même piste physique => I/O unique Le même cylindre physique => I/O séquentielles Compromis entre bon placement et trop de perte de place Allocation d un ensemble de blocs par «granule» Interface (IDE, SCSI) 5 6 NAND Flash: le futur des SGBD? Evolution des mémoires secondaires iodrive Octal, 10,24 To PCIe Lecture : IOPS 6,7 Go/s Ecriture : IOPS 3,9 Go/s 96 «package» de Flash Flash Disques magnétiques Capacité 200 Go x10 2 To Go/$ 0,05 x IOPS 200 x1 200 Capacité Go/$ IOPS 14 Go (2001) x Go 0,0003 x1000 0, (SCSI) x1000 > 1 M (PCIe) >5000 (SATA) OCZ Vertex 4-2.5" SATA III Capacité : 512 Go - Prix : env. 600 euros Lecture : IOPS Mo/s Ecriture : IOPS Mo/s Compression, chiffrement, PCM Capacité IOPS cells, 4 bits/cell > 1 M (1 chip) Cartes Micro SD, SD et clés USB Capacité : 1 32 Go (2 To annoncés en SD) Prix : 1 à 2 euros le Go Lecture : env IOPS - env. 20 Mo/s Ecriture : max. 200 IOPS - env. 10 Mo/s Consommation électrique Plus faible que les disques magnétiques Proportionnel à l'usage! 7 8

3 The Good The Bad The hardware! A single flash chip offers great performance e.g., direct read: random (25µs), sequentiel (50ns/byte) e.g., troughput of 40 MB/s Read, 10 MB/s Program Random access is as fast as sequential access Low energy consumption A flash device contains many flash chips (e.g., 32, 64) and provides inter-chips parallelism Flash devices may include some (power-failure resistant) SRAM The severe constraints of flash chips! C1: Program granularity: Program must be performed at flash page granularity C2: Must erase a block before updating a page C3: Pages must be programmed sequentially within a block C4: Limited lifetime (from 10 4 up to 10 6 erase operations) Pages must be programmed sequentially within the block (256 pages) Program granularity: a page (32 KB) Erase granularity: a block (1 MB) 9 10 And The FTL The software!, the Flash Translation Layer emulates a classical block device and handle flash constraints Read sector Write sector No constraint! GARBAGE COLLECTION MAPPING WEAR LEVELING Read page (C2) Erase before prog. Program page Erase block Constraints (C1) Program granularity (C3) Sequential program within a block (C4) Limited lifetime How do flash devices impact DBMS design? : Assumptions Rule 1 (?): Flash devices behave as flash chips DBMS design coping with flash chip constraints Rule 2 (?): Updates and random writes are too expensive Buffer updates, use log-based strategies (Random IOsSequential IOs) Rule 3 (?): Reads are cheap (even random ones) Make aggressive use of random reads, e.g., delay access to attributes Others rules: Do not use all the flash logical space Use a degree of parallelism relative to the number of chips Partition logical space Use semi-random writes Are these assumptions relevant? SSD FTL Flash chips 11 12
 Pages must be programmed sequentially within the block (256 pages) Program granularity: a page (32 KB) Erase granularity: a block (1 MB) 9 10 And The")
4 Benchmarking methodology (example): Device state Impact of write locality Random Writes Samsung SSD Out of the box Random Writes Samsung SSD After filling the device Granularity for the Memoright SSD Locality for the Samsung, Memoright and Mtron SSDs Enforce a well-defined device state 13 SR, RR and SW are very efficient RW are very expensive, unless limited to a focused area Sequential writes should be limited to a few partitions Surprisingly, no device supports parallel IO submission 14 Opacity: Why are FTL so unpredictable? Flash devices vendors mask design decision to protect their advantage Dynamicity: The market is too dynamic to build a DBMS design on a stable sand Leading markets: The flash internal software is tailored for mass markets (e.g., photo, file system) Opportunity: Flash devices vendors include opportunistically some technology in the internal flash software: e.g., deduplication Complexity: Flash devices are complex systems 15 How to tackle the FTL unpredictability? Main idea: Move the complexity to the DBMS Provide a tunnel for IOs that respect Flash constraints maximal performance Manage other unconstrained IOs in best effort Bimodal flash device DBMS unconstrained constr. patterns patterns (C1, C2, C3) Page map., Garb. Coll. (C1, C2, C3) Block map., Wear Leveling (C4) Flash chips (C1) Program granularity (C2) Erase before prog. (C3) Sequential prog. within a block (C4) Limited lifetime But this strategy does not cope with highly parallel devices More research is highly required 16

5 Now, Back to HARD DISK DRIVES Modèles de stockage des données Les données sont stockées sous forme de attributs, de taille fixe ou variable... stockés eux-mêmes sous forme de tuples... stockés dans des pages (blocs disques)... stockés dans des fichiers attributs tuples pages fichiers Rappel : le SGBD gère un cache de pages en RAM à la façon d une mémoire virtuelle Stockage des tuples (attributs de taille fixe) Stockage des tuples (att. de taille variable) Deux alternatives de stockage (le nombre d attributs est fixe): Att1 Att2 Att3 Att4 T1 T2 T3 T4 Att1 Att2 Att3 Att4 $ $ $ $ Adresse de base (B) Adresse = B+T1+T2 Att1 Att2 Att3 Att4 Les informations concernant les types/tailles d attributs Sont partagées par tous les tuples d un fichier Sont stockées dans le catalogue système Accéder au i ème attribut la lecture totale du tuple Tableau d offsets des attributs La deuxième alternative offre Un accès direct au i ème attribut Un petit coût de stockage supplémentaire (taille de «offset» > taille «$») 19 20

6 Pages : tuples de taille fixe Pages: tuples de taille variable Emplacement 1 Emplacement 2 Emplacement 1 Emplacement 2 Rid = (i,n) Page i Emplacement N Trou Emplacement N Rid = (i,2) Rid = (i,1) Emplacement M N Page compacte (pas de trou) Nombre de tuples M M Bitmap (0=trous) Page éparse Nombre d emplacements Identifiant d un tuple (Row id) : Rid = < id page, emplacement #> Remarque la Clé d un tuple est un «pointeur logique», le Rid est un «pointeur physique» N Pointeurs d emplacements Pointeur N vers l espace libre Nombre d emplacements Déplacement des tuples dans la page sans changer le Rid Fichiers non ordonnés Soit la table Doctor suivante id number(4) Le modèle de stockage NSM (N-ary Storage Model ou Raw-based) Le modèle de stockage DSM (Decomposition Storage Model ou Column-based) Optimisation des I/O Le modèle de stockage PAX (Partition Attributes Across) Optimisation du cache first_name char(30) gender char(1) specialty char(20) 1 Maria F Pediatrics 2 Antonio M Dermatology 3 Dominique F Psychology 1 Maria F Pediatrics 2 Antonio M Dermatology 3 Dominique F Psychology Pages disques ID1 1 ID2 2 ID3 3 ID1 Maria ID2 Antonio ID3 Dominique ID1 F ID2 M ID3 F ID1 Pediatrics ID2 Dermatology ID3 Psychology ID1 ID2 1 2 Maria Antonio F M Pediatrics Dermatology ID3 3 Dominique F Psychology 23 Objectifs Indexation Offrir un accès rapide à tous les tuples d un fichier satisfaisant un même critère A partir d une clé (discriminante ou non, mono ou multi-attributs) Sur des fichiers ordonnés sur cette clé, ou non ordonnés, ou ordonnés sur une autre clé Moyen Créer une structure de données accélératrice associant des adresses de tuples aux valeurs de clés Index Table (ou hiérarchie de tables) implémentant cet accélérateur 24

7 Catégories d index (1) Catégories d index (2) Index primaire ou plaçant (primary or clustered) Tuples du fichier organisés par rapport à l index Les tuples sont stockés «dans» l index 1 seul index primaire par table Souvent construit par le SGBD sur la clé primaire Index secondaire ou non plaçant (secondary or unclustered) Tuples organisés indépendamment de l index Seuls les Rid des tuples sont «dans» l index Plusieurs index secondaires possibles par table Clé K K1 K2 Kn Page 1 Page 2 Page i Tuples triés sur K Clé L K1 K2 Kn Page 1 Page 2 Page i Tuples non triés sur L 25 Index dense (dense) Contient toutes les clés référence tous les tuples Index non dense (sparse) Ne contient pas toutes les clés Ne référence pas tous les tuples (e.g., référence une seule fois chaque page) Nécessite que le fichier soit trié sur les clés Contient alors la plus grande clé de chaque bloc + l'adresse du bloc NB : Densité d un index : tuple tuple tuple Page 1 Page 2 Page i nb d entrées dans l'index nb de tuples dans la table tuple tuple tuple Page 1 Page 2 Page i 26 Mais au fait Catégories d index (3) Peut-on créer un index non dense non plaçant? Peut-on créer un index dense et plaçant? Peut-on créer un index primaire (c.à.d, plaçant) sur une clé secondaire (c.à.d, non discriminante)? Peut-on créer un index secondaire (c.à.d, non plaçant) sur une clé primaire (c.à.d, discriminante)? Index arborescents Index hiérarchisés ou multi-niveaux Permet de gérer de gros index (i.e., très gros fichiers ) Principe : chaque index est indexé Fonctionnement L index est trié (mais trop gros peu performant ) Pourquoi l index à indexer doit-il être trié? On indexe l index Par un second index non dense ( 2ème niveau) On peut continuer (jusqu à obtenir un index non dense qui tiennent dans une seule page ) 27 28
 Contient toutes les clés référence tous les tuples Index non dense (sparse) Ne contient pas toutes les clés Ne référence pas tous les tuples (e.g.")
8 Exemple : Arbre-B+ Arbre-B (B-tree) Un arbre-b d'ordre m est un arbre tel que: (i) chaque noeud contient k clés triées, avec m <= k <= 2m, sauf la racine pour laquelle k vérifie 1<= k <= 2m. (ii) tout noeud non feuille possède (k+1) fils. Le ième fils contient des clés comprises entre la (i-1)ème et la ième clé du père. (iii) l'arbre est équilibré. 1) en mettant toutes les clés des articles dans un arbre B+ et en pointant sur ces articles par des adresses relatives ==> INDEX NON PLACANT 2) en rangeant les articles au plus bas niveau de l'arbre B+ ==> INDEX PLACANT Hauteur d'un Arbre-B La hauteur d'un arbre-b est déterminé par son ordre et le nombre de clés contenues. pour stocker N clés : log 2m (N) h log m (N) Soit h=3 pour N=8000 et m=10 Ou h=3 pour N=8 millions et m=100 Ou encore h=3 pour N=1 milliard et m=500 h est très important car il détermine le nombre d E/S nécessaire pour traverser l arbre lors d une sélection Dans la pratique, qu est ce qui détermine m? Et pourquoi est-ce important que l arbre soit équilibré? A faire chez soi : comprendre la mise à jour dans un arbre-b Objectif Organisations par Hachage Offrir un accès rapide à tous les tuples d un fichier satisfaisant un même critère (idem orga. arborescentes) Eviter le coût lié à la traversée d une arborescence Moyen Calculer l adresse du tuple à l'aide d'une fonction de hachage appliquée à la clé de recherche La sélection se fait directement en recalculant cette même fonction 31 Hachage statique Clé Fonction de hachage i n } Paquets Les fonctions de hachage génèrent des collisions Donc des débordements de paquets Un fichier ayant débordé ne garantit plus de bons temps d'accès (1 + p), avec p potentiellement grand Il ne garantit pas non plus l uniformité (prédictibilité) des temps d accès Solution idéale: réorganisation progressive 32

9 Hachage extensible Et la gestion multi-attributs? H (KEY) XXXX X X X Signature Le paquet 01 éclate en deux paquets 001 et on double la taille du répertoire - on considère un bit de plus dans chaque signature Répertoire Paquets Paquets Ex: Table Médecins fréquemment interrogée sur l attribut Spécialité mais également sur l attribut Adresse Organisations arborescentes Tri multi-critères A1, A2, An Permet de traiter les critères du type (A1 θ x) AND (A2 θ y) Peut-on traiter par exemple (A2 θ y) seul? Organisations hachées Hachage multi-attributs A1, A2, An Certains attributs peuvent être privilégiés en leur allouant plus de bits, en positionnant ces bits en début de chaîne Peut-on traiter par exemple (A2 = y) seul? h1(a1), h2(a2), hn(an) Répertoire 33 h1(a1), h2(a2), hn(an) 34 Comparaisons B+Tree vs. Hachage Organisations arborescentes Supporte les point (égalité) et range (inégalité) queries Le nb d E/S dépend de la hauteur de l arbre (usuellement h reste petit) La taille de l index est potentiellement importante Le coût de mise à jour est potentiellement important Organisations hachées Ne supporte que les point queries Performance optimale (resp. mauvaise) quand les données sont bien (resp. mal) distribuées 35 Utilisation d index multicritères cas part. Construction d index couvrant une requête Accès à l index (sans accès à la relation) permet de répondre à la requête Accélération drastique d un pattern de requêtes particulier Attributs à mettre dans l index couvrant Tous les attributs nécessaires à la requête Attributs intervenant dans les sélections Attributs intervenant dans les projections Exemple Pattern de requête SELECT P.nom FROM Personne P WHERE P.salaire > Y; Index couvrant Index sur la clé suivante : P.salaire, P.nom 36
 AND (A2 θ y) Peut-on traiter par exemple (A2 θ y) seul?")
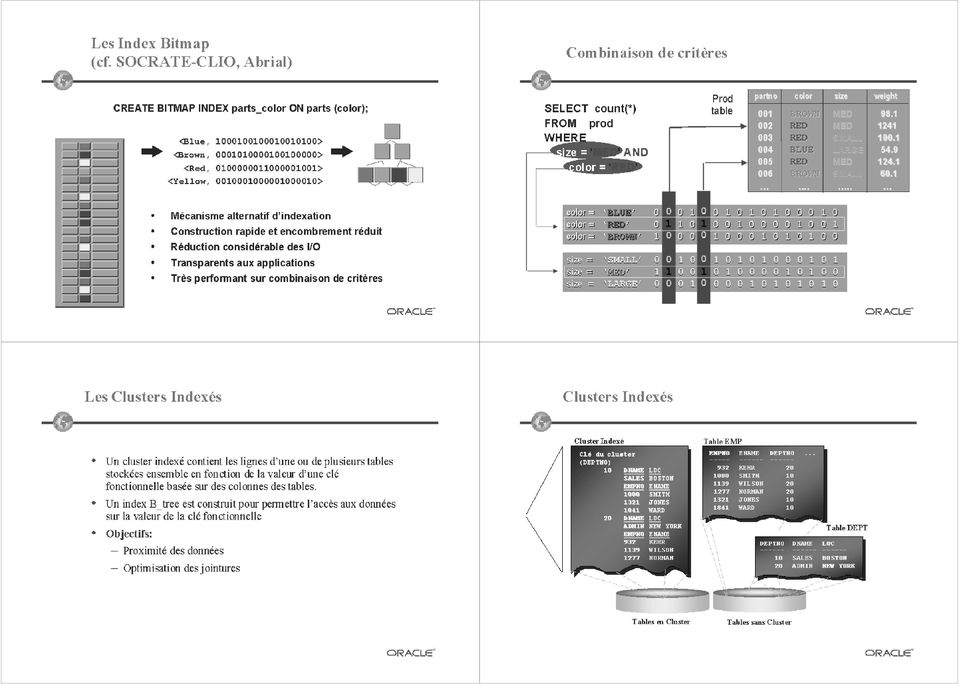
10 Index Bitmap Index de jointure Index Bitmap = index secondaire dense non trié A chaque clé, on associe un bitmap 1 entrée par tuple 1/0 = contient oui/non la valeur Utilisé si Art Berthe Nurse Zouk 1) clé varie sur un domaine de faible cardinalité 2) requêtes multi-critères sans sélectivité dominante Pourquoi? Art Zouk Berthe Art Zouk Berthe Art Zouk Nurse Peut être vu comme une façon de compresser les listes inversées (listes de Rid) 37 vers Doctor Join Index Matérialisation d une association (jointure) Exemple IJ Doc,Visit Star Join index Pour les schémas en étoile (star schema) Stocké sous forme de bitmap clés = valeur d attributs d une dimension bits = référencent les tuples de Fact Utilisé pour les requêtes en étoile σ : des sélections sur les dimensions : entre les dimensions et la table de faits id Les prédicats sont tous appliqués par AND/OR de bitmaps Lundi mardi mercredi D1 Jour 1 Lundi 2 mardi 3 mercredi IJ vers Visit docid visitid XL XXL FACT D1 D2 id Desc Art Zouk Berthe Frank Bif D2 id Taille 1 XL 2 XXL D3 38 Organisation des données sur disque Logique Physique Base de données Database Récipient logique pour regrouper des objets applicatifs liés et administrés ensemble Tablespace Datafiles Oracle Lieu de stockage d une structure : Table, index, partition de table Granule d allocation = Ensemble de blocs contigus Granule d I/O Idéalement multiple d un Bloc OS Segment Extent Block Bloc OS Support partiellement emprunté à Pascale Borla Salamet Oracle France 39 40
 Exemple IJ Doc,Visit Star Join index Pour les schémas en étoile (star schema) Stocké sous forme de bitmap clés = valeur d attributs d une dimension bits =")
11 41 42 Data blocs Un data block est l unité de gestion de l espace disque Il est la plus petite unité d E/S Géré indépendamment de son contenu (table, index ) Tuples (row data) Entête Espace libre (PCTFREE, PCTUSED) Répertoire de tuples (row directory) Répertoire de table (table directory) 43 44
 Répertoire de table (table")
12 PCTFREE et PCTUSED Paramètre PCTFREE Pourcentage d un bloc réservé aux mises à jour futures Quand PCTFREE est atteint : le bloc est retiré de la freelist (liste des blocs dans lesquels il est possible d insérer de nouvelles données) Paramètre PCTUSED Pourcentage d occupation minimum d un bloc en dessous duquel des données peuvent à nouveau être insérées Quand PCTUSED est atteint : le bloc est remis dans la freelist 40%, par défaut Pourquoi si faible? La taille moyenne d un tuple suffirait Utilisation de PCTFREE et PCTUSED PCTFREE=20, PCTUSED=40 INSERTION (Max 80% du bloc) Mise à jour Si Oracle remet les bloc dans la liste des blocs libre alors que ces blocs disposent de peu d espace libre, le coût des insertions nombreuses (de plusieurs tuples) sera très élevé (jusqu à 1 IO par tuple inséré) Réglage Par le DBA (paramètre du CREATE TABLE) Par l ASS = Automatic Segment Space Management (>Oracle 8i) -> recommandé 45 SUPPRESSION Si PCTUSED<40, alors des insertions peuvent à nouveau être effectuées 46 Table index-organized = index plaçant les tuples entiers sont stockés dans les feuilles plutôt que leur Rowid 47 48
 Mise à jour Si Oracle remet les bloc dans la liste des blocs libre alors")
13
14 53 54 Partitionnement des tables (1) 3 méthodes de partitionnement Partitionnement des tables (2) Possibilité de combiner les modes (partitionnement composite) Exemple CREATE TABLE sales_hash (salesman_id NUMBER(5), salesman_name VARCHAR2(30), sales_amount NUMBER(10), week_no NUMBER(2)) PARTITION BY HASH(salesman_id) PARTITIONS 4 STORE IN (ts1, ts2, ts3, ts4); tablespaces 55 CREATE TABLE sales_composite (salesman_id NUMBER(5), salesman_name VARCHAR2(30), PARTITION BY RANGE(sales_date) SUBPARTITION BY HASH(salesman_id) SUBPARTITION TEMPLATE( SUBPARTITION sp1 TABLESPACE ts1, SUBPARTITION sp2 TABLESPACE ts2, PARTITION sales_jan2000 VALUES LESS THAN(TO_DATE('02/01/2000','DD/MM/YYYY')) PARTITION sales_feb2000 VALUES LESS THAN(TO_DATE('03/01/2000','DD/MM/YYYY')) 56
) PARTITION sales_feb2000 VALUES LESS THAN(TO_DATE('03/01/2000','DD/MM/YYYY'))")
15 Partitionnement des index Index partitionné local Index partitionné global Index global non partitionné sur une table partitionnée Key-Value Store: stockage & indexation L exemple de CASSANDRA (Facebook Apache) Data Store structuré, hautement distribué, scalable et disponible Développé initialement pour supporter les recherches dans les Inbox Facebook Milliards d écritures par jour Basé sur Principe de key-value store DHT (Distributed Hash Table) Eventual consistency Un index bitmap partitionné ne peut qu être local Amount of Stored Data By Sector (in Petabytes, 2009) If you like analogies David J. DeWitt dewitt@microsoft.com Rimma Nehme rimman@microsoft.com Microsoft Jim Gray Systems Lab Madison, Wisconsin Petabytes ZB = enough data to fill a stack of DVDs 619 reaching halfway to Mars Earth Sources: "Big Data: The Next Frontier for Innovation, Competition and Productivity." US Bureau of Labor Statistics McKinsley Global Institute Analysis Mars 1 zettabyte? = 1 million petabytes = 1 billion terabytes = 1 trillion gigabytes 60

16 Key/Value Stores Old guard Use a parallel database system Examples: MongoDB, CouchBase, Cassandra, Windows Azure, Flexible data model such as JSON Records sharded across nodes in a cluster by hashing on key Single record retrievals based on key ebay 10PB on 256 nodes Young turks Hadoop Use a NoSQL system Scalable fault tolerant framework for storing and processing MASSIVE data sets Typically no data model Records stored in distributed file system Facebook - 20PB on 2700 nodes Bing 150PB on 40K nodes 61 Structured & 62 Unstructured Retour à nos moutons Stockage et indexation dans Cassandra Relational DB Systems Structured data w/ known schema ACID Transactions SQL Rigid Consistency Model ETL Longer time to insight Maturity, stability, efficiency NoSQL Systems (Un)(Semi)structured data w/o schema No ACID No transactions No SQL Eventual consistency No ETL Faster time to insight Flexibility 63 64
(Semi)structured data")
17 Cassandra: modèle de données Column Paire (clé: name, valeur:value) associé à un timestamp utilisé pour la synchronisation Name, value : chaînes d octets sans limite de taille Exemple de Column Family Column family Super-column Column dans laquelle la valeur est elle-même une liste de colonnes Column family Similaire à une table (i.e., ensemble de tuples) La structure des tuples n est pas obligatoirement uniforme Exemple de Super-Column Family Illustration 67 68
 La structure des tuples n est pas obligatoirement uniforme 65 66 Exemple de Super-Column")
18 Stockage distribué par consistent hashing Hachage sur un anneau (Distributed Hash Table) Par défaut MD5, mais peut être configuré Hachage préservant l ordre déconseillé (inéqui-distribution) Chaque tuple est haché sur sa clé k et placé sur le noeud proxy d identifiant k Il est répliqué sur N voisins (pas de cohérence forte sauf si exigé) Dont au moins un sur un data center différent du noeud proxy Recherche logarihmique vs. directe Chaque noeud possède une table de routage partielle (ex: avec p entrées) Décdoupage récursif de l espace en 2 recherche logarithmique Cassandra 1 noeud = 1 data center tous les data centers ont une table de routage complète Zone de coordination du noeud N Primary index Index sur chaque noeud Chaque noeud maintient un index local sur la clé primaire des tuples qu il stocke (clé d une (super)-column family) Secondary index Sur n importe quelle Column Mise à jour des index Objectif = supporter des milliards de modifications par jour pas de mise à jour en place sur disque pour éviter les I/O random Log Mise à jour des index (1) MemTable 71 72
 Décdoupage récursif de l espace en 2 recherche logarithmique Cassandra 1 noeud = 1 data center tous les data centers")
19 Mise à jour des index (2) Lecture dans l index (1) SSTable Optimisation Minimiser le nombre de SSTable présentes sur disque Fusion d index par Sort-merge I/O séquentielles Bloom Filter : principe Bloom filter Structure probabiliste compacte pour réaliser des tests d appartenance d un élément à un ensemble Pas de faux négatifs Possibilités de faux positifs, mais avec un ratio f très faible f est influencé par m et k. Par exemple, avec m=16n, k=7, f = (n: nb d éléments dans l ensemble) Minimiser le nombre de SSTable à tester lors des recherches Ajout d un Bloom Filter pour chaque SSTable 75 76

20 Bloom Filter : exemple Bibliographie (1) Site de vulgarisation Disques durs Example : F ={12, 23,45, 48, 67, 88} k independent hash functions, e.g., h1 and h2 h1(12) = 0 h2(12)=7 h1(23) = 10 h2(23)=3 h1(45) = 4 h2(45)=1 h1(48) = 7 h2(48)=0 h1(67) = 3 h2(67)=10 h1(88) = 6 h2(88)= Test the membership of 23, 46, 60 h1(23) = 10 h2(23)=3 h1(46) = 8 h2(46)=10 h1(60) = 4 h2(60)=7 23 F 46 F 60 is a false positive. Jim gray Evolution du matériel pour le stockage persistent des données Présentation : «the five minutes rule» Lien : Présentation de Bernard Ourghanlian (Microsoft France) Lien : /Innovation%20-%20Centrale.pdf/download Cours BD INSA Rouen Stockage Dennis Shasha, Philippe Bonnet Storage Tuning Livre : Database Tuning Lien : Site industriels Prix du matériel (nouvelles technologies de stockage) Sur : Compléments du lien : Sun/sunfire.x _tpch.sybaseIQ.100gb.es.pdf IBM/IBM_595_64_ _ESv2.pdf Sun/sunfire.x _tpch.sybaseIQ.100gb.es.pdf Bibliographie (2) Mohammed J. Zaki Modèle de stockage et d indexation des données Présentations (voir en particulier les lectures 7 et 8) Lien : J. L. Griffin et al. Stockage persistent basé sur la technologie MEMS Article de recherche : Modeling and Performance of MEMS-Based Storage Devices (Sigmetrics 2000) Lien : Sites industriels Stockage persistent basé sur la technologie FLASH Flash disk 3,5 : datasheet.3.5.pdf Flash disk 2.5 : datasheet.2.5.pdf Etude de 2005 : Latence et débit : 79

Techniques de stockage. Techniques de stockage, P. Rigaux p.1/43
 Techniques de stockage Techniques de stockage, P. Rigaux p.1/43 Techniques de stockage Contenu de ce cours : 1. Stockage de données. Supports, fonctionnement d un disque, technologie RAID 2. Organisation
Techniques de stockage Techniques de stockage, P. Rigaux p.1/43 Techniques de stockage Contenu de ce cours : 1. Stockage de données. Supports, fonctionnement d un disque, technologie RAID 2. Organisation
TP11 - Administration/Tuning
 TP11 - Administration/Tuning MIAGE #3-2006/2007 January 9, 2007 1 Architecture physique d une base Oracle 1.1 La structure physique Une base de données Oracle est composé de fichiers (au sens du système
TP11 - Administration/Tuning MIAGE #3-2006/2007 January 9, 2007 1 Architecture physique d une base Oracle 1.1 La structure physique Une base de données Oracle est composé de fichiers (au sens du système
Introduction aux SGBDR
 1 Introduction aux SGBDR Pour optimiser une base Oracle, il est important d avoir une idée de la manière dont elle fonctionne. La connaissance des éléments sous-jacents à son fonctionnement permet de mieux
1 Introduction aux SGBDR Pour optimiser une base Oracle, il est important d avoir une idée de la manière dont elle fonctionne. La connaissance des éléments sous-jacents à son fonctionnement permet de mieux
Structure fonctionnelle d un SGBD
 Fichiers et Disques Structure fonctionnelle d un SGBD Requetes Optimiseur de requetes Operateurs relationnels Methodes d acces Gestion de tampon Gestion de disque BD 1 Fichiers et Disques Lecture : Transfert
Fichiers et Disques Structure fonctionnelle d un SGBD Requetes Optimiseur de requetes Operateurs relationnels Methodes d acces Gestion de tampon Gestion de disque BD 1 Fichiers et Disques Lecture : Transfert
Performances. Gestion des serveurs (2/2) Clustering. Grid Computing
 Clustering. Grid Computing") Présentation d Oracle 10g Chapitre VII Présentation d ORACLE 10g 7.1 Nouvelles fonctionnalités 7.2 Architecture d Oracle 10g 7.3 Outils annexes 7.4 Conclusions 7.1 Nouvelles fonctionnalités Gestion des
Présentation d Oracle 10g Chapitre VII Présentation d ORACLE 10g 7.1 Nouvelles fonctionnalités 7.2 Architecture d Oracle 10g 7.3 Outils annexes 7.4 Conclusions 7.1 Nouvelles fonctionnalités Gestion des
Cours Bases de données 2ème année IUT
 Cours Bases de données 2ème année IUT Cours 13 : Organisation d une base de données, ou comment soulever (un peu) le voile Anne Vilnat http://www.limsi.fr/individu/anne/cours Plan 1 Les clusters de table
Cours Bases de données 2ème année IUT Cours 13 : Organisation d une base de données, ou comment soulever (un peu) le voile Anne Vilnat http://www.limsi.fr/individu/anne/cours Plan 1 Les clusters de table
Big Data et Graphes : Quelques pistes de recherche
 Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de Lyon/Université Claude Bernard Lyon 1/Université
Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de Lyon/Université Claude Bernard Lyon 1/Université
ECR_DESCRIPTION CHAR(80), ECR_MONTANT NUMBER(10,2) NOT NULL, ECR_SENS CHAR(1) NOT NULL) ;
, ECR_MONTANT NUMBER(10,2) NOT NULL, ECR_SENS CHAR(1) NOT NULL) ;") RÈGLES A SUIVRE POUR OPTIMISER LES REQUÊTES SQL Le but de ce rapport est d énumérer quelques règles pratiques à appliquer dans l élaboration des requêtes. Il permettra de comprendre pourquoi certaines
RÈGLES A SUIVRE POUR OPTIMISER LES REQUÊTES SQL Le but de ce rapport est d énumérer quelques règles pratiques à appliquer dans l élaboration des requêtes. Il permettra de comprendre pourquoi certaines
Administration des bases de données relationnelles Part I
 Administration des bases de données relationnelles Part I L administration des bases de données requiert une bonne connaissance - de l organisation et du fonctionnement interne du SGBDR : structures logiques
Administration des bases de données relationnelles Part I L administration des bases de données requiert une bonne connaissance - de l organisation et du fonctionnement interne du SGBDR : structures logiques
Optimisations des SGBDR. Étude de cas : MySQL
 Optimisations des SGBDR Étude de cas : MySQL Introduction Pourquoi optimiser son application? Introduction Pourquoi optimiser son application? 1. Gestion de gros volumes de données 2. Application critique
Optimisations des SGBDR Étude de cas : MySQL Introduction Pourquoi optimiser son application? Introduction Pourquoi optimiser son application? 1. Gestion de gros volumes de données 2. Application critique
Administration de Bases de Données : Optimisation
 Administration de Bases de Données : Optimisation FIP 2 année Exercices CNAM Paris Nicolas.Travers(at) cnam.fr Table des matières 1 Stockagedans unsgbd 3 1.1 Stockage.............................................
Administration de Bases de Données : Optimisation FIP 2 année Exercices CNAM Paris Nicolas.Travers(at) cnam.fr Table des matières 1 Stockagedans unsgbd 3 1.1 Stockage.............................................
Groupe de Discussion Big Data Aperçu des technologies et applications. Stéphane MOUTON stephane.mouton@cetic.be
 Groupe de Discussion Big Data Aperçu des technologies et applications Stéphane MOUTON stephane.mouton@cetic.be Recherche appliquée et transfert technologique q Agréé «Centre Collectif de Recherche» par
Groupe de Discussion Big Data Aperçu des technologies et applications Stéphane MOUTON stephane.mouton@cetic.be Recherche appliquée et transfert technologique q Agréé «Centre Collectif de Recherche» par
SQL. Oracle. pour. 4 e édition. Christian Soutou Avec la participation d Olivier Teste
 Christian Soutou Avec la participation d Olivier Teste SQL pour Oracle 4 e édition Groupe eyrolles, 2004, 2005, 2008, 2010, is BN : 978-2-212-12794-2 Partie III SQL avancé La table suivante organisée en
Christian Soutou Avec la participation d Olivier Teste SQL pour Oracle 4 e édition Groupe eyrolles, 2004, 2005, 2008, 2010, is BN : 978-2-212-12794-2 Partie III SQL avancé La table suivante organisée en
Big Data et Graphes : Quelques pistes de recherche
 Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci http://liris.cnrs.fr/hamamache.kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de
Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci http://liris.cnrs.fr/hamamache.kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de
Mise en oeuvre TSM 6.1
 Mise en oeuvre TSM 6.1 «Bonnes pratiques» pour la base de données TSM DB2 Powered by Qui sommes nous? Des spécialistes dans le domaine de la sauvegarde et de la protection des données 10 ans d expertise
Mise en oeuvre TSM 6.1 «Bonnes pratiques» pour la base de données TSM DB2 Powered by Qui sommes nous? Des spécialistes dans le domaine de la sauvegarde et de la protection des données 10 ans d expertise
NFA 008. Introduction à NoSQL et MongoDB 25/05/2013
 NFA 008 Introduction à NoSQL et MongoDB 25/05/2013 1 NoSQL, c'est à dire? Les bases de données NoSQL restent des bases de données mais on met l'accent sur L'aspect NON-relationnel L'architecture distribuée
NFA 008 Introduction à NoSQL et MongoDB 25/05/2013 1 NoSQL, c'est à dire? Les bases de données NoSQL restent des bases de données mais on met l'accent sur L'aspect NON-relationnel L'architecture distribuée
OpenPaaS Le réseau social d'entreprise
 OpenPaaS Le réseau social d'entreprise Spécification des API datastore SP L2.3.1 Diffusion : Institut MinesTélécom, Télécom SudParis 1 / 12 1OpenPaaS DataBase API : ODBAPI...3 1.1Comparaison des concepts...3
OpenPaaS Le réseau social d'entreprise Spécification des API datastore SP L2.3.1 Diffusion : Institut MinesTélécom, Télécom SudParis 1 / 12 1OpenPaaS DataBase API : ODBAPI...3 1.1Comparaison des concepts...3
Présentation du module Base de données spatio-temporelles
 Présentation du module Base de données spatio-temporelles S. Lèbre slebre@unistra.fr Université de Strasbourg, département d informatique. Partie 1 : Notion de bases de données (12,5h ) Enjeux et principes
Présentation du module Base de données spatio-temporelles S. Lèbre slebre@unistra.fr Université de Strasbourg, département d informatique. Partie 1 : Notion de bases de données (12,5h ) Enjeux et principes
Session S12 Les bases de l optimisation SQL avec DB2 for i
 Session S12 Les bases de l optimisation SQL avec DB2 for i C. GRIERE cgriere@fr.ibm.com STG Lab Services IBM i Avril 2012 Les fleurs et les requêtes SQL Lorsque l on veut planter de nouvelles fleurs dans
Session S12 Les bases de l optimisation SQL avec DB2 for i C. GRIERE cgriere@fr.ibm.com STG Lab Services IBM i Avril 2012 Les fleurs et les requêtes SQL Lorsque l on veut planter de nouvelles fleurs dans
Quick Start Guide This guide is intended to get you started with Rational ClearCase or Rational ClearCase MultiSite.
 Rational ClearCase or ClearCase MultiSite Version 7.0.1 Quick Start Guide This guide is intended to get you started with Rational ClearCase or Rational ClearCase MultiSite. Product Overview IBM Rational
Rational ClearCase or ClearCase MultiSite Version 7.0.1 Quick Start Guide This guide is intended to get you started with Rational ClearCase or Rational ClearCase MultiSite. Product Overview IBM Rational
Informatique pour scientifiques hiver 2003-2004. Plan général Systèmes d exploitation
 Informatique pour scientifiques hiver 2003-2004 27 Janvier 2004 Systèmes d exploitation - partie 3 (=OS= Operating Systems) Dr. Dijana Petrovska-Delacrétaz DIVA group, DIUF 1 Plan général Systèmes d exploitation
Informatique pour scientifiques hiver 2003-2004 27 Janvier 2004 Systèmes d exploitation - partie 3 (=OS= Operating Systems) Dr. Dijana Petrovska-Delacrétaz DIVA group, DIUF 1 Plan général Systèmes d exploitation
Cartographie des solutions BigData
 Cartographie des solutions BigData Panorama du marché et prospective 1 1 Solutions BigData Défi(s) pour les fournisseurs Quel marché Architectures Acteurs commerciaux Solutions alternatives 2 2 Quels Défis?
Cartographie des solutions BigData Panorama du marché et prospective 1 1 Solutions BigData Défi(s) pour les fournisseurs Quel marché Architectures Acteurs commerciaux Solutions alternatives 2 2 Quels Défis?
Master Exploration Informatique des données DataWareHouse
 Master Exploration Informatique des données DataWareHouse Binôme Ahmed BENSI Enseignant tahar ARIB SOMMAIRE I. Conception...1 1. Contexte des contrats...1 2. Contexte des factures...1 II. Modèle physique...2
Master Exploration Informatique des données DataWareHouse Binôme Ahmed BENSI Enseignant tahar ARIB SOMMAIRE I. Conception...1 1. Contexte des contrats...1 2. Contexte des factures...1 II. Modèle physique...2
4. Utilisation d un SGBD : le langage SQL. 5. Normalisation
 Base de données S. Lèbre slebre@unistra.fr Université de Strasbourg, département d informatique. Présentation du module Contenu général Notion de bases de données Fondements / Conception Utilisation :
Base de données S. Lèbre slebre@unistra.fr Université de Strasbourg, département d informatique. Présentation du module Contenu général Notion de bases de données Fondements / Conception Utilisation :
MapReduce. Malo Jaffré, Pablo Rauzy. 16 avril 2010 ENS. Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15
 MapReduce 16 avril 2010 1 / 15") MapReduce Malo Jaffré, Pablo Rauzy ENS 16 avril 2010 Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15 Qu est ce que c est? Conceptuellement Données MapReduce est un framework de calcul distribué
MapReduce Malo Jaffré, Pablo Rauzy ENS 16 avril 2010 Malo Jaffré, Pablo Rauzy (ENS) MapReduce 16 avril 2010 1 / 15 Qu est ce que c est? Conceptuellement Données MapReduce est un framework de calcul distribué
Gestion de mémoire secondaire F. Boyer, Laboratoire Sardes Fabienne.Boyer@imag.fr
 Gestion de mémoire secondaire F. Boyer, Laboratoire Sardes Fabienne.Boyer@imag.fr 1- Structure d un disque 2- Ordonnancement des requêtes 3- Gestion du disque - formatage - bloc d amorçage - récupération
Gestion de mémoire secondaire F. Boyer, Laboratoire Sardes Fabienne.Boyer@imag.fr 1- Structure d un disque 2- Ordonnancement des requêtes 3- Gestion du disque - formatage - bloc d amorçage - récupération
NoSQL. Introduction 1/23. I NoSQL : Not Only SQL, ce n est pas du relationnel, et le contexte. I table d associations - Map - de couples (clef,valeur)
") 1/23 2/23 Anne-Cécile Caron Master MIAGE - BDA 1er trimestre 2013-2014 I : Not Only SQL, ce n est pas du relationnel, et le contexte d utilisation n est donc pas celui des SGBDR. I Origine : recherche
1/23 2/23 Anne-Cécile Caron Master MIAGE - BDA 1er trimestre 2013-2014 I : Not Only SQL, ce n est pas du relationnel, et le contexte d utilisation n est donc pas celui des SGBDR. I Origine : recherche
Les bases de données
 Les bases de données Introduction aux fonctions de tableur et logiciels ou langages spécialisés (MS-Access, Base, SQL ) Yves Roggeman Boulevard du Triomphe CP 212 B-1050 Bruxelles (Belgium) Idée intuitive
Les bases de données Introduction aux fonctions de tableur et logiciels ou langages spécialisés (MS-Access, Base, SQL ) Yves Roggeman Boulevard du Triomphe CP 212 B-1050 Bruxelles (Belgium) Idée intuitive
Oracle Maximum Availability Architecture
 Oracle Maximum Availability Architecture Disponibilité des systèmes d informations Technologies et recommandations 1 Qu est-ce que Oracle Maximum Availability Architecture (MAA)? 1. Objectif : Disponibilité
Oracle Maximum Availability Architecture Disponibilité des systèmes d informations Technologies et recommandations 1 Qu est-ce que Oracle Maximum Availability Architecture (MAA)? 1. Objectif : Disponibilité
<Insert Picture Here> Exadata Storage Server et DB Machine V2
 Exadata Storage Server et DB Machine V2 Croissance de la Volumétrie des Données Volumes multipliés par 3 tous les 2 ans Evolution des volumes de données 1000 Terabytes (Données) 800
Exadata Storage Server et DB Machine V2 Croissance de la Volumétrie des Données Volumes multipliés par 3 tous les 2 ans Evolution des volumes de données 1000 Terabytes (Données) 800
Du 10 Fév. au 14 Mars 2014
 Interconnexion des Sites - Design et Implémentation des Réseaux informatiques - Sécurité et Audit des systèmes - IT CATALOGUE DE FORMATION SIS 2014 1 FORMATION ORACLE 10G 11G 10 FEV 2014 DOUALA CAMEROUN
Interconnexion des Sites - Design et Implémentation des Réseaux informatiques - Sécurité et Audit des systèmes - IT CATALOGUE DE FORMATION SIS 2014 1 FORMATION ORACLE 10G 11G 10 FEV 2014 DOUALA CAMEROUN
Les bases de l optimisation SQL avec DB2 for i
 Les bases de l optimisation SQL avec DB2 for i Christian GRIERE cgriere@fr.ibm.com Common Romandie 3 mai 2011 Les fleurs et les requêtes Lorsque l on veut planter de nouvelles fleurs dans un jardin il
Les bases de l optimisation SQL avec DB2 for i Christian GRIERE cgriere@fr.ibm.com Common Romandie 3 mai 2011 Les fleurs et les requêtes Lorsque l on veut planter de nouvelles fleurs dans un jardin il
Le Langage De Description De Données(LDD)
") Base de données Le Langage De Description De Données(LDD) Créer des tables Décrire les différents types de données utilisables pour les définitions de colonne Modifier la définition des tables Supprimer,
Base de données Le Langage De Description De Données(LDD) Créer des tables Décrire les différents types de données utilisables pour les définitions de colonne Modifier la définition des tables Supprimer,
Cassandra et Spark pour gérer la musique On-line
 Cassandra et Spark pour gérer la musique On-line 16 Juin 2015 @ Paris Hammed RAMDANI Architecte SI 3.0 et BigData mramdani@palo-it.com +33 6 80 22 20 70 Appelez-moi Hammed ;-) (Sidi Mo)Hammed Ramdani @smramdani
Cassandra et Spark pour gérer la musique On-line 16 Juin 2015 @ Paris Hammed RAMDANI Architecte SI 3.0 et BigData mramdani@palo-it.com +33 6 80 22 20 70 Appelez-moi Hammed ;-) (Sidi Mo)Hammed Ramdani @smramdani
Cours Bases de données
 Informations sur le cours Cours Bases de données 9 (10) séances de 3h Polycopié (Cours + TD/TP) 3 année (MISI) Antoine Cornuéjols www.lri.fr/~antoine antoine.cornuejols@agroparistech.fr Transparents Disponibles
Informations sur le cours Cours Bases de données 9 (10) séances de 3h Polycopié (Cours + TD/TP) 3 année (MISI) Antoine Cornuéjols www.lri.fr/~antoine antoine.cornuejols@agroparistech.fr Transparents Disponibles
Oracle 11g Optimisez vos bases de données en production (ressources matérielles, stockage, mémoire, requêtes)
") Avant-propos 1. Lectorat 11 2. Pré-requis 12 3. Objectifs 12 4. Environnement technique 13 Choisir la bonne architecture matérielle 1. Introduction 15 2. Architecture disque 16 2.1 La problématique de
Avant-propos 1. Lectorat 11 2. Pré-requis 12 3. Objectifs 12 4. Environnement technique 13 Choisir la bonne architecture matérielle 1. Introduction 15 2. Architecture disque 16 2.1 La problématique de
6 - Le système de gestion de fichiers F. Boyer, UJF-Laboratoire Lig, Fabienne.Boyer@imag.fr
 6 - Le système de gestion de fichiers F. Boyer, UJF-Laboratoire Lig, Fabienne.Boyer@imag.fr Interface d un SGF Implémentation d un SGF Gestion de la correspondance entre la structure logique et la structure
6 - Le système de gestion de fichiers F. Boyer, UJF-Laboratoire Lig, Fabienne.Boyer@imag.fr Interface d un SGF Implémentation d un SGF Gestion de la correspondance entre la structure logique et la structure
Sur un ordinateur portable ou un All-in-One tactile, la plupart des éléments mentionnés précédemment sont regroupés. 10) 11)
 11)") 1/ Généralités : Un ordinateur est un ensemble non exhaustif d éléments qui sert à traiter des informations (documents de bureautique, méls, sons, vidéos, programmes ) sous forme numérique. Il est en général
1/ Généralités : Un ordinateur est un ensemble non exhaustif d éléments qui sert à traiter des informations (documents de bureautique, méls, sons, vidéos, programmes ) sous forme numérique. Il est en général
Hibernate vs. le Cloud Computing
 Hibernate vs. le Cloud Computing Qui suis-je? Julien Dubois Co-auteur de «Spring par la pratique» Ancien de SpringSource Directeur du consulting chez Ippon Technologies Suivez-moi sur Twitter : @juliendubois
Hibernate vs. le Cloud Computing Qui suis-je? Julien Dubois Co-auteur de «Spring par la pratique» Ancien de SpringSource Directeur du consulting chez Ippon Technologies Suivez-moi sur Twitter : @juliendubois
On distingue deux grandes catégories de mémoires : mémoire centrale (appelée également mémoire interne)
") Mémoire - espace destiné a recevoir, conserver et restituer des informations à traiter - tout composant électronique capable de stocker temporairement des données On distingue deux grandes catégories de
Mémoire - espace destiné a recevoir, conserver et restituer des informations à traiter - tout composant électronique capable de stocker temporairement des données On distingue deux grandes catégories de
Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop
 Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop Soutenance de projet ASR 27/01/2011 Julien Gerlier Siman Chen Encadrés par Bruno
Prototypage et évaluation de performances d un service de traçabilité avec une architecture distribuée basée sur Hadoop Soutenance de projet ASR 27/01/2011 Julien Gerlier Siman Chen Encadrés par Bruno
<Insert Picture Here> Solaris pour la base de donnés Oracle
 Solaris pour la base de donnés Oracle Alain Chéreau Oracle Solution Center Agenda Compilateurs Mémoire pour la SGA Parallélisme RAC Flash Cache Compilateurs
Solaris pour la base de donnés Oracle Alain Chéreau Oracle Solution Center Agenda Compilateurs Mémoire pour la SGA Parallélisme RAC Flash Cache Compilateurs
Utiliser une WebCam. Micro-ordinateurs, informations, idées, trucs et astuces
 Micro-ordinateurs, informations, idées, trucs et astuces Utiliser une WebCam Auteur : François CHAUSSON Date : 8 février 2008 Référence : utiliser une WebCam.doc Préambule Voici quelques informations utiles
Micro-ordinateurs, informations, idées, trucs et astuces Utiliser une WebCam Auteur : François CHAUSSON Date : 8 février 2008 Référence : utiliser une WebCam.doc Préambule Voici quelques informations utiles
Instructions pour mettre à jour un HFFv2 v1.x.yy v2.0.00
 Instructions pour mettre à jour un HFFv2 v1.x.yy v2.0.00 HFFv2 1. OBJET L accroissement de la taille de code sur la version 2.0.00 a nécessité une évolution du mapping de la flash. La conséquence de ce
Instructions pour mettre à jour un HFFv2 v1.x.yy v2.0.00 HFFv2 1. OBJET L accroissement de la taille de code sur la version 2.0.00 a nécessité une évolution du mapping de la flash. La conséquence de ce
De l Etudiant à SBA à l Enseignant Chercheur à l ENSMA
 De l Etudiant à SBA à l Enseignant Chercheur à l ENSMA Ladjel BELLATRECHE bellatreche@ensma.fr http://www.lias lab.fr/members/bellatreche Les déterminants de la motivation selon Rolland Viau Perception
De l Etudiant à SBA à l Enseignant Chercheur à l ENSMA Ladjel BELLATRECHE bellatreche@ensma.fr http://www.lias lab.fr/members/bellatreche Les déterminants de la motivation selon Rolland Viau Perception
Règles et paramètres d'exploitation de Caparmor 2 au 11/12/2009. Pôle de Calcul Intensif pour la mer, 11 Decembre 2009
 Règles et paramètres d'exploitation de Caparmor 2 au 11/12/2009 Pôle de Calcul Intensif pour la mer, 11 Decembre 2009 CAPARMOR 2 La configuration actuelle Les conditions d'accès à distance règles d'exploitation
Règles et paramètres d'exploitation de Caparmor 2 au 11/12/2009 Pôle de Calcul Intensif pour la mer, 11 Decembre 2009 CAPARMOR 2 La configuration actuelle Les conditions d'accès à distance règles d'exploitation
Encryptions, compression et partitionnement des données
 Encryptions, compression et partitionnement des données Version 1.0 Grégory CASANOVA 2 Compression, encryption et partitionnement des données Sommaire 1 Introduction... 3 2 Encryption transparente des
Encryptions, compression et partitionnement des données Version 1.0 Grégory CASANOVA 2 Compression, encryption et partitionnement des données Sommaire 1 Introduction... 3 2 Encryption transparente des
Introduction aux bases de données
 Introduction aux bases de données Références bibliographiques Jeff Ullman,Jennifer Widom, «A First Course in Database systems», Prentice-Hall, 3rd Edition, 2008 Hector Garcia-Molina, Jeff Ullman, Jennifer
Introduction aux bases de données Références bibliographiques Jeff Ullman,Jennifer Widom, «A First Course in Database systems», Prentice-Hall, 3rd Edition, 2008 Hector Garcia-Molina, Jeff Ullman, Jennifer
La présente publication est protégée par les droits d auteur. Tous droits réservés.
 Editeur (Medieninhaber/Verleger) : Markus Winand Maderspergerstasse 1-3/9/11 1160 Wien AUSTRIA Copyright 2013 Markus Winand La présente publication est protégée par les droits d auteur.
Editeur (Medieninhaber/Verleger) : Markus Winand Maderspergerstasse 1-3/9/11 1160 Wien AUSTRIA Copyright 2013 Markus Winand La présente publication est protégée par les droits d auteur.
Les journées SQL Server 2013
 Les journées SQL Server 2013 Un événement organisé par GUSS Les journées SQL Server 2013 SharePoint pour le DBA SQL Configuration, haute disponibilité et performances David Barbarin Patrick Guimonet Un
Les journées SQL Server 2013 Un événement organisé par GUSS Les journées SQL Server 2013 SharePoint pour le DBA SQL Configuration, haute disponibilité et performances David Barbarin Patrick Guimonet Un
Optimisation SQL. Quelques règles de bases
 Optimisation SQL Quelques règles de bases Optimisation des ordres SQL Page 2 1. QUELQUES RÈGLES DE BASE POUR DES ORDRES SQL OPTIMISÉS...3 1.1 INTRODUCTION...3 1.2 L OPTIMISEUR ORACLE...3 1.3 OPTIMISEUR
Optimisation SQL Quelques règles de bases Optimisation des ordres SQL Page 2 1. QUELQUES RÈGLES DE BASE POUR DES ORDRES SQL OPTIMISÉS...3 1.1 INTRODUCTION...3 1.2 L OPTIMISEUR ORACLE...3 1.3 OPTIMISEUR
Introduction à MapReduce/Hadoop et Spark
 1 / 36 Introduction à MapReduce/Hadoop et Spark Certificat Big Data Ludovic Denoyer et Sylvain Lamprier UPMC Plan 2 / 36 Contexte 3 / 36 Contexte 4 / 36 Data driven science: le 4e paradigme (Jim Gray -
1 / 36 Introduction à MapReduce/Hadoop et Spark Certificat Big Data Ludovic Denoyer et Sylvain Lamprier UPMC Plan 2 / 36 Contexte 3 / 36 Contexte 4 / 36 Data driven science: le 4e paradigme (Jim Gray -
Programmation parallèle et distribuée
 Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2015) Marc Parizeau, Département de génie électrique et de génie informatique Plan Données massives («big data») Architecture Hadoop distribution
Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2015) Marc Parizeau, Département de génie électrique et de génie informatique Plan Données massives («big data») Architecture Hadoop distribution
NoSQL. Introduction 1/30. I NoSQL : Not Only SQL, ce n est pas du relationnel, et le contexte. I table d associations - Map - de couples (clef,valeur)
") 1/30 2/30 Anne-Cécile Caron Master MIAGE - SGBD 1er trimestre 2014-2015 I : Not Only SQL, ce n est pas du relationnel, et le contexte d utilisation n est donc pas celui des SGBDR. I Origine : recherche
1/30 2/30 Anne-Cécile Caron Master MIAGE - SGBD 1er trimestre 2014-2015 I : Not Only SQL, ce n est pas du relationnel, et le contexte d utilisation n est donc pas celui des SGBDR. I Origine : recherche
ISC21-1 --- Système d Information Architecture et Administration d un SGBD Compléments SQL
 ISC21-1 --- Système d Information Architecture et Administration d un SGBD Compléments SQL Jean-Marie Pécatte jean-marie.pecatte@iut-tlse3.fr 16 novembre 2006 ISIS - Jean-Marie PECATTE 1 Valeur de clé
ISC21-1 --- Système d Information Architecture et Administration d un SGBD Compléments SQL Jean-Marie Pécatte jean-marie.pecatte@iut-tlse3.fr 16 novembre 2006 ISIS - Jean-Marie PECATTE 1 Valeur de clé
Plan 1/9/2013. Génération et exploitation de données. CEP et applications. Flux de données et notifications. Traitement des flux Implémentation
 Complex Event Processing Traitement de flux de données en temps réel Romain Colle R&D Project Manager Quartet FS Plan Génération et exploitation de données CEP et applications Flux de données et notifications
Complex Event Processing Traitement de flux de données en temps réel Romain Colle R&D Project Manager Quartet FS Plan Génération et exploitation de données CEP et applications Flux de données et notifications
Cours 3. Développement d une application BD. DBA - Maîtrise ASR - Université Evry
 Cours 3 Développement d une application BD 1 Plan du cours Gestion de la sécurité des données Optimisation des schémas de bases via la dénormalisation Utilisation de vues Placement du code applicatif dans
Cours 3 Développement d une application BD 1 Plan du cours Gestion de la sécurité des données Optimisation des schémas de bases via la dénormalisation Utilisation de vues Placement du code applicatif dans
COMMANDES SQL... 2 COMMANDES DE DEFINITION DE DONNEES... 2
 SQL Sommaire : COMMANDES SQL... 2 COMMANDES DE DEFINITION DE DONNEES... 2 COMMANDES DE MANIPULATION DE DONNEES... 2 COMMANDES DE CONTROLE TRANSACTIONNEL... 2 COMMANDES DE REQUETE DE DONNEES... 2 COMMANDES
SQL Sommaire : COMMANDES SQL... 2 COMMANDES DE DEFINITION DE DONNEES... 2 COMMANDES DE MANIPULATION DE DONNEES... 2 COMMANDES DE CONTROLE TRANSACTIONNEL... 2 COMMANDES DE REQUETE DE DONNEES... 2 COMMANDES
Technologies du Web. Ludovic DENOYER - ludovic.denoyer@lip6.fr. Février 2014 UPMC
 Technologies du Web Ludovic DENOYER - ludovic.denoyer@lip6.fr UPMC Février 2014 Ludovic DENOYER - ludovic.denoyer@lip6.fr Technologies du Web Plan Retour sur les BDs Le service Search Un peu plus sur les
Technologies du Web Ludovic DENOYER - ludovic.denoyer@lip6.fr UPMC Février 2014 Ludovic DENOYER - ludovic.denoyer@lip6.fr Technologies du Web Plan Retour sur les BDs Le service Search Un peu plus sur les
Acquisition des données - Big Data. Dario VEGA Senior Sales Consultant
 Acquisition des données - Big Data Dario VEGA Senior Sales Consultant The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated
Acquisition des données - Big Data Dario VEGA Senior Sales Consultant The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated
Principe de TrueCrypt. Créer un volume pour TrueCrypt
 Sommaire : Principe de TrueCrypt...1 Créer un volume pour TrueCrypt...1 Premier montage...6 Réglages...8 Save Currently Mounted Volumes as Favorite...8 Settings > Preferences...9 TrueCrypt Traveller pour
Sommaire : Principe de TrueCrypt...1 Créer un volume pour TrueCrypt...1 Premier montage...6 Réglages...8 Save Currently Mounted Volumes as Favorite...8 Settings > Preferences...9 TrueCrypt Traveller pour
Chapitre V : La gestion de la mémoire. Hiérarchie de mémoires Objectifs Méthodes d'allocation Simulation de mémoire virtuelle Le mapping
 Chapitre V : La gestion de la mémoire Hiérarchie de mémoires Objectifs Méthodes d'allocation Simulation de mémoire virtuelle Le mapping Introduction Plusieurs dizaines de processus doivent se partager
Chapitre V : La gestion de la mémoire Hiérarchie de mémoires Objectifs Méthodes d'allocation Simulation de mémoire virtuelle Le mapping Introduction Plusieurs dizaines de processus doivent se partager
Consolidation. Grid Infrastructure avec la 11gR2
 Consolidation Grid Infrastructure avec la 11gR2 Priorités IT durant les périodes difficiles Examiner et Limiter les dépenses d investissement Devenir plus efficace pour réduire les frais d'exploitation
Consolidation Grid Infrastructure avec la 11gR2 Priorités IT durant les périodes difficiles Examiner et Limiter les dépenses d investissement Devenir plus efficace pour réduire les frais d'exploitation
Programmation parallèle et distribuée
 Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2014) Marc Parizeau, Département de génie électrique et de génie informatique Plan Mégadonnées («big data») Architecture Hadoop distribution
Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2014) Marc Parizeau, Département de génie électrique et de génie informatique Plan Mégadonnées («big data») Architecture Hadoop distribution
Le langage SQL pour Oracle - partie 1 : SQL comme LDD
 Le langage SQL pour Oracle - partie 1 : SQL comme LDD 1 SQL : Introduction SQL : Structured Query Langage langage de gestion de bases de donn ees relationnelles pour Définir les données (LDD) interroger
Le langage SQL pour Oracle - partie 1 : SQL comme LDD 1 SQL : Introduction SQL : Structured Query Langage langage de gestion de bases de donn ees relationnelles pour Définir les données (LDD) interroger
CYCLE CERTIFIANT ADMINISTRATEUR BASES DE DONNÉES
 SGBD / Aide à la décision CYCLE CERTIFIANT ADMINISTRATEUR BASES DE DONNÉES Réf: KAO Durée : 15 jours (7 heures) OBJECTIFS DE LA FORMATION Ce cycle complet vous apportera les connaissances nécessaires pour
SGBD / Aide à la décision CYCLE CERTIFIANT ADMINISTRATEUR BASES DE DONNÉES Réf: KAO Durée : 15 jours (7 heures) OBJECTIFS DE LA FORMATION Ce cycle complet vous apportera les connaissances nécessaires pour
SCHOLARSHIP ANSTO FRENCH EMBASSY (SAFE) PROGRAM 2015-2 APPLICATION FORM
 PROGRAM 2015-2 APPLICATION FORM") SCHOLARSHIP ANSTO FRENCH EMBASSY (SAFE) PROGRAM 2015-2 APPLICATION FORM APPLICATION FORM / FORMULAIRE DE CANDIDATURE Note: If there is insufficient space to answer a question, please attach additional
SCHOLARSHIP ANSTO FRENCH EMBASSY (SAFE) PROGRAM 2015-2 APPLICATION FORM APPLICATION FORM / FORMULAIRE DE CANDIDATURE Note: If there is insufficient space to answer a question, please attach additional
WEB page builder and server for SCADA applications usable from a WEB navigator
 Générateur de pages WEB et serveur pour supervision accessible à partir d un navigateur WEB WEB page builder and server for SCADA applications usable from a WEB navigator opyright 2007 IRAI Manual Manuel
Générateur de pages WEB et serveur pour supervision accessible à partir d un navigateur WEB WEB page builder and server for SCADA applications usable from a WEB navigator opyright 2007 IRAI Manual Manuel
Kick Off SCC 2015. EMC l offre EXTREMIO. fmarti@fr.scc.com Philippe.rolland@emc.com. Vers de nouveaux horizons
 Kick Off SCC 2015 EMC l offre EXTREMIO fmarti@fr.scc.com Philippe.rolland@emc.com Vers de nouveaux horizons Context Marché Les baies de stockages traditionnelles ont permis de consolider fortement Les
Kick Off SCC 2015 EMC l offre EXTREMIO fmarti@fr.scc.com Philippe.rolland@emc.com Vers de nouveaux horizons Context Marché Les baies de stockages traditionnelles ont permis de consolider fortement Les
Bases de Données relationnelles et leurs systèmes de Gestion
 III.1- Définition de schémas Bases de Données relationnelles et leurs systèmes de Gestion RAPPELS Contraintes d intégrité sous Oracle Notion de vue Typage des attributs Contrainte d intégrité Intra-relation
III.1- Définition de schémas Bases de Données relationnelles et leurs systèmes de Gestion RAPPELS Contraintes d intégrité sous Oracle Notion de vue Typage des attributs Contrainte d intégrité Intra-relation
1 ère Partie Stratégie et Directions Stockage IBM
 Cédric ARAGON Directeur des Ventes de Stockage IBM France 1 ère Partie Stratégie et Directions Stockage IBM Agenda Les défis actuels posés par la croissance des volumes de données IBM: acteur majeur sur
Cédric ARAGON Directeur des Ventes de Stockage IBM France 1 ère Partie Stratégie et Directions Stockage IBM Agenda Les défis actuels posés par la croissance des volumes de données IBM: acteur majeur sur
HSCS 6.4 : mieux appréhender la gestion du stockage en environnement VMware et service de fichiers HNAS Laurent Bartoletti Product Marketing Manager
 HSCS 6.4 : mieux appréhender la gestion du stockage en environnement VMware et service de fichiers HNAS Laurent Bartoletti Product Marketing Manager Hitachi Storage Command Suite Portfolio SAN Assets &
HSCS 6.4 : mieux appréhender la gestion du stockage en environnement VMware et service de fichiers HNAS Laurent Bartoletti Product Marketing Manager Hitachi Storage Command Suite Portfolio SAN Assets &
Ecole des Hautes Etudes Commerciales HEC Alger. par Amina GACEM. Module Informatique 1ière Année Master Sciences Commerciales
 Ecole des Hautes Etudes Commerciales HEC Alger Évolution des SGBDs par Amina GACEM Module Informatique 1ière Année Master Sciences Commerciales Evolution des SGBDs Pour toute remarque, question, commentaire
Ecole des Hautes Etudes Commerciales HEC Alger Évolution des SGBDs par Amina GACEM Module Informatique 1ière Année Master Sciences Commerciales Evolution des SGBDs Pour toute remarque, question, commentaire
Langage SQL (1) 4 septembre 2007. IUT Orléans. Introduction Le langage SQL : données Le langage SQL : requêtes
 4 septembre 2007. IUT Orléans. Introduction Le langage SQL : données Le langage SQL : requêtes") Langage SQL (1) Sébastien Limet Denys Duchier IUT Orléans 4 septembre 2007 Notions de base qu est-ce qu une base de données? SGBD différents type de bases de données quelques systèmes existants Définition
Langage SQL (1) Sébastien Limet Denys Duchier IUT Orléans 4 septembre 2007 Notions de base qu est-ce qu une base de données? SGBD différents type de bases de données quelques systèmes existants Définition
Sécuristation du Cloud
 Schémas de recherche sur données chiffrées avancés Laboratoire de Cryptologie Thales Communications & Security 9 Avril 215 9/4/215 1 / 75 Contexte Introduction Contexte Objectif Applications Aujourd hui
Schémas de recherche sur données chiffrées avancés Laboratoire de Cryptologie Thales Communications & Security 9 Avril 215 9/4/215 1 / 75 Contexte Introduction Contexte Objectif Applications Aujourd hui
La rencontre du Big Data et du Cloud
 La rencontre du Big Data et du Cloud Libérez le potentiel de toutes vos données Visualisez et exploitez plus rapidement les données de tous types, quelle que soit leur taille et indépendamment de leur
La rencontre du Big Data et du Cloud Libérez le potentiel de toutes vos données Visualisez et exploitez plus rapidement les données de tous types, quelle que soit leur taille et indépendamment de leur
Tout ce que vous avez toujours voulu savoir sur SAP HANA. Sans avoir jamais osé le demander
 Tout ce que vous avez toujours voulu savoir sur SAP HANA Sans avoir jamais osé le demander Agenda Pourquoi SAP HANA? Qu est-ce que SAP HANA? SAP HANA pour l intelligence d affaires SAP HANA pour l analyse
Tout ce que vous avez toujours voulu savoir sur SAP HANA Sans avoir jamais osé le demander Agenda Pourquoi SAP HANA? Qu est-ce que SAP HANA? SAP HANA pour l intelligence d affaires SAP HANA pour l analyse
Java et les bases de données
 Michel Bonjour http://cuiwww.unige.ch/~bonjour CENTRE UNIVERSITAIRE D INFORMATIQUE UNIVERSITE DE GENEVE Plan Introduction JDBC: API SQL pour Java - JDBC, Java, ODBC, SQL - Architecture, interfaces, exemples
Michel Bonjour http://cuiwww.unige.ch/~bonjour CENTRE UNIVERSITAIRE D INFORMATIQUE UNIVERSITE DE GENEVE Plan Introduction JDBC: API SQL pour Java - JDBC, Java, ODBC, SQL - Architecture, interfaces, exemples
Big Data. Cyril Amsellem Consultant avant-vente. 16 juin 2011. Talend 2010 1
 Big Data Cyril Amsellem Consultant avant-vente 16 juin 2011 Talend 2010 1 Big Data Architecture globale Hadoop Les projets Hadoop (partie 1) Hadoop-Core : projet principal. HDFS : système de fichiers distribués
Big Data Cyril Amsellem Consultant avant-vente 16 juin 2011 Talend 2010 1 Big Data Architecture globale Hadoop Les projets Hadoop (partie 1) Hadoop-Core : projet principal. HDFS : système de fichiers distribués
Sommaire. 3. Les grands principes de GFS L architecture L accès de fichier en lecture L accès de fichier en écriture Bilan
 1 Sommaire 1. Google en chiffres 2. Les raisons d être de GFS 3. Les grands principes de GFS L architecture L accès de fichier en lecture L accès de fichier en écriture Bilan 4. Les Evolutions et Alternatives
1 Sommaire 1. Google en chiffres 2. Les raisons d être de GFS 3. Les grands principes de GFS L architecture L accès de fichier en lecture L accès de fichier en écriture Bilan 4. Les Evolutions et Alternatives
M1 Informatique, Réseaux Cours 9 : Réseaux pour le multimédia
 M1 Informatique, Réseaux Cours 9 : Réseaux pour le multimédia Olivier Togni Université de Bourgogne, IEM/LE2I Bureau G206 olivier.togni@u-bourgogne.fr 24 mars 2015 2 de 24 M1 Informatique, Réseaux Cours
M1 Informatique, Réseaux Cours 9 : Réseaux pour le multimédia Olivier Togni Université de Bourgogne, IEM/LE2I Bureau G206 olivier.togni@u-bourgogne.fr 24 mars 2015 2 de 24 M1 Informatique, Réseaux Cours
Cours 8 Not Only SQL
 Cours 8 Not Only SQL Cours 8 - NoSQL Qu'est-ce que le NoSQL? Cours 8 - NoSQL Qu'est-ce que le NoSQL? Catégorie de SGBD s'affranchissant du modèle relationnel des SGBDR. Mouvance apparue par le biais des
Cours 8 Not Only SQL Cours 8 - NoSQL Qu'est-ce que le NoSQL? Cours 8 - NoSQL Qu'est-ce que le NoSQL? Catégorie de SGBD s'affranchissant du modèle relationnel des SGBDR. Mouvance apparue par le biais des
Plateforme Technologique Innovante. Innovation Center for equipment& materials
 Plateforme Technologique Innovante Innovation Center for equipment& materials Le Besoin Centre indépendant d évaluation des nouveaux produits, procédés et services liés à la fabrication des Micro-Nanotechnologies
Plateforme Technologique Innovante Innovation Center for equipment& materials Le Besoin Centre indépendant d évaluation des nouveaux produits, procédés et services liés à la fabrication des Micro-Nanotechnologies
ORACLE 10g Découvrez les nouveautés. Jeudi 17 Mars Séminaire DELL/INTEL/ORACLE
 ORACLE 10g Découvrez les nouveautés Jeudi 17 Mars Séminaire DELL/INTEL/ORACLE Le Grid Computing d Entreprise Pourquoi aujourd hui? Principes et définitions appliqués au système d information Guy Ernoul,
ORACLE 10g Découvrez les nouveautés Jeudi 17 Mars Séminaire DELL/INTEL/ORACLE Le Grid Computing d Entreprise Pourquoi aujourd hui? Principes et définitions appliqués au système d information Guy Ernoul,
Application Form/ Formulaire de demande
 Application Form/ Formulaire de demande Ecosystem Approaches to Health: Summer Workshop and Field school Approches écosystémiques de la santé: Atelier intensif et stage d été Please submit your application
Application Form/ Formulaire de demande Ecosystem Approaches to Health: Summer Workshop and Field school Approches écosystémiques de la santé: Atelier intensif et stage d été Please submit your application
Sybase Adaptive Server Enterprise 15
 Sybase Adaptive Server Enterprise 15 Prêt pour Sybase Adaptive Server Enterprise 15? Novembre 2006 Documentation technique # 29 Introduction Cette présentation liste les fonctionnalités importantes de
Sybase Adaptive Server Enterprise 15 Prêt pour Sybase Adaptive Server Enterprise 15? Novembre 2006 Documentation technique # 29 Introduction Cette présentation liste les fonctionnalités importantes de
EX4C Systèmes d exploitation. Séance 14 Structure des stockages de masse
 EX4C Systèmes d exploitation Séance 14 Structure des stockages de masse Sébastien Combéfis mardi 3 mars 2015 Ce(tte) œuvre est mise à disposition selon les termes de la Licence Creative Commons Attribution
EX4C Systèmes d exploitation Séance 14 Structure des stockages de masse Sébastien Combéfis mardi 3 mars 2015 Ce(tte) œuvre est mise à disposition selon les termes de la Licence Creative Commons Attribution
Le Langage SQL version Oracle
 Université de Manouba École Supérieure d Économie Numérique Département des Technologies des Systèmes d Information Le Langage SQL version Oracle Document version 1.1 Mohamed Anis BACH TOBJI anis.bach@isg.rnu.tn
Université de Manouba École Supérieure d Économie Numérique Département des Technologies des Systèmes d Information Le Langage SQL version Oracle Document version 1.1 Mohamed Anis BACH TOBJI anis.bach@isg.rnu.tn
EPREUVE OPTIONNELLE d INFORMATIQUE CORRIGE
 EPREUVE OPTIONNELLE d INFORMATIQUE CORRIGE QCM Remarque : - A une question correspond au moins 1 réponse juste - Cocher la ou les bonnes réponses Barème : - Une bonne réponse = +1 - Pas de réponse = 0
EPREUVE OPTIONNELLE d INFORMATIQUE CORRIGE QCM Remarque : - A une question correspond au moins 1 réponse juste - Cocher la ou les bonnes réponses Barème : - Une bonne réponse = +1 - Pas de réponse = 0
AVRIL 2014. Au delà de Hadoop. Panorama des solutions NoSQL
 AVRIL 2014 Panorama des solutions NoSQL QUI SOMMES NOUS? Avril 2014 2 SMILE, EN QUELQUES CHIFFRES 1er INTÉGRATEUR EUROPÉEN DE SOLUTIONS OPEN SOURCE 3 4 NOS EXPERTISES ET NOS CONVICTIONS DANS NOS LIVRES
AVRIL 2014 Panorama des solutions NoSQL QUI SOMMES NOUS? Avril 2014 2 SMILE, EN QUELQUES CHIFFRES 1er INTÉGRATEUR EUROPÉEN DE SOLUTIONS OPEN SOURCE 3 4 NOS EXPERTISES ET NOS CONVICTIONS DANS NOS LIVRES
Bases de données documentaires et distribuées Cours NFE04
 Bases de données documentaires et distribuées Cours NFE04 Introduction a la recherche d information Auteurs : Raphaël Fournier-S niehotta, Philippe Rigaux, Nicolas Travers prénom.nom@cnam.fr Département
Bases de données documentaires et distribuées Cours NFE04 Introduction a la recherche d information Auteurs : Raphaël Fournier-S niehotta, Philippe Rigaux, Nicolas Travers prénom.nom@cnam.fr Département
Jean-François Boulicaut & Mohand-Saïd Hacid
 e siècle! Jean-François Boulicaut & Mohand-Saïd Hacid http://liris.cnrs.fr/~jboulica http://liris.cnrs.fr/mohand-said.hacid Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205
e siècle! Jean-François Boulicaut & Mohand-Saïd Hacid http://liris.cnrs.fr/~jboulica http://liris.cnrs.fr/mohand-said.hacid Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205
Exemple PLS avec SAS
 Exemple PLS avec SAS This example, from Umetrics (1995), demonstrates different ways to examine a PLS model. The data come from the field of drug discovery. New drugs are developed from chemicals that
Exemple PLS avec SAS This example, from Umetrics (1995), demonstrates different ways to examine a PLS model. The data come from the field of drug discovery. New drugs are developed from chemicals that
Hadoop, les clés du succès
 Hadoop, les clés du succès Didier Kirszenberg, Responsable des architectures Massive Data, HP France Copyright 2015 Hewlett-Packard Development Company, L.P. The information contained herein is subject
Hadoop, les clés du succès Didier Kirszenberg, Responsable des architectures Massive Data, HP France Copyright 2015 Hewlett-Packard Development Company, L.P. The information contained herein is subject
Catherine Chochoy. Alain Maneville. I/T Specialist, IBM Information Management on System z, Software Group
 1 Catherine Chochoy I/T Specialist, IBM Information Management on System z, Software Group Alain Maneville Executive I/T specialist, zchampion, IBM Systems and Technology Group 2 Le défi du Big Data (et
1 Catherine Chochoy I/T Specialist, IBM Information Management on System z, Software Group Alain Maneville Executive I/T specialist, zchampion, IBM Systems and Technology Group 2 Le défi du Big Data (et
Organiser vos données - Big Data. Patrick Millart Senior Sales Consultant
 Organiser vos données - Big Data Patrick Millart Senior Sales Consultant The following is intended to outline our general product direction. It is intended for information purposes only, and may not be
Organiser vos données - Big Data Patrick Millart Senior Sales Consultant The following is intended to outline our general product direction. It is intended for information purposes only, and may not be
BIG DATA. Veille technologique. Malek Hamouda Nina Lachia Léo Valette. Commanditaire : Thomas Milon. Encadré: Philippe Vismara
 BIG DATA Veille technologique Malek Hamouda Nina Lachia Léo Valette Commanditaire : Thomas Milon Encadré: Philippe Vismara 1 2 Introduction Historique des bases de données : méthodes de stockage et d analyse
BIG DATA Veille technologique Malek Hamouda Nina Lachia Léo Valette Commanditaire : Thomas Milon Encadré: Philippe Vismara 1 2 Introduction Historique des bases de données : méthodes de stockage et d analyse
Bases de données Cours 1 : Généralités sur les bases de données
 Cours 1 : Généralités sur les bases de données POLYTECH Université d Aix-Marseille odile.papini@univ-amu.fr http://odile.papini.perso.esil.univmed.fr/sources/bd.html Plan du cours 1 1 Qu est ce qu une
Cours 1 : Généralités sur les bases de données POLYTECH Université d Aix-Marseille odile.papini@univ-amu.fr http://odile.papini.perso.esil.univmed.fr/sources/bd.html Plan du cours 1 1 Qu est ce qu une