Happy birthday ZSet High performance computing dans ZSet
|
|
|
- Angèline Bordeleau
- il y a 10 ans
- Total affichages :
Transcription
1 Happy birthday ZSet High performance computing dans ZSet F. Feyel & P. Gosselet

2 Architectures SMP NUMA memory memory memory Distribué memory memory 2 memory memory Hybride memory memory memory memory memory memory

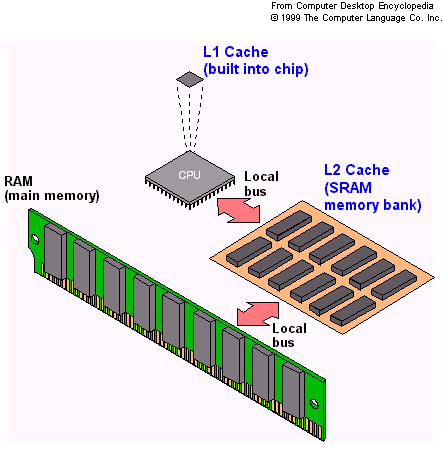
3 Architectures 3

4 Architectures cpu cpu exemple AMD Opteron 2218 L1 L1 128 KB, accès en 1-3 cycles horloge L2 L2 main memory Latence disk network 1024 KB, 5-25 cycles horologe 8 GB, cycles horloge ~ 12 millisecondes??? Minimiser les accès mémoire, préserver le cache 4

5 Architecture cpu cpu cpu cpu Intel Xeon E5462 L1 L1 L1 L1 16 KB L2 L2 main memory 2x6 MB 8 GB Votre portable favori repose sur ce schéma! 5

6 But du HPC CU CU CU CU CU CU CU Objectif du HPC : les faire toutes tourner! 6

7 Où gagner du temps? Deux grandes étapes dans Z implicite Intégration matériau Résolution du linéaire tangent Accélérer 7 la résolution de ces deux étapes

8 Deux cas différents cpu cpu cpu cpu L1 L1 L1 L1 L2 Votre portable, votre station de tra L2 main memory memory memory memory memory Votre cluster, calculateur... 8

9 Multi-threading cpu cpu cpu cpu L1 L1 L1 L1 L2 L2 main memory private memory thread thread private memory shared memory thread private memory 9 private memory thread

10 Multithreading Utilisation du multithreading «transparent» des librairies mathématiques top 15:10:26 up 11 days, 5:52, 3 users, load average: 5.67, 7.04, 6.99 Tasks: 298 total, 3 running, 295 sleeping, 0 stopped, 0 zombie Cpu(s): 13.9%us, 0.5%sy, 18.7%ni, 67.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Mem: k total, k used, k free, k buffers Swap: k total, 0k used, k free, k cached PID USER PR NI VIRT RES SHR S % %MEM TIME COMMAND marcadon g 19g 29m R ,49 Zebulon_cpp_Lin

11 Attention, dans «top», 100% = 1 coeur Commande shift+1 Tasks: 298 total, 3 running, 295 sleeping, 0 stopped, 0 zombie Cpu0 : 98.1%us, 1.9%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu1 : 1.9%us, 0.0%sy, 0.0%ni, 98.1%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu2 : 0.0%us, 1.9%sy, 0.0%ni, 98.1%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu3 : 1.9%us, 0.0%sy, 0.0%ni, 98.1%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu4 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu5 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu6 : 98.1%us, 1.9%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu7 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu8 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu9 : 0.0%us, 5.8%sy, 94.2%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu10 :100.0%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu11 : 0.0%us, 1.9%sy, 98.1%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu12 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu13 : 0.0%us, 0.0%sy,100.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu14 : 0.0%us, 0.0%sy,100.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu15 :100.0%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Mem: k total, k used, k free, k buffers Swap: k total, 0k used, k free, k cached

12 Accélère tout ce qui utilise les fonctions BLAS Donc certains solveurs de Zébulon : dscpack, mumps, dissection Intégration Zrun smp 4 des lois de comportement, utilisation de

13 Le multithreading, c'est bien : Fonctionne «sans se fatiguer» Fonctionne bien Gains appréciables Par contre, suppose une mémoire partagée Donc restreint à une seule machine / noeud

14 Les solveurs linéaires directs dans Zset Trois solveurs linéaires creux (aboutis) Sym. DSCPack X Mumps X Dissection X Non-sym. Multithread DD // X X X X X X X D'autres solveurs plus vieux ou expérimentaux, à ne pas utiliser sauf cas particulier Frontal Sparse-direct

15 DSCPack Le premier solveur linéaire optimisé interfacé dans Zset En interne, pointeurs 32bits, donc limité en taille de problème Ne traite pas les modes rigides Sauf ruse, non utilisable en décomposition de domaines Très performant

16 Mumps Attention! Mumps ne détecte pas très bien les modes rigides Fonctionne pour des problèmes «pas trop tordus» Utilisation possible en décomposition de domaines (feti ou generic_dd) Mumps est aussi utilisable via la DD, en solveur direct Non extensible, mais plus robuste
 Mumps est aussi utilisable via la DD,")
17 Dissection «Dissection» Un nouveau solveur développé à l'onera Parallélisme massif Détection propre des modes rigides Performances similaires à DSCPack Optimisation en cours (Total+Intel)

18 Comparaison des principaux solveurs linéaires 700 MUMPS DSCPACK DISSECTION 600 Temps (s) Nb dofs

19 Comparaison des principaux solveurs linéaires DISSECTION DSCPACK MUMPS Speedup # threads 6 7 8

20 Mémoire distribuée ZSet ZSet memory memory memory memory ZSet ZSet

21 Mémoire distribuée Le solveur Mumps Permet de faire du parallélisme en solveur direct ***linear_solver mumps **parallel 4 A lancer via Zrun smpi hostfile hfile cube.inp Intéressant sur des gros problèmes
22 Exemple, cube 25x25x25 quad, ddls Mono-coeur : 194 s Multi-threads (8) : 62 s Parallèle (16 fois mono-thread) : 74 s Avantages facile pour l'utilisateur, fonctionne avec le contact (!), mémoire répartie (plus GROS) Inconvénients Non extensible
23 Vers l'extensibilité Pour les gros problèmes seule la mémoire distribuée est réaliste (clusters) Protocole MPI : chaque processeur est responsable de ses données et de ce qu'il échange avec les autres MPI send / recv : échanges ciblés MPI All gather / reduce : communications globales Pour obtenir bonnes performances, il faut des algorithmes qui minimisent le partage de données (privilégiant les échanges ciblés et de petites quantités) Deux ingrédients : décompositions de domaine et solveur itératif
 L'attribution d'un sous-domaine par processeur (virtuel) permet de bien séparer les données Zrun -mpi toto.")
24 Décomposition de domaine sans recouvrement Version mécanique de la partition de graphe : Utilisation de metis/splitmesh/scotch... (****mesher) L'attribution d'un sous-domaine par processeur (virtuel) permet de bien séparer les données Zrun -mpi toto.inp (avec mise en donnée adaptée) L'interface joue un rôle fondamental
25 Principe Trois groupes d'équations : Équilibre des sous-domaines sous l'effet des chargements imposés et des réactions des voisins Continuité des déplacements aux interfaces Équilibre des réactions (action-réaction) La première équation est un super-comportement qui lie les déplacements d'interface et les réactions Cette équation est satisfaite exactement (grâce à un solveur direct), le sous-domaine devient une boîte noire On Choisit d'une inconnue d'interface principale (dep/effort) puis on itère jusqu'à annuler l'erreur sur la quantité duale
26 Solveur itératif Deux grandes opérations : Produit opérateur vecteur : calcul local (descente remontée) + échange de vecteur d'interface avec voisin Produit scalaire produit scalaire + somme de scalaire all-to-all Peu de communication mais besoin de synchronisme entre les sous-domaines = équilibrage de charges Efficace si le nombre d'itération varie peu avec la taille des problèmes par sous-domaine 2 H k C (1+log ( )) h
27 Performance Les méthodes fonctionnent grâce à un préconditionnement à deux échelles Représentation fiable du voisinage immédiat Transmission globale des effets à grande longueur de pénétration. On assure que les problèmes de Neumann soient bien posés.
28 Exemple : approche primale
29 Exemple : approche primale u0 =0 Erreur = déséquilibre des réactions
30 Exemple : approche primale Erreur = déséquilibre des réactions Preconditionneur u0 =0

31 Exemple : approche primale Correction u1 Erreur = déséquilibre des réactions Preconditionneur u0 =0
32 Problème d'extensibilité Seul les voisins communiquent, l'information met du temps à se propager
33 Extensibilité Contrainte d'équilibre des torseurs des efforts extérieurs pour les sous-domaines flottants Initialisation + projection Résolution d'un problème grossier qui équilibre globalement les torseurs extérieurs Principe de Saint-Venant Extensibilité garantie en 2D/3D
34 Variantes mises en oeuvre Choix de l'inconnue d'interface FETI : efforts BDD : déplacement Mixte : condition de Robin (expérimental) Hybride : choix pour chaque ddl (recherche) Préconditionneurs Variantes optimales et sous-optimales Prise en compte de certaines hétérogénéités Problèmes grossiers (+/-) compliqués (2D/3D) Problèmes grossiers pour plaques (expérimental) Problèmes grossiers type FETIDP/BDDC (expérimental) Utilisable avec n'importe quel solveur itératif Gradient conjugué, GMRes, BiCG Accélérations
35 Mise en données typique ***linear_solver generic_dd **local_solver mumps no_option **dof_kind *dof all dual **precond lumped **scaling topological **projector_schur none **projector_scaling none **iterative_solver nncg *precision 1.e-06 *max_iteration 50

36 Quelques performances Passage du plus gros cube possible ddl par domaine 1 domaine par noeud 8 threads par domaine
37 Insertion dans une résolution Les décompositions de domaine sont un solveur linéaire Elles s'insèrent dans n'importe quel processus non-linéaire pour remplacer le solveur tangent Recherches en cours (+/- stables) Résolution de problèmes non-linéaires par sous-domaine Réutilisation de l'information numérique pour accélérer une séquence de résolution (via le recyclage des sous-espaces de Krylov) Vérification de la qualité des calculs (estimation des erreurs de discrétisation)
38 Accélération Krylov Version linéaire de la réduction de modèle Après chaque résolution, tri de l'information la plus significative et réutilisation (déflation ou préco.) Encapsulage des solveurs classique **iterative_solver nnsrks *eps_srks 1.e-10 *base_solver nncg
39 Séquence de pb NL Tirage de coefficients matériaux Un speed-up de 40% en temps peut être raisonnablement espéré
40 Vérification Estimation a-posteriori de la qualité des maillages ZZ2 Erreur en relation de comportement (parallélisé) Objectifs : Donner un critère d'arrêt pour les DD en fonction de la discrétisation R ler jusqu'à garantir une certaine qualité (en cours) Exploiter l'information pour accélérer les calculs fins
41 Résultats préliminaires
42 Zfuture Simplification DD comme solveur linéaire Vérification Accélérations Krylov Stabilisation Et des features actuellement expérimentaux Non-linéaire par sous-domaines Traitement différencié des ddl normaux et tangents Introduction des outils actuellement fonctionnels des derniers raffinements FETIDP pour le 3D Traitement des très grosses hétérogénéités / des interfaces chahutées aussi R lage parallèle Contact parallèle Parallélisme en temps
Aspects théoriques et algorithmiques du calcul réparti L agglomération
 Aspects théoriques et algorithmiques du calcul réparti L agglomération Patrick CIARLET Enseignant-Chercheur UMA [email protected] Françoise LAMOUR [email protected] Aspects théoriques
Aspects théoriques et algorithmiques du calcul réparti L agglomération Patrick CIARLET Enseignant-Chercheur UMA [email protected] Françoise LAMOUR [email protected] Aspects théoriques
Segmentation d'images à l'aide d'agents sociaux : applications GPU
 Segmentation d'images à l'aide d'agents sociaux : applications GPU Richard MOUSSA Laboratoire Bordelais de Recherche en Informatique (LaBRI) - UMR 5800 Université de Bordeaux - France Laboratoire de recherche
Segmentation d'images à l'aide d'agents sociaux : applications GPU Richard MOUSSA Laboratoire Bordelais de Recherche en Informatique (LaBRI) - UMR 5800 Université de Bordeaux - France Laboratoire de recherche
Initiation au HPC - Généralités
 Initiation au HPC - Généralités Éric Ramat et Julien Dehos Université du Littoral Côte d Opale M2 Informatique 2 septembre 2015 Éric Ramat et Julien Dehos Initiation au HPC - Généralités 1/49 Plan du cours
Initiation au HPC - Généralités Éric Ramat et Julien Dehos Université du Littoral Côte d Opale M2 Informatique 2 septembre 2015 Éric Ramat et Julien Dehos Initiation au HPC - Généralités 1/49 Plan du cours
Architecture des calculateurs
 Formation en Calcul Scientifique - LEM2I Architecture des calculateurs Violaine Louvet 1 1 Institut Camille jordan - CNRS 12-13/09/2011 Introduction Décoder la relation entre l architecture et les applications
Formation en Calcul Scientifique - LEM2I Architecture des calculateurs Violaine Louvet 1 1 Institut Camille jordan - CNRS 12-13/09/2011 Introduction Décoder la relation entre l architecture et les applications
Runtime. Gestion de la réactivité des communications réseau. François Trahay Runtime, LaBRI sous la direction d'alexandre Denis Université Bordeaux I
 Runtime Gestion de la réactivité des communications réseau François Trahay Runtime, LaBRI sous la direction d'alexandre Denis Université Bordeaux I 1 Le calcul hautes performances La tendance actuelle
Runtime Gestion de la réactivité des communications réseau François Trahay Runtime, LaBRI sous la direction d'alexandre Denis Université Bordeaux I 1 Le calcul hautes performances La tendance actuelle
Limitations of the Playstation 3 for High Performance Cluster Computing
 Introduction Plan Limitations of the Playstation 3 for High Performance Cluster Computing July 2007 Introduction Plan Introduction Intérêts de la PS3 : rapide et puissante bon marché L utiliser pour faire
Introduction Plan Limitations of the Playstation 3 for High Performance Cluster Computing July 2007 Introduction Plan Introduction Intérêts de la PS3 : rapide et puissante bon marché L utiliser pour faire
Eléments d architecture des machines parallèles et distribuées
 M2-RISE - Systèmes distribués et grille Eléments d architecture des machines parallèles et distribuées Stéphane Vialle [email protected] http://www.metz.supelec.fr/~vialle Notions d architecture
M2-RISE - Systèmes distribués et grille Eléments d architecture des machines parallèles et distribuées Stéphane Vialle [email protected] http://www.metz.supelec.fr/~vialle Notions d architecture
Multiprogrammation parallèle générique des méthodes de décomposition de domaine
 Multiprogrammation parallèle générique des méthodes de décomposition de domaine Andréa Schwertner-Charão To cite this version: Andréa Schwertner-Charão. Multiprogrammation parallèle générique des méthodes
Multiprogrammation parallèle générique des méthodes de décomposition de domaine Andréa Schwertner-Charão To cite this version: Andréa Schwertner-Charão. Multiprogrammation parallèle générique des méthodes
Rencontre sur la thématique du Calcul Haute Performance - 13 juin 2012. Better Match, Faster Innovation
 Better Match, Faster Innovation Rencontre sur la thématique du Calcul Haute Performance - 13 juin 2012 Meeting on the theme of High Performance Computing TABLE DES MATIÈRES Qu est ce qu un imatch? STI
Better Match, Faster Innovation Rencontre sur la thématique du Calcul Haute Performance - 13 juin 2012 Meeting on the theme of High Performance Computing TABLE DES MATIÈRES Qu est ce qu un imatch? STI
Contributions à l expérimentation sur les systèmes distribués de grande taille
 Contributions à l expérimentation sur les systèmes distribués de grande taille Lucas Nussbaum Soutenance de thèse 4 décembre 2008 Lucas Nussbaum Expérimentation sur les systèmes distribués 1 / 49 Contexte
Contributions à l expérimentation sur les systèmes distribués de grande taille Lucas Nussbaum Soutenance de thèse 4 décembre 2008 Lucas Nussbaum Expérimentation sur les systèmes distribués 1 / 49 Contexte
Chapitre 2. Cluster de calcul (Torque / Maui) Grid and Cloud Computing
 Grid and Cloud Computing") Chapitre 2. Cluster de calcul (Torque / Maui) Grid and Cloud Computing 2. Cluster de calcul (Torque/Maui) Batch/Job Scheduler Gestion automatique d'une séries de jobs Interface de définition des jobs et
Chapitre 2. Cluster de calcul (Torque / Maui) Grid and Cloud Computing 2. Cluster de calcul (Torque/Maui) Batch/Job Scheduler Gestion automatique d'une séries de jobs Interface de définition des jobs et
T.P. FLUENT. Cours Mécanique des Fluides. 24 février 2006 NAZIH MARZOUQY
 T.P. FLUENT Cours Mécanique des Fluides 24 février 2006 NAZIH MARZOUQY 2 Table des matières 1 Choc stationnaire dans un tube à choc 7 1.1 Introduction....................................... 7 1.2 Description.......................................
T.P. FLUENT Cours Mécanique des Fluides 24 février 2006 NAZIH MARZOUQY 2 Table des matières 1 Choc stationnaire dans un tube à choc 7 1.1 Introduction....................................... 7 1.2 Description.......................................
<Insert Picture Here> Solaris pour la base de donnés Oracle
 Solaris pour la base de donnés Oracle Alain Chéreau Oracle Solution Center Agenda Compilateurs Mémoire pour la SGA Parallélisme RAC Flash Cache Compilateurs
Solaris pour la base de donnés Oracle Alain Chéreau Oracle Solution Center Agenda Compilateurs Mémoire pour la SGA Parallélisme RAC Flash Cache Compilateurs
Windows serveur 2008 installer hyperv
 Windows serveur 2008 installer hyperv 1 Description Voici la description fournit par le site Microsoft. «Windows Server 2008 Hyper-V est le moteur de virtualisation (hyperviseur) fourni dans Windows Server
Windows serveur 2008 installer hyperv 1 Description Voici la description fournit par le site Microsoft. «Windows Server 2008 Hyper-V est le moteur de virtualisation (hyperviseur) fourni dans Windows Server
Info0804. Cours 6. Optimisation combinatoire : Applications et compléments
 Recherche Opérationnelle Optimisation combinatoire : Applications et compléments Pierre Delisle Université de Reims Champagne-Ardenne Département de Mathématiques et Informatique 17 février 2014 Plan de
Recherche Opérationnelle Optimisation combinatoire : Applications et compléments Pierre Delisle Université de Reims Champagne-Ardenne Département de Mathématiques et Informatique 17 février 2014 Plan de
Architecture des ordinateurs
 Décoder la relation entre l architecture et les applications Violaine Louvet, Institut Camille Jordan CNRS & Université Lyon 1 Ecole «Découverte du Calcul» 2013 1 / 61 Simulation numérique... Physique
Décoder la relation entre l architecture et les applications Violaine Louvet, Institut Camille Jordan CNRS & Université Lyon 1 Ecole «Découverte du Calcul» 2013 1 / 61 Simulation numérique... Physique
Rapport 2014 et demande pour 2015. Portage de Méso-NH sur Machines Massivement Parallèles du GENCI Projet 2015 : GENCI GEN1605 & CALMIP-P0121
 Rapport 2014 et demande pour 2015 Portage de Méso-NH sur Machines Massivement Parallèles du GENCI Projet 2015 : GENCI GEN1605 & CALMIP-P0121 Rappel sur Méso-NH : Modélisation à moyenne échelle de l atmosphère
Rapport 2014 et demande pour 2015 Portage de Méso-NH sur Machines Massivement Parallèles du GENCI Projet 2015 : GENCI GEN1605 & CALMIP-P0121 Rappel sur Méso-NH : Modélisation à moyenne échelle de l atmosphère
Métriques de performance pour les algorithmes et programmes parallèles
 Métriques de performance pour les algorithmes et programmes parallèles 11 18 nov. 2002 Cette section est basée tout d abord sur la référence suivante (manuel suggéré mais non obligatoire) : R. Miller and
Métriques de performance pour les algorithmes et programmes parallèles 11 18 nov. 2002 Cette section est basée tout d abord sur la référence suivante (manuel suggéré mais non obligatoire) : R. Miller and
Programmation parallèle et distribuée
 ppd/mpassing p. 1/43 Programmation parallèle et distribuée Communications par messages Philippe MARQUET [email protected] Laboratoire d informatique fondamentale de Lille Université des sciences
ppd/mpassing p. 1/43 Programmation parallèle et distribuée Communications par messages Philippe MARQUET [email protected] Laboratoire d informatique fondamentale de Lille Université des sciences
Parallélisme et Répartition
 Parallélisme et Répartition Master Info Françoise Baude Université de Nice Sophia-Antipolis UFR Sciences Département Informatique [email protected] web du cours : deptinfo.unice.fr/~baude Septembre 2009 Chapitre
Parallélisme et Répartition Master Info Françoise Baude Université de Nice Sophia-Antipolis UFR Sciences Département Informatique [email protected] web du cours : deptinfo.unice.fr/~baude Septembre 2009 Chapitre
Équilibrage Dynamique de Charge pour des Calculs Parallèles sur Cluster Linux - Une Évaluation de l Environnement AMPI.
 Facultés Universitaires Notre-Dame de la Paix, Namur Institut d Informatique Année académique 2003-2004 Équilibrage Dynamique de Charge pour des Calculs Parallèles sur Cluster Linux - Une Évaluation de
Facultés Universitaires Notre-Dame de la Paix, Namur Institut d Informatique Année académique 2003-2004 Équilibrage Dynamique de Charge pour des Calculs Parallèles sur Cluster Linux - Une Évaluation de
Quantification d incertitude et Tendances en HPC
 Quantification d incertitude et Tendances en HPC Laurence Viry E cole de Physique des Houches 7 Mai 2014 Laurence Viry Tendances en HPC 7 Mai 2014 1 / 47 Contents 1 Mode lisation, simulation et quantification
Quantification d incertitude et Tendances en HPC Laurence Viry E cole de Physique des Houches 7 Mai 2014 Laurence Viry Tendances en HPC 7 Mai 2014 1 / 47 Contents 1 Mode lisation, simulation et quantification
Cluster High Performance Computing. Dr. Andreas Koch, Cluster Specialist
 Cluster High Performance Computing Dr. Andreas Koch, Cluster Specialist TABLE DES MATIÈRES 1 RÉSUMÉ... 3 2 INTRODUCTION... 4 3 STRUCTURE D UN CLUSTER HPC... 6 3.1 INTRODUCTION... 6 3.2 MONTAGE SIMPLE...
Cluster High Performance Computing Dr. Andreas Koch, Cluster Specialist TABLE DES MATIÈRES 1 RÉSUMÉ... 3 2 INTRODUCTION... 4 3 STRUCTURE D UN CLUSTER HPC... 6 3.1 INTRODUCTION... 6 3.2 MONTAGE SIMPLE...
Analyse de performance, monitoring
 Analyse de performance, monitoring Plan Principes de profilage Projet TPTP dans Eclipse Utilisation des profiling tools de TPTP Philippe Collet Master 1 Informatique 2009-2010 http://deptinfo.unice.fr/twiki/bin/view/minfo/gl
Analyse de performance, monitoring Plan Principes de profilage Projet TPTP dans Eclipse Utilisation des profiling tools de TPTP Philippe Collet Master 1 Informatique 2009-2010 http://deptinfo.unice.fr/twiki/bin/view/minfo/gl
3A-IIC - Parallélisme & Grid GRID : Définitions. GRID : Définitions. Stéphane Vialle. [email protected] http://www.metz.supelec.
 3A-IIC - Parallélisme & Grid Stéphane Vialle [email protected] http://www.metz.supelec.fr/~vialle Principes et Objectifs Evolution Leçons du passé Composition d une Grille Exemple d utilisation
3A-IIC - Parallélisme & Grid Stéphane Vialle [email protected] http://www.metz.supelec.fr/~vialle Principes et Objectifs Evolution Leçons du passé Composition d une Grille Exemple d utilisation
4.2 Unités d enseignement du M1
 88 CHAPITRE 4. DESCRIPTION DES UNITÉS D ENSEIGNEMENT 4.2 Unités d enseignement du M1 Tous les cours sont de 6 ECTS. Modélisation, optimisation et complexité des algorithmes (code RCP106) Objectif : Présenter
88 CHAPITRE 4. DESCRIPTION DES UNITÉS D ENSEIGNEMENT 4.2 Unités d enseignement du M1 Tous les cours sont de 6 ECTS. Modélisation, optimisation et complexité des algorithmes (code RCP106) Objectif : Présenter
Architectures d implémentation de Click&DECiDE NSI
 Architectures d implémentation de Click&DECiDE NSI de 1 à 300 millions de ligne de log par jour Dans ce document, nous allons étudier les différentes architectures à mettre en place pour Click&DECiDE NSI.
Architectures d implémentation de Click&DECiDE NSI de 1 à 300 millions de ligne de log par jour Dans ce document, nous allons étudier les différentes architectures à mettre en place pour Click&DECiDE NSI.
Retour d expérience, portage de code Promes dans le cadre de l appel à projets CAPS-GENCI
 , portage de code Promes dans le cadre de l appel à projets CAPS-GENCI PROMES (UPR 8521 CNRS) Université de Perpignan France 29 juin 2011 1 Contexte 2 3 4 Sommaire Contexte 1 Contexte 2 3 4 Laboratoire
, portage de code Promes dans le cadre de l appel à projets CAPS-GENCI PROMES (UPR 8521 CNRS) Université de Perpignan France 29 juin 2011 1 Contexte 2 3 4 Sommaire Contexte 1 Contexte 2 3 4 Laboratoire
Les environnements de calcul distribué
 2 e Atelier CRAG, 3 au 8 Décembre 2012 Par Blaise Omer YENKE IUT, Université de Ngaoundéré, Cameroun. 4 décembre 2012 1 / 32 Calcul haute performance (HPC) High-performance computing (HPC) : utilisation
2 e Atelier CRAG, 3 au 8 Décembre 2012 Par Blaise Omer YENKE IUT, Université de Ngaoundéré, Cameroun. 4 décembre 2012 1 / 32 Calcul haute performance (HPC) High-performance computing (HPC) : utilisation
Infrastructures Parallèles de Calcul
 Infrastructures Parallèles de Calcul Clusters Grids Clouds Stéphane Genaud 11/02/2011 Stéphane Genaud () 11/02/2011 1 / 8 Clusters - Grids - Clouds Clusters : assemblage de PCs + interconnexion rapide
Infrastructures Parallèles de Calcul Clusters Grids Clouds Stéphane Genaud 11/02/2011 Stéphane Genaud () 11/02/2011 1 / 8 Clusters - Grids - Clouds Clusters : assemblage de PCs + interconnexion rapide
Programmation parallèle et distribuée
 Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2015) Marc Parizeau, Département de génie électrique et de génie informatique Plan Données massives («big data») Architecture Hadoop distribution
Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2015) Marc Parizeau, Département de génie électrique et de génie informatique Plan Données massives («big data») Architecture Hadoop distribution
Journée Utiliateurs 2015. Nouvelles du Pôle ID (Informatique) Pierre Neyron, LIG/CNRS
 Pierre Neyron, LIG/CNRS") Journée Utiliateurs 2015 Nouvelles du Pôle ID (Informatique) Pierre Neyron, LIG/CNRS 1 Pôle ID, Grid'5000 Ciment Une proximité des platesformes Autres sites G5K Grenoble + CIMENT Pôle ID = «Digitalis»
Journée Utiliateurs 2015 Nouvelles du Pôle ID (Informatique) Pierre Neyron, LIG/CNRS 1 Pôle ID, Grid'5000 Ciment Une proximité des platesformes Autres sites G5K Grenoble + CIMENT Pôle ID = «Digitalis»
Communications performantes par passage de message entre machines virtuelles co-hébergées
 Communications performantes par passage de message entre machines virtuelles co-hébergées François Diakhaté1,2 1 CEA/DAM Île de France 2 INRIA Bordeaux Sud Ouest, équipe RUNTIME Renpar 2009 1 Plan Introduction
Communications performantes par passage de message entre machines virtuelles co-hébergées François Diakhaté1,2 1 CEA/DAM Île de France 2 INRIA Bordeaux Sud Ouest, équipe RUNTIME Renpar 2009 1 Plan Introduction
INF6500 : Structures des ordinateurs. Sylvain Martel - INF6500 1
 INF6500 : Structures des ordinateurs Sylvain Martel - INF6500 1 Cours 4 : Multiprocesseurs Sylvain Martel - INF6500 2 Multiprocesseurs Type SISD SIMD MIMD Communication Shared memory Message-passing Groupe
INF6500 : Structures des ordinateurs Sylvain Martel - INF6500 1 Cours 4 : Multiprocesseurs Sylvain Martel - INF6500 2 Multiprocesseurs Type SISD SIMD MIMD Communication Shared memory Message-passing Groupe
INFO-F-404 : Techniques avancées de systèmes d exploitation
 Nikita Veshchikov e-mail : [email protected] téléphone : 02/650.58.56 bureau : 2N8.213 URL : http://student.ulb.ac.be/~nveshchi/ INFO-F-404 : Techniques avancées de systèmes d exploitation Table
Nikita Veshchikov e-mail : [email protected] téléphone : 02/650.58.56 bureau : 2N8.213 URL : http://student.ulb.ac.be/~nveshchi/ INFO-F-404 : Techniques avancées de systèmes d exploitation Table
Journée Scientifique Onera
 [[À la croisée des révolutions numériques]] Journée Scientifique Onera Date : 20 mai 2014 Lieu : ONERA - Centre de Châtillon - 29 avenue de la Division Leclerc, 92322 Inscription : Gratuite Obligatoire.
[[À la croisée des révolutions numériques]] Journée Scientifique Onera Date : 20 mai 2014 Lieu : ONERA - Centre de Châtillon - 29 avenue de la Division Leclerc, 92322 Inscription : Gratuite Obligatoire.
Big Data. Cyril Amsellem Consultant avant-vente. 16 juin 2011. Talend 2010 1
 Big Data Cyril Amsellem Consultant avant-vente 16 juin 2011 Talend 2010 1 Big Data Architecture globale Hadoop Les projets Hadoop (partie 1) Hadoop-Core : projet principal. HDFS : système de fichiers distribués
Big Data Cyril Amsellem Consultant avant-vente 16 juin 2011 Talend 2010 1 Big Data Architecture globale Hadoop Les projets Hadoop (partie 1) Hadoop-Core : projet principal. HDFS : système de fichiers distribués
Atelier : Virtualisation avec Xen
 Virtualisation et Cloud Computing Atelier : Virtualisation avec Xen Plan Présentation de Xen Architecture de Xen Le réseau Gestion des domaines DomU dans Xen Installation de Xen Virt. & Cloud 12/13 2 Xen
Virtualisation et Cloud Computing Atelier : Virtualisation avec Xen Plan Présentation de Xen Architecture de Xen Le réseau Gestion des domaines DomU dans Xen Installation de Xen Virt. & Cloud 12/13 2 Xen
Contribution à la conception à base de composants logiciels d applications scientifiques parallèles.
 - École Normale Supérieure de LYON - Laboratoire de l Informatique du Parallélisme THÈSE en vue d obtenir le grade de Docteur de l École Normale Supérieure de Lyon - Université de Lyon Discipline : Informatique
- École Normale Supérieure de LYON - Laboratoire de l Informatique du Parallélisme THÈSE en vue d obtenir le grade de Docteur de l École Normale Supérieure de Lyon - Université de Lyon Discipline : Informatique
Monitoring continu et gestion optimale des performances énergétiques des bâtiments
 Monitoring continu et gestion optimale des performances énergétiques des bâtiments Alexandre Nassiopoulos et al. Journée d inauguration de Sense-City, 23/03/2015 Croissance de la demande énergétique et
Monitoring continu et gestion optimale des performances énergétiques des bâtiments Alexandre Nassiopoulos et al. Journée d inauguration de Sense-City, 23/03/2015 Croissance de la demande énergétique et
Programmation linéaire
 1 Programmation linéaire 1. Le problème, un exemple. 2. Le cas b = 0 3. Théorème de dualité 4. L algorithme du simplexe 5. Problèmes équivalents 6. Complexité de l Algorithme 2 Position du problème Soit
1 Programmation linéaire 1. Le problème, un exemple. 2. Le cas b = 0 3. Théorème de dualité 4. L algorithme du simplexe 5. Problèmes équivalents 6. Complexité de l Algorithme 2 Position du problème Soit
Sujet proposé par Yves M. LEROY. Cet examen se compose d un exercice et de deux problèmes. Ces trois parties sont indépendantes.
 Promotion X 004 COURS D ANALYSE DES STRUCTURES MÉCANIQUES PAR LA MÉTHODE DES ELEMENTS FINIS (MEC 568) contrôle non classant (7 mars 007, heures) Documents autorisés : polycopié ; documents et notes de
Promotion X 004 COURS D ANALYSE DES STRUCTURES MÉCANIQUES PAR LA MÉTHODE DES ELEMENTS FINIS (MEC 568) contrôle non classant (7 mars 007, heures) Documents autorisés : polycopié ; documents et notes de
FOG : Free Open-Source Ghost. Solution libre de clonage et de déploiement de systèmes d'exploitation.
 FOG : Free Open-Source Ghost Solution libre de clonage et de déploiement de systèmes d'exploitation. JoSy-Plume 22 novembre 2010 Logiciel développé par Chuck Syperski et Jian Zhang, IT à l'université "DuPage"
FOG : Free Open-Source Ghost Solution libre de clonage et de déploiement de systèmes d'exploitation. JoSy-Plume 22 novembre 2010 Logiciel développé par Chuck Syperski et Jian Zhang, IT à l'université "DuPage"
Retour d expérience en Astrophysique : utilisation du Cloud IaaS pour le traitement de données des missions spatiales
 Retour d expérience en Astrophysique : utilisation du Cloud IaaS pour le traitement de données des missions spatiales Cécile Cavet cecile.cavet at apc.univ-paris7.fr Centre François Arago (FACe), Laboratoire
Retour d expérience en Astrophysique : utilisation du Cloud IaaS pour le traitement de données des missions spatiales Cécile Cavet cecile.cavet at apc.univ-paris7.fr Centre François Arago (FACe), Laboratoire
Rapport d activité. Mathieu Souchaud Juin 2007
 Rapport d activité Mathieu Souchaud Juin 2007 Ce document fait la synthèse des réalisations accomplies durant les sept premiers mois de ma mission (de novembre 2006 à juin 2007) au sein de l équipe ScAlApplix
Rapport d activité Mathieu Souchaud Juin 2007 Ce document fait la synthèse des réalisations accomplies durant les sept premiers mois de ma mission (de novembre 2006 à juin 2007) au sein de l équipe ScAlApplix
Une comparaison de méthodes de discrimination des masses de véhicules automobiles
 p.1/34 Une comparaison de méthodes de discrimination des masses de véhicules automobiles A. Rakotomamonjy, R. Le Riche et D. Gualandris INSA de Rouen / CNRS 1884 et SMS / PSA Enquêtes en clientèle dans
p.1/34 Une comparaison de méthodes de discrimination des masses de véhicules automobiles A. Rakotomamonjy, R. Le Riche et D. Gualandris INSA de Rouen / CNRS 1884 et SMS / PSA Enquêtes en clientèle dans
T. Gasc 1,2,3, F. De Vuyst 1, R. Motte 3, M. Peybernes 4, R. Poncet 5
 Modélisation de la performance et optimisation d un algorithme hydrodynamique de type Lagrange-Projection sur processeurs multi-cœurs T. Gasc 1,2,3, F. De Vuyst 1, R. Motte 3, M. Peybernes 4, R. Poncet
Modélisation de la performance et optimisation d un algorithme hydrodynamique de type Lagrange-Projection sur processeurs multi-cœurs T. Gasc 1,2,3, F. De Vuyst 1, R. Motte 3, M. Peybernes 4, R. Poncet
Optimisation non linéaire Irène Charon, Olivier Hudry École nationale supérieure des télécommunications
 Optimisation non linéaire Irène Charon, Olivier Hudry École nationale supérieure des télécommunications A. Optimisation sans contrainte.... Généralités.... Condition nécessaire et condition suffisante
Optimisation non linéaire Irène Charon, Olivier Hudry École nationale supérieure des télécommunications A. Optimisation sans contrainte.... Généralités.... Condition nécessaire et condition suffisante
Tests de performance du matériel
 3 Tests de performance du matériel Après toute la théorie du dernier chapitre, vous vous demandez certainement quelles sont les performances réelles de votre propre système. En fait, il y a plusieurs raisons
3 Tests de performance du matériel Après toute la théorie du dernier chapitre, vous vous demandez certainement quelles sont les performances réelles de votre propre système. En fait, il y a plusieurs raisons
Introduction à la Programmation Parallèle: MPI
 Introduction à la Programmation Parallèle: MPI Frédéric Gava et Gaétan Hains L.A.C.L Laboratoire d Algorithmique, Complexité et Logique Cours du M2 SSI option PSSR Plan 1 Modèle de programmation 2 3 4
Introduction à la Programmation Parallèle: MPI Frédéric Gava et Gaétan Hains L.A.C.L Laboratoire d Algorithmique, Complexité et Logique Cours du M2 SSI option PSSR Plan 1 Modèle de programmation 2 3 4
CA ARCserve Backup Option NAS (Network Attached Storage) NDMP (Network Data Management Protocol)
 NDMP (Network Data Management Protocol)") Page 1 WHITE PAPER: CA ARCserve Backup Option NAS (Network Attached Storage) NDMP (Network Data Management Protocol) : protection intégrée pour les environnements NAS hétérogènes CA ARCserve Backup Option
Page 1 WHITE PAPER: CA ARCserve Backup Option NAS (Network Attached Storage) NDMP (Network Data Management Protocol) : protection intégrée pour les environnements NAS hétérogènes CA ARCserve Backup Option
Outil d aide au choix Serveurs Lot 4 Marché Groupement de Recherche
 Outil d aide au choix Serveurs Lot 4 Marché Groupement de Recherche Serveurs DELL PowerEdge Tour Rack standard R310 T110II Rack de calcul Lames R815 M610 R410 R910 M620 R415 R510 T620 R620 R720/R720xd
Outil d aide au choix Serveurs Lot 4 Marché Groupement de Recherche Serveurs DELL PowerEdge Tour Rack standard R310 T110II Rack de calcul Lames R815 M610 R410 R910 M620 R415 R510 T620 R620 R720/R720xd
Architecture distribuée
 Architecture distribuée Conception et développement d algorithmes distribués pour le moteur Baboukweb Jean-Christophe DALLEAU Département de Mathématiques et Informatique Université de La Réunion 26 juin
Architecture distribuée Conception et développement d algorithmes distribués pour le moteur Baboukweb Jean-Christophe DALLEAU Département de Mathématiques et Informatique Université de La Réunion 26 juin
Les clusters Linux. 4 août 2004 Benoît des Ligneris, Ph. D. [email protected]. white-paper-cluster_fr.sxw, Version 74 Page 1
 Les clusters Linux 4 août 2004 Benoît des Ligneris, Ph. D. [email protected] white-paper-cluster_fr.sxw, Version 74 Page 1 Table des matières Introduction....2 Haute performance (High
Les clusters Linux 4 août 2004 Benoît des Ligneris, Ph. D. [email protected] white-paper-cluster_fr.sxw, Version 74 Page 1 Table des matières Introduction....2 Haute performance (High
Gestion de mémoire secondaire F. Boyer, Laboratoire Sardes [email protected]
 Gestion de mémoire secondaire F. Boyer, Laboratoire Sardes [email protected] 1- Structure d un disque 2- Ordonnancement des requêtes 3- Gestion du disque - formatage - bloc d amorçage - récupération
Gestion de mémoire secondaire F. Boyer, Laboratoire Sardes [email protected] 1- Structure d un disque 2- Ordonnancement des requêtes 3- Gestion du disque - formatage - bloc d amorçage - récupération
Performances et optimisations
 Performances et optimisations Outils pour le calcul scientifique à haute performance École doctorale sciences pour l ingénieur juin 2001 Philippe MARQUET [email protected] Laboratoire d informatique fondamentale
Performances et optimisations Outils pour le calcul scientifique à haute performance École doctorale sciences pour l ingénieur juin 2001 Philippe MARQUET [email protected] Laboratoire d informatique fondamentale
StruxureWare Power Monitoring v7.0. La nouvelle génération en matière de logiciel de gestion complète d énergie
 StruxureWare Power Monitoring v7.0 La nouvelle génération en matière de logiciel de gestion complète d énergie Évolution des deux plate-formes originales Power Monitoring v7.0 SMS ION Enterprise 2012 Struxureware
StruxureWare Power Monitoring v7.0 La nouvelle génération en matière de logiciel de gestion complète d énergie Évolution des deux plate-formes originales Power Monitoring v7.0 SMS ION Enterprise 2012 Struxureware
DG-ADAJ: Une plateforme Desktop Grid
 DG-ADAJ: Une plateforme pour Desktop Grid Olejnik Richard, Bernard Toursel Université des Sciences et Technologies de Lille Laboratoire d Informatique Fondamentale de Lille (LIFL UMR CNRS 8022) Bât M3
DG-ADAJ: Une plateforme pour Desktop Grid Olejnik Richard, Bernard Toursel Université des Sciences et Technologies de Lille Laboratoire d Informatique Fondamentale de Lille (LIFL UMR CNRS 8022) Bât M3
Introduction au maillage pour le calcul scientifique
 Introduction au maillage pour le calcul scientifique CEA DAM Île-de-France, Bruyères-le-Châtel [email protected] Présentation adaptée du tutorial de Steve Owen, Sandia National Laboratories, Albuquerque,
Introduction au maillage pour le calcul scientifique CEA DAM Île-de-France, Bruyères-le-Châtel [email protected] Présentation adaptée du tutorial de Steve Owen, Sandia National Laboratories, Albuquerque,
Figure 3.1- Lancement du Gambit
 3.1. Introduction Le logiciel Gambit est un mailleur 2D/3D; pré-processeur qui permet de mailler des domaines de géométrie d un problème de CFD (Computational Fluid Dynamics).Il génère des fichiers*.msh
3.1. Introduction Le logiciel Gambit est un mailleur 2D/3D; pré-processeur qui permet de mailler des domaines de géométrie d un problème de CFD (Computational Fluid Dynamics).Il génère des fichiers*.msh
Asynchronisme : Cadres continu et discret
 N d ordre : 151 Année 2006 HABILITATION À DIRIGER DES RECHERCHES UNIVERSITÉ DE FRANCHE-COMTÉ Spécialité Informatique présentée par Sylvain CONTASSOT-VIVIER Docteur en Informatique Sujet Asynchronisme :
N d ordre : 151 Année 2006 HABILITATION À DIRIGER DES RECHERCHES UNIVERSITÉ DE FRANCHE-COMTÉ Spécialité Informatique présentée par Sylvain CONTASSOT-VIVIER Docteur en Informatique Sujet Asynchronisme :
Tout savoir sur le matériel informatique
 Tout savoir sur le matériel informatique Thème de l exposé : Les Processeurs Date : 05 Novembre 2010 Orateurs : Hugo VIAL-JAIME Jérémy RAMBAUD Sommaire : 1. Introduction... 3 2. Historique... 4 3. Relation
Tout savoir sur le matériel informatique Thème de l exposé : Les Processeurs Date : 05 Novembre 2010 Orateurs : Hugo VIAL-JAIME Jérémy RAMBAUD Sommaire : 1. Introduction... 3 2. Historique... 4 3. Relation
Mathématique et Automatique : de la boucle ouverte à la boucle fermée. Maïtine bergounioux Laboratoire MAPMO - UMR 6628 Université d'orléans
 Mathématique et Automatique : de la boucle ouverte à la boucle fermée Maïtine bergounioux Laboratoire MAPMO - UMR 6628 Université d'orléans [email protected] Plan 1. Un peu de
Mathématique et Automatique : de la boucle ouverte à la boucle fermée Maïtine bergounioux Laboratoire MAPMO - UMR 6628 Université d'orléans [email protected] Plan 1. Un peu de
Stephan Hadinger, Sr. Mgr Solutions Architecture, AWS. Salon du Big Data 11 mars 2015
 Stephan Hadinger, Sr. Mgr Solutions Architecture, AWS Salon du Big Data 11 mars 2015 Accélération de l innovation +500 +280 Amazon EC2 Container Service +159 AWS Storage Gateway Amazon Elastic Transcoder
Stephan Hadinger, Sr. Mgr Solutions Architecture, AWS Salon du Big Data 11 mars 2015 Accélération de l innovation +500 +280 Amazon EC2 Container Service +159 AWS Storage Gateway Amazon Elastic Transcoder
Exécution des instructions machine
 Exécution des instructions machine Eduardo Sanchez EPFL Exemple: le processeur MIPS add a, b, c a = b + c type d'opération (mnémonique) destination du résultat lw a, addr opérandes sources a = mem[addr]
Exécution des instructions machine Eduardo Sanchez EPFL Exemple: le processeur MIPS add a, b, c a = b + c type d'opération (mnémonique) destination du résultat lw a, addr opérandes sources a = mem[addr]
La valeur des SSD partagés dans l'informatique d'entreprise
 La valeur des SSD partagés dans l'informatique d'entreprise La technologie Mt. Rainier de QLogic intègre des SSD dotés de la connectivité SAN Principales découvertes La technologie Mt. Rainier de QLogic
La valeur des SSD partagés dans l'informatique d'entreprise La technologie Mt. Rainier de QLogic intègre des SSD dotés de la connectivité SAN Principales découvertes La technologie Mt. Rainier de QLogic
Windows Server 2008. Chapitre 1: Découvrir Windows Server 2008
 Windows Server 2008 Chapitre 1: Découvrir Windows Server 2008 Objectives Identifier les caractéristiques de chaque édition de Windows Server 2008 Identifier les caractéristiques généraux de Windows Server
Windows Server 2008 Chapitre 1: Découvrir Windows Server 2008 Objectives Identifier les caractéristiques de chaque édition de Windows Server 2008 Identifier les caractéristiques généraux de Windows Server
Introduction aux algorithmes MapReduce. Mathieu Dumoulin (GRAAL), 14 Février 2014
, 14 Février 2014") Introduction aux algorithmes MapReduce Mathieu Dumoulin (GRAAL), 14 Février 2014 Plan Introduction de la problématique Tutoriel MapReduce Design d algorithmes MapReduce Tri, somme et calcul de moyenne
Introduction aux algorithmes MapReduce Mathieu Dumoulin (GRAAL), 14 Février 2014 Plan Introduction de la problématique Tutoriel MapReduce Design d algorithmes MapReduce Tri, somme et calcul de moyenne
Cluster High Availability. Holger Hennig, HA-Cluster Specialist
 Cluster High Availability Holger Hennig, HA-Cluster Specialist TABLE DES MATIÈRES 1. RÉSUMÉ...3 2. INTRODUCTION...4 2.1 GÉNÉRALITÉS...4 2.2 LE CONCEPT DES CLUSTERS HA...4 2.3 AVANTAGES D UNE SOLUTION DE
Cluster High Availability Holger Hennig, HA-Cluster Specialist TABLE DES MATIÈRES 1. RÉSUMÉ...3 2. INTRODUCTION...4 2.1 GÉNÉRALITÉS...4 2.2 LE CONCEPT DES CLUSTERS HA...4 2.3 AVANTAGES D UNE SOLUTION DE
L exclusion mutuelle distribuée
 L exclusion mutuelle distribuée L algorithme de L Amport L algorithme est basé sur 2 concepts : L estampillage des messages La distribution d une file d attente sur l ensemble des sites du système distribué
L exclusion mutuelle distribuée L algorithme de L Amport L algorithme est basé sur 2 concepts : L estampillage des messages La distribution d une file d attente sur l ensemble des sites du système distribué
Portage d applications sur le Cloud IaaS Portage d application
 s sur le Cloud IaaS Cécile Cavet cecile.cavet at apc.univ-paris7.fr Centre François Arago (FACe), Laboratoire AstroParticule et Cosmologie (APC), LabEx UnivEarthS APC, Univ. Paris Diderot, CNRS/IN2P3,
s sur le Cloud IaaS Cécile Cavet cecile.cavet at apc.univ-paris7.fr Centre François Arago (FACe), Laboratoire AstroParticule et Cosmologie (APC), LabEx UnivEarthS APC, Univ. Paris Diderot, CNRS/IN2P3,
Programmation parallèle et distribuée
 Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2014) Marc Parizeau, Département de génie électrique et de génie informatique Plan Mégadonnées («big data») Architecture Hadoop distribution
Programmation parallèle et distribuée (GIF-4104/7104) 5a - (hiver 2014) Marc Parizeau, Département de génie électrique et de génie informatique Plan Mégadonnées («big data») Architecture Hadoop distribution
Masses de données et calcul : à l IRIT. 8 octobre 2013
 Masses de données et calcul : la recherche en lien avec les Big Data à l IRIT 8 octobre 2013 08/10/2013 1 L IRIT en qq chiffres 700 personnes sur tous les sites toulousains 5 tutelles 7 thèmes et 21 équipes
Masses de données et calcul : la recherche en lien avec les Big Data à l IRIT 8 octobre 2013 08/10/2013 1 L IRIT en qq chiffres 700 personnes sur tous les sites toulousains 5 tutelles 7 thèmes et 21 équipes
Evaluation des performances de programmes parallèles haut niveau à base de squelettes
 Evaluation des performances de programmes parallèles haut niveau à base de squelettes Enhancing the Performance Predictability of Grid Applications with Patterns and Process Algebras A. Benoit, M. Cole,
Evaluation des performances de programmes parallèles haut niveau à base de squelettes Enhancing the Performance Predictability of Grid Applications with Patterns and Process Algebras A. Benoit, M. Cole,
Windows 2000: W2K: Architecture. Introduction. W2K: amélioration du noyau. Gamme windows 2000. W2K pro: configuration.
 Windows 2000: Introduction W2K: Architecture Système d'exploitation multitâche multithread 32 bits à architecture SMP. Multiplateforme: intel x86, Compaq Alpha Jusqu'à 64 Go de mémoire vive Système d'exploitation
Windows 2000: Introduction W2K: Architecture Système d'exploitation multitâche multithread 32 bits à architecture SMP. Multiplateforme: intel x86, Compaq Alpha Jusqu'à 64 Go de mémoire vive Système d'exploitation
Le Ro le Hyper V Troisie me Partie Haute disponibilite des machines virtuelles
 Le Ro le Hyper V Troisie me Partie Haute disponibilite des machines virtuelles Microsoft France Division DPE Table des matières Présentation... 2 Objectifs... 2 Pré requis... 2 Quelles sont les principales
Le Ro le Hyper V Troisie me Partie Haute disponibilite des machines virtuelles Microsoft France Division DPE Table des matières Présentation... 2 Objectifs... 2 Pré requis... 2 Quelles sont les principales
Protection des données avec les solutions de stockage NETGEAR
 Protection des données avec les solutions de stockage NETGEAR Solutions intelligentes pour les sauvegardes de NAS à NAS, la reprise après sinistre pour les PME-PMI et les environnements multi-sites La
Protection des données avec les solutions de stockage NETGEAR Solutions intelligentes pour les sauvegardes de NAS à NAS, la reprise après sinistre pour les PME-PMI et les environnements multi-sites La
Etablit des Budgets et des Quotas Utilisateurs par Montant, Nombre de pages, copies et types de fichiers.
 Print Manager Plus de Software Shelf permet de centraliser le suivi et l'audit de toute l'activité d'impression sur un réseau de serveurs d'impressions Windows XP or Windows NT/2000/2003/2008. Il permet
Print Manager Plus de Software Shelf permet de centraliser le suivi et l'audit de toute l'activité d'impression sur un réseau de serveurs d'impressions Windows XP or Windows NT/2000/2003/2008. Il permet
Modélisation multi-agents - Agents réactifs
 Modélisation multi-agents - Agents réactifs Syma cursus CSI / SCIA Julien Saunier - [email protected] Sources www-lih.univlehavre.fr/~olivier/enseignement/masterrecherche/cours/ support/algofourmis.pdf
Modélisation multi-agents - Agents réactifs Syma cursus CSI / SCIA Julien Saunier - [email protected] Sources www-lih.univlehavre.fr/~olivier/enseignement/masterrecherche/cours/ support/algofourmis.pdf
Grid5000 aujourd'hui : Architecture & utilisation
 1 Grid5000 aujourd'hui : Architecture & utilisation [email protected] 11 octobre 2005 Contexte 2 Grid5000 est : Une plateforme expérimentale pour le grid computing Ouverte à de nombreux thèmes de
1 Grid5000 aujourd'hui : Architecture & utilisation [email protected] 11 octobre 2005 Contexte 2 Grid5000 est : Une plateforme expérimentale pour le grid computing Ouverte à de nombreux thèmes de
Introduction à MATLAB R
 Introduction à MATLAB R Romain Tavenard 10 septembre 2009 MATLAB R est un environnement de calcul numérique propriétaire orienté vers le calcul matriciel. Il se compose d un langage de programmation, d
Introduction à MATLAB R Romain Tavenard 10 septembre 2009 MATLAB R est un environnement de calcul numérique propriétaire orienté vers le calcul matriciel. Il se compose d un langage de programmation, d
1 Introduction et modèle mathématique
 Optimisation parallèle et mathématiques financières Optimisation parallèle et mathématiques financières Pierre Spiteri 1 IRIT ENSEEIHT, UMR CNRS 5505 2 rue Charles Camichel, B.P. 7122 F-31 071 Toulouse,
Optimisation parallèle et mathématiques financières Optimisation parallèle et mathématiques financières Pierre Spiteri 1 IRIT ENSEEIHT, UMR CNRS 5505 2 rue Charles Camichel, B.P. 7122 F-31 071 Toulouse,
Génération de code binaire pour application multimedia : une approche au vol
 Génération de binaire pour application multimedia : une approche au vol http://hpbcg.org/ Henri-Pierre Charles Université de Versailles Saint-Quentin en Yvelines 3 Octobre 2009 Présentation Présentation
Génération de binaire pour application multimedia : une approche au vol http://hpbcg.org/ Henri-Pierre Charles Université de Versailles Saint-Quentin en Yvelines 3 Octobre 2009 Présentation Présentation
Symantec Backup Exec.cloud
 Protection automatique, continue et sécurisée qui sauvegarde les données vers le cloud ou via une approche hybride combinant la sauvegarde sur site et dans le cloud. Fiche technique : Symantec.cloud Seulement
Protection automatique, continue et sécurisée qui sauvegarde les données vers le cloud ou via une approche hybride combinant la sauvegarde sur site et dans le cloud. Fiche technique : Symantec.cloud Seulement
10 leçon 2. Leçon n 2 : Contact entre deux solides. Frottement de glissement. Exemples. (PC ou 1 er CU)
") 0 leçon 2 Leçon n 2 : Contact entre deu solides Frottement de glissement Eemples (PC ou er CU) Introduction Contact entre deu solides Liaisons de contact 2 Contact ponctuel 2 Frottement de glissement 2
0 leçon 2 Leçon n 2 : Contact entre deu solides Frottement de glissement Eemples (PC ou er CU) Introduction Contact entre deu solides Liaisons de contact 2 Contact ponctuel 2 Frottement de glissement 2
Simulation du transport de matière par diffusion surfacique à l aide d une approche Level-Set
 Simulation du transport de matière par diffusion surfacique à l aide d une approce Level-Set J. Brucon 1, D. Pino-Munoz 1, S. Drapier 1, F. Valdivieso 2 Ecole Nationale Supérieure des Mines de Saint-Etienne
Simulation du transport de matière par diffusion surfacique à l aide d une approce Level-Set J. Brucon 1, D. Pino-Munoz 1, S. Drapier 1, F. Valdivieso 2 Ecole Nationale Supérieure des Mines de Saint-Etienne
ANALYSE CATIA V5. 14/02/2011 Daniel Geffroy IUT GMP Le Mans
 ANALYSE CATIA V5 1 GSA Generative Structural Analysis 2 Modèle géométrique volumique Post traitement Pré traitement Maillage Conditions aux limites 3 Ouverture du module Choix du type d analyse 4 Calcul
ANALYSE CATIA V5 1 GSA Generative Structural Analysis 2 Modèle géométrique volumique Post traitement Pré traitement Maillage Conditions aux limites 3 Ouverture du module Choix du type d analyse 4 Calcul
Introduction aux algorithmes répartis
 Objectifs et plan Introduction aux algorithmes répartis Sacha Krakowiak Université Joseph Fourier Projet Sardes (INRIA et IMAG-LSR http://sardes.inrialpes.fr/people/krakowia! Introduction aux algorithmes
Objectifs et plan Introduction aux algorithmes répartis Sacha Krakowiak Université Joseph Fourier Projet Sardes (INRIA et IMAG-LSR http://sardes.inrialpes.fr/people/krakowia! Introduction aux algorithmes
Exchange 2007 : Améliorations et nouvelles fonctionnalités Atelier 136. Société GRICS
 Exchange 2007 : Améliorations et nouvelles fonctionnalités Atelier 136 Par : Paul Boucher Société GRICS Plan de la présentation Historique Nouveautés Prérequis Installation et migration Outils d administration
Exchange 2007 : Améliorations et nouvelles fonctionnalités Atelier 136 Par : Paul Boucher Société GRICS Plan de la présentation Historique Nouveautés Prérequis Installation et migration Outils d administration
Présentation d HyperV
 Virtualisation sous Windows 2008 Présentation d HyperV Agenda du module Présentation d Hyper-V Installation d Hyper-V Configuration d Hyper-V Administration des machines virtuelles Offre de virtualisation
Virtualisation sous Windows 2008 Présentation d HyperV Agenda du module Présentation d Hyper-V Installation d Hyper-V Configuration d Hyper-V Administration des machines virtuelles Offre de virtualisation
Etude d Algorithmes Parallèles de Data Mining
 REPUBLIQUE TUNISIENNE MINISTERE DE L ENSEIGNEMENT SUPERIEUR, DE LA TECHNOLOGIE ET DE LA RECHERCHE SCIENTIFIQUE UNIVERSITE DE TUNIS ELMANAR FACULTE DES SCIENCES DE TUNIS DEPARTEMENT DES SCIENCES DE L INFORMATIQUE
REPUBLIQUE TUNISIENNE MINISTERE DE L ENSEIGNEMENT SUPERIEUR, DE LA TECHNOLOGIE ET DE LA RECHERCHE SCIENTIFIQUE UNIVERSITE DE TUNIS ELMANAR FACULTE DES SCIENCES DE TUNIS DEPARTEMENT DES SCIENCES DE L INFORMATIQUE
Etude d Exchange, Google Apps, Office 365 et Zimbra
 I. Messagerie Exchange 2013 2 1) Caractéristiques 2 2) Pourquoi une entreprise choisit-elle Exchange? 2 3) Offres / Tarifs 2 4) Pré requis pour l installation d Exchange 2013 3 II. Google Apps : 5 1) Caractéristiques
I. Messagerie Exchange 2013 2 1) Caractéristiques 2 2) Pourquoi une entreprise choisit-elle Exchange? 2 3) Offres / Tarifs 2 4) Pré requis pour l installation d Exchange 2013 3 II. Google Apps : 5 1) Caractéristiques
BIG DATA en Sciences et Industries de l Environnement
 BIG DATA en Sciences et Industries de l Environnement François Royer www.datasio.com 21 mars 2012 FR Big Data Congress, Paris 2012 1/23 Transport terrestre Traçabilité Océanographie Transport aérien Télémétrie
BIG DATA en Sciences et Industries de l Environnement François Royer www.datasio.com 21 mars 2012 FR Big Data Congress, Paris 2012 1/23 Transport terrestre Traçabilité Océanographie Transport aérien Télémétrie
HPC by OVH.COM. Le bon calcul pour l innovation OVH.COM
 4 HPC by OVH.COM Le bon calcul pour l innovation 2 6 5 6 2 8 6 2 OVH.COM 5 2 HPC by OVH.COM 6 HPC pour High Performance Computing Utilisation de serveurs et de grappes de serveurs (clusters), configurés
4 HPC by OVH.COM Le bon calcul pour l innovation 2 6 5 6 2 8 6 2 OVH.COM 5 2 HPC by OVH.COM 6 HPC pour High Performance Computing Utilisation de serveurs et de grappes de serveurs (clusters), configurés
Contrôle Non Destructif : Implantation d'algorithmes sur GPU et multi-coeurs. Gilles Rougeron CEA/LIST Département Imagerie Simulation et Contrôle
 Contrôle Non Destructif : Implantation d'algorithmes sur GPU et multi-coeurs Gilles Rougeron CEA/LIST Département Imagerie Simulation et Contrôle 1 CEA R & D for Nuclear Energy 5 000 people Nuclear systems
Contrôle Non Destructif : Implantation d'algorithmes sur GPU et multi-coeurs Gilles Rougeron CEA/LIST Département Imagerie Simulation et Contrôle 1 CEA R & D for Nuclear Energy 5 000 people Nuclear systems
Chapitre 2 : Abstraction et Virtualisation
 Virtualisation et Cloud Computing Chapitre 2 : Abstraction et Virtualisation Objectifs Présenter la notion de niveaux d abstraction séparés par des interfaces bien définies Description des avantages et
Virtualisation et Cloud Computing Chapitre 2 : Abstraction et Virtualisation Objectifs Présenter la notion de niveaux d abstraction séparés par des interfaces bien définies Description des avantages et