Apprentissage automatique et méga données
|
|
|
- Clementine Chrétien
- il y a 10 ans
- Total affichages :
Transcription
1 Apprentissage automatique et méga données Stéphane Canu asi.insa-rouen.fr/enseignants/~scanu Séminiare ICube 2015, Strasbourg June 11, 2015

2 Plan 1 Introduction Une brève définition de l apprentissage statistique Les principaux algorithmes d apprentissage 2 Etudes de cas Apprendre à rechercher l information Apprendre à recommander Apprendre à étiqueter une image avec un réseaux de neurones 3 La science des données 4 Les outils pour l apprentissage statistique 5 Conclusion

3 Plan 1 Introduction Une brève définition de l apprentissage statistique Les principaux algorithmes d apprentissage 2 Etudes de cas Apprendre à rechercher l information Apprendre à recommander Apprendre à étiqueter une image avec un réseaux de neurones 3 La science des données 4 Les outils pour l apprentissage statistique 5 Conclusion

4 Apprentissage : humain vs. machine Les apprentissages d un enfant marcher : un an parler : deux ans raisonner : le reste

5 Apprendre à raisonner

6 Deux définitions de l apprentissage Arthur Samuel (1959) Machine Learning: Field of study that gives computers the ability to learn without being explicitly programmed. Tom Mitchell (The Discipline of Machine Learning, 2006) How can we build computer systems that automatically improve with experience, and what are the fundamental laws that govern all learning processes? A computer program CP is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E

7 Une tâche T «apprenable» Machine Learning A computer program CP learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E Construire un programme CP experience E : statistiques performance measure P : optimisation tasks T : utilité traduction automatique jouer aux échec conduire,... et faire ce que l on fait

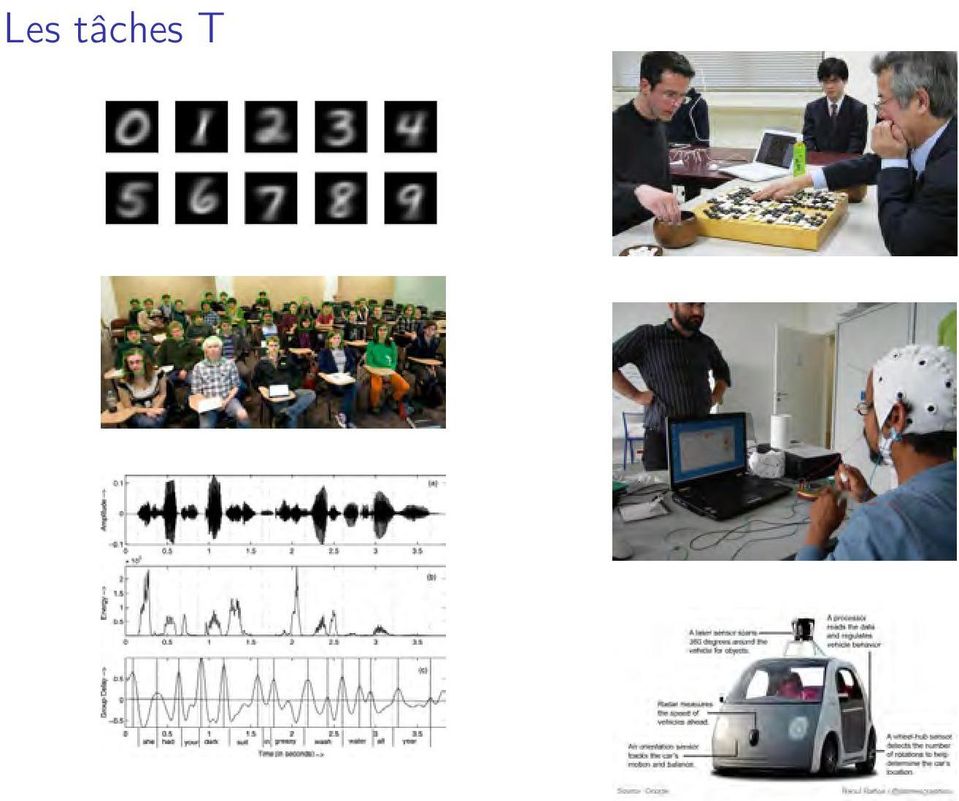
8 Les tâches T
9 L experience E : les données capteurs variables qualitatives / ordinales / quantitatives texte chaine de caractères parole temps - série temporelle images/vidéos dépendances 2/3 d réseaux graphes jeux séquences d interactions flots tickets de caisse, web logs, traffic... étiquettes information d évaluation Les mégadonnées (volume, vitesse, variété, véracité et valeur) Des données qui arrivent sans qu on ait décidé de les collecter l importance des pré-traitements (nettoyage, normalisation, codage... ) et de la représentation : de la donnée au vecteur

10 Objectifs, tâches et mesures de performance P non supervisé clustering homogénéité des groupes supervisé classification bi classe nombre d erreur (0/1) multi classe détection nombre de non détection ordonnancement erreur de rang regression erreur quadratique renforcement expliquer... et semi supervisé, transductif, séquentiel, actif... probabilité de gagner qualité du résumé Généraliser 1 bien faire (minimiser P) sur les futures données qu on ne connait pas square loss 0/1 loss hinge loss logistic loss
 sur les futures données qu on ne connait pas 0")
11 L apprentissage comme un problème d optimisation bi critère interpolation min f H data, interpolation. s ajuster aux données Apprendre c est sélectionner une bonne hypothèse un bon model H (ensemble d hypothèses universelles) cout d ajustement aux données
")
12 L apprentissage comme un problème d optimisation bi critère interpolation t(x) min f H min f H data, interpolation data, interpolation and the target function. s ajuster aux données bien généraliser Apprendre c est sélectionner une bonne hypothèse un bon model H (ensemble d hypothèses universelles) P = deux critères contradictoires cout d ajustement aux données pénalité favorisant une certaine régularité une bonne gestion de cette contradiction
 P = deux critères contradictoires cout d ajustement aux données pénalité")
13 Exemples de model H (ensemble d hypothèses universelles) p dictionnaire fixe f (x) = α j φ j (x) dictionnaire adapté aux observations f (x) = n les machines à noyaux f (x) = i=1 α ik(x, x i ) j=1 p α j φ j (x, x i ) j=1 dictionnaire adapté aux observations et aux étiquettes p f (x) = α j φ j (x, x i, y i ) i=1 les réseaux de neurones de type perceptron multicouche f (x) = ( p k=1 α p ) kφ j=1 β jx méthodes d ensemble
 i=1 les réseaux de neurones de type perceptron multicouche f (x) = ( p k=1 α p ) kφ j=1 β jx méthodes")
14 Les objectifs de l apprentissage automatique Algorithmes d apprentissage bonne généralisation généricité passage à l échelle Questions théoriques (Vapnik s Book, Valiant, 1984) apprenabilité, sous quelles conditions? complexité (en temps, en échantillon)

15 Une brève histoire de l apprentissage artificiel 1940 Etude de la logique en temps qu objet mathématique (Shannon, Godel et al) Test de Turing, 1956 Dartmouth conférence : artificial intelligence "Within a generation... the problem of creating artificial intelligence will substantially be solved." 1960 Le perceptron 1970 AI symbolique : les systèmes experts 1980 AI Winter & Réseaux de neurones (perceptron non linéaire) 1990 SVM & COLT 2000 les applications : Google, Amazon (recommendation), spam filtering, OCR, parole, traduction Big data, Go player
 1990 SVM & COLT 2000 les")
16 Une brève histoire des modes en apprentissage

17 Top 10 algorithmes en fouille de données Arbres de décision (et les forêts) C4.5, CART, SVM, AdaBoost, knn, Bayesien k-means, Apriori, EM, Naive Bayes, PageRank, identified by the IEEE International Conference on Data Mining (ICDM) in December 2006

18 Top 10 algorithmes en fouille de données Arbres de décision (et les forêts) C4.5, CART, SVM, AdaBoost, knn, Bayesien k-means, Apriori, EM, Naive Bayes, PageRank, en 2014 un 11 ème : deep networks identified by the IEEE International Conference on Data Mining (ICDM) in December 2006

19 Meilleure compréhension du monde à partir d observations en vue de prédiction C est beau mais Comment ça marche?.

20 Plan 1 Introduction Une brève définition de l apprentissage statistique Les principaux algorithmes d apprentissage 2 Etudes de cas Apprendre à rechercher l information Apprendre à recommander Apprendre à étiqueter une image avec un réseaux de neurones 3 La science des données 4 Les outils pour l apprentissage statistique 5 Conclusion

21 Etude de cas web : google, facebook... Marketing : Walmart & big data volume variété vitesse Quelques challenges + image + la traduction automatique : deep learning strikes back Jürgen Schmidhuber, Deep Learning in Neural Networks: An Overview
22 Plan 1 Introduction Une brève définition de l apprentissage statistique Les principaux algorithmes d apprentissage 2 Etudes de cas Apprendre à rechercher l information Apprendre à recommander Apprendre à étiqueter une image avec un réseaux de neurones 3 La science des données 4 Les outils pour l apprentissage statistique 5 Conclusion
23 Une brève histoire des moteurs de recherche solution manuelle 1995 solution logique modèle statistique + valeur propre
24 Une brève histoire des moteurs de recherche solution manuelle 1995 solution logique modèle statistique + valeur propre
25 La recherche sur le web comme un problème de matrice page 2 page 1 page 3 page 6 page 5 page 4 Y = 0 0 1/ /3 0 1/ / /2 1/ /3 1/ /2 1/2 0 IP(visiter la page) = une mesure de l intérêt de la page Y : IP(j i) = matrice des transitions
26 math.cornell.edu/~mec/winter2009/ralucaremus/lecture3/lecture3.html Formalisation du problème Modèle IP(visiter p i ) = j IP(visiter p j )IP(j i) + IP(hasard) IP = (1 δ)y IP + δ I1 IP observation = information + bruit avec Y la matrice des transitions et IP le vecteur des probabilités de visiter une page
27 math.cornell.edu/~mec/winter2009/ralucaremus/lecture3/lecture3.html Formalisation du problème Modèle IP(visiter p i ) = j IP(visiter p j )IP(j i) + IP(hasard) IP = (1 δ)y IP + δ I1 IP observation = information + bruit avec Y la matrice des transitions et IP le vecteur des probabilités de visiter une page Problème : retrouver IP(visiter p i ) MIP = IP avec M = (1 δ)y + δ I1 C est un problème de valeur propre de très grande taille avec δ = 0.15
28 Les leçons de l histoire des moteurs de recherche l arrivée des big data innover avec la recherche fondamentale & académique mégadonnées créer des partenariats poser les problèmes : faire des maths et des statistiques poser les vrai usages : interroger un moteur de recherche business model : la valeur c est la requête programmation à base d exemples organiser l information au niveau mondial vers la recommandation
29 Plan 1 Introduction Une brève définition de l apprentissage statistique Les principaux algorithmes d apprentissage 2 Etudes de cas Apprendre à rechercher l information Apprendre à recommander Apprendre à étiqueter une image avec un réseaux de neurones 3 La science des données 4 Les outils pour l apprentissage statistique 5 Conclusion
30 La recommandation de tous les jours Systèmes existants Libre: Myrrix (facto, Web Mahout), Easyrec (item-based, Web), Duine (multi approches), Propriétaires: KXpro...
31 Quelle méthode choisir? Netflix Challenge ( ) Recommandation de films Moteur maison : CineMatch Améliorer les performances de 10% critère : erreur quadratique Les données spectateurs films 100 millons d évaluations (de 1 à 5) taux de remplissage : 1,3 % test sur les 3 millions les plus récents téléchargements des données
32
33 Faire de la science un sport!
34 La recommandation comme un problème de matrice V Y U 1 1 d d ? F = <U ; V > 1 1 U i, V j une mesure d appétence de l utilisateur i pour le produit j
35 Les résultats sur Netflix erreur initiale : factorisation - 4 % nombres de facteurs -.5 % améliorations % normalisation poids temps bagging : - 3 % = mélange 100 méthodes Koren, Y., Bell, R.M., Volinsky, C.: Matrix factorization techniques for recommender systems. IEEE Computer 42(8), (2009)
36 La recommandation comme un problème de matrice V Y U 1 1 d d ? F = <U ; V > 1 1 U i, V j une mesure d appétence de l utilisateur i pour le produit j
37 Formalisation du problème Modèle Y = F + R observation = information + bruit avec F régulière et R une matrice de bruit.
38 Formalisation du problème Modèle Y = F + R observation = information + bruit avec F régulière et R une matrice de bruit. Problème : construire F un estimateur de F min F L(Y, F ) } {{ } attache aux données + λ Ω( F ) } {{ } pénalisation optimiser un cout bien choisi avec F = UV factorisation (...à l aide de valeurs propres)
39 Les leçons de Netflix trop d efforts spécifiques pour être généralisée Modèle statistique : factorisation is the solution prendre en compte les spécificités (ici l effet temps et les feedback implicites) une optimisation de type gradient stochastique flexible qui passe à l échelle quels usages pour la recommandation?
40 Plan 1 Introduction Une brève définition de l apprentissage statistique Les principaux algorithmes d apprentissage 2 Etudes de cas Apprendre à rechercher l information Apprendre à recommander Apprendre à étiqueter une image avec un réseaux de neurones 3 La science des données 4 Les outils pour l apprentissage statistique 5 Conclusion
41 The formal neuron Defines a hyperplane x 2 w t x + b = 0 x 1, w 1 x 2, w 2... x p, w p 1, b h y = ϕ(w t x + b) x 1 x input w weight, b bias ϕ activation function y output ϕ(t) = tanh(t)
42 The formal neuron as a learning machine Fitting the data for the 2 classes classification problem given n pairs of input output data x i, y i, i = 1, n find w such that ϕ(w t x i ) } {{ } prediction of the model = y }{{} i ground truth 5 make some initial guess for w pick some data extract information improve w what about new data generalization?
43 Fitting the data with an energy-based model Fitting the data min w IR p+1 n i=1 ( ϕ(w t x i ) } {{ } prediction y i }{{} truth Improve w w new = w old ρ (ϕ(w t x i ) y i ) w ϕ(w t x i ) } {{ } extracted information ) 2 Algorithm 1 Adaline Data: w initialization, ρ fixed stepsize Result: w while not converged do x i, y i pick a point i at random d (w t x i y i )x i w w ρd check that the cost decease end
44 Fitting the data with an energy-based model (part of P) Coding the output (truth?) { 1 if xi class 1 y i = 1 else Fitting the data As a loss min w IR p+1 n i=1 ( ϕ(w t x i ) } {{ } prediction p y i }{{} truth t (ϕ(w t x i ) y i ) 2 = yi 2(y iϕ(w t x i ) 1) 2. } {{ } score z i n cost(z i ) z i = ϕ(w t x i )y i min w IR p+1 i=1 ) 2 { 0 if sign(w 0/1 loss cost(z i ) = t x i ) = sign(y i ) 1 else As a constraint sign(w t 1 x i )sign(y i ) square loss 0/1 loss hinge loss logistic loss
45 Non linearity combining linear neurons Alpaydın, Introduction to Machine Learning, 2010
46 Neural networks as universal approximator Running several neurons at the same time y = ϕ(w 3 h (2) ) h (2) = ϕ(w 2 h (1) ) h (1) = ϕ(w 1 x) x Multilayered neural network: learning internal representation W 1, W 2, W 3 from L. Arnold PhD
47 OCR: the MNIST database (Y. LeCun, 1989)
48 The caltech 101 database (2004) 101 classes 30 training images per category...and the winner is NOT a deep network dataset is too small
49 Deep architecture lessons from caltech 101 (2009) R abs Rectification Layer N Local Contrast Normalization Layer P A Average Pooling and Subsampling Layer in What is the Best Multi-Stage Architecture for Object Recognition? Jarrett et al, 2009
50 The image net database (Deng et al., 2012) ImageNet = 15 million labeled high-resolution images of 22,000 categories. Large-Scale Visual Recognition Challenge (a subset of ImageNet) 1000 categories. 1.2 million training images, 50,000 validation images, 150,000 testing images.
51 Deep architecture and the image net The architecture of the CNN [Krizhevsky, Sutskever, Hinton, 2012] 60 million parameters using 2 GPU regularization data augmentation dropout weight decay
52 A new fashion in image processing Baidu: 5% Y. LeCun StatLearn tutorial
53 Learning Deep architecture min W IR d n f (x i, W ) y i 2 + λ w 2 i=1 d = n = 1, λ = f is a deep NN Y. Bengio tutorial
54 Then a m. occurs: learning internal representation Y. LeCun StatLearn tutorial
55 Deep architecture: more contests and benchmark records speech (phoneme) recognition, automatic translation, Optical Character Recognition (OCR), ICDAR Chinese handwriting recognition benchmark, Grand Challenge on Mitosis Detection, Road sign recognition Higgs boson challenge
56 Machine Learning in High Energy Physics The winning model is "brute force" a bag of 70 dropout neural networks three hidden layers of 600 neurons produced by 2-fold stratified cross-validations
57 Comment ça marche? Programmation par l exemple (et beaucoup - des méga données) un bon critère : intégre des connaissances a priori adjustment aux données (énergie) un ou des mécanismes de régularisation une bonne procédure d optimisation des ressources informatiques suffisantes
58 Ce que l on ne comprend pas gérer et protéger les données et les contextes? qu est-ce qu apprendre? pourquoi les architectures profondes fonctionnent? apprendre à apprendre (transfert, transport)? quelles garanties peut on avoir? comment gérer les dynamiques? comment optimiser efficacement des fonctionnelles non convexes et non régulières? comment automatiser la chaine de traitement nécessaire à l apprentissage? Statistiques + optimisation + informatique vers la science des données..
59 Plan 1 Introduction Une brève définition de l apprentissage statistique Les principaux algorithmes d apprentissage 2 Etudes de cas Apprendre à rechercher l information Apprendre à recommander Apprendre à étiqueter une image avec un réseaux de neurones 3 La science des données 4 Les outils pour l apprentissage statistique 5 Conclusion
60 New trends in ML fashion: big data ICML 2014 workshops Designing Machine Learning Platforms for Big Data Xiangxiang Meng, Wayne Thompson, Xiaodong Lin New Learning Frameworks and Models for Big Data Massih-Reza Amini, Eric Gaussier, James Kwok, Yiming Yang Deep Learning Models for Emerging Big Data Applications Shan Suthaharan, Jinzhu Jia Unsupervised Learning for Bioacoustic Big Data Hervé Glotin, P. Dugan, F. Chamroukhi, C. Clark, Yann LeCun Knowledge-Powered Deep Learning for Text Mining Bin Gao, Scott Yih, Richard Socher, Jiang Bian Optimizing Customer Lifetime Value in Online Marketing Georgios Theocharous, Mohammad Ghavamzadeh, Shie Mannor Comment traiter ces big data : data science
61
62 New trends in ML fashion: data science Hilary Mason,
63 Data Scientist Voted Sexiest Job of 21st Century
64 New trends in ML fashion: big data hiring boom
65 Big data brief history Original source at
66 Les tâches T hivedata.com/
67 M.L. fashion as classifier comparison (from scikit-learn)
68 Une brève histoire de la mode en technology (by Gartner) Gartner s 2014 Hype Cycle for Emerging Technologies Maps the Journey to Digital Business
69 Une brève histoire de la mode en technology (by Gartner) Gartner s 2000 Hype Cycle for Emerging Technologies Maps the Journey to Digital Business
70 Quelles propriétés passage à l échelle parcimonie : sélectionner les exemples et les variables randomisation traiter la masse par le hasard Structured Sparse Principal Component Analysis (R. Jenatton, G. Obozinski and F. Bach)
71 Plan 1 Introduction Une brève définition de l apprentissage statistique Les principaux algorithmes d apprentissage 2 Etudes de cas Apprendre à rechercher l information Apprendre à recommander Apprendre à étiqueter une image avec un réseaux de neurones 3 La science des données 4 Les outils pour l apprentissage statistique 5 Conclusion
72 Les outils de la science des données
73 Les outils de la science des données 2013 Data Science Salary Survey oreilly.com/data/free/files/stratasurvey.pdf
74 Les outils de la science des données 2013 Data Science Salary Survey oreilly.com/data/free/files/stratasurvey.pdf
75 Logiciels (mloss.org) environ. interactifs R (opensource), Matlab, Java Weka, Rapid miner, MLlib (Spark), spark.apache.org Python Orange, SciPy, Shogun, MLpy,... C, C++ Vowpal Wabbit, hunch.net/~vw Torch (Lua), liblinear, libsvm, ML as a service Google prediction API, Microsoft Azure Machine Learning API,
76 Question méthode 1 définir objectifs, les contraintes et les couts 2 étude préliminaire récupérer des données construire un bac à sable affiner les objectifs et les couts en interagissant avec les données proposer un modèle et choisir une solution (un alto) 3 mise en oeuvre sur de véritable flots de données randomisation outils adaptés
77 Plan 1 Introduction Une brève définition de l apprentissage statistique Les principaux algorithmes d apprentissage 2 Etudes de cas Apprendre à rechercher l information Apprendre à recommander Apprendre à étiqueter une image avec un réseaux de neurones 3 La science des données 4 Les outils pour l apprentissage statistique 5 Conclusion
78 Quelques prédictions... à propos du futur Data science - Applications multi compétences chaine de traitements Outils pour l apprentissage l apprentissage sans paramètres (off-the-shelf) passage à l échelle (4v - big data - mégadonnées) Algorithmes d apprentissage optimisation (mégadonnées, non convexe) dynamique (interactions) apprendre à apprendre (transfert) Théorie de l apprentissage la nature de l information
79 Pour en savoir plus livres Bishop, C. M Neural Networks for Pattern Recognition. Oxford: Oxford University Press. Duda, R. O., P. E. Hart, and D. G. Stork Pattern Classification, 2nd ed. New York: Wiley. Hastie, T., R. Tibshirani, and J. Friedman The Elements of Statistical Learning: Data Mining, Inference, and Prediction. New York: Springer. A. Cornuéjols & L. Miclet, "L apprentissage artificiel. Concepts et algorithmes". Eyrolles. 2 ème éd conférences xcml, NIPS, COLT, séminaire SMILE, Paris Machine Learning Applications Group revues JMLR, Machine Learning, Foundations and Trends in Machine Learning, machine learning survey
Tour d horizon de l apprentissage statistique. from Machine Learning to Big Data Analytics
 Tour d horizon de l apprentissage statistique. from Machine Learning to Big Data Analytics Stéphane Canu asi.insa-rouen.fr/enseignants/~scanu Codeur en Seine 2014, Université de Rouen 27 novembre 2014
Tour d horizon de l apprentissage statistique. from Machine Learning to Big Data Analytics Stéphane Canu asi.insa-rouen.fr/enseignants/~scanu Codeur en Seine 2014, Université de Rouen 27 novembre 2014
Apprentissage symbolique et statistique à l ère du mariage pour tous
 Apprentissage symbolique et statistique à l ère du mariage pour tous Stéphane Canu asi.insa-rouen.fr/enseignants/~scanu RFIA 2014, INSA Rouen 2 juillet 2014 Apprentissage : humain vs. machine Les apprentissages
Apprentissage symbolique et statistique à l ère du mariage pour tous Stéphane Canu asi.insa-rouen.fr/enseignants/~scanu RFIA 2014, INSA Rouen 2 juillet 2014 Apprentissage : humain vs. machine Les apprentissages
Optimisation et apprentissage statistique. Une introduction à l apprentissage statistique
 Optimisation et apprentissage statistique. Une introduction à l apprentissage statistique Stéphane Canu asi.insa-rouen.fr/enseignants/~scanu Ecole d été BasMatI 2015, Porquerolles June 2, 2015 Plan 1 Une
Optimisation et apprentissage statistique. Une introduction à l apprentissage statistique Stéphane Canu asi.insa-rouen.fr/enseignants/~scanu Ecole d été BasMatI 2015, Porquerolles June 2, 2015 Plan 1 Une
Introduction au Data-Mining
 Introduction au Data-Mining Gilles Gasso, Stéphane Canu INSA Rouen -Département ASI Laboratoire LITIS 8 septembre 205. Ce cours est librement inspiré du cours DM de Alain Rakotomamonjy Gilles Gasso, Stéphane
Introduction au Data-Mining Gilles Gasso, Stéphane Canu INSA Rouen -Département ASI Laboratoire LITIS 8 septembre 205. Ce cours est librement inspiré du cours DM de Alain Rakotomamonjy Gilles Gasso, Stéphane
Grégoire de Lassence. Copyright 2006, SAS Institute Inc. All rights reserved.
 Grégoire de Lassence 1 Grégoire de Lassence Responsable Pédagogie et Recherche Département Académique Tel : +33 1 60 62 12 19 [email protected] http://www.sas.com/france/academic SAS dans
Grégoire de Lassence 1 Grégoire de Lassence Responsable Pédagogie et Recherche Département Académique Tel : +33 1 60 62 12 19 [email protected] http://www.sas.com/france/academic SAS dans
L'intelligence d'affaires: la statistique dans nos vies de consommateurs
 L'intelligence d'affaires: la statistique dans nos vies de consommateurs Jean-François Plante, HEC Montréal Marc Fredette, HEC Montréal Congrès de l ACFAS, Université Laval, 6 mai 2013 Intelligence d affaires
L'intelligence d'affaires: la statistique dans nos vies de consommateurs Jean-François Plante, HEC Montréal Marc Fredette, HEC Montréal Congrès de l ACFAS, Université Laval, 6 mai 2013 Intelligence d affaires
Les défis statistiques du Big Data
 Les défis statistiques du Big Data Anne-Sophie Charest Professeure adjointe au département de mathématiques et statistique, Université Laval 29 avril 2014 Colloque ITIS - Big Data et Open Data au cœur
Les défis statistiques du Big Data Anne-Sophie Charest Professeure adjointe au département de mathématiques et statistique, Université Laval 29 avril 2014 Colloque ITIS - Big Data et Open Data au cœur
Anticiper et prédire les sinistres avec une approche Big Data
 Anticiper et prédire les sinistres avec une approche Big Data Julien Cabot Directeur Big Data Analytics OCTO [email protected] @julien_cabot OCTO 2013 50, avenue des Champs-Elysées 75008 Paris - FRANCE Tél
Anticiper et prédire les sinistres avec une approche Big Data Julien Cabot Directeur Big Data Analytics OCTO [email protected] @julien_cabot OCTO 2013 50, avenue des Champs-Elysées 75008 Paris - FRANCE Tél
Spécificités, Applications et Outils
 Spécificités, Applications et Outils Ricco Rakotomalala Université Lumière Lyon 2 Laboratoire ERIC Laboratoire ERIC 1 Ricco Rakotomalala [email protected] http://chirouble.univ-lyon2.fr/~ricco/data-mining
Spécificités, Applications et Outils Ricco Rakotomalala Université Lumière Lyon 2 Laboratoire ERIC Laboratoire ERIC 1 Ricco Rakotomalala [email protected] http://chirouble.univ-lyon2.fr/~ricco/data-mining
Simon Lacoste-Julien Chercheur CR Équipe-Projet SIERRA, INRIA - École Normale Supérieure
 Simon Lacoste-Julien Chercheur CR Équipe-Projet SIERRA, INRIA - École Normale Supérieure Mot tendance pour décrire *beaucoup* de données! Buzz: Google Trends search terms volume Obama announces Big Data
Simon Lacoste-Julien Chercheur CR Équipe-Projet SIERRA, INRIA - École Normale Supérieure Mot tendance pour décrire *beaucoup* de données! Buzz: Google Trends search terms volume Obama announces Big Data
Les datas = le fuel du 21ième sicècle
 Les datas = le fuel du 21ième sicècle D énormes gisements de création de valeurs http://www.your networkmarketin g.com/facebooktwitter-youtubestats-in-realtime-simulation/ Xavier Dalloz Le Plan Définition
Les datas = le fuel du 21ième sicècle D énormes gisements de création de valeurs http://www.your networkmarketin g.com/facebooktwitter-youtubestats-in-realtime-simulation/ Xavier Dalloz Le Plan Définition
Big Data et Graphes : Quelques pistes de recherche
 Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de Lyon/Université Claude Bernard Lyon 1/Université
Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de Lyon/Université Claude Bernard Lyon 1/Université
Apprentissage Statistique
 Apprentissage Statistique Master DAC - Université Paris 6, [email protected], http://www-connex.lip6.fr/~gallinar/ Année 2014-2015 Partie 1 Introduction Apprentissage Automatique Problématique
Apprentissage Statistique Master DAC - Université Paris 6, [email protected], http://www-connex.lip6.fr/~gallinar/ Année 2014-2015 Partie 1 Introduction Apprentissage Automatique Problématique
Big Data et Graphes : Quelques pistes de recherche
 Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci http://liris.cnrs.fr/hamamache.kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de
Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci http://liris.cnrs.fr/hamamache.kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de
Une méthode de classification supervisée sans paramètre pour l apprentissage sur les grandes bases de données
 Une méthode de classification supervisée sans paramètre pour l apprentissage sur les grandes bases de données Marc Boullé Orange Labs 2 avenue Pierre Marzin 22300 Lannion [email protected],
Une méthode de classification supervisée sans paramètre pour l apprentissage sur les grandes bases de données Marc Boullé Orange Labs 2 avenue Pierre Marzin 22300 Lannion [email protected],
Apprentissage statistique dans les graphes et les réseaux sociaux
 Apprentissage statistique dans les graphes et les réseaux sociaux Patrick Gallinari Collaboration : L. Denoyer, S. Peters Université Pierre et Marie Curie AAFD 2010 1 Plan Motivations et Problématique
Apprentissage statistique dans les graphes et les réseaux sociaux Patrick Gallinari Collaboration : L. Denoyer, S. Peters Université Pierre et Marie Curie AAFD 2010 1 Plan Motivations et Problématique
Techniques du Data Mining pour la prédiction de faillite des entreprises et la gestion du risque de crédit
 Techniques du Data Mining pour la prédiction de faillite des entreprises et la gestion du risque de crédit Adil Belhouari HEC - Montréal - Journées de l Optimisation 2005-09 Mai 2005 PLAN DE LA PRÉSENTATION
Techniques du Data Mining pour la prédiction de faillite des entreprises et la gestion du risque de crédit Adil Belhouari HEC - Montréal - Journées de l Optimisation 2005-09 Mai 2005 PLAN DE LA PRÉSENTATION
Objectif et contexte business : piliers du traitement efficace des données -l exemple de RANK- Khalid MEHL Jean-François WASSONG 10 mars 2015
 Objectif et contexte business : piliers du traitement efficace des données -l exemple de RANK- Khalid MEHL Jean-François WASSONG 10 mars 2015 1. fifty-five : présentation 2. Objectifs de Rank 3. Une approche
Objectif et contexte business : piliers du traitement efficace des données -l exemple de RANK- Khalid MEHL Jean-François WASSONG 10 mars 2015 1. fifty-five : présentation 2. Objectifs de Rank 3. Une approche
Introduction au Data-Mining
 Introduction au Data-Mining Alain Rakotomamonjy - Gilles Gasso. INSA Rouen -Département ASI Laboratoire PSI Introduction au Data-Mining p. 1/25 Data-Mining : Kèkecé? Traduction : Fouille de données. Terme
Introduction au Data-Mining Alain Rakotomamonjy - Gilles Gasso. INSA Rouen -Département ASI Laboratoire PSI Introduction au Data-Mining p. 1/25 Data-Mining : Kèkecé? Traduction : Fouille de données. Terme
Introduction au datamining
 Introduction au datamining Patrick Naïm janvier 2005 Définition Définition Historique Mot utilisé au départ par les statisticiens Le mot indiquait une utilisation intensive des données conduisant à des
Introduction au datamining Patrick Naïm janvier 2005 Définition Définition Historique Mot utilisé au départ par les statisticiens Le mot indiquait une utilisation intensive des données conduisant à des
Formation Actuaire Data Scientist. Programme au 24 octobre 2014
 Formation Actuaire Data Scientist Programme au 24 octobre 2014 A. Eléments logiciels et programmation Python 24h Objectif : Introduction au langage Python et sensibilisation aux grandeurs informatiques
Formation Actuaire Data Scientist Programme au 24 octobre 2014 A. Eléments logiciels et programmation Python 24h Objectif : Introduction au langage Python et sensibilisation aux grandeurs informatiques
Informatique / Computer Science
 Informatique / Computer Science Vous trouverez ici les conditions de candidature pour les différentes voies de M2 de la mention «Informatique / Computer Science». Certaines formations ne seront cependant
Informatique / Computer Science Vous trouverez ici les conditions de candidature pour les différentes voies de M2 de la mention «Informatique / Computer Science». Certaines formations ne seront cependant
Apprentissage Automatique
 Apprentissage Automatique Introduction-I [email protected] www.lia.univ-avignon.fr Définition? (Wikipedia) L'apprentissage automatique (machine-learning en anglais) est un des champs
Apprentissage Automatique Introduction-I [email protected] www.lia.univ-avignon.fr Définition? (Wikipedia) L'apprentissage automatique (machine-learning en anglais) est un des champs
Enjeux mathématiques et Statistiques du Big Data
 Enjeux mathématiques et Statistiques du Big Data Mathilde Mougeot LPMA/Université Paris Diderot, [email protected] Mathématique en Mouvements, Paris, IHP, 6 Juin 2015 M. Mougeot (Paris
Enjeux mathématiques et Statistiques du Big Data Mathilde Mougeot LPMA/Université Paris Diderot, [email protected] Mathématique en Mouvements, Paris, IHP, 6 Juin 2015 M. Mougeot (Paris
Laboratoire 4 Développement d un système intelligent
 DÉPARTEMENT DE GÉNIE LOGICIEL ET DES TI LOG770 - SYSTÈMES INTELLIGENTS ÉTÉ 2012 Laboratoire 4 Développement d un système intelligent 1 Introduction Ce quatrième et dernier laboratoire porte sur le développement
DÉPARTEMENT DE GÉNIE LOGICIEL ET DES TI LOG770 - SYSTÈMES INTELLIGENTS ÉTÉ 2012 Laboratoire 4 Développement d un système intelligent 1 Introduction Ce quatrième et dernier laboratoire porte sur le développement
Intelligence Artificielle et Systèmes Multi-Agents. Badr Benmammar [email protected]
 Intelligence Artificielle et Systèmes Multi-Agents Badr Benmammar [email protected] Plan La première partie : L intelligence artificielle (IA) Définition de l intelligence artificielle (IA) Domaines
Intelligence Artificielle et Systèmes Multi-Agents Badr Benmammar [email protected] Plan La première partie : L intelligence artificielle (IA) Définition de l intelligence artificielle (IA) Domaines
BIG DATA : une vraie révolution industrielle (1) Les fortes évolutions liées à la digitalisation
 Les fortes évolutions liées à la digitalisation") BIG DATA : une vraie révolution industrielle (1) Les fortes évolutions liées à la digitalisation - définition - étapes - impacts La révolution en cours du big data - essai de définition - acteurs - priorités
BIG DATA : une vraie révolution industrielle (1) Les fortes évolutions liées à la digitalisation - définition - étapes - impacts La révolution en cours du big data - essai de définition - acteurs - priorités
Surmonter les 5 défis opérationnels du Big Data
 Surmonter les 5 défis opérationnels du Big Data Jean-Michel Franco Talend Connect 9 octobre 2014 Talend 2014 1 Agenda Agenda Le Big Data depuis la découverte jusqu au temps réel en passant par les applications
Surmonter les 5 défis opérationnels du Big Data Jean-Michel Franco Talend Connect 9 octobre 2014 Talend 2014 1 Agenda Agenda Le Big Data depuis la découverte jusqu au temps réel en passant par les applications
Eléments de statistique
 Eléments de statistique L. Wehenkel Cours du 9/12/2014 Méthodes multivariées; applications & recherche Quelques méthodes d analyse multivariée NB: illustration sur base de la BD résultats de probas en
Eléments de statistique L. Wehenkel Cours du 9/12/2014 Méthodes multivariées; applications & recherche Quelques méthodes d analyse multivariée NB: illustration sur base de la BD résultats de probas en
4.2 Unités d enseignement du M1
 88 CHAPITRE 4. DESCRIPTION DES UNITÉS D ENSEIGNEMENT 4.2 Unités d enseignement du M1 Tous les cours sont de 6 ECTS. Modélisation, optimisation et complexité des algorithmes (code RCP106) Objectif : Présenter
88 CHAPITRE 4. DESCRIPTION DES UNITÉS D ENSEIGNEMENT 4.2 Unités d enseignement du M1 Tous les cours sont de 6 ECTS. Modélisation, optimisation et complexité des algorithmes (code RCP106) Objectif : Présenter
La rencontre du Big Data et du Cloud
 La rencontre du Big Data et du Cloud Libérez le potentiel de toutes vos données Visualisez et exploitez plus rapidement les données de tous types, quelle que soit leur taille et indépendamment de leur
La rencontre du Big Data et du Cloud Libérez le potentiel de toutes vos données Visualisez et exploitez plus rapidement les données de tous types, quelle que soit leur taille et indépendamment de leur
Quatre axes au service de la performance et des mutations Four lines serve the performance and changes
 Le Centre d Innovation des Technologies sans Contact-EuraRFID (CITC EuraRFID) est un acteur clé en matière de l Internet des Objets et de l Intelligence Ambiante. C est un centre de ressources, d expérimentations
Le Centre d Innovation des Technologies sans Contact-EuraRFID (CITC EuraRFID) est un acteur clé en matière de l Internet des Objets et de l Intelligence Ambiante. C est un centre de ressources, d expérimentations
Catherine Chochoy. Alain Maneville. I/T Specialist, IBM Information Management on System z, Software Group
 1 Catherine Chochoy I/T Specialist, IBM Information Management on System z, Software Group Alain Maneville Executive I/T specialist, zchampion, IBM Systems and Technology Group 2 Le défi du Big Data (et
1 Catherine Chochoy I/T Specialist, IBM Information Management on System z, Software Group Alain Maneville Executive I/T specialist, zchampion, IBM Systems and Technology Group 2 Le défi du Big Data (et
Post-processing of multimodel hydrological forecasts for the Baskatong catchment
 + Post-processing of multimodel hydrological forecasts for the Baskatong catchment Fabian Tito Arandia Martinez Marie-Amélie Boucher Jocelyn Gaudet Maria-Helena Ramos + Context n Master degree subject:
+ Post-processing of multimodel hydrological forecasts for the Baskatong catchment Fabian Tito Arandia Martinez Marie-Amélie Boucher Jocelyn Gaudet Maria-Helena Ramos + Context n Master degree subject:
Projet SINF2275 «Data mining and decision making» Projet classification et credit scoring
 Projet SINF2275 «Data mining and decision making» Projet classification et credit scoring Année académique 2006-2007 Professeurs : Marco Saerens Adresse : Université catholique de Louvain Information Systems
Projet SINF2275 «Data mining and decision making» Projet classification et credit scoring Année académique 2006-2007 Professeurs : Marco Saerens Adresse : Université catholique de Louvain Information Systems
BIG DATA en Sciences et Industries de l Environnement
 BIG DATA en Sciences et Industries de l Environnement François Royer www.datasio.com 21 mars 2012 FR Big Data Congress, Paris 2012 1/23 Transport terrestre Traçabilité Océanographie Transport aérien Télémétrie
BIG DATA en Sciences et Industries de l Environnement François Royer www.datasio.com 21 mars 2012 FR Big Data Congress, Paris 2012 1/23 Transport terrestre Traçabilité Océanographie Transport aérien Télémétrie
Hervé Couturier EVP, SAP Technology Development
 Hervé Couturier EVP, SAP Technology Development Hervé Biausser Directeur de l Ecole Centrale Paris Bernard Liautaud Fondateur de Business Objects Questions à: Hervé Couturier Hervé Biausser Bernard Liautaud
Hervé Couturier EVP, SAP Technology Development Hervé Biausser Directeur de l Ecole Centrale Paris Bernard Liautaud Fondateur de Business Objects Questions à: Hervé Couturier Hervé Biausser Bernard Liautaud
Modélisation du comportement habituel de la personne en smarthome
 Modélisation du comportement habituel de la personne en smarthome Arnaud Paris, Selma Arbaoui, Nathalie Cislo, Adnen El-Amraoui, Nacim Ramdani Université d Orléans, INSA-CVL, Laboratoire PRISME 26 mai
Modélisation du comportement habituel de la personne en smarthome Arnaud Paris, Selma Arbaoui, Nathalie Cislo, Adnen El-Amraoui, Nacim Ramdani Université d Orléans, INSA-CVL, Laboratoire PRISME 26 mai
Le BigData, aussi par et pour les PMEs
 Parole d expert Le BigData, aussi par et pour les PMEs Stéphane MOUTON, CETIC Département Software and Services Technologies Avec le soutien de : LIEGE CREATIVE Le Big Data, aussi par et pour les PMEs
Parole d expert Le BigData, aussi par et pour les PMEs Stéphane MOUTON, CETIC Département Software and Services Technologies Avec le soutien de : LIEGE CREATIVE Le Big Data, aussi par et pour les PMEs
TRAVAUX DE RECHERCHE DANS LE
 TRAVAUX DE RECHERCHE DANS LE DOMAINE DE L'EXPLOITATION DES DONNÉES ET DES DOCUMENTS 1 Journée technologique " Solutions de maintenance prévisionnelle adaptées à la production Josiane Mothe, FREMIT, IRIT
TRAVAUX DE RECHERCHE DANS LE DOMAINE DE L'EXPLOITATION DES DONNÉES ET DES DOCUMENTS 1 Journée technologique " Solutions de maintenance prévisionnelle adaptées à la production Josiane Mothe, FREMIT, IRIT
20 ans du Master SIAD de Toulouse - BigData par l exemple - Julien DULOUT - 22 mars 2013. 20 ans du SIAD -"Big Data par l'exemple" -Julien DULOUT
 20 ans du Master SIAD de Toulouse - BigData par l exemple - Julien DULOUT - 22 mars 2013 20 ans du SIAD -"BigData par l'exemple" -Julien DULOUT Qui a déjà entendu parler du phénomène BigData? Qui a déjà
20 ans du Master SIAD de Toulouse - BigData par l exemple - Julien DULOUT - 22 mars 2013 20 ans du SIAD -"BigData par l'exemple" -Julien DULOUT Qui a déjà entendu parler du phénomène BigData? Qui a déjà
L écosystème Hadoop Nicolas Thiébaud [email protected]. Tuesday, July 2, 13
 L écosystème Hadoop Nicolas Thiébaud [email protected] HUG France 250 membres sur la mailing liste 30 présentations 9 meetups organisés, de 20 à 100 invités Présence de Cloudera, MapR, Hortonworks,
L écosystème Hadoop Nicolas Thiébaud [email protected] HUG France 250 membres sur la mailing liste 30 présentations 9 meetups organisés, de 20 à 100 invités Présence de Cloudera, MapR, Hortonworks,
Big Data -Comment exploiter les données et les transformer en prise de décisions?
 IBM Global Industry Solution Center Nice-Paris Big Data -Comment exploiter les données et les transformer en prise de décisions? Apollonie Sbragia Architecte Senior & Responsable Centre D Excellence Assurance
IBM Global Industry Solution Center Nice-Paris Big Data -Comment exploiter les données et les transformer en prise de décisions? Apollonie Sbragia Architecte Senior & Responsable Centre D Excellence Assurance
Organisé par StatSoft France et animé par Dr Diego Kuonen, expert en techniques de data mining.
 2 jours : Mardi 15 et mercredi 16 novembre 2005 de 9 heures 30 à 17 heures 30 Organisé par StatSoft France et animé par Dr Diego Kuonen, expert en techniques de data mining. Madame, Monsieur, On parle
2 jours : Mardi 15 et mercredi 16 novembre 2005 de 9 heures 30 à 17 heures 30 Organisé par StatSoft France et animé par Dr Diego Kuonen, expert en techniques de data mining. Madame, Monsieur, On parle
Exemple PLS avec SAS
 Exemple PLS avec SAS This example, from Umetrics (1995), demonstrates different ways to examine a PLS model. The data come from the field of drug discovery. New drugs are developed from chemicals that
Exemple PLS avec SAS This example, from Umetrics (1995), demonstrates different ways to examine a PLS model. The data come from the field of drug discovery. New drugs are developed from chemicals that
Le Futur de la Visualisation d Information. Jean-Daniel Fekete Projet in situ INRIA Futurs
 Le Futur de la Visualisation d Information Jean-Daniel Fekete Projet in situ INRIA Futurs La visualisation d information 1.Présentation 2.Bilan 3.Perspectives Visualisation : 3 domaines Visualisation scientifique
Le Futur de la Visualisation d Information Jean-Daniel Fekete Projet in situ INRIA Futurs La visualisation d information 1.Présentation 2.Bilan 3.Perspectives Visualisation : 3 domaines Visualisation scientifique
CLOUD COMPUTING et Relation Client/Fournisseur Une Révolution culturelle?
 CLOUD COMPUTING et Relation Client/Fournisseur Une Révolution culturelle? Stéphane Lemarchand Avocat Associé Matinale IPT - AGENDA Définition, Typologie des Services et Acteurs Problématiques connues Réalité
CLOUD COMPUTING et Relation Client/Fournisseur Une Révolution culturelle? Stéphane Lemarchand Avocat Associé Matinale IPT - AGENDA Définition, Typologie des Services et Acteurs Problématiques connues Réalité
Présentation par François Keller Fondateur et président de l Institut suisse de brainworking et M. Enga Luye, CEO Belair Biotech
 Présentation par François Keller Fondateur et président de l Institut suisse de brainworking et M. Enga Luye, CEO Belair Biotech Le dispositif L Institut suisse de brainworking (ISB) est une association
Présentation par François Keller Fondateur et président de l Institut suisse de brainworking et M. Enga Luye, CEO Belair Biotech Le dispositif L Institut suisse de brainworking (ISB) est une association
WEB page builder and server for SCADA applications usable from a WEB navigator
 Générateur de pages WEB et serveur pour supervision accessible à partir d un navigateur WEB WEB page builder and server for SCADA applications usable from a WEB navigator opyright 2007 IRAI Manual Manuel
Générateur de pages WEB et serveur pour supervision accessible à partir d un navigateur WEB WEB page builder and server for SCADA applications usable from a WEB navigator opyright 2007 IRAI Manual Manuel
Les enjeux du Big Data Innovation et opportunités de l'internet industriel. Datasio 2013
 Les enjeux du Big Data Innovation et opportunités de l'internet industriel François Royer [email protected] Accompagnement des entreprises dans leurs stratégies quantitatives Valorisation de patrimoine
Les enjeux du Big Data Innovation et opportunités de l'internet industriel François Royer [email protected] Accompagnement des entreprises dans leurs stratégies quantitatives Valorisation de patrimoine
Introduction à MapReduce/Hadoop et Spark
 1 / 36 Introduction à MapReduce/Hadoop et Spark Certificat Big Data Ludovic Denoyer et Sylvain Lamprier UPMC Plan 2 / 36 Contexte 3 / 36 Contexte 4 / 36 Data driven science: le 4e paradigme (Jim Gray -
1 / 36 Introduction à MapReduce/Hadoop et Spark Certificat Big Data Ludovic Denoyer et Sylvain Lamprier UPMC Plan 2 / 36 Contexte 3 / 36 Contexte 4 / 36 Data driven science: le 4e paradigme (Jim Gray -
La solution idéale de personnalisation interactive sur internet
 FACTORY121 Product Configurator (summary) La solution idéale de personnalisation interactive sur internet FACTORY121 cité comme référence en «Mass Customization» au MIT et sur «mass-customization.de» Specifications
FACTORY121 Product Configurator (summary) La solution idéale de personnalisation interactive sur internet FACTORY121 cité comme référence en «Mass Customization» au MIT et sur «mass-customization.de» Specifications
PANKA. PORTFOLIO Karina Pannhasith. Karina Pannhasith. URBANIA Ipad Magazine School Project 2012 Photoshop Illustrator Dreamweaver Hype - HTML5
 PORTFOLIO PANKA Web Designer URBANIA Ipad Magazine School Project 2012 Photoshop Illustrator Dreamweaver Hype - HTML5 MASSIMO VIGNELLI The life of a designer is a life of fight : fight against the ugliness.
PORTFOLIO PANKA Web Designer URBANIA Ipad Magazine School Project 2012 Photoshop Illustrator Dreamweaver Hype - HTML5 MASSIMO VIGNELLI The life of a designer is a life of fight : fight against the ugliness.
Accélérer l agilité de votre site de e-commerce. Cas client
 Accélérer l agilité de votre site de e-commerce Cas client L agilité «outillée» devient nécessaire au delà d un certain facteur de complexité (clients x produits) Elevé Nombre de produits vendus Faible
Accélérer l agilité de votre site de e-commerce Cas client L agilité «outillée» devient nécessaire au delà d un certain facteur de complexité (clients x produits) Elevé Nombre de produits vendus Faible
Stratégie DataCenters Société Générale Enjeux, objectifs et rôle d un partenaire comme Data4
 Stratégie DataCenters Société Générale Enjeux, objectifs et rôle d un partenaire comme Data4 Stéphane MARCHINI Responsable Global des services DataCenters Espace Grande Arche Paris La Défense SG figures
Stratégie DataCenters Société Générale Enjeux, objectifs et rôle d un partenaire comme Data4 Stéphane MARCHINI Responsable Global des services DataCenters Espace Grande Arche Paris La Défense SG figures
Bigdata et Web sémantique. les données + l intelligence= la solution
 Bigdata et Web sémantique les données + l intelligence= la solution 131214 1 big data et Web sémantique deux notions bien différentes et pourtant... (sable et silicium). «bigdata» ce n est pas que des
Bigdata et Web sémantique les données + l intelligence= la solution 131214 1 big data et Web sémantique deux notions bien différentes et pourtant... (sable et silicium). «bigdata» ce n est pas que des
Ne cherchez plus, soyez informés! Robert van Kommer
 Ne cherchez plus, soyez informés! Robert van Kommer Le sommaire La présentation du contexte applicatif Le mariage: Big Data et apprentissage automatique Dialogues - interactions - apprentissages 2 Le contexte
Ne cherchez plus, soyez informés! Robert van Kommer Le sommaire La présentation du contexte applicatif Le mariage: Big Data et apprentissage automatique Dialogues - interactions - apprentissages 2 Le contexte
L utilisation d un réseau de neurones pour optimiser la gestion d un firewall
 L utilisation d un réseau de neurones pour optimiser la gestion d un firewall Réza Assadi et Karim Khattar École Polytechnique de Montréal Le 1 mai 2002 Résumé Les réseaux de neurones sont utilisés dans
L utilisation d un réseau de neurones pour optimiser la gestion d un firewall Réza Assadi et Karim Khattar École Polytechnique de Montréal Le 1 mai 2002 Résumé Les réseaux de neurones sont utilisés dans
Algorithmes de recommandation, Cours Master 2, février 2011
 , Cours Master 2, février 2011 Michel Habib [email protected] http://www.liafa.jussieu.fr/~habib février 2011 Plan 1. Recommander un nouvel ami (ex : Facebook) 2. Recommander une nouvelle relation
, Cours Master 2, février 2011 Michel Habib [email protected] http://www.liafa.jussieu.fr/~habib février 2011 Plan 1. Recommander un nouvel ami (ex : Facebook) 2. Recommander une nouvelle relation
Groupe de Discussion Big Data Aperçu des technologies et applications. Stéphane MOUTON [email protected]
 Groupe de Discussion Big Data Aperçu des technologies et applications Stéphane MOUTON [email protected] Recherche appliquée et transfert technologique q Agréé «Centre Collectif de Recherche» par
Groupe de Discussion Big Data Aperçu des technologies et applications Stéphane MOUTON [email protected] Recherche appliquée et transfert technologique q Agréé «Centre Collectif de Recherche» par
Comment mesurer de façon efficace le succès en ligne d une marque de luxe?
 Comment mesurer de façon efficace le succès en ligne d une marque de luxe? emetrics Summit Paris 2010 Paris, 16 juin 2010 David Sadigh, directeur associé [email protected] A propos d IC-Agency: Notre
Comment mesurer de façon efficace le succès en ligne d une marque de luxe? emetrics Summit Paris 2010 Paris, 16 juin 2010 David Sadigh, directeur associé [email protected] A propos d IC-Agency: Notre
Introduction aux algorithmes MapReduce. Mathieu Dumoulin (GRAAL), 14 Février 2014
, 14 Février 2014") Introduction aux algorithmes MapReduce Mathieu Dumoulin (GRAAL), 14 Février 2014 Plan Introduction de la problématique Tutoriel MapReduce Design d algorithmes MapReduce Tri, somme et calcul de moyenne
Introduction aux algorithmes MapReduce Mathieu Dumoulin (GRAAL), 14 Février 2014 Plan Introduction de la problématique Tutoriel MapReduce Design d algorithmes MapReduce Tri, somme et calcul de moyenne
Introduction. Informatique décisionnelle et data mining. Data mining (fouille de données) Cours/TP partagés. Information du cours
 Cours/TP partagés. Information du cours") Information du cours Informatique décisionnelle et data mining www.lia.univ-avignon.fr/chercheurs/torres/cours/dm Juan-Manuel Torres [email protected] LIA/Université d Avignon Cours/TP
Information du cours Informatique décisionnelle et data mining www.lia.univ-avignon.fr/chercheurs/torres/cours/dm Juan-Manuel Torres [email protected] LIA/Université d Avignon Cours/TP
Coup de Projecteur sur les Réseaux de Neurones
 Coup de Projecteur sur les Réseaux de Neurones Les réseaux de neurones peuvent être utilisés pour des problèmes de prévision ou de classification. La représentation la plus populaire est le réseau multicouche
Coup de Projecteur sur les Réseaux de Neurones Les réseaux de neurones peuvent être utilisés pour des problèmes de prévision ou de classification. La représentation la plus populaire est le réseau multicouche
JSIam Introduction talk. Philippe Gradt. Grenoble, March 6th 2015
 Introduction talk Philippe Gradt Grenoble, March 6th 2015 Introduction Invention Innovation Market validation is key. 1 Introduction Invention Innovation Market validation is key How to turn a product
Introduction talk Philippe Gradt Grenoble, March 6th 2015 Introduction Invention Innovation Market validation is key. 1 Introduction Invention Innovation Market validation is key How to turn a product
Big data et données géospatiales : Enjeux et défis pour la géomatique. Thierry Badard, PhD, ing. jr Centre de Recherche en Géomatique
 Big data et données géospatiales : Enjeux et défis pour la géomatique Thierry Badard, PhD, ing. jr Centre de Recherche en Géomatique Événement 25e anniversaire du CRG Université Laval, Qc, Canada 08 mai
Big data et données géospatiales : Enjeux et défis pour la géomatique Thierry Badard, PhD, ing. jr Centre de Recherche en Géomatique Événement 25e anniversaire du CRG Université Laval, Qc, Canada 08 mai
Analyses croisées de sites Web pour détecter les sites de contrefaçon. Prof. Dr. Olivier Biberstein
 Analyses croisées de sites Web pour détecter les sites de contrefaçon Prof. Dr. Olivier Biberstein Division of Computer Science 14 Novembre 2013 Plan 1. Présentation générale 2. Projet 3. Travaux futurs
Analyses croisées de sites Web pour détecter les sites de contrefaçon Prof. Dr. Olivier Biberstein Division of Computer Science 14 Novembre 2013 Plan 1. Présentation générale 2. Projet 3. Travaux futurs
Data Mining. Vincent Augusto 2012-2013. École Nationale Supérieure des Mines de Saint-Étienne. Data Mining. V. Augusto.
 des des Data Mining Vincent Augusto École Nationale Supérieure des Mines de Saint-Étienne 2012-2013 1/65 des des 1 2 des des 3 4 Post-traitement 5 représentation : 6 2/65 des des Définition générale Le
des des Data Mining Vincent Augusto École Nationale Supérieure des Mines de Saint-Étienne 2012-2013 1/65 des des 1 2 des des 3 4 Post-traitement 5 représentation : 6 2/65 des des Définition générale Le
Classification Automatique de messages : une approche hybride
 RECIAL 2002, Nancy, 24-27 juin 2002 Classification Automatique de messages : une approche hybride O. Nouali (1) Laboratoire des Logiciels de base, CE.R.I.S., Rue des 3 frères Aïssiou, Ben Aknoun, Alger,
RECIAL 2002, Nancy, 24-27 juin 2002 Classification Automatique de messages : une approche hybride O. Nouali (1) Laboratoire des Logiciels de base, CE.R.I.S., Rue des 3 frères Aïssiou, Ben Aknoun, Alger,
SHAREPOINT PORTAL SERVER 2013
 Powered by TCPDF (www.tcpdf.org) SHAREPOINT PORTAL SERVER 2013 Sharepoint portal server 2013 DEVELOPING MICROSOFT SHAREPOINT SERVER 2013 CORE SOLUTIONS Réf: MS20488 Durée : 5 jours (7 heures) OBJECTIFS
Powered by TCPDF (www.tcpdf.org) SHAREPOINT PORTAL SERVER 2013 Sharepoint portal server 2013 DEVELOPING MICROSOFT SHAREPOINT SERVER 2013 CORE SOLUTIONS Réf: MS20488 Durée : 5 jours (7 heures) OBJECTIFS
Informatique / Computer Science
 Informatique / Computer Science Vous trouverez ici les conditions de candidature pour les différentes voies de M2 de la mention «Informatique / Computer Science». Certaines formations ne seront cependant
Informatique / Computer Science Vous trouverez ici les conditions de candidature pour les différentes voies de M2 de la mention «Informatique / Computer Science». Certaines formations ne seront cependant
Lamia Oukid, Ounas Asfari, Fadila Bentayeb, Nadjia Benblidia, Omar Boussaid. 14 Juin 2013
 Cube de textes et opérateur d'agrégation basé sur un modèle vectoriel adapté Text Cube Model and aggregation operator based on an adapted vector space model Lamia Oukid, Ounas Asfari, Fadila Bentayeb,
Cube de textes et opérateur d'agrégation basé sur un modèle vectoriel adapté Text Cube Model and aggregation operator based on an adapted vector space model Lamia Oukid, Ounas Asfari, Fadila Bentayeb,
1-Introduction 2. 2-Installation de JBPM 3. 2-JBPM en action.7
 Sommaire 1-Introduction 2 1-1- BPM (Business Process Management)..2 1-2 J-Boss JBPM 2 2-Installation de JBPM 3 2-1 Architecture de JOBSS JBPM 3 2-2 Installation du moteur JBoss JBPM et le serveur d application
Sommaire 1-Introduction 2 1-1- BPM (Business Process Management)..2 1-2 J-Boss JBPM 2 2-Installation de JBPM 3 2-1 Architecture de JOBSS JBPM 3 2-2 Installation du moteur JBoss JBPM et le serveur d application
Language requirement: Bilingual non-mandatory - Level 222/222. Chosen candidate will be required to undertake second language training.
 This Category II position is open to all interested parties. Toutes les personnes intéressées peuvent postuler ce poste de catégorie II. Senior Manager, Network and Systems Services Non-Public Funds Information
This Category II position is open to all interested parties. Toutes les personnes intéressées peuvent postuler ce poste de catégorie II. Senior Manager, Network and Systems Services Non-Public Funds Information
BIG Data et R: opportunités et perspectives
 BIG Data et R: opportunités et perspectives Guati Rizlane 1 & Hicham Hajji 2 1 Ecole Nationale de Commerce et de Gestion de Casablanca, Maroc, [email protected] 2 Ecole des Sciences Géomatiques, IAV Rabat,
BIG Data et R: opportunités et perspectives Guati Rizlane 1 & Hicham Hajji 2 1 Ecole Nationale de Commerce et de Gestion de Casablanca, Maroc, [email protected] 2 Ecole des Sciences Géomatiques, IAV Rabat,
Analytics & Big Data. Focus techniques & nouvelles perspectives pour les actuaires. Université d Eté de l Institut des Actuaires Mardi 8 juillet 2014
 Analytics & Big Data Focus techniques & nouvelles perspectives pour les actuaires Local Optimization European Minded Université d Eté de l Institut des Actuaires Mardi 8 juillet 2014 Intervenants : Alexandre
Analytics & Big Data Focus techniques & nouvelles perspectives pour les actuaires Local Optimization European Minded Université d Eté de l Institut des Actuaires Mardi 8 juillet 2014 Intervenants : Alexandre
PeTEX Plateforme pour e-learning et expérimentation télémétrique
 PeTEX Plateforme pour e-learning et expérimentation télémétrique 142270-LLP-1-2008-1-DE-LEONARDO-LMP 1 Information sur le projet Titre: Code Projet: Année: 2008 Type de Projet: Statut: Accroche marketing:
PeTEX Plateforme pour e-learning et expérimentation télémétrique 142270-LLP-1-2008-1-DE-LEONARDO-LMP 1 Information sur le projet Titre: Code Projet: Année: 2008 Type de Projet: Statut: Accroche marketing:
Entreposage de données complexes pour la médecine d anticipation personnalisée
 Manuscrit auteur, publié dans "9th International Conference on System Science in Health Care (ICSSHC 08), Lyon : France (2008)" Entreposage de données complexes pour la médecine d anticipation personnalisée
Manuscrit auteur, publié dans "9th International Conference on System Science in Health Care (ICSSHC 08), Lyon : France (2008)" Entreposage de données complexes pour la médecine d anticipation personnalisée
0 h(s)ds et h [t = 1 [t, [ h, t IR +. Φ L 2 (IR + ) Φ sur U par
ds et h [t = 1 [t, [ h, t IR +. Φ L 2 (IR + ) Φ sur U par") Probabilités) Calculus on Fock space and a non-adapted quantum Itô formula Nicolas Privault Abstract - The aim of this note is to introduce a calculus on Fock space with its probabilistic interpretations,
Probabilités) Calculus on Fock space and a non-adapted quantum Itô formula Nicolas Privault Abstract - The aim of this note is to introduce a calculus on Fock space with its probabilistic interpretations,
We make your. Data Smart. Data Smart
 We make your We make your Data Smart Data Smart Une société Une société du du groupe Le groupe NP6 SPECIALISTE LEADER SECTEURS EFFECTIFS SaaS Marketing : 50% Data intelligence : 50% 15 sociétés du CAC
We make your We make your Data Smart Data Smart Une société Une société du du groupe Le groupe NP6 SPECIALISTE LEADER SECTEURS EFFECTIFS SaaS Marketing : 50% Data intelligence : 50% 15 sociétés du CAC
Introduction aux outils BI de SQL Server 2014. Fouille de données avec SQL Server Analysis Services (SSAS)
") MIT820: Entrepôts de données et intelligence artificielle Introduction aux outils BI de SQL Server 2014 Fouille de données avec SQL Server Analysis Services (SSAS) Description générale Ce tutoriel a pour
MIT820: Entrepôts de données et intelligence artificielle Introduction aux outils BI de SQL Server 2014 Fouille de données avec SQL Server Analysis Services (SSAS) Description générale Ce tutoriel a pour
[email protected] http://chirouble.univ-lyon2.fr/~ricco/cours/ Publications, ressources, liens, logiciels,
 Université Lumière Lyon 2 Tutoriels Tanagra - http://tutoriels-data-mining.blogspot.fr/ 1 [email protected] http://chirouble.univ-lyon2.fr/~ricco/cours/ Publications, ressources, liens,
Université Lumière Lyon 2 Tutoriels Tanagra - http://tutoriels-data-mining.blogspot.fr/ 1 [email protected] http://chirouble.univ-lyon2.fr/~ricco/cours/ Publications, ressources, liens,
Optimisation et programmation mathématique. Professeur Michel de Mathelin. Cours intégré : 20 h
 Télécom Physique Strasbourg Master IRIV Optimisation et programmation mathématique Professeur Michel de Mathelin Cours intégré : 20 h Programme du cours d optimisation Introduction Chapitre I: Rappels
Télécom Physique Strasbourg Master IRIV Optimisation et programmation mathématique Professeur Michel de Mathelin Cours intégré : 20 h Programme du cours d optimisation Introduction Chapitre I: Rappels
K. Ammar, F. Bachoc, JM. Martinez. Séminaire ARISTOTE - 23 octobre 2014 - Palaiseau
 Apport des modèles de krigeage à la simulation numérique K Ammar, F Bachoc, JM Martinez CEA-Saclay, DEN, DM2S, F-91191 Gif-sur-Yvette, France Séminaire ARISTOTE - 23 octobre 2014 - Palaiseau Apport des
Apport des modèles de krigeage à la simulation numérique K Ammar, F Bachoc, JM Martinez CEA-Saclay, DEN, DM2S, F-91191 Gif-sur-Yvette, France Séminaire ARISTOTE - 23 octobre 2014 - Palaiseau Apport des
MASTER SIS PRO : logique et sécurité DÉTECTION D INTRUSIONS. Odile PAPINI, LSIS. Université de Toulon et du Var. papini@univ-tln.
 MASTER SIS PRO : logique et sécurité DÉTECTION D INTRUSIONS Odile PAPINI, LSIS. Université de Toulon et du Var. [email protected] Plan Introduction Généralités sur les systèmes de détection d intrusion
MASTER SIS PRO : logique et sécurité DÉTECTION D INTRUSIONS Odile PAPINI, LSIS. Université de Toulon et du Var. [email protected] Plan Introduction Généralités sur les systèmes de détection d intrusion
Ingénierie et gestion des connaissances
 Master Web Intelligence ICM Option Informatique Ingénierie et gestion des connaissances Philippe BEAUNE [email protected] 18 novembre 2008 Passer en revue quelques idées fondatrices de l ingénierie
Master Web Intelligence ICM Option Informatique Ingénierie et gestion des connaissances Philippe BEAUNE [email protected] 18 novembre 2008 Passer en revue quelques idées fondatrices de l ingénierie
TRS: Sélection des sous-graphes représentants par l intermédiaire des attributs topologiques et K-medoïdes
 TRS: Sélection des sous-graphes représentants par l intermédiaire des attributs topologiques et K-medoïdes Mohamed Moussaoui,Wajdi Dhifli,Sami Zghal,Engelbert Mephu Nguifo FSJEG, Université de Jendouba,
TRS: Sélection des sous-graphes représentants par l intermédiaire des attributs topologiques et K-medoïdes Mohamed Moussaoui,Wajdi Dhifli,Sami Zghal,Engelbert Mephu Nguifo FSJEG, Université de Jendouba,
Instructions Mozilla Thunderbird Page 1
 Instructions Mozilla Thunderbird Page 1 Instructions Mozilla Thunderbird Ce manuel est écrit pour les utilisateurs qui font déjà configurer un compte de courrier électronique dans Mozilla Thunderbird et
Instructions Mozilla Thunderbird Page 1 Instructions Mozilla Thunderbird Ce manuel est écrit pour les utilisateurs qui font déjà configurer un compte de courrier électronique dans Mozilla Thunderbird et
Les participants repartiront de cette formation en ayant une vision claire de la stratégie et de l éventuelle mise en œuvre d un Big Data.
 Big Data De la stratégie à la mise en oeuvre Description : La formation a pour objet de brosser sans concession le tableau du Big Data. Les participants repartiront de cette formation en ayant une vision
Big Data De la stratégie à la mise en oeuvre Description : La formation a pour objet de brosser sans concession le tableau du Big Data. Les participants repartiront de cette formation en ayant une vision
Fouille de données massives avec Hadoop
 Fouille de données massives avec Hadoop Sebastiao Correia [email protected] Talend 2013 AAFD'14 29-30 avril 2014 1 Agenda Présentation de Talend Définition du Big Data Le framework Hadoop 3 thématiques
Fouille de données massives avec Hadoop Sebastiao Correia [email protected] Talend 2013 AAFD'14 29-30 avril 2014 1 Agenda Présentation de Talend Définition du Big Data Le framework Hadoop 3 thématiques
Intelligence Economique - Business Intelligence
 Intelligence Economique - Business Intelligence Notion de Business Intelligence Dès qu'il y a une entreprise, il y a implicitement intelligence économique (tout comme il y a du marketing) : quelle produit
Intelligence Economique - Business Intelligence Notion de Business Intelligence Dès qu'il y a une entreprise, il y a implicitement intelligence économique (tout comme il y a du marketing) : quelle produit
Les technologies du Big Data
 Les technologies du Big Data PRÉSENTÉ AU 40 E CONGRÈS DE L ASSOCIATION DES ÉCONOMISTES QUÉBÉCOIS PAR TOM LANDRY, CONSEILLER SENIOR LE 20 MAI 2015 WWW.CRIM.CA TECHNOLOGIES: DES DONNÉES JUSQU'À L UTILISATEUR
Les technologies du Big Data PRÉSENTÉ AU 40 E CONGRÈS DE L ASSOCIATION DES ÉCONOMISTES QUÉBÉCOIS PAR TOM LANDRY, CONSEILLER SENIOR LE 20 MAI 2015 WWW.CRIM.CA TECHNOLOGIES: DES DONNÉES JUSQU'À L UTILISATEUR
A GRASPxELS approach for the Job Shop with generic time-lags and new statistical determination of the parameters
 A GRASPxELS approach for the Job Shop with generic time-lags and new statistical determination of the parameters Présenté par : Equipe de travail : Laboratoire : Maxime CHASSAING Philippe LACOMME, Nikolay
A GRASPxELS approach for the Job Shop with generic time-lags and new statistical determination of the parameters Présenté par : Equipe de travail : Laboratoire : Maxime CHASSAING Philippe LACOMME, Nikolay
http://blog.khaledtannir.net
 Algorithme de parallélisations des traitements Khaled TANNIR Doctorant CIFRE LARIS/ESTI http://blog.khaledtannir.net [email protected] 2e SéRI 2010-2011 Jeudi 17 mars 2011 Présentation Doctorant CIFRE
Algorithme de parallélisations des traitements Khaled TANNIR Doctorant CIFRE LARIS/ESTI http://blog.khaledtannir.net [email protected] 2e SéRI 2010-2011 Jeudi 17 mars 2011 Présentation Doctorant CIFRE
Le MDM (Master Data Management) Pierre angulaire d'une bonne stratégie de management de l'information
 Pierre angulaire d'une bonne stratégie de management de l'information") Darren Cooper Information Management Consultant, IBM Software Group 1st December, 2011 Le MDM (Master Data Management) Pierre angulaire d'une bonne stratégie de management de l'information Information
Darren Cooper Information Management Consultant, IBM Software Group 1st December, 2011 Le MDM (Master Data Management) Pierre angulaire d'une bonne stratégie de management de l'information Information
Data issues in species monitoring: where are the traps?
 Data issues in species monitoring: where are the traps? French breeding bird monitoring : Animations locales : - dealing with heterogenous data - working with multi-species multi-sites monitoring schemes
Data issues in species monitoring: where are the traps? French breeding bird monitoring : Animations locales : - dealing with heterogenous data - working with multi-species multi-sites monitoring schemes
How to Login to Career Page
 How to Login to Career Page BASF Canada July 2013 To view this instruction manual in French, please scroll down to page 16 1 Job Postings How to Login/Create your Profile/Sign Up for Job Posting Notifications
How to Login to Career Page BASF Canada July 2013 To view this instruction manual in French, please scroll down to page 16 1 Job Postings How to Login/Create your Profile/Sign Up for Job Posting Notifications
$SSOLFDWLRQGXNULJHDJHSRXUOD FDOLEUDWLRQPRWHXU
 $SSOLFDWLRQGXNULJHDJHSRXUOD FDOLEUDWLRQPRWHXU Fabien FIGUERES [email protected] 0RWVFOpV : Krigeage, plans d expériences space-filling, points de validations, calibration moteur. 5pVXPp Dans le
$SSOLFDWLRQGXNULJHDJHSRXUOD FDOLEUDWLRQPRWHXU Fabien FIGUERES [email protected] 0RWVFOpV : Krigeage, plans d expériences space-filling, points de validations, calibration moteur. 5pVXPp Dans le
Conférence Bales II - Mauritanie. Patrick Le Nôtre. Directeur de la Stratégie - Secteur Finance Solutions risques et Réglementations
 Conférence Bales II - Mauritanie Patrick Le Nôtre Directeur de la Stratégie - Secteur Finance Solutions risques et Réglementations AGENDA Le positionnement et l approche de SAS Notre légitimité dans les
Conférence Bales II - Mauritanie Patrick Le Nôtre Directeur de la Stratégie - Secteur Finance Solutions risques et Réglementations AGENDA Le positionnement et l approche de SAS Notre légitimité dans les