Apprentissage et factorisation matricielle pour la recommandation
|
|
|
- Patrice Larouche
- il y a 10 ans
- Total affichages :
Transcription
1 Apprentissage et factorisation matricielle pour la recommandation Décembre 2012, GdR ISIS Julien Delporte & Stéphane Canu

2 Plan de la présentation 1 Le problème de la recommandation Les problèmes de recommandation Les données : Big Data 2 Factorisation et apprentissage Factorisation et décomposition en valeurs singulières Factorisation et Netflix Apprentissage pour la recommandation 3 Recommandation avec préférences et liens Problème Tuenti Optimisation alternée Résultats expérimentaux

3 La recommandation de tous les jours
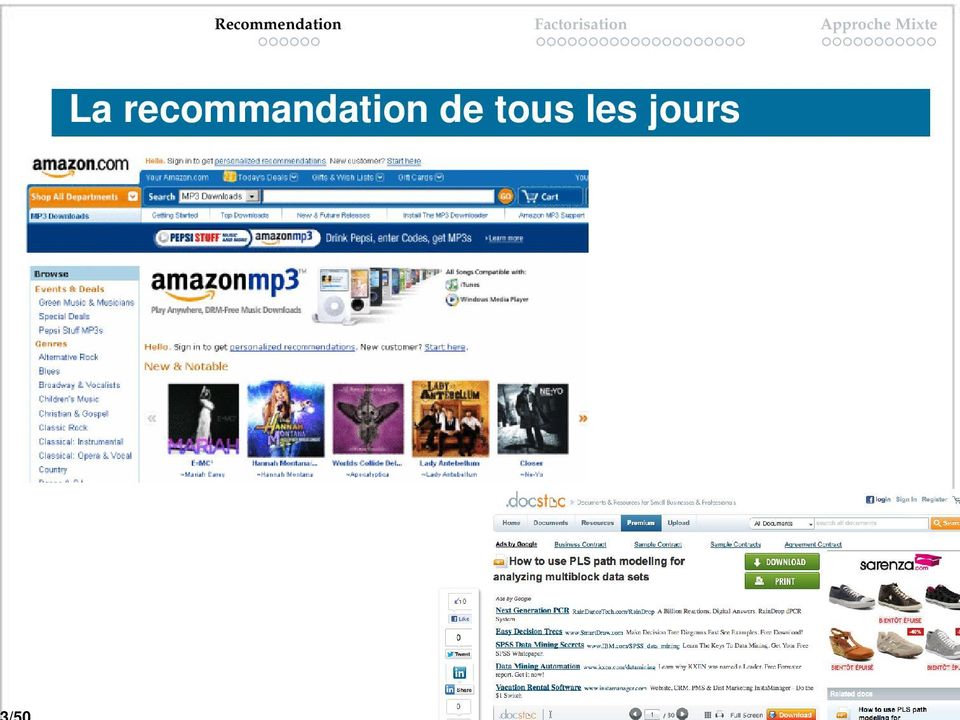
4 Recommendation Factorisation Approche Mixte Recommander musique, films, amis, lieux...

5 Les problèmes liés à la recommandation Problèmes types la recommandation d articles (publicité, lignes de code,...) la recommandation d amis (à partir de graphes) identification de variables cachées (profiles, groupes,...) Latent variables le monde bouge (temps) long tail problem cold start le système de recommandation (pré et post processing)

6 Les données de base : matrice client/produit TABLE: Matrice d achat Produit Client peut signifier : l utilisateur n apprécie pas l article l utilisateur ne connaît pas l article (ou n a pas encore signifié son goût).

7 Les types de données : matrice client/produit TABLE: Matrice de vote (rating) Films?? 4? 1?????? Spectateur 3???? 4 3?? 2? 1 5?????? 5??? 2???????? 1??? 2??? 2????? 1????? 1??? 5 3 4???? 1 1 4? signifie que nous ne connaissons pas l avis du spectateur


8 A 1 million dollars Challenge ( ) Netflix Challenge Recommandation de films Moteur maison : cinematch Améliorer les performances de 10% Gagné en 2009 par fusion : KorBell s Pragmatic Chaos

9 Les types de données : Big Data La matrice des achats volumineuse creuse datée Matrice bloc 3d Autres données possibles Données contextuelles sur les clients sur les articles Réseau social (représentation : graphe) Matrices associées Données multi blocs structurés
 Matrices associées Données multi blocs")
10 Données multi blocs (tableaux = matrices) produits clients achats

11 Données multi blocs (tableaux = matrices) produits clients achats temps

12 Données multi blocs (tableaux = matrices) produits clients achats temps

13 Données multi blocs (tableaux = matrices) produits clients achats temps

14 Données multi blocs (tableaux = matrices) produits c 2 c 6 clients achats c 3 c 4 temps c 1 c 5

15 Résumons nous : systèmes de recommandation disponible. certains fonctionnent bien...et d autres moins bien moteur : l exploitation de la matrice d achat Exploiter toutes les données disponibles multiblocs (temps, utilisateur, produit) structurés (arbres, graphes, relations) création de variables cachées : profils orrienté «usage»
 création de variables cachées : profils orrienté")
16 Plan de la présentation 1 Le problème de la recommandation Les problèmes de recommandation Les données : Big Data 2 Factorisation et apprentissage Factorisation et décomposition en valeurs singulières Factorisation et Netflix Apprentissage pour la recommandation 3 Recommandation avec préférences et liens Problème Tuenti Optimisation alternée Résultats expérimentaux

17 Factorisation matricielle Films : V 5 Utilisateurs : U Y Matrice des observations : Y 3,2 = 5

18 Factorisation matricielle Y = UV + bruit V (variables latentes items) 5 (variables latentes users)u Y Matrice des observations : Y 3,2 = 5

19 Complétion de matrice Y = UV + bruit V (variables latentes items) (variables latentes users)u Ŷ ij = U i V j (problème de complétion)

20 Comment trouver U et V? Problème de reconstruction de la matrice Y min Ŷ avec L(Y, Ŷ ) := Y Ŷ 2 F rang(ŷ ) = k Eckart & Young 1936 Solution : décomposition en valeurs singulières (SVD) Ŷ = UV (= U ΣV ) Méthode de résolution «exacte» sur matrices creuses algorithme : processus de Lanczos Bidiagonalisation Y = WBZ diagonalisation de B (rotations de givens GVL 8.6.1) logiciel : PROPACK a a. http ://soi.stanford.edu/ rmunk/propack/

21 Comment calculer U et V? min L(Y, UV ) avec rang(u) = rang(v ) = k U,V SGD (Stochastic Gradient Descent) Calcul de gradient règle de mise à jour par descente de gradient Ui NEW Vj NEW = Ui OLD p Ui L(Y, U, V ) = Vj OLD p Vj L(Y, U, V ) Algorithmes efficaces S. Funk process a, PLSA, MMMF (Srebro et al, 2004),... code : RSVD b, CofiRank c,... a. http ://sifter.org/ simon/journal/ html b. http ://code.google.com/p/pyrsvd/ c. http ://
22 Optimisation alternée Formulation Générale min U,V L(U, V, Y ) + Ω(U, V ) attache aux données : L(U, V, Y ) pénalisation : Ω(U, V ) Algorithme qui passe à l échelle calculer le gradient et isoler le terme à mettre à jour pour obtenir la règle example : pour L(U, V, Y ) = UV Y 2 et Ω(U, V ) = 0 on a : U i = (Y i V ).(VV ) 1 utilisé dans CoFi pour implicit feedback datasets [2]
23 Un succès de la factoriasation Netflix Challenge ( ) Recommandation de films Moteur maison : CineMatch Améliorer les performances de 10% critère : erreur quadratique Les données spectateurs films 100 millons d évaluations (de 1 à 5) taux de remplissage : 1,3 % test sur les 3 millions les plus récents téléchargements des donées
24 baseline : CineMatch factorisation : SVD régularisée à k facteurs U i, V j IR k min U,V (Y ij Ui V j ) 2 + λ( U i 2 + V i 2 ) i,j normalisation : moyenne globale µ, pour l utilisateur i bi (Y ij Ui V j µ b i b j ) 2 + λ( U i 2 + V i 2 ) min U,V i,j poids : implicit feedback cij : niveau de confiance c ij (Y ij Ui V j µ b i b j ) 2 + λ( U i 2 + V i 2 ) min U,V temps i,j min U,V (Y ij U i (t) V j ) 2 + λ( U i 2 + V i 2 ) i,j Mélanges de modèles
25 Les résultats sur Netflix erreur initiale : factorisation - 4 % nombres de facteurs -.5 % améliorations % normalisation poids temps bagging : - 3 % = mélange 100 méthodes Koren, Y., Bell, R.M., Volinsky, C. : Matrix factorization techniques for recommender systems. IEEE Computer 42(8), (2009)
26 Les leçons de Netflix trop d efforts spécifiques pour être généralisée factorisation is the solution poids : implicit feedback prendre en compte les spécificités (ici l effet temps) une algorithmique de type gradient stochastique flexible qui passe à l échelle
27 Modèles de complétion de matrice data = info + bruit Y = M + bruit et M régulière problèmes d optimisation non convexe et non différentiable Régularité norme(m) rang(m) factorisation : M = UV parcimonie non linéaire : noyaux blocs (classification croisée) M = UBV U ij {0, 1} probabiliste : blocs latent Bruit Modèle de buit : gaussien Yij N (M ij, σ 2 ) logistic Yij B(M ij )
28 Modèles du bruit : attache aux données continue Gaussien l2 : frobenius entropie divergences 0/1 distance du χ 2 : AFC cout logistique cout charnière Rang NDCG@k (Normalized Discounted Cumulative Gain) relaxation convexe (CoFiRank) problèmes d optimisation non convexe
29 Exemple des données 0/1 : l ACP logistique Observations : y ij {0, 1} Loi de Bernouilli : Y ij B(P ij (θ ij )) Yij : le passage à l acte P ij probabilité d acheter θ ij appétence ou fonction d utilité Modèle logistique : P ij = IP(Y ij = 1) = expθ ij 1 + exp θ ij k Modèle d utilité : θ ij = U κ,i V κ,j = Ui V j Cout : min L(U, V ) U,V L(U, V ) = n i κ=1 p y ij Ui V j + log ( ) 1 + exp U i V j j
30 Modèles de régularité Rang(M) : Eckart & Young 1936 = SVD norme de Frobenius : U 2 F = i,j U2 ij norme parcimonieuse : U 1 = i,j U ij contraintes de positivité : U i,j 0 Mx normes d opérateurs : M p = sup p x x p p = 1 : max lignes p = 2 : max λ i p = : max colonnes max normes M q p = sup x Mx p x q norme nucléaire M = Tr ( M M ) = λ i normes mixtes, groupées, structurées ou pondérées... problèmes d optimisation non convexe et non différentiable
31 Optimisation non convexe et non différentiable Traitement de la non convexité cardinalité : rang(m) relaxation sous modulaire 1 relaxation l1 (non différentiable) : l 0 l 1 vue comme son enveloppe convexe rang(m) norme nucléaire 2 M = Tr ( M M ) = λ i Optimisation non convexe et non différentiable 3 min U,V J(U, V ) = L(Y, UV ) + λ Ω(U, V ) (U, V ) min loc 0 c J(U, V ) sous différentielle de Clark 1. tutorial MLSS 2012 de F. Bach Learning with submodular functions di.ens.fr/~fbach/ 2. Pour l heuristique de la norme nucléaire voir : [Fazel, Hindi, Boyd 01] et [Recht, Fazel, Parillo 08] 3. S. Sra, Scalable nonconvex inexact proximal splitting, NIPS 2012.
32 Optimisation non convexe et non différentiable Réécriture : séparation de la partie non convexe différentiable de la partie non différentiable convexe : J(U, V ) = L(Y, UV )+λ Ω(U, V ) = J 1 (U, V ) } {{ } + J 2 (U, V ) } {{ } différentiable f convexe f Condition d optimalité locale (stationarité) 4 : 0 c J(U, V ) J 1 (U, V ) J 2 (U, V ) Possibilité d utiliser un algorithme proximal 4. proposition corollary 1, F. Clarke, Optimization and nonsmooth analysis, 1987
33 NNMF (Non-Negative Matrix Factorization) Y = UV + b et V ij 0 Coûts usuels Distance euclidienne Divergence de Kullback-Leibler Divergence de Itakura-Saito Algorithme Algorithme multiplicatif (garantit positivité et parcimonie) a U NEW = U OLD U L(Y,U,V ) + U L(Y,U,V ) (idem sur V ) a. voir le site de C. Févotte perso.telecom-paristech.fr/~fevotte
34 Approches non linéaires Les réseaux de neurones Restricted Boltzmann Machines et architectures profondes, L utilisation de noyaux : kernel-cofi données clients et produits sont des points dans un RKHS appétence de c pour p : f (c, p) = c, Fp F est un opérateur (une matrice) et 2 noyaux min L(F, Y ) + Ω(F) F Ω(F) régularisation (typiquement F 2 F ou F ) Algorithme régularisation spectrale adaptée aux opérateurs [1] optimisation en dimension finie
35 Classification croisée Co-Clustering Y = M + bruit But : Identifier simultanément des groupes d utilisateurs des groupes d articles Algorithmes K-moyennes SVD (spectral coclustering) NNM tri Factorisation [3] modèles à blocks latent extension aux blocs de données voir G. G. Govaert & M. Nadif
36 Social-based recommendation Recommandation d amis (Y = graphe social) completion de matrice sur le réseau social utilisation des préférences d utilisateurs Graphe social en tant qu outil appui pour la recommendation d articles construction de graphes de confiance...
37 Résumé tratement des big data modèle Factorisation terme d attache aux données pénalité Classification croisée (blocs) algorithmes gradient stochastique optimisation alternée non linéaire et non convexe problème : extension aux données complexes
38 Plan de la présentation 1 Le problème de la recommandation Les problèmes de recommandation Les données : Big Data 2 Factorisation et apprentissage Factorisation et décomposition en valeurs singulières Factorisation et Netflix Apprentissage pour la recommandation 3 Recommandation avec préférences et liens Problème Tuenti Optimisation alternée Résultats expérimentaux
39 Contexte Tuenti Réseau social espagnol 80% des ans l utilisent Aussi gros que facebook (en Espagne) le système de recommandation Possibilité d aimer un lieu (bar, restaurant, théâtre,...) Recommandation de lieu
40 Les données Les tailles 13 millions d utilisateurs lieux 200 millions de connexions user user user 3 0 user Parcimonie 4 lieux par utilisateurs 20 amis par utilisateurs
41 Formulation du problème fonction objectif min U,V (i,j) Y c ij pour pénaliser les 1 plus que les 0 Ω U,V = µ U 2 Fro + (1 µ) V 2 Fro c ij ( Ui V j Y ij ) 2 + λωu,v (1) fonction de décision Ŷ ij = U i V j (2)
42 Formulation du problème fonction objectif min U,V,α (i,j) Y c ij ( Ui V j + k F i α ik U k V j F i Y ij ) 2 + ΩU,V (1) c ij pour pénaliser les 1 plus que les 0 Ω U,V = µ U 2 Fro + (1 µ) V 2 Fro F i l enesemble des «amis» de i α ik influence de l «ami» k sur i (k F i ) fonction de décision «renforcée» Ŷ ij = U i V j + k F i α ik U k V j F i (2)
43 Algorithme Moindres carrés alternés SE CoFi Input : Y and F intialize U,V and α Repeat For each user i U update U i For each item j V update V j For each item i U For each item k F i update α ik Until convergence
44 Algorithme Détail des gradients Calcul des dérivées partielles les règles de mise à jour ( ) U i Y i C i V T A i UVC i V T F i (VC i V T + λ 1 I) 1 V j (U T C j U + λ 2 I) 1 U T C j Y j avec U i = U i + k Fi α ik α ik U k F i Y i U i V ( ) α ik U k V 1 F i Ci V T U T U i VC i V T U T i i F i + λ 3 k F i k i
45 Astuce de calcul pour un produit coûteux La parcimonie entre en jeu réécrire : VC i V T = VV T + V Yi (C i I) Yi V T Y i C i matrice diagonale dont la majorité des termes est 1. renforcer les erreur pour Y ij = 1 influence des lieux : VV T se calcule une seule fois. Y i les lieux visités par i (4 en moyenne) calcul du produit de droite que pour certaines colonnes de V (4 en moyenne).
46 Performances en terme de MAP et de RANK MAP et rang moyen MAP = 1 U U i=1 M P(k)Y ik k=1 Y RANK = Y ij rank ij i,j Y 0.95 imf SE CoFi LLA RSR Trust average 0.05 MAP RANK imf SECoFi LLA RSR Trust Average tests réalisés sur un serveur 24 cores avec 100Go RAM number of factors d number of factors d
47 Retour sur les influences des amis frequency of the histogram Distribution values of ἀalpha Le principe d affinité (homophily) est vérifié (pas d influence négative)
48 Conclusion Bilan prise en compte de la matrice ET du graphe gestion d un gros volume de données amélioration de la recommandation de lieux mesure de l influence Perspectives utiliser la flexibilité de l approche prendre en compte les données contextuelles GPS, types de lieux,... vers la recommandation d amis (apprendre tous les α)
49 Questions Recommendation Factorisation Approche Mixte
50 J. Abernethy, F. Bach, T. Evgeniou, and J.P. Vert. A new approach to collaborative filtering : Operator estimation with spectral regularization. The Journal of Machine Learning Research, 10 : , Y. Hu, Y. Koren, and C. Volinsky. Collaborative filtering for implicit feedback datasets. In Data Mining, ICDM 08. Eighth IEEE International Conference on, pages Ieee, L. Labiod and M. Nadif. Co-clustering under nonnegative matrix tri-factorization. In Neural Information Processing, pages Springer, 2011.
Tour d horizon de l apprentissage statistique. from Machine Learning to Big Data Analytics
 Tour d horizon de l apprentissage statistique. from Machine Learning to Big Data Analytics Stéphane Canu asi.insa-rouen.fr/enseignants/~scanu Codeur en Seine 2014, Université de Rouen 27 novembre 2014
Tour d horizon de l apprentissage statistique. from Machine Learning to Big Data Analytics Stéphane Canu asi.insa-rouen.fr/enseignants/~scanu Codeur en Seine 2014, Université de Rouen 27 novembre 2014
INF6304 Interfaces Intelligentes
 INF6304 Interfaces Intelligentes filtres collaboratifs 1/42 INF6304 Interfaces Intelligentes Systèmes de recommandations, Approches filtres collaboratifs Michel C. Desmarais Génie informatique et génie
INF6304 Interfaces Intelligentes filtres collaboratifs 1/42 INF6304 Interfaces Intelligentes Systèmes de recommandations, Approches filtres collaboratifs Michel C. Desmarais Génie informatique et génie
Introduction au Data-Mining
 Introduction au Data-Mining Gilles Gasso, Stéphane Canu INSA Rouen -Département ASI Laboratoire LITIS 8 septembre 205. Ce cours est librement inspiré du cours DM de Alain Rakotomamonjy Gilles Gasso, Stéphane
Introduction au Data-Mining Gilles Gasso, Stéphane Canu INSA Rouen -Département ASI Laboratoire LITIS 8 septembre 205. Ce cours est librement inspiré du cours DM de Alain Rakotomamonjy Gilles Gasso, Stéphane
Apprentissage Automatique
 Apprentissage Automatique Introduction-I [email protected] www.lia.univ-avignon.fr Définition? (Wikipedia) L'apprentissage automatique (machine-learning en anglais) est un des champs
Apprentissage Automatique Introduction-I [email protected] www.lia.univ-avignon.fr Définition? (Wikipedia) L'apprentissage automatique (machine-learning en anglais) est un des champs
Optimisation et programmation mathématique. Professeur Michel de Mathelin. Cours intégré : 20 h
 Télécom Physique Strasbourg Master IRIV Optimisation et programmation mathématique Professeur Michel de Mathelin Cours intégré : 20 h Programme du cours d optimisation Introduction Chapitre I: Rappels
Télécom Physique Strasbourg Master IRIV Optimisation et programmation mathématique Professeur Michel de Mathelin Cours intégré : 20 h Programme du cours d optimisation Introduction Chapitre I: Rappels
Résolution de systèmes linéaires par des méthodes directes
 Résolution de systèmes linéaires par des méthodes directes J. Erhel Janvier 2014 1 Inverse d une matrice carrée et systèmes linéaires Ce paragraphe a pour objet les matrices carrées et les systèmes linéaires.
Résolution de systèmes linéaires par des méthodes directes J. Erhel Janvier 2014 1 Inverse d une matrice carrée et systèmes linéaires Ce paragraphe a pour objet les matrices carrées et les systèmes linéaires.
K. Ammar, F. Bachoc, JM. Martinez. Séminaire ARISTOTE - 23 octobre 2014 - Palaiseau
 Apport des modèles de krigeage à la simulation numérique K Ammar, F Bachoc, JM Martinez CEA-Saclay, DEN, DM2S, F-91191 Gif-sur-Yvette, France Séminaire ARISTOTE - 23 octobre 2014 - Palaiseau Apport des
Apport des modèles de krigeage à la simulation numérique K Ammar, F Bachoc, JM Martinez CEA-Saclay, DEN, DM2S, F-91191 Gif-sur-Yvette, France Séminaire ARISTOTE - 23 octobre 2014 - Palaiseau Apport des
de calibration Master 2: Calibration de modèles: présentation et simulation d
 Master 2: Calibration de modèles: présentation et simulation de quelques problèmes de calibration Plan de la présentation 1. Présentation de quelques modèles à calibrer 1a. Reconstruction d une courbe
Master 2: Calibration de modèles: présentation et simulation de quelques problèmes de calibration Plan de la présentation 1. Présentation de quelques modèles à calibrer 1a. Reconstruction d une courbe
L'intelligence d'affaires: la statistique dans nos vies de consommateurs
 L'intelligence d'affaires: la statistique dans nos vies de consommateurs Jean-François Plante, HEC Montréal Marc Fredette, HEC Montréal Congrès de l ACFAS, Université Laval, 6 mai 2013 Intelligence d affaires
L'intelligence d'affaires: la statistique dans nos vies de consommateurs Jean-François Plante, HEC Montréal Marc Fredette, HEC Montréal Congrès de l ACFAS, Université Laval, 6 mai 2013 Intelligence d affaires
5. Apprentissage pour le filtrage collaboratif
 686 PARTIE 5 : Au-delà de l apprentissage supervisé 5. Apprentissage pour le filtrage collaboratif Il semble que le nombre de choix qui nous sont ouverts augmente constamment. Films, livres, recettes,
686 PARTIE 5 : Au-delà de l apprentissage supervisé 5. Apprentissage pour le filtrage collaboratif Il semble que le nombre de choix qui nous sont ouverts augmente constamment. Films, livres, recettes,
Cours d analyse numérique SMI-S4
 ours d analyse numérique SMI-S4 Introduction L objet de l analyse numérique est de concevoir et d étudier des méthodes de résolution de certains problèmes mathématiques, en général issus de problèmes réels,
ours d analyse numérique SMI-S4 Introduction L objet de l analyse numérique est de concevoir et d étudier des méthodes de résolution de certains problèmes mathématiques, en général issus de problèmes réels,
Analyse de la vidéo. Chapitre 4.1 - La modélisation pour le suivi d objet. 10 mars 2015. Chapitre 4.1 - La modélisation d objet 1 / 57
 Analyse de la vidéo Chapitre 4.1 - La modélisation pour le suivi d objet 10 mars 2015 Chapitre 4.1 - La modélisation d objet 1 / 57 La représentation d objets Plan de la présentation 1 La représentation
Analyse de la vidéo Chapitre 4.1 - La modélisation pour le suivi d objet 10 mars 2015 Chapitre 4.1 - La modélisation d objet 1 / 57 La représentation d objets Plan de la présentation 1 La représentation
Intégration de la dimension sémantique dans les réseaux sociaux
 Intégration de la dimension sémantique dans les réseaux sociaux Application : systèmes de recommandation Maria Malek LARIS-EISTI [email protected] 1 Contexte : Recommandation dans les réseaux sociaux
Intégration de la dimension sémantique dans les réseaux sociaux Application : systèmes de recommandation Maria Malek LARIS-EISTI [email protected] 1 Contexte : Recommandation dans les réseaux sociaux
Une comparaison de méthodes de discrimination des masses de véhicules automobiles
 p.1/34 Une comparaison de méthodes de discrimination des masses de véhicules automobiles A. Rakotomamonjy, R. Le Riche et D. Gualandris INSA de Rouen / CNRS 1884 et SMS / PSA Enquêtes en clientèle dans
p.1/34 Une comparaison de méthodes de discrimination des masses de véhicules automobiles A. Rakotomamonjy, R. Le Riche et D. Gualandris INSA de Rouen / CNRS 1884 et SMS / PSA Enquêtes en clientèle dans
INTRODUCTION À L ANALYSE FACTORIELLE DES CORRESPONDANCES
 INTRODUCTION À L ANALYSE FACTORIELLE DES CORRESPONDANCES Dominique LAFFLY Maître de Conférences, Université de Pau Laboratoire Société Environnement Territoire UMR 5603 du CNRS et Université de Pau Domaine
INTRODUCTION À L ANALYSE FACTORIELLE DES CORRESPONDANCES Dominique LAFFLY Maître de Conférences, Université de Pau Laboratoire Société Environnement Territoire UMR 5603 du CNRS et Université de Pau Domaine
Filtrage stochastique non linéaire par la théorie de représentation des martingales
 Filtrage stochastique non linéaire par la théorie de représentation des martingales Adriana Climescu-Haulica Laboratoire de Modélisation et Calcul Institut d Informatique et Mathématiques Appliquées de
Filtrage stochastique non linéaire par la théorie de représentation des martingales Adriana Climescu-Haulica Laboratoire de Modélisation et Calcul Institut d Informatique et Mathématiques Appliquées de
Une méthode de classification supervisée sans paramètre pour l apprentissage sur les grandes bases de données
 Une méthode de classification supervisée sans paramètre pour l apprentissage sur les grandes bases de données Marc Boullé Orange Labs 2 avenue Pierre Marzin 22300 Lannion [email protected],
Une méthode de classification supervisée sans paramètre pour l apprentissage sur les grandes bases de données Marc Boullé Orange Labs 2 avenue Pierre Marzin 22300 Lannion [email protected],
4.2 Unités d enseignement du M1
 88 CHAPITRE 4. DESCRIPTION DES UNITÉS D ENSEIGNEMENT 4.2 Unités d enseignement du M1 Tous les cours sont de 6 ECTS. Modélisation, optimisation et complexité des algorithmes (code RCP106) Objectif : Présenter
88 CHAPITRE 4. DESCRIPTION DES UNITÉS D ENSEIGNEMENT 4.2 Unités d enseignement du M1 Tous les cours sont de 6 ECTS. Modélisation, optimisation et complexité des algorithmes (code RCP106) Objectif : Présenter
Formation Actuaire Data Scientist. Programme au 24 octobre 2014
 Formation Actuaire Data Scientist Programme au 24 octobre 2014 A. Eléments logiciels et programmation Python 24h Objectif : Introduction au langage Python et sensibilisation aux grandeurs informatiques
Formation Actuaire Data Scientist Programme au 24 octobre 2014 A. Eléments logiciels et programmation Python 24h Objectif : Introduction au langage Python et sensibilisation aux grandeurs informatiques
Systèmes de recommandation de produits Projet CADI Composants Avancés pour la DIstribution
 Journée DAPA du 26 mars 2009 Systèmes de recommandation de produits Projet CADI Composants Avancés pour la DIstribution Michel de Bollivier [email protected] Agenda Projet CADI La recommandation
Journée DAPA du 26 mars 2009 Systèmes de recommandation de produits Projet CADI Composants Avancés pour la DIstribution Michel de Bollivier [email protected] Agenda Projet CADI La recommandation
BIG Data et R: opportunités et perspectives
 BIG Data et R: opportunités et perspectives Guati Rizlane 1 & Hicham Hajji 2 1 Ecole Nationale de Commerce et de Gestion de Casablanca, Maroc, [email protected] 2 Ecole des Sciences Géomatiques, IAV Rabat,
BIG Data et R: opportunités et perspectives Guati Rizlane 1 & Hicham Hajji 2 1 Ecole Nationale de Commerce et de Gestion de Casablanca, Maroc, [email protected] 2 Ecole des Sciences Géomatiques, IAV Rabat,
Analyse en Composantes Principales
 Analyse en Composantes Principales Anne B Dufour Octobre 2013 Anne B Dufour () Analyse en Composantes Principales Octobre 2013 1 / 36 Introduction Introduction Soit X un tableau contenant p variables mesurées
Analyse en Composantes Principales Anne B Dufour Octobre 2013 Anne B Dufour () Analyse en Composantes Principales Octobre 2013 1 / 36 Introduction Introduction Soit X un tableau contenant p variables mesurées
Apprentissage statistique dans les graphes et les réseaux sociaux
 Apprentissage statistique dans les graphes et les réseaux sociaux Patrick Gallinari Collaboration : L. Denoyer, S. Peters Université Pierre et Marie Curie AAFD 2010 1 Plan Motivations et Problématique
Apprentissage statistique dans les graphes et les réseaux sociaux Patrick Gallinari Collaboration : L. Denoyer, S. Peters Université Pierre et Marie Curie AAFD 2010 1 Plan Motivations et Problématique
Apprentissage automatique et méga données
 Apprentissage automatique et méga données Stéphane Canu asi.insa-rouen.fr/enseignants/~scanu Séminiare ICube 2015, Strasbourg June 11, 2015 Plan 1 Introduction Une brève définition de l apprentissage statistique
Apprentissage automatique et méga données Stéphane Canu asi.insa-rouen.fr/enseignants/~scanu Séminiare ICube 2015, Strasbourg June 11, 2015 Plan 1 Introduction Une brève définition de l apprentissage statistique
Sujet proposé par Yves M. LEROY. Cet examen se compose d un exercice et de deux problèmes. Ces trois parties sont indépendantes.
 Promotion X 004 COURS D ANALYSE DES STRUCTURES MÉCANIQUES PAR LA MÉTHODE DES ELEMENTS FINIS (MEC 568) contrôle non classant (7 mars 007, heures) Documents autorisés : polycopié ; documents et notes de
Promotion X 004 COURS D ANALYSE DES STRUCTURES MÉCANIQUES PAR LA MÉTHODE DES ELEMENTS FINIS (MEC 568) contrôle non classant (7 mars 007, heures) Documents autorisés : polycopié ; documents et notes de
La classification automatique de données quantitatives
 La classification automatique de données quantitatives 1 Introduction Parmi les méthodes de statistique exploratoire multidimensionnelle, dont l objectif est d extraire d une masse de données des informations
La classification automatique de données quantitatives 1 Introduction Parmi les méthodes de statistique exploratoire multidimensionnelle, dont l objectif est d extraire d une masse de données des informations
Vérification audiovisuelle de l identité
 Vérification audiovisuelle de l identité Rémi Landais, Hervé Bredin, Leila Zouari, et Gérard Chollet École Nationale Supérieure des Télécommunications, Département Traitement du Signal et des Images, Laboratoire
Vérification audiovisuelle de l identité Rémi Landais, Hervé Bredin, Leila Zouari, et Gérard Chollet École Nationale Supérieure des Télécommunications, Département Traitement du Signal et des Images, Laboratoire
Introduction au Data-Mining
 Introduction au Data-Mining Alain Rakotomamonjy - Gilles Gasso. INSA Rouen -Département ASI Laboratoire PSI Introduction au Data-Mining p. 1/25 Data-Mining : Kèkecé? Traduction : Fouille de données. Terme
Introduction au Data-Mining Alain Rakotomamonjy - Gilles Gasso. INSA Rouen -Département ASI Laboratoire PSI Introduction au Data-Mining p. 1/25 Data-Mining : Kèkecé? Traduction : Fouille de données. Terme
Anticiper et prédire les sinistres avec une approche Big Data
 Anticiper et prédire les sinistres avec une approche Big Data Julien Cabot Directeur Big Data Analytics OCTO [email protected] @julien_cabot OCTO 2013 50, avenue des Champs-Elysées 75008 Paris - FRANCE Tél
Anticiper et prédire les sinistres avec une approche Big Data Julien Cabot Directeur Big Data Analytics OCTO [email protected] @julien_cabot OCTO 2013 50, avenue des Champs-Elysées 75008 Paris - FRANCE Tél
Annexe 6. Notions d ordonnancement.
 Annexe 6. Notions d ordonnancement. APP3 Optimisation Combinatoire: problèmes sur-contraints et ordonnancement. Mines-Nantes, option GIPAD, 2011-2012. [email protected] Résumé Ce document
Annexe 6. Notions d ordonnancement. APP3 Optimisation Combinatoire: problèmes sur-contraints et ordonnancement. Mines-Nantes, option GIPAD, 2011-2012. [email protected] Résumé Ce document
Algorithmes de recommandation, Cours Master 2, février 2011
 , Cours Master 2, février 2011 Michel Habib [email protected] http://www.liafa.jussieu.fr/~habib février 2011 Plan 1. Recommander un nouvel ami (ex : Facebook) 2. Recommander une nouvelle relation
, Cours Master 2, février 2011 Michel Habib [email protected] http://www.liafa.jussieu.fr/~habib février 2011 Plan 1. Recommander un nouvel ami (ex : Facebook) 2. Recommander une nouvelle relation
Les datas = le fuel du 21ième sicècle
 Les datas = le fuel du 21ième sicècle D énormes gisements de création de valeurs http://www.your networkmarketin g.com/facebooktwitter-youtubestats-in-realtime-simulation/ Xavier Dalloz Le Plan Définition
Les datas = le fuel du 21ième sicècle D énormes gisements de création de valeurs http://www.your networkmarketin g.com/facebooktwitter-youtubestats-in-realtime-simulation/ Xavier Dalloz Le Plan Définition
Classification Automatique de messages : une approche hybride
 RECIAL 2002, Nancy, 24-27 juin 2002 Classification Automatique de messages : une approche hybride O. Nouali (1) Laboratoire des Logiciels de base, CE.R.I.S., Rue des 3 frères Aïssiou, Ben Aknoun, Alger,
RECIAL 2002, Nancy, 24-27 juin 2002 Classification Automatique de messages : une approche hybride O. Nouali (1) Laboratoire des Logiciels de base, CE.R.I.S., Rue des 3 frères Aïssiou, Ben Aknoun, Alger,
La Licence Mathématiques et Economie-MASS Université de Sciences Sociales de Toulouse 1
 La Licence Mathématiques et Economie-MASS Université de Sciences Sociales de Toulouse 1 La licence Mathématiques et Economie-MASS de l Université des Sciences Sociales de Toulouse propose sur les trois
La Licence Mathématiques et Economie-MASS Université de Sciences Sociales de Toulouse 1 La licence Mathématiques et Economie-MASS de l Université des Sciences Sociales de Toulouse propose sur les trois
Renforcement des trois compétences : compréhension orale, expression orale et expression écrite à partir de documents et vidéos.
 Master Mathématiques et Applications Spécialité : Ingénierie mathématique et modélisation Parcours : Mathématique et Informatique : Statistique, Signal, Santé (MI3S) 2015-2016 RÉSUMÉ DES COURS : (dernière
Master Mathématiques et Applications Spécialité : Ingénierie mathématique et modélisation Parcours : Mathématique et Informatique : Statistique, Signal, Santé (MI3S) 2015-2016 RÉSUMÉ DES COURS : (dernière
Calcul de développements de Puiseux et application au calcul du groupe de monodromie d'une courbe algébrique plane
 Calcul de développements de Puiseux et application au calcul du groupe de monodromie d'une courbe algébrique plane Poteaux Adrien XLIM-DMI, UMR-CNRS 6172 Université de Limoges Soutenance de thèse 15 octobre
Calcul de développements de Puiseux et application au calcul du groupe de monodromie d'une courbe algébrique plane Poteaux Adrien XLIM-DMI, UMR-CNRS 6172 Université de Limoges Soutenance de thèse 15 octobre
Comment rendre un site d e-commerce intelligent
 Comment rendre un site d e-commerce intelligent Alexei Kounine CEO +33 (0) 6 03 09 35 14 [email protected] Christopher Burger CTO +49 (0) 177 179 16 99 [email protected] L embarras du choix Donner envie
Comment rendre un site d e-commerce intelligent Alexei Kounine CEO +33 (0) 6 03 09 35 14 [email protected] Christopher Burger CTO +49 (0) 177 179 16 99 [email protected] L embarras du choix Donner envie
Une application de méthodes inverses en astrophysique : l'analyse de l'histoire de la formation d'étoiles dans les galaxies
 Une application de méthodes inverses en astrophysique : l'analyse de l'histoire de la formation d'étoiles dans les galaxies Ariane Lançon (Observatoire de Strasbourg) en collaboration avec: Jean-Luc Vergely,
Une application de méthodes inverses en astrophysique : l'analyse de l'histoire de la formation d'étoiles dans les galaxies Ariane Lançon (Observatoire de Strasbourg) en collaboration avec: Jean-Luc Vergely,
Le pilotage des collaborations et l interopérabilité des systèmes d information Vers une démarche intégrée
 Colloque : Systèmes Complexes d Information et Gestion des Risques pour l Aide à la Décision Le pilotage des collaborations et l interopérabilité des systèmes d information Vers une démarche intégrée BELKADI
Colloque : Systèmes Complexes d Information et Gestion des Risques pour l Aide à la Décision Le pilotage des collaborations et l interopérabilité des systèmes d information Vers une démarche intégrée BELKADI
Souad EL Bernoussi. Groupe d Analyse Numérique et Optimisation Rabat http ://www.fsr.ac.ma/ano/
 Recherche opérationnelle Les démonstrations et les exemples seront traités en cours Souad EL Bernoussi Groupe d Analyse Numérique et Optimisation Rabat http ://www.fsr.ac.ma/ano/ Table des matières 1 Programmation
Recherche opérationnelle Les démonstrations et les exemples seront traités en cours Souad EL Bernoussi Groupe d Analyse Numérique et Optimisation Rabat http ://www.fsr.ac.ma/ano/ Table des matières 1 Programmation
Echantillonnage Non uniforme
 Echantillonnage Non uniforme Marie CHABERT IRIT/INP-ENSEEIHT/ ENSEEIHT/TéSASA Patrice MICHEL et Bernard LACAZE TéSA 1 Plan Introduction Echantillonnage uniforme Echantillonnage irrégulier Comparaison Cas
Echantillonnage Non uniforme Marie CHABERT IRIT/INP-ENSEEIHT/ ENSEEIHT/TéSASA Patrice MICHEL et Bernard LACAZE TéSA 1 Plan Introduction Echantillonnage uniforme Echantillonnage irrégulier Comparaison Cas
I. Programmation I. 1 Ecrire un programme en Scilab traduisant l organigramme montré ci-après (on pourra utiliser les annexes):
:") Master Chimie Fondamentale et Appliquée : spécialité «Ingénierie Chimique» Examen «Programmation, Simulation des procédés» avril 2008a Nom : Prénom : groupe TD : I. Programmation I. 1 Ecrire un programme
Master Chimie Fondamentale et Appliquée : spécialité «Ingénierie Chimique» Examen «Programmation, Simulation des procédés» avril 2008a Nom : Prénom : groupe TD : I. Programmation I. 1 Ecrire un programme
Reconnaissance de visages 2.5D par fusion des indices de texture et de profondeur ICI 12/12/12
 Reconnaissance de visages 2.5D par fusion des indices de texture et de profondeur ICI 12/12/12 2 Discrimination Invariance Expressions faciales Age Pose Eclairage 11/12/2012 3 Personne Inconnue Identité
Reconnaissance de visages 2.5D par fusion des indices de texture et de profondeur ICI 12/12/12 2 Discrimination Invariance Expressions faciales Age Pose Eclairage 11/12/2012 3 Personne Inconnue Identité
Modélisation du comportement habituel de la personne en smarthome
 Modélisation du comportement habituel de la personne en smarthome Arnaud Paris, Selma Arbaoui, Nathalie Cislo, Adnen El-Amraoui, Nacim Ramdani Université d Orléans, INSA-CVL, Laboratoire PRISME 26 mai
Modélisation du comportement habituel de la personne en smarthome Arnaud Paris, Selma Arbaoui, Nathalie Cislo, Adnen El-Amraoui, Nacim Ramdani Université d Orléans, INSA-CVL, Laboratoire PRISME 26 mai
Arbres binaires de décision
 1 Arbres binaires de décision Résumé Arbres binaires de décision Méthodes de construction d arbres binaires de décision, modélisant une discrimination (classification trees) ou une régression (regression
1 Arbres binaires de décision Résumé Arbres binaires de décision Méthodes de construction d arbres binaires de décision, modélisant une discrimination (classification trees) ou une régression (regression
Coup de Projecteur sur les Réseaux de Neurones
 Coup de Projecteur sur les Réseaux de Neurones Les réseaux de neurones peuvent être utilisés pour des problèmes de prévision ou de classification. La représentation la plus populaire est le réseau multicouche
Coup de Projecteur sur les Réseaux de Neurones Les réseaux de neurones peuvent être utilisés pour des problèmes de prévision ou de classification. La représentation la plus populaire est le réseau multicouche
Résolution d équations non linéaires
 Analyse Numérique Résolution d équations non linéaires Said EL HAJJI et Touria GHEMIRES Université Mohammed V - Agdal. Faculté des Sciences Département de Mathématiques. Laboratoire de Mathématiques, Informatique
Analyse Numérique Résolution d équations non linéaires Said EL HAJJI et Touria GHEMIRES Université Mohammed V - Agdal. Faculté des Sciences Département de Mathématiques. Laboratoire de Mathématiques, Informatique
Le théorème de Perron-Frobenius, les chaines de Markov et un célèbre moteur de recherche
 Le théorème de Perron-Frobenius, les chaines de Markov et un célèbre moteur de recherche Bachir Bekka Février 2007 Le théorème de Perron-Frobenius a d importantes applications en probabilités (chaines
Le théorème de Perron-Frobenius, les chaines de Markov et un célèbre moteur de recherche Bachir Bekka Février 2007 Le théorème de Perron-Frobenius a d importantes applications en probabilités (chaines
Introduction au datamining
 Introduction au datamining Patrick Naïm janvier 2005 Définition Définition Historique Mot utilisé au départ par les statisticiens Le mot indiquait une utilisation intensive des données conduisant à des
Introduction au datamining Patrick Naïm janvier 2005 Définition Définition Historique Mot utilisé au départ par les statisticiens Le mot indiquait une utilisation intensive des données conduisant à des
Chapitre 6 Apprentissage des réseaux de neurones et régularisation
 Chapitre 6 : Apprentissage des réseaux de neurones et régularisation 77 Chapitre 6 Apprentissage des réseaux de neurones et régularisation Après une introduction rapide aux réseaux de neurones et à la
Chapitre 6 : Apprentissage des réseaux de neurones et régularisation 77 Chapitre 6 Apprentissage des réseaux de neurones et régularisation Après une introduction rapide aux réseaux de neurones et à la
20 ans du Master SIAD de Toulouse - BigData par l exemple - Julien DULOUT - 22 mars 2013. 20 ans du SIAD -"Big Data par l'exemple" -Julien DULOUT
 20 ans du Master SIAD de Toulouse - BigData par l exemple - Julien DULOUT - 22 mars 2013 20 ans du SIAD -"BigData par l'exemple" -Julien DULOUT Qui a déjà entendu parler du phénomène BigData? Qui a déjà
20 ans du Master SIAD de Toulouse - BigData par l exemple - Julien DULOUT - 22 mars 2013 20 ans du SIAD -"BigData par l'exemple" -Julien DULOUT Qui a déjà entendu parler du phénomène BigData? Qui a déjà
Application de K-means à la définition du nombre de VM optimal dans un cloud
 Application de K-means à la définition du nombre de VM optimal dans un cloud EGC 2012 : Atelier Fouille de données complexes : complexité liée aux données multiples et massives (31 janvier - 3 février
Application de K-means à la définition du nombre de VM optimal dans un cloud EGC 2012 : Atelier Fouille de données complexes : complexité liée aux données multiples et massives (31 janvier - 3 février
Exercice : la frontière des portefeuilles optimaux sans actif certain
 Exercice : la frontière des portefeuilles optimaux sans actif certain Philippe Bernard Ingénierie Economique & Financière Université Paris-Dauphine Février 0 On considère un univers de titres constitué
Exercice : la frontière des portefeuilles optimaux sans actif certain Philippe Bernard Ingénierie Economique & Financière Université Paris-Dauphine Février 0 On considère un univers de titres constitué
Historique. Architecture. Contribution. Conclusion. Définitions et buts La veille stratégique Le multidimensionnel Les classifications
 L intelligence économique outil stratégique pour l entreprise Professeur Bernard DOUSSET [email protected] http://atlas.irit.fr Institut de Recherche en Informatique de Toulouse (IRIT) Equipe Systèmes d
L intelligence économique outil stratégique pour l entreprise Professeur Bernard DOUSSET [email protected] http://atlas.irit.fr Institut de Recherche en Informatique de Toulouse (IRIT) Equipe Systèmes d
Extraction d informations stratégiques par Analyse en Composantes Principales
 Extraction d informations stratégiques par Analyse en Composantes Principales Bernard DOUSSET IRIT/ SIG, Université Paul Sabatier, 118 route de Narbonne, 31062 Toulouse cedex 04 [email protected] 1 Introduction
Extraction d informations stratégiques par Analyse en Composantes Principales Bernard DOUSSET IRIT/ SIG, Université Paul Sabatier, 118 route de Narbonne, 31062 Toulouse cedex 04 [email protected] 1 Introduction
Agenda de la présentation
 Le Data Mining Techniques pour exploiter l information Dan Noël 1 Agenda de la présentation Concept de Data Mining ou qu est-ce que le Data Mining Déroulement d un projet de Data Mining Place du Data Mining
Le Data Mining Techniques pour exploiter l information Dan Noël 1 Agenda de la présentation Concept de Data Mining ou qu est-ce que le Data Mining Déroulement d un projet de Data Mining Place du Data Mining
Info0804. Cours 6. Optimisation combinatoire : Applications et compléments
 Recherche Opérationnelle Optimisation combinatoire : Applications et compléments Pierre Delisle Université de Reims Champagne-Ardenne Département de Mathématiques et Informatique 17 février 2014 Plan de
Recherche Opérationnelle Optimisation combinatoire : Applications et compléments Pierre Delisle Université de Reims Champagne-Ardenne Département de Mathématiques et Informatique 17 février 2014 Plan de
1 Complément sur la projection du nuage des individus
 TP 0 : Analyse en composantes principales (II) Le but de ce TP est d approfondir nos connaissances concernant l analyse en composantes principales (ACP). Pour cela, on reprend les notations du précédent
TP 0 : Analyse en composantes principales (II) Le but de ce TP est d approfondir nos connaissances concernant l analyse en composantes principales (ACP). Pour cela, on reprend les notations du précédent
MapReduce. Nicolas Dugué [email protected]. M2 MIAGE Systèmes d information répartis
 MapReduce Nicolas Dugué [email protected] M2 MIAGE Systèmes d information répartis Plan 1 Introduction Big Data 2 MapReduce et ses implémentations 3 MapReduce pour fouiller des tweets 4 MapReduce
MapReduce Nicolas Dugué [email protected] M2 MIAGE Systèmes d information répartis Plan 1 Introduction Big Data 2 MapReduce et ses implémentations 3 MapReduce pour fouiller des tweets 4 MapReduce
Chapitre 5 : Flot maximal dans un graphe
 Graphes et RO TELECOM Nancy A Chapitre 5 : Flot maximal dans un graphe J.-F. Scheid 1 Plan du chapitre I. Définitions 1 Graphe Graphe valué 3 Représentation d un graphe (matrice d incidence, matrice d
Graphes et RO TELECOM Nancy A Chapitre 5 : Flot maximal dans un graphe J.-F. Scheid 1 Plan du chapitre I. Définitions 1 Graphe Graphe valué 3 Représentation d un graphe (matrice d incidence, matrice d
Intelligence Artificielle et Systèmes Multi-Agents. Badr Benmammar [email protected]
 Intelligence Artificielle et Systèmes Multi-Agents Badr Benmammar [email protected] Plan La première partie : L intelligence artificielle (IA) Définition de l intelligence artificielle (IA) Domaines
Intelligence Artificielle et Systèmes Multi-Agents Badr Benmammar [email protected] Plan La première partie : L intelligence artificielle (IA) Définition de l intelligence artificielle (IA) Domaines
Big Data et Graphes : Quelques pistes de recherche
 Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci http://liris.cnrs.fr/hamamache.kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de
Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci http://liris.cnrs.fr/hamamache.kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de
4 Exemples de problèmes MapReduce incrémentaux
 4 Exemples de problèmes MapReduce incrémentaux 1 / 32 Calcul des plus courtes distances à un noeud d un graphe Calcul des plus courts chemins entre toutes les paires de noeuds d un graphe Algorithme PageRank
4 Exemples de problèmes MapReduce incrémentaux 1 / 32 Calcul des plus courtes distances à un noeud d un graphe Calcul des plus courts chemins entre toutes les paires de noeuds d un graphe Algorithme PageRank
Data Mining. Vincent Augusto 2012-2013. École Nationale Supérieure des Mines de Saint-Étienne. Data Mining. V. Augusto.
 des des Data Mining Vincent Augusto École Nationale Supérieure des Mines de Saint-Étienne 2012-2013 1/65 des des 1 2 des des 3 4 Post-traitement 5 représentation : 6 2/65 des des Définition générale Le
des des Data Mining Vincent Augusto École Nationale Supérieure des Mines de Saint-Étienne 2012-2013 1/65 des des 1 2 des des 3 4 Post-traitement 5 représentation : 6 2/65 des des Définition générale Le
Mesure agnostique de la qualité des images.
 Mesure agnostique de la qualité des images. Application en biométrie Christophe Charrier Université de Caen Basse-Normandie GREYC, UMR CNRS 6072 Caen, France 8 avril, 2013 C. Charrier NR-IQA 1 / 34 Sommaire
Mesure agnostique de la qualité des images. Application en biométrie Christophe Charrier Université de Caen Basse-Normandie GREYC, UMR CNRS 6072 Caen, France 8 avril, 2013 C. Charrier NR-IQA 1 / 34 Sommaire
Le Futur de la Visualisation d Information. Jean-Daniel Fekete Projet in situ INRIA Futurs
 Le Futur de la Visualisation d Information Jean-Daniel Fekete Projet in situ INRIA Futurs La visualisation d information 1.Présentation 2.Bilan 3.Perspectives Visualisation : 3 domaines Visualisation scientifique
Le Futur de la Visualisation d Information Jean-Daniel Fekete Projet in situ INRIA Futurs La visualisation d information 1.Présentation 2.Bilan 3.Perspectives Visualisation : 3 domaines Visualisation scientifique
Introduction. I Étude rapide du réseau - Apprentissage. II Application à la reconnaissance des notes.
 Introduction L'objectif de mon TIPE est la reconnaissance de sons ou de notes de musique à l'aide d'un réseau de neurones. Ce réseau doit être capable d'apprendre à distinguer les exemples présentés puis
Introduction L'objectif de mon TIPE est la reconnaissance de sons ou de notes de musique à l'aide d'un réseau de neurones. Ce réseau doit être capable d'apprendre à distinguer les exemples présentés puis
Calculer avec Sage. Revision : 417 du 1 er juillet 2010
 Calculer avec Sage Alexandre Casamayou Guillaume Connan Thierry Dumont Laurent Fousse François Maltey Matthias Meulien Marc Mezzarobba Clément Pernet Nicolas Thiéry Paul Zimmermann Revision : 417 du 1
Calculer avec Sage Alexandre Casamayou Guillaume Connan Thierry Dumont Laurent Fousse François Maltey Matthias Meulien Marc Mezzarobba Clément Pernet Nicolas Thiéry Paul Zimmermann Revision : 417 du 1
Grandes lignes ASTRÉE. Logiciels critiques. Outils de certification classiques. Inspection manuelle. Definition. Test
 Grandes lignes Analyseur Statique de logiciels Temps RÉel Embarqués École Polytechnique École Normale Supérieure Mercredi 18 juillet 2005 1 Présentation d 2 Cadre théorique de l interprétation abstraite
Grandes lignes Analyseur Statique de logiciels Temps RÉel Embarqués École Polytechnique École Normale Supérieure Mercredi 18 juillet 2005 1 Présentation d 2 Cadre théorique de l interprétation abstraite
Analytics & Big Data. Focus techniques & nouvelles perspectives pour les actuaires. Université d Eté de l Institut des Actuaires Mardi 8 juillet 2014
 Analytics & Big Data Focus techniques & nouvelles perspectives pour les actuaires Local Optimization European Minded Université d Eté de l Institut des Actuaires Mardi 8 juillet 2014 Intervenants : Alexandre
Analytics & Big Data Focus techniques & nouvelles perspectives pour les actuaires Local Optimization European Minded Université d Eté de l Institut des Actuaires Mardi 8 juillet 2014 Intervenants : Alexandre
PREPROCESSING PAR LISSAGE LOESS POUR ACP LISSEE
 PREPROCESSING PAR LISSAGE LOESS POUR ACP LISSEE Jean-Paul Valois, Claude Mouret & Nicolas Pariset Total, 64018 Pau Cédex MOTS CLEFS : Analyse spatiale, ACP, Lissage, Loess PROBLEMATIQUE En analyse multivariée,
PREPROCESSING PAR LISSAGE LOESS POUR ACP LISSEE Jean-Paul Valois, Claude Mouret & Nicolas Pariset Total, 64018 Pau Cédex MOTS CLEFS : Analyse spatiale, ACP, Lissage, Loess PROBLEMATIQUE En analyse multivariée,
1 Introduction et modèle mathématique
 Optimisation parallèle et mathématiques financières Optimisation parallèle et mathématiques financières Pierre Spiteri 1 IRIT ENSEEIHT, UMR CNRS 5505 2 rue Charles Camichel, B.P. 7122 F-31 071 Toulouse,
Optimisation parallèle et mathématiques financières Optimisation parallèle et mathématiques financières Pierre Spiteri 1 IRIT ENSEEIHT, UMR CNRS 5505 2 rue Charles Camichel, B.P. 7122 F-31 071 Toulouse,
Analyse des correspondances avec colonne de référence
 ADE-4 Analyse des correspondances avec colonne de référence Résumé Quand une table de contingence contient une colonne de poids très élevé, cette colonne peut servir de point de référence. La distribution
ADE-4 Analyse des correspondances avec colonne de référence Résumé Quand une table de contingence contient une colonne de poids très élevé, cette colonne peut servir de point de référence. La distribution
Calcul différentiel. Chapitre 1. 1.1 Différentiabilité
 Chapitre 1 Calcul différentiel L idée du calcul différentiel est d approcher au voisinage d un point une fonction f par une fonction plus simple (ou d approcher localement le graphe de f par un espace
Chapitre 1 Calcul différentiel L idée du calcul différentiel est d approcher au voisinage d un point une fonction f par une fonction plus simple (ou d approcher localement le graphe de f par un espace
Contrôle stochastique d allocation de ressources dans le «cloud computing»
 Contrôle stochastique d allocation de ressources dans le «cloud computing» Jacques Malenfant 1 Olga Melekhova 1, Xavier Dutreilh 1,3, Sergey Kirghizov 1, Isis Truck 2, Nicolas Rivierre 3 Travaux partiellement
Contrôle stochastique d allocation de ressources dans le «cloud computing» Jacques Malenfant 1 Olga Melekhova 1, Xavier Dutreilh 1,3, Sergey Kirghizov 1, Isis Truck 2, Nicolas Rivierre 3 Travaux partiellement
Sujet 4: Programmation stochastique propriétés de fonction de recours
 Sujet 4: Programmation stochastique propriétés de fonction de recours MSE3313: Optimisation Stochastiqe Andrew J. Miller Dernière mise au jour: October 19, 2011 Dans ce sujet... 1 Propriétés de la fonction
Sujet 4: Programmation stochastique propriétés de fonction de recours MSE3313: Optimisation Stochastiqe Andrew J. Miller Dernière mise au jour: October 19, 2011 Dans ce sujet... 1 Propriétés de la fonction
3 Approximation de solutions d équations
 3 Approximation de solutions d équations Une équation scalaire a la forme générale f(x) =0où f est une fonction de IR dans IR. Un système de n équations à n inconnues peut aussi se mettre sous une telle
3 Approximation de solutions d équations Une équation scalaire a la forme générale f(x) =0où f est une fonction de IR dans IR. Un système de n équations à n inconnues peut aussi se mettre sous une telle
Bases de données documentaires et distribuées Cours NFE04
 Bases de données documentaires et distribuées Cours NFE04 Introduction a la recherche d information Auteurs : Raphaël Fournier-S niehotta, Philippe Rigaux, Nicolas Travers pré[email protected] Département
Bases de données documentaires et distribuées Cours NFE04 Introduction a la recherche d information Auteurs : Raphaël Fournier-S niehotta, Philippe Rigaux, Nicolas Travers pré[email protected] Département
L écosystème Hadoop Nicolas Thiébaud [email protected]. Tuesday, July 2, 13
 L écosystème Hadoop Nicolas Thiébaud [email protected] HUG France 250 membres sur la mailing liste 30 présentations 9 meetups organisés, de 20 à 100 invités Présence de Cloudera, MapR, Hortonworks,
L écosystème Hadoop Nicolas Thiébaud [email protected] HUG France 250 membres sur la mailing liste 30 présentations 9 meetups organisés, de 20 à 100 invités Présence de Cloudera, MapR, Hortonworks,
AICp. Vincent Vandewalle. To cite this version: HAL Id: inria-00386678 https://hal.inria.fr/inria-00386678
 Sélection prédictive d un modèle génératif par le critère AICp Vincent Vandewalle To cite this version: Vincent Vandewalle. Sélection prédictive d un modèle génératif par le critère AICp. 41èmes Journées
Sélection prédictive d un modèle génératif par le critère AICp Vincent Vandewalle To cite this version: Vincent Vandewalle. Sélection prédictive d un modèle génératif par le critère AICp. 41èmes Journées
Introduction aux systèmes temps réel. Iulian Ober IRIT [email protected]
 Introduction aux systèmes temps réel Iulian Ober IRIT [email protected] Définition Systèmes dont la correction ne dépend pas seulement des valeurs des résultats produits mais également des délais dans
Introduction aux systèmes temps réel Iulian Ober IRIT [email protected] Définition Systèmes dont la correction ne dépend pas seulement des valeurs des résultats produits mais également des délais dans
Enjeux mathématiques et Statistiques du Big Data
 Enjeux mathématiques et Statistiques du Big Data Mathilde Mougeot LPMA/Université Paris Diderot, [email protected] Mathématique en Mouvements, Paris, IHP, 6 Juin 2015 M. Mougeot (Paris
Enjeux mathématiques et Statistiques du Big Data Mathilde Mougeot LPMA/Université Paris Diderot, [email protected] Mathématique en Mouvements, Paris, IHP, 6 Juin 2015 M. Mougeot (Paris
ÉTUDE ET DÉVELOPPEMENT D UN SYSTÈME EXPERT BASÉ SUR LES RÉSEAUX DE NEURONES POUR LE DIAGNOSTIC DES DÉFAUTS DE ROULEMENTS
 ÉTUDE ET DÉVELOPPEMENT D UN SYSTÈME EXPERT BASÉ SUR LES RÉSEAUX DE NEURONES POUR LE DIAGNOSTIC DES DÉFAUTS DE ROULEMENTS B. Badri 1 ; M. Thomas 1 ; S. Sassi 2 (1) Department of Mechanical Engineering,
ÉTUDE ET DÉVELOPPEMENT D UN SYSTÈME EXPERT BASÉ SUR LES RÉSEAUX DE NEURONES POUR LE DIAGNOSTIC DES DÉFAUTS DE ROULEMENTS B. Badri 1 ; M. Thomas 1 ; S. Sassi 2 (1) Department of Mechanical Engineering,
Différentiabilité ; Fonctions de plusieurs variables réelles
 Différentiabilité ; Fonctions de plusieurs variables réelles Denis Vekemans R n est muni de l une des trois normes usuelles. 1,. 2 ou.. x 1 = i i n Toutes les normes de R n sont équivalentes. x i ; x 2
Différentiabilité ; Fonctions de plusieurs variables réelles Denis Vekemans R n est muni de l une des trois normes usuelles. 1,. 2 ou.. x 1 = i i n Toutes les normes de R n sont équivalentes. x i ; x 2
CHAPITRE I. Modélisation de processus et estimation des paramètres d un modèle
 CHAPITRE I Modélisation de processus et estimation des paramètres d un modèle I. INTRODUCTION. Dans la première partie de ce chapitre, nous rappelons les notions de processus et de modèle, ainsi que divers
CHAPITRE I Modélisation de processus et estimation des paramètres d un modèle I. INTRODUCTION. Dans la première partie de ce chapitre, nous rappelons les notions de processus et de modèle, ainsi que divers
Programmation linéaire
 Programmation linéaire DIDIER MAQUIN Ecole Nationale Supérieure d Electricité et de Mécanique Institut National Polytechnique de Lorraine Mathématiques discrètes cours de 2ème année Programmation linéaire
Programmation linéaire DIDIER MAQUIN Ecole Nationale Supérieure d Electricité et de Mécanique Institut National Polytechnique de Lorraine Mathématiques discrètes cours de 2ème année Programmation linéaire
Principe de symétrisation pour la construction d un test adaptatif
 Principe de symétrisation pour la construction d un test adaptatif Cécile Durot 1 & Yves Rozenholc 2 1 UFR SEGMI, Université Paris Ouest Nanterre La Défense, France, [email protected] 2 Université
Principe de symétrisation pour la construction d un test adaptatif Cécile Durot 1 & Yves Rozenholc 2 1 UFR SEGMI, Université Paris Ouest Nanterre La Défense, France, [email protected] 2 Université
Fouillez facilement dans votre système Big Data. Olivier TAVARD
 Fouillez facilement dans votre système Big Data Olivier TAVARD A propos de moi : Cofondateur de la société France Labs Développeur (principalement Java) Formateur en technologies de moteurs de recherche
Fouillez facilement dans votre système Big Data Olivier TAVARD A propos de moi : Cofondateur de la société France Labs Développeur (principalement Java) Formateur en technologies de moteurs de recherche
Contents. 1 Introduction Objectifs des systèmes bonus-malus Système bonus-malus à classes Système bonus-malus : Principes
 Université Claude Bernard Lyon 1 Institut de Science Financière et d Assurances Système Bonus-Malus Introduction & Applications SCILAB Julien Tomas Institut de Science Financière et d Assurances Laboratoire
Université Claude Bernard Lyon 1 Institut de Science Financière et d Assurances Système Bonus-Malus Introduction & Applications SCILAB Julien Tomas Institut de Science Financière et d Assurances Laboratoire
MCMC et approximations en champ moyen pour les modèles de Markov
 MCMC et approximations en champ moyen pour les modèles de Markov Gersende FORT LTCI CNRS - TELECOM ParisTech En collaboration avec Florence FORBES (Projet MISTIS, INRIA Rhône-Alpes). Basé sur l article:
MCMC et approximations en champ moyen pour les modèles de Markov Gersende FORT LTCI CNRS - TELECOM ParisTech En collaboration avec Florence FORBES (Projet MISTIS, INRIA Rhône-Alpes). Basé sur l article:
Nouvelles propositions pour la résolution exacte du sac à dos multi-objectif unidimensionnel en variables binaires
 Nouvelles propositions pour la résolution exacte du sac à dos multi-objectif unidimensionnel en variables binaires Julien Jorge [email protected] Laboratoire d Informatique de Nantes Atlantique,
Nouvelles propositions pour la résolution exacte du sac à dos multi-objectif unidimensionnel en variables binaires Julien Jorge [email protected] Laboratoire d Informatique de Nantes Atlantique,
Fonctions de plusieurs variables : dérivés partielles, diérentielle. Fonctions composées. Fonctions de classe C 1. Exemples
 45 Fonctions de plusieurs variables : dérivés partielles, diérentielle. Fonctions composées. Fonctions de classe C 1. Exemples Les espaces vectoriels considérés sont réels, non réduits au vecteur nul et
45 Fonctions de plusieurs variables : dérivés partielles, diérentielle. Fonctions composées. Fonctions de classe C 1. Exemples Les espaces vectoriels considérés sont réels, non réduits au vecteur nul et
Bases de données réparties: Fragmentation et allocation
 Pourquoi une base de données distribuée? Bibliographie Patrick Valduriez, S. Ceri, Guiseppe Delagatti Bases de données réparties: Fragmentation et allocation 1 - Introduction inventés à la fin des années
Pourquoi une base de données distribuée? Bibliographie Patrick Valduriez, S. Ceri, Guiseppe Delagatti Bases de données réparties: Fragmentation et allocation 1 - Introduction inventés à la fin des années
FaceBook aime les Maths!
 FaceBook aime les Maths! Michel Rigo http://www.discmath.ulg.ac.be/ http://orbi.ulg.ac.be/ Réseaux Visualizing my Twitter Network by number of followers. Michael Atkisson http://woknowing.wordpress.com/
FaceBook aime les Maths! Michel Rigo http://www.discmath.ulg.ac.be/ http://orbi.ulg.ac.be/ Réseaux Visualizing my Twitter Network by number of followers. Michael Atkisson http://woknowing.wordpress.com/
Détection d utilisateurs malveillants dans les réseaux sociaux
 Détection d utilisateurs malveillants dans les réseaux sociaux Luc-Aurélien Gauthier Patrick Gallinari Laboratoire d Informatique de Paris 6 Université Pierre et Marie Curie 4, place Jussieu 75005 Paris
Détection d utilisateurs malveillants dans les réseaux sociaux Luc-Aurélien Gauthier Patrick Gallinari Laboratoire d Informatique de Paris 6 Université Pierre et Marie Curie 4, place Jussieu 75005 Paris
Rapport d'analyse des besoins
 Projet ANR 2011 - BR4CP (Business Recommendation for Configurable products) Rapport d'analyse des besoins Janvier 2013 Rapport IRIT/RR--2013-17 FR Redacteur : 0. Lhomme Introduction...4 La configuration
Projet ANR 2011 - BR4CP (Business Recommendation for Configurable products) Rapport d'analyse des besoins Janvier 2013 Rapport IRIT/RR--2013-17 FR Redacteur : 0. Lhomme Introduction...4 La configuration
Master IAD Module PS. Reconnaissance de la parole (suite) Alignement temporel et Programmation dynamique. Gaël RICHARD Février 2008
 Alignement temporel et Programmation dynamique. Gaël RICHARD Février 2008") Master IAD Module PS Reconnaissance de la parole (suite) Alignement temporel et Programmation dynamique Gaël RICHARD Février 2008 1 Reconnaissance de la parole Introduction Approches pour la reconnaissance
Master IAD Module PS Reconnaissance de la parole (suite) Alignement temporel et Programmation dynamique Gaël RICHARD Février 2008 1 Reconnaissance de la parole Introduction Approches pour la reconnaissance
BIG DATA. Veille technologique. Malek Hamouda Nina Lachia Léo Valette. Commanditaire : Thomas Milon. Encadré: Philippe Vismara
 BIG DATA Veille technologique Malek Hamouda Nina Lachia Léo Valette Commanditaire : Thomas Milon Encadré: Philippe Vismara 1 2 Introduction Historique des bases de données : méthodes de stockage et d analyse
BIG DATA Veille technologique Malek Hamouda Nina Lachia Léo Valette Commanditaire : Thomas Milon Encadré: Philippe Vismara 1 2 Introduction Historique des bases de données : méthodes de stockage et d analyse
TRAVAUX DE RECHERCHE DANS LE
 TRAVAUX DE RECHERCHE DANS LE DOMAINE DE L'EXPLOITATION DES DONNÉES ET DES DOCUMENTS 1 Journée technologique " Solutions de maintenance prévisionnelle adaptées à la production Josiane Mothe, FREMIT, IRIT
TRAVAUX DE RECHERCHE DANS LE DOMAINE DE L'EXPLOITATION DES DONNÉES ET DES DOCUMENTS 1 Journée technologique " Solutions de maintenance prévisionnelle adaptées à la production Josiane Mothe, FREMIT, IRIT
L apprentissage automatique
 L apprentissage automatique L apprentissage automatique L'apprentissage automatique fait référence au développement, à l analyse et à l implémentation de méthodes qui permettent à une machine d évoluer
L apprentissage automatique L apprentissage automatique L'apprentissage automatique fait référence au développement, à l analyse et à l implémentation de méthodes qui permettent à une machine d évoluer