Calcul scientifique haute performance sur GPUs.
|
|
|
- Raphaël Papineau
- il y a 10 ans
- Total affichages :
Transcription
1 Calcul scientifique haute performance sur GPUs. David Michéa(1), Dimitri Komatitsch(2,3), Gordon Erlebacher(4) and Dominik Göddeke(5) Portage de SPECFEM3D (SEM) sous CUDA + MPI Portage CUDA du code différences finies ONDES3D (1) BRGM, Orléans, France (2) University of Pau, CNRS and INRIA Magique3D, Pau, France (3) Institut universitaire de France, Paris, France (4) Florida State University, USA (5) TU Dortmund, Germany
 University of Pau, CNRS and INRIA Magique3D, Pau, France (3) Institut universitaire de France, Paris,")
2 SPECFEM3D Dimitri Komatitsch Jeroen Tromp David Michéa Min Chen Vala Hjörleifsdóttir Sue Kientz Qinya Liu Alessia Maggi Brian Savage Bernhard Schuberth Leif Strand Carl Tape Jesus Labarta But : modéliser la propagation d ondes sismiques dans la terre entière ou dans des régions densément peuplées à la suite de grands tremblements de terre SPECFEM3D est open source (GNU GPL v2) Le code Fortran original sans CUDA a été principalement développé par Dimitri Komatitsch and Jeroen Tromp à l université de Harvard, Caltech et Princeton (USA) et à l université de Pau (France) depuis 1996 Il a été optimisé avec le Barcelona Supercomputing Center, Espagne (Jesus Labarta et al.) et David Michéa de l INRIA (HPC-Europa program, 2007)
 depuis 1996 Il a été optimisé avec le Barcelona Supercomputing Center, Espagne (Jesus Labarta et al.")
3 Spectral-Element Method Developed in Computational Fluid Dynamics (Patera 1984) Introduced for 3D elastodynamics by Komatitsch et al., Chaljub et al. Large curved spectral finite-elements with high-degree polynomial interpolation: accuracy of a pseudospectral method, flexibility of a finiteelement method Mesh honors the main discontinuities (velocity, density) and topography Very efficient on parallel computers, no linear system to invert (diagonal mass matrix) Curved 27-node elements are mapped to unit cube provides efficient way of capturing curvature of sphere, and accuracy for surface waves High-degree pseudospectral finite elements: Number of integration Gauss Lobatto Legendre (NGLL) points = 5 to 9 usually

4 Maillage : une sphère cubique Gnomonic mapping (Sadourny 1972) Ronchi et al. (1996), Chaljub (2000) Analytical mapping from six faces of cube to unit sphere

5 Structure du code A chaque itération de la boucle en temps, trois principaux types d opérations sont effectuées : Mise à jour (sans dépendances) de tableaux globaux composés de points uniques du maillage Calculs purements locaux du produit de matrices de dérivations prédéfinies avec une copie locale des vecteurs déplacements le long de plans de coupes dans les 3 directions (i, j & k) d un élément spectral 3D Mise à jour (sans dépendances) d autres tableaux globaux composés de points uniques du maillage
 d un élément spectral 3D Mise à jour (sans dépendances) d autres tableaux globaux composés de points uniques du")
6 Numérotation locale vs numérotation globale En 3D et pour NGLL=5, pour un maillage hexahédrique régulier, il y a : 125 points d intégration dans chaque élément 27 appartiennent uniquement à cet élément 98 appartiennent à plusieurs éléments Problème : on doit sommer les contributions locales dans les tableaux globaux

7 Coloriage du maillage Problème : s assurer que les contributions de deux noeuds locaux n impactent jamais le même point global à partir de différentes warps. Utilisation du coloriage : supprimer les dépendances entre les points du maillage dans un même kernel

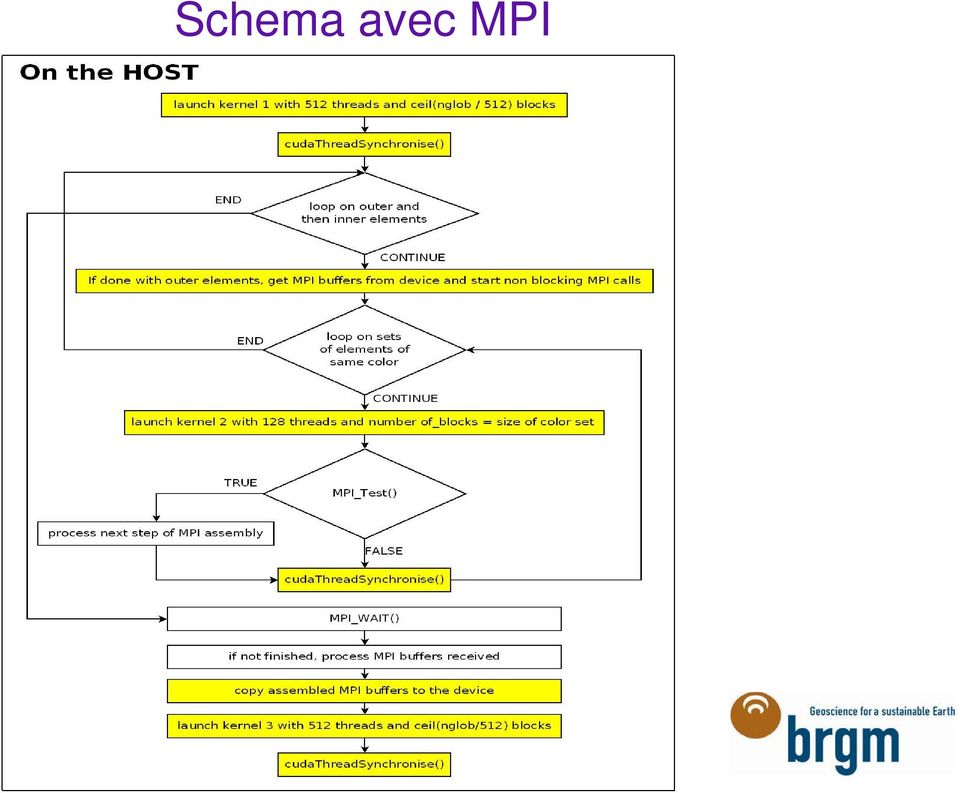
8 Parallélisation avec MPI Ancien schéma de communication (MPI bloquant) Mise à jour effectuées directement dans les tableaux Tous les éléments sont calculés avant l envoi des messages Nouveau schéma de communication (MPI non bloquant) Mise à jour effectuées d abord dans les buffers Les messages sont envoyés après le calcul des éléments externes A B A B C D C D Coût des communications pour la version CPU ~ 5%, Sur la version TESLA GPU, avec un speed-up de 15, le coût des communications ~44% > Nécessité d utiliser des communications MPI asynchrones. > Les communications MPI sont bien recouvertes par le calcul sur GPU.

9 Schema des 2 versions sans MPI (v2 : out of GPU core)
")
10 Schema avec MPI
11 Coalescence des accès en mémoire globale Dans les kernels 1 & 3, Tous les accès sont parfaitement coalescés Dans le kernel 2, Tous les accès aux tableaux locaux sont parfaitement coalescés (125 pts alignés sur 128 floats) Par contre, Lors de l accès aux tableaux globaux dans le kernel 2, l indirection nécessaire pour gérer la topologie non structurée du maillage (ie local global) entraîne des accès non-coalescés inévitables.
 entraîne des accès")
12 Optimisation du code CPU : défauts de cache V4.0 => Il est crucial de réutiliser les points communs en les gardant dans le cache V4.0 V3.6

13 Résultats - Accélération Mesh size GTX GTX Version 1 Version 1 Version 2 Time / element Speedup Time / element Speedup Time / element Speedup Transfer time 65 MB 0.94 µs µs µs % 405 MB 0.79 µs µs µs % 633 MB 0.77 µs µs µs % Le speedup final pour le code CUDA + MPI est de 25x Les performances se dégradent pour les trop petits modèles, le nb d éléments dans chaque couleur doit être > 1024

14 Validation

15 Portage sous CUDA du code différences finies ONDES3D ONDES3D est un programme qui simule la propagation d ondes sismiques dans un milieu élastique hétérogène. Il utilise la méthode des différences finies du 4eme ordre. Il a été écrit par Hideo Aoschi & Arianne Ducellier du BRGM. Il implémente les couches absorbantes C-PML de D.Komatitsch and R.Martin (Geophysics, 2007)

16 Structure du code <initializations/> <time loop> <update source momentum/> CPU <memcpy H->D (few data)/> <compute velocity vector from stress tensor/> <compute stress tensor from velocity vector/> <memcpy D->H (few data)/> <record seismograms/> CPU </time loop> GPU GPU Toutes les structures de données sont hébergées sur le GPU, à l exception des sismogrammes.

17 Stencil différences finies du 4eme ordre Méthode des différences finies : un méthode simple mais une implémentation délicate sur GPU > Le stencil de calcul conduit à une forte redondance de lecture > Nécessité d utiliser massivement la mémoire partagée

18 Topologie du bloc de points (1 thread par point) > Pour un bloc de points à calculer, besoin de connaître les valeurs d un «halo» de points autour > Il faut réduire le ratio halo_points / block_points pour réduire la redondance de lecture > Approche intuitive : des blocs 3D qui minimisent ce ratio > Problème : pas assez de mémoire partagée pour avoir des blocs 3D assez gros pour avoir un bon ratio.

19 Algorithme à fenêtre coulissante Utilisation de l approche de P. Micikevicius de NVIDIA (2009) : un algorithme à fenêtre coulissante > Utiliser un pavage 2D au lieu des blocs 3D et boucler sur l axe Z. > En 2D, il y a assez de mémoire partagée pour avoir des pavés suffisamment gros pour obtenir un bon ratio entre les points calculés et les points du halo. > Les données suivant l axe Z sont décalées en registres à chaque itération suivant un mécanisme de pipeline => à part pour les halos, les données d un point ne sont chargés qu une fois depuis la mémoire globale à chaque itération (en temps).

20 bloc 2D On utilise un thread par point dans le plan xy et on le pave avec des blocs de 16x8 threads. Pour un bloc : 4*16+4*8+16*8 données chargées par 16*8 threads => 1.75 accès en mémoire globale / thread pour chaque itération

21 Schema de fonctionnement des kernels
22 coalescence des accès mémoire (globale) Pour notre carte NVIDIA 8800 GTX, D après le CUDA Programming Guide, l accès en mémoire globale par tous les threads d une half-warp est coalescé en une transaction mémoire s il satisfait ces 3 conditions : Les threads doivent accéder des mots de 32 bits, résultant en une transaction mémoire de 64 octets. Ces 16 mots doivent se trouver dans le même segment de taille égale à la taille de la transaction mémoire Les threads doivent accéder ces mots séquentiellement. => Le profiler CUDA nous donne gst_uncoalesced = 0. Les lectures ne sont pas coalescées pour les halos, ni pour les C-PMLs qui sont accédées via une indirection pour ne pas gâcher de mémoire.
23 Speedup Speedup : de 40x à 50x Le speedup dépend de : > l épaisseur des C-PMLs: si l épaisseur des C-PML n est pas multiple de 16 (blockdim.x), les threads d une half-warp divergent dans les C-PMLs. > Dimensions du modèle Si la largeur du modèle n est pas multiple de 16 (blockdim.x), certains threads sont inactifs et les threads d une half-warp divergent pour les C-PMLs situées à droite.
24 Scaling Le scaling suivant Z est quasi linéaire. Malgré les accès coalescés, le scaling suivant X (en terme de nb de blocs) n est pas régulier. Ceci est probablement dû à des exigences hardware non documentées.
25 Validation
26 Conclusions & perspectives > Portage réussi de codes FD & SEM sur grappe de GPUs > Les résultats sont satisfaisant en terme d accélération > Les principales limitations ont été les ressources internes de la carte (registres + shmem), particulièrement si nous voulons ajouter d autres paramètres comme de l atténuation (l occupancy pour ONDES3D est de 0.166, principale limite : le nombre limité de registres) > Nous avons réalisé un premier prototype de couplage calcul-visualisation interactif qui nous permet de visualiser la simulation tournant sur notre grappe de GPU en temps réel sur notre banc de réalité virtuelle et d interagir avec celle-ci. > Nous n avons pas encore testé nos codes sur la nouvelle architecture FERMI de NVIDIA à voir > Si le BRGM devait s investir durablement dans le GPGPU, le prochain projet se fera en utilisant le standard OpenCL.
Rencontre sur la thématique du Calcul Haute Performance - 13 juin 2012. Better Match, Faster Innovation
 Better Match, Faster Innovation Rencontre sur la thématique du Calcul Haute Performance - 13 juin 2012 Meeting on the theme of High Performance Computing TABLE DES MATIÈRES Qu est ce qu un imatch? STI
Better Match, Faster Innovation Rencontre sur la thématique du Calcul Haute Performance - 13 juin 2012 Meeting on the theme of High Performance Computing TABLE DES MATIÈRES Qu est ce qu un imatch? STI
Initiation au HPC - Généralités
 Initiation au HPC - Généralités Éric Ramat et Julien Dehos Université du Littoral Côte d Opale M2 Informatique 2 septembre 2015 Éric Ramat et Julien Dehos Initiation au HPC - Généralités 1/49 Plan du cours
Initiation au HPC - Généralités Éric Ramat et Julien Dehos Université du Littoral Côte d Opale M2 Informatique 2 septembre 2015 Éric Ramat et Julien Dehos Initiation au HPC - Généralités 1/49 Plan du cours
Contrôle Non Destructif : Implantation d'algorithmes sur GPU et multi-coeurs. Gilles Rougeron CEA/LIST Département Imagerie Simulation et Contrôle
 Contrôle Non Destructif : Implantation d'algorithmes sur GPU et multi-coeurs Gilles Rougeron CEA/LIST Département Imagerie Simulation et Contrôle 1 CEA R & D for Nuclear Energy 5 000 people Nuclear systems
Contrôle Non Destructif : Implantation d'algorithmes sur GPU et multi-coeurs Gilles Rougeron CEA/LIST Département Imagerie Simulation et Contrôle 1 CEA R & D for Nuclear Energy 5 000 people Nuclear systems
T. Gasc 1,2,3, F. De Vuyst 1, R. Motte 3, M. Peybernes 4, R. Poncet 5
 Modélisation de la performance et optimisation d un algorithme hydrodynamique de type Lagrange-Projection sur processeurs multi-cœurs T. Gasc 1,2,3, F. De Vuyst 1, R. Motte 3, M. Peybernes 4, R. Poncet
Modélisation de la performance et optimisation d un algorithme hydrodynamique de type Lagrange-Projection sur processeurs multi-cœurs T. Gasc 1,2,3, F. De Vuyst 1, R. Motte 3, M. Peybernes 4, R. Poncet
Sujet proposé par Yves M. LEROY. Cet examen se compose d un exercice et de deux problèmes. Ces trois parties sont indépendantes.
 Promotion X 004 COURS D ANALYSE DES STRUCTURES MÉCANIQUES PAR LA MÉTHODE DES ELEMENTS FINIS (MEC 568) contrôle non classant (7 mars 007, heures) Documents autorisés : polycopié ; documents et notes de
Promotion X 004 COURS D ANALYSE DES STRUCTURES MÉCANIQUES PAR LA MÉTHODE DES ELEMENTS FINIS (MEC 568) contrôle non classant (7 mars 007, heures) Documents autorisés : polycopié ; documents et notes de
Introduction à CUDA. [email protected]
 36 Introduction à CUDA [email protected] 38 Comment programmer les GPU? Notion de kernel exemple (n produits scalaires): T ci =ai b ( ai, b : vecteurs 3D, ci for(int i=0;i
36 Introduction à CUDA [email protected] 38 Comment programmer les GPU? Notion de kernel exemple (n produits scalaires): T ci =ai b ( ai, b : vecteurs 3D, ci for(int i=0;i
Projet IGGI. Infrastructure pour Grappe, Grille et Intranet. Fabrice Dupros. CASCIMODOT - Novembre 2005. Systèmes et Technologies de l Information
 Projet IGGI Infrastructure pour Grappe, Grille et Intranet CASCIMODOT - Novembre 2005 Fabrice Dupros CONTEXTE > Etablissement Public à caractère Industriel et Commercial (EPIC) Sous la tutelle des Ministères
Projet IGGI Infrastructure pour Grappe, Grille et Intranet CASCIMODOT - Novembre 2005 Fabrice Dupros CONTEXTE > Etablissement Public à caractère Industriel et Commercial (EPIC) Sous la tutelle des Ministères
Une bibliothèque de templates pour CUDA
 Une bibliothèque de templates pour CUDA Sylvain Collange, Marc Daumas et David Defour Montpellier, 16 octobre 2008 Types de parallèlisme de données Données indépendantes n threads pour n jeux de données
Une bibliothèque de templates pour CUDA Sylvain Collange, Marc Daumas et David Defour Montpellier, 16 octobre 2008 Types de parallèlisme de données Données indépendantes n threads pour n jeux de données
Limitations of the Playstation 3 for High Performance Cluster Computing
 Introduction Plan Limitations of the Playstation 3 for High Performance Cluster Computing July 2007 Introduction Plan Introduction Intérêts de la PS3 : rapide et puissante bon marché L utiliser pour faire
Introduction Plan Limitations of the Playstation 3 for High Performance Cluster Computing July 2007 Introduction Plan Introduction Intérêts de la PS3 : rapide et puissante bon marché L utiliser pour faire
Architecture des ordinateurs
 Décoder la relation entre l architecture et les applications Violaine Louvet, Institut Camille Jordan CNRS & Université Lyon 1 Ecole «Découverte du Calcul» 2013 1 / 61 Simulation numérique... Physique
Décoder la relation entre l architecture et les applications Violaine Louvet, Institut Camille Jordan CNRS & Université Lyon 1 Ecole «Découverte du Calcul» 2013 1 / 61 Simulation numérique... Physique
M2-Images. Rendu Temps Réel - OpenGL 4 et compute shaders. J.C. Iehl. December 18, 2013
 Rendu Temps Réel - OpenGL 4 et compute shaders December 18, 2013 résumé des épisodes précédents... création des objets opengl, organisation des données, configuration du pipeline, draw,... opengl 4.3 :
Rendu Temps Réel - OpenGL 4 et compute shaders December 18, 2013 résumé des épisodes précédents... création des objets opengl, organisation des données, configuration du pipeline, draw,... opengl 4.3 :
Info0804. Cours 6. Optimisation combinatoire : Applications et compléments
 Recherche Opérationnelle Optimisation combinatoire : Applications et compléments Pierre Delisle Université de Reims Champagne-Ardenne Département de Mathématiques et Informatique 17 février 2014 Plan de
Recherche Opérationnelle Optimisation combinatoire : Applications et compléments Pierre Delisle Université de Reims Champagne-Ardenne Département de Mathématiques et Informatique 17 février 2014 Plan de
Quantification d incertitude et Tendances en HPC
 Quantification d incertitude et Tendances en HPC Laurence Viry E cole de Physique des Houches 7 Mai 2014 Laurence Viry Tendances en HPC 7 Mai 2014 1 / 47 Contents 1 Mode lisation, simulation et quantification
Quantification d incertitude et Tendances en HPC Laurence Viry E cole de Physique des Houches 7 Mai 2014 Laurence Viry Tendances en HPC 7 Mai 2014 1 / 47 Contents 1 Mode lisation, simulation et quantification
Aspects théoriques et algorithmiques du calcul réparti L agglomération
 Aspects théoriques et algorithmiques du calcul réparti L agglomération Patrick CIARLET Enseignant-Chercheur UMA [email protected] Françoise LAMOUR [email protected] Aspects théoriques
Aspects théoriques et algorithmiques du calcul réparti L agglomération Patrick CIARLET Enseignant-Chercheur UMA [email protected] Françoise LAMOUR [email protected] Aspects théoriques
CORBA haute performance
 CORBA haute performance «CORBA à 730Mb/s!» Alexandre DENIS PARIS/IRISA, Rennes [email protected] Plan Motivations : concept de grille de calcul CORBA : concepts fondamentaux Vers un ORB haute performance
CORBA haute performance «CORBA à 730Mb/s!» Alexandre DENIS PARIS/IRISA, Rennes [email protected] Plan Motivations : concept de grille de calcul CORBA : concepts fondamentaux Vers un ORB haute performance
Tout ce que vous avez toujours voulu savoir sur SAP HANA. Sans avoir jamais osé le demander
 Tout ce que vous avez toujours voulu savoir sur SAP HANA Sans avoir jamais osé le demander Agenda Pourquoi SAP HANA? Qu est-ce que SAP HANA? SAP HANA pour l intelligence d affaires SAP HANA pour l analyse
Tout ce que vous avez toujours voulu savoir sur SAP HANA Sans avoir jamais osé le demander Agenda Pourquoi SAP HANA? Qu est-ce que SAP HANA? SAP HANA pour l intelligence d affaires SAP HANA pour l analyse
BILAN du projet PEPS 1 EOLIN (Eolien LMI INSA)
") BILAN du projet PEPS 1 EOLIN (Eolien LMI INSA) Lab. de Math de l INSA de ROUEN FR CNRS 3335 et EA 3226 PLAN 1. Introduction 2. Bilan scientifique 3. Bilan financier 4. Conclusion 1 Introduction Le projet
BILAN du projet PEPS 1 EOLIN (Eolien LMI INSA) Lab. de Math de l INSA de ROUEN FR CNRS 3335 et EA 3226 PLAN 1. Introduction 2. Bilan scientifique 3. Bilan financier 4. Conclusion 1 Introduction Le projet
Architecture des calculateurs
 Formation en Calcul Scientifique - LEM2I Architecture des calculateurs Violaine Louvet 1 1 Institut Camille jordan - CNRS 12-13/09/2011 Introduction Décoder la relation entre l architecture et les applications
Formation en Calcul Scientifique - LEM2I Architecture des calculateurs Violaine Louvet 1 1 Institut Camille jordan - CNRS 12-13/09/2011 Introduction Décoder la relation entre l architecture et les applications
Retour d expérience, portage de code Promes dans le cadre de l appel à projets CAPS-GENCI
 , portage de code Promes dans le cadre de l appel à projets CAPS-GENCI PROMES (UPR 8521 CNRS) Université de Perpignan France 29 juin 2011 1 Contexte 2 3 4 Sommaire Contexte 1 Contexte 2 3 4 Laboratoire
, portage de code Promes dans le cadre de l appel à projets CAPS-GENCI PROMES (UPR 8521 CNRS) Université de Perpignan France 29 juin 2011 1 Contexte 2 3 4 Sommaire Contexte 1 Contexte 2 3 4 Laboratoire
Introduction à la Programmation Parallèle: MPI
 Introduction à la Programmation Parallèle: MPI Frédéric Gava et Gaétan Hains L.A.C.L Laboratoire d Algorithmique, Complexité et Logique Cours du M2 SSI option PSSR Plan 1 Modèle de programmation 2 3 4
Introduction à la Programmation Parallèle: MPI Frédéric Gava et Gaétan Hains L.A.C.L Laboratoire d Algorithmique, Complexité et Logique Cours du M2 SSI option PSSR Plan 1 Modèle de programmation 2 3 4
Synthèse d'images I. Venceslas BIRI IGM Université de Marne La
 Synthèse d'images I Venceslas BIRI IGM Université de Marne La La synthèse d'images II. Rendu & Affichage 1. Introduction Venceslas BIRI IGM Université de Marne La Introduction Objectif Réaliser une image
Synthèse d'images I Venceslas BIRI IGM Université de Marne La La synthèse d'images II. Rendu & Affichage 1. Introduction Venceslas BIRI IGM Université de Marne La Introduction Objectif Réaliser une image
Segmentation d'images à l'aide d'agents sociaux : applications GPU
 Segmentation d'images à l'aide d'agents sociaux : applications GPU Richard MOUSSA Laboratoire Bordelais de Recherche en Informatique (LaBRI) - UMR 5800 Université de Bordeaux - France Laboratoire de recherche
Segmentation d'images à l'aide d'agents sociaux : applications GPU Richard MOUSSA Laboratoire Bordelais de Recherche en Informatique (LaBRI) - UMR 5800 Université de Bordeaux - France Laboratoire de recherche
. Plan du cours. . Architecture: Fermi (2010-12), Kepler (12-?)
, Kepler (12-?)") Plan du cours Vision mate riel: architecture cartes graphiques NVIDIA INF 560 Calcul Paralle le et Distribue Cours 3 Vision logiciel: l abstraction logique de l architecture propose e par le langage CUDA
Plan du cours Vision mate riel: architecture cartes graphiques NVIDIA INF 560 Calcul Paralle le et Distribue Cours 3 Vision logiciel: l abstraction logique de l architecture propose e par le langage CUDA
Génération de code binaire pour application multimedia : une approche au vol
 Génération de binaire pour application multimedia : une approche au vol http://hpbcg.org/ Henri-Pierre Charles Université de Versailles Saint-Quentin en Yvelines 3 Octobre 2009 Présentation Présentation
Génération de binaire pour application multimedia : une approche au vol http://hpbcg.org/ Henri-Pierre Charles Université de Versailles Saint-Quentin en Yvelines 3 Octobre 2009 Présentation Présentation
Rapport d activité. Mathieu Souchaud Juin 2007
 Rapport d activité Mathieu Souchaud Juin 2007 Ce document fait la synthèse des réalisations accomplies durant les sept premiers mois de ma mission (de novembre 2006 à juin 2007) au sein de l équipe ScAlApplix
Rapport d activité Mathieu Souchaud Juin 2007 Ce document fait la synthèse des réalisations accomplies durant les sept premiers mois de ma mission (de novembre 2006 à juin 2007) au sein de l équipe ScAlApplix
Rapport de stage Master 2
 Rapport de stage Master 2 Informatique Haute Performance et Simulation, 2 ème année Ecole Centrale Paris Accélération des méthodes statistiques sur GPU Auteur : CHAI Anchen. Responsables: Joel Falcou et
Rapport de stage Master 2 Informatique Haute Performance et Simulation, 2 ème année Ecole Centrale Paris Accélération des méthodes statistiques sur GPU Auteur : CHAI Anchen. Responsables: Joel Falcou et
Contribution à la conception à base de composants logiciels d applications scientifiques parallèles.
 - École Normale Supérieure de LYON - Laboratoire de l Informatique du Parallélisme THÈSE en vue d obtenir le grade de Docteur de l École Normale Supérieure de Lyon - Université de Lyon Discipline : Informatique
- École Normale Supérieure de LYON - Laboratoire de l Informatique du Parallélisme THÈSE en vue d obtenir le grade de Docteur de l École Normale Supérieure de Lyon - Université de Lyon Discipline : Informatique
Vers du matériel libre
 Février 2011 La liberté du logiciel n est qu une partie du problème. Winmodems Modem traditionnel Bon fonctionnement Plus cher Electronique propriétaire Blob sur DSP intégré au modem Bien reçu par les
Février 2011 La liberté du logiciel n est qu une partie du problème. Winmodems Modem traditionnel Bon fonctionnement Plus cher Electronique propriétaire Blob sur DSP intégré au modem Bien reçu par les
4. Utilisation d un SGBD : le langage SQL. 5. Normalisation
 Base de données S. Lèbre [email protected] Université de Strasbourg, département d informatique. Présentation du module Contenu général Notion de bases de données Fondements / Conception Utilisation :
Base de données S. Lèbre [email protected] Université de Strasbourg, département d informatique. Présentation du module Contenu général Notion de bases de données Fondements / Conception Utilisation :
Happy birthday ZSet High performance computing dans ZSet
 Happy birthday ZSet High performance computing dans ZSet F. Feyel & P. Gosselet Architectures SMP NUMA memory memory memory Distribué memory memory 2 memory memory Hybride memory memory memory memory memory
Happy birthday ZSet High performance computing dans ZSet F. Feyel & P. Gosselet Architectures SMP NUMA memory memory memory Distribué memory memory 2 memory memory Hybride memory memory memory memory memory
Figure 3.1- Lancement du Gambit
 3.1. Introduction Le logiciel Gambit est un mailleur 2D/3D; pré-processeur qui permet de mailler des domaines de géométrie d un problème de CFD (Computational Fluid Dynamics).Il génère des fichiers*.msh
3.1. Introduction Le logiciel Gambit est un mailleur 2D/3D; pré-processeur qui permet de mailler des domaines de géométrie d un problème de CFD (Computational Fluid Dynamics).Il génère des fichiers*.msh
Reconstruction de bâtiments en 3D à partir de nuages de points LIDAR
 Reconstruction de bâtiments en 3D à partir de nuages de points LIDAR Mickaël Bergem 25 juin 2014 Maillages et applications 1 Table des matières Introduction 3 1 La modélisation numérique de milieux urbains
Reconstruction de bâtiments en 3D à partir de nuages de points LIDAR Mickaël Bergem 25 juin 2014 Maillages et applications 1 Table des matières Introduction 3 1 La modélisation numérique de milieux urbains
Maarch Framework 3 - Maarch. Tests de charge. Professional Services. http://www.maarch.fr. 11, bd du Sud Est 92000 Nanterre
 Maarch Professional Services 11, bd du Sud Est 92000 Nanterre Tel : +33 1 47 24 51 59 Fax : +33 1 47 24 54 08 Maarch Framework 3 - Maarch PS anime le développement d un produit d archivage open source
Maarch Professional Services 11, bd du Sud Est 92000 Nanterre Tel : +33 1 47 24 51 59 Fax : +33 1 47 24 54 08 Maarch Framework 3 - Maarch PS anime le développement d un produit d archivage open source
Résolution de systèmes linéaires par des méthodes directes
 Résolution de systèmes linéaires par des méthodes directes J. Erhel Janvier 2014 1 Inverse d une matrice carrée et systèmes linéaires Ce paragraphe a pour objet les matrices carrées et les systèmes linéaires.
Résolution de systèmes linéaires par des méthodes directes J. Erhel Janvier 2014 1 Inverse d une matrice carrée et systèmes linéaires Ce paragraphe a pour objet les matrices carrées et les systèmes linéaires.
Chapitre V : La gestion de la mémoire. Hiérarchie de mémoires Objectifs Méthodes d'allocation Simulation de mémoire virtuelle Le mapping
 Chapitre V : La gestion de la mémoire Hiérarchie de mémoires Objectifs Méthodes d'allocation Simulation de mémoire virtuelle Le mapping Introduction Plusieurs dizaines de processus doivent se partager
Chapitre V : La gestion de la mémoire Hiérarchie de mémoires Objectifs Méthodes d'allocation Simulation de mémoire virtuelle Le mapping Introduction Plusieurs dizaines de processus doivent se partager
État de l art des simulations multi-agents sur GPU
 État de l art des simulations multi-agents sur GPU Emmanuel Hermellin Fabien Michel Jacques Ferber [email protected] [email protected] [email protected] LIRMM - Laboratoire Informatique Robotique
État de l art des simulations multi-agents sur GPU Emmanuel Hermellin Fabien Michel Jacques Ferber [email protected] [email protected] [email protected] LIRMM - Laboratoire Informatique Robotique
Linux embarqué: une alternative à Windows CE?
 embarqué: une alternative à Windows CE? : une alternative à Windows CE Présentation Mangrove Systems Distribution embarqué Perspective WinCe / Questions Mangrove systems Créé en 2001 Soutien Soutien Ministère
embarqué: une alternative à Windows CE? : une alternative à Windows CE Présentation Mangrove Systems Distribution embarqué Perspective WinCe / Questions Mangrove systems Créé en 2001 Soutien Soutien Ministère
Manuel de validation Fascicule v4.25 : Thermique transitoire des structures volumiques
 Titre : TTLV100 - Choc thermique dans un tuyau avec condit[...] Date : 02/03/2010 Page : 1/10 Manuel de Validation Fascicule V4.25 : Thermique transitoire des structures volumiques Document : V4.25.100
Titre : TTLV100 - Choc thermique dans un tuyau avec condit[...] Date : 02/03/2010 Page : 1/10 Manuel de Validation Fascicule V4.25 : Thermique transitoire des structures volumiques Document : V4.25.100
IRL : Simulation distribuée pour les systèmes embarqués
 IRL : Simulation distribuée pour les systèmes embarqués Yassine El Khadiri, 2 ème année Ensimag, Grenoble INP Matthieu Moy, Verimag Denis Becker, Verimag 19 mai 2015 1 Table des matières 1 MPI et la sérialisation
IRL : Simulation distribuée pour les systèmes embarqués Yassine El Khadiri, 2 ème année Ensimag, Grenoble INP Matthieu Moy, Verimag Denis Becker, Verimag 19 mai 2015 1 Table des matières 1 MPI et la sérialisation
Windows Server 2008. Chapitre 1: Découvrir Windows Server 2008
 Windows Server 2008 Chapitre 1: Découvrir Windows Server 2008 Objectives Identifier les caractéristiques de chaque édition de Windows Server 2008 Identifier les caractéristiques généraux de Windows Server
Windows Server 2008 Chapitre 1: Découvrir Windows Server 2008 Objectives Identifier les caractéristiques de chaque édition de Windows Server 2008 Identifier les caractéristiques généraux de Windows Server
EX4C Systèmes d exploitation. Séance 14 Structure des stockages de masse
 EX4C Systèmes d exploitation Séance 14 Structure des stockages de masse Sébastien Combéfis mardi 3 mars 2015 Ce(tte) œuvre est mise à disposition selon les termes de la Licence Creative Commons Attribution
EX4C Systèmes d exploitation Séance 14 Structure des stockages de masse Sébastien Combéfis mardi 3 mars 2015 Ce(tte) œuvre est mise à disposition selon les termes de la Licence Creative Commons Attribution
La Forge INRIA : bilan et perspectives. Hervé MATHIEU - 11 mai 2010
 1 La Forge INRIA : bilan et perspectives Hervé MATHIEU - 11 mai 2010 Le plan 2 La Forge (Quoi, Quand, Comment) Les chiffres de la Forge INRIA Un exemple de projet Bilan/Perspectives Conclusion Qu'est ce
1 La Forge INRIA : bilan et perspectives Hervé MATHIEU - 11 mai 2010 Le plan 2 La Forge (Quoi, Quand, Comment) Les chiffres de la Forge INRIA Un exemple de projet Bilan/Perspectives Conclusion Qu'est ce
I. Programmation I. 1 Ecrire un programme en Scilab traduisant l organigramme montré ci-après (on pourra utiliser les annexes):
:") Master Chimie Fondamentale et Appliquée : spécialité «Ingénierie Chimique» Examen «Programmation, Simulation des procédés» avril 2008a Nom : Prénom : groupe TD : I. Programmation I. 1 Ecrire un programme
Master Chimie Fondamentale et Appliquée : spécialité «Ingénierie Chimique» Examen «Programmation, Simulation des procédés» avril 2008a Nom : Prénom : groupe TD : I. Programmation I. 1 Ecrire un programme
Potentiels de la technologie FPGA dans la conception des systèmes. Avantages des FPGAs pour la conception de systèmes optimisés
 Potentiels de la technologie FPGA dans la conception des systèmes Avantages des FPGAs pour la conception de systèmes optimisés Gérard FLORENCE Lotfi Guedria Agenda 1. Le CETIC en quelques mots 2. Générateur
Potentiels de la technologie FPGA dans la conception des systèmes Avantages des FPGAs pour la conception de systèmes optimisés Gérard FLORENCE Lotfi Guedria Agenda 1. Le CETIC en quelques mots 2. Générateur
Big Data et Graphes : Quelques pistes de recherche
 Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci http://liris.cnrs.fr/hamamache.kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de
Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci http://liris.cnrs.fr/hamamache.kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de
Calcul multi GPU et optimisation combinatoire
 Année universitaire 2010 2011 Master recherche EEA Spécialité : SAID Systèmes Automatiques, Informatiques et Décisionnels Parcours : Systèmes Automatiques Calcul multi GPU et optimisation combinatoire
Année universitaire 2010 2011 Master recherche EEA Spécialité : SAID Systèmes Automatiques, Informatiques et Décisionnels Parcours : Systèmes Automatiques Calcul multi GPU et optimisation combinatoire
Rapport 2014 et demande pour 2015. Portage de Méso-NH sur Machines Massivement Parallèles du GENCI Projet 2015 : GENCI GEN1605 & CALMIP-P0121
 Rapport 2014 et demande pour 2015 Portage de Méso-NH sur Machines Massivement Parallèles du GENCI Projet 2015 : GENCI GEN1605 & CALMIP-P0121 Rappel sur Méso-NH : Modélisation à moyenne échelle de l atmosphère
Rapport 2014 et demande pour 2015 Portage de Méso-NH sur Machines Massivement Parallèles du GENCI Projet 2015 : GENCI GEN1605 & CALMIP-P0121 Rappel sur Méso-NH : Modélisation à moyenne échelle de l atmosphère
ÉdIteur officiel et fournisseur de ServIceS professionnels du LogIcIeL open Source ScILab
 ÉdIteur officiel et fournisseur de ServIceS professionnels du LogIcIeL open Source ScILab notre compétence d'éditeur à votre service créée en juin 2010, Scilab enterprises propose services et support autour
ÉdIteur officiel et fournisseur de ServIceS professionnels du LogIcIeL open Source ScILab notre compétence d'éditeur à votre service créée en juin 2010, Scilab enterprises propose services et support autour
Cours 13. RAID et SAN. 2004, Marc-André Léger
 Cours 13 RAID et SAN Plan Mise en contexte Storage Area Networks Architecture Fibre Channel Network Attached Storage Exemple d un serveur NAS EMC2 Celerra Conclusion Démonstration Questions - Réponses
Cours 13 RAID et SAN Plan Mise en contexte Storage Area Networks Architecture Fibre Channel Network Attached Storage Exemple d un serveur NAS EMC2 Celerra Conclusion Démonstration Questions - Réponses
Exemple d application en CFD : Coefficient de traînée d un cylindre
 Exemple d application en CFD : Coefficient de traînée d un cylindre 1 Démarche générale Avec Gambit Création d une géométrie Maillage Définition des conditions aux limites Avec Fluent 3D Choix des équations
Exemple d application en CFD : Coefficient de traînée d un cylindre 1 Démarche générale Avec Gambit Création d une géométrie Maillage Définition des conditions aux limites Avec Fluent 3D Choix des équations
Les environnements de calcul distribué
 2 e Atelier CRAG, 3 au 8 Décembre 2012 Par Blaise Omer YENKE IUT, Université de Ngaoundéré, Cameroun. 4 décembre 2012 1 / 32 Calcul haute performance (HPC) High-performance computing (HPC) : utilisation
2 e Atelier CRAG, 3 au 8 Décembre 2012 Par Blaise Omer YENKE IUT, Université de Ngaoundéré, Cameroun. 4 décembre 2012 1 / 32 Calcul haute performance (HPC) High-performance computing (HPC) : utilisation
TRAVAUX DE RECHERCHE DANS LE
 TRAVAUX DE RECHERCHE DANS LE DOMAINE DE L'EXPLOITATION DES DONNÉES ET DES DOCUMENTS 1 Journée technologique " Solutions de maintenance prévisionnelle adaptées à la production Josiane Mothe, FREMIT, IRIT
TRAVAUX DE RECHERCHE DANS LE DOMAINE DE L'EXPLOITATION DES DONNÉES ET DES DOCUMENTS 1 Journée technologique " Solutions de maintenance prévisionnelle adaptées à la production Josiane Mothe, FREMIT, IRIT
Gestion de mémoire secondaire F. Boyer, Laboratoire Sardes [email protected]
 Gestion de mémoire secondaire F. Boyer, Laboratoire Sardes [email protected] 1- Structure d un disque 2- Ordonnancement des requêtes 3- Gestion du disque - formatage - bloc d amorçage - récupération
Gestion de mémoire secondaire F. Boyer, Laboratoire Sardes [email protected] 1- Structure d un disque 2- Ordonnancement des requêtes 3- Gestion du disque - formatage - bloc d amorçage - récupération
physicien diplômé EPFZ originaire de France présentée acceptée sur proposition Thèse no. 7178
 Thèse no. 7178 PROBLEMES D'OPTIMISATION DANS LES SYSTEMES DE CHAUFFAGE A DISTANCE présentée à l'ecole POLYTECHNIQUE FEDERALE DE ZURICH pour l'obtention du titre de Docteur es sciences naturelles par Alain
Thèse no. 7178 PROBLEMES D'OPTIMISATION DANS LES SYSTEMES DE CHAUFFAGE A DISTANCE présentée à l'ecole POLYTECHNIQUE FEDERALE DE ZURICH pour l'obtention du titre de Docteur es sciences naturelles par Alain
Présentation du module Base de données spatio-temporelles
 Présentation du module Base de données spatio-temporelles S. Lèbre [email protected] Université de Strasbourg, département d informatique. Partie 1 : Notion de bases de données (12,5h ) Enjeux et principes
Présentation du module Base de données spatio-temporelles S. Lèbre [email protected] Université de Strasbourg, département d informatique. Partie 1 : Notion de bases de données (12,5h ) Enjeux et principes
Grandes lignes ASTRÉE. Logiciels critiques. Outils de certification classiques. Inspection manuelle. Definition. Test
 Grandes lignes Analyseur Statique de logiciels Temps RÉel Embarqués École Polytechnique École Normale Supérieure Mercredi 18 juillet 2005 1 Présentation d 2 Cadre théorique de l interprétation abstraite
Grandes lignes Analyseur Statique de logiciels Temps RÉel Embarqués École Polytechnique École Normale Supérieure Mercredi 18 juillet 2005 1 Présentation d 2 Cadre théorique de l interprétation abstraite
Completed Projects / Projets terminés
 Completed Projects / Projets terminés Nouvelles normes Nouvelles éditions Publications spéciales publiées en français CAN/CSA-ISO/CEI 10164-9-97 (C2001), 1 re édition Technologies de l information Interconnexion
Completed Projects / Projets terminés Nouvelles normes Nouvelles éditions Publications spéciales publiées en français CAN/CSA-ISO/CEI 10164-9-97 (C2001), 1 re édition Technologies de l information Interconnexion
BIG Data et R: opportunités et perspectives
 BIG Data et R: opportunités et perspectives Guati Rizlane 1 & Hicham Hajji 2 1 Ecole Nationale de Commerce et de Gestion de Casablanca, Maroc, [email protected] 2 Ecole des Sciences Géomatiques, IAV Rabat,
BIG Data et R: opportunités et perspectives Guati Rizlane 1 & Hicham Hajji 2 1 Ecole Nationale de Commerce et de Gestion de Casablanca, Maroc, [email protected] 2 Ecole des Sciences Géomatiques, IAV Rabat,
Efficient Object Versioning for Object- Oriented Languages From Model to Language Integration
 Efficient Object Versioning for Object- Oriented Languages From Model to Language Integration Pluquet Frédéric July, 3rd 2012 Etude de techniques efficaces de versionnement d objets pour les langages orientés
Efficient Object Versioning for Object- Oriented Languages From Model to Language Integration Pluquet Frédéric July, 3rd 2012 Etude de techniques efficaces de versionnement d objets pour les langages orientés
Systèmes et traitement parallèles
 Systèmes et traitement parallèles Mohsine Eleuldj Département Génie Informatique, EMI [email protected] 1 Système et traitement parallèle Objectif Etude des architectures parallèles Programmation des applications
Systèmes et traitement parallèles Mohsine Eleuldj Département Génie Informatique, EMI [email protected] 1 Système et traitement parallèle Objectif Etude des architectures parallèles Programmation des applications
Approche par groupe de gènes pour les données longitudinales d expression génique avec une application dans un essai vaccinal contre le VIH
 Approche par groupe de gènes pour les données longitudinales d expression génique avec une application dans un essai vaccinal contre le VIH Boris Hejblum 1,2,3 & Rodolphe Thiébaut 1,2,3 1 Inserm, U897
Approche par groupe de gènes pour les données longitudinales d expression génique avec une application dans un essai vaccinal contre le VIH Boris Hejblum 1,2,3 & Rodolphe Thiébaut 1,2,3 1 Inserm, U897
UNIVERSITÉ D ORLÉANS ÉCOLE DOCTORALE MIPTIS MATHÉMATIQUES, INFORMATIQUE, PHYSIQUE THÉORIQUE ET INGÉNIEURIE DES SYSTÈMES. THÈSE présentée par :
 UNIVERSITÉ D ORLÉANS ÉCOLE DOCTORALE MIPTIS MATHÉMATIQUES, INFORMATIQUE, PHYSIQUE THÉORIQUE ET INGÉNIEURIE DES SYSTÈMES Laboratoire d Informatique Fondamentale d Orléans THÈSE présentée par : Hélène COULLON
UNIVERSITÉ D ORLÉANS ÉCOLE DOCTORALE MIPTIS MATHÉMATIQUES, INFORMATIQUE, PHYSIQUE THÉORIQUE ET INGÉNIEURIE DES SYSTÈMES Laboratoire d Informatique Fondamentale d Orléans THÈSE présentée par : Hélène COULLON
Runtime. Gestion de la réactivité des communications réseau. François Trahay Runtime, LaBRI sous la direction d'alexandre Denis Université Bordeaux I
 Runtime Gestion de la réactivité des communications réseau François Trahay Runtime, LaBRI sous la direction d'alexandre Denis Université Bordeaux I 1 Le calcul hautes performances La tendance actuelle
Runtime Gestion de la réactivité des communications réseau François Trahay Runtime, LaBRI sous la direction d'alexandre Denis Université Bordeaux I 1 Le calcul hautes performances La tendance actuelle
SIMULATION DU PROCÉDÉ DE FABRICATION DIRECTE DE PIÈCES THERMOPLASTIQUES PAR FUSION LASER DE POUDRE
 SIMULATION DU PROCÉDÉ DE FABRICATION DIRECTE DE PIÈCES THERMOPLASTIQUES PAR FUSION LASER DE POUDRE Denis DEFAUCHY Gilles REGNIER Patrice PEYRE Amine AMMAR Pièces FALCON - Dassault Aviation 1 Présentation
SIMULATION DU PROCÉDÉ DE FABRICATION DIRECTE DE PIÈCES THERMOPLASTIQUES PAR FUSION LASER DE POUDRE Denis DEFAUCHY Gilles REGNIER Patrice PEYRE Amine AMMAR Pièces FALCON - Dassault Aviation 1 Présentation
Programmation parallèle et distribuée
 ppd/mpassing p. 1/43 Programmation parallèle et distribuée Communications par messages Philippe MARQUET [email protected] Laboratoire d informatique fondamentale de Lille Université des sciences
ppd/mpassing p. 1/43 Programmation parallèle et distribuée Communications par messages Philippe MARQUET [email protected] Laboratoire d informatique fondamentale de Lille Université des sciences
Simulations de systèmes quantiques fortement corrélés:
 Simulations de systèmes quantiques fortement corrélés: propriétés magnétiques, supraconductrices et influence du désordre Sylvain Capponi Laboratoire de Physique Théorique - IRSAMC Université Paul Sabatier
Simulations de systèmes quantiques fortement corrélés: propriétés magnétiques, supraconductrices et influence du désordre Sylvain Capponi Laboratoire de Physique Théorique - IRSAMC Université Paul Sabatier
Stephan Hadinger, Sr. Mgr Solutions Architecture, AWS. Salon du Big Data 11 mars 2015
 Stephan Hadinger, Sr. Mgr Solutions Architecture, AWS Salon du Big Data 11 mars 2015 Accélération de l innovation +500 +280 Amazon EC2 Container Service +159 AWS Storage Gateway Amazon Elastic Transcoder
Stephan Hadinger, Sr. Mgr Solutions Architecture, AWS Salon du Big Data 11 mars 2015 Accélération de l innovation +500 +280 Amazon EC2 Container Service +159 AWS Storage Gateway Amazon Elastic Transcoder
SensOrLabs. a protocol validation platform for the IoT. Dominique Barthel, Quentin Lampin IMT/OLPS/BIZZ/MIS Apr 7th 2014, ST, CEA, LIG
 SensOrLabs a protocol validation platform for the IoT Dominique Barthel, Quentin Lampin IMT/OLPS/BIZZ/MIS Apr 7th 2014, ST, CEA, LIG SensOrLabs inspired by the ANR Senslab project http://www.senslab.info/
SensOrLabs a protocol validation platform for the IoT Dominique Barthel, Quentin Lampin IMT/OLPS/BIZZ/MIS Apr 7th 2014, ST, CEA, LIG SensOrLabs inspired by the ANR Senslab project http://www.senslab.info/
//////////////////////////////////////////////////////////////////// Administration bases de données
 ////////////////////// Administration bases de données / INTRODUCTION Système d informations Un système d'information (SI) est un ensemble organisé de ressources (matériels, logiciels, personnel, données
////////////////////// Administration bases de données / INTRODUCTION Système d informations Un système d'information (SI) est un ensemble organisé de ressources (matériels, logiciels, personnel, données
Mini_guide_Isis.pdf le 23/09/2001 Page 1/14
 1 Démarrer...2 1.1 L écran Isis...2 1.2 La boite à outils...2 1.2.1 Mode principal...3 1.2.2 Mode gadgets...3 1.2.3 Mode graphique...3 2 Quelques actions...4 2.1 Ouvrir un document existant...4 2.2 Sélectionner
1 Démarrer...2 1.1 L écran Isis...2 1.2 La boite à outils...2 1.2.1 Mode principal...3 1.2.2 Mode gadgets...3 1.2.3 Mode graphique...3 2 Quelques actions...4 2.1 Ouvrir un document existant...4 2.2 Sélectionner
"Modélisation interactive d'un genou humain"
 Stage M2 PRO IICAO, du 1er avril au 31 septembre 2008 "Modélisation interactive d'un genou humain" Vincent Vansuyt Sous la tutelle de François Faure et François Boux de Casson Dans l'équipe Evasion, laboratoire
Stage M2 PRO IICAO, du 1er avril au 31 septembre 2008 "Modélisation interactive d'un genou humain" Vincent Vansuyt Sous la tutelle de François Faure et François Boux de Casson Dans l'équipe Evasion, laboratoire
Le data center moderne virtualisé
 WHITEPAPER Le data center moderne virtualisé Les ressources du data center ont toujours été sous-utilisées alors qu elles absorbent des quantités énormes d énergie et occupent une surface au sol précieuse.
WHITEPAPER Le data center moderne virtualisé Les ressources du data center ont toujours été sous-utilisées alors qu elles absorbent des quantités énormes d énergie et occupent une surface au sol précieuse.
Big Data et Graphes : Quelques pistes de recherche
 Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de Lyon/Université Claude Bernard Lyon 1/Université
Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de Lyon/Université Claude Bernard Lyon 1/Université
LABO 5 ET 6 TRAITEMENT DE SIGNAL SOUS SIMULINK
 LABO 5 ET 6 TRAITEMENT DE SIGNAL SOUS SIMULINK 5.1 Introduction Simulink est l'extension graphique de MATLAB permettant, d une part de représenter les fonctions mathématiques et les systèmes sous forme
LABO 5 ET 6 TRAITEMENT DE SIGNAL SOUS SIMULINK 5.1 Introduction Simulink est l'extension graphique de MATLAB permettant, d une part de représenter les fonctions mathématiques et les systèmes sous forme
Formation Webase 5. Formation Webase 5. Ses secrets, de l architecture MVC à l application Web. Adrien Grand <[email protected]> Centrale Réseaux
 Formation Webase 5 Ses secrets, de l architecture MVC à l application Web Adrien Grand Centrale Réseaux Sommaire 1 Obtenir des informations sur Webase 5 2 Composants de Webase 5 Un
Formation Webase 5 Ses secrets, de l architecture MVC à l application Web Adrien Grand Centrale Réseaux Sommaire 1 Obtenir des informations sur Webase 5 2 Composants de Webase 5 Un
HPC by OVH.COM. Le bon calcul pour l innovation OVH.COM
 4 HPC by OVH.COM Le bon calcul pour l innovation 2 6 5 6 2 8 6 2 OVH.COM 5 2 HPC by OVH.COM 6 HPC pour High Performance Computing Utilisation de serveurs et de grappes de serveurs (clusters), configurés
4 HPC by OVH.COM Le bon calcul pour l innovation 2 6 5 6 2 8 6 2 OVH.COM 5 2 HPC by OVH.COM 6 HPC pour High Performance Computing Utilisation de serveurs et de grappes de serveurs (clusters), configurés
Systèmes Multi-Agents et GPGPU : état des lieux et directions pour l avenir
 Systèmes Multi-Agents et GPGPU : état des lieux et directions pour l avenir Emmanuel Hermellin a [email protected] Fabien Michel a [email protected] Jacques Ferber a [email protected] a LIRMM -
Systèmes Multi-Agents et GPGPU : état des lieux et directions pour l avenir Emmanuel Hermellin a [email protected] Fabien Michel a [email protected] Jacques Ferber a [email protected] a LIRMM -
Table des matières PRESENTATION DU LANGAGE DS2 ET DE SES APPLICATIONS. Introduction
 PRESENTATION DU LANGAGE DS2 ET DE SES APPLICATIONS Depuis SAS 9.2 TS2M3, SAS propose un nouveau langage de programmation permettant de créer et gérer des tables SAS : le DS2 («Data Step 2»). Ces nouveautés
PRESENTATION DU LANGAGE DS2 ET DE SES APPLICATIONS Depuis SAS 9.2 TS2M3, SAS propose un nouveau langage de programmation permettant de créer et gérer des tables SAS : le DS2 («Data Step 2»). Ces nouveautés
Etude d Algorithmes Parallèles de Data Mining
 REPUBLIQUE TUNISIENNE MINISTERE DE L ENSEIGNEMENT SUPERIEUR, DE LA TECHNOLOGIE ET DE LA RECHERCHE SCIENTIFIQUE UNIVERSITE DE TUNIS ELMANAR FACULTE DES SCIENCES DE TUNIS DEPARTEMENT DES SCIENCES DE L INFORMATIQUE
REPUBLIQUE TUNISIENNE MINISTERE DE L ENSEIGNEMENT SUPERIEUR, DE LA TECHNOLOGIE ET DE LA RECHERCHE SCIENTIFIQUE UNIVERSITE DE TUNIS ELMANAR FACULTE DES SCIENCES DE TUNIS DEPARTEMENT DES SCIENCES DE L INFORMATIQUE
Modélisation des interfaces matériel/logiciel
 Modélisation des interfaces matériel/logiciel Présenté par Frédéric Pétrot Patrice Gerin Alexandre Chureau Hao Shen Aimen Bouchhima Ahmed Jerraya 1/28 TIMA Laboratory SLS Group 46 Avenue Félix VIALLET
Modélisation des interfaces matériel/logiciel Présenté par Frédéric Pétrot Patrice Gerin Alexandre Chureau Hao Shen Aimen Bouchhima Ahmed Jerraya 1/28 TIMA Laboratory SLS Group 46 Avenue Félix VIALLET
transformer en avantage compétitif en temps réel vos données Your business technologists. Powering progress
 transformer en temps réel vos données en avantage compétitif Your business technologists. Powering progress Transformer les données en savoir Les données sont au cœur de toute activité, mais seules elles
transformer en temps réel vos données en avantage compétitif Your business technologists. Powering progress Transformer les données en savoir Les données sont au cœur de toute activité, mais seules elles
ANALYSE NUMERIQUE ET OPTIMISATION. Une introduction à la modélisation mathématique et à la simulation numérique
 1 ANALYSE NUMERIQUE ET OPTIMISATION Une introduction à la modélisation mathématique et à la simulation numérique G. ALLAIRE 28 Janvier 2014 CHAPITRE I Analyse numérique: amphis 1 à 12. Optimisation: amphis
1 ANALYSE NUMERIQUE ET OPTIMISATION Une introduction à la modélisation mathématique et à la simulation numérique G. ALLAIRE 28 Janvier 2014 CHAPITRE I Analyse numérique: amphis 1 à 12. Optimisation: amphis
SDLV120 - Absorption d'une onde de compression dans un barreau élastique
 Titre : SDLV120 - Absorption d'une onde de compression dan[...] Date : 09/11/2011 Page : 1/9 SDLV120 - Absorption d'une onde de compression dans un barreau élastique Résumé On teste les éléments paraxiaux
Titre : SDLV120 - Absorption d'une onde de compression dan[...] Date : 09/11/2011 Page : 1/9 SDLV120 - Absorption d'une onde de compression dans un barreau élastique Résumé On teste les éléments paraxiaux
FORUM NTIC BIG DATA, OPEN DATA Big Data: les challenges, les défis
 FORUM NTIC BIG DATA, OPEN DATA Big Data: les challenges, les défis Joseph Salmon Télécom ParisTech Jeudi 6 Février Joseph Salmon (Télécom ParisTech) Big Data Jeudi 6 Février 1 / 18 Agenda Contexte et opportunités
FORUM NTIC BIG DATA, OPEN DATA Big Data: les challenges, les défis Joseph Salmon Télécom ParisTech Jeudi 6 Février Joseph Salmon (Télécom ParisTech) Big Data Jeudi 6 Février 1 / 18 Agenda Contexte et opportunités
RIE LE RENDU THEO. 2 e trim ÉTAPE DE FINITION BOÎTE DE DIALOGUE. remarques
 THEO RIE LE RENDU 2 e trim JANVIER 2008 remarques ÉTAPE DE FINITION Le rendu est la partie finale de notre création, à ce moment on décide que notre 3D est finie et l on en réalise une image 2D Cette image
THEO RIE LE RENDU 2 e trim JANVIER 2008 remarques ÉTAPE DE FINITION Le rendu est la partie finale de notre création, à ce moment on décide que notre 3D est finie et l on en réalise une image 2D Cette image
Les mésocentres HPC àportée de clic des utilisateurs industriels
 Les mésocentres HPC àportée de clic des utilisateurs industriels Université de Reims Champagne-Ardenne (URCA) Centre de Calcul ROMEO Multidisciplinary university more than 22 000 students a wide initial
Les mésocentres HPC àportée de clic des utilisateurs industriels Université de Reims Champagne-Ardenne (URCA) Centre de Calcul ROMEO Multidisciplinary university more than 22 000 students a wide initial
WEA Un Gérant d'objets Persistants pour des environnements distribués
 Thèse de Doctorat de l'université P & M Curie WEA Un Gérant d'objets Persistants pour des environnements distribués Didier Donsez Université Pierre et Marie Curie Paris VI Laboratoire de Méthodologie et
Thèse de Doctorat de l'université P & M Curie WEA Un Gérant d'objets Persistants pour des environnements distribués Didier Donsez Université Pierre et Marie Curie Paris VI Laboratoire de Méthodologie et
Concept de machine virtuelle
 Concept de machine virtuelle Chap. 5: Machine virtuelle Alain Sandoz Semestre été 2007 1 Introduction: Java Virtual Machine Machine Virtuelle Java: qu est-ce que c est? c est la spécification d une machine
Concept de machine virtuelle Chap. 5: Machine virtuelle Alain Sandoz Semestre été 2007 1 Introduction: Java Virtual Machine Machine Virtuelle Java: qu est-ce que c est? c est la spécification d une machine
Métriques de performance pour les algorithmes et programmes parallèles
 Métriques de performance pour les algorithmes et programmes parallèles 11 18 nov. 2002 Cette section est basée tout d abord sur la référence suivante (manuel suggéré mais non obligatoire) : R. Miller and
Métriques de performance pour les algorithmes et programmes parallèles 11 18 nov. 2002 Cette section est basée tout d abord sur la référence suivante (manuel suggéré mais non obligatoire) : R. Miller and
Disponibilité et fiabilité des services et des systèmes
 Disponibilité et fiabilité des services et des systèmes Anthony Busson Introduction Un site Web commercial perd de l argent lorsque leur site n est plus disponible L activité d une entreprise peut être
Disponibilité et fiabilité des services et des systèmes Anthony Busson Introduction Un site Web commercial perd de l argent lorsque leur site n est plus disponible L activité d une entreprise peut être
Introduction au calcul parallèle avec OpenCL
 Introduction au calcul parallèle avec OpenCL Julien Dehos Séminaire du 05/01/2012 Sommaire Introduction Le calculateur du CGR/LISIC/LMPA Généralités sur OpenCL Modèles Programmation Optimisation Conclusion
Introduction au calcul parallèle avec OpenCL Julien Dehos Séminaire du 05/01/2012 Sommaire Introduction Le calculateur du CGR/LISIC/LMPA Généralités sur OpenCL Modèles Programmation Optimisation Conclusion
Introduction à la programmation des GPUs
 Introduction à la programmation des GPUs Anne-Sophie Mouronval Mesocentre de calcul de l Ecole Centrale Paris Laboratoire MSSMat Avril 2013 Anne-Sophie Mouronval Introduction à la programmation des GPUs
Introduction à la programmation des GPUs Anne-Sophie Mouronval Mesocentre de calcul de l Ecole Centrale Paris Laboratoire MSSMat Avril 2013 Anne-Sophie Mouronval Introduction à la programmation des GPUs
Parallélisme et Répartition
 Parallélisme et Répartition Master Info Françoise Baude Université de Nice Sophia-Antipolis UFR Sciences Département Informatique [email protected] web du cours : deptinfo.unice.fr/~baude Septembre 2009 Chapitre
Parallélisme et Répartition Master Info Françoise Baude Université de Nice Sophia-Antipolis UFR Sciences Département Informatique [email protected] web du cours : deptinfo.unice.fr/~baude Septembre 2009 Chapitre
Formation à la C F D Computational Fluid Dynamics. Formation à la CFD, Ph Parnaudeau
 Formation à la C F D Computational Fluid Dynamics Formation à la CFD, Ph Parnaudeau 1 Qu est-ce que la CFD? La simulation numérique d un écoulement fluide Considérer à présent comme une alternative «raisonnable»
Formation à la C F D Computational Fluid Dynamics Formation à la CFD, Ph Parnaudeau 1 Qu est-ce que la CFD? La simulation numérique d un écoulement fluide Considérer à présent comme une alternative «raisonnable»
AdBackup Entreprise. Solution de sauvegarde pour Moyennes et Grandes Entreprises. Société Oodrive www.adbackup-corporatesolutions.
 Solution de sauvegarde pour Moyennes et Grandes Entreprises Société Oodrive www.adbackup-corporatesolutions.com Sommaire Présentation d Oodrive...3 Carte d identité...3 Références clients...3 Les enjeux...4
Solution de sauvegarde pour Moyennes et Grandes Entreprises Société Oodrive www.adbackup-corporatesolutions.com Sommaire Présentation d Oodrive...3 Carte d identité...3 Références clients...3 Les enjeux...4
Les technologies du Big Data
 Les technologies du Big Data PRÉSENTÉ AU 40 E CONGRÈS DE L ASSOCIATION DES ÉCONOMISTES QUÉBÉCOIS PAR TOM LANDRY, CONSEILLER SENIOR LE 20 MAI 2015 WWW.CRIM.CA TECHNOLOGIES: DES DONNÉES JUSQU'À L UTILISATEUR
Les technologies du Big Data PRÉSENTÉ AU 40 E CONGRÈS DE L ASSOCIATION DES ÉCONOMISTES QUÉBÉCOIS PAR TOM LANDRY, CONSEILLER SENIOR LE 20 MAI 2015 WWW.CRIM.CA TECHNOLOGIES: DES DONNÉES JUSQU'À L UTILISATEUR
Relever les défis des véhicules autonomes
 EMM 2014 12eme rencontre européenne de mécatronique Relever les défis des véhicules autonomes Mathias Perrollaz Ingénieur expert Inria Christian Laugier Directeur de recherche Inria E-Motion Team Annecy,
EMM 2014 12eme rencontre européenne de mécatronique Relever les défis des véhicules autonomes Mathias Perrollaz Ingénieur expert Inria Christian Laugier Directeur de recherche Inria E-Motion Team Annecy,
HAUTE DISPONIBILITÉ DE MACHINE VIRTUELLE AVEC HYPER-V 2012 R2 PARTIE CONFIGURATION OPENVPN SUR PFSENSE
 HAUTE DISPONIBILITÉ DE MACHINE VIRTUELLE AVEC HYPER-V 2012 R2 PARTIE CONFIGURATION OPENVPN SUR PFSENSE Projet de semestre ITI soir 4ème année Résumé configuration OpenVpn sur pfsense 2.1 Etudiant :Tarek
HAUTE DISPONIBILITÉ DE MACHINE VIRTUELLE AVEC HYPER-V 2012 R2 PARTIE CONFIGURATION OPENVPN SUR PFSENSE Projet de semestre ITI soir 4ème année Résumé configuration OpenVpn sur pfsense 2.1 Etudiant :Tarek
Partie 7 : Gestion de la mémoire
 INF3600+INF2610 Automne 2006 Partie 7 : Gestion de la mémoire Exercice 1 : Considérez un système disposant de 16 MO de mémoire physique réservée aux processus utilisateur. La mémoire est composée de cases
INF3600+INF2610 Automne 2006 Partie 7 : Gestion de la mémoire Exercice 1 : Considérez un système disposant de 16 MO de mémoire physique réservée aux processus utilisateur. La mémoire est composée de cases