fonction processus biologiques criblage
|
|
|
- Martial Duquette
- il y a 10 ans
- Total affichages :
Transcription
1 Transcriptome 1 Transcriptome : ensemble des ARNm ou transcrits présents dans une population de cellules dans des conditions données. Plan Introduction Acquisition des données Description des données Transformation, normalisation et filtrage Analyse des données de transcriptome Gènes différentiellement exprimés Gènes co-exprimés Interprétation Caractérisation d un ensemble de gènes

2 Applications 2 Accès au niveau d expression de milliers de gènes simultanément Indication sur la fonction des gènes ou implication des gènes dans des processus biologiques criblage antérieur à des expérimentations plus ciblées, plus longues et plus coûteuses Reconstruction de réseaux de régulation (cinétique) Exemples Traitement chimique, antibiotique, : gènes de résistance, processus biologique (ex: transformation et compétence), toxicité Tissus sain vs. tissus malade cancer : oncogènes et gènes suppresseurs, diagnostique clinique et traitement adapté Organes différents : gènes spécifiques et «gènes de ménage» Différents stades de développement : gènes impliqués au cours des différentes phases


3 Contexte 3 ADN gènes transcription ARNm (transcriptome) traduction Protéines régulation structure cellulaire réplication réparation métabolisme

4 Contexte 4 ADN gènes transcription régulation ex: ARNnc type miarn ARNm (transcriptome) quantité de protéines non proportionnelle à celle de l ARNm traduction Protéines régulation quantité de protéines non proportionnelle à leur activité structure cellulaire réplication réparation métabolisme

5 Acquisition des données 5 Échantillon 1 Échantillon 2 ARNm extraction réverse transcription et amplification ADNc scan marquage + hybridation puis lavage

6 probesets gènes Analyse et interprétation des données 6 mesures conditions normalisation filtrage Identification des gènes différentiellement exprimés interprétation Caractérisation d un ensemble de gènes Identification des ensembles de gènes co-exprimés

7 Données de transcriptome 7 Accès au niveau d expression de milliers de gènes simultanément Intensité de fluorescence par spot proportionnelle à la quantité d ADN hybridé abondance relative des transcrits : ratio (quantification absolue encore difficile)

8 Mesure du niveau d expression 8 échantillon 1 = fluorochrome vert (Cy3) échantillon 2 = fluorochrome rouge (Cy5) 2 canaux : intensité de vert intensité de rouge 1 spot = ensemble d oligonucléotides tous les mêmes variations de séquence plusieurs séquences spécifiques d un gène des spots différents peuvent correspondre au même gène un spot peut correspondre à plusieurs gènes

9 Données de transcriptome 9 De nombreuses sources d erreur et de variabilité Variabilité biologique Population de cellules ou patients/tissus différents Variabilité technique Étape d'amplification Incorporation des fluorochromes Bruit (artefacts, bruit de fond) Données manquantes (mesures absentes pour certains réplicats) Erreur, ex : Saturation du scanner pour les fluorochromes de la plaque pour la radioactivité du spot sur la puce
 Erreur, ex : Saturation du scanner pour les fluorochromes de la plaque pour la")
10 Acquisition des données 10 Échantillon 1 Échantillon 2 ARNm extraction réverse transcription et amplification ADNc scan marquage + hybridation puis lavage

11 Données de transcriptome 11 Solution : réplicats & traitement statistique Nombre de réplicats augmente la fiabilité des résultats Réplicat biologique & réplicat technique

12 Réplicats & validation 12 Motivation Variabilité des mesures 2 expériences de puces avec les mêmes paramètres produisent des résultats (légèrement) différents estimer l erreur non systématique associée à une mesure évaluer le niveau de variabilité des mesures

13 Réplicats & validation 13 Nombre et nature des réplicats dépendent des objectifs de l étude réplicat technique : plusieurs extraits d un même échantillon ex: dye swap variabilité due au bruit expérimental réplicat biologique : échantillons différents provenant d expériences menées en parallèle ex: population de cellules, patient différent variabilité «naturelle» d un système


14 Réplicats 14 Réplicats biologiques Expérience Réplicat 1 Réplicat 2 Extrait 1 Extrait 2 Réplicats techniques Label Cy3 Label Cy5 Spot 1 Spot 2 Spot 3


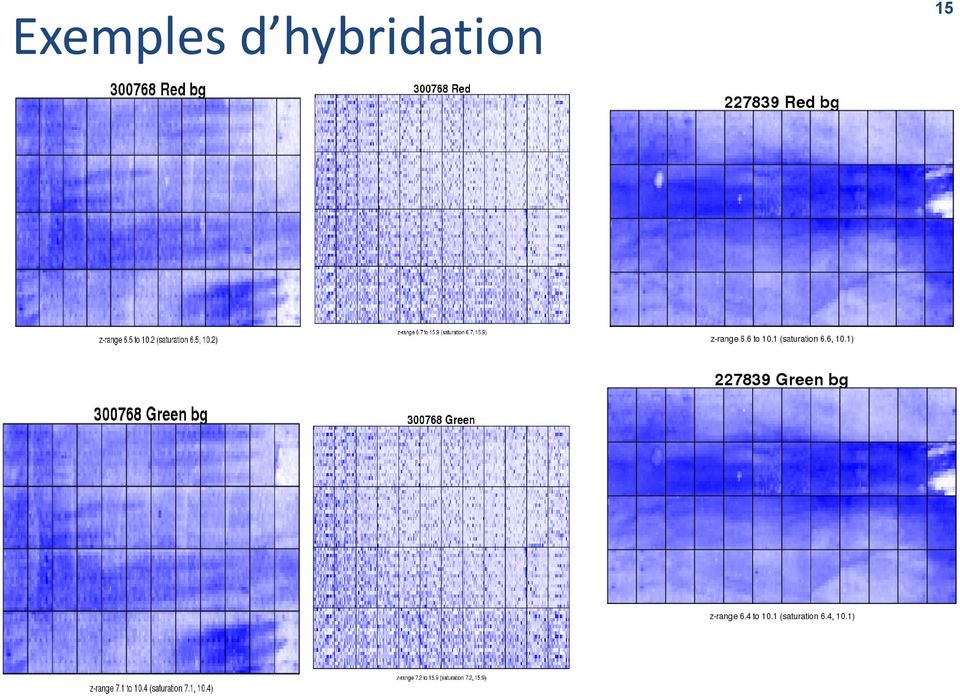
15 Exemples d hybridation 15
16 Validation 16 Validation directe : Northern blot, qpcr, TaqMan indirecte : hybridation in situ, Western blot

17 Transformation des données 17 Données initiales valeurs des intensités pour les différentes conditions/canaux Variations de l expression ratios T = I rouge /I verte effet multiplicatif : 1: pas de changement 2: 2x plus exprimé 0.5: 2x moins exprimé fold change : -1/T lorsque T<1 (ex: 0.5 donne -2) difficultés pour les analyses mathématiques dues à la discontinuité entre -1 et 1 transformation logarithmique mesure continue log 2 (0.5) = -1 ; log 2 (1) = 0 ; log 2 (2) = 1
 difficultés pour les analyses mathématiques dues à la discontinuité entre -1 et 1 transformation")
18 Filtrage 18 Motivation valeurs de (trop) faible intensité non exprimé? valeur manquante (problème sur la puce)? outlier (valeurs aberrantes)

19 Filtrage 19 Valeurs de faible intensité les valeurs dépassant légèrement le bruit de fond ont plus de chance d être imprécises ou de mauvaise qualité Filtrage : on élimine les valeurs inférieures à I médiane + 2 x σ(bruit de fond) I moyenne + 2 x σ(bruit de fond)
 I moyenne + 2 x")
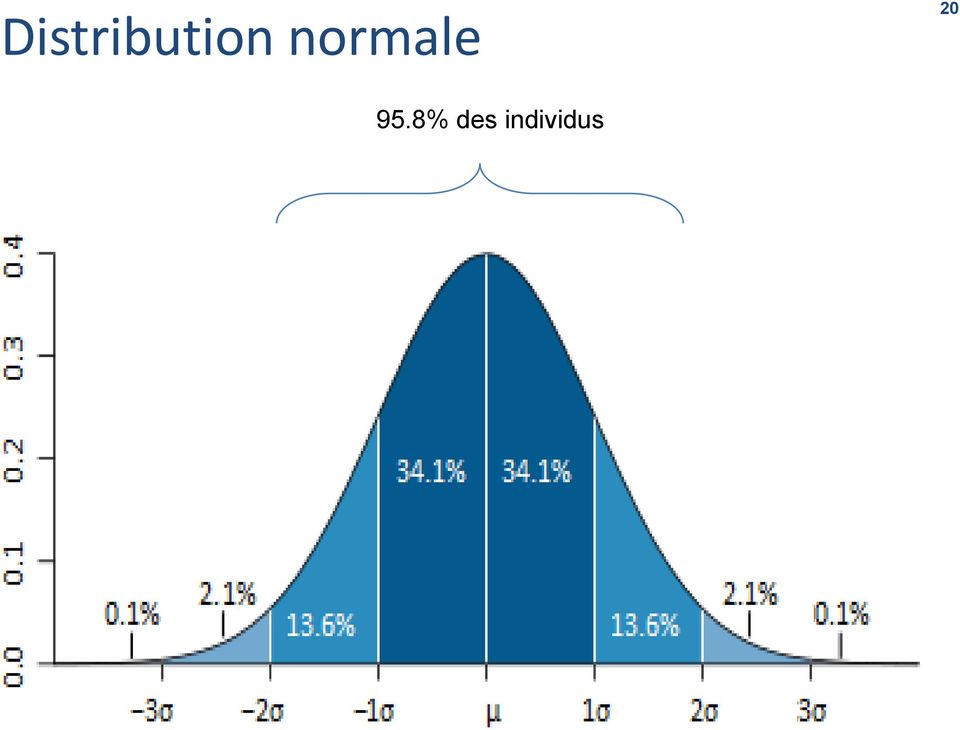
20 Distribution normale % des individus
21 Filtrage des outliers (dye swap) Variabilité des réplicats Exemple: 2 échantillons A et B 1 ère expérience A rouge (Cy5) et B vert (Cy3) pour le i-ème gène on a 2 ème expérience (dye swap) A vert et B rouge pour le i-ème gène on a on attend équivalent à 21 i i i i i B A G R T i i i i i A B G R T * ) * ( i i i i i i A B B A T T 0 ) * ( log T i T i
22 Filtrage des outliers (2 réplicats) 22 Moyenne et écarttype Inspection manuelle afin d identifier le spot aberrant suppression des spots
23 Normalisation 23 Motivations quantité d ARN différentes dans les échantillons efficacité de la détection de fluorescence biais systématiques, artefacts ex: pour un même échantillon marqué vert et rouge, le log 2 (ratio) est rarement 0. Normalisation: transformation des données pour corriger ces effets.
24 Normalisation 24 Approches: ensemble de contrôle soit gènes de ménage, soit exogène (sous-)ensemble des intensités sur la puce suppose que la plupart des gènes ont le même niveau d'expression Nombreuses méthodes: intensité totale centrage sur la moyenne des log régression linéaire lowess
25 Lowess 25 Régression linéaire Locally weighted scatter plot smoothing
26 Normalisation lowess 26 M-A plot M: ordonnées, ratios des intensités. log 2 R log 2 G = log 2 (R/G) A: abscisses, moyenne des intensités du spot. ½ (log 2 R + log 2 G)
27 Normalisation 27
28 Avant normalisation 28 Distribution des intensités rouges et vertes sur 3 hybridations
29 Après normalisation intra-puces 29
30 Après normalisation inter-puces 30


31 probesets gènes Analyse et interprétation des données 31 échantillons conditions normalisation filtrage Identification des gènes différentiellement exprimés interprétation Caractérisation d un ensemble de gènes Identification des ensembles de gènes co-exprimés
32 Gènes différentiellement exprimés 32 Motivation Gènes activés (induits) ou inactivés (réprimés) dans certaines conditions expérimentales/environnementales Identification des gènes différentiellement exprimés Fold change Modèles statistiques
33 Gènes différentiellement exprimés 33 Fold-change seuil au-delà duquel un gène est considéré comme différentiellement exprimé Ex : 2x plus ou 2x moins exprimé s écarte de plus de 2x l écart type Pas un test statistique, pas de niveau de confiance Ne tient pas compte de la variance au sein des réplicats

34 Fold change, seuil variable 34 fenêtre dans laquelle on considère l écart-type R-I plot
35 Modèles statistiques 35 t-test 2 conditions Analyse de variance (ANOVA) >2 conditions Bayésiens, modèles de mélange (mixture models),
36 t-test 36 But : déterminer si un gène est différentiellement exprimé entre 2 conditions Motivation : Le niveau d expression du gène est mesuré dans les 2 conditions en faisant n réplicats ex : R 1, R 2 et G 1, G 2, Si le gène n est pas différentiellement exprimé, la moyenne des ratios d expression du gène vaut 1 R G? two sample t-test permet de déterminer si les valeurs observées proviennent de distributions ayant la même moyenne
37 t-test 37 Échantillons : R 1, R 2, R 3 et G 1, G 2,G 3 On suppose que les mesures proviennent de distributions normales N R (μ R,σ R2 ) et N 2 (μ G,σ G2 ) Erreur standard à la moyenne : ESM = σ / n Erreur standard de la différence des moyennes : ESDM 2 2 ESM R ESM G distributions normales

38 t-test 38 Pour des mesures qui suivent une loi normale, on a ~95% de chances de rester à moins de 2σ de la moyenne réelle Formule : d où t doit être compris entre -2 et 2 t R G ESDM distribution normale
39 t-test 39 H 0 : les valeurs observées proviennent de distributions ayant la même moyenne (le gène n est pas différentiellement exprimé) Calcul de Probabilité donnée par la loi de probabilité de t t R G ESDM
40 p-valeur 40 p-valeur : probabilité d obtenir un résultat au moins aussi extrême probabilité : p(x = X) fonction de répartition p-valeur : p(x > X) distribution normale exemple avec un dé à 6 faces p(3) = 1/6 p(au moins 3) = p(3) + p(4) + p(5) + p(6) = 4/6 p(moins de 3) = 2/6
41 t-test 41 Application R : contrôle G : traitement R 1 R 2 G 1 G 2 p-value _at _at _at _at _at

42 Volcano plot 42 fold change vs. p-valeur (t-test ou autre)
43 ANOVA 43 Hypothèse testée : les moyennes des différentes conditions sont égales Variabilité inter-classes i.e. variabilité entre les conditions Variabilité intra-classe i.e. variabilité observée à l intérieur de chaque condition F S S inter int ra N Remarque: pour 2 conditions, cela équivaut au t-test c 1 c S S c 2 int er ri ( Ti T ) i1 c ri 2 int ra ( Tij Ti ) i1 j1
44 Tests multiples 44 H 0 : le gène g a un niveau d expression constant seuil α typique de 5% i.e. g est considéré comme différentiellement exprimé si p-valeur(g) 0.05 Idée : plus on augmente le nombre de tests, plus on a de chances de décider qu un gène est différentiellement exprimé alors qu il ne l est pas combien de faux positifs et de faux négatifs?
45 Erreurs de 1 ère et 2 ème espèce 45 Erreur de 1 ère espèce (Type 1 error) : probabilité α de rejeter H 0 alors qu elle est vraie probabilité de décider qu un gène est diff. exprimé alors qu il ne l est pas faux positif Erreur de 2 ème espèce (Type 2 error) : probabilité β d accepter H 0 alors qu elle est fausse probabilité de décider qu un gène n est pas diff. exprimé alors qu il l est Décision faux négatif Situation H 0 vraie H 0 fausse (diff. expr.) accepter H 0 rejeter H 0 Conséquence : En testant les gènes de la puce avec α = 5% on s attend à obtenir x0.05 faux positifs soit gènes qui ne sont en réalité pas différentiellement exprimés 1-α β α 1-β
46 Distribution normale % des individus
47 Correction pour tests multiples 47 False Discovery Rate (FDR) Benjamini & Hochberg 95 Principe : ajuster le seuil α en fonction des résultats observés (p-valeurs obtenues) m tests ayant des p-valeurs P 1..P m triées par ordre croissant Pour un seuil α trouver le plus grand k tel que k P k m et déclarer les gènes 1..k différentiellement exprimés
48 Application de la FDR 48 gène g différentiellement exprimé si P k k m R 1 R 2 G 1 G 2 p-value α * k/m _at _at _at _at _at aucun gène n est déclaré différentiellement exprimé pour α = 0.05
49 Gènes co-exprimés 49 Motivation : les gènes ayant des profils d expression similaires sont potentiellement co-régulés et participent à un même processus biologique But : regrouper les gènes impliqués dans un même processus biologique Robinson et al. 2002
50 Qu est-ce que le clustering? 50 analyse de clustering regroupement des objets en clusters un cluster : une collection d objets similaires au sein d un même cluster dissimilaires aux objets appartenant à d autres clusters classification non supervisée : pas de classes prédéfinies Applications typiques afin de mieux comprendre les données comme prétraitement avant d autres analyses
51 Principales approches 51 partitionnement partitionne les objets et évalue les partitions (les ensembles) ex: k-means hiérarchique décomposition hiérarchique d ensembles d objets densité basée sur une fonction de densité ou de connectivité grille basée sur une structure de granularité à plusieurs niveaux basée sur un modèle construction d un modèle pour chaque cluster
 X )( Y X i Y Y) http://www.mathworks.")
52 Gènes co-exprimés 52 Profils d expression Mesure de similarité entre 2 profils : Coefficient de corrélation de Pearson -1 : corrélation négative 0 : indépendance n i1 r 1 : corrélation positive Clustering des profils Ensembles de gènes ayant des profils d expression similaires ( X i ( n 1) X )( Y X i Y Y)
53 gènes gènes Structures de données 53 Matrice de données : les profils d expression Matrice de distance (ou dissimilarité) : pour chaque paire de gènes, le coefficient de corrélation conditions expérimentales x x 1f... x 1p x i1... x if... x ip x... x... x n1 nf np 0 d(2,1) d(3,1) : d( n,1) gènes 0 d(3,2) : d( n,2) 0 :
54 k-means 54 4 étapes 1. Partitionne les objets en k ensembles non vides 2. Calcule le centroïde de chaque partition/cluster 3. Assigne à chaque objet le cluster dont le centroïde est le plus proche 4. boucle en 2, jusqu à ce les clusters soient stables.
55 k-means, exemple

56 k-means, application 56 k = 16 clusters
57 Clustering hiérarchique 57 Utilisation d une matrice de distance : ne nécessite pas de spécifier le nombre de clusters Step 0 Step 1 Step 2 Step 3 Step 4 a a b b a b c d e c c d e d d e e Step 4 Step 3 Step 2 Step 1 Step 0 agglomérative séparative
58 AGNES (Agglomerative Nesting) 58 Utilise une matrice de dissimilarité Fusionne les nœuds les moins dissimilaires
59 DIANA (Divisive Analysis) 59 Inverse d AGNES
60 Dendrogramme : clusters fusionnés hiérarchiquement 60 Décompose les données en plusieurs niveaux imbriqués de partitionnement Un clustering est obtenu en coupant le dendrogramme au niveau choisi
61 Mesures de similarité entre 2 clusters 61 complete linkage plus petite similarité/plus grande distance entre toutes les paires de gènes entre 2 clusters average linkage similarité moyenne entre les paires de gènes single linkage plus grande similarité/plus petite distance entre 2 gènes de 2 clusters
62 Clustering hiérarchique 62 Robinson et al. 2002
63 Caractérisation d une liste de gènes 63 Motivation jusqu à plusieurs milliers de gènes co-exprimés ou différentiellement exprimés analyse «manuelle» impossible Principe Rechercher les caractéristiques communes aux gènes Surreprésentation statistique
64 Exemple 64 P07245 Q03677 P22768 P05150 P04076 Q01217 P18544 P08566 P14843 P49089 P49090 Amino-acid biosynthesis ATP-binding Complete proteome Cytoplasm Amino-acid biosynthesis Cell membrane Complete proteome Dioxygenase Amino-acid biosynthesis Arginine biosynthesis ATP-binding Complete proteome Amino-acid biosynthesis Arginine biosynthesis Complete proteome Cytoplasm Amino-acid biosynthesis Arginine biosynthesis Complete proteome Lyase Amino-acid biosynthesis Arginine biosynthesis Complete proteome Kinase Amino-acid biosynthesis Aminotransferase Arginine biosynthesis Complete proteome Amino-acid Aromatic amino acid biosynthesis biosynthesis ATP-binding Complete proteome Amino-acid Aromatic amino acid biosynthesis biosynthesis Complete proteome Phosphoprotein Amino-acid Glutamine biosynthesis Asparagine biosynthesis Complete proteome amidotransferase Amino-acid Glutamine biosynthesis Asparagine biosynthesis Complete proteome amidotransferase Amino-acid Branched-chain amino acid


65 Sources de données 65 localisation chromosomique voies métaboliques ensembles de gènes complexes protéiques co-citation domaines protéiques Gene Ontology
66 KEGG Pathways 66 Classification de processus biologiques 1. Metabolism 1. Carbohydrate Metabolism Glycolysis / Gluconeogenesis Citrate cycle (TCA cycle) Genetic Information Processing 3. Environmental Information Processing 4. Cellular Processes 5. Human Diseases 6. Drug Development
67 KEGG Pathways 67 code d enzime (EC number) Ensemble des gènes codant pour les enzymes impliquées dans un pathway
68 Gene Ontology 68 Vocabulaire contrôlé : le même terme pour parler de la même chose Ensemble de termes (définitions) reliés par des relations de type est-un ou fait-parti-de Trois ontologies: Biological process Molecular function Cellular component
69 Gene Ontology 69 Gene Ontology GO: Biological process GO: Cellular component GO: Molecular function à chaque terme correspond un ensemble de gènes annotés avec ce terme ou un plus spécifique
70 Mots-clés Uniprot/Swissprot 70 à chaque motclé correspond un ensemble de protéines annotées avec ce mot-clé
 à un domaine correspond un ensemble de")
71 Domaines protéiques 71 InterPro intègre les principales banques de domaines (Pfam, ProSite, SMART) à un domaine correspond un ensemble de protéines
 min( q, t) t g k q g avec k c q g = G : nombre total de gènes q = Q : nombre")
72 Test de surreprésentation 72 Loi binomiale χ 2 Pourcentage G Q : gènes co-exprimés T : gènes annotés biosynthèse des acides aminés Loi hypergéométrique : probabilité d avoir au moins le nombre d éléments communs observé entre 2 échantillons issus d une même population test de surreprésentation p valeur( c, t, q, g) min( q, t) t g k q g avec k c q g = G : nombre total de gènes q = Q : nombre de gènes co-exprimés t = T : nombre de gènes annotés biosynthèse des a.a. c = Q T : nombre de gènes communs t k
73 Recherche de caractéristiques communes 73 Annotations Gene Ontology Domaines protéiques Complexes multi-protéiques Voies métaboliques biosynthèse a.a. Correction pour tests multiples (FDR ou autre) On conserve les caractéristiques statistiquement significatives

74 Visualisation 74 Diagramme de Venn Aire proportionnelle à la taille des ensembles Chevauchement proportionnel aux gènes communs possible pour un petit nombre d ensembles

75 Application 75 Gènes différentiellement exprimés dans le cerveau des patients atteints du syndrome de Down (trisomie 21)
76 Communauté, standards et banques de données 76 Microarray Gene Expression Data (MGED) society MIAME (Minimum Information About a Microarray Experiment) interprétation non ambigüe reproductibilité MGED (MicroArray Gene Expression Data) MAGE-ML (Markup Language): format d échange MAGE-OM (Object Model) MGED Ontology: vocabulaire contrôlé Entrepôts GEO (Gene Expression Omnibus) au NCBI ArrayExpress SMD (Stanford Microarray Database)
BASE. Vous avez alors accès à un ensemble de fonctionnalités explicitées ci-dessous :
 BASE BioArray Software Environment (BASE) est une base de données permettant de gérer l importante quantité de données générées par des analyses de bio-puces. BASE gère les informations biologiques, les
BASE BioArray Software Environment (BASE) est une base de données permettant de gérer l importante quantité de données générées par des analyses de bio-puces. BASE gère les informations biologiques, les
TD de Biochimie 4 : Coloration.
 TD de Biochimie 4 : Coloration. Synthèse de l expérience 2 Les questions posées durant l expérience 2 Exposé sur les méthodes de coloration des molécules : Générique Spécifique Autres Questions Pourquoi
TD de Biochimie 4 : Coloration. Synthèse de l expérience 2 Les questions posées durant l expérience 2 Exposé sur les méthodes de coloration des molécules : Générique Spécifique Autres Questions Pourquoi
2D-Differential Differential Gel Electrophoresis & Applications en neurosciences
 2D-Differential Differential Gel Electrophoresis & Applications en neurosciences Jean-Etienne Poirrier Centre de Neurobiologie Cellulaire et Moléculaire Centre de Recherches du Cyclotron Université de
2D-Differential Differential Gel Electrophoresis & Applications en neurosciences Jean-Etienne Poirrier Centre de Neurobiologie Cellulaire et Moléculaire Centre de Recherches du Cyclotron Université de
Introduction aux bases de données: application en biologie
 Introduction aux bases de données: application en biologie D. Puthier 1 1 ERM206/Technologies Avancées pour le Génome et la Clinique, http://tagc.univ-mrs.fr/staff/puthier, [email protected] ESIL,
Introduction aux bases de données: application en biologie D. Puthier 1 1 ERM206/Technologies Avancées pour le Génome et la Clinique, http://tagc.univ-mrs.fr/staff/puthier, [email protected] ESIL,
La segmentation à l aide de EG-SAS. A.Bouhia Analyste principal à la Banque Nationale du Canada. Chargé de cours à l UQAM
 La segmentation à l aide de EG-SAS A.Bouhia Analyste principal à la Banque Nationale du Canada. Chargé de cours à l UQAM Définition de la segmentation - Au lieu de considérer une population dans son ensemble,
La segmentation à l aide de EG-SAS A.Bouhia Analyste principal à la Banque Nationale du Canada. Chargé de cours à l UQAM Définition de la segmentation - Au lieu de considérer une population dans son ensemble,
Objectifs. Clustering. Principe. Applications. Applications. Cartes de crédits. Remarques. Biologie, Génomique
 Objectifs Clustering On ne sait pas ce qu on veut trouver : on laisse l algorithme nous proposer un modèle. On pense qu il existe des similarités entre les exemples. Qui se ressemble s assemble p. /55
Objectifs Clustering On ne sait pas ce qu on veut trouver : on laisse l algorithme nous proposer un modèle. On pense qu il existe des similarités entre les exemples. Qui se ressemble s assemble p. /55
La classification automatique de données quantitatives
 La classification automatique de données quantitatives 1 Introduction Parmi les méthodes de statistique exploratoire multidimensionnelle, dont l objectif est d extraire d une masse de données des informations
La classification automatique de données quantitatives 1 Introduction Parmi les méthodes de statistique exploratoire multidimensionnelle, dont l objectif est d extraire d une masse de données des informations
Introduction au Data-Mining
 Introduction au Data-Mining Alain Rakotomamonjy - Gilles Gasso. INSA Rouen -Département ASI Laboratoire PSI Introduction au Data-Mining p. 1/25 Data-Mining : Kèkecé? Traduction : Fouille de données. Terme
Introduction au Data-Mining Alain Rakotomamonjy - Gilles Gasso. INSA Rouen -Département ASI Laboratoire PSI Introduction au Data-Mining p. 1/25 Data-Mining : Kèkecé? Traduction : Fouille de données. Terme
CHAPITRE 3 LA SYNTHESE DES PROTEINES
 CHAITRE 3 LA SYNTHESE DES ROTEINES On sait qu un gène détient dans sa séquence nucléotidique, l information permettant la synthèse d un polypeptide. Ce dernier caractérisé par sa séquence d acides aminés
CHAITRE 3 LA SYNTHESE DES ROTEINES On sait qu un gène détient dans sa séquence nucléotidique, l information permettant la synthèse d un polypeptide. Ce dernier caractérisé par sa séquence d acides aminés
Biomarqueurs en Cancérologie
 Biomarqueurs en Cancérologie Définition, détermination, usage Biomarqueurs et Cancer: définition Anomalie(s) quantitative(s) ou qualitative(s) Indicative(s) ou caractéristique(s) d un cancer ou de certaines
Biomarqueurs en Cancérologie Définition, détermination, usage Biomarqueurs et Cancer: définition Anomalie(s) quantitative(s) ou qualitative(s) Indicative(s) ou caractéristique(s) d un cancer ou de certaines
Approche par groupe de gènes pour les données longitudinales d expression génique avec une application dans un essai vaccinal contre le VIH
 Approche par groupe de gènes pour les données longitudinales d expression génique avec une application dans un essai vaccinal contre le VIH Boris Hejblum 1,2,3 & Rodolphe Thiébaut 1,2,3 1 Inserm, U897
Approche par groupe de gènes pour les données longitudinales d expression génique avec une application dans un essai vaccinal contre le VIH Boris Hejblum 1,2,3 & Rodolphe Thiébaut 1,2,3 1 Inserm, U897
Dr E. CHEVRET UE2.1 2013-2014. Aperçu général sur l architecture et les fonctions cellulaires
 Aperçu général sur l architecture et les fonctions cellulaires I. Introduction II. Les microscopes 1. Le microscope optique 2. Le microscope à fluorescence 3. Le microscope confocal 4. Le microscope électronique
Aperçu général sur l architecture et les fonctions cellulaires I. Introduction II. Les microscopes 1. Le microscope optique 2. Le microscope à fluorescence 3. Le microscope confocal 4. Le microscope électronique
Introduction au Data-Mining
 Introduction au Data-Mining Gilles Gasso, Stéphane Canu INSA Rouen -Département ASI Laboratoire LITIS 8 septembre 205. Ce cours est librement inspiré du cours DM de Alain Rakotomamonjy Gilles Gasso, Stéphane
Introduction au Data-Mining Gilles Gasso, Stéphane Canu INSA Rouen -Département ASI Laboratoire LITIS 8 septembre 205. Ce cours est librement inspiré du cours DM de Alain Rakotomamonjy Gilles Gasso, Stéphane
Projet SINF2275 «Data mining and decision making» Projet classification et credit scoring
 Projet SINF2275 «Data mining and decision making» Projet classification et credit scoring Année académique 2006-2007 Professeurs : Marco Saerens Adresse : Université catholique de Louvain Information Systems
Projet SINF2275 «Data mining and decision making» Projet classification et credit scoring Année académique 2006-2007 Professeurs : Marco Saerens Adresse : Université catholique de Louvain Information Systems
Statistiques Descriptives à une dimension
 I. Introduction et Définitions 1. Introduction La statistique est une science qui a pour objectif de recueillir et de traiter les informations, souvent en très grand nombre. Elle regroupe l ensemble des
I. Introduction et Définitions 1. Introduction La statistique est une science qui a pour objectif de recueillir et de traiter les informations, souvent en très grand nombre. Elle regroupe l ensemble des
CATALOGUE DES PRESTATIONS DE LA
 1/23 La plate-forme Biopuces et Séquençage de Strasbourg est équipée des technologies Affymetrix et Agilent pour l étude du transcriptome et du génome sur puces à ADN. SOMMAIRE ANALYSE TRANSCRIPTIONNELLE...
1/23 La plate-forme Biopuces et Séquençage de Strasbourg est équipée des technologies Affymetrix et Agilent pour l étude du transcriptome et du génome sur puces à ADN. SOMMAIRE ANALYSE TRANSCRIPTIONNELLE...
Annales du Contrôle National de Qualité des Analyses de Biologie Médicale
 Annales du Contrôle National de Qualité des Analyses de Biologie Médicale ARN du virus de l hépatite C : ARN-VHC ARN-VHC 03VHC1 Novembre 2003 Edité : mars 2006 Annales ARN-VHC 03VHC1 1 / 8 ARN-VHC 03VHC1
Annales du Contrôle National de Qualité des Analyses de Biologie Médicale ARN du virus de l hépatite C : ARN-VHC ARN-VHC 03VHC1 Novembre 2003 Edité : mars 2006 Annales ARN-VHC 03VHC1 1 / 8 ARN-VHC 03VHC1
Précision d un résultat et calculs d incertitudes
 Précision d un résultat et calculs d incertitudes PSI* 2012-2013 Lycée Chaptal 3 Table des matières Table des matières 1. Présentation d un résultat numérique................................ 4 1.1 Notations.........................................................
Précision d un résultat et calculs d incertitudes PSI* 2012-2013 Lycée Chaptal 3 Table des matières Table des matières 1. Présentation d un résultat numérique................................ 4 1.1 Notations.........................................................
LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING»
 LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING» Gilbert Saporta Professeur de Statistique Appliquée Conservatoire National des Arts et Métiers Dans leur quasi totalité, les banques et organismes financiers
LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING» Gilbert Saporta Professeur de Statistique Appliquée Conservatoire National des Arts et Métiers Dans leur quasi totalité, les banques et organismes financiers
Analyses de Variance à un ou plusieurs facteurs Régressions Analyse de Covariance Modèles Linéaires Généralisés
 Analyses de Variance à un ou plusieurs facteurs Régressions Analyse de Covariance Modèles Linéaires Généralisés Professeur Patrice Francour [email protected] Une grande partie des illustrations viennent
Analyses de Variance à un ou plusieurs facteurs Régressions Analyse de Covariance Modèles Linéaires Généralisés Professeur Patrice Francour [email protected] Une grande partie des illustrations viennent
Introduction à l approche bootstrap
 Introduction à l approche bootstrap Irène Buvat U494 INSERM buvat@imedjussieufr 25 septembre 2000 Introduction à l approche bootstrap - Irène Buvat - 21/9/00-1 Plan du cours Qu est-ce que le bootstrap?
Introduction à l approche bootstrap Irène Buvat U494 INSERM buvat@imedjussieufr 25 septembre 2000 Introduction à l approche bootstrap - Irène Buvat - 21/9/00-1 Plan du cours Qu est-ce que le bootstrap?
Déroulement d un projet en DATA MINING, préparation et analyse des données. Walid AYADI
 1 Déroulement d un projet en DATA MINING, préparation et analyse des données Walid AYADI 2 Les étapes d un projet Choix du sujet - Définition des objectifs Inventaire des données existantes Collecte, nettoyage
1 Déroulement d un projet en DATA MINING, préparation et analyse des données Walid AYADI 2 Les étapes d un projet Choix du sujet - Définition des objectifs Inventaire des données existantes Collecte, nettoyage
Chapitre 3. Les distributions à deux variables
 Chapitre 3. Les distributions à deux variables Jean-François Coeurjolly http://www-ljk.imag.fr/membres/jean-francois.coeurjolly/ Laboratoire Jean Kuntzmann (LJK), Grenoble University 1 Distributions conditionnelles
Chapitre 3. Les distributions à deux variables Jean-François Coeurjolly http://www-ljk.imag.fr/membres/jean-francois.coeurjolly/ Laboratoire Jean Kuntzmann (LJK), Grenoble University 1 Distributions conditionnelles
Logiciel XLSTAT version 7.0. 40 rue Damrémont 75018 PARIS
 Logiciel XLSTAT version 7.0 Contact : Addinsoft 40 rue Damrémont 75018 PARIS 2005-2006 Plan Présentation générale du logiciel Statistiques descriptives Histogramme Discrétisation Tableau de contingence
Logiciel XLSTAT version 7.0 Contact : Addinsoft 40 rue Damrémont 75018 PARIS 2005-2006 Plan Présentation générale du logiciel Statistiques descriptives Histogramme Discrétisation Tableau de contingence
Nombres, mesures et incertitudes en sciences physiques et chimiques. Groupe des Sciences physiques et chimiques de l IGEN
 Nombres, mesures et incertitudes en sciences physiques et chimiques. Groupe des Sciences physiques et chimiques de l IGEN Table des matières. Introduction....3 Mesures et incertitudes en sciences physiques
Nombres, mesures et incertitudes en sciences physiques et chimiques. Groupe des Sciences physiques et chimiques de l IGEN Table des matières. Introduction....3 Mesures et incertitudes en sciences physiques
Estimation et tests statistiques, TD 5. Solutions
 ISTIL, Tronc commun de première année Introduction aux méthodes probabilistes et statistiques, 2008 2009 Estimation et tests statistiques, TD 5. Solutions Exercice 1 Dans un centre avicole, des études
ISTIL, Tronc commun de première année Introduction aux méthodes probabilistes et statistiques, 2008 2009 Estimation et tests statistiques, TD 5. Solutions Exercice 1 Dans un centre avicole, des études
INF6304 Interfaces Intelligentes
 INF6304 Interfaces Intelligentes filtres collaboratifs 1/42 INF6304 Interfaces Intelligentes Systèmes de recommandations, Approches filtres collaboratifs Michel C. Desmarais Génie informatique et génie
INF6304 Interfaces Intelligentes filtres collaboratifs 1/42 INF6304 Interfaces Intelligentes Systèmes de recommandations, Approches filtres collaboratifs Michel C. Desmarais Génie informatique et génie
4. Résultats et discussion
 17 4. Résultats et discussion La signification statistique des gains et des pertes bruts annualisés pondérés de superficie forestière et du changement net de superficie forestière a été testée pour les
17 4. Résultats et discussion La signification statistique des gains et des pertes bruts annualisés pondérés de superficie forestière et du changement net de superficie forestière a été testée pour les
Analyse de la variance Comparaison de plusieurs moyennes
 Analyse de la variance Comparaison de plusieurs moyennes Biostatistique Pr. Nicolas MEYER Laboratoire de Biostatistique et Informatique Médicale Fac. de Médecine de Strasbourg Mars 2011 Plan 1 Introduction
Analyse de la variance Comparaison de plusieurs moyennes Biostatistique Pr. Nicolas MEYER Laboratoire de Biostatistique et Informatique Médicale Fac. de Médecine de Strasbourg Mars 2011 Plan 1 Introduction
L ANALYSE EN COMPOSANTES PRINCIPALES (A.C.P.) Pierre-Louis GONZALEZ
 Pierre-Louis GONZALEZ") L ANALYSE EN COMPOSANTES PRINCIPALES (A.C.P.) Pierre-Louis GONZALEZ INTRODUCTION Données : n individus observés sur p variables quantitatives. L A.C.P. permet d eplorer les liaisons entre variables et
L ANALYSE EN COMPOSANTES PRINCIPALES (A.C.P.) Pierre-Louis GONZALEZ INTRODUCTION Données : n individus observés sur p variables quantitatives. L A.C.P. permet d eplorer les liaisons entre variables et
Identification de nouveaux membres dans des familles d'interleukines
 Identification de nouveaux membres dans des familles d'interleukines Nicolas Beaume Jérôme Mickolajczak Gérard Ramstein Yannick Jacques 1ère partie : Définition de la problématique Les familles de gènes
Identification de nouveaux membres dans des familles d'interleukines Nicolas Beaume Jérôme Mickolajczak Gérard Ramstein Yannick Jacques 1ère partie : Définition de la problématique Les familles de gènes
Biochimie I. Extraction et quantification de l hexokinase dans Saccharomyces cerevisiae 1. Assistants : Tatjana Schwabe Marcy Taylor Gisèle Dewhurst
 Biochimie I Extraction et quantification de l hexokinase dans Saccharomyces cerevisiae 1 Daniel Abegg Sarah Bayat Alexandra Belfanti Assistants : Tatjana Schwabe Marcy Taylor Gisèle Dewhurst Laboratoire
Biochimie I Extraction et quantification de l hexokinase dans Saccharomyces cerevisiae 1 Daniel Abegg Sarah Bayat Alexandra Belfanti Assistants : Tatjana Schwabe Marcy Taylor Gisèle Dewhurst Laboratoire
Chapitre 3 : Principe des tests statistiques d hypothèse. José LABARERE
 UE4 : Biostatistiques Chapitre 3 : Principe des tests statistiques d hypothèse José LABARERE Année universitaire 2010/2011 Université Joseph Fourier de Grenoble - Tous droits réservés. Plan I. Introduction
UE4 : Biostatistiques Chapitre 3 : Principe des tests statistiques d hypothèse José LABARERE Année universitaire 2010/2011 Université Joseph Fourier de Grenoble - Tous droits réservés. Plan I. Introduction
données en connaissance et en actions?
 1 Partie 2 : Présentation de la plateforme SPSS Modeler : Comment transformer vos données en connaissance et en actions? SPSS Modeler : l atelier de data mining Large gamme de techniques d analyse (algorithmes)
1 Partie 2 : Présentation de la plateforme SPSS Modeler : Comment transformer vos données en connaissance et en actions? SPSS Modeler : l atelier de data mining Large gamme de techniques d analyse (algorithmes)
Tests de comparaison de moyennes. Dr Sahar BAYAT MASTER 1 année 2009-2010 UE «Introduction à la biostatistique»
 Tests de comparaison de moyennes Dr Sahar BAYAT MASTER 1 année 2009-2010 UE «Introduction à la biostatistique» Test de Z ou de l écart réduit Le test de Z : comparer des paramètres en testant leurs différences
Tests de comparaison de moyennes Dr Sahar BAYAT MASTER 1 année 2009-2010 UE «Introduction à la biostatistique» Test de Z ou de l écart réduit Le test de Z : comparer des paramètres en testant leurs différences
Dan Istrate. Directeur de thèse : Eric Castelli Co-Directeur : Laurent Besacier
 Détection et reconnaissance des sons pour la surveillance médicale Dan Istrate le 16 décembre 2003 Directeur de thèse : Eric Castelli Co-Directeur : Laurent Besacier Thèse mené dans le cadre d une collaboration
Détection et reconnaissance des sons pour la surveillance médicale Dan Istrate le 16 décembre 2003 Directeur de thèse : Eric Castelli Co-Directeur : Laurent Besacier Thèse mené dans le cadre d une collaboration
Théorie et Codage de l Information (IF01) exercices 2013-2014. Paul Honeine Université de technologie de Troyes France
 exercices 2013-2014. Paul Honeine Université de technologie de Troyes France") Théorie et Codage de l Information (IF01) exercices 2013-2014 Paul Honeine Université de technologie de Troyes France TD-1 Rappels de calculs de probabilités Exercice 1. On dispose d un jeu de 52 cartes
Théorie et Codage de l Information (IF01) exercices 2013-2014 Paul Honeine Université de technologie de Troyes France TD-1 Rappels de calculs de probabilités Exercice 1. On dispose d un jeu de 52 cartes
Régression linéaire. Nicolas Turenne INRA [email protected]
 Régression linéaire Nicolas Turenne INRA [email protected] 2005 Plan Régression linéaire simple Régression multiple Compréhension de la sortie de la régression Coefficient de détermination R
Régression linéaire Nicolas Turenne INRA [email protected] 2005 Plan Régression linéaire simple Régression multiple Compréhension de la sortie de la régression Coefficient de détermination R
«Manuel Pratique» Gestion budgétaire
 11/06/01 B50/v2.31/F/MP005.01 «Manuel Pratique» Gestion budgétaire Finance A l usage des utilisateurs de Sage BOB 50 Solution Sage BOB 50 2 L éditeur veille à la fiabilité des informations publiées, lesquelles
11/06/01 B50/v2.31/F/MP005.01 «Manuel Pratique» Gestion budgétaire Finance A l usage des utilisateurs de Sage BOB 50 Solution Sage BOB 50 2 L éditeur veille à la fiabilité des informations publiées, lesquelles
MABioVis. Bio-informatique et la
 MABioVis Modèles et Algorithmes pour la Bio-informatique et la Visualisation Visite ENS Cachan 5 janvier 2011 MABioVis G GUY MELANÇON (PR UFR Maths Info / EPI GRAVITE) (là, maintenant) - MABioVis DAVID
MABioVis Modèles et Algorithmes pour la Bio-informatique et la Visualisation Visite ENS Cachan 5 janvier 2011 MABioVis G GUY MELANÇON (PR UFR Maths Info / EPI GRAVITE) (là, maintenant) - MABioVis DAVID
CAPTEURS - CHAINES DE MESURES
 CAPTEURS - CHAINES DE MESURES Pierre BONNET Pierre Bonnet Master GSI - Capteurs Chaînes de Mesures 1 Plan du Cours Propriétés générales des capteurs Notion de mesure Notion de capteur: principes, classes,
CAPTEURS - CHAINES DE MESURES Pierre BONNET Pierre Bonnet Master GSI - Capteurs Chaînes de Mesures 1 Plan du Cours Propriétés générales des capteurs Notion de mesure Notion de capteur: principes, classes,
UFR de Sciences Economiques Année 2008-2009 TESTS PARAMÉTRIQUES
 Université Paris 13 Cours de Statistiques et Econométrie I UFR de Sciences Economiques Année 2008-2009 Licence de Sciences Economiques L3 Premier semestre TESTS PARAMÉTRIQUES Remarque: les exercices 2,
Université Paris 13 Cours de Statistiques et Econométrie I UFR de Sciences Economiques Année 2008-2009 Licence de Sciences Economiques L3 Premier semestre TESTS PARAMÉTRIQUES Remarque: les exercices 2,
TABLE DES MATIÈRES. Bruxelles, De Boeck, 2011, 736 p.
 STATISTIQUE THÉORIQUE ET APPLIQUÉE Tome 2 Inférence statistique à une et à deux dimensions Pierre Dagnelie TABLE DES MATIÈRES Bruxelles, De Boeck, 2011, 736 p. ISBN 978-2-8041-6336-5 De Boeck Services,
STATISTIQUE THÉORIQUE ET APPLIQUÉE Tome 2 Inférence statistique à une et à deux dimensions Pierre Dagnelie TABLE DES MATIÈRES Bruxelles, De Boeck, 2011, 736 p. ISBN 978-2-8041-6336-5 De Boeck Services,
Plateforme. DArT (Diversity Array Technology) Pierre Mournet
 Pierre Mournet") Plateforme DArT (Diversity Array Technology) Pierre Mournet Lundi 8 avril 203 Pourquoi des DArT? Développement rapide et peu onéreux de marqueurs : Pas d information de séquence nécessaire. Pas de pré-requis
Plateforme DArT (Diversity Array Technology) Pierre Mournet Lundi 8 avril 203 Pourquoi des DArT? Développement rapide et peu onéreux de marqueurs : Pas d information de séquence nécessaire. Pas de pré-requis
Intelligence Artificielle et Systèmes Multi-Agents. Badr Benmammar [email protected]
 Intelligence Artificielle et Systèmes Multi-Agents Badr Benmammar [email protected] Plan La première partie : L intelligence artificielle (IA) Définition de l intelligence artificielle (IA) Domaines
Intelligence Artificielle et Systèmes Multi-Agents Badr Benmammar [email protected] Plan La première partie : L intelligence artificielle (IA) Définition de l intelligence artificielle (IA) Domaines
Conception de Médicament
 Conception de Médicament Approche classique HTS Chimie combinatoire Rational Drug Design Ligand based (QSAR) Structure based (ligand et ou macromolec.) 3DQSAR Docking Virtual screening Needle in a Haystack
Conception de Médicament Approche classique HTS Chimie combinatoire Rational Drug Design Ligand based (QSAR) Structure based (ligand et ou macromolec.) 3DQSAR Docking Virtual screening Needle in a Haystack
Data Mining. Vincent Augusto 2012-2013. École Nationale Supérieure des Mines de Saint-Étienne. Data Mining. V. Augusto.
 des des Data Mining Vincent Augusto École Nationale Supérieure des Mines de Saint-Étienne 2012-2013 1/65 des des 1 2 des des 3 4 Post-traitement 5 représentation : 6 2/65 des des Définition générale Le
des des Data Mining Vincent Augusto École Nationale Supérieure des Mines de Saint-Étienne 2012-2013 1/65 des des 1 2 des des 3 4 Post-traitement 5 représentation : 6 2/65 des des Définition générale Le
Baccalauréat ES Pondichéry 7 avril 2014 Corrigé
 Baccalauréat ES Pondichéry 7 avril 204 Corrigé EXERCICE 4 points Commun à tous les candidats. Proposition fausse. La tangente T, passant par les points A et B d abscisses distinctes, a pour coefficient
Baccalauréat ES Pondichéry 7 avril 204 Corrigé EXERCICE 4 points Commun à tous les candidats. Proposition fausse. La tangente T, passant par les points A et B d abscisses distinctes, a pour coefficient
Statistique Descriptive Élémentaire
 Publications de l Institut de Mathématiques de Toulouse Statistique Descriptive Élémentaire (version de mai 2010) Alain Baccini Institut de Mathématiques de Toulouse UMR CNRS 5219 Université Paul Sabatier
Publications de l Institut de Mathématiques de Toulouse Statistique Descriptive Élémentaire (version de mai 2010) Alain Baccini Institut de Mathématiques de Toulouse UMR CNRS 5219 Université Paul Sabatier
LIVRE BLANC Décembre 2014
 PARSING MATCHING EQUALITY SEARCH LIVRE BLANC Décembre 2014 Introduction L analyse des tendances du marché de l emploi correspond à l évidence à une nécessité, surtout en période de tension comme depuis
PARSING MATCHING EQUALITY SEARCH LIVRE BLANC Décembre 2014 Introduction L analyse des tendances du marché de l emploi correspond à l évidence à une nécessité, surtout en période de tension comme depuis
Principe d un test statistique
 Biostatistiques Principe d un test statistique Professeur Jean-Luc BOSSON PCEM2 - Année universitaire 2012/2013 Faculté de Médecine de Grenoble (UJF) - Tous droits réservés. Objectifs pédagogiques Comprendre
Biostatistiques Principe d un test statistique Professeur Jean-Luc BOSSON PCEM2 - Année universitaire 2012/2013 Faculté de Médecine de Grenoble (UJF) - Tous droits réservés. Objectifs pédagogiques Comprendre
Chapitre 5 LE MODELE ENTITE - ASSOCIATION
 Chapitre 5 LE MODELE ENTITE - ASSOCIATION 1 Introduction Conception d une base de données Domaine d application complexe : description abstraite des concepts indépendamment de leur implémentation sous
Chapitre 5 LE MODELE ENTITE - ASSOCIATION 1 Introduction Conception d une base de données Domaine d application complexe : description abstraite des concepts indépendamment de leur implémentation sous
Probabilités conditionnelles Loi binomiale
 Exercices 23 juillet 2014 Probabilités conditionnelles Loi binomiale Équiprobabilité et variable aléatoire Exercice 1 Une urne contient 5 boules indiscernables, 3 rouges et 2 vertes. On tire au hasard
Exercices 23 juillet 2014 Probabilités conditionnelles Loi binomiale Équiprobabilité et variable aléatoire Exercice 1 Une urne contient 5 boules indiscernables, 3 rouges et 2 vertes. On tire au hasard
Analyse de la vidéo. Chapitre 4.1 - La modélisation pour le suivi d objet. 10 mars 2015. Chapitre 4.1 - La modélisation d objet 1 / 57
 Analyse de la vidéo Chapitre 4.1 - La modélisation pour le suivi d objet 10 mars 2015 Chapitre 4.1 - La modélisation d objet 1 / 57 La représentation d objets Plan de la présentation 1 La représentation
Analyse de la vidéo Chapitre 4.1 - La modélisation pour le suivi d objet 10 mars 2015 Chapitre 4.1 - La modélisation d objet 1 / 57 La représentation d objets Plan de la présentation 1 La représentation
Gestion obligataire passive
 Finance 1 Université d Evry Séance 7 Gestion obligataire passive Philippe Priaulet L efficience des marchés Stratégies passives Qu est-ce qu un bon benchmark? Réplication simple Réplication par échantillonnage
Finance 1 Université d Evry Séance 7 Gestion obligataire passive Philippe Priaulet L efficience des marchés Stratégies passives Qu est-ce qu un bon benchmark? Réplication simple Réplication par échantillonnage
Relation entre deux variables : estimation de la corrélation linéaire
 CHAPITRE 3 Relation entre deux variables : estimation de la corrélation linéaire Parmi les analyses statistiques descriptives, l une d entre elles est particulièrement utilisée pour mettre en évidence
CHAPITRE 3 Relation entre deux variables : estimation de la corrélation linéaire Parmi les analyses statistiques descriptives, l une d entre elles est particulièrement utilisée pour mettre en évidence
FORMATION CONTINUE SUR L UTILISATION D EXCEL DANS L ENSEIGNEMENT Expérience de l E.N.S de Tétouan (Maroc)
") 87 FORMATION CONTINUE SUR L UTILISATION D EXCEL DANS L ENSEIGNEMENT Expérience de l E.N.S de Tétouan (Maroc) Dans le cadre de la réforme pédagogique et de l intérêt que porte le Ministère de l Éducation
87 FORMATION CONTINUE SUR L UTILISATION D EXCEL DANS L ENSEIGNEMENT Expérience de l E.N.S de Tétouan (Maroc) Dans le cadre de la réforme pédagogique et de l intérêt que porte le Ministère de l Éducation
présentée DEVANT L UNIVERSITÉ DE RENNES 1 pour obtenir le grade de : DOCTEUR DE L UNIVERSITÉ DE RENNES 1 PAR Emilie GUÉRIN TITRE DE LA THÈSE :
 N Ordre de la Thèse 3282 THÈSE présentée DEVANT L UNIVERSITÉ DE RENNES 1 pour obtenir le grade de : DOCTEUR DE L UNIVERSITÉ DE RENNES 1 Mention : BIOLOGIE PAR Emilie GUÉRIN Équipe d accueil : École Doctorale
N Ordre de la Thèse 3282 THÈSE présentée DEVANT L UNIVERSITÉ DE RENNES 1 pour obtenir le grade de : DOCTEUR DE L UNIVERSITÉ DE RENNES 1 Mention : BIOLOGIE PAR Emilie GUÉRIN Équipe d accueil : École Doctorale
MAB Solut. vos projets. MABLife Génopole Campus 1 5 rue Henri Desbruères 91030 Evry Cedex. www.mabsolut.com. intervient à chaque étape de
 Mabsolut-DEF-HI:Mise en page 1 17/11/11 17:45 Page1 le département prestataire de services de MABLife de la conception à la validation MAB Solut intervient à chaque étape de vos projets Création d anticorps
Mabsolut-DEF-HI:Mise en page 1 17/11/11 17:45 Page1 le département prestataire de services de MABLife de la conception à la validation MAB Solut intervient à chaque étape de vos projets Création d anticorps
Document d orientation sur les allégations issues d essais de non-infériorité
 Document d orientation sur les allégations issues d essais de non-infériorité Février 2013 1 Liste de contrôle des essais de non-infériorité N o Liste de contrôle (les clients peuvent se servir de cette
Document d orientation sur les allégations issues d essais de non-infériorité Février 2013 1 Liste de contrôle des essais de non-infériorité N o Liste de contrôle (les clients peuvent se servir de cette
Arbres binaires de décision
 1 Arbres binaires de décision Résumé Arbres binaires de décision Méthodes de construction d arbres binaires de décision, modélisant une discrimination (classification trees) ou une régression (regression
1 Arbres binaires de décision Résumé Arbres binaires de décision Méthodes de construction d arbres binaires de décision, modélisant une discrimination (classification trees) ou une régression (regression
Big Data et Graphes : Quelques pistes de recherche
 Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci http://liris.cnrs.fr/hamamache.kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de
Big Data et Graphes : Quelques pistes de recherche Hamamache Kheddouci http://liris.cnrs.fr/hamamache.kheddouci Laboratoire d'informatique en Image et Systèmes d'information LIRIS UMR 5205 CNRS/INSA de
Critères pour les méthodes de quantification des résidus potentiellement allergéniques de protéines de collage dans le vin (OIV-Oeno 427-2010)
") Méthode OIV- -MA-AS315-23 Type de méthode : critères Critères pour les méthodes de quantification des résidus potentiellement allergéniques de protéines de collage (OIV-Oeno 427-2010) 1 Définitions des
Méthode OIV- -MA-AS315-23 Type de méthode : critères Critères pour les méthodes de quantification des résidus potentiellement allergéniques de protéines de collage (OIV-Oeno 427-2010) 1 Définitions des
Introduction au datamining
 Introduction au datamining Patrick Naïm janvier 2005 Définition Définition Historique Mot utilisé au départ par les statisticiens Le mot indiquait une utilisation intensive des données conduisant à des
Introduction au datamining Patrick Naïm janvier 2005 Définition Définition Historique Mot utilisé au départ par les statisticiens Le mot indiquait une utilisation intensive des données conduisant à des
La problématique des tests. Cours V. 7 mars 2008. Comment quantifier la performance d un test? Hypothèses simples et composites
 La problématique des tests Cours V 7 mars 8 Test d hypothèses [Section 6.1] Soit un modèle statistique P θ ; θ Θ} et des hypothèses H : θ Θ H 1 : θ Θ 1 = Θ \ Θ Un test (pur) est une statistique à valeur
La problématique des tests Cours V 7 mars 8 Test d hypothèses [Section 6.1] Soit un modèle statistique P θ ; θ Θ} et des hypothèses H : θ Θ H 1 : θ Θ 1 = Θ \ Θ Un test (pur) est une statistique à valeur
L analyse d images regroupe plusieurs disciplines que l on classe en deux catégories :
 La vision nous permet de percevoir et d interpreter le monde qui nous entoure. La vision artificielle a pour but de reproduire certaines fonctionnalités de la vision humaine au travers de l analyse d images.
La vision nous permet de percevoir et d interpreter le monde qui nous entoure. La vision artificielle a pour but de reproduire certaines fonctionnalités de la vision humaine au travers de l analyse d images.
Big data et sciences du Vivant L'exemple du séquençage haut débit
 Big data et sciences du Vivant L'exemple du séquençage haut débit C. Gaspin, C. Hoede, C. Klopp, D. Laborie, J. Mariette, C. Noirot, MS. Trotard [email protected] INRA - MIAT - Plate-forme
Big data et sciences du Vivant L'exemple du séquençage haut débit C. Gaspin, C. Hoede, C. Klopp, D. Laborie, J. Mariette, C. Noirot, MS. Trotard [email protected] INRA - MIAT - Plate-forme
t 100. = 8 ; le pourcentage de réduction est : 8 % 1 t Le pourcentage d'évolution (appelé aussi taux d'évolution) est le nombre :
 est le nombre :") Terminale STSS 2 012 2 013 Pourcentages Synthèse 1) Définition : Calculer t % d'un nombre, c'est multiplier ce nombre par t 100. 2) Exemples de calcul : a) Calcul d un pourcentage : Un article coûtant
Terminale STSS 2 012 2 013 Pourcentages Synthèse 1) Définition : Calculer t % d'un nombre, c'est multiplier ce nombre par t 100. 2) Exemples de calcul : a) Calcul d un pourcentage : Un article coûtant
PROGRAMME (Susceptible de modifications)
") Page 1 sur 8 PROGRAMME (Susceptible de modifications) Partie 1 : Méthodes des revues systématiques Mercredi 29 mai 2013 Introduction, présentation du cours et des participants Rappel des principes et des
Page 1 sur 8 PROGRAMME (Susceptible de modifications) Partie 1 : Méthodes des revues systématiques Mercredi 29 mai 2013 Introduction, présentation du cours et des participants Rappel des principes et des
Lois de probabilité. Anita Burgun
 Lois de probabilité Anita Burgun Problème posé Le problème posé en statistique: On s intéresse à une population On extrait un échantillon On se demande quelle sera la composition de l échantillon (pourcentage
Lois de probabilité Anita Burgun Problème posé Le problème posé en statistique: On s intéresse à une population On extrait un échantillon On se demande quelle sera la composition de l échantillon (pourcentage
La PCR quantitative (qpcr) et le guide de bonnes pratiques MIQE : adaptation et pertinence dans le contexte de la biologie clinique
 et le guide de bonnes pratiques MIQE : adaptation et pertinence dans le contexte de la biologie clinique") Synthèse Ann Biol Clin 2014 ; 72 (3) : 265-9 La PCR quantitative (qpcr) et le guide de bonnes pratiques MIQE : adaptation et pertinence dans le contexte de la biologie clinique Quantitative PCR (qpcr)
Synthèse Ann Biol Clin 2014 ; 72 (3) : 265-9 La PCR quantitative (qpcr) et le guide de bonnes pratiques MIQE : adaptation et pertinence dans le contexte de la biologie clinique Quantitative PCR (qpcr)
Le Data Mining au service du Scoring ou notation statistique des emprunteurs!
 France Le Data Mining au service du Scoring ou notation statistique des emprunteurs! Comme le rappelle la CNIL dans sa délibération n 88-083 du 5 Juillet 1988 portant adoption d une recommandation relative
France Le Data Mining au service du Scoring ou notation statistique des emprunteurs! Comme le rappelle la CNIL dans sa délibération n 88-083 du 5 Juillet 1988 portant adoption d une recommandation relative
Parallélisation de l algorithme des k-médoïdes. Application au clustering de courbes.
 Parallélisation de l algorithme des k-médoïdes. Application au clustering de courbes. Benjamin Auder 1 & Jairo Cugliari 2 1 Laboratoire LMO. Université Paris-Sud. Bât 425. 91405 Orsay Cedex, France. [email protected]
Parallélisation de l algorithme des k-médoïdes. Application au clustering de courbes. Benjamin Auder 1 & Jairo Cugliari 2 1 Laboratoire LMO. Université Paris-Sud. Bât 425. 91405 Orsay Cedex, France. [email protected]
INTRODUCTION AU DATA MINING
 INTRODUCTION AU DATA MINING 6 séances de 3 heures mai-juin 2006 EPF - 4 ème année - Option Ingénierie d Affaires et de Projets Bertrand LIAUDET TP DE DATA MINING Le TP et le projet consisteront à mettre
INTRODUCTION AU DATA MINING 6 séances de 3 heures mai-juin 2006 EPF - 4 ème année - Option Ingénierie d Affaires et de Projets Bertrand LIAUDET TP DE DATA MINING Le TP et le projet consisteront à mettre
MAP 553 Apprentissage statistique
 MAP 553 Apprentissage statistique Université Paris Sud et Ecole Polytechnique http://www.cmap.polytechnique.fr/~giraud/map553/map553.html PC1 1/39 Apprentissage? 2/39 Apprentissage? L apprentissage au
MAP 553 Apprentissage statistique Université Paris Sud et Ecole Polytechnique http://www.cmap.polytechnique.fr/~giraud/map553/map553.html PC1 1/39 Apprentissage? 2/39 Apprentissage? L apprentissage au
Statistique : Résumé de cours et méthodes
 Statistique : Résumé de cours et méthodes 1 Vocabulaire : Population : c est l ensemble étudié. Individu : c est un élément de la population. Effectif total : c est le nombre total d individus. Caractère
Statistique : Résumé de cours et méthodes 1 Vocabulaire : Population : c est l ensemble étudié. Individu : c est un élément de la population. Effectif total : c est le nombre total d individus. Caractère
Master de Bioinformatique et Biologie des Systèmes Toulouse http://m2pbioinfo.biotoul.fr Responsable : Pr. Gwennaele Fichant
 Master de Bioinformatique et Biologie des Systèmes Toulouse http://m2pbioinfo.biotoul.fr Responsable : Pr. Gwennaele Fichant Parcours: Master 1 : Bioinformatique et biologie des Systèmes dans le Master
Master de Bioinformatique et Biologie des Systèmes Toulouse http://m2pbioinfo.biotoul.fr Responsable : Pr. Gwennaele Fichant Parcours: Master 1 : Bioinformatique et biologie des Systèmes dans le Master
Que faire lorsqu on considère plusieurs variables en même temps?
 Chapitre 3 Que faire lorsqu on considère plusieurs variables en même temps? On va la plupart du temps se limiter à l étude de couple de variables aléatoires, on peut bien sûr étendre les notions introduites
Chapitre 3 Que faire lorsqu on considère plusieurs variables en même temps? On va la plupart du temps se limiter à l étude de couple de variables aléatoires, on peut bien sûr étendre les notions introduites
Collecter des informations statistiques
 Collecter des informations statistiques FICHE MÉTHODE A I Les caractéristiques essentielles d un tableau statistique La statistique a un vocabulaire spécifique. L objet du tableau (la variable) s appelle
Collecter des informations statistiques FICHE MÉTHODE A I Les caractéristiques essentielles d un tableau statistique La statistique a un vocabulaire spécifique. L objet du tableau (la variable) s appelle
La gestion de données dans le cadre d une application de recherche d alignement de séquence : BLAST.
 La gestion de données dans le cadre d une application de recherche d alignement de séquence : BLAST. Gaël Le Mahec - p. 1/12 L algorithme BLAST. Basic Local Alignment Search Tool est un algorithme de recherche
La gestion de données dans le cadre d une application de recherche d alignement de séquence : BLAST. Gaël Le Mahec - p. 1/12 L algorithme BLAST. Basic Local Alignment Search Tool est un algorithme de recherche
INDICES DE PRIX EXPÉRIMENTAUX DES SERVICES FINANCIERS
 Distr. GÉNÉRALE CES/AC.49/2003/9 29 septembre 2003 FRANÇAIS Original: ANGLAIS COMMISSION DE STATISTIQUE et COMMISSION ÉCONOMIQUE POUR L EUROPE (CEE-ONU) ORGANISATION INTERNATIONALE DU TRAVAIL (OIT) CONFÉRENCE
Distr. GÉNÉRALE CES/AC.49/2003/9 29 septembre 2003 FRANÇAIS Original: ANGLAIS COMMISSION DE STATISTIQUE et COMMISSION ÉCONOMIQUE POUR L EUROPE (CEE-ONU) ORGANISATION INTERNATIONALE DU TRAVAIL (OIT) CONFÉRENCE
Traitement bas-niveau
 Plan Introduction L approche contour (frontière) Introduction Objectifs Les traitements ont pour but d extraire l information utile et pertinente contenue dans l image en regard de l application considérée.
Plan Introduction L approche contour (frontière) Introduction Objectifs Les traitements ont pour but d extraire l information utile et pertinente contenue dans l image en regard de l application considérée.
Leçon N 4 : Statistiques à deux variables
 Leçon N 4 : Statistiques à deux variables En premier lieu, il te faut relire les cours de première sur les statistiques à une variable, il y a tout un langage à se remémorer : étude d un échantillon d
Leçon N 4 : Statistiques à deux variables En premier lieu, il te faut relire les cours de première sur les statistiques à une variable, il y a tout un langage à se remémorer : étude d un échantillon d
Stéphane Tufféry DATA MINING & STATISTIQUE DÉCISIONNELLE. 04/04/2008 Stéphane Tufféry - Data Mining - http://data.mining.free.fr
 Stéphane Tufféry DATA MINING & STATISTIQUE DÉCISIONNELLE 1 Plan du cours Qu est-ce que le data mining? A quoi sert le data mining? Les 2 grandes familles de techniques Le déroulement d un projet de data
Stéphane Tufféry DATA MINING & STATISTIQUE DÉCISIONNELLE 1 Plan du cours Qu est-ce que le data mining? A quoi sert le data mining? Les 2 grandes familles de techniques Le déroulement d un projet de data
Cours 9 : Plans à plusieurs facteurs
 Cours 9 : Plans à plusieurs facteurs Table des matières Section 1. Diviser pour regner, rassembler pour saisir... 3 Section 2. Définitions et notations... 3 2.1. Définitions... 3 2.2. Notations... 4 Section
Cours 9 : Plans à plusieurs facteurs Table des matières Section 1. Diviser pour regner, rassembler pour saisir... 3 Section 2. Définitions et notations... 3 2.1. Définitions... 3 2.2. Notations... 4 Section
Probabilités et Statistiques. Feuille 2 : variables aléatoires discrètes
 IUT HSE Probabilités et Statistiques Feuille : variables aléatoires discrètes 1 Exercices Dénombrements Exercice 1. On souhaite ranger sur une étagère 4 livres de mathématiques (distincts), 6 livres de
IUT HSE Probabilités et Statistiques Feuille : variables aléatoires discrètes 1 Exercices Dénombrements Exercice 1. On souhaite ranger sur une étagère 4 livres de mathématiques (distincts), 6 livres de
Séries Statistiques Simples
 1. Collecte et Représentation de l Information 1.1 Définitions 1.2 Tableaux statistiques 1.3 Graphiques 2. Séries statistiques simples 2.1 Moyenne arithmétique 2.2 Mode & Classe modale 2.3 Effectifs &
1. Collecte et Représentation de l Information 1.1 Définitions 1.2 Tableaux statistiques 1.3 Graphiques 2. Séries statistiques simples 2.1 Moyenne arithmétique 2.2 Mode & Classe modale 2.3 Effectifs &
IMMUNOLOGIE. La spécificité des immunoglobulines et des récepteurs T. Informations scientifiques
 IMMUNOLOGIE La spécificité des immunoglobulines et des récepteurs T Informations scientifiques L infection par le VIH entraîne des réactions immunitaires de l organisme qui se traduisent par la production
IMMUNOLOGIE La spécificité des immunoglobulines et des récepteurs T Informations scientifiques L infection par le VIH entraîne des réactions immunitaires de l organisme qui se traduisent par la production
TABLE DES MATIERES. C Exercices complémentaires 42
 TABLE DES MATIERES Chapitre I : Echantillonnage A - Rappels de cours 1. Lois de probabilités de base rencontrées en statistique 1 1.1 Définitions et caractérisations 1 1.2 Les propriétés de convergence
TABLE DES MATIERES Chapitre I : Echantillonnage A - Rappels de cours 1. Lois de probabilités de base rencontrées en statistique 1 1.1 Définitions et caractérisations 1 1.2 Les propriétés de convergence
TSTI 2D CH X : Exemples de lois à densité 1
 TSTI 2D CH X : Exemples de lois à densité I Loi uniforme sur ab ; ) Introduction Dans cette activité, on s intéresse à la modélisation du tirage au hasard d un nombre réel de l intervalle [0 ;], chacun
TSTI 2D CH X : Exemples de lois à densité I Loi uniforme sur ab ; ) Introduction Dans cette activité, on s intéresse à la modélisation du tirage au hasard d un nombre réel de l intervalle [0 ;], chacun
Spécificités, Applications et Outils
 Spécificités, Applications et Outils Ricco Rakotomalala Université Lumière Lyon 2 Laboratoire ERIC Laboratoire ERIC 1 Ricco Rakotomalala [email protected] http://chirouble.univ-lyon2.fr/~ricco/data-mining
Spécificités, Applications et Outils Ricco Rakotomalala Université Lumière Lyon 2 Laboratoire ERIC Laboratoire ERIC 1 Ricco Rakotomalala [email protected] http://chirouble.univ-lyon2.fr/~ricco/data-mining
Classification non supervisée
 AgroParisTech Classification non supervisée E. Lebarbier, T. Mary-Huard Table des matières 1 Introduction 4 2 Méthodes de partitionnement 5 2.1 Mesures de similarité et de dissimilarité, distances.................
AgroParisTech Classification non supervisée E. Lebarbier, T. Mary-Huard Table des matières 1 Introduction 4 2 Méthodes de partitionnement 5 2.1 Mesures de similarité et de dissimilarité, distances.................
IFT 6261: L Analytique Web. Fares Aldik, Consultant principal, Analytique Web et optimisation Bell Marchés Affaires services d expérience client
 IFT 6261: L Analytique Web Fares Aldik, Consultant principal, Analytique Web et optimisation Bell Marchés Affaires services d expérience client 2012 01 04 Analytique Web : une pratique multidisciplinaire
IFT 6261: L Analytique Web Fares Aldik, Consultant principal, Analytique Web et optimisation Bell Marchés Affaires services d expérience client 2012 01 04 Analytique Web : une pratique multidisciplinaire
TRS: Sélection des sous-graphes représentants par l intermédiaire des attributs topologiques et K-medoïdes
 TRS: Sélection des sous-graphes représentants par l intermédiaire des attributs topologiques et K-medoïdes Mohamed Moussaoui,Wajdi Dhifli,Sami Zghal,Engelbert Mephu Nguifo FSJEG, Université de Jendouba,
TRS: Sélection des sous-graphes représentants par l intermédiaire des attributs topologiques et K-medoïdes Mohamed Moussaoui,Wajdi Dhifli,Sami Zghal,Engelbert Mephu Nguifo FSJEG, Université de Jendouba,
TESTS D'HYPOTHESES Etude d'un exemple
 TESTS D'HYPOTHESES Etude d'un exemple Un examinateur doit faire passer une épreuve type QCM à des étudiants. Ce QCM est constitué de 20 questions indépendantes. Pour chaque question, il y a trois réponses
TESTS D'HYPOTHESES Etude d'un exemple Un examinateur doit faire passer une épreuve type QCM à des étudiants. Ce QCM est constitué de 20 questions indépendantes. Pour chaque question, il y a trois réponses
Soit la fonction affine qui, pour représentant le nombre de mois écoulés, renvoie la somme économisée.
 ANALYSE 5 points Exercice 1 : Léonie souhaite acheter un lecteur MP3. Le prix affiché (49 ) dépasse largement la somme dont elle dispose. Elle décide donc d économiser régulièrement. Elle a relevé qu elle
ANALYSE 5 points Exercice 1 : Léonie souhaite acheter un lecteur MP3. Le prix affiché (49 ) dépasse largement la somme dont elle dispose. Elle décide donc d économiser régulièrement. Elle a relevé qu elle
Introduction aux Statistiques et à l utilisation du logiciel R
 Introduction aux Statistiques et à l utilisation du logiciel R Christophe Lalanne Christophe Pallier 1 Introduction 2 Comparaisons de deux moyennes 2.1 Objet de l étude On a mesuré le temps de sommeil
Introduction aux Statistiques et à l utilisation du logiciel R Christophe Lalanne Christophe Pallier 1 Introduction 2 Comparaisons de deux moyennes 2.1 Objet de l étude On a mesuré le temps de sommeil
Chapitre II La régulation de la glycémie
 Chapitre II La régulation de la glycémie Glycémie : concentration de glucose dans le sang valeur proche de 1g/L Hypoglycémie : perte de connaissance, troubles de la vue, voire coma. Hyperglycémie chronique
Chapitre II La régulation de la glycémie Glycémie : concentration de glucose dans le sang valeur proche de 1g/L Hypoglycémie : perte de connaissance, troubles de la vue, voire coma. Hyperglycémie chronique
Bases de données documentaires et distribuées Cours NFE04
 Bases de données documentaires et distribuées Cours NFE04 Introduction a la recherche d information Auteurs : Raphaël Fournier-S niehotta, Philippe Rigaux, Nicolas Travers pré[email protected] Département
Bases de données documentaires et distribuées Cours NFE04 Introduction a la recherche d information Auteurs : Raphaël Fournier-S niehotta, Philippe Rigaux, Nicolas Travers pré[email protected] Département
Étude sur les taux de revalorisation des contrats individuels d assurance vie au titre de 2013 n 26 mai 2014
 n 26 mai 2014 Étude sur les taux de revalorisation des contrats individuels d assurance vie au titre de 2013 Sommaire 1.INTRODUCTION 4 2.LE MARCHÉ DE L ASSURANCE VIE INDIVIDUELLE 6 2.1.La bancassurance
n 26 mai 2014 Étude sur les taux de revalorisation des contrats individuels d assurance vie au titre de 2013 Sommaire 1.INTRODUCTION 4 2.LE MARCHÉ DE L ASSURANCE VIE INDIVIDUELLE 6 2.1.La bancassurance