Méthodes de sondage Echantillonnage et Redressement
|
|
|
- Sylvaine Jobin
- il y a 10 ans
- Total affichages :
Transcription
1 Méthodes de sondage Echantillonnage et Redressement Guillaume Chauvet École Nationale de la Statistique et de l Analyse de l Information 27 avril 2015 Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
 Echantillonnage 27 avril")
2 Panorama du cours 1 Echantillonnage en population finie 2 Méthodes d échantillonnage 3 Méthodes de redressement Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
 Echantillonnage")
3 Objectifs du cours Présenter les méthodes d inférence dans le cas d une population finie d individus. Donner les principales méthodes d échantillonnage utilisées dans les enquêtes. Décrire les méthodes de redressement qui permettent d utiliser une information auxiliaire au moment de l estimation. Donner des exemples pratiques. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198

4 Echantillonnage en population finie Echantillonnage en population finie Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198

5 Echantillonnage en population finie Notations Notations Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198

6 Echantillonnage en population finie Notations Notations On se place dans le cadre d une population finie U d individus ou unités statistiques, supposées identifiables par un label. On notera simplement U = {1,..., k,..., N} où N désigne la taille de la population U. On s intéresse à une variable d intérêt y (éventuellement vectorielle), qui prend la valeur y k sur l individu k de U. La variable y est vue ici comme non aléatoire : la population U étant fixée, la valeur prise par y sur chaque individu est parfaitement définie et déterministe. On souhaite disposer d indicateurs pour la population U (totaux, moyennes, fractiles, indices,...). Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198

7 U
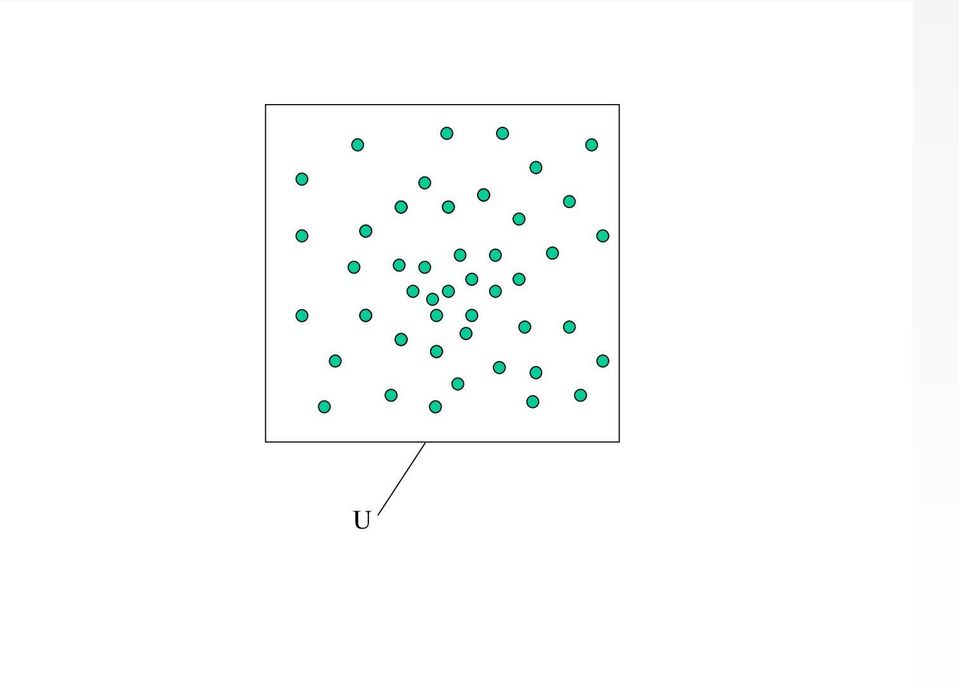
8 Echantillonnage en population finie Notations Notations Essentiellement pour des considérations pratiques, la variable d intérêt n est pas observée sur l ensemble de la population : effectuer un recensement coûte cher, et suppose de disposer d une base de sondage donnant la liste de l ensemble des individus de la population, même dans le cas d un recensement traditionnel, l ensemble des données recueillies est rarement exploité, augmenter la taille d un questionnaire augmente le fardeau de réponse, et diminue les taux de réponse, de façon générale, la non-réponse diminue la taille de l échantillon effectivement observé. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198

9 Echantillonnage en population finie Notations Exemples Exemple 1 : Les enquêtes-ménages de l Insee visent à décrire les conditions de vie des ménages (emploi, logement, patrimoine,... ). Les ménages enquêtés sont sélectionnés dans un échantillon de zones appelé l Echantillon- Maître. Exemple 2 : Les enquêtes-entreprises sont réalisées à l aide d une base de sondage (répertoire SIRENE) et de sources externes. Exemple 3 : Enquête auprès d un échantillon de personnes pour connaître une opinion politique, les habitudes en termes de media, l avis sur un produit... On utilise souvent dans ce cas des méthodes de tirage empiriques (échantillonnage par quotas, échantillonnage de volontaires). Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198

10 Echantillonnage en population finie Notations Paramètre d intérêt On s intéresse à un paramètre d intérêt de la forme θ(y k, k U) θ. Un estimateur de ce paramètre sera de la forme ˆθ(y k, k S) ˆθ(S) ˆθ, où S désigne l échantillon aléatoire finalement observé. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198

11 Echantillonnage en population finie Notations Paramètre d intérêt Total et moyenne On peut s intéresser au total t y = k U y k d une variable quantitative sur la population, ou encore à sa valeur moyenne µ y = 1 N y k. Exemple : Chiffre d affaires total des entreprises d un secteur d activité, pourcentage d étudiants fumeurs,... k U Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198

12 Echantillonnage en population finie Notations Paramètre d intérêt Estimation sur domaine Un cas particulier important est celui de l estimation sur une sous-population U d (appelée domaine) d un total t yd = k U d y k ou d une moyenne µ yd = 1 N d k U d y k avec N d la taille du domaine. Il peut s agir d un domaine au sens géographique (habitants d une région), socio-démographique (individus de moins de 20 ans), temporel (individus présents à une date donnée),... Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
, socio-démographique (individus de moins de 20 ans),")
13 U d U

14 Echantillonnage en population finie Notations Paramètre d intérêt Estimation par substitution Savoir estimer un total permet de traiter le cas de très nombreux paramètres qui peuvent s exprimer comme des fonctions de totaux. C est le cas d un ratio, d un coefficient de corrélation, d une variance, d un coefficient de régression,... Ces paramètres sont estimés par substitution, en remplaçant chaque total inconnu par son estimateur. Exemple 1 : R = t y t x estimé par ˆR = ˆt y ˆt x. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198

15 Echantillonnage en population finie Notations Paramètre d intérêt Estimation par substitution Exemple 2 : OR = p A 1 p A p B estimé par ÔR = 1 p B ˆp A 1 ˆp A. ˆp B 1 ˆp B Il est également possible d estimer des paramètres plus complexes tels que des fractiles (médianes), ou des indices (Gini, utilisé comme indicateur d inégalité). Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
, ou des indices (Gini, utilisé comme indicateur d inégalité).")
16 Echantillonnage en population finie Notations Plan de sondage La sélection de l échantillon aléatoire S se fait à l aide d un plan de sondage p sur U, c est à dire à l aide d une loi de probabilité sur les parties de U : s U p(s) 0 et s U p(s) = 1. On note S l échantillon aléatoire, et on distinguera l estimateur ˆθ(y k, k S) ˆθ(S), l estimation ˆθ(y k, k s) ˆθ(s). On appelle algorithme d échantillonnage une méthode pratique permettant de sélectionner un échantillon selon le plan de sondage choisi. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198

17 Echantillonnage en population finie Notations Exemple Soit la population U = {1, 2, 3, 4}, et p( ) le plan de sondage défini par : p({1, 2}) = 0.2 p({1, 4}) = 0.1 p({3, 4}) = 0.3 p({1, 2, 3}) = 0.3 p({2, 3, 4}) = 0.1 La variable aléatoire S prend ses valeurs dans On a par exemple {{1, 2}, {1, 4}, {3, 4}, {1, 2, 3}, {2, 3, 4}}. P(S = {1, 2}) = p({1, 2}) = 0.2 A la différence des lois de probabilités classiques (normale, exponentielle, binomiale,...) l aléatoire ne porte pas sur la variable mais sur le sous-ensemble d individus observés. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198

18 Echantillonnage en population finie Notations Comparaison avec une variable aléatoire réelle Soit X une variable aléatoire distribuée selon une loi de Poisson P(λ). La variable aléatoire X prend ses valeurs dans On a pour k N : N = {0, 1, 2,...}. P(X = k) = exp λ λk k!. L espérance de X correspond à la valeur moyenne de ses valeurs possibles, pondérées par leurs probabilités : E[X] = k N k P(X = k) = λ. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198

19 Echantillonnage en population finie Notations Mesures de précision L espérance d un estimateur ˆθ(S) se définit de façon analogue : ] E p [ˆθ(S) = ˆθ(s) P(S = s) s U = p(s) ˆθ(s). s U Le biais d un estimateur ˆθ(S) correspond à son erreur moyenne : B p [ˆθ(S) ] = E p [ˆθ(S) θ ] = s U p(s) [ˆθ(s) θ ]. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
 correspond à son erreur moyenne : B p [ˆθ(S) ] = E p")
20 Echantillonnage en population finie Notations Mesures de précision On s intéressera également à la Variance V p [ˆθ(S) ] [ } ] 2 = E p {ˆθ(S) Ep [ˆθ(S)] = s U p(s) {ˆθ(s) Ep [ˆθ(S)]} 2, et à l Erreur Quadratique Moyenne (EQM) EQM p [ˆθ(S) ] = E p [ {ˆθ(S) θ } 2 ] = B p [ˆθ(S) ] 2 + Vp [ˆθ(S) ]. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
![[ˆθ(S)]} 2, et à l Erreur Quadratique Moyenne (EQM) EQM p [ˆθ(S) ] = E p [ {ˆθ(S) θ } 2 ]](/docs-images/41/5832808/images/page_20.jpg "= B p [ˆθ(S) ] 2 + Vp [ˆθ(S) ].")
21 Echantillonnage en population finie Notations Quelques simulations Pour illustrer la notion de biais et de variance, on considère l exemple d une population de N = individus âgés de 15 à 20 ans. Dans cette population, un échantillon de taille n = 50 est sélectionné et enquêté. Pour chaque individu enquêté, on obtient son poids (en kg), sa taille (en cm) et son âge. On s intéresse à l estimation du poids moyen et de la taille moyenne (carré noir). Chaque échantillon permet d obtenir une estimation (points bleus) de ces paramètres. La moyenne des estimations est représentée par le point rouge. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
22 poids taille poids taille poids taille poids taille poids taille poids taille poids taille poids taille poids taille
23 Echantillonnage en population finie Notations Probabilités d inclusion d ordre 1 On note π k la probabilité d inclusion de l unité k, c est à dire la probabilité que l unité k soit retenue dans l échantillon : π k = P(k S) = p(s) s/k s La somme des probabilités d inclusion donne la taille moyenne de l échantillon sélectionné : π k = E p [n(s)]. k U En pratique, les probabilités d inclusion π k sont fixées avant le tirage à l aide d une information auxiliaire. On utilise ensuite un plan de sondage qui respecte ces probabilités d inclusion. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
24 Echantillonnage en population finie Notations Probabilités d inclusion d ordre 2 On note π kl la probabilité que deux unités distinctes k et l soient sélectionnées conjointement dans l échantillon : π kl = P(k, l S) = p(s) s/k,l s Ces probabilités doubles interviennent notamment dans la variance des estimateurs. Il est souvent difficile de les calculer exactement, sauf pour des plans de sondage particuliers. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
25 Echantillonnage en population finie Notations Application Soit la population U = {1, 2, 3, 4}, et p( ) le plan de sondage défini par : p({1, 2}) = 0.2 p({1, 4}) = 0.1 p({3, 4}) = 0.3 p({1, 2, 3}) = 0.3 p({2, 3, 4}) = 0.1 Calculer les probabilités d inclusion d ordre 1, et donner la taille moyenne d échantillon obtenue à l aide de ce plan de sondage. Donner les probabilités d inclusion d ordre 2 : des unités 1 et 2, des unités 1 et 4, des unités 2 et 4. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
26 Echantillonnage en population finie Notations Variables indicatrices L utilisation de la variable I k = 1(k S), indiquant l appartenance à l échantillon de l unité k, permet souvent de simplifier les calculs. Pour deux unités k et l distinctes, on a notamment les propriétés suivantes : E p (I k ) = π k, V p (I k ) = π k (1 π k ), Cov p (I k, I l ) = π kl π k π l kl. On note = [ kl ] k,l U la matrice de variance-covariance du plan de sondage p( ). Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
27 Echantillonnage en population finie Notations En résumé Un plan de sondage est une loi de probabilité sur les parties de U. L alea porte sur le sous-ensemble S d individus observés. Les notions d espérance et de de variance d un estimateur ˆθ(S) s adaptent de façon naturelle : ] B p [ˆθ(S) = ] p(s) [ˆθ(s) θ, s U V p [ˆθ(S) ] = s U p(s) {ˆθ(s) Ep [ˆθ(S)]} 2. On appelle probabilités d inclusion d ordre 1 et 2 : π k = P(k S), π kl = P(k, l S). Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
28 Echantillonnage en population finie Estimation de Horvitz-Thompson Estimation de Horvitz-Thompson Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
29 Echantillonnage en population finie Estimation de Horvitz-Thompson Objectif Nous nous intéressons essentiellement, dans la suite de ce cours, à l estimation du total t y = k U y k de la variable y, et d une moyenne µ y = 1 N y k. k U Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
30 Echantillonnage en population finie Estimation de Horvitz-Thompson La π-estimation La connaissance des probabilités π k permet une estimation sans biais d un total sous le plan de sondage, i.e. sous le mécanisme aléatoire associé au plan de sondage. Le total t y est estimé sans biais par ˆt yπ = k S y k = y k I k (1) π k π k k U si tous les π k sont > 0. On parle d estimateur de Horvitz-Thompson ou encore de π-estimateur. C est un estimateur pondéré, où les poids de sondage d k = 1/π k ne dépendent pas de la variable d intérêt. Principe : un individu k de l échantillon représente d k = 1/π k individus de la population. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
31 Echantillonnage en population finie Estimation de Horvitz-Thompson Biais de couverture Si certaines probabilités d inclusion sont nulles, le π-estimateur est biaisé : E [ˆt yπ ] = k U π k >0 Ce problème peut notamment se poser : y k = t y k U π k =0 en cas de défaut de couverture de la base de sondage (liste des individus pas à jour, ou individus impossibles à joindre), quand on choisit de laisser de côté une partie de la population (cut-off sampling, parfois utilisé dans les enquêtes-entreprise). y k. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
32 Echantillonnage en population finie Estimation de Horvitz-Thompson Enquête "Sans-Domicile 2001" (De Peretti et al., 2006) Sans-domicile : personne qui dort dans un lieu non prévu pour l habitation ou prise en charge par un organisme fournissant un hébergement gratuit ou à faible participation. Méthode d échantillonnage indirect : sélection d un échantillon de jours services d aide (hébergement, restauration). Champ de l enquête : sans-domicile ayant fréquenté, au moins une fois dans la semaine d enquête, soit un service d hébergement, soit une distribution de repas chauds. Exclut les personnes : qui dorment dans la rue pour une période de temps courte et ne font pas appel à un centre ou à une distribution de repas, qui ne font pas (ou ne peuvent pas faire) appel au circuit d assistance. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
33 Echantillonnage en population finie Estimation de Horvitz-Thompson Variance La variance du π-estimateur est donnée par V p [ˆt yπ ] = k,l U Cette variance peut être estimée sans biais par v HT [ˆt yπ ] = k,l S y k π k y l π l kl. (2) y k π k y l π l kl π kl (3) si tous les π kl sont strictement positifs. On parle de l estimateur de variance de Horvitz-Thompson. Principe : un couple (k, l) d individus de l échantillon représente 1/π kl couples de la population. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
34 Echantillonnage en population finie Estimation de Horvitz-Thompson Définitions Définition Un plan de sondage p( ) est dit de taille fixe, égale à n, si seuls les échantillons de taille n ont une probabilité non nulle d être tirés : Card(s) n p(s) = 0. Définition Un plan de sondage p( ) est dit simple si deux échantillons de même taille ont la même probabilité d être sélectionnés : Card(s 1 ) = Card(s 2 ) p(s 1 ) = p(s 2 ). Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
35 Echantillonnage en population finie Estimation de Horvitz-Thompson Exemples Soit la population U = {1, 2, 3, 4}. Exemple 1 : p({1, 2}) = 0.2 p({1, 4}) = 0.1 p({3, 4}) = 0.3 p({1, 2, 3}) = 0.3 p({2, 3, 4}) = 0.1 Exemple 2 : p({1, 2}) = 1/3 p({1, 4}) = 1/3 p({3, 4}) = 1/3 Exemple 3 : p({1, 2, 3}) = 1/4 p({1, 2, 4}) = 1/4 p({1, 3, 4}) = 1/4 p({2, 3, 4}) = 1/4 Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
36 Echantillonnage en population finie Estimation de Horvitz-Thompson Variance Pour un plan de taille fixe, la variance du π-estimateur peut se réécrire sous la forme ] 1 [ yk V p [ˆt yπ = y ] 2 l kl. (4) 2 π k π l k l U Cette variance peut être estimée sans biais par v Y G [ˆt yπ ] = 1 2 k l S [ yk y ] 2 l kl (5) π k π l π kl si tous les π kl sont strictement positifs. On parle de l estimateur de variance de Yates-Grundy. Si le plan de sondage vérifie les conditions de Yates-Grundy : k l U kl 0, cet estimateur de variance est toujours positif. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
37 Echantillonnage en population finie Estimation de Horvitz-Thompson Biais de l estimateur de variance Proposition Pour un plan de sondage quelconque, on a : E p { vht [ˆt yπ ]} = Vp [ˆt yπ ] + Pour un plan de sondage de taille fixe, on a : E p { vy G [ˆt yπ ]} = Vp [ˆt yπ ] 1 2 k,l U π kl =0 k,l U π kl =0 y k y l. [ yk π k π l y ] 2 l. π k π l Si y est à valeurs positives, les deux estimateurs de variance sont respectivement biaisés positivement et négativement. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
38 Echantillonnage en population finie Estimation de Horvitz-Thompson Choix des probabilités d inclusion D après la formule de Yates-Grundy, la variance est nulle si les probabilités d inclusion sont proportionnelles à la variable d intérêt. En pratique, ce choix n est pas possible car : une enquête comporte généralement de nombreuses variables d intérêt, ces variables sont inconnues au stade de l échantillonnage. On peut définir ces probabilités d inclusion proportionnellement à une mesure de taille. Interprétation : si les individus peuvent être de tailles très différentes, on utilise les probabilités d inclusion pour lisser les rapports y k /π k. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
39 Echantillonnage en population finie Estimation de Horvitz-Thompson Probabilités proportionnelles à la taille La taille moyenne d échantillon sélectionné est donnée par E p [n(s)] = k U π k. Si n désigne la taille d échantillon souhaitée, les probabilités d inclusion proportionnelles à une variable auxiliaire positive x sont données par π k = n x k l U x. l La variable x k doit être connue avant le tirage pour chaque individu k de U. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
40 Echantillonnage en population finie Estimation de Horvitz-Thompson Recalcul des probabilités d inclusion Si certaines unités sont particulièrement grosses (au sens de la variable auxiliaire x), on peut obtenir des probabilités d inclusion supérieures à 1. Dans ce cas, on sélectionne d office les unités correspondantes, et on recalcule les probabilités d inclusion des autres unités. Exemple : population de N = 6 entreprises dont on connait le nombre d employés Unité x Donner les probabilités d inclusion correspondant à un tirage de taille 4, à probabilités proportionnelles au nombre d employés. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
41 Echantillonnage en population finie Calcul de précision Intervalle de confiance Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
42 Echantillonnage en population finie Calcul de précision Intervalle de confiance On suppose que ˆt yπ estime sans biais t y. Alors un intervalle de confiance pour t y de niveau approximatif 1 α est donné par : [ IC 1 α [t y ] = ˆt yπ ± z 1 α 2 V p [ˆt yπ ] ], avec z 1 α le quantile d ordre 1 α 2 2 d une loi normale centrée réduite N (0, 1). Rappel : α = 0.05 z = 1.96 α = 0.10 z 0.95 = 1.64 Interprétation (pour α = 0.05) : le vrai total t y est contenu dans l intervalle de confiance pour (approximativement) 95% des échantillons. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
43 Echantillonnage en population finie Calcul de précision Intervalle de confiance Comme la vraie variance V p [ˆt yπ ] est généralement inconnue, on la remplace par un estimateur noté v [ˆt yπ ]. On obtient l intervalle de confiance estimé : [ ÎC 1 α [t y ] = ˆt yπ ± z 1 α v [ˆt ] ] 2 yπ. L intervalle de confiance est (approximativement) valide : si l estimateur ˆt yπ suit approximativement une loi N [ t y, V p (ˆt yπ )], si l estimateur de variance v (ˆt yπ ) est faiblement consistant. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
44 Echantillonnage en population finie Calcul de précision Coefficient de variation La précision de l estimation du total peut également être donnée sous la forme du coefficient de variation ) V p (ˆt yπ v (ˆt ) yπ CV p [ˆt yπ ] = t y estimé par ˆ CV [ˆt yπ ] = ˆt yπ. Il s agit d une grandeur sans dimension, plus facile à comparer et à interpréter que la variance. Avec un niveau de confiance de 0.95, l intervalle de confiance du total est donné par [ ÎC 0.95 [t y ] = ˆt yπ ± 1.96 v [ˆt ] ] yπ = ˆt yπ [1 ± 1.96 ˆ CV [ˆt yπ ] ]. Interprétation : un CV de x% correspond à un total connu à plus ou moins 2 x%, avec un niveau de confiance de Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
45 Echantillonnage en population finie Calcul de précision En résumé La connaissance des probabilités d inclusion d ordre 1 permet de calculer l estimateur de Horvitz-Thompson du total ˆt yπ = y k. π k k S Pour un plan de sondage quelconque, sa variance est estimée sans biais par ] v HT [ˆt yπ = y k y l kl π k π l π kl si tous les π kl sont strictement positifs. k,l S En utilisant une approximation normale pour ˆt yπ, on obtient l intervalle de confiance [ ˆt yπ ± z 1 α 2 v [ˆt ] ] { vht (ˆt yπ où v(ˆt yπ ) yπ ) pds quelconque, v Y G (ˆt yπ ) pds de taille fixe. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
46 Echantillonnage en population finie Estimation d une fonction de totaux Estimation d une fonction de totaux Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
47 Echantillonnage en population finie Estimation d une fonction de totaux Estimateur par substitution On s intéresse à un paramètre de la forme θ = f(t y ) avec y k = (y 1k,..., y qk ) T un q-vecteur de variables d intérêt, et f : R q R. Il est naturel d estimer θ en remplaçant le total t y inconnu par son π- estimateur. On obtient l estimateur par substitution : ˆθ π = f(ˆt yπ ). Si la fonction f( ) est différentiable au voisinage de t y, on obtient : ˆθ π θ [ f (t y ) ] T [ˆt yπ t y ] = ˆt uπ t u, (6) en notant u k = [f (t y )] T [y k ]. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
48 Echantillonnage en population finie Estimation d une fonction de totaux Technique de linéarisation Sous l approximation (6), on a ] E p [ˆθπ θ ] V p [ˆθπ θ 0, V p [ˆt uπ ]. On parle de l approximation de variance par linéarisation pour ˆθ π, avec u k u k (θ) = [ f (t y ) ] T [yk ] la variable linéarisée du paramètre θ. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
49 Echantillonnage en population finie Estimation d une fonction de totaux Estimation de variance Pour un plan de sondage quelconque, on obtient : V p [ˆθπ ] V p [ˆt uπ ] = k,l U Pour passer à un estimateur de variance : u k π k u l π l kl. 1 on remplace la formule de variance par l estimateur de variance correspondant au pds utilisé, 2 on remplace dans u k les paramètres inconnus par des estimateurs variable linéarisée estimée û k. On obtient finalement : ] v [ˆθπ = k,l S û k π k û l π l kl π kl. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
50 Echantillonnage en population finie Estimation d une fonction de totaux Application : estimation d un ratio Paramètre R = ty t x, estimé par substitution par ˆR π = ˆt yπ ˆt xπ. Calcul de la variable linéarisée : Calcul de variance : f(x 1, x 2 ) = x 1 x 2 f (x 1, x 2 ) = ( 1, x ) 1 x 2 (x 2 ) 2 u k (R) = 1 y k t y t x (t x ) 2 x k = 1 (y k Rx k ) t x û k (R) = 1 (y k ˆt ˆR π x k ) xπ V p [ˆθπ ] ] v [ˆθπ k,l U = k,l S u k π k u l π l kl, û k π k û l π l kl π kl. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
51 Echantillonnage en population finie Estimation d une fonction de totaux Exemple Population U de taille 10, dans laquelle un échantillon de taille n = 4 est sélectionné selon un SRS. Estimation des totaux t x et t y. k x k y k x = 4.5 s 2 x = 8.3 ȳ = 4 s 2 y = 16.7 ˆt xπ = N x = 45 v [ˆt ] xπ = N 2 1 f n s2 x = 125 ˆt yπ = Nȳ = 40 v [ˆt ] yπ = N 2 1 f n s2 y = 250 Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
52 Echantillonnage en population finie Estimation d une fonction de totaux Exemple Population U de taille 10, dans laquelle un échantillon de taille n = 4 est sélectionné selon un SRS. Estimation du ratio t y /t x. k x k y k û k = ˆt 1 (y k ˆRx k ) xπ x = 4.5 s 2 x = 8.3 ȳ = 4 s 2 y = 16.7 û = 0 s 2 û = ˆt xπ = N x = 45 v [ˆt ] xπ = N 2 1 f n s2 x = 125 ˆt yπ = Nȳ = 40 v [ˆt ] yπ = N 2 1 f [ ] n s2 y = 250 ˆR = ȳ x = 0.89 v ˆR = N 2 1 f n s2 û = 0.07 Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
53 Méthodes d échantillonnage Méthodes d échantillonnage Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
54 Méthodes d échantillonnage Tirage de Bernoulli Le tirage de Bernoulli Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
55 Méthodes d échantillonnage Tirage de Bernoulli Principe On se donne une même probabilité d inclusion π k π pour chaque unité de la population. Le choix se fait indépendamment d une unité à l autre : Etape 1 : on génère u 1 U[0, 1]. Si u 1 π, l unité 1 est retenue dans l échantillon. Etape 2 : on génère u 2 U[0, 1] indépendamment de u 1. Si u 2 π, l unité 2 est retenue dans l échantillon.... Etape N : on génère u N U[0, 1] indépendamment de u 1,..., u N 1. Si u N π, l unité N est retenue dans l échantillon. C est un principe de piles ou faces indépendants, avec une même pièce mais un lancer différent pour chaque unité. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
56 Méthodes d échantillonnage Tirage de Bernoulli Estimateur de Horvitz-Thompson En utilisant les propriétés d une loi U([0, 1]), on a : P(k S) = P(u k π) = F U (π) = π. Les probabilités d inclusion souhaitées sont donc bien respectées, et le total t y est estimé sans biais par ˆt yπ = 1 y k. π k S Du fait de l indépendance dans la sélection des unités : π kl = π 2 pour k l, ) 1 π V p (ˆt yπ = yk 2 π. D autre part, la taille d échantillon n(s) est aléatoire et suit une loi B(N, π). Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198 k U
57 Méthodes d échantillonnage Tirage de Bernoulli Application Dans la population ci-dessous, utiliser les nombres aléatoires pour sélectionner un échantillon selon un tirage de Bernoulli, et en déduire une estimation de t y. Unité π k u k y k Tirage Quelle est la taille moyenne d échantillon attendue? Quelle est la taille d échantillon effectivement obtenue? Comparer ˆt yπ et t y, et commenter la différence observée. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
58 Estimateur d une moyenne Si la taille de la population N est connue, on peut choisir entre les estimateurs ˆµ yπ = ˆt yπ N = 1 E[n(S)] µ y = ˆt yπ ˆN π = 1 n(s) y k, k S y k. On peut montrer que ces deux estimateurs sont non biaisés pour t y, mais que l estimateur par substitution µ y est généralement préférable en termes de variance : ( 1 V p (ˆµ yπ ) = n 1 ) 1 yk 2 N N, V p ( µ y ) ( 1 n 1 N k S ) 1 N k U (y k µ y ) 2. k U
59 Méthodes d échantillonnage Sondage aléatoire simple Sondage aléatoire simple sans remise Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
60 Méthodes d échantillonnage Sondage aléatoire simple Sondage aléatoire simple sans remise Définition-propriété Il existe un unique plan de sondage p( ) vérifiant les propriétés : 1 p( ) est un plan simple, 2 p( ) est un plan de taille fixe n. On l appelle plan de sondage aléatoire simple sans remise SRS de taille n dans U SRS(U; n). Il s agit donc du plan qui donne la même probabilité à tous les échantillons de taille n d être sélectionnés. On a : { 1/C n p(s) = N si n(s) = n, 0 sinon. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
61 Méthodes d échantillonnage Sondage aléatoire simple Estimateur de Horvitz-Thompson Proposition Soient k et l deux unités distinctes quelconques. Alors : π k = n N, π kl = n(n 1) N(N 1). Le π-estimateur du total peut donc se réécrire sous la forme ˆt yπ = N n k S = N ȳ. y k Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
62 Méthodes d échantillonnage Sondage aléatoire simple Variance du π-estimateur La variance du π-estimateur s obtient à partir de la formule de Sen-Yates- Grundy : V p [ˆt yπ ] = N 2 1 f n S2 y avec S 2 y = 1 N 1 On l estime sans biais par v SRS (ˆt yπ ) = N 2 1 f n s2 y avec s 2 y = 1 n 1 On note f = n/n le taux de sondage. (y k µ y ) 2. k U (y k ȳ) 2. k S Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
63 Méthodes d échantillonnage Sondage aléatoire simple Variance de la moyenne estimée Par linéarité, la moyenne µ y peut être estimée sans biais par ȳ = 1 y k. n k S La variance de cet estimateur est donnée par Remarques : V p [ȳ] = 1 f n S2 y. (7) Le facteur (1 f) donne le gain de variance dû au tirage sans remise. On l appelle correction de population finie. Ce gain peut être très important (cas des enquêtes-entreprise). Si le taux de sondage est faible, la variance ne dépend que de la taille d échantillon n. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
64 Méthodes d échantillonnage Sondage aléatoire simple A retenir Dans un sondage aléatoire simple sans remise (SRS) : 1 la moyenne simple dans l échantillon estime sans biais la moyenne simple dans la population, 2 la dispersion calculée sur l échantillon estime sans biais la dispersion dans la population. Dans une enquête avec un faible taux de sondage, la variance est (approximativement) inversement proportionnelle à la taille d échantillon. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
65 Méthodes d échantillonnage Sondage aléatoire simple Cas d une proportion Dans le cas particulier où le paramètre d intérêt est une proportion notée P, la variable d intérêt y est une variable indicatrice dont on cherche à estimer la moyenne. Exemple { : proportion d étudiants portant des lunettes dans la promotion, 1 si l étudiant k porte des lunettes, y k = 0 sinon. En particulier, le paramètre peut s écrire sous la forme P = 1 N y k, k U et être estimé par ˆP = 1 y k. n k S Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
66 Méthodes d échantillonnage Sondage aléatoire simple Proposition Dans le cas d une variable indicatrice (0/1) y, on a : S 2 y = s 2 y = N P (1 P ), N 1 n n 1 ˆP (1 ˆP ). La variance de l estimateur de la moyenne ˆP peut alors se réécrire V p [ ˆP ] = 1 f n et être estimée sans biais par N P (1 P ), N 1 v[ ˆP ] = 1 f n 1 ˆP (1 ˆP ). Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
67 Méthodes d échantillonnage Sondage aléatoire simple Application : détermination de taille d échantillon On cherche une taille d échantillon minimale permettant de respecter avec un niveau de confiance fixé (par exemple de 95 % ) une contrainte de précision en termes : 1 soit d erreur absolue : P connu à plus ou moins 0.02 ˆP P soit d erreur relative : P connu à 8 % près ˆP P P Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
68 Méthodes d échantillonnage Sondage aléatoire simple Application : détermination de taille d échantillon Erreur absolue Avec un niveau de confiance de 95 % la contrainte de précision peut se réécrire : ˆP P β 1.96 V p ( ˆP ) β [ n 1 ] N N N 1 P (1 P ) β n 1 [ ] 2. 1 N + N 1 β 1 N 1.96 P (1 P ) On peut toujours se placer dans le pire des cas en prenant P = 0.5, mais il est préférable de disposer d un a priori (même vague) sur le paramètre P. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
69 Méthodes d échantillonnage Sondage aléatoire simple Application : détermination de taille d échantillon Erreur relative Avec un niveau de confiance de 95 % la contrainte de précision peut se réécrire : ˆP P P γ 1.96 CV p( ˆP ) γ [ n 1 ] N 1 P γ N N 1 P n 1 N + N 1 N 1 [ γ 1.96 ] 2 P. 1 P Calculer cette borne nécessite de disposer d un a priori sur le paramètre P, ou au moins d un majorant pour ce paramètre. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
70 Méthodes d échantillonnage Sondage aléatoire simple Application Parmi les 350 étudiants de l Ensai, on veut estimer la proportion qui portent des lunettes. Quelle taille d échantillon faut-il sélectionner pour que cette proportion soit estimée à 10% près, avec un niveau de confiance de 0.95 : 1 en utilisant l information suivante : 50% des personnes de la population française portent des lunettes ; 2 en utilisant maintenant l information suivante : 20% des ans portent des lunettes. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
71 Méthodes d échantillonnage Sondage aléatoire simple Algorithmes de sélection Algorithme 1 Méthode de sélection draw by draw 1 Pour k = 1,..., n, sélectionner une unité dans U à probabilités égales parmi les unités qui n ont pas déjà été tirées. Inconvénient : méthode lente, qui nécessite n lectures de fichier. Algorithme 2 Méthode du tri aléatoire 1 On attribue un nombre aléatoire u k U[0, 1] à chaque unité k U. 2 On trie la population selon les u k croissants (ou décroissants). 3 L échantillon est constitué des n premiers individus de la population triée. Inconvénient : nécessite un tri du fichier. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
72 Avantage : la taille de la population peut être inconnue au départ. Algorithmes de sélection Algorithme 3 Méthode de sélection-rejet 1 On initialise j = 0. 2 Pour k = 1,..., N, faire : n j Avec une probabilité, on sélectionne l unité k et j = j + 1. N (k 1) Avantage : nécessite une seule lecture de fichier. Algorithme 4 Méthode du réservoir 1 Les n premières unités sont tirées dans l échantillon. 2 Pour k = n + 1,..., N, faire : Avec une probabilité n, on sélectionne l unité k. k On tire à probabilités égales une unité dans l échantillon, qui est remplacée par k.
73 Méthodes d échantillonnage Sondage aléatoire simple stratifié Le sondage aléatoire simple stratifié Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
74 Méthodes d échantillonnage Sondage aléatoire simple stratifié Information auxiliaire On parle d information auxiliaire lorsqu une information est connue sur l ensemble de la population, sous forme détaillée ou synthétique. Il est fréquent de disposer d une information auxiliaire sur la population, qui va permettre de partitionner la population et d obtenir un plan de sondage plus efficace que le SRS. Exemples d information auxiliaire : le sexe et l âge, pour une enquête auprès d individus physiques, la taille (nombre d employés) pour les enquêtes-entreprise. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
75 Méthodes d échantillonnage Sondage aléatoire simple stratifié Motivations pour la stratification (Cochran, 1977) Précision maîtrisée pour des sous-populations, simplicité administrative (enquêtes conduites par différentes agences), plans de sondage adaptés aux sous-populations, gain global de précision. Principales questions : 1 Comment construire les strates? 2 Quelle taille d échantillon sélectionner dans chaque strate? 3 Quel plan de sondage utiliser dans chaque strate? Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
76 Méthodes d échantillonnage Sondage aléatoire simple stratifié Notation et sondage stratifié Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
77 Méthodes d échantillonnage Sondage aléatoire simple stratifié Définition La population U est dite stratifiée quand les unités peuvent être partitionnées en H sous-populations disjointes U 1,..., U H appelées strates. Le plan de sondage est dit stratifié quand des échantillons indépendants sont sélectionnés dans chaque strate. On parle de Sondage aléatoire simple stratifié (STSRS) si des échantillons aléatoires simples sont sélectionnés dans chaque strate. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
78 Méthodes d échantillonnage Sondage aléatoire simple stratifié Décomposition On note N h la taille de la strate U h. Un total t y peut se décomposer sous la forme H t y = t yh, h=1 avec t yh = k U h y k le total de la variable y dans U h. La moyenne µ y peut se décomposer sous la forme d une moyenne pondérée µ y = 1 N H N h µ yh, h=1 avec µ yh = t yh /N h la moyenne dans la strate U h. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
79 Méthodes d échantillonnage Sondage aléatoire simple stratifié Estimation d un total Dans chaque strate U h, on sélectionne un échantillon S h de taille n h selon un SRS(U h, n h ). Pour deux unités quelconques k l U h, on a donc les probabilités d inclusion π k = n h N h π kl = n h(n h 1) N h (N h 1). Pour deux unités quelconques k et l appartenant à deux strates distinctes U h et U h, respectivement : π kl = n h n h. N h N h Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
80 Méthodes d échantillonnage Sondage aléatoire simple stratifié Estimation d un total Par linéarité, le total t y peut être estimé sans biais par ˆt yπ = H ˆt yhπ = h=1 avec ȳ h la moyenne simple dans S h. H N h ȳ h La variance s obtient par sommation (les tirages sont indépendants dans les strates) : h=1 V p [ˆt yπ ] = H ] V p [ˆt yhπ. h=1 Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
81 Méthodes d échantillonnage Sondage aléatoire simple stratifié Estimation d un total Dans le cas d un SRS stratifié, on obtient V p [ˆt yπ ] = H h=1 que l on estime par v ST [ˆt yπ ] = H h=1 Nh 2 1 f h Syh 2 avec Syh 2 n = 1 h N h 1 Nh 2 1 f h s 2 yh avec s 2 yh n = 1 h n h 1 avec f h = n h /N h le taux de sondage dans la strate U h. k U h (y k µ yh ) 2, k S h (y k ȳ h ) 2, Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
82 Méthodes d échantillonnage Sondage aléatoire simple stratifié Estimation d une moyenne De façon analogue, la moyenne µ y peut être estimée sans biais par ˆµ yπ = H h=1 N h N ȳh. Sa variance est donnée par V p [ˆµ yπ ] = H h=1 et peut être estimée sans biais par v ST [ˆµ yπ ] = H h=1 ( ) 2 Nh 1 f h Syh 2 N n, h ( ) 2 Nh 1 f h s 2 yh N n. h Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
83 Méthodes d échantillonnage Sondage aléatoire simple stratifié Allocations pour le tirage stratifié Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
84 Méthodes d échantillonnage Sondage aléatoire simple stratifié Allocation d échantillon entre les strates On suppose que la taille globale d échantillon n est fixée, et que les strates ont été définies. On doit choisir les tailles n 1,..., n H dans chaque strate. des sous-échantillons à sélectionner Nous revenons sur quelques allocations classiques pour le sondage aléatoire simple stratifié : Allocation Proportionnelle, Allocation Optimale, Allocation de compromis. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
85 Méthodes d échantillonnage Sondage aléatoire simple stratifié Allocation Proportionnelle Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
86 Méthodes d échantillonnage Sondage aléatoire simple stratifié Allocation Proportionnelle Avec une allocation proportionnelle, le taux de sondage est le même dans chaque strate : f h = n h N h = n N = f. On peut le réécrire sous la forme n h = n N h N. Autrement dit, plus la strate est grande, plus l échantillon sélectionné dedans est grand. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
87 Méthodes d échantillonnage Sondage aléatoire simple stratifié Allocation Proportionnelle Chaque unité de la population possède la même probabilité d inclusion π k = n/n, et l estimateur stratifié de la moyenne est identique à la moyenne simple sur l échantillon : ˆµ yπ = H h=1 N h N ȳh = H h=1 n h n ȳh = ȳ. Cette allocation conduit à un plan de sondage auto-pondéré où tous les individus possèdent le même poids d k = N/n. La variance de l estimateur stratifié du total est donnée par V p [ˆt yπ ] = N 2 1 f n H h=1 N h N S2 yh. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
88 Méthodes d échantillonnage Sondage aléatoire simple stratifié Equation de décomposition de la variance La dispersion de la variable y dans la population U peut se décomposer sous la forme S 2 y = H N h 1 N 1 S2 yh h=1 } {{ } Sy,intra 2 + H N h N 1 (µ yh µ y ) 2 h=1 } {{ } Sy,inter 2 H N h h=1 N S2 yh + H N h h=1 N (µ yh µ y ) 2 Le premier terme mesure la dispersion à l intérieur des strates, alors que le second terme mesure la dispersion entre les strates. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
89 Méthodes d échantillonnage Sondage aléatoire simple stratifié Equation de décomposition de la variance Notons que la dispersion globale S 2 y est fixée. Le poids de chacune des deux composantes dépend de la variable de stratification choisie. Exemple k y k x 1k x 2k Décomposition de la variance pour S 2 y : si x 1k est la variable de stratification, si x 2k est la variable de stratification. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
90 Méthodes d échantillonnage Sondage aléatoire simple stratifié Retour vers l allocation proportionnelle La variance de l estimateur stratifié avec allocation proportionnelle est approximativement donnée par de sorte que : ] V p [ˆt yπ N 2 1 f n S2 y,intra, le SRS stratifié à allocation proportionnelle est (presque) toujours plus efficace que le SRS, la stratification devrait être choisie de façon à ce que la dispersion à l intérieur des strates soit minimisée. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
91 Méthodes d échantillonnage Sondage aléatoire simple stratifié Allocation de Neyman Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
92 Méthodes d échantillonnage Sondage aléatoire simple stratifié Principe L allocation de Neyman donne, pour une stratification donnée et une variable d intérêt donnée, l allocation d échantillon pour laquelle la variance du π- estimateur est minimisée. On cherche à résoudre un problème de minimisation (de la variance) sous contraintes (taille globale d échantillon fixée) : min n h V [ˆt yπ ] t.q. H n h = n h=1 Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
93 Méthodes d échantillonnage Sondage aléatoire simple stratifié Principe Avec un sondage aléatoire simple stratifié, ce problème de minimisation peut se réécrire : min n h H [ 1 h=1 n h 1 N h ] N 2 h S2 yh t.q. H n h = n. h=1 En utilisant une technique de Lagrangien, on obtient : N h S yh n h = n H j=1 N. js yj Notons en particulier que le calcul de cette allocation optimale nécessite la connaissance des dispersions dans les strates. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
94 Méthodes d échantillonnage Sondage aléatoire simple stratifié Principe L allocation de Neyman indique qu il faut sélectionner un échantillon plus grand : dans les grandes strates, dans les strates présentant une forte dispersion. L allocation n est optimale que pour la variable d intérêt particulière y : pour une autre variable d intérêt, elle peut conduire à des résultats plus imprécis que l allocation proportionnelle (voire que le sondage aléatoire simple). Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
95 Méthodes d échantillonnage Sondage aléatoire simple stratifié Calcul de l allocation L allocation de Neyman peut conduire à des tailles d échantillon supérieures aux tailles de strates, si ces dernières présentent une forte dispersion et/ou sont de grande taille. Dans ce cas : 1 on effectue un recensement dans les strates concernées (on fixe n h = N h ), 2 on recalcule l allocation d échantillon dans les autres strates. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
96 Méthodes d échantillonnage Sondage aléatoire simple stratifié Mise en oeuvre pratique En pratique, on peut dériver une allocation proche de l allocation de Neyman : si on possède un a priori sur la dispersion dans les strates (approche "métier"), ou si on peut estimer cette dispersion à l aide d une enquête antérieure. Un problème alternatif peut être d optimiser la précision sous une contrainte de coût global C fixé H C 0 + C h n h = C, h=1 où C 0 donne le coût fixe de l enquête, et C h le coût associé à une unité de U h. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
97 Méthodes d échantillonnage Sondage aléatoire simple stratifié Principe On résout le problème d optimisation : min n h H [ 1 h=1 n h 1 N h ] N 2 h S2 yh t.q. C 0 + H C h n h = C. h=1 En utilisant une technique de Lagrangien, on obtient : [ Nh S yh / ] C h n h = [C C 0 ] H. j=1 Cj N j S yj Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
98 Méthodes d échantillonnage Sondage aléatoire simple stratifié Allocation de compromis Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
99 Méthodes d échantillonnage Sondage aléatoire simple stratifié Allocation de compromis (1) Imaginons que l on souhaite obtenir la même précision dans chaque strate, par exemple si les strates sont des domaines d estimation. On veut obtenir ( 1 V (ȳ h ) = 1 ) Syh 2 n h N = Cste. h Si les strates sont suffisamment grandes, on obtient : n h = n Syh 2 H j=1 S2 yj. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
100 Méthodes d échantillonnage Sondage aléatoire simple stratifié Allocation de compromis (2) Supposons maintenant que l on souhaite obtenir une allocation optimale, sous des contraintes de taille globale d échantillon fixée, de précision dans les strates supérieure à un seuil fixé. Il s agit d un problème réaliste (contraintes imposées par Eurostat dans les enquêtes). Il est généralement difficile d obtenir une solution explicite, mais ce type de problème peut être résolu (par exemple) à l aide de la proc NLP de SAS. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
101 Méthodes d échantillonnage Sondage aléatoire simple stratifié Principales questions 1 Comment construire les strates? de façon à ce que la dispersion intra soit minimisée 2 Quelle taille d échantillon sélectionner dans chaque strate? tirer de plus gros échantillons dans les strates avec une grande dispersion 3 Quel plan de sondage utiliser dans chaque strate? le SRS par strate est une bonne stratégie si les unités présentes dans une même strate sont proches (au sens de la variable d intérêt) Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
102 Méthodes d échantillonnage Tirage à probabilités inégales Introduction Nous avons vu précedemment que la stratification était une méthode simple permettant de réduire la variance des estimateurs. Si les strates sont homogènes relativement à la variable d intérêt (dispersion intra faible), le sondage aléatoire simple stratifié constitue une stratégie efficace d échantillonnage. En pratique, il peut subsister une forte hétérogénéité dans les strates. Dans ce cas, on peut rechercher une stratégie d échantillonnage plus efficace en individualisant les probabilités de sélection π k de chacun des individus. On doit ensuite faire le choix d un algorithme de tirage, i.e. d une méthode pratique de sélection respectant les probabilités d inclusion choisies. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
103 Méthodes d échantillonnage Tirage à probabilités inégales Algorithmes de tirage Il existe en pratique des dizaines d algorithmes de tirage permettant de respecter un jeu de probabilités d inclusion fixé (voir Tillé, 2006). Nous détaillerons deux de ces algorithmes : le tirage poissonien, le tirage systématique. Les différents algorithmes se distinguent par les probabilités d inclusion d ordre 2 obtenues, i.e. par la variance des estimateurs. Cependant, il n existe pas d algorithme uniformément préférable en termes de variance. Le choix de la méthode à utiliser dépend de la connaissance que l on a de la base de sondage mais aussi des contraintes pratiques sur l échantillonnage. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
104 Méthodes d échantillonnage Tirage à probabilités inégales Propriétés d un algorithme de tirage Pour un algorithme de tirage, on se posera généralement les questions suivantes : 1 Est-ce que l algorithme est exact, i.e. permet de respecter exactement un jeu de probabilités d inclusion (π k ) k U fixé? 2 Est-ce que l algorithme est de taille fixe, i.e. ne sélectionne que des échantillons de la taille (moyenne) voulue? 3 Est-ce que les probabilités π kl sont calculables, et que vaut la variance du π-estimateur avec cet algorithme? 4 Est-ce que ces probabilités π kl : sont > 0 : assure qu on dispose d un estimateur sans biais de variance. vérifient les conditions de Yates-Grundy : assure qu on dispose d un estimateur toujours positif de variance (pour un plan de taille fixe). Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
105 Méthodes d échantillonnage Tirage à probabilités inégales Le tirage de Poisson Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
106 Méthodes d échantillonnage Tirage à probabilités inégales Principe C est une généralisation du tirage de Bernoulli au cas des probabilités inégales : Etape 1 : on génère u 1 U[0, 1]. Si u 1 π 1, l unité 1 est retenue dans l échantillon. Etape 2 : on génère u 2 U[0, 1] indépendamment de u 1. Si u 2 π 2, l unité 2 est retenue dans l échantillon.... Etape N : on génère u N U[0, 1] indépendamment de u 1,..., u N 1. Si u N π N, l unité N est retenue dans l échantillon. C est un principe de piles ou faces indépendants, avec une pièce et un lancer différents pour chaque unité. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
107 Méthodes d échantillonnage Tirage à probabilités inégales Estimation de Horvitz-Thompson En utilisant les propriétés d une loi U[0, 1], on a : P(k S) = P(u k π k ) = F U (π k ) = π k. Du fait de l indépendance dans la sélection des unités : π kl = π k π l si k l. Le plan de sondage peut être entièrement spécifié. Pour une partie quelconque s = {i 1,..., i p } de U, on a : P(S = s) = k s π k k u\s (1 π k ). Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
108 Méthodes d échantillonnage Tirage à probabilités inégales Application Dans la population ci-dessous, utiliser les nombres aléatoires pour sélectionner un échantillon selon un tirage de Poisson, et en déduire une estimation de t y. Unité π k u k y k Tirage Quelle est la taille moyenne d échantillon attendue? Quelle est la taille d échantillon effectivement obtenue? Comparer ˆt yπ et t y, et commenter la différence observée. Comparer avec le tirage de Bernoulli. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
109 Méthodes d échantillonnage Tirage à probabilités inégales Estimateur de Horvitz-Thompson La variance s obtient à partir de l expression générale de Horvitz-Thompson : V pois [ˆt yπ ] = k U ( yk π k ) 2 π k (1 π k ), (8) que l on estime sans biais par v [ˆt yπ ] = k S ( yk π k ) 2 (1 π k ). En particulier, cela implique que la taille d échantillon est aléatoire : V pois [n(s)] = k U π k (1 π k ). Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
110 Méthodes d échantillonnage Tirage à probabilités inégales Estimateur par le ratio Si la taille de la population N est connue, on préfère à l estimateur de Horvitz-Thompson l estimateur par le ratio ˆt yr = Ṋ N π ˆt yπ. Sa variance est approximativement donnée par V pois [ˆt yr ] ( Ek π k k U ) 2 π k (1 π k ) (9) avec E k = y k µ y. On peut utiliser l estimateur de variance v [ˆt yr ] = k S ( ek π k ) 2 (1 π k ) (10) avec e k = y k ˆt yπ ˆN π. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
111 Méthodes d échantillonnage Tirage à probabilités inégales Estimateur par le ratio (2) Pour l estimation de la moyenne µ y, on peut utiliser l estimateur par substitution µ y = ˆt yπ ˆN π, de variance (approximative) V pois [ µ y ] 1 N 2 k U On peut utiliser l estimateur de variance v [ µ y ] = 1ˆN 2 π k S ( Ek π k ( ek π k ) 2 π k (1 π k ). (11) ) 2 (1 π k ). (12) L estimateur par substitution µ y peut être calculé même si la taille de la population est inconnue. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
112 Méthodes d échantillonnage Tirage à probabilités inégales Utilisation Le tirage poissonien est rarement utilisé pour un tirage d échantillon, en raison de sa grande variance. On trouve cependant des applications dans le cas d échantillonnage forestier (Schreuder et al., 1993). Le tirage poissonien est également utilisé dans un contexte de non-réponse. On parle de non-réponse totale quand certains individus échantillonnés ne peuvent finalement pas être enquêtés. Pour exploiter l échantillon de répondants, noté S r, il est généralement nécessaire de modéliser le mécanisme de réponse. Une modélisation classique consiste à supposer que l échantillon S r est obtenu par sous-échantillonnage dans l échantillon S d origine. Plus de détails dans le cours sur les Données Manquantes (Attachés). Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
113 Méthodes d échantillonnage Tirage à probabilités inégales Le tirage systématique Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
114 Méthodes d échantillonnage Tirage à probabilités inégales Principe C est une méthode simple et très rapide permettant de sélectionner un échantillon à probabilités inégales et de taille fixe. Principe : On pose V k = k l=1 π l pour k U, avec la convention V 0 = 0. On tire une variable aléatoire u selon une loi uniforme U[0, 1]. On sélectionne toutes les unités k telles que, pour un entier i {1,..., n} : V k 1 u + (i 1) < V k. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
115 Méthodes d échantillonnage Tirage à probabilités inégales Exemple Population U de taille N = 14 avec n = 4 : π 1 = π 2 = π 5 = π 6 = π 7 = π 8 = π 12 = 1/7, π 3 = π 4 = π 9 = π 10 = π 11 = π 13 = π 14 = 3/ V 0 V 1 V 2 V 3 V 4 V 5 V 6 V 7 V 8 V 9 V 10 V 11 V 12 V 13 V 14 u = 0.82 [V 3, V 4 ] l unité 4 est sélectionnée, 1 + u = 1.82 [V 8, V 9 ] l unité 9 est sélectionnée, 2 + u = 2.82 [V 10, V 11 ] l unité 11 est sélectionnée, 3 + u = 3.82 [V 13, V 14 ] l unité 14 est sélectionnée. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
116 Méthodes d échantillonnage Tirage à probabilités inégales Probabilités d inclusion Les probabilités π k sont exactement respectées. En effet : P(k S) = P(V k 1 u + (i 1) < V k ) = V k V k 1 = π k. Les probabilités d inclusion d ordre deux sont plus difficiles à calculer (Tillé, 2006, p. 126). Beaucoup d unités présentent des probabilités d inclusion doubles égales à 0 (méthode très peu aléatoire) il n existe pas d estimateur sans biais de variance pour l estimateur de Horvitz-Thompson. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
117 Méthodes d échantillonnage Tirage à probabilités inégales Applications du tirage systématique Exemple 1 : sélection pour contrôle d un sous-échantillon de questionnaires, arrivant à flux tendu. Exemple 2 : enquête auprès des clients entrant dans un magasin. Exemple 3 : tirage de logements dans un pâté de maison lors d une enquête ménage. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
118 Méthodes d échantillonnage Tirage à probabilités inégales Cas des probabilités égales On suppose dans la suite de cette section que les probabilités d inclusion sont égales (π k = n/n), et que le pas de tirage p = N/n est entier. Dans ce cas, l algorithme peut être simplifié de la façon suivante : On tire un individu i au hasard parmi les p premiers. On sélectionne les individus i, i + p,..., i + (n 1)p. On a en particulier { n/n si k l [p], π kl = 0 sinon. Il n existe pas d estimateur sans biais de variance, et les conditions de Yates- Grundy ne sont pas vérifiées. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
119 Méthodes d échantillonnage Tirage à probabilités inégales Exemple Sélection d un échantillon de taille 3 dans une population de taille 12 selon un tirage systématique à probabilités égales (π k = 1 4 ) V 0 V 1 V 2 V 3 V 4 V 5 V 6 V 7 V 8 V 9 V 10 V 11 V 12 u = 0.82 [V 3, V 4 ] l unité 4 est sélectionnée, 1 + u = 1.82 [V 7, V 8 ] l unité 8 est sélectionnée, 2 + u = 2.82 [V 11, V 12 ] l unité 12 est sélectionnée. Seuls 4 échantillons sont sélectionnables, chacun avec une probabilité de 0.25 : {1, 5, 9} {2, 6, 10} {3, 7, 11} {4, 8, 12} Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
120 Méthodes d échantillonnage Tirage à probabilités inégales Précision du tirage systématique Dans le cas précédent (probabilités égales, pas de tirage entier), le tirage est équivalent à un tirage par grappes de taille m = 1 dans la population U g = {u 1,..., u p }, avec u i = {i, i + p,..., i + (n 1)p}. Principe du tirage par grappes : 1 on tire un échantillon S I de grappes (ici, de taille m = 1), 2 tous les individus contenus dans les grappes de s I sont retenus dans l échantillon s finalement enquêté. Pour plus de détails : cours de Méthodologie d Enquête (Attachés). Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
121 Méthodes d échantillonnage Tirage à probabilités inégales Précision du tirage systématique (2) Le π-estimateur peut se réécrire sous la forme ˆt yπ = N n u i S I Y i, avec Y i = k u i y k le total sur la grappe u i. En utilisant les résultats du SRS, on obtient avec V sys [ˆt yπ ] S 2 Y = 1 p 1 = N 2 1 f n u i U g S 2 Y n [ Y i t ] 2 y. p Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
122 Méthodes d échantillonnage Tirage à probabilités inégales Comparaison avec le SRS On appelle design-effect (ou effet de plan) DEFF p (y) = V p [ˆt yπ ] V SRS [ˆt yπ ] le rapport entre la variance associée à un plan de sondage, et la variance associée au SRS de même taille. On a ici : DEFF sys (y) = S2 Y /n Sy 2. D autre part, en utilisant une décomposition de la variance : Sy 2 = n 1 p S 2 (p 1) yi + N 1 n(n 1) S2 Y (13) i=1 1 p Syi ( S 2 p n Y /n ). i=1 Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
123 Méthodes d échantillonnage Tirage à probabilités inégales Comparaison avec le SRS (2) Le tirage systématique sera donc efficace par rapport au SRS si dans l équation (13), le terme de dispersion intra est grand, autrement dit si les grappes sont hétérogènes en intra. Ce sera par exemple le cas si la population est triée avant le tirage selon une variable auxiliaire x k corrélée avec la variable d intérêt. Le tirage systématique peut au contraire être très inefficace si les grappes sont homogènes en intra : c est une difficulté et une situation habituelle dans le cas d un tirage par grappes. Le cas le plus défavorable est celui où la variable d intérêt présente une périodicité + le pas de tirage p = N/n est proportionnel à cette périodicité. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
124 Méthodes d échantillonnage Tirage à probabilités inégales Exemple Considérons une population U de taille 12 sur laquelle on relève trois caractéristiques y 1, y 2, y 3 (valeur moyenne 40) : Unité y y y On sélectionne un échantillon de taille 2 selon un tirage systématique 6 échantillons possibles. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
125 Méthodes d échantillonnage Tirage à probabilités inégales Exemple On obtient comme valeurs échantillonnées possibles pour y 1 pour y 2 et pour y 3 {10, 50} {10, 50} {10, 60} {15, 60} {45, 60} {45, 65}, {10, 10} {45, 50} {60, 60} {15, 10} {50, 45} {65, 60}, {15, 45} {45, 65} {10, 10} {60, 50} {60, 10} {50, 60}. On obtient également : y 1 y 2 y 3 DEFF p (y) Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
126 Méthodes de redressement Méthodes de redressement Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
127 Méthodes de redressement Principe Nous revenons au cas de l estimation d un total. On suppose qu un échantillon S a été sélectionné selon un plan de sondage p( ). Un estimateur direct est donné par : ˆt yπ = y k = d k y k. π k k S k S Dans cet estimateur, les poids de sondage d k dépendent de l information auxiliaire mobilisée au moment de l échantillonnage : SRS d k = N/n SRS stratifié d k = N h /n h pour k U h Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
128 Méthodes de redressement Principe Il se peut qu une partie de l information auxiliaire n ait pas été utilisée au moment de la sélection de l échantillon, ou qu elle n ait pas été disponible. Si cette information est explicative de la variable d intérêt, il va être néanmoins intéressant de l utiliser. On peut le faire au stade de l estimation, en redressant l estimateur de Horvitz-Thompson. Poids de sondage d k Poids redressés w k Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
129 Méthodes de redressement Principe On dit que l on redresse l échantillon lorsque l on modifie le système de pondérations associé à S afin de respecter un certain nombre d informations auxiliaires. On parle d information auxiliaire lorsque l on dispose d une information connue sur l ensemble de la population. Exemples : Chiffre d affaire total des entreprises d un secteur d activité, Répartition par sexe et par âge d une population d individus. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
130 Méthodes de redressement Estimateur par calage Estimateur par calage Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
131 Méthodes de redressement Estimateur par calage Principe On suppose ici que l on dispose d un vecteur x k = [x 1k,..., x pk ] de variables auxiliaires, dont les totaux t x = [t x1,..., t xp ] sur la population sont connus. Avant calage, on a pour toute variable y l estimateur sans biais du total : ˆt yπ = k S d k y k, E p [ˆt yπ ] = t y, et en particulier pour les variables de calage : E p [ˆt xπ ] = tx. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
132 Méthodes de redressement Estimateur par calage Modification des poids On cherche de nouveaux poids w k qui 1 restent proches des poids de départ d k, 2 vérifient les équations de calage w k x k = t x. k S Plus formellement, on résoud le problème suivant : ( ) wk min d k G s.c. w k x k = t x w k k s k s d k où G désigne une fonction de distance. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
133 Méthodes de redressement Estimateur par calage Modification des poids On cherche à réduire la variance de l estimation à l aide du calage sur les totaux connus. La variance est nulle pour les variables auxiliaires ; elle sera faible pour les variables d intérêt bien expliquées par les variables auxiliaires. Pour respecter les totaux de variables auxiliaires, on accepte de biaiser légèrement l estimation. Ce biais sera généralement négligeable car on assure que les poids calés restent proches des poids d origine. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
134 Méthodes de redressement Estimateur par calage Solution théorique On choisit une fonction de distance G telle que G(w k /d k ) mesure la distance entre le poids initial d k et le poids final w k. Nous supposons que G(1) = 0, G est positive et convexe (i.e, plus w k /d k s éloigne de 1, plus G(w k /d k ) est grand) Le Lagrangien s écrit L = ( ) d k G(w k /d k ) λ w k x k t x k s k s où λ = [λ 1,..., λ p ] est un vecteur de multiplicateurs de Lagrange. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
135 Méthodes de redressement Estimateur par calage Solution théorique (2) La résolution du problème d optimisation conduit à : avec F la fonction inverse de G. w k = d k F [λ x k ] Le vecteur λ peut être déterminé en résolvant le système (non-linéaire) constitué par les équations de calage d k F [λ x k ]x k = t x, k s par exemple à l aide de la méthode itérative de Newton-Raphson. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
136 Méthodes de redressement Estimateur par calage Fonctions de distance usuelles : la méthode linéaire G(r) = 1 2 (r 1)2 et F (u) = 1 + u. La convergence est obtenue à l étape 2 de l algorithme de Newton, et on obtient l estimateur par la régression généralisée ˆt y,greg = k s w k y k = ˆt yπ + ˆb π [ tx ˆt xπ ] avec ˆb π = [ k S x k x k π k ] 1 k S x k y k π k. Cette méthode de calage peut conduire à des poids finaux w k négatifs. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
137 Méthodes de redressement Estimateur par calage Les fonctions de distance usuelles (2) La méthode raking ratio G(r) = r log(r) r + 1 et F (u) = exp(u). Cette méthode permet d assurer que les poids finaux w k sont > 0. Les méthodes bornées Elles peuvent être vues comme des versions "tronquées" des deux méthodes précédentes. Ces deux méthodes permettent de spécifier explicitement des bornes LO et UP pour les rapports de poids, i.e. d assurer que pour tout individu k S LO w k UP. d k Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
138 Méthodes de redressement Estimateur par calage Estimation après calage Après calage, on a pour toute variable y l estimateur calé : ˆt yw = k s w k y k. L estimation est exacte pour les totaux de variables auxiliaires : ˆt xw = t x. Elle est approximativement sans biais pour les autres variables d intérêt : ] E p [ˆt yw ty. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
139 Méthodes de redressement Estimateur par la régression généralisée Estimateur par la régression généralisée Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
140 Méthodes de redressement Estimateur par la régression généralisée Motivation de l estimateur par la régression L estimateur par la régression généralisée est obtenu par calage avec la méthode linéaire. Il est motivé par le modèle y k = β x k + ɛ k avec V m [ɛ k ] = σ 2 k. (14) Si on dispose des données sur toute la population, le meilleur estimateur de β s obtient par les MCG : b = [ k U x k x k σ 2 k ] 1 k U x k y k σ 2 k et E k = y k b x k. On les remplace par leurs estimateurs ˆb π et e k = y k ˆb π x k pour obtenir l estimateur par la régression : ˆt y,greg = ˆb π t } {{ x } + ˆt }{{} eπ. prédiction du total estimation de l erreur totale Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
141 Méthodes de redressement Estimateur par la régression généralisée Fonctions de distance usuelles : la méthode linéaire On peut réécrire l estimateur GREG sous la forme : ˆt y,greg = ˆt yπ + ˆb π [ tx ˆt xπ ]. En utilisant l approximation ˆt y,greg ˆt yπ + b [ t x ˆt xπ ], on obtient : E p [ˆt y,greg ] V p [ˆt y,greg ] ] E p [ˆt yπ + b {t x ˆt xπ } = t y, V p [ˆt yπ b ˆt ] xπ = V p [ˆt Eπ ]. L estimateur GREG est donc approximativement sans biais, et sa variance est approximativement donnée par les résidus de la régression de la variable y k sur les variables auxiliaires x k. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
142 Méthodes de redressement Estimateur par la régression généralisée Fonctions de distance usuelles : la méthode linéaire Application : régression simple On se place dans le cas d un SRS(n). On suppose que l on utilise les variables auxiliaires x k = [1, x k ], de totaux connus. Le modèle de régression sousjacent est : y k = a + b x k + E k. On obtient b = k U (x k µ x)(y k µ y) k U (x k µ x) 2 = Sxy S 2 x a = µ y b µ x ˆb = k S (x k x)(y k ȳ) k S (x k x) 2 = sxy s 2 x â = ȳ ˆb x En notant ρ = Sxy S xs y le coefficient de corrélation linéaire, on a : V srs [ˆt y,greg ] N 2 1 f n S2 y(1 ρ 2 ). Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
143 Méthodes de redressement Variance d un estimateur calé Variance d un estimateur calé Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
144 Méthodes de redressement Variance d un estimateur calé Variance d un estimateur calé Quelle que soit la fonction de distance utilisée, la variance de l estimateur calé ˆt yw est approximativement celle de l estimateur par la régression. La variance de l estimateur calé ˆt yw est donc approximativement égale à V p [ˆt yw ] k,l U E k π k E l π l kl où E k = y k b x k donne les résidus de la régression de y sur le vecteur de variables auxiliaires x k dans la population U. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
145 Méthodes de redressement Variance d un estimateur calé Estimation de variance Deux estimateurs de variance peuvent être utilisés : v 1 [ˆt yw ] v 2 [ˆt yw ] = k,l S = k,l S e k π k e l π l kl π kl g k e k π k g l e l π l kl π kl, où g k = w k /d k, et e k = y k ˆb T π x k donne les résidus estimés. Le second estimateur est généralement (légèrement) préférable. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
146 Méthodes de redressement Variance d un estimateur calé Estimation de variance Un logiciel classique d estimation de variance pour l estimation de totaux ˆt yπ peut être utilisé pour l estimation de variance d estimateurs calés ˆt yw de la façon suivante : Effectuer sur l échantillon S la régression pondérée (par les poids d k ) de la variable y sur les variables auxiliaires x 1,..., x p, Prendre les résidus e k de la régression et calculer les g k = w k /d k, Utiliser le logiciel en remplaçant les y k par les e k (estimateur de variance v 1 ) ou par les g k e k (estimateur de variance v 2 ). Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
147 Méthodes de redressement Variance d un estimateur calé Exemple Echantillon de taille n = 5 tiré selon un SRS dans une population de taille N = 100. On suppose connu le total t x = 320. x 0k x 1k y k ˆt xπ = 300 ˆt yπ = 600 v(ˆt yπ ) = N 2 1 f n s2 y = Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
148 Méthodes de redressement Variance d un estimateur calé Exemple Echantillon de taille n = 5 tiré selon un SRS dans une population de taille N = 100. On suppose connu le total t x = 320. x 0k x 1k y k e k = y k â ˆb x 1k ˆt xπ = 300 ˆt yπ = 600 v(ˆt yπ ) = N 2 1 f n s2 y = â = 0.3 ˆb = 1.9 ˆt yw = 638 v(ˆt yw ) = N 2 1 f n s2 e = Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
149 Application des méthodes de redressement Application des méthodes de redressement Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
150 Application des méthodes de redressement Estimateur par le ratio Estimateur par le ratio Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
151 Application des méthodes de redressement Estimateur par le ratio L estimateur par le ratio On suppose connu le total t x d une seule variable auxiliaire (positive) x k. L estimateur par le ratio est défini par avec w k = d k tx ˆt xπ. ˆt yr = ˆt yπ t x = w k y k ˆt xπ k S Exemple : enquête auprès d entreprises, avec redressement sur la variable d effectif salarié. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
152 Application des méthodes de redressement Estimateur par le ratio Motivation L estimateur par le ratio est motivé par le modèle y k = β x k + ɛ k avec V m [ɛ k ] = σ 2 x k. C est un cas particulier de l estimateur par la régression généralisée, obtenu avec x k = x k et σ 2 k = σ2 x k. On a : et ˆb π = [ ] 1 x k x k x k y k σk 2 π k σk 2 π k k S ˆt yπ ˆt xπ = ˆR π, k S ˆt eπ = k S y k ˆb π x k π k k S y k ˆR π x k π k = 0. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
153 Application des méthodes de redressement Estimateur par le ratio Exemple de données y y/x x x Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
154 Application des méthodes de redressement Estimateur par le ratio Propriétés de l estimateur par le ratio L estimateur par le ratio est approximativement non biaisé pour le total t y. On a ] ] V p [ˆt yr V p [ˆt Eπ avec E k = y k b x k y k R x k. La variance est donc réduite si les variables y k et x k sont approximativement proportionnelles. L estimateur par le ratio est calé sur le total t x : ˆt xr = t x. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
155 Application des méthodes de redressement Estimateur par le ratio Cas du sondage aléatoire simple Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
156 Application des méthodes de redressement Estimateur par le ratio Application au sondage aléatoire simple Dans le cas d un SRS(n), on obtient : On peut l estimer par V p [ˆt yr ] ṽ [ˆt yr ] N 2 1 f n = N 2 1 f n mais E k = y k R x k n est pas calculable sur l échantillon. On la remplace par la variable donnant les résidus estimés e k = y k ˆR π x k pour obtenir l estimateur de variance final : v [ˆt yr ] = N 2 1 f n S 2 E. s 2 E, s 2 e. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
157 Application des méthodes de redressement Estimateur par le ratio Exemple Echantillon de taille n = 5 tiré selon un SRS dans une population de taille N = 100. On suppose connu le total t x = 320. x k y k ˆt xπ = 300 ˆt yπ = 600 v(ˆt yπ ) = N 2 1 f n s2 y = Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
158 Application des méthodes de redressement Estimateur par le ratio Exemple Echantillon de taille n = 5 tiré selon un SRS dans une population de taille N = 100. On suppose connu le total t x = 320. x k y k e k = y k ˆR π x k ˆt xπ = 300 ˆt yπ = 600 ˆR π = 2 ˆt yr = 640 v(ˆt yπ ) = N 2 1 f n s2 y = v(ˆt yr ) = N 2 1 f n s2 e = Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
159 Application des méthodes de redressement Estimateur par le ratio Efficacité de l estimateur par le ratio Dans le cas du SRS, l estimateur par le ratio est préférable à l estimateur direct si ] V p [ˆt yr ] 1 V p [ˆt S2 y 2RS xy + Sx 2 yπ Sy 2 1 ρ 1 cv x 2 cv y avec cv x = Sx/µ 2 x et cv y = Sy/µ 2 y. Même si les variables x et y sont corrélées positivement, l estimateur direct peut être plus efficace. Si la corrélation est négative, l estimateur direct est toujours plus efficace. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
160 Application des méthodes de redressement Estimateur par le ratio Efficacité de l estimateur par le ratio (2) On peut également montrer que V srs [ˆt yr ] Vsrs [ˆt y,greg ] N 2 1 f ( n S2 y ρ R S ) 2 x, S y avec ˆt y,greg l estimateur par la régression simple obtenu avec le vecteur x k = (1, x k ). L estimateur par la régression simple est donc toujours meilleur (asymptotiquement) que l estimateur par le ratio dans le cas d un sondage aléatoire simple. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
161 Application des méthodes de redressement Estimateur par le ratio Cas du sondage aléatoire simple stratifié Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
162 Application des méthodes de redressement Estimateur par le ratio Application au sondage aléatoire simple stratifié Si le total t x sur l ensemble de la population est connu, on obtient l estimateur par le ratio combiné ˆt H yπ h=1 ˆt y,rc = t x = t N hȳ h x ˆt H xπ h=1 N h x h et sa variance est approximativement égale à ] ] V p [ˆt y,rc V p [ˆt Eπ = H h=1 Nh 2 1 f h SEh 2 n. h avec E k = y k R x k. La variance est donc réduite si les variables y et x sont approximativement proportionnelles sur l ensemble de la population. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
163 Application des méthodes de redressement Estimateur par le ratio Application au sondage aléatoire simple stratifié (2) Cette variance peut être estimée par avec e k = y k ˆR π x k. v [ˆt y,rc ] = H h=1 Nh 2 1 f h s 2 eh n, h D un autre côté, si les totaux par strate t xh sont connus, on peut appliquer un redressement par le ratio strate par strate. On obtient l estimateur par le ratio séparé ˆt y,rs = H h=1 t xh ˆt yh ˆt xh = H h=1 t xh ȳ h x h. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
164 Application des méthodes de redressement Estimateur par le ratio Cas d un sondage aléatoire simple stratifié Sa variance est approximativement donnée par V p [ˆt y,rs ] H h=1 N 2 h 1 f h SEh 2 n h avec E k = y k R h x k pour k U h, et R h = t yh /t xh. La variance est donc réduite si les variables y et x sont approximativement proportionnelles dans les strates. Cette variance peut être estimée par v [ˆt y,rs ] = H h=1 Nh 2 1 f h s 2 eh n, h avec e k = y k ˆR h x k et ˆR h = ˆt yh /ˆt xh. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
165 Application des méthodes de redressement Estimateur post-stratifié Estimateur post-stratifié Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
166 Application des méthodes de redressement Estimateur post-stratifié Principe On suppose que l on connaît après le tirage de l échantillon une partition de la population en H groupes notés U 1,..., U H. On parle de poststratification. Les effectifs des post-strates, notés N 1,..., N H, sont supposés connus. Le π-estimateur peut se réécrire ˆt yπ = = H y k π k k S h H h=1 h=1 ˆt yh avec S h l intersection de S et de U h. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
167 Application des méthodes de redressement Estimateur post-stratifié Principe de post-stratification L estimateur post-stratifié est défini par avec ˆt ypost = µ yh = H N h µ yh, h=1 k S h y k π k k S h 1 π k = ˆt yh ˆN h l estimateur par substitution de la moyenne µ yh dans la post-strate U h. Chaque post-strate peut être vue comme un domaine, non pris en compte lors de l échantillonnage. L estimateur post-stratifié s obtient à l aide d un redressement par le ratio dans chaque post-strate. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
168 Application des méthodes de redressement Estimateur post-stratifié Motivation L estimateur post-stratifié est motivé par le modèle y k = β h + ɛ k et V m (ɛ k ) = σ 2 h dans chaque strate U h. C est un cas particulier de l estimateur par la régression généralisée, obtenu avec x k = [1(k U 1 ),..., 1(k U H )] T et σ 2 k = σ2 h pour k U h. On a : et ˆb π = [ ] 1 x k x k x k y k σk 2 π k σk 2 π k k S [ µ y1,..., µ yh ] T, k S e k = y k ˆb π x k y k µ yh pour k U h. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
169 Application des méthodes de redressement Estimateur post-stratifié Propriétés de l estimateur post-stratifié L estimateur par le ratio est approximativement non biaisé pour le total t y. On a ] ] V p [ˆt y,post V p [ˆt Eπ avec E k = y k b x k y k µ yh. La variance est donc réduite si la variable y est peu dispersée dans chaque post-strate. L estimateur post-stratifié est calé sur les effectifs des post-strates : ˆN hpost = N h h = 1,..., H. On obtient un estimateur de variance : en prenant l estimateur v[ˆt Eπ ] associé au pds p( ), en remplaçant les résidus inconnus E k par les résidus estimés e k = y k µ yh pour k S h. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
170 Application des méthodes de redressement Estimateur post-stratifié Cas du sondage aléatoire simple L estimateur post-stratifié se réécrit : ˆt ypost = H N h ȳ h avec ȳ h = 1 n h h=1 Sa variance vaut approximativement k S h y k. V p [ˆt ypost ] N 2 1 f n S2 E = N 2 1 f n H N h 1 N 1 S2 yh, h=1 } {{ } S y,intra 2 et peut être estimée par v [ˆt ypost ] = N 2 1 f n S2 e = N 2 1 f n H h=1 n h 1 n 1 s2 yh. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
171 Mise en oeuvre pratique d un calage Mise en oeuvre pratique d un calage Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
172 Mise en oeuvre pratique d un calage Comment choisir les variables de calage? Les variables auxiliaires les plus explicatives doivent être utilisées pour le calage (sélection avec une PROC GLM, par exemple). Les variables utilisées pour concevoir le plan de sondage doivent être utilisées pour le calage (ex : variables de stratification). Si le calage est utilisé pour compenser de la non-réponse, les variables explicatives de la probabilité de réponse devraient être incluses dans le calage. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
173 Mise en oeuvre pratique d un calage Est-ce que toute l information auxiliaire doit être utilisée dans le calage? En principe, plus on utilise de variables de calage, plus les résidus sont faibles et donc plus la variance de l estimateur calé diminue. En pratique : le nombre de variables de calage doit rester faible devant la taille de l échantillon, les variables les plus explicatives sont généralement suffisantes pour obtenir une forte diminution de la variance. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
174 Mise en oeuvre pratique d un calage Peut-on utiliser plusieurs niveaux d information auxiliaire? C est possible avec la macro CALMAR 2, qui permet d utiliser jusqu à trois niveaux d information auxiliaire. Par exemple, pour une enquête auprès des ménages : information auxiliaire sur les unités primaires (ex : les communes), information auxiliaire sur les ménages, information auxiliaire sur les individus. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
175 Mise en oeuvre pratique d un calage La macro SAS CALMAR2 La macro SAS CALMAR2 Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
176 Mise en oeuvre pratique d un calage La macro SAS CALMAR2 Paramètres pour les tables SAS en entrée DATAMEN = nom de la table contenant les données de l échantillon Observations : unités échantillonnées, Variables : variables de calage, variable identifiante, poids initial. MARMEN = nom de la table contenant l information auxiliaire Observations : variables de calage, Variables : nom de variable, nombre de modalités, marges associées. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
177 Mise en oeuvre pratique d un calage La macro SAS CALMAR2 Paramètres pour les tables SAS en entrée POIDS = variable Variable numérique donnant les poids initiaux des individus de l échantillon. PONDQK = variable Variable numérique de pondération pour les individus de l échantillon, différente de POIDS (utilisée si le modèle (14) est supposé hétéroscédastique). IDENT = variable Variable identifiante pour les unités échantillonnées. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
178 Mise en oeuvre pratique d un calage La macro SAS CALMAR2 Paramètres pour les tables SAS en entrée PCT = OUI or NON Si PCT=OUI, les marges pour les variables catégorielles de la table DATA- MAR sont données en pourcentage. EFFTOT = valeur Nombre total d unités dans la population (à renseigner si PCT=OUI). Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
179 Mise en oeuvre pratique d un calage La macro SAS CALMAR2 Paramètres pour la méthode de calage M = 1,2,3 or 4 Fonction de distance : 1 Méthode linéaire 2 Méthode Raking Ratio 3 Méthode Logit 4 méthode linéaire tronquée LO = valeur Borne Inférieure pour les rapports de poids (à spécifier si M=3 ou 4). Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
180 Mise en oeuvre pratique d un calage La macro SAS CALMAR2 Paramètres pour la méthode de calage UP = valeur Borne Supérieure pour les rapports de poids (à spécifier si M=3 ou 4). SEUIL = valeur Seuil déterminant l arrêt de l algorithme de Newton (optionnel). MAXITER = valeur entière Nombre maximum d itérations de l algorithme de Newton (optionnel). Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
181 Mise en oeuvre pratique d un calage La macro SAS CALMAR2 Paramètres pour les tables SAS en sortie DATAPOI = nom de la table SAS contenant les poids finaux observations : unités échantillonnées non supprimées, variables : variable identifiante, poids final. MISAJOUR = OUI ou NON Spécifie le traitement de variables en sortie : Si MISAJOUR=OUI, la variable donnant les poids calés est ajoutée à la table DATAPOI, Si MISAJOUR=NON, une nouvelle table SAS est créée. L ancienne table SAS est détruite. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
182 Mise en oeuvre pratique d un calage La macro SAS CALMAR2 Paramètres pour les tables SAS en sortie POIDSFIN = variable Nom de la variable donnant les poids calés. LABELPOI = label Label associé à la variable donnant les poids calés. OBSELI = OUI ou NON Si OBSELI=OUI, crée une table SAS OBSELI avec, pour chaque unité supprimée de l échantillon d origine, la variable identifiante, les variables de calage et les poids initiaux. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
183 Mise en oeuvre pratique d un calage La macro SAS CALMAR2 Un petit exemple Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
184 Mise en oeuvre pratique d un calage La macro SAS CALMAR2 Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
185 Mise en oeuvre pratique d un calage La macro SAS CALMAR2 Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
186 Mise en oeuvre pratique d un calage La macro SAS CALMAR2 Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
187 Mise en oeuvre pratique d un calage La macro SAS CALMAR2 Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
188 Mise en oeuvre pratique d un calage La macro SAS CALMAR2 Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
189 Mise en oeuvre pratique d un calage La macro SAS CALMAR2 Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
190 Mise en oeuvre pratique d un calage La macro SAS CALMAR2 Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
191 Mise en oeuvre pratique d un calage La macro SAS CALMAR2 Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
192 Mise en oeuvre pratique d un calage La macro SAS CALMAR2 Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
193 Mise en oeuvre pratique d un calage La macro SAS CALMAR2 Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
194 Mise en oeuvre pratique d un calage La macro SAS CALMAR2 Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
195 Mise en oeuvre pratique d un calage La macro SAS CALMAR2 Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
196 Mise en oeuvre pratique d un calage La macro SAS CALMAR2 Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
197 Mise en oeuvre pratique d un calage La macro SAS CALMAR2 Bibliographie Ardilly, P. (2005). Panorama des principales méthodes d estimation sur petits domaines. Actes des Journées de Méthodologie Statistique, Insee. Ardilly, P. (2006), Les Techniques de Sondage, Technip, Paris. Ardilly, P., et Tillé, Y. (2003), Exercices corrigés de méthodes de sondage Sondage, Technip, Paris. Cochran, W.G (1977), Sampling Techniques, Wiley, New-York. De Peretti, P. et al (2006). L enquête sans-domicile Insee Méthodes, 116, Paris. Deville, J-C. (1991). Une théorie des enquêtes par quotas. Techniques d Enquête, 17, Hajek, J. (1964). Asymptotic theory of rejective sampling with varying probabilities from a finite population. Annals of Mathematical Statistics, 35, Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
198 Mise en oeuvre pratique d un calage La macro SAS CALMAR2 Bibliographie Loonis, V. (2009). La construction du nouvel échantillon de l Enquête Emploi en Continu à partir des fichiers de la Taxe d Habitation. Actes des Journées de Méthodologie Statistique, Paris. Rao, J.N.K (2003). Small Area Estimation. New-York, Wiley. Särndal, C.-E., and Swensson, B., and Wretman, J.H. (1992), Model Assisted Survey Sampling, Springer-Verlag, New-York. Sautory, O., et Le Guennec, J. (2003). La macro CALMAR2 : Redressement d un échantillon par calage sur marges, Insee. Schreuder, H.T., and Gregoire, T.G., and Wood, G.B. (1993). Sampling Methods for Multiresource Forest Inventry, Wiley, New-York. Tillé, Y. (2006). Sampling algorithms, Springer, New-York. Guillaume Chauvet (ENSAI) Echantillonnage 27 avril / 198
Théorie des sondages : cours 5
 Théorie des sondages : cours 5 Camelia Goga IMB, Université de Bourgogne e-mail : [email protected] Master Besançon-2010 Chapitre 5 : Techniques de redressement 1. poststratification 2. l estimateur
Théorie des sondages : cours 5 Camelia Goga IMB, Université de Bourgogne e-mail : [email protected] Master Besançon-2010 Chapitre 5 : Techniques de redressement 1. poststratification 2. l estimateur
Chapitre 3 : INFERENCE
 Chapitre 3 : INFERENCE 3.1 L ÉCHANTILLONNAGE 3.1.1 Introduction 3.1.2 L échantillonnage aléatoire 3.1.3 Estimation ponctuelle 3.1.4 Distributions d échantillonnage 3.1.5 Intervalles de probabilité L échantillonnage
Chapitre 3 : INFERENCE 3.1 L ÉCHANTILLONNAGE 3.1.1 Introduction 3.1.2 L échantillonnage aléatoire 3.1.3 Estimation ponctuelle 3.1.4 Distributions d échantillonnage 3.1.5 Intervalles de probabilité L échantillonnage
Les simulations dans l enseignement des sondages Avec le logiciel GENESIS sous SAS et la bibliothèque Sondages sous R
 Les simulations dans l enseignement des sondages Avec le logiciel GENESIS sous SAS et la bibliothèque Sondages sous R Yves Aragon, David Haziza & Anne Ruiz-Gazen GREMAQ, UMR CNRS 5604, Université des Sciences
Les simulations dans l enseignement des sondages Avec le logiciel GENESIS sous SAS et la bibliothèque Sondages sous R Yves Aragon, David Haziza & Anne Ruiz-Gazen GREMAQ, UMR CNRS 5604, Université des Sciences
STA108 Enquêtes et sondages. Sondages àplusieurs degrés et par grappes
 STA108 Enquêtes et sondages Sondages àplusieurs degrés et par grappes Philippe Périé, novembre 2011 Sondages àplusieurs degrés et par grappes Introduction Sondages à plusieurs degrés Tirage des unités
STA108 Enquêtes et sondages Sondages àplusieurs degrés et par grappes Philippe Périé, novembre 2011 Sondages àplusieurs degrés et par grappes Introduction Sondages à plusieurs degrés Tirage des unités
CONCOURS D ENTREE A L ECOLE DE 2007 CONCOURS EXTERNE. Cinquième épreuve d admissibilité STATISTIQUE. (durée : cinq heures)
") CONCOURS D ENTREE A L ECOLE DE 2007 CONCOURS EXTERNE Cinquième épreuve d admissibilité STATISTIQUE (durée : cinq heures) Une composition portant sur la statistique. SUJET Cette épreuve est composée d un
CONCOURS D ENTREE A L ECOLE DE 2007 CONCOURS EXTERNE Cinquième épreuve d admissibilité STATISTIQUE (durée : cinq heures) Une composition portant sur la statistique. SUJET Cette épreuve est composée d un
La nouvelle planification de l échantillonnage
 La nouvelle planification de l échantillonnage Pierre-Arnaud Pendoli Division Sondages Plan de la présentation Rappel sur le Recensement de la population (RP) en continu Description de la base de sondage
La nouvelle planification de l échantillonnage Pierre-Arnaud Pendoli Division Sondages Plan de la présentation Rappel sur le Recensement de la population (RP) en continu Description de la base de sondage
La survie nette actuelle à long terme Qualités de sept méthodes d estimation
 La survie nette actuelle à long terme Qualités de sept méthodes d estimation PAR Alireza MOGHADDAM TUTEUR : Guy HÉDELIN Laboratoire d Épidémiologie et de Santé publique, EA 80 Faculté de Médecine de Strasbourg
La survie nette actuelle à long terme Qualités de sept méthodes d estimation PAR Alireza MOGHADDAM TUTEUR : Guy HÉDELIN Laboratoire d Épidémiologie et de Santé publique, EA 80 Faculté de Médecine de Strasbourg
LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING»
 LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING» Gilbert Saporta Professeur de Statistique Appliquée Conservatoire National des Arts et Métiers Dans leur quasi totalité, les banques et organismes financiers
LA NOTATION STATISTIQUE DES EMPRUNTEURS OU «SCORING» Gilbert Saporta Professeur de Statistique Appliquée Conservatoire National des Arts et Métiers Dans leur quasi totalité, les banques et organismes financiers
Chapitre 7. Statistique des échantillons gaussiens. 7.1 Projection de vecteurs gaussiens
 Chapitre 7 Statistique des échantillons gaussiens Le théorème central limite met en évidence le rôle majeur tenu par la loi gaussienne en modélisation stochastique. De ce fait, les modèles statistiques
Chapitre 7 Statistique des échantillons gaussiens Le théorème central limite met en évidence le rôle majeur tenu par la loi gaussienne en modélisation stochastique. De ce fait, les modèles statistiques
Estimation et tests statistiques, TD 5. Solutions
 ISTIL, Tronc commun de première année Introduction aux méthodes probabilistes et statistiques, 2008 2009 Estimation et tests statistiques, TD 5. Solutions Exercice 1 Dans un centre avicole, des études
ISTIL, Tronc commun de première année Introduction aux méthodes probabilistes et statistiques, 2008 2009 Estimation et tests statistiques, TD 5. Solutions Exercice 1 Dans un centre avicole, des études
Moments des variables aléatoires réelles
 Chapter 6 Moments des variables aléatoires réelles Sommaire 6.1 Espérance des variables aléatoires réelles................................ 46 6.1.1 Définition et calcul........................................
Chapter 6 Moments des variables aléatoires réelles Sommaire 6.1 Espérance des variables aléatoires réelles................................ 46 6.1.1 Définition et calcul........................................
Table des matières. I Mise à niveau 11. Préface
 Table des matières Préface v I Mise à niveau 11 1 Bases du calcul commercial 13 1.1 Alphabet grec...................................... 13 1.2 Symboles mathématiques............................... 14 1.3
Table des matières Préface v I Mise à niveau 11 1 Bases du calcul commercial 13 1.1 Alphabet grec...................................... 13 1.2 Symboles mathématiques............................... 14 1.3
TABLE DES MATIERES. C Exercices complémentaires 42
 TABLE DES MATIERES Chapitre I : Echantillonnage A - Rappels de cours 1. Lois de probabilités de base rencontrées en statistique 1 1.1 Définitions et caractérisations 1 1.2 Les propriétés de convergence
TABLE DES MATIERES Chapitre I : Echantillonnage A - Rappels de cours 1. Lois de probabilités de base rencontrées en statistique 1 1.1 Définitions et caractérisations 1 1.2 Les propriétés de convergence
M2 IAD UE MODE Notes de cours (3)
") M2 IAD UE MODE Notes de cours (3) Jean-Yves Jaffray Patrice Perny 16 mars 2006 ATTITUDE PAR RAPPORT AU RISQUE 1 Attitude par rapport au risque Nousn avons pas encore fait d hypothèse sur la structure de
M2 IAD UE MODE Notes de cours (3) Jean-Yves Jaffray Patrice Perny 16 mars 2006 ATTITUDE PAR RAPPORT AU RISQUE 1 Attitude par rapport au risque Nousn avons pas encore fait d hypothèse sur la structure de
Introduction à l approche bootstrap
 Introduction à l approche bootstrap Irène Buvat U494 INSERM buvat@imedjussieufr 25 septembre 2000 Introduction à l approche bootstrap - Irène Buvat - 21/9/00-1 Plan du cours Qu est-ce que le bootstrap?
Introduction à l approche bootstrap Irène Buvat U494 INSERM buvat@imedjussieufr 25 septembre 2000 Introduction à l approche bootstrap - Irène Buvat - 21/9/00-1 Plan du cours Qu est-ce que le bootstrap?
Statistiques Descriptives à une dimension
 I. Introduction et Définitions 1. Introduction La statistique est une science qui a pour objectif de recueillir et de traiter les informations, souvent en très grand nombre. Elle regroupe l ensemble des
I. Introduction et Définitions 1. Introduction La statistique est une science qui a pour objectif de recueillir et de traiter les informations, souvent en très grand nombre. Elle regroupe l ensemble des
Le modèle de Black et Scholes
 Le modèle de Black et Scholes Alexandre Popier février 21 1 Introduction : exemple très simple de modèle financier On considère un marché avec une seule action cotée, sur une période donnée T. Dans un
Le modèle de Black et Scholes Alexandre Popier février 21 1 Introduction : exemple très simple de modèle financier On considère un marché avec une seule action cotée, sur une période donnée T. Dans un
Simulation de variables aléatoires
 Chapter 1 Simulation de variables aléatoires Références: [F] Fishman, A first course in Monte Carlo, chap 3. [B] Bouleau, Probabilités de l ingénieur, chap 4. [R] Rubinstein, Simulation and Monte Carlo
Chapter 1 Simulation de variables aléatoires Références: [F] Fishman, A first course in Monte Carlo, chap 3. [B] Bouleau, Probabilités de l ingénieur, chap 4. [R] Rubinstein, Simulation and Monte Carlo
Baccalauréat ES/L Amérique du Sud 21 novembre 2013
 Baccalauréat ES/L Amérique du Sud 21 novembre 2013 A. P. M. E. P. EXERCICE 1 Commun à tous les candidats 5 points Une entreprise informatique produit et vend des clés USB. La vente de ces clés est réalisée
Baccalauréat ES/L Amérique du Sud 21 novembre 2013 A. P. M. E. P. EXERCICE 1 Commun à tous les candidats 5 points Une entreprise informatique produit et vend des clés USB. La vente de ces clés est réalisée
La classification automatique de données quantitatives
 La classification automatique de données quantitatives 1 Introduction Parmi les méthodes de statistique exploratoire multidimensionnelle, dont l objectif est d extraire d une masse de données des informations
La classification automatique de données quantitatives 1 Introduction Parmi les méthodes de statistique exploratoire multidimensionnelle, dont l objectif est d extraire d une masse de données des informations
Fiche qualité relative à l enquête Santé et Itinéraire Professionnel 2010 (SIP) Carte d identité de l enquête
 Carte d identité de l enquête") Fiche qualité relative à Santé et Itinéraire Professionnel 2010 (SIP) Nom Années de Périodicité Panel (suivi d échantillon) Services concepteurs Service réalisant Sujets principaux traités dans Carte d
Fiche qualité relative à Santé et Itinéraire Professionnel 2010 (SIP) Nom Années de Périodicité Panel (suivi d échantillon) Services concepteurs Service réalisant Sujets principaux traités dans Carte d
Méthodes de Simulation
 Méthodes de Simulation JEAN-YVES TOURNERET Institut de recherche en informatique de Toulouse (IRIT) ENSEEIHT, Toulouse, France Peyresq06 p. 1/41 Remerciements Christian Robert : pour ses excellents transparents
Méthodes de Simulation JEAN-YVES TOURNERET Institut de recherche en informatique de Toulouse (IRIT) ENSEEIHT, Toulouse, France Peyresq06 p. 1/41 Remerciements Christian Robert : pour ses excellents transparents
Séminaire TEST. 1 Présentation du sujet. October 18th, 2013
 Séminaire ES Andrés SÁNCHEZ PÉREZ October 8th, 03 Présentation du sujet Le problème de régression non-paramétrique se pose de la façon suivante : Supposons que l on dispose de n couples indépendantes de
Séminaire ES Andrés SÁNCHEZ PÉREZ October 8th, 03 Présentation du sujet Le problème de régression non-paramétrique se pose de la façon suivante : Supposons que l on dispose de n couples indépendantes de
Feuille 6 : Tests. Peut-on dire que l usine a respecté ses engagements? Faire un test d hypothèses pour y répondre.
 Université de Nantes Année 2013-2014 L3 Maths-Eco Feuille 6 : Tests Exercice 1 On cherche à connaître la température d ébullition µ, en degrés Celsius, d un certain liquide. On effectue 16 expériences
Université de Nantes Année 2013-2014 L3 Maths-Eco Feuille 6 : Tests Exercice 1 On cherche à connaître la température d ébullition µ, en degrés Celsius, d un certain liquide. On effectue 16 expériences
Précision d un résultat et calculs d incertitudes
 Précision d un résultat et calculs d incertitudes PSI* 2012-2013 Lycée Chaptal 3 Table des matières Table des matières 1. Présentation d un résultat numérique................................ 4 1.1 Notations.........................................................
Précision d un résultat et calculs d incertitudes PSI* 2012-2013 Lycée Chaptal 3 Table des matières Table des matières 1. Présentation d un résultat numérique................................ 4 1.1 Notations.........................................................
Exploitation et analyse des données appliquées aux techniques d enquête par sondage. Introduction.
 Exploitation et analyse des données appliquées aux techniques d enquête par sondage. Introduction. Etudes et traitements statistiques des données : le cas illustratif de la démarche par sondage INTRODUCTION
Exploitation et analyse des données appliquées aux techniques d enquête par sondage. Introduction. Etudes et traitements statistiques des données : le cas illustratif de la démarche par sondage INTRODUCTION
t 100. = 8 ; le pourcentage de réduction est : 8 % 1 t Le pourcentage d'évolution (appelé aussi taux d'évolution) est le nombre :
 est le nombre :") Terminale STSS 2 012 2 013 Pourcentages Synthèse 1) Définition : Calculer t % d'un nombre, c'est multiplier ce nombre par t 100. 2) Exemples de calcul : a) Calcul d un pourcentage : Un article coûtant
Terminale STSS 2 012 2 013 Pourcentages Synthèse 1) Définition : Calculer t % d'un nombre, c'est multiplier ce nombre par t 100. 2) Exemples de calcul : a) Calcul d un pourcentage : Un article coûtant
CONCEPTION ET TIRAGE DE L ÉCHANTILLON
 CHAPITRE 4 CONCEPTION ET TIRAGE DE L ÉCHANTILLON Ce chapitre technique 1 s adresse principalement aux spécialistes de sondage, mais aussi au coordinateur et aux autres responsables techniques de l enquête.
CHAPITRE 4 CONCEPTION ET TIRAGE DE L ÉCHANTILLON Ce chapitre technique 1 s adresse principalement aux spécialistes de sondage, mais aussi au coordinateur et aux autres responsables techniques de l enquête.
PROBABILITES ET STATISTIQUE I&II
 PROBABILITES ET STATISTIQUE I&II TABLE DES MATIERES CHAPITRE I - COMBINATOIRE ELEMENTAIRE I.1. Rappel des notations de la théorie des ensemble I.1.a. Ensembles et sous-ensembles I.1.b. Diagrammes (dits
PROBABILITES ET STATISTIQUE I&II TABLE DES MATIERES CHAPITRE I - COMBINATOIRE ELEMENTAIRE I.1. Rappel des notations de la théorie des ensemble I.1.a. Ensembles et sous-ensembles I.1.b. Diagrammes (dits
3 Approximation de solutions d équations
 3 Approximation de solutions d équations Une équation scalaire a la forme générale f(x) =0où f est une fonction de IR dans IR. Un système de n équations à n inconnues peut aussi se mettre sous une telle
3 Approximation de solutions d équations Une équation scalaire a la forme générale f(x) =0où f est une fonction de IR dans IR. Un système de n équations à n inconnues peut aussi se mettre sous une telle
Fonctions de plusieurs variables
 Module : Analyse 03 Chapitre 00 : Fonctions de plusieurs variables Généralités et Rappels des notions topologiques dans : Qu est- ce que?: Mathématiquement, n étant un entier non nul, on définit comme
Module : Analyse 03 Chapitre 00 : Fonctions de plusieurs variables Généralités et Rappels des notions topologiques dans : Qu est- ce que?: Mathématiquement, n étant un entier non nul, on définit comme
Programmes des classes préparatoires aux Grandes Ecoles
 Programmes des classes préparatoires aux Grandes Ecoles Filière : scientifique Voie : Biologie, chimie, physique et sciences de la Terre (BCPST) Discipline : Mathématiques Seconde année Préambule Programme
Programmes des classes préparatoires aux Grandes Ecoles Filière : scientifique Voie : Biologie, chimie, physique et sciences de la Terre (BCPST) Discipline : Mathématiques Seconde année Préambule Programme
Value at Risk. CNAM GFN 206 Gestion d actifs et des risques. Grégory Taillard. 27 février & 13 mars 20061
 Value at Risk 27 février & 13 mars 20061 CNAM Gréory Taillard CNAM Master Finance de marché et estion de capitaux 2 Value at Risk Biblioraphie Jorion, Philippe, «Value at Risk: The New Benchmark for Manain
Value at Risk 27 février & 13 mars 20061 CNAM Gréory Taillard CNAM Master Finance de marché et estion de capitaux 2 Value at Risk Biblioraphie Jorion, Philippe, «Value at Risk: The New Benchmark for Manain
Approche modèle pour l estimation en présence de non-réponse non-ignorable en sondage
 Approche modèle pour l estimation en présence de non-réponse non-ignorable en sondage Journées de Méthodologie Statistique Eric Lesage Crest-Ensai 25 janvier 2012 Introduction et contexte 2/27 1 Introduction
Approche modèle pour l estimation en présence de non-réponse non-ignorable en sondage Journées de Méthodologie Statistique Eric Lesage Crest-Ensai 25 janvier 2012 Introduction et contexte 2/27 1 Introduction
Baccalauréat S Antilles-Guyane 11 septembre 2014 Corrigé
 Baccalauréat S ntilles-guyane 11 septembre 14 Corrigé EXERCICE 1 6 points Commun à tous les candidats Une entreprise de jouets en peluche souhaite commercialiser un nouveau produit et à cette fin, effectue
Baccalauréat S ntilles-guyane 11 septembre 14 Corrigé EXERCICE 1 6 points Commun à tous les candidats Une entreprise de jouets en peluche souhaite commercialiser un nouveau produit et à cette fin, effectue
UFR de Sciences Economiques Année 2008-2009 TESTS PARAMÉTRIQUES
 Université Paris 13 Cours de Statistiques et Econométrie I UFR de Sciences Economiques Année 2008-2009 Licence de Sciences Economiques L3 Premier semestre TESTS PARAMÉTRIQUES Remarque: les exercices 2,
Université Paris 13 Cours de Statistiques et Econométrie I UFR de Sciences Economiques Année 2008-2009 Licence de Sciences Economiques L3 Premier semestre TESTS PARAMÉTRIQUES Remarque: les exercices 2,
Probabilités sur un univers fini
 [http://mp.cpgedupuydelome.fr] édité le 7 août 204 Enoncés Probabilités sur un univers fini Evènements et langage ensembliste A quelle condition sur (a, b, c, d) ]0, [ 4 existe-t-il une probabilité P sur
[http://mp.cpgedupuydelome.fr] édité le 7 août 204 Enoncés Probabilités sur un univers fini Evènements et langage ensembliste A quelle condition sur (a, b, c, d) ]0, [ 4 existe-t-il une probabilité P sur
Annexe commune aux séries ES, L et S : boîtes et quantiles
 Annexe commune aux séries ES, L et S : boîtes et quantiles Quantiles En statistique, pour toute série numérique de données à valeurs dans un intervalle I, on définit la fonction quantile Q, de [,1] dans
Annexe commune aux séries ES, L et S : boîtes et quantiles Quantiles En statistique, pour toute série numérique de données à valeurs dans un intervalle I, on définit la fonction quantile Q, de [,1] dans
Probabilités Loi binomiale Exercices corrigés
 Probabilités Loi binomiale Exercices corrigés Sont abordés dans cette fiche : (cliquez sur l exercice pour un accès direct) Exercice 1 : épreuve de Bernoulli Exercice 2 : loi de Bernoulli de paramètre
Probabilités Loi binomiale Exercices corrigés Sont abordés dans cette fiche : (cliquez sur l exercice pour un accès direct) Exercice 1 : épreuve de Bernoulli Exercice 2 : loi de Bernoulli de paramètre
3. Caractéristiques et fonctions d une v.a.
 3. Caractéristiques et fonctions d une v.a. MTH2302D S. Le Digabel, École Polytechnique de Montréal H2015 (v2) MTH2302D: fonctions d une v.a. 1/32 Plan 1. Caractéristiques d une distribution 2. Fonctions
3. Caractéristiques et fonctions d une v.a. MTH2302D S. Le Digabel, École Polytechnique de Montréal H2015 (v2) MTH2302D: fonctions d une v.a. 1/32 Plan 1. Caractéristiques d une distribution 2. Fonctions
Exercice autour de densité, fonction de répatition, espérance et variance de variables quelconques.
 14-3- 214 J.F.C. p. 1 I Exercice autour de densité, fonction de répatition, espérance et variance de variables quelconques. Exercice 1 Densité de probabilité. F { ln x si x ], 1] UN OVNI... On pose x R,
14-3- 214 J.F.C. p. 1 I Exercice autour de densité, fonction de répatition, espérance et variance de variables quelconques. Exercice 1 Densité de probabilité. F { ln x si x ], 1] UN OVNI... On pose x R,
Le modèle de régression linéaire
 Chapitre 2 Le modèle de régression linéaire 2.1 Introduction L économétrie traite de la construction de modèles. Le premier point de l analyse consiste à se poser la question : «Quel est le modèle?». Le
Chapitre 2 Le modèle de régression linéaire 2.1 Introduction L économétrie traite de la construction de modèles. Le premier point de l analyse consiste à se poser la question : «Quel est le modèle?». Le
Correction de l examen de la première session
 de l examen de la première session Julian Tugaut, Franck Licini, Didier Vincent Si vous trouvez des erreurs de Français ou de mathématiques ou bien si vous avez des questions et/ou des suggestions, envoyez-moi
de l examen de la première session Julian Tugaut, Franck Licini, Didier Vincent Si vous trouvez des erreurs de Français ou de mathématiques ou bien si vous avez des questions et/ou des suggestions, envoyez-moi
Probabilités sur un univers fini
 [http://mp.cpgedupuydelome.fr] édité le 10 août 2015 Enoncés 1 Proailités sur un univers fini Evènements et langage ensemliste A quelle condition sur (a,, c, d) ]0, 1[ 4 existe-t-il une proailité P sur
[http://mp.cpgedupuydelome.fr] édité le 10 août 2015 Enoncés 1 Proailités sur un univers fini Evènements et langage ensemliste A quelle condition sur (a,, c, d) ]0, 1[ 4 existe-t-il une proailité P sur
TABLE DES MATIÈRES. Bruxelles, De Boeck, 2011, 736 p.
 STATISTIQUE THÉORIQUE ET APPLIQUÉE Tome 2 Inférence statistique à une et à deux dimensions Pierre Dagnelie TABLE DES MATIÈRES Bruxelles, De Boeck, 2011, 736 p. ISBN 978-2-8041-6336-5 De Boeck Services,
STATISTIQUE THÉORIQUE ET APPLIQUÉE Tome 2 Inférence statistique à une et à deux dimensions Pierre Dagnelie TABLE DES MATIÈRES Bruxelles, De Boeck, 2011, 736 p. ISBN 978-2-8041-6336-5 De Boeck Services,
Exercices supplémentaires sur l introduction générale à la notion de probabilité 2009-2010
 Exercices supplémentaires sur l introduction générale à la notion de probabilité 2009-2010 Exercices fortement conseillés : 6, 10 et 14 1) Un groupe d étudiants est formé de 20 étudiants de première année
Exercices supplémentaires sur l introduction générale à la notion de probabilité 2009-2010 Exercices fortement conseillés : 6, 10 et 14 1) Un groupe d étudiants est formé de 20 étudiants de première année
Souad EL Bernoussi. Groupe d Analyse Numérique et Optimisation Rabat http ://www.fsr.ac.ma/ano/
 Recherche opérationnelle Les démonstrations et les exemples seront traités en cours Souad EL Bernoussi Groupe d Analyse Numérique et Optimisation Rabat http ://www.fsr.ac.ma/ano/ Table des matières 1 Programmation
Recherche opérationnelle Les démonstrations et les exemples seront traités en cours Souad EL Bernoussi Groupe d Analyse Numérique et Optimisation Rabat http ://www.fsr.ac.ma/ano/ Table des matières 1 Programmation
Chapitre 2/ La fonction de consommation et la fonction d épargne
 hapitre 2/ La fonction de consommation et la fonction d épargne I : La fonction de consommation keynésienne II : Validations et limites de la fonction de consommation keynésienne III : Le choix de consommation
hapitre 2/ La fonction de consommation et la fonction d épargne I : La fonction de consommation keynésienne II : Validations et limites de la fonction de consommation keynésienne III : Le choix de consommation
Chapitre 2 Le problème de l unicité des solutions
 Université Joseph Fourier UE MAT 127 Mathématiques année 2011-2012 Chapitre 2 Le problème de l unicité des solutions Ce que nous verrons dans ce chapitre : un exemple d équation différentielle y = f(y)
Université Joseph Fourier UE MAT 127 Mathématiques année 2011-2012 Chapitre 2 Le problème de l unicité des solutions Ce que nous verrons dans ce chapitre : un exemple d équation différentielle y = f(y)
CAPTEURS - CHAINES DE MESURES
 CAPTEURS - CHAINES DE MESURES Pierre BONNET Pierre Bonnet Master GSI - Capteurs Chaînes de Mesures 1 Plan du Cours Propriétés générales des capteurs Notion de mesure Notion de capteur: principes, classes,
CAPTEURS - CHAINES DE MESURES Pierre BONNET Pierre Bonnet Master GSI - Capteurs Chaînes de Mesures 1 Plan du Cours Propriétés générales des capteurs Notion de mesure Notion de capteur: principes, classes,
Rappels sur les suites - Algorithme
 DERNIÈRE IMPRESSION LE 14 septembre 2015 à 12:36 Rappels sur les suites - Algorithme Table des matières 1 Suite : généralités 2 1.1 Déition................................. 2 1.2 Exemples de suites............................
DERNIÈRE IMPRESSION LE 14 septembre 2015 à 12:36 Rappels sur les suites - Algorithme Table des matières 1 Suite : généralités 2 1.1 Déition................................. 2 1.2 Exemples de suites............................
CALCUL D UN SCORE ( SCORING) Application de techniques de discrimination LES OBJECTIFS DU SCORING
 Application de techniques de discrimination LES OBJECTIFS DU SCORING") CALCUL D UN SCORE ( SCORING) Application de techniques de discrimination LES OBJECTIFS DU SCORING SÉLECTION DES RISQUES PRÉVISION DES DÉFAUTS SUIVI ET CONTRÔLE Pierre-Louis GONZALEZ Différents types de
CALCUL D UN SCORE ( SCORING) Application de techniques de discrimination LES OBJECTIFS DU SCORING SÉLECTION DES RISQUES PRÉVISION DES DÉFAUTS SUIVI ET CONTRÔLE Pierre-Louis GONZALEZ Différents types de
Exercices - Polynômes : corrigé. Opérations sur les polynômes
 Opérations sur les polynômes Exercice 1 - Carré - L1/Math Sup - Si P = Q est le carré d un polynôme, alors Q est nécessairement de degré, et son coefficient dominant est égal à 1. On peut donc écrire Q(X)
Opérations sur les polynômes Exercice 1 - Carré - L1/Math Sup - Si P = Q est le carré d un polynôme, alors Q est nécessairement de degré, et son coefficient dominant est égal à 1. On peut donc écrire Q(X)
Introduction à la Statistique Inférentielle
 UNIVERSITE MOHAMMED V-AGDAL SCIENCES FACULTE DES DEPARTEMENT DE MATHEMATIQUES SMI semestre 4 : Probabilités - Statistique Introduction à la Statistique Inférentielle Prinemps 2013 0 INTRODUCTION La statistique
UNIVERSITE MOHAMMED V-AGDAL SCIENCES FACULTE DES DEPARTEMENT DE MATHEMATIQUES SMI semestre 4 : Probabilités - Statistique Introduction à la Statistique Inférentielle Prinemps 2013 0 INTRODUCTION La statistique
Licence MASS 2000-2001. (Re-)Mise à niveau en Probabilités. Feuilles de 1 à 7
Mise à niveau en Probabilités. Feuilles de 1 à 7") Feuilles de 1 à 7 Ces feuilles avec 25 exercices et quelques rappels historiques furent distribuées à des étudiants de troisième année, dans le cadre d un cours intensif sur deux semaines, en début d année,
Feuilles de 1 à 7 Ces feuilles avec 25 exercices et quelques rappels historiques furent distribuées à des étudiants de troisième année, dans le cadre d un cours intensif sur deux semaines, en début d année,
FIMA, 7 juillet 2005
 F. Corset 1 S. 2 1 LabSAD Université Pierre Mendes France 2 Département de Mathématiques Université de Franche-Comté FIMA, 7 juillet 2005 Plan de l exposé plus court chemin Origine du problème Modélisation
F. Corset 1 S. 2 1 LabSAD Université Pierre Mendes France 2 Département de Mathématiques Université de Franche-Comté FIMA, 7 juillet 2005 Plan de l exposé plus court chemin Origine du problème Modélisation
Lois de probabilité. Anita Burgun
 Lois de probabilité Anita Burgun Problème posé Le problème posé en statistique: On s intéresse à une population On extrait un échantillon On se demande quelle sera la composition de l échantillon (pourcentage
Lois de probabilité Anita Burgun Problème posé Le problème posé en statistique: On s intéresse à une population On extrait un échantillon On se demande quelle sera la composition de l échantillon (pourcentage
Le Data Mining au service du Scoring ou notation statistique des emprunteurs!
 France Le Data Mining au service du Scoring ou notation statistique des emprunteurs! Comme le rappelle la CNIL dans sa délibération n 88-083 du 5 Juillet 1988 portant adoption d une recommandation relative
France Le Data Mining au service du Scoring ou notation statistique des emprunteurs! Comme le rappelle la CNIL dans sa délibération n 88-083 du 5 Juillet 1988 portant adoption d une recommandation relative
Principe d un test statistique
 Biostatistiques Principe d un test statistique Professeur Jean-Luc BOSSON PCEM2 - Année universitaire 2012/2013 Faculté de Médecine de Grenoble (UJF) - Tous droits réservés. Objectifs pédagogiques Comprendre
Biostatistiques Principe d un test statistique Professeur Jean-Luc BOSSON PCEM2 - Année universitaire 2012/2013 Faculté de Médecine de Grenoble (UJF) - Tous droits réservés. Objectifs pédagogiques Comprendre
Exercices - Fonctions de plusieurs variables : corrigé. Pour commencer
 Pour commencer Exercice 1 - Ensembles de définition - Première année - 1. Le logarithme est défini si x + y > 0. On trouve donc le demi-plan supérieur délimité par la droite d équation x + y = 0.. 1 xy
Pour commencer Exercice 1 - Ensembles de définition - Première année - 1. Le logarithme est défini si x + y > 0. On trouve donc le demi-plan supérieur délimité par la droite d équation x + y = 0.. 1 xy
Optimisation non linéaire Irène Charon, Olivier Hudry École nationale supérieure des télécommunications
 Optimisation non linéaire Irène Charon, Olivier Hudry École nationale supérieure des télécommunications A. Optimisation sans contrainte.... Généralités.... Condition nécessaire et condition suffisante
Optimisation non linéaire Irène Charon, Olivier Hudry École nationale supérieure des télécommunications A. Optimisation sans contrainte.... Généralités.... Condition nécessaire et condition suffisante
Probabilités III Introduction à l évaluation d options
 Probabilités III Introduction à l évaluation d options Jacques Printems Promotion 2012 2013 1 Modèle à temps discret 2 Introduction aux modèles en temps continu Limite du modèle binomial lorsque N + Un
Probabilités III Introduction à l évaluation d options Jacques Printems Promotion 2012 2013 1 Modèle à temps discret 2 Introduction aux modèles en temps continu Limite du modèle binomial lorsque N + Un
PROBLEMES D'ORDONNANCEMENT AVEC RESSOURCES
 Leçon 11 PROBLEMES D'ORDONNANCEMENT AVEC RESSOURCES Dans cette leçon, nous retrouvons le problème d ordonnancement déjà vu mais en ajoutant la prise en compte de contraintes portant sur les ressources.
Leçon 11 PROBLEMES D'ORDONNANCEMENT AVEC RESSOURCES Dans cette leçon, nous retrouvons le problème d ordonnancement déjà vu mais en ajoutant la prise en compte de contraintes portant sur les ressources.
Biostatistiques Biologie- Vétérinaire FUNDP Eric Depiereux, Benoît DeHertogh, Grégoire Vincke
 www.fundp.ac.be/biostats Module 140 140 ANOVA A UN CRITERE DE CLASSIFICATION FIXE...2 140.1 UTILITE...2 140.2 COMPARAISON DE VARIANCES...2 140.2.1 Calcul de la variance...2 140.2.2 Distributions de référence...3
www.fundp.ac.be/biostats Module 140 140 ANOVA A UN CRITERE DE CLASSIFICATION FIXE...2 140.1 UTILITE...2 140.2 COMPARAISON DE VARIANCES...2 140.2.1 Calcul de la variance...2 140.2.2 Distributions de référence...3
Estimation: intervalle de fluctuation et de confiance. Mars 2012. IREM: groupe Proba-Stat. Fluctuation. Confiance. dans les programmes comparaison
 Estimation: intervalle de fluctuation et de confiance Mars 2012 IREM: groupe Proba-Stat Estimation Term.1 Intervalle de fluctuation connu : probabilité p, taille de l échantillon n but : estimer une fréquence
Estimation: intervalle de fluctuation et de confiance Mars 2012 IREM: groupe Proba-Stat Estimation Term.1 Intervalle de fluctuation connu : probabilité p, taille de l échantillon n but : estimer une fréquence
Programmation linéaire
 Programmation linéaire DIDIER MAQUIN Ecole Nationale Supérieure d Electricité et de Mécanique Institut National Polytechnique de Lorraine Mathématiques discrètes cours de 2ème année Programmation linéaire
Programmation linéaire DIDIER MAQUIN Ecole Nationale Supérieure d Electricité et de Mécanique Institut National Polytechnique de Lorraine Mathématiques discrètes cours de 2ème année Programmation linéaire
Contents. 1 Introduction Objectifs des systèmes bonus-malus Système bonus-malus à classes Système bonus-malus : Principes
 Université Claude Bernard Lyon 1 Institut de Science Financière et d Assurances Système Bonus-Malus Introduction & Applications SCILAB Julien Tomas Institut de Science Financière et d Assurances Laboratoire
Université Claude Bernard Lyon 1 Institut de Science Financière et d Assurances Système Bonus-Malus Introduction & Applications SCILAB Julien Tomas Institut de Science Financière et d Assurances Laboratoire
Calculs de probabilités conditionelles
 Calculs de probabilités conditionelles Mathématiques Générales B Université de Genève Sylvain Sardy 20 mars 2008 1. Indépendance 1 Exemple : On lance deux pièces. Soit A l évènement la première est Pile
Calculs de probabilités conditionelles Mathématiques Générales B Université de Genève Sylvain Sardy 20 mars 2008 1. Indépendance 1 Exemple : On lance deux pièces. Soit A l évènement la première est Pile
Soit la fonction affine qui, pour représentant le nombre de mois écoulés, renvoie la somme économisée.
 ANALYSE 5 points Exercice 1 : Léonie souhaite acheter un lecteur MP3. Le prix affiché (49 ) dépasse largement la somme dont elle dispose. Elle décide donc d économiser régulièrement. Elle a relevé qu elle
ANALYSE 5 points Exercice 1 : Léonie souhaite acheter un lecteur MP3. Le prix affiché (49 ) dépasse largement la somme dont elle dispose. Elle décide donc d économiser régulièrement. Elle a relevé qu elle
Tests non-paramétriques de non-effet et d adéquation pour des covariables fonctionnelles
 Tests non-paramétriques de non-effet et d adéquation pour des covariables fonctionnelles Valentin Patilea 1 Cesar Sanchez-sellero 2 Matthieu Saumard 3 1 CREST-ENSAI et IRMAR 2 USC Espagne 3 IRMAR-INSA
Tests non-paramétriques de non-effet et d adéquation pour des covariables fonctionnelles Valentin Patilea 1 Cesar Sanchez-sellero 2 Matthieu Saumard 3 1 CREST-ENSAI et IRMAR 2 USC Espagne 3 IRMAR-INSA
Déroulement d un projet en DATA MINING, préparation et analyse des données. Walid AYADI
 1 Déroulement d un projet en DATA MINING, préparation et analyse des données Walid AYADI 2 Les étapes d un projet Choix du sujet - Définition des objectifs Inventaire des données existantes Collecte, nettoyage
1 Déroulement d un projet en DATA MINING, préparation et analyse des données Walid AYADI 2 Les étapes d un projet Choix du sujet - Définition des objectifs Inventaire des données existantes Collecte, nettoyage
EVALUATION DE LA QUALITE DES SONDAGES EN LIGNE : CAS D UN SONDAGE D OPINION AU BURKINA FASO
 EVALUATION DE LA QUALITE DES SONDAGES EN LIGNE : CAS D UN SONDAGE D OPINION AU BURKINA FASO Auteur Baguinébié Bazongo 1 Ingénieur Statisticien Economiste Chef de l Unité de recherche à l Institut national
EVALUATION DE LA QUALITE DES SONDAGES EN LIGNE : CAS D UN SONDAGE D OPINION AU BURKINA FASO Auteur Baguinébié Bazongo 1 Ingénieur Statisticien Economiste Chef de l Unité de recherche à l Institut national
Statistique Descriptive Élémentaire
 Publications de l Institut de Mathématiques de Toulouse Statistique Descriptive Élémentaire (version de mai 2010) Alain Baccini Institut de Mathématiques de Toulouse UMR CNRS 5219 Université Paul Sabatier
Publications de l Institut de Mathématiques de Toulouse Statistique Descriptive Élémentaire (version de mai 2010) Alain Baccini Institut de Mathématiques de Toulouse UMR CNRS 5219 Université Paul Sabatier
MODÈLE CROP DE CALIBRATION DES PANELS WEB
 MODÈLE CROP DE CALIBRATION DES PANELS WEB 550, RUE SHERBROOKE OUEST MONTRÉAL (QUÉBEC) H3A 1B9 BUREAU 900 TOUR EST T 514 849-8086, POSTE 3064 WWW.CROP.CA Le Protocole CROP de calibration des panels en ligne
MODÈLE CROP DE CALIBRATION DES PANELS WEB 550, RUE SHERBROOKE OUEST MONTRÉAL (QUÉBEC) H3A 1B9 BUREAU 900 TOUR EST T 514 849-8086, POSTE 3064 WWW.CROP.CA Le Protocole CROP de calibration des panels en ligne
CHAPITRE V SYSTEMES DIFFERENTIELS LINEAIRES A COEFFICIENTS CONSTANTS DU PREMIER ORDRE. EQUATIONS DIFFERENTIELLES.
 CHAPITRE V SYSTEMES DIFFERENTIELS LINEAIRES A COEFFICIENTS CONSTANTS DU PREMIER ORDRE EQUATIONS DIFFERENTIELLES Le but de ce chapitre est la résolution des deux types de systèmes différentiels linéaires
CHAPITRE V SYSTEMES DIFFERENTIELS LINEAIRES A COEFFICIENTS CONSTANTS DU PREMIER ORDRE EQUATIONS DIFFERENTIELLES Le but de ce chapitre est la résolution des deux types de systèmes différentiels linéaires
Les indices à surplus constant
 Les indices à surplus constant Une tentative de généralisation des indices à utilité constante On cherche ici en s inspirant des indices à utilité constante à définir un indice de prix de référence adapté
Les indices à surplus constant Une tentative de généralisation des indices à utilité constante On cherche ici en s inspirant des indices à utilité constante à définir un indice de prix de référence adapté
Exercices types Algorithmique et simulation numérique Oral Mathématiques et algorithmique Banque PT
 Exercices types Algorithmique et simulation numérique Oral Mathématiques et algorithmique Banque PT Ces exercices portent sur les items 2, 3 et 5 du programme d informatique des classes préparatoires,
Exercices types Algorithmique et simulation numérique Oral Mathématiques et algorithmique Banque PT Ces exercices portent sur les items 2, 3 et 5 du programme d informatique des classes préparatoires,
Actuariat I ACT2121. septième séance. Arthur Charpentier. Automne 2012. [email protected]. http ://freakonometrics.blog.free.
 Actuariat I ACT2121 septième séance Arthur Charpentier [email protected] http ://freakonometrics.blog.free.fr/ Automne 2012 1 Exercice 1 En analysant le temps d attente X avant un certain événement
Actuariat I ACT2121 septième séance Arthur Charpentier [email protected] http ://freakonometrics.blog.free.fr/ Automne 2012 1 Exercice 1 En analysant le temps d attente X avant un certain événement
4. Résultats et discussion
 17 4. Résultats et discussion La signification statistique des gains et des pertes bruts annualisés pondérés de superficie forestière et du changement net de superficie forestière a été testée pour les
17 4. Résultats et discussion La signification statistique des gains et des pertes bruts annualisés pondérés de superficie forestière et du changement net de superficie forestière a été testée pour les
BTS Groupement A. Mathématiques Session 2011. Spécialités CIRA, IRIS, Systèmes électroniques, TPIL
 BTS Groupement A Mathématiques Session 11 Exercice 1 : 1 points Spécialités CIRA, IRIS, Systèmes électroniques, TPIL On considère un circuit composé d une résistance et d un condensateur représenté par
BTS Groupement A Mathématiques Session 11 Exercice 1 : 1 points Spécialités CIRA, IRIS, Systèmes électroniques, TPIL On considère un circuit composé d une résistance et d un condensateur représenté par
FOTO - L OMNIBUS MENSUEL DE CROP LE NOUVEAU CROP-EXPRESS
 FOTO - L OMNIBUS MENSUEL DE CROP LE NOUVEAU CROP-EXPRESS 550, RUE SHERBROOKE OUEST MONTRÉAL (QUÉBEC) H3A 1B9 BUREAU 900 TOUR EST T 514 849-8086, POSTE 3064 Réflexions méthodologiques Depuis des années,
FOTO - L OMNIBUS MENSUEL DE CROP LE NOUVEAU CROP-EXPRESS 550, RUE SHERBROOKE OUEST MONTRÉAL (QUÉBEC) H3A 1B9 BUREAU 900 TOUR EST T 514 849-8086, POSTE 3064 Réflexions méthodologiques Depuis des années,
Variables Aléatoires. Chapitre 2
 Chapitre 2 Variables Aléatoires Après avoir réalisé une expérience, on ne s intéresse bien souvent à une certaine fonction du résultat et non au résultat en lui-même. Lorsqu on regarde une portion d ADN,
Chapitre 2 Variables Aléatoires Après avoir réalisé une expérience, on ne s intéresse bien souvent à une certaine fonction du résultat et non au résultat en lui-même. Lorsqu on regarde une portion d ADN,
Travaux dirigés d introduction aux Probabilités
 Travaux dirigés d introduction aux Probabilités - Dénombrement - - Probabilités Élémentaires - - Variables Aléatoires Discrètes - - Variables Aléatoires Continues - 1 - Dénombrement - Exercice 1 Combien
Travaux dirigés d introduction aux Probabilités - Dénombrement - - Probabilités Élémentaires - - Variables Aléatoires Discrètes - - Variables Aléatoires Continues - 1 - Dénombrement - Exercice 1 Combien
INF6304 Interfaces Intelligentes
 INF6304 Interfaces Intelligentes filtres collaboratifs 1/42 INF6304 Interfaces Intelligentes Systèmes de recommandations, Approches filtres collaboratifs Michel C. Desmarais Génie informatique et génie
INF6304 Interfaces Intelligentes filtres collaboratifs 1/42 INF6304 Interfaces Intelligentes Systèmes de recommandations, Approches filtres collaboratifs Michel C. Desmarais Génie informatique et génie
Chapitre 3. Les distributions à deux variables
 Chapitre 3. Les distributions à deux variables Jean-François Coeurjolly http://www-ljk.imag.fr/membres/jean-francois.coeurjolly/ Laboratoire Jean Kuntzmann (LJK), Grenoble University 1 Distributions conditionnelles
Chapitre 3. Les distributions à deux variables Jean-François Coeurjolly http://www-ljk.imag.fr/membres/jean-francois.coeurjolly/ Laboratoire Jean Kuntzmann (LJK), Grenoble University 1 Distributions conditionnelles
Programmation linéaire et Optimisation. Didier Smets
 Programmation linéaire et Optimisation Didier Smets Chapitre 1 Un problème d optimisation linéaire en dimension 2 On considère le cas d un fabricant d automobiles qui propose deux modèles à la vente, des
Programmation linéaire et Optimisation Didier Smets Chapitre 1 Un problème d optimisation linéaire en dimension 2 On considère le cas d un fabricant d automobiles qui propose deux modèles à la vente, des
Le patrimoine des ménages retraités : résultats actualisés. Secrétariat général du Conseil d orientation des retraites
 CONSEIL D ORIENTATION DES RETRAITES Séance plénière du 08 juillet 2015 à 9 h 30 «Le patrimoine des retraités et l épargne retraite» Document N 2 bis Document de travail, n engage pas le Conseil Le patrimoine
CONSEIL D ORIENTATION DES RETRAITES Séance plénière du 08 juillet 2015 à 9 h 30 «Le patrimoine des retraités et l épargne retraite» Document N 2 bis Document de travail, n engage pas le Conseil Le patrimoine
Attitude des ménages face au risque. M1 - Arnold Chassagnon, Université de Tours, PSE - Automne 2014
 Attitude des ménages face au risque - M1 - Arnold Chassagnon, Université de Tours, PSE - Automne 2014 Plan du cours 1. Introduction : demande de couverture et comportements induits pa 2. Représentations
Attitude des ménages face au risque - M1 - Arnold Chassagnon, Université de Tours, PSE - Automne 2014 Plan du cours 1. Introduction : demande de couverture et comportements induits pa 2. Représentations
ÉVALUATION FORMATIVE. On considère le circuit électrique RC représenté ci-dessous où R et C sont des constantes strictement positives.
 L G L G Prof. Éric J.M.DELHEZ ANALYSE MATHÉMATIQUE ÉALUATION FORMATIE Novembre 211 Ce test vous est proposé pour vous permettre de faire le point sur votre compréhension du cours d Analyse Mathématique.
L G L G Prof. Éric J.M.DELHEZ ANALYSE MATHÉMATIQUE ÉALUATION FORMATIE Novembre 211 Ce test vous est proposé pour vous permettre de faire le point sur votre compréhension du cours d Analyse Mathématique.
Comment se servir de cet ouvrage? Chaque chapitre présente une étape de la méthodologie
 Partie I : Séries statistiques descriptives univariées (SSDU) A Introduction Comment se servir de cet ouvrage? Chaque chapitre présente une étape de la méthodologie et tous sont organisés selon le même
Partie I : Séries statistiques descriptives univariées (SSDU) A Introduction Comment se servir de cet ouvrage? Chaque chapitre présente une étape de la méthodologie et tous sont organisés selon le même
Évaluation de la régression bornée
 Thierry Foucart UMR 6086, Université de Poitiers, S P 2 M I, bd 3 téléport 2 BP 179, 86960 Futuroscope, Cedex FRANCE Résumé. le modèle linéaire est très fréquemment utilisé en statistique et particulièrement
Thierry Foucart UMR 6086, Université de Poitiers, S P 2 M I, bd 3 téléport 2 BP 179, 86960 Futuroscope, Cedex FRANCE Résumé. le modèle linéaire est très fréquemment utilisé en statistique et particulièrement
Évaluations aléatoires : Comment tirer au sort?
 Évaluations aléatoires : Comment tirer au sort? William Parienté Université Catholique de Louvain J-PAL Europe povertyactionlab.org Plan de la semaine 1. Pourquoi évaluer? 2. Comment mesurer l impact?
Évaluations aléatoires : Comment tirer au sort? William Parienté Université Catholique de Louvain J-PAL Europe povertyactionlab.org Plan de la semaine 1. Pourquoi évaluer? 2. Comment mesurer l impact?
La fumée de tabac secondaire (FTS) en Mauricie et au Centre-du- Québec, indicateurs du plan commun tirés de l ESCC de 2007-2008
 en Mauricie et au Centre-du- Québec, indicateurs du plan commun tirés de l ESCC de 2007-2008") La fumée de tabac secondaire (FTS) en Mauricie et au Centre-du- Québec, indicateurs du plan commun tirés de l ESCC de 2007-2008 Ce document se veut une analyse succincte des indicateurs se rapportant à
La fumée de tabac secondaire (FTS) en Mauricie et au Centre-du- Québec, indicateurs du plan commun tirés de l ESCC de 2007-2008 Ce document se veut une analyse succincte des indicateurs se rapportant à
Le risque Idiosyncrasique
 Le risque Idiosyncrasique -Pierre CADESTIN -Magali DRIGHES -Raphael MINATO -Mathieu SELLES 1 Introduction Risque idiosyncrasique : risque non pris en compte dans le risque de marché (indépendant des phénomènes
Le risque Idiosyncrasique -Pierre CADESTIN -Magali DRIGHES -Raphael MINATO -Mathieu SELLES 1 Introduction Risque idiosyncrasique : risque non pris en compte dans le risque de marché (indépendant des phénomènes
Arbres binaires de décision
 1 Arbres binaires de décision Résumé Arbres binaires de décision Méthodes de construction d arbres binaires de décision, modélisant une discrimination (classification trees) ou une régression (regression
1 Arbres binaires de décision Résumé Arbres binaires de décision Méthodes de construction d arbres binaires de décision, modélisant une discrimination (classification trees) ou une régression (regression
Direction des Études et Synthèses Économiques Département des Comptes Nationaux Division des Comptes Trimestriels
 Etab=MK3, Timbre=G430, TimbreDansAdresse=Vrai, Version=W2000/Charte7, VersionTravail=W2000/Charte7 Direction des Études et Synthèses Économiques Département des Comptes Nationaux Division des Comptes Trimestriels
Etab=MK3, Timbre=G430, TimbreDansAdresse=Vrai, Version=W2000/Charte7, VersionTravail=W2000/Charte7 Direction des Études et Synthèses Économiques Département des Comptes Nationaux Division des Comptes Trimestriels
Probabilités. I Petits rappels sur le vocabulaire des ensembles 2 I.1 Définitions... 2 I.2 Propriétés... 2
 Probabilités Table des matières I Petits rappels sur le vocabulaire des ensembles 2 I.1 s................................................... 2 I.2 Propriétés...................................................
Probabilités Table des matières I Petits rappels sur le vocabulaire des ensembles 2 I.1 s................................................... 2 I.2 Propriétés...................................................
Modèles à Événements Discrets. Réseaux de Petri Stochastiques
 Modèles à Événements Discrets Réseaux de Petri Stochastiques Table des matières 1 Chaînes de Markov Définition formelle Idée générale Discrete Time Markov Chains Continuous Time Markov Chains Propriétés
Modèles à Événements Discrets Réseaux de Petri Stochastiques Table des matières 1 Chaînes de Markov Définition formelle Idée générale Discrete Time Markov Chains Continuous Time Markov Chains Propriétés
La problématique des tests. Cours V. 7 mars 2008. Comment quantifier la performance d un test? Hypothèses simples et composites
 La problématique des tests Cours V 7 mars 8 Test d hypothèses [Section 6.1] Soit un modèle statistique P θ ; θ Θ} et des hypothèses H : θ Θ H 1 : θ Θ 1 = Θ \ Θ Un test (pur) est une statistique à valeur
La problématique des tests Cours V 7 mars 8 Test d hypothèses [Section 6.1] Soit un modèle statistique P θ ; θ Θ} et des hypothèses H : θ Θ H 1 : θ Θ 1 = Θ \ Θ Un test (pur) est une statistique à valeur
Probabilités et Statistiques. Feuille 2 : variables aléatoires discrètes
 IUT HSE Probabilités et Statistiques Feuille : variables aléatoires discrètes 1 Exercices Dénombrements Exercice 1. On souhaite ranger sur une étagère 4 livres de mathématiques (distincts), 6 livres de
IUT HSE Probabilités et Statistiques Feuille : variables aléatoires discrètes 1 Exercices Dénombrements Exercice 1. On souhaite ranger sur une étagère 4 livres de mathématiques (distincts), 6 livres de